こんにちは。LINEヤフーで画像生成やデザイン生成の研究開発を担当している 北田 (@shunk031) です。先日 2025 年 10 月 19 日から 23 日までアメリカ・ハワイにて開催された International Conference on Computer Vision, ICCV 2025 に参加・発表してきました。
本記事では、ICCV のワークショップ・本会議で得られた知見を共有します。 まず、私を含む LINEヤフー社員が国際的な議論を主導したワークショップの主催報告と、広告・デザイン生成の専門ワークショップで得られた知見を紹介します。そして、本会議における拡散モデルの高速化・制御技術およびデザインの階層化・構造化生成といった最新トレンドを分析し、弊社研究チームの発表の概要とともにお伝えします。

FOUND ワークショップの開催報告
ワークショップの概要と主催者としての活動
本ワークショップは「Foundation Data for Vision: Challenges and Opportunities (FOUND)」という名称で、私(北田)および小松を含む LINEヤフー社員がオーガナイザーとして参画し、ICCV 2025 に採択されました。
テーマ設定の背景には、近年の基盤モデル(Foundation Models)の進展において不可欠な「データ」に焦点を当て、その課題と機会について国際的な議論の場を提供するという目的があります。
この採択は、世界最高峰の国際会議である ICCV において、日本人研究者が主導する数少ない貴重な事例であり、日本発の研究および産業界の取り組みが世界的に評価されたことを示します。
LINEヤフーとしての貢献と当日の様子
弊社 LINEヤフーは本ワークショップを主導的にオーガナイズしました。これにより、コンピュータビジョン分野の未来を形作る「基盤データ」という喫緊のテーマに対し、国際的な議論を牽引する立場であることを一定程度示すことができました。


当日は、アカデミアや産業界から多くの研究者や実務家が参加し、活発な技術交流が行われました。特に、ワークショップ後に、同じく ICCV 2025 で開催した LIMIT ワークショップと共催した懇親会は非常に盛況でした。本懇親会を通じて参加者間の深いネットワーキングを促進し、今後の国際的な共同研究の可能性を広げる貴重な機会となりました。

今回の主催経験を活かし、今後国際会議でワークショップを主催したい、あるいはプロポーザルの書き方や運営に不安があるといった方がいらっしゃいましたら、ぜひお気軽にご連絡ください。特にリードオーガナイザーを務めた福原さん、共催の LIMIT ワークショップをリードした産総研の片岡さんは豊富な経験をお持ちですので、具体的なアドバイスが可能です。また私(北田)もサポートできると思います。日本から国際会議での議論を主導する研究者・技術者が増えることを心から�願っています。
聴講ワークショップからの知見
私の業務担当領域および専門である画像生成・デザイン生成、および事業貢献(特に広告・マーケティング)の観点から聴講した 2 つのワークショップについて報告します。
Computer Vision in Advertising and Marketing (CVAM) 参加報告
CVAM ワークショップ は、デジタル広告およびマーケティング領域におけるコンピュータビジョン(CV)の最新応用が主題でした。
事業貢献の観点で得られた知見として、本ワークショップのテーマである「広告・マーケティング分野における CV 技術の適用」には、具体的にはクリエイティブの生成やマーケティングシステムの最適化、ブランドインテリジェンスなどが含まれていました。
