Hello. I'm Chaeseung Lee, also known as Argon, and I work as a site reliability engineer (SRE) in the service reliability (SR) team.
The SR team is part of the service engineering department, and we focus on improving the quality and ensuring the availability of services provided by the LINE app. To achieve this, we operate automation platforms like AWX, Rundeck, and Concourse CI, check technical elements required for service launches and events, and provide solutions to help development teams focus more on development and operations.
My primary role is as an open chat SRE, where I strive to enhance the reliability of the open chat service. I also manage the AWX platform to aid in automating tasks for company employees. In this article, I want to share how we introduced an AWX support bot using retrieval-augmented generation (RAG) to effectively handle recurring inquiries while operating the AWX platform.
Motivation for developing the AWX support bot
People often know they should read the guides before starting something new, but in reality, they tend to dive in without doing so. This issue becomes more pronounced when the volume of guide documents is extensive, making it hard to locate the needed information. As a result, many users, eager to get started quickly, end up asking the same questions repeatedly to the management. This leads to a significant drain on operational resources as the management has to respond to these inquiries.
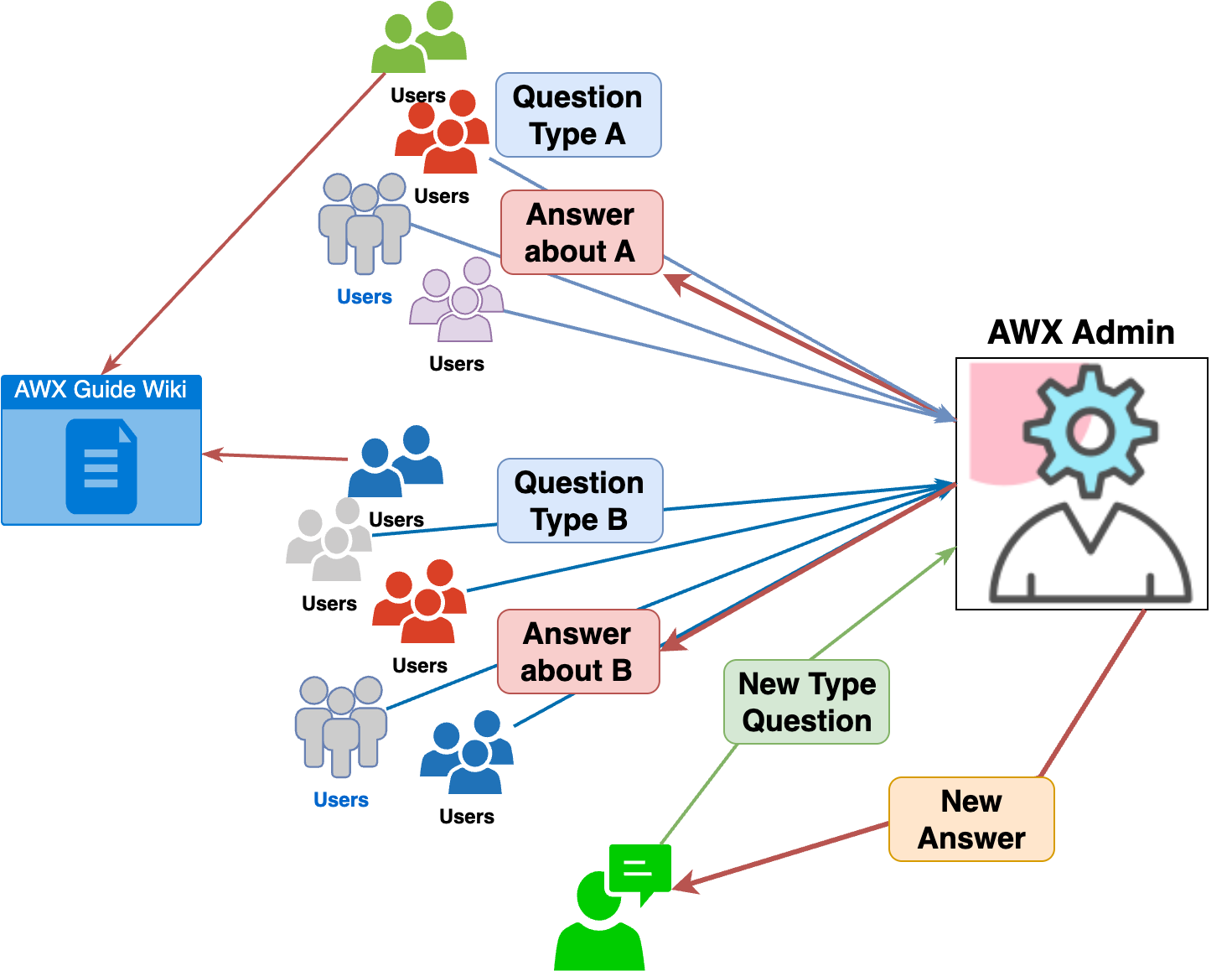
To address this issue, we needed a system that could automatically respond to inquiries that could be easily resolved by reading the guide documents. So, we developed the AWX support bot using retrieval-augmented generation (RAG), which combines search and generation.
