はじめに
ここ数年、生成モデルは人工知能の分野で革新的なツールとして浮上し、研究者や業界のリーダーから大きな注目を集めています。生成モデルは、ディープラーニング技術の進歩に基づき、高品質の画像や動画などの複雑なデータ形式を生成するうえで前例のない能力を示しています。特に、敵対的生成ネットワーク(generative adversarial network、以下GAN)や変分オートエンコーダ(variational autoencoder、VAE)、拡散モデル(diffusion model)などの新しいアーキテクチャが登場し、生成技術は学問的な探求にとどまらず、実際の産業での応用に急速に拡大しています。このような発展は、エンターテインメントや広告、コンテンツ制作などのクリエイティブ産業における新たな可能性を開くだけでなく、科学的シミュレーションや仮想環境、拡張現実などのさまざまな分野でも著しい発展を引き起こしています。
しかし、従来の機械学習手法とは異なり、生成モデルは、生成された成果物に対する正解(ground truth、以下GT)を持っていない点で、定量的な評価が非常に難しいという限界があります。結果はさまざまな形で生成され、表現される可能性があるため、必ずしもある一つの正解と同じように生成されるべきだと仮定できないのです。生成モデルの品質を評価�するために、FID(Fréchet Inception Distance)やIS(inception score)、CLIPScoreのような代替的な評価指標が用いられていますが、これらの指標もモデル性能のすべての側面を十分に反映することは難しいです。
今回の記事では、FIDやISなどビジョン(vision)生成モデルによって生成された成果物を評価するさまざまな方法を詳しく見ていき、実際のアプリケーションに生成モデルを適用する際に、どのような点を考慮すべきかを探ります。
ビジョンモデルの性能評価方法とは?
画像生成モデルの評価方法について説明する前に、より明確で理解しやすい基準を設定するため、まず、古典的なビジョンタスクとそのタスクを解決するためのビジョンモデルの性能評価方法を見てみます。これにより、モデルの性能評価の課題における背景をより理解しやすくなるでしょう。
ビジョンモデルの性能を評価する方法は、大きく分けて定性的方法と定量的方法に分けられます。定性的方法は、人間が主観的な基準で成果物を検討し、性能を表現する方法です。この方法は、人間が直接成果物を評価するため、定量的評価では反映できない微妙な品質の違いまで反映できるという利点があります。しかし一方で、人それぞれの基準によって結果が異なる可能性があり、一貫性の確保が難しいという欠点があります。また、何より人間が直接確認しなければならないという点で、時間とコストがかかります。
これに対して定量的方法�は、一貫した評価基準を作り、それによってモデルの性能を客観的な指標と数値で評価する方法です。この方法は、数値で表せない部分は評価時に考慮できないという欠点がありますが、結果が一貫しているため、モデル間の比較が容易で、効率的にモデルの性能を評価できるという利点があります。
上記のような利点から定量的評価方法は、現在さまざまな古典的なビジョンタスクで活用されています。定量的評価方法についてより詳しく見ていきましょう。
ビジョンモデルの種類とその性能評価方法
従来のコンピュータビジョン分野の主なタスクには、画像の分類(classification)や検出(detection)、分割(segmentation)などがあります。これらの分野では決まった正解(GT)があるため、定量的評価のためのデータセットを作るのが比較的容易です。実際の事例とともに見てみましょう。
画像分類(image classification)
画像分類は、与えられた画像がどのクラスに属するかを分類する問題です。以下のように、画像分類の場合、各画像に対してタスクで定義したクラス(class)のうち、どのクラスに属するかを事前に決めておく作業(GT Annotation)が行われます。その後、モデルはデータセットの画像を予測し、その予測値が正解と一致するかどうかを確認することで、モデルの性能を示します。以下の場合、3つのテストケースのうち2つを正解したので、精度(accuracy)は約66.6%です。
