들어가며
안녕하세요. 저희 AMD(Applied ML Dev) 팀에서는 생성형 AI를 포함한 다양한 AI/ML 모델을 개발하고 서비스에 적용하고 있습니다.
앞서 발행한 AI로 생성한 이미지는 어떻게 평가할까요? (기본편)에서는 생성형 AI 모델의 성능을 평가하는 다양한 방법론을 살펴봤는데요. 이번에는 생성형 AI을 활용한 몇 가지 애플리케이션을 소개하면서, 이와 같은 애플리케이션의 성능을 향상시키기 위해 생성형 AI 평가 방법을 어떻게 활용하고 있는지 공유하고자 합니다.
사진 속에서 주인공을 제외한 배경 인물을 AI로 제거하는 방법
여행지에서 멋진 풍경을 배경으로 사진을 찍었는데 예상치 못한 인물들이 같이 찍혀 있어서 사진을 여러 번 다시 찍어야 했던 경험이 있으신가요? 이런 불편함을 해소하는 데 생성형 이미지 AI 기술을 활용할 수 있습니다.
다음은 생성형 이미지 AI 기술을 활용해 배경 인물을 제거한 결과입니다.
| 원본 이미지 | 배경 인물 제거 이미지 |
|---|---|
 |  |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
배경 인물 제거(background person removal, 이하 BPR)는 다음과 같은 과정으로 진행됩니다.
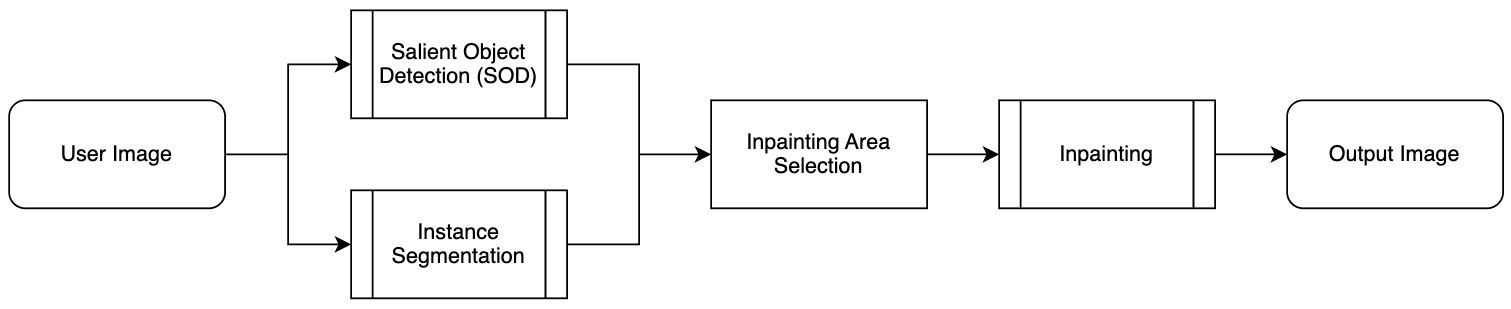
위 과정은 크게 세 단계로 나눌 수 있습니다.
- 인스턴스 분할(instance segmentation)
- 입력 이미지 내 각 픽셀이 어떤 객체에 속하는지 식별하는 과정으로, 인스턴스 분할 모델을 활용해 사람이나 건물, 나무 등 다양한 객체를 구분하고 개별적으로 인식합니다.
- 주요 객체 탐지(salient object detection)
- 이미지에서 가장 눈에 띄는 주요 객체를 식별하는 과정으로, 주요 객체 탐지 모델을 이용해 시선이 집중되는 영역을 픽셀 단위로 추출함으로써 메인 피사체와 배경 인물을 구분할 수 있습니다.
- 인페인팅(inpainting) 수행
- 주요 영역에 속하지 않는 배경 인물들이 포함된 영역을 인페인팅 기술을 사��용해 자연스럽게 제거하고 복원하는 과정입니다.
- 여기서 '인페인팅'이란 이미지의 특정 부분을 삭제한 후 주변 환경과 조화를 이루도록 재구성하는 기술입니다.
여기서 마지막 단계인 인페인팅 수행 단계는 배경 인물 제거 결과에 가장 큰 영향을 주는 단계이기 때문에 성능이 좋은 인페인팅 모델을 사용해야 합니다. 최근에는 생성형 이미지 모델을 이용한 인페인팅 기술이 많이 발표되고 있는데요. 인페이팅 기술에 대해서 조금 더 깊이 살펴보겠습니다.
