はじめに
こんにちは、データサイエンティストの栗本です。
LINEヤフーでは、最新の知見を業務に取り入れるべく、論文の社内共有会や社外研究会への参加などを積極的に行っています。その一環として、業務に関連するトピックを扱う海外カン��ファレンスに社員が会社負担で参加できる制度があります。
その制度を利用して、2025年9月22日〜26日にプラハ(チェコ)で開催された国際会議RecSys 2025に聴講参加してきましたので、その内容について報告します。
(※ 写真は自身で撮影したものか、論文から引用したものです)
目次
- RecSysについて
- 概要
- 3つの特徴
- 6つのメイントピック
- Best Paper (Candidates)
- Short Paper
- Full Paper
- 気になった論文
- Towards LLM-Based Usability Analysis for Recommender User Interfaces(栗本)
- How Do Users Perceive Recommender Systems' Objectives?(栗本)
- Not All Impressions Are Created Equal: Psychology-Informed Retention Optimization for Short-Form Video Recommendation(栗本)
- The Future is Sparse: Embedding Compression for Scalable Retrieval in Recommender Systems(木村)
- Generalized User Representations for Large-Scale Recommendations and Downstream Tasks (近藤)
- Off-Policy Evaluation of Candidate Generators in Two-Stage Recommender Systems (堀)
- 現地参加のメリット
- おわりに
- おまけ
RecSysについて
概要
ACM Conference on Recommender Systems (RecSys) は名前の通り推薦システムに特化した国際会議です。今年で19回目の開催となります。テーマ特化の会議ということもあってかBigTechもバンバン新作を投稿してくるため、この領域に関心のある研究者・実務者にとっては動向を見逃せない学会です。
3つの特徴
類似学会と比べて特徴的な点として、以下が挙げられます。
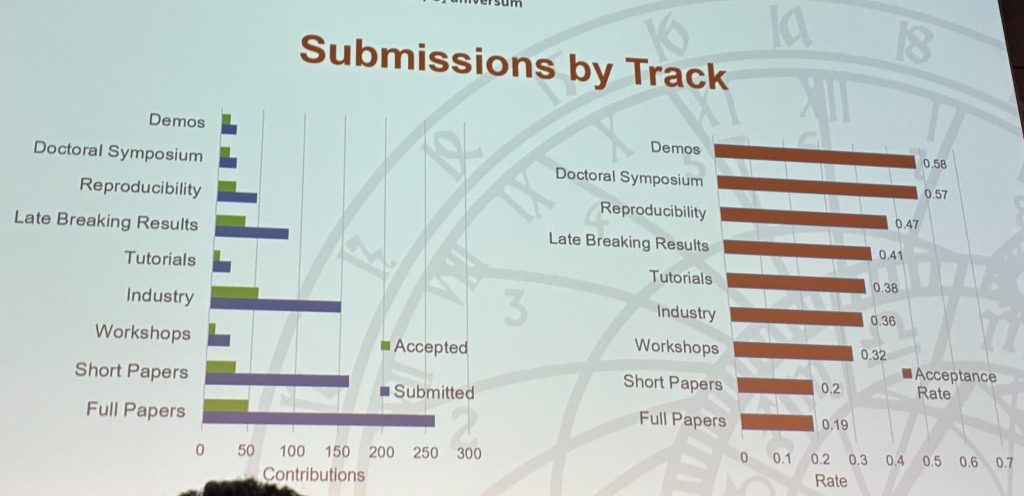
| 特徴 | 説明 |
|---|---|
| 企業からの投稿が多い | 企業での実運用・研究が盛んな技術領域のため、企業からの発表が非常に多いです。実際、RecSys 2025ではIndustryが投稿種別で最多となっています。また、Industry Trackでは学術的な新規性よりも、新しい課題を発見して解決を試みたり新しい技術を活用して実際にプロダクトを改善したり、といった実務的な有用性が高く評価される印象です。採択率もFull, Shortの20%前後と比べると、Industryでは36%程度と比較的高め。 |
