はじめに
こんにちは。SR(Service Reliability)チームでSRE(Site Reliability Engineer、サイト信頼性エンジニア)業務を担当しているChaeseung Lee(argon)です。
SRチームは、Service Engineering室に所属しており、LINEアプリが提供するサービスの品質向上と可用性の確保を目指して技術活動を行い、AWXやRundeck、Concourse CIなどの自動化プラットフォームを運用しています。また、サービスのリリースやイベントに必要な技術的要素を確認し、適切なソリューションを提供することで、開発組織が開発や運用に集中できるようにサポートしています。
私はオープンチャットのSREとして、主にオープンチャットサービスの信頼性を高めることに努めています。同時に、従業員の業務自動化を支援するためのAWXプラットフォームの管理も担当しています。今回の記事では、AWXプラットフォームを運用する中で、繰り返し発生する問い合わせに効果的に対応するため、RAG(Retrieval-augmented generation、検索拡張生成)を活用したAWXサポートボットの導入事例について紹介したいと思います。
AWXサポートボット開発の動機
何かを始めるときはガイドを読むべきだと分かっていても、実際には読まずに始めてしま��うことがよくあります。このような問題は、特に初期段階で読むべきガイドの量が膨大な場合や、自分に必要な情報がなかなか見つからないときによく発生します。このとき、ユーザーが早く始めたいと思い、管理側に同じ問い合わせが重複して送られてくると、管理者はそれに対応するために運用リソースを大きく消耗することになります。
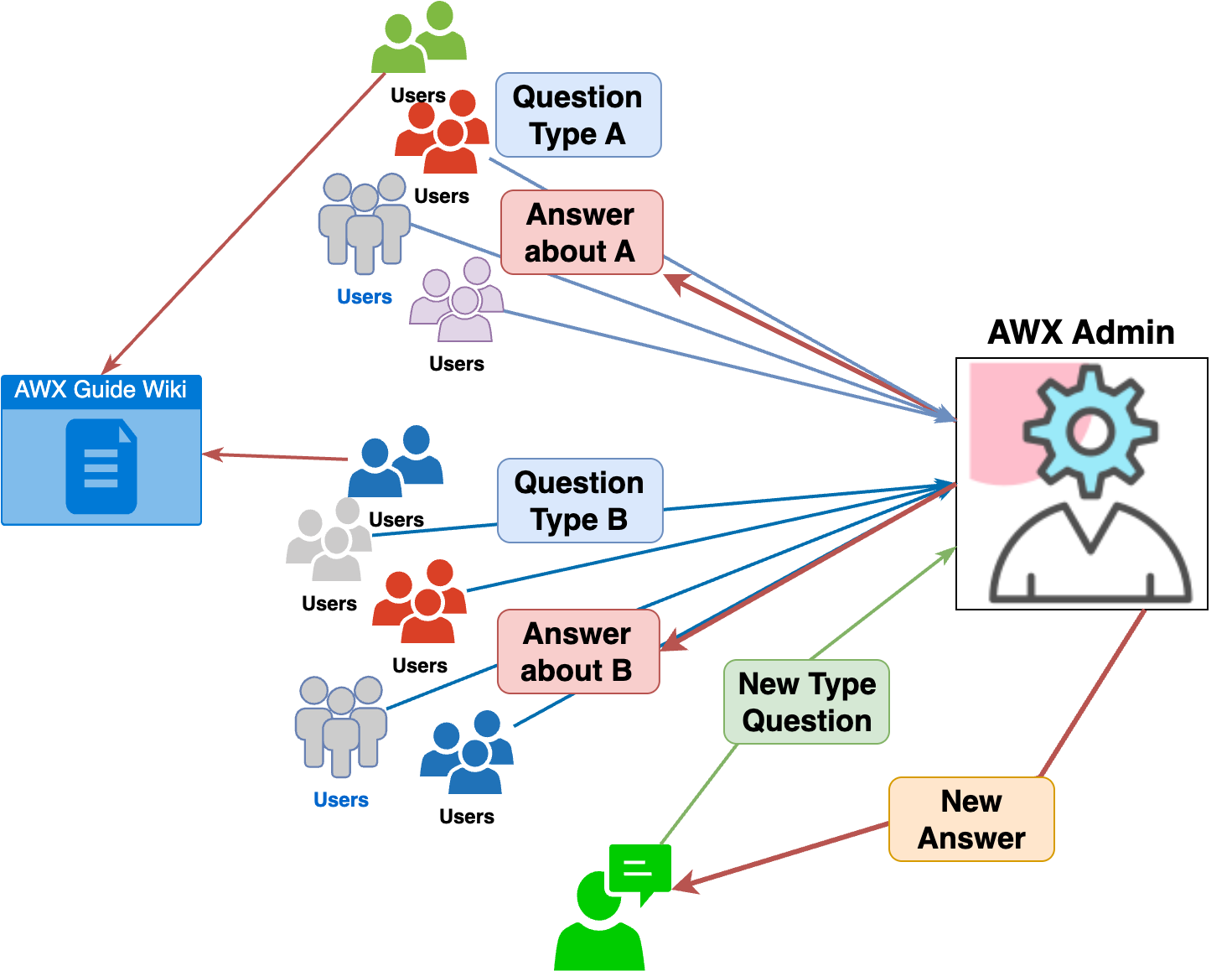
上記の問題を解決するために、ガイドを読めば解決できる問い合わせに対しては、自動で一次回答を提供できるシステムが必要だと考え、検索と生成を組み合わせたRAG手法を活用し、AWXサポートボットを開発することにしました。
AWXサポートボットの実装に使用したフレームワークとツールの紹介