| Input | GT | Prediction | Result |
|---|---|---|---|
 | Angry | Angry | O |
 | Happy | Happy | O |
 | Neutral | Happy | X |
物体検出(object detection)
物体検出は、与えられた画像から対象とした物体の位置を見つける問題です。画像分類とは異なり、検出の場合、画像に特定の物体が含まれているかどうかを判断するだけでなく、その物体がどこに位置するかまで特定する必要があります。この違いから、検出タスクでは評価基準を決める際、下の画像のように正解の物体とその位置を「バウンディングボックス(bounding box)」の形で記録し、モデルの予測結果をその記録と比較することで性能を��評価します。
検出では、上の画像のようなGTをもとに「mAP@[ IoU=0.50 ]」または「mAP@[ IoU=0.50:0.95 ]」などの評価方法を主に使用します。この方法は、特定の正解基準(intersection of union, IoU)での平均予測性能(mean average precision、mAP)を測定する方法です。 mAPとIoUをより詳しく見てみましょう。
mAP
mAPは「mean average precision」の略で、次の式のようにクラスごとに平均精度を求めた後、その値を再度平均して計算できます。

上記の式でCはクラスの数、APcはc番目のクラスのAPを意味します。では、APはどのように計算するのでしょうか?APを計算するには、まず、精度と再現率(recall)を知る必要があります。
- 精度
- 再現率
- True Positive(TP):正しく予測されたPositive(個数)
- False Positive(FP):Positiveと誤って予測されたNegative(個数)
- False Negative(FN):Negativeと誤って予測されたPositive(個数)
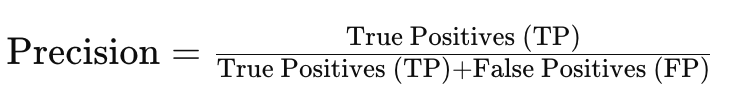
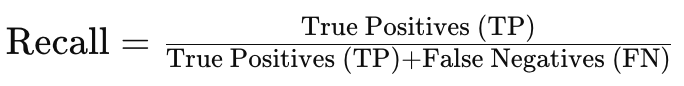
ここで、再現率による精度を以下のよう��にPR-Graphで表すことができます。
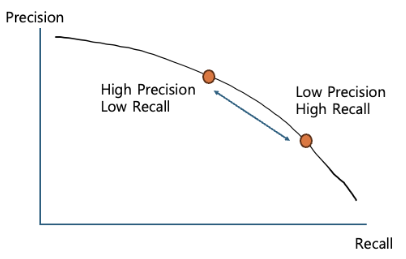
物体検出で使用するAPはこのグラフの面積(積分値)ですが、検出ではなぜこのように複雑な方法で性能を測定するのでしょうか?
特定のクラスが「検出された」、「検出されなかった」というのは、バイナリ分類(binary classification)の問題です。この場合、分類器が特定のクラスであると予測する結果値がどの基準を超えたときに成功したと判断するための閾値(threshold)を決定する必要があります。ところで、通常、再現率と精度はトレードオフの関係が成立します。一方が上がればもう一方は下がる、ということです。つまり、閾値を低く設定すれば高い再現率と低い精度の性能が確保され、高く設定すればその逆のケースが発生します。
したがって、検出モデルの安定性なども検討するためには、閾値を1つではなく複数設定して精度を計算し、その平均値で性能を評価します。PR-Graphを積分するのは難しいため、通常「11-point interpolation(再現率を均等に分割した11の位置での精度を計算して平均する)」手法などで簡略化して計算します。
IoU
次に、IoUについて見てみましょう。 以下のBicycleクラスの例では、緑色のラインボックス(GT)と赤色のラインボックス(予測)があり、2つのボックスが重なっている黄色のボックスがあります。それぞれの面積をG、R、Yとします。
