Hello, I'm Heewoong Park, a Machine Learning (ML) engineer from the AI Services Lab team. Our team is developing and serving various AI/ML models related to OpenChat. In a previous post titled Developing OpenChat Clean Score Model using Machine Learning (post written in Korean), we introduced the "OpenChat Clean Score Model" that evaluates each OpenChat from the perspective of how well etiquette is maintained, and whether inappropriate content is being transferred during conversations. In this post, we'd like to share how we're improving the "OpenChat Personalized Recommendation Model".
Introduction to the OpenChat recommendation service and model
OpenChat is an open chat room service on the LINE app where anonymous users with similar interests can gather and chat without having to add each other as friends. It's a feature currently available for users in Japan, Thailand, and Taiwan.
On the main page of the OpenChat mobile app, there's a search bar, recommended OpenChat rooms, and OpenChat rankings to help users find and join OpenChat rooms they like. The service we're discussing in this post is the "Recommended for you" OpenChat personalized recommendation service, which is displayed at the top of the main page of OpenChat as of November 2023.
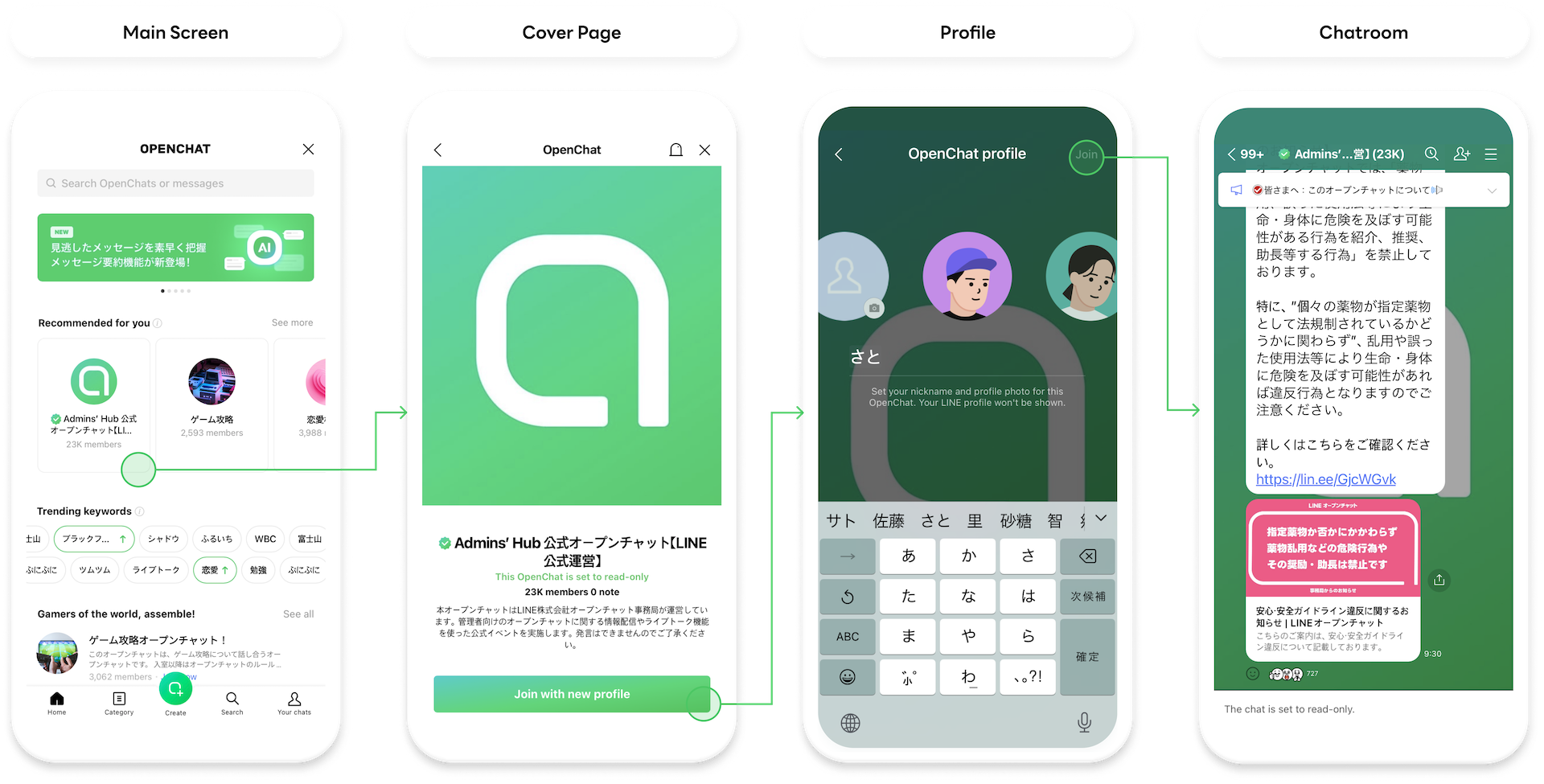
Features of the OpenChat recommendation service
OpenChat is a dynamic service that changes rapidly. The planning and operation teams continuously release new features to meet user demands, revamp the main configuration screen, and carry out marketing events to simultaneously stimulate the activity of existing users and attract new users to the service.