詳細を説明する前に、AWXサポートボットの実装に使用したフレームワークとツールを紹介します。

- Slackボットフレームワーク:Bolt for Python
- Slackでは、さまざまな言語ベースのボットフレームワークを提供しています。その中で、個人的に馴染みのあるPythonボットフレームワークを選択しました。
- LLMフレームワーク:LangChain
- LangChainフレームワークは、PythonとJavaScriptの2つの言語で提供されています。
- AWXサポートボットには多くの機能が必要なかったため、LangChainを使うことにしました。もし、より複雑なワークフローや状態管理、マルチエージェントコラボレーションを求める場合は、LangGraphの利用をおすすめします。
- 埋め込みモデル:paraphrase-multilingual-mpnet-base-v2
- 文をベクトルに変換する埋め込みモデルには、SBERTモデルやOpenAIテキスト埋め込みモデルなどさまざまな選択肢があります。その中で、オープンソースのSBERTモデルを選択しました。
- LINEヤフーでは、多国籍のメンバーが一緒にサービスを開発しているため、問い合わせも多言語で寄せられています。これを考慮し、SBERTが提供する性能評価表を参照して、多言語をサポートするモデルの中でテキスト間の類似度比較に最も優れているparaphrase-multilingual-mpnet-base-v2を選択しました。
- ベクトルDB:OpenSearch
- LLM:OpenAI(ChatGPT)
- LINEヤフーでは、適切な用途で申請すればOpenAI APIを使用できるので、OpenAIを選択しました。
- OpenAI Enterpriseの場合、基本的にビジネスデータを学習していないことも考慮しました(参考:https://openai.com/enterprise-privacy/)。
- LangChainフレームワークではOpenAIだけでなく、OllamaやAmazon BedrockなどさまざまなLLMと連携できるため、それぞれの環境に適したLLMを選択できます。
LLMとRAGとは?