Frameworks and tools used for implementing the AWX support bot
Before going into details, let me introduce the frameworks and tools used to implement the AWX support bot.

- Slack bot framework: Bolt for Python
- Slack provides bot frameworks based on various languages. I chose the Python bot framework, which I'm personally familiar with.
- LLM framework: LangChain
- The LangChain framework is available in both Python and JavaScript.
- The AWX support bot didn't need many features, so we opted for LangChain. If you're looking for more complex workflows, state management, or multi-agent collaboration, I recommend using LangGraph.
- Embedding model: paraphrase-multilingual-mpnet-base-v2
- There are various options for embedding models that convert sentences into vectors, such as the SBERT model and OpenAI text embedding model. We chose the open-source SBERT model.
- Since LY develops services with employees from various countries, inquiries are received in multiple languages. Considering this, we referred to the performance evaluation table provided by SBERT and selected the paraphrase-multilingual-mpnet-base-v2, which has the best sentence comparison performance among multilingual models.
- Vector DB: OpenSearch
- LLM: OpenAI (ChatGPT)
- Our company allows the use of the OpenAI API for appropriate purposes, so we chose OpenAI.
- We also considered that OpenAI Enterprise does not learn business data by default (reference).
- The LangChain framework supports integration with various LLMs, such as Ollama and Amazon Bedrock, allowing you to choose the LLM suitable for your environment.
What are LLM and RAG?
To grasp the RAG technique, it's essential to first understand large language models (LLM) and their limitations.
An LLM is a deep learning model that is pre-trained on a vast amount of data. It can extract meaning from text and understand the relationships between words and phrases to generate outputs. While it can produce relevant responses based on the data it has learned, it may also generate inappropriate responses due to certain limitations.
- Difficulty in reflecting the latest information: Since responses are based on pre-trained data, they might not include the most current information.
- Possibility of generating false information: For questions not covered in the pre-trained data, the model might provide inaccurate or false information.
- Difficulty in verifying sources: It can be challenging to identify the exact sources of the responses generated by the model.
To overcome these limitations, the retrieval-augmented generation (RAG) technique is employed. RAG guides the LLM to generate accurate responses by supplying it with context (reliable data) along with the question. Below is an example comparing the responses of a traditional LLM and an LLM using the RAG technique with context.

As shown, using retrieval-augmented generation (RAG) allows the LLM to extend AI services to specific domains or internal organizational databases, such as LY's AWX service, without requiring additional data training.
Embedding and vector search for using RAG
RAG is a process that guides the LLM to generate more accurate responses by providing it with reliable data from an external database along with the user's query. However, if all data from the external database is provided to the LLM every time a query is made, unnecessary data will be included in the response generation, making it inefficient. For example, if a query asks, "Who is the AWX administrator in our company?" and unrelated context like 'AWX registration method' and 'user guide' is provided, it would be inefficient.
To improve this, when a user makes a query, it's necessary to retrieve only the data from the external database that is similar to the user's query. But how can we search for data similar to the user's query in the external database? To do this, it's essential to understand embedding and vector search.
