안녕하세요. LINE VOOM 서비스의 추천 시스템을 개발하는 ML 엔지니어 이창현, 백진우입니다. 저희는 LINE VOOM의 실시간 추천 시스템을 위한 대규모 벡터 데이터베이스 도입 프로젝트를 진행했습니다. 이번 글에서는 그 도입 과정을 자세히 소개하고자 합니다.
LINE VOOM이란
먼저 저희가 개발하고 있는 서비스, LINE VOOM을 소개하겠습니다. LINE VOOM은 LINE 앱 내에서 서비스하는 비디오 콘텐츠 중심의 소셜 네트워크 서비스입니다. 현재 일본과 대만, 태국 등에서 서비스하고 있습니다.
LINE VOOM에서는 누구나 콘텐츠 크리에이터가 되어 콘텐츠를 업로드할 수 있으며, 사용자는 다양한 콘텐츠를 탐색하고 소비할 수 있습니다. For you 탭에서는 사용자가 흥미를 느낄 만한 동영상을 연속적으로 시청할 수 있고, Following 탭에서는 팔로우한 크리에이터의 콘텐츠를 모아볼 수 있습니다.
이 글에서는 주로 For you 탭에서 제공하는 추천 프로세스를 다룰 예정입니다. For you 탭은 사용자에게 개인화한 콘텐츠 추천 결과를 제공하는 탭입니다. 사용자의 콘텐츠 피드백, 예를 들어 이전에 시청 혹은 클릭했거나 '좋아요'를 누른 등의 피드백을 토대로 사용자가 선호할 만한 콘텐츠를 추출해 제공합니다.
기존 추천 시스템의 문제점
이전에 사용하던 추천 시스템의 전체 작동 흐름은 다음과 같습니다.
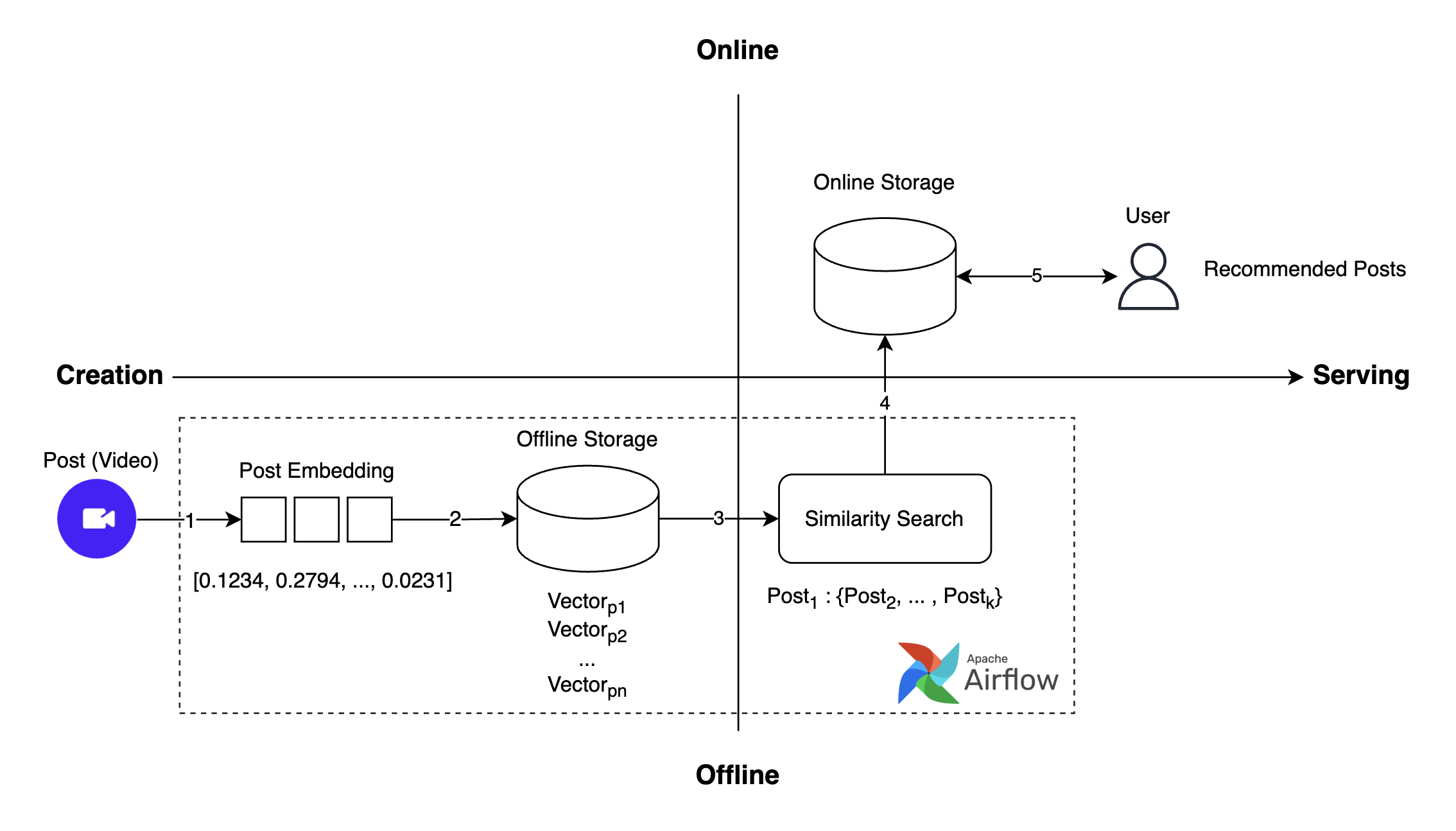
- 포스트 작성: 사용자가 비디오 포스트를 작성합니다.
- 포스트 임베딩 생성: 작성된 포스트에 대한 임베딩을 생성합니다.
- 포스트 임베딩 저장: 생성된 임베딩을 벡터 데이터베이스에 저장합니다.
- 유사한 포스트 검색(ANN(approximate nearest neighbor)): 유사성 검색을 통해 해당 포스트와 유사한 포스트들을 찾습니다.
- 추천 포스트 요청 및 가져오기: 사용자에게 추천된 포스트들을 제공합니다.
이 과정을 통해 사용자는 자신의 관심사에 맞는 다양한 콘텐츠를 쉽게 접할 수 있었는데요. 한 가지 문제가 있었습니다.
문제점: 즉시성 부족
기존 추천 시스템은 포스트 임베딩을 생성해 저장한 후 추천 후보군을 추출해서 인메모리 데이터베이스에 저장하는 과정을 모두 일 단위 오프라인 배치 작업으로 처리했습니다. 이 때문에 추천 후보군을 업데이트하는 데 최대 하루가 걸린다는 한계가 있었고, 이 한계는 사용자 경험에 다음과 같은 문제를 초래했습니다.
- 크리에이터 A가 새해를 맞아 'Happy New Year'라는 내용의 영상을 게시했을 때 이 영상이 사용자들에게 즉시 추천되지 않습니다.
- 크리에이터 B가 월드컵 경기 중 골을 넣은 장면을 담은 영상을 게시했지만 이 영상 역시 사용자들에게 즉시 추천되지 않습니다.
이와 같이 신선한 콘텐츠를 바로 볼 수 없다는 '즉시성 부족' 문제는 사용자 경험을 저하했습니다. 이를 해결하기 위해 시스템을 개선할 필요가 있었고, 실시간 추천 시스템을 구현하는 프로젝트를 시작했습니다.
이 프로젝트의 목표는 사용자가 게시한 포스트를 즉각 추천 후보군에 반영해 더 신선한 포스트를 사용자에게 추천하는 것이었습니다. 이를 위해서 기존 시스템의 많은 부분을 변경했는데요. 일 단위로 후보군 풀(포스트 풀)을 생성하던 방식을 모델 기반의 실시간 후보군 생성 방식으로 변경했고, 벡터 검색 방식을 오프라인 연산에서 온라인 연산으로 전환했습니다.
그중 이 글에서는 벡터 검색 구조의 변경에 중점을 두고 설명하려고 합니다.
새로운 실시간 추천 �시스템의 구조와 벡터 DB가 필요했던 이유
새로 개발한 실시간 추천 시스템의 전체적인 작동 흐름은 다음과 같습니다.
