哈囉,我是 Dahee Eo,目前在 Enablement Engineering 團隊擔任站台可靠性工程師(SRE)。
我們團隊的角色是用各種方式支援「Enablement」,讓 LINE 服務能夠以更高的效能、效率和安全性提供給使用者。具體來說,我們負責媒體平台的站台可靠性工程,還有跟全球伺服器負載平衡(GSLB)以及內容傳遞網路(CDN)相關的任務,這些可以說是流量的起點。
這篇文章是延續「提升可靠性的 SLI/SLO 導入 Part 1:介紹與必要性」,想跟大家分享我在營運媒體平台時,定義並實際應用服務等級指標(SLI)/服務等級目標(SLO)的經驗。
將 SLI/SLO 導入「平台」而非「服務」
LY Corporation 有一個叫做 OBS 的媒體平台,主要負責儲存、處理和傳遞 LINE 與 LINE 家族服務中使用的照片和影片。OBS 是眾多 LINE 服務裡,絕大多數有用到媒體的服務都會用到的代表性��平台。例如,在 LINE App 聊天室裡傳送的所有媒體訊息,都是透過 OBS 處理的。因此,這個平台的可靠性格外重要,我們決定定義 SLI/SLO,讓最終用戶可以享受更高品質的服務。
大多數 SLI/SLO 都是以「服務」為基礎來設定。這是因為站在用戶角度,用「服務」來衡量可靠性會比用「服務裡的某個平台」來得直觀。不過,OBS 是被大約 160 個不同的 LINE 服務共用的平台,只要這個平台出問題,就會直接影響到各個服務,因此我們選擇另外獨立定義 SLI/SLO。
如何定義平台的關鍵用戶旅程?
雖然我們是基於上述背景開始,但在設定關鍵用戶旅程(CUJ)時,遇到的平台與服務不同的挑戰。關於 CUJ 的細節可參考 Part 1,這邊簡單說明給第一次看這篇文章的朋友:
- 讓用戶能夠使用服務的流程或步驟,稱為「用戶旅程」;而在用戶旅程中,針對核心功能與服務的旅程則稱為「CUJ」。
- 舉例來說,像是「用戶在影音服務播放影片的過程」、「用戶在訊息服務傳送訊息的流程」或「加好友的步驟」等,都屬於用戶旅程。
平台是透過 API 提供功能,要逐一檢查每個服務是怎麼在邏輯上使用這些 API 其實非常困難。因此,我們一開始就把主要 API 本身當作 CUJ,並針對每個功能設定 SLI/SLO。
OBS 提供的各種功能裡,這篇文章會簡單介紹三個主要功能。
| API | 說明 |
|---|---|
