こんにちは。AI Services LabチームのMLエンジニアHeewoong Parkです。私たちのチームでは、オープンチャットに関するさまざまなAI/MLモデルを開発し、提供しています。以前、「機械学習を活用したオープンチャットのクリーンスコアモデル開発記(韓国語)」という記事で、「不適切なコンテンツのやりとりがなく、会話中のエチケットがどれだけ守られているか」という観点から各オープンチャットを評価し、スコア化する「オープンチャットのクリーンスコアモデル」を紹介しました。今回は「オープンチャットのパーソナライズレコメンドモデル」をどのように改善しているのかを紹介します。
オープンチャットのレコメンドサービスとレコメンドモデルの紹介
オープンチャット(OpenChat)とは、興味の似ている匿名のユーザーが集まり、LINEの友だちになっていなくてもトークができるオープンなチャットサービスです。現在、日本やタイ、台湾でサービスを行っ��ています。
オープンチャットのモバイルアプリのメインページでは、ユーザーがオープンチャットを検索できます。さらに気に入ったオープンチャットを見つけて参加できるように、オープンチャットの検索窓やオススメのオープンチャット、オープンチャットのランキングを表示しています。この記事では、2023年11月現在、オープンチャットのメインページ上部に表示されている「あなたへのオススメ」というオープンチャットのパーソナライズレコメンドサービスについて紹介します。
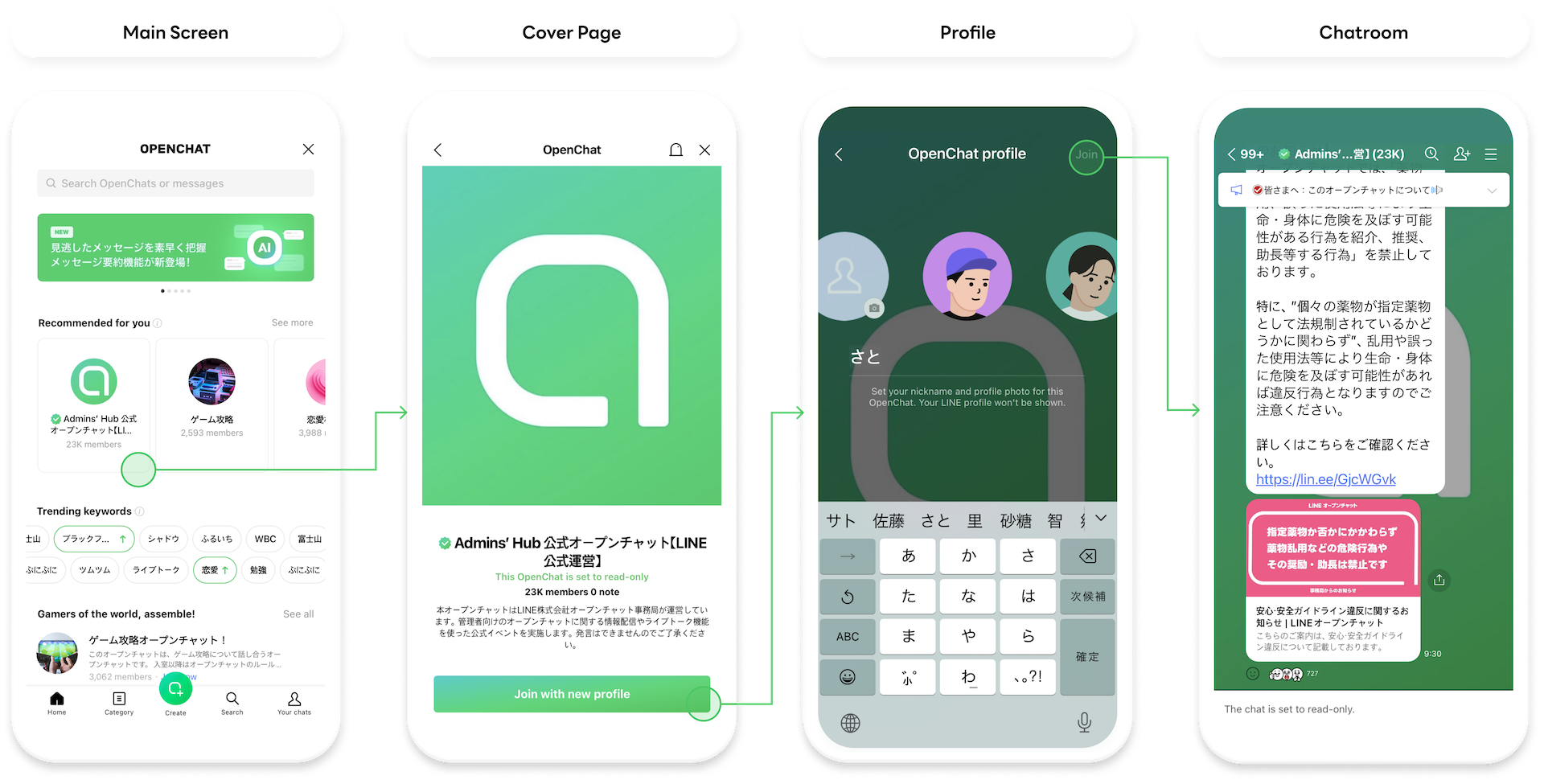
オープンチャットのレコメンドサービスの特徴
オープンチャットサービスは、速いスピードで変化するダイナミックなサービスです。企画・運営チームはユーザーのニーズに合わせて、新しい機能のリリース、メイン設定画面の改善、マーケティングイベントの実施などを継続的に行っています。それにより、既存ユーザーの活動を促進したり、新しいユーザーをサービスへ誘導したりします。
この活動によってユーザー層が変化し、サービスが成熟すると、それに応じてサービスを利用するユーザーの行動や使い方が変わることもあります。こうした変化はモデル自体のパフォーマンスとは別に、レコメンド指標に直接影響を与えます。
また、オープンチャットはさまざまなコンテンツを含むサービスで、固定的なものではありません。一度作成するとほとんど変化しない投稿や動画、販売��商品とは異なり、常に参加メンバーが変わり、新しいメッセージを作成します。ひとつのオープンチャットの中には複数のサブトークルームを作成でき、それぞれのトークルームではテキストだけでなく、画像や動画、投稿形式のメッセージなど、さまざまなメッセージをやりとりできます。
