Hello. I am Heewoong Park, an ML engineer from the AI Services Lab team. Our team develops and serves various AI/ML models related to OpenChat. Previously, in the post Improving OpenChat recommendation model with offline and online A/B test, we introduced the process of improving a model that recommends OpenChats tailored to individual user preferences.
In the OpenChat service, we are preparing features that encourage more active setting of hashtags that appropriately reveal the topic and characteristics of chat rooms while helping them be well-searched. In this article, I would like to share how we are developing a hashtag prediction model that helps specify hashtags when creating an OpenChat.
OpenChat hashtag prediction model
When creating an OpenChat, users must set the OpenChat name and can optionally leave a description of the OpenChat. At this time, we encourage users to use hashtags in the description field to enter keywords so that the OpenChat can be well-searched. We plan to improve this process by receiving hashtags in a separate field on the OpenChat creation screen, and we are preparing a feature that suggests hashtags using an ML model to make it easier for users to select hashtags. I will explain how we modeled and trained the hashtag prediction model for this suggestion feature.
Dataset construction
First, for the ground-truth hashtag data, we can extract a set of hashtags from the descriptions written by users who voluntarily included hashtags. Although the proportion of OpenChats where ground-truth labels can be extracted isn't high, we were able to secure more than 1 million data thanks to the thousands or tens of thousands of new OpenChats created every day.
As input for the prediction model, we only used the name and description of the OpenChat available at the time of OpenChat creation. The name and description were concatenated into a single string by inserting a delimiter to simplify the model structure. When constructing the training dataset, we remove the hashtag part from the description to exclude obvious cases where the answer appears in the input, and then compose the input text. We can also consider the author's information as a model input feature. Especially when the name and description of the OpenChat are insufficient, the hashtag information of other OpenChats created or participated in by the same user in the past would be very useful. This part is left as future work.
The table below shows which hashtags appear frequently in each region. Looking at the rankings, in Japan (JP), hashtags representing age groups (40代, 30代, 50代) are often used. This shows a preference for gatherings among people of the same age group. In Thailand (TH) and Taiwan (TW), hashtags related to fashion (เสื้อผ้า, แฟชั่น), price (ราคาถูก, ราคาส่ง), purchase (團購, 代購), and goods (生活用品) are frequently used. This indicates that various consumer activities are actively conducted through OpenChat.
| Rank | JP | TH | TW |
|---|---|---|---|
| 1 | 雑談 | บอท | 團購 |
| 2 | 恋愛 | เสื้อผ้า | 聊天 |
| 3 | なりきり | ราคาถูก | 美食 |
| 4 | 40代 | เสื้อผ้าแฟชั่น | 代購 |
| 5 | 相談 | กระเป๋า | 批發 |
| 6 | 30代 | ราคาส่ง | 交友 |
| 7 | 50代 | ขายส่ง | 美妝 |
| 8 | 既婚 | พรีออเดอร์ | 生活用品 |
| 9 | 癒し | แฟชั่น | 分享 |
| 10 | ゲーム | รองเท้า | 對戲 |
The following table shows the distribution of how many hashtags were extracted per OpenChat, confirming that it is more common for users to input multiple hashtags than just one.
| Number of hashtags | JP | TH | TW |
|---|---|---|---|
| 1 | 30.5% | 47.1% | 38.2% |
| 2 | 15.5% | 14.9% | 13.9% |
| 3 | 13.3% | 11.9% | 13.7% |
| 4 | 9.2% | 7.6% | 9.5% |
| 5 | 6.2% | 4.8% | 6.4% |
| 6 | 4.5% | 3.2% | 4.3% |
| 7 | 3.3% | 2.2% | 2.9% |
| 8 | 2.6% | 1.6% | 2.1% |
| 9 | 2.0% | 1.2% | 1.6% |
| 10 | 1.6% | 0.9% | 1.2% |
Modeling as a multi-label classification problem
We modeled this problem as a multi-label classification where the OpenChat name and description are input, and a set of relevant hashtags is output.
We decided to adopt a classification task where hashtags are selected from a predefined set of classes rather than a generative task for the following reasons:
- The project's starting point was to classify with more diverse keywords than the fixed OpenChat categories within 50.
- To reduce the risk of controversial hashtags being output from a generative model. By composing the dataset with pre-reviewed hashtags, we can minimize risk.
- The size of the training dataset is sufficient, and training a classification model specialized for the problem performs better than a generative model trained on publicly available text data.
We did not formulate it as a multi-class classification where only one class is chosen from the class set because allowing multiple hashtags not only improves searchability but also reflects the users' behavior, as seen in the distribution above.
The output space of a multi-label classification model is a vector space whose dimension is equal to the number of classes, and each component value of the vector is assigned a value of 0 or 1, indicating whether an instance belongs to the class. For example, if the output class set is and the label of an instance is , it is converted to a vector (1, 0, 1).
Generally, a multi-label classifier is trained using a binary cross-entropy loss (BCE loss) for each component of the output space. However, the goal of the hashtag prediction is to select the top K hashtags in order of relevance rather than judging the relevance of each hashtag for the OpenChat. It is more natural to think that users pick a few that come to mind immediately rather than considering the relevance of all possible hashtags when creating an OpenChat.
Therefore, we adapted a categorical cross-entropy loss (CCE loss), which is commonly used in multi-class classifier training, for our problem. CCE loss is calculated by substituting the ground-truth one-hot vector for and the predicted probability vector for in the cross-entropy defined between two distributions , . To apply it to multi-label classification training, we substituted a normalized multi-label vector with a sum of 1 for instead of a one-hot vector. Reusing the previous example, if the case is , the vector becomes (0.5, 0, 0.5).
For reference, in this article, hashtags are referred to as classes or labels from the perspective of classification tasks and data, and as inference results or model outputs from the perspective of the model.
Implementation using Hugging Face's Transformers
The model implementation utilized the Hugging Face's Transformers package. In simplified code, the input examples dataset consists of fields for OpenChat name, description, and hashtags for each row.
In the preprocessing function, the name and description without hashtags are concatenated into a single string and tokenized to create an input token sequence. For the hashtags array used as labels, we use the sklearn.preprocessing.MultiLabelBinarizer module to create a binary matrix. If the output space (the set of entire hashtags) is large, encoding in a dense format can excessively consume memory. Since only a small portion of the tens of thousands of hashtags are attached to a single OpenChat, encoding in a sparse format can reduce memory usage, and using the LIL (list of list) format allows for quick retrieval of any i-th row.
