はじめに
こんにちは。AI Services LabチームのMLエンジニアHeewoong Parkです。私たちのチームでは、オープンチャットに関するさまざまなAI/MLモデルを開発し、提供しています。以前公開したオフラインとオンラインのA/Bテストを通じてオープンチャットのレコメンドモデルを改善では、ユーザー個人の好みに合ったオープンチャットをレコメンドするモデルの改善プロセスを紹介しました。
オープンチャットサービスでは、チャットルームのテーマと特性を適切に表しながら検索されやすくするハッシュタグを、より積極的に設定するように誘導する一方、そのハッシュタグの効果的な活用を支援する機能を開発しています。この記事では、オープンチャット作成時のハッシュタグ指定に役立つハッシュタグ予測モデルをどのように開発しているのか紹介したいと思います。
オープンチャットのハッシュタグ予測モデル(OpenChat Hashtag Prediction Model)
オープンチャット作成時、ユーザーはオープンチャットの「名前(name)」を必ず指定する必要があります。加えて、そのオープンチャットについての「説明文(description)」を記載できます。そのとき、オープンチャットがよく検索されるように、ハッシュタグを活用して説明欄にキーワードを記載するように誘導しています。このプロセスをオープンチャットの作成画面で別途フィールドにハッシュタグを入力する形に改善しようとしていますが、ユーザーがより簡単にハッシュタグを選択できるようにMLモデルを利用して提案する機能を準備しています。この提案機能のためのハッシュタグ予測モデルをどのようにモデル化し、学習させたのか説明します。
データセットの構築(Construction of Ground-Truth Dataset)
まず、ハッシュタグの正解データの場合、ユーザーが自発的にハッシュタグを含めて作成した説明文からハッシュタグセットを抽出できます。正解の抽出が可能なオープンチャットの割合は高くありませんが、毎日数千、数万の新しいオープンチャットが作成されているため、100万件以上のデータを確保できました。
予測モデルの入力として、オープンチャットの作成時に利用可能なオープンチャットの名前と説明文のみを使用しました。名前と説明文は区切り文字を挿入して1つの文字列に連結し、モデル構造を単純化しました。学習データセットを構築する際には、正解が入力に現れる自明なケースを除外するために、説明文からハッシュタグ部分を削除し、入力テキストを構成します。モデルの入力特徴として作成者情報を考慮することもできます。特に、オープンチャットの名前と説明が不十分な場合は�、同じユーザーが過去に作成または活動した他のオープンチャットのハッシュタグが非常に有用な情報となりますが、これについては今後の改善課題としました。
下表は、各地域でどのようなハッシュタグがよく使われているかを示したものです。ランキングを見ると、日本(以下JP)では年齢層を表すハッシュタグ(40代、30代、50代)が多く使われています。これにより、同年代同士の集まりを好んでいることがわかります。タイ(以下TH)や台湾(以下TW)では、ファッション(เสื้อผ้า、แฟชั่น)、価格(ราคาถูก、ราคาส่ง)、購買(團購、代購)、生活用品などのハッシュタグが多く使われています。これにより、さまざまな消費活動がオープンチャットを通じて活発に行われていることがわかります。
| ランキング | JP | TH | TW |
|---|---|---|---|
| 1 | 雑談 | บอท | 團購 |
| 2 | 恋愛 | เสื้อผ้า | 聊天 |
| 3 | なりきり | ราคาถูก | 美食 |
| 4 | 40代 | เสื้อผ้าแฟชั่น | 代購 |
| 5 | 相談 | กระเป๋า | 批發 |
| 6 | 30代 | ราคาส่ง | 交友 |
| 7 | 50代 | ขายส่ง | 美妝 |
| 8 | 既婚 | พรีออเดอร์ | 生活用品 |
| 9 | 癒し | แฟชั่น | 分享 |
| 10 | ゲーム | รองเท้า | 對戲 |
以下は、オープンチャットごとに抽出されたハッシュタグ数の分布を示したものです。ユーザーが2つ以上のハッシュタグを使用する場合が、1つだけ使用する場合より一般的であることが確認できます。
| ハッシュタグ数 | JP | TH | TW |
|---|---|---|---|
| 1 | 30.5% | 47.1% | 38.2% |
| 2 | 15.5% | 14.9% | 13.9% |
| 3 | 13.3% | 11.9% | 13.7% |
| 4 | 9.2% | 7.6% | 9.5% |
| 5 | 6.2% | 4.8% | 6.4% |
| 6 | 4.5% | 3.2% | 4.3% |
| 7 | 3.3% | 2.2% | 2.9% |
| 8 | 2.6% | 1.6% | 2.1% |
| 9 | 2.0% | 1.2% | 1.6% |
| 10 | 1.6% | 0.9% | 1.2% |
マルチラベル分類問題としてのモデル化(Modeling as Multi-Label Classification)