Such activities change the user base and as the service matures, how users use the service also change. These changes directly impact recommendation metrics, independent of the model's own performance.
Also, OpenChat is a service that contains various content. Unlike posts, videos, or products for sale that hardly change once created, OpenChat continuously changes its participating members and generates new messages. Within one OpenChat, several sub-chats can be created and in each chat, users can exchange various messages such as text, images, videos, and post-style messages.
Therefore, the OpenChat recommendation model needs to use various types of data as features, and when extracting item or user features, it should be performed repetitively so that the latest information can be reflected for the same target.
Another characteristic of OpenChat is that users rarely join multiple OpenChat rooms in a short period. Once a user finds an OpenChat they like and join, they tend to spend more time being active and staying in the same one, rather than joining other OpenChat rooms right away. This characteristic contrasts with short-form content recommendations, which lead to continuous item consumption when appropriately recommended. Therefore, session-based or sequential recommendations suitable for short-form content recommendation services do not fit well with OpenChat recommendations.
Also, users rarely tend to rejoin an OpenChat once they leave it, so it's advisable to exclude OpenChat rooms that a user has previously joined from their recommendations to provide more diverse suggestions. This means that OpenChat recommendations differ from online shopping item recommendations, which need to reflect the user's purchasing habits (including repurchases) significantly.
Introduction to the OpenChat recommendation model
The OpenChat personalized recommendation model follows the widely used two-stage framework in recommendation systems. This framework consists of a candidate selection stage, which selects hundreds or thousands of candidate items with a small amount of computation, and a ranking stage, which determines the order among the candidates using a more precise model.
When selecting candidates, we use a method that matches popular OpenChat rooms using demographic information after making an estimate of the user's preferences, and a method that selects OpenChat rooms where there is a lot of overlap with members who have interacted in the past.
As a ranking model, we adopted the Field-aware Factorization Machines (FFM) model, which can efficiently compute while considering the interaction between users and items as a second-order term. The ranking model is trained daily to reflect the constantly changing activity, preference, and trends of OpenChat. Pre-training and fine-tuning are carried out in parallel to advance the model update completion time. Fine-tuning can be done in a short time using the latest pre-trained model. We generate personalized recommendation results by inferring from the fine-tuned model every day, and for users with high activity, we update the recommendation list by reflecting the features updated every hour.
It might be a good idea to compare the OpenChat recommendation model with the LINE VOOM post recommendation model by reading the LINE Timeline's New Challenge Part 3 - Discover Recommendation Model (post in Korean) published on the LINE Engineering blog related to the OpenChat recommendation model.
Introduction to the process of improving the existing OpenChat recommendation model
Now, let's delve into the main topic. It's been four years since we started offering the OpenChat recommendation service, and during that time, we've made several major improvements to the model. When we improve the recommendation model, we generally proceed in the following manner.
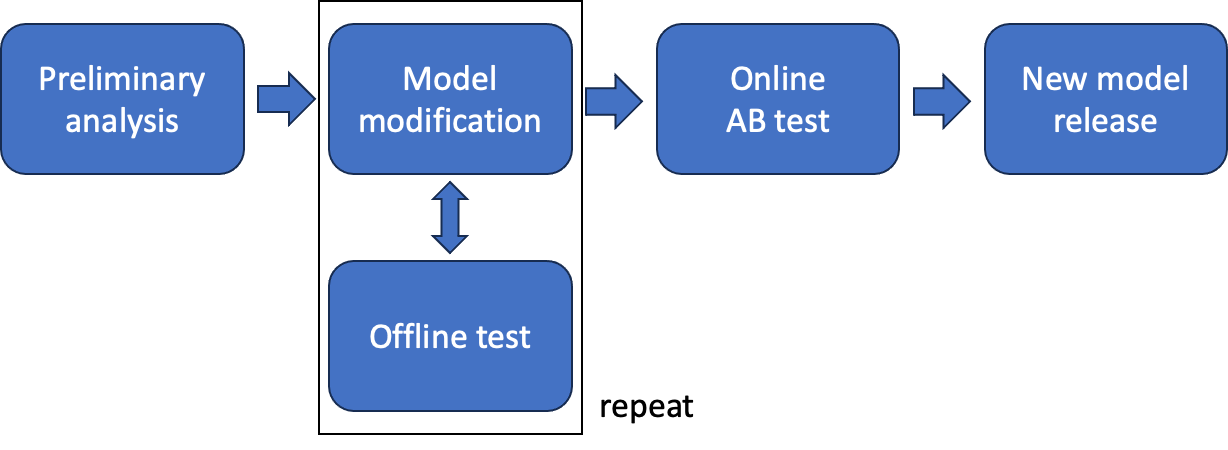
- Conduct preliminary literature research and analyze existing recommendation results
- Identify improvements based on the analysis results, implement them in the model, and confirm the performance of the offline test
- Continuously attempt to improve the performance of the offline test compared to the existing model during the planned period
- Select the optimal model through offline testing and validate by conducting an online A/B test with the existing model
- Release the new model if significant performance improvement is achieved
Among these steps, I'll discuss the two most important testing processes, offline testing and online testing, and the gap that occurs between these two tests and the issues caused by this gap.