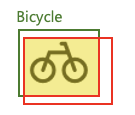
このとき、IoUは次のように計算できます。
- IoU = Y / (G + R - Y)
つまり、IoUはGTと予測ボックスとの積集合の面積を和集合の面積で割った値と言えます。予測がGTと完全に一致する場合はIoUは1になり、全く重ならない場合は0になります。
mAP@[IoU]
mAPとIoUの概念を把握したので、次はmAP@[ IoU=0.50 ]とmAP@[ IoU=0.50:0.95 ]の意味を解釈してみましょう。
- mAP@[ IoU=0.50 ]は、IoUが0.5以上の予測成果物に対して見つけたと判断してmAPを計算したものです。
- mAP@[ IoU=0.50:0.95 ]は、IoU基準を0.5から0.95まで0.05ずつ増やしながらmAPを計算し、その結果の平均を計算したものです。
mAP@[IoU]は現在、物体検出タスクで最も広く使われている評価方法です。
画像分割(semantic segmentation)
画像分割は、与えられた画像内の各オブジェクトを分割する問題です。これは、各オブジェクトの外角線を見つける問題で、物体検出の高度化とも言えます。

画像分割を評価する際には、通常、すべてのクラスでIoUを計算し、その平均値を計算する「mIoU」を使用します。
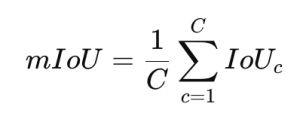
上記の式でCはクラスの数、IoUcはc番目のクラスのIoUです。
mIoUの他にも、使用目的に応じて、境界部分をより精密にチェックするための「boundary IoU」や、簡単な評価のため��に全ピクセルのうち正しく分類されたピクセルの割合を計算する「ピクセル精度(pixel accuracy)」などの方法も使用します。
画像生成モデルの評価方法
生成モデルでの評価方法が特別な理由
前述のように、従来のビジョン分野のモデルは、与えられた正解(GT)を用いてモデルの性能をある程度正確に測定できました。ところで、生成モデルの場合はどうでしょうか?生成モデルは、与えられた条件(テキストプロンプトなど)から実際の画像を生成するモデルです。しかし、生成された画像は学習データには存在しない場合がほとんどです。
例えば、以下の画像を見てみましょう。下の画像は、「テニスラケットを持っている男性をLINE風に描いてください」というプロンプトを使い、LINEヤフーで使用しているイラスト(参考)のような感じの画像をリクエストした結果です。

上の2つの画像のどちらが良いものでしょうか?右の画像の男性はラケットを2本も持っているので、左の画像より良いものでしょうか?個人の好みによって評価が分かれると思います。実際、与えられたプロンプトを満たすケースは無数に考えられ、現実には全く存在しないものもあるかもしれません(例:「宇宙を飛んでいる象を描いてください」)。
そのため、評価のためにGTを割り当てたり、比較対象を選定したりすることは非常に��困難です。このような理由から、通常の画像生成モデルでは、生成された成果物を評価する際に、従来の方法とは異なる基準を適用します。
一般的に最も多く使われる基準は、視覚的品質(visual quality)やリアリズム(realism)、プロンプト整合性(prompt alignment)などの基準です。最近では、公平性(fairness)や毒性(toxicity)などのAIの安全性(safety)要素を評価内容に含めることもあります。
これらは、従来のビジョン分野の評価方法では代替できません。そのため、生成モデルを評価するための新しい方法が提案される必要がありました。 次章では、生成モデルを評価する方法について本格的に見ていきましょう。
視覚的品質の評価方法
生成された成果物の視覚的品質を評価する方法は、画像処理(image processing)分野で使用する画質評価方法と、機械学習を利用して視覚的品質を予測する方法に分けられます。各系列の評価方法について解説し、どのようなメリットとデメリットがあるのか確認してみます。