| シングルトラック | 大規模な学会だと本会議の発表が並列で行われることが多いのですが、比較的小規模ということもあってか本会議の発表は1か所で行われます。これによって、「セレンディピティ」的な出会いが生まれやすい、質疑が盛り上がりやすいといった利点が生まれています。 |
| 日本人参加者が多い | RecSys ChallengeというKaggleのような学会コンペがあり、優勝したリクルートさんや入賞したNTTドコモさんのように強いチームが複数存在することから、日本人参加者の割合が投稿論文の割合に比して非常に大きいです。 |
6�つのメイントピック
学会運営から、RecSys 2025のメイントピックとして以下6つが紹介されました。

| トピック | 所感 |
|---|---|
| LLMs in Recommendation Systems | これは本当に多かったです。一昔前の「深層学習を使って〇〇してみました」の大流行がそのままLLMでもという印象。 |
| Cold-Start and Sparse Data Challenges | コールドスタート問題(利用ログが全くない新規等のユーザにどう推薦するか)自体は昔からありますが、従来の推薦システムが苦手としLLMが得意としている問題というのもあって、増えていたのだと思います。 |
| Multi-Objective Optimization | 多様性やセレンディピティの考慮など、単なる精度改善以上のものにしていこうという「Beyond accuracy」の潮流がここ数年あり、引き続き盛り上がっているという印象です。また、複数のステークホルダーの観点を考慮しようという研究も見られました。 |
| User Feedback and Negative Signals | これはあまり印象に残らなかったです。他トピックが問題設定なのに比べて、これだけ使う情報の種類という切り方だったために、単に気づかなかっただけかもしれません。 |
| Retrieval and Ranking at Scale | BigTechの発表でこの手の発表が多かったです。弊社と比べてもさらに一段二段上のスケールゆえ、こういった課題に直面し解決に取り組むのも一足先なのだろうという印象です。 |
| Advanced Embedding Techniques | 同上で、やはり非常に多く��のユーザにプロダクトを提供する上での困り事や工夫の話が多く見られました。Embeddingは推薦のベースになることが多いので、推薦領域の中では基礎的な研究開発という趣を感じました。(semantic IDの話題など) |
Best Paper (Candidates)
Short Paper
Short PaperのBest Paper Candidatesには以下の3論文が選ばれていました。

- Beyond Top-1: Addressing Inconsistencies in Evaluating Counterfactual Explanations for Recommender Systems
- Biases in LLM-Generated Musical Taste Profiles for Recommendation
- Emotion Vector-Based Fine-Tuning of Large Language Models for Age-Aware Teenage Book Recommendations