| DOWNLOAD | 從 CDN 或 OBS 下��載物件的 API |
| UPLOAD | 將物件上傳到 OBS 的 API |
| OBJECT_INFO | 取得儲存在 OBS 物件中 metadata 的 API |
如同 Part 1 所提到,可以作為 SLI 的指標有可用性、吞吐量、延遲等。根據 SLI/SLO 的量測原則,我們為每個 CUJ 選擇了一到兩個 SLI,如下:
| API | SLI |
|---|---|
| DOWNLOAD | 可用性(+ 吞吐量) |
| UPLOAD | 可用性(+ 吞吐量) |
| OBJECT_INFO | 可用性、延遲 |
一開始我們也打算把吞吐量列為 DOWNLOAD 和 UPLOAD API 的 SLI,但最後還是排除了,原因如下:
- 媒體類型很多元,包括音訊、檔案、圖片、影片等。
- 一次上傳/下載的媒體大小也差異很大。
因為這些特性,不同服務依照類型和大小的表現差異很大,很難用統一標準來衡量。所以最後我們決定還是會量測吞吐量,但不列入 SLI,只做為參考指標。
SLI/SLO 指標的蒐集
理想上,SLI/SLO 的指標應該從最貼近用戶的 API Gateway 等端點蒐集,因為所有請求和回應都會經過這裡。但 OBS 的特性讓我們難以直接從服務端蒐集相關指標,因此決定從 log 產生並使用所需的指標。
指標蒐集架構如下圖,採用 Kafka、Vector、Prometheus:

上述架構的整體流程如下:
- OBS 伺服器即時輸出的 log 會送到訊息佇列 Kafka,產生訊息。
- OBS 是全球規模的伺服器,處理大量請求與流量,log 產出量也很大,所以用 Kafka 來處理。
- Vector(可觀測性資料管線)消費 Kafka 的 log,轉換成 SLI/SLO 所需的指標。
- Vector 匯出轉換後的指標,Prometheus 進行蒐集與儲存。
- SLI/SLO 需要超過一個月的長期資料,加上查詢複雜,所以有套用 Recording Rules 來優化效能。
- 最後,這個資料來源會透過 Grafana 查詢並視覺化。
雖然整體流程看起來很單純,但實作時遇到不少困難,這邊分享其中兩個經驗。
Log 量太大!Vector 最佳化
SLI/SLO 的最終目標是量測用戶是否能安心無礙地使用服務,因此必須即時蒐集指標並設置警示,當 SLI/SLO 或錯誤預算低於標準時,負責人能立即應對。但因 log 量極大(每天約 350TB),導致 Vector 從 Kafka 消費時遇到問題。
