시작하며
안녕하세요. SR(Service Reliability) 팀에서 SRE(site reliability engineer, 사이트 안정성 엔지니어링) 업무를 맡고 있는 이채승(argon)입니다.
SR 팀은 Service Engineering 실에 속해서 LINE 앱에서 제공하는 서비스의 품질 향상 및 가용성 확보를 위한 기술 활동을 수행하고 있습니다. 이를 위해 AWX와 Rundeck, Concourse CI와 같은 자동화 플랫폼을 운영하며, 서비스 출시와 이벤트에 필요한 기술적 요소를 확인하고 적절한 솔루션을 제공해 개발 조직이 개발과 운영에 더욱 집중할 수 있도록 지원합니다.
저의 주 업무는 오픈챗 SRE로 오픈챗 서비스의 신뢰성을 높이기 위해 노력하고 있으며, 동시에 전사 직원들의 업무 자동화를 돕기 위한 AWX 플랫폼 운영 업무를 겸하고 있습니다. 이번 글에서는 AWX 플랫폼을 운영하면서 반복되는 문의에 효과적으로 대응하기 위해 RAG(Retrieval-augmented generation, 검색 증강 생성)를 활용한 AWX 지원 봇 도입 사례를 소개드리고자 합니다.
AWX 지원 봇 개발 동기
사람들은 뭔가를 시작할 때 가이드 문서를 읽어야 한다는 사실을 알고 있음에도 실제로는 읽지 않고 시작하는 경우가 많습니다. 이런 문제는 특히 초기에 읽어야 할 가이드 문서의 분량이 방대한 경우 나에게 필요한 정보를 찾기 어려워지면서 발생하는데요. 이때 많은 사용자들이 빨리 시작하고 싶은 마음에 관리 측에 동일한 문의를 중복으로 남기기 시작하면 관리자는 이에 대응하느라 운영 리소스를 크게 소모하게 됩니다.
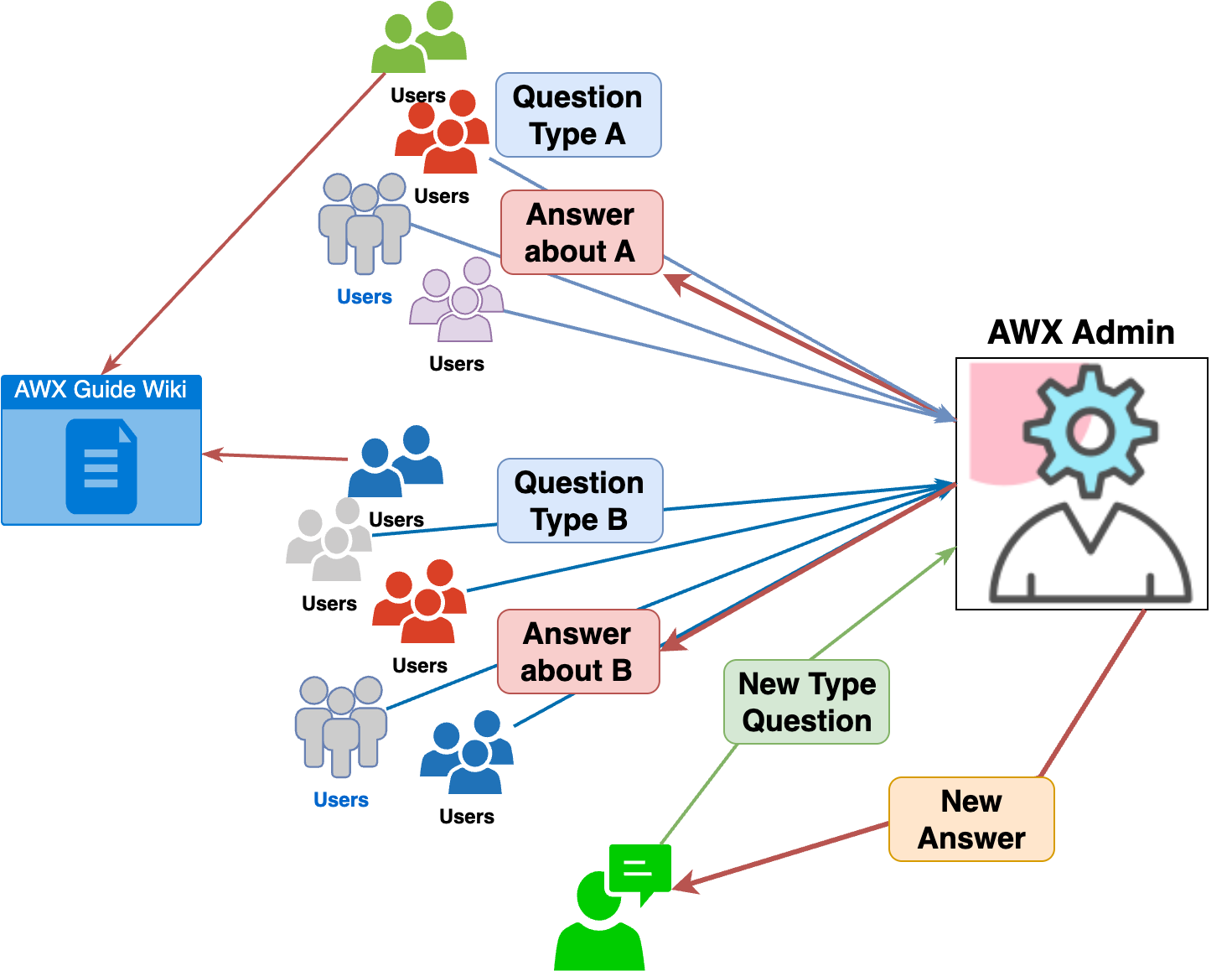
위와 같은 문제를 해결하기 위해 가이드 문서를 읽어본다면 충분히 알 수 있는 문의에 대해서는 1차적으로 자동 답변을 제공할 수 있는 시스템이 필요했고, 검색과 생성을 결합한 RAG 기법을 활용해 AWX 지원 봇을 개발하게 되었습니다.
AWX 지원 봇 구현에 사용한 프레임워크 및 툴 소개
자세한 설명에 앞서 AWX 지원 봇 구현에 사용한 프레임워크 및 툴을 소개하겠습니다.

- Slack 봇 프레임워크: Bolt for Python
- Slack에서는 다양한 언어 기반의 봇 프레임워크를 제공하고 있습니다. 그중 개인적으로 익숙한 Python 봇 프레임워크를 선택했습니다.
- LLM 프레임워크: LangChain
