들어가며
LINE 앱에서 제공하는 실시간 커뮤니케이션 서비스인 LINE 1:1 통화와 LINE 그룹 통화, LINE 미팅은 인터넷 프로토콜을 통해 실시간으로 음성 및 영상 데이터를 전송합니다. 이를 통해 사용자들은 어느 곳에서든 편리하게 음성 및 영상 통화를 경험할 수 있습니다.
실시간 커뮤니케이션 서비스의 핵심 과제는 실시간성과 좋은 품질을 동시에 유지하는 것입니다. 사용자들이 서비스를 이용하면서 느끼는 불편함이나 문제점을 파악하고 개선하려면 객관적이고 공정한 품질 측정과 평가가 필수입니다. 이 글에서는 먼저 어떤 측면에서 품질을 측정하고 있는지 알아보고, 대표적인 세 가지 품질 측정 영역인 에코 제거(acoustic echo cancellation, 이하 AEC)와 주파수 응답(frequency response), 손실 강건성(loss robustness) 측정 방법을 살펴보겠습니다.
품질 측정 측면
저희는 서비스 품질의 중요성을 인식하고 다음과 같은 다양한 측면에서 철저히 품질을 측정하고 있습니다.
어쿠스틱 환경 대응
어쿠스틱 환경이란 통화하는 사람의 음향학적 환경을 의미합니다. 통화하는 사람의 공간적 특성은 통화 품질에 영향을 미칠 수 있는데요. 예를 들어 주변이 시끄럽거나 울림이 심한 곳에 있으면 통화 품질이 나빠져 불편을 느낄 수 있습니다. 저희는 이런 어쿠스틱 환경에서의 음성 처리 기술 성능을 평가하고 기술 개선점을 도출하고자 무향실 환경을 갖추고 음성 처리 기술 성능에 영향을 미치는 음향 변수를 측정하고 있습니다.
먼저 (구) LINE Engineering 블로그에서 발행한 화상 회의할 때 음성 품질을 높이는 기술이라는 글에서 음성 품질을 높이기 위한 사용자의 통화 환경 구성 방법을 설명했으니 참고하시기 바랍니다.
어쿠스틱 환경에서의 음향 변수로는 배경 잡음과 음량 수준, 잔향 수준, 에코 등이 있습니다. 이런 음향 변수들을 특성별로 나눠 정량화하는데요. 예를 들어 배경 잡음의 경우 주변 잡음을 얼마나 제거하는지를 정량화하고, 에코의 경우 에코를 얼마나 제거하는지 정량화합니다.
이런 음향 변수를 측정하기 위한 무향실 환경도 갖추고 있습니다. 무향실 환경에서는 음향 변수를 다양하게 시뮬레이션해서 실제 환경과 가깝게 재현할 수 있고, 이를 통해 내부에서 수행하는 음성 처리 기술이 적합하게 작동하는지 측정할 수 있습니다. 예를 들어, 카페에서 통화하는 환경을 시뮬레이션하기 위해 카페에서 녹음한 잡음을 재생해서 이런 잡음이 음성 품질에 미치는 영향을 측정합니다.

네트워크 환경 변화 대응
네트워크에서는 패킷 손실과 패킷 지연, 대역폭 제한, 네트워크 혼잡과 같은 변화가 지속적으로 발생하고, 이런 네트워크 환경의 변화는 실시간 통화 서비스 품질에 매우 큰 영향을 줍니다. 따라서 사용자가 뛰어난 서비스 품질을 일관되게 경험할 수 있으려면 네트워크 환경 변화가 서비스 품질에 미치는 영향을 측정하고 좋은 품질을 유지하기 위한 기술과 전략을 개발해야 합니다. 이를 위해서 먼저 네트워크 환경 변화를 실시간으로 정확하게 분석하고 진단하는 기술이 있어야 하고, 진단 결과를 기반으로 서비스 품질을 유지하기 위해 비트레이트 조정이나 데이터 재전송 등과 같은 다양한 전략을 수행해야 하는데요. 이와 같은 활동은 사용자들이 체감하는 품질에 직접적인 영향을 주기 때문에 네트워크 환경 변화에 대응하는 기술과 전략을 정량적으로 측정하는 것은 매우 중요합니다.
현실에서 네트워크 환경 변화는 다양한 형태로 발생합니다. 저희는 이를 상황별로 모델링해 다양한 시나리오를 만들고, 각 시나리오를 모의 실험에 적용해서 현실에서의 네트워크 환경 변화를 시뮬레이션합니다. 그리고 그때의 품질(음질, 화질, FPS(frames per second, 초당 프레임 수), 데이터 사용량 등)을 정량적으로 측정해 네트워크 환경 변화 및 대응 전략이 효과적으로 작동하는지 평가합니다.
아래 그림은 실제 환경에서 일어나는 패킷 손실을 모델링한 시나리오를 모의 실험으로 재현한 예시입니다.

위 예시처럼 네트워크 에뮬레이터를 활용해 패킷 손실을 유발해서 실제 환경을 재현하며 패킷 손실로 인한 음질 저하를 정량적으로 측정합니다. 네트워크 에뮬레이터는 패킷 손실 외에도 패킷 지연, 대역폭 제한 등의 네트워크 환경 변화를 시뮬레이션할 수 있고, 여러 개의 네트워크 에뮬레이터를 연결해 여러 가지 네트워크 환경 변화를 동시에 시뮬레이션할 수도 있습니다.
저희는 이런 모의 실험을 통해 다양한 네트워크 환경 변화를 시뮬레이션해서 각 환경에서의 품질을 정량적으로 측정하고 있으며, 이런 측정을 반복하며 기술 신뢰도를 평가하고 개선 사항을 도출하고 있습니다.
글로벌 환경 대응
LINE 앱은 글로벌 서비스로 전 세계에서 활용하고 있습니다. 따라서 글로벌 사용자들에게 지속적으로 뛰어난 품질을 제공하는 것은 매우 중요합니다. 그런데 각 지역의 통신 네트워크나 인프라에는 다양한 ISP(Internet service provider)와 네트워크 토폴로지, 대역폭 배분, 망 환경 및 관리 방식이 사용되고 있습니다. 또한 와이파이 인프라나 사용 행태, 문화가 다를 수도 있고, 주중이나 주말, 지역 이벤트 등에 따라 네트워크 환경이 변할 수도 있습니다.
이런 지역별 차이와 환경 변화에 대응하기 위해 전 세계 약 15개 국가에 자체 개발한 품질 측정 도구를 배치하고 각 국가의 망 환경 특성을 지속적으로 모니터링하고 있습니다. 이를 통해 국가별, 지역별 네트워크 특성과 변화를 파악하고 최적의 설정을 적용해 사용자들에게 최상의 서비스 품질을 제공합니다.
자체 개발한 품질 측정용 H/W 및 S/W를 탑재한 측정 도구는 자동으로 통화를 걸고 받으면서 음성 및 영상 품질, 지연, 통화 연결 시간 등의 각종 품질 지표를 측정합니다. 품질을 측정할 때에는 POLQA(ITU-T P.863)과 PSNR(ITU-T J.340) 같은 국제 표준 측정 지표뿐 아니라 표준은 아니지만 업계에서 많이 사용하는 측정 지표도 활용합니다.

이와 같은 글로벌 품질 모니터링을 통해 타 서비스와 품질을 비교하고 분석해서 강점과 개선점을 도출합니다. 글로벌 모니터링 시스템에서는 품질 측정 도구에서 측정된 지표를 집계해서 이를 종합적인 서비스 품질 평가 점수로 표현하는데요. 서비스 품질 평가 점수는 아래와 같이 각기 다른 색상으로 구분돼 품질 수준을 지역별로 쉽게 파악할 수 있습니다. 아래 그림의 지도에서 초록색은 품질이 원활한 곳, 회색은 품질이 보통인 곳, 빨간색은 품질이 좋지 않거나 측정이 안 되는 지역을 나타냅니다.
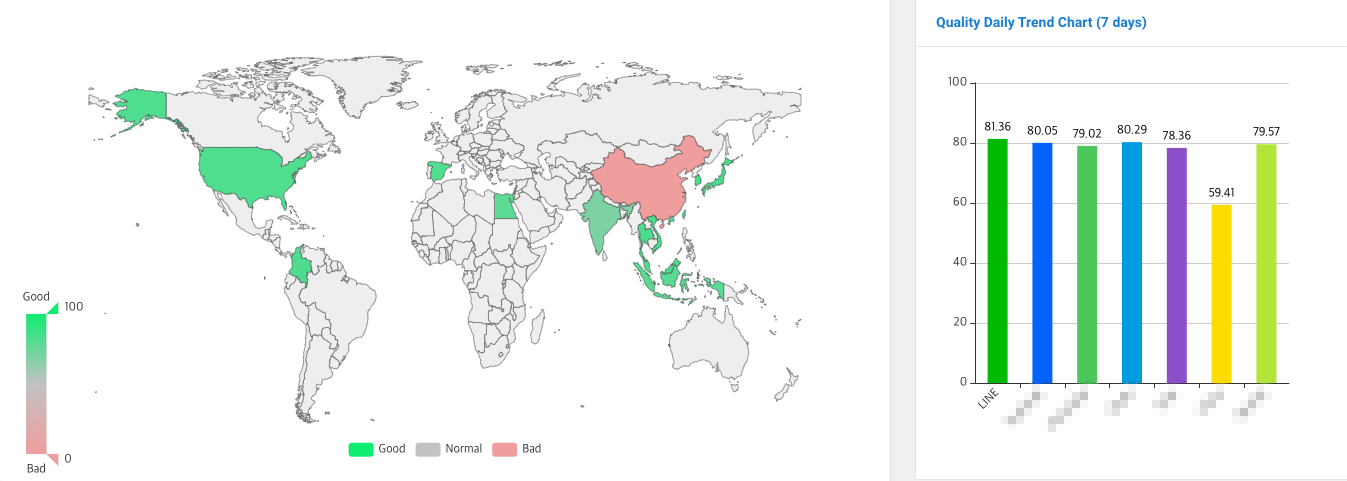
저희는 이와 같이 각 국가와 지역의 특수한 네트워크 및 환경을 고려해 품질을 개선하기 위한 대응책을 연구하고 시행하고 있으며, 모든 지역에서 최상의 서비스 품질을 제공하기 위해 끊임없이 노력하고 있습�니다.
외부 시험 의뢰
외부 시험 의뢰를 통해서 독립적인 측정도 진행하고 있습니다. 외부 시험은 제3자인 전문가들이 저희 제품의 성능을 측정하고 음성 및 영상 품질을 정량적으로 분석하는 중요한 과정입니다.
외부 시험 과정에서는 외부 시험 업체와 측정 시나리오를 목적에 맞게 조율해 시험 환경에서 품질 변화를 정확히 파악합니다. 더 나아가, 타 서비스와 성능을 비교해 시장에서의 제품 경쟁력을 평가하는 과정도 포함됩니다. 이를 통해 중립적인 시각에서 평가한 품질을 받아들이고 사용자 만족도를 높이기 위한 개선점을 도출합니다.
AEC 성능 측정
AEC(acoustic echo cancellation)란 음성 통화 시스템에서 발생하는 음향 에코를 억제하는 기술로, 사용자의 음성이 통화 상대방의 마이크를 거쳐 다시 들려오는 현상을 줄여주는 역할을 합니다. 아래는 음성 통화 시스템에서 에코가 발생하는 예를 나타낸 그림입니다.
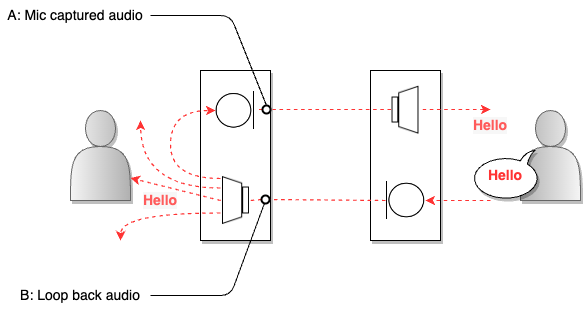
위 그림에서 오른쪽 사용자의 소리(B)가 왼쪽 사용자의 스피커로 출력되면, 그 소리 역시 마이크에 수집(A)됩니다. 소리가 어떤 매체에 반향되어 다시 돌아오는 것을 에코라고 하는데요. 수집한 소리를 전달하는 마이크는 가장 큰 반향원이라고 할 수 있습니다. 만일 이처럼 사용자의 소리가 상대방의 마이크에서 수집돼 그대로 다시 사용자에게 전달되면 사용자는 시간차를 두고 본인의 목소리를 다시 듣게 됩니다. 통화용 AEC는 이러한 음향 에코를 실시간으로 감지하고 적절히 필터링 제거해 음성 통화 품질을 향상시킵니다.
