「良い画像」を生成するのは簡単ではない
LINEヤフーには、特定の比率で最小限のディテールを維持しながら人体やオブジェクトを定義する画像スタイルが存在します(参考)。私たちのチームでは、生成AIを利用して、このスタイルが適用された画像をプロンプトのみで生成するtext-to-image(テキストトゥイメージ)モデルを作成するプロジェクトを行いました。
このプロジェクトは、社内デザイナーの反復的な画像作成業務を最小限に抑えるために始まりました。社内のデザイン業務の中には、状況に応じて少しずつ異なるイラストを描く作業があります。この作業を自動化することで、デザイナーがよりクリエイティブな業務に集中できる環境が整うと考えました。
以下の画像は、私たちが求める最終的な成果物のスタイルやレベルを示しています。
 |  |
いつものことですが、生成AIモデルに一貫して良い画像を生成させることは容易ではありませんでした。例えば、以下の例のように、「hold the LINE」というプラカードを持った女性の画像を生成することを考えてみましょう。内部で利用するスタイルに似た画像が生成されることもありますが、そうでない画像もよく生成されます。実際、以下の2つの画像の生成には同じモデルを使用しました。単に画像生成時に設定したハイパーパラメータが異なるだけです(ハイパーパラメータについては後ほど詳しく説明します)。
| 入力 | 希望する結果 | 希望しない結果 |
|---|---|---|
| 「hold the LINE」というプラカードを持った女性を描いてください! (A woman is holding a picket sign. The sign has the words "hold the LINE" written on it.) | 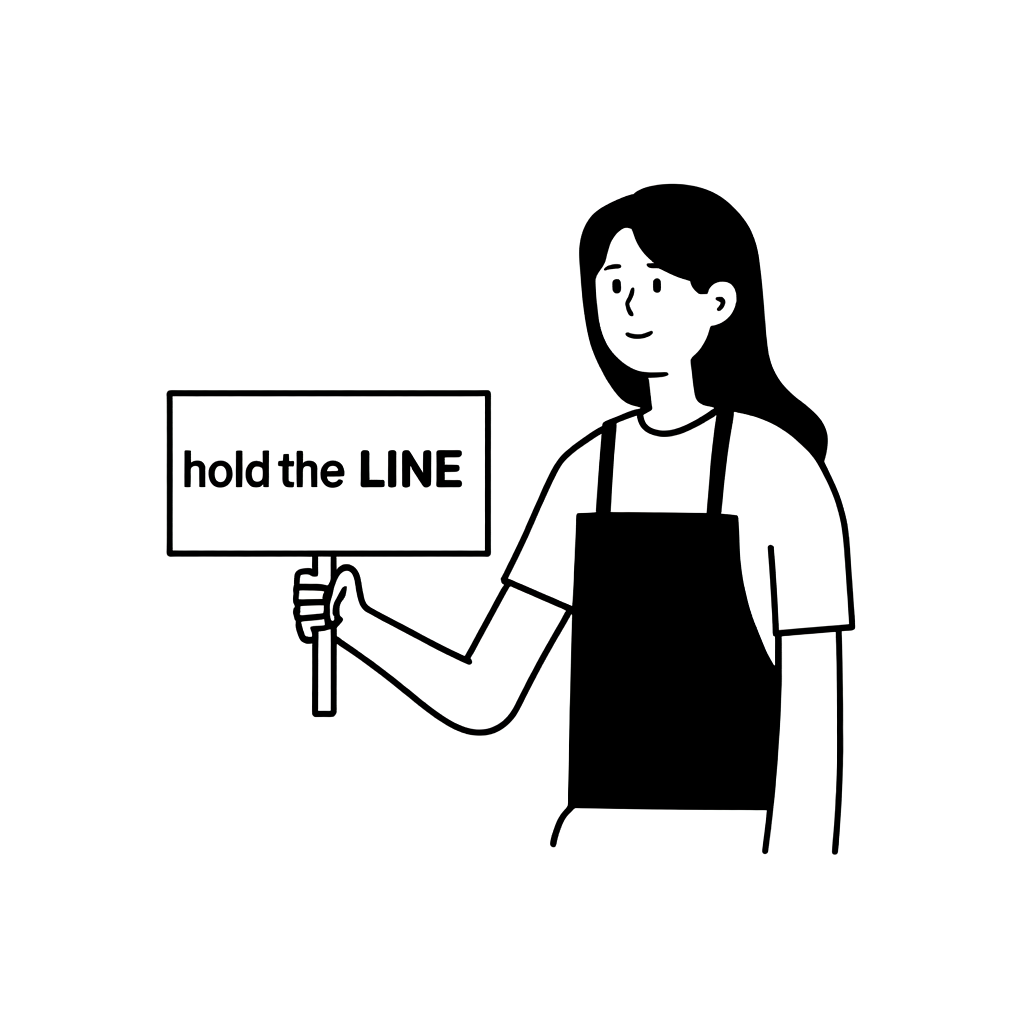 | 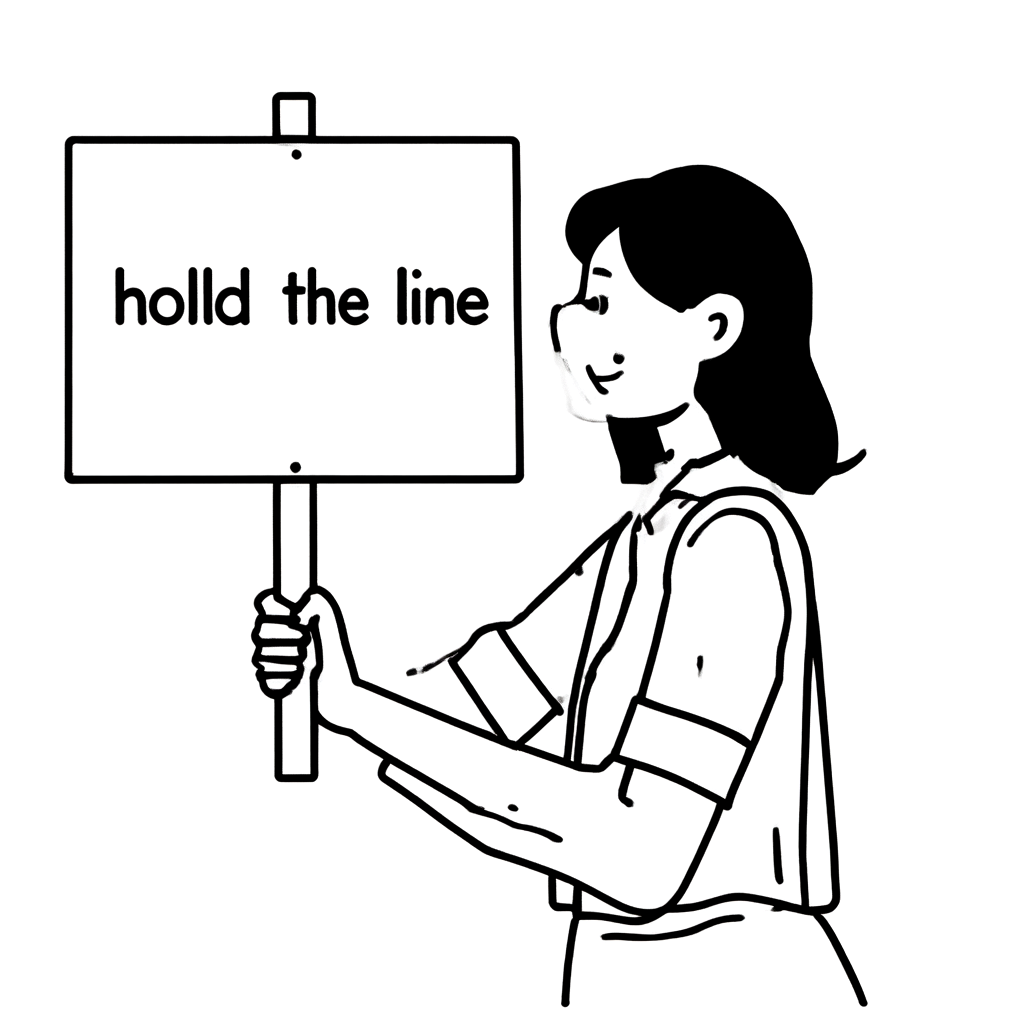 |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
良い画像を生成するためにまず確認すること
この記事では、まず、AIを使った画像を生成する方法から説明します。Diffusionモデルから始め、Stable Diffusion系のモデルを中心に見ていきます。また、Stable Diffusionモデルで画像を生成する際に広く使われるさまざまなハイパーパラメータと、それぞれの機能も併せて紹介します。
良い画像を生成する方法を見つけるには、画像を何度も生成してみる必要があります。そのため、通常、いくつかのハイパーパラメータを選定して数値を調整しながら画像を一つずつ生成してみることになります。特定の範囲内で複数の値を変更しながら画像を生成するのは、非常に手間がかかるため、自動化できれば良いでしょう。このような作業を自動化するには、まず「良い画像」とは何かを数値化して評価する必要があります。そこで、私たちは以前説明した画像評価方法(参考:AIで生成された画像をどのように評価するのか?(基本編))の一部を紹介し、これらを用いたハイパーパラメータの探索方法を紹介します。また、画像を数値化して評価する方法以外に、プロンプトを用いたハイパーパラメータの評価方法についても紹介する予定ですので、ご期待ください。では、本格的に始めたいと思います。
AIが画像を生成する仕組み
まず、生成モデルがどのように画像を生成するのか、DiffusionモデルとStable Diffusionモデルを中心に簡単に見ていきましょう(以降の説明はStable Diffusionモデルに基づいています)。
Diffusionモデル
Diffusionモデルは、画像生成の分野で広く使われているアプローチの一つであるDiffusionプロセスで画像を学習し、生成するモデルです。Diffusionプロセスは、画像からノイズを徐々に除去(denoise)し、高品質の画像を生成する方法です。

- 順方向Diffusionプロセス:Diffusionプロセスは、元の画像に徐々にノイズを加え、画像を完全にランダムな状態に変換するプロセスです。各ステップでは、一定量のガウス雑音(Gaussian noise)を追加します。ノイズを追加する方法は、マルコフ連鎖(Markov chain)でモデル化され、各段階は以前の段階の結果に依存することなく、独立して行われます。