オープンチャットのレコメンドモデルは、多くの種類のデータをフィーチャー(モデルが学習するための入力変数)として利用する必要があります。アイテムやユーザーのフィーチャーを抽出する際には、同じ対象に対しても最新の情報が反映されるように、繰り返し行う必要があります。
オープンチャットは、一人のユーザーが短時間に連続して、複数のオープンチャットへの参加しないという特徴もあります。オープンチャットのユーザーは、気に入ったオープンチャットを発見して参加すると、そこでの活動や滞在の時間が長くなり、他のオープンチャットに参加したいと言う気持ちが減ります。オススメが適切だった場合、この特性は、継続的なアイテムの消費につながる短い形式のコンテンツレコメンドとは対照的です。ですので、短い形式のコンテンツレコメンドのようなサービスに適したセッションベース(session-based)、またはシーケンシャル(sequential)レコメンドは、オープンチャットには適していません。
またオープンチャットの場合、同じオープンチャットへの再参加はあまりありません。一度参加した履歴があるオープンチャットは、多様性などを考慮してレコメンドの対象から除外したほうがいいでしょう。つまりオープンチャットのレコメンドは、再購入パターンの反映が重要なオンラインショッピングのアイテムのレコメンドとも異なります。
オープンチャットのレコメンドモデルの紹介
オープンチャットのパーソナライズレコメンドモデルは、レコメンドシステムで広く活用されている2段階(two-stage)のフレームワークを採用しています。このフレームワークは、数百、数千の候補アイテムを少ない計算量で選定する候補選定(candidate selection)段階と、より精密なモデルで各候補を順位付けるランキング(ranking)段階で構成されます。
候補の選定には、ユーザーを推定した上で人口統計学的情報(年齢や性別など)を利用して人気のあるオープンチャットをマッチングする手法があります。さらにインタラクションが発生したオープンチャットと、参加メンバーが多く重なるオープンチャットを選択する手法を使います。
ランキングモデルでは、ユーザーとアイテムとのインタラクションを二次項として、考慮しながら効率的に計算できるField-aware Factorization Machines(FFM)モデルを採用しました。ランキングモデルは、常に変化するオープンチャットの活動性や好み、流行などを反映するために毎日学習します。モデルの更新完了時期を早めるため、事前学習(pre-training)と微調整(fine-tuning)を並行して行います。微調整の場合、以前に事前学習されたモデルから短時間で訓練できます。微調整を完了したモデルから、毎日推論してパーソナライズされたレコメンドの結果を生成します。さらに活動性の高いユーザーに対しては、1時間ごとに更新されるフィーチャーを��反映して、オススメ一覧を更新します。
