생성형 AI 모델로 이미지 생성은 쉽죠, 그런데 '좋은 이미지' 생성도 쉬웠으면 좋겠어요!
저희 회사에는 고유한 비율로 최소한의 디테일만 유지한 채 인체와 개체를 정의하는 특유의 이미지 스타일이 존재합니다(참고). 저희 팀에서는 생성형 AI를 이용해 이 스타일이 적용된 이미지를 프롬프트만으로 생성하는 텍스트 투 이미지(text-to-image) 모델을 만드는 프로젝트를 진행했습니다.
이 프로젝트는 사내 디자이너분들의 반복적인 이미지 생성 업무를 최소화하기 위해 시작했습니다. 사내 디자인 업무 중에는 상황에 맞게 이미지를 조금씩 다른 이미지를 그리는 업무가 있는데요. 이 작업을 자동화할 수 있다면 디자이너 분들이 보다 창의성을 요하는 업무에 집중할 수 있는 환경이 조성될 것이라고 믿었습니다.
아래 이미지는 앞서 말씀드린 저희 이미지 스타일에 따라 제작된 이미지로, 저희가 원하는 �최종 결과물의 스타일과 수준을 보여줍니다.
 |  |
늘 그렇듯 생성형 AI 모델이 항상 좋은 이미지를 생성하도록 만드는 것은 쉽지 않았습니다. 예를 들어 아래 예시와 같이 'hold the LINE'이라는 피켓을 들고 있는 여성의 이미지를 생성하는 일을 생각해 보겠습니다. 저희 이미지 스타일과 유사한 이미지가 생성될 수도 있겠으나, 그렇지 않은 이미지들도 자주 생성될 것입니다. 실제로 아래 두 이미지 생성에 사용한 모델은 동일한 모델입니다. 단지 이미지 생성 시 설정한 하이퍼파라미터만 다를 뿐입니다(하이퍼파라미터에 대해서는 뒤에서 자세히 설명하겠습니다).
| 입력 | 희망편 | 절망편 |
|---|---|---|
| hold the LINE 피켓을 들고 있는 여성을 그려줘! (A woman is holding a picket sign. The sign has the words "hold the LINE" written on it.) | 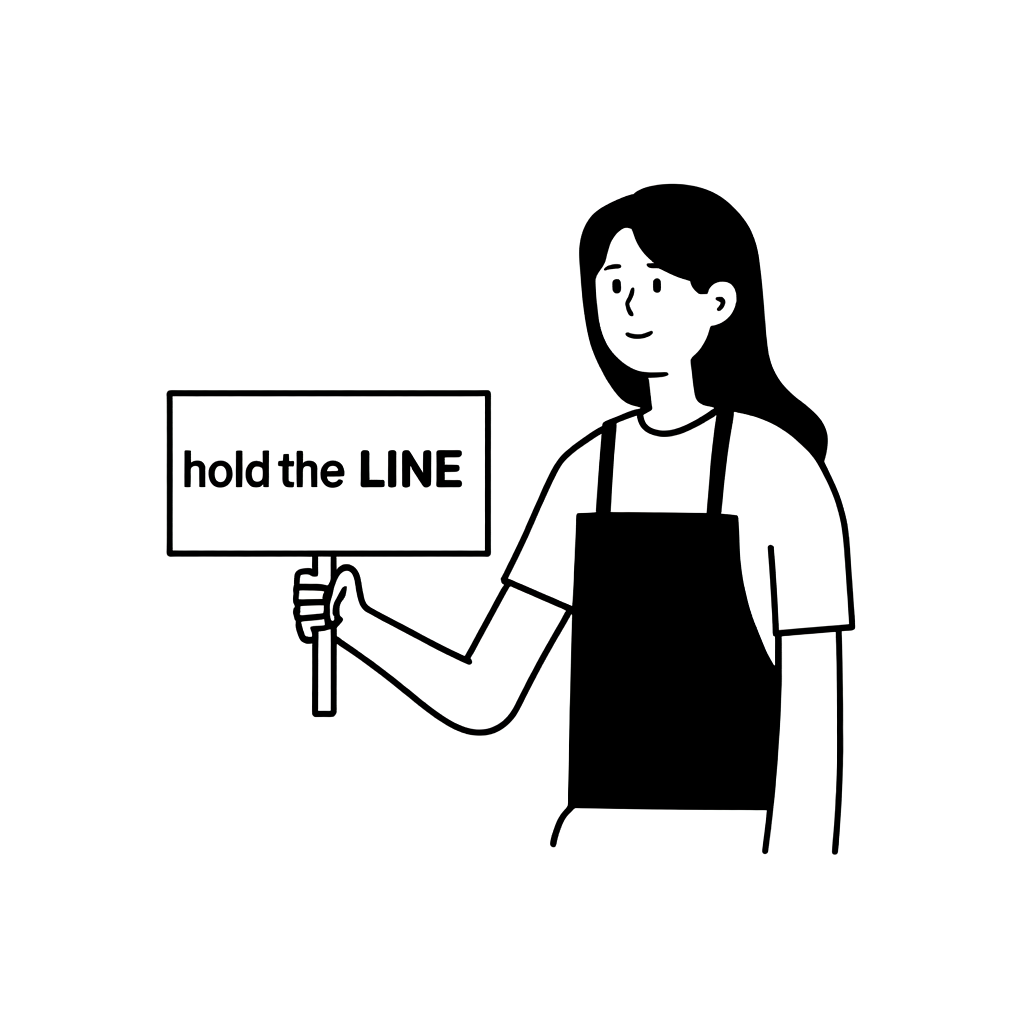 | 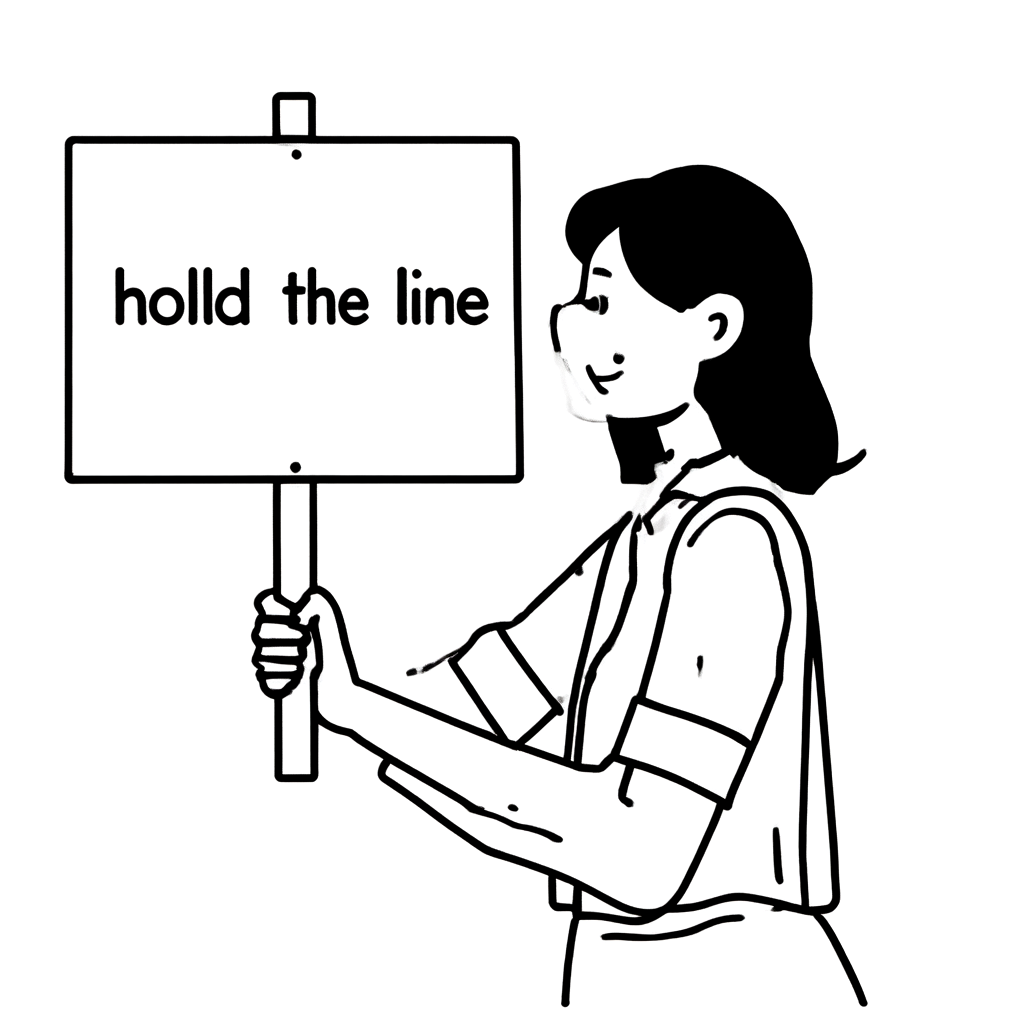 |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
좋은 이미지를 생성하기 위해 먼저 살펴볼 것
이 글에서는 먼저 AI를 이용해 이미지를 생성하는 방법부터 살펴보겠습니다. 디퓨전(Diffusion) 모델로 시작해 스테이블 디퓨전(Stable Diffusion) 계열의 모델을 중점적으로 살펴보고자 하며, 스테이블 디퓨전 모델로 이미지 생성 시 널리 사용되는 여러 하이퍼파라미터와 각각의 기능도 함께 소개하겠습니다.