- 逆方向ノイズ除去プロセス:ノイズ除去プロセスは、ノイズが付加された画像から元の画像を復元するプロセスです。ノイズは学習済みモデルを用いて除去します。一度に除去するのではなく、徐々に除去し、初期ノイズが元の画像に近い状態になるように復元していきます。そのために、モデルは現在のノイズ画像と各段階でノイズを除去する確率分布を学習します。つまり、除去するノイズの予測値は確率的(stochastic)に決定されます。
画像は、サンプリングされたランダムなガウス雑音に逆方向ノイズ除去プロセスを適用することで生成されます。
Stable Diffusionモデル
Stable Diffusion(以下SD)は、Diffusionモデルの一実装です。SDの特徴を簡単に説明します。
従来のDiffusionモデルは、前述のDiffusionプロセスを「ピクセル空間(pixel space)」で適用します。そのため、大きな画像(例:1024x1024ピクセル)を生成する際には非常に多くの演算量が必要です。
このような欠点を改善するために、ピクセル空間ではなく「潜在空間(latent space)」でDiffusionプロセスを適用するSDモデルが提案されました。つまり、従来のDiffusionモデルが画像自体からノイズを減らす概念であるのに対し、SDモデルは画像の「潜在ベクトル(latent vector)」でノイズを減らす概念です。ここで、潜在ベクトルは潜在空間における位置であるため、埋め込みと考えることができます。この潜在ベクトルは画像を変分オートエンコーダー(variational autoencoder、以下VAE)でエンコードして生成し、画像はこの潜在ベクトルをVAEでデコードして生成します。
画像生成方式のうち、テキストを追加情報として提供するtext-to-image手法では、画像を生成する際に、ノイズ除去のプロセスでテキストの埋め込み生成にアテンション(attention)メカニズムを利用します。また、画像生成モデルをファインチューニングする際には、主にノイズ除去器(denoiser)�であるU-Netをファインチューニングします。
SDXLとSD3.5モデル
私たちの実験では、SDの初期バージョンであるSD1ではなく、SDXL(SD-xlarge)とSD3.5を使用しました。この2つのモデルは、初期バージョンのSDモデルのパラメータ数の増加に伴い改良されたモデルです(参考までに、この記事に添付された画像はほとんどSD3.5で生成しました)。
SDXLの構造はSDと大きな違いはありません。ただし、テキストエンコーダー(CLIP-G/14)がもう1つ追加され、これにより、初期SDであるSD1よりも多様なプロンプトの情報を抽出できるという利点があります。
SD3.5は、テキストエンコーダー(T5 XXL)がもう1つ追加され、ノイズ除去器が変更されました。また、学習方式がDiffusionプロセス方式からフローマッチング(flow matching)方式に変更され、名前と違ってDiffusionモデルではなくフローモデルに変わりました。U-Netの代わりに導入されたノイズ除去器は、MMDiT(Multimodal Diffusion Transformer)というトランスフォーマーです。このトランスフォーマーは、テキストと画像のモダリティ(modality)ごとに別々のスタックを持ち、モダリティごとに全結合層(linear layer)を持っているため、U-Netに比べてテキストに対する学習可能なパラメータが増えたと言えます。アテンションを計算する際は、セルフ/クロスアテンションを別々に計��算するのではなく、各モダリティを1つに統合(concatenation)し、2つのアテンションを1つのブロック(計算単位)で処理します。
Diffusionモデルは、画像にノイズを加え、これを除去する方法を学習して画像を生成します。一方、フローモデルは、複雑な画像データ分布と単純な正規分布をマッチングし、単純な正規分布を利用して画像を生成できることを前提としています。つまり、正規分布からサンプルを1つ選択すれば、それにマッチした画像データを生成できることを前提としています。