沒聽過 Vector 的朋友,Vector 是 DataDog 開源的專案,在官方網站介紹為「輕量、超高速的可觀測性管線建構工具」。它負責所有 log、指標、追蹤資料的蒐集(sources)、轉換(transforms)�、路由(sinks)。
我們團隊之前已經有一個 Vector 叢集(詳見Managing Multi-CDN Logs and Traffic with Vector(韓文)),這次為了處理更多 log,進行了擴充與強化,叢集數量也從一個增加到兩個以支援大規模處理。
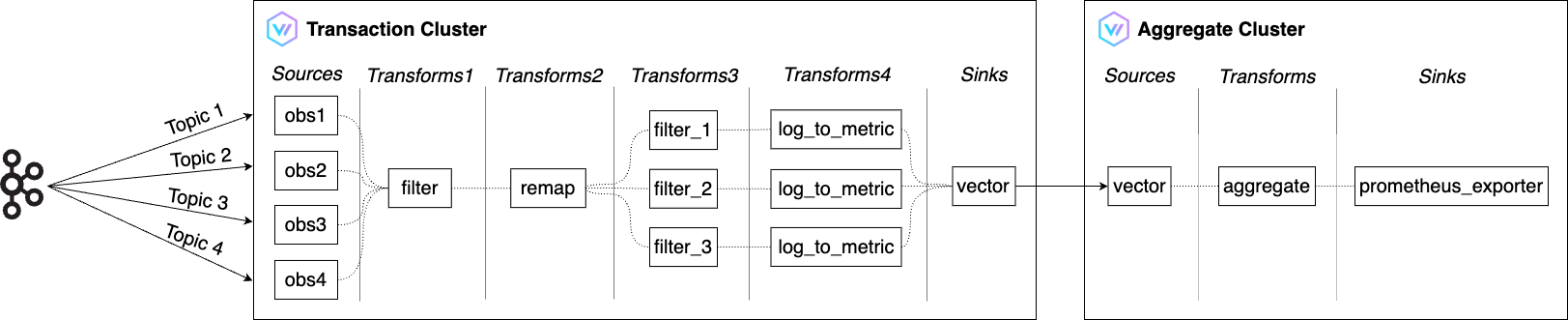
上述架構的流程如下:
- 交易叢集(Transaction Cluster)
- 用 Filter 從 Kafka 收到的大量 OBS log 中,只篩選出 SLI 所需的 log。
- 用 Remap 轉換成想要的格式。
- 用 Log to metric 轉成可用於量測可用性、吞吐量、延遲的指標。
- 用 Vector 的 Sink 之一 Vector,把轉換後的指標送到彙總叢集(Aggregate Cluster)。
- Vector 的 Sink 負責把資料從 Vector 傳送到外部服務。
- 彙總叢集(Aggregate Cluster)
- 用 Aggregate 把交易叢集收到的指標進行彙總減量。
- 當 prometheus_exporter 匯出 SLI 所需的指標後,由 Prometheus 進行蒐集與儲存。
指標最佳化
Vector 最佳化後,原本以為即時產生指標就萬事俱備,可以做 SLI/SLO dashboard 了,但��其實這只是美好想像而已。實際在 dashboard 查詢一週的指標時,竟然要等上一分鐘才跑出來。這是因為指標的基數太高,加上 PromQL(Prometheus 查詢語言)寫得很複雜。
為了解決這問題,我們套用了 Recording Rules。Recording Rules 會把常用或運算很重的表達式預先計算好,結果儲存成另一個指標。之後查詢時,只要撈結果就好,比每次現算快很多。
我們把 SLI/SLO 和錯誤預算會用到的表達式都預先彙總存起來,查詢效能大幅提升。下面是 Recording Rules 的設定片段:
