はじめに
こんにちは。私たちAMD(Applied ML Dev)チームでは、生成AIを含むさまざまなAI/MLモデルを開発し、サービスに適用しています。
先日公開したAIで生成された画像をどのように評価するのか?(基本編)では、生成AIモデルの性能を評価するさまざまな方法論を紹介しました。今回は、生成AIを活用したいくつかのアプリケーションと、そのアプリケーションの性能を向上させるために、生成AIの評価方法をどのように活用しているかについて紹介したいと思います。
写真内の被写体を除く背景の人物をAIで除去する方法
旅行先で素敵な景色を背景に写真を撮ったのに、予想外の人物が一緒に写っていて、何度も写真を撮り直した経験はありませんか?このような不便を解消するために、画像生成AI技術を活用できます。
以下は、画像生成AI技術を活用して背景の人物を除去した結果です。
| 原画像 | 背景の人物を除去した画像 |
|---|---|
 |  |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
背景の人物除去(background person removal、以下BPR)は、次のようなプロセスで行われます。
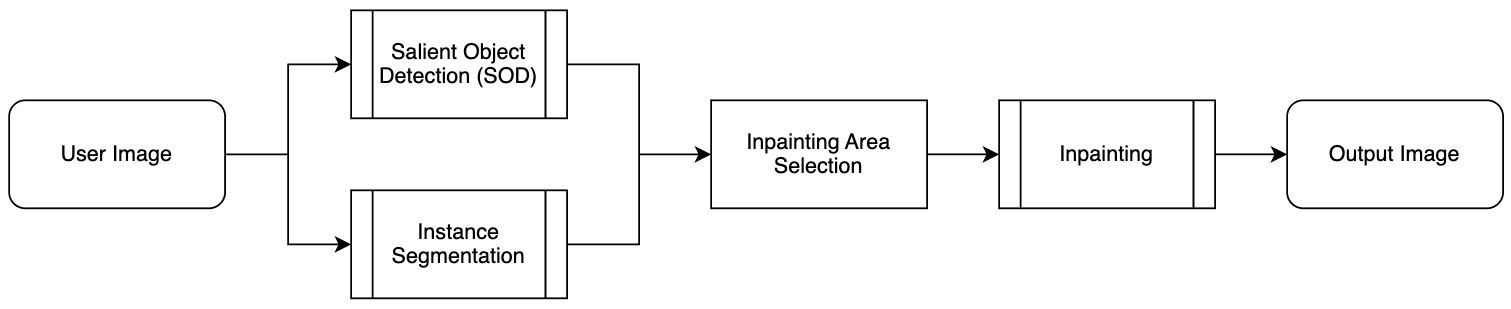
上記のプロセスは、大きく3つの段階に分けられます。
- インスタンス分割(instance segmentation)
- 入力画像内の各ピクセルがどのオブジェクトに属するかを識別する段階です。インスタンス分割モデルを利用して人や建物、木などさまざまなオブジェクトを区別し、個別に認識します。
- 顕著性物体検出(salient object detection)
- 画像で最も目立つ顕著性物体を識別する段階です。顕著性物体検出モデルを用いて視線が集中する領域をピクセル単位で抽出することで、メインの被写体と背景の人物を区別できます。
- インペインティング(inpainting)の実行
- 主な領域に属さない背景の人物が含まれている領域を、インペインティング技術を用いて自然に除去または復元する段階です。
- ここで言う「インペインティング」とは�、画像の特定の部分を除去し、周囲の環境と調和するように再構成する技術です。
ここで最後の段階であるインペインティングの実行は、背景の人物を除去した結果に最も大きな影響を与えるため、性能の良いインペインティングモデルを使用する必要があります。最近、画像生成モデルを用いたインペインティング技術が多く発表されていますが、インペインティング技術についてより詳しく見てみましょう。
インペインティング技術とは?