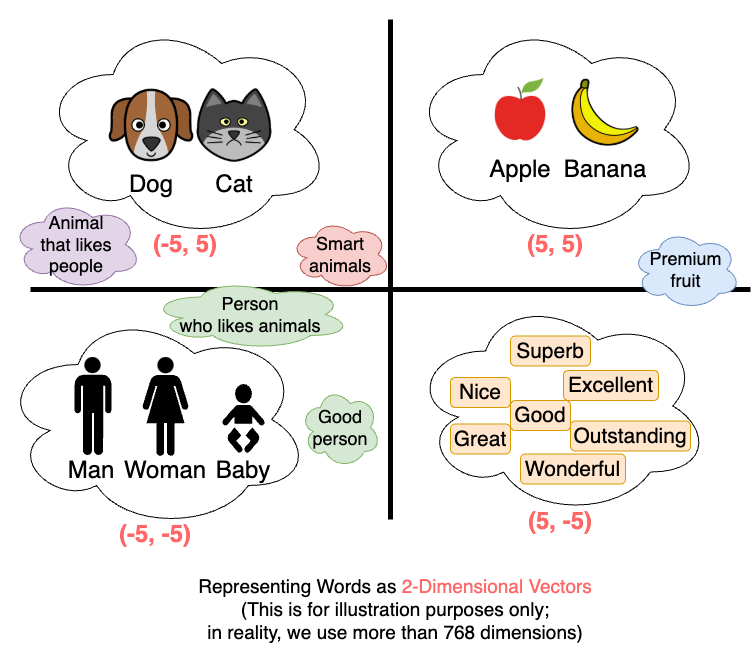
First, embedding is the process of converting various data types, such as text, images, and audio, into vector forms. For example, when embedding text data, it is converted into high-dimensional vector (matrix) values.
- "Argon is AWX Admin" → (-0.0335848405957222, -0.06817212700843811, ..., -0.12750950455665588, -0.05369032919406891)
Embedding is performed through an embedding model, like Sentence Transformers, which is pre-trained to group similar words together. This way, similar words are placed close to each other in high-dimensional space.
The place where data embedded as vectors is indexed is called the vector database (DB), and searching these indexed vectors is known as vector search.
As mentioned earlier, embedded data is represented as vectors, and similar data items are located close to each other in vector space. For example, "buy" and "purchase" are different words but have similar meanings, so their embedded vector values are also similar and located close to each other. Therefore, in a simple keyword search, "purchase" might not be found when searching for "buy", but with vector search, results corresponding to "purchase" can also be retrieved.