オープンチャットのレコメンドモデルに関連しては、LINE Engineeringブログに掲載された「LINE TIMELINEの新たな挑戦vol.3 - ディスカバー・レコメンド・モデル」を読んで、LINE VOOM投稿のレコメンドモデルとオープンチャットのレコメンドモデルを比較するのもいいでしょう。
従来のオープンチャットレコメンドモデルを改善するプロセスの紹介
オープンチャットのレコメンドサービスを提供し始めてから、4年がたちました。その間に私たちは何度も大規模にモデルを改善してきました。私たちがレコメンドモデルを改善する際は、大体以下のようなプロセスで行います。
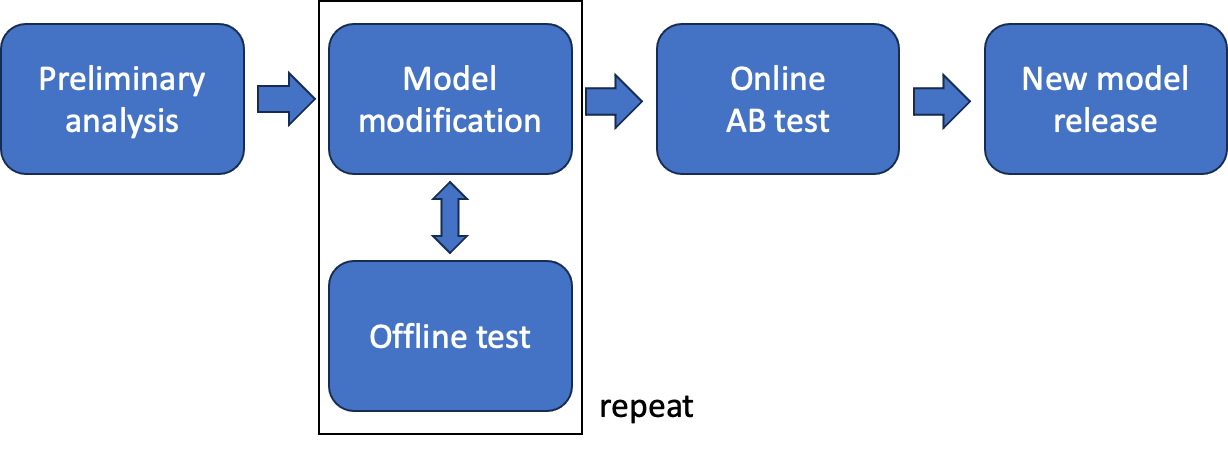
- 事前文献調査および既存のレコメンド結果の分析
- 分析結果を基に改善点を導き出し、モデルに実装してオフラインテスト性能を確認
- 計画期間中、従来のモデルに対するオフラインテストのパフォーマンスを最大限向上させるため、継続的に改善を試みる
- オフラインテストによって最適なモデルを選定し、従来のモデルとのオンラインA/Bテストを実施して検証
- 有意な性能向上を達成した場合、新しいモデルをリリース
上記のプロセスで、最も重要な2つのテストであるオフラインテストとオンラインテストについて説明します。その後、2�つのテストの間に発生するギャップと、そのギャップによる問題について紹介します。
オフラインテストとは
オフラインテストは蓄積された履歴データで正解セットを構成し、モデルを比較するプロセスです。オープンチャットレコメンドでは、ユーザーが特定のオープンチャットに参加したかどうかを正解ラベルとして利用します。テストデータには、サービス中のモデルの露出バイアスを回避するように、レコメンド以外の経路(検索やユーザー間の招待など)で参加したケースのみを使用します。トレーニングデータとテストデータは、タイムスタンプで区別します。モデルを毎日学習させるため、1日分のテストデータを用意し、その日以前のデータのみをトレーニングに使用します。検証信頼性を確保するため、少なくとも1週間以上のテストデータセットに対して各モデルの学習と評価を行います。サービス中に、モデルがユーザーごとに上位k個をレコメンドアイテムとして選定すると、その中からランダムにユーザーに表示されると想定し、選定された上位k個に対して評価指標を算出します。
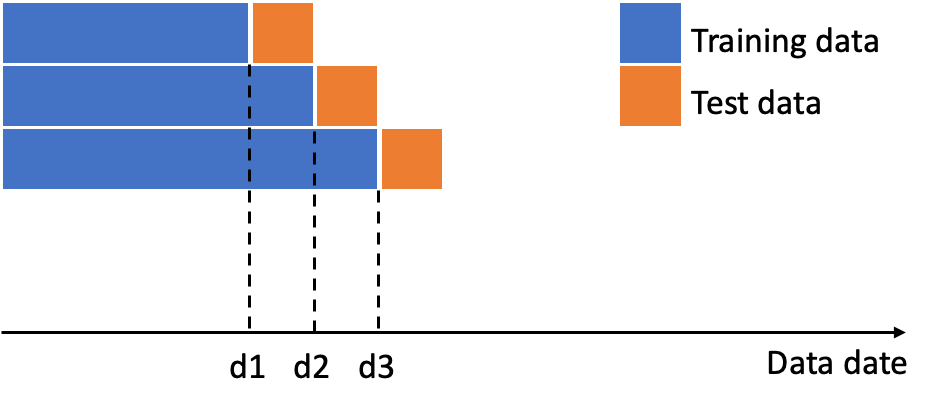
オフラインテストで使用する評価指標