인페인팅 기술이란?
인페인팅 기술은 이미지의 특정 영역을 제거하고 그 빈자리를 자연스럽게 채워 넣는 기술입니다. 예를 들어 사진 속 인물이나 물체를 삭제한 후 그 공간을 주변 환경과 조화롭게 재구성해 채워 넣는 작업에 활용할 수 있습니다.
인페인팅 모델은 생성형 AI의 한 종류로, 이미지의 결손 부분을 채우는 데 특화된 모델이라고 할 수 있습니다. 접근 방식에 따라서 크게 두 가지 주요 모델로 나눌 수 있는데요. 디퓨전(diffusion) 계열 모델과 GAN(generative adversarial network) 계열 모델로 나뉩니다.
이 두 가지 접근 방식은 각각 고유한 메커니즘과 장점을 가지고 있으며, 이미지 복원 작업에서 서로 다른 방식으로 활용됩니다. 하나씩 간략히 살펴보겠습니다.
- 디퓨전 계열 모델
- 이미지를 점진적으로 변화시켜 손상된 영역을 복원하는 방법입니다.
- 보통 이미지의 노이즈를 제거하거나 점진적으로 이미지를 개선하는 방식으로 작동합니다. 예를 들어 랜덤 노이즈인 초기 상태에서 노이즈를 점차 줄여가며 원본 이미지의 형태를 찾아가는 과정으로 진행됩니다.
- 복잡한 이미�지의 세부 사항을 자연스럽게 복원하는 데 특히 유리합니다.
- 다만, 좋은 결과가 나올 때도 있지만 가끔 이상한 물체가 생성되기도 합니다.
- 이미지 생성을 위해 반복적으로 노이즈 제거 과정을 거치기 때문에 일반적으로 GAN 계열 모델에 비해 이미지 생성 속도가 느립니다.
- 디퓨전 계열 모델에 대한 보다 자세한 설명은 먼저 발행된 AI로 생성한 이미지는 어떻게 평가할까요? (블랙박스 최적화 적용편)을 참고하시기 바랍니다.
- 이미지를 점진적으로 변화시켜 손상된 영역을 복원하는 방법입니다.
- GAN 계열 모델
- GAN 모델은 생성자(generator)와 판별자(discriminator)라는 두 개의 신경망이 경쟁하면서 학습하는 구조입니다.
- 생성자는 결손된 이미지를 복원하려 시도하고, 판별자는 생성된 이미지가 실제 이미지와 얼마나 유사한지를 평가합니다. 이 과정을 반복하면서 점점 더 정교하고 사실적인 이미지를 생성합니다.
저희는 BPR 애플리케이션에 다음 인페인팅 모델을 포함한 다양한 모델을 적용해서 테스트해 봤는데요. 원본 이미지의 해상도가 낮거나 인페인팅해야 하는 영역이 작은 경우에는 대부분의 모델에서 좋은 결과가 나왔지만, 원본 이미지의 해상도가 높고 인페인팅해야 하는 영역이 큰 경우에는 모델에 따라 큰 차이가 발생했습니다.
- LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions(WACV 2022, 참고)
- HINT(High-quality INPainting Transformer with Mask-Aware Encoding and Enhanced Attention)(TMM 2024, 참고)
- FLUX. 1-Fill-dev(Arxiv 2024, 참고)
먼저 다음은 어떤 인페인팅 모델을 사용하든 좋은 결과가 나온 경우입니다.
| 원본 이미지(빨간선: 인페인팅 영역) | LaMa 인페인팅 모델 결과 |
|---|---|
 |  |
| HINT 인페인팅 모델 결과 | FLUX. 1-Fill-dev 인페인팅 모델 결과 |
 |  |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
다음은 사용한 인페인팅 모델에 따라 결과에 큰 차이가 발생한 경우입니다.
| 원본 이미지(빨간선: 인페인팅 영역) | LaMa 인페인팅 모델 결과 |
|---|---|
 |  |
| HINT 인페인팅 모델 결과 | FLUX. 1-Fill-dev 인페인팅 모델 결과 |
 |  |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
위 테스트 결과로 알 수 있듯 사용할 모델을 선정할 때 논문에서 제시하는 성능 지표만 보고 판단하는 것은 어렵습니다. 각 모델이 실제 응용 사례에서 어떤 성능을 보여줄지 명확히 파악하기 어렵기 때문입니다.
