들어가며
안녕하세요. AI Services Lab 팀의 ML 엔지니어 박희웅입니다. 저희 팀에서는 오픈챗과 관련된 다양한 AI/ML 모델을 개발해 서빙하고 있는데요. 앞서 오프라인과 온라인 A/B 테스트를 통해 오픈챗 추천 모델 개선하기 포스트에서 사용자 개인의 취향에 맞는 오픈챗들을 추천하는 모델의 개선 과정을 소개 드린 바 있습니다.
오픈챗 서비스에서는 채팅방의 주제와 특성을 적절히 드러내면서 잘 검색되도록 도와주는 해시태그를 보다 적극적으로 설정하도록 유도하는 한편, 이를 효과적으로 활용하는 기능들을 준비하고 있는데요. 이번 글에서는 오픈챗을 생성할 때 해시태그를 지정하는 것을 돕는 해시태그 예측 모델을 어떻게 개발하고 있는지 공유드리고자 합니다.
오픈챗 해시태그 예측 모델
오픈챗 생성 시 사용자는 오픈챗 '이름(name)'을 필수로 정해야 하며, 부가로 본 오픈챗에 대한 '설명글(description)'을 남길 수 있습니다. 이때 오픈챗이 잘 검색될 수 있도록 설명란에 해시태그를 활용해 키워드를 기입하도록 유도하고 있습니다. 이 과정을 오픈챗 생성 화면에서 별도 필드로 해시태그를 입력받는 형태로 개선하려고 하며, 이때 사용자가 보다 수월하게 해시태그를 선택할 수 있도록 ML 모델을 이용해 제시하는 기능을 준비하고 있습니다. 이와 같이 제시하는 기능을 위한 해시태그 예측 모델을 어떻게 모델링하고 학습했는지 말씀드리겠습니다.
데이터셋 구축
먼저 해시태그 정답 데이터의 경우 사용자가 자발적으로 해시태그를 포함해서 작성한 설명글에서 해시태그 셋을 추출해 볼 수 있습니다. 정답 추출이 가능한 오픈챗의 비중이 높지는 않지만, 날마다 수천, 수만의 오픈챗이 새로 생성되는 덕분에 100만 건 이상의 데이터를 확보할 수 있었습니다.
예측 모델의 입력으로는 오픈챗 생성 시점에 가용한 오픈챗의 이름과 설명글만 이용했습니다. 이름과 설명글은 구분자를 삽입해 하나의 문자열로 이어붙여 모델 구조를 단순화했습니다. 학습 데이터셋을 구축할 때에는 정답이 입력에 나타나는 자명한 케이스를 제외하기 위해 설명글에서 해시태그 부분은 제거한 후 입력 텍스트를 구성합니다. 모델 입력 피처로 작성자 정보를 고려할 수도 있습니다. 특히 오픈챗의 이름과 설명이 부실한 경우에는 과거 같은 사용자가 생성하거나 활동했던 다른 오픈챗의 해시태그 정보가 매우 유용할 텐데요. 이 부분은 추후 개선 과제로 남겨두었습니다.
아래 표는 각 지역별로 어떤 해시태그가 많이 등장했는지 보여줍니다. 랭킹을 보면 일본(이하 JP)에서는 연령대를 나타낸 해시태그(40代, 30�代, 50代)를 많이 활용합니다. 이를 통해 같은 나이대끼리의 모임을 선호하는 것을 알 수 있습니다. 태국(이하 TH)이나 대만(이하 TW)에서는 패션(เสื้อผ้า, แฟชั่น), 가격(ราคาถูก, ราคาส่ง), 구매(團購, 代購), 용품(生活用品) 등의 해시태그를 많이 활용합니다. 이를 통해 각종 소비 행위가 오픈챗을 통해 활발하게 이뤄지고 있음을 파악할 수 있습니다.
| 순위 | JP | TH | TW |
|---|---|---|---|
| 1 | 雑談 | บอท | 團購 |
| 2 | 恋愛 | เสื้อผ้า | 聊天 |
| 3 | なりきり | ราคาถูก | 美食 |
| 4 | 40代 | เสื้อผ้าแฟชั่น | 代購 |
| 5 | 相談 | กระเป๋า | 批發 |
| 6 | 30代 | ราคาส่ง | 交友 |
| 7 | 50代 | ขายส่ง | 美妝 |
| 8 | 既婚 | พรีออเดอร์ | 生活用品 |
| 9 | 癒し | แฟชั่น | 分享 |
| 10 | ゲーム | รองเท้า | 對戲 |
다음은 오픈챗 하나당 몇 개의 해시태그가 추출됐는지 분포를 나타낸 것으로, 사용자가 두 개 이상의 해시태그를 사용하는 경우가 하나만 사용하는 경우보다 일반적이라는 것을 확인할 수 있습니다.
| 해시태그 개수 | JP | TH | TW |
|---|---|---|---|
| 1 | 30.5% | 47.1% | 38.2% |
| 2 | 15.5% | 14.9% | 13.9% |
| 3 | 13.3% | 11.9% | 13.7% |
| 4 | 9.2% | 7.6% | 9.5% |
| 5 | 6.2% | 4.8% | 6.4% |
| 6 | 4.5% | 3.2% | 4.3% |
| 7 | 3.3% | 2.2% | 2.9% |
| 8 | 2.6% | 1.6% | 2.1% |
| 9 | 2.0% | 1.2% | 1.6% |
| 10 | 1.6% | 0.9% | 1.2% |
다중 레이블 분류 문제로 모델링
저희는 이 문제를 오픈챗 이름과 설명이 입력으로 들어올 때 적절한 해시태그 셋을 출력하는 다중 레이블 분류(multi-label classification)로 모델링했습니다.
우선 생성형 문제가 아닌 정해진 클래스 셋 중에서 해시태그를 선택하는 분류형 문제로 채택한 이유는 다음과 같습니다.
- 프로젝트의 시발점이 50개 이내의 고정된 오픈챗 카테고리보다 더 다양한 키워드로 분류하는 것이었기 때문입니다.
- 생성형 모델에서 논란의 소지가 될만한 해시태그가 출력되는 리스크를 줄이기 위함입니다. 사전에 검수된 해시태그로만 데이터셋을 구성함으로써 위험을 최소화할 수 있습니다.
- 학습 데이터셋 크기가 충분해 문제에 특화된 분류 모델을 훈련했을 때 공개된 텍스트 데이터로 학습된 생성형 모델보다 성능이 우수합니다.
클래스 셋 중 오직 하나만 택하는 다중 클래스 분류(multi-class classification)로 모델링하지 않은 이유는, 복수 개의 해시태그를 허용하면 검색이 더 잘 될 뿐만 아니라, 앞서 분포에서 봤듯이 사용자들이 이미 설명글에서 그와 같은 방식으로 활용하고 있기 때문입니다.
다중 레이블 분류 모형의 출력 공간은 클래스 개수만큼의 차원을 가진 벡터로 표현되며, 각 벡터의 성분 값은 해당 클래스에 속하는지 여부로 0과 1 값을 할당합니다. 예를 들어 출력 클래스 셋이 일 때 어떤 인스턴스의 레이블이 이면 (1, 0, 1) 벡터로 변환되는 식입니다.
일반적으로는 이렇게 표현된 출력 공간에 대해 각 성분별로 이진 교차 엔트로피 손실 함수(binary cross-entropy loss; BCE loss)를 이용해 다중 레이블 분류기를 학습합니다. 그러나 해시태그 예측 문제는 해당 오픈챗에 대해 각 해시태그의 관련 여부를 판단하는 것보다는 연관성 순으로 상위 K개의 해시태그를 골라내는 것이 목적입니다. 사용자 또한 오픈챗을 생성할 때 가능한 모든 해시태그의 관련성을 일일이 따져보고 선택한다기보다는 즉각적으로 떠오르는 몇 개를 고른다고 생각하는 것이 자연스러울 것입니다.
따라서 본 문제에서는 다중 클래스 분류기 학습에 많이 사용되는 카테고리 교차 엔트로피 손실 함수(categorical cross-entropy loss; CCE loss, 이하 CCE 손실 함수)를 약간 변형해 학습에 이용했습니다. CCE 손실 함수는 두 분포 , 간에 정의된 교차 엔트로피 에서 에는 정답 원-핫(one-hot) 벡터를, 에는 예측된 확률 벡터를 대입해 계산하는데요. 다중 레이블 분류 학습에 적용하기 위해 에 원-핫 벡터 대신 합이 1이 되도록 정규화된 다중 레이블 벡터를 대입했습니다. 앞의 예시를 재활용해 보면 경우 벡터는 (0.5, 0, 0.5)가 됩니다.