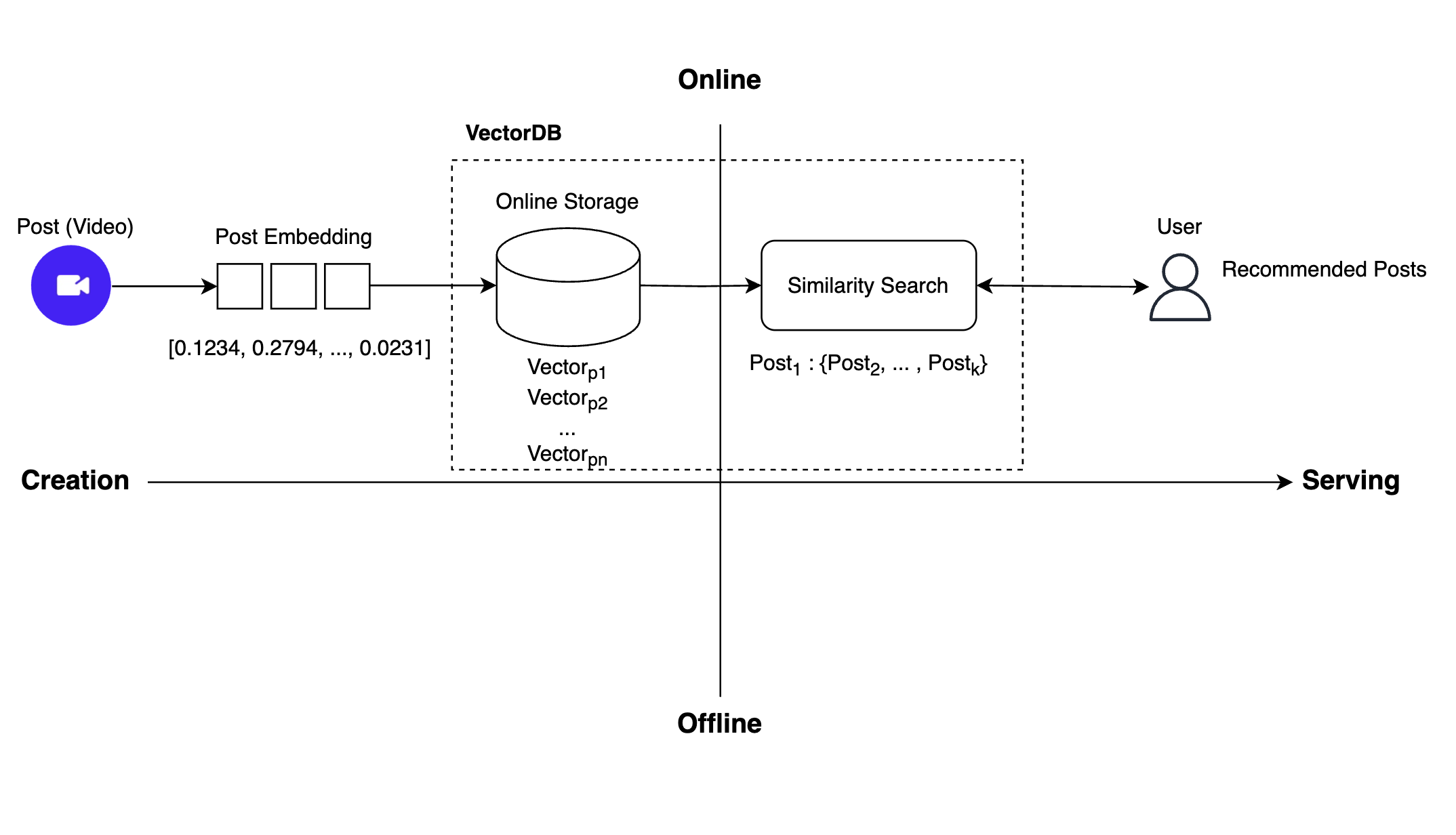
위와 같이 실시간 추천을 구현하기 위해 이전 추천 시스템에서 오프라인으로 수행하던 작업들을 온라인으로 전환해야 했는데요. 이를 위해 두 가지 작업이 필요했습니다. 첫 번째로 포스트 임베딩을 저장해 두는 공간을 오프라인 저장소에서 온라인 저장소로 교체해야 했습니다. 두 번째로 이전에는 유사성 검색을 통해 추천 가능한 모든 포스트를 오프라인에서 미리 찾아 그 결과를 온라인 저장소에 저장하는 방식으로 진행했는데요. 이제는 중간 저장 과정 없이 즉시 유사성 검색을 수행해야 했습니다.
저희는 온라인 저장소와 실시간 유사성 검색, 이 두 가지 기능을 구현하려면 벡터 DB를 도입해야 한다고 판단했고, 여러 벡터 DB 플랫폼을 탐색하기 시작했습니다.
지금까지의 과정을 요약해 보겠습니다.
- 기존 추천 시스템은 오프라인 저장소와 배치 처리를 통해 유사성 검색을 수행했으며, 이로 인해 즉시성이 떨어지는 문제가 있었습니다.
- 기존 추천 시스템의 주요 문제는 포스트 생성 후 추천 후보군에 포함되기까지 최대 하루가 소요된다는 점이었으며, 이 때문에 사용자들에게 즉시 포스트를 제공하지 못하고 있었습니다.
- 기존 시스템의 문제를 해결하기 위해 오프라인 작업을 모두 온라인으로 전환하기로 결정했고, 이를 위해서는 포스트 임베딩을 온라인 ��저장소에 저장하고, 중간 과정 없이 실시간으로 유사성 검색을 수행하는 시스템으로 개선해야 했습니다.
- 온라인 저장소와 유사성 검색을 실시간으로 처리하려면 벡터 DB를 도입할 필요가 있었습니다.
벡터 DB 선정 기준과 Milvus를 선택한 이유
최근 벡터 DB 생태계가 발전하면서 다양한 선택지가 생겼는데요. 저희는 그중에서 적합한 플랫폼을 선정하기 위해 다음과 같은 몇 가지 기준을 세웠습니다.
- 벡터 전용 DB여야 한다.
- 오픈소스여야 한다.
- 온프레미스 환경에 직접 구축할 수 있어야 한다.
- 실시간 추천을 위해 높은 부하에서도 안정적으로 작동하며 지연 시간이 낮아야 한다.
이러한 기준을 두고 탐색했을 때, 적절한 프레임워크는 Milvus와 Qdrant가 있었습니다. 이제 두 프레임워크를 비교해 보겠습니다.
| 기준 | Milvus | Qdrant |
|---|---|---|
| 성능(QPS(query per second), 지연 시간)(참고) | 2406 req/s, 1ms | 326 req/s, 4ms |
| 스토리지/컴퓨팅 분리 | O | X |
| 스트림과 배치 지원 | O | X |
| GitHub 별 개수(커뮤니티 규모 및 �활성도 간접 측정) | 35.9K stars | 24.6K stars |
| 지원하는 인메모리 인덱스 유형 개수 | 10(참고) | 1(HNSW만 지원) |
Milvus는 성능 면에서 Qdrant에 비해 우수했고, 스토리지와 컴퓨팅을 분리해 안정성 또한 더 높았습니다. 또한 다양한 인덱스 알고리즘을 지원하고 있어서 여러 실험을 통해 저희 시나리오에 맞게 성능을 최적화할 수 있는 가능성이 크다고 판단했습니다. 스트림과 배치 작업이 분리되어 있어 온라인 INSERT와 오프라인 벌크 INSERT 기능을 지원하기 때문에 향후 임베딩 업데이트에 대응하는 기능도 구현할 수 있을 것으로 판단했으며, 더불어 활발한 커뮤니티 덕분에 문제 발생 시 정보를 쉽게 얻을 수 있다는 장점도 있었습니다.
위와 같은 이유로 저희는 Milvus를 채택하기로 결정했습니다.
Milvus 소개
Milvus는 수십억 개 이상의 대규모 벡터 데이터에 대한 유사도 검색을 전제로 설계됐기 때문에 아래와 같이 구조가 복잡합니다. 대규모 벡터 데이터에 대한 유사도 검색이 목적이었기에 클러스터 버전으로는 공개된 사용 사례가 많지 않았고, 이에 따라 성능과 안정성이 어떠할지는 불확실한 요소로 남아 있었습니다.