저희는 자체 기술로 AEC를 직접 개발하고 있고, 머신 러닝 기술을 도입해 고품질의 에코 제거 성능을 제공합니다. 이를 통해 LINE 앱 사용자가 에코로 불편함을 느끼지 않고 깨끗하고 높은 음질로 음성 통화를 즐길 수 있도록 품질을 측정하고 있는데요. 어떻게 측정하고 있는지 본격적으로 설명하기 전에 AEC 성능 측정과 성능 지표 설명에서 사용할 용어의 의미를 정의하고 넘어가겠습니다.
- Near-end: 통화 시스템에서 측정이 이루어지는 쪽에 있는 사용자를 의미합니다.
- Far-end: Near-end와 통화를 하는 상대방 사용자를 의미합니다.
- Single talk(싱글 톡): Near-end 또는 Far-end가 한쪽만 말하고 있는 경우를 의미합니다.
- Double talk(더블 톡): Near-end와 Far-end가 둘 다 말하고 있는 경우를 의미합니다.
AEC 성능 측정 방법
AEC 성능은 오디오를 손상시키지 않으면서 에코를 억제하는 능력을 정량화해 평가하며, 성능을 측정할 때에는 다음과 같은 절차를 따릅니다.
측정 환경 구성
먼저 AEC 성능을 측정하기 위한 측정 시스템 환경을 구성합니다.
품질 측정 툴 선정
AEC 기능을 평가하고 성능을 개선하는 데에는 AECMOS를 활용하고 있습니다. AECMOS는 오디오를 손상시키지 않으면서 에코를 억제하는 능력을 객관적인 지표로 측정하는 툴입니다. 현재 업계나 학계에서 AEC 성능을 평가할 때 사용하고 있는데요. 새로운 알고리즘의 성능을 평가하거나 기존 기술과 비교할 때 혹은 논문이나 연구 보고서에서 실험 결과를 분석하고 다른 연구와 비교해 연구의 유효성을 입증할 때 활용되고 있습니다.
AECMOS에는 아래 3가지 측정 모드가 있습니다.
- 48kHz, 시나리오 기반 모델(Run_1668423760_Stage_0.onnx)
- 16kHz, 시나리오 기반 모델(Run_1663915512_Stage_0.onnx)
- 16kHz 모델(Run_1663829550_Stage_0.onnx)
시나리오 기반 모델은 ST FE(Far-end single talk)와 ST NE(Near-end single talk), DT(Double talk) 구간 정보를 알고 있어서 더 정확한 결과를 도출해 낼 수 있는데요. 저희는 48kHz, 시나리오 기반 모델을 AEC 성능 측정에 사용하고 있습니다.
AECMOS에는 아래와 같이 네 개의 세부 지표가 있습니다(더 자세한 내용은 'AEC 성능 지표의 의미' 절을 참고하세요).
| 지표 | 설명 |
|---|---|
| ST FE Echo DMOS | Far-end single talk 에코 제거 품질 |
| ST NE MOS | Near-end single talk 음성 보존 품질 |
| DT Echo DMOS | Double talk 에코 제거 품질 |
| DT Other MOS | Double talk 음성 보존 품질 |
테스트 데이터 셋 선정
테스트 데이터 셋은 AEC challenge에서 제공하는 test_set_icassp2022 데이터 셋을 사용합니다. 이 데이터 셋은 DT 케이스 300개, ST FE 케이스 300개, ST NE 케이스 200개의 음원을 제공합니다.
측정 대상 모듈 준비
성능 측정 대상이 되는 AEC 모듈을 준비합니다.
AEC 성능 측정
측정 환경 구성이 완료되면 다음과 같은 절차로 AEC 성능을 측정합니다.
- A(에코가 섞여 있는 원 음성, AECMOS에서는 'Mic captured audio'로 표현)와 B(에코의 소스가 되는 음성, AECMOS에서는 'Loop back audio'로 표현)를 AEC에 입력합니다.
- 시나리오 파일과 AEC 처리 결과인 C(에코가 제거된 음성, AECMOS에서는 'Enhanced audio'로 표현)와 A, B를 AECMOS 측정 툴에 입력해 ST FE Echo DMOS, ST NE MOS, DT Echo DMOS, DT Other MOS를 측정합니다.
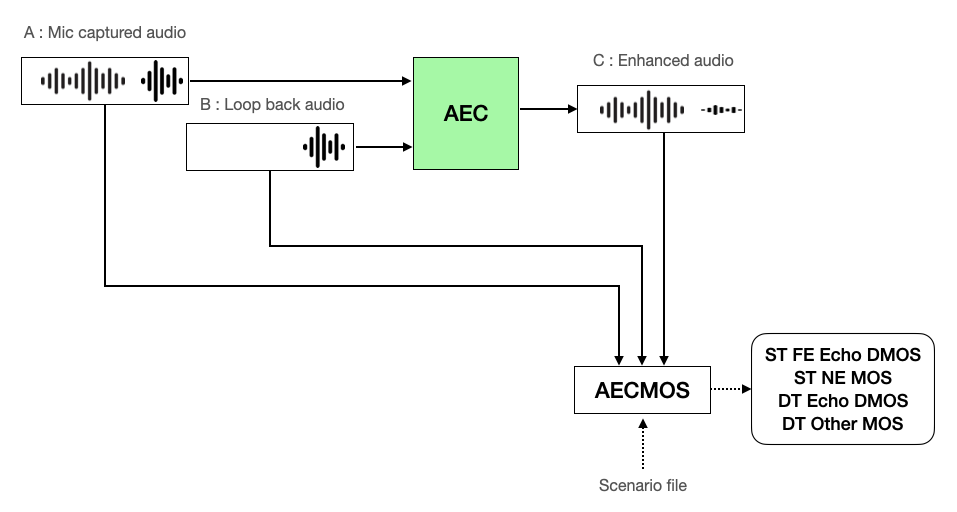
AEC 성능 평가
AEC 성능 측정 결과를 분석해 어떤 측면에서 차이가 생겼는지, 어떤 점이 개선됐고 어떤 점이 미흡한지 고려해 향후 개발 및 업데이트 계획을 수립합니다.
AECMOS 지표의 의미와 지표에 따른 체감 품질 비교
AECMOS로 측정한 지표의 의미를 살펴보고, 지표별 점수에 대한 체감 품질을 비교해 보겠습니다. 설명할 때에는 편의상 Near-end를 '나'로 가정하겠습니다.
성능 지표의 의미
앞서 설명드린 바와 같이 AECMOS에는 4가지 지표가 있으며 각 지표는 다음과 같은 의미가 있습니다.
- ST FE Echo DMOS: 에코만 있는 환경(A에 Far-end의 소리만 있는 환경)에서 에코 제거 후 남아 있는 에코 양에 대한 척도입니다. 1~5 사이의 점수로 표현되고, 숫자가 높을수록 에코가 잘 제거됐다고 판단합니다.
- ST NE MOS: Near-end 소리만 있고 에코가 없는 환경(A에 Near-end 소리만 있는 환경, B의 소리 존재 여부는 중요하지 않음)에서 보존된 내 음성의 품질에 대한 척도입니다. 1~5 사이의 점수로 표현되고, 숫자가 높을수록 음성 품질이 좋다고 판단합니다.
- DT Echo DMOS: 더블 톡 환경(A에 Near-end 소리와 Far-end 소리가 같이 있는 환경)에서 에코 제거 후 남아 있는 에코의 품질에 대한 척도입니다. 1~5 사이의 점수로 표현되고, 숫자가 높을수록 에코가 잘 제거됐다고 판단합니다.
- DT Other MOS: 더블 톡 환경(A에 Near-end 소리와 Far-end 소리가 같이 있는 환경)에서 에코 제거 후 보존된 음성의 품질에 대한 척도입니다. 1~5 사이의 점수로 표현되고, 숫자가 높을수록 음성 품질이 좋다고 판단합니다.
최고의 통화 품질을 얻기 위해서는 모든 점수가 고르게 높아야 합니다. 그렇지만 현실적으로 정확히 에코 신호 부분만 판별해 내기는 거의 불가능하기 때문에, 에코 제거 과정에서 목소리 손상도 같이 발생하는데요. 특히, 에코와 목소리가 같은 구간에 동시에 존재하는 더블 톡 구간에서는 두 개의 목소리가 섞여 버리기 때문에 에코 제거 과정에서 목소리가 손상될 가능성이 더 높아집니다. 이런 점 때문에 에코 제거와 음성 보존은 트레이드오프 관계에 놓입니다.
ST FE Echo DMOS와 DT Echo DMOS는 에코를 잘 제거할 수록 점수가 올라가고, ST NE MOS와 DT Other MOS는 음성을 잘 보존하면 점수가 올라갑니다. 따라서, 높은 ST FE Echo DMOS와 DT Echo DMOS 점수를 위해서 모든 음성을 제거하면 에코와 목소리를 모두 제거해 높은 점수를 얻을 수 있지만, 상대방은 내 목소리를 제대로 들을 수 없습니다. 반대로 높은 ST NE MOS와 DT Other MOS 점수를 위해서 신호를 제거하지 않으면 내 목소리가 그대로 남아 높은 점수를 얻을 수 있지만 에코가 심해서 대화가 어렵습니다.
AECMOS 성능 지표에 따른 체감 품질 비교
아래 표에서 AECMOS의 4가지 품질 지표인 ST FE Echo DMOS와 ST NE MOS, DT Echo DMOS, DT Other MOS의 점수대별로 음성 품질 차이를 체감할 수 있습니다.
