시작하며
안녕하세요. Enablement Engineering 팀에서 SRE(Site Reliability Engineer)로 일하고 있는 어다희입니다. 저희 팀은 LINE 서비스를 보다 높은 성능으로 효율적이고 안전하게 사용자에게 제공할 수 있도록 다방면에서 'Enablement'를 지원하는 역할을 수행합니다. 구체적으로 미디어 플랫폼에 대한 사이트 안정성 엔지니어링(site reliability engineering)과 더불어 트래픽의 시작점이라고 할 수 있는 GSLB(global server load balancer)와 CDN(content delivery network) 관련 업무를 담당하고 있는데요. 이번 글에서는 앞서 이전 LINE Engineering 블로그에서 발행됐던 Multi CDN 트래픽 모니터링을 위한 클러스터 구축기(이후 1탄)의 2탄으로 'Vector를 활용해 멀티 CDN 로그 및 트래픽을 관리한 이야기'를 공유해 보려고 합니다.
이 글은 로그와 모니터링, 쿠버네티스에 대한 경험이 어느 정도 있는 분들을 독자로 상정하고 작성했습니다.
멀티 CDN 모니터링 시스템의 개선점과 개선 목표
그동안 1탄에서 승헌 님께서 소개한 대로 시스템을 잘 사용해 왔는데요. 여느 서비스들처럼 시간이 흐르면서 개선점이 도출되기 시작했습니다. 도출된 개선점은 아래 세 가지로 정리할 수 있습니다.
다양한 데이터 소스와 산재된 대시보드를 한 군데로 통합해 관리 포인트를 최소화
멀티 CDN을 사용하다 보니 자연스럽게 CDN별 혹은 하위 상품별 등 다양한 구분에 따라 여러 데이터 소스가 생기고 이를 모니터링하기 위한 대시보드들이 만들어졌습니다. 이번 작업을 통해 이를 한 군데로 통합하는 것을 첫 번째 개선 사항으로 정했습니다.
직접 개발한 익스포터(exporter) 관리가 허들이 되어 대체 가능한 방법 찾기
1탄에서 소개한 것처럼 로그를 표준화했는데요. CDN 업체에서 포맷을 업데이트하거나 커스텀 로그 필드를 추가할 경우 익스포터를 함께 업데이트해야 하는 불편함이 있었습니다. 이를 해결하기 위해 다양한 방법을 모색하다가 Vector라는 오픈소스를 발견했고, 이 오픈소스의 log_to_metric 기능으로 익스포터를 대체하는 것을 두 번째 개선 사항으로 정했습니다.
통합 모니터링 체계 기반 마련
CDN과 연관된 많은 내부 제품과 플랫폼이 있고 모두 각각의 로그 및 메트릭 수집 체계가 있습니다. 이에 종합적인 인사이트를 얻을 수 있도록 Vector를 이용해 통합된 모니터링 체계를 마련하고자 했고, 이를 위해 Vector로 변경하기 어려운 로그와 메트릭을 재가공해 모니터링 체계 통합의 기반을 마련하는 작업을 세 번째 개선 사항으로 정했습니다.
Vector 소개
개선점과 목표에서 말씀드린 내용을 정리해 보면 이 글의 주인공은 'Vector'라고 할 수 있는데요. 아직 국내에는 많이 알려지지 않은 것 같습니다. 작업 내용을 공유하기 전에 먼저 Vector가 무엇인지 간단하게 소개하겠습니다.
Vector란?
Vector는 DataDog의 오픈소스 프로젝트로 홈페이지에서 'A lightweight, ultra-fast tool for building observability pipelines'라고 자신을 소개하고 있습니다. 직역하면 '관찰 가능한(observability) 파이프라인을 구축하기 위한 가볍고 매우 빠른 도구'라고 할 수 있는데요. 모든 로그와 메트릭, 트레이스를 수집하고(Sources), 변환해서(Transforms), 라우팅하는(Sinks)하는 역할을 담당합니다.
아마 이와 같이 글로 설명을 읽는 것보다 설정 파일 코드를 보면 Vector의 역할을 더 쉽게 이해하실 수 있을 것이라고 생각합니다. 아래 코드를 보시겠습니다.
[sources.in]
type = "stdin"
[transforms.transform]
type = "remap"
inputs = ["in"]
source = ". = parse_json!(.message)"
[sinks.out]
inputs = ["transform"]
type = "console"
encoding.codec = "json"- Sources: 관찰하려는 데이터 소스에서 Vector로 데이터를 수집하거나 수신하는 역할을 수행합니다.
- Transforms: 관찰하려는 데이터가 파이프라인을 통과할 때 조작하거나 변경하는 작업을 수행합니다.
- Sinks: Vector에서 외부 서비스 대상으로 데이터를 전송하는 역할을 수행합니다.
위 예제 코드는 표준 입력(stdin)으로 입력받은 데이터를, transforms에서 JSON으로 파싱해서, 콘솔에 JSON 형식으로 출력하는 역할을 수행하는 코드입니다. 로컬 환경에서 Vector 서버를 실행해 확인해 보면 아래와 같이 결과를 확인할 수 있습니다. 참고로 -c 옵션을 이용하면 설정 파일 경로를 지정할 수 있습니다.