では、単純な正規分布をどのように実際のデータとマッピングするかを考える必要があります。フローマッチングでは、データ空間を変形させるベクトル場(vector field)を学習する方法でアプローチしました。理解を助けるために以下の画像で説明します。
まず、以下の左の画像を見てください。任意の空間に正規分布(1つのピークを持つ円形)とデータ分布(2つのピークを持つ歪んだ長い形)が存在するとしてみましょう。このとき、左側の正規分布が右側のデータ分布に変形していく形を想像してみると、右側に移動するにつれ徐々に上下に伸びていく形が描かれるでしょう。このような変化には、空間のすべてのポイントに変化する程度があるはずです。この変化量をベクトル場として表現できます。フローマッチングは、このベクトル場を学習する形でロジックを整理した方法です。
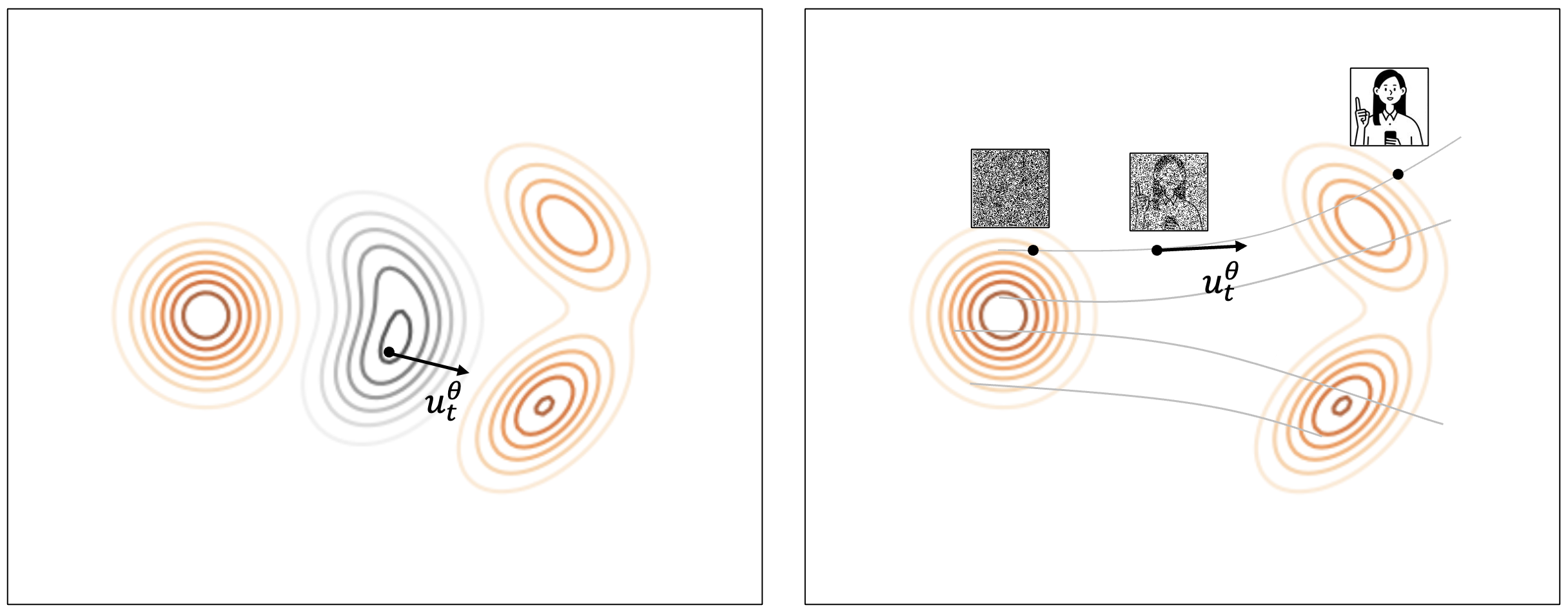
次に、上の右側の画像を��見てみましょう。Diffusionプロセスと比較して説明すると、ランダムノイズからノイズを除去していくプロセスは、上の右側の画像のように、ランダム分布のいずれかのサンプルからいずれかのデータポイントに移動していく過程と言えます。したがって、フローマッチングで画像を生成する方法は、ランダムノイズをサンプリングした後、ランダムな距離だけ移動することを繰り返すことです。ここで、移動する方向と距離を速度(velocity, u_t^{\theta})と表現します。この速度は、ベクトル場を微分すると求められるため、フローマッチングモデルは、入力が同じであれば常に同じ結果が出る決定論的(deterministic)という利点があります。
画像生成時に調整できるハイパーパラメータとその役割
次に、画像生成時に調整できるハイパーパラメータのうち、私たちが実験で使用したハイパーパラメータの種類とそれぞれの役割を紹介します。
シード、ランダムノイズ、潜在ベクトル
画像生成モデルは、ランダムノイズを入力として受け取ります。これが画像生成の出発点ですが、シード(seed)はこのランダムノイズを生成するための基準となる整数値です。同じシードであれば、常に同じランダムノイズを生成します。また、前述のステーブルディフュージョンでは、画像ではなく画像の潜在ベクトルでノイズを減らすという概念に変わったと説明しました。ここでさらに考えてみると、ランダムノイズも潜在空間のどこかに存在する潜在ベクトルであることがわかります。
整理すると、シードはモデル入力の初期値を決定し、ランダムノイズはモデル入力の初期値です。シードは整数値、ランダムノイズは潜在ベクトルという違いがありますが、この2つは説明したいポイントによって、どちらも「初期値」という意味合いを持つため、よく混同して使われることもあります。ここでこれらの概念を分けて詳しく説明した理由は、後の「良いスタートポイントを見つける」では区別して使うためです。
プロンプト
プロンプトは、画像生成モデルにノイズ以外に追加情報を入力できる窓口の一つです。このように、テキストを追加情報として提供する画像生成モデルをtext-to-image生成モデルと言います。text-to-image生成モデルは、ノイズ除去器が画像を学習する際に画像のキャプションを一緒に学習し、「どのようなキャプションのとき、どのような画像だったか」のような情報を学習した状態なので動作できます。
ちなみに、プロンプトはユーザーの意図を反映したカスタマイズされた結果を得るには有効ですが、画像の構図や色などを完全に制御するにはやや不十分です。
Classifier-Free Guidance
Classifier-Free Guidance(以下CFG)は、生成された画像にプロンプトの情報をどれだけ反映するかを調整する手法の一つです。CFGは、ノイズ除去のプロセスで2つの情報を活用します。1つはプロンプトのテキスト条件付きで予測されたノイズ、もう1つは条件なしまたはネガティブプロンプトベースで予測されたノイズです。CFGは、この2つのノイズの違いを活用します。
2つのノイズの違いをどれだけ反映するかは、ハイパーパラメータで定義��します。値が高いほど、条件付きノイズの情報をより多く使用します。これにより、プロンプトの情報をより反映した画像が生成されます。もし目的のオブジェクトが画像に表現されていない場合は、CFGの値を高く設定して、より強く反映させることもできます。
Reward Guidance