좋은 이미지를 생성하는 방법을 알아내기 위해서는 이미지를 여러 번 생성해 봐야 하기 때문에 보통 몇 가지 하이퍼파라미터를 선정해 수치를 조정해 가며 이미지를 하나씩 생성해 보게 되는데요. 특정 범위 안에서 여러 값을 바꿔가며 이미지를 생성하는 일은 엄청난 수고가 필요한 일입니다. 따라서 자동화할 수 있다면 좋겠죠. 이런 작업을 자동화하려면 우선 '좋은 이미지'라는 게 무엇인지 수치화해 평가할 수 있어야 합니다. 이에 저희는 앞서 설명했던 이미지 평가 방법(참고: AI로 생성한 이미지는 어떻게 평가할까요? (기본편)) 중 일부를 소개하고, 이것을 활용한 하이퍼파라미터 탐색 방법을 소개하려고 합니다. 이미지를 수치화해서 평가하는 방법 외에도 프롬프트를 활용한 하이퍼파�라미터 평가 방법도 소개할 예정이니 많은 관심 부탁드리며 본격적으로 시작해 보겠습니다.
AI가 이미지를 생성하는 방법
우선 생성 모델이 어떻게 이미지를 생성하는지 디퓨전 모델과 스테이블 디퓨전 모델을 중심으로 간략히 살펴보겠습니다(이후 설명은 스테이블 디퓨전 모델이 기준입니다).
디퓨전 모델
디퓨전 모델은 이미지 생성 분야에서 널리 사용하는 접근 방식 중 하나인 디퓨전 프로세스로 이미지를 학습 및 생성하는 모델입니다. 디퓨전 프로세스는 이미지의 노이즈를 점진적으로 제거(denoise)해 고품질의 이미지를 생성하는 방식입니다.

- 전방향 디퓨전 프로세스: 디퓨전 프로세스는 원본 이미지에 점진적으로 노이즈를 추가해 이미지를 완전히 무작위한 상태로 변환하는 과정입니다. 각 단계에서 일정량의 가우스 잡음(Gaussian noise)을 추가하는데요. 노이즈를 추가하는 방식은 마르코프 체인(Markov chain)으로 모델링되며, 각 단계는 이전 단계의 결과에 의존하지 않고 독립적으로 진행됩니다.
- 역방향 노이즈 제거 프로세스: 노이즈 제거 프로세스는 노이즈가 추가된 이미지로부터 원본 이미지를 복원하는 과정입니다. 노이즈는 학습된 모델을 이용해 제거하는데요. 한 번에 제거하는 것이 아니라 점진적으로 제거해 초기 노이즈가 원본 이미지에 가까운 상태가 되도록 복원해 나갑니다. 이를 위해 모델은 현재 상태의 노이즈 이미지와 각 단계별로 노이즈를 제거할 확률 분포를 학습합니다. 즉, 제거할 노이즈 예측 값은 확률적(stochastic)으로 결정됩니다.
이미지는 샘플링된 랜덤 가우스 잡음에 역방향 노이즈 제거 프로세스를 적용하는 형태로 생성됩니다.
스테이블 디퓨전 모델
스테이블 디퓨전(이하 SD)은 디퓨전 모델의 한 구현체입니다. SD의 특징을 간략히 살펴보겠습니다.
기존 디퓨전 모델은 앞서 살펴본 디퓨전 프로세스를 '픽셀 공간(pixel space)'에서 적용합니다. 따라서 큰 이미지(예: 1024x1024 픽셀)를 생성할 때에는 매우 많은 연산량이 필요합니다.
이런 단점을 개선하기 위해 픽셀 공간이 아닌 '잠재 공간(latent space)'에서 디퓨전 프로세스를 적용하는 SD 모델이 제안됐습니다. 즉 기존 디퓨전 모델이 이미지 자체에서 노이즈를 줄이는 개념이라면, SD 모델은 이미지의 '잠재 벡터(latent vector)'에서 노이즈를 줄이는 개념입니다. 여기서 잠재 벡터는 잠재 공간에서의 위치이기 때문에 임베딩이라고 생각해도 무방합니다. 이 잠재 벡터는 이미지를 변분오토인코더(variational autoencoder, 이하 VAE)로 인코드해 생성하고, 이미지는 이 잠재 벡터를 VAE로 디코드해 생성합니다.
이미지 생성 방식 중 텍스트를 추가 정보로 제공하는 텍스트 투 이미지 방식에서는 이미지를 생성할 때 노이즈 제거 과정에서 텍스트 임베딩 생성에 어텐션(attention) 메커니즘을 �활용하며, 이미지 생성 모델을 파인튜닝할 때는 주로 노이즈 제거기(denoiser)인 U-Net을 파인튜닝합니다.
SDXL와 SD3.5 모델
저희 실험에서는 SD의 초기 버전인 SD1을 쓰지 않고 SDXL(SD-xlarge)과 SD3.5을 사용했습니다. 이 두 모델은 초기 버전의 SD 모델의 파라미터 수 증가에 따라 개량된 모델입니다(참고로 이 글에 첨부된 이미지는 대부분 SD3.5로 생성했습니다).
SDXL의 구조는 SD와 큰 차이는 없습니다. 다만 텍스트 인코더(CLIP-G/14)가 하나 더 추가됐으며, 이에 따라 초기 SD인 SD1보다 프롬프트의 정보를 다양하게 추출할 수 있다는 장점이 있습니다.
