The original article was published on May 21, 2025.
The Applied ML Dev (AMD) team develops and applies various AI/ML models, including generative AI, to LY Corporation services.
In the previously published Evaluating AI-generated images (The basics), we explored various methodologies for evaluating the performance of generative AI models. This time, we aim to introduce some applications using generative AI and share how we utilize evaluation methods of generative AI to enhance the performance of such applications.
Removing people from photos using AI
Have you ever taken a photo at a travel destination with a beautiful landscape as the background, only to find unexpected people in the shot, requiring multiple retakes? You can alleviate this inconvenience using generative image AI technologies.
Here's the result of using generative image AI technology to remove people in the background.
| Original image | Image with people removed |
|---|---|
 |  |
Background person removal (BPR) proceeds through the following process:
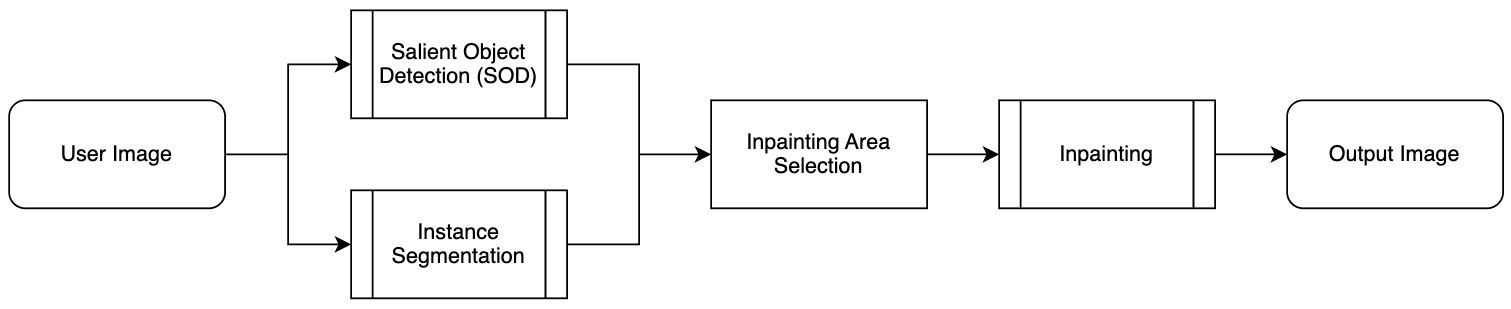
This process can be broadly divided into three stages.
- Instance segmentation
- This is the process of identifying which object each pixel in the input image belongs to, using an instance segmentation model to distinguish and individually recognize various objects such as people, buildings, trees, and so on.
- Salient object detection
- This process identifies the most noticeable major objects in the image. It distinguishes the main subject from background people by pixel-by-pixel extracting the areas where gaze is focused using a salient object detection model.
- Inpainting
- This involves the natural removal and restoration of areas containing background people who aren't part of the main area using inpainting technology.
- "Inpainting" is a technique that reconstructs a deleted part of an image to harmonize with the surrounding environment.
The final stage of the inpainting process, which greatly influences the outcome of background person removal, requires using a high-performance inpainting model. Recently, many inpainting technologies using generative image models have been developed. Let's take a closer look at inpainting technologies.
What is inpainting?
Inpainting is a technique for removing specific areas of an image and filling in the void naturally. For example, it can be used to fill in empty space in a way that fits well with the surrounding environment after deleting people or objects in a photo.
An inpainting model is a type of generative AI model specialized in filling missing parts of an image. Models can be broadly divided into two main types based on their approach: diffusion models and generative adversarial network (GAN) models.
These two approaches each have unique mechanisms and advantages and are used differently in image restoration tasks. Let's take a brief look at each.
- Diffusion models
- A method for progressively transforming an image to restore damaged areas.
- It usually operates by removing noise from an image or improving it incrementally. For instance, it proceeds by gradually reducing noise from an initial random noise state to find the shape of the original image.
- It's especially suitable for restoring the details of complex images naturally.
- However, while good results can emerge, sometimes strange objects are generated.