画像処理ベースの評価方法
画像処理ベースの評価方法には、PSNRとSSIMがあります。それぞれ見ていきましょう。
PSNR (peak signal-to-noise ratio)
PSNRは最も代表的な画質評価方法の一つで、「最大信号対雑音比」を意味します。値が高いほど性能が優れていることを示し、次のように計算します。
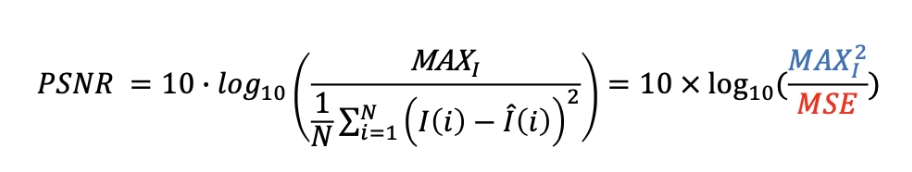
上記の式で、MAXlは最大信号値を表し、通常は255を使用します。MSEは平均二乗誤差(mean square error)で、次のように計算します。
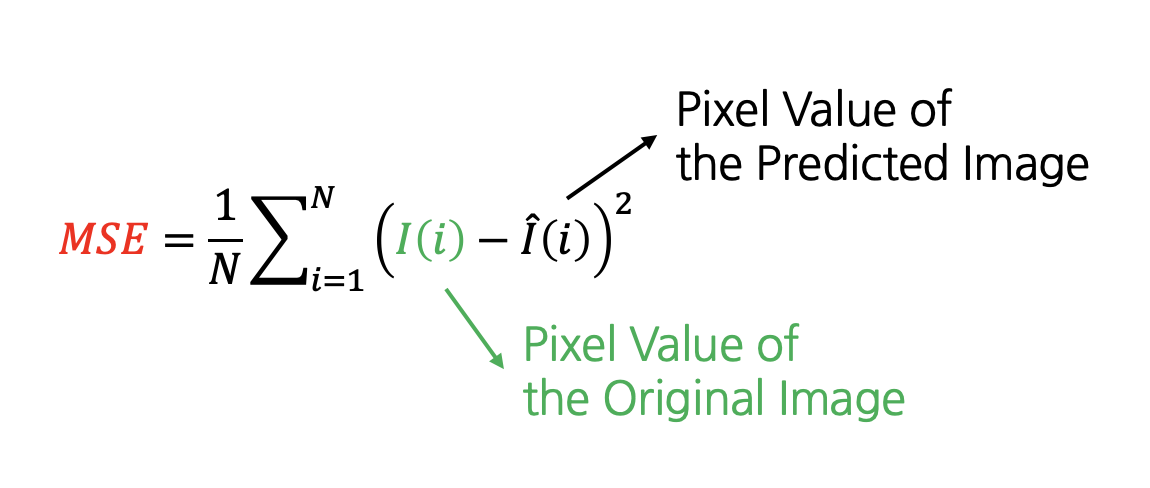
上記の式で、Nは画像の画素数を表し、I(i)はi番目のピクセル値を表します。原画像と予測画像のピクセル値の差を2乗して評価するため、画像全体で少しずつ差がある場合よりも、特定の領域で大きな差がある場合の画質が悪いと評価されます。
PSNRを用いた画質評価には、必ず原画像が必要という特徴があります。また、原画像にどれだけ似ているかを示す指標であるため、PSNRが高いからといって必ずしも画質が良いことを保証するものではありません。例えば、原画像に対してコントラスト比の改善や色補正などの画質改善を行ったとしましょう。そうすると、改善すればするほど与えられた式に従って原画像との差は広がるため、PSNRは変化しますが、実際に人が感じる画質は良くなる可能性があります。
したがって、この評価方法は主に圧縮画像の復元力を測定する際に多く使用されます。生成モデルの評価では、特定の部分がオリジナルと同様に生成されているかどうかを評価するために、インペインティング(inpainting)のような分野で限定的に使用できます。
SSIM (structural similarity index map)
SSIMはPSNRのデメリットを補完し、人間の視覚システム(human visual system)をよりよく反映できる評価方法として提案されました。SSIMでは、原画像と予測画像との間の輝度とコントラスト、構造的類似性を次のように計算します。
| 輝度 | コントラスト | 構造 |
|---|---|---|
|
|
|
|
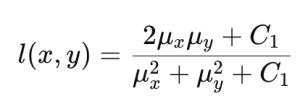
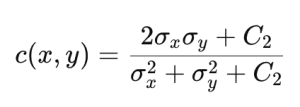
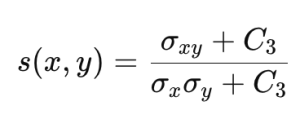
上記の式でCiは計算の安定性を保つための定数値です。これを用いてSSIMは次のように計算します。
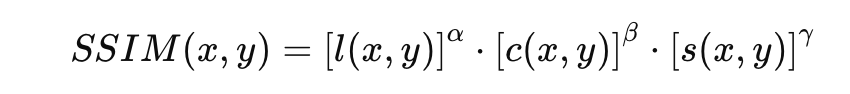
通常、 とします。SSIMは、人間が知覚する画質に近い概念を考慮して設計された評価方法ですが、PSNRと同様に原画像が必要なため、生成モデルの評価には限界があります。
機械学習ベースのモデル評価方法
機械学習ベースのモデル評価方法には、ISとFID、LPIPS、Aesthetic Score、CLIPIQA、Q-ALIGNがあります。一つずつ見ていきましょう。
IS (inception score)
ISは2016年に公開されたテクニカルレポートImproved Techniques for Training GANsで紹介された手法で、Inception v3分類器を使用することから「inception score」と名付けられました。
この手法は、「よく学習されたモデルであれば、生成した画像に含まれる成果物を機械学習モデルが簡単に把握できる」という仮定に基づいて動作します。つまり、与えられた画像に対してInception v3分類器が分類した結果が非常に確信を持って特定のクラスと言えるものであれば、その入力画像が特定のクラスの特徴をはっきり持っているという意味に解釈して、良い生成モデルであるという結論に至るような設計となっています(ここで「確信を持って特定のクラスと言える」というのは「Confidence Score」というのを導入し、分類結果そのスコアが高いか低いかを判断します)。
