はじめに
こんにちは。Enablement EngineeringチームでSRE(site reliability engineer)業務を担当しているDahee Eoです。
私たちのチームは、LINEサービスをより高性能で効率的かつ安全にユーザーへ提供できるよう、さまざまな面から「Enablement」をサポートする役割を担っています。具体的には、メディアプラットフォームのサイト信頼性エンジニアリング(site reliability engineering)に加え、トラフィックの起点となるGSLB(global server load balancing)とCDN(content delivery network)に関する業務を担当しています。
今回の記事では、信頼性向上のためのSLI/SLO導入vol.1 - 紹介と必要性に続き、メディアプラットフォームにSLI/SLOを定義して運用を行った経験を紹介したいと思います。
サービスではなく、プラットフォームにSLI/SLOを導入する
LINEヤフーには、LINEおよびLINEファミリーサービスで使用される画像や動画などを、保存�・加工して配信するメディアプラットフォーム、OBSがあります。OBSは、LINEの多くのサービスのうち、メディアを使用するほとんどのサービスで利用されている代表的なプラットフォームの一つです。例えば、LINEアプリのチャットルームでやり取りするメディアメッセージはすべて、OBSを利用しています。そのため、このプラットフォームの信頼性(reliability)は非常に重要であり、エンドユーザーにより良い品質のサービスを提供するために、SLI(service level indicator)/SLO(service level objective)を定義することにしました。
ほとんどのSLI/SLOは「サービス」をベースに設定します。ユーザーの視点で信頼性を測定するためには、サービス内部で使用される「プラットフォーム」よりも、サービスをベースに測定する方が容易であるためです。しかし、OBSの場合、約160に及ぶさまざまなLINEサービスで利用されており、このプラットフォームに問題が発生すると、すぐに各サービスに影響が出る可能性があります。そのため、SLI/SLOを別途定義しました。
プラットフォームのCUJをどのように定義するのか?
上記のような背景でスタートしましたが、CUJ(critical user journey)の設定からサービスとは違う壁にぶつかりました。CUJについて詳しくは第1弾で確認できますが、この記事からお読みになっている方のために簡単に紹介しますと、以下のとおりです。
- ユーザーがサービスを利用するプロセスや流れを定義したものを「ユーザージャーニー(user journey)」と呼び、ユーザージャーニーのコア機能やサービスに関するジャーニーを「クリティカ�ルユーザージャーニー(critical user journey、 CUJ)」と呼びます。
- 動画サービスで「ユーザーが動画を再生するために体験する一連のプロセス」や、メッセージングサービスで「ユーザーがメッセージを送信するために体験する流れ」または「友だちを追加する際に体験するプロセス」などがユーザージャーニーです。
プラットフォームはAPIを通じて機能を提供しますが、それを各サービスでどのロジックにどのように使用するかを、いちいち確認するのは非常に手間がかかって大変です。そこで、1次的に主なAPI自体をCUJに設定し、各機能のSLI/SLOを設定することにしました。
ここでは、OBSが提供するさまざまな機能のうち、3つの主要な機能について簡単に紹介します。
| API | 説明 |
|---|---|
| DOWNLOAD | CDNまたはOBSからオブジェクトをダウンロードするためのAPI |
| UPLOAD | OBSにオブジェクトをアップロードするためのAPI |
| OBJECT_INFO | OBSに保存されているオブジェクトのメタデータを取得するAPI |
第1弾で説明したように、SLIで使用できるメトリクスには、可用性(availability)、処理能力(throughput)、待ち時間(latency)などがあります。SLI/SLOの測定原則に基づき、各CUJの特性に合わせて以下の1~2つのSLIを選定しました。