RAG手法を理解するには、まずLLM(Large Language Model)とその課題を知る必要があります。
LLMは、膨大な量のデータで事前学習されたディープラーニングモデルです。テキストから意味を抽出し、単語やフレーズ間の関係を理解して出力を生成します。学習したデータに基づいて適切な回答を生成することもありますが、以下のような課題があるため、不適切な回答を生成することもあります。
- 最新情報の反映が難しい:回答は事前学習されたデータに基づいているため、最新の情報を反映できません。
- 誤った情報を生成する可能性:事前学習データにない質問に対しては、不正確または誤った情報が回答として提供される可能性があります。
- �情報源の確認が難しい:モデルが生成した回答の情報源が不明確です。
このような課題を補うために、RAG手法を用います。RAGは、LLMに質問とともにコンテキスト(信頼できるデータ)を提供することで、そのコンテキストに基づいて正確な回答を生成するように誘導するプロセスです。以下は、従来のLLMの回答とRAG手法を使用してコンテキストを提供したLLMの回答を比較した例です。

このようにRAGを使用すると、LLMはデータを追加で学習する必要がなく、特定のドメインや組織内DB(例:LINEヤフーのAWXサービス)にもAIサービスを拡張できます。
RAGを使用するための埋め込みとベクトル検索
前述のように、RAGは、LLMに質問する際に外部DBの信頼できるデータを一緒に提供することで、より正確な回答を生成するように誘導するプロセスです。しかし、質問するたびに外部DBのすべてのデータをLLMに提供すると、回答生成に不要なデータも含まれることになり、非効率です。例えば、「社内のAWX管理者は誰ですか?」という問い合わせに対して、この質問と関係のないコンテキストである「AWXの登録方法」や「ユーザーガイド」などのデータをすべて一緒に提供すると非効率でしょう。
この問題を改善するには、ユーザーが質問したときに、外部DBからその問い合わせに類似したデータのみを取得する必要があります。しかし、外部DBからユーザーの問い合わせに類似したデータを検索するにはどうすればいいのでしょうか?そのためには、埋め込み(embedding)とベクトル検索(vector search)について理解する必要があります。
まず、埋め込みとは、テキストや画像、オーディオなど、さまざまなデータをベクトル形式に変換することです。例えば、テキストデータを埋め込むと、以下のように高次元のベクトル(行列)値に変換されます。
- "Argon is AWX Admin" → (-0.0335848405957222, -0.06817212700843811, ..., -0.12750950455665588, -0.05369032919406891)
埋め込みは、意味が類似した単語を集めるように、事前に学習された埋め込みモデル(例:Sentence Transformers)によって行われます。そのため、以下のように高次元空間で類似した単語が互いに近くに配置されます。
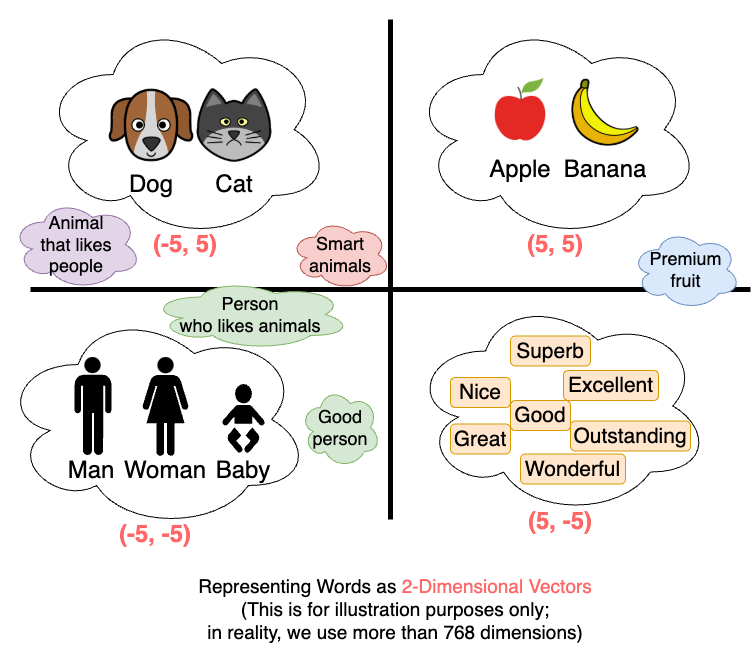