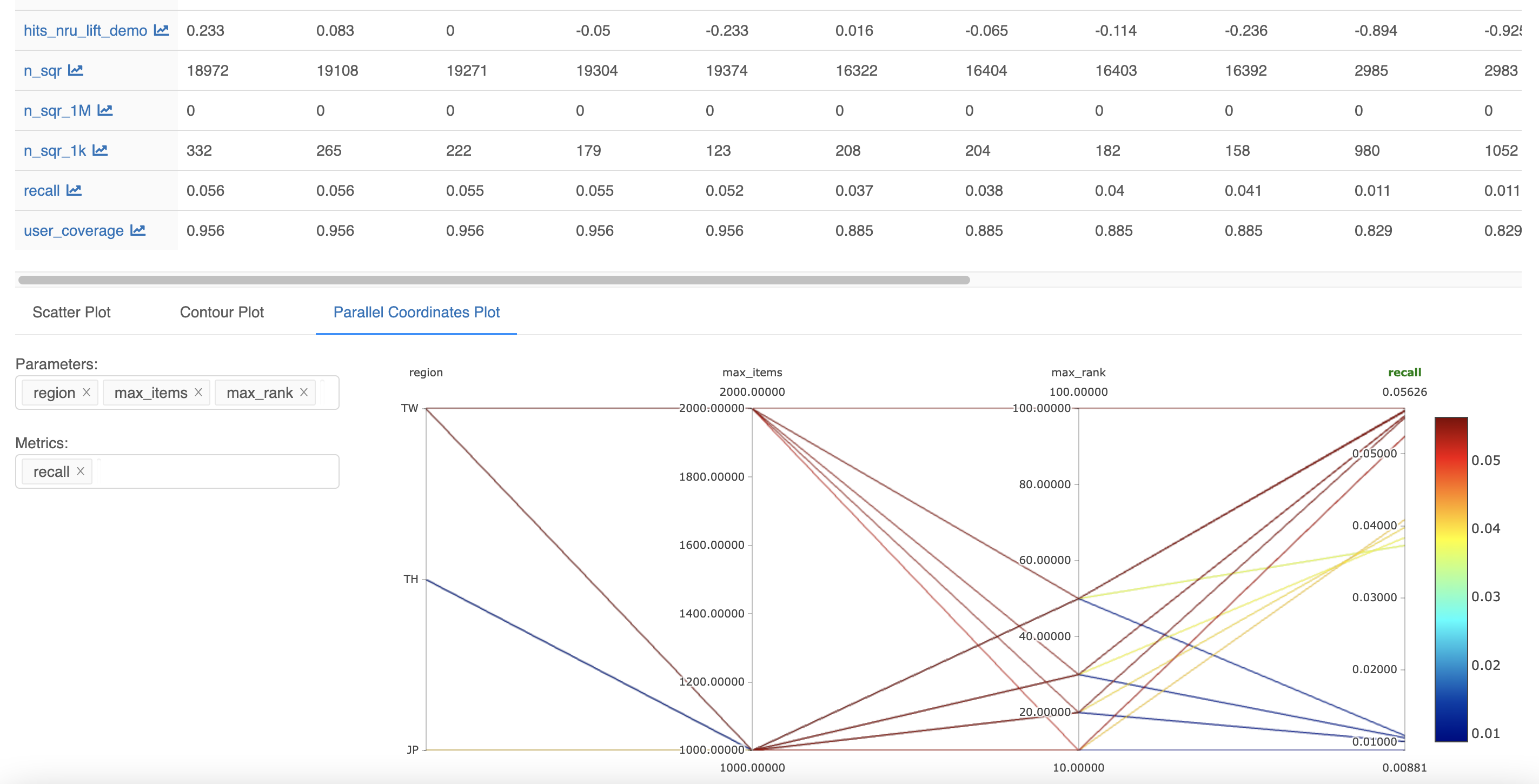
メイン指標として採用したのは、TP(true positive)数です。モデルがレコメンドした結果をテストデータにおいて、各ユーザーが実際に参加したオープンチャットと比較しました。どれだけ一致するかを数え、全ユーザーの結果を合算しました。モデルを比較するときは、同じテストセットに対してリストサイズkを固定したため、PrecisionまたはRecall指標とスケールが異なるだけで、比較の面では同等です。実際に参加したオープンチャットが1つでもあるユーザー数を集計するHit rate値も、モデルのレコメンド結果です。外れ値は、ユーザーの影響を受けにくい意味のある数値です。ただし、ユーザーあたりの参加数が多くない特性上、レコメンド結果が実際に露出されないオフライン環境と相まってTP数と大きな差はないため、メインの指標としては使用していません。
さらに、全ユーザーを対象に1日にオススメされるユニークなオープンチャットの数も見ています。オープンチャットのメインページには、パーソナライズレコメンド以外にも、少数の人気のある、または厳選されたオープンチャットを表示するランキングや、エディターのオススメセクションがあります。これらのセクションに比べて、ユーザーが積極的に探さなくても、多様なオープンチャットがあることを見せるのに効果があることをアピールするための数値です。
他にもさまざまな補助指標を検討しており、新たな定義も試みています。しかし、モデルの選択が簡単で、すでに多くの方が慣れ親しんでいるため、指標について説明する必要がないコミュニケーションの利便性を考慮して、主にメインの指標を活用しています。
下図のようにMLFlowプラットフォームを使って、オフラインテストで算出され��た各種パラメータや指標をログに記録し、モデル間のパフォーマンスを比較しています。
オンラインA/Bテストとは
オンラインA/Bテストとは、ユーザーをランダムに2つのグループAとBに分け、各グループに従来のモデルのレコメンドと新しいモデルのレコメンドを見せる対照実験です。グループごとに評価指標を集計し、どちらのモデルが優れているかを判断します。オフラインテストとは異なり、テスト中に新しいモデルが実際のサービスに反映されるため、実際のユーザーの直接的・間接的な反応を評価指標として測定できます。
オンラインA/Bテストで使用する評価指標 - オープンチャットレコメンドKPI
オンラインA/Bテストで評価基準にした主な指標は、以下のとおりです。KPIの定義に含まれるすべての行為は、レコメンドによる結果のみを集計します。CPIとUU-CPI指標を優先的に判断基準とし、他の指標は補助指標として、またはモデルを分析するために使用します。