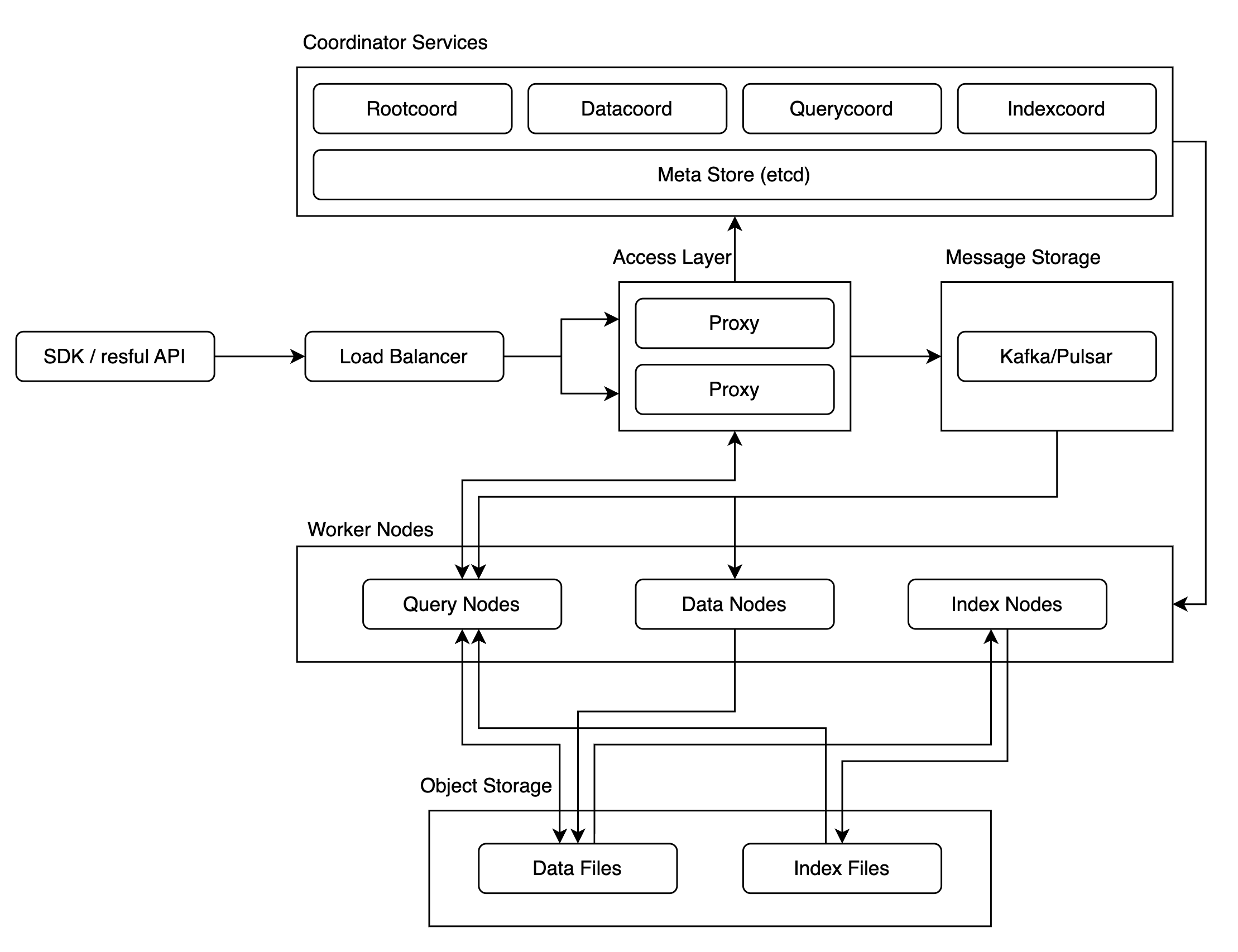
저희는 이 불확실성을 해소하고 Milvus를 성공적으로 도입하기 위해 성능과 안정성을 철저히 검증해야 했고, 이를 위해 카오스 테스트와 성능 테스트를 진행했습니다.
먼저 카오스 테스트에서는 시스템이 얼마나 안정적으로 작동하는지 확인하고, 만약 시스템이 불안정하게 작동하는 상황이 있다면 이를 어떤 방법으로 안정화할 수 있는지에 중점을 두고 테스트를 진행했습니다.
다음으로 성능 테스트에서는 ANN 벤치마크에서 확인할 수 있는 벡터 검색 성능이 저희 환경에서도 재현되는지, 한정된 자원으로 처리량을 어떻게 최대화하고 응답 시간을 최소화할 수 있는지 등에 중점을 두고 테스트를 진행했습니다.
그럼 각 테스트 방법과 결과를 하나씩 살펴보겠습니다.
Milvus 검증 1: 카오스 테스트
카오스 테스트는 시스템의 안정성과 복원력을 평가하기 위해 고의적으로 시스템에 혼란을 일으키는 테스트 방법입니다. 저희는 쿼리, 조회(search), 삽입, 삭제, 인덱스 생성, 로드, 릴리스 등과 같은 API 세트를 준비해 놓고, 특정 API 요청을 지속적 혹은 반복적으로 Milvus 클러스터에 보내면서 파드 킬(pod kill), 스케일 인/아웃/업 등의 상황을 주입하면서 모니터링을 진행했습니다.
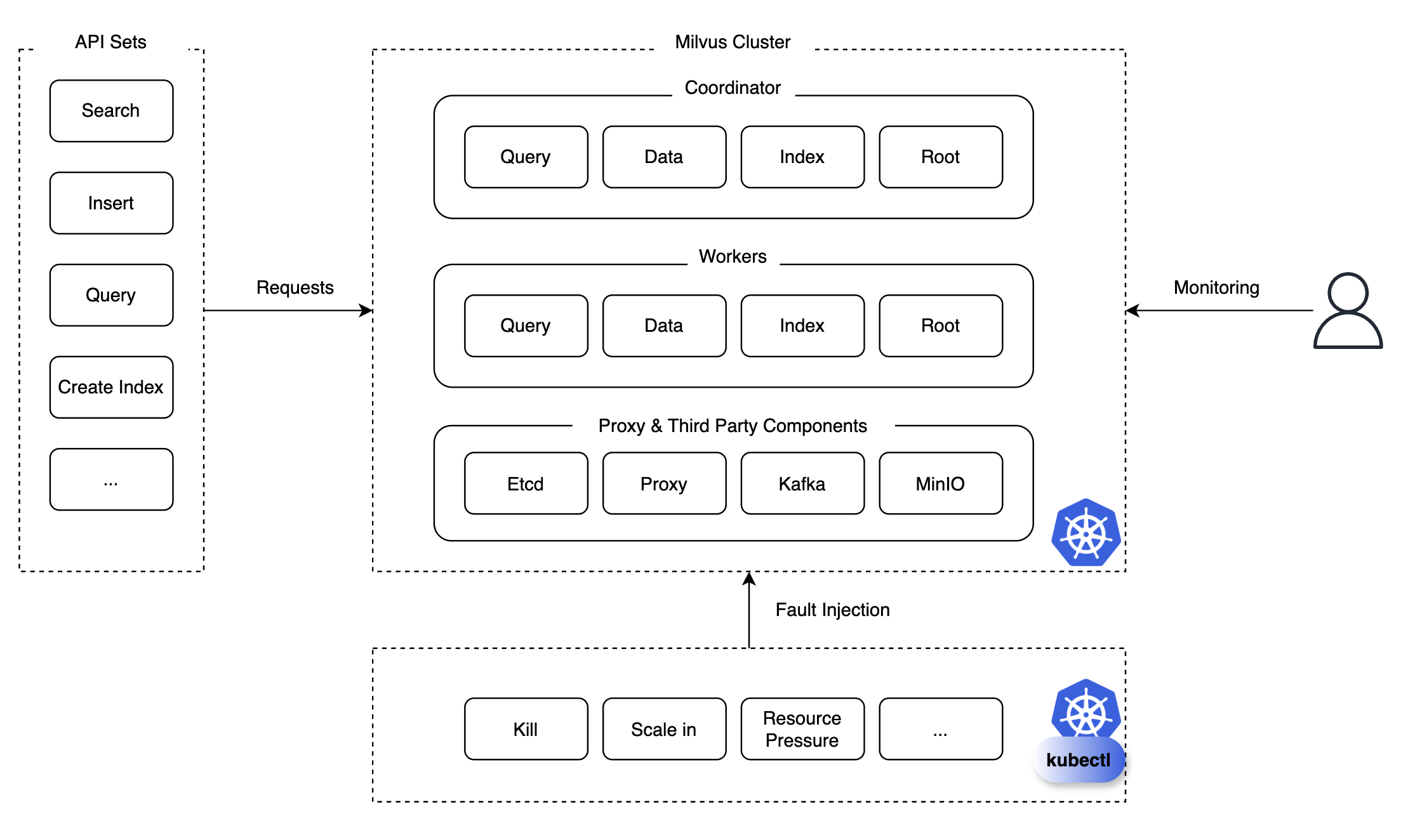
모니터링 시에는 해당 컴포넌트의 복구 가능 여부, 복구에 소요되는 시간, 복구되기 전 발생하는 문제 등을 면밀하게 관찰하고 검토했으며, 이와 같이 모니터링한 덕분에 향후 장애로 이어질 수 있는 문제를 발견해 예방할 수 있는 조치를 취할 수 있었습니다. 그럼 테스트 결과와 함께 어떤 문제가 있었고 이를 해결하기 위해 어떤 조치를 취했는지 말씀드리겠습니다.