What is offline testing?
Offline testing is a process of comparing models by constructing a labeled set with accumulated historical data. In OpenChat recommendations, we use whether a user has joined a specific OpenChat as the ground-truth label, and for the test data, we only use those who have joined through non-recommendation paths (such as search or user invitations) to avoid the exposure bias of the model in service. Training data and test data are distinguished based on timestamps. Since we train the model daily, we prepare a day's worth of test data and use only data before that date for training. To ensure validation reliability, we train and evaluate the model for each test data set for at least a week. Assuming that the model selects the top k items per user as recommended items and randomly exposes them to the user during the service, we calculate the evaluation metrics for the selected top k items.
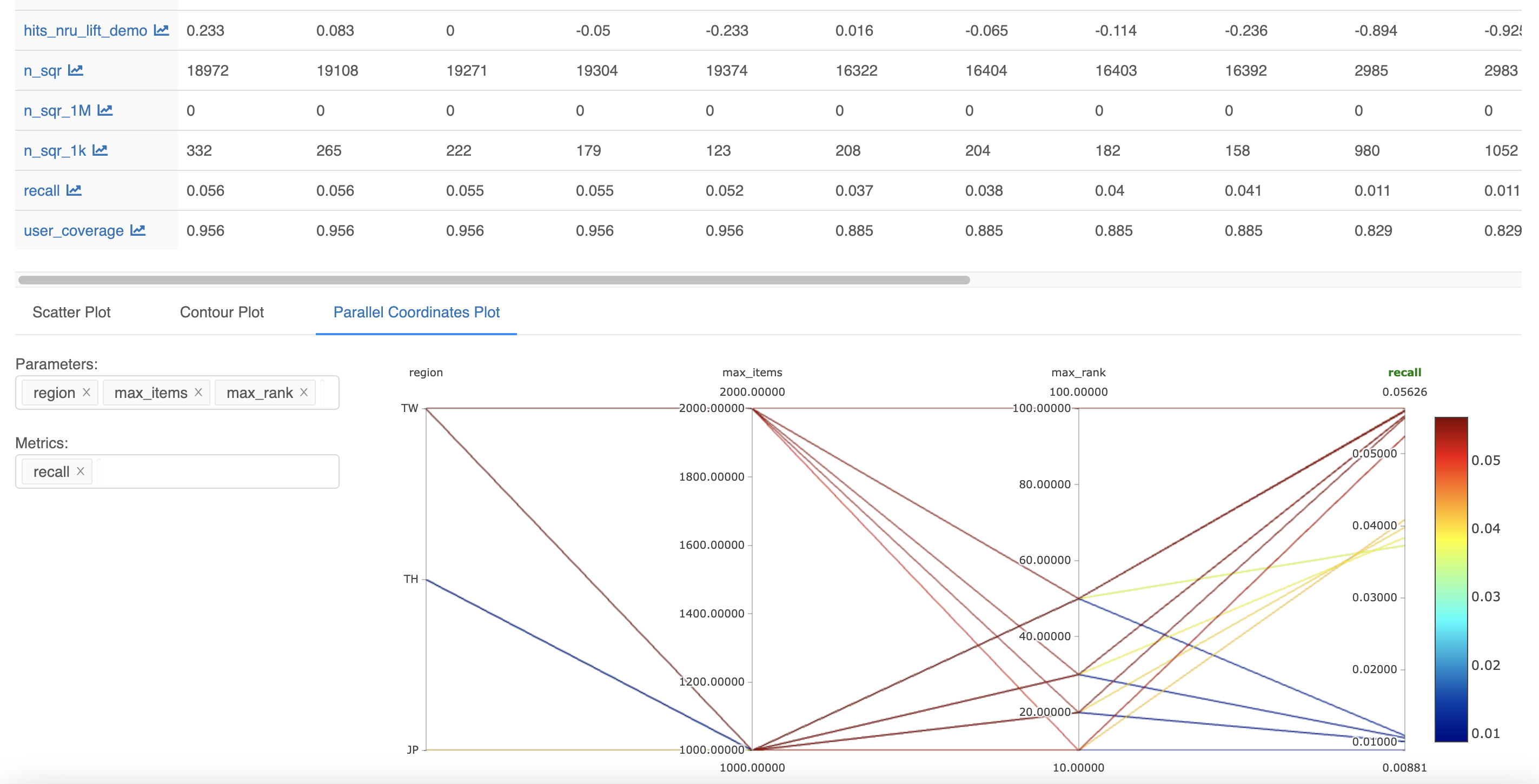
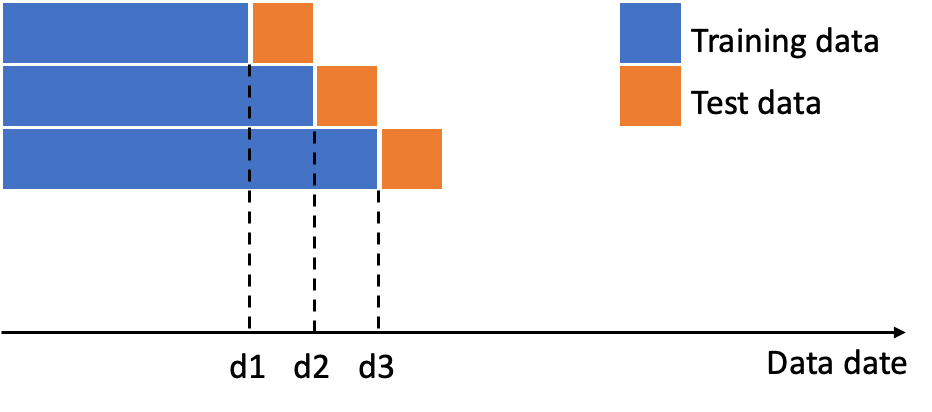 Evaluation metrics used in offline testing
Evaluation metrics used in offline testing
The main metric we used is the total count of true positives (TP), which measures how many of the model's recommendations match the OpenChat rooms that each user actually joined in the test data. When comparing models, precision or recall metrics are equivalent in terms of comparison, as we fixed the list size k for the same test set, only the scale is different. The hit rate, which counts the number of users who have at least one OpenChat they actually joined in the model's recommendation results, is also a meaningful figure that's less influenced by outlier users. However, due to the characteristic of not having many joinings per user, it doesn't significantly differ from the TP count in an offline environment where the recommendation results aren't actually exposed, so we didn't use it as a main metric.
In addition, we also look at the number of unique OpenChat rooms recommended to all users during a day. On the OpenChat main page, there are ranking and editor recommendation sections that show a small number of popular or carefully selected OpenChat rooms in addition to personalized recommendations. This is a figure to appeal to the contribution of showing various OpenChat rooms without the user's active exploration behavior compared to these sections.
We're also exploring various auxiliary measures and trying to define new ones. However, considering the convenience of communication that model selection is straightforward and many people are already familiar with it, there's no need for separate explanation of the metrics, so we primarily use the main metric.
As shown in the picture below, we're using the MLFlow platform to log various parameters and metrics derived from offline tests and compare the performance between models.
