시작하며
안녕하세요. Enablement Engineering 팀에서 SRE(site reliability engineer)로 일하고 있는 어다희입니다.
저희 팀은 LINE 서비스를 보다 높은 성능으로 효율적이고 안전하게 사용자에게 제공할 수 있도록 다방면에서 'Enablement'를 지원하는 역할을 수행합니다. 구체적으로 미디어 플랫폼에 대한 사이트 안정성 엔지니어링(Site Reliability Engineering)과 더불어 트래픽의 시작점이라고 할 수 있는 GSLB(global server load balancing)와 CDN(content delivery network) 관련 업무를 담당하고 있습니다.
이번 글에서는 신뢰성 향상을 위한 SLI/SLO 도입 1편 - 소개와 필요성에 이어서 미디어 플랫폼에 SLI/SLO를 정의해 운영 업무에 적용한 후기를 공유해 보려 합니다.
서비스가 아닌 플랫폼에 SLI/SLO를 도입하기
LY에는 LINE 및 LINE 패밀리 서비스에서 사용되는 사진과 동영상 등��을 저장 및 가공하고 딜리버리하는 미디어 플랫폼인 OBS가 있습니다. OBS는 LINE의 많은 서비스 중 미디어를 사용하는 대부분의 서비스에서 사용하는 대표 플랫폼 중 하나입니다. 예를 들어 LINE 앱 대화방에서 주고받는 미디어 메시지는 전부 OBS를 사용합니다. 그러므로 이 플랫폼의 신뢰성(reliability)은 굉장히 중요하며, 최종 사용자에게 더 좋은 품질의 서비스를 제공할 수 있도록 SLI(service level indicator)/SLO(service level objective)를 정의하게 되었습니다.
대부분의 SLI/SLO는 '서비스'를 기준으로 설정합니다. 사용자 입장에서 신뢰성을 측정하기 위해서는 서비스 내부에서 사용되는 '플랫폼'보다는 서비스를 기준으로 측정하는 것이 용이하기 때문입니다. 하지만 OBS의 경우 약 160개에 이르는 다양한 LINE 서비스에서 사용하고 있으며, 이 플랫폼의 문제는 곧 각 서비스의 문제로 직결될 수 있기 때문에 별도로 SLI/SLO를 정의하게 되었습니다.
플랫폼의 CUJ를 어떻게 정의할 것인가?
위와 같은 배경으로 시작했으나 CUJ(critical user journey) 설정부터 서비스와 다른 벽에 부딪혔습니다. CUJ에 대한 자세한 설명은 1편에서 확인할 수 있는데요. 이 글을 시작으로 접하시는 분들을 위해 간단히 설명하면 아래와 같습니다.
- 사용자가 서비스를 사용하는 과정 혹은 흐름을 정의한 것을 '사용자 여정(user journey)'이라고 부르며, 사용자 여정 중 핵심 기능 및 서비스에 대한 여정을 '핵심 사용자 여정(critical user journey, CUJ)'이라고 부릅니다.
- 동영상 서비스에서 '사용자가 서비스에서 동영상을 재생하기 위해 거치는 과정'이나, 메시징 서비스에서 '사용자가 메시��지를 전송하기 위해 거치는 흐름' 혹은 '친구를 추가할 때 거치는 과정' 등이 사용자 여정입니다.
플랫폼은 API를 통해 기능을 제공하는데 이를 각 서비스에서 어느 로직에 어떻게 사용하는지 일일이 확인하는 것은 굉장히 까다롭고 어렵습니다. 그래서 1차적으로 주요 API 자체를 CUJ로 설정해 각 기능별 SLI/SLO를 설정하기로 했습니다.