참고로 이 글에서는 해시태그를 분류 작업 및 데이터 관점에서는 상황에 따라 클래스 혹은 레이블로, 모델 관점에서는 추론 결과나 모델 출력이라고 지칭하겠습니다.
Hugging Face의 Transformers를 이용한 구현
모델 구현은 Hugging Face의 Transformers 패키지를 활용했습니다. 간략화된 코드로 소개하자면, 우선 입력된 examples 데이터셋은 각 행마다 오픈챗 name, description, hashtags 필드로 구성돼 있습니다.
전처리 함수에서는 먼저 이름과 해시태그를 제거한 설명을 하나의 문자열로 이어붙이고 이를 토큰화해 입력 토큰 시퀀스를 만듭니다. 레이블로 사용할 hashtags 배열에 대해서는 sklearn.preprocessing.MultiLabelBinarizer 모듈을 이용해 이진 행렬로 만듭니다. 이때 출력 공간(고유한 전체 해시태그 셋) 크기가 클 경우 밀집(dense) 형식으로 인코딩하면 메모리를 과도하게 차지합니다. 수만 개의 해시태그 중에서 하나의 오픈챗에 달리는 해시태그는 극히 일부이므로 희소(sparse) 형식으로 인코딩하면 메모리 사용량을 절감할 수 있으며, 그중에서도 LIL(list of list) 형식을 이용하면 임의의 i번째 행을 신속하게 조회하는 것도 가능합니다.
import pandas as pd
from sklearn.preprocessing import MultiLabelBinarizer
def preprocess(examples: pd.DataFrame, tokenizer, classes, max_length=None):
examples["input_text"] = examples.apply(
lambda x: f"{x['name']}\n{x['description_without_tags']}"
)
encoded_inputs = tokenizer(
examples["input_text"].to_list(),
truncation=True,
max_length=max_length
)
mlb = MultiLabelBinarizer(classes=classes, sparse_output=True)
mlb_output = mlb.fit_transform(examples["hashtags"])
encoded_inputs["labels"] = mlb_output.tolil()
return Dataset(encoded_inputs)전처리 후에는 Transformers 모델 학습을 위해 Dataset 객체 형태로 구성합니다. 이는 GPU 연산이 필요한 데이터를 torch.Tensor 형식으로 변환하는 역할을 담당합니다. 앞서 희소 형식으로 인코딩했던 labels 필드는 해당 데이터 인스턴스를 포함하는 미니 배치 연산 시점에만 밀집 텐서(dense tensor) 형식으로 저장되도록 __getitem__ 메서드 내부에서 변환함으로써 메모리 효율을 높일 수 있습니다.
import torch
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __len__(self):
return len(self.encodings["input_ids"])
def __getitem__(self, idx):
# process input other than labels
item = {k: torch.tensor(v[idx]) for k, v in self.encodings.items() if "labels" not in k}
# convert labels from lil matrix row
lil_row = self.encodings["labels"].getrowview(idx)
labels_ndarray = lil_row.toarray().squeeze(0)
item["labels"] = torch.tensor(labels_ndarray, dtype=float)
return item앞서 제안한 변형된 손실 함수로 다중 레이블 분류 모델을 학습하기 위해 transformers.trainer.Trainer 클래스를 수정해 다음과 같이 MultiLabelTraniner 클래스를 만들었습니다. 이 클래스를 활용해 기존 transformers.trainer.Trainer와 같은 방식으로 학습 과정을 진행합니다.
from torch import nn
import transformers
class MultiLabelTrainer(transformers.trainer.Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get("labels") # all elements are 0 or 1
labels /= labels.sum(dim=-1, keepdim=True) # normalize by sum
outputs = model(**inputs)
logits = outputs.get('logits')
log_probs = nn.functional.log_softmax(logits, dim=-1)
loss = -(labels * log_probs).sum(dim=-1).mean() # compute the suggested CE loss
return (loss, outputs) if return_outputs else loss오프라인 실험 결과
오프라인 실험을 진행할 때 가장 직관적으로 떠올릴 수 있는 평가 지표는 가장 높은 점수로 예측된 레이블 중 정답의 비율이 얼마나 되는지를 평가하는 precision@1(정밀도) 지표입니다. 설정된 한도 범위 내에서 최대한 관련 있는 해시태그들을 제시하는 시나리오를 염두에 두고 있었기에 recall@K(재현율) 지표들도 주요 비교 대상으로 선정했습니다. recall@K 지표 같은 경우 K개의 예측 레이블 간의 점수 우열은 고려하지 않기에 이를 보완하기 위해 순위까지 반영한 ndcg@K 지표도 참고했습니다.
위 평가 지표들을 산출하고 집계하는 코드는 다음과 같이 구현할 수 있습니다. recall@K와 ndcg@K를 산출할 때 점수 상위 K개 외의 예측 결과는 평가에 영향을 주지 않으므로 정렬 시 상위 K개만 고려하는 것으로 연산을 효율화할 수 있습니다. 비슷한 맥락으로 출력된 로짓(logit) 값이 0보다 작은 경우에는 예측된 레이블이 정답일 가능성이 미미하므로, 이들에게는 보통 산출되는 로짓 값(-15 ~ 15)보다 더 작은 음수 값(-100)을 할당했습니다. 이렇게 구현된 compute_metrics 함수는 MultiLabelTrainer 생성자의 인자로 전달할 수 있습니다.
import numpy as np
import sklearn
def compute_metrics(eval_pred, ks=(1, 3, 5, 7, 10, 15, 30)):
logits, labels = eval_pred
binary_labels = (labels > 0).astype(int)
label_lengths = np.sum(binary_labels, axis=-1)
# only consider positive logits for faster computation
logits = np.where(logits > 0, logits, -100)
# select top maxk at first and then sort them for faster computation
maxk_ind = np.argpartition(-logits, max(ks), axis=-1)[..., :max(ks)]
maxk_logits = np.take_along_axis(logits, maxk_ind, axis=-1)
maxk_ind_sortind = np.argsort(-maxk_logits, axis=-1)
maxk_ind_sorted = np.take_along_axis(maxk_ind, maxk_ind_sortind, axis=-1)
_metrics = {}
_metrics["precisionAt1"] = np.take_along_axis(binary_labels, maxk_ind_sorted[..., :1], axis=-1).mean()
_metrics[f"ndcgAt{max(ks)}"] = sklearn.metrics.ndcg_score(labels, logits, k=max(ks))
recalls = {}
for k in ks:
topk_ind = maxk_ind_sorted[..., :k]
TPs = np.take_along_axis(binary_labels, topk_ind, axis=-1).sum(axis=-1)
recalls[f"recallAt{k}"] = (TPs / np.maximum(label_lengths, 1)).mean()
_metrics.update(recalls)
return _metrics평가 지표를 선정하고 산출하기 위한 코드를 작성한 후, 일본과 태국, 대만 등의 지역에서 여러 언어로 작성된 오픈챗들을 하나의 모델로 처리하기 위해 사전 학습된 다중 언어 모델(pretrained multilingual LM)로 초기화한 후 분류기를 학습했습니다. 평가 셋은 학습 데이터셋에 포함된 150만 개의 오픈챗 중 1%의 데이터를 별도로 분리해 구성했습니다.