- LangChain 프레임워크는 Python과 JavaScript, 이 두 가지 언어로 제공됩니다.
- AWX 지원 봇은 많은 기능이 필요하지 않아서 LangChain을 사용했는데요. 만약 조금 더 복잡한 워크플로와 상태 관리, 다중 에이전트 협업을 원하신다면 LangGraph를 사용하는 것을 권장합니다.
- 임베딩 모델: paraphrase-multilingual-mpnet-base-v2
- 문장을 벡터로 변환해 주는 임베딩 모델은 SBERT 모델, OpenAI 텍스트 임베딩 모델 등 다양한 선택지가 있으며, 그중 오픈소스인 SBERT 모델을 선택했습니다.
- LY는 여러 나라의 임직원이 함께 서비스를 개발하고 있기 때문에 문의 또한 여러 언어로 접수됩니다. 이를 고려해 SBERT에서 제공하는 성능 평가 표를 참조해서 다국어를 지원하는 모델 중 문장 비교 성능이 가장 괜찮은 paraphrase-multilingual-mpnet-base-v2를 선택했습니다.
- 벡터 DB: OpenSearch
- LLM: OpenAI(ChatGPT)
- 저희 회사에서는 적절한 용도로 신청하면 OpenAI API를 사용할 수 있기 때문에 OpenAI를 선택했습니다.
- OpenAI Enterprise의 경우 기본적으로 비즈니스 데이터를 학습하지 않고 있다는 점도 고려했습니다(참고: https://openai.com/enterprise-privacy/).
- LangChain 프레임워크에서는 OpenAI뿐 아니라 Ollama나 Amazon Bedrock 등 다양한 LLM과 연동할 수 있는 프레임워크를 지원하고 있기 때문에 각자의 환경에 적합한 LLM을 선택할 수 있습니다.
LLM과 RAG란?
RAG 기법을 이해하기 위해서는 먼저 LLM(large language model)과 LLM의 한계를 알아야 합니다.
LLM은 방대한 양의 데이터로 사전 학습된 딥러닝 모델로, 텍스트에서 의미를 추출하고 단어 및 구문의 관계를 이해해 결과물을 생성합니다. 학습한 데이터를 바탕으로 적절한 답변을 생성하기도 하지만 다음과 같은 몇 가지 한계 때문에 적절하지 않은 답변을 생성하기도 합니다.
- 최신 정보 반영의 어려움: 답변이 사전 학습된 데이터에 기반하므로 최신 정보를 반영하지 못합니다.
- 허위 정보 생성 가능성: 사전 학습 시 사용한 데이터에 없는 질문에 대해서는 부정확하거나 허위 정보가 답변으로 제공될 수 있습니다.
- 출처 확인의 어려움: 모델이 생성한 답변의 출처를 명확히 알 수 없습니다.