| ST FE Echo DMOS | 오디오 캡처 위치 | 오디오 파일 | 설명 |
|---|---|---|---|
| 원본 | Mic captured audio(A) | 상대방(Far-end)이 혼자 말하고(B), 그 소리가 내 스피커로 출력되면서 내 마이크에 수집(A)됩니다. A에서 에코를 들을 수 있습니다. | |
| Loop back audio(B) | |||
| 1.x | Enhanced audio(C) | 에코가 잘 제거되지 않았습니다. | |
| 2.x | Enhanced audio(C) | 에코가 줄어들었지만 잔여 에코가 들리는 구간이 많이 있습니다. | |
| 3.x | Enhanced audio(C) | 전반적으로 에코가 많이 제거됐지만 잔여 에코가 가끔씩 들립니다. | |
| 4.x | Enhanced audio(C) | 에코가 완전히 제거돼 들리지 않습니다. |
| ST NE MOS | 오디오 캡처 위치 | 오디오 파일 | 설명 |
|---|---|---|---|
| 원본 | Mic captured audio(A) |
에코가 없는 환경에서 내(Near-end)가 말하는 동안 Far-end 쪽에서 큰 소리가 발생하는 상황입니다. B에 Far-end 소리가 있지만, A에는 내 음성만 있습니다. | |
| Loop back audio(B) | |||
| 1.x | Enhanced audio(C) | 에코가 없는 환경임에도 Near-end 목소리 손상이 크게 발생합니다. 손상이 있는 구간은 알아들을 수 없습니다. | |
| 2.x | Enhanced audio(C) | 에코가 없는 환경임에도 Near-end 목소리 손상이 발생합니다. 손상이 있는 구간은 주의 깊게 들어야 알아들을 수 있습니다. | |
| 3.x | Enhanced audio(C) | 에코가 없는 환경임에도 Near-end 목소리 손상이 약하게 발생합니다. 손상이 있지만 알아들을 수 있습니다. | |
| 4.x | Enhanced audio(C) | Near-end 목소리가 손상된 구간이 거의 없습니다. |
| DT Echo DMOS | 오디오 캡처 위치 | 오디오 파일 | 설명 |
|---|---|---|---|
| 원본 | Mic captured audio(A) | Near-end가 먼저 말을 시작하고 Far-end가 같이 말을 해(B) 두 명의 목소리가 내 마이크에 함께 수집(A)됩니다. | |
| Loop back audio(B) | |||
| 1.x | Enhanced audio(C) | 에코가 잘 제거되지 않았습니다. | |
| 2.x | Enhanced audio(C) | 에코가 줄어들었지만 잔여 에코가 들리는 구간이 많이 있습니다. | |
| 3.x | Enhanced audio(C) | 전반적으로 에코가 많이 제거됐지만 잔여 에코가 가끔씩 들립니다. | |
| 4.x | Enhanced audio(C) | 에코가 완전히 제거돼 들리지 않습니다. Near-end 목소리에 손상이 발생했지만 DT ECHO DMOS 점수는 잔여 에코량만 평가하기 때문에 높은 점수가 측정됐습니다. |
| DT Other MOS | 오디오 캡처 위치 | 오디오 파일 | 설명 |
|---|---|---|---|
| 원본 | Mic captured audio(A) | Near-end가 먼저 말을 시작하고 Far-end가 같이 말을 해(B) 두 명의 목소리가 내 마이크에 함께 수집(A)됩니다. | |
| Loop back audio(B) | |||
| 1.x | Enhanced audio(C) | 더블 톡 구간에서 Near-end 목소리의 손상이 크게 발생합니다. 손상이 있는 구간은 알아들을 수 없습니다. | |
| 2.x | Enhanced audio(C) | 더블 톡 구간에서 Near-end 목소리의 손상이 발생합니다. 손상이 있는 구간은 말을 하고 있다는 상황만 인지가 가능합니다. | |
| 3.x | Enhanced audio(C) | 더블 톡 구간에서 Near-end 목소리의 손상이 약하게 발생합니다. 손상이 있는 구간은 주의깊게 들어야 알아들을 수 있습니다. | |
| 4.x | Enhanced audio(C) | 더블 톡 구간에서 Near-end 목소리의 손상이 있지만 알아들을 수 있습니다. Far-end의 에코량은 DT Other MOS 점수에는 반영되지 않으며, DT Echo DMOS 값에 영향을 미칩니다. |
AEC 성능 측정 요약
저희는 자사의 AEC 기술을 신뢰할 수 있게 평가하고 향상시키기 위해 아래와 같이 성능을 측정합니다.
- 재현성과 일관성 보장: AECMOS를 통해 반복 가능한 환경에서 성능을 측정합니다. 동일한 데이터베이스를 사용하고, 네트워크 영향을 줄이기 위해 로컬에서 테스트를 진행합니다. 이와 같이 동일한 환경에서 일관된 결과를 얻을 수 있는 측정 방법을 사용하면 AEC 기술의 성능 변화나 개선 사항을 정확하게 파악할 수 있습니다.
- 신뢰할 수 있는 지표 사용: AECMOS 지표는 업계 및 학계에서 AEC의 성능 평가와 비교 분석에 널리 활용하는 중요한 지표입니다. 이 지표를 사용하면 측정한 성능의 신뢰를 확보할 수 있으며, 제품의 수치와 성능을 정량적으로 평가하고 발전 방향을 설정할 수 있습니다.
- 다양한 에코 상황에서의 성능 확인: 다양한 에코 환경에서 AEC 기술이 어떻게 작용하는지 정량적으로 확인할 수 있도록 아래와 같은 방법을 사용합니다.
- 대용량의 데이터베이스: 싱글 톡, 더블 톡이 시나리오에 따라 섞여 있는 데이터베이스를 2400개 이상 사용합니다.
- 다양한 녹음 환경: 다양한 오디오 장치(마이크, 스피커)와 환경에서 녹음돼 음성과 에코의 크기와 특징이 다양한 데이터를 사용합니다.
이렇듯 다양한 조건에서 신뢰할 수 있게 성능을 평가해 어떤 에코 상황에서도 저희 AEC 기술이 효과적으로 작동해 최상의 음성 품질을 제공할 수 있도록 노력하고 있습니다.
또한 에코 제거와 음성 보존이 서로 트레이드오프 관계이기 때문에 발생하는 성능 문제를 극복하고자 머신 러닝을 이용한 에코 제거 기술도 개발했고, 그 결과 전체 성능 지표가 기존 기술보다 고르게 향상됐습니다. 머신 러닝의 특성상 연산량이 많을수록 성능이 좋아지지만 아직 실시간 통화 서비스에서는 많은 연산을 사용할 수 없기에 연산량을 적절히 조절하며 튜닝하고 있습니다(이와 같은 고성능 AEC는 LINE 데스크톱에 한정해 탑재합니다).
지금까지 많은 부분을 개선해 왔는데요. 추후 더블 톡 상황에서 더욱 성능을 향상하고, 모바일 앱에도 고성능 AEC를 탑재하는 것을 목표로 하고 있습니다.
주파수 응답 측정
다음으로 주파수 응답 측정 방법을 살펴볼 텐데요. 먼저 주파수 응답 측정과 관련된 여러 개념을 간단히 살펴보고 주파수 응답 측정 방법과 절차를 알아보겠습니다.
주파수와 샘플링 레이트란
진동의 주기적인 반복 횟수를 주파수라고 합니다. 주파수는 일반적으로 초당 진동 횟수로 표시하며, 단위는 헤르츠(Hz)를 사용합니다. 높은 주파수는 짧은 주기로 빠르게 반복되는 진동을 나타내며, 낮은 주파수는 긴 주기로 천천히 반복되는 진동을 나타냅니다.
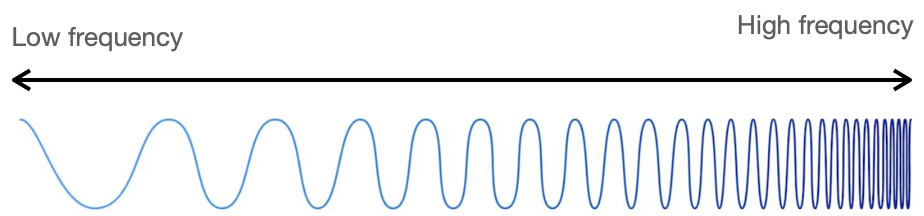
소리는 공기나 다른 매질에서 발생하는 진동으로 만들어지기 때문에, 소리 역시 주파수로 표현할 수 있습니다. 주파수의 높낮이는 소리의 음높이를 결정합니다. 높은 주파수를 가진 성분은 높은 음높이를, 낮은 주파수를 가진 성분은 낮은 음높이를 갖습|니다. 예를 들어 피아노의 도(C)음은 주파수가 약 261.63Hz이며, 미(E)음은 주파수가 약 329.63Hz입니다.
아날로그 신호를 디지털 신호로 변환할 때��는 샘플링이라는 과정을 거칩니다. 샘플링은 원본 신호를 일정 주기로 측정한 값들(샘플)로 구성한 신호로 변환하는 과정을 의미하며, 초당 샘플링하는 빈도를 샘플링 레이트라고 합니다. 디지털 신호 처리에서 중요한 개념 중 하나인 나이퀴스트-섀넌 샘플링 이론은 디지털로 신호를 표현하기 위해 필요한 샘플링 레이트를 정하는 데 사용하는데요. 이 이론에 따르면, 디지털화할 신호의 최대 주파수의 2배 이상으로 샘플링 레이트를 설정하면 원본 신호를 완벽하게 디지털로 재현할 수 있습니다. 간단히 말하면, 주파수가 20,000Hz인 아날로그 신호를 디지털화하려면 40,000Hz 이상의 샘플링 레이트를 사용해야 한다는 것입니다. 이렇게 하면 디지털화한 신호는 원본 신호와 거의 동일한 정보를 포함하게 됩니다.
주파수 응답이란
주파수 응답은 오디오 시스템의 출력 신호가 다양한 주파수 대역에서 얼마나 정확하게 전달되는지 나타내는 지표로, 오디오 시스템이 저주파 대역부터 고주파 대역까지 얼마나 넓은 주파수 범위를 잘 재생하는지 평가하는 데 사용합니다. 주파수 대역별로 입출력 소리 크기를 비교하며, 측정 단위로 데시벨(decibel, dB)을 사용합니다. 데시벨은 인간의 귀가 인지하는 소리의 크기와 비슷하도록 로그 스케일로 표현하는데요. 음수로 갈수록 작은 소리를 의미하며, 데시벨 값의 차이가 클수록 인간은 청각적으로 큰 차이를 느낄 수 있습니다.
주파수 응답 측정은 오디오 시스템의 성능을 평가하는 중요한 방법입니다. 더 넓은 주파수 범위에서 더 정확히 재생할 수록 더 성능이 우수한 오디오 시스템으로 간주됩니다. 이는 음악이나 음성을 보다 자연스럽게 재생하는 데 도움이 되며, 사용자에게 높은 품질의 오디오 경험을 제공하는 데 기여합니다.
음성 통화에서 말하는 사람의 음성 신호는 낮은 음역부터 높은 음역까지 다양한 주파수 범위에 포함됩니다. 오디오 시스템이 이러한 다양한 주파수를 정확하게 재생할 수 있다면, 음성 통화의 품질이 향상될 것입니다. 따라서 저희는 사용자에게 최상의 음성 통화 경험을 제공하기 위해 주파수 응답을 중요하게 여기고 있으며, 이를 위해 주파수 응답 측정을 수행해 그 결과를 기반으로 LINE 앱 음성 통화 서비스의 주파수 응답을 지속적으로 개선하고 있습니다.
가청 주파수와 주파수 응답
가청 주파수는 인간의 귀로 들을 수 있는 주파수 범위를 말합니다. 일반적으로 인간의 귀는 약 20Hz~20kHz 사이의 주파수를 들을 수 있습니다. 따라서 주파수 응답은 주로 이 가청 주파수 범위 내에서 측정합니다.
주파수 응답은 일반적으로 원본 신호 대비 출력 신호의 주파수 대역별 게인(gain, 강도 변화)을 그래프로 표현해 평가합니다. 이 그래프는 주파수별 게인 차이를 시각적으로 나타낸 것으로 주파수 대역별로 시스템 출력 신호의 특징을 확인할 수 있습니다. 아래 주파수 응답을 측정한 결과 예시를 보겠습니다.
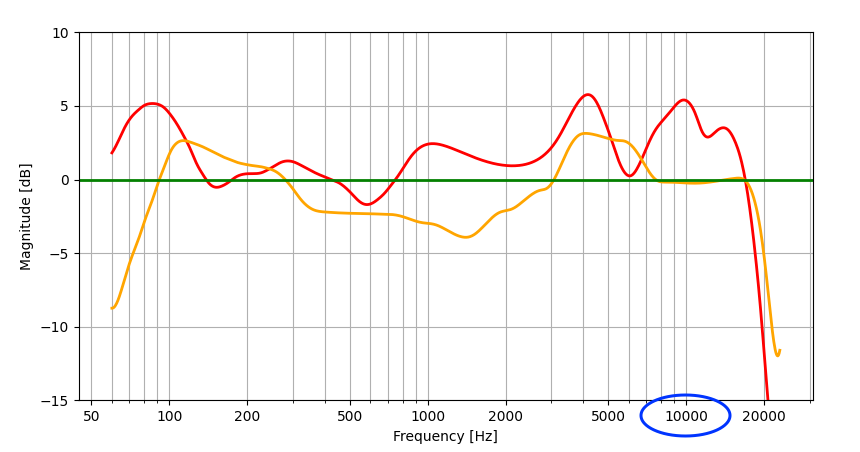
위 그래프는 두 개의 오디오 시스템의 주파수 응답을 각각 빨간색과 오렌지색으로 보여주고 있습니다. 여기서 이상적인 주파수 응답(초록색)과 빨간색, 오렌지색 주파�수 응답과의 차이를 한눈에 알 수 있는데요. 예를 들어 10kHz(파란색 원으로 표시한 곳) 부근의 주파수 응답을 보면, 오렌지색 주파수 응답의 경우 이상적인 주파수 응답과 비슷하지만, 빨간색 주파수 응답의 경우 이상적인 주파수 응답보다 약 5dB 크게 출력하고 있습니다. 따라서 10kHz에서는 오렌지색이 빨간색보다 더 이상적인 주파수 응답 특성을 갖고 있다고 말할 수 있습니다.