Using this approach, when a user's query is received, it is embedded, and then using the k-nearest neighbors (k-NN) method, data similar to the query's vector value—meaning sentences close to the query—can be retrieved in order of proximity. Below is an example of embedding multiple sentences and performing a vector search.
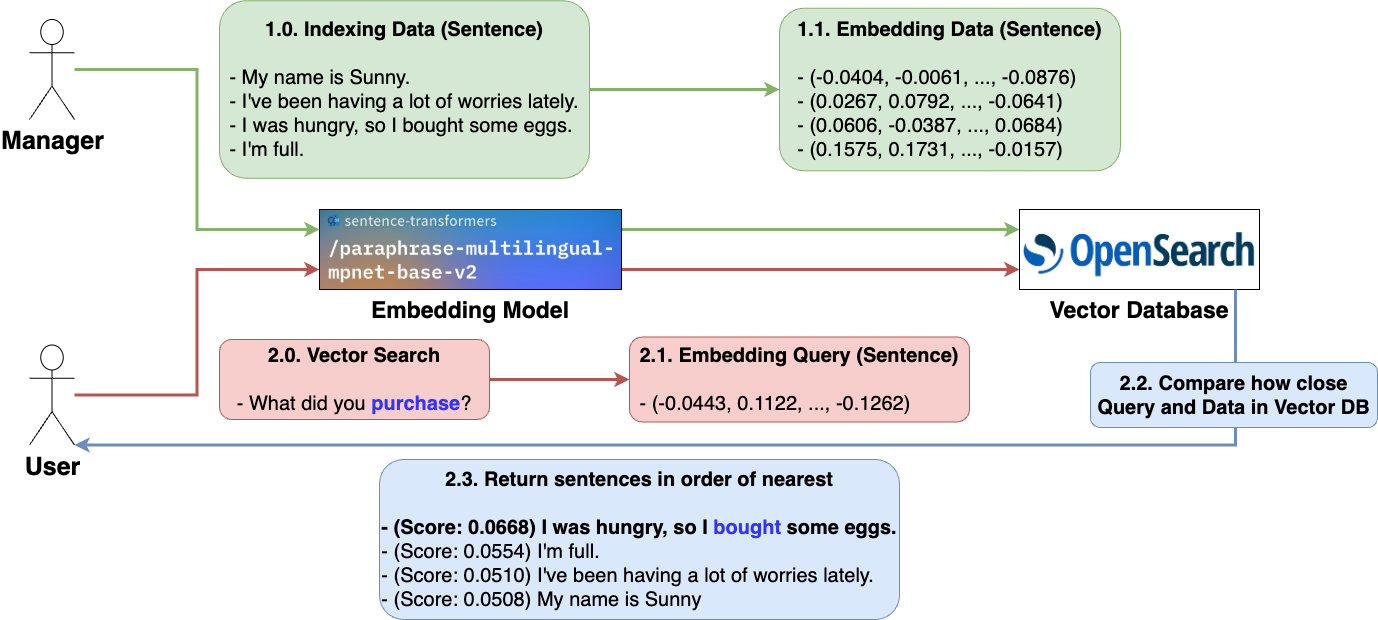
- Vector search doesn't provide answers to the queried sentence; it simply retrieves sentences with high similarity.
- Among several sentences, the one with the highest score (similarity) to the queried sentence "concern" contains a word "worry" with a similar meaning.
Introduction to the AWX support bot workflow
We have learned how to retrieve sentences similar to the user's query using vector search to implement retrieval-augmented generation (RAG). By providing the user's query along with similar sentences retrieved through vector search to the LLM, RAG can be configured.
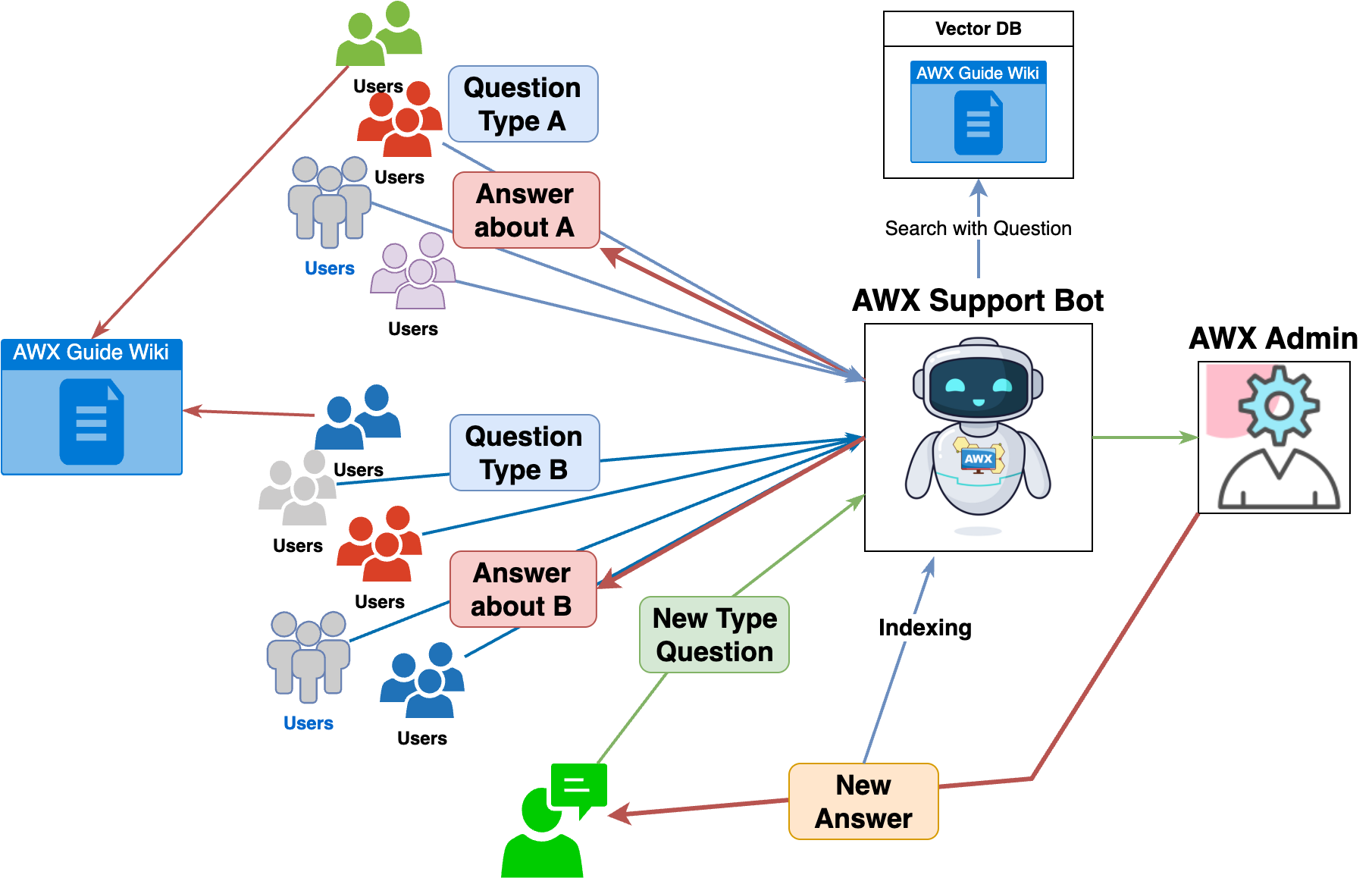
Now, let's return to the AWX support bot workflow using RAG. The workflow of the AWX support bot is as follows:
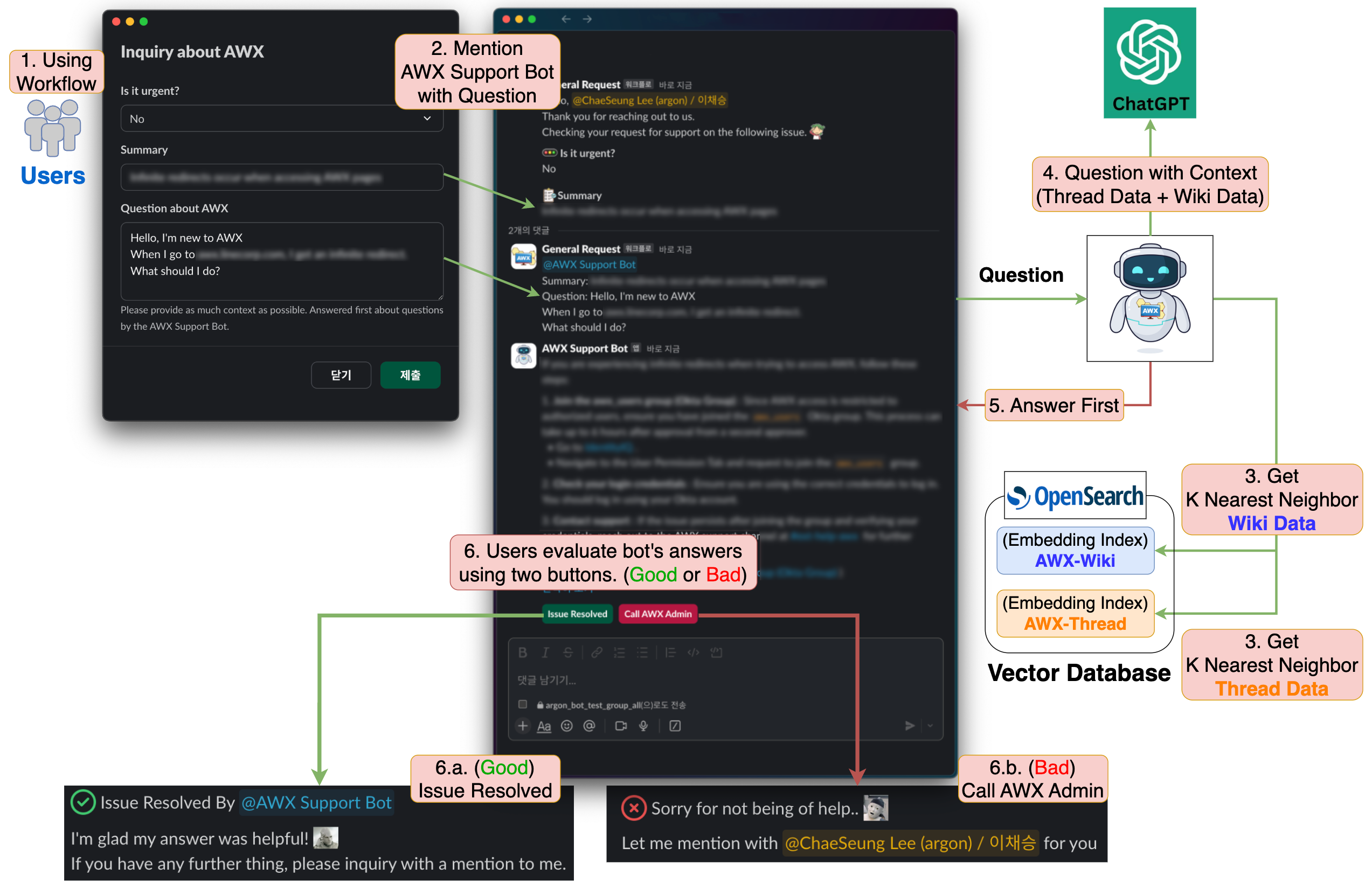
- The user makes an inquiry through the Slack workflow.