What is online A/B testing?
Online A/B testing is a control experiment that divides users into two random groups, A and B, and shows each group the recommendations of the existing model and the new model. We judge which model is superior by aggregating evaluation metrics for each group. Unlike offline tests, the new model is actually reflected in the service during the test, so you can measure the direct or indirect reactions of actual users as evaluation metrics.
Evaluation metrics used in online A/B testing - OpenChat recommendation KPIs
The main metrics used as evaluation criteria in online A/B testing are as follows. All behaviors included in the KPI definition aggregate only the results of recommendations. We primarily judge based on the conversion per impression (CPI) and unique user CPI (UU CPI) metrics, and use other metrics as auxiliary metrics or for analyzing the model.
| KPI | Definition | Explanation |
|---|---|---|
| Conversion per impression (CPI) | Number of joins / Number of exposures | In the OpenChat service, you can only participate in chat rooms if you join, so we're most interested in the action of joining. This corresponds to the act of purchasing in a typical product recommendation problem. |
| Unique user CPI (UU CPI) | Number of joiners / Number of exposed users | Compared to the non-UU CPI metric, this is a metric that is less affected by the activity of extreme minority users and has a high correlation with representative service metrics such as the number of active users. |
| Click-through rate (CTR) | Number of cover views / Number of exposures | When a user shows interest in an exposed item and clicks on it, the cover view of the respective OpenChat pops up. Users can apply to join from the pop-up window, and if no approval is needed, they can immediately join and participate in the OpenChat. |
| Conversion rate (CVR) | Number of joins / Number of cover views | Unlike the above metrics, this metric has relatively less daily fluctuations because it excludes the number of exposures, which is sensitive to timing or marketing, from the calculation. |
| Request CPI | Number of join requests / Number of exposures | This is a metric to look at whether the user was interested in the recommended item, regardless of the approval of the administrator. |
Points to note when using online A/B test evaluation metrics
It's somewhat unreasonable to compare recommendation models exposed at different times using the above metrics. As mentioned earlier, OpenChat is a service environment that changes dynamically, and accordingly, the metric values change. Due to the service's characteristic of high activity among teenagers, it is also greatly affected by temporal factors such as vacations or the start of a new semester. Teenage users tend to react more actively to recommendations compared to other age groups.