주파수 대역별 음성의 특징
주파수 대역별 음성의 특징은 다음과 같습니다.
- 100Hz 이하: 저주파수로 분류합니다. 음성 통화에서 이 대역의 신호는 음성에 아무런 도움이 되지 않습니다. 오히려 이 부분의 음압이 높으면 듣기 불편한 음성으로 들릴 수 있습니다.
- 100Hz~250Hz: 중저주파수로 분류합니다. 주로 음성 통화에서 음성의 저음 톤과 함께 진동을 담당하며 음성의 안정성을 표현하는 역할을 합니다.
- 250Hz~2kHz: 중주파수로 분류합니다. 이 대역은 음성의 주요 부분 중 하나로, 음성의 명료성과 선명성을 표현하는 역할을 합니다.
- 2kHz~8kHz: 고주파수로 분류합니다. 고주파수 대역은 음성의 고음 부분과 음성의 마찰음(ㅅ, ㅆ) 같은 세부 사항을 담당합니다.
- 8kHz~20kHz: 초고주파수로 분류합니다. 이 주파수 대역은 음성의 치찰음(ㅈ, ㅊ) 특성을 표현하는 역할을 합니다.
- 20kHz 이상: 음성 신호가 거의 존재하지 않는 대역으로, 인간의 청각으로 인지하기 어려운 영역입니다.
주파수 응답 측정 방법
주파수 응답은 오디오 신호가 흘러가는 모든 경로에 영향을 받습니다. 통화 시스템에서는 마이크와 스피커 장치와 통화 모듈의 특성이 영향을 미칩니다.
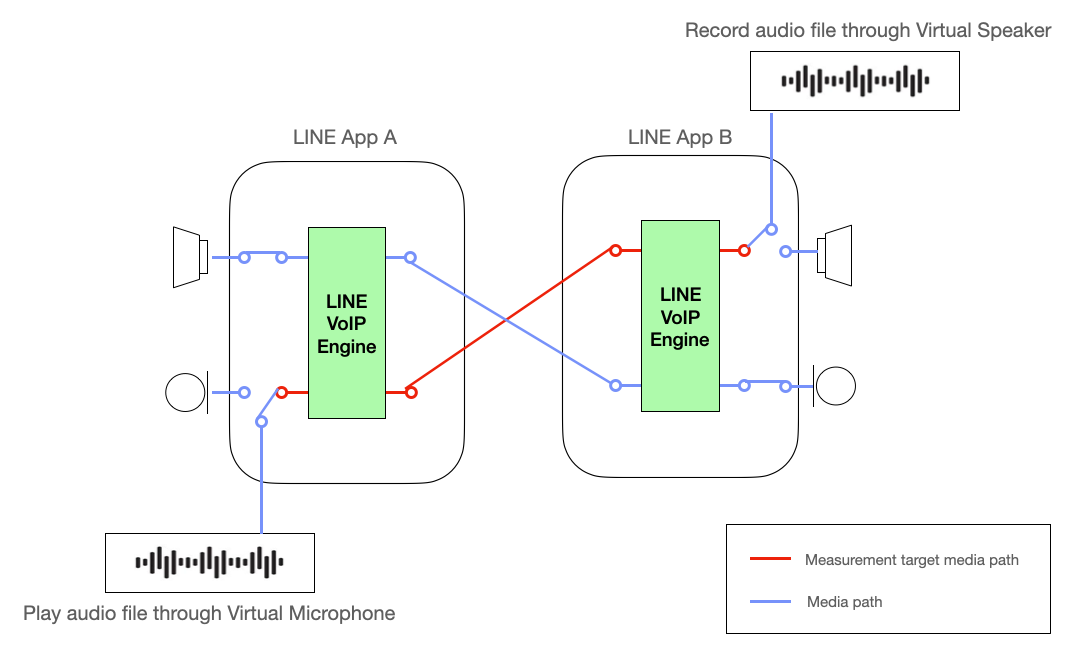
저희는 통화 모듈의 주파수 응답을 정확하게 측정하기 위해 가상의 오디오 장치를 사용합니다. 이는 주파수 측정 시 오디오 장치의 영향을 최소화하기 위한 것인데요. 가상 오디오 장치는 오디오 신호의 왜곡 없이 입출력할 수 있어서 LINE 통화 모듈만의 특성을 정확하게 측정할 수 있습니다.
아래 그림에서 빨간색 선은 주파수 응답 측정의 대상 경로를 나타냅니다. 가상 오디오 장치를 사용함으로써 주파수 응답 측정 결과에서 오디오 장치의 영향을 배제하고 통화 모듈만의 특성을 정확하게 측정할 수 있습니다. 이를 통해 통화 모듈의 주파수 응답을 정확하게 분석하고 품질을 향상시키는 데 필요한 정보를 효과적으로 얻을 수 있습니다.
주파수 응답 측정 절차
LINE 앱 통화 모듈의 주파수 응답 측정은 아래 절차를 따릅니다.
테스트 신호 선택
측정하고자 하는 오디오 시스템에 목적에 맞는 테스트 신호를 선택합니다. 이 테스트 신호의 주파수 대역은 일반적으로 20Hz~20kHz까지의 가청 주파수 범위의 신호를 갖는 음성 신호로 구성됩니다. 테스트 신호를 음성 신호로 구성하는 이유는 통화 모듈이 음성 이외의 신호를 주로 잡음으로 간주하고 제거할 수 있기 때문입니다.
테스트 신호는 IEEE에서 제공하는 통신 장치의 전기 음향 성능 평가 표준(IEEE 269-2010) 신호를 사용합니다. 아래 링크는 이런 측정에 사용하는 테스트 신호입니다.
- 미디어 파일 다운로드
- IEEE_269-2010_Male_mono_48_kHz.wav: 초기 안정화용 음원
- IEEE_269-2010_Male_mono_48_kHz.wav, IEEE_Female_mono_48_kHz.wav: 주파수 응답 측정용 음원
측정 시스템 환경 구성 1 - 측정 환경 구성
주파수 응답을 측정하기 위한 시스템 환경을 구성합니다.
- Adobe Audition: 테스트 신호를 재생하고, 측정 대상 오디오 시스템의 출력 신호를 녹음하는 S/W입니다.
- VB-AUDIO: 가상 오디오 장치로 오디오 신호의 왜곡 없이 마이크 입력과 스피커 출력을 할 수 있는 S/W입니다. 설치 후 가상 마이크/스피커 장치인 VB-Cable을 사용할 수 있습니다.
- 주파수 응답 측정 툴: 측정용 신호와 출력 신호, 두 개의 wav 파일을 입력받아 주파수 응답을 그려주는 코드입니다.
주파수 응답을 그려주는 코드
import sys import warnings import numpy as np import matplotlib.pyplot as plt import scipy.io.wavfile as wf from scipy.io.wavfile import WavFileWarning from numpy import ComplexWarning from scipy.interpolate import make_interp_spline # Calculate the center frequencies of 1/12 octave bands. def calculate_octave_bands(start_freq, end_freq): bands = [] while start_freq <= end_freq: bands.append(start_freq) start_freq *= 2**(1/12) # Increase by 1/12 octave. return bands # Ignore the WavFileWarning warnings.filterwarnings("ignore", category=WavFileWarning) warnings.filterwarnings("ignore", category=ComplexWarning) if len(sys.argv) != 3: print("Usage: python script.py <ref_audio_file.wav> <deg_audio_file.wav>") sys.exit(1) ref_fs, ref_audio_data = wf.read(sys.argv[1]) # Load the reference audio file deg_fs, deg_audio_data = wf.read(sys.argv[2]) # Load the degraded audio file # Check if sample rates are different if ref_fs != deg_fs: print("Error: Sample rates are different. Cannot process audio files with different sample rates.") exit() # Check if sample types are different if ref_audio_data.dtype != deg_audio_data.dtype: print("Error: Sample rates are different. Cannot process audio files with different sample types.") exit() # Check the audio sample type if ref_audio_data.dtype == np.float32: kMaxSample = 1.0 else: kMaxSample = 32768 # For int16, 0 dBFS is 32678 with an int16 signal kNfft = 32768 win = np.hamming(kNfft) num_segments = min(len(ref_audio_data), len(deg_audio_data)) // kNfft ref_audio = np.zeros((kNfft, num_segments)) deg_audio = np.zeros((kNfft, num_segments)) # Take a slice and multiply by a window for i in range(num_segments): ref_audio[:, i] = ref_audio_data[i * kNfft : (i + 1) * kNfft] * win deg_audio[:, i] = deg_audio_data[i * kNfft : (i + 1) * kNfft] * win # Initialize arrays to store spectral data for each frame num_frames = ref_audio.shape[1] ref_audio_sp = np.zeros((kNfft // 2 + 1, num_frames)) ref_audio_s_mag = np.zeros((kNfft // 2 + 1, num_frames)) deg_audio_sp = np.zeros((kNfft // 2 + 1, num_frames)) deg_audio_s_mag = np.zeros((kNfft // 2 + 1, num_frames)) # Process each frame for i in range(num_frames): ref_audio_sp[:, i] = np.fft.rfft(ref_audio[:, i]) # Calculate real FFT for each frame ref_audio_s_mag[:, i] = np.abs(ref_audio_sp[:, i]) * 2 / np.sum(win) # Scale the magnitude of FFT for each frame deg_audio_sp[:, i] = np.fft.rfft(deg_audio[:, i]) # Calculate real FFT for each frame deg_audio_s_mag[:, i] = np.abs(deg_audio_sp[:, i]) * 2 / np.sum(win) # Scale the magnitude of FFT for each frame avg_ref_audio_s_mag = np.mean(ref_audio_s_mag, axis=1) avg_deg_audio_s_mag = np.mean(deg_audio_s_mag, axis=1) f_axis = np.linspace(0, ref_fs/2, len (avg_ref_audio_s_mag)) center_frequencies = calculate_octave_bands(60, ref_fs / 2) # Aggregate the spectral data in the frequency domain into 1/12 octave bands. ref_band_spectra = [] deg_band_spectra = [] for center_freq in center_frequencies: lower = center_freq / (2**(1/24)) # Lower frequency limit of the band. upper = center_freq * (2**(1/24)) # Upper frequency limit of the band. indices = np.where((f_axis >= lower) & (f_axis <= upper)) ref_band_spectrum = np.mean(avg_ref_audio_s_mag[indices]) ref_band_spectra.append(ref_band_spectrum) deg_band_spectrum = np.mean(avg_deg_audio_s_mag[indices]) deg_band_spectra.append(deg_band_spectrum) ref_band_spectra=np.array(ref_band_spectra) ref_band_spectra=20 * np.log10(ref_band_spectra / kMaxSample) # Convert to dBFS deg_band_spectra=np.array(deg_band_spectra) deg_band_spectra=20 * np.log10(deg_band_spectra / kMaxSample) # Convert to dBFS diff_spectrum=deg_band_spectra-ref_band_spectra #smoothing center_frequencies_smooth = np.logspace(np.log10(min(center_frequencies)), np.log10(max(center_frequencies)), 1000) spline_ref = make_interp_spline(center_frequencies, ref_band_spectra, k=3) spline_deg = make_interp_spline(center_frequencies, deg_band_spectra, k=3) spline_diff = make_interp_spline(center_frequencies, diff_spectrum, k=3) ref_band_spectra_smooth = spline_ref(center_frequencies_smooth) deg_band_spectra_smooth = spline_deg(center_frequencies_smooth) diff_spectrum_smooth = spline_diff(center_frequencies_smooth) plt.semilogx(center_frequencies_smooth, ref_band_spectra_smooth, label='Input', color='cornflowerblue') plt.semilogx(center_frequencies_smooth, deg_band_spectra_smooth, label='Output', color='orange') plt.semilogx(center_frequencies_smooth, diff_spectrum_smooth, label='Output-Input', color='limegreen') # Add a green target line at 0dB plt.axhline(y=0, color='green', linestyle='-', label='Target') plt.xlabel('Frequency [Hz]') plt.ylabel('Magnitude [dB]') plt.legend() plt.grid(which='both', axis='both') frequency_labels = [50, 100, 200, 500, 1000, 2000, 5000, 10000, 20000] plt.xticks(frequency_labels, [str(label) for label in frequency_labels]) plt.ylim(-130, 20) plt.show()
측정 시스템 환경 구성 2 - 측정 오디오 시스템 연결
LINE 음성 통화의 주파수 응답을 측정하기 위해 A, B 두 대의 장치를 사용합니다.