私たちはこの問題を、オープンチャットの名前と説明が入力されると適切なハッシュタグセットが出される、マルチラベル分類(multi-label classification)としてモデル化しました。
まず、生成タスクではなく、事前に定義されたクラスセットからハッシュタグを選択する分類タスクとして採用した理由は、以下のとおりです。
- プロジェクトの出発点は、50以内の固定されたオープンチャットカテゴリよりも多様なキーワードで分類することだったためです。
- 生成モデルから物議を醸すようなハッシュタグが出力されるリスクを減らすためで、事前にチェックされたハッシュタグのみでデータセットを構成することにより、リスクを最小限に抑えられます。
- 学習データセットのサイズは十分で、問題に特化した分類モデルをトレーニングした場合、公開されたテキストデータで学習した生成モデルよりも性能が優れています。
クラスセットのうち1つだけを選択するマルチクラス分類(multi-class classification)としてモデル化しなかった理由は、複数のハッシュタグを許可するとより検索されやすくなるだけでなく、上記の分布に見られるように、ユーザーはすでに説明文で��そのように活用しているためです。
マルチラベル分類モデルの出力空間は、クラス数と同じ次元を持つベクトルで表現されます。各ベクトルの成分値には、そのクラスに属するかどうかによって0または1の値が割り当てられます。例えば、出力クラスセットがの場合、あるインスタンスのラベルがであれば、(1, 0, 1)ベクトルに変換されます。
一般的には、このように表現された出力空間に対して、各成分ごとにバイナリ交差エントロピー損失関数(binary cross-entropy loss; BCE loss)を用いてマルチラベル分類器を学習します。しかし、ハッシュタグ予測問題の目的は、オープンチャットに対して各ハッシュタグの関連性を判断するのではなく、関連性の高い上位K個のハッシュタグを選択することです。ユーザーがオープンチャットを作成する際にも、可能性のあるすべてのハッシュタグの関連性をいちいち判断して選ぶよりは、すぐに思い浮かぶいくつかのハッシュタグを選ぶと考えるのが自然でしょう。
したがって、この問題では、マルチクラス分類器の学習によく使われるカテゴリカルクロスエントロピー損失関数(categorical cross-entropy loss; CCE loss、以下CCE損失関数)を少し変形して学習に利用しました。CCE損失関数は、2つの分布、の間で定義されたクロスエントロピーで、には正解のワンホット(one-hot)ベクトルを、には予測された確率ベクトルを代入して計算します。これをマルチラベル分類学習に適用するために、にワンホットベクトルではなく、合計が1になるように正規化されたマルチラベルベクトルを代入しました。前述の例で考えると、の場合、ベクトルは(0.5, 0, 0.5)になります。
ちなみに、この記事ではハッシュタグのことを、分類作業やデータ観点ではクラスやラベル、モデル観点では推論結果やモデル出力と呼ぶことにします。
Hugging FaceのTransformersを使った実装(Implementation with transformers)
モデルの実装は、Hugging FaceのTransformersパッケージを利用しました。簡略化したコードを紹介すると、まず入力されたexamplesデータセットは、各行ごとにオープンチャットのname、description、hashtagsフィールドで構成されています。
前処理関数では、まず名前とハッシュタグを取り除いた説明を1つの文字列に連結し、それをトークン化して入力トークンシーケンスを作成します。ラベルとして使用されるhashtags配列については、sklearn.preprocessing.MultiLabelBinarizerモジュールを使ってバイナリ行列にします。このとき、出力空間(一意のハッシュタグ全体の集合)のサイズが大きい場合、密(dense)な形式でエンコードするとメモリを過剰に消費します。数万のハッシュタグのうち、1つのオープンチャットに付けられるハッシュタグはごく一部なので、疎(sparse)な形式でエンコードするとメモリ使用量を削減でき、その中でもLIL(list of list)形式を利用すれば、任意のi番目の行を迅速に取得することも可能です。
Dataset preprocessing
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
def preprocess(examples: pd.DataFrame, tokenizer, classes, max_length=None):
examples["input_text"] = examples.apply(
lambda x: f"{x['name']}\n{x['description_without_tags']}"
)
encoded_inputs = tokenizer(
examples["input_text"].to_list(),
truncation=True,
max_length=max_length
)