OBS에서 제공하는 다양한 기능 중 이 글에서는 세 가지 주요 기능만 간단히 소개하겠습니다.
| API | 설명 |
|---|---|
| DOWNLOAD | CDN 또는 OBS로부터 오브젝트를 다운로드하기 위한 API |
| UPLOAD | OBS에 오브젝트를 업로드하기 위한 API |
| OBJECT_INFO | OBS에 저장된 오브젝트의 메타 정보를 조회하는 API |
1편에서 말씀드린 것처럼 SLI로 사용할 수 있는 메트릭에는 가용성(availability), 처리량(throughput), 대기 시간(latency) 등이 있습니다. SLI/SLO 측정 원칙에 따라 각 CUJ별 특성에 맞게 아래와 같이 한두 개 정도의 SLI를 선정했습니다.
| API | SLI |
|---|---|
| DOWNLOAD | 가용성(+처리량) |
| UPLOAD | 가용성(+처리량) |
| OBJECT_INFO | 가용성, 대기 시간 |
최초에는 처리량도 DOWNLOAD와 UPLOAD API의 SLI로 사용하기로 했지만 결론적으로 제외했습니다. 이유는 두 API의 다음과 같은 특성 때문입니다.
- 미디어 유형이 오디오, 파일, 이미지, 비디오로 다양합니다.
- 한 번에 업/다운로드되는 미디어 크기 역시 다양합니다.
위와 같은 특성 때문에 서비스별로 유형과 크기에 따른 성능 편차가 심해 일관된 기준을 적용하기 어려웠습니다. 그래서 처리량을 측정하기는 하지만 SLI에서는 제거해 참고 메트릭으로만 활용할 수 있도록 설정했습니다.
SLI/SLO 메트릭 수집하기
SLI/SLO 메트릭 수집은 모든 요청과 응답이 통과하면서 사용자와 가장 가까운 곳인 API 게이트웨이와 같은 엔드포인트에서 수집하는 것이 가장 이상적입니다. 하지만 OBS 특성상 서비스에서 SLI/SLO 관련 메트릭을 수집하기 어려운 상황이었기에 로그에서 필요한 메트릭을 생성해 사용하기로 했습니다.
메트릭 수집 아키텍처는 Kafka와 Vector, Prometheus를 사용해 아래와 같이 설계했습니다.

위 아키텍처의 전체적인 흐름은 다음과 같습니다.
- OBS 서버에서 출력되는 실시간 로그를 메시지 큐인 Kafka로 보내 메시지를 생산합니다.
- OBS는 매우 많은 요청과 트래픽을 처리하는 대규모 글로벌 서버를 보유하고 있습니다. 이에 따라 출력되는 실시간 로그의 양 또한 굉장히 많기 때문에 Kafka를 사용해 이를 처리합니다.
- Kafka에서 생산된 로그를 관찰가능성(observability) 파이프라인인 Vector가 소비해 SLI/SLO에 필요한 메트릭으로 변환합니다.
- Vector가 변환된 메트릭을 익스포트하면 Prometheus가 이를 수집해 저장합니다.
- SLI/SLO는 1개월 이상의 장기 데이터가 필요하며 쿼리가 복잡하기 때문에 Recording Rules를 적용해 성능을 최적화했습니다.
- 마지막으로 이 데이터 소스를 Grafana에서 조회해 시각화합니다.
전체 흐름은 간단해 보이지만 구현하면서 많은 시행착오를 거쳤는데요. 그중 두 가지를 공유하겠습니다.
로그양이 너무 많아요! Vector 최적화
SLI/SLO의 궁극적인 목적은 사용자가 불편함 없이 신뢰를 느끼며 서비스를 사용하고 있는지 측정하는 것입니다. 따라서 메트릭을 실시간으로 수집해야 하며, SLI/SLO와 오류 예산(error budget) 수치가 설정한 기준보다 떨어질 경우 알람을 보내 담당자가 대응할 수 있도록 만드는 게 중요합니다. 하지만 하루 약 350TB 수준의 많은 로그 때문에 Vector가 Kafka에서 소비하는 과정에 문제가 발생했습니다.
여기서 잠시 Vector를 처음 들어보는 분들을 위해 간단히 설명하면, Vector는 DataDog의 오픈소스 프로젝트로 홈페이지에서 Vector를 'A lightweight, ultra-fast tool for building observability pipelines'라고 소개하고 있습니다. 이를 직역하면 '관찰가능한(observability) 파이프라인을 구축하기 위한 가볍고 매우 빠른 도구'라고 할 수 있는데요. 모든 로그와 메트릭, 트레이스를 수집하고(sources), 변환해서(transforms), 라우팅하는(sinks)하는 역할을 담당합니다.