SD3.5는 텍스트 인코더(T5 XXL)가 하나 더 추가되고 노이즈 제거기가 변경됐습니다. 또한 학습 방식이 디퓨전 프로세스 방식에서 플로 매칭(flow matching) 방식으로 변경되면서 이름과 다르게 디퓨전 모델이 아닌 플로 모델로 바뀌었습니다. U-Net 대신 도입된 노이즈 제거기는 MMDiT(Multimodal Diffusion Transformer)라는 트랜스포머입니다. 이 트랜스포머는 텍스트와 이미지의 각 모달리티(modality)별로 별도 스택을 갖고 있고 각 모달리티별로 선형(linear) 레이어를 갖고 있기 때문에 U-Net과 비교해 텍스트에 대한 학습 가능한 파라미터가 늘어났다고 볼 수 있습니다. 어텐션을 계산할 때에는 셀프/크로스 어텐션을 따로 계산하지 않고 각 모달리티를 하나로 통합(concatenation)해 두 어텐션을 하나의 블록(계산 단위)에��서 처리합니다.
디퓨전 모델은 이미지에 노이즈를 입히고 이를 제거하는 방법을 학습해 이미지를 생성합니다. 반면 플로 모델은 복잡한 이미지 데이터 분포와 간단한 정규 분포를 매칭해서 간단한 정규 분포를 활용해 이미지를 생성할 수 있다고 전제합니다. 즉, 정규 분포에서 샘플을 하나 선택하면 그와 매칭된 이미지 데이터를 생성할 수 있다고 전제합니다.
그렇다면 간단한 정규 분포를 어떻게 실제 데이터와 매핑할 것인가를 고민해야 하는데요. 플로 매칭에서는 해당 데이터 공간을 변형시키는 벡터 장(vector field)을 학습하는 방법으로 접근했습니다. 이해를 돕기 위해 아래 이미지와 함께 설명하겠습니다.
먼저 아래 왼쪽 그림을 보시겠습니다. 아래 왼쪽 그림과 같이 임의의 공간에 정규 분포(봉이 하나인 원형)와 데이터 분포(봉이 두 개인 일그러진 긴 형태)가 존재한다고 가정해 봅시다. 이때 왼쪽의 정규 분포가 오른쪽의 데이터 분포로 변형돼 가는 형태를 상상해 보면, 오른쪽으로 이동하면서 점차 위아래로 늘어나는 모양이 그려질 것입니다. 이와 같은 변화 과정에는 공간의 모든 지점마다 변하는 정도가 있을 텐데요. 이 변화량을 벡터 장으로 표현할 수 있습니다. 플로 매칭은 이 벡터 장을 학습하는 형태로 논리를 정리한 방식입니다.
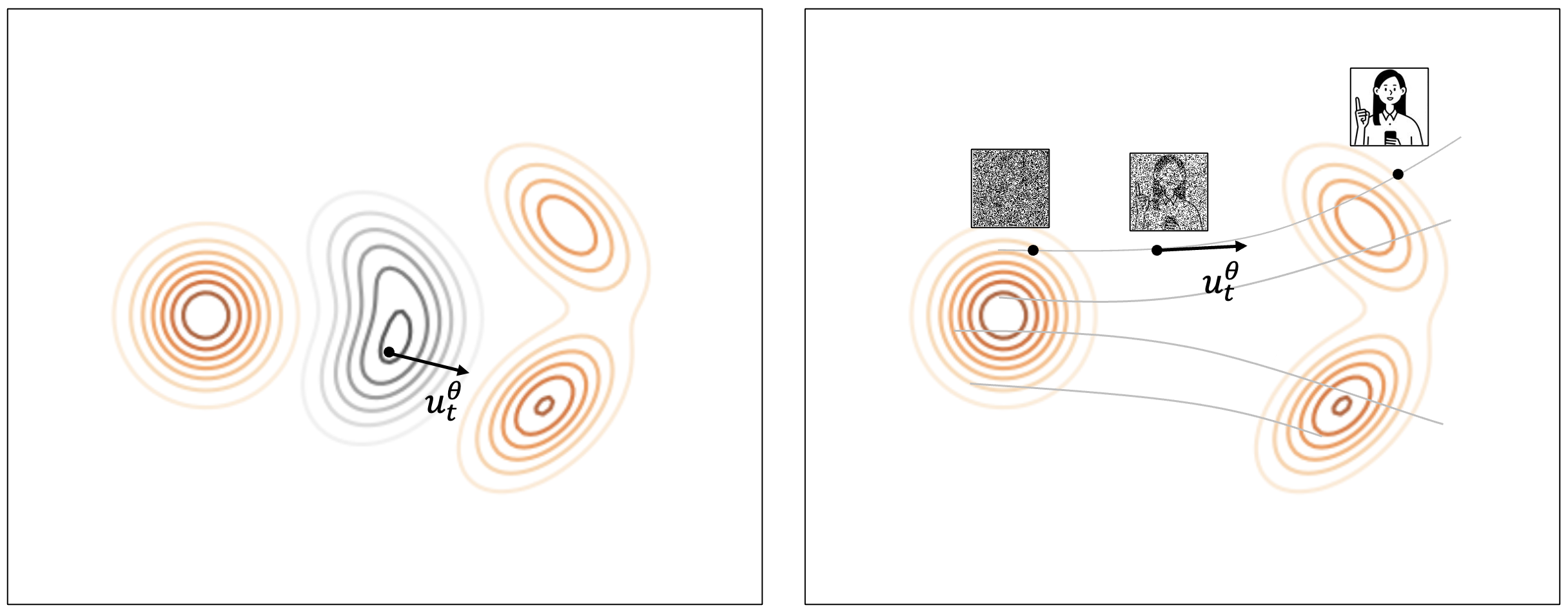
다음으로 위 오른쪽 그림을 보시겠습니다. 디퓨전 프로세스와 비교해 설명하면, 랜덤 노이즈에서 노이즈를 제거해 나가는 과정은 위 오른쪽 그림과 같이 랜덤 분포의 어느 한 샘플에서 어느 한 데이터 포인트로 이동해 나가는 과정이라고 볼 수 있습니다. 따라서 플로 매칭에서 이미지를 생성하는 방식은 랜덤 노이즈를 샘플링한 후 임의의 거리만큼 이동하는 것을 반복하는 것입니다. 여기서 이동할 방향과 거리를 속도(velocity, )라고 표현하는데요. 이 속도는 벡터장을 미분하면 구할 수 있기 때문에 플로 매칭 모델은 입력이 같으면 항상 같은 결과가 나오는 결정적(deterministic)이라는 장점이 있습니다.
이미지 생성 시 조절할 수 있는 하이퍼파라미터들과 그 역할
다음으로 이미지 생성 시 조절할 수 있는 하이퍼파라미터 중 저희가 실험에서 사용한 하이퍼파라미터의 종류와 각각의 역할을 소개하겠습니다.
시드, 랜덤 노이즈, 잠재 벡터
이미지 생성 모델은 랜덤 노이즈를 입력으로 받습니다. 이것이 이미지 생성의 시작점인데요. 시드(seed)는 이 랜덤 노이즈를 생성하기 위한 기준 정숫값입니다. 같은 시드라면 항상 동일한 랜덤 노이즈를 생성합니다. 또한 앞서 스테이블 디퓨전에서는 이미지가 아닌 이미지의 잠재 벡터에서 노이즈를 줄이는 개념으로 바뀌었다고 말씀드렸는데요. 여기서 조금 더 생각해 보면, 랜덤 노이즈 또한 잠재 공간의 어느 지점에 존재하는 잠재 벡터라는 것을 알 수 있습니다.
정리하면, 시드는 모델 입력의 초깃값을 결정하고, 랜덤 노이즈는 모델 입력의 초깃값입니다. 시드는 정숫값이고, 랜덤 노이즈는 잠재 벡터라는 차이가 있지만 이 둘은 설명하려는 포인트가 어디냐에 따라서 모두 '초깃값'이라는 의미를 가질 수 있기 때문에 종종 혼용돼 사용되기도 하는데요. 여기서 이 개념들을 분리해 자세히 설명한 이유는 이후 '좋은 시작 지점 찾기'에서는 구분해서 사용하기 때문입니다.