아직 '그래서 이게 뭐야?'라고 생각할 수 있을 것 같습니다. 이해를 돕기 위해 아래와 같이 비슷한 툴을 모아서 간단히 정리해 봤습니다. Vector처럼 로그를 수집하거나 모으는 역할을 수행하는 도구로 Logstash와 Beats, Fluentd, FluentBit 등이 있으며 각 도구의 특징은 다음과 같습니다.
| 도구 | 특징 | 장/단점 |
|---|---|---|
 |
|
|
 |
|
|
 |
|
|
 |
|
|
 |
|
|
Vector 아키텍처
이제 Vector가 어떤 도구인지 감이 오셨을 것 같습니다. 다음으로 Vector를 어떤 구조와 방식으로 사용할 수 있는지 Vector에서 제안하는 세 가지 아키텍처 Aggregator와 Agent, Unified를 간단히 살펴보겠습니다(참고). 저희는 아래 세 방식 중 Aggregator 방식을 선택했습니다.
| 구분 | ��내용 | 구조 |
|---|---|---|
| Aggregator |
|
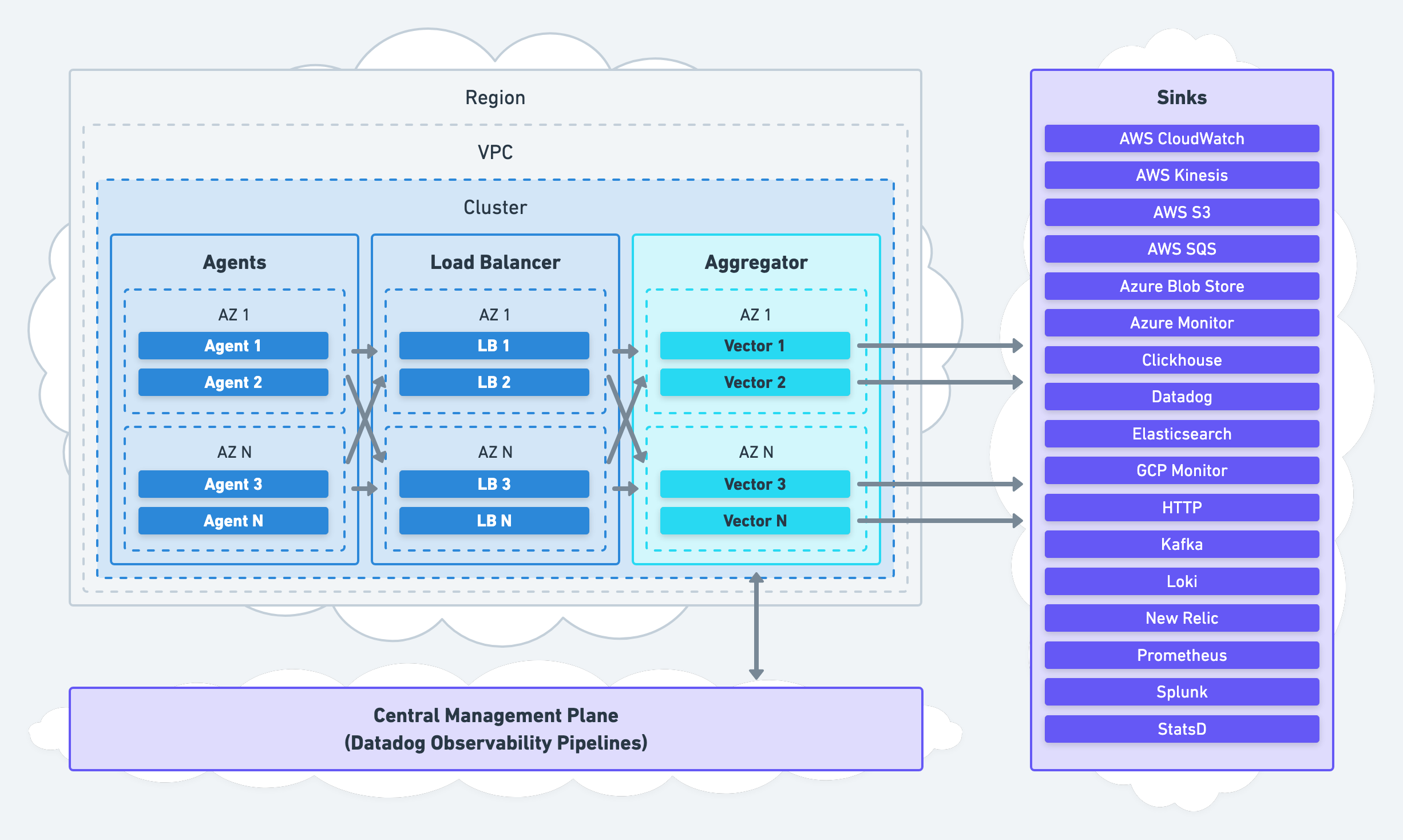
|
| Agent |
|
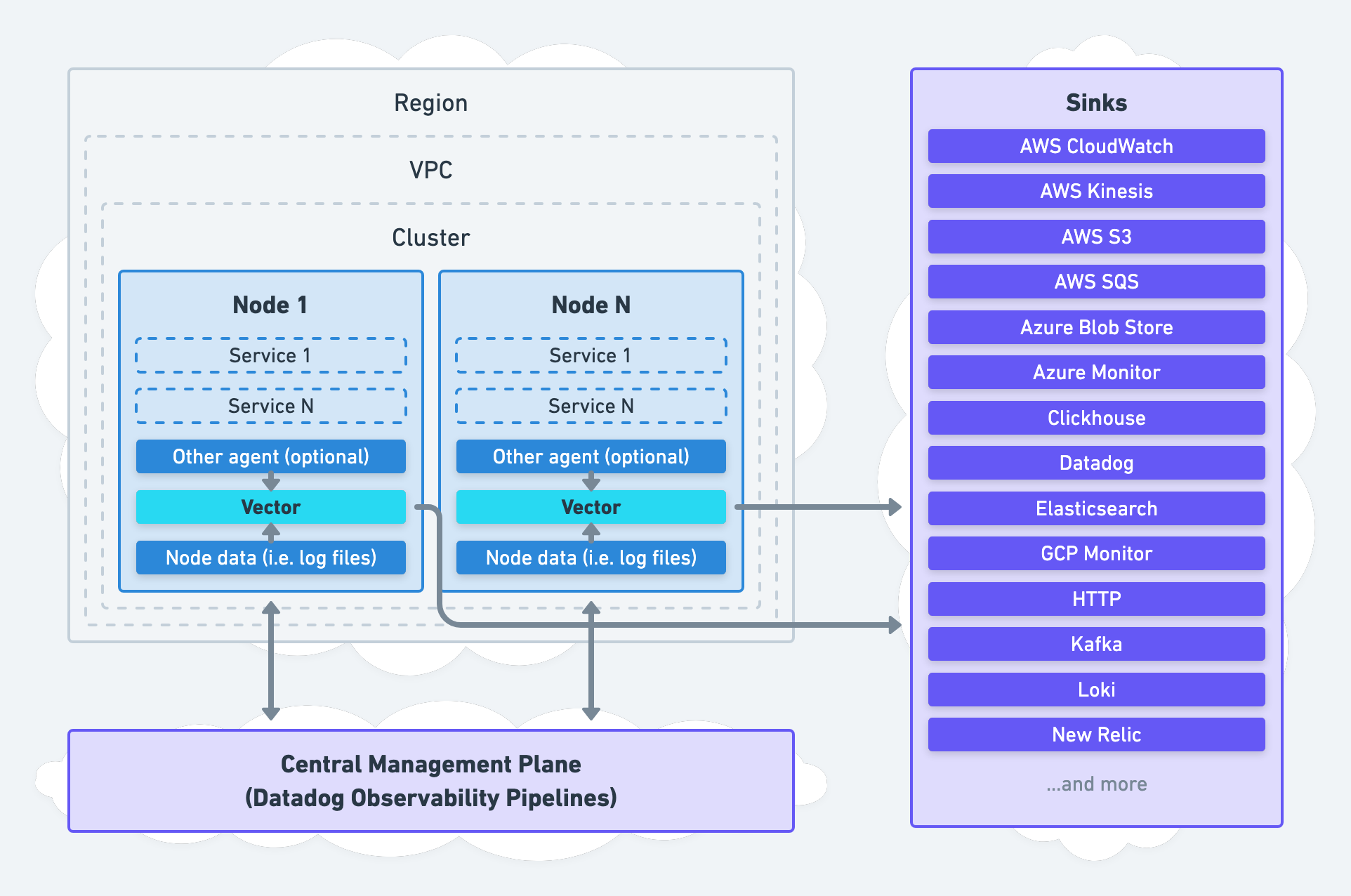
|
| Unified |
|
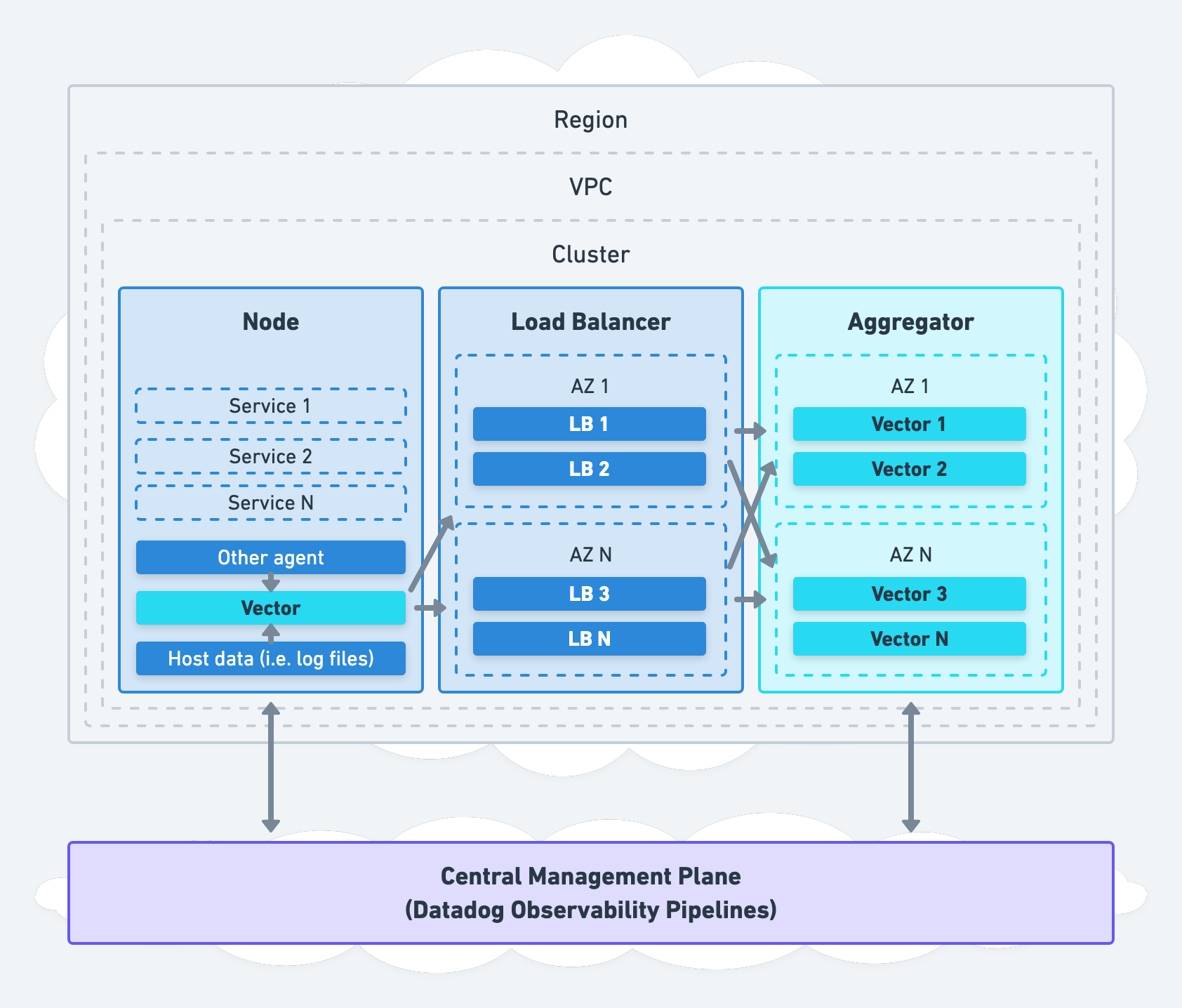
|
Vector 클러스터 구축하기
Vector가 무엇인지, 어떻게 사용할 수 있는지 살펴봤습니다. 이제 저희가 Vector 클러스터를 구축한 방법을 말씀드리겠습니다.
