こんにちは。LINEヤフー株式会社で自然言語処理の研究開発をしている平子です。
本記事では、クエリ理解タスクの中核技術であるクエリ埋め込みにおいて、軽量モデルであるStaticEmbeddingを採用し推論速度の問題を解決した取り組みについて紹介します。具体的には、StaticEmbeddingの導入背景からユーザー行動ログを活用した学習手法やトークナイザ設計の工夫、さらにベンチマーク評価や推論速度の比較、埋め込みの性質に関する分析などについて解説します。
クエリ理解に特化した埋め込みモデル
検索エンジンが検索結果を返す前に行う処理を総称してクエリ理解と呼びます。具体例としては、ユーザーの入力を支援するクエリ推薦・クエリ補完・スペル訂正や、検索エンジンの意図解釈を支援するクエリ分類・属性抽出などがあります。これらは検索サービスの根幹を担うプロセスであり、Yahoo!検索におけるユーザー体験向上の要となっています。
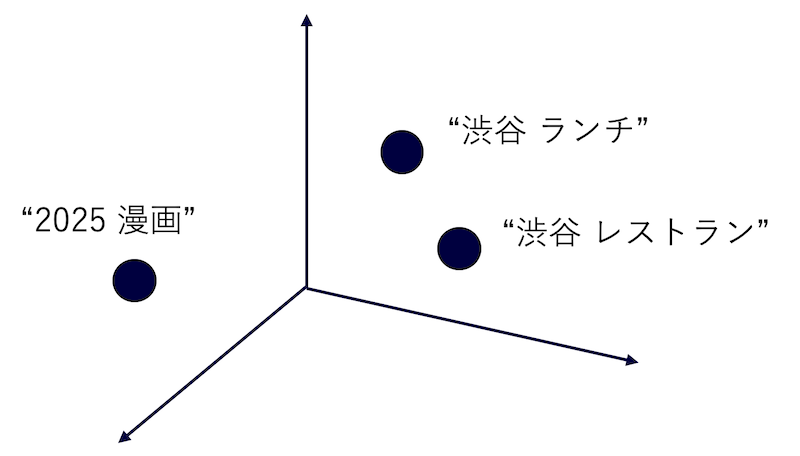
これらのクエリ理解タスクを解くための中核技術として、クエリ埋め込みがあります。クエリ埋め込みとは、ユーザーの検索意図をベクトル空間上に反映したベクトルモデルで、「渋谷 ランチ」と「渋谷 レストラン」のように似た検索意図を持つクエリはベクトル空間上で近く位置し、「2025 漫画」のように異なる検索意図を持つクエリは遠くに位置しています。
一見すると文埋め込みを利用すれば良さそうですが、自然文と検索クエリは異なる特徴を持つため実際にはうまくいきません。検索意図を正確に捉えるために、クエリ埋め込みは以下の2つの性質を持つ必要があります。
- 検索クエリは少ないキーワードの組み合わせで表現されることが多く、文脈情報に乏しい。この少ない文脈情報から検索意図を正確に捉えるためには、「ワンピース 109」は漫画(109巻)と服(渋谷109)の2つの検索意図を含むが、「ワンピース 夏服」は服の検索意図しかないといった細かな検索意図の違いを、短いクエリから捉える必要がある。
- 検索クエリは短いため、同義語置換のような簡単な操作で表層全体が変化しやすい。そのため「ディズニー 最寄り」と「TDL アクセス」のように表層は大きく異なるものの検索意図は類似しているものが多く、それらを適切に捉える必要がある。