이와 같은 한계를 보완하기 위해 RAG 기법을 사용합니다. RAG는 LLM에게 질문과 �함께 콘텍스트(신뢰할 수 있는 데이터)를 전달해서 콘텍스트를 바탕으로 정확한 답변을 생성하도록 유도하는 프로세스입니다. 다음은 기존 LLM의 답변과 RAG 기법을 사용해 콘텍스트를 전달한 LLM의 답변을 비교한 예시입니다.

이와 같이 RAG를 사용하면 LLM은 데이터를 추가로 학습할 필요 없이 특정 도메인이나 조직 내부 DB(예: LY의 AWX 서비스)로 AI 서비스를 확장할 수 있습니다.
RAG를 사용하기 위한 임베딩과 벡터 검색
이처럼 RAG는 LLM에 질의할 때 외부 DB의 신뢰할 수 있는 데이터를 함께 전달해 더 정확한 답변을 생성하도록 유도하는 프로세스입니다. 하지만 질문할 때마다 외부 DB의 모든 데이터를 LLM에게 함께 전달한다면 답변 생성에 불필요한 데이터도 함께 전달되므로 비효율적일 것입니다. 예를 들어, "우리 회사의 AWX 관리자는 누구야?"라는 문의에 이 질문과 무관한 콘텍스트인 'AWX 가입 방법'과 '사용자 가이드' 등의 데이터를 모두 함께 전달한다면 비효율적이겠죠?
이 문제를 개선하려면 사용자가 질문했을 때 외부 DB에서 사용자의 문의와 유사한 데이터만 가져오는 작업이 필요합니다. 그런데 외부 DB에서 사용자의 문의와 유사한 데이터를 검색하려면 어떻게 해야 할까요? 이를 위해선 임베딩(embedding)과 벡터 검색(vector search)을 이해할 필요가 있습니다.
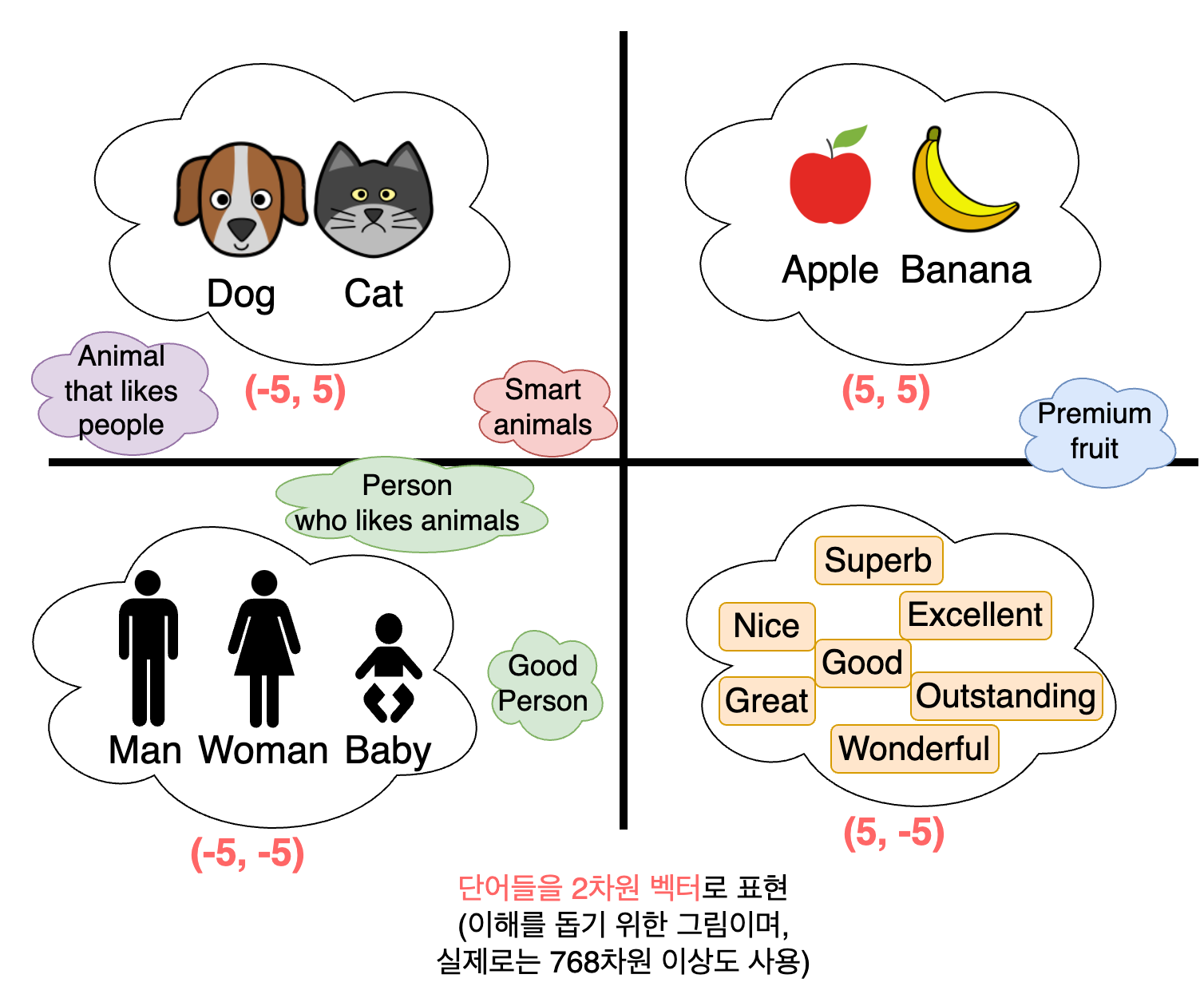
먼저 임베딩은 텍스트나 이미지, 오디오와 같은 다양한 데이터를 벡터 형태로 변환하는 작업입니다. 예를 들어 텍스트 데이터를 임베딩하면 아래와 같이 고차원의 벡터(행렬) 값으로 변환됩니다.