mlb = MultiLabelBinarizer(classes=classes, sparse_output=True)
mlb_output = mlb.fit_transform(examples["hashtags"])
encoded_inputs["labels"] = mlb_output.tolil()
return Dataset(encoded_inputs)前処理の後、Transformersモデル学習のためにDatasetオブジェクトの形で構成します。これは、GPU演算が必要なデータをtorch.Tensor形式に変換する役割を担っています。先に疎な形式でエンコードされたlabelsフィールドは、そのデータインスタンスを含むミニバッチ演算時のみ密なテンソル(dense tensor)形式で保存されるように__getitem__メソッド内部で��変換することで、メモリ効率を高められます。
Dataset
import torch
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __len__(self):
return len(self.encodings["input_ids"])
def __getitem__(self, idx):
# process input other than labels
item = {k: torch.tensor(v[idx]) for k, v in self.encodings.items() if "labels" not in k}
# convert labels from lil matrix row
lil_row = self.encodings["labels"].getrowview(idx)
labels_ndarray = lil_row.toarray().squeeze(0)
item["labels"] = torch.tensor(labels_ndarray, dtype=float)
return item前述で提案した変形された損失関数でマルチラベル分類モデルを学習するために、transformers.trainer.Trainerクラスを修正して以下のようにMultiLabelTrainerクラスを作成しました。そのクラスを活用して、既存のtransformers.trainer.Trainerと同じ方法で学習を進めます。
MultiLabelTrainer
from torch import nn
import transformers
class MultiLabelTrainer(transformers.trainer.Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get("labels") # all elements are 0 or 1
labels /= labels.sum(dim=-1, keepdim=True) # normalize by sum
outputs = model(**inputs)
logits = outputs.get('logits')
log_probs = nn.functional.log_softmax(logits, dim=-1)
loss = -(labels * log_probs).sum(dim=-1).mean() # compute the suggested CE loss
return (loss, outputs) if return_outputs else lossオフライン実験の結果(Offline Experiment Results)
オフライン実験を行う際に最も直感的に思い浮かぶ評価指標は、precision@1(精度)指標です。この指標は、最も高いスコアで予測されたラベルのうち正解の割合がどれくらいかを評価します。設定された制限内で、可能な限り多くの関連性のあるハッシュタグを提案するシナリオを検討していたため、recall@K(再現率)指標も主な比較対象として選定しました。recall@K指標の場合、K個の予測ラベル間のスコアの優劣は考慮しないため、それを補完するためにランキングも反映したndcg@K指標も参考にしました。
上記の評価指標を算出して集計するコードは、以下のように実装できます。recall@Kとndcg@Kを算出する場合、上位K個のスコア以外の予測結果は評価に影響を与えないため、ソート時に上位K個のみを考慮することで演算を効率化できます。同様に、出力されたロジット(logit)値が0より小さい場合、予測されたラベルが正解である可能性は低いため、通常算出されるロジット値(-15~15)よりも小さい負の値(-100)を割り当てました。このように実装されたcompute_metrics関数は、MultiLabelTrainerのコンストラクタの引数として渡せます。
Compute metrics
import numpy as np
import sklearn
def compute_metrics(eval_pred, ks=(1, 3, 5, 7, 10, 15, 30)):
logits, labels = eval_pred
binary_labels = (labels > 0).astype(int)