| API | SLI |
|---|---|
| DOWNLOAD | 可用性(+処理能力) |
| UPLOAD | 可用性(+処理能力) |
| OBJECT_INFO | 可用性、待ち時間 |
当初は、処理能力もDOWNLOADとUPLOAD APIのSLIとして使用することにしましたが、最終的に除外しました。その理由は、2つのAPIの以下のような特性のためです。
- メディアのタイプが、オーディオ、ファイル、画像、ビデオなどさまざま
- 一度にアップロード/ダウンロードされるメディアのサイズもさまざま
上記のような特性から、サービスごとにタイプとサイズによるパフォーマンスのばらつきが大きく、一貫した基準を適用することが困難でした。そのため、処理能力は測定しましたが、SLIからは除外して参考メトリクスとしてのみ活用するように設定しました。
SLI/SLOメトリクスを収集する
SLI/SLOメトリクスの収集は、すべてのリクエストとレスポンスが経由し、ユーザーから最も近いAPIゲートウェイなどのエンドポイントで収集するのが最も理想的です。しかし、OBSの特性上、サービスからSLI/SLO関連メトリク��スを収集するのは難しい状況でした。そのため、必要なメトリクスをログから生成して使用することにしました。
メトリクス収集のアーキテクチャは、KafkaとVector、Prometheusを使って以下のように設計しました。

上記のアーキテクチャの全体的な流れは以下のようになります。
- OBSサーバーから出力されるリアルタイムログをメッセージキューであるKafkaに送り、メッセージを生成します。
- OBSは、大量のリクエストとトラフィックを処理する大規模なグローバルサーバーを保有しています。そのため、出力されるリアルタイムログの量も非常に多く、Kafkaを使ってそれらを処理します。
- Kafkaで生成されたログを、観測可能性(observability)パイプラインであるVectorが消費し、SLI/SLOに必要なメトリクスに変換します。
- 変換されたメトリクスをVectorがエクスポートすると、Prometheusはそれを収集して保存します。
- SLI/SLOには1か月以上の長期データが必要で、クエリが複雑なため、Recording Rulesを適用してパフォーマンスを最適化しました。
- 最後に、このデータソースをGrafanaで取得して可視化します。
全体的な流れはシンプルに見えますが、実装する中で多くの試行錯誤を重ねました。そのうち2つを紹介します。
ログの量が多すぎる!Vectorの最適化
SLI/SLOの最終的な目的は、ユーザーが不便なく、信頼してサービスを利用しているかどうかを測定することです。そのため、メトリクスをリアルタイムで収集し、SLI/SLOとエラーバジェット(error budget)の数値が設定した基準を下回った場合、アラートを送信して担当者が対応できるようにすることが重要です。しかし、1日に約350TBに及ぶ大量のログのため、VectorがKafkaからログを消費中に問題が発生しました。
ここで、Vectorを初めて聞く方のために簡単に解説します。VectorはDataDogのオープンソースプロジェクトで、ホームページではVectorを「A lightweight, ultra-fast tool for building observability pipelines」と紹介しています。直訳すると「観測可能性(observability)パイプラインを構築するための軽量で非常に高速なツール」という意味です。Vectorは、あらゆるログやメトリクス、トレースを収集し(sources)、変換して(transforms)、ルーティングする(sinks)役割を担います。
私たちのチームには、以前公開した記事、Vectorを利用してマルチCDNのログとトラフィックを管理する(韓国語)で紹介したVectorクラスタが存在しました。そのクラスタがより多くのログを処理できるよう、以下のように高度化・拡張し、従来はクラスタ1つで運用していたものを大規模な処理のために2つに増設しました。