ISの計算式は、以下のとおりです。
![]()
条件付き確率 p(y∣x) は、各画像xがクラスyに含まれる確率を表します。良いモデルほど、入力画像が特定のクラスにマッピングされるため、この条件付�き確率のエントロピーは低くなります。p(y)はクラスの分布を表します。多様性の高い画像セットほど、p(y)の分布は均一になります。
この2つの分布間の類似度をカルバック・ライブラー情報量(Kullback-Leibler divergence、以下KLD)を使って比較します。KLD値は、画像が明確に特定のクラスに属しており、クラス分布が均一であるほど高い値を持ちます。このように計算したKLDの平均値に指数関数を適用してISを計算します。
ISは生成モデルの開発初期に広く使用されましたが、以下のようなデメリットがあり、次に説明するFIDアルゴリズムなどの登場以降、使用頻度が大幅に減少しました。
- 計算式でクラス全体の分布のみを考慮し、クラス内の分布などを考慮しない。
- 分類器モデルが判断するクラスの特徴が人間の基準と一致しない可能性がある。
- 事前学習済み分類器に含まれていないクラスを生成する場合には適用が難しい。
FID (Fréchet inception distance)
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibriumという論文で紹介されたこの方法は、生成モデルによって生成された画像の品質と多様性を評価するために考案された指標です。生成された画像の分布と実画像の分布との差をFrechet距離を用いて測定し、モデルの性能を評価します。
FIDを測定するには、まず、画像エンベッダー(embedder)を利用して入力画像の特徴�(feature)ベクトルを抽出します。この特徴ベクトルは、高次元で表現される画像情報を低次元で縮小した形で表現します。
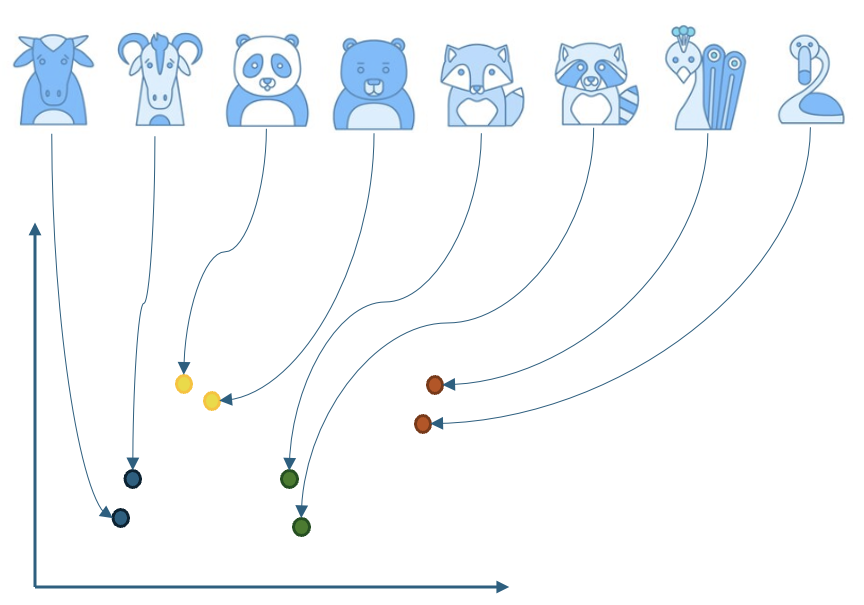
以下のようにさまざまな動物画像を2次元で表現する例を見てみましょう。画像エンベッダーは、学習時に画像間の類似点と相違点などをよく表せる特徴を学習し、似たような動物は似た位置に、似ていない動物は異なる位置にマッピングします。
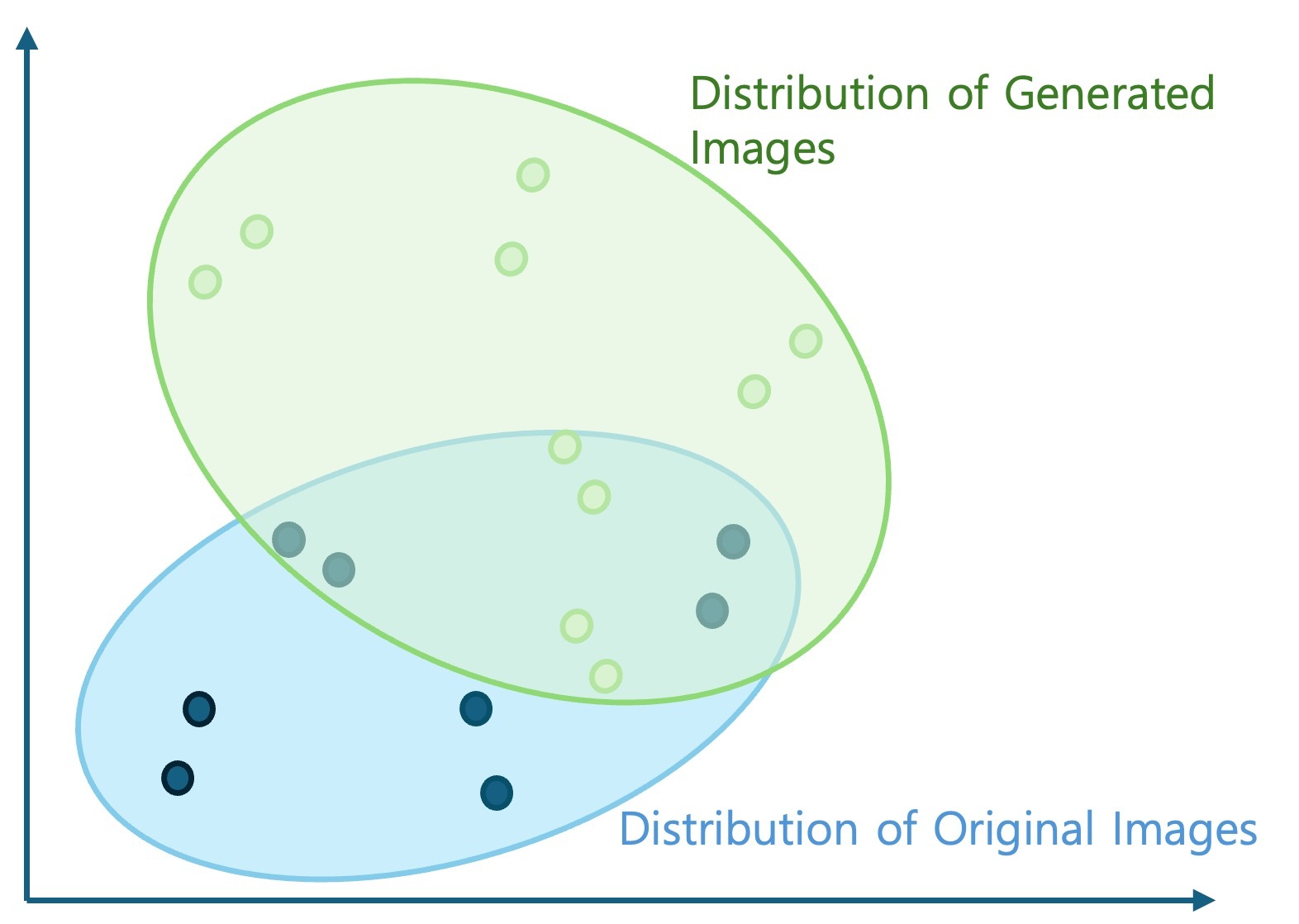
これを下の画像のように各動物のクラスではなく、一般的な画像と生成された画像で考えてみましょう。そうすると、生成された画像が既存の一般的な画像と類似してよく生成された場合、似た位置に分布します。そうではなく、歪みなどによって相違点が多く、一般的な画像と視覚的に区別しやすい形で生成された場合、薄緑色の領域のように異なる位置に分布します。
では、一般画像と生成画像の分布類似度を計算する方法を本格的に見ていきます。そのためには、まず、抽出された特徴ベクトルの分布をモデル化する必要があります。多変量正規分布に従うと仮定してみましょう。この仮定に基づいて各分布の平均ベクトル(μ)と共分散行列(Σ)を計算し、これを利用して2つの正規分布間のFréchet距離(またはWasserstein-2距離)を次の式で計算します。
![]()
ここで、||·||² はベクトルのL2ノルム(norm)の2乗で、Trは行列の対角成分の合計(trace)です。式から分かるように、FIDは2つの分布の差であるため、生成された画像の分布が実画像の分布に似ているほど、FID値が低くなります。したがって、FID値が低い場合は、モデルが実際のデータの特性をよく学習して高品質な画像を生成していることを示します。逆にFID値が高い場合は、生成された画像の品質が低いか、多様性に欠けていることを示します。