Reward Guidance(以下RG)は、CFGと同様に、画像にプロンプトの情報をどれだけ反映させるかを調整する手法の一つです。この手法は、元のモデルの表現力と新しく学習したファインチューニングされたモデルの表現力の違いを活用します。情報としては、テキスト条件付きで予測されたノイズのみを使用しますが、ファインチューニングされたモデルが予測したノイズと元のモデルが予測したノイズの違いを利用します。
この2つの違いをどのくらい反映するかは、ハイパーパラメータで定義します。値が高いほど、ファインチューニングされたモデルのノイズをより多く使用します。これにより、ファインチューニングされたモデルの情報をより多く反映した画像が生成されます。希望するスタイルで学習したモデルの特性をより反映させたい場合は、RGの値を高く設定し、より強く反映させることができます。
Skip-Layer Guidance
Skip-Layer Guidance(以下SLG)はSD3系で使用された手法で、テキスト条件付きで予測されたノイズを活用します。上記の手法と同様に、ノイズ除去器(SD3のMMDiT)のすべてのブロックを用いて予測したノイズと、一部のブロックを演算から除外(skip)して予測したノイズの違いを活用します。関連コミュニティでは、このSLGを��適切に利用すれば、指の本数が増えたり、関節がねじれたりするなど、人体の構造が不適切に表現される問題をかなり緩和できるという意見が提示されています。
Low-Rank Adaptationスケール
Low-Rank Adaptation(以下LoRA)は、学習が難しい大きなモデルを少ないパラメータでファインチューニングする手法の一つです。LoRAスケールは、ノイズ除去器に学習されたLoRAパラメータが、演算時にどのくらい影響を与えるかを決定する値です。つまり、ファインチューニングした情報をどのくらい反映するかを決定するものです。このハイパーパラメータは、ノイズ除去器のすべての演算に影響を与えるため、上記の手法と独立した手法とは言えません。
ここで紹介したパラメータ以外にも、画像生成に関与するハイパーパラメータは非常に多くありますが、私たちは実験の際に上記のハイパーパラメータのみを使用しました。SLGの場合、初期実験の結果、私たちがファインチューニングしたモデルでは良いハイパーパラメータを見つけるのが難しかったため、その後の実験では0に固定し、他の3つのハイパーパラメータ(CFG、RG、LoRAスケール)のみで実験を行いました。
複雑な話はここまでにします。重要なことは、このようなハイパーパラメータを一つ一つ手作業で生成してグリッド探索(grid search)を行うのは、非常に大変だということです。私たちには時間もお金も足りません。もう少し効率的な方法を見つけなければなりません。
良いスタートポイントを見つける
このプロジェクトを進める過程で、空のプロンプト(null prompt)を利用したシードマイニング(seed mining)という方法を用いて、画像の品質を向上させるフレームワークを提案する論文(参考:1、2、3、4)を見ました。これらの論文を見て、良いスタートポイントを見つけられるアイデアを得ました。
シードマイニングの主なアイデアは、「シードごとに持っている固有の情報を見つけて整理しておき、画像生成時にその情報を活用して最適なシードを使おう」ということです。シードが持っている固有の情報を抽出するために、空のプロンプトを使います。空のプロンプトとは、長さが0の文字列を指します。つまり、シードマイニングはテキスト条件なしで画像を生成し、その画像の埋め込みやキャプションなどによって特性を抽出(mining)し、良いシード候補群を用意しておくプロセスです。前述でシードは整数値だと説明しましたが、その整数値からどのように情報を抽出するのか疑問に思われるかもしれません。シードマイニングは、シードを用いて生成したランダムノイズである潜在ベクトルから関連情報を抽出することです。
私たちは、マイニングの段階まで適用するには時間がなかったので、「良いシードを判断する」というアイデアだけを借用しました。また、良いシードであれば、プロンプトのテキストに含まれるすべての情報を持っているものと仮定しました。