広告効果の最大化を目指す弊社の事業において、ビジュアルコンテンツの理解と生成は喫緊の課題です。CVAM への参加を通じて、最新の画像生成技術を単にクリエイティブ制作に留めるのではなく、いかに広告効果測定や消費者行動の予測と結びつけるかという議論の重要性を再確認できました。
Workshop on Graphic Design Understanding and Generation 2025 (GDUG) 参加報告
GDUG ワークショップ は、グラフィックデザインやドキュメント��の認識・生成における重要な概念、技術的制約、および倫理的側面の議論を目的としていました。

デザイン生成の観点から得られた知見として、多くの研究がピクセルベースの画像生成に注力する一方で、現実世界のデザインワークフロー、例えばポスターやオンライン広告、ウェブサイトの作成においては、クリエイターはピクセルではなく構造化されたドキュメント(例:レイヤー化されたオブジェクト表現、スタイルの属性、タイポグラフィ)を扱うため、研究と実務の間に乖離があるという問題意識が共有されました。
招待講演では、既存のデザインをテキスト、前景要素、背景といったネイティブなレイヤーに分解するレイヤー分解の最新手法(例:Accordion パイプライン)が紹介されました。これにより、デザイン生成技術は、単なる「フラットな単一・単層出力」から、現実のデザインプロセスで用いられる複数の層を有するレイヤー構造を扱う方向へと進化していることが明確になり、弊社のデザイン生成技術開発における今後の方向性を考え直す重要な示唆となりました。
本会議の参加報告と主要トレンド分析
ICCV 2025 全体の統計と規模感
ICCV 2025 はハワイ・コンベンション・センターで開催され、参加者数は 7,000人近くに上りました。11,000件を超える論文が投�稿され、そのうち約2,600件が採択されています(採択率 24%程度)。
主要な研究トレンドのトップ 3 は、生成 AI(画像&動画)、マルチビュー・センサーからの 3D 処理、およびマルチモーダル学習であり、特に生成モデル分野では「Diffusion」モデルから「Flow」モデルへの移行が進んでいることが主要なトレンドだと感じました。より詳しいトレンドの概要や分析は cvpaper.challenge の有志による ICCV 2025 Report が参考になります。

弊社研究チームによる発表「PINO」の紹介
弊社による研究発表「PINO (Person-Interaction Noise Optimization)」は、長時間の、カスタマイズ可能な、任意のサイズのグループモーション生成を可能にする技術です。
本研究は、弊社サマーインターンの成果であり、東京科学大学の太田さんが主体となって取り組んでくださったものです。
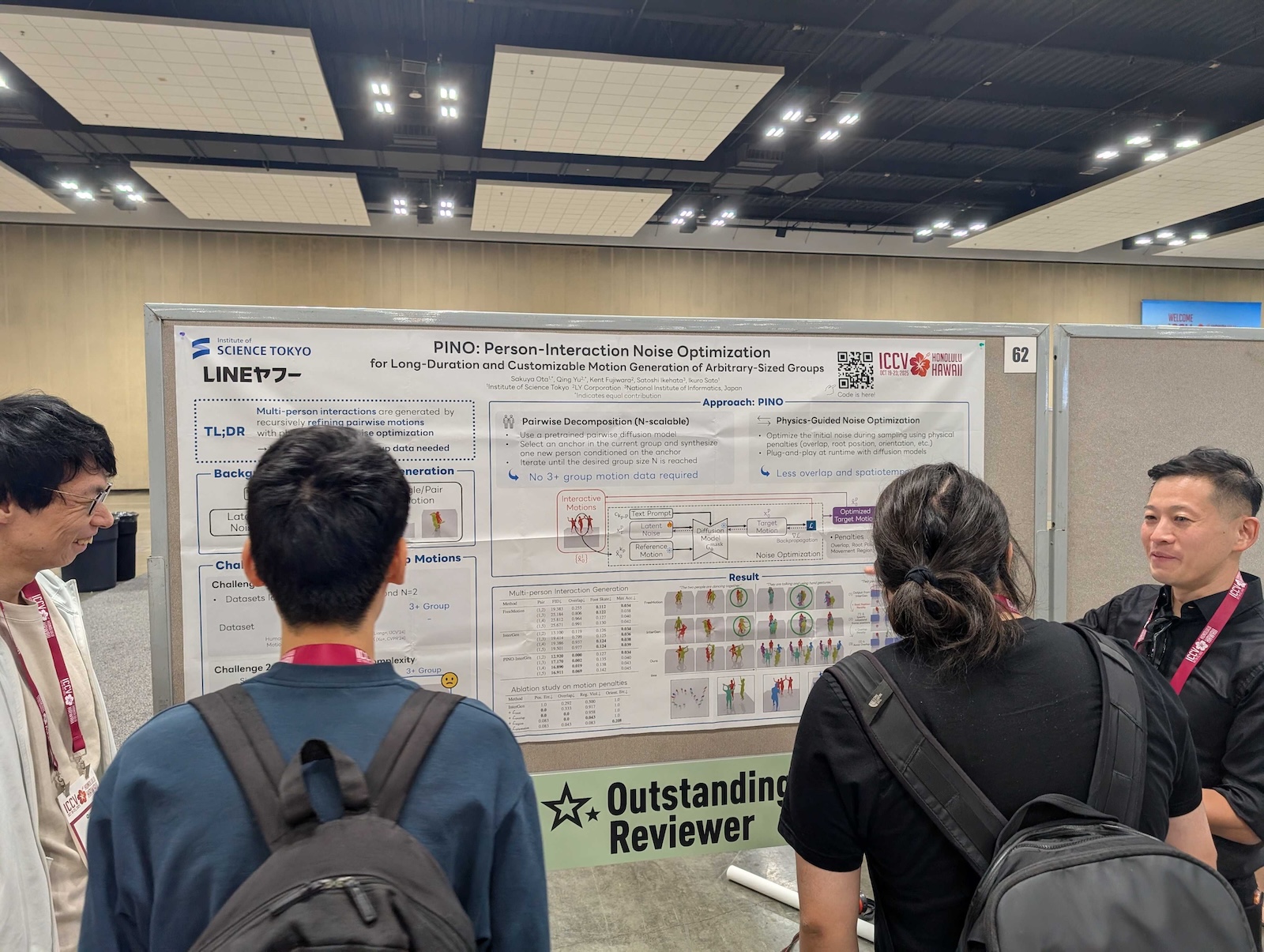
PINO の概要と成果として、ベースとなる拡散モデル(例:InterGen)を使用してモーションシーケンスをデノイズ(ノイズ除去)する際に、ノイズ入力を最適化するというユニークなアプローチを採用しています。
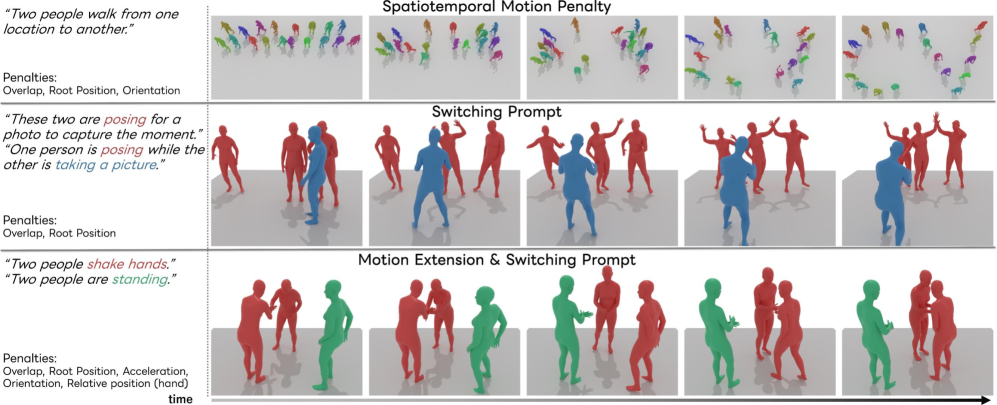
この最適化により、生成されたモーションがテキストプロンプトに合致するだけでなく、身体の重なりや貫通といった物理的な不自然さを防ぐコスト関数を導入することで、物理的妥当性を確保しています。