label_lengths = np.sum(binary_labels, axis=-1)
# only consider positive logits for faster computation
logits = np.where(logits > 0, logits, -100)
# select top maxk at first and then sort them for faster computation
maxk_ind = np.argpartition(-logits, max(ks), axis=-1)[..., :max(ks)]
maxk_logits = np.take_along_axis(logits, maxk_ind, axis=-1)
maxk_ind_sortind = np.argsort(-maxk_logits, axis=-1)
maxk_ind_sorted = np.take_along_axis(maxk_ind, maxk_ind_sortind, axis=-1)
_metrics = {}
_metrics["precisionAt1"] = np.take_along_axis(binary_labels, maxk_ind_sorted[..., :1], axis=-1).mean()
_metrics[f"ndcgAt{max(ks)}"] = sklearn.metrics.ndcg_score(labels, logits, k=max(ks))
recalls = {}
for k in ks:
topk_ind = maxk_ind_sorted[..., :k]
TPs = np.take_along_axis(binary_labels, topk_ind, axis=-1).sum(axis=-1)
recalls[f"recallAt{k}"] = (TPs / np.maximum(label_lengths, 1)).mean()
_metrics.update(recalls)
return _metrics評価指標を選定して算出するためのコードを作成した後、日本やタイ、台湾などの地域で多言語によるオープンチャットを1つのモデルとして処理するために、事前学習済み多言語モデル(pretrained multilingual LM)を用いて初期化した後、分類器を学習しました。評価セットは、学習データセットに含まれる150万のオープンチャットのうち、1%のデータを分離して構成しました。
下表は、Hugging Face Modelsリポジトリに公開されている複数の事前学習済みモデルを用いて初期化し、学習したハッシュタグ分類器の性能を比較したものです。'-base'モデルよりもパラメータ数が多い'-large'モデルの方がすべての指標で優れていました。sentence-transformers/LaBSEモデルは'-base'モデルに対して、隠れ埋め込み(hidden embedding)次元数や自己注意(self-attention)レイヤー数は同じですが、トークン語彙はより多く持っています。また、'-base'モデルより性能が良く、'-large'モデルに匹敵する性能を持っています。比較したモデルの中では、xlm-roberta-largeに複数の多言語コーパスを追加学習したmultilingual-e5-largeモデルが最も優れていたため、そのモデルを採用して実験を進めました。
| 事前学習済みモデル | ndcg@30 | precision@1 | recall@1 | recall@3 | recall@7 | recall@30 |
|---|---|---|---|---|---|---|
| xlm-roberta-base | 61.45% | 59.56% | 27.41% | 44.93% | 57.07% | 73.10% |
| xlm-roberta-large | 62.17% | 60.01% | 27.54% | 45.49% | 57.58% | 74.05% |
| sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | 57.54% | 56.44% | 25.43% | 41.62% | 52.99% | 69.19% |
| sentence-transformers/LaBSE | 62.09% | 60.11% | 27.68% | 45.44% | 57.74% | 73.80% |
| intfloat/multilingual-e5-base | 62.26% | 60.30% | 27.86% | 45.76% | 57.86% | 73.80% |
| intfloat/multilingual-e5-large | 62.97% | 60.66% | 28.15% | 46.23% | 58.51% | 74.76% |