そしてBest Paperに選ばれた論文はBeyond Top-1: Addressing Inconsistencies in Evaluating Counterfactual Explanations for Recommender Systemsです。

Counterfactual Explanation(反実仮想説明)は、入力を変えたとき推薦がどう変わるかを説明する手法・研究ドメインです。しかし評価手続きが標準化されておらず、推薦モデルの性能に評価が左右される不一致が先行研究で指摘されていました。具体的には多くの研究がTop-1の変化だけを基準にしている一方で、推薦システムはTop-Nのランキングを出力とすることが多いため、正確に評価できていないのではないか?という点です。
そこで、さまざまなデータセット/モデル/反実仮想説明手法で検証を行い、Top-1評価ではモデル性能が少し変わっただけで反実仮想説明手法の相対順位が入れ替わることを示しました。また、Top-1ではなくTop-Nで評価すると頑健性が増すことを報告しています。
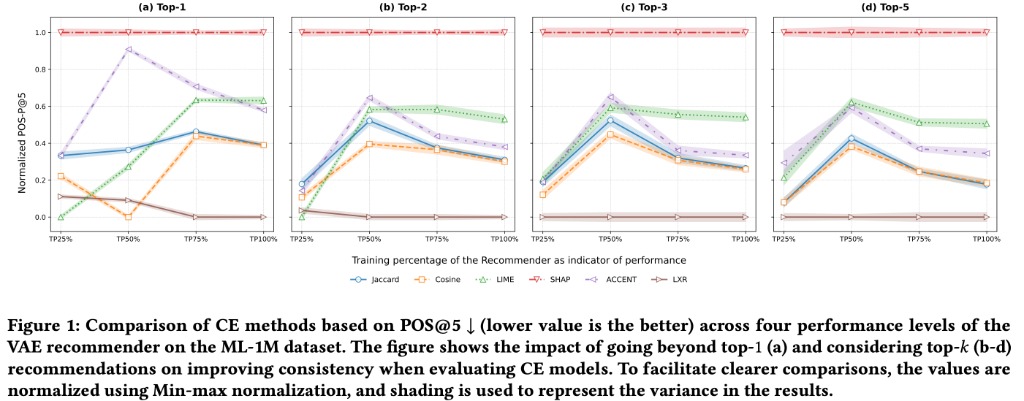
推薦システムのモデル改善の研究だとTop-1で評価することはまずないと思いますが、こういった論文が出てくるということはおそらく説明生成の領域では一般的だったようです。とすると、今後このドメインでの研究成果が信用されていく上で重要な転換点となる研究なのではと思いました。
Full Paper
Full PaperのBest Paper Candidatesには以下の5論文が選ばれていました。日本からWantedlyさんの論文も選ばれています(すごい!)。

- A Non-Parametric Choice Model That Learns How Users Choose Between Recommended Options
- IP2: Entity-Guided Interest Probing for Personalized News Recommendation
- Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
- Off-Policy Evaluation and Learning for Matching Markets
- You Don't Bring Me Flowers: Mitigating Unwanted Recommendations Through Conformal Risk Control
そしてBest Paperに選ばれた論文はYou Don't Bring Me Flowers: Mitigating Unwanted Recommendations Through Conformal Risk Controlです。

内容はLayerXさんの2025-10-07機械学習勉強会やWantedlyさんのRecSys'25参加レポートに詳しいため割愛します。
気になった論文
ここでは、参加したメンバーの気になった論文をご紹介します。
Towards LLM-Based Usability Analysis for Recommender User Interfaces (栗本)
IntRSという推薦 × インターフェースのワークショップでの論文です。