기존에 저희 팀에는 앞서 Vector를 활용해 멀티 CDN 로그 및 트래픽 관리하기라는 글에서 소개했던 Vector 클러스터가 존재했습니다. 이 클러스터가 더 많은 로그를 처리할 수 있도록 아래와 같이 고도화하고 확장했으며, 기존에 클러스터 하나로 운영하던 것을 대규모 처리를 위해 두 개로 증설했습니다.
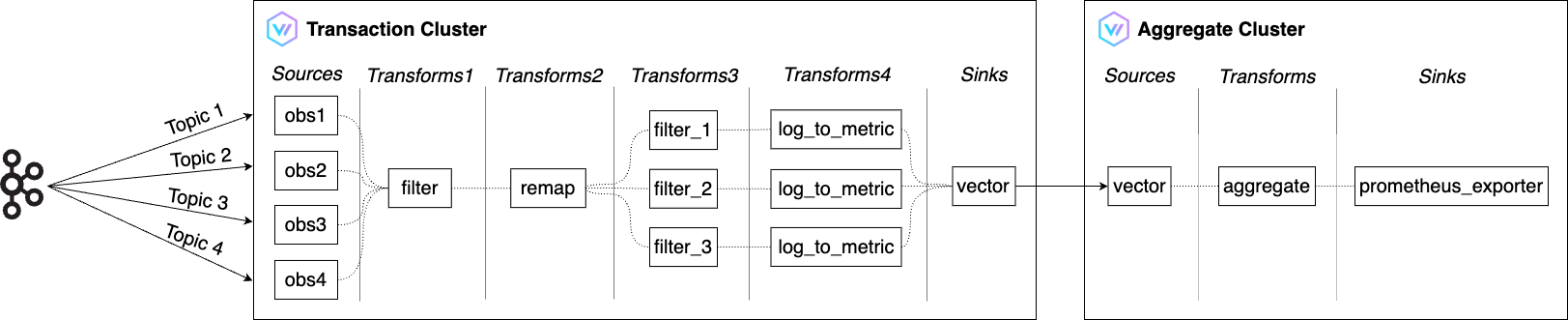
위 아키텍처의 전체적인 흐름은 다음과 같습니다.
- 트랜잭션 클러스터(Transaction Cluster)
- Filter를 활용해 Kafka로부터 받은 수많은 OBS 로그 중 SLI에 필요한 로그만 조건에 맞게 필터링
- Remap을 활용해 원하는 형태로 변형
- Log to metric을 활용해 가용성(availability), 처리량(throughput), 대��기 시간(latency)을 측정하기 위한 메트릭으로 변환
- 변환된 메트릭을 Vector의 Sinks 중 하나인 Vector를 활용해 애그리게이트 클러스터로 전달
- Vector의 Sinks는 Vector에서 외부 서비스로 데이터를 전송하는 역할
- 애그리게이트 클러스터(Aggregate Cluster)
- 트랜잭션 클러스터로부터 받은 메트릭 볼륨을 Aggregate를 활용해 감소
- prometheus_exporter를 활용해 SLI에 필요한 메트릭을 내보내면 Prometheus가 가져가 저장
메트릭 최적화
Vector를 최적화해 메트릭이 실시간으로 밀림 없이 생성되면서 SLI/SLO 대시보드 생성에 필요한 모든 준비가 끝났다고 생각했습니다. 하지만 이는 저의 희망 사항이었을 뿐이었습니다. 대시보드에서 일주일 치 메트릭을 조회하면 로딩하는 데 1분 정도 걸렸기 때문입니다. 그도 그럴 것이 메트릭의 카디널리티(cardinaliry)가 높은데 PromQL(prometheus query)마저 매우 복잡했습니다.
이를 해결하기 위해 Recording Rules를 적용했습니다. Recording Rules는 자주 사용하거나 계산에 많은 비용이 드는 표현식을 미리 계산해 그 결과를 별도의 메트릭으로 저장하는 기능입니다. 미리 계산된 결과를 쿼리하면 필요할 때마다 원래 표현식을 실행하는 것보다 훨씬 빠르게 결과를 얻을 수 있습니다.