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
def preprocess(examples: pd.DataFrame, tokenizer, classes, max_length=None):
examples["input_text"] = examples.apply(
lambda x: f"{x['name']}\n{x['description_without_tags']}"
)
encoded_inputs = tokenizer(
examples["input_text"].to_list(),
truncation=True,
max_length=max_length
)
mlb = MultiLabelBinarizer(classes=classes, sparse_output=True)
mlb_output = mlb.fit_transform(examples["hashtags"])
encoded_inputs["labels"] = mlb_output.tolil()
return Dataset(encoded_inputs)After preprocessing, the data is structured in the form of a Dataset object for training the Transformers model. This object is responsible for converting data that requires GPU computation into the torch.Tensor format. The labels field, which was encoded in a sparse format earlier, is converted to a dense tensor format only at the time of mini-batch computation, thereby improving memory efficiency.
import torch
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __len__(self):
return len(self.encodings["input_ids"])
def __getitem__(self, idx):
# process input other than labels
item = {k: torch.tensor(v[idx]) for k, v in self.encodings.items() if "labels" not in k}
# convert labels from lil matrix row
lil_row = self.encodings["labels"].getrowview(idx)
labels_ndarray = lil_row.toarray().squeeze(0)
item["labels"] = torch.tensor(labels_ndarray, dtype=float)
return itemTo train a multi-label classification model with the proposed modified loss function, we created a MultiLabelTrainer class by customizing the compute_loss method of the transformers.trainer.Trainer class as follows.
from torch import nn
import transformers
class MultiLabelTrainer(transformers.trainer.Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get("labels") # all elements are 0 or 1
labels /= labels.sum(dim=-1, keepdim=True) # normalize by sum
outputs = model(**inputs)
logits = outputs.get('logits')
log_probs = nn.functional.log_softmax(logits, dim=-1)
loss = -(labels * log_probs).sum(dim=-1).mean() # compute the suggested CE loss
return (loss, outputs) if return_outputs else lossOffline experiment results
The most intuitive evaluation metric that comes to mind when conducting offline experiments is the precision@1 metric, which evaluates the proportion of correct answers among the labels predicted with the highest scores. Since we were considering a scenario where we present as many relevant hashtags as possible within a predefined limit, recall@K metrics were also selected as major comparison targets. Since recall@K metrics do not differentiate between different orderings within the top K predicted labels, we also compared ndcg@K metrics, which reflects the ranking.
The code to calculate and aggregate these evaluation metrics can be implemented as follows. When calculating recall@K and ndcg@K, since prediction results outside the top K scores do not affect the evaluation, computation can be optimized by considering only the top K during sorting. In a similar context, if the output logit value is less than 0, the predicted label is unlikely to be correct, so we assign a smaller negative value (-100) than the usual logit values (-15 to 15). The implemented compute_metrics function can be passed as an argument to the MultiLabelTrainer constructor.
import numpy as np
import sklearn
def compute_metrics(eval_pred, ks=(1, 3, 5, 7, 10, 15, 30)):
logits, labels = eval_pred
binary_labels = (labels > 0).astype(int)
label_lengths = np.sum(binary_labels, axis=-1)
# only consider positive logits for faster computation
logits = np.where(logits > 0, logits, -100)
# select top maxk at first and then sort them for faster computation
maxk_ind = np.argpartition(-logits, max(ks), axis=-1)[..., :max(ks)]
maxk_logits = np.take_along_axis(logits, maxk_ind, axis=-1)
maxk_ind_sortind = np.argsort(-maxk_logits, axis=-1)
maxk_ind_sorted = np.take_along_axis(maxk_ind, maxk_ind_sortind, axis=-1)
_metrics = {}
_metrics["precisionAt1"] = np.take_along_axis(binary_labels, maxk_ind_sorted[..., :1], axis=-1).mean()
_metrics[f"ndcgAt{max(ks)}"] = sklearn.metrics.ndcg_score(labels, logits, k=max(ks))
recalls = {}
for k in ks:
topk_ind = maxk_ind_sorted[..., :k]
TPs = np.take_along_axis(binary_labels, topk_ind, axis=-1).sum(axis=-1)
recalls[f"recallAt{k}"] = (TPs / np.maximum(label_lengths, 1)).mean()
_metrics.update(recalls)
return _metricsAs for model training, we initialized the classifier with a pretrained multilingual LM to handle OpenChats written in multiple languages from regions such as Japan, Thailand, and Taiwan with a single model. The evaluation set was constructed by separating 1% of the data from the 1.5 million OpenChats in the training dataset.
The following table compares the performance of hashtag classifiers trained by initializing with various open-weight models available in the Hugging Face Models repository. The -large models with more parameters performed better in all metrics than the -base models. The sentence-transformers/LaBSE model, which has the same number of hidden embedding dimensions and self-attention layers as the -base model but a larger token vocabulary, performed better than the -base model and comparable to the -large model. Among the compared models, the multilingual-e5-large model, which further trained xlm-roberta-large with multiple multilingual corpora, performed the best, so we chose this model for subsequent experiments.
| Pretrained model | ndcg@30 | precision@1 | recall@1 | recall@3 | recall@7 | recall@30 |
|---|---|---|---|---|---|---|
| xlm-roberta-base | 61.45% | 59.56% | 27.41% | 44.93% | 57.07% | 73.10% |
| xlm-roberta-large | 62.17% | 60.01% | 27.54% | 45.49% | 57.58% | 74.05% |
| sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | 57.54% | 56.44% | 25.43% | 41.62% | 52.99% | 69.19% |
| sentence-transformers/LaBSE | 62.09% | 60.11% | 27.68% | 45.44% | 57.74% | 73.80% |
| intfloat/multilingual-e5-base | 62.26% | 60.30% | 27.86% | 45.76% | 57.86% | 73.80% |
| intfloat/multilingual-e5-large | 62.97% | 60.66% | 28.15% | 46.23% | 58.51% | 74.76% |
The following table shows the performance evaluation results by region to check whether the multilingual model works well for each language. Naturally, the metrics for JP region OpenChats, which had a high proportion in the training dataset, were high, while the metrics for TH and TW regions were relatively low. We also tried training separate models for each region, but there was almost no difference in performance compared to a single multilingual model. For the TH and TW regions, we plan to improve the preprocessing method to expand the training dataset and construct the class set with more distinct topic hashtags.