インペインティング技術は、画像の特定の領域を除去し、その空白を自然に埋める技術です。例えば、写真内の人物やオブジェクトを削除した後、その空間を周囲の環境と調和するように再構成して埋める作業に活用できます。
インペインティングモデルは生成AIの一種で、画像の欠損部分を補完することに特化したモデルと言えます。インペインティングモデルは、アプローチによって大きく2つの主要なモデルに分けられます。それは、ディフュージョン(diffusion)系のモデルとGAN(generative adversarial network)系のモデルです。
この2つのアプローチは、それぞれ独自のメカニズムと利点を持っており、画像復元作業においてそれぞれ異なる方法で利用されます。一つずつ簡単に説明します。
- ディフュージョンモデル
- 画像を徐々に変化させ、損傷した領域を復元する方法です。
- 通常、画像からノイズを除去したり、徐々に画像を改善したりすることで動作します。例えば、最初のランダムノイズの状態から徐々にノイズを減らしていき、原画像の形状を見つけるプロセスで行�われます。
- 複雑な画像のディテールを自然に復元するケースに特に有利です。
- ただし、良い結果が出ることもありますが、時には奇妙なオブジェクトが生成されることもあります。
- 画像生成のために繰り返しノイズ除去が行われるため、一般的にGANモデルに比べて画像生成速度が遅くなります。
- ディフュージョンモデルについてより詳しくは、先日公開されたAIで生成された画像をどのように評価するのか?(ブラックボックス最適化適用編)を参照してください。
- 画像を徐々に変化させ、損傷した領域を復元する方法です。
- GANモデル
- GANモデルは、生成者(generator)と識別者(discriminator)という2つのニューラルネットワークが競争しながら学習する構造です。
- 生成者は欠損した画像を復元しようとし、識別者は生成された画像が実際の画像とどれだけ似ているかを評価します。このプロセスを繰り返すことで、ますます精巧でリアルな画像を生成します。
私たちは、BPRアプリケーションに以下のインペインティングモデルを含むさまざまなモデルを適用してテストを行いました。原画像の解像度が低い場合や、インペイントする領域が小さい場合には、ほとんどのモデルで良い結果が出ました。しかし、原画像の解像度が高く、インペイントする領域が大きい場合には、モデルによって大きな差が出ました。
- LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions(WACV 2022、参考)
- HINT(High-quality INPainting Transformer with Mask-Aware Encoding and Enhanced Attention)(TMM 2024、参考)
- FLUX. 1-Fill-dev(Arxiv 2024、参考)
まず、以下は使用したインペインティングモデルに関係なく良い結果が出た例です。
| 原画像(赤線:インペインティング領域) | LaMaインペインティングモデルの結果 |
|---|---|
 |  |
| HINTインペインティングモデルの結果 | FLUX. 1-Fill-devインペインティングモデルの結果 |
 |  |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
以下は、使用したインペインティングモデルによって結果が大きく異なった例です。
| 原画像(赤線:インペインティング領域) | LaMaインペインティングモデルの結果 |
|---|---|
 |  |
| HINTインペインティングモデルの結果 | FLUX. 1-Fill-devインペインティングモデルの結果 |
 |  |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
上記のテスト結果からわかるように、使用するモデルを選定する際、論文で提示された性能指標のみで判断するのは困難です。各モデルが実際の応用事例で�どのような性能を示すのか明確に把握することが難しいためです。
一般的に、論文では決められた解像度(例:256x256)で評価を行います。しかし、これは実際の使用環境とは異なる可能性があります。また、論文によって評価に使用したインペインティング領域が異なり、多くの場合、実際に私たちが直面する現実とは異なる状況で評価が行われます。さらに、インペインティングは画像生成モデルの一種であるため、正解というものは存在しません。さまざまな形状で生成されたすべての画像が正解となる可能性があり、評価はなお一層複雑になります。
したがって、モデルの実際の性能を評価する際には、さまざまな要素を考慮する必要があります。論文で提示された指標は、全体的な性能の傾向をある程度示すことができますが、BPRタスクの正確なインペインティング性能を表すことはできません。例えば、あるテストでは良い結果を示したモデルが、別のテストでは期待外れの結果を示すケースもありました。
このような理由から、私たちは最新の生成画像の評価方法を適用することで、どの評価方法が実際の人間による評価結果に最も近いかを確認することにしました。これにより、BPR機能に最も適したインペインティングモデルを選択できる基準を設けることを目指しました。では、実験の内容と結果について詳しく紹介します。
インペインティングモデル評価の実施
生成モデルを評価する最も信頼性の高い方法は、人間による評価です。しかし、この方法はコストと時間がかかり、自動化が難しいという欠点があります。そこで�、私たちは人が評価した結果とほぼ同じような結果が出る生成モデルの評価方法を確立することを目標としました。そして、その目標を達成するために、人による評価結果と最も大きな関連性を示す評価方法を見つけるために実験を行いました。その実験には、次の2つのデータセットを使用しました。