일반적으로 논문에서는 정해진 해상도(예: 256x256)에서 평가�를 진행합니다. 이는 실제 사용 환경과는 다를 수 있습니다. 또한 논문마다 평가에 사용한 인페인팅 영역이 다르며, 대부분 실제로 우리가 직면하는 현장과는 다른 상황에서 평가가 진행됩니다. 게다가 인페인팅은 이미지 생성 모델의 일종이므로 어떤 정답이란 것이 존재하지 않습니다. 다양한 형태로 생성된 이미지 모두가 정답이 될 수 있으며, 이는 평가를 더욱 복잡하게 만듭니다.
따라서 모델의 실제 성능을 평가할 때는 다양한 요소를 고려해야 합니다. 논문에 제시된 지표들이 어느 정도 대략적인 성능의 경향을 보여줄 수는 있지만, BPR 작업에서 발현될 정확한 인페인팅 성능을 대변하지는 못합니다. 예를 들어 어떤 테스트에서는 좋은 결과를 보여준 모델이 다른 테스트에서는 실망스러운 결과를 보여주는 경우도 있었습니다.
이와 같은 이유로 저희는 어떤 평가 방법이 실제 사람이 평가하는 결과와 유사한지 최신 생성형 이미지 평가 방법을 적용해 확인하고자 했습니다. 이를 통해 BPR 기능에 사용할 가장 적합한 인페인팅 모델을 선택할 수 있는 기준을 마련하고자 했습니다. 그럼 자세한 실험 과정과 결과를 공유하겠습니다.
인페인팅 모델 평가 진행
생성형 모델을 평가하는 방법 중 가장 신뢰할 수 있는 방법은 사람이 직접 평가하는 것입니다. 다만 이 방식은 많은 비용과 시간이 소요되며 자동화하기 어렵다는 단점이 있습니다. 따라서 저희는 최대한 사람이 평가한 결과와 같은 결과가 나올 수 있는 생성형 모델 평가 방법을 마련하는 것을 목표로 잡았습니다. 이 목표를 달성하기 위해 사람의 평가 결과와 가장 큰 연관성을 보이는 평가 방법를 찾기 위한 실험을 진행했으며, 다음 두 가지 데이터셋을 사용해 실험을 진행했습니다.
첫 번째 데이터셋은 목표 애플리케이션인 BPR에서 생성된 이미지 결과의 품질 편차가 큰 데이터만 모아 놓은 BPR 평가 데이터셋이고, 두 번째는 인페인팅에서 자주 사용하는 Places365 평가 데이터셋입니다. 각 데이터셋을 사용한 평가 방법과 결과를 하나씩 살펴보겠습니다.
BPR 평가 데이터셋을 사용한 평가 방법과 결과
실험에 사용한 데이터셋 및 인페인팅 모델
BPR 평가 데이터셋은 BPR를 통해 나온 결과의 품질이 엇갈리는 10개의 이미지로 구성돼 있습니다. 저희는 이를 이용해 다양한 인페인팅 모델과 평가 방법을 테스트했습니다.
본 실험에 사용한 인페인팅 모델은 2022년부터 2024년 사이에 발표된 아래 11개 인페인팅 모델입니다.
- LaMa(WACV 2022), MAT(CVPR 2022), MAE-FAR(ECCV 2022), ZITS++(TPAMI 2023), CoordFILL(AAAI 2023), SCAT(AAAI 2023), HINT(TMM 2024), MxT(BMVC 2024), PUT(TPAMI 2024), Latent Codes for Pluralistic Image Inpainting(CVPR 2024), FLUX. 1-Fill-dev(Arxiv 2024)
실험에 사용한 이미지 평가 방법
본 실험에 사용한 이미지의 평가 방법은 다음과 같습니다(각 평가 방법에 대한 자세한 설명은 먼저 발행된 AI로 생성된 이미지는 어떻게 평가할까요? (기본편)을 참고해 주세요).
- LAION Aesthetics score-v2(이하 Aesthetics score), CLIP-IQA, Q-Align: 단일 이미지를 보고 해당 이미지의 품질을 측정하는 방법입니다.
- PickScore, ImageReward, HPS v2: 이미지와 해당 이미지를 생성하기 위한 프롬프트를 사용해 이미지-텍스트 정렬과 이미지 품질을 함께 평가합니다.