테스트 결과
먼저 아래는 테스트 결과 중 주요 결과를 추려 놓은 표입니다.
| API | 카오스 시나리오 | 결과 |
|---|---|---|
| Search | Scale in Querynode | 정상 작동 |
| Search | Scale out Querynode | 정상 작동 |
| Search | Kill Querynode | 정상 작동 |
| Search | Kill Querycoord | 컬렉션이 릴리스되며 유사도 검색 불가 상태에 빠짐 |
| Search | Kill Etcd (과반 이상) | 클러스터 다운 및 컬렉션 메타데이터 손실로 조회 불가능 |
| ... | ... | ... |
| Insert | Kill Datanode | 정상 작동 |
| Insert | Kill Querynode | 정상 작동 |
| Insert | Kill Proxy | 정상 작동 |
| Create Index | Kill Indexcoord | 인덱스 생성 실패, 복구하는 데 102초 소요 |
위 표에서 붉은색으로 표시한 시나리오는 실제 서비스에서 장애로 이어질 수 있는 심각한 이슈였기 때문에 이를 예방하기 위해 안정성을 높이는 조치를 취해야 했는데요. Milvus의 시스템 �안정성을 높이기 위해 저희가 적용한 몇 가지 해결책을 소개하겠습니다.
컬렉션 고가용성 구성
먼저 'Kill Querycoord' 시나리오와 같이 컬렉션(collection)이 갑자기 릴리스되면서 유사도 검색이 불가한 상태에 빠지는 것을 방지하기 위해 아래와 같이 컬렉션 사본을 하나 마련해 두고 임베딩을 이중으로 기록하는 방식(dualwriting)으로 컬렉션 단위의 고가용성(high availability, HA) 구성을 구현했습니다. 컬렉션에서 벡터를 검색하는 클라이언트 단에서는 별칭(alias)을 사용해 하나의 컬렉션이 가용하지 않은 경우 즉시 다른 컬렉션을 참조하도록 구성했습니다.
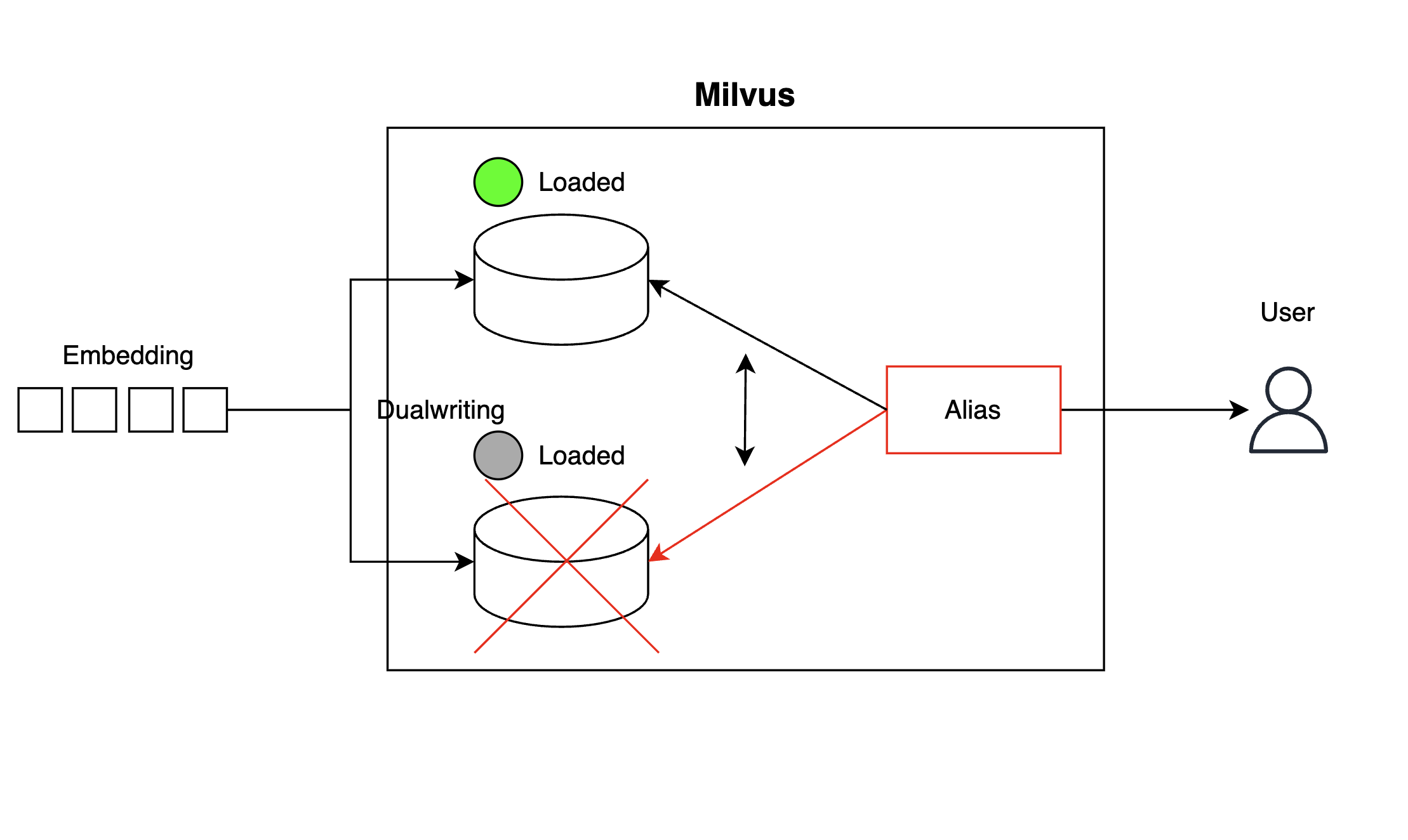
위와 같이 구성하면 컬렉션 하나가 불능 상태에 빠질 경우 아래와 같이 런타임에서 별칭을 교체(alias switching)해 사본 컬렉션을 참조하도록 만들어 장애 시간을 최소화할 수 있습니다.
client.create_alias(collection_name="collection_1", alias="Alias")
client.alter_alias(collection_name="collection_2", alias="Alias")코디네이터 고가용성 구성
Milvus의 코디네이터(coordinator)의 경우 워커 노드를 제어하는 역할을 수행하기 때문에 단일 파드로 구성됩니다. 따라서 코디네이터 파드�가 중단되면 그 즉시 장애로 이어질 수 있는데요. 저희는 이 코디네이터를 아래와 같이 액티브-스탠바이(active-standby) 모드로 설정해 고가용성 구성을 구현함으로써 단일 실패 지점이 되는 것을 방지했습니다.
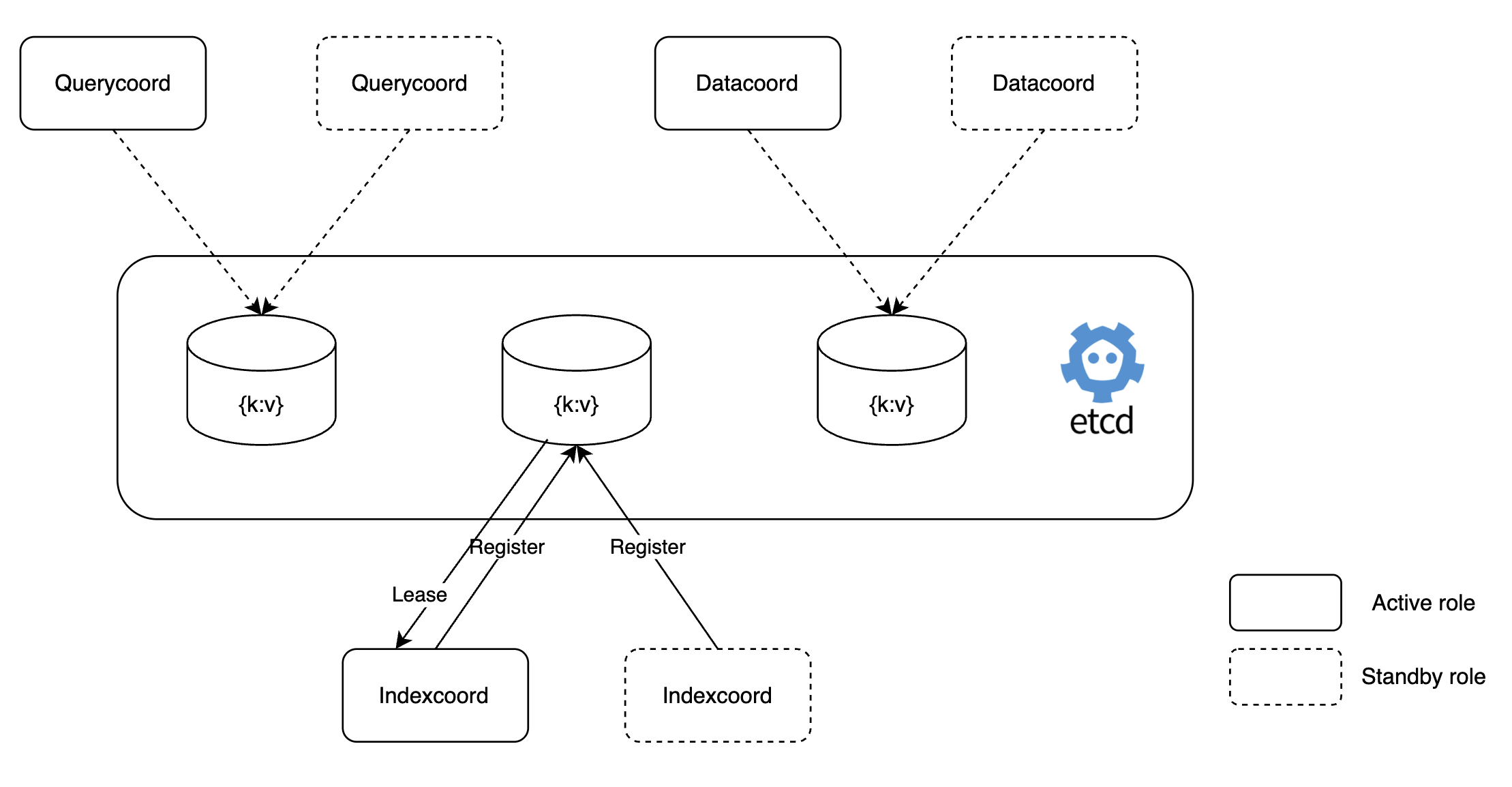
이를 통해 'Kill Indexcoord' 시나리오와 같이 인덱스 코디네이터(Indexcoord)가 중단되는 경우 즉시 스탠바이 역할의 인덱스 코디네이터가 작동해 인덱스 생성에 실패하는 상황을 예방할 수 있게 되었습니다. 다음은 이와 같이 설정한 예시와 스탠바이 모드로 작동하는 'dataCoordinator'의 로그입니다.