1つ目は、目標アプリケーションであるBPRで生成された画像結果の品質偏差が大きいデータのみを集めたBPR評価データセットで、2つ目は、インペインティングでよく使われているPlaces365評価データセットです。それぞれのデータセットを使った評価方法とその結果を一つずつ見ていきましょう。
BPR評価データセットを使用した評価方法と結果
実験に使用したデータセットとインペインティングモデル
BPR評価データセットは、BPRで得られた結果の品質がまちまちな10枚の画像で構成されています。これを利用して、さまざまなインペインティングモデルと評価方法をテストしました。
本実験で使用したインペインティングモデルは、2022年から2024年の間に発表された以下の11のインペインティングモデルです。
- LaMa (WACV 2022), MAT (CVPR 2022), MAE-FAR (ECCV 2022), ZITS++ (TPAMI 2023), CoordFILL (AAAI 2023), SCAT (AAAI 2023), HINT (TMM 2024), MxT (BMVC 2024), PUT (TPAMI 2024), Latent codes for pluralistic image inpainting (CVPR 2024), FLUX. 1-Fill-dev (Arxiv 2024)
実験に使用した画像評価方法
本実験で使用した画像の評価方法は、以下のとおりです(各評価方法について詳しくは、先日公開した「AIで生成された画像をどのように評価するのか?(基本編)」を参照してください)。
- LAION Aesthetic Score-v2(以下Aesthetic Score)、CLIP-IQA、Q-Align:単一画像の品質を測定する手法です。
- PickScore、ImageReward、HPS-V2:画像とその画像を生成するためのプロンプトを使用して、画像とテキストの一致度および画像品質を同時に評価します。
ちなみに、本実験では、インフェイティングモデルに関する論文でよく使われるFID(原画像とインペイントされた結果の画像との分布間のFréchet距離を測定する指標)を使用しませんでした。FIDは、正確な結果を得るために10,000枚以上の多数のデータセットを使用することを推奨して�いるためです(後に紹介するPlaces365評価データセットの実験では、FIDを使用しました)。
また、結果評価の基準となる人間による評価では、モデルによって生成された画像を見て、1点(最低)から5点(最高)の間でスコアをつける方法で評価を行いました。
事前準備 - 画像を評価するためのプロンプト作成
評価方法のうちPickScoreとImageReward、HPS-V2は、画像を評価するために画像を生成したプロンプトが必要です。しかし、BPRに用いられたインペインティングモデルは画像生成に使用したプロンプトが存在しないため、MicrosoftのPhi-3.5-vision-instructモデルを用いて画像を模倣するプロンプトを生成しました。このとき、BPRの結果として、背景の人物がいない画像が生成される必要があります。そのため、生成されたプロンプトに背景の人物に関する内容が含まれないよう、次のようにプロンプトを生成するためのプロンプトを作成しました。
- 画像の描写を生成するためのプロンプト
"""
Describe the image within 20 words.You should follow the below rules.
- Describe the overall appearance and background of the image without mentioning any of the people.
- You should not mention about the person.
- DO NOT mention about other pedestrians or other patrons or other persons in the background.For example, You can describe the image like below.
- A sunny day at a riverside walkway with trees, a clear sky, and the Eiffel Tower in the background.
- A vibrant street scene with a bright orange food stall and a clear blue sky.
- A street scene with a building and a British flag. There are potted plants and a statue visible.But you should not describe the image like below.
- A person in a grey jacket and black pants is carrying a black bag, walking in a hallway with a security guard in the background.
- The image depicts a city street scene with a person sitting on the road, surrounded by urban architecture and a few pedestrians walking in the background.