私たちは以前の取り組みで、ユーザー行動ログを活用することでこれらの問題を解決した高性能なクエリ埋め込みモデルUBIQUE[1]を開発しました。この手法では、ユーザー行動ログから表層に依らず検索意図が一致しているクエリペア(例: 同じURLへのクリックに繋がった検索クエリのペア)を大規模に収集しTransformerベースのモデルを対照学習することで、クエリ理解タスクで最先端の性能を達成しました。この研究成果は自然言語処理分野の国際会議であるNAACL 2025 Industry Trackに採択され、言語処理機能をAPI経由で提供するAzukiで社内向けに公開されています。
UBIQUEはTransformerベースで高精度な表現が可能ですが、実務での運用では推論速度がボトルネックとなることがありました。特に課題となったのは、GPUではなくCPUでの推論が求められるケースです。CPU推論はGPU推論に比べて大幅に運用コストを抑えられるため、実務的に重要な選択肢となります。しかしながら、Transformerベースのモデルは高速化手法(蒸留や量子化)を適用してもCPU上では十分な推論速度を達成できず、私たちに必要な要件を満たすことはできませんでした。このような背景から、CPU上で高速かつ高精度なクエリ埋め込みを実現するには、モデル設計そのものを見直す必要がありました。
StaticEmbeddingを活用した高速なクエリ埋め込みの構築
推論速度の問題の解決策として、私たちは高速な文埋め込みモデルであるStaticEmbeddingに着目しました。このモデルは埋め込み層のみから構成され、テキスト中の各トークンの静的な埋め込みの平均を取るだけという、非常にシンプルなアーキテクチャとなっています。このようなシンプルなアーキテクチャであっても、近年の文埋め込みの構築に用いられる大規模データによる対照学習を実施することで、高品質な埋め込み表現を得られることが知られています。
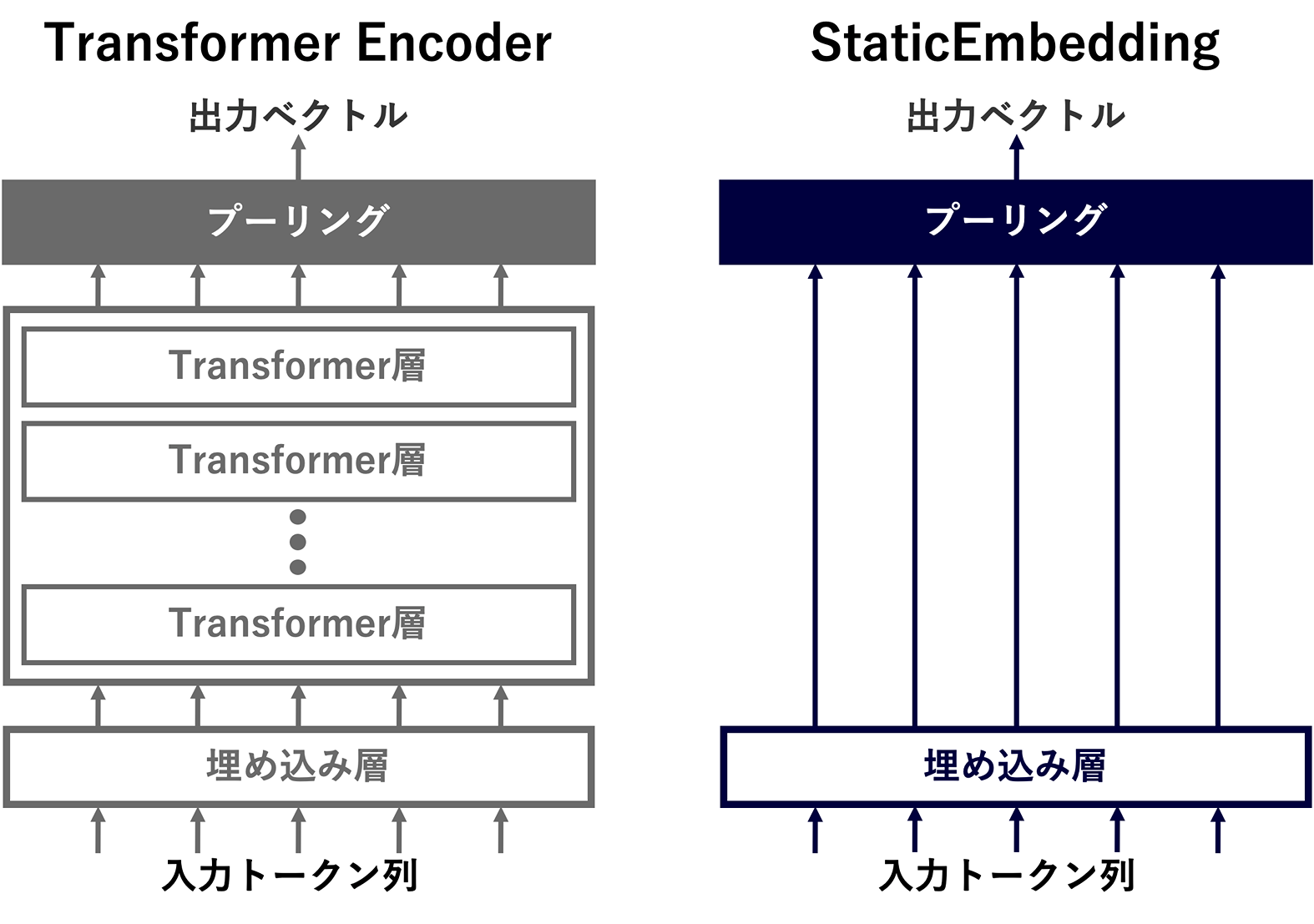