良いシードを判断する方法は、多く研究されています(参考:1、2、3)。これらの研究は主に、SDに内在する「主題無視(subject neglect)」と「主題混合(subject mixing)」の問題を解決するための方法を提案しました。主題無視は、入力されたプロンプトの情報が画像に表現されない場合を指し、主題混合は、テキストのあるオブジェクトについての説明が画像では他のオブジェクトに混合される場合を指します。
以下の画像は、主題混合の代表的な例で、SDXLに「a cat and a rabbit」というプロンプトを入力して生成したものです。一見問題ないように見えますが、よく見ると奇妙な点があります。猫はウサギと同じ耳を持ち、ウサギは猫と同じ顔をしているからです。

このような問題は、ノイズ除去器に入力された潜在ベクトルにプロンプト関連の情報がないか、情報があっても不正確な位置にある場合に発生します。この2つの問題を解決するために、研究者たちは、潜在ベクトルとテキスト埋め込みの間のアテンションマップを利用した損失を定義し、これを最小限に抑える方向に潜在ベクトルを更新する方法を提案しました。
SD3.5を使用している私たちは、グラフィックスカードの状況上、潜在ベクトルを直接更新することは困難であったため、損失に焦点を当てました。損失を測定することで、そのシードにプロンプトに関する十分な情報があるかどうかを判断できるため、この損失でシードの適合性を判断することにしました。
以下の画像は、プロンプトとハイパーパラメータは固定し、シードのみを変更して作成したものです。損失はSD3.5と内部で利用するスタイルでファインチューニングしたモデルで、ランダムなシードと固定されたプロンプトの間で測定しました。損失値は小数点以下4桁まで表示し、結果のうち3番目に小さい値である0.0393を超える値は「0.0393超過」と表記しました。
| シード | 0 | 42 | 3143890026 |
|---|---|---|---|
| 損失 | 0.0393超過 | 0.0393超過 | 0.0380 |
| 画像 |  |  |  |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
| シード | 2571218620 | 200427519 | 893102645 |
|---|---|---|---|
| 損失 | 0.0380 | 0.0383 | 0.0393 |
| 画像 |  |  |  |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
上記の表を見ると、損失が低いほど画像の品質が良くなる傾向がありますが、必ずしもそうではないことがわかります。シードは初期ランダムノイズを決定する値であるため、そのシードとプロンプトの間で測定した損失が低ければ低いほど、完成する画像の品質が良いとは限らないという限界があります。私たちは上記を経て、その後の実験で「a cat and a rabbit」というプロンプトのシードとして「3143890026」を使うことにしました。
生成された画像の品質を判断する
前述の「良いスタートポイントを見つける」では、生成された画像の品質を目で見て判断しました。しかし、多くの画像を処理するには、このプロセスを自動化する必要があり、そのためには画像の品質を数値化する必要があります。私たちのプロジェクトでは、そのために先日公開したAIで生成された画像をどのように評価するのか?(基本編)で説明したいくつかの指標のうち、4つの指標を使用しました。それは、CLIP ScoreとVQA Score、HPS-V2、Pick Scoreです。
これに関連した内容をもう一度簡単に説明すると、良い画像は以下の2つの条件を満たすと言えます。
- 画像がプロンプトの情報を十分に表現していること。
- プロンプトに基づいて見たとき、画像に不自然な点がなく、全体的に一貫性があること。
最初の条件は、プロンプトと画像との関係を測定する条件として、CLIP ScoreとVQA Scoreを用いて測定しました。この2つの指標は、プロンプトの内容が画像にどれだけ含まれているかを判断できる指標です。
2つ目の条件は、画像の質的な完成度を評価する条件としてHPS -V2とPick Scoreで測定しました。この2つの指標は、入力されたプロンプトに基づいて自動生成された複数の画像のうち、どれが一番良い画像だと判断するかという人間の好みを調査したデータを活用して学習されています。そのため、生成された画像が良い画像であるかどうかを判断できる指標として使用できます。