다음 표는 Hugging Face Models 저장소에 공개된 여러 사전 학습된 모델들로 초기화해 학습한 해시태그 분류기의 성능을 비교한 결과입니다. '-base' 모델보다는 파라미터 수가 많은 '-large' 모델 쪽이 모든 지표에서 더 우수했습니다. sentence-transformers/LaBSE 모델은 '-base' 모델과 히든 임베딩(hidden embedding) 차원 수와 셀프 어텐션(self-attention) 레이어 수가 동일하지만 토큰 어휘가 많은 모델인데 '-base' 모델보다 성능이 좋았고 '-large' 모델에 버금가는 성능을 나타냈습니다. 비교한 모델 중에서는 xlm-roberta-large에 여러 다중어 말뭉치를 추가 학습한 multilingual-e5-large 모델이 가장 우수했기에 이 모델을 채택해 이후 실험을 진행했습니다.
| 사전 학습된 모델 | ndcg@30 | precision@1 | recall@1 | recall@3 | recall@7 | recall@30 |
|---|---|---|---|---|---|---|
| xlm-roberta-base | 61.45% | 59.56% | 27.41% | 44.93% | 57.07% | 73.10% |
| xlm-roberta-large | 62.17% | 60.01% | 27.54% | 45.49% | 57.58% | 74.05% |
| sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | 57.54% | 56.44% | 25.43% | 41.62% | 52.99% | 69.19% |
| sentence-transformers/LaBSE | 62.09% | 60.11% | 27.68% | 45.44% | 57.74% | 73.80% |
| intfloat/multilingual-e5-base | 62.26% | 60.30% | 27.86% | 45.76% | 57.86% | 73.80% |
| intfloat/multilingual-e5-large | 62.97% | 60.66% | 28.15% | 46.23% | 58.51% | 74.76% |
다음 표는 다중어 모델이 각 언어별로 잘 작동하고 있는지 확인하기 위해 지역별로 성능을 평가한 결과입니다. 아무래도 학습 데이터셋에서 비중이 높았던 JP 지역 오픈챗에 대한 지표가 높았고, TH 및 TW 지역 지표는 상대적으로 낮았습니다. 추가로 지역마다 별도의 모델을 학습하는 방식도 시도해 봤지만 단일 다중어 모델의 성능과 차이가 거의 없었습니다. TH와 TW 지역에 대해서는 추후 전처리 과정을 고도화해 학습 데이터셋을 확대하면서도 토픽이 보다 뚜렷한 해시태그로 클래스 셋을 구성하는 등의 접근 방식으로 개선해 볼 생각입니다.
| 지역 | 인스턴스 수 | precision@1 | ndcg@30 | recall@1 | recall@3 | recall@7 | recall@30 |
|---|---|---|---|---|---|---|---|
| JP | 11615 | 71.32% | 71.49% | 31.77% | 52.11% | 65.45% | 81.11% |
| TH | 1242 | 53.95% | 66.02% | 37.84% | 56.98% | 69.24% | 85.79% |
| TW | 2083 | 52.04% | 58.08% | 27.69% | 44.90% | 56.45% | 73.41% |
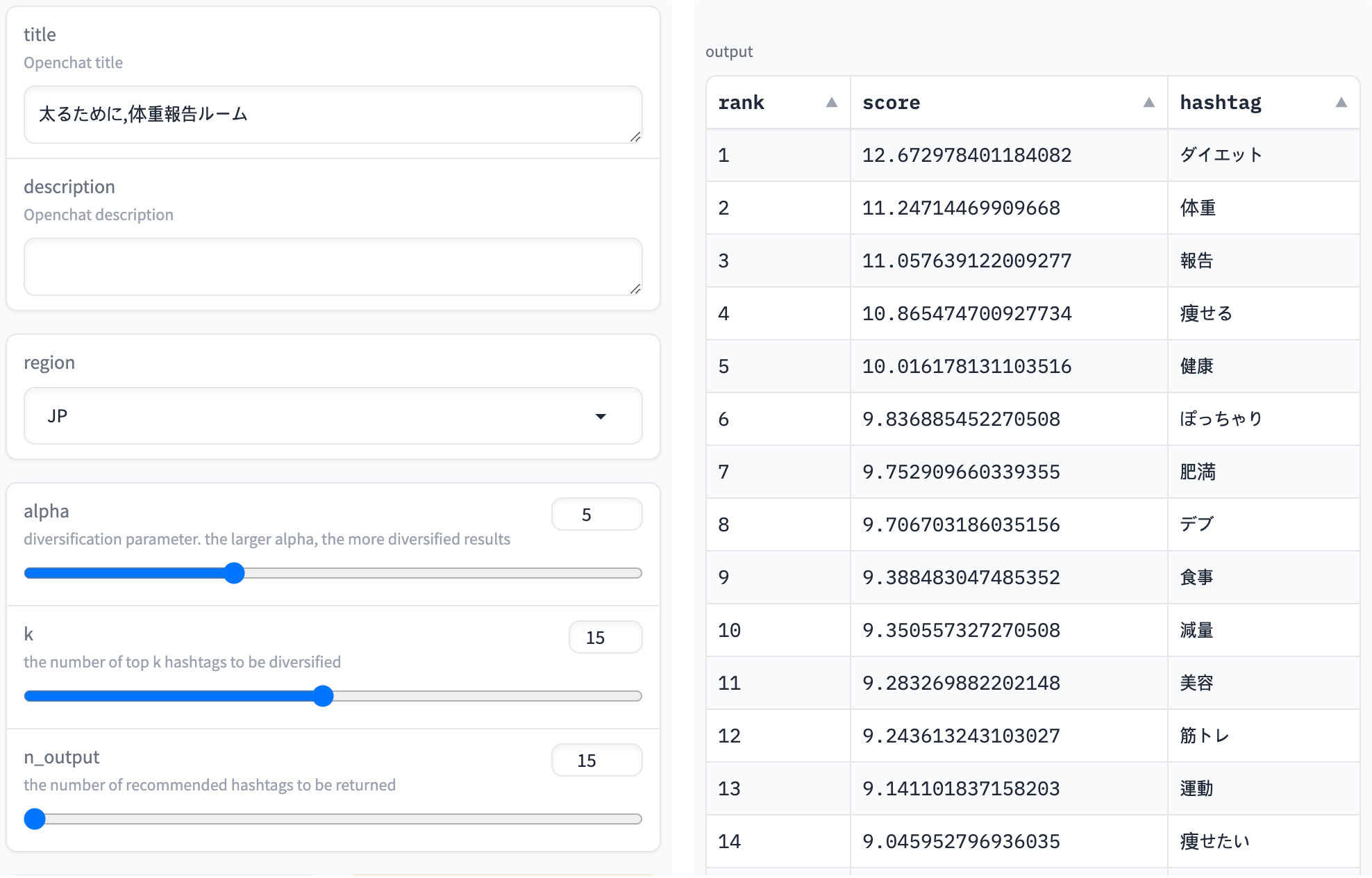
다음 스크린숏은 '太るために,体重報告ルーム' (번역: '살찌기 위해, 체중 보고실') 오픈챗 이름에 대한 추론 결과를 보여주고 있습니다. 'ダイエット(다이어트)'나 '体重(체중)' 등 관련이 있을 법한 해시태그가 높은 점수로 예측되는 것을 확인할 수 있습니다. 제목은 '살찌기 위해'이지만 아무래도 살 빼기 위해 체중을 서로 보고하는 경우가 일반적이다 보니 '減量(감량)' 같은 키워드도 상위권에 나타났습니다.
실시간 제안을 위한 모델 개선
여러 입력 시점에서 추론
오픈챗 생성 시점에 실시간 추론을 통해 사용자에게 어울리는 해시태그를 제안하는 시나리오에서는 모델 추론을 요청받는 시점이 비단 한 번이 아닐 수도 있습니다. 오픈챗 생성 과정을 순서대로 살펴보면 각각 다음과 같은 시점에 모델 추론을 요청받을 수 있습니다.
- 설명글은 필수 입력 사항이 아니므로, 오픈챗 이름만 입력이 완료된 상태에서 어울리는 해시태그를 먼저 제안해 볼 수 있습니다.
- 사용자가 설명글을 작성하고 있을 때 해시태그를 제안해 내용 연상에 도움을 주고 수월하게 작문하도록 유도할 �수 있습니다.
- 앞서 모델 학습 데이터셋을 구축할 때 주로 고려했던 기본적인 상황으로, 오픈챗 이름과 설명글을 모두 작성 완료한 상태에서 해시태그를 제안합니다.
- 오픈챗 하나에 여러 해시태그를 입력할 수 있는 스펙이라면, 사용자가 해시태그를 선택할 때마다 이를 모델 입력에 반영해 다음 해시태그를 제안합니다.