참고로 본 실험에서는 인페이팅 모델 논문에서 자주 사용하는 FID(원본 이미지와 인페인팅된 결과 이미지 사이의 분포 간의 Fréchet 거리를 측정하는 지표)는 사용하지 않았습니다. FID는 정확한 결과를 얻기 위해서 10,000장 이상의 많은 수의 데이터셋을 사용하기를 권장하기 때문입니다(아래 소개할 Places365 평가 데이터셋 실험에서는 FID를 사용했습니다).
또한 결과 평가의 기준으로 삼을 사람의 평가는 모델이 생성한 이미지 결과를 보고 1점(최악)에서 5점(최고) 사이로 점수를 매겨 평가하는 방식으로 진행했습니다.
사전 준비 - 이미지를 평�가하기 위한 프롬프트 생성
평가 방법 중 PickScore와 ImageReward, HPS v2는 이미지를 평가하려면 이미지를 생성한 프롬프트가 필요합니다. 그런데 BPR에 사용된 인페인팅 모델은 이미지 생성에 사용한 프롬프트가 따로 존재하지 않으므로, Microsoft의 Phi-3.5-vision-instruct 모델을 활용해 이미지를 모사하는 프롬프트를 생성했습니다. 이때 BPR의 결과로 배경 사람이 없는 이미지가 생성되어야 하므로 생성된 프롬프트에 배경 사람 관련 내용이 포함되지 않도록 다음과 같이 프롬프트를 만들기 위한 프롬프트를 작성했습니다.
- 이미지에 어울리는 모사를 생성하기 위한 프롬프트
"""
Describe the image within 20 words.You should follow the below rules.
- Describe the overall appearance and background of the image without mentioning any of the people.
- You should not mention about the person.
- DO NOT mention about other pedestrians or other patrons or other persons in the background.For example, You can describe the image like below.
- A sunny day at a riverside walkway with trees, a clear sky, and the Eiffel Tower in the background.
- A vibrant street scene with a bright orange food stall and a clear blue sky.
- A street scene with a building and a British flag. There are potted plants and a statue visible.But you should not describe the image like below.
- A person in a grey jacket and black pants is carrying a black bag, walking in a hallway with a security guard in the background.
- The image depicts a city street scene with a person sitting on the road, surrounded by urban architecture and a few pedestrians walking in the background.
- The image depicts a cozy indoor setting with a person seated at a table, enjoying a meal. The room is well-lit with natural light, and there are other patrons in the background.
""" - 프롬프트 생성 결과


A historic square with a prominent tower, cobblestone pavement, and traditional European architecture. A statue stands in the center of a square with a fountain, surrounded by buildings with lit windows. * 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
평가 결과 및 결과 분석
아래는 사람이 평가한 결과와 각 평가 방법의 결과 지표와의 연관성(Pearson correlation coefficient)을 나타낸 것입니다. 1에 가까울수록 연관성이 높고, 0에 가까울수록 연관성이 없는 것입니다.
| 지표명 | Aesthetics score | CLIP-IQA | Q-Align | PickScore | ImageReward | HPS v2 |
|---|---|---|---|---|---|---|
| 연관성 | 0.924 | 0.187 | 0.384 | 0.282 | 0.279 | -0.290 |
아래는 각 평가 방법 사이의 연관성을 나타내는 연관성 매트릭스를 히트 맵과 함께 나타낸 그래프입니다. 마찬가지로 1에 가까울수록 연관성이 높고, 0에 가까울수록 연관성이 없는 것입니다.