下図は、UBIQUEのベースであるTransformer EncoderとStaticEmbeddingのアーキテクチャの比較図になります。Transformer Encoderでは、入力トークン列を埋め込み層でベクトル列に変換し、それを複数のTransformer層に通した後にプーリングをすることで出力ベクトルを得ます。Transformer層ではself-attentionや線形変換などの計算コストが高い処理が行われており、この層での処理がTransformer Encoderの計算の大半を占めています。StaticEmbeddingはこの計算コストが高いTransformer層を全て排除し、埋め込み層で変換したベクトル列をそのままプーリングすることで出力ベクトルを��得ます。つまり、埋め込み表現を得るための演算処理が各トークン表現の辞書引きとプーリング(平均)のみであり、Transformer Encoderと比較して大幅に高速化することが期待できます。
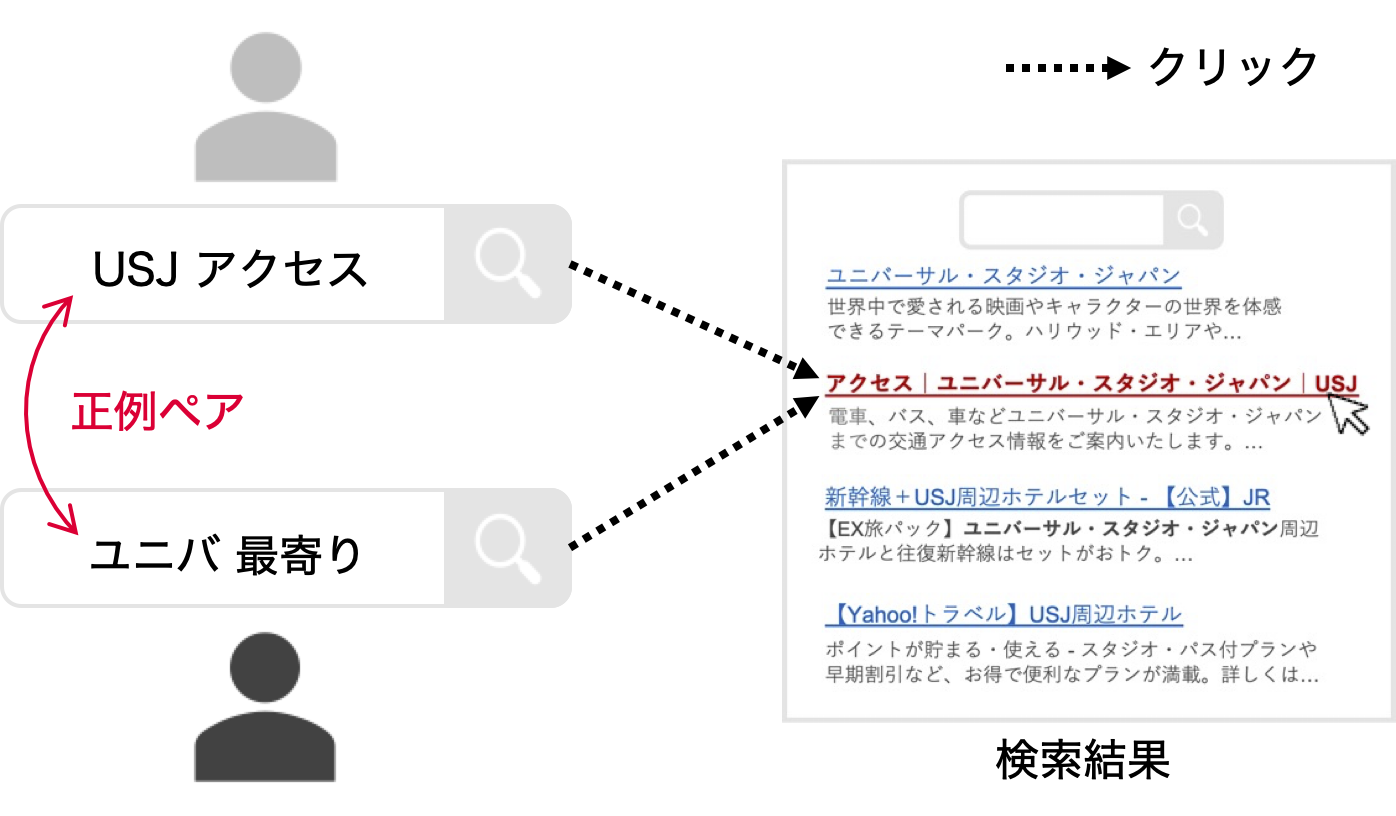
このStaticEmbeddingをUBIQUEと同様にユーザー行動ログから構築したクエリペアを用いて学習することで、クエリ特化StaticEmbeddingを構築しました。学習データは下図のように同じURLへのクリックに繋がった検索クエリのペアを正例とすることで構築しています。また、複数のクリック情報の活用によるクエリペアの信頼性の向上や、ヒューリスティックなフィルタリングによるノイズの軽減も行っているので、気になる方はUBIQUE論文をご参照ください。
また、StaticEmbeddingはトークン埋め込みの単なる平均なので、トークナイザの影響が大きいと考えられます。そのため検索ログを用いてトークナイザを独自に構築するとともに、語彙数を一般的な単言語文埋め込みと比較して大きい値(256,000)に設定しました。検索クエリには、ニュースやトレンドなどの情報ニーズが反映された多様なエンティティを含んでいます。語彙数を大きくすることで、これらのエンティティに対してそれぞれ独自のベクトル表現を割り当てることができ、性能の向上が期待できます。トークナイザの性能への影響は、後ほどの分析で詳しく述べます。
クエリ特化StaticEmbeddingの評価・分析
クエリ理解ベンチマークでの評価