埋め込み過程でベクトルとして埋め込まれたデータがインデックス化される場所がベクトルDBです。そして、このベクトルDBにインデックス化されたベクトルを検索するのがベクトル検索です。
前述で埋め込まれたデータはベクトルとして表現され、互いに類似したデータ項目はベクトル空間で互いに近くに位置すると説明しました。例えば、「Buy」と「Purchase」は異なる単語ですが、意味が似ているため、埋め込まれたベクトル値も似ており、互いに近くに位置します。したがって、単純なキーワード検索では、「Buy」で検索したときに「Purchase」は見つかりませんが、ベクトル検索を使用すると、「Purchase�」に該当する結果も検索できます。
これを利用し、ユーザーからの問い合わせがあった場合、それを埋め込んだ後、k-NN(k近傍法)を用いて問い合わせのベクトル値と類似したデータ、つまり、問い合わせに近い文を近い順にk個取得する方法で検索できます。以下は、複数の文を埋め込み、ベクトル検索を行う例です。
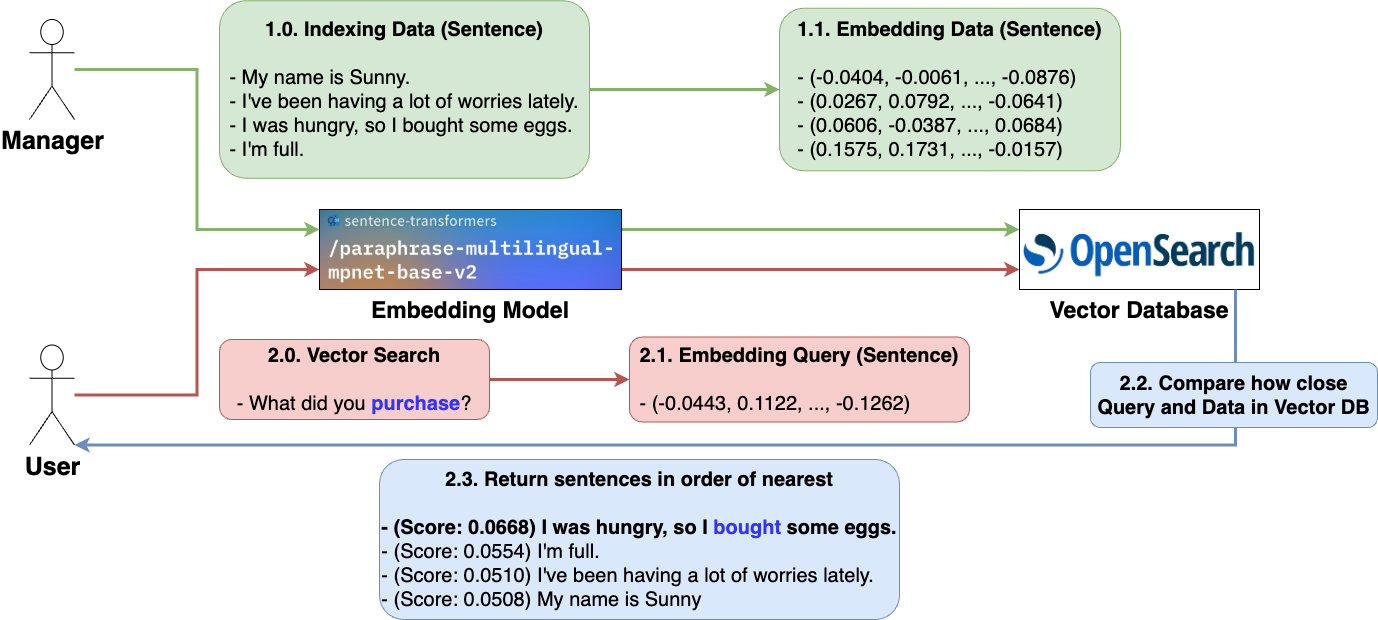
- ベクトル検索は、質問文に対する回答ではなく、単純に類似度の高い文を取得する作業です。
- 複数の文のうち、質問文(「心配事」)に対するスコア(類似度)が最も高い文は、似た意味を持つ単語(「悩み」)が含まれている文です。
AWXサポートボットのワークフローの紹介
RAGを使用するために、ユーザーの問い合わせに類似した文をベクトル検索で取得する方法について説明しました。ベクトル検索を利用して、ユーザーの問い合わせとその文と類似した文を一緒にLLMに提供することで、RAGを構成できます。