- A, B 장치 공통 설정: VB-Cable의 입/출력 샘플링 레이트 설정을 48kHz로 설정합니다. 이는 최대 24kHz까지의 신호를 표현할 수 있기 때문에 인간의 청각 주파수를 모두 커버할 수 있습니다.
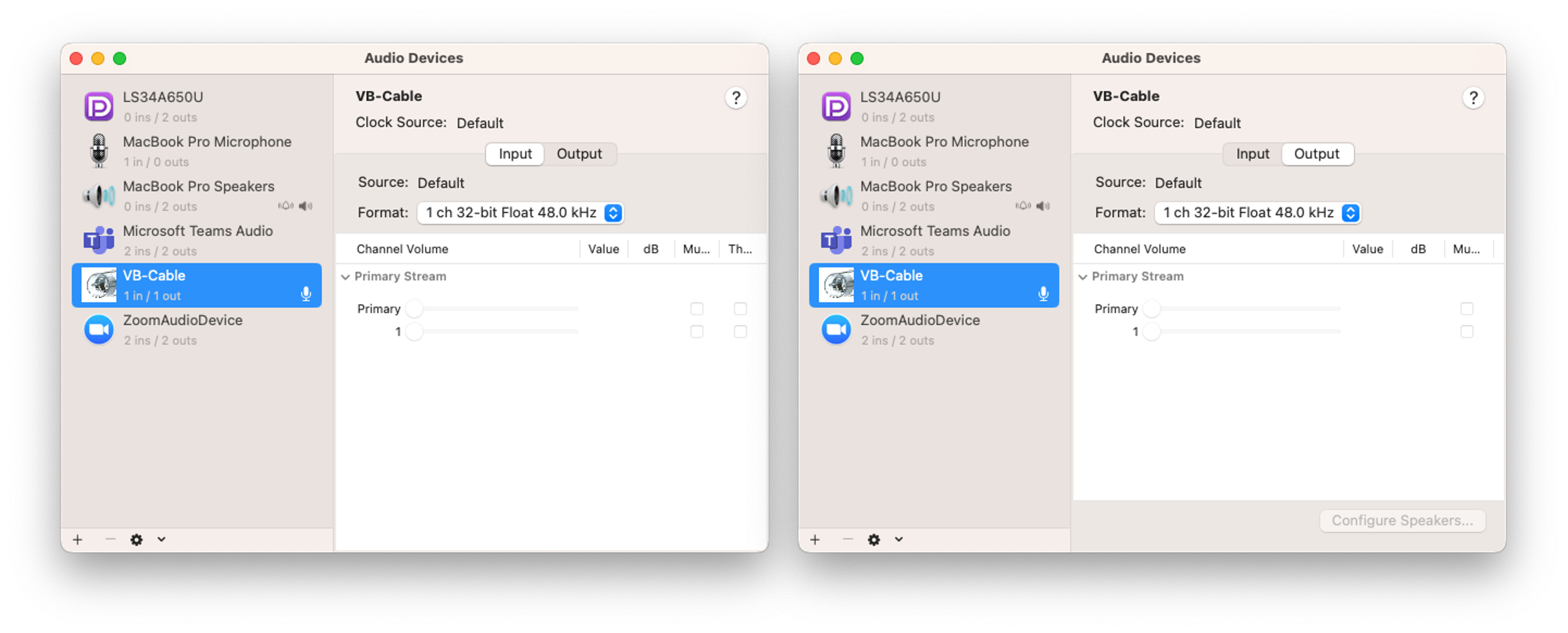
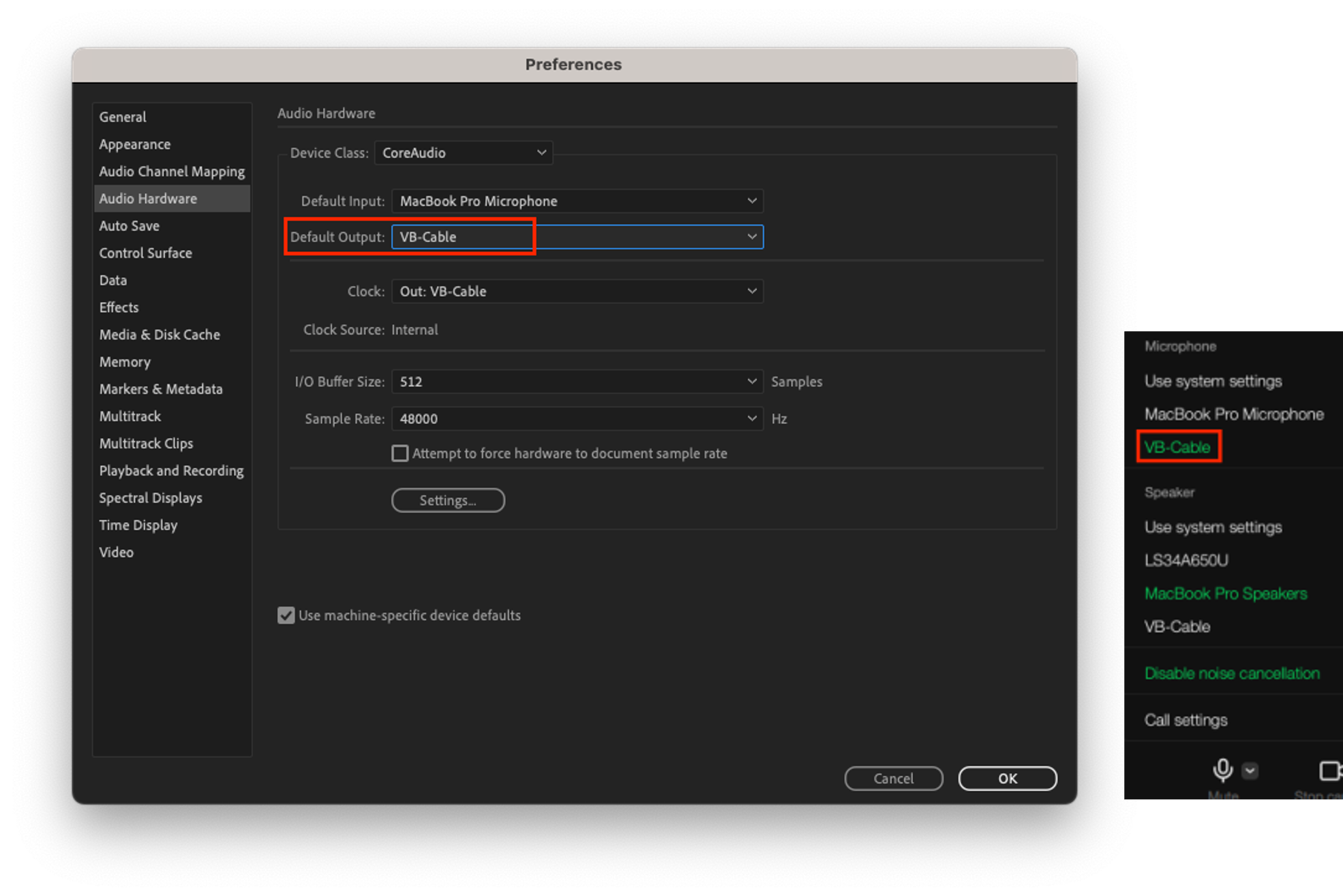
- A 장치에서는 Adobe Audition의 스피커 출력을 VB-Cable로 설정하고, LINE 앱의 마이크를 VB-Cable로 설정합니다. Adobe Audition에서 재생한 오디오가 VB-Cable을 통해 LINE 앱의 마이크 입력으로 전달됩니다.
- B 장치에서는 LINE 앱의 스피커 장치를 VB-Cable로 설정하고, Adobe Audition의 마이크 입력을 VB-Cable로 설정합니다. LINE 앱의 스피커 출력이 VB-Cable을 통해 Adobe Audition의 오디오 입력으로 전달됩니다.
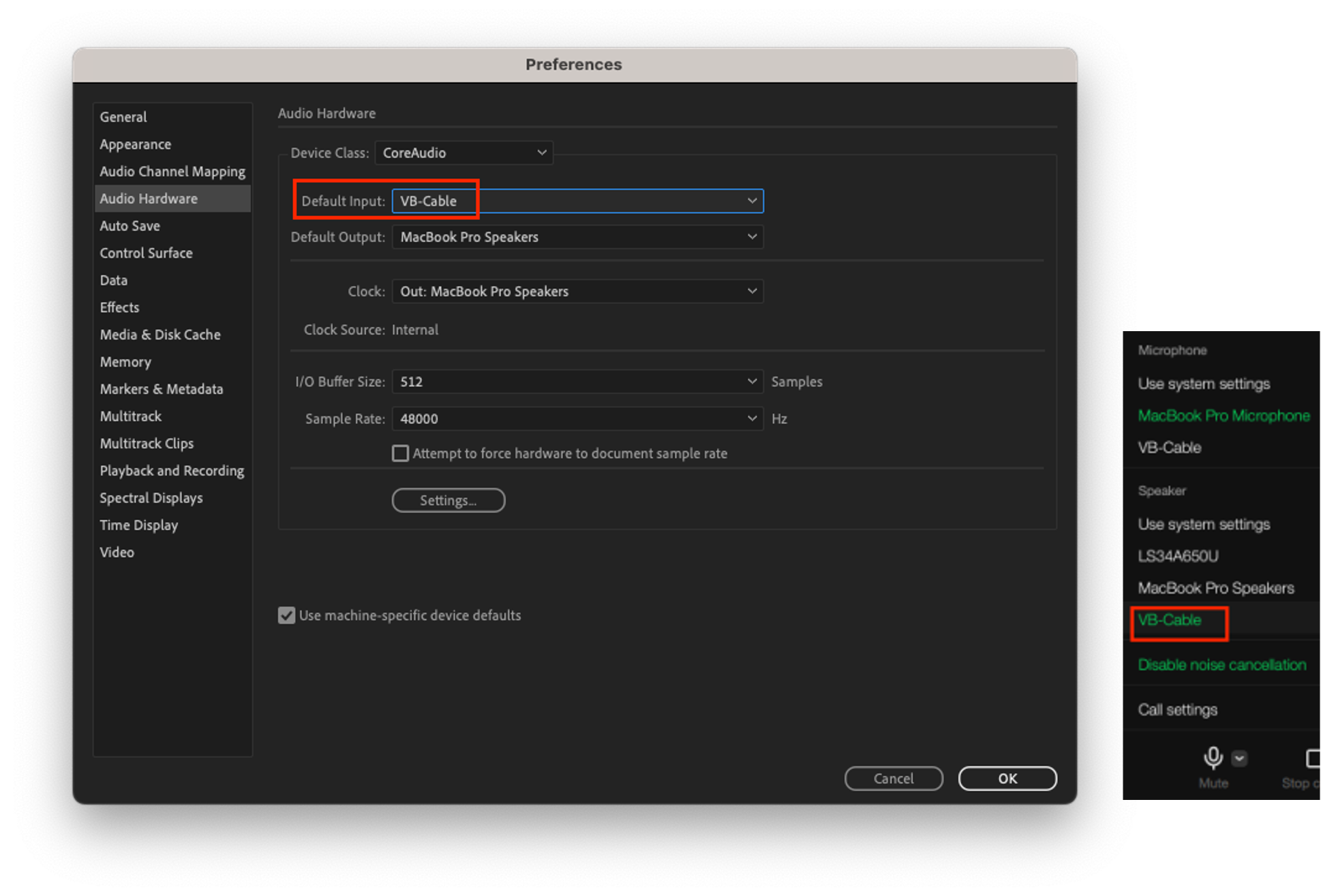
신호 검증 및 주파수 응답 측정
- 안정화 신호 재생
LINE 앱 음성 통화를 연결하고, A의 Adobe Audition에서는 안정화 신호인 IEEE_269-2010_Male_mono_48_kHz.wav를 15초 이상 재생합니다. 이 단계는 안정화 신호가 재생되는 동안 음성 통화 모듈이 적응하는 시간을 확보하기 위한 것입니다. - 시스템 출력 신호 녹음
통화 시스템의 출력을 기록하기 위해 B의 Adobe Audition에서 녹음을 시작합니다. 이때 녹음되는 파일의 샘플링 레이트는 48kHz를 사용합니다. - 측정용 신호 재생
A의 Adobe Audition에서 측정용 신호를 재생합니다. 측정용 신호는 IEEE_269-2010_Male_mono_48_kHz.wav와 IEEE_Female_mono_48_kHz.wav, 두 개의 음원을 사용합니다. 각 음원에는 총 네 개의 문장이 포함돼 있으며, 재생 시 여성, 남성 순으로 한 문장씩 번갈아 가면서 재생합니다. - 시스템 출력 신호 검증
모든 문장 재생이 완료되면 B 녹음을 멈춥니다. 측정용 신호가 A의 전송단과 B의 수신단을 거쳐 B에서 녹음됐습니다. 이제 녹음된 오디오 파일에는 LINE 앱 오디오 시스템의 주파수 응답 특성이 반영돼 있습니다. - 음량 조정(이 단계는 필요 시 진행)
LINE 앱은 사용자에게 균일한 음량을 제공하기 위해 큰 음성은 크기를 줄이고, 작은 음성은 크기를 키우는 등의 음량 조절을 수행합니다. 이로 인해 원음과 출력 음량 간의 차이가 발생할 수 있습니다. 이런 음량 차이는 주파수 응답 분석 시 의도하지 않은 해석 오류를 유발할 수 있으므로 주파수 응답을 측정하기 전에 A의 오디오 재생 볼륨을 조절해 출력 음량을 유사하게 조정하는 단계를 선택적으로 진행할 수 있습니다. A의 오디오 재생 볼륨을 변경했다면 1단계부터 다시 수행합니다. 만약, 주파수 응답 측정 과정에서 볼륨 조정 단계를 수행했다면 측정 결과에는 반드시 재생 볼륨 조정량을 명시해야 합니다. - 주파수 응답 측정
주파수 응답 분석 툴에 측정용 신호(3단계)와 시스템 출력 신호(4단계)를 입력해 주파수 응답 그래프를 작성합니다. 만약 5단계에서 음량 조정 과정을 수행했다면, 5단계에서 조정한 음��량을 측정용 신호(3단계)에 반영해 주파수 응답 분석 툴에 입력합니다. 주파수 대역은 핸드셋과 헤드셋에서 사용하는 1/12 옥타브 대역으로 측정됩니다.