クエリ特化StaticEmbeddingを以下の4つのクエリ理解タスクで構築されたクエリ理解ベンチマーク[1]により評価しました。
- 同義クエリ抽出: 検索意図が一致するクエリをベクトル空間上で引き当てる(評価指標: MRR、社内データ)
- クエリ推薦: ユーザーが次に検索する関連検索キーワードをベクトル空間上で引き当てる(評価指標: NDCG@10、社内データ)
- クエリ分類: クエリを埋め込み表現からカテゴリ別に分類する(評価指標: Macro-F1、社内データ)
- 短文リランキング: クエリとのベクトル空間上での関連性に応じて短いテキスト(商品名)を並び替える(評価指標: NDCG、公開データ[2])
また、ベースラインとして以下の3つのモデルと比較しました。
- Ruri v3: 日本語で最先端の文埋め込みモデル(cl-nagoya/ruri-v3-310m)。
- fastText: 検索クエリで教師なし学習した静的な単語埋め込み。各単語ベクトルの平均を得ることでクエリ表現を得る。
- UBIQUE: ユーザー行動ログから構築したデータでDistilBERT(line-corporation/line-distilbert-base-japanese)を対照学習したモデル。
| モデル | 同義クエリ抽出 | クエリ推薦 | クエリ分類 | 短文リランキング | 平均 |
|---|---|---|---|---|---|
| Ruri v3 | 75.8 | 78.1 | 60.0 | 89.5 | 75.9 |
| fastText | 22.9 | 84.8 | 61.5 | 87.7 | 64.2 |
| UBIQUE | 91.4 | 91.2 | 67.8 | 90.5 | 85.2 |
| クエリ特化StaticEmbedding | 86.9 | 91.6 | 62.1 | 90.4 | 82.8 |
クエリ特化StaticEmbeddingはRuri v3と比較して平均で6.9pt上回っていました。非常にシンプルなモデルであっても最先端の文埋め込みモデルよりも高い性能を示しており、クエリ特化のモデルを構築する重要性が確認できます。fastTextと比較すると特に同義クエリ抽出で大幅な性能の違いがあり、同じ静的埋め込みでも学習方法の違いにより大きな差があることがわかります。また、DistilBERTベースであるUBIQUEと比較しても性能を97%以上維持しています。これらの結果から、静的埋め込みの平均であっても適切に学習することで、クエリ理解に秀でた埋め込みモデルを構築できることがわかりました。