近年非常に発展しているマルチモーダルLLM(画像+テキスト)により、スクリーンショットからの半自動的なヒューリスティック評価が可能かを検証した論文です。Amazon、YouTube、Spotifyなど主要プラットフォームにおいて、新規ユーザ相当の状態でスクリーンショットを取得、Gemini 2.5 Flashを使用してレイアウトや情報量、推薦の透明性などを評価。基準ごとに達成/未達+理由+改善提案を生成しています。

実験では150評価(10サイト×2シナリオ×基準)を実行し、約216秒で完了。UI関係の評価は良好だったようですが、推薦関連の評価はまだまだで、現時点ではまずこういったものに投げた後に人手で確認・優先順位づけをするのが良さそうとのこと。
同じGemini 2.5でもProだったりChatGPT 5 Proだったり、最新のモデルだとまた結果も変わってきそうです。しかし、パッと見で判断できる改善ポイントはもうある程度自動化できそう、ということをますます感じさせる研究でした。
How Do Users Perceive Recommender Systems' Objectives? (Full Paper) (栗本)
昨今、精度改善はもちろんだけどそれ以外の観点も考慮しようねという"Beyondaccuracy"という潮流があり、多様性や新規性等も考慮した多目的推薦システムの研究開発が進んでいます。こういったシステムは、「アルゴリズムが用いる評価指標(例:多様性を数値化したもの)が、ユーザの主観的な認識(例:多様だと感じる感覚)を正しく反映している」という重要な前提に基づいているものの、この前提が本当に正しいかは十分に検証されていませんでした。
そこで、書籍と映画の2つのドメインでユーザ調査を実施し、推薦システムの各目的(関連性、多様性、新規性など)に対する「システムの指標」と「ユーザの認識」の間のミスマッチを定量的に評価しています。結果、「多様性」「新規性」「探索」といった精度以外の目的についてはユーザの解釈が大きく分かれ、特に30%以上のユーザが「多様性」や「新規性」を「探索」と同じ意味で捉えており、定義との間に概念的なズレがあることを示しました。
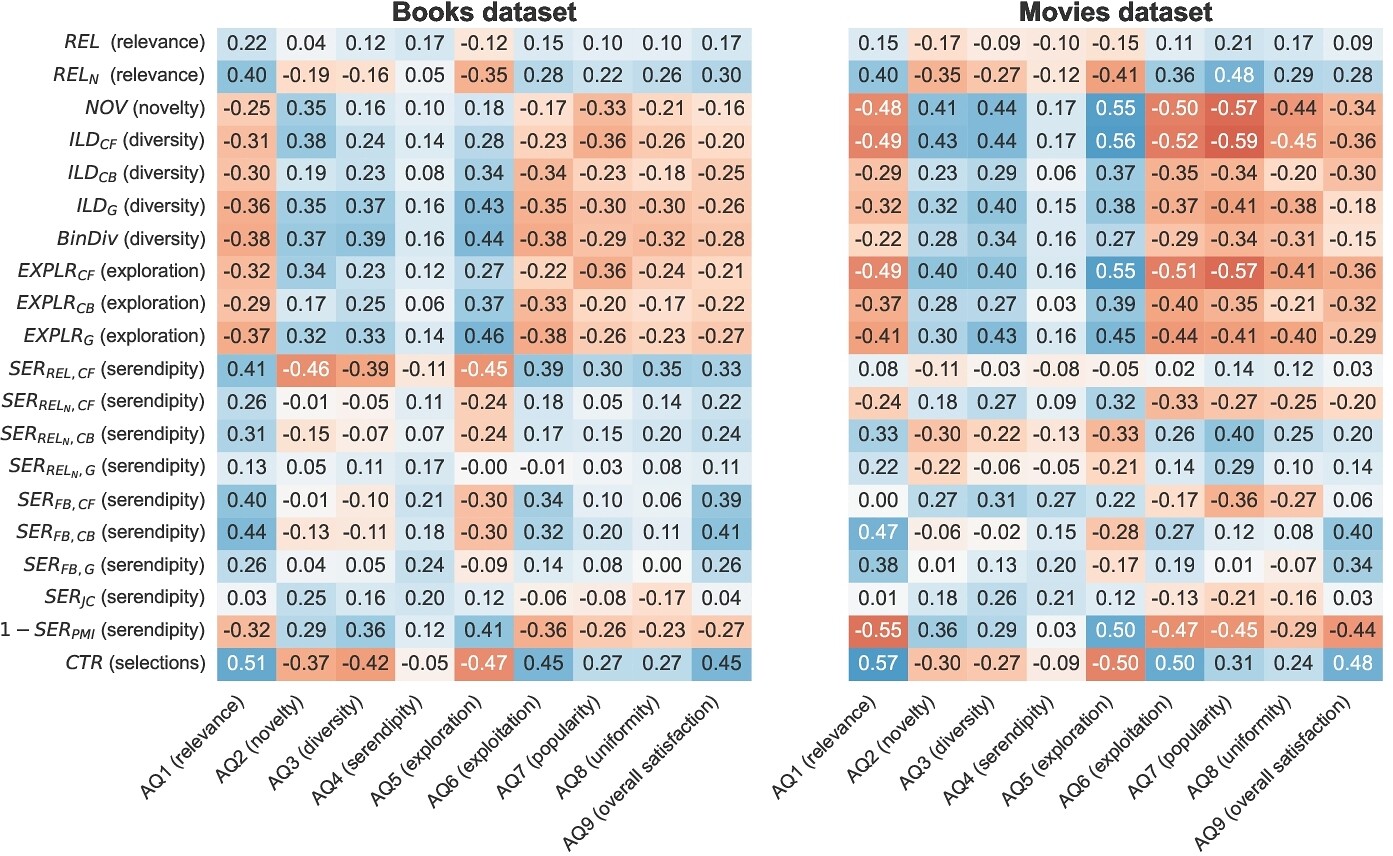
いくら指標を改善できてもそもそもユーザの感覚とはズレてるよね、となったらせっかく改善してもユーザは特に嬉しくないと思いますし、今行っている改善が上手くいけば、ユーザは実際嬉しいのかは推薦に限らず気をつけたい話だと感じました。今回私の一番好みの論文です。
Not All Impressions Are Created Equal: Psychology-Informed Retention Optimization for Short-Form Video Recommendation (Extended Abstract) (栗本)
Metaの方々の研究です。動画サービスにおける既存のリテンション学習の枠組みでは各動画のimpressionを等価に扱うものの、短尺の連続視聴では全部が同じ重みになるはずがありません。そこで、人々が過去の体験を主に最も強烈な瞬間(ピーク)と最終瞬間(エンド)に基づいて評価するという、ピーク・エンドの法則に基づくモデリング手法を提案しています。ここで、ピークとエンドの定義は以下の通りです。
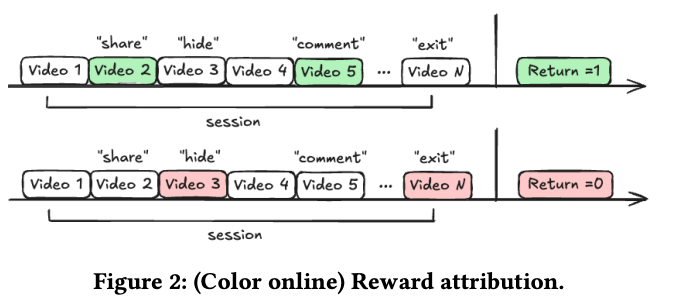
- ピーク
- 能動的反応が出た動画(正:フォロー/コメント/シェア、負:非表示/ディスライク/即離脱)
- エンド