- "Argon is AWX Admin" → (-0.0335848405957222, -0.06817212700843811, ..., -0.12750950455665588, -0.05369032919406891)
임베딩은 의미가 유사한 단어들을 모으도록 사전에 학습된 임베딩 모델(예: Sentence Transformers)을 통해 변환 작업을 수행하기 때문에 아래와 같이 고차원 공간에서 유사한 단어들이 서로 가까운 위치에 배치됩니다.
임베딩 과정을 통해 벡터로 임베딩된 데이터들이 인덱싱되는 곳이 벡터 DB이고 이 벡터 DB에 인덱싱된 벡터를 검색하는 것이 벡터 검색입니다.
앞서 임베딩된 데이터는 벡터로 표현되며 서로 유사한 데이터 항목은 벡터 공간에서 서로 가까이 위치한다고 말씀드렸죠? 단적인 예로, 'Buy'와 'Purchase'는 서로 다른 단어이지만 의미가 유사하기 때문에 임베딩한 벡터값 역시 비슷해 서로 가까이 위치합니다. 따라서 단순 키워드 검색에서는 'Buy'로 검색했을 때 'Purchase'를 찾을 수 없지만, 벡터 검색을 사용하면 'Purchase'에 해당하는 결과도 함께 검색할 수 있습니다.
이를 이용해 사용자의 문의가 들어오면 이를 임베딩한 후 k-NN(최근접 이웃) 방식으로 문의의 벡터값과 유사한 데이터들을, 즉 문의와 가까운 문장들을 가까운 순서대로 k개 가져오는 방식으로 검색할 수 있습니다. 아래는 여러 개의 문장을 임베딩해서 벡터 검색하는 예시입니다.
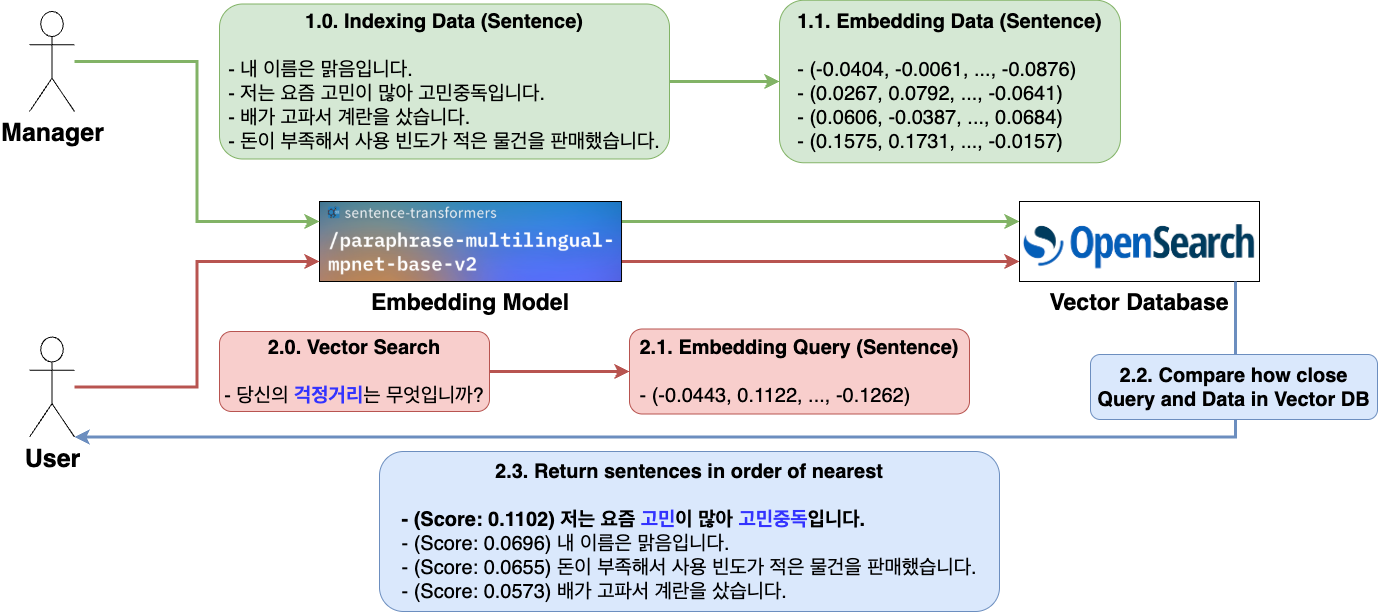
* 벡터 검색은 질의한 문장에 대한 답변이 아니라 단순히 유사도가 높은 문장들을 가져오는 작업입니다.