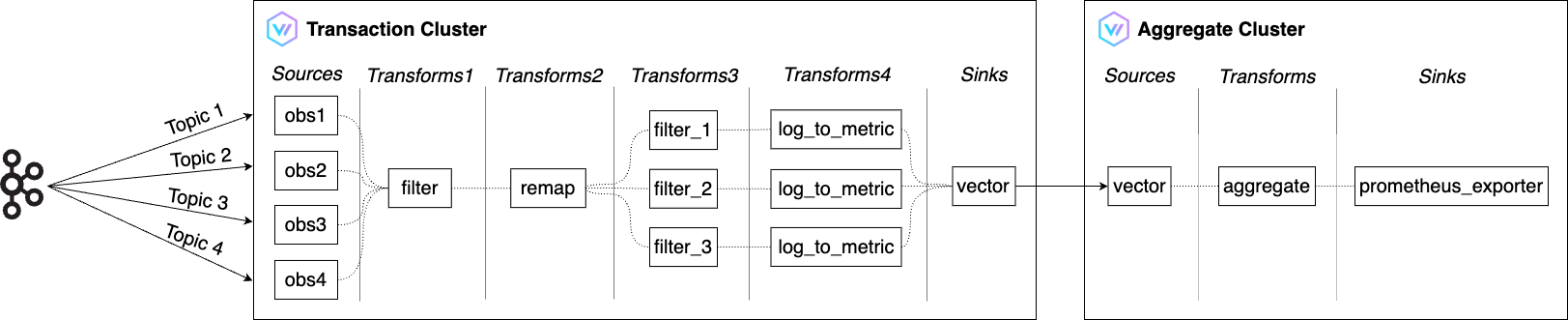
上記のアーキテクチャの全体的な流れは以下のようになります。
- トランザクションクラスタ(Transaction Cluster)
- Filterを利用して、Kafkaから受け取った多数のOBSログのうち、SLIに必要なログのみを指定した条件でフィルタリング
- Remapを利用して必要な形に変換
- Log to metricを利用して、可用性(availability)、処理能力(throughput)、待ち時間(latency)を測定するためのメトリクスに変換
- VectorのSinksの一つであるVectorを利用し、変換されたメトリクスをアグリゲートクラスタに送信
- VectorのSinksは、Vectorから外部サービスへデータを送信する役割を担う
- アグリゲートクラスタ(Aggregate Cluster)
- トランザクションクラスタから受け取ったメトリクスボリュームをAggregateを利用して削減
- prometheus_exporterを利用してSLIに必要なメトリクスをエクスポートすると、Prometheusが取得して保存
メトリクスの最適化
Vectorを最適化し、メトリクスがリアルタイムかつ低遅延で生成されるようになったので、SLI/SLOダッシュボードの作成に必要な準備はすべて完了したと考えていました。しかし、それはあくまで私の希望に過ぎませんでした。ダッシュボードで1週間分のメトリクスを閲覧するには、読み込みに1分くらいかかったからです。それもそのはず、メトリクスのカーディナリティ(cardinality)が高く、PromQL(prometheus query)も非常に複雑でした。
この問題を解決するために、Recording Rulesを適用しました。Recording Rulesは、頻繁に使用される式や計算に多くの費用がかかる式を事前に計算して、その結果を別のメトリクスとして保存する機能です。事前に計算された結果をクエリすることで、必要なたびに元の式を実行するよりもはるかに速く結果を得られます。
私たちは、Recording Rulesを利用してSLI/SLOとエラーバジェットに必要な式を事前に集計・保存することで、メトリクスクエリのパフォーマンスを向上させることができました。以下はRecording Rulesを定義したコードの一部です。
- obs-rules.yaml
groups:
- name: obs
rules:
- record: obs_download_availability
expr: |
sum by (service_code, space_id) (rate(obs_client_http_status{api="DOWNLOAD", error_code="null"}[1m]))
/
sum by (service_code, space_id) (rate(obs_client_http_status{api="DOWNLOAD"}[1m]))
- record: obs_download_throughput_p50
expr: |
histogram_quantile(0.50, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD""}[1m])))
- record: obs_download_throughput_p90
expr: |
histogram_quantile(0.90, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD"}[1m])))
- record: obs_download_throughput_p99
expr: |
histogram_quantile(0.99, sum by(le, service_code, space_id) (rate(obs_client_http_throughput_summary_bucket{api="DOWNLOAD"}[1m])))