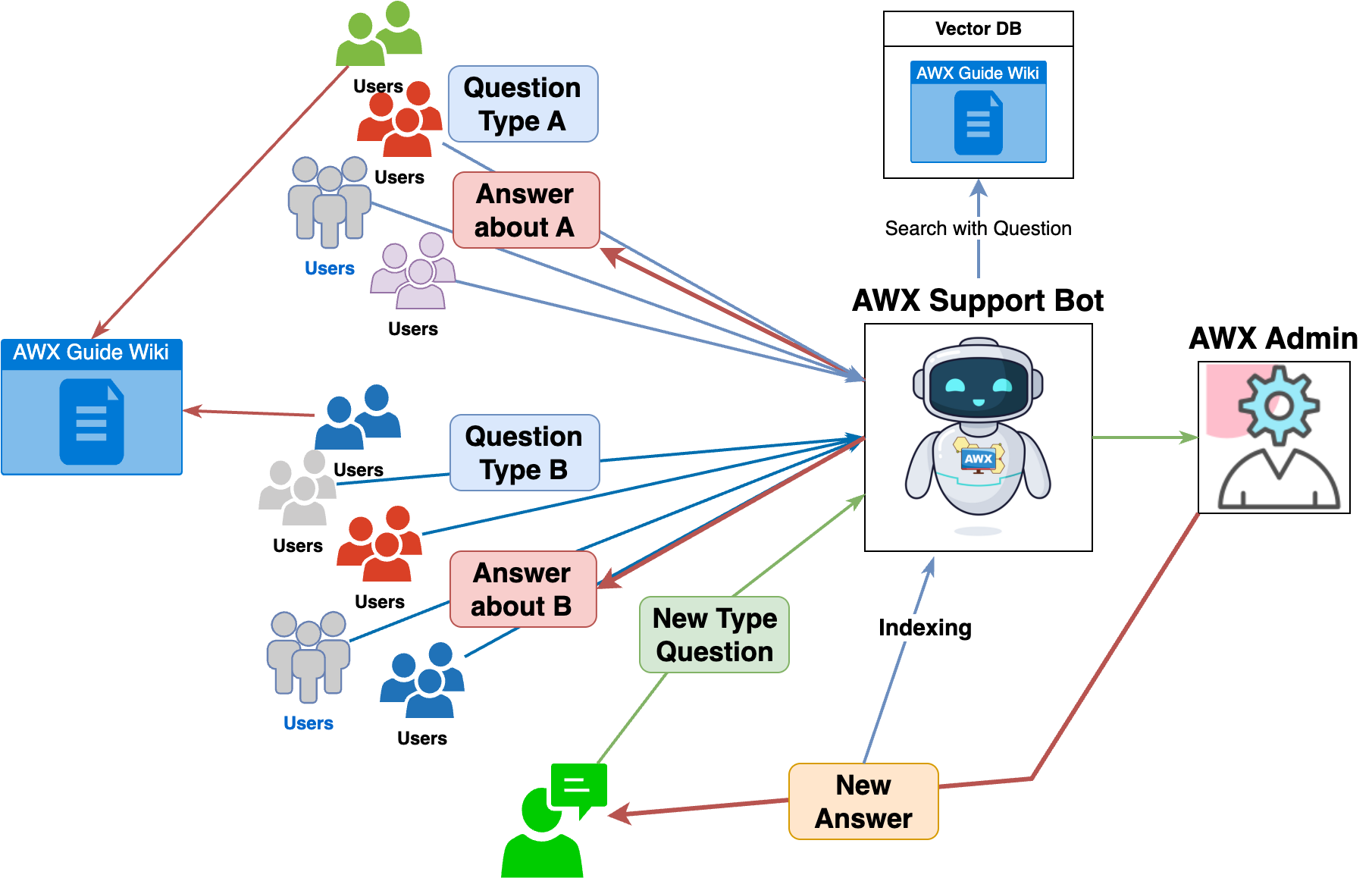
では、本題に戻り、RAGを使用したAWXサポートボットのワークフローを見てみましょう。AWXサポートボットのワークフローは、以下のとおりです。
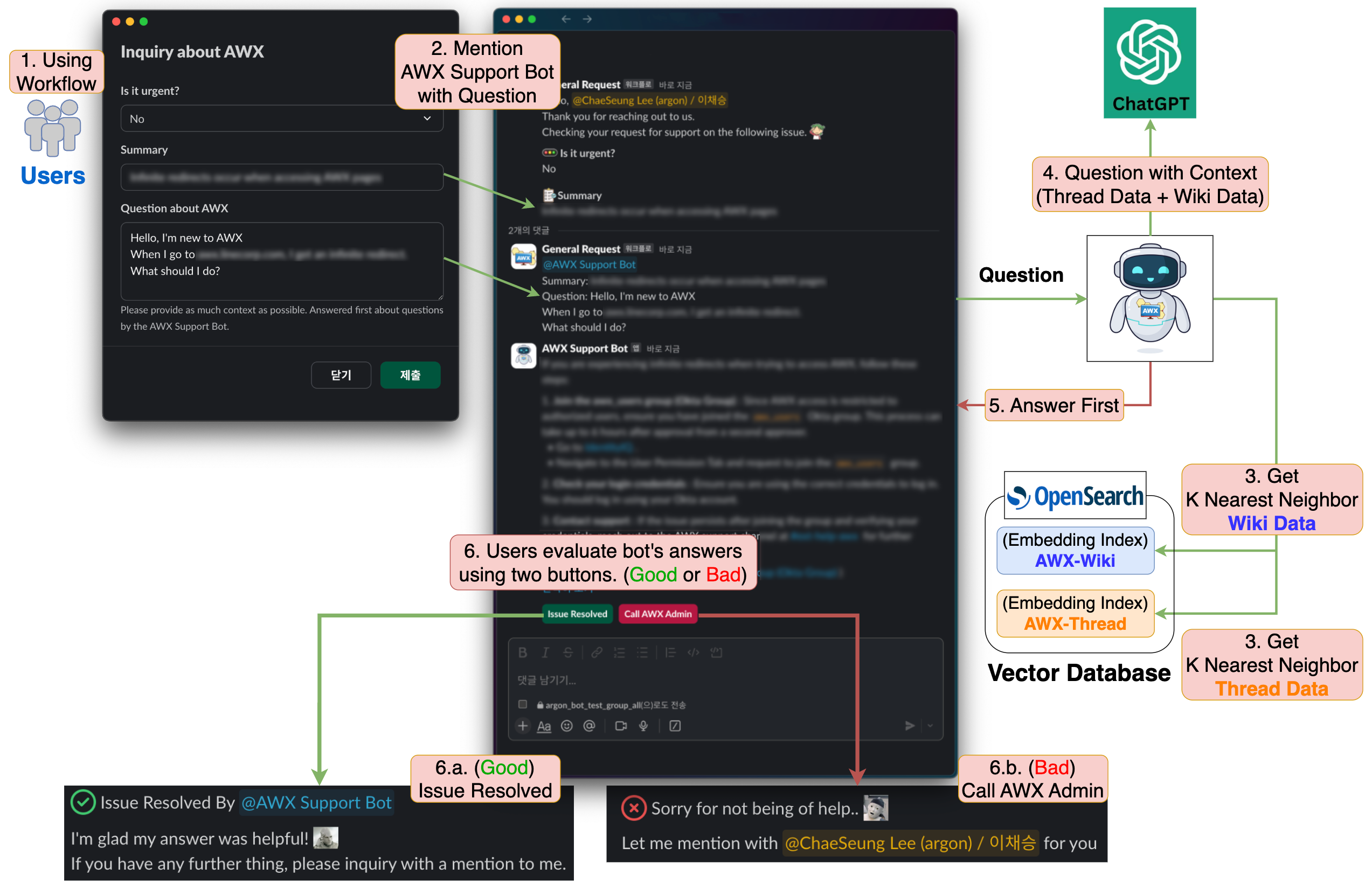
- ユーザーがSlackワークフ�ローを通じて問い合わせを行います。
- AWXサポートボットは、まず、ユーザーの問い合わせを確認します。
- ユーザーの問い合わせに類似した「社内wikiのドキュメントデータ」と「Slackの問い合わせスレッドデータ」をそれぞれk個ずつ取得します。
- 3で取得した「信頼できるデータ」とユーザーの問い合わせをLLMに提供します。
- LLMの回答を一次回答としてユーザーに提供します。
- ユーザーはLLMの回答が有効かどうかを評価します。
- (Good)問題が解決した場合、ユーザーは「Issue Resolved」ボタンをクリックして、管理者を呼び出すことなく問い合わせを完了します。
- (Bad)問題が解決しない場合、「Call AWX Admin」ボタンをクリックして、管理者を呼び出します。
AWXサポートボットは、上記のようにユーザーの問い合わせに対して一次回答を提供することで、AWX管理者のリソースを削減します。
より良い回答を提供するために活用しているデータ
では、AWXサポートボットが参照するベクトルDBには、どのようなデータがインデックス化されているのでしょうか?下図は、各データがどのようにインデックス化されるかを示しています。