* 여러 문장 중 질의한 문장('걱정거리')과 점수(유사도)가 가장 높은 문장은 의미가 유사한 단어('고민')가 포함돼 있는 문장입니다.
AWX 지원 봇의 워크플로 소개
RAG를 사용하기 위해 사용자의 문의와 유사한 문장들을 벡터 검색으로 가져오는 방법을 알아봤습니다. 벡터 검색을 이용해 사용자의 문의를 해당 문장과 유사한 문장과 함께 LLM에게 함께 전달하면 RAG를 구성할 수 있습니다.
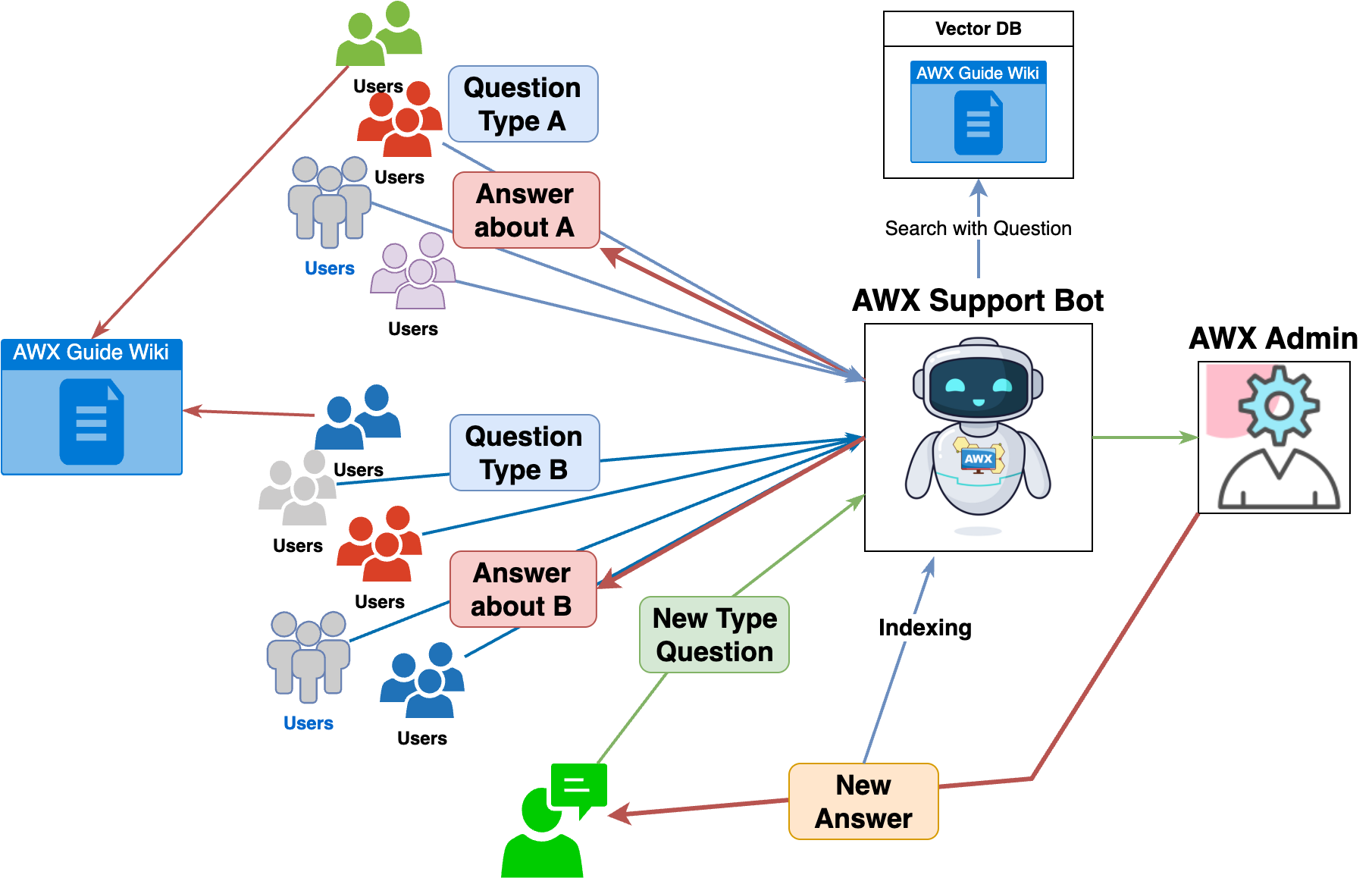
그렇다면 이제 다시 돌아와서 RAG를 사용한 AWX 지원 봇의 워크플로를 살펴보겠습니다. AWX 지원 봇의 워크플로는 아래와 같습니다.