| KPI | 定義 | 説明 |
|---|---|---|
| CPI(conversion per impression) | 参加数/露出数 |
オープンチャットサービスは、参加することでトークルームでコメントできるようになる 参加という行為に最も注目 これは通常の商品レコメンドの問題における購買行為に相当する |
| UU(unique user)CPI | 参加者数/露出されたユーザー数 | UU以外のCPI指標に比べて極端な少数ユーザーの活動に影響を受けにくい指標で、代表的なサービス指標であるアクティブ(active)ユーザー数などと関連性の高い指標 |
| CTR(click-through rate) | カバーページビュー数/露出数 |
ユーザーが露出(提案)されたアイテムに興味を示してクリックすると、そのオープンチャットのカバーページがポップアップ表示される ユーザーはポップアップから参加申請ができ、承認が必要ない場合はすぐにトークルームに参加可能 |
| CVR(conversion rate) | 参加数/カバーページビュー数 | 上記の指標とは異なり、時期的な影響やマーケティングに敏感な露出数を計算式から除外するため、比較的日々の変動が少ない指標 |
| Request CPI | 参加申請数 / 露出数 |
管理者の承認に関係なく、ユーザーがオススメのアイテムに興味を示したかどうかを見るための指標 |
オンラインA/Bテスト評価指標��を使用する際の注意点
上記の指標を利用して、異なる期間に露出されたレコメンドモデルを比較するのはやや無理があります。前述のように、オープンチャットはサービス環境がダイナミックに変化し、それに応じて指標の数値も変化します。10代のユーザーの活動性が高いサービスの特性上、学校の休み時期や新学期開始などの時期的要因に大きく影響されることもあります。10代のユーザーは他の年齢層に比べ、オススメに対する反応も活発です。
また、データ収集および使用に関するポリシーや、オススメアイテムフィルタリングルールなどの変更は、レコメンドのパフォーマンスを改善する作業とは別に行われています。そのため、指標の変動要因をどれかひとつに断定できません。さらに、曜日効果も存在するため、オフラインテストセットの構成と同様、最低1週間以上(推奨は2週間)はテストする必要があります。
加えて、従来のモデルによって形成されたフィルターバブル(filter bubble、ユーザーの履歴を基に提供するパーソナライズアルゴリズムの結果が、まるでバブルの中に閉じ込められたようにユーザーが好むものだけで構成される現象)は、新しいモデルの露出により若干変動もあります。単に以前と露出されるリストが異なるだけで、まるでリリース効果のようにテスト初期の指標に影響を与えます。