# value.yaml
dataCoordinator:
enabled: true
# You can set the number of replicas greater than 1 only if you also need to set activeStandby.enabled to true.
replicas: 2 # Otherwise, remove this configuration item.
resources: {}
nodeSelector: {}
affinity: {}
tolerations: []
extraEnv: []
heaptrack:
enabled: false
profiling:
enabled: false # Enable live profiling
activeStandby:
enabled: true # Set this to true to have RootCoordinators work in active-standby mode.[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]백업 시스템 구성
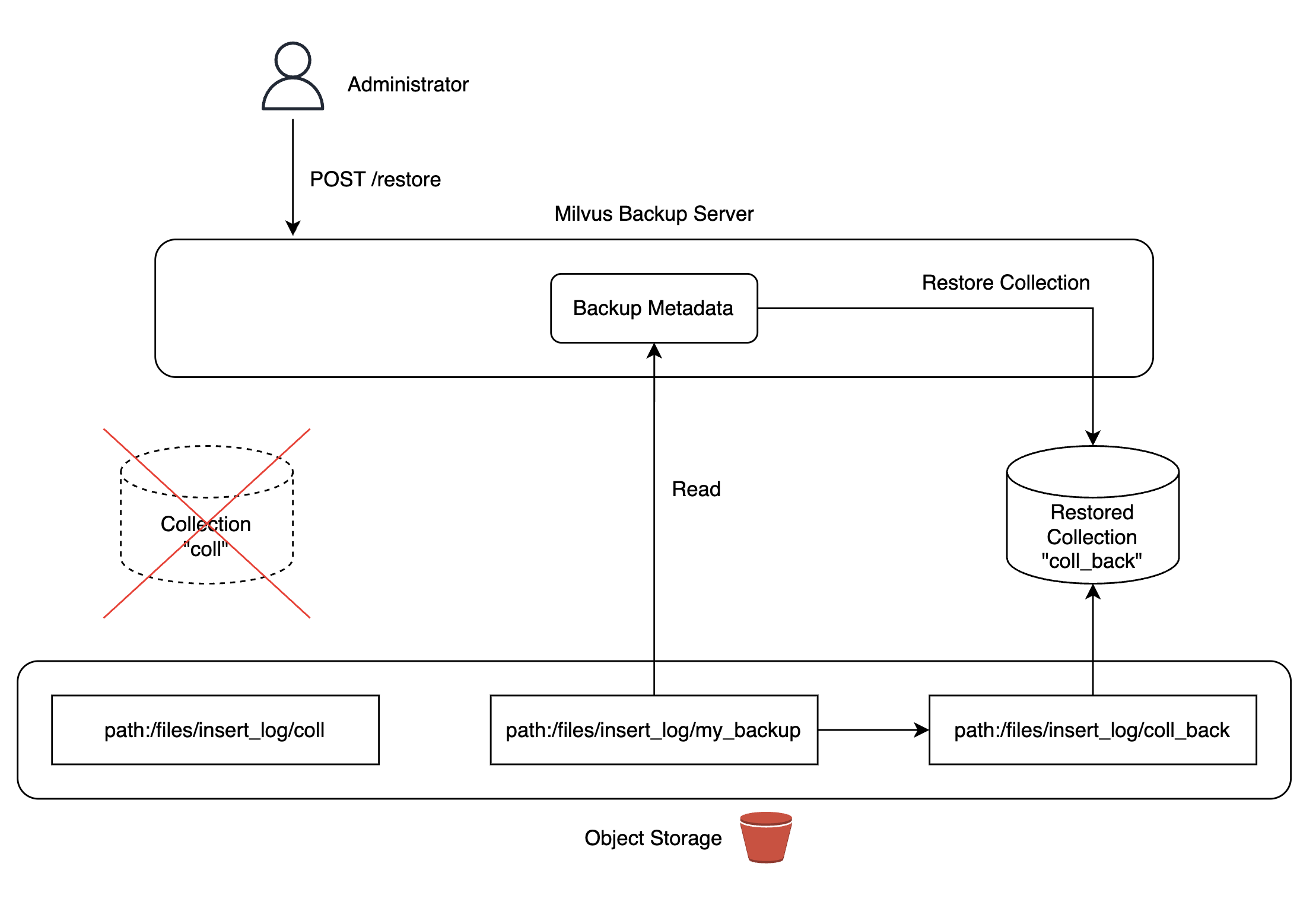
'Kill Etcd(과반 이상)' 시나리오와 같이 과반 이상의 etcd가 중단되면 Milvus 클러스터 전체가 다운되며 컬렉션 메타데이터 유실과 같은 문제가 발생할 수 있으며, 이는 실제 서비스에서 치명적인 장애 상황으로 이어질 수 있습니다.
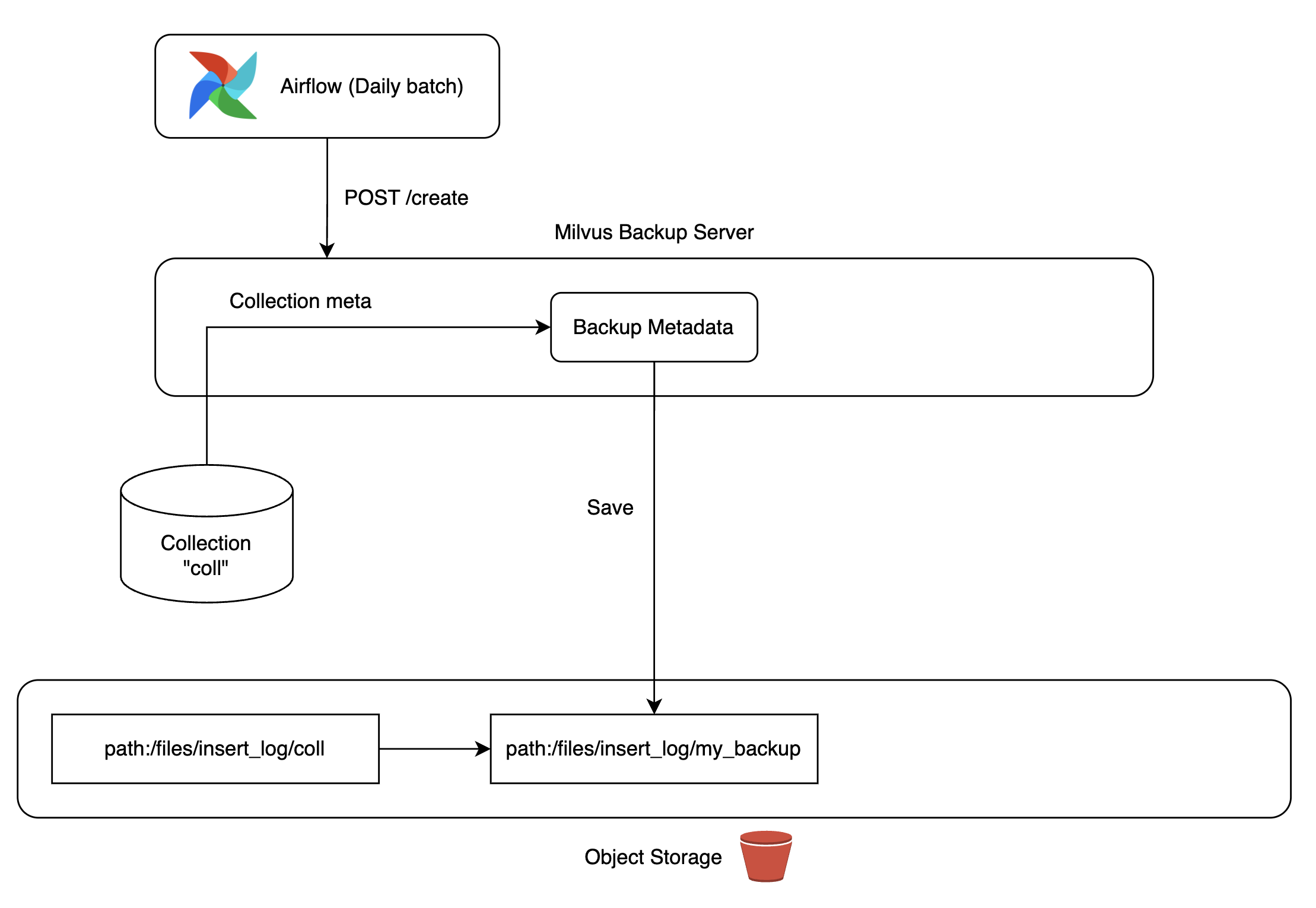
이 문제를 해결하기 위해 Milvus에서 제공하는 백업 도구를 활용해 백업 서버를 구축했습니다. 저희가 관리하는 쿠버네티스 클러스터에 MinIO를 배포하고 MinIO 스토리지에 데이터 복제본을 만들어서 필요 시 언제든 컬렉션으로 복구할 수 있도록 구성했습니다.