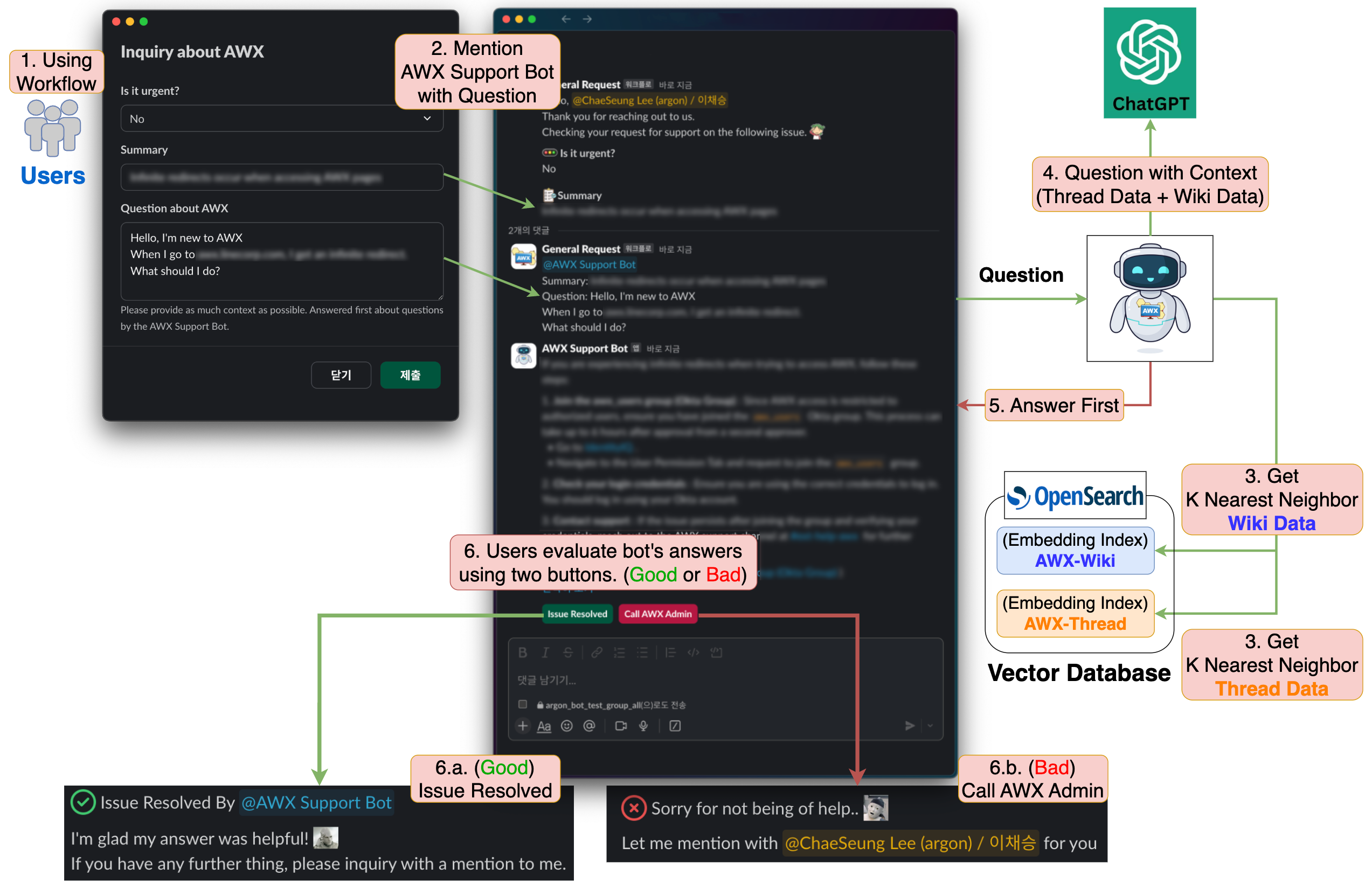
- 사용자가 Slack 워크플로를 통해 문의합니다.