- The AWX support bot first checks the user's inquiry.
- It retrieves k similar "internal wiki document data" and "Slack inquiry thread data" for the user's inquiry.
- The "reliable data" retrieved in step 3, along with the user's inquiry, is provided to the LLM together.
- The LLM's response is provided to the user as a first response.
- The user evaluates whether the LLM's response is valid.
- (Good) If the issue is resolved, the user clicks the "Issue Resolved" button to complete the inquiry without involving the administrator.
- (Bad) If the issue is not resolved, the user clicks the "Call AWX Admin" button to notify the administrator.
The AWX support bot reduces the resources of the AWX administrator by providing a first response to the user's inquiry as shown above.
Data used to provide better responses
What data is being indexed in the vector database (DB) that the AWX support bot references? The following diagram illustrates how each piece of data is indexed.
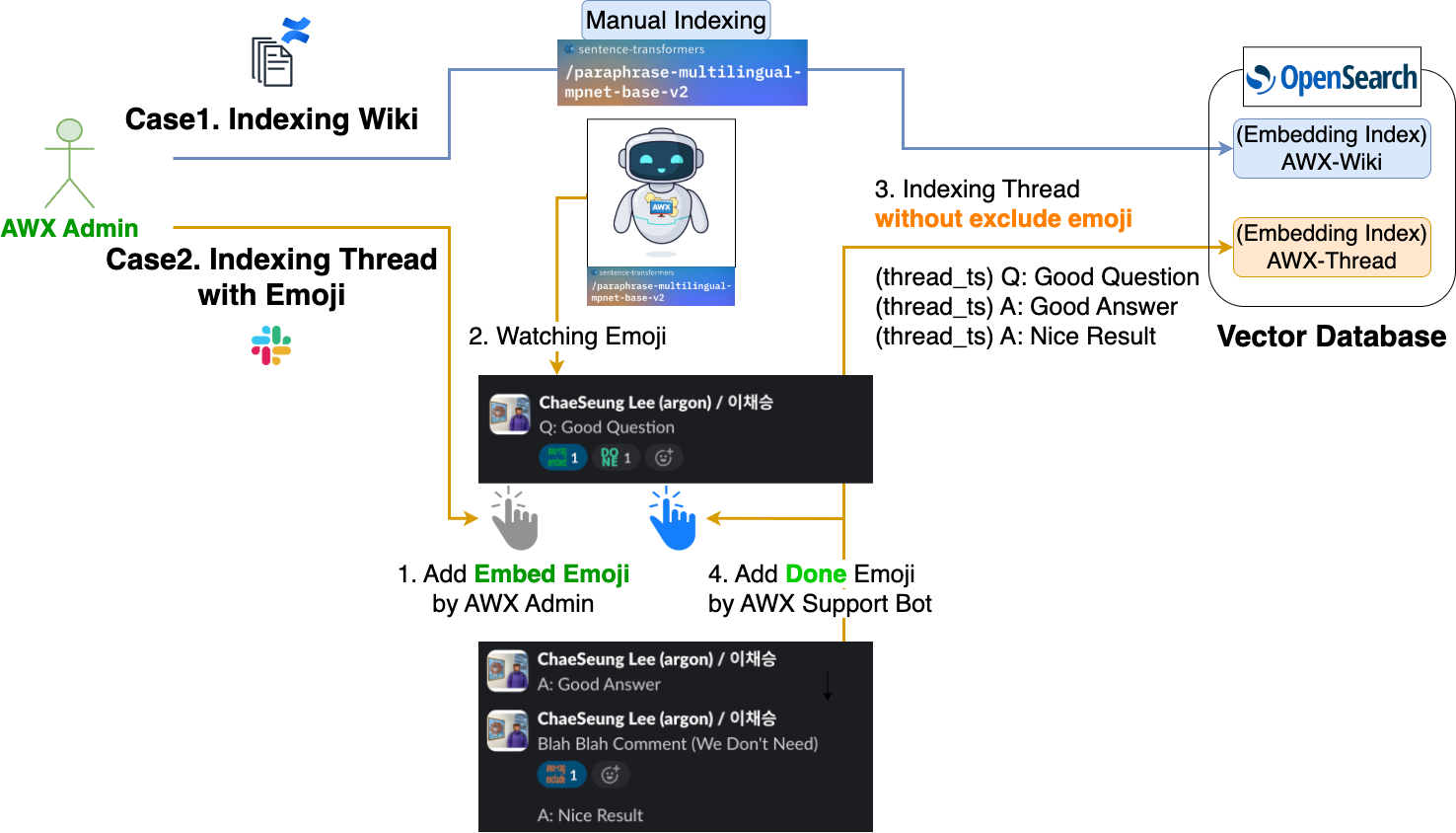
As shown in the diagram above, the AWX support bot references two indexes: internal wiki document data and Slack thread data.
- Internal wiki AWX guide document data
- To guide the LLM to generate accurate responses, it can reference internal AWX guide document data.