- obs-rules.yaml
groups:
- name: obs
rules:
- record: obs_download_availability
expr: |
sum by (service_code, space_id) (rate(obs_client_http_status{api="DOWNLOAD", error_code="null"}[1m]))
/
sum by (service_code, space_id) (rate(obs_client_http_status{api="DOWNLOAD"}[1m]))
- record: obs_download_throughput_p50
expr: |
histogram_quantile(0.50, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD""}[1m])))
- record: obs_download_throughput_p90
expr: |
histogram_quantile(0.90, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD"}[1m])))
- record: obs_download_throughput_p99
expr: |
histogram_quantile(0.99, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD"}[1m])))
# ... truncated ...
- record: obs_object_info_latency_p50
expr: |
histogram_quantile(0.50, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))
- record: obs_object_info_latency_p90
expr: |
histogram_quantile(0.90, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))
- record: obs_object_info_latency_p99
expr: |
histogram_quantile(0.99, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))套用 Recording Rules 的指標大致分為三類:
- 可用性
- 計算方式為
(成功請求數 / 請求總數) x 100%。 - 這個計算是用 Vector 產生的指標來算。
- 計算方式為
- 吞吐量
- 在 Vector 的 log_to_metric 以 histogram 方式產生。
- 我們計算並套用 50 百分位、90 百分位、99 百分位。
- 延遲
- 延遲的計算與吞吐量相同,也是 histogram 產生。
- 同樣計算 50/90/99 百分位。
下面是錯誤預算計算用的 PromQL 範例,分別是套用 Recording Rules 前後。可以看到套用後查詢式簡單很多,除了可讀性提升,查詢效能也變快了。
- 未套用 Recording Rules
(($slo_period*24*60*(1-$slo_object_availability)) - ( count_over_time( ( ( ( sum(rate(obs_client_http_status{api="DOWNLOAD", service_code=~"$service_code", space_id=~"$space_id", error_code="null"}[$__interval])) / sum(rate(obs_client_http_status{api="DOWNLOAD", service_code=~"$service_code", space_id=~"$space_id"}[$__interval])) ) ) < ($sli_criterion_availability / 100) )[${slo_period}d:1m] ) or on() vector(0) ) - 套用 Recording Rules 後
(($slo_period*24*60*(1-$slo_object_availability)) - ( (count_over_time((obs_download_availability{service_code=~"$service_code", space_id=~"$space_id"} < ($sli_criterion_availability / 100))[${slo_period}d:1m])) or on() vector(0) ))