프롬프트
프롬프트는 이미지 생성 모델에 노이즈 외에 추가로 정보를 넣을 수 있는 창구 중 하나입니다. 이와 같이 텍스트를 추가 정보로 제공하는 이미지 생성 모델을 텍스트 투 이미지 생성 모델이라고 합니다. 텍스트 투 이미지 생성 모델은 노이즈 제거기가 이미지를 학습할 때 이미지의 캡션을 같이 학습하면서 '어떤 캡션일 때 어떤 이미지더라'와 같은 정보를 학습한 상태이기 때문에 작동할 수 있습니다.
참고로 프롬프트는 사용자의 의도를 반영한 맞춤형 결과를 얻는 데에는 유용하지만 이미지의 구도나 색깔 등을 완벽히 제어하기에는 다소 부족합니다.
Classifier-Free Guidance
Classifier-Free Guidance(이하 CFG)는 생성된 이미지에 프롬프트의 정보를 얼마나 반영할지 조절하는 방법 중 하나입니다. CFG는 노이즈 제거 과정에서 두 가지 정보를 활용하는데요. 하나는 프롬프트의 텍스트 조건부로 예측된 노이즈이고 다른 하나는 조건 없이 또는 네거티브 프롬프트 기반으로 예측된 노이즈입니다. CFG는 이 두 노이즈의 차이를 활용합니다.
두 노이즈의 차이를 얼마나 반영할지는 하이퍼파라미터로 정의합니다. 값이 높을수록 조건부 노이즈의 정보를 더 사용하며, 이에 따라 프롬프트의 정보를 보다 더 반영한 이미지가 생성됩니다. 만약 원하는 객체가 이미지에 표현되지 않았다면 CFG의 값을 더 높게 설정해 더 강하게 반영되도록 할 수도 있습니다.
Reward Guidance
Reward Guidance(이하 RG)는 CFG와 마찬가지로 이미지에 프롬프트의 정보를 얼마나 반영할지 조절하는 방법 중 하나입니다. 이 방법은 원래 모델의 표현력과 새로 학습한 파인튜닝된 모델의 표현력의 차이를 활용합니다. 정보로는 텍스트 조�건부로 예측된 노이즈만을 사용하는데, 파인튜닝된 모델이 예측한 노이즈와 원래 모델이 예측한 노이즈의 차이를 활용합니다.
이 둘의 차이를 얼마나 반영할지는 하이퍼파라미터로 정의합니다. 값이 높을수록 파인튜닝된 모델의 노이즈를 더 사용하며, 이에 따라 파인튜닝된 모델의 정보를 보다 더 반영한 이미지가 생성됩니다. 원하는 스타일로 학습한 모델의 특성을 더 반영하고 싶다면 RG의 값을 더 높게 설정해 더 강하게 반영되도록 할 수 있습니다.
Skip-Layer Guidance
Skip-Layer Guidance(이하 SLG)는 SD3 계열에서 사용된 방법으로 텍스트 조건부로 예측된 노이즈를 활용하는데요. 위 방법들과 유사하게 노이즈 제거기(SD3의 MMDiT)의 모든 블록을 활용해 예측한 노이즈와, 일부 블록을 연산에서 제외(skip)하고 예측한 노이즈의 차이를 활용합니다. 관련 커뮤니티에서는 이 SLG를 적절히 활용하면 손가락 개수가 이상하게 많아지거나 관절이 꼬이는 등 인체의 구조가 부적절하게 표현되는 문제를 상당 부분 완화시킬 수 있다는 의견이 제시되고 있습니다.
Low-Rank Adaptation 스케일
Low-Rank Adaptation(이하 LoRA)은 학습하기 어려운 큰 모델을 적은 수의 파라미터만으로 파인튜닝하는 방법 중 하나입니다. LoRA 스케일은 노이즈 제거기에 학습된 LoRA 파라미터들이 연산 시에 어느 정도 영향을 줄지 결정하는 값입니다. 즉 파인튜닝한 정보를 얼마나 반영할지를 결정하는 것입니다. 이 하이퍼파라미터는 노이즈 제거기의 모든 연산에 영향을 미치기 때문에 위 방법들과 독립적인 방법이라고 보기는 어렵습니다.
여기서 소개한 파라미터 외에도 이미지 생성에 관여할 수 있는 하이퍼파라미터는 매우 많지만 저희는 실험 시 위에서 소개한 하이퍼파라미터만 사용했습니다. SLG의 경우 초기 실험 결과 저희가 파인튜닝한 모델에서는 좋은 하이퍼파라미터를 찾는 것이 어려웠기 때문에 이후 실험에서는 0으로 고정했고, 나머지 세 하이퍼파라미터(CFG, RG, LoRA 스케일)만을 이용해 실험을 진행했습니다.
복잡한 내용은 이쯤에서 각설하겠습니다. 중요한 사실은 이런 하이퍼파라미터를 손으로 다 하나씩 생성해 보며 그리드 탐색(grid search)을 하는 것은 너무도 힘든 일이라는 것입니다. 우리에겐 시간도, 돈도 부족합니다. 조금 더 효율적인 방법을 찾아야 합니다.
좋은 시작 지점 찾기
이 프로젝트를 진행하는 과정에서 빈 프롬프트(null prompt)를 이용한 시드 마이닝(seed mining)이란 방법을 이용해 이미지의 품질을 향상시키는 프레임워크를 제안하는 논문들(참고: 1, 2, 3, 4)을 보게 되었는데요. 이 논문들을 보면서 좋은 시작 지점을 찾을 수 있는 아이디어를 얻었습니다.
시드 마이닝의 주요 아이디어는 '시드마다 가지고 있는 고유한 정보를 찾아서 잘 정리해 뒀다가 이미지 생성 시 이 정보를 활용해 최적의 시드를 사용하자'입니다. 시드가 가진 고유한 정보를 추출하기 위해 빈 프롬프트를 사용하는데요. 빈 프롬프트란 길이가 0인 문자열을 가리킵니다. 즉 시드 마이닝은 텍스트 조건 없이 이미지를 생성해서 해당 이미지의 임베딩이나 캡셔닝 등으로 특성을 추출(mining)해 좋은 시드 후보군을 ��준비해 두는 과정입니다. 여기서 앞서 시드는 정숫값이라고 설명했는데 그 정숫값에서 어떻게 정보를 추출한다는 것인지 의아해하실 수 있는데요. 시드 마이닝은 시드를 이용해 생성한 랜덤 노이즈인 잠재 벡터에서 관련 정보를 추출하는 것입니다.
저희는 마이닝 단계까지 적용하기에는 시간이 부족해 '좋은 시드를 판단한다'는 아이디어만 차용했습니다. 또한 좋은 시드라면 프롬프트의 텍스트가 담고 있는 모든 정보를 갖고 있는 것이라고 가정했습니다.
좋은 시드를 판단하는 방법은 많이 연구되고 있는데요(참고: 1, 2, 3). 이 연구들은 주로 SD에 내재된 '주제 무시(subject neglect)'와 '주제 섞임(subject mixing)' 문제를 해결하기 위한 방법들을 제안했습니다. 주제 무시는 입력된 프롬프트의 정보가 이미지에 표현되지 않는 경우를 말하며, 주제 섞임은 텍스트에 있는 어느 한 개체의 설명이 이미지에서는 다른 개체에 섞이는 경우를 말합니다.