以下は、多言語モデルが各言語でうまく機能しているかどうかを確認するために、地域ごとのパフォーマンスを評価した結果です。やはり学習データセットに占める割合が高いJP地域のオープンチャットの指標が��高く、THとTW地域の指標は比較的に低くなっています。さらに、地域ごとに別々のモデルを学習させてみましたが、単一多言語モデルとの性能差はほとんどありませんでした。THとTW地域については、今後、前処理を高度化して学習データセットを拡大し、より明確なトピックのハッシュタグでクラスセットを構成するなどのアプローチで改善していく予定です。
| 地域 | インスタンス数 | precision@1 | ndcg@30 | recall@1 | recall@3 | recall@7 | recall@30 |
|---|---|---|---|---|---|---|---|
| JP | 11615 | 71.32% | 71.49% | 31.77% | 52.11% | 65.45% | 81.11% |
| TH | 1242 | 53.95% | 66.02% | 37.84% | 56.98% | 69.24% | 85.79% |
| TW | 2083 | 52.04% | 58.08% | 27.69% | 44.90% | 56.45% | 73.41% |
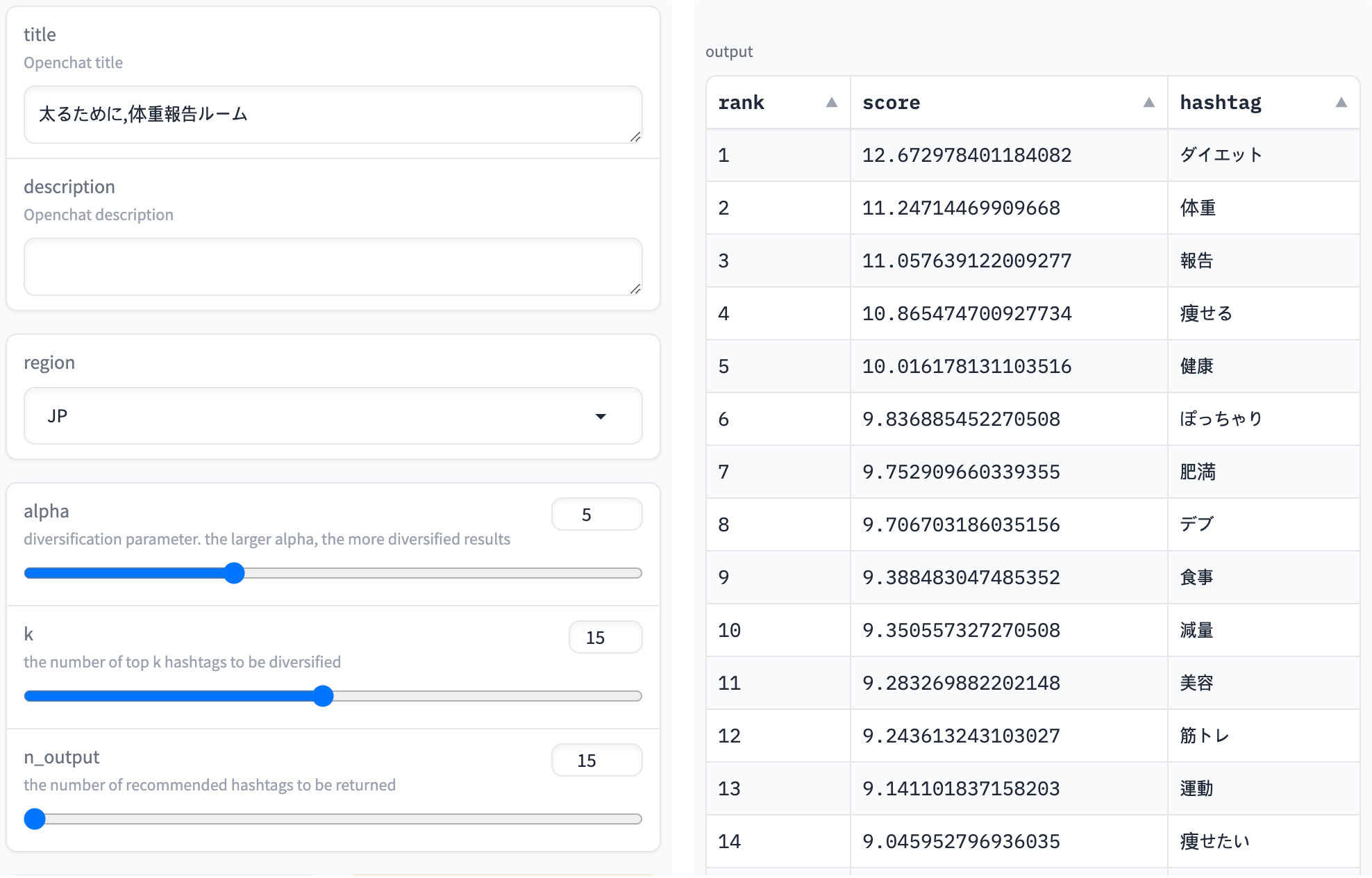
以下のスクリーンショットは、「太るために,体重報告ルーム」というオープンチャットの名前に対する推論結果を示しています。「ダイエット」や「体重」など、関連性が高そうなハッシュタグが高いスコアで予測されていることが確認できます。タイトルは「太るために」ですが、体重を減らすために体重を報告し合うことが多いので、「減量」などのキーワードも上位に表示されています。
リアルタイム提案のためのモデル改善(Improving Model for Real-Time Suggestion)
複数の入力時点での推論(Inference at Different Timings)
オープンチャットの作成時にリアルタイム推論でユーザーに合ったハッシュタグを提案するシナリオでは、モデル推論をリクエストするタイミングは一度だけとは限りません。オープンチャットの作成プロセスを順を追って見ていくと、それぞれ以下のようなタイミングでモデル推論をリクエストできます。
- 説明文は必須入力項目ではないので、オープンチャットの名前だけが入力された状態で、適切なハッシュタグを先に提案できます。
- ユーザーが説明文を書いているときに、ハッシュタグを提案することで、発想を助け、書きやすくすることができます。
- 前述のモデル学習データセットを構築する際に主に考慮した基本的な状況で、オープンチャットの名前と説明文を両方とも作成完了した状態でハッシュタグを提案します。
- 1つのオープンチャットに複数のハッシュタグを入力できる仕様であれば、ユーザーがハッシュタグを選択するたびに、それをモデル入力に反映して次のハッシュタグを提案します。
上記の4つのケースのうち最初の3つのケースは、学習データセットにある程度反映されていると考えられます。まず、ケース3は主に考慮した基本的な状況ですが、オープンチャットの名前とハッシュタグを除いた説明文で入力テキストを作成しました。また、オープンチャットの説明文は選択入力なので、ハッシュタグが入力から削除され、学習データセットに名前だけが残っているケースも結構多いため、ケース1もある程度反映されています。さらに、データセットには説明文の長さがさまざまなオープンチャットが含まれているため、長い説明文を書いているときに推論するケース2と似た状況もある程度反映されています。
最後のケース4を見てみましょう。既に選択されたハッシュタグは、モデルの入力としては使用できますが、出力からは除外する必要があります。このケースでの精度を高めるために、2つ以上のハッシュタグが抽出されたオープンチャットの場合、抽��出されたハッシュタグの一部を入力テキストに追加し、残りを正解ラベルで構成したインスタンスを学習データセットに追加しました。
例えば、あるオープンチャットの名前は「太るために,体重報告ルーム」で、抽出されたハッシュタグは[「ダイエット」, 「体重」, 「健康」]である場合、以下のように複数の学習データのインスタンスを生成します。
| 入力テキスト | 出力ラベル |
|---|---|
| '太るために,体重報告ルーム' | ['ダイエット', '体重', '健康'] |
| '太るために,体重報告ルーム\n#ダイエット' | ['体重', '健康'] |
| '太るために,体重報告ルーム\n#ダイエット #体重' | ['健康'] |
次は、ハッシュタグの一部を入力テキストに反映して学習した場合、モデルの性能が向上するかどうかを確認してみましょう。評価データセットは、以下のようにさまざまな推論時点に分けて構築し、各ケースの性能変化を比較します。
| ケースID | 入力テキスト | 出力ラベル |
|---|---|---|
| ケース1 | 名前 | ハッシュタグ |
| ケース2 | 名前 + ハッシュタグを除いた説明文の前半 | ハッシュタグ |
| ケース3 | 名前 + ハッシュタグを除いた説明文 | ハッシュタグ |
| ケース4 | 名前 + ハッシュタグを除いた説明文 + 最初のハッシュタグ | 最初のハッシュタグを除いたハッシュタグ |
上記は、データ量が最も多いJP地域のデータを用いて、モデルの学習と評価を行ったものです。
