들어가며
최근 몇 년간 생성 모델은 인공 지능 분야에서 혁신적인 도구로 부상하며 연구자와 산업 리더들의 큰 관심을 받고 있습니다. 생성 모델은 딥러닝 기술의 발전을 바탕으로 고품질의 이미지와 비디오와 같은 복잡한 데이터 형식을 생성하는 데 있어 전례 없는 능력을 보여주고 있습니다. 특히 생성적 적대 신경망(generative adversarial network, 이하 GAN)과 변분 오토인코더(variational autoencoder, VAE), 확산 모델(diffusion model)과 같은 새로운 아키텍처가 등장하면서 생성 기술은 학문적 탐구를 넘어 실제 산업에서의 응용으로 빠르게 확장되고 있습니다. 이러한 발전은 엔터테인먼트와 광고, 콘텐츠 제작 등의 창의적인 산업에서 새로운 가능성을 열었을 뿐만 아니라, 과학적 시뮬레이션과 가상 환경, 증강 현실과 같은 다양한 분야에서도 중요한 발전을 이끌어 내고 있습니다.
그러나 생성 모델은 기존의 머신 러닝 기법과는 달리 생성된 결과물에 대한 정답(ground truth, 이하 GT)을 갖고 있지 않다는 점에서 정량적으로 평가하기가 매우 어렵다는 한계가 있습니다. 결과가 다양한 형태로 생성되고 표현될 수 있기 때문에 꼭 어떤 하나의 정답과 똑같이 생성돼야 한다고 가정할 수 없는 것입니다. 생성 모델의 품질을 평가하기 위해 FID(Fréchet Inception Distance)나 IS(inception score), CLIPScore와 같은 대체적인 평가 지표들이 활용되고 있지만, 이러한 지표 역시 모델 성능의 모든 측면을 충분히 반영하지 못한다는 아쉬움이 있습니다.
저희는 이번 글에서 FID나 IS 등 비전(vision) 생성 모델을 통해 생성된 결과물을 평가하는 여러 방법을 자세히 살펴보고, 실제 애플리케이션에 생성 모델을 적용하고자 할 때 어떤 부분을 고려해야 하는지 알아보겠습니다.
비전 모델의 성능 평가 방법이란?
이미지 생성 모델의 평가 방법을 이야기하기 전에 보다 명확하고 이해하기 쉬운 기준을 설정하기 위해 고전적인 비전 태스크들과 이 태스크를 해결하기 위한 비전 모델의 성능을 평가하는 방법을 먼저 살펴보겠습니다. 이를 통해서 모델의 성능 평가 문제의 맥락을 보다 쉽게 이해할 수 있을 것입니다.
비전 모델의 성능을 평가하는 방법은 크게 정성적 방법과 정량적 방법으로 나눌 수 있습니다. 정성적 방법은 사람이 자신의 주관적 기준으로 결과물을 검토해 성능을 표현하는 방법입니다. 이 방법은 사람이 직접 결과물을 평가하기 때문에 정량적 평가가 반영하지 못하는 세부적인 품질 차이까지 반영할 수 있다는 장점이 있지만, 한편으로는 각 사람의 기준에 따라 결과가 다르게 나올 수 있어 일관성을 확보하기 어렵다는 단점이 있습니다. 또한 무엇보다 사람이 직접 확인해야 한다는 점에서 시간과 비용이 많이 소모됩니다.
이에 반해 정량적 방법은 일관적인 평가 ��기준을 만들어 이에 따라 모델의 성능을 객관적인 지표와 수치로 평가하는 방법입니다. 이 방법은 숫자로 표현할 수 없는 부분은 평가 시 고려하기 힘들다는 단점이 있지만, 결과가 일관적이어서 모델 간 비교가 용이하고, 효율적으로 모델의 성능을 평가할 수 있다는 장점이 있습니다.
정량적 평가 방법은 위와 같은 장점 덕분에 현재 다양한 고전 비전 태스크에서 활용되고 있습니다. 정량적 평가 방법을 조금 더 자세히 살펴보겠습니다.
비전 모델의 종류와 그 성능 평가 방법
기존 컴퓨터 비전 분야의 주요 태스크로는 이미지 분류(classification)와 검출(detection), 분할(segmentation) 등이 있습니다. 이런 분야는 정해진 정답(GT)이 있기 때문에 정량 평가를 위한 데이터셋을 만들기가 상대적으로 용이합니다. 실제 사례와 함께 살펴보겠습니다.
이미지 분류(image classification)
이미지 분류는 주어진 이미지가 어느 클래스에 속하는지 분류하는 문제입니다. 다음 그림과 같이 이미지 분류의 경우 각 이미지에 대해 태스크에서 정의한 클래스(class) 중 어떤 클래스에 속하는지 미리 정해 놓는 작업(GT Annotation)을 진행합니다. 이후 모델을 통해 데이터셋의 이미지를 예측하고 그 예측값이 정답과 일치하는지 확인해 모델의 성능을 나타낼 수 있습니다. 아래와 같은 경우 세 개의 테스트 케이스 중 두 개를 맞췄기 때문에 정확도(accuracy)는 약 66.6%입니다.
| Input | GT | Prediction | Result |
|---|---|---|---|
 | Angry | Angry | O |
 | Happy | Happy | O |
 | Neutral | Happy | X |
물체 검출(object detection)
물체 검출은 주어진 이미지에서 대상으로 삼은 물체의 위치를 찾아내는 문제입니다. 검출의 경우 이미지에 있는 특정 물체를 검출한다는 의미는 이미지가 특정 물체를 포함하고 있는지 판단하는 것뿐만 아니라 그 물체가 어디에 있는지까지 맞춰야 한다는 점에서 이미지 분류 태스크와 차이가 있습니다. 이런 차이 때문에 검출 태스크에서는 평가 기준을 정할 때 다음 그림과 같이 정답 물체와 그 위치를 '바운딩 박스(bounding box)'의 형태로 기록해 놓고, 모델이 예측한 결과를 이와 비교해 성능을 평가합니다.
