こんにちは。LINE VOOMサービスのレコメンドシステムを開発しているMLエンジニアのChang Hyun Lee、Jin Woo Baekです。私たちは、LINE VOOMのリアルタイムレコメンドシステムのための大規模なベクトルデータベース(以下、ベクトルDB)を導入するプロジェクトを行いました。この記事では、その導入過程について詳しく紹介したいと思います。
LINE VOOMとは
まず、私たちが開発しているサービス、LINE VOOMを紹介します。LINE VOOMは、LINEアプリ内で提供している動画コンテンツを中心としたソーシャルネットワークサービスです。現在、日本と台湾、タイでサービスを展開しています。
LINE VOOMでは、誰でもコンテンツクリエイターになってコンテンツをアップロードできます。ユーザーはさまざまなコンテンツを閲覧、視聴できます。For youタブでは、ユーザーが興味を持ちそうな動画を連続して視聴可能で、Followingタブでは、フォローしたクリエイターのコンテンツをまとめて見ることが可能です。
この記事では、主にFor youタブで提供されるレコメンドプロセスについて説明します。For youタブは、ユーザーにパーソナライズされたコンテンツの推薦結果を提供するタブです。ユーザーのコンテンツに関するフィードバック、例えば、以前に視聴またはクリックしたこと、「いいね!」を押したことなどのフィードバックを基に、ユーザーが好みそうなコンテンツを抽出して提供します。
従来のレコメンドシステムの課題
以前使用していたレコメンドシステムの全体的な動作フローは、以下のとおりです。
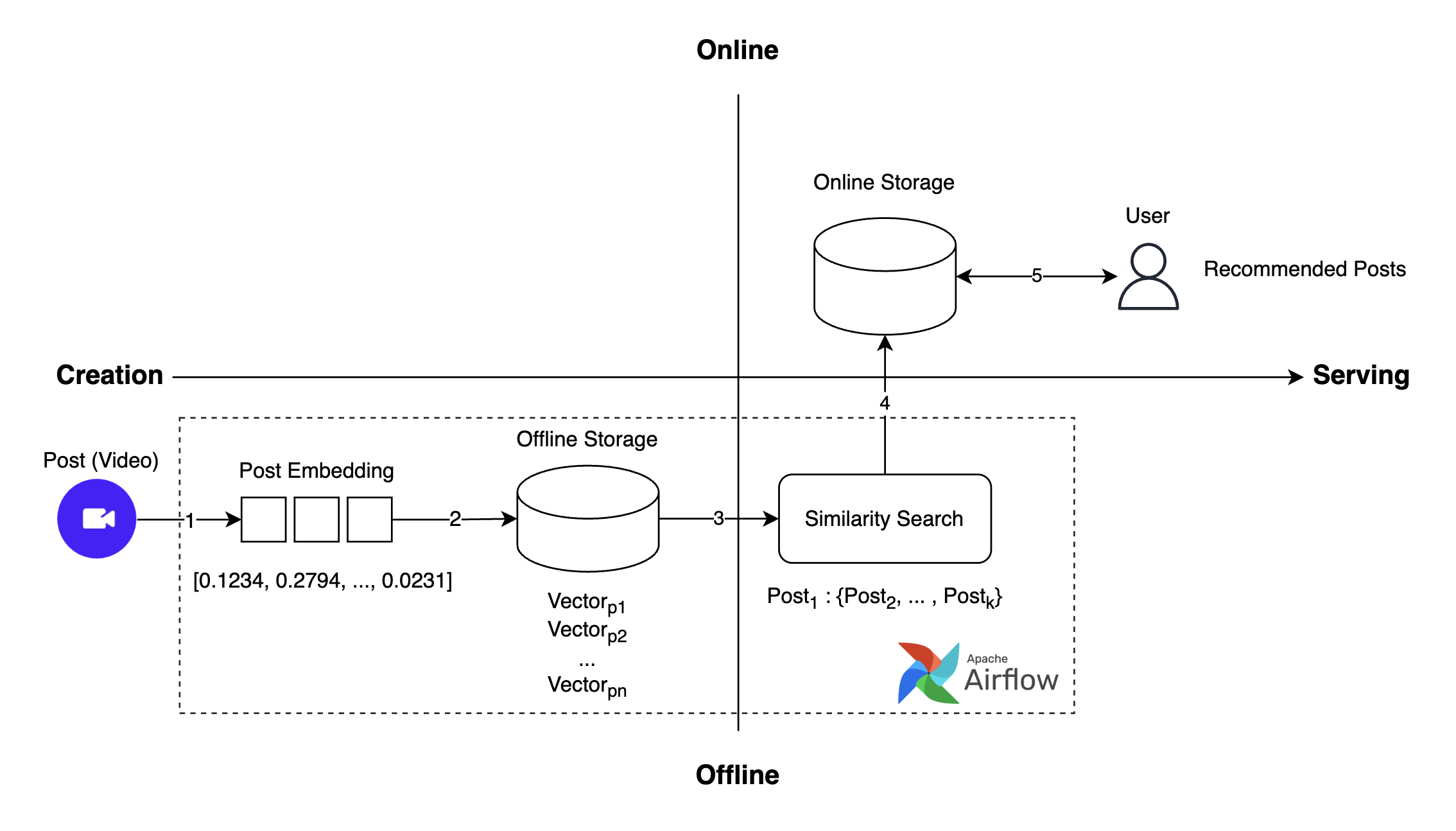
- 投稿の作成:ユーザーが動画の投稿を作成します。
- 投稿埋め込みの生成:作成された投稿に対する埋め込みを生成します。
- 投稿埋め込みの保存:生成された埋め込みをベクトルデータベースに保存します。
- 類似投稿の検索(ANN(approximate nearest neighbor)):類似性検索を通じて類似投稿を検索します。
- レコメンド投稿のリクエストおよび取得:ユーザーにレコメンドされた投稿を提供します。
このプロセスを通じて、ユーザーは自分の興味に合ったさまざまなコンテンツを容易に閲覧できるようになります。しかし、一つ課題がありました。
課題��:即時性の欠如
従来のレコメンドシステムは、投稿の埋め込みを生成・保存した後、推薦候補群を抽出し、インメモリデータベースに保存する一連のプロセスを、すべて日単位のオフラインバッチ処理で行っていました。そのため、推薦候補群の更新に最大で1日かかるという限界があり、この限界はユーザー体験に以下の問題を引き起こしていました。
- クリエイターAが新年を迎え、「Happy New Year」という内容の動画を投稿しても、この動画がすぐにユーザーにレコメンドされません。
- クリエイターBがサッカーワールドカップの試合中にゴールを決めたシーンを収めた動画を投稿しましたが、この動画もすぐにユーザーにレコメンドされません。
このように、新しいコンテンツをすぐに閲覧できないという「即時性の欠如」の問題は、ユーザー体験を低下させました。この課題を解決するために、システムを改善する必要があり、リアルタイムレコメンドシステムを実装するプロジェクトを開始しました。