- The image depicts a cozy indoor setting with a person seated at a table, enjoying a meal. The room is well-lit with natural light, and there are other patrons in the background.
""" - プロンプトの生成結果


A historic square with a prominent tower, cobblestone pavement, and traditional European architecture. A statue stands in the center of a square with a fountain, surrounded by buildings with lit windows. * 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
評価結果と結果分析
以下は、人間が評価した結果と各評価方法の結果指標との関連性(Pearson correlation coefficient)を示したものです。1に近いほど関連性が高く、0に近いほど関連性��がないことを示しています。
| 指標名 | Aesthetics score | CLIP-IQA | Q-Align | PickScore | ImageReward | HPS v2 |
|---|---|---|---|---|---|---|
| 関連性 | 0.924 | 0.187 | 0.384 | 0.282 | 0.279 | -0.290 |
以下は、各評価方法間の関連性を示す関連性マトリックスをヒートマップとともに示したグラフです。同様に、1に近いほど関連性が高く、0に近いほど関連性がないことを示しています。
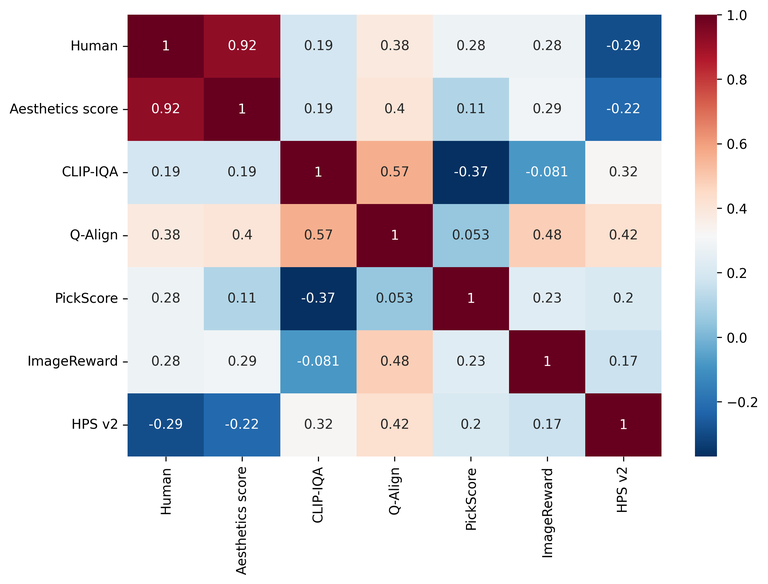
まず、Aesthetic Scoreが人間による評価と最も高い関連性(0.924)を示し、画像の全体的な品質を評価する際に最も信頼できる指標であることがわかりました。これは、Aesthetic ScoreがBPRに必要なインペインティングの結果に対して、人間が直感的に知覚する画像の品質を適切に反映できることを示唆しています。
一方、CLIP-IQAとQ-Alignは、人間による評価との関連性が高くないこと(それぞれ0.187と0.384)が示されました。これらの指標は、画像の特定の要素を評価するには有用かもしれませんが、全体的な画像の品�質を評価するには限界がある可能性があります。
PickScoreとImageReward、HPS-V2のような指標は、画像とプロンプトの間の一致度と生成された画像の品質の両方を評価することに焦点を当てている指標です。しかし、今回の画像品質評価の実験では、期待に応えられませんでした。これは、これらの評価方法が画像の品質よりもテキストとの一致度により焦点を当てているためかもしれません。
以下は、例の画像に対するいくつかのモデルの結果とそれに対応するAesthetic Score評価結果のスコアをまとめた表です。
| インペインティングモデル | 原画像(赤線:インペインティング領域) | FLUX. 1-Fill-dev | Latent codes for pluralistic image inpainting |
|---|---|---|---|
| Aesthetics score | - | 4.75 | 4.71 |
| 結果画像 | | |  |
| インペインテ�ィングモデル | MAE-FAR | HINT | MxT |
| Aesthetics score | 4.705 | 4.56 | 4.52 |
| 結果画像 |  |  |  |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