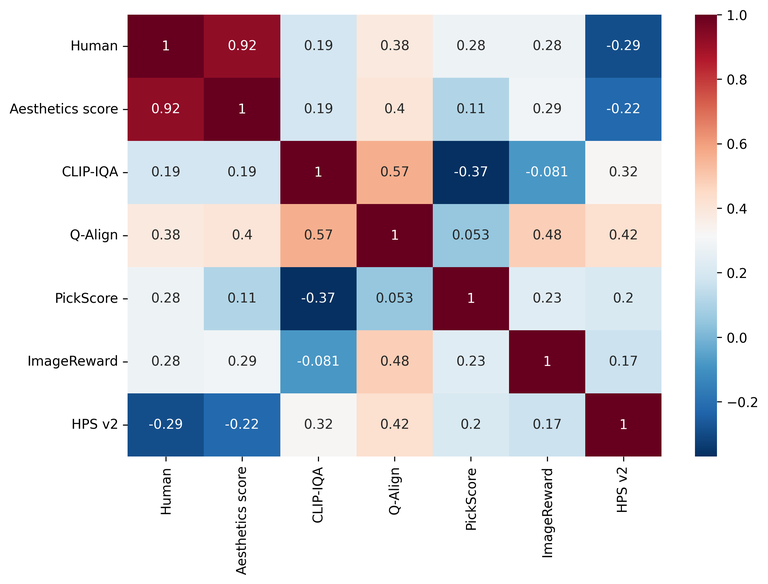
우선 Aesthetics score가 사람의 평가와 가장 높은 연관성(0.924)를 보이면서 이미지의 전반적인 품질을 평가할 때 사용할 수 있는 가장 신뢰할 만한 지표인 것으로 나타났습니다. 이는 Aesthetics score가 BPR에 필요한 인페인팅 작업 결과에 대해서 인간이 직관적으로 느끼는 이미지의 품질을 적절히 반영할 수 있음을 시사합니다.
반면 CLIP-IQA와 Q-Align은 사람의 평가와의 연관성이 높지 않은 것(각각 0.187과 0.384)으로 나타났습니다. 이는 이 지표들이 이미지의 특정 요소를 평가하는 데에는 유용할 수 있으나 전체적인 이미지 품질을 평가할 때에는 그 역할이 제한적일 수 있음을 의미합니다.
PickScore나 ImageReward, HPS v2와 같은 지표들은 이미지와 프롬프트 간의 정렬과 생성된 이미지의 품질을 모두 평가하는 데 초점을 맞추고 있는 지표들인데요. 이번 이미지 품질 평가 실험에서는 기대에 미치지 못하는 결�과를 보였습니다. 이는 해당 평가 방법들이 이미지의 품질보다는 텍스트와의 정렬에 더 초점을 맞추고 있기 때문일 수도 있습니다.
다음은 예시 이미지에 대한 몇 가지 모델의 결과와 이에 해당하는 Aesthetics score 평가 결과 점수를 정리한 표입니다.
| 인페인팅 모델 | 원본 이미지(빨간선: 인페인팅 영역) | FLUX. 1-Fill-dev | Latent Codes for Pluralistic Image Inpainting |
|---|---|---|---|
| Aesthetics score | - | 4.75 | 4.71 |
| 결과 이미지 | | |  |
| 인페인팅 모델 | MAE-FAR | HINT | MxT |
| Aesthetics score | 4.705 | 4.56 | 4.52 |
| 결과 이미지 |  |  |  |
* 이미지를 우클릭해서 새로운 탭이나 창에서 열면 이미지를 원본 크기로 확인하실 수 있습니다.
위 표와 함께 Aesthetics score 점수와 이미지의 품질을 종합적으로 분석하면 점수가 이미지의 품질과 어떻게 연계되는지 다음과 같이 파악할 수 있습니다.
- 먼저 FLUX. 1-Fill-dev 이미지를 살펴보면 인페인팅 영역이 정교하게 생성된 것을 확인할 수 있고, Aesthetics score 또한 높은 점수를 기록해 이미지 품질과 점수가 잘 일치함을 보여줍니다.
- Latent Codes for Pluralistic Image Inpainting과 MAE-FAR는 FLUX. 1-Fill-dev만큼 자연스러운 이미지는 아니었으나 적당한 품질을 보여줬으며, 이에 따라 Aesthetics score 점수는 FLUX. 1-Fill-dev보다 다소 낮은 점수가 매겨진 것을 알 수 있습니다.
- HINT와 MxT는 생성된 이미지에 아티팩트가 포함되는 등 전반적으로 품질이 낮았고, Aesthetics score 점수 또한 낮게 나타났습니다.
Places365 평가 데이터셋을 사용한 평가 방법과 결과
실험에 사용한 데이터셋 및 인페인팅 모델
Places365 데이터셋은 다양한 비전 관련 모델 학습 및 평가에 널리 쓰이는 데이터셋으로 일상생활에서 볼 수 있는 도시나 풍경 등 약 180만 장의 데이터셋으로 구성돼 있습니다. 그중 Places365 평가 데이터셋은 딱 36,500장의 이미지로 구성돼 있는 데이터셋으로, 이미지로만 구성돼 있고 평가를 위한 인페인팅 영역은 정해져 있지 않습니다. 이 때문에 각 논문에서 제각각인 인페인팅 영역을 사용하여 평가를 진행하여 수치를 기술합니다.