このプロジェクトの目標は、ユーザーが投稿したコンテンツを即座に推薦候補群に反映し、より新鮮な投稿をユーザーにレコメンドすることでした。そのために、従来のシステムの多くの部分を変更しました。日単位で候補群プール(ポストプール)を生成していた方式をモデルベースのリアルタイム候補群生成方式に変更し、ベクトル検索の方式をオフライン演算からオンライン演算に切り替えました。
この記事では、その中でもベクトル検索構造の変更に焦点を当てて説明します。
新しいリアルタイムレコメンドシステムの構造と、ベクトルDBが必要だった理由
新しく開発したリアルタイムレコメンドシステムの全体的な動作フローは、以下のとおりです。
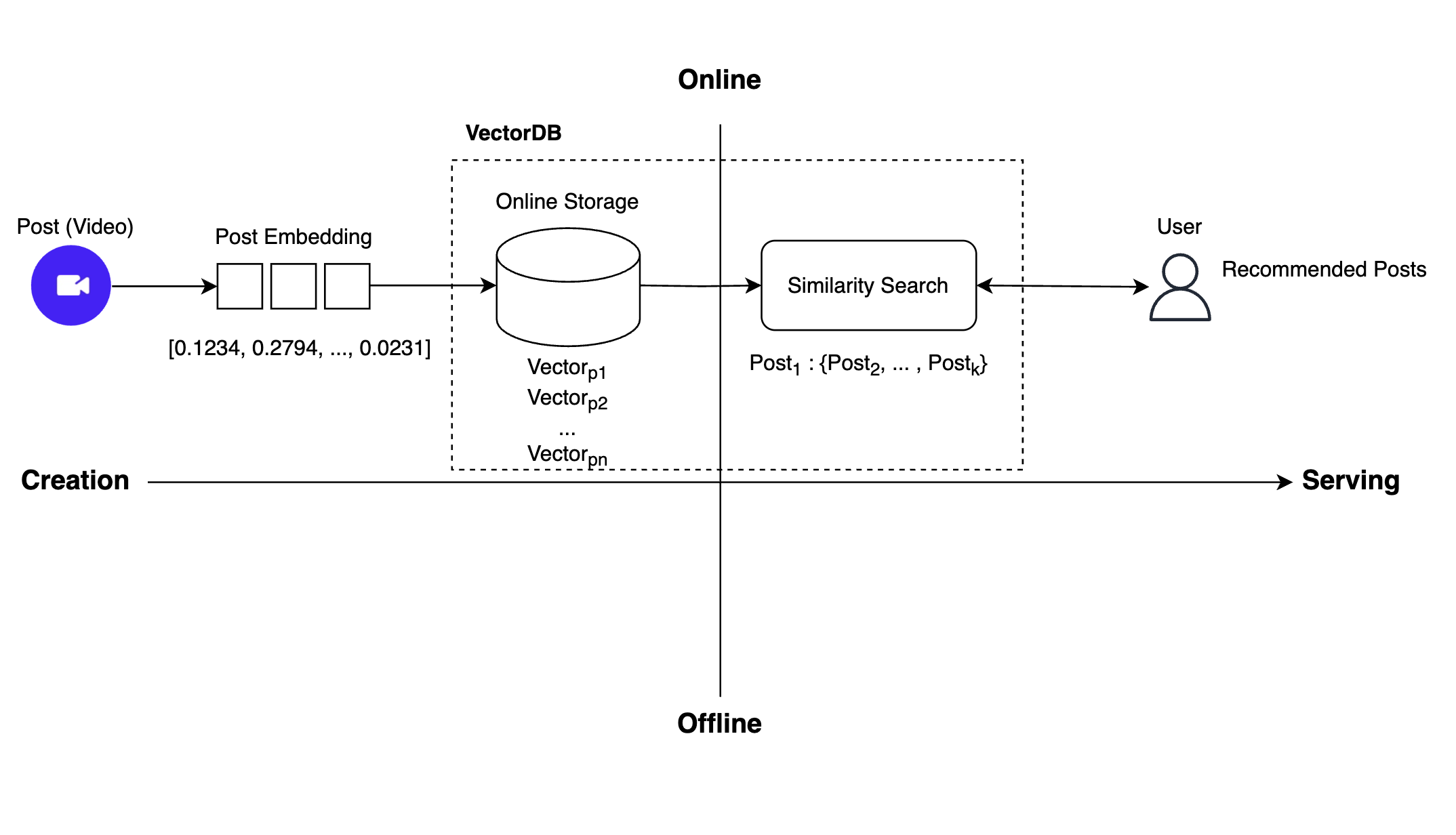
上記のようにリアルタイムレコメンドを実装するため、以前のレコメンドシステムではオフラインで行っていた作業をオンラインに切り替える必要がありました。そのためには、2つの作業が必要でした。まず、投稿の埋め込みを保存する場所をオフラインストレージからオンラインストレージに切り替える必要がありました。次に、以前は類似性検索を通じてレコメンド可能なすべての投稿をオフラインで事前に見つけ、その結果をオンラインストレージに保存していましたが、それを中間保存のプロセスなしで即座に類似性検索を行う必要がありました。
私たちは、オンラインストレージとリアルタイムの類似性検索という、この2つの機能を実装するには、ベクトルDBを導入する必要があると判断し、複数のベクトルDBプラットフォームを検討し始めました。
ここまでのプロセスをまとめます。
- 従来のレコメンドシステムは、オフラインストレージとバッチ処理を通じて類似性検索を行っていたため、即時性が低いという課題がありました。
- 従来のレコメンドシステムの主な課題は、投稿が作成されてから推薦候補群に含まれるまでに、最大で1日かかるという点で�した。そのため、ユーザーにすぐに投稿を提供できていませんでした。
- 従来のシステムの課題を解決するために、オフライン作業をすべてオンラインに切り替えることにしました。そのためには、投稿埋め込みをオンラインストレージに保存し、中間プロセスなしでリアルタイムに類似性検索を行うシステムに改善する必要がありました。
- オンラインストレージと類似性検索をリアルタイムに処理するには、ベクトルDBを導入する必要がありました。
ベクトルDBの選定基準とMilvusを選択した理由
最近、ベクトルDBのエコシステムが発展し、さまざまな選択肢が生まれました。私たちは、その中から適切なプラットフォームを選定するために、以下のような基準を設定しました。
- ベクトル専用DBであること
- オープンソースであること
- オンプレミス環境に直接構築できること
- リアルタイムレコメンドのため、高負荷でも安定して動作し、レイテンシが低いこと
このような基準で調査した結果、適切なフレームワークはMilvusとQdrantでした。これから、その2つのフレームワークを比較してみます。
| 基準 | Milvus | Qdrant |
|---|---|---|
| パフォーマンス(QPS(query per second)、レイテンシ)(参考) | 2406 req/s, 1ms | 326 req/s, 4ms |
| ストレージ�/コンピューティングの分離 | O | X |
| ストリームとバッチのサポート | O | X |
| GitHubスター数(コミュニティ規模と活性度の間接的測定) | 35.9K stars | 24.6K stars |
| サポートするインメモリインデックスタイプの数 | 10 (参考) | 1 (HNSW のみサポート) |