- Since the model undergoes repeated noise removal processes for image generation, it's generally slower than GAN models at generating images.
- For a more detailed explanation of diffusion models, refer to the previously published Evaluating AI-generated images (Blackbox optimization).
- A method for progressively transforming an image to restore damaged areas.
- GAN models
- GAN models have a structure where two neural networks, the generator and the discriminator, learn competitively.
- The generator attempts to restore missing images, while the discriminator evaluates the similarity of generated images to real ones. Through this iterative process, progressively more sophisticated and realistic images are generated.
We applied various inpainting models in BPR applications. While most models produced good results with low-resolution original images or small inpainting areas, significant differences appeared between models with high-resolution original images and large inpainting areas.
- LaMa: Resolution-robust large mask inpainting with fourier convolutions (WACV 2022)
- HINT: High-quality INPainting transformer with mask-aware encoding and enhanced attention (TMM 2024)
- FLUX. 1-Fill-dev (Arxiv 2024)
First, here are cases where good results were achieved regardless of which inpainting model was used.
| Original image (red line: inpainting area) | LaMa inpainting model result |
|---|---|
 |  |
| HINT inpainting model result | FLUX. 1-Fill-dev inpainting model result |
 |  |
Next are cases where significant differences in results occur depending on the inpainting models used.
| Original image (red line: inpainted area) | LaMa inpainting model result |
|---|---|
 |  |
| HINT inpainting model result | FLUX. 1-Fill-dev inpainting model result |
 |  |
As the test results above show, it's challenging to choose a model based solely on the performance indicators presented in papers. It's because it's hard to clearly determine how each model will perform in real-life applications.
Typically, papers evaluate at a fixed resolution (for example, 256x256), which might differ from actual use cases. Furthermore, each paper uses different inpainting areas for evaluation, often at variance with real-world scenarios. Inpainting is a form of image generation where there is no single correct answer. Various generated image forms could all be correct, making evaluation even more complex.
Thus, you need to consider diverse factors when evaluating a model's performance. While the indicators presented in papers show some general performance trends, they don't accurately represent the precise inpainting performance for BPR tasks. For example, a model showing excellent results in one test might produce disappointing outcomes in another.
For these reasons, we aimed to verify which evaluation method most resembles human assessment by applying the latest generative image evaluation methods. This approach provides the basis for selecting the most suitable inpainting model for BPR functionality. Let's share the detailed experimental processes and results.
Evaluation of inpainting models
The most reliable way of evaluating generative models is human assessment. However, this method involves high costs and time requirements and is difficult to automate. Therefore, our goal was to find generative model evaluation methods that yield results as closely resembling human ones as possible. To achieve this, we conducted experiments to find the evaluation methods that showed the greatest correlation with human assessment results, using the following two datasets.
The first dataset is the BPR evaluation dataset, composed only of data with a significant quality variance in image results generated from BPR, and the second is the Places365 evaluation dataset commonly used in inpainting. We'll review the evaluation methods and results employing each dataset.
Evaluation methods and results using the BPR evaluation dataset
Dataset and inpainting models used in the experiment
The BPR evaluation dataset consists of 10 images with divergent quality results from BPR. We used this to test various inpainting models and evaluation methods.
The inpainting models used in this experiment are the 11 models listed below, published from 2022 to 2024.
- LaMa (WACV 2022), MAT (CVPR 2022), MAE-FAR (ECCV 2022), ZITS++ (TPAMI 2023), CoordFILL (AAAI 2023), SCAT (AAAI 2023), HINT (TMM 2024), MxT (BMVC 2024), PUT (TPAMI 2024), Latent codes for pluralistic image inpainting (CVPR 2024), FLUX. 1-Fill-dev (Arxiv 2024)
Evaluation methods used in the experiment
The evaluation methods used in this experiment are as follows (for a detailed explanation of each evaluation method, please refer to Evaluating AI-generated images (The basics)).
- LAION aesthetics score-v2 (hereafter aesthetics score), CLIP-IQA, Q-Align: A method for measuring the quality of a single image.
- PickScore, ImageReward, HPS v2: Evaluate image-text alignment and image quality using the image and its generation prompt.