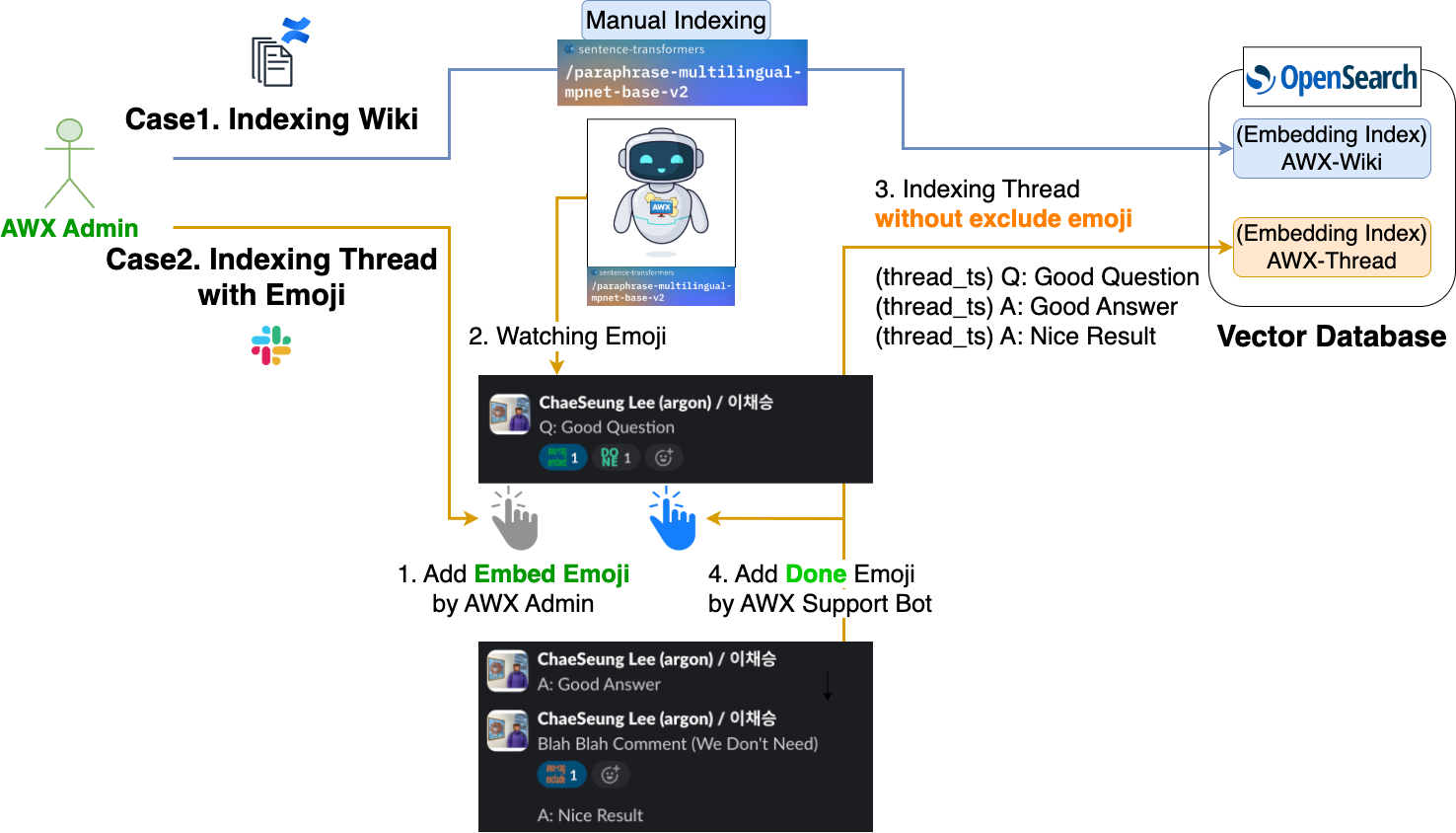
上図に示すように、AWXサポートボットは、社内wikiのドキュメントデータとSlackのスレッドデータ、この2つのインデックスを参照しています。
- 社内wikiのAWXガイド文書データ
- LLMが正確な回答を生成するように誘導するため、社内AWXガイド文書データを参照できます。
- 参照する文書の量が多い場合は、LangChainコミュニティのDocument loadersやDoclingのような文書構造化ツールを使ってチャンキング(chunking)を行い、インデックス化するのが理想です。しかし、現在のガイド文書の量はそれほど多くないため、正確な回答を生成するためにAWX管理者が手動で必要な部分のみを構造化し、インデックス化しています。
- LLMが正確な回答を生成するように誘導するため、社内AWXガイド文書データを参照できます。
- 過去の質問/回答が正常に完了したSlackスレッドデータ
- LLMが正確な回答を生成するように誘導するために、過去のユーザーからの問い合わせや回答履歴も参照できます。
- Slackチャンネルでやり取りされるメッセージをすべてインデックス化することはできないため、絵文字を利用して必要なメッセージのみをインデックス化するように設定しました。
- 以下のような手順で必要なメッセージのみをインデックス化します。
- AWX管理者が対象メッセージに「埋め込み絵文字」を追加します。