손실 강건성(loss robustness) 측정
실시간 커뮤니케이션 서비스에서는 패킷 손실(loss)에 강건한(robust) 메커니즘을 구현해야 좋은 음성 품질과 안정적인 서비스를 제공할 수 있는데요. 먼저 패킷 손실이 발생하는 이유와 이에 어떻게 대처하는지 살펴보고 LINE 앱에서 손실 강건성을 측정하는 방법을 알아보겠습니다.
패킷 손실과 음성 품질
앞서 말씀드렸던 것처럼 실시간 커뮤니케이션 서비스에서는 인터넷 프로토콜을 통해 실시간으로 음성 데이터를 전송합니다. 이런 서비스는 실시간성이 중요하기 때문에 지연 시간을 줄이기 위해 TCP(Transmission Control Protocol)가 아니라 UDP(User Datagram Protocol)를 사용합니다.
TCP는 신뢰성 있는 데이터 전송을 위해 모든 데이터 패킷을 확인하고 재전송하므로 패킷 손실이 발생하면 지연 시간이 늘어납니다. 따라서 실시간 커뮤니케이션 서비스에서는 사용자 경험이 저하될 수 있습니다. 이에 반해 UDP는 TCP와 같은 확인 및 재전송 과정이 없으므로 실시간 통신에 적합합니다. 그러나 UDP에서는 데이터 패킷 전송이 보장되지 않으며, TCP와 같은 흐름 제어나 오류 복구 기능이 없습니다. 따라서 네트워크를 통해 전송한 데이터 패킷이 손실되면서 음성이 손실되는 문제가 발생할 수 있습니다.
패킷 손실 발생 원인과 영향
패킷은 여러 가지 원인으로 손실될 수 있습니다. 네트워크 혼잡으로 손실될 수도 있고, 네트워크 대역폭이 ��한계에 도달하거나 과도하게 많은 데이터가 동시에 전송되는 경우 라우터나 스위치에서 패킷을 처리하지 못해 일부 패킷이 손실될 수도 있습니다. 또한 무선 네트워크에서는 신호 간섭이나 갑작스러운 신호 약화, 건물 내 장애물 등으로 패킷이 손실될 수 있습니다.
그렇다면 패킷이 손실되면 음성 품질에 어떤 영향을 줄까요?
실시간 커뮤니케이션 서비스에서는 마이크의 음성 신호를 코덱으로 압축하며, 압축된 데이터를 패킷에 실어 인터넷을 통해 수십 ms 간격마다 전송합니다. 음성 데이터 패킷이 손실된다는 것은 해당 구간의 음성이 손실된다는 것을 의미합니다. 화상 회의 혹은 일상 통화에서 상대방의 음성이 끊기거나 잘 알아들을 수 없게 되기 때문에 커뮤니케이션에 지장이 생길 수 있습니다.

음성 손실 복구 기술
그렇다면 패킷 손실로 발생하는 음성 손실은 어떻게 복구할 수 있을까요? 현재 업계에서는 패킷 손실을 복구하기 위해서 다양한 기술과 메커니즘을 사용하고 있으며, 대표적으로 다음 기술들이 있습니다.
- 패킷 손실 은닉(packet loss concealment, 이하 PLC)
PLC는 패킷이 손실된 구간에 누락된 음성 데이터를 보간하는 기술입니다. 이를 통해 패킷 손실에 따른 음질 저하를 완화하고 사용자 경험을 향상시킵니다. 손실 복구를 위한 추가 데이터가 발생하지 않고 적은 손실에 효과적이지만, 패킷 손실이 커질수록 효과가 떨어집니다. - 순방향 오류 수정(forward error correction, 이하 FEC)
FEC는 오류 정정 코드를 추가해 데이터 패킷 손실을 복구하는 방법입니다. 송신 측에서 원래의 소스 패킷과 함께 일부 복구 정보도 함께 전송하며, 수신 측은 이 복구 정보를 사용해 손실된 소스 패킷을 복구합니다. 재전송보다는 지연 시간이 짧지만, 미리 복구 정보를 보내야 하므로 데이터 사용량이 증가하는 단점이 있습니다. - 패킷 재전송(packet retransmission)
패킷이 손실된 경우 수신 측에서 손실된 패킷을 송신 측으로 다시 요청해 복구하는 방법입니다. 손실 요청부터 다시 전달되기까지 소요되는 시간 때문에 상당한 지연을 발생시킬 수 있는 문제가 있습니다.
LINE 앱에서 사용하는 음성 손실 복구 기술
위와 같이 패킷 손실 복구 기술들은 각각 장단점이 있기 때문에 LINE 앱에서는 네트워크 상황에 따라 위 기술을 적절히 사용해 패킷 손실을 복구하고 있습니다.
송신 측
LINE 앱에서는 기본적으로 RFC 8627을 응용한 2-D FEC Protection 기술을 이용합니다.
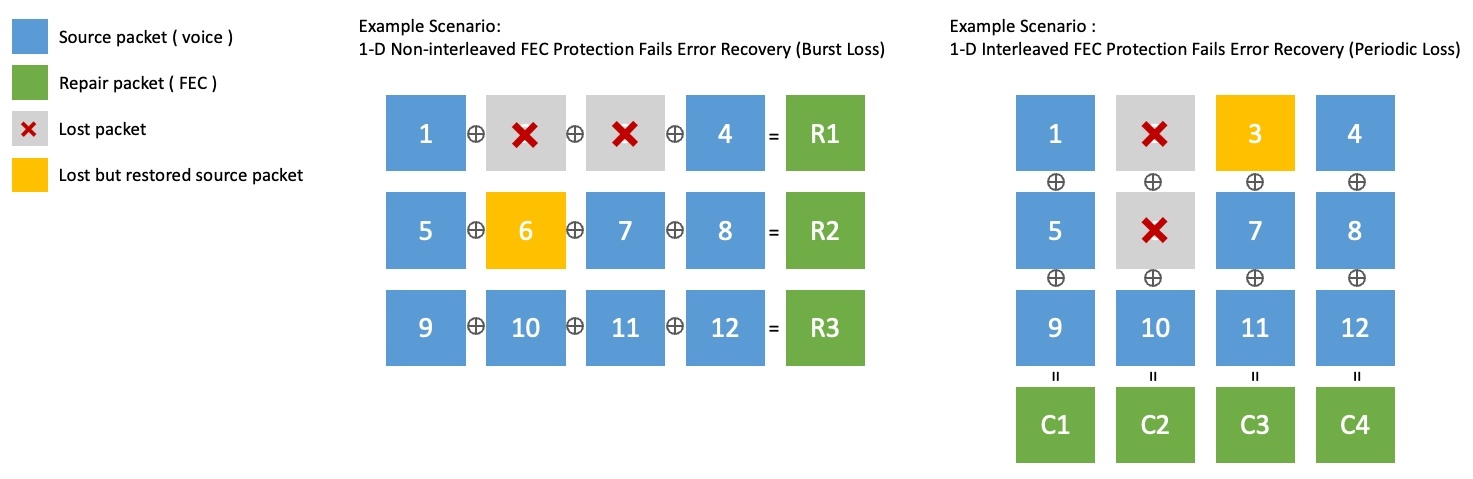
단일 차원의 FEC는 소스 패킷의 그룹을 행 단위로(1-D Non-interleaved), 혹은 열 단위로(1-D Interleaved) XOR 연산해 복구 패킷을 생성하는데요. 둘 이상의 연속된 패킷 손실은 복구할 수 없다는 한계가 있습니다. 아래 그림은 이와 같은 한계를 보여주는 예시입니다.
- 아래 그림 왼쪽 1-D Non-interleaved에서는 6번 패킷을 복구했으나 2, 3번의 연속된 패킷 손실은 복구할 수 없습니다.
- 아래 그림 오른쪽 1-D Interleaved에서는 3번 패킷을 복구했으나, 2, 6번의 연속된 패킷 손실은 복구할 수 없습니다.
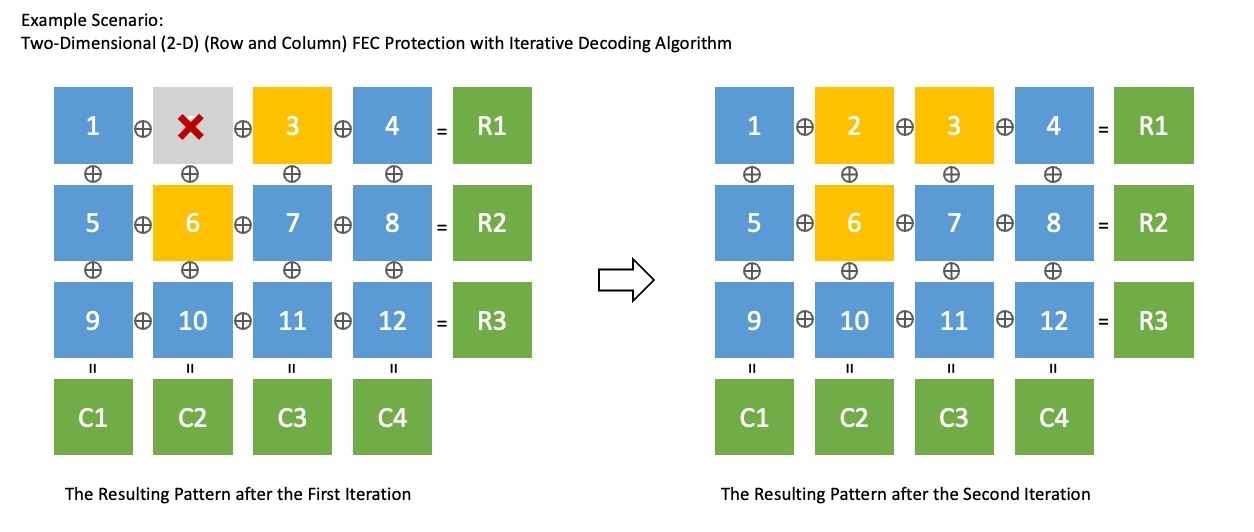
 2-D FEC Protection은 단일 차원의 Interleaved FEC와 non-interleaved FEC를 혼합한 기술입니다. 다양한 손실 패턴에 대응할 수 있고, 반복 디코딩 알고리즘(iterative decoding algorithm)으로 일반적인 FEC보다 효과적으로 손실을 복구할 수 있습니다. 아래 그림은 위와 동일한 상황에서 2-D FEC Protection을 사용해 두 번 반복으로 패킷을 모두 복구하는 예시입니다.