Also, changes to data collection and usage policies or recommendation item filtering rules are being made separately from the work to improve recommendation performance, making it difficult to definitively attribute changes in metrics to any one factor. There's also a day-of-the-week effect, so just like when creating an offline test set, you should run the test for at least a week (two weeks is recommended).
Here, the filter bubble (the phenomenon where the result of a personalized algorithm provided based on a user's history is composed only of perspectives the user prefers, as if trapped in a bubble) formed due to the existing model may slightly change as the new model is exposed, and the mere fact that the exposure list is different from before can affect the initial test metrics like a release effect.
The gap between offline and online testing
In offline testing, we cannot use the ground-truth label that occurs in the recommendation section where the model's results are actually exposed during the service. In other words, we can confirm from the offline test performance that the model has accurately grasped the user's joining tendency, but this is not a result of whether the user will join the OpenChat recommended by the model.
For instance, OpenChat rooms, which often have many members join due to offline social interactions or connections in services outside of LINE, tend to have relatively low join rates when recommended. In situations where joining OpenChat rooms requires approval from the administrator (room owner), even if the model accurately predicts the user's preference, recommends the room, and the user applies to join, it won't result in a successful join if the administrator doesn't approve the request.
Also, in offline testing, there is a gap caused by omitting the comparison of hourly recommendations, which not only requires a lot of computation to generate inference results but also complicates the test setup.
Problems derived from the process of improving the existing model as the service matures
In several model version upgrade processes we've carried out so far, the improvement in offline test performance has also shown up in online A/B testing, indicating that the model improvement process has worked well. In the previous version upgrade, performance significantly improved through enhancements such as adding powerful features that can understand user preferences or individual characteristics of OpenChat, or reducing the learning or inference cycle.
However, after the service got on track and the main features were reflected in the model to some extent, the improvement margin decreased, and cases began to occur where the superiority of model performance in offline and online tests wasn't the same. And the gap between the two tests, which I mentioned earlier, was pointed out as the cause.
If the online test results aren't good, you need to repeat the improvement process you've done so far. Since multiple improvements accumulate during the repetitive offline testing process, it's not easy to pinpoint which change specifically had a negative impact on online test performance. There's also a method to adjust the offline test evaluation metric to be as directly proportional as possible to the online test evaluation metric. However, this approach requires a lot of work, and continuous adjustments are needed as it can be influenced by the service environment.
Introduction of ad hoc A/B testing
We introduced ad hoc A/B testing to solve the issues mentioned above.
What is ad hoc A/B testing?
Ad hoc A/B testing is the same as the existing A/B testing in that it's an online performance test, but it differs in that it tests model performance on the spot (ad hoc) for individual change units.
When testing, to reduce the risk of the ad hoc model, we set the ratio of A to B not to 5:5, but to a smaller group B ratio of 9:1. Even if the size of group B is reduced to 1/5, it doesn't require five times the period to secure reliability from a statistical perspective. This is because the required increase in samples is partially offset as the size of group A, which is the control group, actually increases.