The inpainting model studies often use FID (Fréchet distance between distributions of the original image and the inpainted result image). However, we did not use FID in this experiment because it recommends using over 10,000 images for accurate results (FID is used in the subsequent Places365 evaluation dataset experiment).
For reference, human evaluation as a criterion for result evaluation was conducted by scoring model-generated image results on a scale from 1 (worst) to 5 (best).
Preparation - Generating prompts for image evaluation
Among the evaluation methods, PickScore, ImageReward, and HPS v2 require prompts for generating images to evaluate them. However, because inpainting models used in BPR don't have specific prompts for image generation, we generated prompts mimicking the images using Microsoft’s Phi-3.5-vision-instruct model. Since an image resulting from BPR should be generated without background people, the generated prompt didn't include content about background people. Here's the prompt created for generating the prompt.
- Prompt to generate a description of the image
"""
Describe the image within 20 words.You should follow the below rules.
- Describe the overall appearance and background of the image without mentioning any of the people.
- You should not mention about the person.
- DO NOT mention about other pedestrians or other patrons or other persons in the background.For example, You can describe the image like below.
- A sunny day at a riverside walkway with trees, a clear sky, and the Eiffel Tower in the background.
- A vibrant street scene with a bright orange food stall and a clear blue sky.
- A street scene with a building and a British flag. There are potted plants and a statue visible.But you should not describe the image like below.
- A person in a grey jacket and black pants is carrying a black bag, walking in a hallway with a security guard in the background.
- The image depicts a city street scene with a person sitting on the road, surrounded by urban architecture and a few pedestrians walking in the background.
- The image depicts a cozy indoor setting with a person seated at a table, enjoying a meal. The room is well-lit with natural light, and there are other patrons in the background.
""" - Prompt generation results
Right-click and open the image in a new tab or window to view it in its original size. 

A historic square with a prominent tower, cobblestone pavement, and traditional European architecture. A statue stands in the center of a square with a fountain, surrounded by buildings with lit windows.
Evaluation results and analysis
Below is the correlation (Pearson correlation coefficient) between human evaluation results and each evaluation method’s result indicators. The closer to 1, the higher the correlation, and the closer to 0, the less correlation.
| Indicator name | Aesthetics score | CLIP-IQA | Q-Align | PickScore | ImageReward | HPS v2 |
|---|---|---|---|---|---|---|
| Correlation | 0.924 | 0.187 | 0.384 | 0.282 | 0.279 | -0.290 |
Below is a graph showing the correlation matrix between each evaluation method's correlation along with a heat map. Similarly, the closer to 1, the higher the correlation, and the closer to 0, the less correlation.
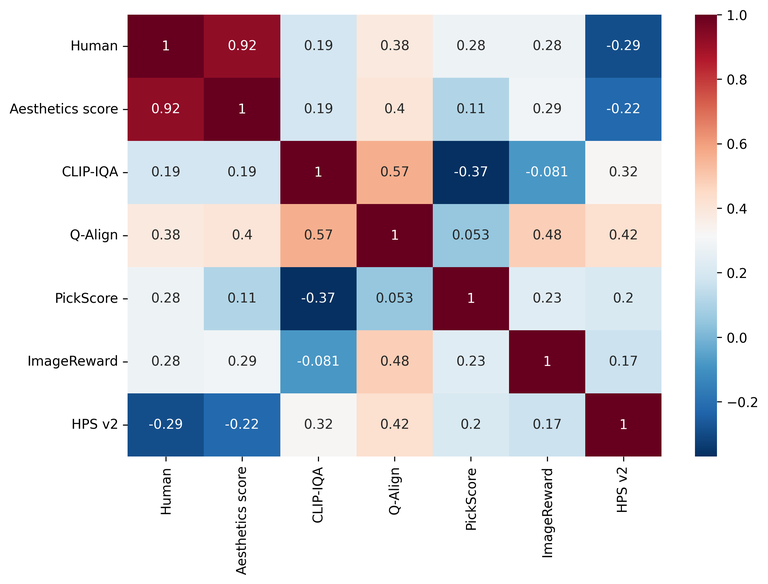
Firstly, aesthetics score shows the highest correlation (0.924) with human evaluations, indicating that it's the most reliable indicator for assessing overall image quality. This suggests that aesthetics score can adequately reflect the intuitive quality of images that humans perceive in inpainting tasks needed for BPR.