아래 이미지는 주제 섞임의 대표적인 예시로, SDXL에 "a cat and a rabbit"이라는 프롬프트를 입력해 생성한 것입니다. 언뜻 보기에는 문제없어 보이지만 자세히 보면 이상한 점을 찾을 수 있습니다. 고양이는 토끼와 같은 귀를 갖고 있고, 토끼는 고양이와 같은 얼굴을 갖고 있기 때문입니다.

위와 같은 문제들은 노이즈 제거기에 입력된 잠재 벡터에 프롬프트와 관련된 정보가 없거나, 정보가 있지만 부정확한 위치에 있는 경우에 발생합니다. 이 두 문제를 해결하기 위해 연구자들은 잠재 벡터와 텍스트 임베딩 사이의 어텐션 맵을 활용한 손실을 정의하고 이를 최소화하는 방향으로 잠재 벡터를 갱신하는 방법을 제안했습니다.
저희는 SD3.5를 사용하는 입장에서 그래픽 카드 여건 상 잠재 벡터를 직접 갱신하는 것은 어려웠기 때문에 손실에 집중했습니다. 손실을 측정하면 해당 시드에 프롬프트에 대한 정보가 충분한지 아닌지 판단할 수 있기 때문에 이 손실로 시드의 적합성을 판단해 보기로 결정했습니다.
아래 이미지들은 프롬프트와 하이퍼파라미터는 고정하고 시드만 변경해 생성한 것입니다. 손실은 SD3.5와 저희 내부 스타일로 파인튜닝한 모델로 임의의 시드와 고정된 프롬프트 사이에서 측정했습니다. 손실값은 소수점 넷째 자리까지 표시했으며, 결과 중 세 번째로 작은 값인 0.0393을 넘어선 값들은 '0.0393 초과'로 표기했습니다.
| 시드 | 0 | 42 | 3143890026 |
|---|---|---|---|
| 손실 | 0.0393 초과 | 0.0393 초과 | 0.0380 |
| 이미지 |  |  |  |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
| 시드 | 2571218620 | 200427519 | 893102645 |
|---|---|---|---|
| 손실 | 0.0380 | 0.0383 | 0.0393 |
| 이미지 |  |  |  |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
위 표를 보면 손실이 낮을수록 대체로 이미지의 품질이 좋아지는 경향이 있긴 하나 꼭 그렇지는 않다는 것을 알 수 있습니다. 시드는 초기 랜덤 노이즈를 결정하는 값이기 때문에 이 시드와 프롬프트 사이에서 측정한 손실이 낮을수록 무조건 완성될 이미지의 품질이 좋아진다고 보장할 수는 없다는 한계가 있습니다. 저희는 위 과정을 통해 이후 실험에서 "a cat and a rabbit"이라는 프롬프트에 대한 시드로 '3143890026'를 사용하기로 결정했습니다.
생성된 이미지가 얼마나 괜찮은지 판단하기
앞서 '좋은 시작 지점을 찾기'에서는 생성된 이미지가 얼마나 좋은지 눈으로 판단했습니다. 그런데 많은 이미지를 처리하려면 이 과정을 자동화해야 하고, 이를 위해서는 이미지의 품질을 수치화할 필요가 있습니다. 저희 프로젝트에서는 이를 위해 앞서 발행한 AI로 생성된 이미지는 어떻게 평가할까요? (기본편)에서 설명한 여러 지표 중 네 가지를 사용했습니다. 바로 CLIP Score와 VQA Score, HPS-V2, Pick Score입니다.
이와 관련된 내용을 다시 짧게 설명하자면, 좋은 이미지는 다음 두 조건을 만족한다고 볼 수 있습니다.
- 이미지가 프롬프트의 정보를 충분히 표현하고 있어야 한다.
- 프롬프트에 기반해 살펴볼 때 이미지에 이상한 요소가 없어야 하며 전체적으로 일관성이 있어야 한다.
첫 번째 조건은 프롬프트와 이미지와의 관계를 측정해야 하는 조건으로 CLIP Score와 VQA Score를 활용해 측정했습니다. 이 두 지표는 프롬프트의 내용이 이미지에 얼마나 포함돼 있는지 판단할 수 있는 지표입니다.
두 번째 조건은 이미지의 질적 완성도를 평가하는 조건으로 HPS -V2와 Pick Score로 측정했습니다. 이 두 지표는 입력된 프롬프트를 기반으로 자동 생성된 여러 이미지 중 어느 것이 제일 좋아 보이는지 사람의 선호도를 조사한 데이터를 활용해 학습됐기 때문에 생성된 이미지가 좋은 이미지인지 판단할 수 있는 지표로 사용할 수 있습니다.
서로 스케일이 다른 지표 정규화하기
위 네 가지 지표를 사용하기로 결정한 뒤 문제가 하나 발생했습니다. 선택한 지표들의 스케일이 서로 다르다는 것입니다. 스케일 정의는 모두 0~1 사이였지만, 점수를 측정하는 점수기가 저희 데이터에 대해 측정한 값에는 각 지표별로 차이가 있었습니다. 이 점수를 정규화하지 않고 그대로 가져와 평균을 계산해 버리면 평가가 특정 지표에 편향된 모습으로 나타날 가능성이 높았습니다.
이를 완화하기 위해 HPS-V2 평가용 데이터셋을 이용해 각 지표를 정규화했습니다. 해당 데이터셋은 이미지-프롬프트 쌍에 대해서 사람이 1~10점 사이로 점수를 매긴 데이터셋으로 각 점수별로 데이터 �분포가 다릅니다. 각 점수기의 측정값을 정규화하기 위해 점수별로 계층적 샘플링을 수행해 데이터를 처리했습니다. 그리고 가장 좋은 경우라고 할 수 있는 '기준으로 삼은 저희 이미지 스타일을 따르기 위해 학습 시 사용한 데이터셋'을 최고 점수 군인 11점으로 설정하고, 이에 맞춰 전체 데이터를 11개의 등급(bin)으로 구분했습니다.
구체적으로 말씀드리자면, 점수기의 측정값을 평균 내 각 등급별로 점수를 통합했습니다. 데이터셋에서 1점으로 평가된 데이터들에 대한 측정값을 모델별로 평균 내고, 2점대도 마찬가지 방식으로 평균 냈습니다. 그리고 정규화에 쓸 평균과 표준 편차를 총 11개의 측정값을 기반으로 계산했습니다.
아래 그래프를 보면 평가 등급이 높을수록 각 점수기의 점수 또한 대체로 높아지는 것을 확인할 수 있습니다(참고로 VQA(보라색 점선)는 오른쪽 척도, 나머지 세 지표는 왼쪽 척도가 기준입니다). 다만 점수기들이 두 번째 등급에 가장 낮은 점수를 주는 경향이 있었는데요. 저희는 좋은 점수를 부여받은 이미지 위주로 사용할 것이기 때문에 낮은 점수에서 발생한 이 현상은 무시했습니다.