スケールの異なる指標を正規化する
上記の4つの指標を使うことにした後、問題が一つ発生しました。選択した指標のスケールが異なるということです。スケールの定義はすべて0~1の間でしたが、スコアを測定する評価モデルが私たちのデータに対して測定した値には、指標ごとに違いがありました。このスコアを正規化せずにそのままインポートして平均を計算してしまうと、評価が特定の指標に偏った形で表示される可能性が高かったです。
これを緩和するために、HPS-V2評価用データセットを用いて各指標を正規化しました。このデータセットは、画像とプロンプトのペアに対して人間が1から10までの尺度で採点したデータセットで、スコアごとにデータ分布が異なります。各評価モデルの測定値を正規化するために、スコアごとに階層的サンプリングを実行してデータを処理しました。そして、最適なケースである「内部で利用するスタイルに従うために学習時に使用したデータセット」を最高得点である11点に設定し、それに合わせて全データを11の等級(bin)に分けました。
具体的には、評価モデルの測定値を平均化し、各階級のスコアを統合しました。データセット��で1点と評価されたデータに対する測定値をモデルごとに平均化し、2点台も同様に平均化しました。そして、正規化に使う平均と標準偏差を計11個の測定値を基に計算しました。
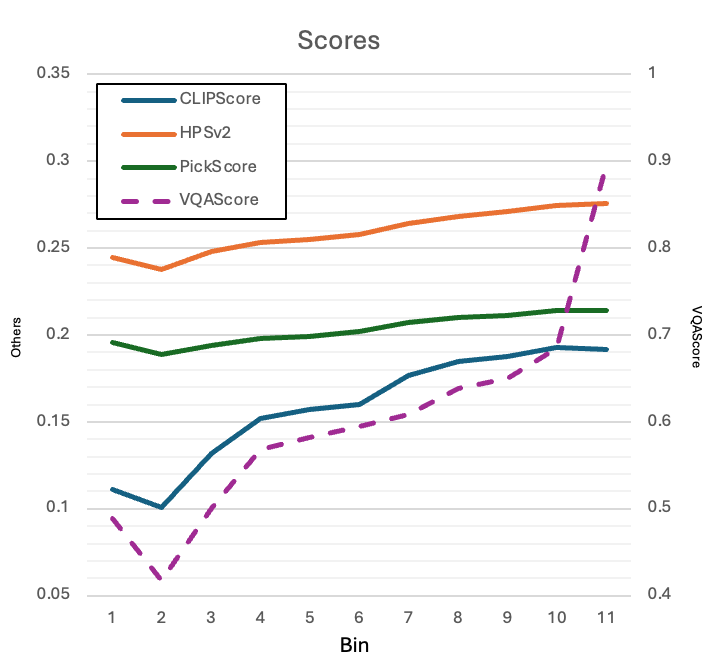
以下のグラフを見ると、評価等級が高いほど各評価モデルのスコアもおおむね高くなることが確認できます(ちなみに、VQA(紫色の点線)は右側の尺度、他の3つの指標は左側の尺度が基準です)。ただし、評価モデルは2番目の等級に最も低いスコアを与える傾向がありました。私たちは良いスコアを付与された画像を中心に使用するため、低いスコアで発生したこの現象は無視しました。
上記を経て最終的に求めた各指標の平均と標準偏差は、以下のとおりです。
| CLIP score | HPS-V2 | Pick score | VQA score | |
|---|---|---|---|---|
| 平均 | 0.1587 | 0.2591 | 0.2031 | 0.6029 |
| 標準偏差 | 0.0323 | 0.0127 | 0.0086 | 0.1248 |
画像に対するスコアは、4つの評価モデルが測定した上記の表の値をそれぞれ正規化し、その値の平均で定義しました。もちろん、このように正規化しても限界はあります。これだけでは、内部で利用するスタイルに従ったかどうかを評価するのは難しいためです。10等級と11等級のスコアに大きな差が出るVQA Scoreもありますが、そうでないCLIP ScoreやHPS-V2のような場合も存在します。内部で利用するスタイルのデータとの類似度を測定する方法も検討しましたが、スタイルが似ていることを評価できる妙案が見つからず、とりあえずこの4つの指標のみを活用しました。また、前述のLoRAスケールで補完しました。
LoRAスケールは、デフォルト値の1の場合は新しく学習した画像の特性をそのまま反映し、0の場合はその特性を全く反映しません。値が大きすぎると、画像の特性が歪む可能性があります。私たちは、モデルが生成した画像は内部で利用するスタイルに従うことを前提にするため、LoRAスケールが一定範囲(0.8~1.2)を超えないように設定しました。
ブラックボックス最適化で内部構造が不明な関数の最適値を求める
これで、画像を自動的に評価する方法の準備が整いました。次に、この指標を用いて最適なハイパーパラメータを探索します。ハイパーパラメータ探索に広く使われているグリッド探索は、良い画像であることを判断することはできますが、探索コストが非常に高くなります。その代わりに、私たちは画像自動評価指標を確保したので、これを活用したブラックボックス最適化手法を適用することにしました。ブラックボックス最適化は、ベイジアン最適化(Bayesian optimization)の別名で、内部構造が不明な関数の最適値を見つける手法です。
以下の2つのグラフはブラックボックス最適化プロセスの一例です。このグラフとともにブラックボックス最適化プロセスがどのように行われるかを概説します。