推論速度の比較
クエリ特化StaticEmbeddingとDistilBERTベースのUBIQUEのCPU上の推論速度の比較を行いました。推論速度の向上のため、UBIQUEはINT8に量子化しています。
| モデル | 平均レイテンシ(ms) |
|---|---|
| UBIQUE(DistilBERT) | 18.8 |
| クエリ特化StaticEmbedding | 1.8 |
比較の結果、StaticEmbeddingを活用することで従来のモデルと比較して10 倍以上高速化することが確認できました。値としてもCPU上で1.8msと非常に小さく、低リソース環境でも高速に動作することが期待できます。UBIQUEは蒸留モデルの利用と量子化によりTransformerモデルのCPU推論としては小さいレイテンシを達成できていますが、これでも私たちの要件を満たすことはできませんでした。
クエリ埋め込みとしての性質の分析
クエリ特化StaticEmbeddingをクエリ埋め込みとしての重要な性質である「短いクエリから正確に検索意図を捉えられるか」「表層の変化に頑健か」という2つの側面から分析しました。
1つ目の「短いクエリから正確に検索意図を捉えられるか」という点を調査するため、代表的な多義語である「ワンピース」に関連するクエリを検索意図に応じて漫画、服、漫画 or 服の3つに分類し埋め込みの分布を可視化しました。埋め込みはt-SNEを用いて2次元に圧縮しています。
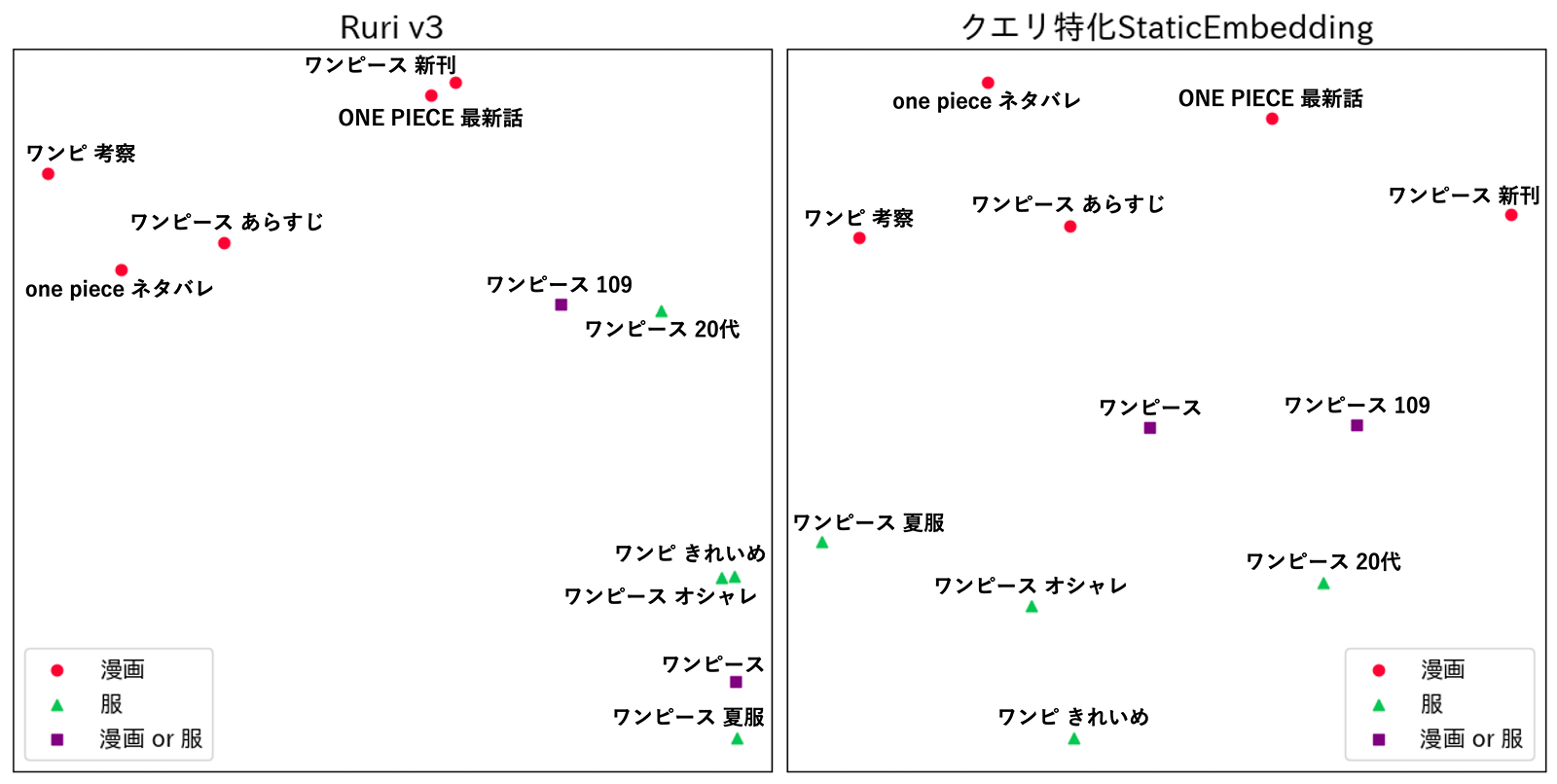
この結果、クエリ特化StaticEmbeddingではワンピース関連のクエリに対する埋め込みが各検索意図ごとに綺麗に別れて分布しており、短いクエリから検索意図を正確に捉えていることがわかりました。一方でRuri v3では漫画 or 服という細かい検索意図を��捉えきれず、服の検索意図と混ざってしまっていました。