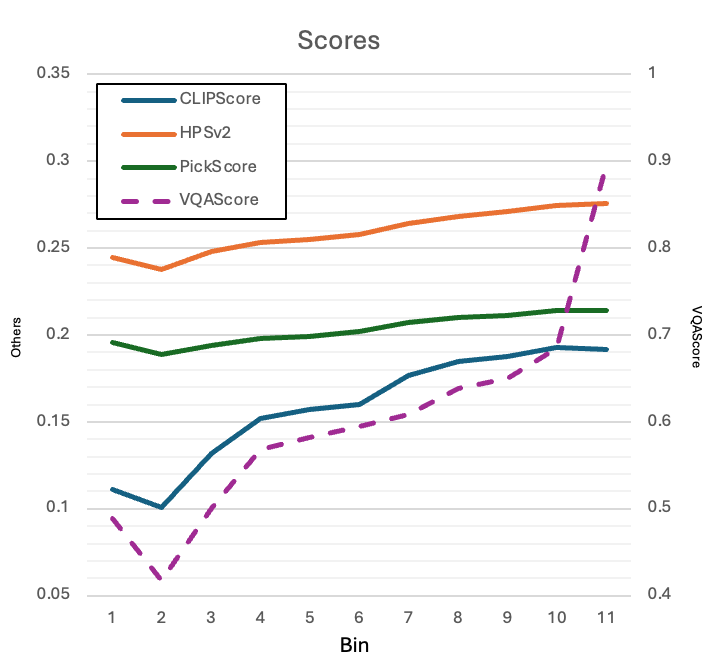
위 과정을 거쳐 최종적으로 구한 각 지표별 평균과 표준 편차는 다음과 같습니다.
| CLIP Score | HPS-V2 | Pick Score | VQA Score | |
|---|---|---|---|---|
| 평균 | 0.1587 | 0.2591 | 0.2031 | 0.6029 |
| 표준 편차 | 0.0323 | 0.0127 | 0.0086 | 0.1248 |
이미지에 대한 점수는 네 점수기가 측정한 위 표의 값을 각각 정규화한 뒤 그 값의 평균으로 정의했습니다. 물론 이렇게 정규화해도 한계는 있습니다. 이것으로 저희 이미지 스타일을 잘 따랐는지 평가하는 것은 어렵기 때문입니다. 10등급과 11등급의 점수가 큰 차이를 보이는 VQA Score도 있지만 그렇지 않은 CLIP Score나 HPS-V2 같은 경우도 존재합니다. 저희 이미지 스타일 데이터와의 유사도를 측정하는 방법도 고려해 봤으나 스타일이 비슷하다는 것을 평가할 만한 뾰족한 수를 찾지 못해 일단 이 네 가지 지표만 활용했는데요. 대신 앞서 말씀드린 LoRA 스케일로 보완했습니다.
LoRA 스케일은 기본 값인 1인 경우 새로 학습한 이미지의 특성을 그대로 반영하며, 0일 경우 그 특성을 전혀 반영하지 않습니다. 값이 너무 클 경우에��는 이미지의 특성이 왜곡될 수도 있습니다. 저희는 모델이 생성한 이미지는 저희 이미지 스타일을 따르는 것이라고 전제하기 위해 LoRA 스케일이 일정 범위(0.8~1.2)를 벗어나지 않도록 설정했습니다.
블랙박스 최적화로 내부 구조를 모르는 함수의 최적값 찾기
이제 이미지를 자동으로 평가할 방법은 준비됐습니다. 이 지표를 활용해 최적의 하이퍼파라미터를 탐색할 차례인데요. 하이퍼파라미터 탐색에 널리 사용되는 그리드 탐색은 좋은 이미지라는 것을 판단할 수는 있지만 탐색 비용이 너무 많이 듭니다. 대신, 저희는 이미지 자동 평가 지표를 확보했으니 이를 활용한 블랙박스 최적화 방법을 적용하기로 결정했습니다. 블랙박스 최적화는 베이지안 최적화(Bayesian optimization)의 다른 이름으로, 내부 구조를 모르는 함수의 최적값을 찾는 방법입니다.
아래 두 그래프는 블랙박스 최적화 과정의 한 예시입니다. 이 그래프와 함께 블랙박스 최적화 과정이 어떻게 진행되는지 개괄적으로 설명하겠습니다.
먼저 아래 상단 그래프의 빨간 점선이 앞서 말한 내부 구조를 모르는 주어진 함수(블랙박스 함수)의 그래프입니다. 이 함수의 최적값(이 경우에는 최댓값)을 찾는 것이 목표인데요. 저희는 이 블랙박스 함수의 형태는 모르지만, 이미 알고 있는 함수로 이 블랙박스 함수를 근사할 수 있습니다. 이를 위해 먼저 이 블랙박스 함수의 값을 몇 군데 직접 측정해 봅니다. 빨간 점선 위의 빨간 점들이 측정한 것입니다. 이 데이터에 기반해 근사 함수를 적절히 매핑해 볼 수 있습니다. 파란색 실선이 근�사 함수의 그래프이고, 연보라색으로 넓게 칠해진 범위가 근사 함수를 기반으로 예측한 신뢰 구간을 나타냅니다.
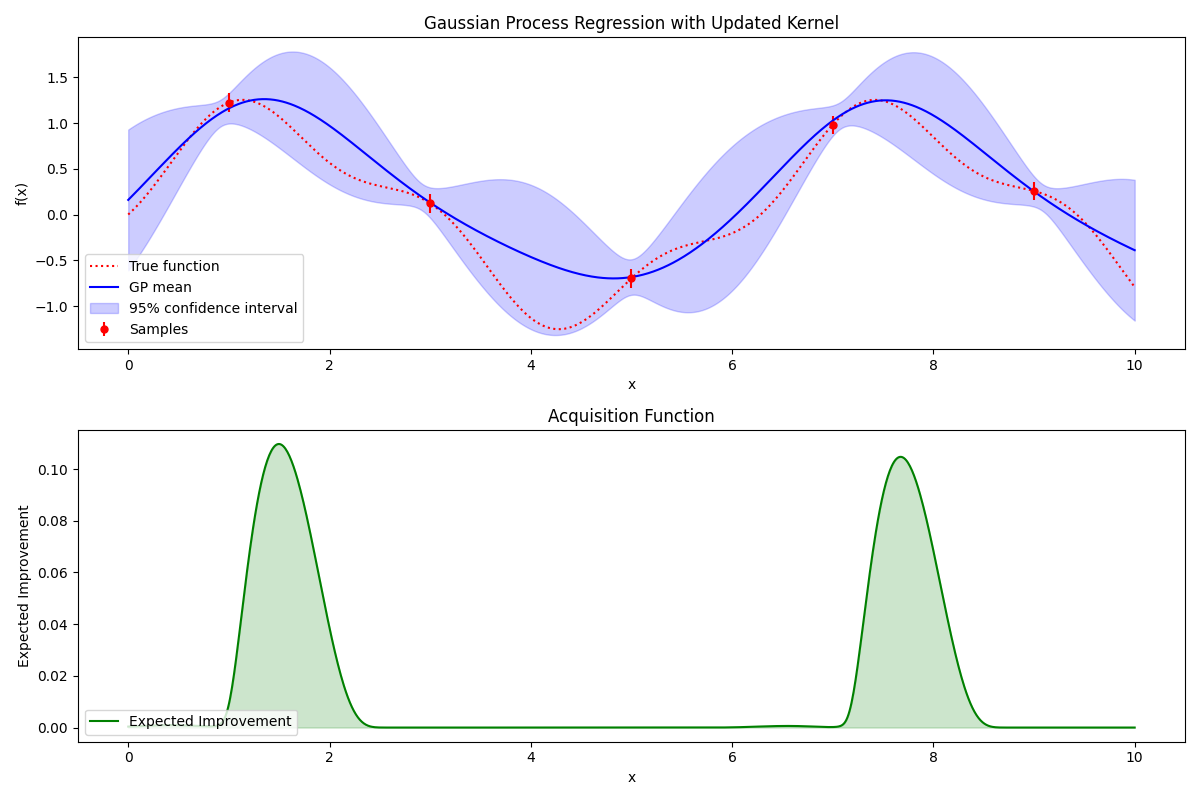
블랙박스 최적화는 최소 탐색으로 최적의 위치를 찾아가는 과정이기 때문에 이제 다음 문제는 '다음 탐색 지점을 어떻게 결정하느냐'입니다. 위 이미지의 하단 그래프와 함께 설명하겠습니다. 가장 값이 높을 것 같은 곳이 좋은 후보라고 볼 수 있겠죠? 이 후보는 아직 탐색되지 않은 영역(연보라색 신뢰 구간이 넓은 곳)과 이미 좋은 결과(실제 함숫값이 높은 곳)를 보인 영역을 모두 고려(expected Improvement)해 가장 값이 높을 법한 곳으로 결정합니다. 이 과정이 우리가 내부 구조를 모르는 함수의 최댓값의 위치를 탐색해 나가는 블랙박스 최적화입니다.