검출에서는 위 그림 형태의 GT를 바탕으로 'mAP@[ IoU=0.50 ]' 또는 'mAP@[ IoU=0.50:0.95 ]' 등의 평가 방법을 주로 사용합니다. 이 방법은 특정 정답 기준(intersection of union, IoU)에서의 평균 예측 성능(mean average precision, mAP)을 측정하는 방법인데요. mAP와 IoU를 보다 자세히 살펴보겠습니다.
mAP
mAP는 'mean average precision'의 약자로, 다음 식처럼 클래스마다 평균 정밀도를 구한 후 이 값을 다시 평균해 계산할 수 있습니다.

위 식에서 C는 클래스의 개수이고, APc는 c 번째 클래스의 AP를 의미합니다. 그럼 AP는 어떻게 계산할 수 있을까요? AP를 계산하려면 먼저 정밀도와 재현율(recall)을 알아야 합니다.
- 정밀도
- 재현율
- True Positive(TP): 올바르게 예측한 Positive (개수)
- False Positive(FP): Positive로 잘못 예측된 Negative (개수)
- False Negative(FN): Negative로 잘못 예측된 Positive (개수)
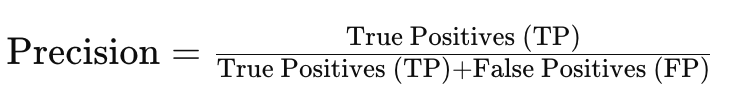
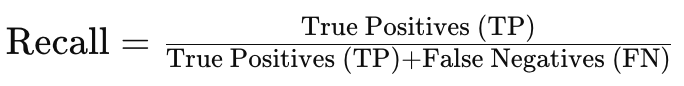
여기서 재현율에 따른 정밀도를 다음 그림처럼 PR-Graph로 나타낼 수 있습니다.
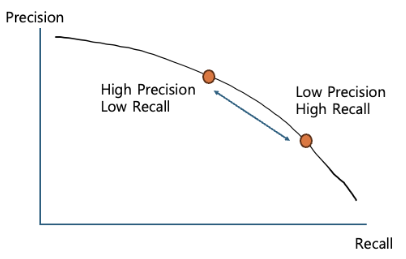
물체 검출에서 사용하는 AP는 이 그래프의 면적(적분값)인데요. 검출에서는 왜 이렇게 복잡한 방법으로 성능을 측정할까요?
특정 클래스가 '검출되었다', '아니다'는 이진 분류 (binary classification)의 문제입니다. 이 경우 분류기가 특정 클래스라고 예측하는 결괏값이 어느 기준을 넘겼을 때 성공한 것이라고 판단할지 결정하기 위한 임곗값(threshold)을 결정해야 합니다. 그런데 일반적으로 재현율과 정밀도는 트레이드오프 관계가 성립합니다. 한쪽이 올라가면 다른 쪽은 낮아지는 것이죠. 즉 임곗값을 낮게 설정하면 높은 재현율과 낮은 정밀도의 성능이 확보되고, 높게 설정하면 반대의 경우가 발생합니다.
따라서 검출 모델의 안정성 등을 같이 검토하기 위해서는 임곗값을 하나가 아니라 여러 개 설정해 정밀도를 계산하고 그 값의 평균으로 성능을 평가합니다. PR-Graph를 적분하는 것은 어렵기 때문에 일반적으로 '11-point interpolation(재현율을 균등하게 나눈 11개의 위치에서의 정밀도를 계산한 후 평균)' 기법 등으로 간소화해서 계산합니다.
IoU
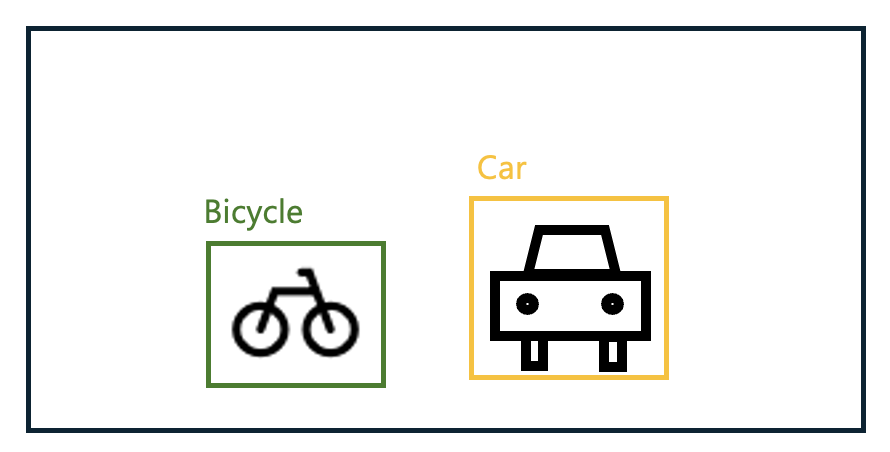
다음으로 IoU에 대해서 알아보겠습니다. 아래는 Bicycle 클래스 예시에는 초록색 선 박스(GT)와 빨간색 선 박스(예측)가 있고, 두 박스가 겹치는 노란색 박스가 있습니다. 각 면적을 G, R, Y라고 하겠습니다.