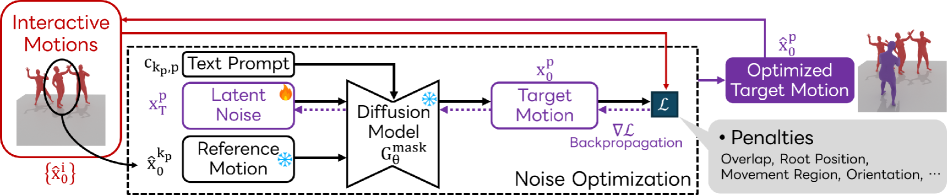
さらに、ユーザーはルートポジション、領域、および方向をペナルティ項を通じて制御でき、モーションのカスタマイズ性を実現しています。
注目すべき技術トレンド:画像生成・デザイン生成分野
私の業務担当領域である画像生成、デザイン生成の視点から、本会議で確認された主要な技術トレンドを、事業貢献の可能性を含めて分析します。
拡散モデルの効率化と信頼性向上:Flow モデルの優位性
拡散モデル(DM)の進化の焦点は、リアリティだけでなく、速度、制御、信頼性に移っています。
Flow ベース生成と高速サンプリングの動向として、Flow Matching モデルは、生成モデルの訓練パラダイムとして有効性が高まっています。特に「Contrastive Flow Matching」は、推定された Flow と独立したサンプルによる Flow との非類似性を最大化することで、従来の Flow Matching よりも一貫して優れた性能(優れた FID スコア)を示し、高品質かつ高速な生成を可能にしています。
![図は [Stoica+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/8fe12f9bd6ba4c69934046d1cb25b188.png?updatedAt=1763448523000)
インバージョンフリー(Inversion-Free)編集については、事前学習された Flow モデル(SD3, FLUX.1 など)を利用する「FlowEdit」が、編集に必要な「インバージョン(逆変換)」ステップを不要とし、編集対象の画像から目標とする分布へのより短い直接的な経路をたどることで、高いテキスト整合性と構造保存性(優れた LPIPS)を達成しています。特に FlowEdit は評価されて Best Student Paper Award を受賞していました。
![図は FlowEdit [Kulikov+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/9ba93e9ec1ff41ea88fa4df3bfb929fa.png?updatedAt=1763448583000)
制御生成(FlowChef)に関しては、Rectified Flow Models (RFMs) の特性(サンプリング軌跡が直線的で非線形誤差項がゼロに近づく)を利用し、勾配計算を省略(Gradient Skipping)することで、インペインティングや超解像などのタスクにおいて、追加�訓練や大規模なバックプロパゲーションなしで決定論的かつ効率的な制御生成を実現していました。
![図は FlowChef [Patel+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/6bb883f6132b4eccb46c5d72b465b77b.png?updatedAt=1763448621000)
生成品質の評価と改善(人間中心のアプローチ)
人間の選好に基づく最適化の手法として、画像生成モデルの品質を人間の好みに合わせるため、大規模で多様なデータセット(HPDv3:108万のテキスト - 画像ペア)と不確実性考慮型ランキング損失を組み合わせた評価モデル(HPSv3)が提案・構築されました。これにより、プロンプトに応じて最適なモデルを選択する Model-wise Preference や、サンプリングごとに最良の画像を評価する Sample-wise Preference が可能になります。