저희는 특정 프롬프트와 하이퍼파라미터로 생성된 이미지를 입력하면 이미지 점수를 리턴하는 함수를 블랙박스 함수로 정의한 뒤, 탐색할 공간은 세 가지 하이퍼파라미터(CFG, RG: 1.0~10.0, LoRA: 0.8 ~ 1.2)가 가질 수 있는 공간으로 정의했습니다. 베이지안 최적화 방법은 현재에도 많은 연구가 진행되고 있는 분야인데요. 이번 실험에서는 베이지안 최적화 라이브러리(참고)가 제공하는 기본 탐색 방식을 사용했으며, 3회 초기 탐색을 진행한 뒤 10회 탐색을 진행했습니다.
"a cat and a rabbit" 프롬프트로 블랙박스 최적화 진행
먼저 "a cat and a rabbit"이라는 프롬프트로 블랙박스 최적화를 진행했습니다. 시드로는 앞서 탐색한 시드값(3143890026)을 사용했습니다. 총 13장의 이미지가 생성됐는데요. 아래는 그중 일부를 가져와 점수를 기준으로 내림차순으로 정렬한 것입니다. 가장 점수가 높은 1번 이미지는 실제로도 이미지의 완성도가 가장 높아 보입니다. 또한 이 탐색 과정에서 품질이 나쁜 것이 아니라 아예 다른 스타일의 이미지가 생성될 수도 있다는 점도 확인할 수 있었습니다.
| 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 이미지 |  |  |  |  |  |
| 점수 | 0.2395 | 0.2386 | 0.2243 | 0.2227 | 0.2088 |
| CFG | 9.1839 | 4.7532 | 1.0383 | 9.9996 | 1.0652 |
| RG | 1.0142 | 1.0010 | 1.0328 | 9.8277 | 9.9207 |
| LoRA | 1.0235 | 1.0881 | 1.0931 | 1.1984 | 0.8468 |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
"A woman is holding a picket sign. The sign has the words "hold the LINE" written on it." 프롬프트로 블랙박스 ��최적화 진행
이 프롬프트의 경우에도 앞서 설명한 시드 탐색 방식을 사용해 시드(2581769315)를 찾아냈습니다. 이후 위와 마찬가지로 총 13장의 이미지를 생성해 그중 일부를 가져와 점수를 기준으로 내림차순으로 정렬했습니다.
| 번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 이미지 | 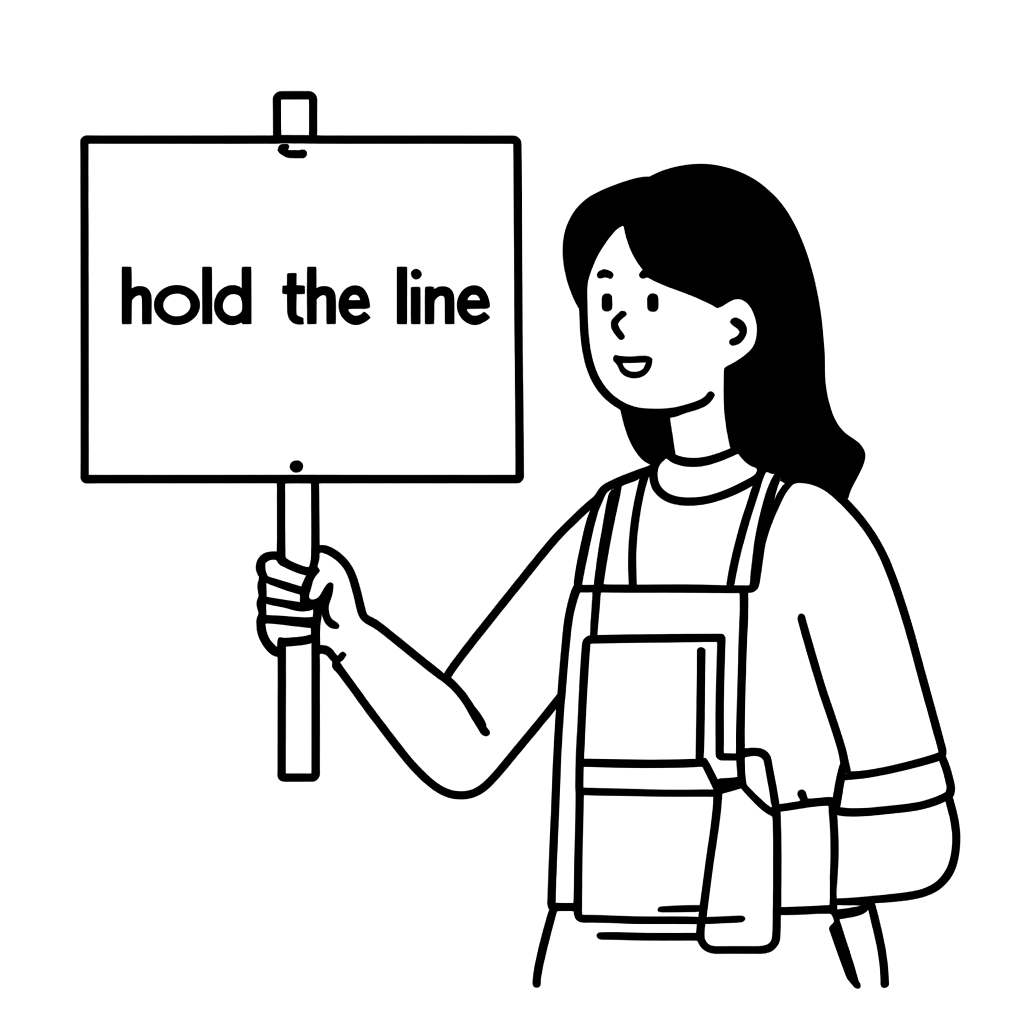 | | | 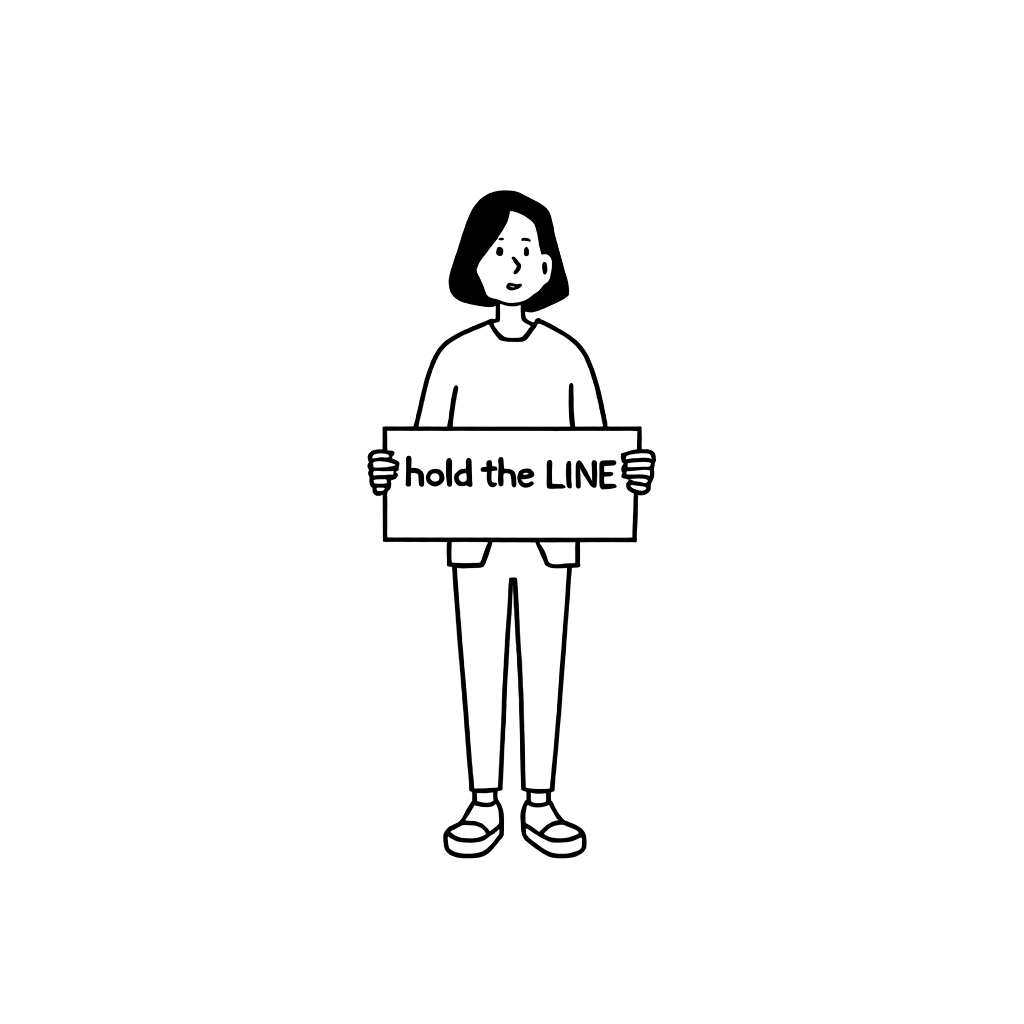 |  |
| 점수 | 0.2734 | 0.2681 | 0.2639 | 0.2524 | 0.2497 |
| CFG | 2.7732 | 2.3208 | 3.0985 | 9.9996 | 9.9936 |
| RG | 3.4702 | 2.6763 | 4.335 | 9.8277 | 4.3512 |
| LoRA | 0.8212 | 0.8369 | 0.9913 | 1.1984 | 1.1492 |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
가장 높은 점수를 달성한 1번 이미지는 언뜻 보면 괜찮아 보이지만 매우 좋다고 보기는 어렵습니다. 왼손 표현이 멜빵 앞치마 표현과 섞이면서 모호하게 표현됐기 때문입니다. 저희는 오히려 3번 이미지가 더 좋아 보인다고 판단했는데요. 옷의 디테일이 최대한 생략되면서 글씨 또한 원하는 형태로 출력됐기 때문입니다.