위 네 가지 상황 중 앞 세 가지 상황은 학습 데이터셋에 어느 정도 반영됐다고 간주할 수 있습니다. 먼저 3번은 직접적으로 고려했던 상황으로 오픈챗 이름과 해시태그를 제외한 설명글로 입력 텍스트를 만들었습니다. 또한 오픈챗 설명글은 선택 입력 사항이기에 해시태그가 입력에서 제거되고 학습 데이터셋에 이름만 남는 경우도 제법 많이 있어서 1번 상황도 어느 정도 반영돼 있습니다. 여기에 더해 데이터셋에는 설명글의 길이가 다양한 오픈챗들이 포함돼 있으므로 긴 설명글을 작성하는 도중에 추론하는 2번 상황과 유사한 상황도 어느 정도 반영돼 있습니다.
마지막 4번 상황을 살펴보겠습니다. 이미 선택된 해시태그는 모델 입력으로는 활용할 수 있지만 출력에서는 제외해야 합니다. 이 상황에서의 정확도를 높이기 위해 추출된 해시태그가 두 개 이상인 오픈챗들에 대해, 추출된 해시태그의 일부는 입력 텍스트에 덧붙이고 나머지를 정답 레이블로 구성한 인스턴스들을 학습 데이터셋에 추가했습니다.
예를 들어 어떤 오픈챗의 이름이 '太るために,体重報告ルーム' 이고 추출된 해시태그가 ['ダイエット', 体重', '健康']이라고 했을 때, 다음처럼 여러 개의 학습 데이터 인스턴스를 생성합니다.
| 입력 텍스트 | 출력 레이블 |
|---|---|
| '太るために,体重報告ルーム' | ['ダイエット', '体重', '健康'] |
| '太るために,体重報告ルーム\n#ダイエット' | ['体重', '健康'] |
| '太るために,体重報告ルーム\n#ダイエット #体重' | ['健康'] |
이제 해시태그 중 일부를 입력 텍스트에 반영해 학습했을 때 모델 성능이 향상되는지 확인해 보겠습니다. 평가 데이터셋은 다음과 같이 다양한 추론 시점별로 나눠 구축해 상황별 성능 변화 정도를 비교합니다.
| 케이스 ID | 입력 텍스트 | 출력 레이블 |
|---|---|---|
| 케이스 1 | 이름 | 해시태그 |
| 케이스 2 | 이름 + 해시태그를 제외한 설명글의 앞 절반 부분 | 해시태그 |
| 케이스 3 | 이름 + 해시태그를 제외한 설명글 | 해시태그 |
| 케이스 4 | 이름 + 해시태그를 제외한 설명글 + 첫 번째 해시태그 | 첫 번째를 제외한 해시태그 |
이 비교는 양이 가장 많은 JP 지역 데이터로 모델 학습 및 평가했습니다.
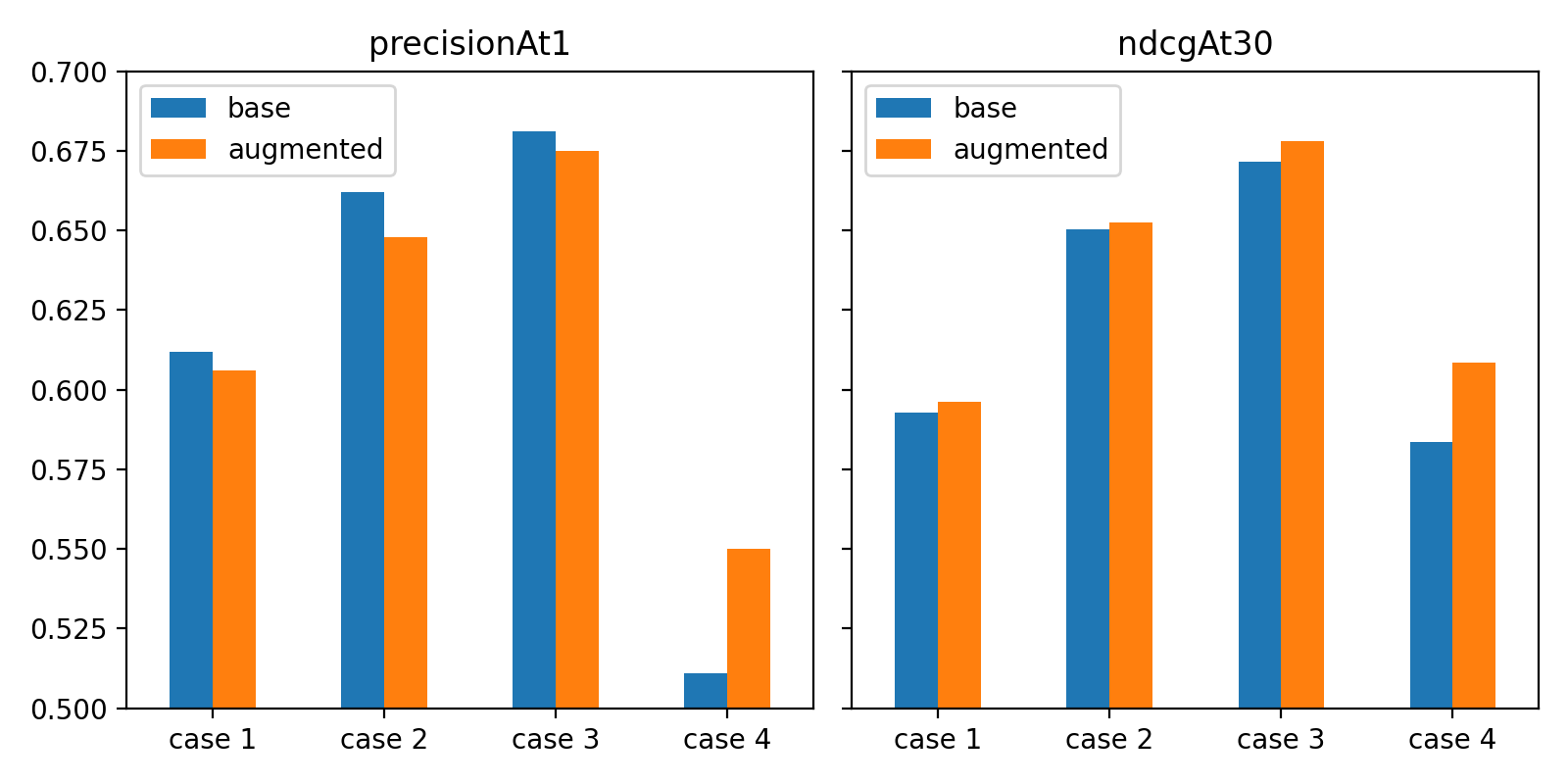
기본(base) 모델과 학습 데이터셋을 증강해 학습한 모델을 비교해 보면, 첫 해시태그가 입력으로 주어진 케이스 4에서는 precision@1과 ndcg@30 지표 모두 해당 상황의 데이터를 추가해 학습한 모델 쪽이 확실히 좋았습니다.
그 외 케이스에서는 지표별로 서로 다른 결과가 나타났는데요. 데이터 증강 시 톱 1 예측 결과에 대한 평가 지표는 약간 낮아졌지만, 톱 30 예측 결과까지 고려했을 때에는 더 우수했습니다. 샘플을 골라 관찰해 보니 기본 모델 쪽에서 입력 텍스트에 포함된 키워드가 출력 해시태그로 예측되는 경우가 더 잦았으며, 평��가 셋에는 추출된 정답 레이블 중 하나가 제목에 포함된 비중이 작지 않았기에 precision@1 지표가 다소 높게 나타났습니다.
현재 최대 30개까지 제안 결과를 노출하는 스펙을 구상 중이기에 이를 감안하면 증강된 모델 결과가 더 바람직하다고 판단할 수 있습니다. 참고로, 입력 정보량이 많아질수록(케이스 1 → 3) 성능이 높아지다가 케이스 4에서는 성능이 낮아졌는데요. 케이스 4 그룹은 정답 레이블 개수가 줄어들어 맞추기 더 어려운 인스턴스들로 구성되었기 때문입니다.
제안 결과의 다양화
오프라인 테스트와 달리 실시간 제안에서는 추천하는 해시태그의 다양성을 염두에 둬야 합니다. 다중 레이블 분류 모형이 학습하는 클래스 셋이 커질수록 의미 혹은 형태 관점에서 유사한 해시태그가 클래스 셋에 여럿 포함되면서 비슷한 해시태그가 예측 상위권에 몰려나오는 경우가 왕왕 발생합니다.