- AWXサポートボットは、埋め込み絵文字が追加されたメッセージを確認します。その後、そのメッセージのサブスレッドのうち、除外絵文字が追加されたメッセージ(不要なメッセージ)を除外したメッセージをインデックス化します。
- インデックス作成が完了すると、AWXサポートボットは、そのメッセージに「完了絵文字」を追加します。
AWXサポートボットは、社内wikiのAWXガイド文書データよりもSlackスレッドデータを優先的に参照するように設定されています。これは、Slackチャンネルでの質問と回答のパターンがよく構造化されており、似たような質問が多く、フューショットプロンプト(few shot prompting)効果が期待できると判断したためです。そこで、システムプロンプトにSlackスレッドデータを優先的に参照するように設定しました。
おわりに
ここまで、AWXサポートボットをなぜ、どのように作成したのか、そのワークフローとともに詳しく見てきました。初めてRAGに触れ、現状に大きなメリットをもたらすと確信し、このプロジェクトを進めました。おかげでAIのトレンドを全体的に理解する貴重な経験を得ることができました。
今回のプロジェクトを終えた後、オープンチャットのSREとして、オープンチャットサービスの業務負荷を軽減するボットを作ってみたいと思い、新しい概念を学び始めています。次回は、サービスの業務負荷を軽減するサービスボットの導入記をLINEヤフーTech Blogで紹介できることを期待しています。
最後に、この記事がAWXサービスに限らず、問い合わせチャンネルを管理されている方のお役に立てれば幸いです。最後までお読みいただき、ありがとうございました。