まず、以下の上段のグラフの赤い点線が前述した内部構造が不明な与えられた関数(ブラックボックス関数)のグラフです。この関数の最適値(この場合は最大値)を見つけることが目標です。私たちはこのブラックボックス関数の形はわかりませんが、すでに知っている関数でこのブラックボックス関数を近似できます。そのために、まず、このブラックボックス関数の値をいくつか直接測定してみます。赤い点線上の赤い点が測定したものです。このデータに基づいて、近似関数を適切にマッピングできます。青い実線が近似関数のグラフで、薄紫色の広い範囲が近似関数に基づいて予測した信頼区間を示します。
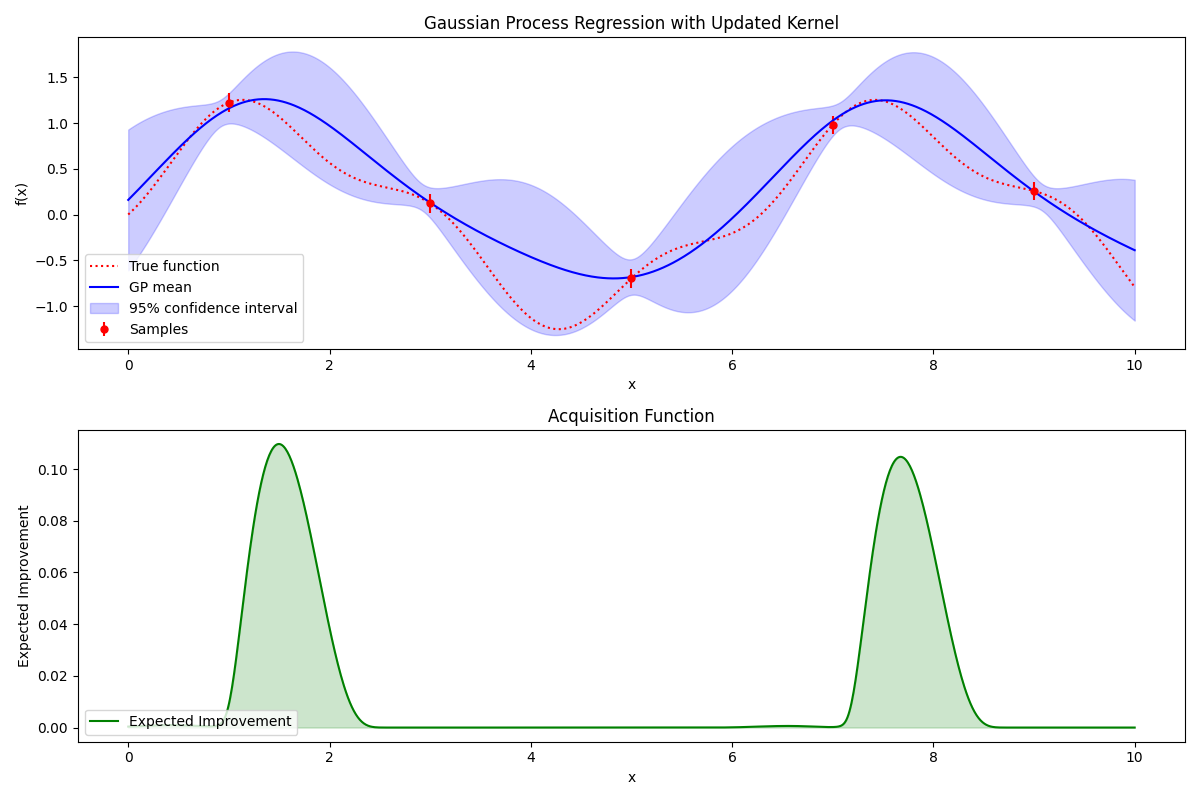
ブラックボックス最適化は最小限の探索で最適な位置を見つける�プロセスなので、次に問題となるのは「次の探索ポイントをどのように決定するか」です。上の画像の下段のグラフとともに説明します。最も値が高くなりそうなところが良い候補だと考えられますね?その候補は、まだ探索されていない領域(薄紫色の信頼区間が広いところ)と、すでに良い結果(実際の関数値が高いところ)を示した領域の両方を考慮(expected Improvement)し、最も値が高くなる可能性のあるところとして決定します。このプロセスが、内部構造が不明な関数の最大値の位置を探索していくブラックボックス最適化です。
私たちは、特定のプロンプトとハイパーパラメータで生成された画像を入力すると、画像スコアを返す関数をブラックボックス関数として定義しました。そして、探索する空間を3つのハイパーパラメータ(CFG、RG:1.0~10.0、LoRA:0.8 ~ 1.2)が取りうる空間として定義しました。ベイジアン最適化は現在も多くの研究が行われている分野ですが、今回の実験ではベイジアン最適化ライブラリ(参考)が提供する基本的な探索方式を使用し、3回の初期探索の後、10回の探索を行いました。
「a cat and a rabbit」プロンプトでブラックボックス最適化を実施
まず、「a cat and a rabbit」というプロンプトを使ってブラックボックス最適化を行いました。シードには、以前探索したシード値(3143890026)を使用しました。合計13枚の画像が生成されましたが、以下はその一部をスコアの高い順に並べ替えたものです。最もスコアが高い画像1は、実際に画像の完成度が一番高く見えます。また、この探索プロセスでは、品質が悪いだけでなく、全く違うスタイルの画像が生成される可能性もあることが確認できました。
| 番号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 画像 |  |  |  |  |  |
| スコア | 0.2395 | 0.2386 | 0.2243 | 0.2227 | 0.2088 |
| CFG | 9.1839 | 4.7532 | 1.0383 | 9.9996 | 1.0652 |
| RG | 1.0142 | 1.0010 | 1.0328 | 9.8277 | 9.9207 |
| LoRA | 1.0235 | 1.0881 | 1.0931 | 1.1984 | 0.8468 |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
「A woman is holding a picket sign. The sign has the words "hold the LINE" written on it.」プロンプトでブラックボックス最適化を実施
このプロンプトの場合も、前述で説明したシード探索の方法でシード(2581769315)を見つけました。その後、上記と同様に、合計13枚の画像を生成し、その一部をスコアの高い順に並べ替えました。
| 番号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 画像 | 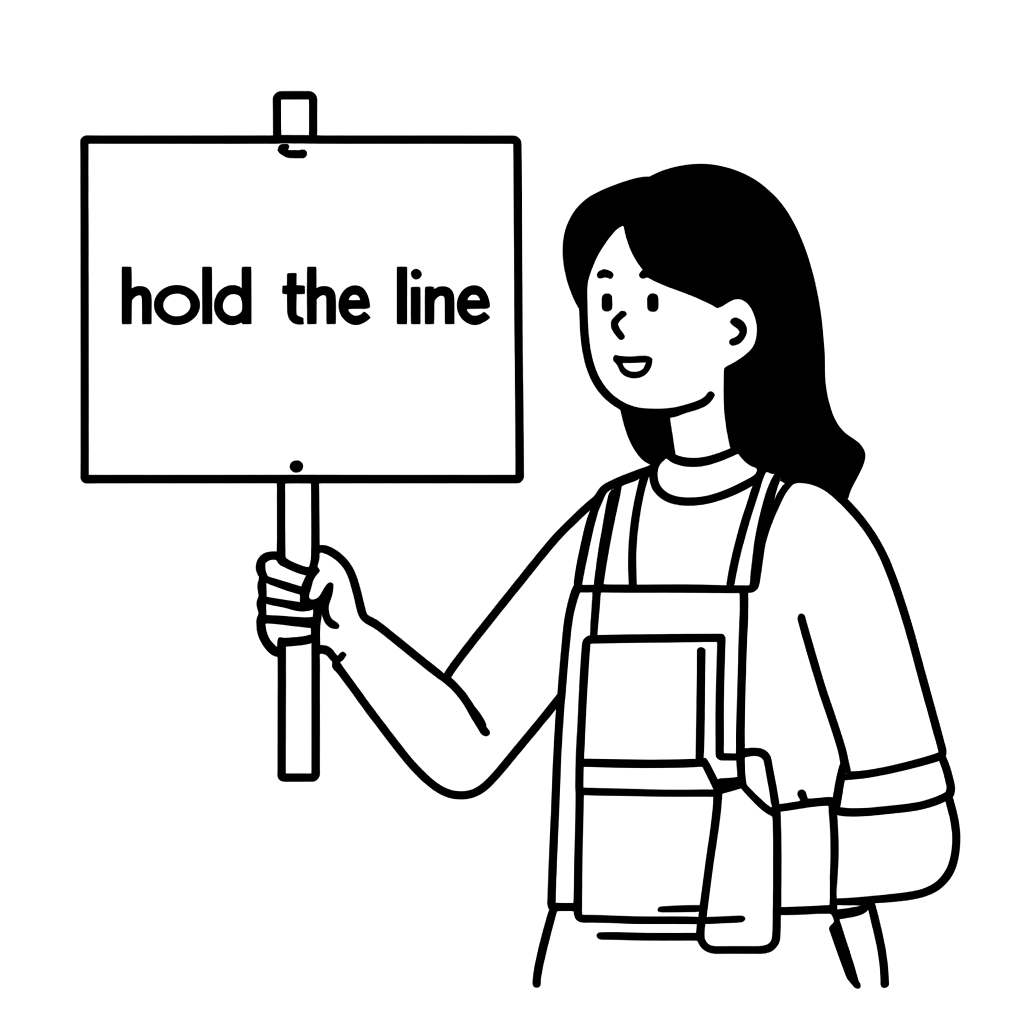 | | | 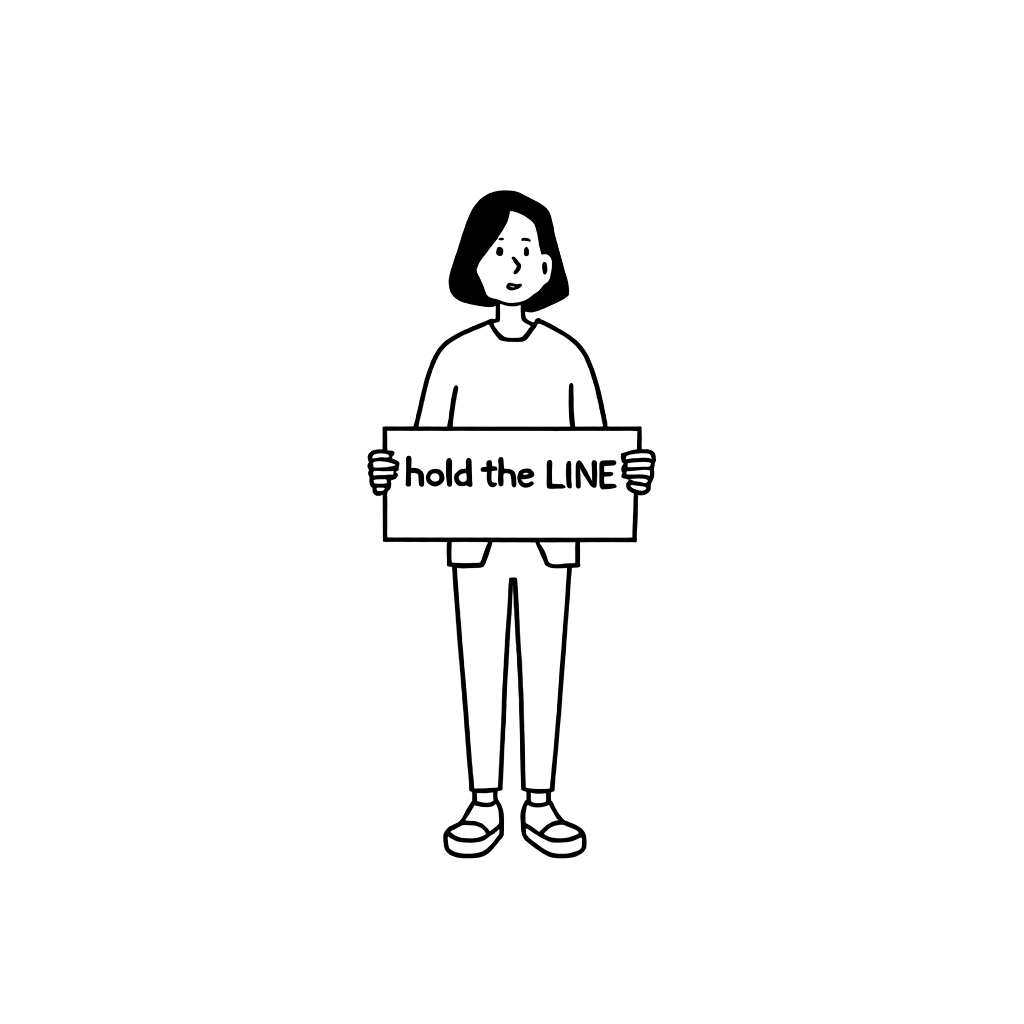 |  |
| スコア | 0.2734 | 0.2681 | 0.2639 | 0.2524 | 0.2497 |