| Regions | Number of instances | precision@1 | ndcg@30 | recall@1 | recall@3 | recall@7 | recall@30 |
|---|---|---|---|---|---|---|---|
| JP | 11615 | 71.32% | 71.49% | 31.77% | 52.11% | 65.45% | 81.11% |
| TH | 1242 | 53.95% | 66.02% | 37.84% | 56.98% | 69.24% | 85.79% |
| TW | 2083 | 52.04% | 58.08% | 27.69% | 44.90% | 56.45% | 73.41% |
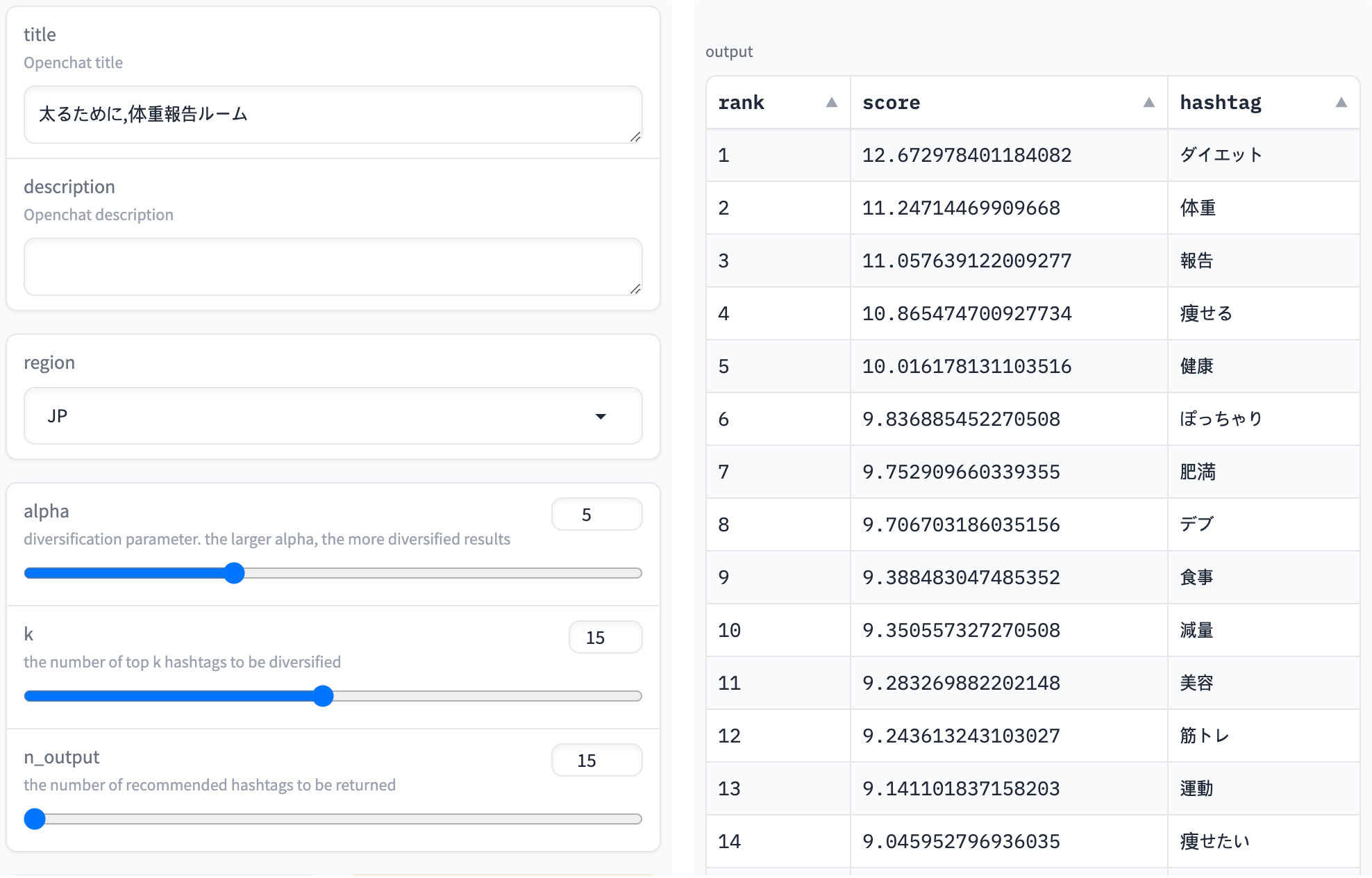
The following screenshot shows the inference results for the OpenChat name "太るために,体重報告ルーム" (translated: "To gain weight, weight report room"). It can be confirmed that hashtags such as ダイエット (diet) and 体重 (weight), which are likely to be related, are predicted with high scores. Although the title is "to gain weight", since it is more common to report weight to lose weight, keywords like 減量 (weight loss) also appeared in the top ranks.
Model improvement for real-time suggestions
Inference at multiple input points
In a scenario where hashtags are suggested to users through real-time inference at the time of OpenChat creation, the timing of model inference requests may not be limited to just once. Looking at the OpenChat creation process step-by-step, model inference can be requested at the following points:
- Since the description isn't a required input, suitable hashtags can be suggested first when only the OpenChat name is completed.
- When the user is writing a description, hashtags can be suggested to help with content association and encourage easy writing.
- In the situation mainly considered when constructing the model training dataset, hashtags are suggested when both the OpenChat name and description are completed.
- If the specification allows multiple hashtags to be entered for one OpenChat, each time a user selects a hashtag, it is reflected in the model input to suggest the next hashtag.
Among the four situations above, the first three situations can be considered somewhat reflected in the training dataset. First, situation 3 was directly considered, as the input text of the model was created with the OpenChat name and description excluding hashtags. Also, since the OpenChat description is an optional input, there are quite a few cases where only the name remains input in the training dataset, so situation 1 is fairly covered. Additionally, since the dataset includes OpenChats with various description lengths, it indirectly represents situation 2, where inference is triggered while writing a long description.
Let's look at the last situation 4. Already selected hashtags can be used as model input but should be excluded from the output. To improve accuracy in this situation, we augmented instances to the training dataset where, for OpenChats with more than two extracted hashtags, some of the extracted hashtags are appended to the input text, and the rest are composed as output labels.
For example, if an OpenChat's name is "太るために,体重報告ルーム" and the extracted hashtags are ["ダイエット", "体重", "健康"], we generate multiple training data instances as follows:
| Input text | Output label |
|---|---|
| "太るために,体重報告ルーム" | ["ダイエット", "体重", "健康"] |
| "太るために,体重報告ルーム\n#ダイエット" | ["体重", "健康"] |
| "太るために,体重報告ルーム\n#ダイエット #体重" | ["健康"] |
Now, let's see if model performance improves when some hashtags are reflected in the input text during training. The evaluation dataset is divided and constructed according to various inference points to examine the effectiveness of the augmentation by situation.
| Case ID | Input text | Output label |
|---|---|---|
| Case 1 | Name | Hashtags |
| Case 2 | Name + first half of the description excluding hashtags | Hashtags |
| Case 3 | Name + description excluding hashtags | Hashtags |
| Case 4 | Name + description excluding hashtags + first hashtag | Hashtags excluding the first one |
This comparison was conducted with the largest amount of JP region data for model training and evaluation.