オフラインとオンラインテストのギャップ
オフラインテストでは、実際のサービス中にモデル結果が公開されるレコメンドセクションで発生する正解ラベルを利用できま��せん。つまり、オフラインテストのパフォーマンスから、モデルがユーザーの参加傾向をよく把握していることは確認できます。しかし、これがモデルがオススメしたオープンチャットに、ユーザーが参加するかどうかの結果ではありません。
たとえばオープンチャットの場合、オフラインでの交流やLINE以外のサービスでのつながりから招待されて参加する割合が高く、オススメしたときの参加率は相対的に低くなります。オープンチャットへの参加に管理者(ルームオーナー)の承認が必要なオープンチャットの場合、モデルがユーザーの傾向を正しく把握してレコメンドし、ユーザーがオープンチャットに参加申請を行ったとしても、管理者が承認しなければ、結果としては参加できていないことになります。
オフラインテストでは、推論結果を生成するために多くの計算を必要とします。それだけでなく、評価のセットアップを複雑にしています。1時間ごとのオススメに対する比較は、通常省略するため、これによって生じるギャップもあります。
サービスの成熟に伴う従来モデルの改善プロセスの問題点
これまで実施した数回のモデルバージョンアップのプロセスでは、オンラインA/Bテストでも、オフラインテストでのパフォーマンス向上がそのまま現れました。モデル改善プロセスがうまく機能したのです。以前のバージョンアップでは、ユーザーの傾向やオープンチャットの個別の特徴を把握できる強力なフィーチャーを追加しました。学習や推論のサイクルを減らすなどの改善作業を通じて、パフォーマンスが大��幅に向上したからです。
しかし、サービスが軌道に乗り、主なフィーチャーがある程度モデルに反映された後は、改善幅が小さくなりました。オフラインテストとオンラインテストでのモデル性能の優劣が同じでないケースが発生しました。そして、その原因として、前述の2つのテスト間のギャップが指摘されました。
オンラインテストの結果が良くなければ、先に行った改善作業を再び繰り返す必要があります。オフラインテストの繰り返しで、複数の改善点が蓄積されます。そのため、どの変更点がとくにオンラインテストのパフォーマンスに悪影響を与えたのかを特定するのは、容易ではありません。オフラインテストの評価指標をオンラインテストの評価指標と正比例するように、できるだけ調整する方法もあります。しかし手間がかかり、サービス環境に影響を受ける可能性があるため、継続的に修正する作業も必要です。
Adhoc A/Bテストの導入
上記の課題を解決するためにAdhoc A/Bテストを導入しました。
Adhoc A/Bテストとは