- セッション最後に見た動画
これに基づいて、翌日の再来訪確率を予測するモデルの学習に際して、ラベル付けを以��下のように見直しています。
| ラベル | 従来 | 提案 |
|---|---|---|
| 正例 | 翌日にその動画への再来訪あり | セッション内で正のピーク |
| 負例 | 翌日にその動画への再来訪なし | セッション内で負のピーク |
大規模かつ長期間のA/Bテストを行い、Reels セッション数 +0.42%, DAU+0.03%, 全体セッション +0.05%と統計的に有意に改善したとのことでした。つまり、戻ってきたくなるような動画推薦を提供できるようになったようです。
人々の物事の感じ方はさまざまな側面から心理学で研究されているでしょうし、そういった他分野からの知見の応用例として興味深い提案だと思いました。
The Future is Sparse: Embedding Compression for Scalable Retrieval in Recommender Systems (Extended Abstract) (木村)
埋め込みテーブルのサイズ圧縮に関する研究です。推薦システムではユーザやアイテムの埋め込みの類似度をもとにretrievalする機会が多くありますが、大規模なカタログデータを扱う場合、埋め込みテーブルのサイズが膨れ上がりストレージやキャッシュ、メモリを圧迫し問題となります。実際、著者の属するRecombeeという企業では1億件のアイテムの埋め込みテーブルサイズが問題となっているようです。
そこで本論文では、ターゲットの密ベクトルの方向を維持しつつ非ゼロの要素数を大幅に削減したスパースベクトルを得る手法を提案しています。これにより、retrieval性能を極力損なうことなく埋め込みサイズを削減することが可能になります。手法は大��きくSparse Autoencoderでスパース表現を得る部分(左)と、得られたスパース表現から類似度を計算する部分(右)に分けられます。
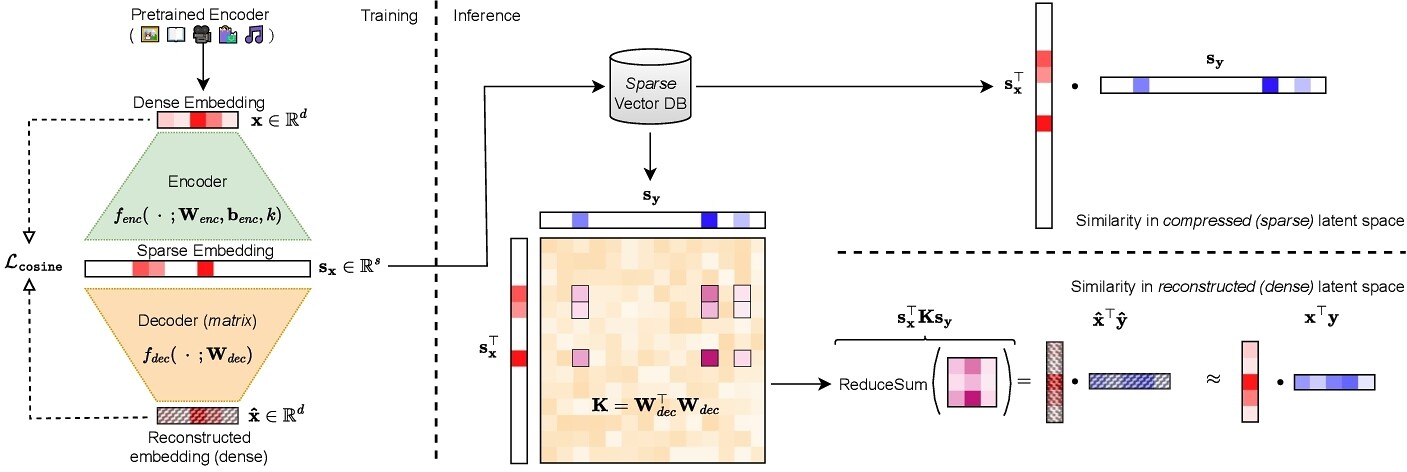
Sparse Autoencoder部分は以下の計算式で表されます。
はベクトルの要素を絶対値の大きい順に 個残し、それ以外の値を全て0にするという関数で、エンコーダ側はこれにより非線形関数になっています。一方デコーダ側は線形関数で、これにより後述のカーネルトリックが適用可能となっています。また、再構成誤差として通常のL2距離ではなくコサイン類似度を採用しているのも、提案法の特徴です。これによりノルムの制約を満たす必要がなくなり方向の再現に集中ができます。
上記によって得られたスパース表現から類似度を計算する方法として論文中では2つ提案されていました。
- スパースベクトル の内積を計算する
- カーネルトリックを利用し再構成ベクトル のコサイン類似度を計算する
計算量は1が 、2が で2の方がやや重いですが、再構成した密ベクトルのコサイン類似度と同等の計算になるので精度は上がることが期待できます。実験章では、ベクトル圧縮手法の先行研究である Matryoshka [Kusupati et al., 2022] と同等の圧縮率の条件下で比較した結果、Recall@100(オフライン評価)およびCTR(オンライン評価)でいずれも有意に高い性能を示したことが報告されていました。