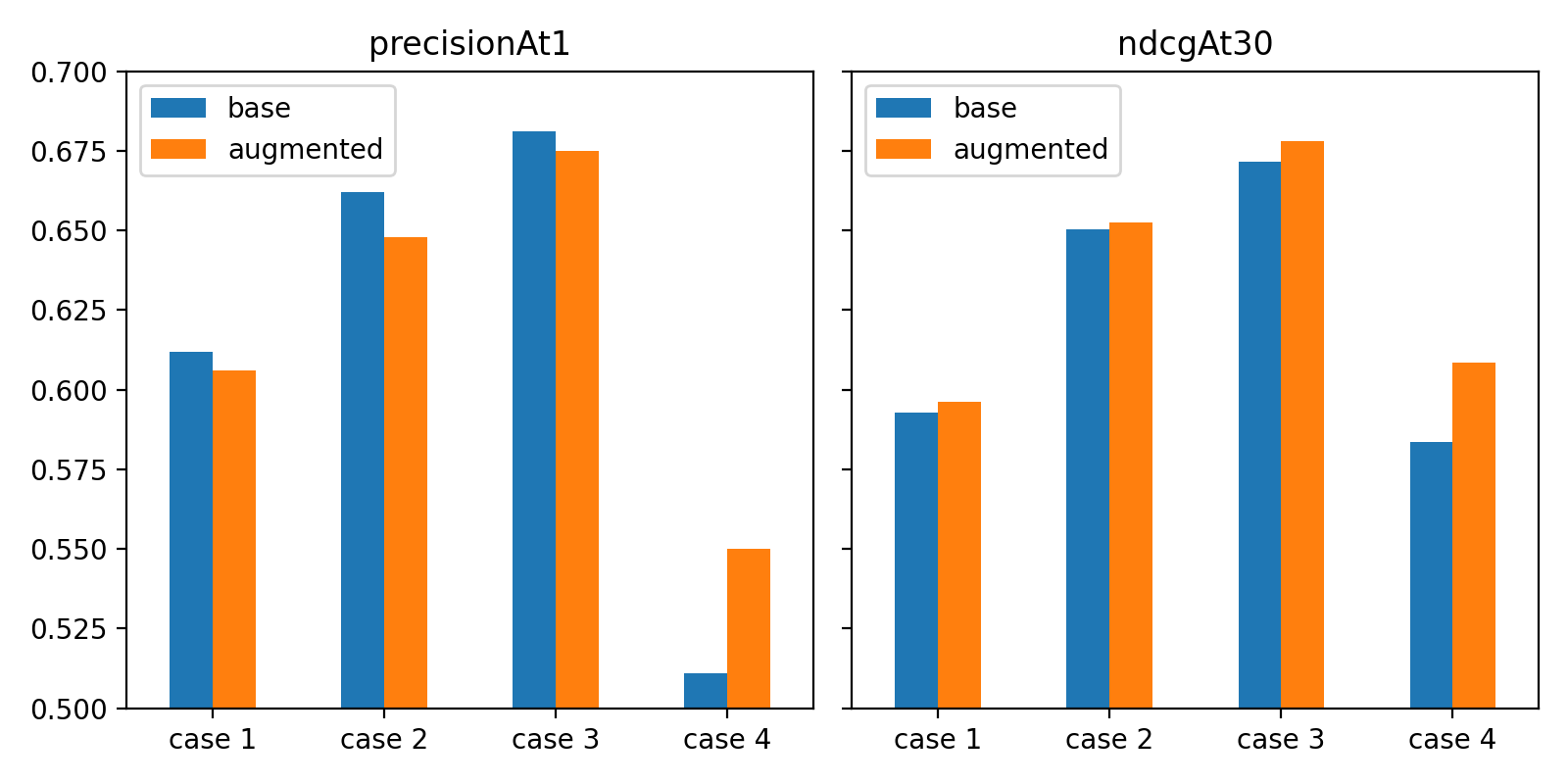
Comparing the base model and the model trained with augmented training datasets, both precision@1 and ndcg@30 metrics were clearly better for the latter model in Case 4, where the first hashtags is given as input.
In other cases, different results appeared for each metric. The evaluation metric for the top 1 prediction slightly decreased during data augmentation, but it was better when considering the top 30 prediction results. After examining selected samples, it turned out that the base model was more likely to predict keywords included in the input text as output hashtags. Due to the fact that a significant portion of the ground-truth labels in the evaluation set also appeared in the title, the precision@1 metric was somewhat high.
Currently, we are considering a specification that exposes up to 30 suggestion results, so considering this, the augmented model results are more desirable. As a note, as the amount of input information increases (Case 1 → 3), performance improves, but in Case 4, performance decreased. This is because the Case 4 group consists of instances that are more difficult to predict due to the reduced number of ground-truth labels per instance.
Diversifying suggestion results
Unlike offline tests, in real-time suggestions, the diversity of recommended hashtags should be considered. As the class set of the multi-label classification model grows, similar hashtags in terms of meaning or surface form are often included in the class set, resulting in similar hashtags showing up a lot in the top predictions.
For example, when the OpenChat name "スプラトゥーン2好きな人おいで" (translated as "People who like Splatoon 2") is input as text, the top 5 prediction results are ["スプラトゥーン2", "スプラ", "スプラトゥーン", "雑談", "スプラ2"]. Out of the 5, 4 start with "スプラ (Supura)".
From the model's perspective, it is advantageous to show all similar hashtags since it cannot be sure which one the user will choose, which is beneficial in terms of the evaluation metrics defined earlier. However, from the perspective of an interactive interface where users are suggested candidates and input them, exposing duplicate hashtags hinders users from expressing their OpenChat with rich keywords, which ultimately negatively affects potential participants finding the OpenChat.
To prevent this, we introduced the Maximal Marginal Relevance (MMR) technique, which considers the similarity with previously selected hashtags as a penalty when appending predicted hashtags to the recommendation list one by one in order of score.
Below is the formula for this technique. The k+1 ranked predicted hashtag selects the hashtag i with the largest adjusted score value as follows:
- : original recommendation score of hashtag i. The output logits (without the softmax normalization) were used as scores
- : penalty weight parameter
- : similarity of two tags i and j
- : the entire class set
- : the set of selected hashtags for recommendation until k-th step
This technique can adjust the degree of diversification by varying the penalty weight parameter . If this value is 0, no penalty is applied, and the larger the value, the heavier the penalty is imposed on duplicate results.
We considered two types of similarity between hashtags.
- First, token set similarity quantifies how much the surface morphemes overlap. It is defined as the Jaccard similarity (intersection size / union size) between the sets obtained by tokenizing the two hashtags.
- The other is embedding similarity, which quantifies their semantic similarity. Hashtag embeddings are obtained by averaging the embeddings of tokens included in the hashtag, and the cosine similarity between two hashtag embeddings is measured. The token embeddings were obtained from the input token embeddings of the pre-trained model for weight initialization.
Now, let's look at the results of applying MMR with various values. Since the goal is to maximize diversity while maintaining prediction performance, we compared recall@K values as performance metrics, and for diversity metrics, we defined the proportion of unique tokens among the top K recommended hashtags as follows:
dTkProp@K := # distinct tokens in top K predicted tags / the sum of token counts over the top K predicted tags
The graph below shows the results of applying MMR to the JP region data, which has the most diverse hashtags.