2つ目の「表層の変化に頑健か」という点を調査するため、クエリ理解ベンチマークの同義クエリ抽出に含まれる同義クエリペアを表層の類似度ごとにグループ分けし、各グループにおける抽出性能を比較しました。下のグラフは、右側が表層が似ている同義クエリペアに対する抽出性能を示していて、左側が表層が似ていない同義クエリペアに対する抽出性能を示しています。表層の類似度の指標にはLevenshtein類似度を利用しました。
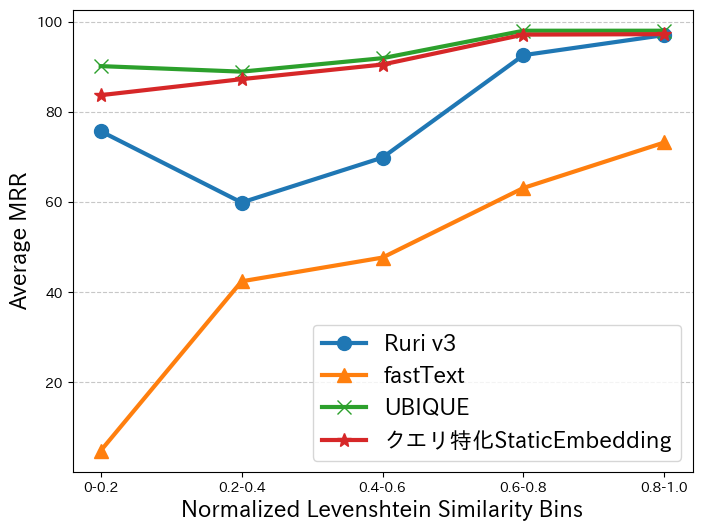
この結果から、クエリ特化StaticEmbeddingは同義クエリペア間の表層の類似度に依らず、高精度に同義クエリを抽出できることがわかりました。一方で、Ruri v3は表層の類似度の違いによって同義クエリ抽出性能も上下しており、表層に影響を受けていることが確認できます。また、同じ静的な単語埋め込みでもユーザー行動ログで学習をしていないfastTextでは、表層が異なる同義クエリペアをほとんど抽出できませんでした。
これらの分析から、クエリ特化StaticEmbeddingはクエリ埋め込みにおいて重要な性質を備えていることが確認できました。静的な埋め込みの平均であっても適切なデータで学習すれば、短いクエリの意図を正確に捉え、表層に頑健な表現を獲得できるというのは非常に興味深い結果でした。
トークナイザの影響分析
トークナイザの変更がクエリ特化StaticEmbeddingの性能に与え�る影響を調査しました。自然文特化のトークナイザとしてRuri v3でも利用されている Sarashinaトークナイザを採用し、検索ログからSentencePiece(Unigram LM)を利用してSarashinaトークナイザと同じ語彙数のトークナイザと、さらに語彙数が大きいトークナイザを構築しました。そして、各トークナイザを用いてクエリ特化StaticEmbeddingを学習しその性能を比較しました。
| トークナイザ | 語彙数 | 同義クエリ 抽出 | クエリ 推薦 | クエリ 分類 | 短文 リランキング | 平均 |
|---|---|---|---|---|---|---|
| Sarashinaトークナイザ | 102,400 | 82.5 | 91.2 | 56.2 | 90.3 | 80.1 |