예를 들어 'スプラトゥーン2好きな人おいで' (번역하면 '스플래툰2 좋아하는 사람들로')라는 오픈챗 이름을 입력 텍스트로 넣으면 예측 톱 5 결과가 ['スプラトゥーン2', 'スプラ', 'スプラトゥーン', '雑談', 'スプラ2']입니다. 5개 중 무려 4개가 'スプラ(스프라)'로 시작합니다.
모델 입장에서는 사용자가 비슷한 해시태그 중 어떤 것을 고를지 확신할 수 없으니 일단 모두 보여주자는 식으로 학습하는 게 앞서 정의한 평가 지표 측면에서 유리합니다. 그러나 사용자에게 후보를 제안하고 입력하게 만드는 상호 인터페이스 측면에서는 중복된 해시태그 노출이 사용자가 풍부한 키워드로 자신의 오픈챗을 표현하는 것을 방해하며, 이는 결과��적으로 잠재적인 참여자가 해당 오픈챗을 찾는 데 악영향을 줍니다.
이를 방지하기 위해 예측 결과가 더욱 다양해지도록 점수순으로 예측된 해시태그를 하나씩 추천 리스트에 추가할 때 앞서 선택된 해시태그와의 유사성을 측정해 페널티로 고려하는 Maximal Marginal Relevance(MMR) 기법을 도입했습니다.
아래는 이 기법을 수식으로 나타낸 것입니다. k+1 순위 예측 해시태그는 다음 조정된 점수 값이 가장 큰 해시태그 i를 선택합니다.
- : original recommendation score of hashtag i.The output logits (without the softmax normalization) were used as scores
- : penalty weight parameter
- : similarity of two tags i and j
- : the entire class set
- : the set of selected hashtags for recommendation until k-th step
이 기법은 페널티 가중치 파라미터 에 따라 다양화가 적용되는 정도가 달라집니다. 이 값이 0이면 페널티가 적용되지 않은 것이며, 값이 커질수록 중복된 결과에 페널티가 더 무겁게 부과됩니다.
해시태그 간의 유사도로는 두 가지를 고려했습니다.
- 먼저 토큰 집합 유사도(token set similarity)는 표면적으로 나타난 형태소들이 얼마나 겹치는지를 정량화한 것입니다. 두 해시태그를 토큰화해서 얻은 집합 간의 Jaccard 유사도(교집합 크기 / 합집합 크기)로 정의했습니다.
- 다른 하나는 의미상 얼마나 비슷한지를 수치화한 임베딩 유사도(embedding similarity)입니다. 해시태그에 포함되는 토큰들의 평균 임베딩으로 해시태그 임베딩을 얻고, 두 해시태그 임베딩 간의 코사인 유사도를 측정했습니다. 이때 토큰 임베딩은 모델 학습 초기화에 사용한 신경망의 토큰 임베딩을 활용했습니다.
그럼 이제 여러 값에 MMR 기법을 적용한 결과를 살펴보겠습니다. 예측 성능을 최대한 유지하면서 다양성을 높이는 것이 목적이므로 성능 지표로는 recall@K 값을 비교했으며, 다양성 지표로는 추천된 상위 K개의 해시태그에 대해 고유한 토큰 비율이 얼마나 되는지를 다음과 같이 정의했습니다.
dTkProp@K := # distinct tokens in top K predicted tags / the sum of token counts over the top K predicted tags
아래 그래프는 해시태그가 가장 다양한 JP 지역 데이터에 MMR 기법을 적용한 결과입니다.
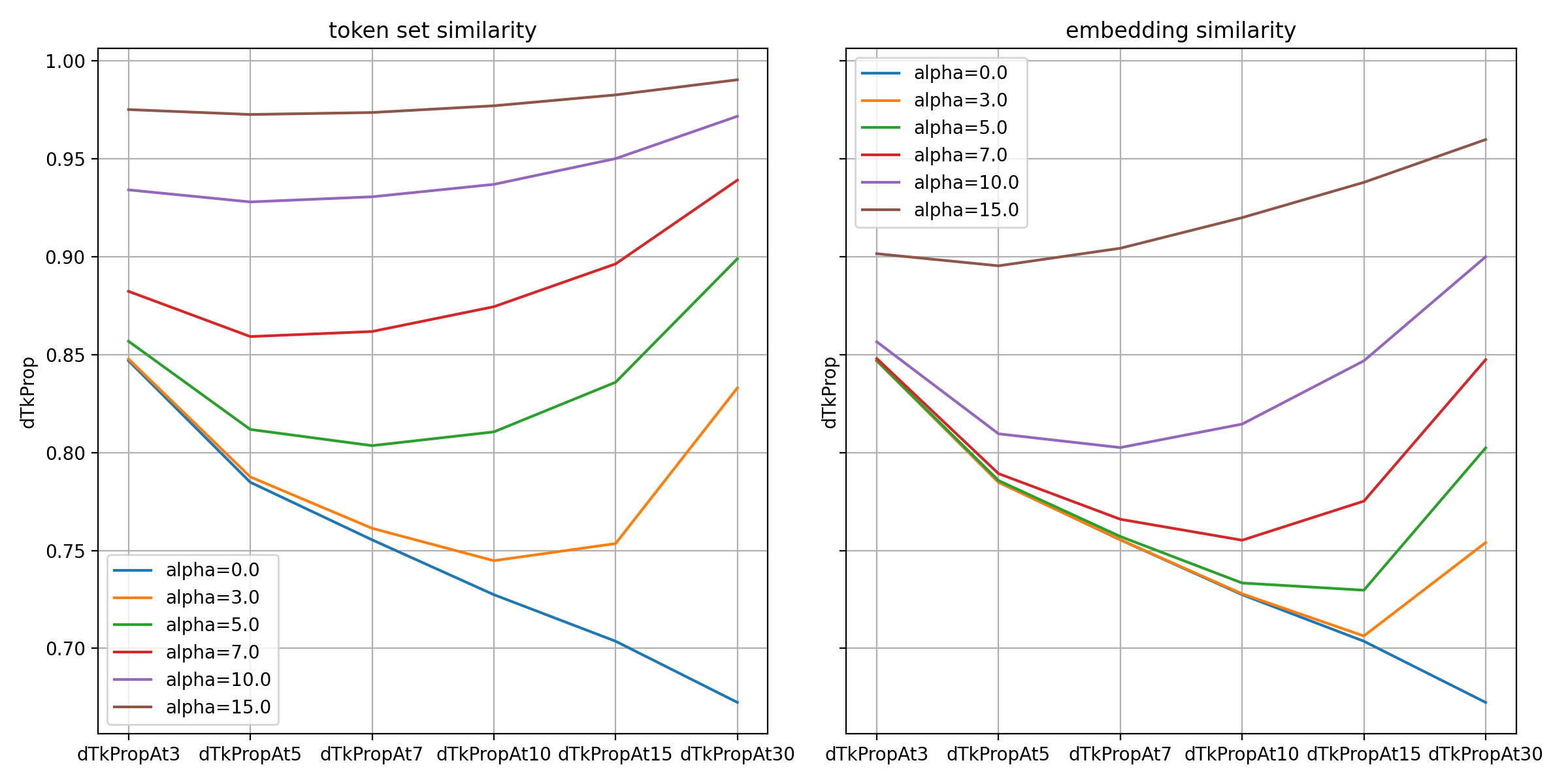
그래프에서 확인할 수 있듯 고유 토큰 비율은 두 가지 유사도 모두 예상한 대로 값이 클수록 높게 나타났습니다. 두 유사도 중에서는 토큰 중복 정도가 직접적으로 페널티에 반영된 토큰 집합 유사도 쪽이 예측된 결과의 고유 토큰 비율이 높았습니다.
아래는 재현율 지표 측면 결과입니다. 값이 클수록 하락폭이 컸으며 특히 토큰 집합 유사도 방식이 더 민감하게 반응했습니다.