自分が開発に携わっている商品推薦システムでも億単位の商品を扱っているため似たような問題があり、素性の付与を一部の商品に限定する、スパース表現を利用するといった対策を施しているのでこの辺りの課題は共感するものがありました。Sparse Autoencoderを用いた研究は自然言語処理分野ではスパースプローブ [Gao et al., 2024] のように特徴量の解釈性を高めるという文脈で扱われている印象だったため、推薦システムにおいても同様に得られたスパースベクトルの解釈が可能なのではと思い、今後の調査が気になります。
Generalized User Representations for Large-Scale Recommendations and Downstream Tasks (Extended Abstract) (近藤)
本研究は、Spotifyによる「汎用ユーザ表現」のためのフレームワークの提案となっています。モデルアーキテクチャとしては、大きく2段階で構成されており、まず1段階目ではオートエンコーダーでリッチなユーザシグナルをコンパクトなユーザ埋め込みに圧縮します。次に、下流のプロセス (retrieval, ranking, search, generation, etc.) がこのユーザ埋め込みに対して軽量のヘッドを適用し、��各タスクのユーザ特徴量として使用します。
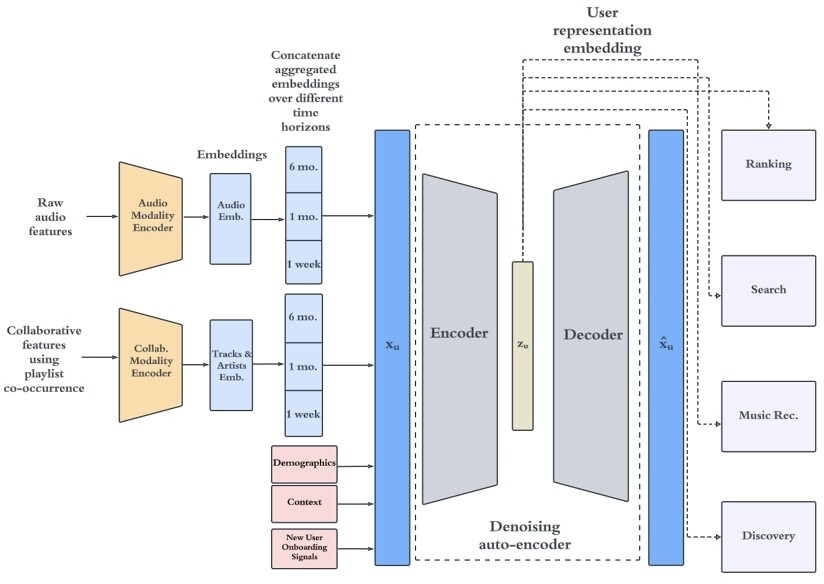
エンコーダの入力に関して、本アーキテクチャの特徴的な部分は、
- オーディオエンコーダ
- オーディオ特徴量から直接トラックの埋め込みを学習し、音響自体の類似性を捉える
- 協調エンコーダ
- ユーザのプレイリストの共起をもとにトラックやアーティストの埋め込みを学習し、行動の近接性を捉える
と異なる2つのモダリティを捉えるエンコーダをそれぞれ用意してトラックやアーティストの埋め込みを得たのち、これらの埋め込みを異なる時間スケール(1週間、1か月、6か月)で集約する操作を行うことでユーザの短期・中期・長期の嗜好を捉えようとする構成になっている点です。
また、モデルサービングにおいてはバッチ推論だけでなく Near-Real-Time (NRT) でも推論できるシステム構成にしており、ユーザイベントをトリガーに推論を実行し、数分以内に埋め込みを更新できるようにすることで、ユーザの興味や気分の短期的な変化を見逃さないようにしているようです。この NRT推論とバッチ推論を併用することで、アクティブユーザへの鮮度とカバレッジのバランスをとることを実現していているとのことでした。
下流タスクとの接続においては、モデル再学習時にベクトル空間の座標とセマンティックな情報との対応が破壊されてしまう問題を気にする必要がありますが、Spotifyでは下流プロダクトと協調してモデルを管理する戦略をとったようでした。
具体的には、
- 各再学習サイクルで、一意のバッチIDがタグ付けされた新しい埋め込みセットを生成
- 下流のモデルは新しいバッチと同期して再学習
することで意味の一貫性を確保するというやり方です。
実験では、本手法によってトラックストリーミング予測などの予測系タスクだけでなく、候補生成や検索リランキングなどのタスクでもパフォーマンスの向上が見られ、ユーザエンゲージメントの向上にもつながる汎用的なユーザ表現が得られたことが示されていました。