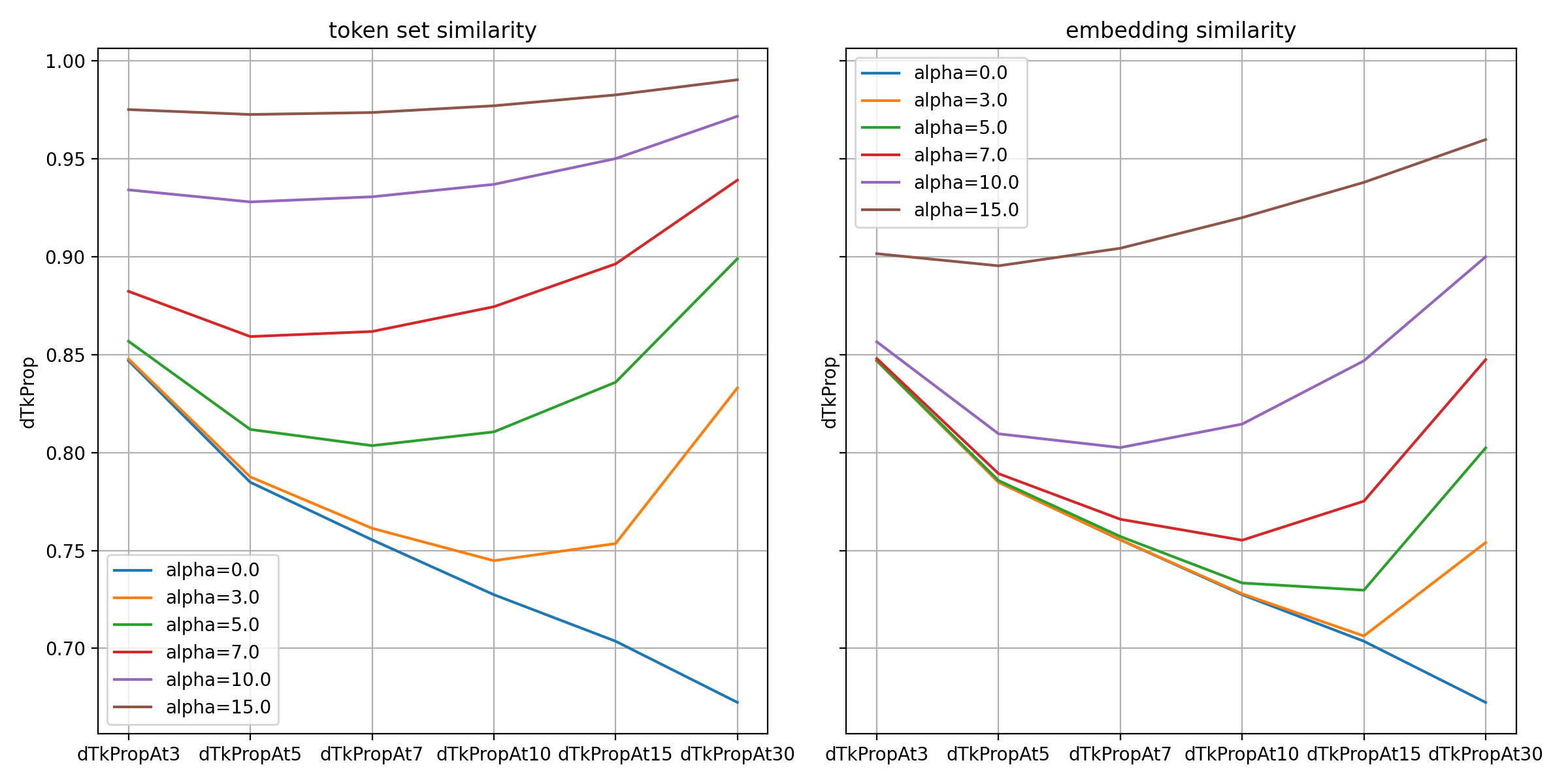
As can be seen from the graph, the proportion of unique tokens increased as expected with larger values for both types of similarity. Among the two similarities, the token set similarity, where token overlap is directly reflected in the penalty, showed a higher proportion of unique tokens in the predicted results.
Below are the results in terms of recall metrics. The larger the value, the greater the decline, and the token set similarity method was affected more sensitively.
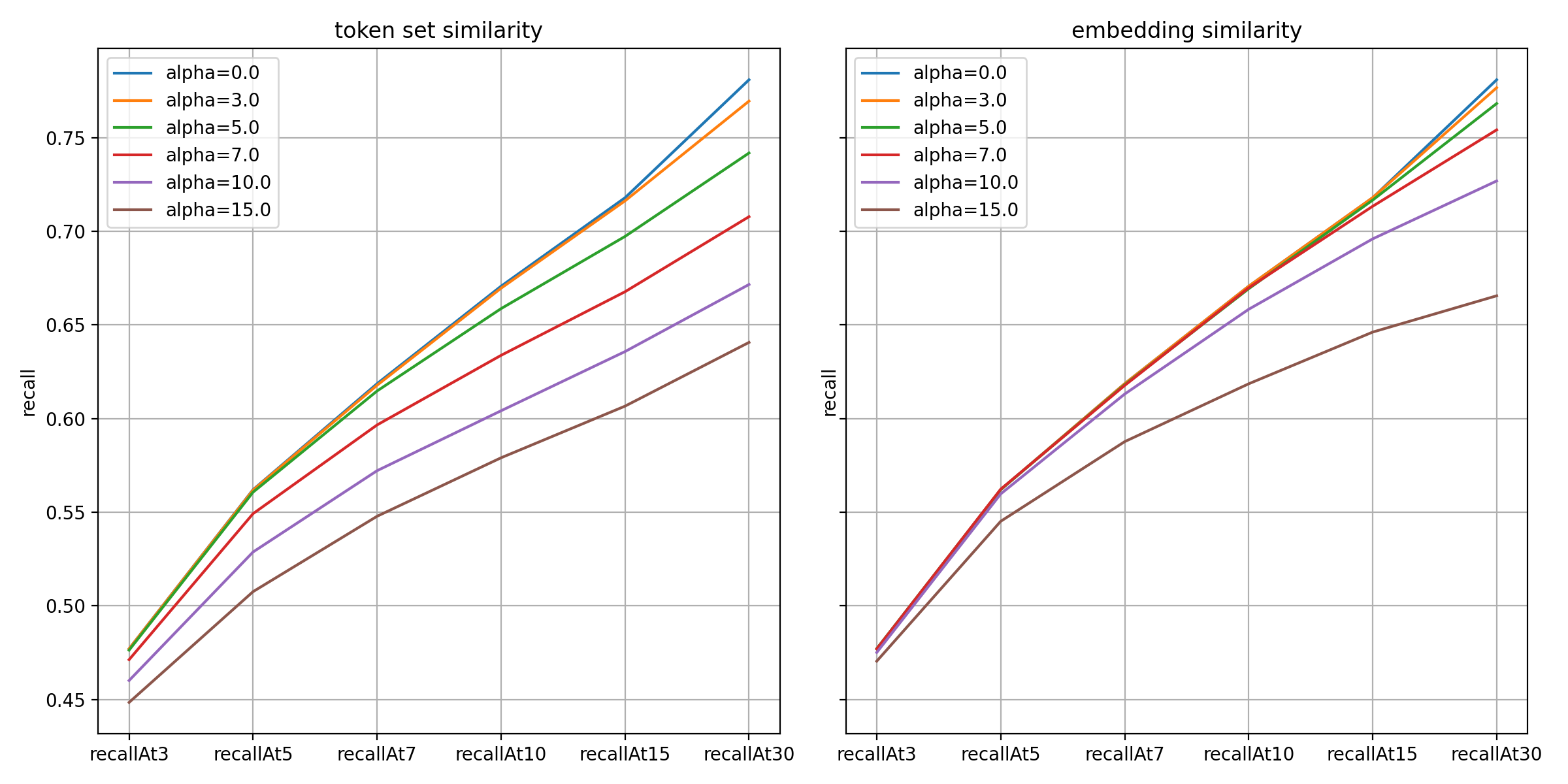
As shown in the results above, prediction performance and diversity are in a trade-off relationship. Considering the balance between the two, we narrowed down the alternatives to values of 5.0-7.0 for the token set similarity method and 10.0-15.0 for the embedding similarity method, and ultimately decided through qualitative evaluation.