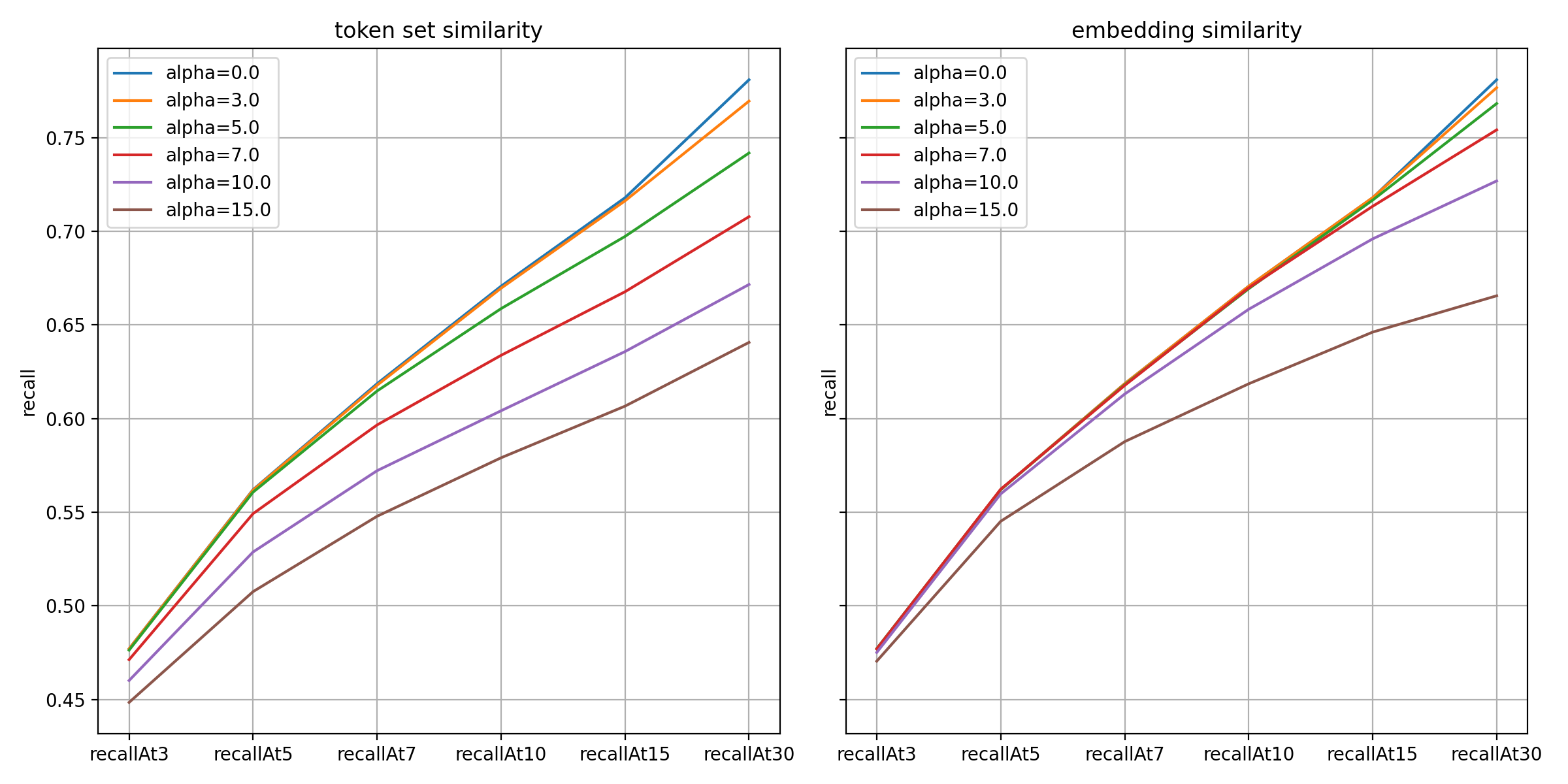
위 결과와 같이 예측 성능과 다양성은 서로 트레이드오프 관계입니다. 둘 간의 균형을 고려해 토큰 집합 유사도 방식은 값을 5.0~7.0으로, 임베딩 유사도 방식은 10.0~15.0 정도로 대안을 좁혔고, 최종적으로는 정성 평가를 거쳐 결정했습니다.
아래 표는 'スプラトゥーン2好きな人おいで'라는 오픈챗에 다양화 기법을 적용한 결과 샘플입니다. 'スプラ' 문자열로 시작하는 해시태그들이 값이 커질수록 상위권에서 점점 줄어드는 것을 확인할 수 있습니다.
| 순위 | 다양화 적용 전 | 토큰 집합 유사도 | 임베딩 유사도 | ||||
|---|---|---|---|---|---|---|---|
| 1 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 | スプラトゥーン2 |
| 2 | スプラ | スプラ | スプラ | スプラ | スプラ | スプラ | スプラ |
| 3 | スプラトゥーン | スプラトゥーン | 雑談 | 雑談 | スプラトゥーン | スプラトゥーン | 雑��談 |
| 4 | 雑談 | 雑談 | ゲーム | ゲーム | 雑談 | 雑談 | ゲーム |
| 5 | スプラ2 | スプラ2 | プラベ | リグマ | スプラ2 | スプラ2 | 楽しい |
| 6 | ゲーム | ゲーム | リグマ | 楽しい | ゲーム | ゲーム | 仲良く |
| 7 | スプラ好き | プラベ | 楽しい | 仲良く | スプラ好き | プラベ | 誰でも |
| 8 | プラベ | リグマ | 仲良く | 誰でも | プラベ | リグマ | 楽しく |
| 9 | リグマ | 楽しい | 誰でも | 楽しく | リグマ | 楽しい | ルール |
| 10 | 楽しい | 仲良く | 楽しく | ルール | 楽しい | 仲良く | 楽しもう |
| 11 | 仲良く | 誰でも | ルール | 楽しもう | 仲良く | 誰でも | 荒らし禁止 |
| 12 | 誰でも | 楽しく | ナワバリ | 荒らし禁止 | 誰でも | 楽しく | Splatoon |
| 13 | 楽しく | Splatoon2 | 楽しもう | イカ | 楽しく | ルール | Switch |
| 14 | Splatoon2 | ルール | 荒らし禁止 | Splatoon | ルール | 楽しもう | enjoy |
| 15 | ルール | ナワバリ | イカ | Switch | 楽しもう | 荒らし禁止 | 学生 |
정성 평가 결과 더욱 확실하게 문자열 중복을 감소시키는 토큰 유사도 방식이 임베딩 유사도 방식보다 더 바람직한 방식이라고 의견이 모아졌습니다.
오프라인 태깅을 위한 신뢰도 높은 출력 선택하기
오픈챗 생성 시점에 실시간으로 해시태그를 제안하는 기능을 준비하던 와중에 오픈챗 서비스 내 광고 표시가 확대됨에 따라 보다 고도화된 오픈챗-광고 매칭을 위해 추론된 해시태그를 활용해 보자는 의견이 나왔습니다.
이 경우 오프라인 배치 방식의 예측으로 태깅을 수행하는데요. 상호 작용하는 인터페이스에서는 사용자가 직접 알맞은 것을 최종 결정하므로 모델이 확장된 맥락에서 해시태그를 제안하는 것이 자연스러웠지만, 이 경우에는 부정확한 해시태그가 부적절한 광고 매칭으로 이어질 수 있기에 정밀도 또한 중요합니다.
이를 고려해 광고 매칭용 오프라인 태깅에서는 두 개의 임계치(threshold) 파라미터를 도입해 신뢰도 높은 모델 출력만 필터링하는 방법을 설계했습니다.
먼저 min_top1 파라미터를 도입했습니다. 톱 1 예측 점수가 낮은 경우, 즉 어떤 클래스도 높은 점수를 받지 못한 경우에는 입력 데이터로 분류 작업을 수행하기에 정보가 충분치 않다고 판단하는 로직을 추가했습니다. 이 로직에서는 min_top1 값을 기준으로 톱 1 예측 점수가 이 임계치보다 작을 때는 해당 오픈챗에 대해서 어떤 해시태그도 태깅하지 않습니다.
다음으로 min_score 파라미터를 도입해 매칭 시스템에 전달되는 최대 K개 해시태그 중 임계치보다 예측 점수가 큰 해시태그들만 선별합니다(참고로 K값은 30으로 정해졌습니다).
그럼 이제 두 임곗값을 결정하기 위해 JP 지역 검증 데이터셋에 대해 예측된 점수의 분포를 살펴보겠습니다.