SLI/SLO 的實際應用
我們利用這些指標,為每個 CUJ 製作了總覽和詳細 dashboard,如下:
| SLI 總覽 | OBJECT_INFO CUJ |
|---|---|
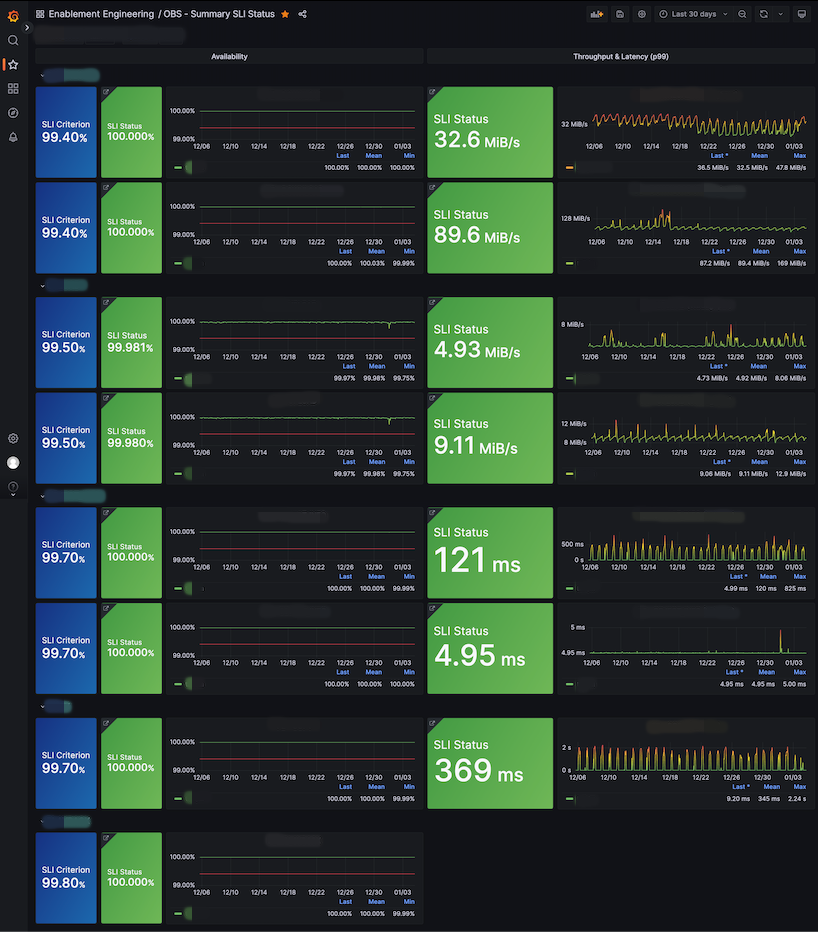 | 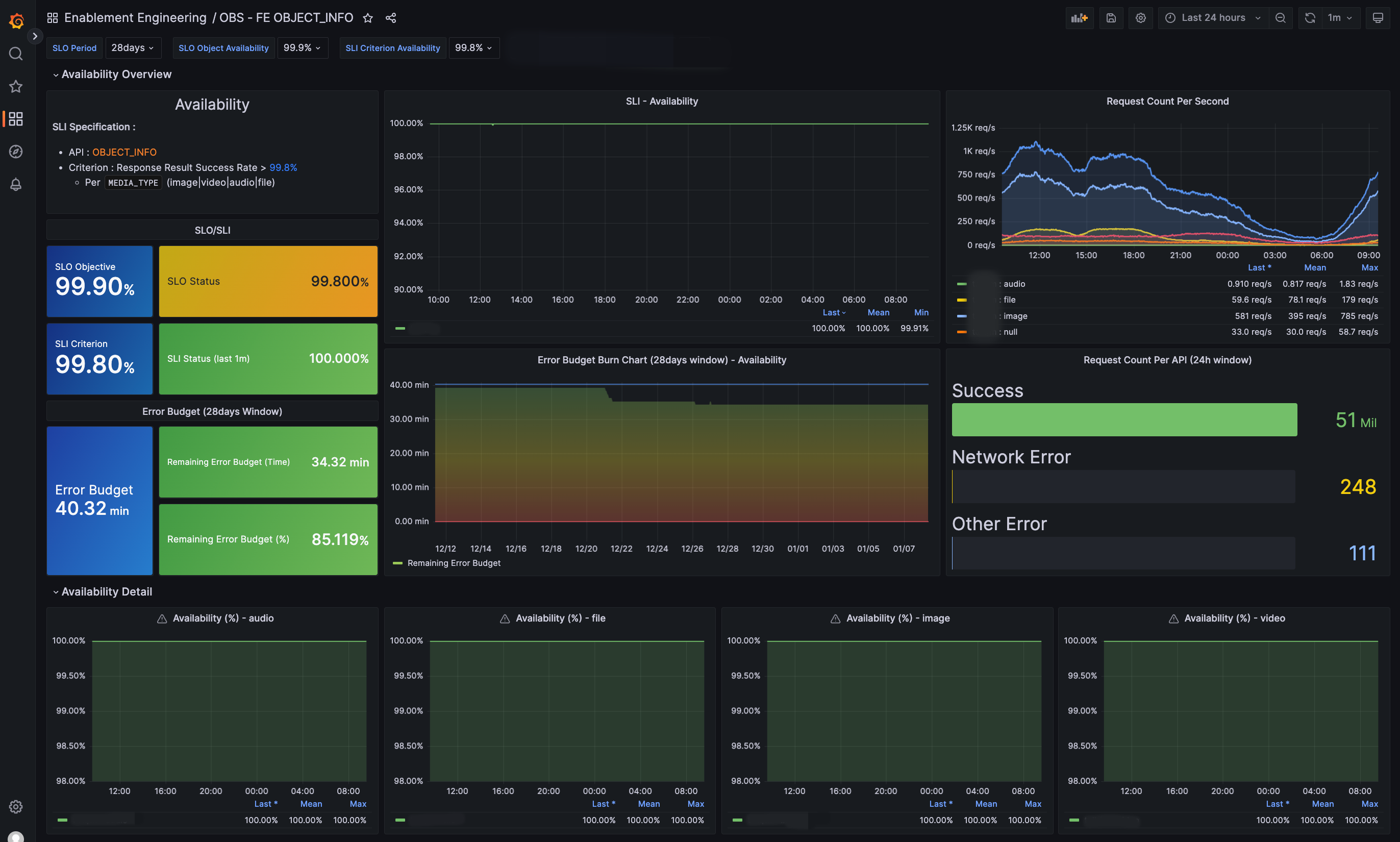 |
在 SLI 總覽 dashboard,可以快速看出目前服務有沒有異常;每個 CUJ 的詳細 dashboard 則能更細緻檢查 SLI/SLO/錯誤預算、請求數與錯誤數等。
我們針對每個 CUJ 設定了對應 SLO 的警示,因此即使平台被多個服務共用,也能知道是哪個服務、哪個功能讓用戶遇到不便。
警示會串接到 Slack,即使沒進 dashboard,也能在 thread 討論串直接看到截圖面板掌握狀況。
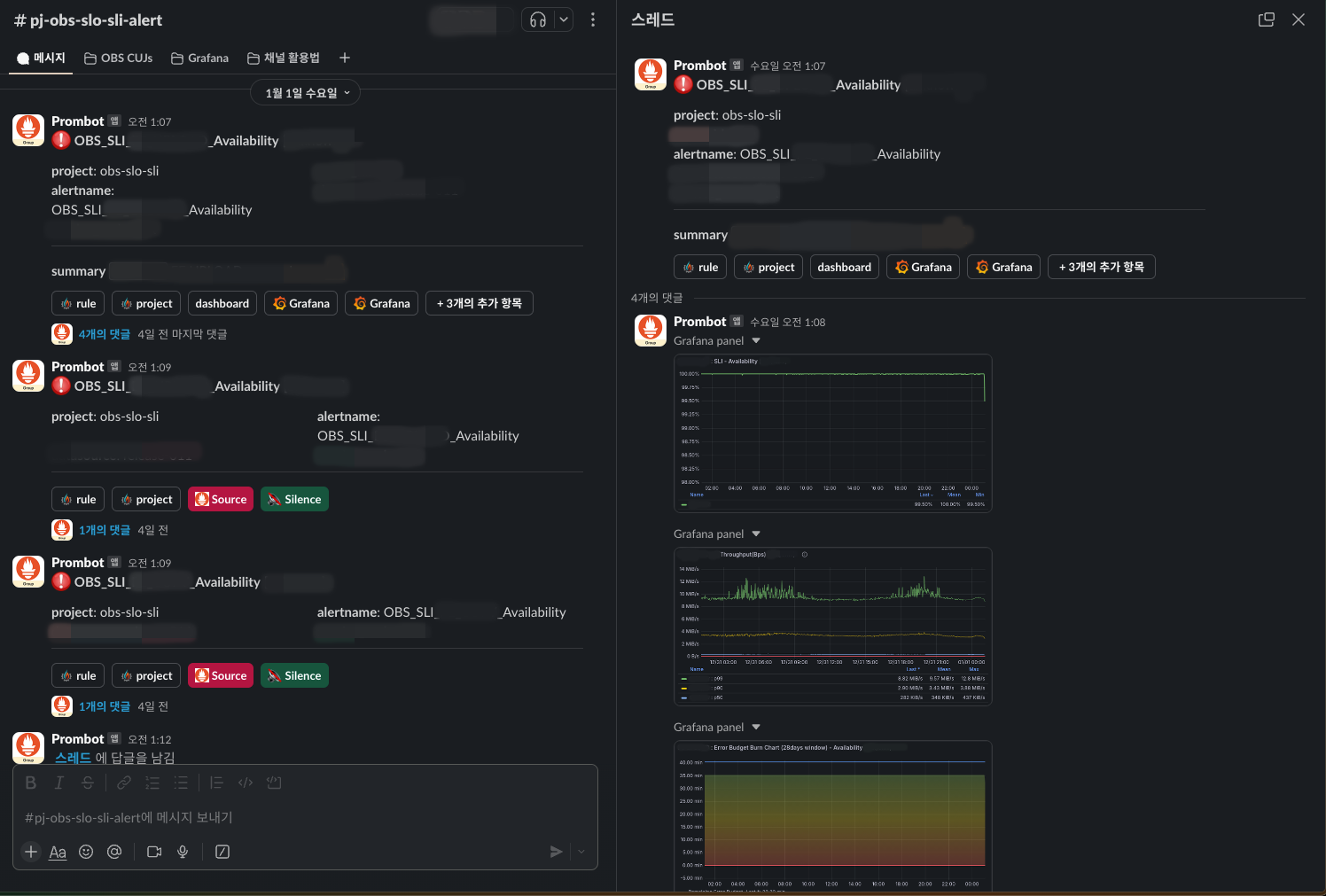
如果警示發生、錯誤預算一直下降,就必須立刻找出原因並解決;但如果錯誤預算還在可接受範圍,就能依照緊急程度決定回應方式,這對降低營運疲勞很有幫助。長期來看,也能根據錯誤預算的狀態,決定要優先開發新功能還是強化穩定性。
未來展望
未來展望分成兩個面向:「OBS SLI/SLO 面向」與「媒體平台 SRE 面向」,這也是我們團隊的角色。
OBS SLI/SLO 方面,目前雖然已經定義好 OBS 自己的 SLI/SLO,但還沒跟用平台的各服務分享。未來會把這些資訊公開給平台用戶服務,一起活用,讓用戶享受到更可靠的服務。
媒體平台 SRE 方面,則是要把 SLI/SLO 應用到其他媒體��平台,不只 OBS。希望能推廣到 LY Corporation 裡各種服務和平台,未來大家都能用共同語言討論 LY 服務的可靠性。
總結
這個專案讓我再次從用戶角度思考 SRE 的角色,也重新確認自己的使命。另外,藉由擴充 Managing Multi-CDN Logs and Traffic with Vector 介紹過的 Vector 叢集,並應用在 CDN 和 OBS 上,累積了不少相關 know-how。
目前我們也正把 SLI/SLO 推廣到 OBS 以外的各種平台和服務。希望這篇文章對許多 SRE 夥伴有所幫助,就分享到這邊,感謝大家耐心閱讀!