The table below is a sample of the results of applying the diversification technique to the OpenChat "スプラトゥーン2好きな人おいで". It can be confirmed that hashtags starting with "スプラ" gradually decrease in the top ranks as the value increases.
| Rank | Before diversification | Token set similarity | Embedding similarity | ||||
|---|---|---|---|---|---|---|---|
| 1 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 |
| 2 | スプラ | スプラ | スプラ | スプラ | スプラ | スプラ | スプラ |
| 3 | スプラトゥーン | スプラトゥーン | 雑談 | 雑談 | スプラトゥーン | スプラトゥーン | 雑��談 |
| 4 | 雑談 | 雑談 | ゲーム | ゲーム | 雑談 | 雑談 | ゲーム |
| 5 | スプラ2 | スプラ2 | プラベ | リグマ | スプラ2 | スプラ2 | 楽しい |
| 6 | ゲーム | ゲーム | リグマ | 楽しい | ゲーム | ゲーム | 仲良く |
| 7 | スプラ好き | プラベ | 楽しい | 仲良く | スプラ好き | プラベ | 誰でも |
| 8 | プラベ | リグマ | 仲良く | 誰でも | プラベ | リグマ | 楽しく |
| 9 | リグマ | 楽しい | 誰でも | 楽しく | リグマ | 楽しい | ルール |
| 10 | 楽しい | 仲良く | 楽しく | ルール | 楽しい | 仲良く | 楽しもう |
| 11 | 仲良く | 誰でも | ルール | 楽しもう | 仲良く | 誰でも | 荒らし禁止 |
| 12 | 誰でも | 楽しく | ナワバリ | 荒らし禁止 | 誰でも | 楽しく | Splatoon |
| 13 | 楽しく | Splatoon2 | 楽しもう | イカ | 楽しく | ルール | Switch |
| 14 | Splatoon2 | ルール | 荒らし禁止 | Splatoon | ルール | 楽しもう | enjoy |
| 15 | ルール | ナワバリ | イカ | Switch | 楽しもう | 荒らし禁止 | 学生 |
The qualitative evaluation concluded that the token similarity method, which more effectively reduces string duplication, is more desirable than the embedding similarity method.
Selecting reliable outputs for offline tagging
While preparing the real-time hashtag suggestion feature at the time of OpenChat creation, the expansion of ad display within the OpenChat service led to the idea of utilizing inferred hashtags for more advanced OpenChat-ad matching.
In this case, tagging is performed through offline batch predictions. In an interactive interface, users make the final decision on the appropriate choice, so it is natural for the model to suggest hashtags in an expanded context. However, in the offline case, inaccurate hashtags can lead to inappropriate ad matching, so precision is also important.
To address this, we designed a method for offline tagging for ad matching that filters only reliable model outputs by introducing two threshold parameters.
First, we introduced the min_top1 parameter. If the top 1 prediction score is low, meaning no class received a high score, we designed logic to determine that the input data is insufficient for classification. According to this logic, if the top 1 prediction score is below the min_top1 threshold, no hashtags are tagged for that OpenChat.
Next, we introduced the min_score parameter to select only hashtags with prediction scores above the threshold among the top K hashtags passed to the matching system (note that K is set to 30).
Now, let's examine the distribution of predicted scores for the JP region validation dataset to determine the two thresholds.
First, when dividing the validation set by top 1 score intervals and examining performance metrics, a strong positive correlation between score values and prediction performance can be observed. Each line aggregates metrics by label count intervals. Somewhat obviously, the more correct labels there are, the higher the precision, which only needs to match one of them, and the lower the recall, which needs to find them all. When there are two or more labels (lines other than the blue line), the precision@1 value reaches above 50% from approximately the 10.0-11.0 score interval.