본 실험에서는 모델에 상관없이 동일한 인페인팅 영역을 설정해 평가를 진행했습니다. 인페이팅 영역은 평균적으로 전체 이미지의 40% 정도에 해당하는 영역으로 설정했습니다.
다음은 본 실험에 사용한 인페인팅 모델입니다. 2022년부터 2024년 사이에 발표된 9개의 인페인팅 모델을 사용했습니다.
- LaMa(WACV 2022), MAT(CVPR 2022), CoordFILL(AAAI 2023), SCAT(AAAI 2023), HINT(TMM 2024), MxT(BMVC 2024), PUT(TPAMI 2024), Latent Codes for Pluralistic Image Inpainting(CVPR 2024), FLUX. 1-Fill-dev(Arxiv 2024)
참고로 앞서 BPR 평가 데이터셋 실험에서 사용한 인페인팅 모델 중 MAE-FAR(ECCV 2022)와 ZITS++(TPAMI 2023) 모델은 몇몇 이미지에서 정상적인 결과가 생성되지 않아 이번 실험에서는 제외했습니다.
실험에 사용한 이미지 평가 방법
본 실험에 사용한 평가 방법은 다음과 같습니다. 참고로 PickScore와 ImageReward, HPS v2는 이미지 생성에 필요한 프롬프트가 필요하기 때문에 BPR 데이터셋을 평가할 때와 동일한 방식으로 프롬프트를 생성했습니다.
- Aesthetics score, CLIP-IQA, Q-Align: 단일 이미지를 보고 해당 이미지의 품질을 측정하는 방법입니다.
- PickScore, ImageReward, HPS v2: 이미지와 해당 이미지를 생성하기 위한 프롬프트를 사용하여 이미지-텍스트 정렬과 이미지 품질을 함께 평가합니다.
- LPIPS: 원본 이미지와 결과 이미지의 쌍을 비교해 결과 이미지의 품질을 측정합니다.
- FID, FD-DINO, CMMD
- FID: 원본 이미지의 분포와 결과 이미지의 분포를 비교해 결과 이미지의 품질을 측정합니다.
- FD-DINO: FID를 개선한 모델입니다. FID가 원본 이미지셋과 생성된 이미지셋 간의 Fréchet 거리를 측정하기 위해 Inception-v3를 백본(backbone)으로 사용해 해당 특성 공간을 사용하는 반면, FD-DINO는 DINOv2-ViT-L/14를 백본으로 사용해 해당 특성 공간에서의 Fréchet 거리를 계산합니다.
- CMMD: FID를 개선한 모델로, CLIP-L 특성 공간에서 가우시안 RBF 커널을 사용해 MMD(maximum mean discrepancy) 거리를 계산합니다.
각 평가 방법을 전체 36,500장의 이미지에 적용했으며, 사람의 평가는 데이터셋 중에서 임의로 20장을 선택해 각 모델 결과에 1점에서 5점까지 점수를 매기는 방식으로 진행했습니다.
평가 결과 및 결과 분석
아래는 앞선 실험과 마찬가지로 사람이 평가한 결과와 각 평가 방법의 결과 지표와의 연관성을 나타낸 것입니다. 1에 가까울수록 연관성이 높고, 0에 가까울수록 연관성이 없는 것입니다.
| 지표명 | Aesthetics score | CLIP-IQA | Q-Align | PickScore | ImageReward | HPS v2 | LPIPS | FID | FD-DINO | CMMD |
|---|---|---|---|---|---|---|---|---|---|---|
| 연관성 | 0.877 | 0.063 | 0.843 | 0.648 | 0.428 | 0.387 | 0.301 | 0.877 | 0.604 | 0.898 |
아래는 각 평가 방법 사이의 연관성을 나타내는 연관성 매트릭스를 히트 맵과 함께 나타낸 그래프입니다. 마찬가지로 1에 가까울수록 연관성이 높고, 0에 가까울수록 연관성이 없는 것입니다.