上記の表と合わせてAesthetic Scoreのスコアと画像の品質を総合的に分析すると、スコアが画像の品質とどのように関連しているのか、以下のように把握できます。
- まず、FLUX.1-Fill-devの画像を見ると、インペインティング領域が精巧に生成されていることがわかります。また、Aesthetic Scoreも高いスコアを記録しており、画像品質とスコアがよく一致していることを示しています。
- Latent Codes for Pluralistic Image InpaintingとMAE-FARは、FLUX.1-Fill-devほど自然な画像ではありませんでしたが、適度な品質を示しています。これにより、Aesthetic Scoreは、FLUX.1-Fill-devよりやや低いスコアがつけられたことがわかります。
- HINTとMxTは、生成された画像にアーティファクトが含まれるなど、全体的に品質が低く、Aesthetic Scoreのスコアも低くなっています。
Places365評価データセットを使用した評価方法と結果
実験に使用したデータセットとインペインティングモデル
Places365データセットは、さまざまなビジョン関連モデルの学習や評価に広く使われています。日常生活で見られる都市や風景など、約180万枚のデータセットで構成されています。その中でも、Places365評価データセットは計36,500枚の画像で構成されており、評価のためのインペインティング領域は決まっていません。そのため、各論文ではそれぞれ異なるインペインティング領域を使用して評価を行い、数値を記述しています。
本実験では、モデルに関係なく同じインペインティング領域を設定して評価を行いました。インペインティング領域は、平均して画像全体の40%程度の領域に設定しました。
以下は、本実験で使用したインペインティングモデルです。2022年から2024年の間に発表された9つのインペインティングモデルを使用しました。
- LaMa (WACV 2022), MAT (CVPR 2022), CoordFILL (AAAI 2023), SCAT (AAAI 2023), HINT (TMM 2024), MxT (BMVC 2024), PUT (TPAMI 2024), Latent codes for pluralistic image inpainting (CVPR 2024), FLUX. 1-Fill-dev (Arxiv 2024)
ちなみに、前述のBPR評価データセットの実験で使用したインペインティングモデルのうち、MAE-FAR(ECCV 2022)とZITS++(TPAMI 2023)モデルは、いくつかの画像で正常な結果が生成されなかったため、今回の実験では除外しました。
実験に使用した画像評価方法
本実験で使用した評価方法は、以下のとおりです。ちなみに、PickScoreとImageReward、HPS-V2は画像を生成するためのプロンプトが必要なので、BPRデータセットを評価したときと同じ方法でプロンプトを生成しました。
- Aesthetics score、CLIP-IQA、Q-Align:単一画像の品質を測定する手法です。
- PickScore、ImageReward、HPS v2:画像とその画像を生成するためのプロンプトを使用して、画像とテキストの一致度および画像品質を同時に評価します。
- LPIPS:原画像と結果画像のペアを比較し、結果画像の品質を測定します。
- FID、FD-DINO、CMMD
- FID:原画像の分布と結果画像の分布とを比較し、結果画像の品質を測定します。
- FD-DINO:FIDを改良したモデルです。FIDは、原画像セットと生成された画像セット間のFréchet距離を測定するためにInception-v3をバックボーン(backbone)として使用し、その特徴空間を使用します。一方、FD-DINOは、DINOv2-ViT-L/14をバックボーンとして使用し、その特性空間におけるFréchet距離を計算します。