- If there is a large amount of documents to reference, it is ideal to index them using document structuring tools like LangChain community's Document loaders or Docling for chunking, but since the amount of guide documents is not that large, the AWX administrator manually structures and indexes only the necessary parts for accurate response generation.
- To guide the LLM to generate accurate responses, it can reference internal AWX guide document data.
- Slack thread data from past questions/answers that were successfully completed
- To guide the LLM to generate accurate responses, it can also reference past user inquiries and response history.
- Since it is not possible to index all messages exchanged in the Slack channel, it is set to index only the necessary messages using emojis.
- The following procedure is used to index only the necessary messages.
- The AWX administrator adds an "embed emoji" to the target message.
- The AWX support bot checks the message with the embed emoji and indexes the messages in the sub-thread of that message, excluding messages with an exclusion emoji (unnecessary messages).
- Once indexing is complete, the AWX support bot adds a "completed emoji" to the message.
The AWX support bot is set to prioritize referencing Slack thread data over internal wiki AWX guide document data. This is because the question and answer patterns in the Slack channel are well-structured, and there are many similar questions, so we expected a few-shot prompting effect. Therefore, the system prompt is set to prioritize referencing Slack thread data.
Conclusion
We have explored in detail why and how the AWX support bot was created, along with its workflow. After discovering retrieval-augmented generation (RAG), I was convinced that it could provide significant benefits in the current situation, so I proceeded with this project. This experience has given me valuable insights into understanding AI trends.
After completing this project, I felt inspired to create a bot that reduces the workload of the open chat service as an open chat SRE, so I'm currently learning new concepts. Through this, I hope to introduce a service bot that reduces service workload in this blog next time. 😄
Finally, I hope this article is helpful not only for those using the AWX service but also for anyone managing inquiry channels. Thank you for reading this lengthy article.