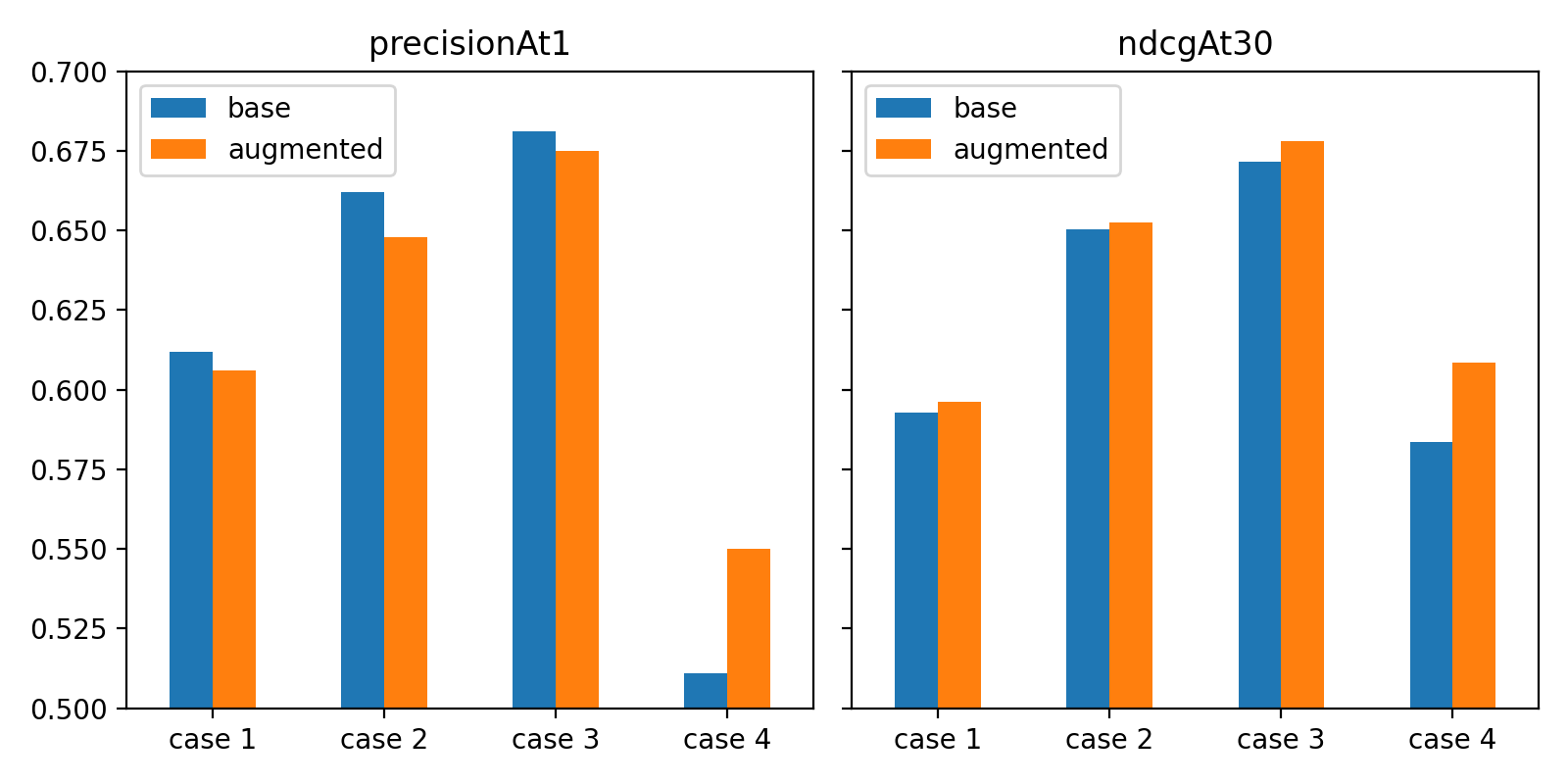
基本(base)モデルと学習デ�ータセットを拡張して学習したモデルを比較すると、最初のハッシュタグが入力として与えられたケース4では、precision@1とndcg@30の指標ともに、そのケースのデータを追加して学習したモデルの方が明らかに良い結果となりました。
その他のケースでは、指標ごとに異なる結果が出ました。データ増強時にトップ1の予測結果に対する評価指標はやや低下しましたが、トップ30の予測結果まで考慮すると、より優れています。サンプルを選んで観察した結果、基本モデルの方で入力テキストに含まれるキーワードが出力ハッシュタグとして予測されることが多くなっています。評価セットでは、抽出された正解ラベルの1つがタイトルに含まれる割合が少なくないため、precision@1指標がやや高くなっています。
現在、最大30個までの提案結果を表示する仕様を検討していますが、これを考慮すると、拡張されたモデルの結果がより望ましいと考えられます。ちなみに、入力情報量が増えるにつれて(ケース1→3)性能が高くなり、ケース4では性能が低下しています。これは、ケース4のグループは正解ラベル数が減少しており、予測がより困難なインスタンスで構成されているためです。
提案結果の多様化(Result Diversification)
オフラインテストとは異なり、リアルタイム提案では、推薦するハッシュタグの多様性を考慮する必要があります。マルチラベル分類モデルが学習するクラスセットが大きくなるにつれて、意味や形の観点から類似したハッシュタグがクラスセットに複数含まれ、似たようなハッシュタグが上位予測に表示される場合が多々あります�。
例えば、「スプラトゥーン2好きな人おいで」というオープンチャットの名前を入力テキストとして入れると、予測トップ5の結果は[「スプラトゥーン2」, 「スプラ」, 「スプラトゥーン」, 「雑談」, 「スプラ2」]となります。5つのうち4つも「スプラ」で始まります。
モデルとしては、ユーザーが似たようなハッシュタグのどれを選択するかわからないため、とりあえず全部表示するように学習した方が、前述で定義した評価指標の観点では有利です。しかし、ユーザーが候補を提案され、それを入力するインタラクティブなインターフェイスの観点では、重複したハッシュタグの表示は、ユーザーが豊富なキーワードで自分のオープンチャットを表現することを妨げ、結果的に潜在的な参加者がそのオープンチャットを見つけるのに悪影響を与えます。
これを防ぐために、予測結果がより多様化するよう、スコア順に予測されたハッシュタグを1つずつ推薦リストに追加する際、先に選択されたハッシュタグとの類似度をペナルティとして考慮するMaximal Marginal Relevance (MMR)手法を導入しました。
以下はその手法を計算式で表したものです。k+1ランキングの予測ハッシュタグは、以下の調整されたスコア値が最大のハッシュタグiを選択します。
- : original recommendation score of hashtag i.The output logits (without the softmax normalization) were used as scores
- : penalty weight parameter
- : similarity of two tags i and j
- : the entire class set
- : the set of selected hashtags for recommendation until k-th step
この手法では、ペナルティ重み付けパラメータ𝛼を変化させることで、多様化の度合いを調整できます。この値が0の場合、ペナルティは適用されず、値が大きくなるほど重複した結果にペナルティが重く課されます。
ハッシュタグ間の類似度としては、2つを考慮しました。
- まず、トークン集合類似度(token set similarity)は、表面的に現れた形態素がどれだけ重なるかを定量化したものです。2つのハッシュタグをトークン化して得られた集合間のJaccard類似度(積集合サイズ/和集合サイズ)として定義しました。
- もう一つは、意味的にどれだけ類似しているかを数値化した埋め込み類似度(embedding similarity)です。ハッシュタグに含まれるトークン埋め込みを平均することでハッシュタグの埋め込みを取得し、2つのハッシュタグの埋め込み間の余弦類似度を測定しました。このとき、トークン埋め込みはモデル学習初期化に使用したニューラルネットワークのトークン埋め込みを活用しました。
では、さまざまな𝛼値にMMR手法を適用した結果を見てみましょう。予測性能を最大限に維持しながら多様性を高めることが目的なので、性能指標としてrecall@Kの値を比較し、多様性指標としては、推薦された上位K個のハッシュタグに対して一意なトークンの割合を以下のように定義しました。
dTkProp@K := # distinct tokens in top K predicted tags / the sum of token counts over the top K predicted tags