백업본은 Airflow DAG을 통해 일 단위로 자동 업데이트해서 컬렉션을 복구하는 상황이 발생하더라도 최신 데이터를 사용할 수 있도록 구성했습니다. 참고로 Milvus 백업 서버를 구성하는 과정에서 발생한 버그를 수정해 Milvus 프로젝트에 기여하기도 했습니다(참고).
 |
|
 |
|
Milvus의 디버깅 도구, Birdwatcher 도입
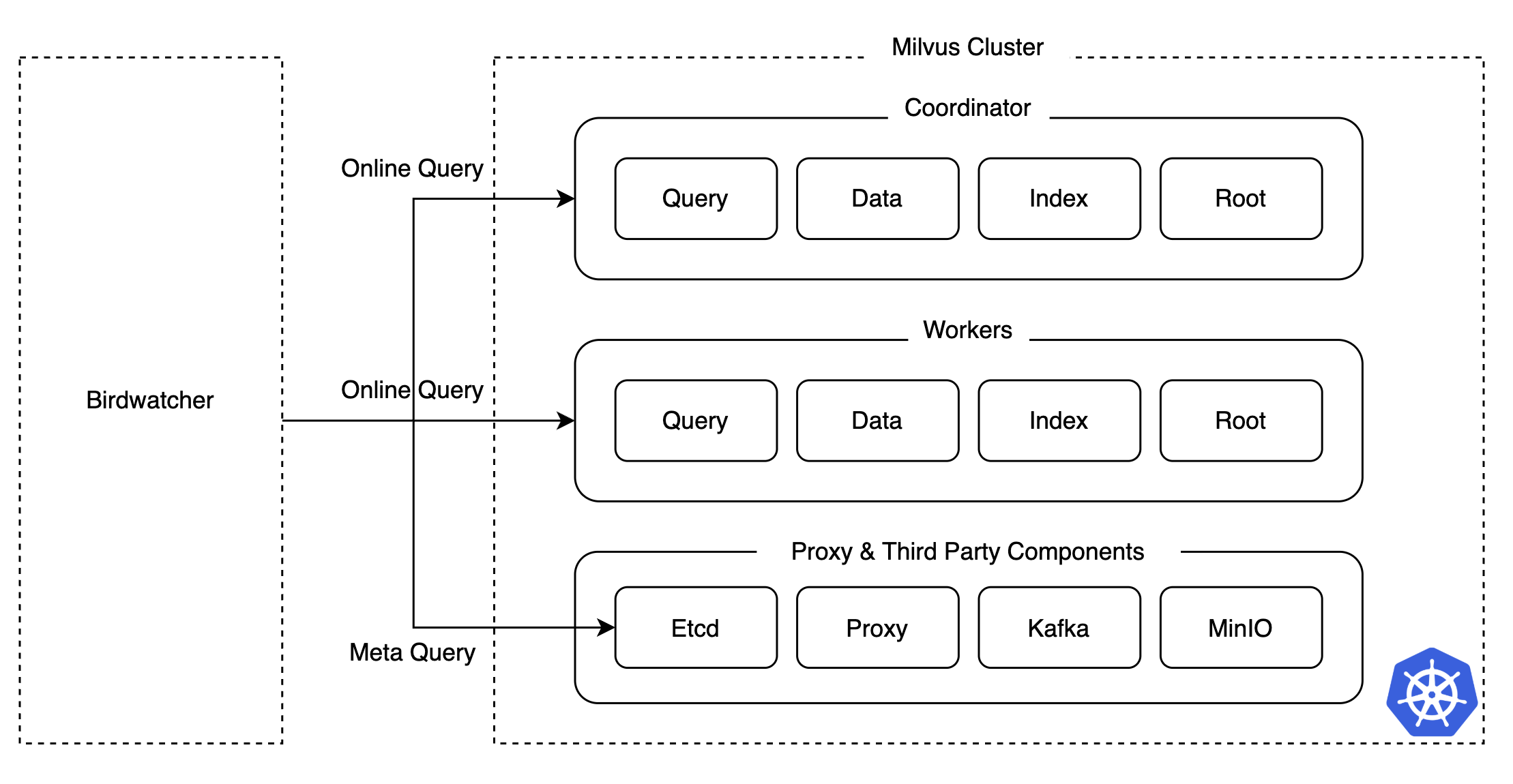
카오스 테스트를 진행하면서 Milvus 클러스터가 정상 작동하지 않는 상황이 발생했을 때, 어떤 컴포넌트에서 이상이 발생했는지 정확히 파악하는 것이 쉽지 않았습니다. 특히 분산 시스템에서는 여러 컴포넌트와 파드의 로그를 일일이 확인해야 하므로 장애 지점 파악과 복구에 많은 시간이 소요되곤 합니다.
이러한 문제를 해결하고 장애 대응 시간을 단축하기 위해서 저희는 Milvus에서 제공하는 디버깅 도구인 Birdwatcher를 활용해 etcd와 직접 연결해서 각 컴포넌트의 상태나 메타데이터를 손쉽게 조회할 수 있게 만들었고, 이를 통해 운영 난이도를 낮출 수 있었습니다.
카오스 테스트 결과 요약
카오스 테스트는 Milvus 클러스터에서 발생할 수 있는 다양한 장애 상황을 미리 시뮬레이션해서 잠재적인 문제를 사전에 식별하고 해결책을 마련하는 데 중요한 역할을 담당했습니다. 특히 코디네이터와 컬렉션의 고가용성 구성, 백업 시스템 구축 및 Birdwatcher 도입 등의 조치는 이후 수년 간 프로덕션 환경을 운영하면서 발생한 장애 상황에서 서비스 중단 시간을 최소화하고 신속히 복구할 수 있도록 만들었습니다.
Milvus 검증 2: 성능 테스트
안정성을 확보하더라도 추천 후보군 추출을 위한 벡터 검색에 많은 시간이 소요되거나 처리량이 낮아 많은 자원이 필요하다면 서비스가 불가능할 수 있습니다. 이를 검증하기 위해서는 성능을 꼼꼼히 테스트할 필요가 있었습니다. 비록 벡터 검색 알고리즘이 활발히 연구되고 있고 벤치마크 결과(참고)가 존재한다고 해도 저희 환경에서 해당 성능이 그대로 재현될지는 반드시 한 번 검증해야 한다고 생각했습니다. 따라서 저희는 벤치마크 성능을 참고하되 하드웨어 및 노드 구성 등 저희의 환경에서 어떤 알고리즘의 성능이 좋은지, 그 성능은 �대략 어떠한지 등을 성능 테스트를 통해 확인하고자 했습니다.
테스트 시나리오
다음은 벡터 검색 성능에 영향을 미치는 튜닝 요소의 일부입니다. 아래 튜닝 요소를 참고해 성능 테스트를 위해 10가지 이상의 시나리오를 만들어서 지연 시간(latency)과 처리량(QPS), 재현율(recall) 성능 등을 측정했는데요. 이 글에서는 그중 아래 굵은 글씨로 표기한 인덱스에 따른 성능 테스트와 확장에 따른 성능 테스트에 집중해 공유드리고자 합니다.