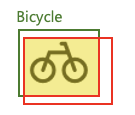
이때 IoU는 다음과 같이 계산할 수 있습니다.
- IoU = Y / (G + R - Y)
즉, IoU는 GT와 예측 박스 간 교집합 면적을 합집합 면적으로 나눈 값이라고 할 수 있습니다. 예측이 GT와 정확히 일치하면 IoU는 1이 되고, 전혀 겹치지 않는다면 0이 될 것입니다.
mAP@[IoU]
mAP와 IoU의 개념을 파악했으니 이제 mAP@[ IoU=0.50 ]와 mAP@[ IoU=0.50:0.95 ]의 의미를 해석해 보겠습니다.
- mAP@[ IoU=0.50 ]는 IoU가 0.5 이상인 예측 결과물들에 대해서 찾았다고 판단한 후 mAP를 계산한 것입니다.
- mAP@[ IoU=0.50:0.95 ]는 IoU 기준을 0.5부터 0.95까지 0.05씩 증가시키면서 mAP를 계산한 뒤 그 결과의 평균을 계산한 값입니다.
mAP@[IoU]는 현재 물체 검출 태스크에서 가장 널리 사용되는 평가 방법입니다.
이미지 분할(semantic segmentation)
이미지 분할은 주어진 이미지 내에서 각 물체를 분할하는 문제입니다. 즉 각 물체의 외각선을 찾아내는 문제로 물체 검출의 발전된 형태로도 볼 수 있습니다.

이미지 분할을 평가할 때는 일반적으로 IoU를 모든 클래스에서 계산한 후 그 평균값을 계산하는 'mIoU' 방식을 사용합니다.
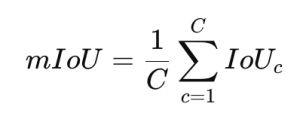
위 식에서 C는 클래스의 개수이고 IoUc는 c 번째 클래스의 IoU입니다.
mIoU 외에도 사용 목적에 따라 경계 부분을 더 정밀하게 보기 위한 'boundary IoU'나, 간단한 평가를 위해 전체 픽셀 중 올바르게 분류된 픽셀의 비율을 계산하는 '픽셀 정확도(pixel accuracy)' 등의 방법도 사용합니다.
이미지 생성 모델의 평가 방법
생성 모델에서의 평가 방법이 특별한 이유
앞서 보신 것처럼 기존 비전 분야의 모델들은 주어진 정답(GT)를 가지고 모델의 성능을 어느 정도 정확하게 측정할 수 있었습니다. 그런데 생성 모델의 경우는 어떨까요? 생성 모델은 주어진 조건(텍스트 프롬프트 등)으로부터 실제 이미지를 만들어 내는 모델인데요. 생성된 이미지는 학습 데이터에는 없던 경우가 대부분입니다.
예를 들어 다음 그림을 보겠습니다. 다음 그림은 "테니스 라켓을 들고 있는 남자를 LINE 스타일로 그려줘."라는 프롬프트를 이용해 저희 회사에서 사용하는 일러스트레이션(참고)과 같은 느낌의 그림을 생성해 달라고 요청한 두 결과입니다.

위 두 그림 중 어떤 그림이 더 좋은 그림일까요? 오른쪽 그림의 남자는 라켓을 두 개나 들고 있으니 왼쪽 그림보다 더 좋은 그림일까요? 아무래도 개인의 취향에 따라 평가가 갈릴 것 같습니다. 실제로 주어진 프롬프트를 만족할 수 있는 경우의 수는 무수히 많을 수도 있고, 현실에 아예 없을 수도 있습니다(예: "우주를 날아가는 코끼리를 그려줘").
따라서 평가를 위한 GT를 할당하거나 비교를 위한 대상을 선정하는 일은 매우 어렵습니다. 이런 이유로 일반적으로 이미지 생성 모델에서는 생성된 결과물을 평가�할 때 기존 방식과는 다른 기준을 적용합니다.
일반적으로 가장 많이 사용하는 기준은 시각적 품질(visual quality)이나 사실성(realism), 프롬프트 일치율(prompt alignment) 등의 기준입니다. 최근에는 공평성(fairness)이나 공격성(toxicity) 같은 AI 안전성(safety) 요소를 평가 내용에 포함하기도 합니다.
이와 같은 것들은 기존 비전 분야의 평가 방법 중 하나로 대체할 수 없습니다. 따라서 생성 모델을 평가하기 위한 새로운 방법이 제시돼야 했는데요. 다음 장에서는 본격적으로 생성 모델을 평가하는 방법을 살펴보겠습니다.
시각적 품질 평가 방법
생성된 결과물의 시각적 품질을 평가하는 방법은 이미지 처리(image processing) 분야에서 사용하는 화질 평가 방법과 머신 러닝을 이용해서 시각적 품질을 예측하는 방법으로 나눌 수 있습니다. 각 계열의 평가 방법들을 살펴보고 어떤 장단점이 있는지 확인해 보겠습니다.
이미지 처리 기반 평가 방법
이미지 처리 기반 평가 방법으로는 PSNR과 SSIM이 있습니다. 하나씩 살펴보겠습니다.
PSNR(peak signal-to-noise ratio)
PSNR은 가장 대표적인 화질 평가 방법 중 하나로 '최대 신호 대 잡음비'를 의미합니다. 값이 높을수록 성능이 뛰어나다는 것을 의미하며, 다음과 같이 계산합니다.