- 사용자의 문의를 AWX 지원 봇이 1차로 확인합니다.
- 사용자의 문의와 유사한 '사내 위키의 문서 데이터'와 'Slack 문의 스레드 데이터'를 각각 k개씩 가져옵니다.
- 3에서 가져온 '신뢰할 수 있는 데이터'와 사용자의 문의를 LLM에게 함께 전달합니다.
- LLM의 답변을 사용자에게 1차로 제공합니다.
- 사용자는 LLM의 답변이 유효한지 평가합니다.
- (Good) 이슈가 해결됐다면, 'Issue Resolved' 버튼을 클릭해 관리자를 호출하지 않고 문의를 완료합니다.
- (Bad) 이슈가 해결되지 않았다면, 'Call AWX Admin' 버튼을 클릭해 관리자를 호출합니다.
AWX 지원 봇은 위와 같이 사용자의 문의에 1차 답변을 제공함으로써 AWX 관리자의 리소스를 줄여줍니다.
더 나은 답변을 제공하기 위해 활용하고 있는 데이터
그렇다면 AWX 지원 봇이 참조하는 벡터 DB에는 어떤 데이터가 인덱싱되고 있을까요? 다음 그림은 각 데이터의 인덱싱이 어떻게 진행되는지 나타낸 그림입니다.
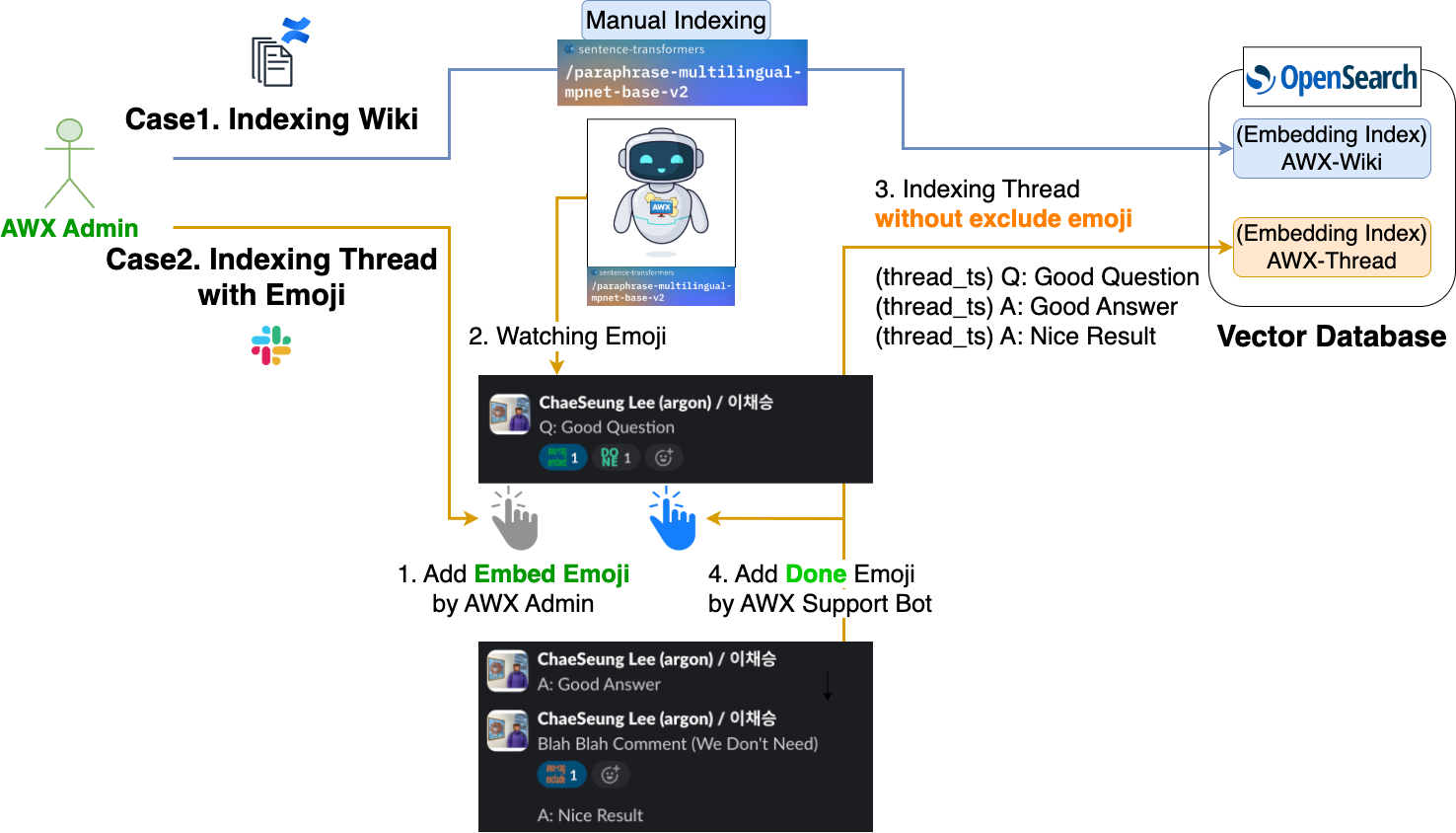
위 그림처럼 AWX 지원 봇은 사내 위키의 문서 데이터와 Slack 스레드 데이터, 이 두 인덱스를 참조하고 있습니다.