먼저 톱 1 점수 구간별로 검증 셋을 구분해 성능 지표를 살펴보면, 점수 값과 예측 성능 간에 강한 양의 상관관계를 확인할 수 있습니다. 각 선은 레이블 개수 구간별로 지표를 집계한 것으로, 정답 레이블이 많을수록 당연하게도 그중 하나만 맞춰도 되는 정밀도는 높아지고 모두 찾아내야 하는 재현율은 낮아집니다. 레이블이 두 개 이상일 경우(파란색 선 외 선) 대략 점수 10.0~11.0 구간부터 precision@1 값이 50% 보다 높게 형성됐습니다.
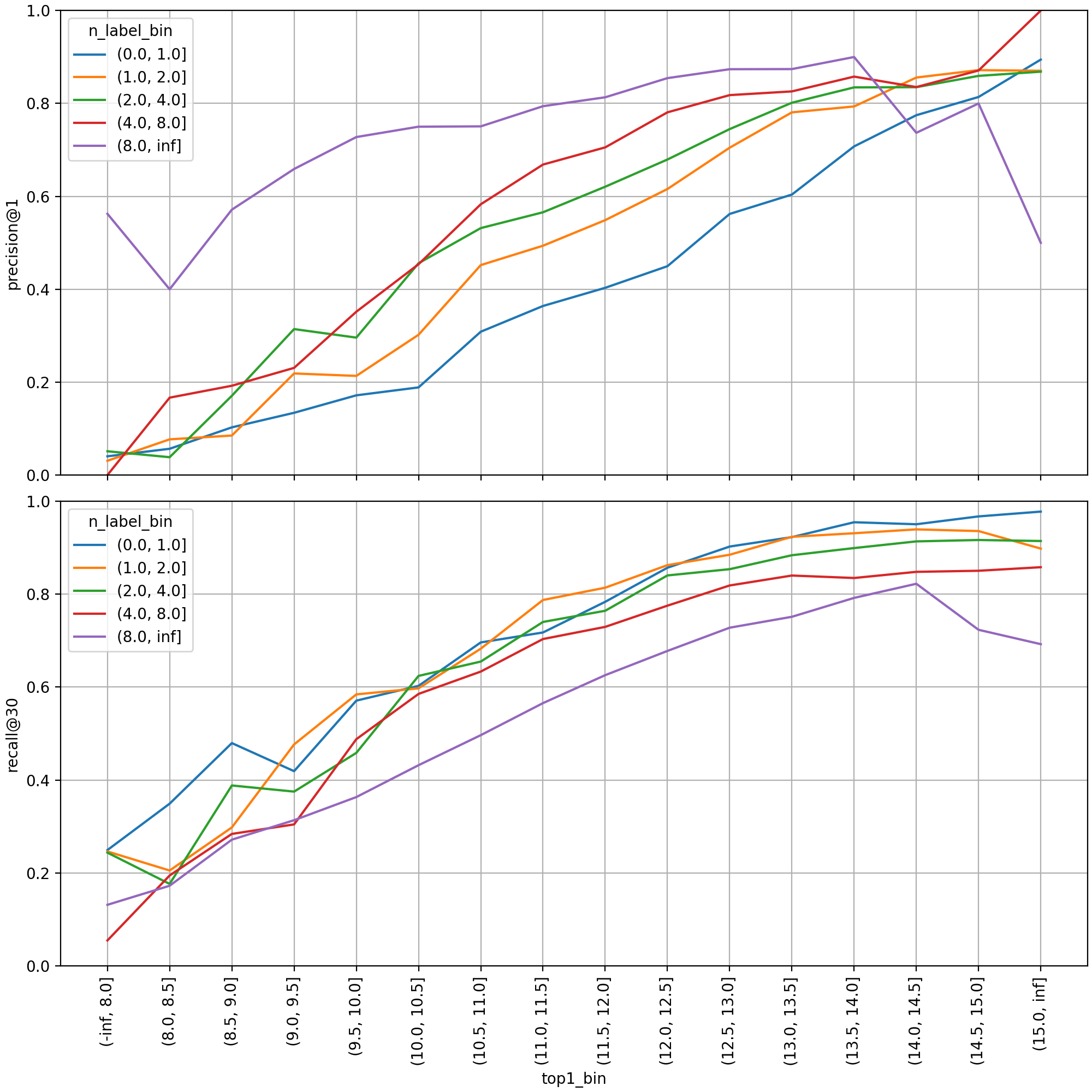
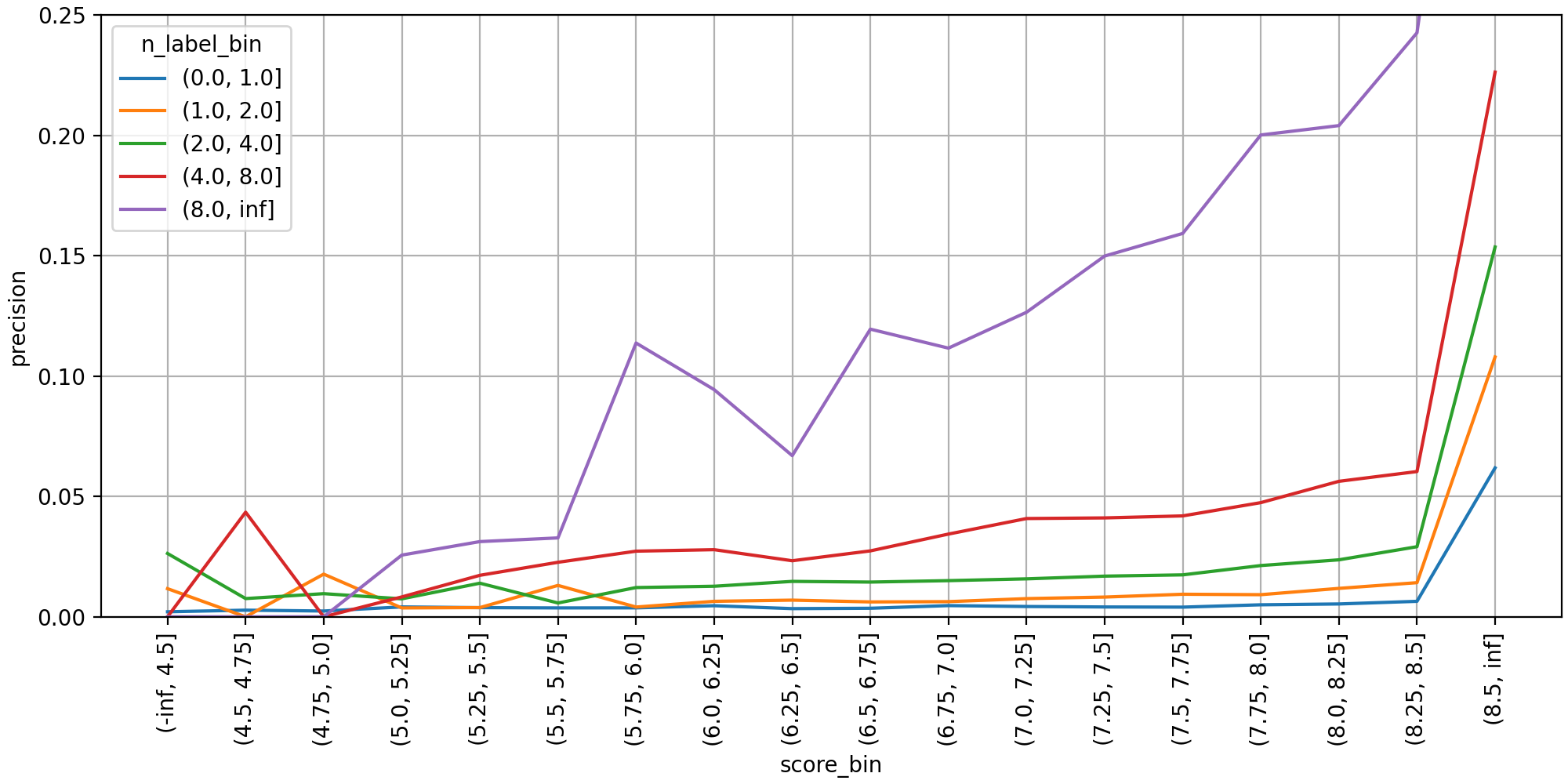
다음으로 min_score 값을 정하기 위해 살펴본 분포 그래프입니다. 톱 30까지 예측된 레이블을 각각 다중 클래스 분류 인스턴스로 취급해 구간별 정밀도를 집계했습니다. 레이블 개수가 8개 보다 많은 경우(보라선) 정밀도가 예측 점수 6.0 근처에서 가파르게 올랐으며, 7.0 이상부터는 점수가 높아질수록 단조 증가했습니다.