Conversely, CLIP-IQA and Q-Align don't show high correlations with human evaluations (0.187 and 0.384, respectively). These indicators may be useful for evaluating specific image elements, but they could be limited in assessing overall image quality.
Indicators such as PickScore, ImageReward, and HPS v2 focus on evaluating both image-text alignment and generated image quality; however, they didn't meet expectations in this image quality evaluation experiment. This may be because these evaluation methods focus more on alignment with text rather than image quality.
Below is a table summarizing the results of several models on example images along with their respective aesthetics score evaluation results.
| Inpainting model | Original image (red line: inpainted area) | FLUX. 1-Fill-dev | Latent codes for pluralistic image inpainting |
|---|---|---|---|
| Aesthetics score | - | 4.75 | 4.71 |
| Result image | | |  |
| Inpainting model | MAE-FAR | HINT | MxT |
| Aesthetics score | 4.705 | 4.56 | 4.52 |
| Result image |  |  |  |
Analyzing the aesthetics score and the quality of the images holistically along with the table above, you can understand how scores are linked to image quality as follows:
- First, the FLUX. 1-Fill-dev image shows that the inpainting area was finely generated and the aesthetics score recorded a high score, showing strong alignment between the image quality and the score.
- Latent codes for pluralistic image inpainting and MAE-FAR weren't as natural as FLUX. 1-Fill-dev, but exhibited decent quality, and the aesthetics score reflected this by being slightly lower than that of FLUX. 1-Fill-dev.
- HINT and MxT had artifacts in the generated images, among other issues, leading to overall lower quality, and consequently lower aesthetics score results.
Evaluation methods and results using the Places365 evaluation dataset
Dataset and inpainting models used in the experiment
The Places365 dataset, widely used for evaluating and training vision-related models, consists of about 1.8 million datasets such as cities and landscapes visible in everyday life. Among them, the Places365 evaluation dataset is composed of exactly 36,500 images, and it consists solely of images without predefined inpainting areas for evaluation. As a result, each study uses different inpainting areas for evaluating and describing metrics.
In this experiment, evaluations were conducted with identical inpainting areas regardless of the model. The inpainting area was determined to average about 40% of the entire image.
The following is an outline of the inpainting models used in this experiment. Nine inpainting models published from 2022 to 2024 were utilized.
- LaMa (WACV 2022), MAT (CVPR 2022), CoordFILL (AAAI 2023), SCAT (AAAI 2023), HINT (TMM 2024), MxT (BMVC 2024), PUT (TPAMI 2024), Latent codes for pluralistic image inpainting (CVPR 2024), FLUX. 1-Fill-dev (Arxiv 2024)
For reference, the MAE-FAR (ECCV 2022) and ZITS++ (TPAMI 2023) models used in the BPR evaluation dataset experiment previously included some images that didn't produce normal results, hence they were excluded from this experiment.
Evaluation methods used in the experiment
The evaluation methods used in this experiment are listed below. Since PickScore, ImageReward, and HPS v2 require prompts for creating images, we generated prompts in the same manner as when evaluating the BPR dataset.
- Aesthetics score, CLIP-IQA, Q-Align: A method to measure the quality of the given image.
- PickScore, ImageReward, HPS v2: Evaluates image-text alignment and the quality of the generated image using the image and its generation prompt.
- LPIPS: Compares pairs of the original and result images to measure the quality of the result images.
- FID, FD-DINO, CMMD
- FID: Measures the quality of the result images by comparing the distributions of original and result images.
- FD-DINO: An improved model of FID. While FID uses Inception-v3 as the backbone for measuring Fréchet distance between feature spaces, FD-DINO does so using DINOv2-ViT-L/14 as the backbone.
- CMMD: An improved model of FID, calculates maximum mean discrepancy (MMD) distance in CLIP-L feature space using the Gaussian radial basis function (RBF) kernel.