| クエリ特化トークナイザ | 102,400 | 85.9 | 91.8 | 61.0 | 90.4 | 82.3 |
| クエリ特化トークナイザ | 256,000 | 86.9 | 91.6 | 62.1 | 90.4 | 82.8 |
比較の結果、クエリログを用いてトークナイザを構築し語彙数を増加させることで性能を向上できることがわかりました。特に同じ語彙数でSarashinaトークナイザと比較したときの性能差が大きく、自然文と大きく形式が異なる検索クエリの処理において専用のトークナイザを構築することの重要性が確認できました。
おわりに
本記事では、StaticEmbeddingを活��用することでクエリ埋め込みの推論速度を大幅に改善した取り組みを紹介しました。構築したモデルはTransformerベースのモデルと比較して10倍以上の速度改善をしつつ、97%以上の性能維持を達成しました。
今後もより良いクエリ埋め込みを構築し、ユーザーの皆様の体験向上に努めたいと考えています。
参考文献
- [1] Sosuke Nishikawa, Jun Hirako, Nobuhiro Kaji, Koki Watanabe, Hiroki Asano, Souta Yamashiro and Shumpei Sano. Search Query Embeddings via User-behavior-driven Contrastive Learning. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track), pages 138-147, 2025.
- [2] Chandan K. Reddy, Lluís Màrquez, Fran Valero, Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopadhyay, Arnab Biswas, Anlu Xing and Karthik Subbian. Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search. arXiv, 2022.