2-D FEC Protection은 단일 차원의 Interleaved FEC와 non-interleaved FEC를 혼합한 기술입니다. 다양한 손실 패턴에 대응할 수 있고, 반복 디코딩 알고리즘(iterative decoding algorithm)으로 일반적인 FEC보다 효과적으로 손실을 복구할 수 있습니다. 아래 그림은 위와 동일한 상황에서 2-D FEC Protection을 사용해 두 번 반복으로 패킷을 모두 복구하는 예시입니다.
하지만 패킷 손실률이 매우 높아지면 2-D FEC Protection으로도 충분하지 않을 수 있습니다. 이런 상황에서는 동일한 원본 패킷을 주기적으로 두 번 이상 재전송하는 기법을 사용합니다. 송신 측은 패킷 손실률을 실시간으로 모니터링해 2-D FEC Protection을 사용할지 주기적인 재전송 기법을 사용할지 결정합니다.
수신 측
수신 측에서는 송신 측에서 전송한 복구 정보들을 이용해 손실 패킷을 복구하는데요. 그럼에도 손실이 있다면 손실된 패킷 재전송을 요청합니다. 재전송은 지연을 발생시키므로 네트워크 레이턴시(network latency)가 높은 환경에서는 작동하지 않도록 제한하고 있습니다. 마지막으로 실시간 패킷 손실 복구가 되지 않은 음성 구간에 대해서는 PLC로 음질 저하를 완화합니다.
음성 품질을 객관적으로 평가하는 방법
먼저 패킷 손실에 적절히 대응해 음성 품질을 잘 보장하고 있는지를 어떻게 평가하는지 알아보겠�습니다. 이를 위해선 먼저 음성 품질을 정량적이고 객관적으로 평가할 수 있어야 하고, 단방향 지연을 측정해야 하며, 데이터 사용량이 적절한지 확인해야 합니다. 하나씩 살펴보겠습니다.
음성 품질 평가
MOS와 주관적 음성 품질 평가
MOS(mean opinion score)는 음성 통화나 음성 기반 서비스의 음성 품질을 평가하는 데 사용하는 가장 일반적인 척도입니다. 1부터 5까지의 척도로 표현하며, 숫자가 높을수록 음성 품질이 좋다고 판단합니다. 이 방법은 실제 음성 신호를 사람들이 들어보고 느껴지는 음질을 주관적으로 평가하는 주관적 음질 측정 방식에서 유래했습니다.
음성 품질에 대한 주관 평가는 ITU-T P.800 권고안을 주로 사용합니다. 이 권고안에서는 주관 평가 시의 환경에 대해서도 엄격하게 규정하고 있는데요. 예를 들어 평가 문장의 녹음과 청취를 위한 공간의 환경은, 공간은 30~120m3, 잔향 시간은 500ms 이하(최적 200~300ms), 실내 소음은 스펙트럼에 피크가 없는 30dBA 이하인 곳이어야 합니다. 또한 평가 참가자는 최근 6개월간 어떠한 주관 평가도 참여하지 않았어야 하며, 특히 청취 주관 평가에는 최근 1년간 참여하지 않았어야 합니다. 이외에도 평가 조건이나 환경에서 생길 수 있는 편차를 제거하기 위한 다양한 조건들이 제시돼 있습니다. 따라서 주관적인 음성 품질 평가는 많은 비용과 시간이 소요될 수밖에 없다는 문제가 있습니다.
객관적 음성 품질 평가와 POLQA
주관적 음성 품질 평가의 문제를 해결하기 위해 음성 품질을 객관적으로 평가할 수 있�는 방법이 필요했습니다. 이를 위해 원 음성 신호와 비교해 주관적 음질 측정 결과와 유사한 평가를 할 수 있는 여러 음성 품질 평가 알고리즘이 개발됐습니다.
여러 알고리즘 중 현재 널리 사용하는 글로벌 표준 알고리즘은 POLQA(Perceptual Objective Listening Quality Analysis)입니다. ITU-T(International Telecommunication Union - Telecommunication Standardization Sector)에서 표준화한 이 알고리즘은 음성 서비스와 코덱의 품질을 평가하는 데 널리 사용하고 있습니다. POLQA는 음성 품질 평가를 수행할 때 인간의 청지각 체계를 모방해 음질을 평가하며, 네트워크 전송과 음성 코덱 압축, 패킷 손실, 지연 등과 같은 네트워크 환경의 변화에 따른 음질 손실을 평가할 수 있습니다.
POLQA에서도 주관적 평가와 마찬가지로 음성 품질 평가 척도로 MOS를 사용합니다. 이를 통해 음성 통화와 음성 서비스의 품질을 객관적으로 측정하고 비교할 수 있습니다. 아래는 실제 음원을 POLQA로 평가한 MOS 점수 샘플입니다. POLQA MOS 점수별 실제 음성 품질을 체감할 수 있습니다.
| POLQA MOS | 샘플 오디오 |
|---|---|
| 원본 | |
| 4.5 | |
| 3.5 | |
| 2.5 | |
| 1.5 |
단방향 지연 평가
음성의 품질이 좋다고 하더라도 음성이 전달되는 단방향 지연이 크다면 양방향 커뮤니케이션은 불편할 수밖에 없습니다. 단방향 지연은 VoIP나 전화 통화와 같은 통신 서비스에서 중요한 매개 변수 중 하나로, 음성이 하나의 지점에서 출발해 목적지까지 도착하는 데 걸리는 시간을 의미합니다.
단방향 전송 시간에 대한 표준 권고안인 ITU-T G.114 (05/2003) One-way transmission time에서는 일반적인 네트워크에서 단방향 지연이 400ms를 초과하지 않을 것을 권장하고 있습니다. 다만 일부 예외의 경우에는 이 제한이 초과될 수도 있는데요. 예를 들어 패킷 손실률이 큰 네트워크 환경에서는 단방향 지연이 좀 더 늘어나더라도 패킷 손실 복구를 위한 대기 시간을 둬서 손실이 어느 정도 복구되는 것이 사용자 경험에 더 좋을 것입니다. 따라서 이와 같은 손실 복구 메커니즘이 적절히 제어되고 있는지 단방향 지연을 측정해야 합니다.
데이터 사용량 평��가
최근에는 모바일 네트워크가 발전해 음성 데이터 사용량이 큰 이슈가 되지 않는 경우도 많습니다. 그러나 LINE 앱은 전 세계에서 사용하기 때문에 네트워크 성능이 열악한 경우도 고려할 필요가 있습니다.
패킷 손실을 복구하기 위해서는 데이터를 추가로 사용해야 하는데요. 이로 인해 비트레이트가 증가하면서 오히려 네트워크 혼잡을 유발할 수 있습니다. 특히 비디오와 같이 비트레이트가 높은 미디어라면 더욱 주의해야 합니다. 따라서 데이터 사용량을 측정해서 손실 복구에 사용하는 데이터 사용량이 적절한지 확인해야 합니다.
패킷 손실 환경에서 음성 품질을 측정하는 방법
음성 품질을 객관적으로 평가하는 방법을 확보했으니 이제 패킷이 손실되는 환경에서 어떻게 음성 품질을 측정하는지 살펴보겠습니다.
음성 품질 및 지연 분석
저희는 신뢰할 수 있는 객관적인 음성 품질 측정을 위해 전문적인 음성 품질 분석 장비(voice quality analyzer)를 사용하고 있습니다. DSLA(Digital Speech Level Analyzer)라고 하는 통신 장비 및 네트워크에서의 통화 품질을 측정할 수 있는 장비입니다. DSLA는 원본 음성 신호를 송신 측 단말에 입력으로 주입하고, 수신 측 단말에서 재생되는 음성 신호를 캡처해 원본 음성 신호와 비교 분석합니다. 분석 완료 후 다양한 분석 결과를 제공하는데요. 앞서 말씀드린 POLQA 알고리즘을 이용해 객관적인 결과를 얻을 수 있습니다. 즉, POLQA MOS와 음성 단방향 지연을 측정할 수 있습니다.
패킷 손실 모델 및 에뮬레이션
네트워크에서는 네트워크 혼잡이나 라우터 버퍼 오버플로, 신호 간섭 등을 이유로 다양한 패턴으로 패킷 손실이 발생합니다. 그중 랜덤 패킷 손실(random packet loss)은 가장 일반적인 패킷 손실 패턴으로 패킷이 네트워크에서 무작위로 손실되는 경우입니다. 또한 버스트 패킷 손실(burst packet loss)은 여러 개의 패킷이 연속적으로 손실되는 경우를 말합니다. 이때 버스트 패킷 손실은 모델링 방법도 다양하고, 상태와 그 상태에 따른 확률 등의 다양한 변수가 존재해 모델과 변수에 따라 손실 발생 정도에 차이가 발생합니다. 이에 저희는 성능을 테스트할 때 랜덤 패킷 손실 패턴을 사용하고 있습니다.
또한 저희는 신뢰할 수 있는 정밀한 네트워크 에뮬레이션을 위해 PacketStorm이라는 전문적인 네트워크 에뮬레이터를 사용하고 있습니다. 이 장비를 사용하면 패킷 손실뿐 아니라 지연(delay)이나 지터(jitter), 순서 변경(reordering), 대역폭 제한(throttling) 등 다양한 네트워크 전송 장애(network impairment)에 대해서도 성능을 테스트할 수 있습니다. 만약 랜덤 패킷 손실 패턴만을 에뮬레이션한다면 macOS에서 제공하는 Network Link Conditioner와 같은 다른 툴을 사용할 수도 있습니다.
측정 시나리오
패킷 손실 환경에서 두 단말의 음성 품질을 측정하는 시나리오를 살펴보겠습니다.
측정 환경 구성
먼저 단말 A, B를 음성 품질 분석 장비(DSLA)의 포트와 각각 연결한 다음, 네트워크를 구성합니다. 네트워크 전송 장애를 송신 측의 업링크(up-link)나 수신 측의 다운링크(down-link)에 적용할 수 있습니다.