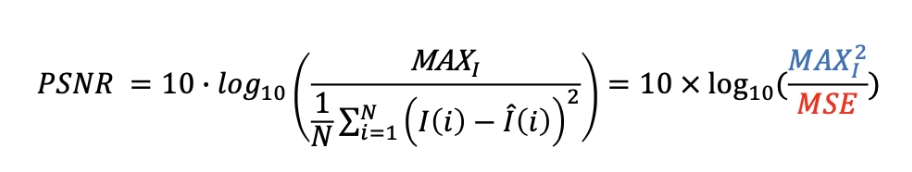
위 식에서 MAXl은 최대 신호값을 의미하며 통상적으로 255를 사용합니다. MSE는 평균 제곱 에러(mean square error)로 다음과 같이 계산합니다.
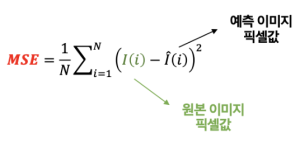
위 식에서 N은 이미지의 화소수를 의미하고 I(i)는 i 번째 픽셀값을 의미합니다. 원본 이미지와 예측 이미지의 픽셀값 차이를 다시 제곱을 통해 평가하기 때문에 전체 이미지에서 조금씩 다른 것보다 특정 영역에서 크게 다른 것이 더 화질이 나쁜 것으로 평가됩니다.
PSNR을 이용한 화질 평가는 반드시 원본 이미지가 필요하다는 특징이 있으며, 원본과 얼마나 유사한지를 나타내는 지표이기 때문에 PSNR이 높은 이미지가 무조건 화질이 좋다는 것을 보장하지는 않습니다. 예를 들어 원본 이미지에 대해 대조비 개선이나 색보정 등의 화질 개선을 진행했다면, 주어진 식에 따라 개선할수록 원본 이미지와 점점 달라지게 되므로 PSNR은 달라지겠지만 실제 사람이 느끼는 화질은 좋아질 수 있습니다.
따라서 이 평가 방법은 주로 압축된 이미지의 복원력을 측정할 때 많이 사용하며, 생성 모델의 평가에서는 특정 부분이 원본과 같게 잘 생성됐는지 등을 평가하기 위해 인페인팅(inpainting) 같은 분야에 제한적으로 사용할 수 있습니다.
SSIM(structural similarity index map)
SSIM은 PSNR의 단점을 보완하고 인간의 시각적 시스템 (human visual system)을 보다 잘 반영할 수 있는 평가 방법으로 제안됐습니다. SSIM에서는 원본 이미지와 예측 이미지 간 밝기와 명암비, 구조적 유사성을 다음과 같이 계산합니다.
| 밝기 | 명암비 | 구조 |
|---|---|---|
|
|
|
|
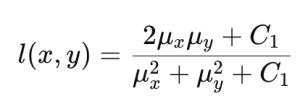
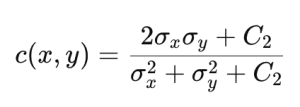
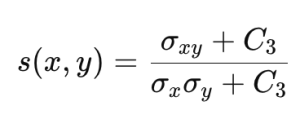
위 식에서 Ci는 계산 안정성을 위한 상수값입니다. 이를 이용해 SSIM은 다음과 같이 계산합니다.
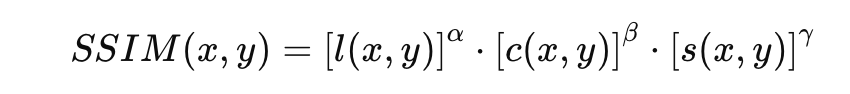
일반적으로 을 사용합니다. SSIM이 사람이 판단하는 화질에 보다 가까운 개념을 고려하여 설계된 평가 방법이긴 하지만, PSNR과 마찬가지로 원본 이미지가 필요하기 때문에 생성 모델 평가에는 제한적으로 사용할 수밖에 없습니다.
머신 러닝 기반 모델 평가 방법
머신 러닝 기반 모델 평가 방법으로는 IS와 FID, LPIPS, Aesthetic Score, CLIPIQA, Q-ALIGN이 있습니다. 하나씩 살펴보겠습니다.
IS(inception score)
IS는 2016년 공개된 테크니컬 리포트 Improved Techniques for Training GANs에서 소개된 방법으로 Inception v3 분류기를 사용하기 때문에 'inception score'라고 이름 지어졌습니다.
이 방법은 '잘 학습된 모델이라면 생성한 이미지에 포함된 결과물을 머신 러닝 모델이 쉽게 파악할 수 있을 것'이라는 가정을 바탕으로 작동합니다. 즉, 주어진 이미지에 대해 Inception v3 분류기가 분류한 결과가 매우 자신 있게 특정 클래스라고 말할 수 있는 결과라면 입력 이미지가 특정 클래스의 특징을 뚜렷하게 가지고 있다는 의미로 해석해 좋은 생성 모델이라는 결과를 얻도록 설계됐습니다(여기서 '자신 있게 특정 클래스라고 말할 수 있다'는 것은 'Confidence Score'라는 것을 도입해 분류 결과 이 점수가 높은지 낮은지로 판단합니다).
IS를 계산하기 위한 식은 다음과 같습니다.