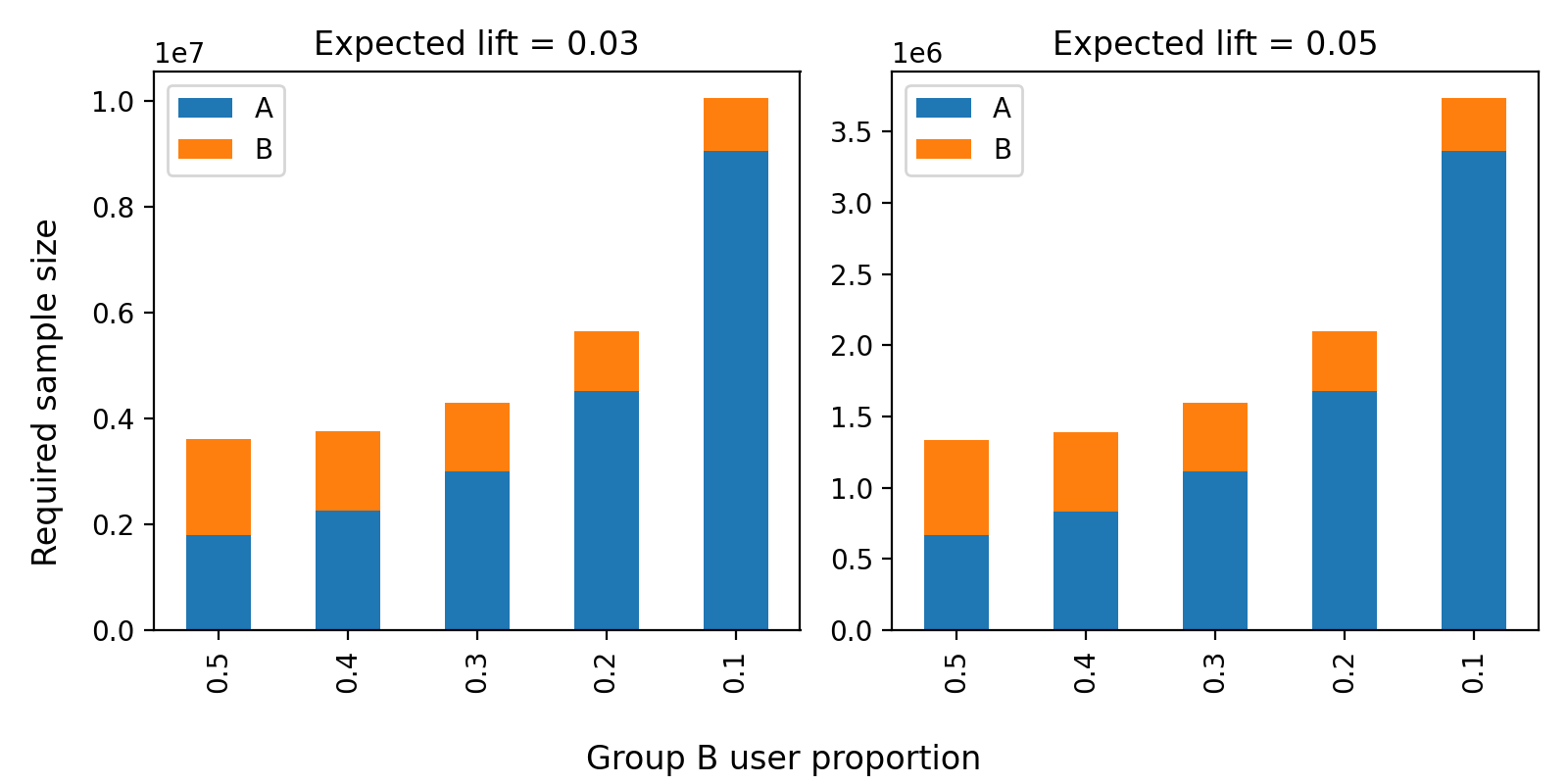
The following image is the result of calculating the required sample size when the proportion of group B decreases from 50% to 10% using the statsmodels package. In the subplot, we assumed a 3% and 5% metric improvement (expected lift) under the conditions of a join rate of 0.01, statistical power of 0.8, and a significance level of 0.05. As you can see from the graph, as the size of group B decreases, the required total sample size increases, but it doesn't increase up to five times when reducing the condition from 50% to 10%. You can confirm that it's sufficient with about three times the sample size.
 The process of improving the model based on ad hoc A/B testing is as follows.
The process of improving the model based on ad hoc A/B testing is as follows.
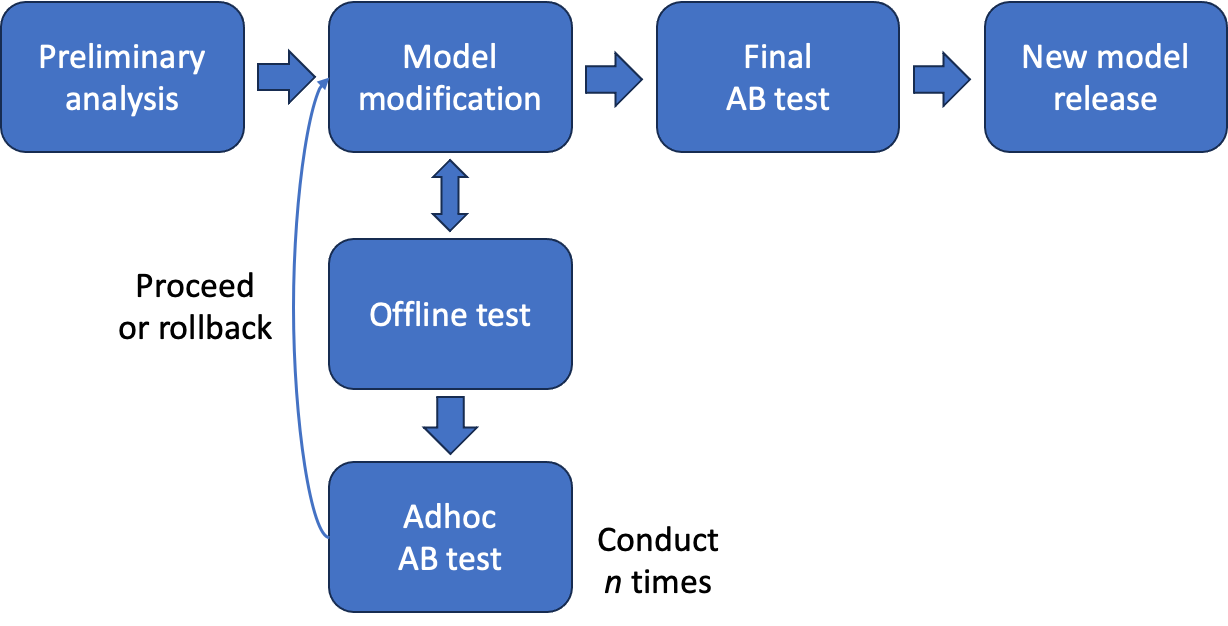
- Derive improvements based on research and analysis and implement them in the ad hoc model (same as before)
- After the offline test, if improvement is confirmed, perform ad hoc A/B testing with the ad hoc model
- If the ad hoc test performance is good, maintain the modifications to the ad hoc model
- If the performance isn't good, roll back the modifications made to the ad hoc model
- Repeat step 2 while implementing additional improvements in the ad hoc model
- After several ad hoc tests, finally compose a new model and conduct A/B testing at a 5:5 ratio as before