Milvusは、パフォーマンス面でQdrantより優れており、ストレージとコンピューティングが分離されているため安定性もさらに高かったです。また、多様なインデックスアルゴリズムをサポートしているため、さまざまな実験を通じて私たちのシナリオに合わせてパフォーマンスを最適化できる可能性が高いと判断しました。ストリームとバッチ作業が分離されており、オンラインINSERTとオフラインバルクINSERT機能をサポートしているため、今後、埋め込みのアップデートに対応する機能も実装できると考えました。さらに、活発なコミュニティのおかげで問題発生時に情報を簡単に入手できるという利点もありました。
以上の理由から、私たちはMilvusを採用することにしました。
Milvusについて
Milvusは、数十億以上の大規模なベクトルデータに対する類似性検索を前提に設計されているため、以下のように複雑�な構造になっています。大規模なベクトルデータに対する類似性検索が目的であったため、クラスタ版では公開された使用事例が少なく、そのため、パフォーマンスや安定性がどうなるかは不確実な要素として残っていました。
私たちはこの不確実性を解消し、Milvusの導入を成功させるために、パフォーマンスと安定性を徹底的に検証する必要がありました。そこで、カオステストとパフォーマンステストを実施しました。
まず、カオステストでは、システムがどれだけ安定して動作するかを確認し、もしシステムが不安定に動作する状況があれば、それをどのような方法で安定化できるかに重点を置いてテストを行いました。
次に、パフォーマンステストでは、ANNベンチマークで確認できるベクトル検索のパフォーマンスが私たちの環境でも再現できるか、限られたリソースでスループットを最大化し、応答時間を最小化できるかなどに重点を置いてテストを行いました。
では、各テスト方法と結果を一つずつ見ていきましょう。
Milvusの検証1:カオステスト
カオステストは、システムの安定性と回復力を評価するために、意図的にシステムに混乱を引き起こすテスト方法です。私たちは、クエリ、検索(search)、挿入、削除、インデックス作成、ロード、リリースなどのAPIセットを用意し、特定のAPIリクエストを継続的または繰り返しMilvusクラスタに送信しながら、Podの強制終了(pod kill)、スケールイン/アウト/アップなどの状況を注入し、モニタリングを行いました。
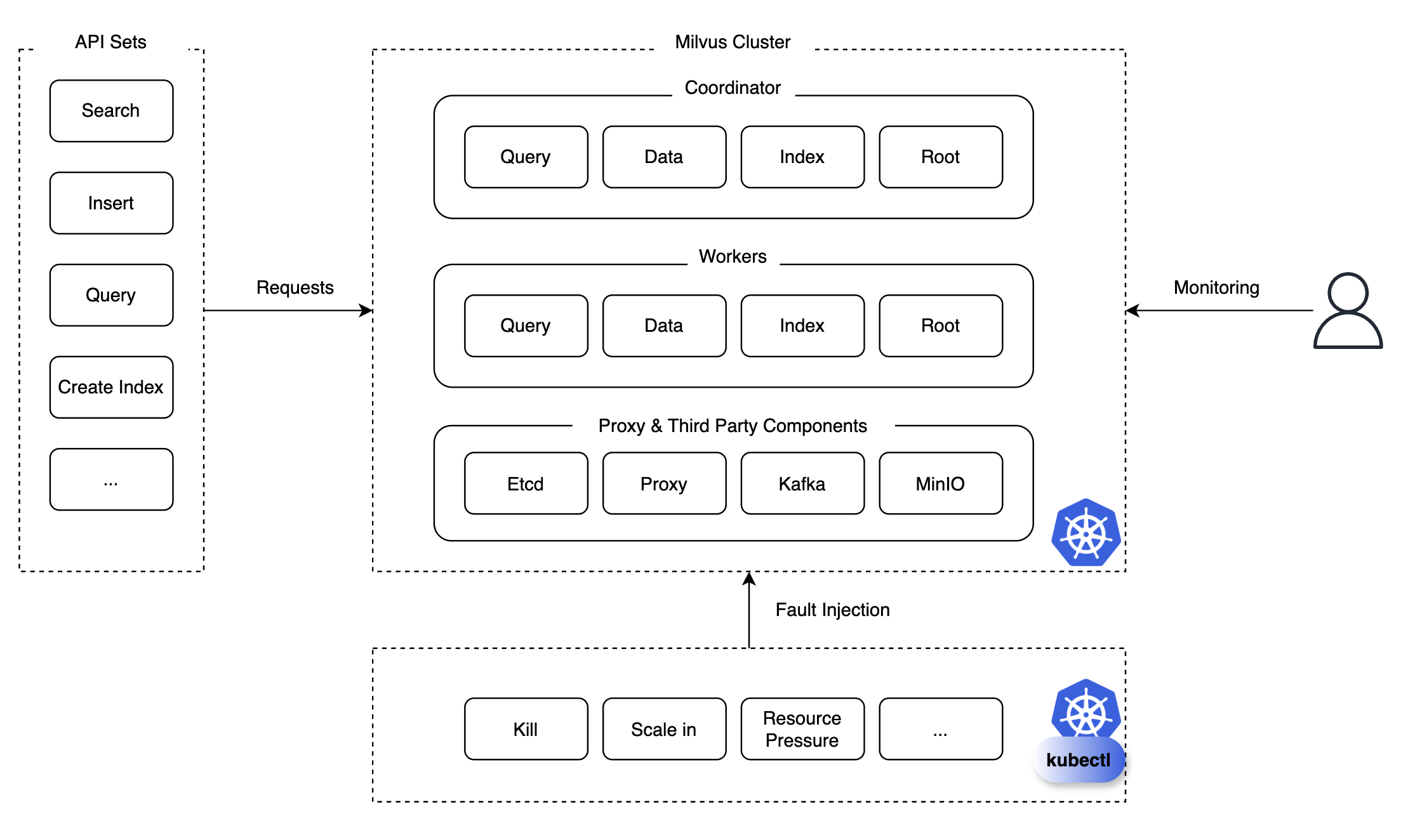
モニタリング時には、対象コンポーネントが復旧可能かどうか、復旧にかかる時間、復旧される前に発生する問題などを綿密に観察・検討しました。このようにモニタリングしたおかげで、今後障害につながる可能性のある問題を発見し、予防措置を講じることができました。では、テスト結果とともに、どのような問題があり、それを解決するためにどのような措置を講じたのかについて説明します。
テスト結果
まず、以下はテスト結果から主なものをまとめた表です。
| API | カオスシナリオ | 結果 |
|---|---|---|
| Search | Scale in Querynode | 正常動作 |
| Search | Scale out Querynode | 正常動作 |
| Search | Kill Querynode | 正常動作 |
| Search ※ | Kill Querycoord ※ | コレクションがリリースされ、類似性検索が利用できなくなった ※ |
| Search ※ | Kill Etcd(過半数以上) ※ | クラスタがダウンし、コレクションのメタデータが失われたため検索不可能になった ※ |