Vector 설치하기 - 쿠버네티스에 Helm 차트로 배포하는 방법 선택
Vector에서는 다양한 설치 방법을 제공하며(참고), 저희는 쿠버네티스에 Helm 차트로 배포하는 방법을 선택했습니다.
쿠버네티스 스펙은 CPU 8 core, RAM 32GB, Disk SSD 100GB인 노드 6대를 사용했으며, 전반적인 구성은 스테이트풀셋(StatefulSet), 퍼시스턴트볼륨클레임(PersistentVolumeClaim), 서비스, 서비스 어카운트, 컨피그맵(ConfigMap), HPA(HorizontalPodAutoscaler)로 구성했습니다. 디플로이먼트가 아닌 스테이트풀셋을 선택한 이유는 글 후반부에 말씀드리겠습니다.
Vector에서 제공하는 공식 Helm 차트에는 이번 프로젝트 진행과 관련 없는 리소스가 많아 Helm 차트를 새로 생성해 배포했습니다. 차트 전체를 다루면 내용이 너무 길어질 것 같아 아래와 같이 스테이트풀셋 부분 위주로 코드를 가져와서 주석으로 설명을 덧붙였습니다.
Helm 차트 코드
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ .Release.Name }}
namespace: {{ .Values.namespace }}
labels:
{{- include "vector-helm.labels" . | nindent 4 }}
annotations:
{{- range $key, $value := .Values.deployment.annotations }}
{{- $key | nindent 4 }}: {{ $value }}
{{- end }}
spec:
{{- if not .Values.autoscaling.enabled }} # Vector 클러스터의 유연성을 위해 HPA를 적용했습니다.
replicas: {{ .Values.autoscaling.minReplicas }}
{{- end }}
selector:
matchLabels:
{{- include "vector-helm.selectorLabels" . | nindent 6 }}
serviceName: {{ .Release.Name }}
template:
metadata:
labels:
{{- include "vector-helm.selectorLabels" . | nindent 8 }}
spec:
serviceAccountName: {{ .Values.serviceAccount.name }}
terminationGracePeriodSeconds: {{ .Values.terminationGracePeriodSeconds }}
# 파드(pod)를 균등하게 분배하기 위해 podAntiAffinity와 topologySpreadConstraints 옵션을 함께 사용했습니다.
{{- if .Values.affinity.enabled }}
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: {{ .Values.affinity.weight }}
podAffinityTerm:
labelSelector:
matchExpressions:
- key: {{ .Values.affinity.matchKey }}
operator: In
values:
- {{ .Values.affinity.matchValues }}
topologyKey: kubernetes.io/hostname
topologySpreadConstraints:
- maxSkew: {{ .Values.topology.maxSkew }}
whenUnsatisfiable: DoNotSchedule
topologyKey: kubernetes.io/hostname
{{- end }}
containers:
- name: {{ .Release.Name }}
image: "{{ .Values.image.repository }}{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
# 설정 파일을 세 개 사용하기 때문에 Vector 구동 시 argument를 --config-dir로 설정했습니다.
# 설정 파일들은 /etc/vector/ 디렉터리 하위에 존재하고, 아래 volumeMounts 쪽에서 관련 내용을 확인할 수 있습니다.
args: ["--config-dir", "/etc/vector/"]
ports:
{{- range $key, $value := .Values.service.portInfo }}
- name: {{ $value.name }}
containerPort: {{ $value.port }}
protocol: {{ $value.protocol }}
{{- end }}
env:
- name: VECTOR_GRACEFUL_SHUTDOWN_LIMIT_SECS
value: "30"
# Vector container 시작 여부 확인
startupProbe:
httpGet:
path: /health
port: 8686
# Vector container 동작 여부 확인(실패 시 컨테이너 재시작)
livenessProbe:
httpGet:
path: /health
port: 8686
terminationGracePeriodSeconds: 60
# Vector container 준비 상태 확인(실패 시 해당 파드의 IP를 서비스 엔드포인트에서 제거)
readinessProbe:
httpGet:
path: /health
port: 8686
resources:
{{- toYaml .Values.resources | nindent 12 }}
volumeMounts:
- name: config
mountPath: {{ .Values.volume.configPath }}
readOnly: true
- name: buffer
mountPath: "/var/lib/vector"
volumes:
- name: config
configMap: # 설정 파일들은 컨피그맵을 통해 설정 후 스테이트풀셋 파일에서 불러와 사용했습니다.
name: {{ .Release.Name }}
# 스테이트풀셋은 상태가 중요하기 때문에 storageClass를 통해 pvc를 사용합니다.
volumeClaimTemplates:
- metadata:
name: buffer
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: {{ .Values.volume.storageClass }}
resources:
requests:
storage: {{ .Values.volume.storageSize }}log_to_metric 기능 사용하기
앞서 두 번째 개선 사항으로 익스포터를 대체하기 위해 로그를 메트릭으로 변환하는 기능인 log_to_metric 기능을 사용한다고 말씀드렸습니다. 개인적으로 Vector를 사용하며 가장 유용한 기능이 아닐까 생각하는데요. 이 기능을 어떻게 사용하고 있는지 말씀드리겠습니다.