以下のグラフは、ハッシュタグが最も多様なJP地域のデータにMMR手法を適��用した結果を示しています。
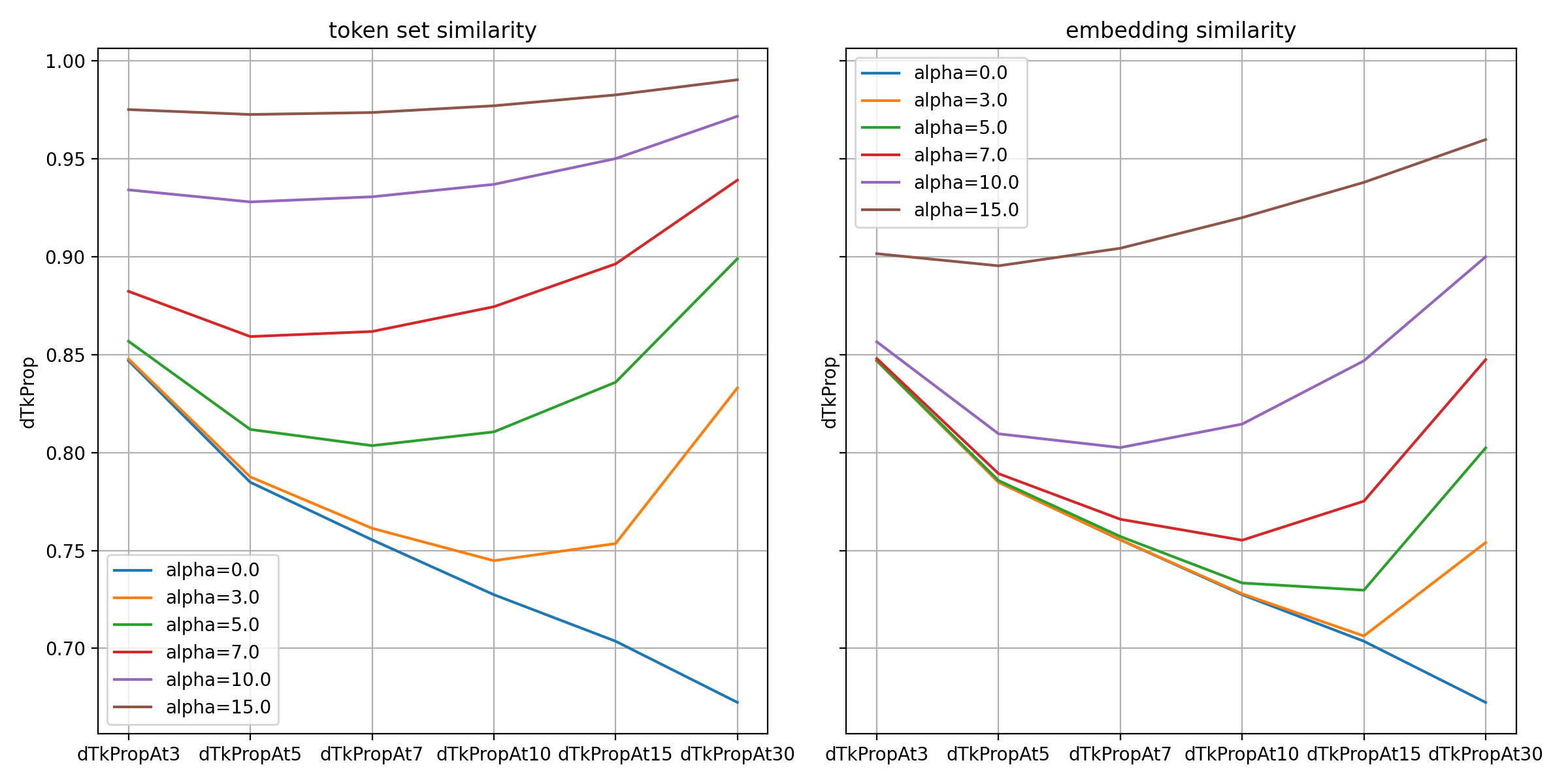
グラフで確認できるように、一意なトークンの割合については、2つの類似度ともに予想通り𝛼値が大きいほど高くなっています。2つの類似度のうち、トークンの重複度が直接ペナルティに反映されたトークン集合類似度の方が、予測結果において一意なトークンの割合が高くなっています。
以下は再現率指標の結果です。𝛼値が大きいほど低下幅が大きく、特にトークン集合類似度の方がより敏感に反応しています。
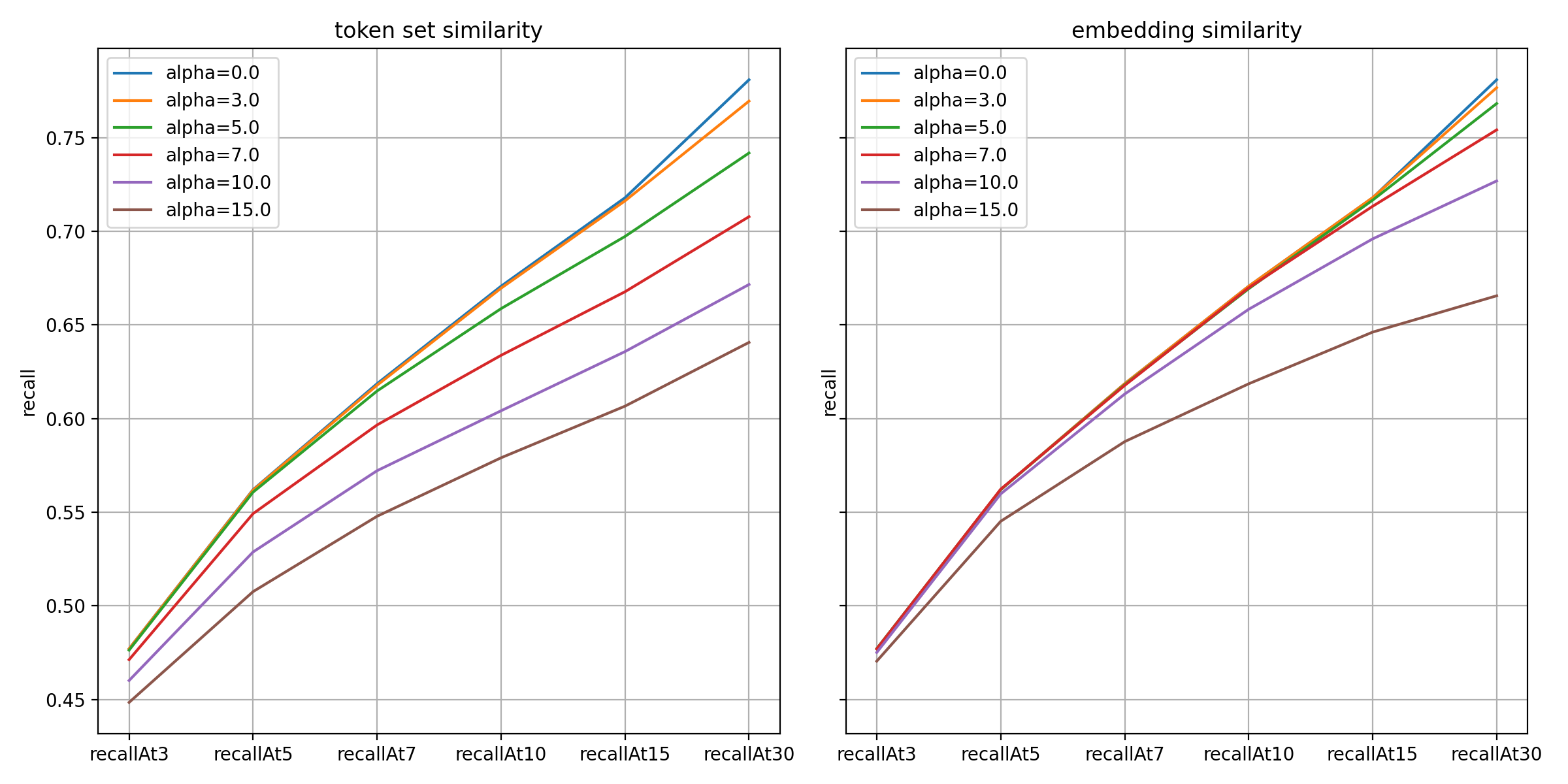
上記の結果のように、予測性能と多様性はトレードオフの関係にあります。両者のバランスを考慮し、トークン集合類似度方式は𝛼値を5.0~7.0、埋め込み類似度方式は10.0~15.0程度に選択肢を絞り込み、最終的に定性評価によって決定しました。
下表は、「スプラトゥーン2好きな人おいで」というオープンチャットに多様化手法を適用した結果のサンプルです。「スプラ」で始まるハッシュタグは、𝛼値が大きくなるにつれて上位からだんだん減っていくことが確認できます。
| ランキング | 多様化の適用前 | トークン集合類似度 | トークン集合類似度 | ||||
|---|---|---|---|---|---|---|---|
| 1 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 |
| 2 | スプラ | スプラ | スプラ | スプラ | スプラ | スプラ | スプラ |
| 3 | スプラトゥーン | スプラトゥーン | 雑談 | 雑談 | スプラトゥーン | スプラトゥーン | 雑��談 |
| 4 | 雑談 | 雑談 | ゲーム | ゲーム | 雑談 | 雑談 | ゲーム |
| 5 | スプラ2 | スプラ2 | プラベ | リグマ | スプラ2 | スプラ2 | 楽しい |
| 6 | ゲーム | ゲーム | リグマ | 楽しい | ゲーム | ゲーム | 仲良く |
| 7 | スプラ好き | プラベ | 楽しい | 仲良く | スプラ好き | プラベ | 誰でも |
| 8 | プラベ | リグマ | 仲良く | 誰でも | プラベ | リグマ | 楽しく |
| 9 | リグマ | 楽しい | 誰でも | 楽しく | リグマ | 楽しい | ルール |
| 10 | 楽しい | 仲良く | 楽しく | ルール | 楽しい | 仲良く | 楽しもう |
| 11 | 仲良く | 誰でも | ルール | 楽しもう | 仲良く | 誰でも | 荒らし禁止 |
| 12 | 誰でも | 楽しく | ナワバリ | 荒らし禁止 | 誰でも | 楽しく | Splatoon |
| 13 | 楽しく | Splatoon2 | 楽しもう | イカ | 楽しく | ルール | Switch |
| 14 | Splatoon2 | ルール | 荒らし禁止 | Splatoon | ルール | 楽しもう | enjoy |
| 15 | ルール | ナワバリ | イカ | Switch | 楽しもう | 荒らし禁止 | 学生 |
定性評価の結果、埋め込み類似度よりも、文字列の重複をより確実に減らすトークン類似度の方が望ましいという結論に至りました。
オフラインタグ付けのための信頼性の高い出力を選択する(Selecting Reliable Output for Offline Tagging)
オープンチャットの作成時にリアルタイムでハッシュタグ�を提案する機能を準備する中で、オープンチャットサービス内での広告表示拡大をきっかけに、より高度なオープンチャットと広告のマッチングのために推論されたハッシュタグを活用しようという意見が出ました。
この場合、オフラインバッチ予測でタグ付けを行います。インタラクティブなインターフェイスでは、ユーザーが自分で適切なものを最終的に決定するため、モデルが拡張されたコンテキストでハッシュタグを提案するのは自然なことでした。しかし、オフラインの場合、不正確なハッシュタグが不適切な広告マッチングにつながる可能性があるため、精度も重要です。
これを考慮し、広告マッチング用のオフラインタグ付けでは、2つの閾値(threshold)パラメータを導入することで、信頼性の高いモデルの出力のみをフィルタリングする方法を設計しました。
まず、min_top1パラメータを導入しました。トップ1の予測スコアが低い場合、つまり、どのクラスも高いスコアを獲得していない場合は、入力データで分類作業を行うのに十分な情報がないと判断するロジックを追加しました。このロジックでは、min_top1の値を基準に、トップ1の予測スコアが閾値より小さい場合、そのオープンチャットに対してどのハッシュタグもタグ付けしません。
次に、min_scoreパラメータを導入し、マッチングシステムに渡される最大K個のハッシュタグのうち、閾値より予測スコアが大きいハッシュタグのみを選別します(ちなみに、K値は30に設定しました)。
では、2つの閾値を決定するために、JP地域の検証データセットに対して予測されたスコアの分布を見て��みましょう。