| ... | ... | ... |
| Insert | Kill Datanode | 正常動作 |
| Insert | Kill Querynode | 正常動作 |
| Insert | Kill Proxy | 正常動作 |
| Create Index ※ | Kill Indexcoord ※ | インデックスの作成に失敗し、復旧に102秒かかった ※ |
赤字(表内の※箇所)で表示したシナリオは、実際のサービスで障害につながる可能性がある深刻な問題だったため、これを予防するために安定性を高める措置を講じる必要がありました。Milvusのシステム安定性を高めるために、私たちが適用したいくつかの解決策を紹介します。
コレクションの高可用性構成
まず、「Kill Querycoord」シナリオのようにコレクション(collection)が突然リリースされ、類似性検索が利用できなくなることを防ぐため、以下のようにコレクションのコピーを一つ用意して、埋め込みを二重に記録する方法(dualwriting)でコレクション単位の高可用性(high availability、HA)構成を実装しました。コレクションからベクトルを検索するクライアント側では、エイリアス(alias)を使用して、一つのコレクションが利用できなくなった場合でもすぐに別のコレクションを参照するように構成しました。
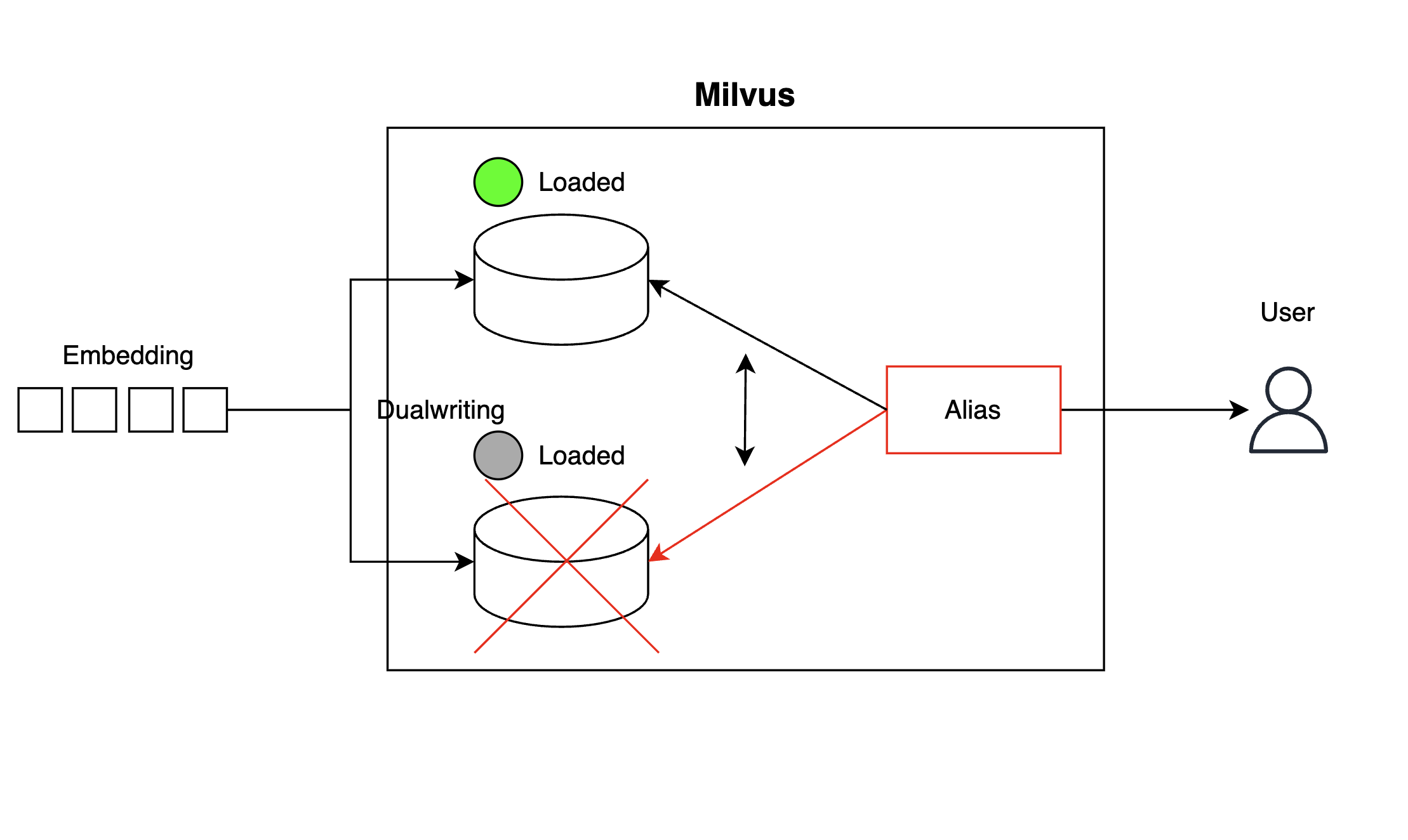
上記のように構成すると、コレクション一つが使用不能になった場合、以下のようにランタイムでエイリアスを切り替え(alias switching)、コピーコレクションを参照するようにして、障害時間を最小限に抑えられます。
client.create_alias(collection_name="collection_1", alias="Alias")
client.alter_alias(collection_name="collection_2", alias="Alias")コーディネーターの高可用性構成
Milvusのコーディネーター(coordinator)の場合、ワーカーノードを制御する役割を担っているため、単一のPodで構成されています。そのため、コーディネーターPodが停止すると、すぐに障害につながる可能性があります。私たちは、このコーディネーターを以下のようにアクティブ-スタンバイ(active-standby)モードに設定し、高可用性構成を実装することで、単一障害点になることを防ぎました。
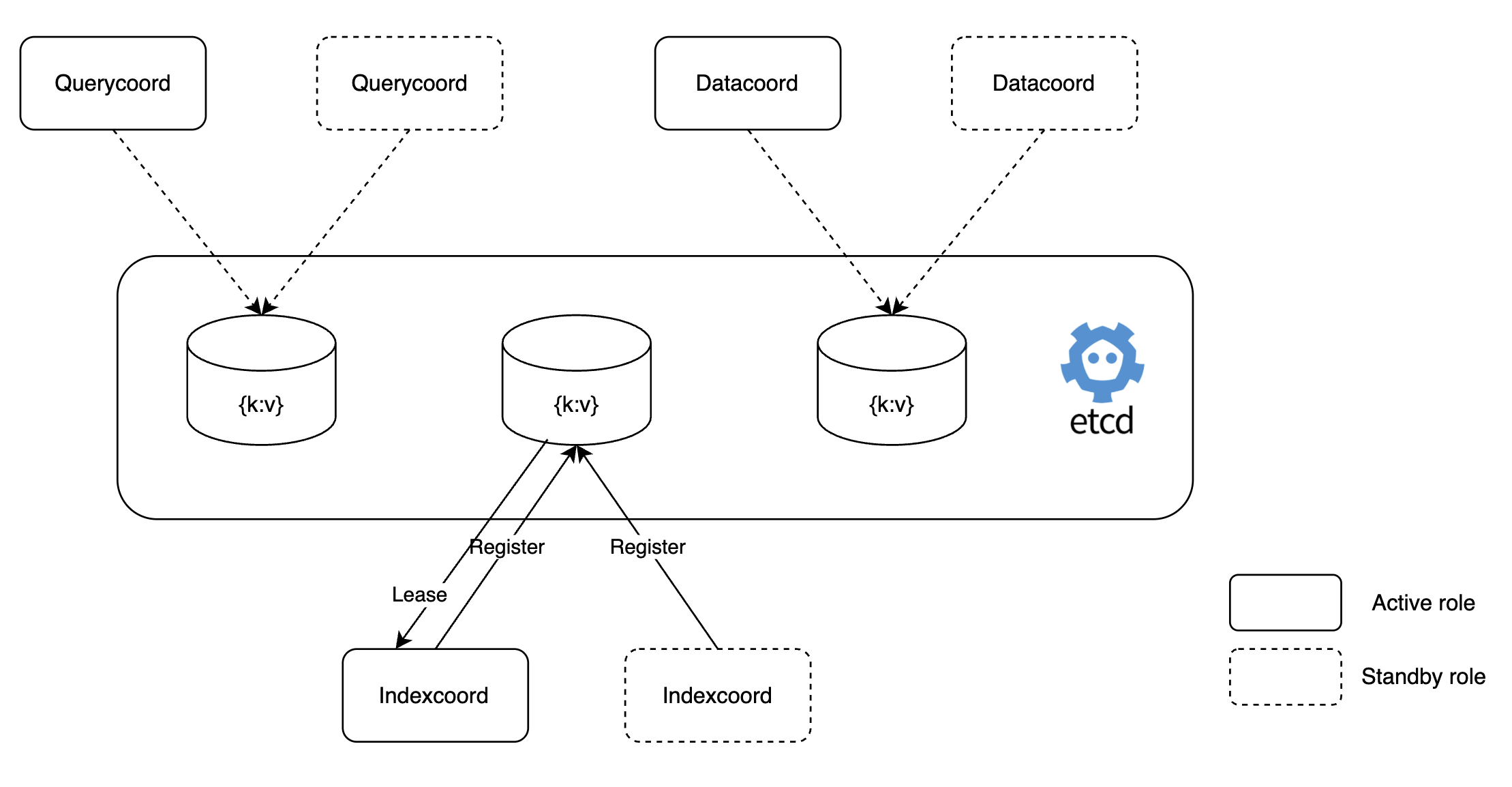
これにより、「Kill Indexcoord」シナリオのようにインデックスコーディネーター(Indexcoord)が停止した場合、すぐにスタンバイ役のインデックスコーディネーターが動作し、インデックス作成に失敗する状況を防げるようになりました。以下は、このように設定した例とスタンバイモードで動作する「dataCoordinator」のログです。
# value.yaml
dataCoordinator:
enabled: true
# You can set the number of replicas greater than 1 only if you also need to set activeStandby.enabled to true.
replicas: 2 # Otherwise, remove this configuration item.