自分の所属するチームでもまさに汎用的なユーザ埋め込みを開発しているので、本研究は RecSys参加前から非常に気になっていた内容でした。内容としてもコンテンツ情報を利用する試みや異なる時間スケールのユーザの嗜好を捉える試みが盛り込まれており、これらは自分たちのチームでも取り組んでいたり高い関心を持っていたりしていたので、他社事例としてとても参考になります。
モデルに対する印象としては、本モデルは初期版という印象でオーディオエンコーダと協調エンコーダが完全に分離されていたり、時間スケールの分離もハンドクラフトで与えているので、この辺りはオーディオシグナルと協調シグナルを相補的に扱える機構の開発や時間スケールを学習内で動的に分離できないかなどの試みが今後なされていくのではないかなと感じます。
Off-Policy Evaluation of Candidate Generators in Two-Stage Recommender Systems (Full Paper) (堀)
現代の大規模推薦システムは、計算効率の観点から「候補生成」と「��ランキング」の二段階構成が主流です。第一段階の候補生成器は、後続のランキングモデルが選択可能なアイテム集合、すなわち行動空間を決定するため、システム全体の性能に極めて大きな影響を与えます。しかし、そのオフライン評価は従来、再現率(Recall)などの情報検索指標に依存しており、ビジネス指標との乖離や下流ポリシーとの相互作用の無視といった課題がありました。この研究では、この評価タスクをオフ方策評価(OPE)の枠組みで捉え直し、候補生成器の評価をOPEの観点から扱う最初の研究として、行動集合が変化する状況に対する新しい推定法を提案しています。
この論文では、行動空間の変化に伴うバイアスに対処するため、重要度サンプリングを基盤とする2系列の推定手法を提案しています。
| 手法 | 説明 |
|---|---|
| Intersection(交差)法 | よりシンプルなベースラインとして、評価対象を旧・新候補集合の共通部分(Intersection)に限定する手法です。ターゲットポリシーの確率をこの共通集合上で再正規化することで、標準的な推定量が持つバイアスを軽減します。推定量として IIPS (Intersection IPS) と IDR (Intersection Doubly-Robust) があります。 |
| Proxy(代理)法 | 本論文の主要な提案であり、「新しいアイテムは、類似した古いアイテムを代理(Proxy)として利用できる」という発想に基づきます。まず、全アイテムを等価クラスに分類し、各クラスに必ず1つ以上の古いアイテムが含まれるように設計します。次に、行動選択確率をクラス単位で合計した周辺化プロペンシティを用いて重要度重みを計算します。これにより、ログに存在しない新規アイテムの情報を、同じクラスに属する古いアイテムの観測データを通じて間接的に評価でき、バイアスを理論的に抑制します。推定量は PIPS (Proxy IPS) と PDR (Proxy Doubly-Robust) です。 |
提案手法の有効性を検証するため、特性が明確な人工データと、現実の環境を反映した実データの両方で実験を行い、提案手法、特にPDRの優位性が一貫して示されました。
総合性能: 実データにおいて、PDRが最も低い平均二乗誤差を達成しました。これはProxy法がバイアスを効果的に削減したことを示唆しています。
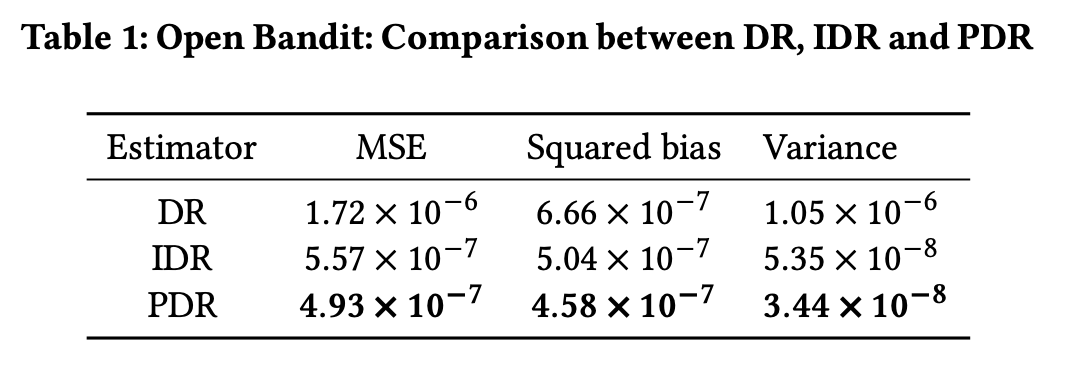