현재 다양한 서비스에서 저희 시스템으로 로그와 메트릭을 제공해 주고 있는데요. 저희가 사용하는 Akamai는 그 특성상 이를 실시간으로 수집하는 것이 어렵습니다. 이 문제를 해결하기 위해 log_to_metric 기능을 활용한 파이프라인을 구축해 상용 CDN을 모니터링하고 있습니다. 파이프라인은 아래 네 단계로 진행됩니다.
- Sources로 CDN 실시간 로그 입력받기
- Transforms으로 정규화(remap)
- Transforms으로 로그를 메트릭으로 변환
- Sinks로 Prometheus 형식에 맞게 메트릭 전송
위 단계를 코드와 함께 살펴보겠습니다. 이해를 돕기 위해 표로 구분했는데요. 모두 한 파일에 들어가며 연결되는 내용입니다.
| Sources |
Source의 이름은 |
| Transforms(remap) |
Transform의 이름은
|
| Tramsforms(log_to_metric) |
Transform의 이름은
|
| Sinks |
Sinks는 메트릭과 로그, 두 개를 진행합니다.
|
위 코드만으로는 구조가 머리에 잘 그려지지 않는 분들은 구조를 시각화해서 볼 수도 있습니다. Vector CLI 명령어를 사용하면 설정을 DOT 파일로 확인할 수 있는데요. 이 파일을 GraphvizOnline 사이트에 입력하면 시각화한 구조를 볼 수 있습니다.
아래 코드는 설정을 DOT 파일로 출력하는 CLI 명령어입니다.
vector graph --config /etc/vector/{파일명}
digraph {
"akamai_cm" [shape=trapezium]
"akamai_cm_log_to_metrics" [shape=diamond]
"cm_remap" -> "akamai_cm_log_to_metrics"
"cm_remap" [shape=diamond]
"akamai_cm" -> "cm_remap"
"akamai_out_iu_kafka" [shape=invtrapezium]
"cm_remap" -> "akamai_out_iu_kafka"
"akamai_out_prometheus" [shape=invtrapezium]
"akamai_cm_log_to_metrics" -> "akamai_out_prometheus"
}다음 그림은 구조를 시각화한 결과입니다. 정방향 사다리꼴(trapezium)이 Sources를, 마름모(diamond)는 Transforms을, 역방향 사다리꼴(invtrapezium)은 Sinks를 의미합니다.
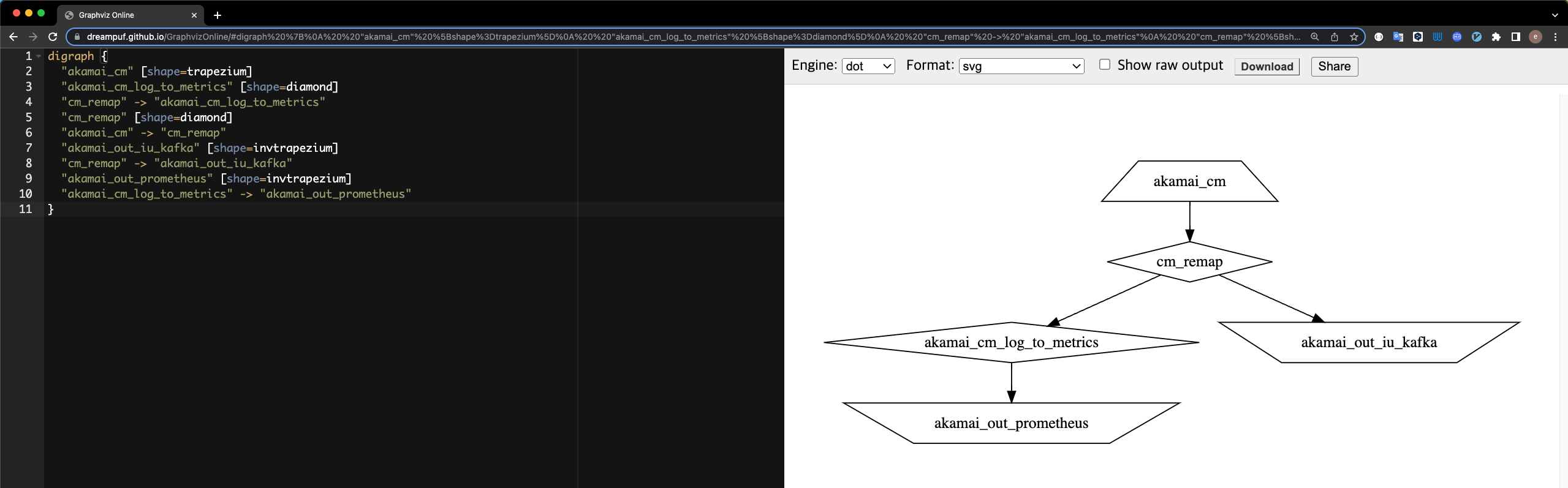
로그와 메트릭 확인하기
Sinks를 통해 Prometheus와 Kafka로 메트릭과 로그를 전송한 뒤 전송한 서버에 접속해 쿼리를 실행하면 결과를 확인할 수 있습니다.
먼저 Prometheus는 log_to_metric 기능을 설명하면서 말씀드린 것처럼 namespace에 지정한 값이 접두사로 붙습니다. 아래 그림을 보면 앞서 namespace에 설정한 대로 태그 값이 잘 포함돼 나오는 것을 확인할 수 있습니다.