resources: {}
nodeSelector: {}
affinity: {}
tolerations: []
extraEnv: []
heaptrack:
enabled: false
profiling:
enabled: false # Enable live profiling
activeStandby:
enabled: true # Set this to true to have RootCoordinators work in active-standby mode.[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]
[INFO] [sessionutil/session_util.go:933] ["serverName: datacoord is in STANDBY ..."]バックアップシステムの構成
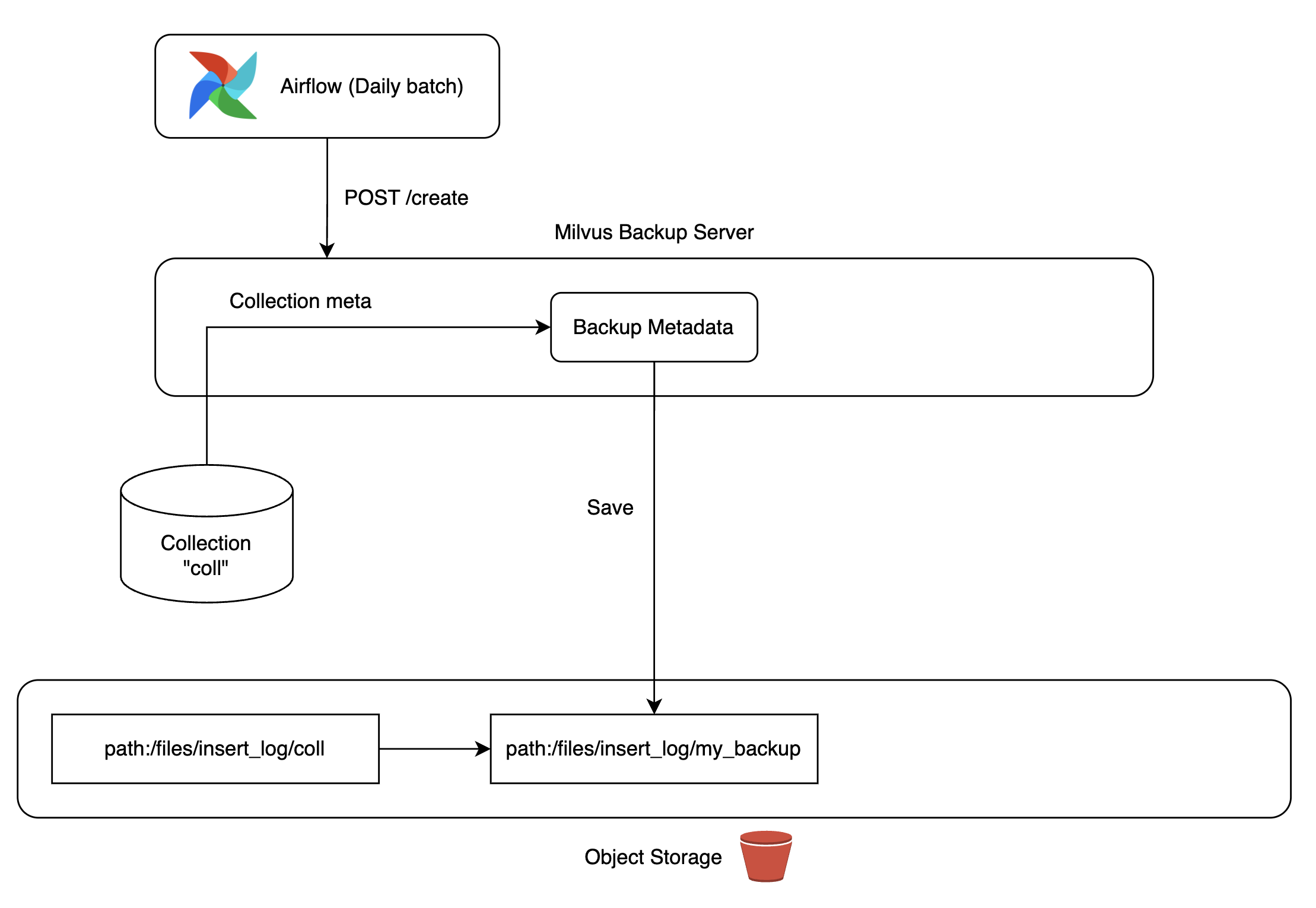
「Kill Etcd(過半数以上)」シナリオのように過半数以上のetcdが停止すると、Milvusクラスタ全体がダウンし、コレクションメタデータの損失などの問題が発生する可能性があり、これは実際のサービスにおいて致命的な障害状況につながる可能性があり�ます。
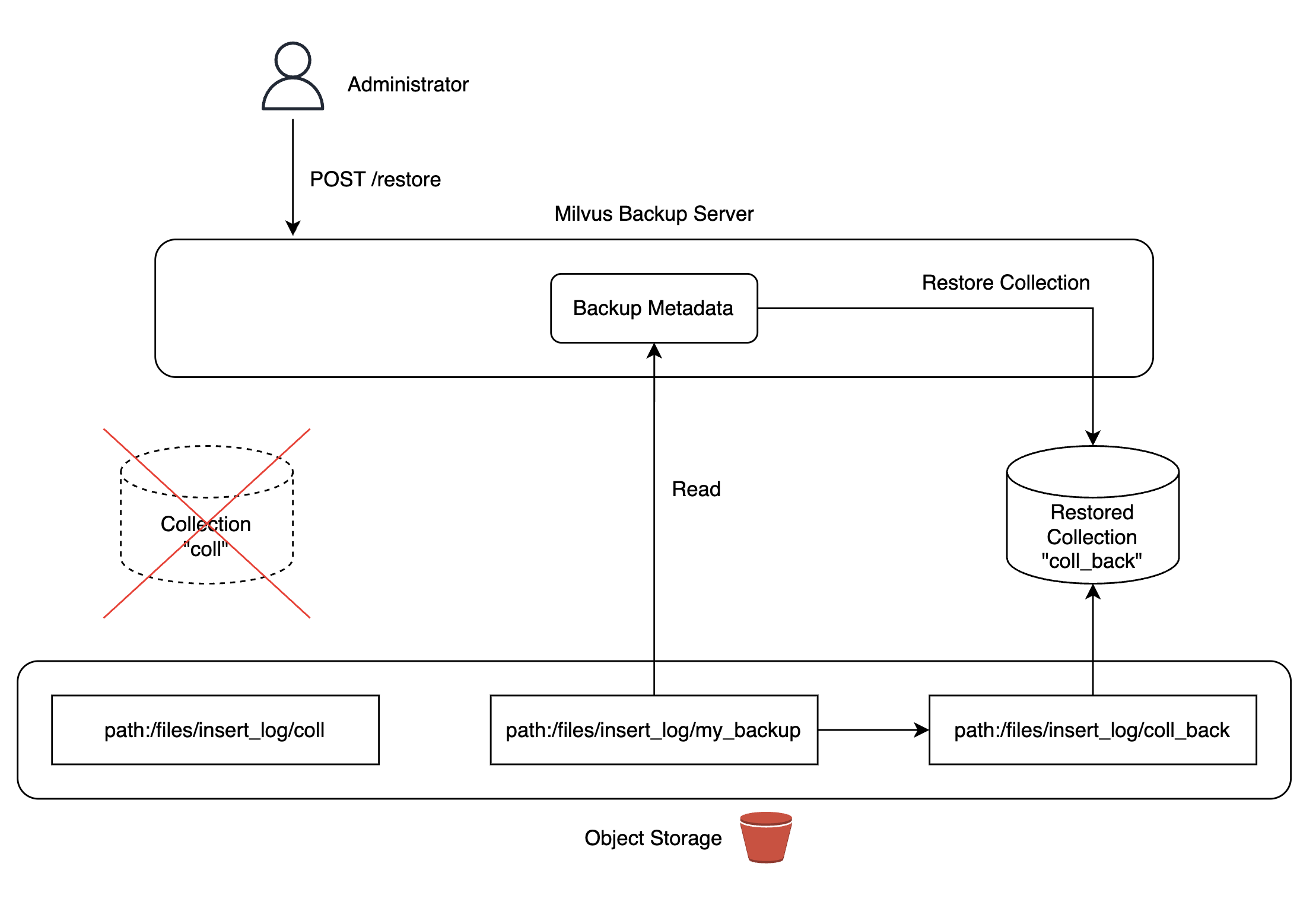
この問題を解決するために、Milvusが提供するバックアップツールを活用してバックアップサーバーを構築しました。私たちが管理するKubernetesクラスタにMinIOをデプロイし、MinIOストレージにデータのレプリカを作成して、必要に応じていつでもコレクションに復元できるように構成しました。
バックアップデータは、Airflow DAGを使って日次で自動更新されるように構成し、コレクションを復元する状況が発生しても最新のデータを使用できるようにしました。ちなみに、Milvusバックアップサーバーを構成する過程で発生したバグを修正し、Milvusプロジェクトに貢献もしました(参考)。
 |
|
 |
|
Milvusのデバッグツール、Birdwatcherの導入
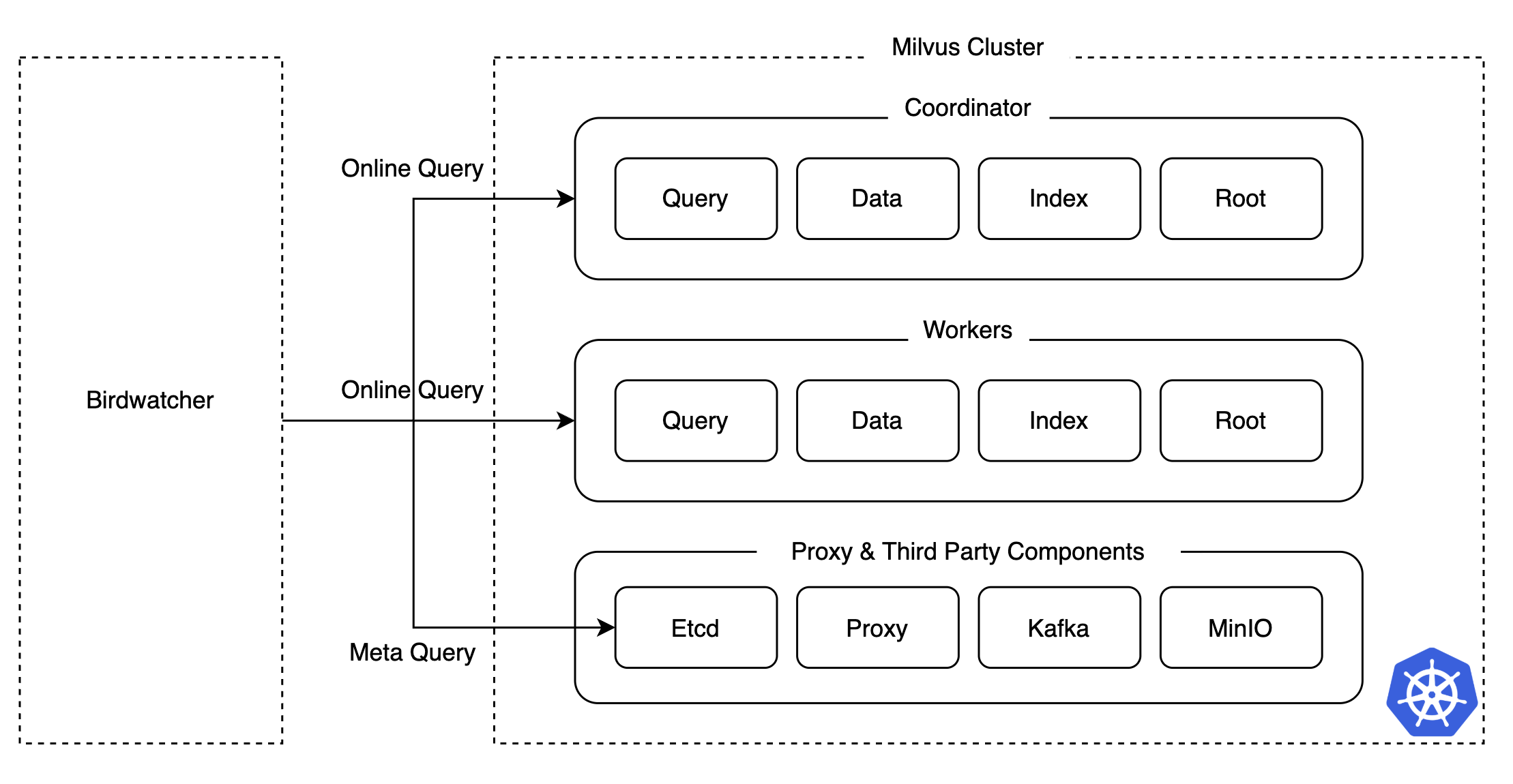
カオステストを実施する中で、Milvusクラスタが正常に動作しない状況が発生したとき、どのコンポーネントに異常が発生したのか正確に把握するのは簡単ではありませんでした。特に、分散システムでは、複数のコンポーネントとPodのログを都度確認する必要があるため、障害箇所の把握と復旧に多くの時間がかかってしまいます。
このような問題を解決し、障害対応時間を短縮するために、私たちはMilvusが提供するデバッグツールであるBirdwatcherを活用しました。Birdwatcherとetcdを直接接続することで、各コンポーネントの状態やメタデータを簡単に取得できるようにし、これによって運用難易度を下げられました。
カオステスト結果のまとめ
カオステストは、Milvusクラスタで発生しうるさまざまな障害状況を事前に�シミュレーションし、潜在的な問題を事前に特定して解決策を準備する上で重要な役割を果たしました。特に、コーディネーターとコレクションの高可用性構成、バックアップシステムの構築、Birdwatcherの導入などの措置は、その後の数年間にわたる本番環境の運用で発生した障害状況において、サービス停止時間を最小限に抑え、迅速な復旧を可能にしました。
Milvus検証2:パフォーマンステスト