- 인덱스
- 인덱스 유형(ANN 알고리즘)
- 인덱스 파라미터
- 확장성과 가용성
- 스케일 업
- 스케일 아웃
- 인메모리 복제
- 검색
- 검색 파라미터
- 배치 크기
- 데이터셋
- 차원(dimension)
- 행 개수
인덱스 유형(ANN 알고리즘) 간 비교
벡터 검색 성능은 사용하는 인덱스 유형(ANN 알고리즘)에 크게 좌우됩니다. 인덱스 유형마다 정확도, 지연 시간, 인덱싱 시간이 다르게 나타나므로, 서비스 시나리오에 맞는 적절한 인덱스 유형을 선택하는 것이 중요합니다. 또한, 임베딩 데이터의 분포에 따라 검색 성능이 달라질 수 있기 때문에, 특정 인덱스 유형이 서비스에 적합한지를 검증하는 것이 필요합니다.
실시간 추천 시스템은 지연 시간이 다른 무엇보다 중요한 요소이기 때문에 공식 문서에서 지연 시간이 가장 적다고 알려진 HNSW 알고리즘을 주요 타깃으로 삼고, 실제 저희 환경에서도 공식 문서와 같은 결과가 나오는지 확인하기 위해 IVF_FLAT을 비교 대상으로 선정해 테스트를 진행했습니다(참고).
| 카테고리 | 인덱스 이름 | 정확도 | 지연 시간 | 처리량 | 인덱스 시간 | 비용 |
|---|---|---|---|---|---|---|
| 그래프 기반 | HNSW | High | Low | High | Slow | High |
| 그래프 기반 | DiskANN | High | High | Mid | Very Slow | Low |
| 그래프 기반 | ScaNN | Mid | Mid | High | Mid | Mid |
| 클러스터 기반 | IVF_FLAT | Mid | Mid | Low | Fast | Mid |
| 클러스터 기반 + 양자화 기반 | IVF + Quantization | Low | Mid | Mid | Mid | Low |
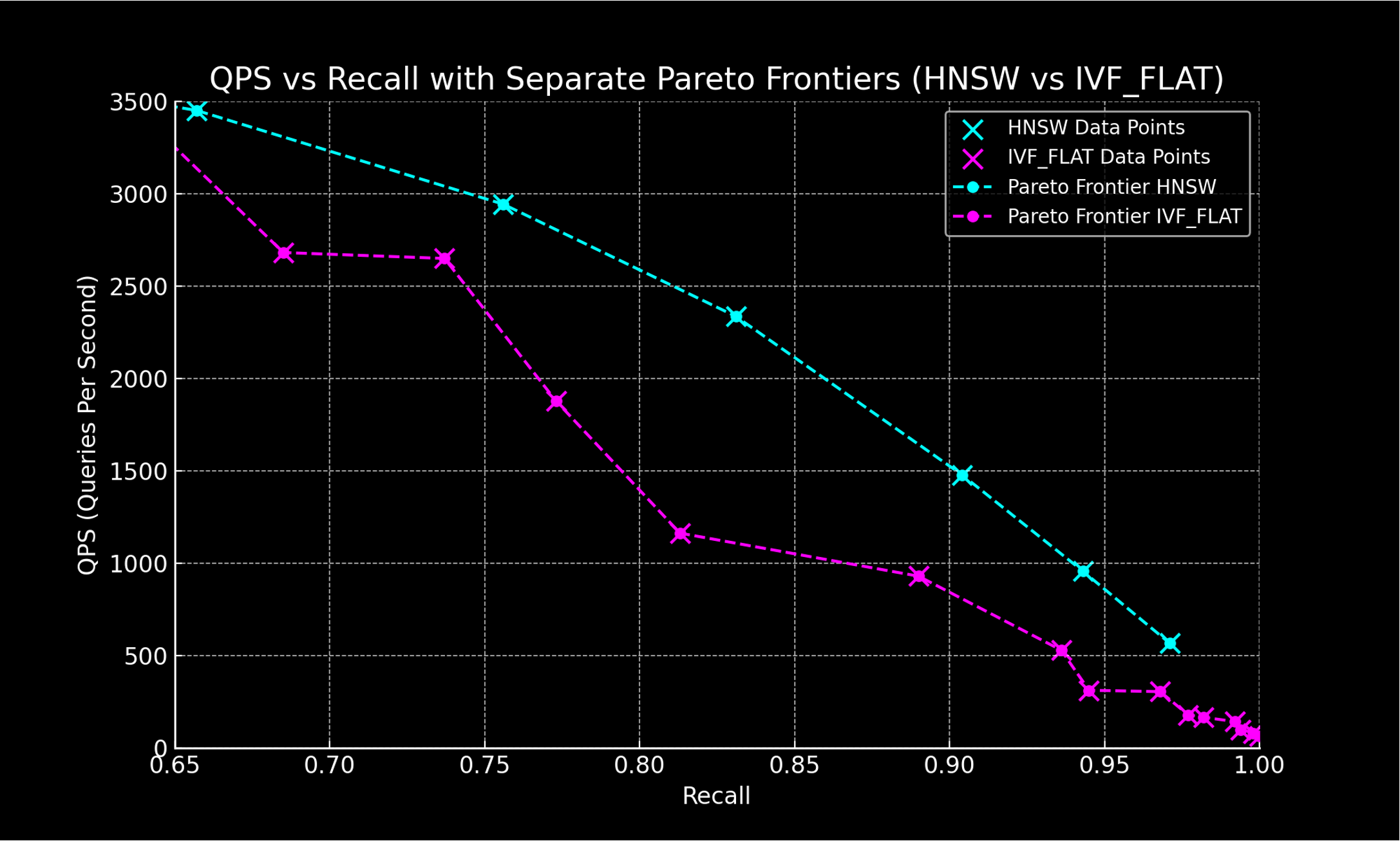
ANN 알고리즘의 성능 평가 지표로는 주로 QPS와 Recall을 사용하는데요. 이 둘은 서로 트레이드 오프 관계입니다. 인덱스 및 검색 파라미터를 조정하면서 성능을 측정한 뒤 가장 우수한 성능을 나타내는 점들을 연결하면 아래와 같이 인덱스 유형 간 성능을 비교할 수 있습니다.
인덱스 유형 간 비교 결과
인덱스 유형 간 비교 결과 HNSW 인덱스는 IVF_FLAT에 비해 높은 처리량과 정확도 성능을 보여주며 저희 환경에서도 그 성능이 일관되게 재현되는 것을 확인할 수 있었습니다.
스케일 업 및 스케일 아웃 테스트
서비스 트래픽이 증가할 때 자원을 추가해 스케일 업 또는 스케일 아웃으로 대응할 수 있는지 확인하는 것이 중요합니다. 쿼리를 담당하는 각 파드에 얼마나 많은 CPU 코어를 할당할지 결정하기 위해 스케일 업 테스트를 진행했고, 복제 수를 어느 정도로 구성할 것인지 결정하기 위해 스케일 아웃 테스트를 진행했습니다.
스케일 업 테스트 결과
아래 표는 쿼리를 담당하는 파드에 할당된 CPU 코어 수를 늘려가며 지연 시간과 처리량, 실패량을 측정한 것입니다. 테스트 결과 각각에 대해 어느 정도 선형적으로 지연 시간과 처리량 성능이 향상되는 것을 확인할 수 있었습니다. 쿼리를 담당하는 각 파드에서는 다중 CPU를 활용할 수 있다는 것을 확인했고, 특히나 CPU가 8인 경우 처리량이 큰 폭으로 개선되는 것을 확인할 수 있었습니다.
| CPU | 요청 수 | Avg(ms) | Min(ms) | Max(ms) | Median(ms) | TP99(ms) | req/s | failures/s |
|---|---|---|---|---|---|---|---|---|
| 2 | 59,961 | 39 | 3 | 195 | 37 | 97 | 991.57 | 0.00 |
| 4 | 105,183 | 22 | 3 | 118 | 13 | 80 | 1,739.38 | 0.00 |
| 8 | 328,307 | 7 | 2 | 82 | 4 | 49 | 5,427.66 | 0.00 |
| 16 | 511,255 | 4 | 2 | 50 | 3 | 21 | 8,433.64 | 0.00 |
| 32 | 644,904 | 3 | 2 | 67 | 3 | 7 | 10,618.27 | 0.00 |
- Avg (ms): 평균 지연 시간 (ms)
- Min (ms): 최소 지연 시간 (ms)
- Median (ms): 지연 시간의 중간 값 (ms)
- TP99 (ms): 백분위 99 지연 시간 (ms)
- req/s: 초당 처리 요청 수
- failures/s: 초당 실패 요청 수
스케일 아웃 테스트 결과
스케일 아웃 테스트에서는 파드의 복제 수가 증가함에 따라 지연 시간 감소 및 처리량 향상이 정비례에 가깝게 개선되는 것을 확인했습니다.
| 복제 수 | 요청 수 | Avg (ms) | Min (ms) | Max (ms) | Median (ms) | TP99 (ms) | req/s | failures/s |
|---|---|---|---|---|---|---|---|---|
| 1 | 106016 | 22 | 2 | 103 | 12 | 81 | 1752.74 | 0.00 |
| 2 | 199456 | 11 | 2 | 262 | 7 | 64 | 3297.60 | 0.00 |
| 4 | 361358 | 6 | 2 | 96 | 4 | 36 | 5958.22 | 0.00 |
| 8 | 578149 | 3 | 2 | 207 | 3 | 10 | 9555.55 | 0.00 |
인메모리 복제 테스트
Milvus에서 처리량을 증가시키는 또 하나의 방법으로 인메모리 복제 개수를 늘리는 방법이 있습니다. 인메모리 복제를 사용하면 데이터의 복제본을 메모리에 저장하기 때문에 메모리 사용량은 늘어나지만, 특정 노드가 바쁘거나 요청을 처리할 수 없는 경우 다른 노드가 요청을 처리할 수 있어서 가용성과 확장성을 확보할 수 있습니다.