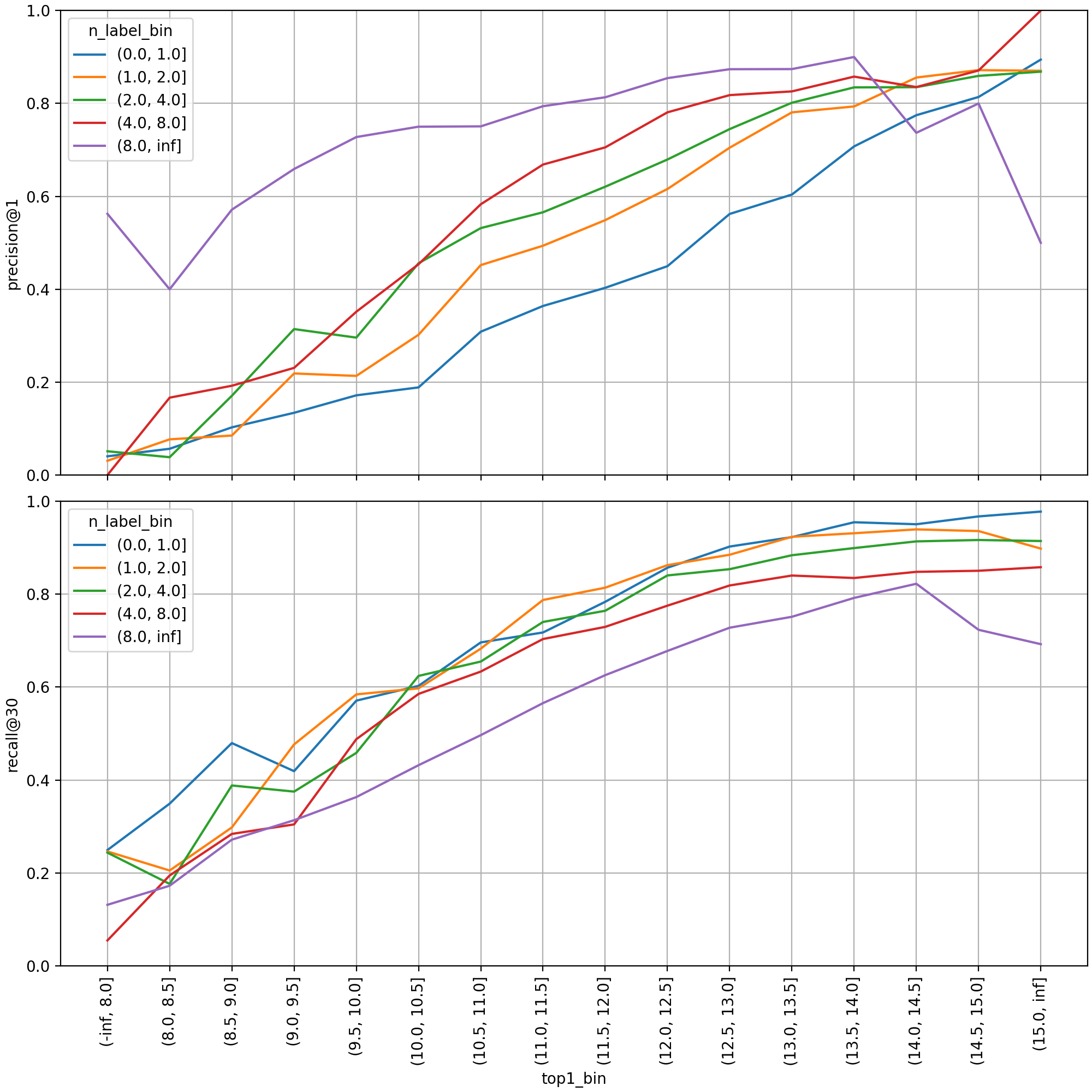
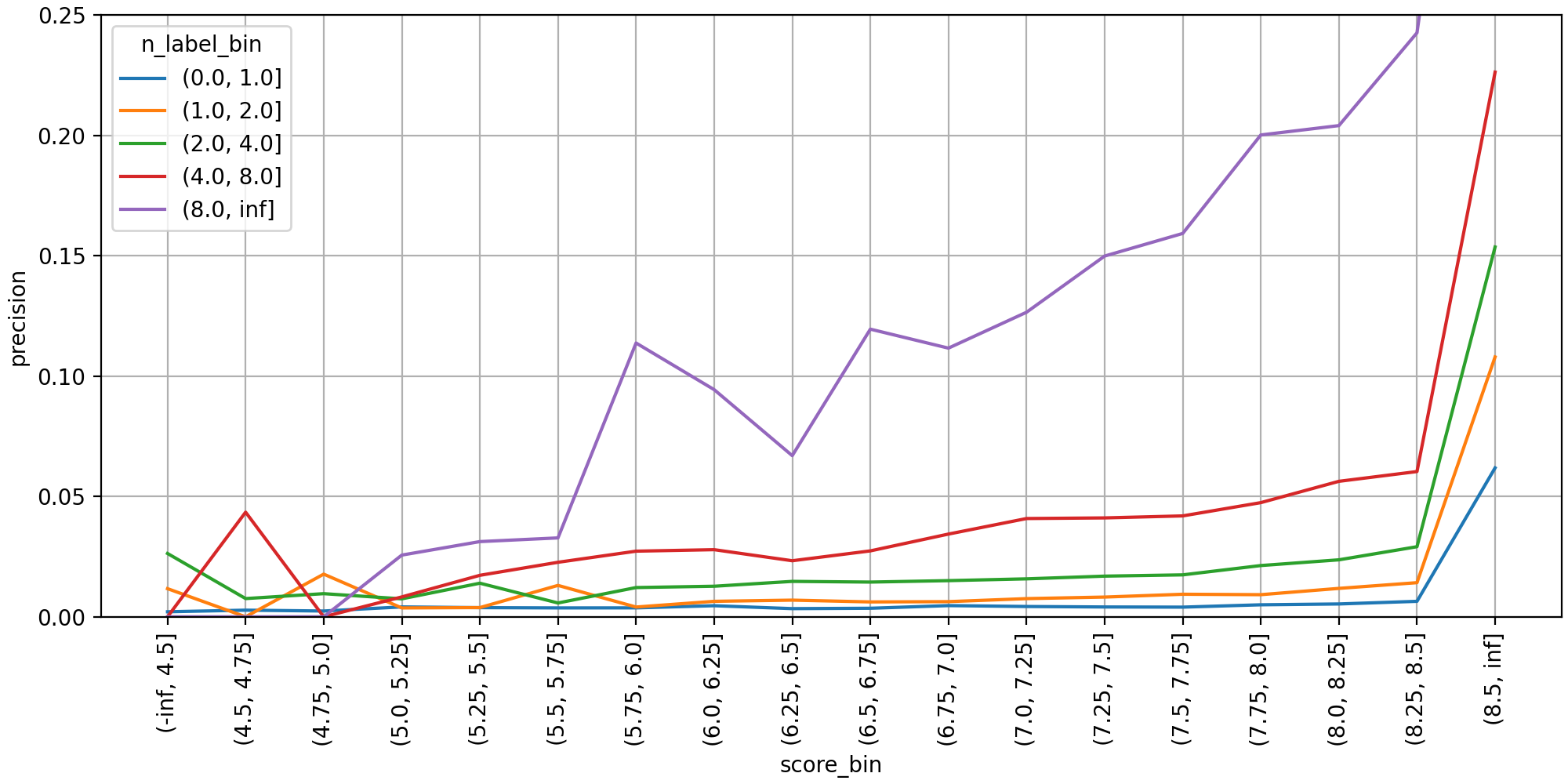
Next is the distribution graph examined to determine the min_score value. The top 30 predicted labels were treated individually as multi-class classification instances, and precision was aggregated by interval. When there are more than 8 labels (purple line), precision rose steeply near a prediction score of 6.0, and from 7.0 and above, it increased monotonically as the score increased.
Now, let's see how much inference results can be provided when selecting hashtags using the above method. The following is a coverage graph of OpenChats that can provide at least one inferred hashtag when judged based on the top 1 score.