그렇다면 위 방법으로 해시태그 선별 시 추론 결과를 얼마나 제공 가능한지 살펴보겠습니다. 다음은 톱 1 점수를 기준으로 판단했을 때 최소 하나 이상의 해시태그 추론 결과를 제공할 수 있는 오픈챗의 커버리지 그래프입니다.
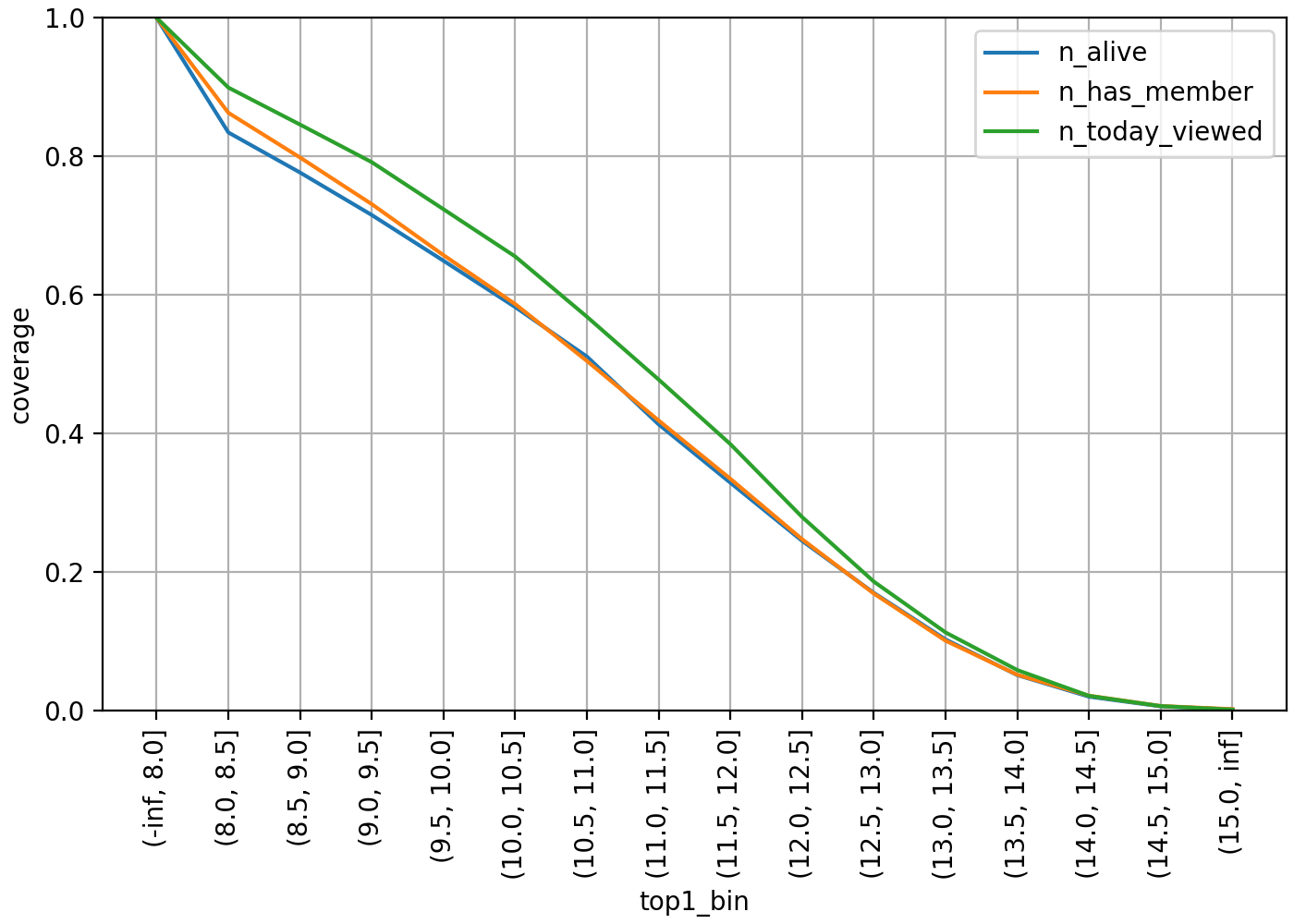
각 선은 오픈챗 활성도별로 모수를 제한해 집계한 것입니다. 파란색 선은 삭제되거나(DELETED) 중지되지(SUSPENDED) 않은 ALIVE 상태, 주황색 선은 최소 한 명 이상의 멤버 보유, 초록색 선은 최소 한 번 이상 당일 페이지뷰가 존재하는 오픈챗을 의미합니다. ALIVE 전체 대상일 때 min_top1 값을 10.0으로 설정하면 커��버리지가 60% 가까이 되었지만, 11.0으로 기준을 높이면 40% 근처로 하락합니다.
아래 표는 min_score 임계치 설정에 따라 출력된 해시태그 개수의 분포입니다. 여기서는 min_top1 값을 10.0으로 고정해 태깅 결과가 아예 없는 오픈챗은 모수에서 제외했으며, 최대 개수 K는 30으로 제한되어 있습니다. min_score 값을 6.0 이하로 작게 설정하면 과반수가 최대 개수만큼 출력됐지만, 7.5 이상이면 10개 이하인 비율이 절반을 넘었습니다.
| 해시태그 개수 구간 | min_score threshold | |||||
|---|---|---|---|---|---|---|
| 5.5 | 6.0 | 6.5 | 7.0 | 7.5 | 8.0 | |
| (29, 30] | 77.27% | 57.87% | 36.33% | 17.68% | 6.53% | 1.84% |
| (25, 29] | 4.48% | 6.69% | 7.23% | 6.11% | 3.76% | 1.44% |
| (20, 25] | 5.59% | 8.96% | 11.14% | 10.35% | 7.25% | 3.92% |
| (15, 20] | 8.79% | 8.80% | 12.68% | 14.59% | 12.26% | 7.93% |
| (10, 15] | 2.89% | 11.69% | 12.98% | 18.06% | 19.61% | 16.75% |
| (5, 10] | 0.91% | 5.24% | 15.81% | 18.46% | 25.29% | 29.44% |
| (0, 5] | 0.08% | 0.78% | 3.84% | 14.75% | 25.30% | 38.68% |
이를 바탕으로 정밀도와 커버리지 사이의 트레이드오프 관계를 감안해 min_top1값은 10.0~11.0, min_score값은 6.0~7.5로 좁혀서 대안을 제시했고, 이것 또한 최종적으로는 정성평가를 통해 결정했습니다.
한 번 결정한 점수 임계치들을 모델 재학습 시에 동일하게 적용하려면, 점수 분포가 이전 모델이든 새 모델이든 크게 달라지지 않는다는 것이 전제돼야 합니다. 그렇기에 모델 학습 파이프라인에서 점수 분포를 자동 모니터링하고 있으며, 새로운 데이터로 여러 차례 모델을 업데이트해 오는 동안 분포가 크게 변화하지 않음을 실��험적으로 확인했습니다.
마치며
지금까지 오픈챗 해시태그 예측 모델을 실시간 추론과 오프라인 태깅 상황에 맞게 개발하고 발전시키는 과정을 소개했습니다. 오프라인 테스트를 통해 다중 레이블 분류를 위한 평가 지표들로 예측 성능을 검증했으며, 다양성과 정밀도를 높여야 하는 시나리오에서는 정성 평가를 통해 임계치 파라미터를 최종 결정했습니다. 추후 사용자가 직접 입력한 해시태그나 모델이 추론한 결과를 오픈챗 추천 모델의 피처로 활용한다거나, 이를 바탕으로 사용자가 관심을 보이는 해시태그 키워드의 순위를 매기고 추천하는 서비스도 구상하고 있습니다.
모든 것의 기본이자 중심은 사용자라는 기준에 따라 사용자가 자신에 취향에 맞는 오픈챗을 쉽게 찾고 마음에 맞는 다른 사용자를 많이 만날 수 있도록 부단히 나아가겠습니다. 끝까지 읽어주셔서 감사합니다.