저희는 SLI/SLO와 오류 예산에 필요한 표현식을 Recording Rules를 이용해 미리 집계 후 저장해서 메트릭 쿼리의 성능을 높일 수 있었습니다. 아래는 Recording Rules를 정의한 코드의 일부를 가져온 것입니다.
- obs-rules.yaml
groups:
- name: obs
rules:
- record: obs_download_availability
expr: |
sum by (service_code, space_id) (rate(obs_client_http_status{api="DOWNLOAD", error_code="null"}[1m]))
/
sum by (service_code, space_id) (rate(obs_client_http_status{api="DOWNLOAD"}[1m]))
- record: obs_download_throughput_p50
expr: |
histogram_quantile(0.50, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD""}[1m])))
- record: obs_download_throughput_p90
expr: |
histogram_quantile(0.90, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD"}[1m])))
- record: obs_download_throughput_p99
expr: |
histogram_quantile(0.99, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD"}[1m])))
# ... 중략 ...
- record: obs_object_info_latency_p50
expr: |
histogram_quantile(0.50, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))
- record: obs_object_info_latency_p90
expr: |
histogram_quantile(0.90, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))
- record: obs_object_info_latency_p99
expr: |
histogram_quantile(0.99, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))Recording Rules를 적용한 메트릭은 크게 세 가지로 구분됩니다.
- 가용성(availability)
- 가용성은
(성공 요청 수 / 전체 요청 수) x 100%로 계산합니다. - Vector를 통해 생성된 메트릭에 위 계산식을 적용합니다.
- 가용성은
- 처리량(throughput)
- 처리량은 Vector의 log_to_metric에서 히스토그램 타입으로 생성됩니다.
- 여기에 50퍼센타일, 90퍼센타일, 99퍼센타일을 계산해 적용합니다.
- 대기 시간(latency)
- 대기 시간은 처리량과 유사하게 Vector의 log_to_metric에서 히스토그램 타입으로 생성됩니다.
- 여기에 50퍼센타일, 90퍼센타일, 99퍼센타일을 계산해 적용합니다.
다음은 오류 예산 계산에 사용된 PromQL의 Recording Rules 적용 전/후 예시입니다. 적용 후 PromQL이 한결 간단해진 것을 확인할 수 있습니다. 가독성뿐 아니라 미리 계산된 메트릭을 사용하면서 쿼리 조회 성능 또한 개선됐습니다.
- Recording Rules 적용 전
(($slo_period*24*60*(1-$slo_object_availability)) - ( count_over_time( ( ( ( sum(rate(obs_client_http_status{api="DOWNLOAD", service_code=~"$service_code", space_id=~"$space_id", error_code="null"}[$__interval])) / sum(rate(obs_client_http_status{api="DOWNLOAD", service_code=~"$service_code", space_id=~"$space_id"}[$__interval])) ) ) < ($sli_criterion_availability / 100) )[${slo_period}d:1m] ) or on() vector(0) ) - Recording Rules 적용 후
(($slo_period*24*60*(1-$slo_object_availability)) - ( (count_over_time((obs_download_availability{service_code=~"$service_code", space_id=~"$space_id"} < ($sli_criterion_availability / 100))[${slo_period}d:1m])) or on() vector(0) ))
SLI/SLO 활용 방법
저희는 구현된 메트릭을 활용해 다음과 같이 요약용과 각 CUJ별로 대시보드를 생성했습니다.