まず、トップ1スコアの区間ごとに検証セットを分け、性能指標を見てみると、スコア値と予測性能との間に強い正の相関関係があることがわかります。各線は、ラベル数の区間ごとに指標を集計したものです。正解ラベルが多ければ多いほど、当然のことながら、そのうちの1つだけマッチさせればよい精度は高くなり、すべてを見つける必要がある再現率は低くなります。ラベルが2つ以上ある場合(青い線以外の線)、およそスコア10.0~11.0の区間からprecision@1の値が50%より高くなっています。
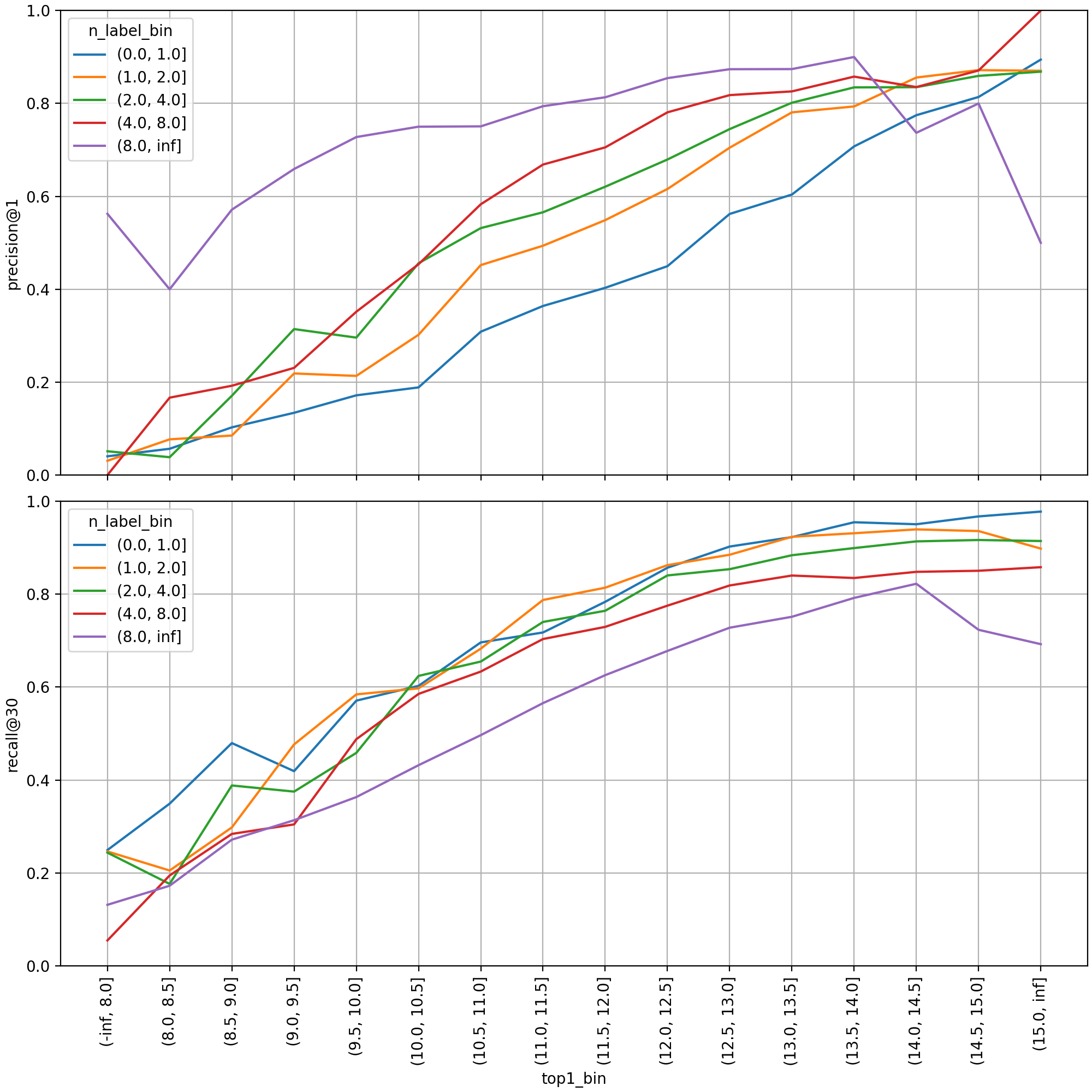
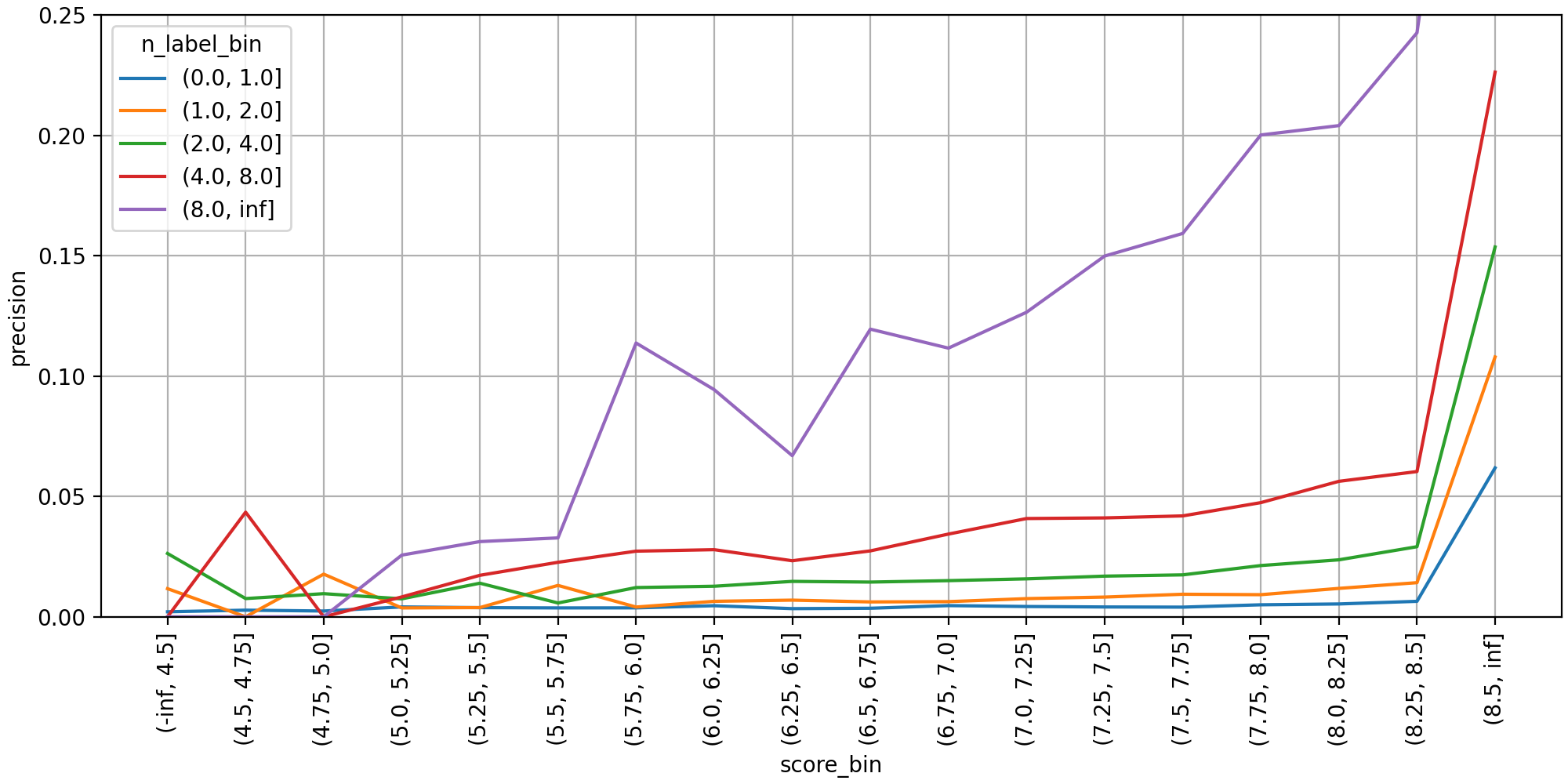
次に、min_scoreの値を決定するために調べた分布グラフです。トップ30まで予測されたラベルをそれぞれマルチクラス分類インスタンスとして扱い、区間ごとの精度を集計しました。ラベル数が8個より多い場合(紫色の線)、予測スコア6.0付近で精度が急上昇し、7.0以上からはスコアが高くなるにつれて単調増加しています。
では、上記の方法でハッシュタグを選別した場合、どれだけの推論結果を提供できるかを見てみましょう。以下は、トップ1のスコアを基準に判断した場合、少なくとも1つ以上のハッシュタグ推論結果を提供できるオープンチャットのカバレッジグラフです。
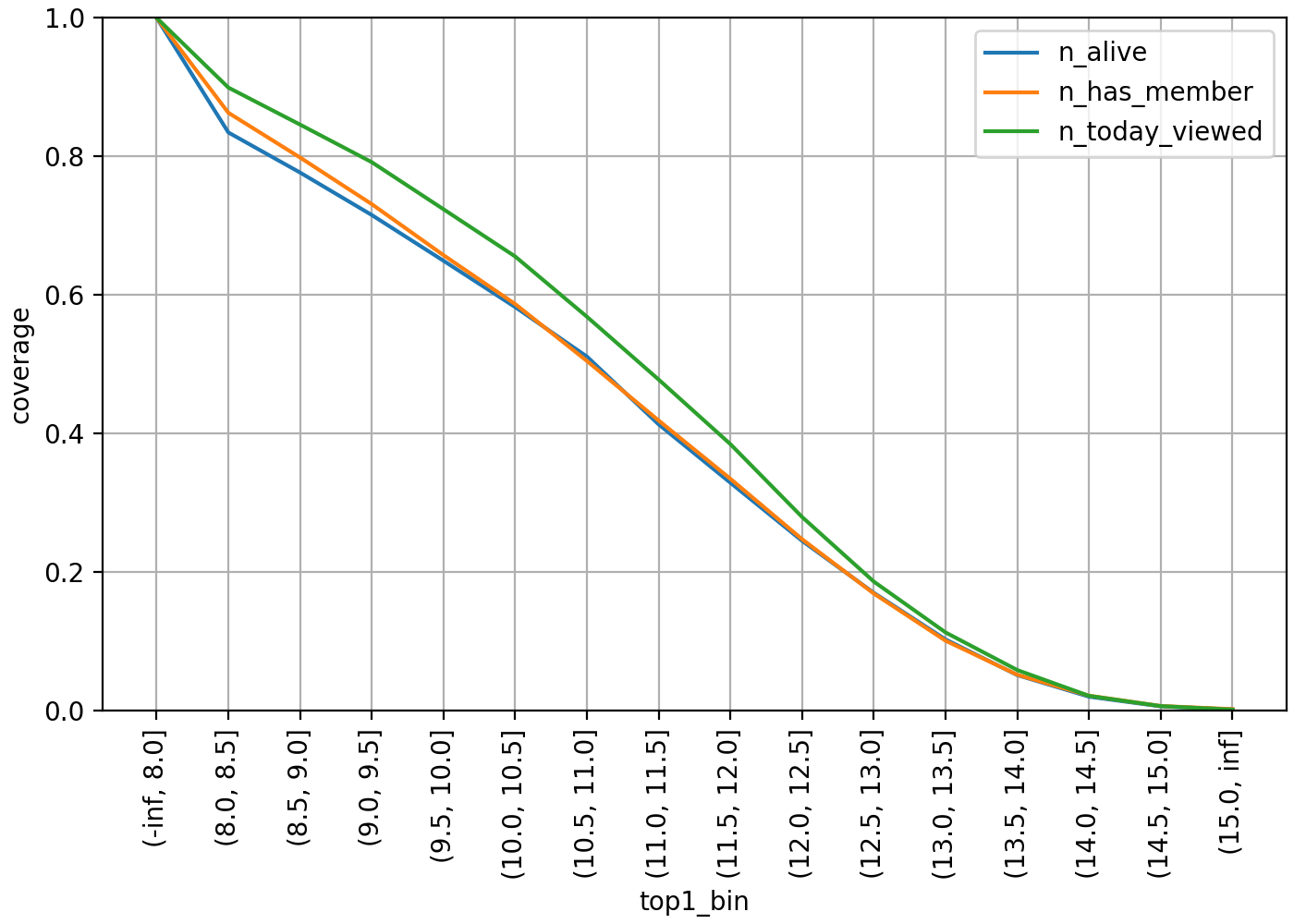
各線は、オープンチャットの活発度に応じて母数を制限して集計したものです。青い線は削除(DELETED)または停止(SUSPENDED)されていないALIVE状態、オレンジ色の線は少なくとも1人以上のメンバーを保有、緑色の線はその日に少なくとも1回以上のページビューが存在するオープンチャットを意味しています。ALIVE全体を対象にした場合、min_top1の値を10.0に設定するとカバレッジが60%近くになりますが、基準を11.0に上げると40%近くまでに低下します。
下表はmin_scoreの閾値設定によって出力されたハッシュタグ数の分布です。ここではmin_top1の値を10.0に固定し、タグ付け結果が全くないオープンチャットを母数から除外しました。また、最大個数Kは30に制限しています。min_scoreの値を6.0以下に小さく設定すると過半数が最大個数まで出力されましたが、7.5以上だと10個以下の割合が半分を超えました。
| ハッシュタグ数の区間 | min_score threshold | |||||
|---|---|---|---|---|---|---|
| 5.5 | 6.0 | 6.5 | 7.0 | 7.5 | 8.0 | |
| (29, 30] | 77.27% | 57.87% | 36.33% | 17.68% | 6.53% | 1.84% |
| (25, 29] | 4.48% | 6.69% | 7.23% | 6.11% | 3.76% | 1.44% |
| (20, 25] | 5.59% | 8.96% | 11.14% | 10.35% | 7.25% | 3.92% |
| (15, 20] | 8.79% | 8.80% | 12.68% | 14.59% | 12.26% | 7.93% |
| (10, 15] | 2.89% | 11.69% | 12.98% | 18.06% | 19.61% | 16.75% |
| (5, 10] | 0.91% | 5.24% | 15.81% | 18.46% | 25.29% | 29.44% |
| (0, 5] | 0.08% | 0.78% | 3.84% | 14.75% | 25.30% | 38.68% |
これに基づいて精度とカバレッジのトレードオフ関係を考慮し、min_top1の値は10.0~11.0、min_scoreの値は6.0~7.5に絞って選択肢を提示しました。また、最終的には定性評価によって決定しました。
一度決定したスコア閾値をモデル再学習時に同じように適用するには、以前のモデルと新しいモデルでスコア分布が大きく変わらないことが前提となります。そのため、モデルの学習パイプラインでスコア分布を自動モニタリングしており、新しいデータで何度もモデルを更新してきましたが、分布が大きく変化しないことを実験的に確認しました。
おわりに
ここまで、オープンチャットハッシュタグ予測モデルをリアルタイム推論とオフラインタグ付けの状況に合わせて開発し、進化させるプロセスを紹介しました。オフラインテストでは、マルチラベル分類のための評価指標で予測性能を検証し、多様性と精度を高める必要があるシナリオでは、定性評価によって閾値パラメータを最終決定しました。今後、ユーザーが入力したハッシュタグやモデルが推論した結果をオープンチャットの推薦モデルの特徴として活用することや、これを基にユーザーが興味を示したハッシュタグのキーワードをランク付けして推薦するサービスも構想しています。
ユーザーがすべての基本であり中心であるという基準に基づいて、ユーザーが自分の好みに合ったオープンチャットを簡単に見つけられ、同じ興味を持つ他のユーザーとたくさん出会えるように、日々精進していきます。最後までお読みいただき、ありがとうございました。