| CFG | 2.7732 | 2.3208 | 3.0985 | 9.9996 | 9.9936 |
| RG | 3.4702 | 2.6763 | 4.335 | 9.8277 | 4.3512 |
| LoRA | 0.8212 | 0.8369 | 0.9913 | 1.1984 | 1.1492 |
* 画像を右クリックして新しいタブやウィンドウで開くと、元のサイズで見ることができます。
最も高いスコアを達成した画像1は、一見すると問題ないように見えますが、あまり良いとは言えません。左手の表現がエプロンの表現と混ざり合って曖昧に表現されているからです。私たちは画像3の方がより良いと判断しました。服のディテールが省略され��、文字も希望の形で出力されたからです。
もう少し詳しく見てみると、画像3よりスコアが高い画像2は、実は正常な画像とは言えません。スコアが低い画像3の方が品質が良いのです。同様に、画像5も画像4より品質が高いと言えます。顔の形が画像4より内部で利用するスタイルに近いためです。画像4の顔は、学習した内部で利用するスタイルと大きな違いがあります。このような例から、特定の画像があるスタイルによく従っているかを評価するには、追加の指標が必要であることがわかります。
結論:効果はありましたか?
はい、画像の自動評価とハイパーパラメータ探索の導入は効果的でした。具体的には、自動評価方法を導入したことで、画像を得るという手間のかかるプロセスを大幅に自動化できました。特に、自動化する際にランダム探索ではなく、統計に基づいた探索を適用したため、より信頼性の高い結果を得られました。また、ハイパーパラメータをどのように設定すべきかを検討するために使っていたリソースを最小限に抑え、業務のためのリソースをより多く確保できました。さらに、最適なシードを決定する方法を確立したことも、検討すべき別の要素をもう一つ排除できたという点で非常に効果的でした。
ただし、ブラックボックス探索で生成された画像の構図や特性があまりにも多様だったことは少し残念でした。この部分で発生した多様性の範囲を縮小できれば、探索空間も最小化できるため、より良い画像を見つける確率が高くなると考えます。また、私たちのシナリオでは、このブラックボックス関数の入力としてCFGとRG、LoRAスケールを使用しました。しかし、これらの3つのハイパーパラメータは、互いに独立しているとは考えにくいため、探索の難度が少し高くなったと思われます。
今後の展開
今後、さらに進めるプロジェクトとしては、大きく以下の3つに集約できます。
- 私たちが求める最終的な成果物のスタイルやレベルに合致しているかどうかを判断する画像評価指標の探索
- 生成される画像をより精緻に制御するためのImage-to-Imageの生成方式の適用
- モデルが生成する画像の自由度を最小限に抑え、画像生成空間を縮小
上記3つのうち、最初の2つは本文でも言及した課題です。現在使用している画像評価指標は、私たちが求める最終的な成果物のスタイルやレベルに従っているかどうかを評価するにはやや不十分であることが実験を通じて確認できました。また、Text-to-Imageモデルで画像を生成すると、画像の構図や画像内のオブジェクト表現における自由度が非常に高くなります。そのため、生成物をより簡単かつ精緻に制御するには、追加で画像情報を提供することが有効だと考えられます。
最後の課題である「生成される画像の自由度を最小限に抑える」は、上記の2つの課題とは少し文脈が異なります。この課題は、この記事で紹介したプロジェクトの実施から導き出されたものです。前述のように、このプロジェクトは、デザイナーの反復業務を最小限に抑えるために始まりました。その反復業務とは、通常、全く新しい画像を描く作業ではなく、既存の画像内で人物が手に持っているオブジェクトを追加したり変更したりする程度のケースが多かったのです�。このようなニーズに対応するためには、モデルの生成自由度を一定レベル以下に調整できる必要があると考え、この課題が導き出されました。
私たちは今後も、このプロジェクトのようにLINEヤフーのメンバーに役立つ適切なAI/MLモデルを開発するために、たゆまぬ努力を続けていきます。その過程でまた良い課題が見つかれば、改めてご報告いたします。長文をお読みいただき、ありがとうございました。