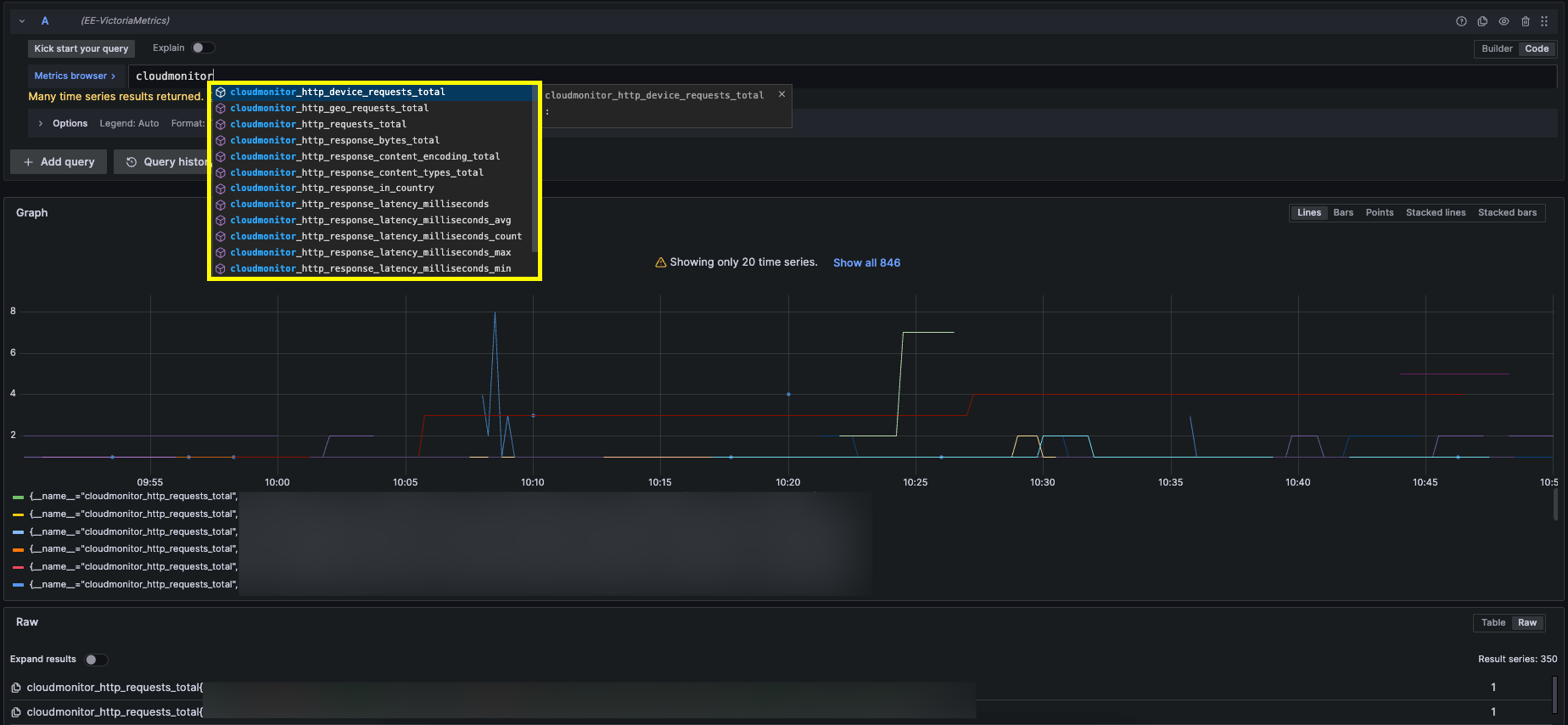
다음은 Kibana를 통해 로그를 확인해 보겠습니다. 구분자는 앞서 Transform(remap) 단계에서 platform 값으로 설정한 값을 사용했으며, 잘 쌓이는 것을 확인할 수 있습니다.

순조롭게 진행되는 줄 알았는데 로그가 사라졌다! - 버퍼링 모델 적용하기
순조롭게 잘 진행된다고 생각했지만, 기존에 익스포터로 받고 있던 로그와 비교해 보니 일부 로그가 소실된 것을 확인할 수 있었습니다. 원인을 분석한 결과 Sinks가 실시간으로 모든 처리를 하지 못해 발생하는 것이었습니다. 이를 해결하기 위해 Vector에서 제공하는 버퍼링 모델을 적용했습니다.
버퍼링 모델은 아래와 같이 Sinks가 처리할 수 있는 것 이상으로 많은 이벤트가 과도하게 입력될 때 운영자가 성능(performance)과 내구성(durability) 중 어느 것을 우선으로 할지 선택할 수 있게 만드는 기능입니다.

| 개념 | 설명 | 예시 |
|---|---|---|
| Buffer | 데이터가 일시적으로 저장되는 메모리 영역으로 처리 속도 조절 및 안전한 데이터 전달을 위해 사용 | 버퍼에 1,000개의 이벤트가 대기 |
| Batching | 버퍼에 저장한 데이터를 그룹으로 만들어 일괄 처리해서 데이터 처리 효율 향상 | 1,000개의 이벤트를 단일 배치로 그룹화 처리 |
| Backpressure | 데이터 처리 속도가 버퍼링 속도를 초과하면 백프레셔(backpressure) 메커니즘을 사용해 속도 제한 및 데이터 손실 방지 | 데이터 처리가 버퍼 속도를 초과해 백프레셔 작동 |
| Sink | 버퍼에 저장한 데이터를 데이터의 최종 목적지(Sink)로 전달 | 데이터를 Kafka 클러스터로 보내는 Sink 구성(prometheus_remote_write 등 다양한 구성 가능) |
버퍼링 모델을 적용한 뒤 Vector에 저장되고 있는 데이터를 확인해 보니 차곡차곡 쌓이고 있는 것을 확인할 수 있었고, 더 이상 로그가 사라지지 않았습니다.