Each evaluation was applied to all 36,500 images, and the human assessment involved randomly selecting 20 images from the dataset and scoring the results of each model from 1 to 5.
Evaluation results and analysis
Below is the correlation (Pearson correlation coefficient) between human evaluation results and each evaluation method's result indicators. The closer to 1, the higher the correlation, and the closer to 0, the less correlation.
| Indicator Name | Aesthetics score | CLIP-IQA | Q-Align | PickScore | ImageReward | HPS v2 | LPIPS | FID | FD-DINO | CMMD |
|---|---|---|---|---|---|---|---|---|---|---|
| Correlation | 0.877 | 0.063 | 0.843 | 0.648 | 0.428 | 0.387 | 0.301 | 0.877 | 0.604 | 0.898 |
Below is a graph showing the correlation matrix between each evaluation method's correlation along with a heat map. Similarly, the closer to 1, the higher the correlation, and the closer to 0, the less correlation.
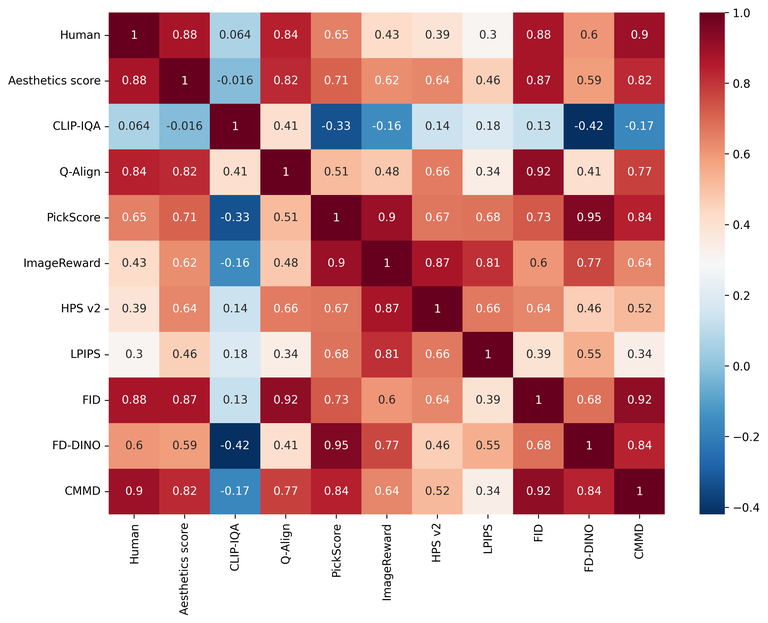
The CMMD method showed the highest correlation (0.898) with human assessment results in this experiment, indicating that it's a highly reliable evaluation method for image quality.
Next, FID and aesthetics score demonstrated high correlation (0.877). It's worth noting that FID-based methods, including CMMD, recommend using a large dataset (over 10,000 images) for evaluating distributions of original and generated images. In contrast, aesthetics score can be used with a smaller dataset for evaluation, suggesting that it offers high reliability even with fewer data.
LPIPS measures the quality by comparing pairs of original and result images, which showed relatively low correlation to subjective human aesthetic assessments. It indicates that comparison based purely on image pairs may not fully reflect the overall quality of an image.
Conclusion
No correct answer is predefined for AI-generated images; thus, various forms could all be correct answers. This trait makes quantifying image quality a highly challenging task. Furthermore, performance metrics in studies dealing with generative image models may not adequately reflect specific task performance.
We explored which evaluation methods should be applied to one specific task using generative models: inpainting. We assumed that the evaluation method best correlated with human assessment would best suit our task, conducting experiments to identify evaluation methods that align with human assessments across two datasets.
Although we didn't obtain perfectly satisfying results, optimal evaluation techniques vary depending on the dataset, fair trends were somewhat identified. This enabled us to establish criteria for selecting suitable inpainting models. However, this method isn't flawless, and we believe many challenges remain to achieve complete automation of evaluation methods.
We'll continue researching to find better evaluation methods that can accurately represent inpainting performance. We will share results worth noting on this blog in the future. Thank you for reading this extensive post.