![図は HPSv3 [Ma+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/ac40a75d2efe4c13bdd31d2b8674b5af.png?updatedAt=1763448655000)
自己反射による反復改善 (Reflection Tuning) というアプローチでは、生成された画像に対して、報酬モデルやマルチモーダル LLM (MLLM) がその欠点をテキストで記述した「反射 (Reflection)」プロンプトを生成し、その指示に基づいて画像を改善する反復的な生成・改善パラダイムが提案されています。これにより、「日光を消す」「服を変える」といった具体的なテキスト指示による修正が可能になりました。
![図は Reflection Tuning [Zhou+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/10a75ffe7d064d31bef1f88384a43063.png?updatedAt=1763448684000)
デザインと広告応用を加速する構造化生成
レイヤーベースの構造化生成では、デザイン生成の課題であった「レイヤーの一貫性」を解決するため、複数の透明な画像レイヤーを同時に一貫性がある形で生成する「DreamLayer」が提案されています。この手法では、レイヤー間で情報を共有する Layer-Shared Self-Attention などの機構を用いて、前景と背景の間の遮蔽関係や空間的レイアウトの不整合を解消可能です。
![図は DreamLayer [Huang+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/000f4423e9b24f2090c882beb8d7e693.png?updatedAt=1763448727000)
レイアウト制御の深化については、レイアウト(配置情報)から画像を生成する「CreatiLayout」(SiamLayout)は、Transformer ベースのモデルであり、レイアウトの空間的整合性、色、形状などにおいて高い性能を発揮します。特に、LayoutDesigner というコンポーネントは、レイアウトプランニングタスクにおいて GPT-4 Turbo を超える最高精度を達成しています。
![図は CreatiLayout [Zhang+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/0eaaf56c4a8246599865da72527f27be.png?updatedAt=1763448771000)
高精度な画像合成(DreamFuse)では、前景と背景の画像を融合する際に、人間に好まれる結果を得るため、Localized DPO (Localized Direct Preference Optimization) という新たな手法を提案しています。これにより、単なるコピー&ペースト画像(ネガティブサンプル)を避ける学習が進み、遠近感やアフィン変換などの融合関連の変換をモデルがより適切に捉えられるようになり、背景の一貫性や前景との調和が向上しています。
![図は DreamFuse [Huang+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/dbeb432d6bb042df860b2a851ce068c6.png?updatedAt=1763448806000)