安定性を確保しても、推薦候補群を抽出するためのベクトル検索に多くの時間がかかったり、スループットが低くて多くのリソースが必要になったりする場合、サービスを提供するのは困難になります。これを検証するためには、パフォーマンスを綿密にテストする必要がありました。ベクトル検索アルゴリズムが活発に研究されており、ベンチマークの結果(参考)が存在するとしても、私たちの環境でもそのまま再現されるかどうかは一度検証する必要があると考えました。したがって、私たちはベンチマークのパフォーマンスを参考にしつつ、ハードウェアやノード構成など、私たちの環境でどのようなアルゴリズムのパフォーマンスが良いか、そのパフォーマンスはどの程度かなどをパフォーマンステストを通じて確認することにしました。
テストシナリオ
以下は、ベクトルパフォーマンスに影響を与えるチューニング要素の一部です。以下のチューニング要素を参考にして、パフォーマンステストのために10種類以上のシナリオを作成し、レイテンシ(latency)とスループット(QPS)、再現率(recall)などのパフォーマンスを測定しました。この記事では、その中でも特に、以下の太字で表記したインデックスによるパフォーマンステストと拡張によるパフォーマンステストに焦点を当てて共有します。
- インデックス
- インデックスタイプ(ANNアルゴリズム)
- インデックスパラメータ
- 拡張性と可用性
- スケールアップ
- スケールアウト
- インメモリレプリケーション
- 検索
- 検索パラメータ
- バッチサイズ
- データセット
- 次元(dimension)
- 行数
インデックスタイプ(ANNアルゴリズム)の比較
ベクトル検索のパフォーマンスは、使用するインデックスタイプ(ANNアルゴリズム)に大きく左右されます。インデックスタイプによって精度、レイテンシ、インテックス作成時間が異なるため、サービスシナリオに適したインデックスタイプを選択することが重要です。また、埋め込みデータの分布によって検索パフォーマンスが変わる可能性があるため、特定のインデックスタイプがサービスに適しているかを検証する必要があります。
リアルタイムレコメンドシステムでは、レイテンシが何よりも重要な要素です。そのため、公式ドキュメントでレイテンシが最も低いとされているHNSWアルゴリズムを主なターゲットとし、実際に私たちの環境でも公式ドキュメントと同じ結果が得られるか確認するために、IVF_FLATを比較対象と�してテストを実施しました(参考)。
| カテゴリー | インデックス名 | 精度 | レイテンシ | スループット | インデックス時間 | コスト |
|---|---|---|---|---|---|---|
| グラフベース | HNSW | High | Low | High | Slow | High |
| グラフベース | DiskANN | High | High | Mid | Very Slow | Low |
| グラフベース | ScaNN | Mid | Mid | High | Mid | Mid |
| クラスタベース | IVF_FLAT | Mid | Mid | Low | Fast | Mid |
| クラスタベース + 量子化ベース | IVF + Quantization | Low | Mid | Mid | Mid | Low |
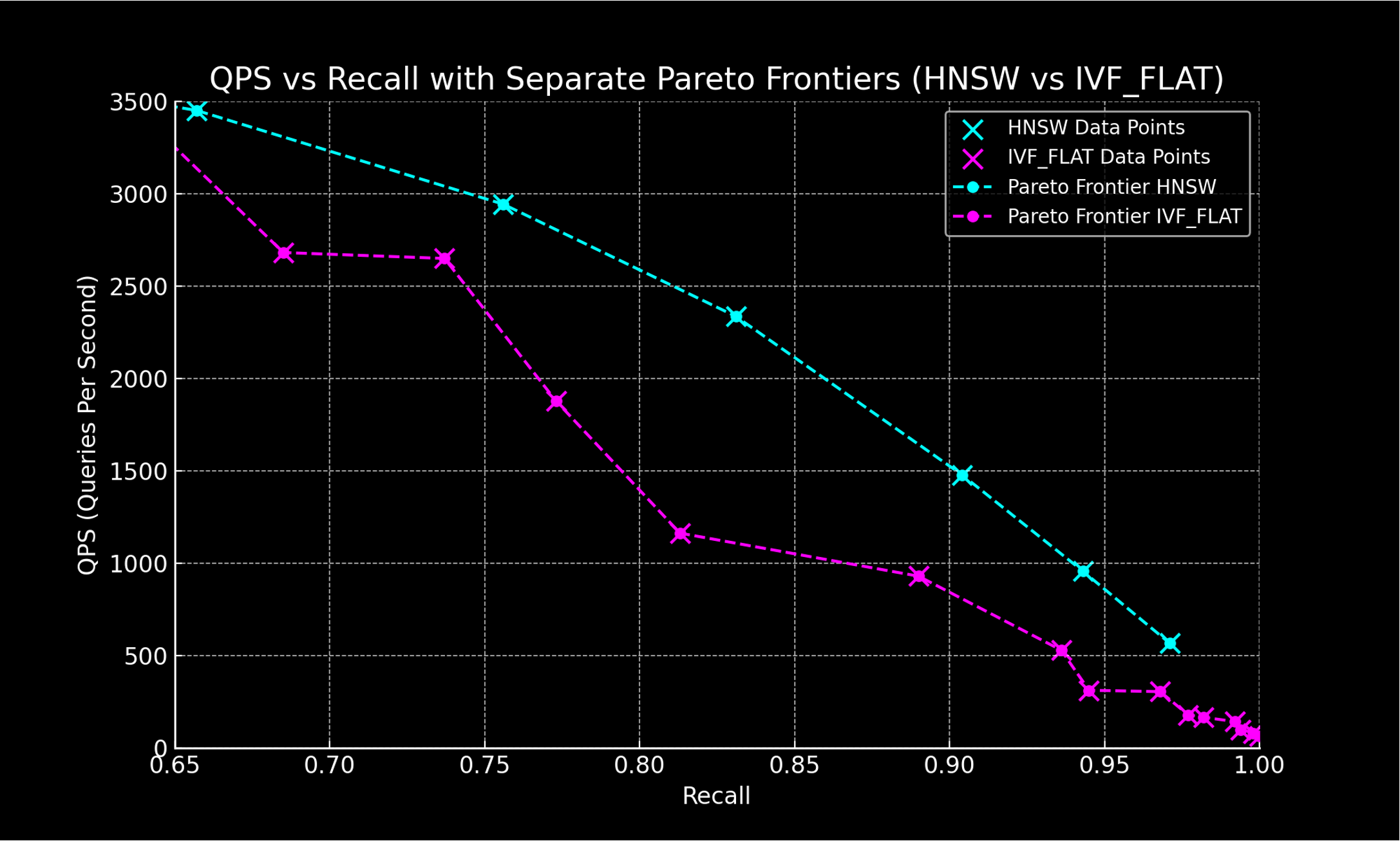
ANNアルゴリズムのパフォーマンス評価指標としては、主にQPSとRecallを使用しますが、この2つには互いにトレードオフの関係があります。そのため、インデックスや検索パラメータを調整しながらパフォーマンスを測定し、最も優れたパフォーマンスを示す点を結びつけることで、以下のようにインデックスタイプごとのパフォーマンスを比較できます。
インデックスタイプの比較結果
インデックスタイプを比較した結果、HNSWインデックスはIVF_FLATと比較して、高いスループットと精度を示し、このパフォーマンス�が私たちの環境でも一貫して再現されることが確認されました。