| SLI 요약 | OBJECT_INFO CUJ |
|---|---|
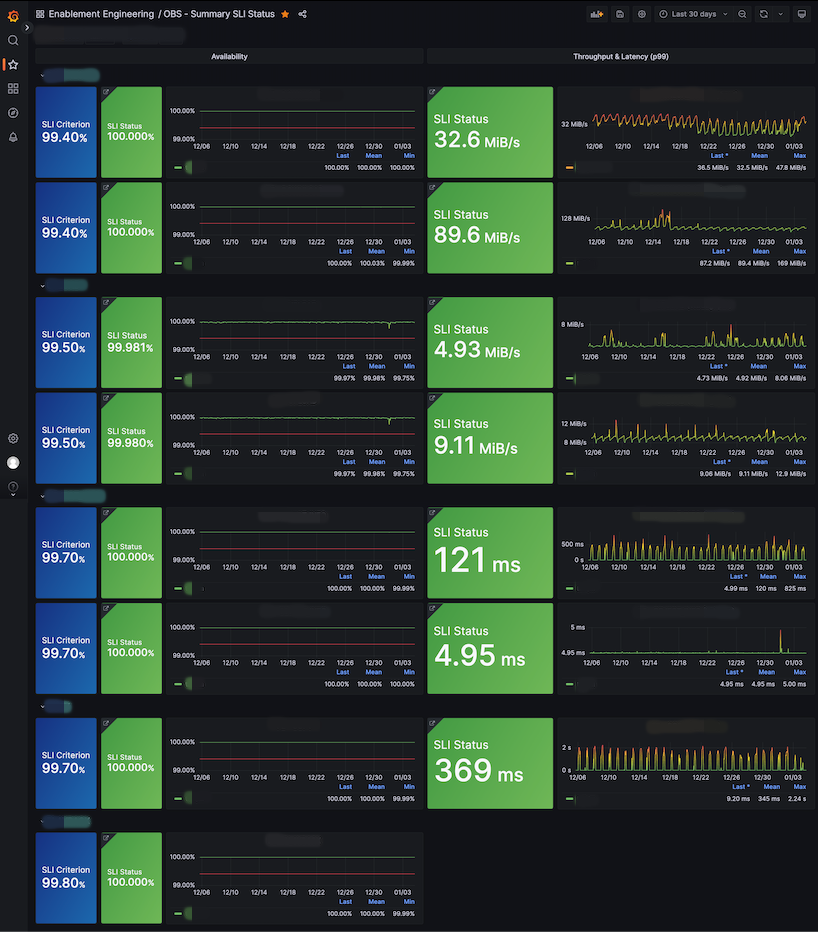 | 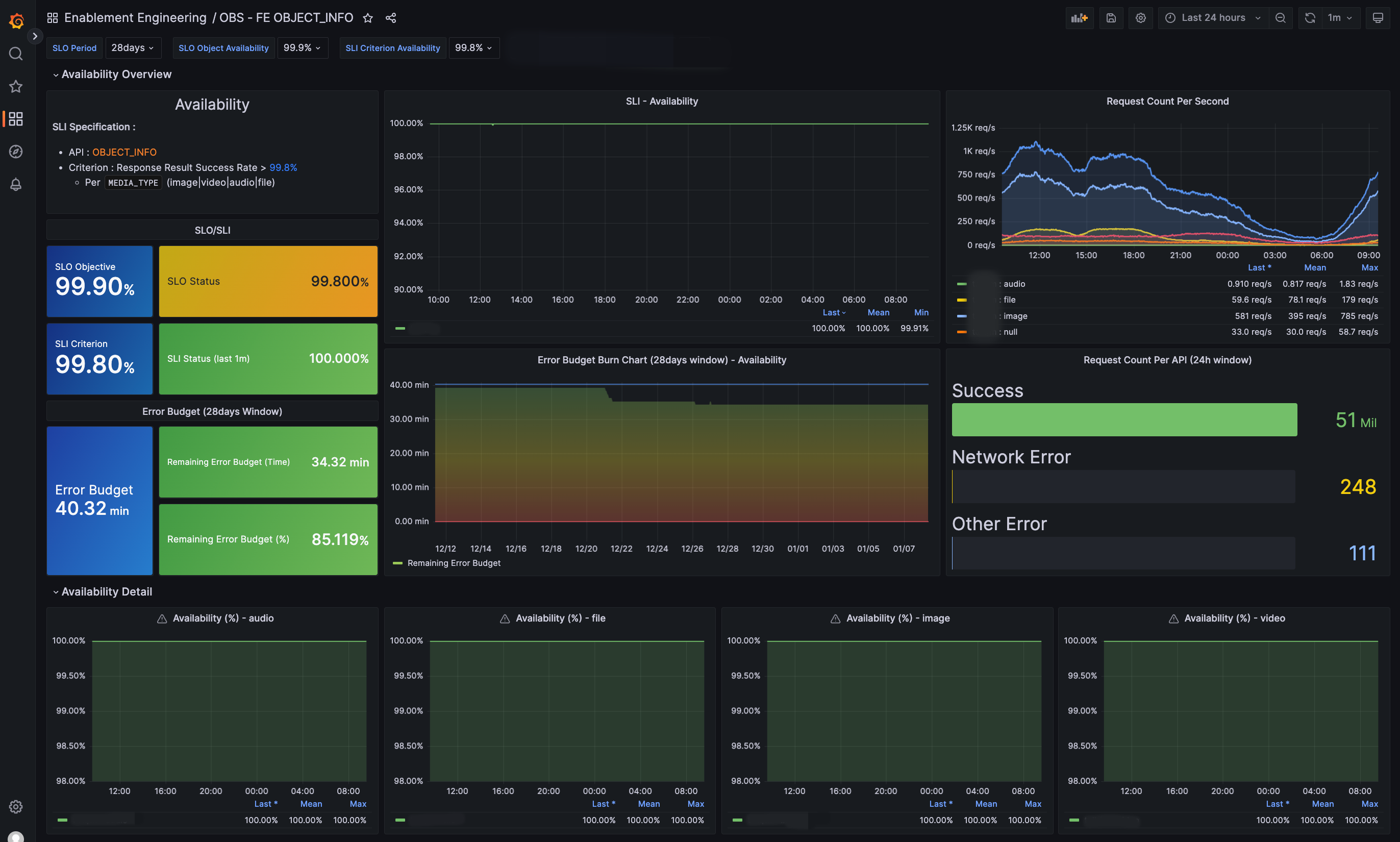 |
SLI 요약 대시보드에서는 현재 서비스에 특이 사항이 있는지 한 눈에 파악할 수 있고, CUJ별 상세 대시보드에서는 SLI/SLO/오류 예산뿐 아니라 요청수나 발생 오류에 대해 보다 세부적으로 확인할 수 있습니다.
각 CUJ별로 목표한 SLO에 맞춰 알람을 설정해 뒀기 때문에 플랫폼을 다양한 서비스에서 사용하는 상황에서도 어느 서비스, 어느 기능에서 사용자가 불편을 겪는지 확인할 수 있습니다.
알람은 Slack과 연동해 놓았으며, 다음과 같이 대시보드에 들어가지 않아도 상황을 확인할 수 있도록 스레드 댓글로 관련 패널을 캡처해 보여주도록 설정했습니다.
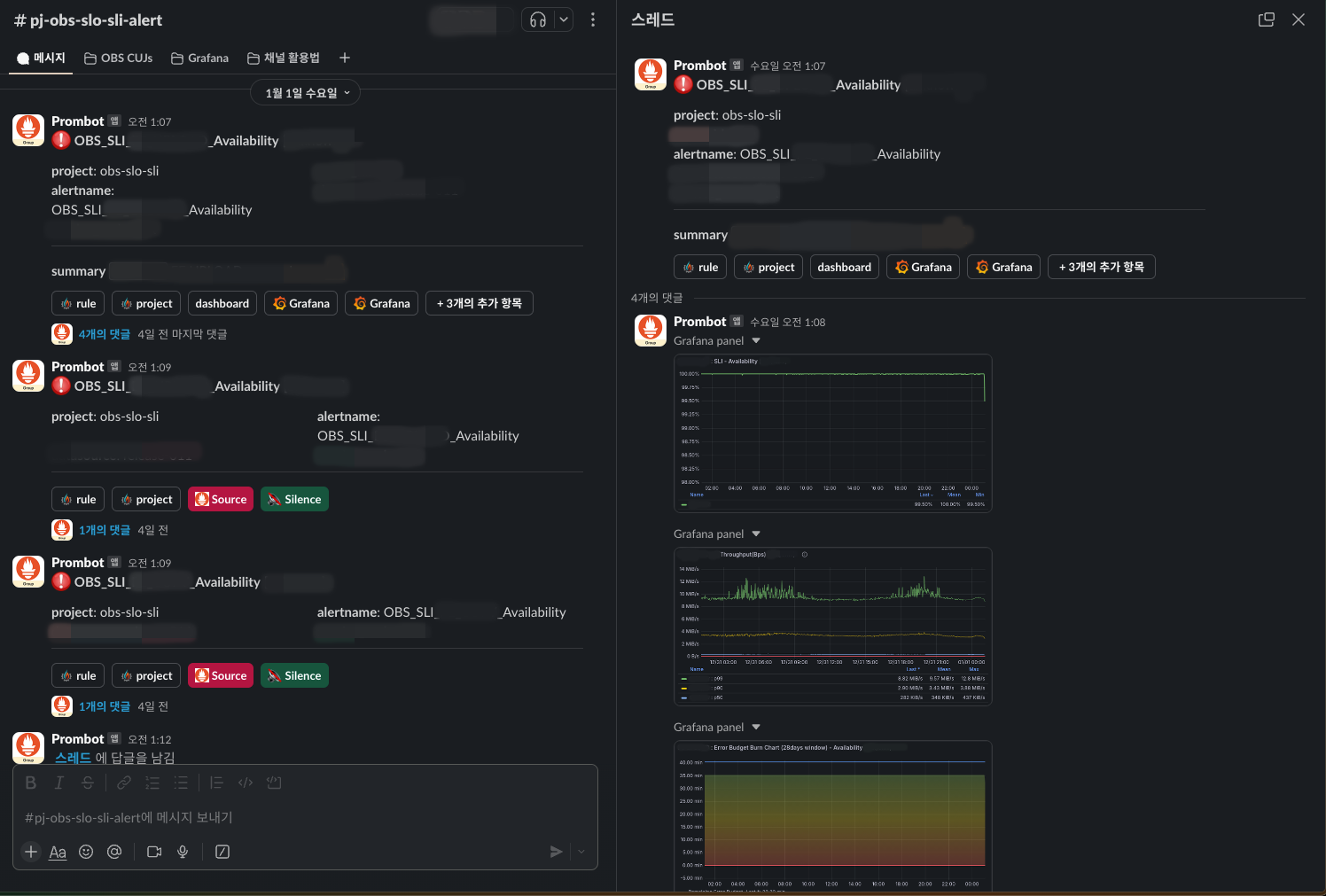