The existing A/B test was a process of final confirmation at the stage before release, assuming a certain amount of performance improvement. On the other hand, the ad hoc A/B test is a process aimed at verifying the performance of individual changes, which helps to reduce the burden. Since online testing is performed longer during a similar development period as before, it also has the advantage of increased reliability.
Application results
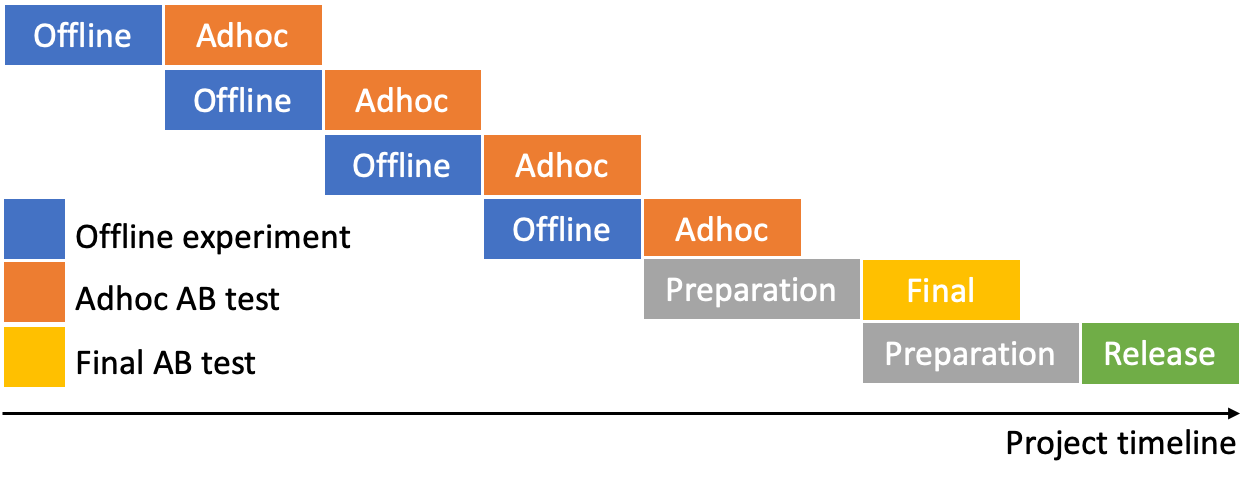
We introduced the results of such improvements in the recent process of improving the OpenChat personalized recommendation model. Below is the timeline of the model improvement process we performed this time, where we conducted the final A/B test after performing ad hoc A/B test four times. To shorten the development period, we minimized the interval between ad hoc A/B tests, and during each test period, we implemented the next ad hoc model and performed offline testing.
In this improvement process, as you can see from the performance improvement graph below, we were fortunate that the ad hoc A/B test results generally improved gradually as the test progressed. We continued to accumulate changes without any rollbacks and updated the ad hoc model (currently, we train and infer models separately by country and aggregate each evaluation indicator).