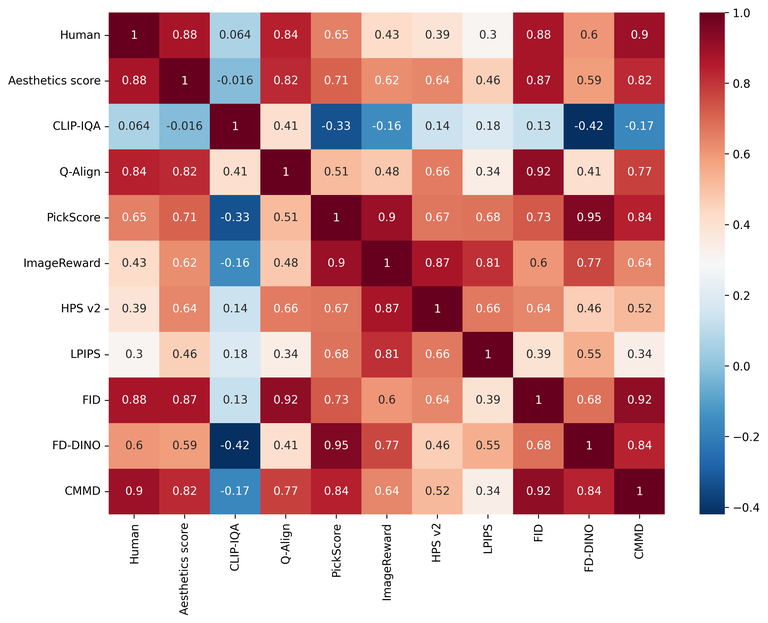
이번 실험 결과에서 사람이 평가한 결과와 가장 연관성이 높은 것으로 나타난 평가 방법은 CMMD(0.898)였습니다. 이는 CMMD가 이미지 품질 평가에 있어서 상당히 신뢰할 수 있는 평가 방법이라는 것을 시사합니다.
다음으로 FID와 Aesthetics score (0.877)의 연관성이 높은 것으로 나타났습니다. 참고로 CMMD를 포함한 FID 계열의 평가 방법은 원본 이미지와 생성된 이미지의 분포를 비교해야 하므로 대규모 데이터셋(10,000장 이상)을 사용하는 것을 권장합니다. 반면 Aesthetics score는 보다 적은 데이터셋을 사용해도 평가할 수 있습니다. 즉 보다 적은 데이터로도 높은 신뢰성을 제공할 수 있다는 것을 의미합니다.
LPIPS는 원본 이미지와 결과 이미지의 쌍을 비교해 품질을 측정하는 방식으로, 인간의 주관적인 미적 평가와의 연관성은 상��대적으로 낮았습니다. 이는 원본 이미지와 결과 이미지의 쌍을 비교하는 것만으로는 이미지의 전체적인 품질을 충분히 반영하지 못할 수도 있다는 것을 보여줍니다.
마치며
AI로 생성된 이미지에는 정답이 정해져 있지 않습니다. 다양한 형태의 이미지가 모두 정답이 될 수 있습니다. 이런 특성 때문에 이미지의 품질을 정확히 수치화하는 것은 매우 어려운 과제입니다. 또한 생성형 이미지 모델을 다룬 논문에서 제시하는 성능 지표는 특정 태스크의 성능을 충분히 반영하지 못하기도 합니다.
이에 저희는 인페인팅이라는 생성 모델을 사용하는 하나의 특정 태스크에 어떤 평가 방법을 적용하는 것이 좋을지 찾아보고자 했습니다. 먼저 저희 태스크에 맞는 평가 방법은 사람의 평가와 가장 연관성이 높은 평가 방법일 것이라고 가정했고, 두 데이터셋을 바탕으로 사람의 평가와 일치하는 평가 방법을 찾는 실험을 진행했습니다.
실험 결과, 데이터셋에 따라 최적의 평가 기법이 다르기에 완벽하게 만족할 만한 결과를 얻지는 못했지만, 어느 정도의 경향이 있다는 것은 확인할 수 있었습니다. 이를 통해 적합한 인페인팅 모델을 선택할 수 있는 기준을 마련할 수 있었습니다. 물론 이 방법 또한 완벽하지는 않다고 생각하며, 평가 방법의 완전한 자동화를 위해서는 여전히 해결해야 할 일이 많다고 생각합니다.
저희는 앞으로도 인페인팅의 성능을 보다 잘 나타낼 수 있는 평가 방법을 찾기 위한 연구를 지속해서 진행하려고 합니다. 향후 또 공유할 만한 결과가 나오면 이 블로그로 공유드리겠습니다. 긴 글 읽어주셔서 감사합니다.