Adhoc A/Bテストは、オンラインパフォーマンステストという点では従来のA/Bテストと同じです。しかし即興(adhoc)で個別の変更点の単位でモデルのパフォーマンスをテストする点で異なります。
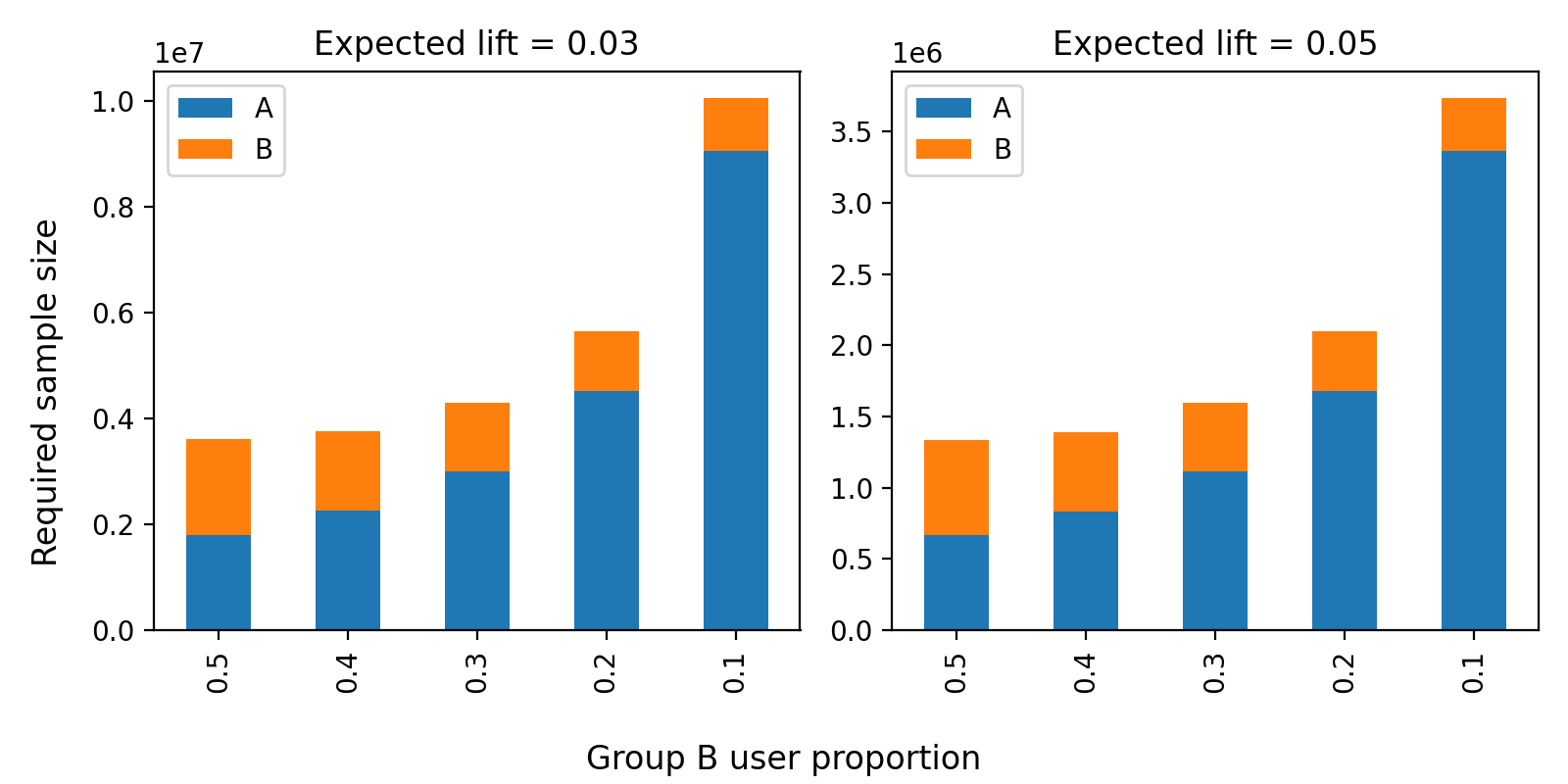
テストするときは、即興モデルのリスクを減らすために、AとBの比率を5:5ではなく、9:1の比率でグループBを小さく設定します。グループBのサイズが1/5に減っても、統計的な観点から信頼性を確保するために5倍の期間が必要ではありません。その理由は、比較対象のグループAのサイズが大きくなるため��、必要なサンプルの増加量がある程度相殺されるからです。
下図は、statsmodelsパッケージを利用して、グループBの割合が50%から10%に減少したときに必要なサンプルサイズを計算した結果です。サブプロットでは、参加率0.01、検出力(statistical power)0.8、有意水準(significance level)0.05の条件下で、それぞれ3%と5%の指標改善(expected lift)を想定しました。グラフを見ると、グループBのサイズが小さくなるにつれて、必要な全体のサンプルサイズが大きくなります。50%から10%に減らす条件で5倍までは増えません。約3倍以内のサンプル数で充分だと確認できます。
Adhoc A/Bテストベースのモデル改善プロセスは、以下のとおりです。
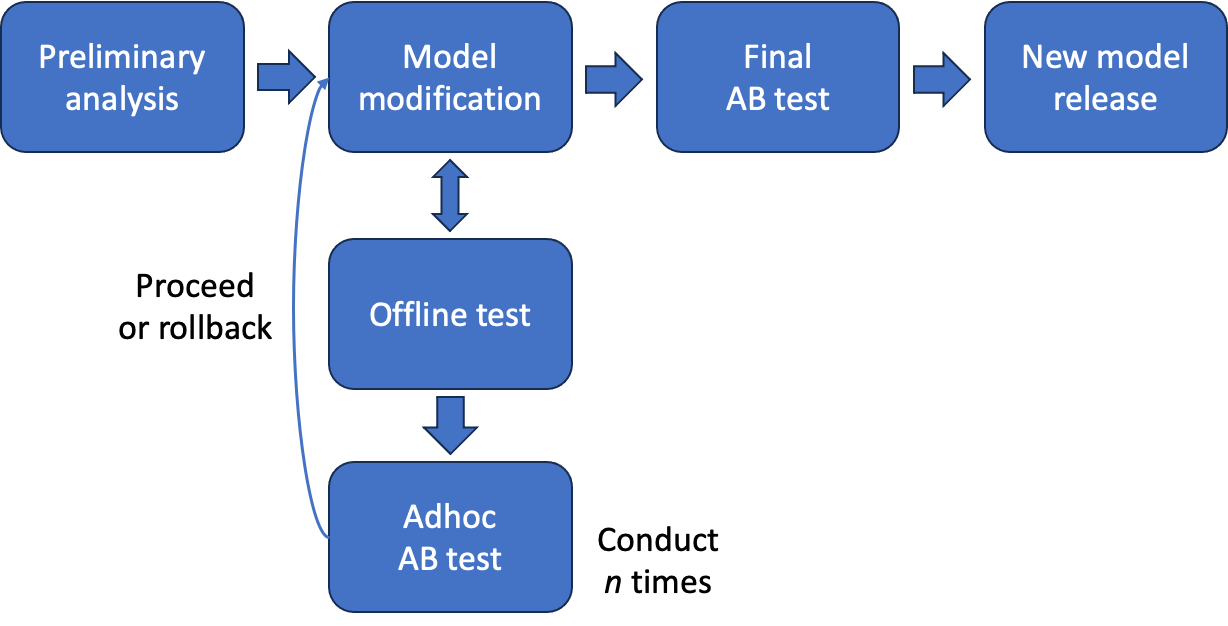
- 調査および分析を基に改善点を導き出し、Adhocモデルに実装する(従来と同じ)
- オフラインテスト後、改善が確認できれば、そのAdhocモデルでAdhoc A/Bテストを実施する
- Adhocテストのパフォーマンスが良い場合、Adhocモデルの改善点を維持する
- パフォーマンスが良くない場合、Adhocモデルで改善点をロールバックする
- 追加の改善点をAdhocモデルに加えて実装し、2を繰り返し実施する
- 3~4回のAddhocテストの後、最終的に新しいモデルを構成し、従来のように5:5の比率でA/Bテストを実施する
従来のA/Bテストがある程度の性能改善を前提とした、リリース前の段階での最終確認作業であったのに対し、Adhoc A/Bテストは負担を軽減して、個々の変更点の性能検証を目的とした作業です。従来と同様の開発期間で、より長くオンラインテストを実施するため、信頼性が高まるというメリットもあります。
適用結果
このように改善した結果を、最近行ったオープンチャットのパーソナライズレコメンドモデルの改善プロセスに導入しました。
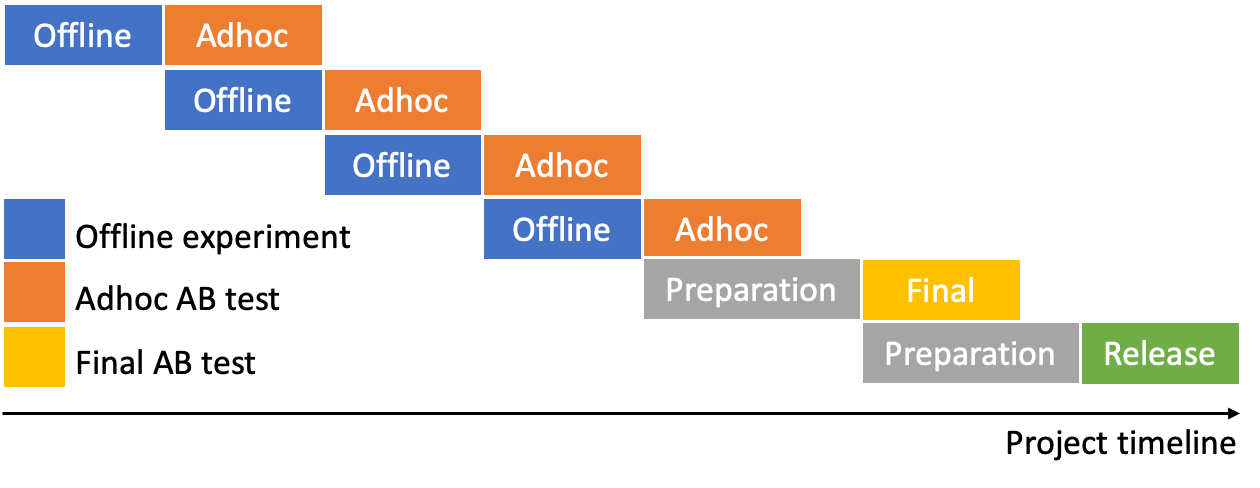