スケールアップとスケールアウトテスト
サービスのトラフィックが増加した際にリソースを追加し、スケールアップまたはスケールアウトで対応できるかを確認することは重要です。クエリを処理する各Podに割り当てるCPUコア数を決定するためにスケールアップテストを実施し、レプリケーション(複製)数をどのように構成するかを決定するためにスケールアウトテストを実施しました。
スケールアップテストの結果
以下の表は、クエリを処理するPodに割り当てるCPUコア数を増やしながら、レイテンシとスループット、失敗数を測定したものです。テストの結果、CPUコア数の増加に伴い、レイテンシとスループットがある程度、線形に向上することが確認されました。これにより、各Podが複数のCPUを効果的に活用できることが分かりました。特にCPUが8の場合、スループットが大幅に改善されました。
| CPU | リクエスト数 | Avg(ms) | Min(ms) | Max(ms) | Median(ms) | TP99(ms) | req/s | failures/s |
|---|---|---|---|---|---|---|---|---|
| 2 | 59,961 | 39 | 3 | 195 | 37 | 97 | 991.57 | 0.00 |
| 4 | 105,183 | 22 | 3 | 118 | 13 | 80 | 1,739.38 | 0.00 |
| 8 | 328,307 | 7 | 2 | 82 | 4 | 49 | 5,427.66 | 0.00 |
| 16 | 511,255 | 4 | 2 | 50 | 3 | 21 | 8,433.64 | 0.00 |
| 32 | 644,904 | 3 | 2 | 67 | 3 | 7 | 10,618.27 | 0.00 |
- Avg (ms):平均レイテンシ(ms)
- Min (ms):最小レイテンシ(ms)
- Median (ms):レイテンシの中央値(ms)
- TP99 (ms):99パーセンタイルレイテンシ(ms)
- req/s:1秒あたりの処理��リクエスト数
- failures/s:1秒あたりの失敗リクエスト数
スケールアウトテストの結果
スケールアウトテストでは、Podのレプリケーション数が増加するにつれて、レイテンシの短縮とスループットの向上がほぼ比例して改善されることが確認されました。
| レプリケーション数 | リクエスト数 | Avg (ms) | Min (ms) | Max (ms) | Median (ms) | TP99 (ms) | req/s | failures/s |
|---|---|---|---|---|---|---|---|---|
| 1 | 106016 | 22 | 2 | 103 | 12 | 81 | 1752.74 | 0.00 |
| 2 | 199456 | 11 | 2 | 262 | 7 | 64 | 3297.60 | 0.00 |
| 4 | 361358 | 6 | 2 | 96 | 4 | 36 | 5958.22 | 0.00 |
| 8 | 578149 | 3 | 2 | 207 | 3 | 10 | 9555.55 | 0.00 |
インメモリレプリケーションテスト
Milvusでスループットを増加させるもう一つの方法として、インメモリレプリケーション数を増やすことがあります。インメモリレプリケーションを使用すると、データのレプリカがメモリに保存されます。そのため、メモリ使用量は増加しますが、特定のノードがビジー状態にある場合やリクエストを処理できない場合に、他のノードがリクエストを処理できるようになり、可用性と拡張性を確保できます。
インメモリレプリケーションテストの結果