알람이 발생하며 오류 예산이 계속해서 줄어드는 경우 즉각적으로 문제의 원인을 찾아 해결해야 하지만, 오류 예산이 허용된 범위에 있는 경우라면 긴급성을 판단해 대응 수준을 선택할 수도 있습니다. 이는 운영 피로도를 줄이는 데 많은 도움을 줄 수 있습니다. 또한 보다 장기적으로는 오류 예산의 상태에 따라 신규 기능 개발과 안정성 중 어느 것에 더 초점을 맞출지 결정할 수 있습니다.
향후 방향
향후 방향은 'OBS SLI/SLO 측면'과 제가 속한 팀의 역할인 '미디어 플랫폼 SRE 측면'의 두 가지로 나눠볼 수 있을 것 같습니다.
OBS SLI/SLO 측면에서 현재 상태는 OBS의 자체적인 SLI/SLO를 정의한 단계로 아직 플랫폼을 사용하는 서비스에까지는 공유되지 않았습니다. 따라서 향후 플랫폼을 사용하는 서비스들에게 이를 알리고 함께 활용함으로써 사용자에게 더 신뢰성 높은 서비스를 제공할 수 있는 방향으로 나아가고자 합니다.
미디어 플랫폼 SRE 측면에서는 OBS 외에 다양하게 존재하는 미디어 플랫폼에 SLI/SLO를 적용하는 것입니다. 단순히 플랫폼 하나에서 끝내지 않고 LY 내 다양한 서비스와 플랫폼에 적용함으로써 LY 서비스의 신뢰성에 대해 공통의 언어로 이야기할 수 있는 방향으로 나아갈 것입니다.
마치며
이 프로젝트는 사용자 입장에서 고민하면서 SRE 역할에 대해 다시 한번 돌이켜보고 마음을 다잡는 계기가 되었습니다. 그뿐만 아니라 Vector를 활용해 멀티 CDN 로그 및 트래픽 관리하기에서 소개했던 Vector 클러스터를 더욱 확장해 CDN과 OBS에 적용함으로써 관련 노하우도 많이 쌓을 수 있었습니다.
저희는 OBS 외에도 다양한 플랫폼과 서비스에 SLI/SLO를 적용하고 고도화해 나가고 있습니다. 이 글이 여러 SRE 분들에게 도움이 되길 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