인메모리 복제 테스트 결과
테스트 결과, 인메모리 복제 개수에 비례해 처리량은 증가하고 평균 지연 시간이 감소하는 것을 확인할 수 있었습니다. TP99 지연 시간 또한 크게 감소했으며, 인메모리 복제 수가 많을수록 유사도 검색의 안정성이 향상되는 것을 확인할 수 있었습니다.
| 인메모리 복제 수 | 요청 수 | Avg (ms) | Min (ms) | Max (ms) | Median (ms) | TP99 (ms) | req/s | failures/s |
|---|---|---|---|---|---|---|---|---|
| 1 | 199,806 | 11.81 | 2.64 | 92.69 | 10.51 | 44.80 | 3,303.02 | 0.00 |
| 2 | 356,680 | 6.54 | 2.42 | 92.33 | 5.44 | 31.95 | 5,888.30 | 0.00 |
| 4 | 483,543 | 4.77 | 2.37 | 63.77 | 4.48 | 11.52 | 7,995.04 | 0.00 |
| 8 | 582,954 | 3.93 | 2.16 | 160.38 | 3.60 | 10.03 | 9,636.69 | 0.00 |
성능 테스트 결과 요약
성능 테스트를 통해 인덱스 유형, CPU 자원 할당, ��파드 복제 수, 인메모리 복제 등 다양한 설정에 따라 벡터 검색의 처리량과 지연 시간이 어떻게 달라지는지를 확인할 수 있었습니다. 특히 HNSW 인덱스는 낮은 지연 시간과 높은 처리량을 보여주며 우리 환경에서도 그 성능이 일관되게 재현되었고, 쿼리를 담당하는 파드의 CPU 코어 수와 복제 수를 늘릴수록 자원 투입에 비례해 처리량 증가와 지연 시간 감소가 나타났습니다. 또한, 인메모리 복제를 적용했을 때도 TP99 지연 시간 감소와 처리량 증가가 확인되어, 메모리 자원을 활용한 방식 역시 서비스 안정성과 성능 향상에 효과적임을 검증할 수 있었습니다.
Milvus 적용 결과
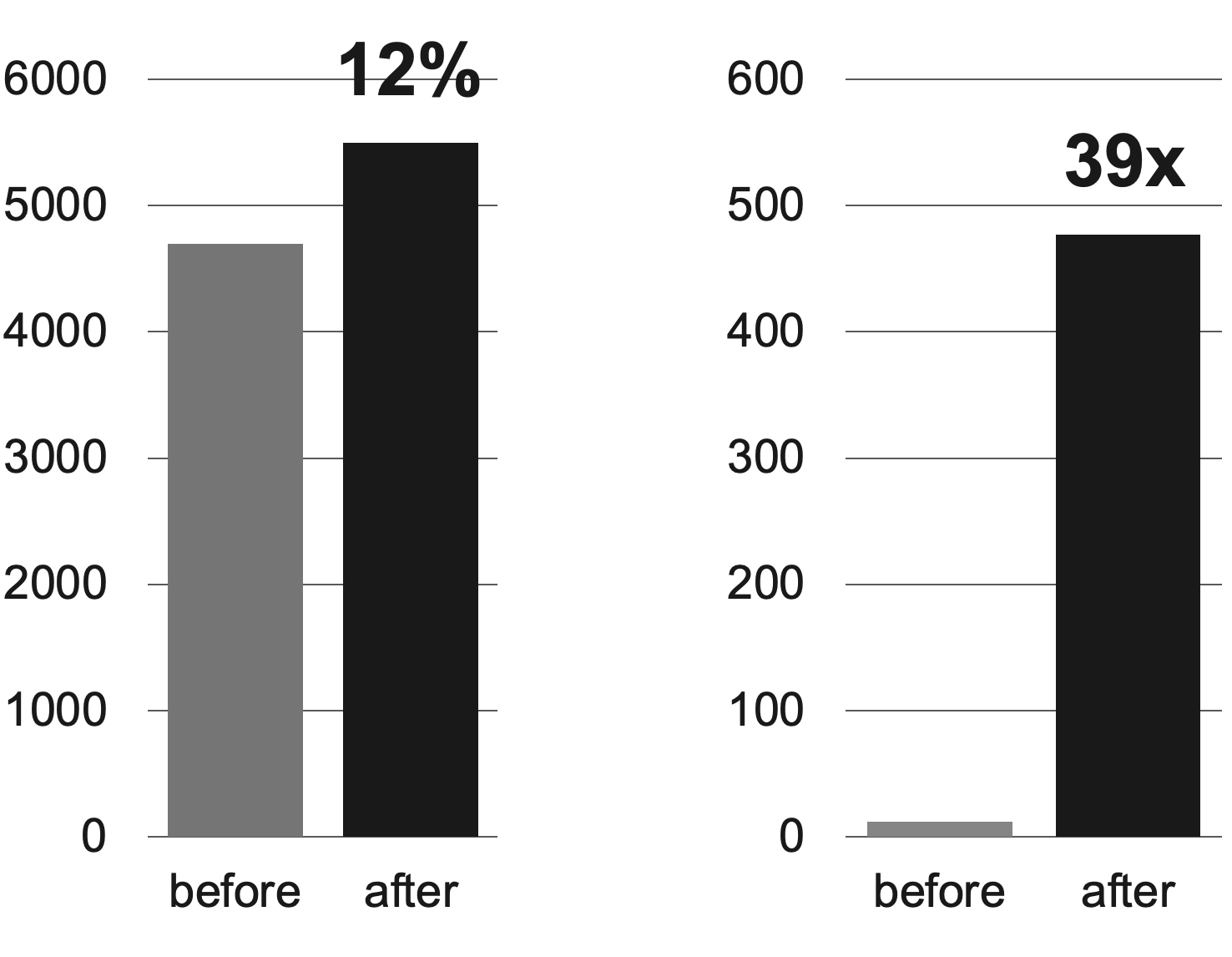
Milvus 기반 실시간 추천 시스템을 도입한 결과 서비스의 즉시성이 향상된 것을 확인할 수 있었습니다. 서비스의 즉시성과 관련된 두 가지 지표와 함께 구체적으로 말씀드리겠습니다.
먼저 아래 왼쪽 그래프는 '7일 이내 생성돼 추천에 노출된 포스트 수'를 표시한 것입니다. 기존 대비 12% 향상됐는데요. 이를 통해 추천 후보군이 기존과 비교해 보다 최신의 포스트로 제공됐다는 것을 알 수 있었습니다.
다음으로 아래 오른쪽 그래프는 '당일 생성돼 추천에 노출된 포스트 수'를 나타낸 것입니다. 기존에는 일 단위 배치로 추천 후보군을 업데이트했기 때문에 '당일에 생성돼 당일 추천에 노출된 포스트 수'가 상당히 적었는데요. Milvus와 함께 실시간 추천 시스템을 적용하면서 수치가 39배 이상 상승했습니다.
마치며
이번 글에서는 기존 추천 시스템을 실시간 추천 시스템으로 개선하기 위해 벡터 DB인 Milvus 클러스터 버전을 도입한 과정과 결과를 공유드렸습니다. 그 과정에서 복잡한 시스템의 성능과 안정성을 확인하고 필요 시 보완하기 위해 성능 테스트와 카오스 테스트를 진행했는데요. 테스트에서 얻은 인사이트로 성능을 극대화할 수 있는 조치와 장애 예방 조치를 취할 수 있었고, 이를 통해 추천 시스템의 즉시성을 크게 높임과 동시에 성능과 안정성을 모두 확보하며 2년 이상 성공적으로 운영해 나갈 수 있었습니다.
이 글이 저희와 같이 추천 시스템을 실시간으로 개선하고자 고민하고 계신 분들에게 도움이 되기를 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