- 사내 위키의 AWX 가이드 문서 데이터
- LLM이 정확한 답변을 생성하도록 유도하기 위해서 사내 AWX 가이드 문서 데이터를 참조할 수 있습니다.
- 참조해야 할 문서의 양이 많다면 LangChain 커뮤니티의 Document loaders나 Docling과 같은 문서 구조화 도구들로 청킹(chunking)해서 인덱싱하는 것이 이상적이지만, 현재 가이드 문서의 양은 그 정도로 많지 않기 때문에 정확한 답변 생성을 위해 AWX 관리자가 수동으로 필요한 부분만 구조화해서 인덱싱하고 있습니다.
- LLM이 정확한 답변을 생성하도록 유도하기 위해서 사내 AWX 가이드 문서 데이터를 참조할 수 있습니다.
- 과거 질문/답변이 성공적으로 완료된 Slack 스레드 데이터
- LLM의 정확한 답변을 생성하도록 유도하기 위해서 지난 사용자 문의 및 답변 이력도 참조할 수 있습니다.
- Slack 채널에서 오가는 모든 메시지를 인덱싱할 수는 없기 때문에 이모지를 이용해 필요한 메시지만 인덱싱하도록 설정했습니다.
- 아래와 같은 절차로 필요한 메시지만 인덱싱합니다.
- AWX 관리자가 대상 메시지에 '임베드 이모지'를 추가합니다.
- AWX 지원 봇이 임베드 이모지가 추가된 메시지를 확인 후 해당 메시지의 하위 스레드 중 제외 이모지가 추가된 메시지(불필요한 메시지)를 제외한 메시지를 인덱싱합니다.
- 인덱싱이 완료되면 AWX 지원 봇이 해당 메시지에 '완료 이모지'를 추가합니다.
AWX 지원 봇은 사내 위키의 AWX 가이드 문서 데이터보다 Slack 스레드 데이터를 우선 참조하도록 설정돼 있습니다. 이는 Slack 채널에서 진행되는 질문과 답변의 패턴이 잘 구조화돼 있고, 유사한 질문이 많아 퓨삿 프롬프팅(few shot prompting) 효과를 기대할 수 있을 것이라고 판단했기 때문입니다. 이에 시스템 프롬프트에 Slack 스레드 데이터를 우선 참조하도록 설정했습니다.
마치며
지금까지 AWX 지원 봇을 왜, 어떻게 만들었는지 워크플로와 함께 자세히 살펴봤습니다. RAG를 접하고 난 뒤 현재 상황에서 확실한 보상을 얻을 수 있다는 확신이 들어서 이 프로젝트를 진행했는데요. 덕분에 AI 트렌드를 전반적으로 이해하는 귀중한 경험을 얻었습니다.
이번 프로젝트를 마치고 난 후 오픈챗 SRE로서 오픈챗 서비스의 업무 부하를 줄여주는 봇을 만들어 보고 싶다는 생각이 들어 새로운 개념들을 학습하고 있습니다. 이를 통해 다음에는 서비스 업무 부하를 줄여주는 서비스 봇 도입기를 이 블로그에서 소개할 수 있기를 바라고 있습니다. 😄
마지막으로 이 글이 AWX 서비스에만 한정되지 않고 문의 채널을 운영하는 모든 분들에게 도움이 되길 바라며 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