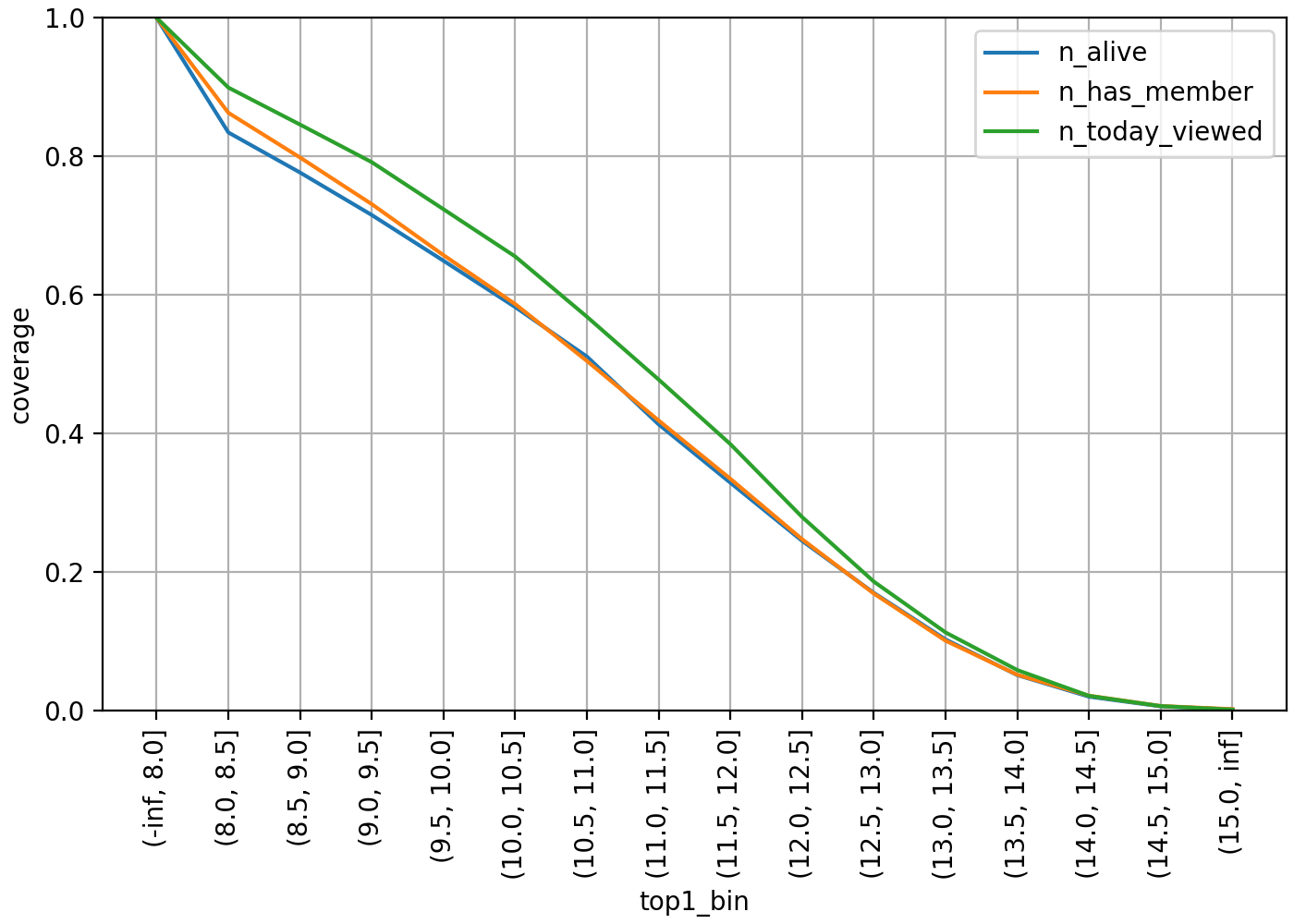
Each line shows the coverage on a subset of OpenChats with respect to their activeness. The blue line represents ALIVE status, which isn't DELETED or SUSPENDED, the orange line represents having at least one member, and the green line represents OpenChats with at least one page view on the day. When the min_top1 value is set to 10.0 for the entire ALIVE target, coverage is close to 60%, but if the threshold is raised to 11.0, it falls to around 40%.
The table below shows the distribution of the number of output hashtags according to the min_score threshold setting. Here, the min_top1 value is fixed at 10.0, excluding OpenChats with no tagging results from the population, and the maximum number K is limited to 30. If the min_score value is set to 6.0 or lower, the number of output hashtags reach to the maximum limit for the majority of OpenChats, but if the threshold is 7.5 or higher, the proportion of 10 or fewer hashtags exceeds half.
| Number of hashtags range | min_score threshold | |||||
|---|---|---|---|---|---|---|
| 5.5 | 6.0 | 6.5 | 7.0 | 7.5 | 8.0 | |
| (29, 30] | 77.27% | 57.87% | 36.33% | 17.68% | 6.53% | 1.84% |
| (25, 29] | 4.48% | 6.69% | 7.23% | 6.11% | 3.76% | 1.44% |
| (20, 25] | 5.59% | 8.96% | 11.14% | 10.35% | 7.25% | 3.92% |
| (15, 20] | 8.79% | 8.80% | 12.68% | 14.59% | 12.26% | 7.93% |
| (10, 15] | 2.89% | 11.69% | 12.98% | 18.06% | 19.61% | 16.75% |
| (5, 10] | 0.91% | 5.24% | 15.81% | 18.46% | 25.29% | 29.44% |
| (0, 5] | 0.08% | 0.78% | 3.84% | 14.75% | 25.30% | 38.68% |
Based on this, considering the trade-off relationship between precision and coverage, we narrowed down the alternatives to min_top1 values of 10.0-11.0 and min_score values of 6.0-7.5, and ultimately decided through qualitative evaluation.
To apply the same score thresholds when retraining the model, it must be assumed that the score distribution does not change significantly between the previous model and the new model. Therefore, we are automatically monitoring the score distribution in the model training pipeline, and experimentally confirmed that the distribution does not change significantly while updating the model several times with new data.
Conclusion
We have introduced the process of developing and advancing the OpenChat hashtag prediction model to suit real-time inference and offline tagging situations. We verified prediction performance through evaluation metrics for multi-label classification in offline tests, and in scenarios where diversity and precision need to be increased, we ultimately determined threshold parameters through qualitative evaluation. In the future, we are considering using user-entered hashtags or model-inferred results as features of the OpenChat recommendation model, or ranking and recommending hashtag keywords that users show interest in.
We will continue to strive to ensure that users can easily find OpenChats that match their preferences and meet other users who share their interests, based on the principle that the user is the foundation and center of everything. Thank you for reading to the end.