모니터링하기
Vector가 잘 작동하는지 확인하기 위해서는 모니터링을 해야 합니다. Vector는 Sources 종류 중 하나로 자체 로그와 메트릭을 제공하고 있으며, 저희는 그중 internal_metrics를 활용했습니다. 그리고 앞서 말씀드린 것처럼 쿠버네티스 기반으로 설치했기 때문에 각 노드별 node_exporter와 kube-state-metrics로 클러스터 상태를 모니터링하고 있습니다.
아래는 모니터링 대시보드를 캡처한 것입니다.
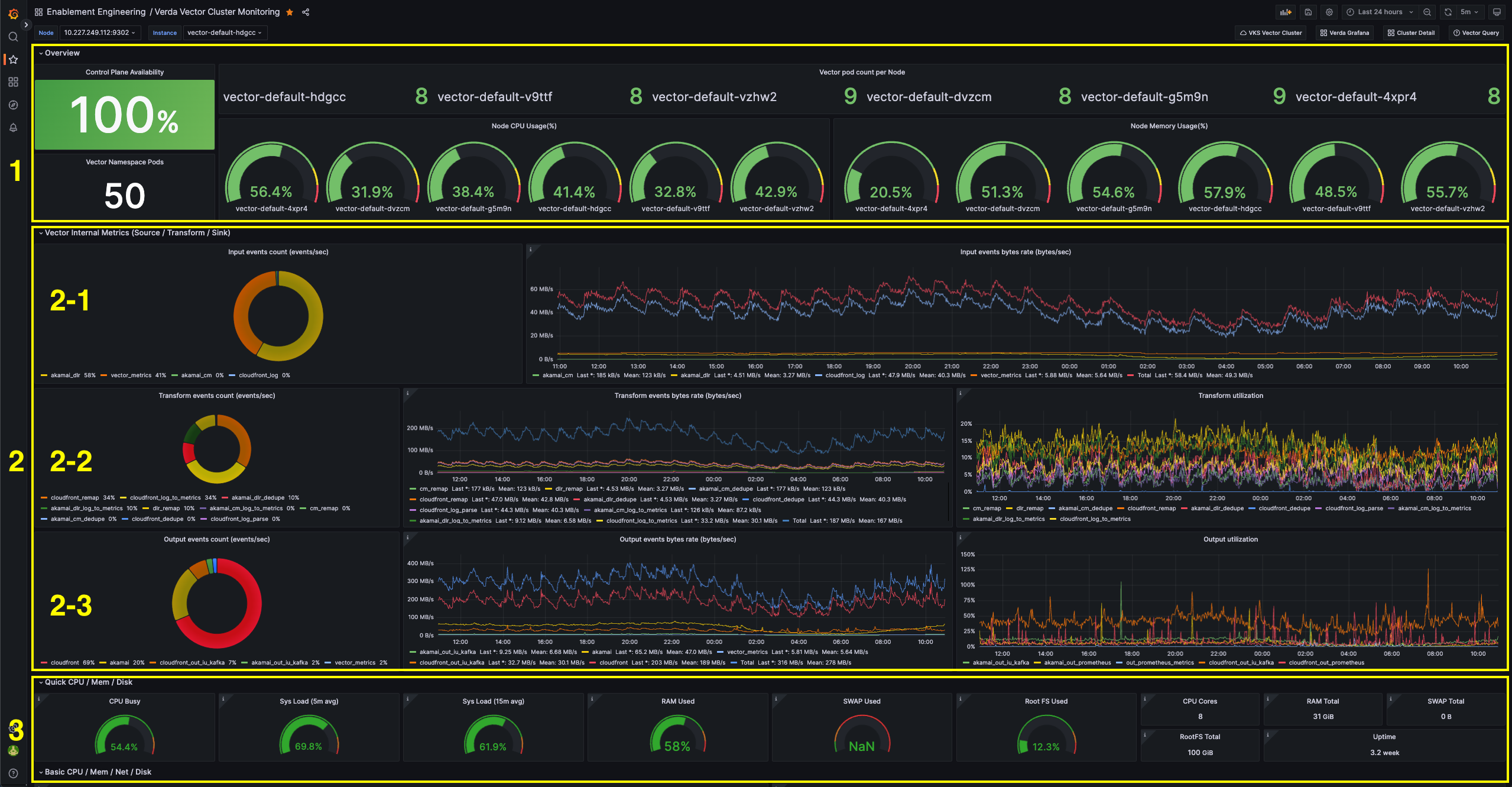
위 그림을 각 영역별로 설명하겠습니다.
- 1번 영역: 전체 쿠버네티스 클러스터 정보
- 각 노드별로 배포된 Vector 네임스페이스의 파드 개수
- 각 노드별 CPU 사용량
- 각 노드별 메모리 사용량
- 2번 영역: Vector internal_metrics 정보
- 2-1: Sources로 들어오는 이벤트 개수와 bytes/sec
- 2-2: Transforms로 들어오는 이벤트 개수와 bytes/sec, 사용량
- 2-3: Sinks로 들어오는 이벤트 개수와 bytes/sec, 사용량
- 3번 영역: 세부 노드 정보
- 왼쪽 위에서 선택한 노드의 세부 정보
사용하다 보면 더 보완할 부분이 생길 수도 있을 것 같은데요. 쿠버네티스 기반으로 Vector 클러스터를 운영하시는 분들에게 조금이나마 도움이 될 수 있기를 바라는 마음으로 현재 상태를 Grafana Labs에 Vector Cluster Monitoring(ID: 19611) 이름으로 공유해 두었습니다.