# ... 중략 ...
- record: obs_object_info_latency_p50
expr: |
histogram_quantile(0.50, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))
- record: obs_object_info_latency_p90
expr: |
histogram_quantile(0.90, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))
- record: obs_object_info_latency_p99
expr: |
histogram_quantile(0.99, sum by(le, service_code, space_id) (rate(obs_client_http_duration_seconds_bucket{api="OBJECT_INFO"}[1m])))Recording Rulesが適用されたメトリクスは大きく3つに分けられます。
- 可用性(availability)
- 可用性は、
(成功したリクエスト数/リクエスト総数)× 100%で計算します。 - Vectorで生成されたメトリクスに上記の計算式を適用します。
- 可用性は、
- 処理能力(throughput)
- 処理能力は、Vectorのlog_to_metricからヒストグラムタイプで生成されます。
- これに50パーセントタイル、90パーセントタイル、99パーセントタイルを計算して適用します。
- 待ち時間(latency)
- 待ち時間は、処理能力と同様に、Vectorのlog_to_metricからヒストグラムタイプで生成されます。
- これに50パーセントタイル、90パーセントタイル、99パーセントタイルを計算して適用します。
以下はエラーバジェットの計算に使われたPromQLのRecording Rulesの適用前後の例です。適用後、PromQLが一段とシンプルになったことが確認できます。可読性だけでなく、事前に計算されたメトリクスを使用することでクエリの検索パフォーマンスも改善されました。
- Recording Rulesの適用前
(($slo_period*24*60*(1-$slo_object_availability)) - ( count_over_time( ( ( ( sum(rate(obs_client_http_status{api="DOWNLOAD", service_code=~"$service_code", space_id=~"$space_id", error_code="null"}[$__interval])) / sum(rate(obs_client_http_status{api="DOWNLOAD", service_code=~"$service_code", space_id=~"$space_id"}[$__interval])) ) ) < ($sli_criterion_availability / 100) )[${slo_period}d:1m] ) or on() vector(0) ) - Recording Rulesの適用後