![]()
조건부 확률 p(y∣x)는 각 이미지 x가 클래스 y에 포함될 확률을 의미합니다. 좋은 모델일수록 입력 이미지가 특정 클래스로 매핑될 것이기 때문에 �이 조건부 확률의 엔트로피는 낮아집니다. p(y)는 클래스의 분포를 나타냅니다. 다양성이 높은 이미지 집합일수록 p(y)의 분포는 균일해집니다.
이 두 분포 간 유사도를 쿨백-라이블러 발산(Kullback–Leibler divergence, 이하 KLD)을 이용해서 비교합니다. KLD 값은 이미지가 특정 클래스에 명확히 속할수록, 클래스 분포가 균일할수록 높은 값을 갖습니다. 이렇게 계산한 KLD의 평균값에 지수 함수를 적용해 IS를 계산합니다.
IS는 생성 모델 개발 초기에는 많이 사용됐지만 아래와 같은 단점이 있어서 다음에 설명할 FID 알고리즘 등의 등장 이후 사용 빈도가 많이 줄었습니다.
- 계산식에서 전체 클래스의 분포만 고려하고 클래스 내의 분포 등을 고려하지 않음
- 분류기 모델이 판단하는 클래스 특징이 사람의 기준과 같지 않을 수 있음
- 사전 학습된 분류기에 포함되지 않은 클래스를 생성할 경우 적용이 어려움
FID(Fréchet inception distance)
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium 논문에서 소개된 이 방법은 생성 모델이 만든 이미지의 품질과 다양성을 평가하기 위해 고안된 지표입니다. 생성된 이미지 분포와 실제 이미지 분포 간의 차이를 Frechet 거리를 사용해 측정해 모델의 성능을 평가합니다.
FID를 측정하기 위해서는 먼저 이미지 임베더(embedder)를 이용해서 입력 이미지의들의 특징(feature) 벡터를 추출합니다. 이 특징 벡터는 고차원으로 표현되는 이미지 정보를 저차원으로 축약해서 나타내줍니다.
아래와 같이 다양한 동물 이미지를 2차원으로 표현하는 예제를 살펴보겠습니다. 이미지 임베더는 학습 시 이미지 간 유사한 점과 차이점 등을 잘 나타낼 수 있는 특징을 학습한 뒤 이에 따라 비슷하게 생긴 동물들은 유사한 위치로, 다르게 생긴 동물들은 다른 위치로 매핑합니다.
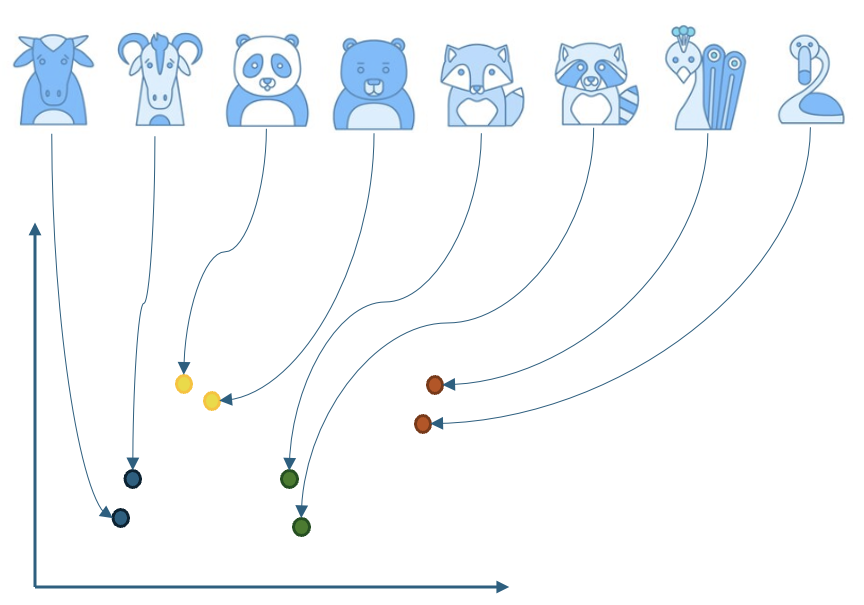
이것을 아래 그림처럼 각 동물의 클래스가 아니라 일반 이미지와 생성된 이미지로 생각해 보겠습니다. 그렇다면 생성된 이미지가 기존의 이미지들과 유사하게 잘 생성됐다면 비슷한 위치에 분포할 것이고, 왜곡 등에 의해서 달라진 부분이 많아 일반 이미지들과 시각적으로 쉽게 구분되는 형태로 생성됐다면 아래 그림의 연두색 영역처럼 다른 위치에 분포할 것입니다.
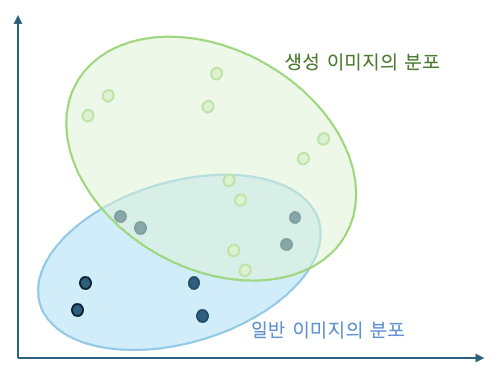
그럼 본격적으로 일반 이미지와 생성 이미지의 분포 유사도를 어떻게 계산하는지 살펴보겠습니다. 이를 위해서는 먼저 추출된 특징 벡터들의 분포를 모델링해야 하는데요. 다변량 정규 분포를 따른다고 가정해 보겠습니다. 이 가정을 바탕으로 각 분포의 평균 벡터(μ)와 공분산 행렬(Σ)을 계산하고 이를 이용해 두 정규 분포 간의 Fréchet 거리(또는 Wasserstein-2 거리)를 다음 수식을 통해 계산합니다.