FIDのメリットは、生成された画像と実画像の分布を直接比較するため、モデルが実際のデータの特性をどれだけよく再現しているかを評価できることです。また、画像の品質と多様性を同時に考慮して、生成モデルの全体的な性能を評価できます。デメリットは、FIDは分布を比較するため、生成された画像の品質を測定するのではなく、生成モデル自体の性能を測定して生成された画像の品質を間接的に示すことです。また、画像エンベッダーはInceptionネットワークのような事前学習済みモデルに依存しているため、評価したいデータセットがこれらのモデルの学習データと大きく異なる場合、正確な評価が難しくなる可能性があります。さらに、�特徴ベクトルが正規分布に従うことを前提としていますが、実際のデータはこの仮定を常に満たすとは限りません。
FIDは現在、生成モデルの性能評価、特にGANのようなモデルの評価に広く使われている指標です。ただし、FID値だけではモデルの性能を完全に評価するには限界があるため、他の評価指標と併せて使用することが推奨されます。
参考までに、従来のFID方法の画像エンベッダーをより高性能なDINO v2-ViT-L/14に置き換えたFD-Dino方法も紹介されています。DINO v2-ViT-L/14は、教師なし学習で学習されたため、従来分類タスクのために学習されたinception v3モデルに比較して、画像の表現力がより豊富です。また、ビジョントランスフォーマー(vision transformer)ベースの手法であるため、画像のグローバルな特性とローカルな特性をより効果的に表現できます。さらに、モデルサイズがより大きく、学習に使用されるデータ量も多いため、従来の手法より精密な品質評価が可能です。
LPIPS (learned perceptual image patch similarity)
次は、The Unreasonable Effectiveness of Deep Features as a Perceptual Metricという論文で紹介されたLPIPSです。LPIPSは、原画像と生成画像の埋め込みをそれぞれ抽出し、特徴空間(feature space)にマッピングした後、特徴空間におけるその両者の距離を計算することで生成された画像の品質を評価する方法です。比較する2つの画像をそれぞれImageNetデータで事前学習されたVGG(Visual Geometry Group)ネットワーク��に入れ、中間レイヤーから特徴量をそれぞれ抽出して次の式のように2つの特徴量間のユークリッド距離(Euclidean distance)を測定します。
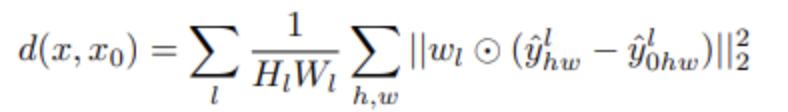
ここで はl番目のレイヤーの重み(weight)で、 はl番目のレイヤーの(h, w)位置の特徴量です。
LPIPSを一般的な画像生成タスクに適用する場合、生成画像と比較する原画像を選ぶことが問題になります。生成画像には原画像と判断される画像が存在しないからです。そのため、一般的には主に原画像と生成画像のペアが存在する場合(例:image reconstruction、image super-resolution、image-inpainting)に利用されます。それ以外の場合は、トレーニングデータから最も類似した実画像を使用する方法があり、あるいは、より高い性能で知られている生成モデルの成果物を使用することもできます。
Aesthetic score
Aesthetic Scoreは、LAION(Large-scale Artificial Intelligence Open Network、大規模な公開データセットとAI研究を通じて人工知能の民主化を目指す非営利団体)が提供するLAION-Aesthetics V1などのデータセットで学習後、生成画像の品質を評価するモデルを使用した評価方法です。このデータセットは、人々に5,000枚のさまざまな画像で構成されているSAC Datasetを与え、以下のように質問することで画像の品質を測定します。
- "この画像がどのくらい気に入ったか、1から10までの尺度で評価してください。"