조금 더 살펴보자면, 3번 이미지보다 점수가 높은 2번 이미지는 사실 정상적인 이미지라고 보기도 어렵습니다. 점수가 낮은 3번 ��이미지의 품질이 더 좋은 것이죠. 이와 유사하게 5번 이미지 역시 4번 이미지보다 품질이 더 높다고 볼 수 있습니다. 얼굴의 형상이 4번 이미지보다 조금 더 저희 이미지 스타일에 가깝기 때문입니다. 4번 이미지의 얼굴은 학습했던 저희 이미지 스타일과 큰 차이가 있습니다. 이와 같은 예시를 통해 특정 이미지가 어떠한 스타일을 잘 따르는가를 평가하기 위해서는 추가 지표가 필요하다는 것을 알 수 있습니다.
결론, 그래서 효과는 있었나요?
네. 이미지 자동 평가와 하이퍼파라미터 탐색 도입은 효과적이었습니다. 구체적으로 말씀드리자면, 자동 평가 방법을 도입하면서 이미지를 얻어내는 지난한 과정 중 많은 부분을 자동화할 수 있었습니다. 특히 자동화하면서 랜덤 탐색이 아닌 통계에 기반한 탐색을 적용했기 때문에 도출된 결과를 보다 신뢰할 수 있었습니다. 또한 하이퍼파라미터를 어떻게 설정해야 하는지 고민하는 데 사용하던 자원을 최소화하면서 업무 관련 고민을 하는 데 투자할 자원을 벌 수 있었습니다. 최적 시드를 결정하는 방법을 확립한 것도 고민해야 할 또 다른 요소 하나를 배제할 수 있게 됐다는 점에서 매우 효과적이었고요.
다만, 블랙박스 탐색 과정에서 생성된 이미지들의 구도나 특성이 너무 다양하다는 점은 다소 아쉬웠습니다. 이 부분에서 발생한 다양성의 범위를 축소할 수 있다면 탐색 공간도 최소화할 수 있을 테니 보다 좋은 이미지를 찾을 확률이 높아지지 않을까 생각합니다. 또한 저희 시나리오에서는 이 블랙박스 함수의 입력으로 CFG와 RG, LoRA 스케일을 사용했는데요. 이 세 가지 하이퍼파라미터는 서로 독립적이라고 보기는 어렵기 때문에 탐색의 ��난도가 조금 더 높아졌을 것이라고 생각합니다.
앞으로 나아갈 길
향후 더 진행해 볼만한 프로젝트는 크게 아래 세 가지로 추려볼 수 있습니다.
- 기준으로 삼은 이미지 스타일에 부합하는지 판단하는 이미지 평가 지표 탐색
- 생성될 이미지를 보다 정교하게 제어하기 위한 이미지 투 이미지 생성 방식 적용
- 모델이 생성하는 이미지의 자유도를 최소화해 이미지 생성 공간 축소
위 세 가지 중 앞 두 가지는 본문에서 언급하기도 한 주제인데요. 현재 사용하고 있는 이미지 평가 지표는 저희 이미지 스타일을 따르느냐를 평가하기에는 다소 부족하다는 것을 실험을 통해 확인할 수 있었습니다. 또한 텍스트 투 이미지 모델로 이미지를 생성하면 이미지의 구도나 이미지 속 개체들을 표현하는 부분에서 자유도가 매우 높아지기 때문에 생성물을 보다 쉽고 정교하게 제어하기 위해 이미지 정보를 추가로 제공하는 것이 도움이 될 것으로 보입니다.
마지막 주제인 '생성되는 이미지의 자유도 최소화'는 위 두 가지 주제와 맥락이 조금 다릅니다. 이 주제는 이 글에서 소개한 프로젝트를 진행하는 과정에서 도출된 주제인데요. 앞서 말씀드렸듯 이 프로젝트는 디자이너분들의 반복 업무를 최소화하기 위해 시작했고, 그러한 반복 업무는 보통 완전히 새로운 이미지를 그리는 작업이 아니라 이미 존재하는 이미지 내에서 인물이 들고 있는 오브젝트를 추가하거나 변경하는 수준인 경우가 많았습니다. 이런 니즈에 대응하기 위해서는 모델의 생성 자유도를 일정 수준 이하로 조정할 수 있어야 한다고 생각했고, 이에 이와 같은 주제가 도출됐습니다.
저희는 앞으로도 이 프로젝트와 같이 LY 임직원에게 필요한 적합한 AI/ML 모델을 개발하기 위해 꾸준히 노력할 예정입니다. 그 과정에서 또 괜찮은 주제가 발견되면 다시 찾아뵙겠습니다. 긴 글 읽어주셔서 감사합니다.