以下は、今回実施したモデル改善プロセスのタイムラインで、Adhoc A/Bテストを4回実施した後、最終A/Bテストを実施しました。開発期間を短縮するために、Adhoc A/Bテスト間の間隔を最短にし、各テストを実施する期間には次のAdhocモデルを実装してオフラインテストを行いました。
以下の性能向上グラフからわかるように、今回の改善プロセスでは、幸いにもAdhoc A/Bテストの結果がテストを重ねるごとに、徐々に改善されています。ロールバックせずに、変更点を積み重ねてAdhocモデルを更新していきました。
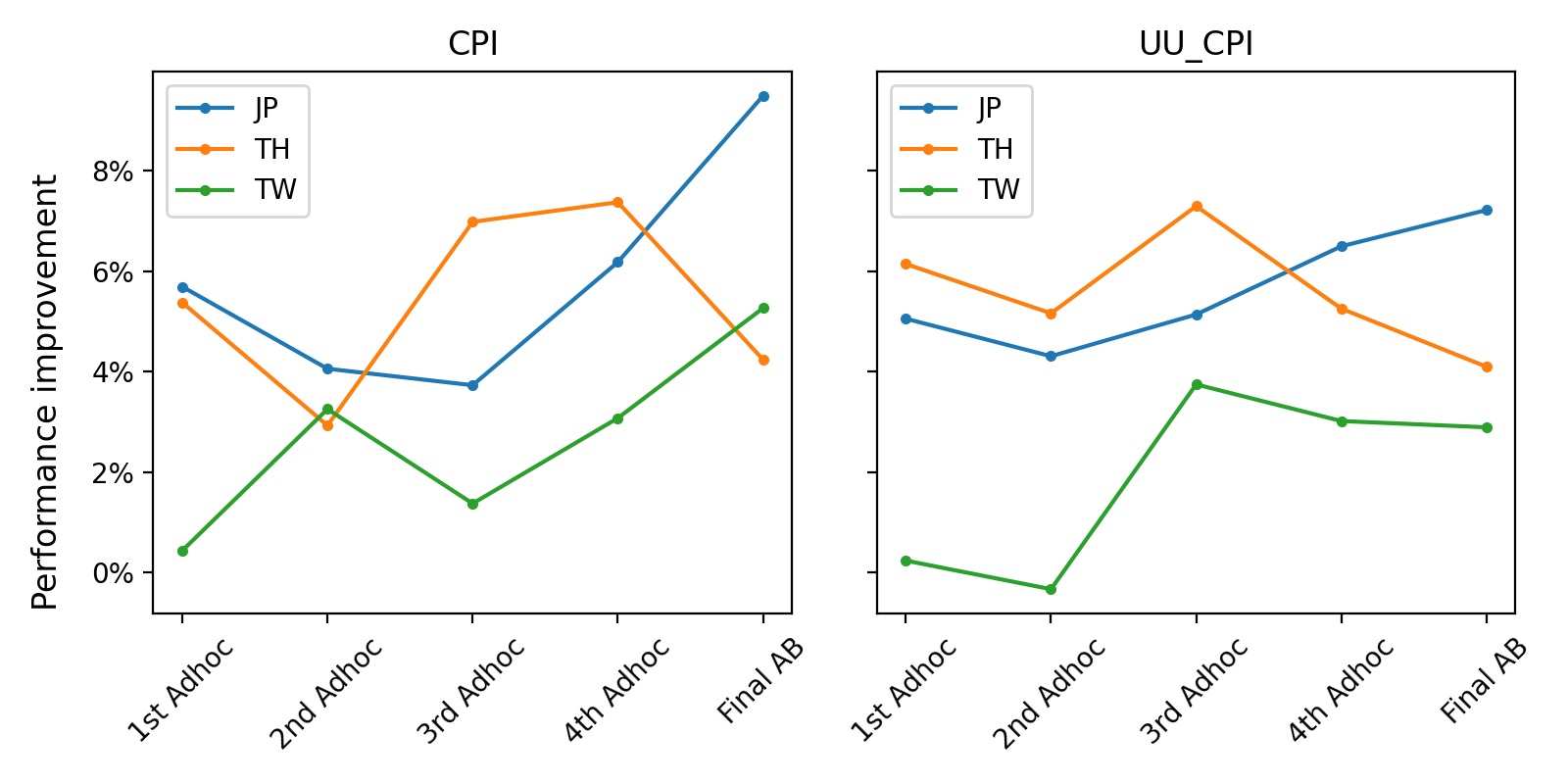
(現時点は、国ごとに別々のモデルを学習して推論し、それぞれ評価指標を集計しています。(JP:日本、TH:タイ、TW:台湾))
直前のテストに比べて向上度がやや低下しているケースもありましたが、有意な程度ではありませんでした。前述のように、異なる期間のKPI値をモデル比較に用いるには限界があり、従来のモデルと比較すると着実に良い結果が得られました。
また、個々の変更点の貢献度を詳しく調べるには、複数の変更点の組み合わせをテストする必要があります。しかしこのような方法では、テスト期間があまりにも長くなります。そこで、変更点を蓄積しながら、その変更点がオンラインテストに重大な悪影響を及ぼすかどうかの確認に焦点を当てました。
タイの場合、最後のAdhoc A/Bテストと最終テストの間に、モデルの性能改善とは別にフィルタリングのポリシーが変更されました。このポリシーの変更により、従来のモデルとの性能格差が縮小され、最終的な改善度は少し右肩下がりのグラフになりました。
この改善結果を適用すると、全体のプロセスが明確に構造化されるという大きなメリットも得られました。計画したテストがどこまで進んでいるかが体系的に整理され、進捗状況を可視化してチーム外部に共有するのに適していました。そのおかげで、遅れずに新しいモデルをリリースすることができました。
おわりに
Adhoc A/Bテストを実施する権限を得られたのは、オープンチャット企画チームの全面的なサポートのおかげです。一部のユーザーにとって新しいモデルでの提案は、一種のリスクがあることかもしれません。オープ�ンチャット企画チームから信頼していただき、私たちはこれまで継続的にモデルを改善する作業を進められました。問題が発生した場合、A/Bテストを速やかに中止して元に戻せるように取り組んだ私たちのチームも、このような信頼につながったと思います。
ユーザーがすべての基本であり中心であるという基準に基づいて、オープンチャットユーザーがより質の高いレコメンドを受けられるよう、今後も精力的に改善に取り組んでまいります。