![]()
여기서 ||·||²는 벡터의 L2 놈(norm)의 제곱이고, Tr은 행렬의 대각 성분의 합(trace)입니다. 수식에서 보듯 FID는 두 분포의 차이이기 때문에 생성된 이미지 분포가 실제 이미지 분포와 유사할수록 FID 값이 낮아집니다. 따라서 값이 낮으면 모델이 실제 데이터의 특성을 잘 학습해 높은 품질의 이미지를 생성한다는 것을 의미하고, 반대로 높다면 이는 생성된 이미지의 품질이 낮거나 다양성이 부족하다는 것을 나타냅니다.
FID의 장점은 생성된 이미지와 실제 이미지의 분포를 직접 비교하므로 모델이 실제 데이터의 특성을 얼마나 잘 재현하는지 평가할 수 있다는 점입니다. 또한 이미지의 품질과 다양성을 동시에 고려해 생성 모델의 전반적인 성능을 평가할 수 있습니다. 단점은 FID는 분포를 비교하기 때문에 생성된 이미지의 품질을 측정한다기보단 생성 모델 자체의 성능을 측정해 생성된 이미지 품질을 간접적으로 나타낸다는 것입니다. 또한 이미지 임베더가 Inception 네트워크와 같은 사전 학습된 모델에 의존하므로, 평가하려는 데이터셋이 이러한 모델의 학습 데이터와 크게 다를 경우 정확한 평가가 어려울 수 있습니다. 추가로, 특징 벡터가 정규 분포를 따른다고 가정하지만 실제 데이터가 이 가정을 항상 만족하지 않을 수 있습니다.
FID는 ��현재 생성 모델의 성능 평가에 널리 사용되는 지표로, 특히 GAN과 같은 모델의 평가에 자주 활용되는데요. 다만 FID 값만으로 모델의 성능을 완전히 평가하기에는 한계가 있으므로 다른 평가 지표와 함께 사용하는 것이 좋습니다.
참고로 기존 FID 방법에서 이미지 임베더를 보다 고성능의 DINO v2-ViT-L/14로 바꾼 FD-DINO 방법도 소개됐습니다. DINO v2-ViT-L/14는 기존에 분류 태스크를 위해 학습된 inception v3 모델과 비교해, 비지도 학습으로 학습됐기 때문에 이미지 표현력이 더욱 풍부합니다. 또한 비전 트랜스포머(vision transformer) 기반 기법이기 때문에 이미지의 전역적/지역적 특성을 보다 효과적으로 나타낼 수 있으며, 모델 사이즈가 더욱 크고 학습에 사용된 데이터량도 많기 때문에 기존 기법보다 더 정밀한 품질 평가가 가능합니다.
LPIPS(learned perceptual image patch similarity)
다음은 The Unreasonable Effectiveness of Deep Features as a Perceptual Metric 논문에서 소개된 LPIPS입니다. LPIPS는 원본 이미지와 생성된 이미지의 임베딩을 각각 추출하여 특징 공간(feature space)에 매핑한 뒤 특징 공간에서 그 사이의 거리를 계산해 생성된 이미지의 품질을 평가하는 방법입니다. 비교할 두 이미지를 각각 ImageNet 데이터로 선학습된 VGG(Visual Geometry Group) 네트워크에 넣고, 중간 레이어들에서 특징값을 각각 뽑아내 다음 식과 같이 두 특징 간의 유클리드 거리(Euclidean distance)를 측정합니다.
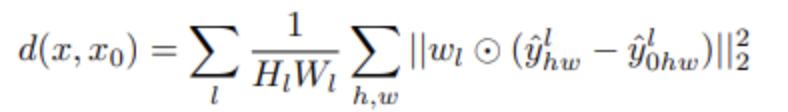
여기서 은 l 번째 레이어를 위한 가중치(weight)이고, 는 l 번째 레이어의 (h, w)위치의 특징값입니다.
LPIPS를 일반적인 이미지 생성 태스크에 적용하다면 생성된 이미지와 비교할 원본 이미지를 고르는 것이 문제가 됩니다. 생성된 이미지에는 원본이라고 판단될 이미지가 없기 때문입니다. 따라서 일반적으로는 원본 이미지와 생성된 이미지의 쌍이 존재하는 경우(예 : image reconstruction, image super-resolution, image-inpainting)에 주로 사용됩니다. 그 외의 경우에 사용하려면 훈련 데이터에서 가장 유사한 실제 이미지를 사용하는 방법이 있으며 혹은 보다 고성능으로 알려진 생성 모델의 결과물을 사용할 수도 있습니다.
Aesthetic Score
Aesthetic Score는 LAION(Large-scale Artificial Intelligence Open Network, 대규모 공개 데이터셋과 AI 연구를 통해 인공 지능의 민주화를 목표로 하는 비영리 조직)에서 제공하는 LAION-Aesthetics V1 등의 데이터셋으로 학습 후 생성된 이미지의 품질을 평가하는 모델을 사용한 평가 방법입니다. 이 데이터셋은 사람들에게 5,000장의 다양한 이미지 SAC Dataset를 주고 다음과 같이 질문해 이미지의 품질을 측정한 데이터셋입니다.
- "이 이미지가 얼마나 마음에 드시는지 1점에서 10점 사이로 평가해 주세요."