頑健性: 候補集合の重複率が低い(=新規アイテムが多い)状況ほど、PDRの優位性が顕著になりました。例えば、重複率30%の条件下では、PDRのMSEはIDRの約7分の1、DRの約49分の1にまで抑えられました。また、報酬モデルが不正確な場合でも、PDRは他のモデルベースの手法より安定した性能を維持しています。
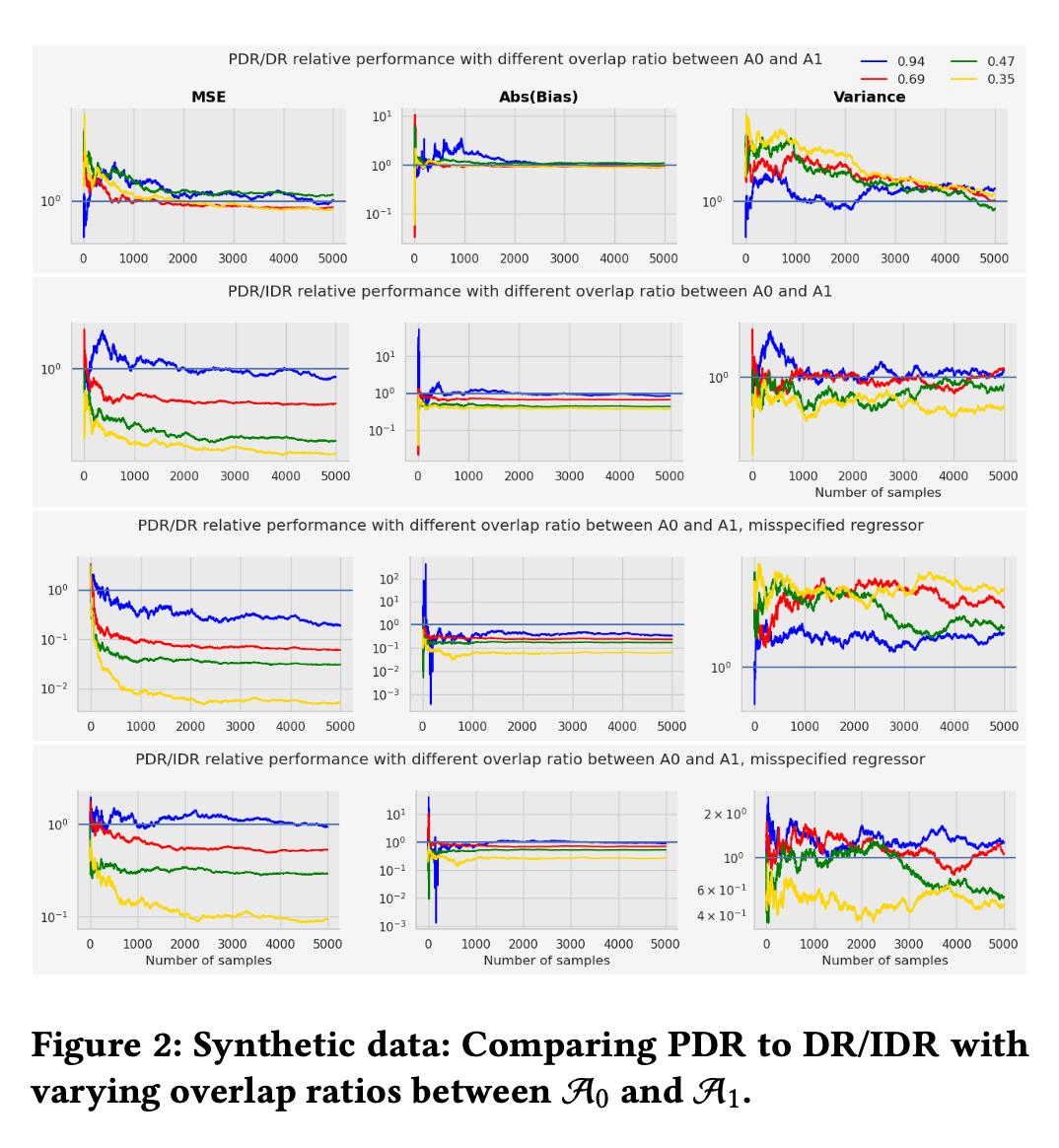
実務における大規模推薦システムでは、二段階構成が広く採用されています。サービスによっては数千万件以上のアイテムから数百件程度へ候補を絞り込むこともあり、候補生成器を更新した結果、新旧候補の重複率が著しく低くなるケースも珍しくありません。まさに、本研究が扱う「第一段階の候補生成器の変更を考慮したオフライン評価」は、多くのレコメンド開発者にとって共通の重要課題だと思いました。この研究では、実務で直面するこの難題を「行動空間が変化するOPE」という的確な観点から捉え、理論と実践を両立した解決策を提示しており、非常に意義深いものだと感じます。
提案手法の性能は、等価クラスや報酬モデルの設計品質に依存するものの、多くの実務者が抱える課題感に直接応えるアプローチである点は論を俟ちません。二段階推薦システムの信頼性向上に大きく貢献する研究であると同時に、推薦システムのオフライン評価を設計することの奥深さと難しさを改めて認識させられました。
現地参加のメリット
まずはやはり、直接的なコミュニケーションを取れるというのは大きかったです。当然ながら著者や著者以外にもさまざまな研究者が会場に来ており、至る所で議論が盛り上がっておりました。弊社メンバーも各々の興味にしたがって、様々に質問や議論をできたようでした。また、私の方で日本人食事会を企画し、アカデミア/インダストリーを問わず多様な業界、職種の方々と交流することもできました。
また、トレンドの兆しも現地参加によってより感じられた部分かなと感じました。論文そのものは少なくとも学会中は公開されており、昨今さまざまなツールで日本語での理解も容易になってきていますが、質疑の盛り上がりや著者との会話からそういった点を肌で感じやすいのは現地ならではのように思います。今回だと、semantic IDのようなembeddingの先を探そうとしている研究領域は、今後研究開発が進んでいきそうだという印象を受けました��。
おわりに
RecSys 2025への現地参加で得た知見や所感について、ざっくりとですがご紹介しました。推薦システムの研究開発に関するさまざまな話題や空気感を肌で感じられ、貴重な知見獲得の機会となったと感じています。アメリカ開催となる来年のRecSysも今から楽しみです。
なお、LINEヤフーはRecSys2025論文読み会で懇親会のスポンサーを務めております。ご都合のつく方は是非ご参加ください。
おまけ
学会の雰囲気などがわかる写真をいくつか紹介して記事を締めくくります。
Keynoteや本会議の発表が行われたメイン会場です。1000人以上入りそうな大きめの会場でしたが、しっかり埋まっていました。

ワークショップやチュートリアルなどが行われたサブ会場です。この写真はNetflixのスポンサーセッションでしたが、立ち見も出る人気っぷりでした。

プラハで最も有名なカレル橋という観光スポットです。

そこから徒歩で行けるプラハ城。

名物というビーフタルタル。

学会の最後に、LINEヤフーのメンバーでパシャリ。