그 외 기능 살펴보기
앞서 살펴본 기능 외에도 Vector에서는 다음과 같이 다양한 옵션과 기능을 제공합니다.
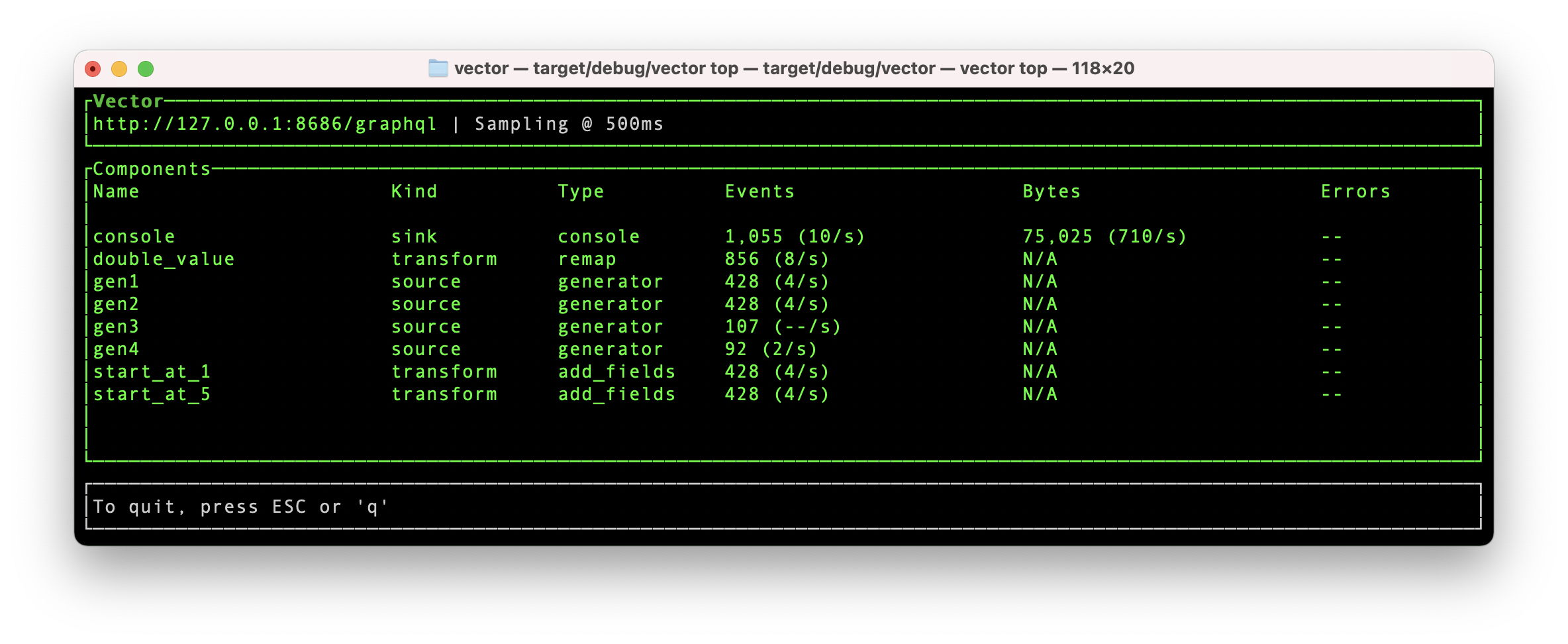
vector top
vector top은 작동 중인 로컬 또는 원격 Vector 프로세스의 주요 지표를 CLI에서 확인할 수 있는 기능입니다.
vector tap
vector tap은 작동 중인 Vector에 탭(tap)을 붙여서 컴포넌트의 입/출력을 모니터링할 수 있는 기능입니다.
- 주요 옵션:
--inputs-of,--outputs-of - 예시:
cm_remap으로 유입되는 이벤트와akamai_cm_log_to_metrics에서 처리 후 이벤트를 1000개마다 1개씩 출력하기(--meta는 실행되는 지점인component_id와kind,type을 표시)-
vector tap --interval 1000 --limit 1 --inputs-of cm_remap --outputs-of akamai_cm_log_to_metrics --meta
-
vector vrl
vector vrl은 Vector에서 지원하는 VRL(Vector Remap Language)을 CLI에서 테스트해 볼 수 있는 기능으로 vector vrl 웹 버전도 제공하고 있습니다.
마치며
위와 같은 과정을 거쳐 글의 도입부에서 설정한 목표를 달성하고 멀티 CDN 트래픽 모니터링을 위한 클러스터를 고도화할 수 있었습니다. �과정을 짧게 정리해 보면, Vector를 활용해 1탄에서 개발했던 익스포터를 대체하고 통합된 모니터링 체계를 위한 기반을 마련했으며, 이를 쿠버네티스에 구축함으로써 오토 스케일링 등 설정 업데이트에 대한 자동화를 구현했는데요. 앞으로 새로운 CDN이 추가될 수도 있고, 기존 CDN 설정 등에 변화가 생길 수도 있는데 이때 Vector를 통해 좀 더 쉽고 빠르게 모니터링할 수 있기를 기대하고 있습니다.
Vector는 저도 이번에 처음 사용해 보는 것이었는데요. 아직은 국내에 참고할 만한 자료가 많지 않아 다양한 시행착오를 겪을 수밖에 없었지만, 이를 통해 많이 배울 수 있었다고 생각합니다. 이 글이 Vector에 관심을 갖고 사용하려는 분들에게 조금이나마 도움이 되길 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