이후 입력 이미지를 OpenAI CLIP ViT-L/14 모델을 이용해 이미지 특징으로 변환한 뒤 선형적 모델을 학습해 1에서 10사이의 결과가 나오도록 학습했습니다. 따라서 이 방법을 사용하면 각 이미지에 대해 사람의 생각과 유사한 형태로 품질을 평가할 수 있어서 최근 이미지 생성 모델 �평가에 많이 활용되고 있습니다. 176,000장의 이미지가 추가된 SAC Dataset과 LAION-Logos 등을 이용해 기존보다 더욱 풍부한 데이터셋을 구성해 성능을 향상시킨 Aesthetic Score-v2도 출시됐습니다.
CLIPIQA
Exploring CLIP for Assessing the Look and Feel of Images 논문에서 소개된 CLIPIQA(CLIP image quality assessment)는 CLIP 모델을 활용해 이미지 품질을 평가하는 방법입니다. CLIPIQA는 기존의 이미지 품질 평가 방법과는 달리 이미지의 시각적 품질을 사람의 주관적 판단과 더욱 가깝게 평가할 수 있도록 설계됐습니다.
이 방법은 CLIP 이미지 임베더를 이용해 평가 대상 이미지의 특징 벡터를 계산한 뒤, "This is a high-quality image"와 "This image has a lot of noise."와 같은 상반된 평가를 나타내는 텍스트 입력에 대한 임베딩과의 유사도를 계산해 측정합니다. 따라서 Aesthetic Score와 마찬가지로 이 방법도 비교 대상 없이 생성된 이미지 한 장도 평가할 수 있다는 장점이 있습니다.
Q-ALIGN
Q-ALIGN: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels 논문에서 제안한 것으로 LMM(large multimodal model)을 학습해 이미지 품질이나 미학 정도 측정(aesthetic assessment), 또는 동영상 품질을 측정하는 모델입니다. 예를 들어 주어진 이미지의 품질이 좋지 않다면 "The quality of the image is poor" 등의 GT를 생성하고, 학습 시 "Can you evaluate the quality of the image?" 등의 쿼리에 대한 응답이 주어진 GT와 일치하도록 학습을 진행합니다.
이 방법은 숫자 대신 문장으로 정의된 평가 레벨을 학습에 사용하기 때문에 기존 LLM의 능력을 최대한 발휘할 수 있어서 기존 대비 더 좋은 평가 성능을 보여줍니다. 또한 이 방법도 Aesthetic Score나 CLIPIQA처럼 각 이미지마다 평가를 진행할 수 있기 때문에 사용하기도 간편합니다.
프롬프트 일치율(prompt alignment)
앞서 설명한 방법들은 생성된 이미지의 화질을 평가하는 것인데요. 생성 모델은 생성을 위해 사용한 프롬프트를 충실히 반영해야 하기 때문에 프롬프트와의 일치율도 평가 대상이 되어야 합니다.
CLIP Score
가장 널리 사용되는 기본적인 평가 방법입니다. CLIP 이미지 임베더와 텍스트 임베더를 사용해 각각 생성된 이미지와 생성 프롬프트를 특징 공간으로 매핑한 후 그 유사도를 다음과 같은 코사인 유사도(cosine similarity)를 이용해 측정합니다.
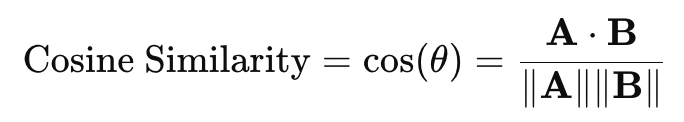
이때 A⋅B는 두 벡터의 내적 (dot product)이고, ∥∥는 벡터의 L2 놈입니다. 두 값이 유사하면 1이고 다르면(orthogonal) 0이 출력됩니다.
QA(question-answering) 기법
QA는 특정 언어 모델에 질문을 보냈을 때 언어 모델이 생성한 답변을 받는 태스크를 의미합니다. 이를 이용해서 프롬프트에 담긴 내용이 실제로 생성됐는지 평가합니다.
VQA(visual-question-answering) Score
Evaluating Text-to-Visual Generation with Image-to-Text Generation 논문에서는 다음과 같은 프롬프트를 이용해서 VQA 방식으로 일치율을 평가합니다.
- "Does this figure show {Prompt}?"
사용된 모델은 CLIP-FlanT5이고, 사전 학습된 모델의 일치율을 평가하기 위해 공개된 VQA 데이터셋을 활용해 재학습해서 사용합니다. 1,600개의 장소와 물체, 특성, 연관성 등을 포함한 복잡한 텍스트 프롬프트를 포함한 벤치마크인 GenAI-Bench 벤치마크에서 다른 방법들보다 사람과 유사하게 평가하는 것으로 나타났습니다.
Gecko Score
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings 논문에서 제안한 방법입니다. 앞서 VQA Score와 유사하게 질문을 통해 생성된 이미지에 프롬프트의 내용이 충실히 반영됐는지 검사합니다. 예를 들어 "a cartoon cat in a professor outfit, ..."이라는 입력 프롬프트가 있다면 LLM 모델을 이용해서 이 프롬프트의 주요 키워드를 추출합니다. 이 경우 예를 들어 cartoon과 cat, professor outfit 등이 추출됐다고 가정할 수 있는데요. 그 후 이를 바탕으로 QA를 생성합니다. 즉, 아래와 같은 QA 쌍이 생성되며, 이를 바탕으로 실제 일치율을 평가합니다.