(($slo_period*24*60*(1-$slo_object_availability)) - ( (count_over_time((obs_download_availability{service_code=~"$service_code", space_id=~"$space_id"} < ($sli_criterion_availability / 100))[${slo_period}d:1m])) or on() vector(0) ))
SLI/SLOの活用方法
私たちは実装されたメトリクスを活用して、以下のようにSLIの要約用と各CUJ用のダッシュボードを作成しました。
| SLIの要約 | OBJECT_INFO CUJ |
|---|---|
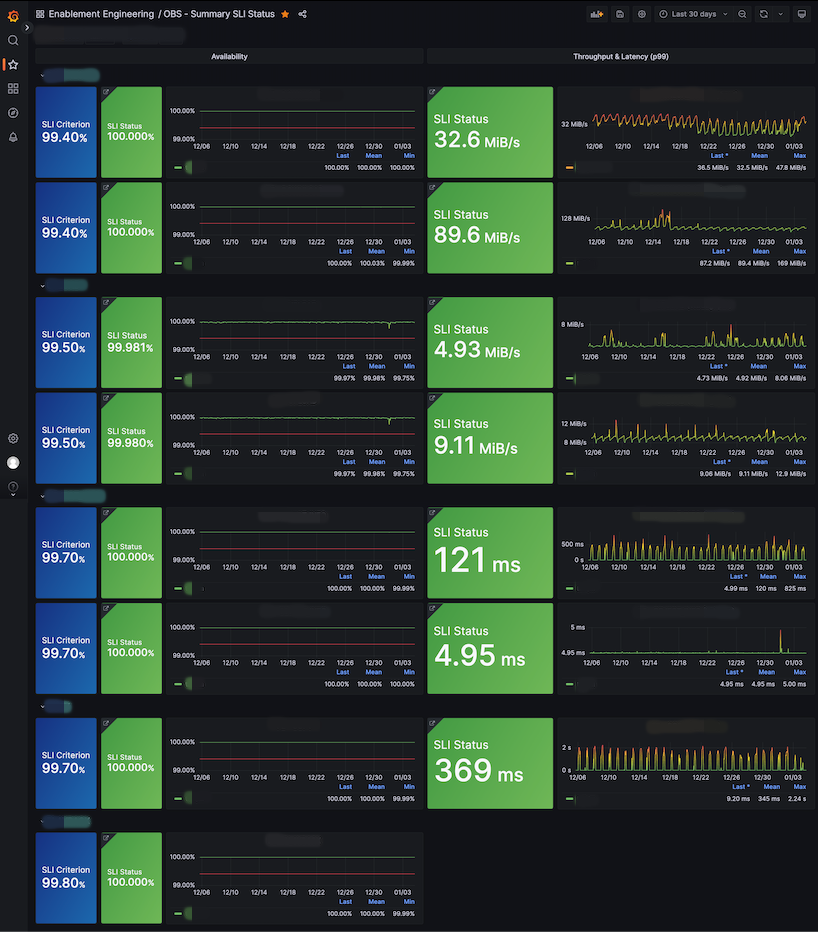 | 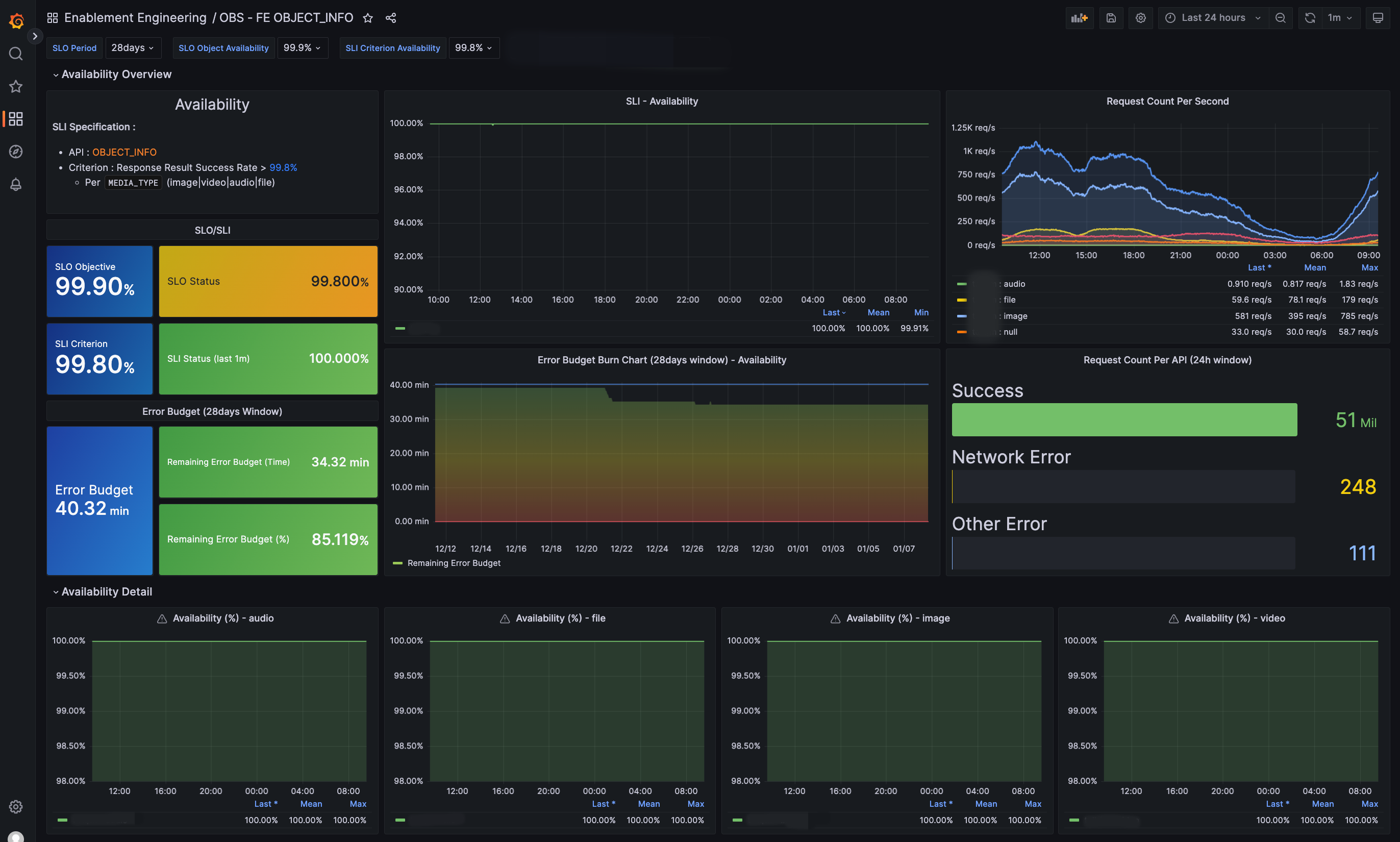 |
SLIの要約のダッシュボードでは、サービスの現状が一目でわかります。各CUJの詳細ダッシュボードでは、SLI/SLO/エラーバジェットだけでなく、リクエスト数や発生エラーについてもより詳しく確認できます。
各CUJで設定したSLOに基づいてアラートを設定しているため、プラットフォームを複数のサービスで使用している状況でも、どのサービス、どの機能でユーザーが不便を感じているかを確認できます。
アラートはSlackと連携しています。以下のように、ダッシュボードに入らなくても状況を確認できるよう、関連パネルをキャプチャしてスレッドのコメントで表示するように設定しました。
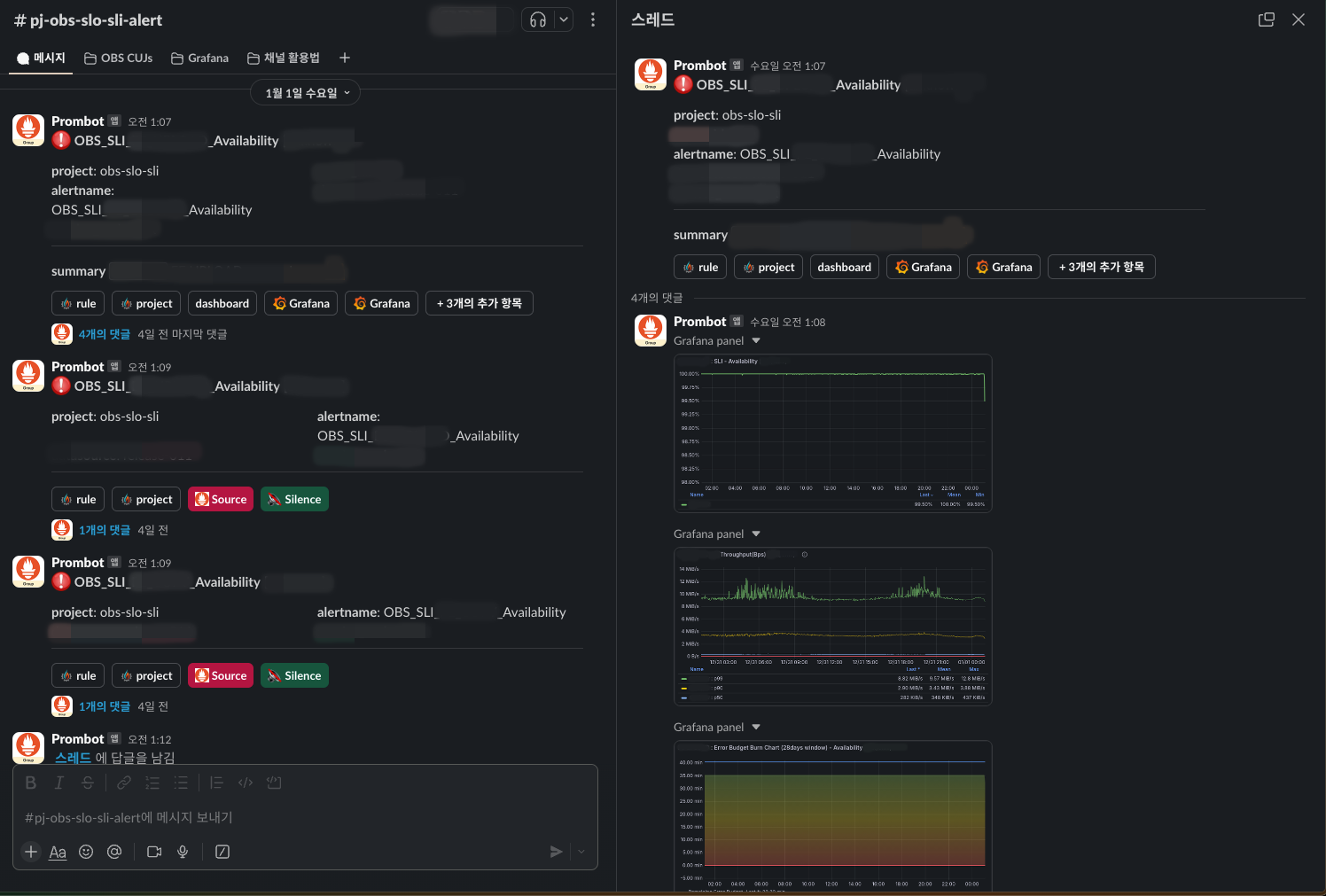
アラートが発生し、エラーバジェットが減少し続ける場合、即座に問題の原因を特定して解決する必要があります。一方、エラーバジェットが許容範囲内であれば、緊急性を判断して対応レベルを選択することもできます。これにより、運用の手間を軽減できます。また、より長期的には、エラーバジェットの状況に応じて、新機能の開発と安定性のどちらに重点を置くかを決定できます。