その後、入力画像をOpenAI CLIP ViT-L/14モデルを用いて画像特徴量に変換し、線形モデルを学習して1から10の間の結果が出るようにしました。この方法を使用すると、各画像について人間の知覚に近い品質評価が可能なため、最近の画像生成モデルの評価に多く採用されています。176,000枚の画像が追加されたSAC DatasetとLAION-Logosなどを利用し、従来よりさらに豊富なデータセットを構成して性能を向上させたAesthetic Score-v2もリリースされました。
CLIPIQA
Exploring CLIP for Assessing the Look and Feel of Imagesという論文で紹介されたCLIPIQA(CLIP image quality assessment)は、CLIPモデルを用いて画像品質を評価する方法です。CLIPIQAは、従来の画像品質評価方法とは異なり、より人間の主観的な判断に近い形で画像の視覚的品質を評価するように設計されています。
この方法は、CLIP画像エンベッダーを利用して評価対象画像の特徴ベクトルを計算し、「This is a high-quality image」と「This image has a lot of noise」のような相反する評価を表すテキスト入力に対する埋め込みとの類似度を計算して測定します。そのため、Aesthetic Scoreと同様に、この方法も比較対象なしで生成された画像1枚でも評価できるというメリットがあります。
Q-ALIGN
Q-ALIGN: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levelsという論文で提案されたもので、LMM(large multimodal model)を学習して画像品質や美的評価(aesthetic assessment)、または動画の品質を測定するモデルです。例えば、与えられた画像の品質が悪い場合、「The quality of the image is poor」などのGTを生成し、学習時に「Can you evaluate the quality of the image?」などのクエリに対する応答が与えられたGTと一致するようにします。
この方法は、数値ではなく文によって定義された評価レベルを学習に使用するため、既存のLLMの能力を最大限に発揮でき、従来�より評価性能が向上しています。また、この方法もAesthetic ScoreやCLIPIQAと同様に、各画像ごとに評価できるため、使い勝手が良いです。
プロンプト整合性(prompt alignment)
前述した方法は、生成画像の画質を評価するものですが、生成モデルは生成に使われたプロンプトを忠実に反映するため、プロンプトとの整合性も評価対象となります。
CLIP Score
最も広く使われている基本的な評価方法です。CLIP画像エンベッダーとテキストエンベッダーを用いて、それぞれ生成画像と生成プロンプトを特徴空間でマッピングし、その類似度を次のようにコサイン類似度(cosine similarity)を利用して測定します。
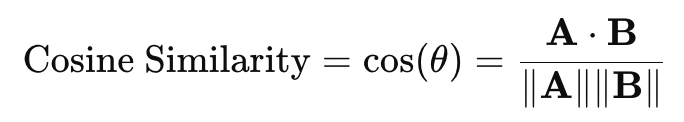
このとき、A⋅Bは2つのベクトルの内積(dot product)であり、∥∥はベクトルのL2ノルムです。2つの値が類似している場合は1、異なっている場合は(orthogonal)0が出力されます。
QA(question-answering)手法
QAとは、特定の言語モデルに質問を送ると、言語モデルが生成した回答を受け取るタスクのことを指します。これを利用して、プロンプトの内容が実際に生成されたかどうかを評価します。
VQA (visual-question-answering) Score
Evaluating Text-to-Visual Generation with Image-to-Text Generationという論文では、以下のようなプロンプトを利用してVQA方式で整合性を評価します。
- "Does this figure show {Prompt}?"