- CMMD:FIDを改良したモデルです。ガウスRBFカーネルを用いてCLIP-L特徴空間におけるMMD(maximum mean discrepancy)距離を計算します。
各評価方法を36,500枚の画像全体に適用しました。また、人間による評価はデータセットの中からランダムに20枚を選択し、各モデルの結果に1点から5点までのスコアをつける方法で行いました。
評価結果と結果分析
以下は、前述の実験と同様に、人間による評価結果と各評価方法の結果指標との関連性を示したものです。1に近いほど関連性が高く、0に近いほど関連性がないことを示しています。
| 指標名 | Aesthetics score | CLIP-IQA | Q-Align | PickScore | ImageReward | HPS v2 | LPIPS | FID | FD-DINO | CMMD |
|---|---|---|---|---|---|---|---|---|---|---|
| 関連性 | 0.877 | 0.063 | 0.843 | 0.648 | 0.428 | 0.387 | 0.301 | 0.877 | 0.604 | 0.898 |
以下は、各評価方法間の関連性を示す関連性マトリックスをヒートマップとともに示したグラフです。同様に、1に近いほど関連性が高く、0に近いほど関連性がないことを示しています。
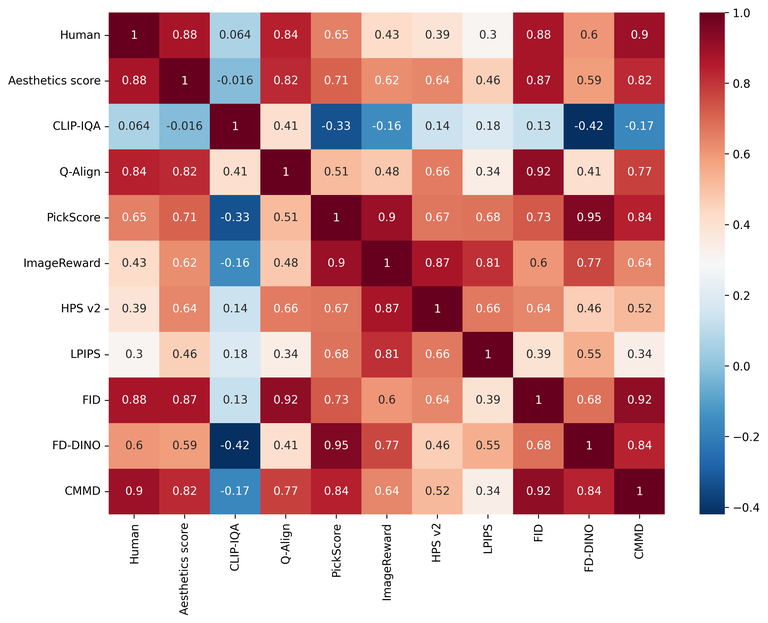
今回の実験結果で、人間による評価結果と最も関連性が高いと示された評価方法は、CMMD(0.898)でした。これは、CMMDが画像品質評価においてかなり信頼できる評価方法であることを示唆しています。
次に、FIDとAesthetic Score (0.877)の関連性が高いことがわかりました。ちなみに、CMMDを含むFID系の評価方法では、原画像と生成された画�像の分布を比較するため、大規模なデータセット(10,000枚以上)を使用することを推奨します。一方、Aesthetic Scoreは、より少ないデータセットを使用しても評価できます。つまり、より少ないデータでも高い信頼性を提供できることを意味します。
LPIPSは、原画像と結果画像のペアを比較して品質を測定する方法ですが、人間の主観的な美的評価との関連性は比較的低いものでした。これは、原画像と結果画像のペアを比較するだけでは、画像の全体的な品質を十分に反映できない可能性があることを示しています。
おわりに
AIで生成された画像には、決まった正解はありません。さまざまな形状の画像がすべて正解になり得ます。そのため、画像の品質を正確に数値化することは非常に難しい課題です。また、生成画像モデルに関する論文で提示された性能指標は、特定のタスクの性能を十分に反映していない場合もあります。
そこで私たちは、インペインティングという生成モデルを使用した特定のタスクに、どのような評価方法を適用するのが良いかを探ることにしました。まず、私たちのタスクに適した評価方法は、人間による評価と最も関連性の高い評価方法であると仮定し、2つのデータセットを基に人間による評価と一致する評価方法を見つける実験を行いました。
実験の結果、データセットによって最適な評価手法が異なるため、完全に満足のいく結果は得られませんでしたが、ある程度の傾向は確認できました。これにより、適切なインペインティングモデルを選択するための基準が設けられました。もちろん、この方法も完璧ではなく、評価方法を完全に自動化するには、まだまだ解決すべき課題があると考えています。
これからも私たちは、インペインティングの性能をより正確に表す評価方法を見つけるための研究を継続的に進めていく予定です。今後、また共有できるような結果が出ましたら、LINEヤフー Tech Blogで紹介したいと思います。長文をお読みいただき、ありがとうございました。