- Q : "Is there a cat?", A : "[Yes, no]"
- Q : "Is the cat a cartoon?", A : "[Yes, no]"
이미지 품질과 프롬프트 일치율 동시 평가
이미지 품질과 프롬프트 일치율은 모두 생성된 이미지를 평가하는 데 중요한 요소입니다. 따라서 두 관점에서 동시에 이미지를 평가하는 방법도 많이 제안됐습니다.
HPS-V2
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis 논문에서는 이미지에 대한 사람의 선호도를 나타내는 대규모의 데이터셋 Human Preference Dataset v2를 제공합니다. 이 데이터셋은 약 80만 장(약 40만 쌍)의 이미지를 포함하고 있으며 각 이미지 중 사람이 선호하는 이미지가 표시돼 있습니다. 이 데이터셋을 바탕으로 CLIP 모델을 재학습하면 사람의 선호도를 잘 나타낼 수 있는 HPS v2(Human Preference Score v2)라는 모델을 확보할 수 있습니다.
예를 들어 {x1, x2}라는 이미지 쌍이 있다고 하겠습니다. 이때 x1과 x2 중 사람이 선호하는 이미지가 x1이라면 이를 y=[1, 0]으로 나타낼 수 있습니다(반대의 경우 y=[0, 1]).
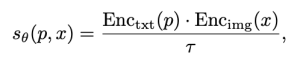
위 식에서 p와 x는 각각 이미지를 생성하기 위한 프롬프트와 생성된 이미지입니다. τ는 CLIP 모델의 'temperature scalar' 값이고, θ는 CLIP 모델의 파라미터입니다. 여기서 temperature scalar 값은 프롬프트와 이미지 간 유사도에 대한 가중치입니다. 주로 1부터 그 이상의 값이 할당되며, 값이 높을수록 프롬프트와 이미지 간 유사도 차이에 의한 영향도가 적게 반영됩니다. Enc()는 각각 텍스트와 이미지 인코더 함수입니다. 이때 학습은 다음 KL-Divergence를 최소화하는 손실 함수를 이용해서 진행됩니다.
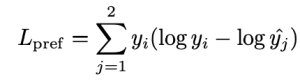
이 때, 은 다음 식을 통해서 얻을 수 있습니다.
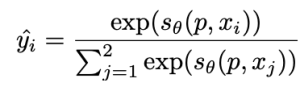
즉 {x1, x2} 중 상대적으로 품질이 낮은 이미지는 해당 프롬프트에 대해 연관이 없다는 식으로 학습이 진행됩니다.
Pick Score
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation 논문에서 제안한 방법입니다. 이 방법의 손실 함수 구성은 HPS-V2와 같습니다. 하지만 평가 모델 학습을 위한 데이터셋을 생성하는 방식에 큰 차이가 있으며, 비슷한 품질의 이미지에 대해 y=[0.5, 0.5] 형태로 표현하는 방식을 추가했습니다.
요약 및 결론
앞서 말씀드린 내용을 간단히 요약해 보겠습니다.
기존 비전 모델에서는 미리 명확한 정답이 존재하는 태스크가 많기 때문에 성능 평가가 상대적으로 용이했습니다. 정해진 평가 방법과 이를 위해 미리 정답을 부여한 데이터셋으로 성능 평가를 진행하며 정량적인 특성으로 쉽게 모델을 비교할 수 있었습니다.
반면, 이미지 생성 모델에서는 정답을 미리 결정하기가 어렵기 때문에 정량적으로 평가하기 위한 평가 방법 설계가 쉽지 않습니다. 따라서 사람이 생각하는 이미지 품질을 최대한 모사하기 위한 다양한 방법이 제안됐는데요. 이런 방법들은 주로 시각적 품질이나, 생성에 사용한 프롬프트와 결과물의 일치율을 바탕으로 품질을 평가합니다.
먼저 시각적 품질을 평가하기 위한 방법은 이미지 처리를 이용한 방법과 머신 러닝 기반의 방법으로 나눠 살펴봤습니다. 특히 FID와 같이 일반적으로 많이 사용하는 방법에 중점을 두고 살펴봤습니다. 다음으로 프롬프트 일치율을 평가하기 위한 방법으로 CLIP Score와 최근에 소개된 QA를 이용한 방법들을 살펴봤습니다. 또한 시각적 품질과 일치율을 동시에 비교하는 방법도 살펴봤습니다.
최근에는 더욱 정밀하고 공정한 이미지 평가를 목표로 다양한 연구가 활발히 이뤄지고 있으며, 이를 위해 새로운 데이터셋과 평가 모델이 지속적으로 제안되고 있습니다. 이러한 연구의 발전은 생성 모델의 성능을 객관적으로 측정하고 개선하는 데 중요한 역할을 하고 있습니다.
요즘 우리는 실생활에서 다양한 생성 이미지를 접하고 있습니다. 이런 이미지 중에는 상당한 품질에 깜짝 놀라게 하는 이미지도 있고, 조금 이상한 느낌에 고개를 갸웃거리게 만드는 이미지도 있는데요. 생성 이미지 평가 방법은 모델의 성능을 균일한 기준에서 평가할 수 있게 할 뿐 아니라, 이를 이용해서 모델의 성능도 개선할 수 있습니다. 또한, 실제 서비스에서 저품질 이미지가 소비자에게 제공되는 것을 막는 필터의 역할도 담당할 수 있습니다.
다음 편에서는 이러한 평가 방법들이 실제 다양한 생성 모델의 성능 개선에 어떻게 적용되고 있는지 살펴보겠습니다. 많은 기대 바랍니다.