ビジュアルテキストの正確な合成に関して、「UniGlyph」は、ピクセルレベルのセグメンテーションマスクを条件として使用する拡散モデルの枠組みにより、ぼやけたグリフやスタイルの不整合といった問題を解決し、特に小さなテキストや複雑なレイアウトのレンダリングで高い性能を示しました。
![図は UniGlyph [Wang+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/02e631e728fd476bada2e4cdff3453f2.png?updatedAt=1763448836000)
「TextMaster」は、文字のグリフとスタイルの双方を制御する統一的なフレームワークであり、OCR 技術を統合して文字特徴の L2 損失を計算し、リアルなテキスト編集を実現可能になりました。
![図は TextMaster [Yan+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/f7fb07a4ddb3462ab05c3fdd80ae4ac7.png?updatedAt=1763448871000)
広告・マーケティング分野への展開として、視線予測(ScanDiff)では、拡散モデルを用いて、ユーザーの視覚刺激(広告など)に対する視線経路(スキャンパス)を予測する「ScanDiff」が提案され、COCO-Search18 などのデータセットで高い性能を達成しています。これは、広告クリエイティブの視認性や効果を最適化する上で、人間の注意機構をモデル化する技術として非常に重要です。
![図は ScanDiff [Cartella+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/334ca269ad494a2882ff7668c8b777f2.png?updatedAt=1763448912000)
広告動画の理解(AdsQA)という新しい研究テーマも提案されています。これは、動画理解のための質問応答(QA)ベンチマークに広告動画の特有な課題を組み込むものです。なお、この分野では、データ品質に対する感度が高い強化学習手法の課題や、プロンプトテンプレートによる性能への影響などが分析されています。
![図は AdsQA [Long+ ICCV'25] より引用](https://vos.line-scdn.net/landpress-content-v2-vcfc68aynwenkh3bno0ixfx8/0f79f0f26e8b456589a0e71cb30bfaab.png?updatedAt=1763448953000)
まとめ
今回の ICCV 2025 参加を通じて、コンピュータビジョン分野、特に画像生成・デザイン生成は、単なるリアリティの追求から技術の「実用化と制御」を最重要視するフェーズに入ったことを強く認識しました。
ワークショップや本会議の動向は、生成 AI がピクセルベースの出力から、デザインワークフローと親和性の高い階層的かつ構造化されたデザイン要素を生成する方向へと明確に進化していることを示しています。また、Flow モデルの発展により、高速かつ高精度な生成と編集が実現しつつあります。これは、広告・マーケティング応用におけるクリエイティブの PDCA サイクルを革新する鍵となります。
LINEヤフーは、基盤データのガバナンスと国際的な議論の主導という責務を果たしつつ、これらの最先端の生成および制御技術を積極的に事業へ応用することで、技術的な競争優位性を確立し、社会へ貢献してまいります。