今後の方向性
今後の方向性は、「OBS SLI/SLOの観点」と、私が所属しているチームの役割である「メディアプラットフォームSREの観点」の2つに分けて考えられます。
OBS SLI/SLOの観点から、現時点ではOBS独自のSLI/SLOを定義した段階であり、まだプラットフォームを利用するサービスにまで共有されていません。今後、プラットフォームを利用するサービスにSLI/SLOを知らせ、一緒に活用することで、ユーザーにより信頼性の高いサービスを提供できる方向へ進んでいきたいと考えています。
メディアプラットフォームSREの観点からは、OBS以外にもさまざまなメディアプラットフォームにSLI/SLOを導入することです。1つのプラットフォームで終わるのではなく、LINEヤフー内のさまざまなサービスやプラットフォームに導入することで、LINEヤフーサービスの信頼性について共通の言語で会話できる方向に進んでいきます。
おわりに
このプロジェクトは、ユーザーの視点で考えながら、SREの役割につい��て改めて振り返り、心を引き締めるきっかけとなりました。また、Vectorを利用してマルチCDNのログとトラフィックを管理する(韓国語)で紹介したVectorクラスタをさらに拡張してCDNとOBSに導入することで、関連ノウハウも多く蓄積できました。
私たちは、OBS以外にもさまざまなプラットフォームとサービスにSLI/SLOを導入し、高度化しています。この記事が多くのSREの方のお役に立てば幸いです。最後までお読みくださり、ありがとうございました。