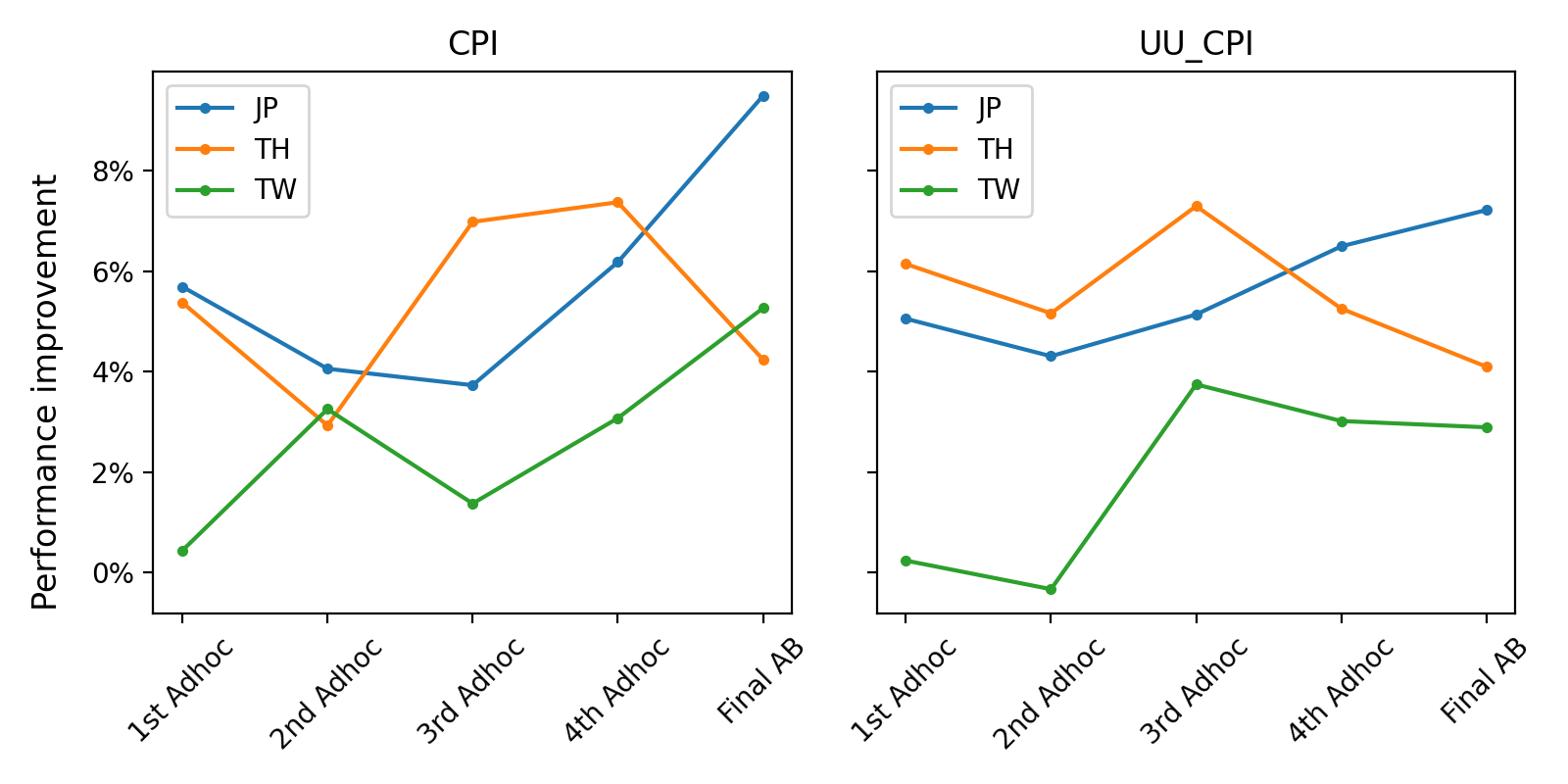
There were also cases where the degree of improvement was slightly lower than the previous test, but not to a significant degree. As mentioned earlier, there are limitations to using KPI values from different periods for model comparison, and because the results were consistently good compared to the existing model. Moreover, to scrutinize the contribution of each individual change point, it's necessary to test combinations of multiple change points, but if conducted in this way, the test period would be too long. Therefore, we mainly focused on confirming whether the change point has a significant negative impact on the online test as the changes are accumulated.
For your information, in the case of Thailand, the filtering policy was changed separately from the model performance improvement between the last ad hoc A/B test and the final test. This policy change reduced the performance gap with the existing model, resulting in a slightly downward graph of the final improvement rate.
After applying the improvement results, we could also gain a great advantage that the entire process was clearly structured. As the planned test was systematically organized to see how far it had progressed, it was suitable for sharing progress with the outside of the team. Thanks to this, the release decision was made without delay, and we were able to successfully release a new model.
Conclusion
The ability to perform ad hoc A/B tests was made possible thanks to the full support of the OpenChat planning team. Although it's limited to some users, presenting the results of a new model is certainly a risky task. The OpenChat planning team trusted our team, which has been continuously improving the model, allowing us to proceed with the work. We believe that our team's ability to quickly stop A/B tests and restore them to their original state in the event of a problem also contributed to this trust.
Based on the principle that the user is at the heart of everything we do, we will continue to vigorously improve our models to ensure that OpenChat users receive higher quality recommendations.