テストの結果、インメモリレプリケーション数に比例してスループットは増加し、平均レイテンシは減少することが確認できました。TP99レイテンシも大幅に減少し、インメモリレプリケーション数が多ければ多いほど、類似性検索の安定性が向上することが確認できました。
| インメモリレプリケーション数 | リクエスト数 | Avg (ms) | Min (ms) | Max (ms) | Median (ms) | TP99 (ms) | req/s | failures/s |
|---|---|---|---|---|---|---|---|---|
| 1 | 199,806 | 11.81 | 2.64 | 92.69 | 10.51 | 44.80 | 3,303.02 | 0.00 |
| 2 | 356,680 | 6.54 | 2.42 | 92.33 | 5.44 | 31.95 | 5,888.30 | 0.00 |
| 4 | 483,543 | 4.77 | 2.37 | 63.77 | 4.48 | 11.52 | 7,995.04 | 0.00 |
| 8 | 582,954 | 3.93 | 2.16 | 160.38 | 3.60 | 10.03 | 9,636.69 | 0.00 |
パフォーマンステスト結果のまとめ
パフォーマンステストを通じて、インデックスタイプ、CPUリソースの割り当て、Podのレプリケーション数、インメモリレプリケーションなど、さまざまな設定によってベクトル検索のスループットとレイテンシがどのように変化するかを確認できました。特に、HNSWインデックスは、低レイテンシと高スループットを示し、私たちの環境でも一貫して再現されました。また、クエリを処理するPodのCPUコア数とレプリケーション数を増やすほど、リソースの投入に比例してスループットが増加し、レイテンシが減少しました。さらに、インメモリレプリケーションを適用したときも、TP99レイテンシの減少とスループットの増加が確認され、メモリリソースを活用した方式もサービスの安定性とパフォーマンス向上に効果的であることが検証されました。
Milvus適用の結果
Milvusベースのリアルタイムレコメンドシステムを導入した結果、サービスの即時性が向上したことを確認できました。サービスの即時性に関連する2つの指標とともに具体的に説明します。
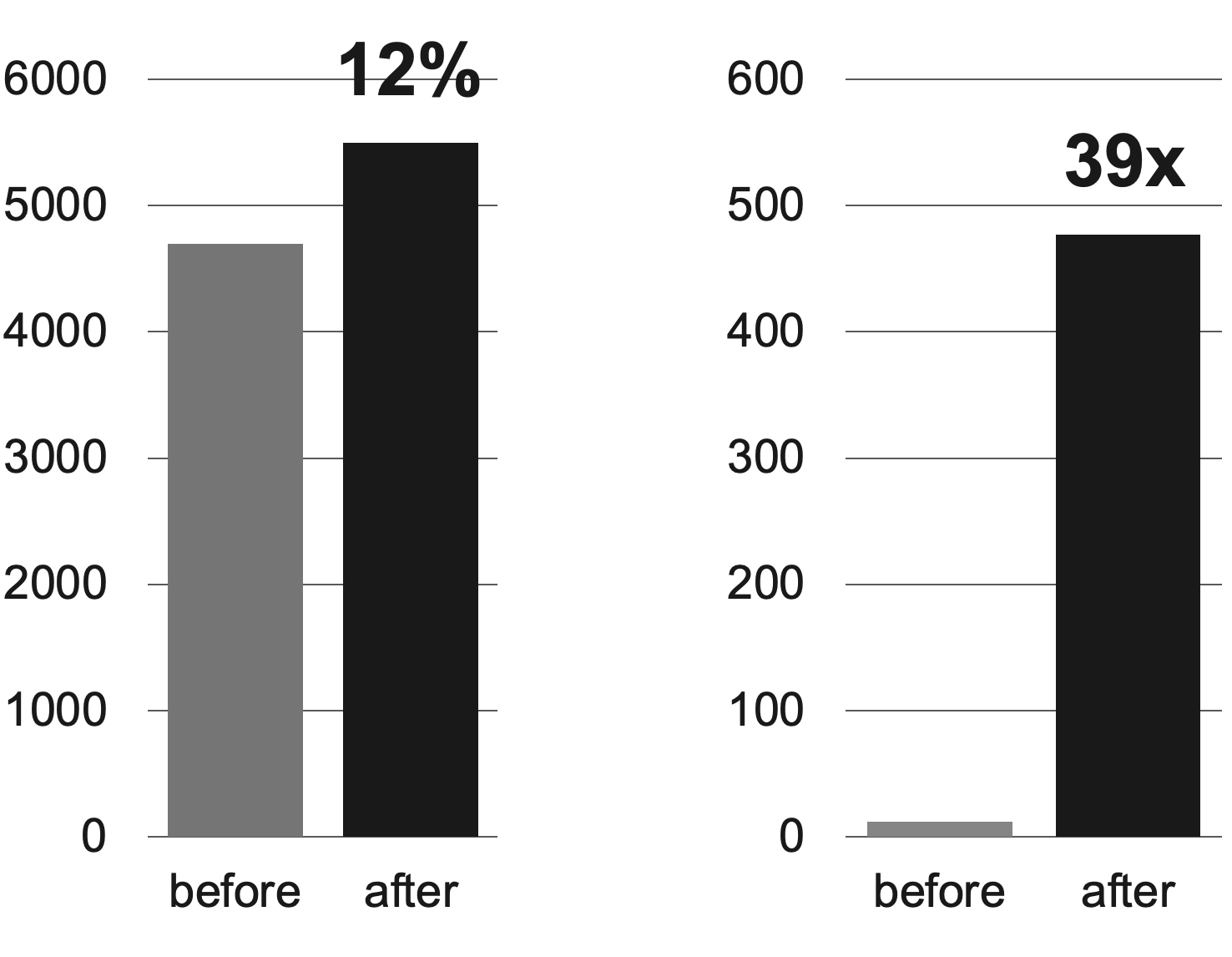
まず、下の左側のグラフは「7日以内に作成され、レコメンドに表示された投稿数」を示したものです。これは、従来に対して12%向上しました。これにより、推薦候補群が従来に比べてより最新の投稿で提供されたことが分かりました。
次に、下の右側のグラフは「作成された当日に、レコメンドに表示された投稿数」を示しています。従来は日単位のバッチで推薦候補群を更新していたため、「作成された当日に、レコメンドに表示された投稿数」がかなり少なかったのですが、Milvusとともにリアルタイムレコメンドシステムを適用したことで、この数値が39倍以上上昇しました。
おわりに
この記事では、従来のレコメンドシステムをリアルタイムレコメンドシステムに改善するために、ベクトルDBであるMilvusのクラスタバージョンを導入した過程と結果を紹介しました。その過程で、複雑なシステムのパフォーマンスと安定性を確認し、必要に応じて補完するためにパフォーマンステストとカオステストを行いました。テストで得られたインサイトにより、パフォーマンスを最大化できる措置と障害予防措置を講じることができました。また、これにより、レコメンドシステムの即時性を大幅に高めると同時にパフォーマンスと安定性の両方を確保し、2年以上問題なく運用を続けることができました。
この記事が、私たちのようにレコメンドシステムをリアルタイムに改善したいと考えている方のお役に立てば幸いです。長文をお読みいただき、ありがとうございました。