使用されているモデルはCLIP-FlanT5で、事前学習済みモデルの整合性を評価するために、一般に公開されているVQAデータセットを活用して再学習されます。1,600の場所やオブジェクト、特性、関連性などを含む複雑なテキストプロンプが含まれているベンチマークのGenAI-Benchでは、他の方法よりも人間に近い評価を行うことが示されています。
Gecko Score
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratingsという論文で提案された方法です。前述のVQA Scoreと同様に、質問を通じて生成画像にプロンプトの内容が忠実に反映されているかを検査します。例えば、「a cartoon cat in a professor outfit, ...」という入力プロンプトがあるとし、LLMモデルを利用してそのプロンプトの主なキーワードを抽出します。この場合、例えばcartoonやcat、professor outfitなどが抽出されたと仮定できます。その後、これを基にQAを生成します。つまり、以下のようなQAペアが生成され、これに基づいて実際の整合性を評価します。
- Q : "Is there a cat?", A:"[Yes, no]"
- Q:"Is the cat a cartoon?", A:"[Yes, no]"
画像品質とプロンプト整合性の同時評価
画像品質とプロンプト整合性は、両方とも生成画像を評価するうえで重要な要素です。そのため、両方の観点から同時に画像を評価する方法も多く提案されています。
HPS-V2
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesisという論文では、画像に対する人間の好みを表す大規模なデータセットHuman Preference Dataset v2を提供しています。このデータセットには、約80万枚(約40万組)の画像が含まれており、各画像のうち人間が好む画像が表示されています。このデータセットを基にCLIPモデルを再学習すると、人間の好みをよく表すHPS v2(Human Preference Score v2)というモデルを確保できます。
例えば、{x1, x2}という画像のペアがあるとします。このとき、x1とx2のうち人間が好む画像がx1の場合、これをy=[1, 0]で表すことができます(逆の場合はy=[0, 1])。
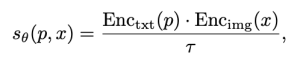
上記の式で、pは画像を生成するためのプロンプトで、xは生成された画像です。τはCLIPモデルの「temperature scalar」値で、θはCLIPモデルのパラメータです。ここでのtemperature scalar値は、プロンプトと画像間の類似度に対する重みです。通常は1以上の値が割り当てられ、値が大きいほどプロンプトと画像間の類似度の差による影響が反映されにくくなります。Enc()はそれぞれテキストと画像のエンコーダー関数です。このときの学習は、次のKL-Divergenceを最小化する損失関数を利用して行われます。
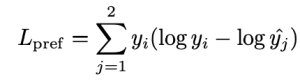
このとき、 は次の式で求められます。
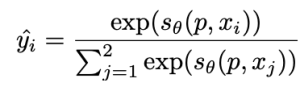
つまり、{x1, x2}のうち相対的に品質が低い画像は、与えられたプロンプトと関連性がないというように学習されます。
Pick score
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generationという論文で提案された方法です。この方法の損失関数の構成はHPS-V2と同じです。ただし、評価モデル学習用データセットを生成する方法に大きな違いがあり、似たような品質の画像に対してy=[0.5, 0.5]の形で表現する方法を追加しました。
まとめと結論
前述した内容を簡単にまとめます。
従来のビジョンモデルでは、事前に明確な正解が存在するタスクが多かったため、性能評価が比較的容易でした。定められた評価方法とそのために事前に正解を付与したデータセットで性能評価を行い、定量的な特性でモデルを簡単に比較できました。
一方、画像生成モデルでは、正解を事前に決めることが難しく、定量的な評価を行うための評価方法の設計が容易ではありません。そのため、人間が知覚する画像品質を最大限に模倣するさまざまな方法が提案されています。これらの方法は、主に視覚的な品質や、生成に使用したプロンプトと成果物の整合性に基づいて品質を評価します。
まず、視覚的品質を評価する方法は、画像処理を利用した方法と機械学習ベースの方法に分けて説明しました。特に、FIDのような一般的に広く使われている方法に焦��点を当てました。次に、プロンプト整合性を評価する方法として、CLIP Scoreや最近導入されたQAを用いた方法を紹介しました。また、視覚的品質と整合性を同時に比較する方法についても紹介しました。
最近では、より正確で公正な画像評価を目指して、さまざまな研究が活発に行われており、新しいデータセットや評価モデルが次々と提案されています。このような研究の発展は、生成モデルの性能を客観的に測定し、改善するうえで重要な役割を果たしています。
今、私たちは生活の中でさまざまな生成画像を目にしています。それらの画像の中には、かなりの品質に驚かされるものもあれば、少し奇妙な感じに首をかしげるようなものもあります。生成画像の評価方法は、モデルの性能を統一された基準で評価できるだけでなく、これを利用してモデルの性能も改善できます。また、実際のサービスにおいて、低品質の画像が消費者に提供されるのを防ぐフィルターの役割も果たすことができます。
次回は、これらの評価方法が実際にさまざまな生成モデルの性能改善に、どのように適用されているのかを探ります。どうぞご期待ください!