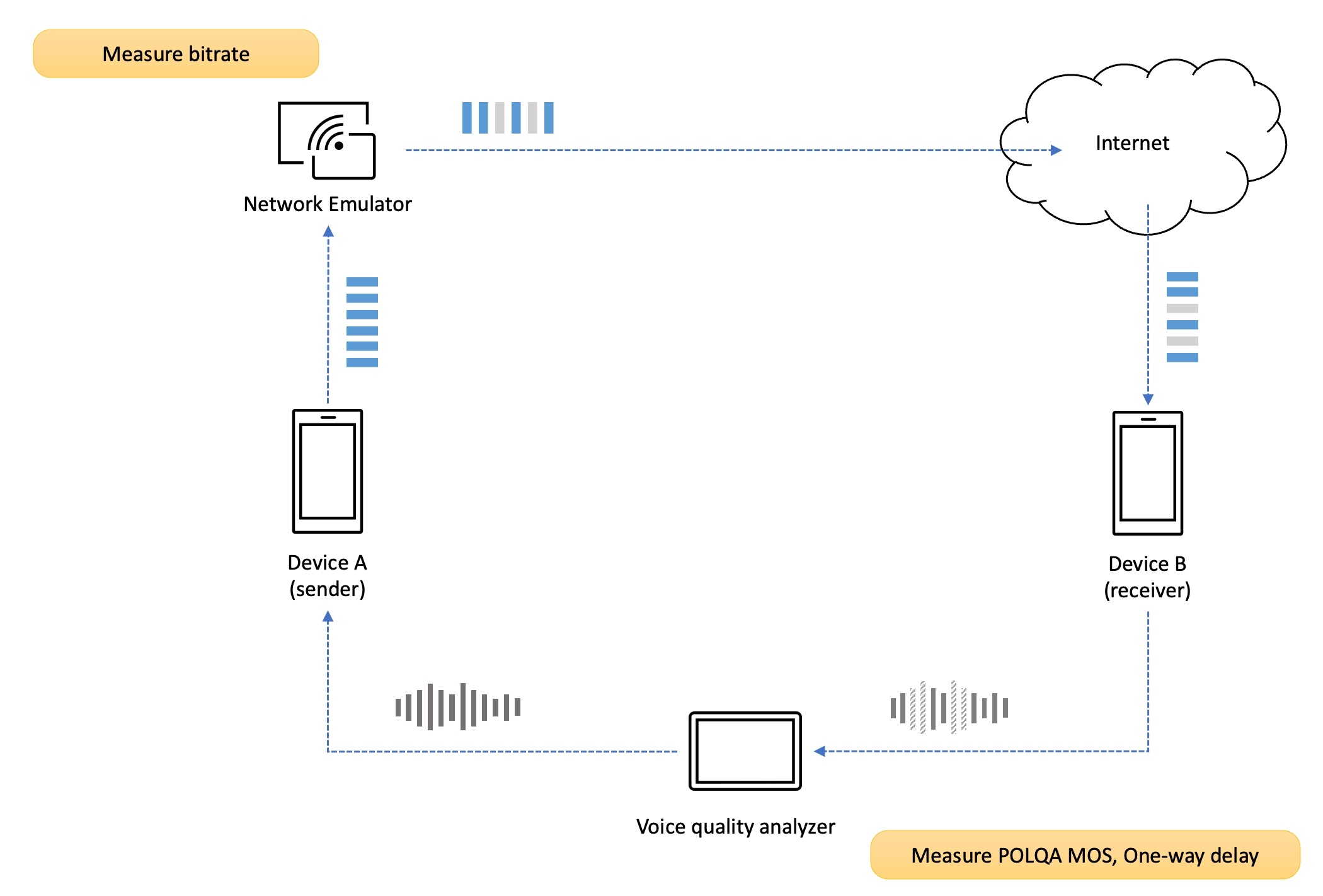
저희는 두 시나리오 모두 측정하며, 위 그림은 송신 측의 업링크에 패킷 손실이라는 전송 장애를 적용한 예시입니다.
통화 연결
다음으로 통화를 연결해야 합니다. LINE 1:1 통화인 경우에는 두 단말에서 서로 통화를 연결하고, LINE 그룹 통화인 경우에는 두 참여자가 같은 그룹에 참여합니다.
측정 및 분석
이제 음성 품질 분석 장비를 이용해 음성 품질 및 음성 지연 측정을 시작합니다. 랜덤 패킷 손실은 항상 동일한 패턴은 아니기 때문에 음성 품질 및 음성 지연의 측정 결과는 매번 달라질 수 있습니다. 동일한 상황에서도 음성 패킷 중 어떤 구간을 손실했느냐에 따라 MOS 값의 차이는 크게 달라집니다. 손실 패킷을 복구하면서 발생하는 지연으로 음성 지연도 차이가 발생할 수 있습니다. 따라서 DSLA 테스트를 반복해 평가 데이터의 신뢰성을 높이는 것이 좋습니다. 저희는 단방향으로 최소 50회 이상 측정해 분석하고 있습니다.
측정 결과 분석
테스트가 끝나면 음성 품질(POLQA MOS)과 음성의 단방향 지연(One-way delay), 데이터 사용량 결과를 수집합니다. 수집한 결과는 다양한 형태로 분석할 수 있습니다. 한 가지 예시로 다음과 같이 손실률에 따라 MOS나 지연 측정 결과의 분포를 비교해 볼 수 있습니다.
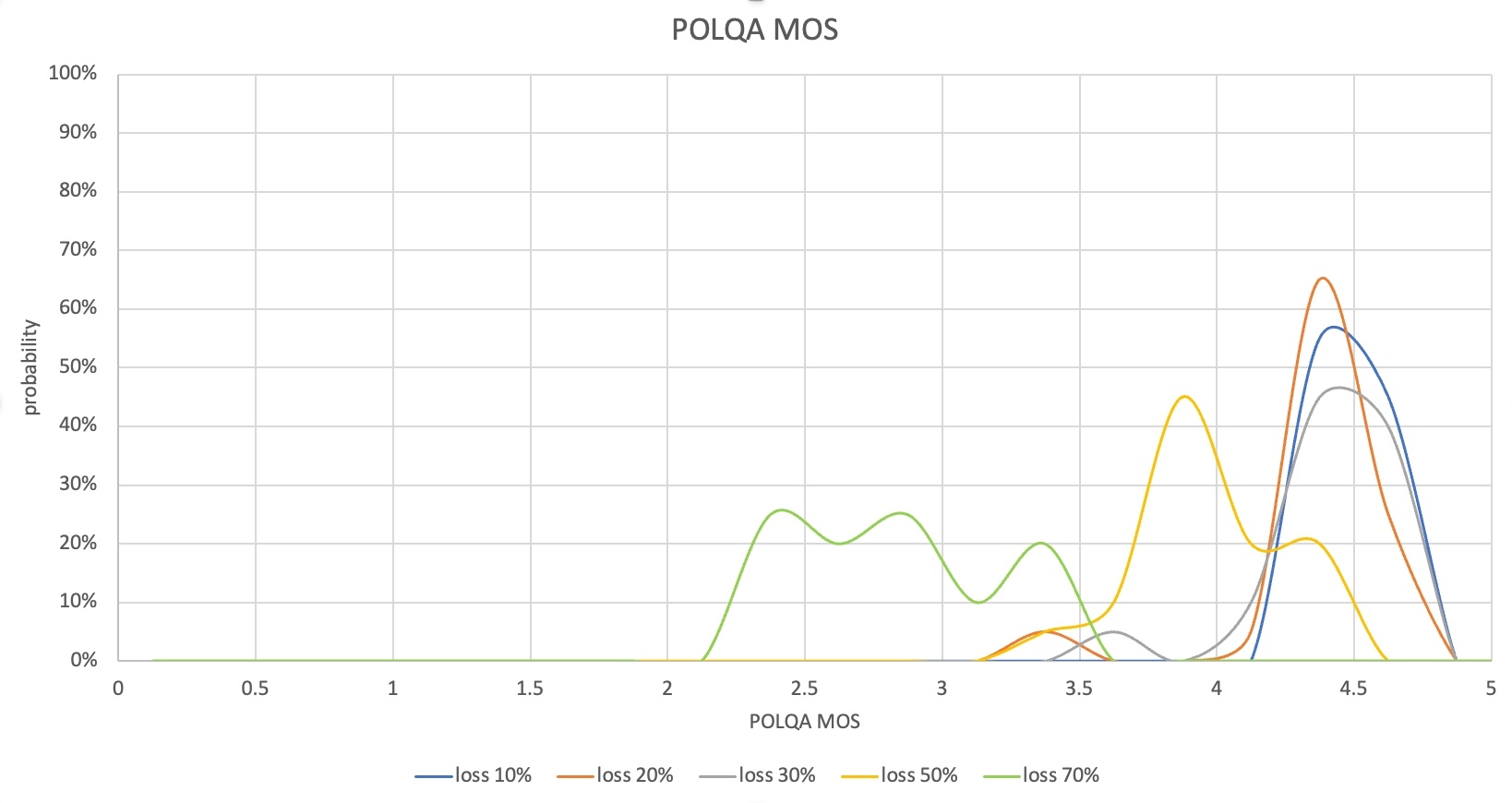
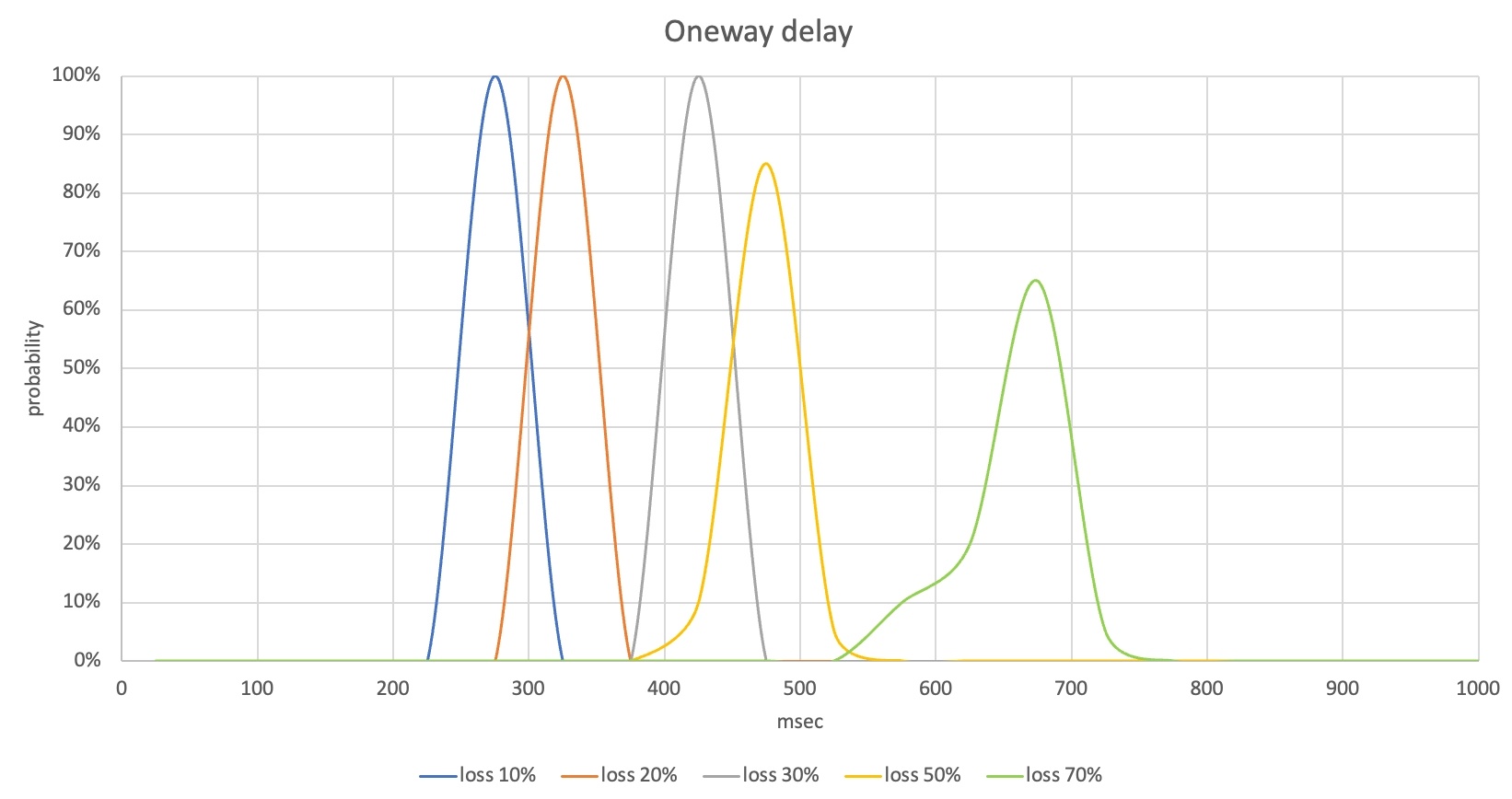
이 경우 손실률 30%까지는 POLQA MOS 분포가 4~4.6으로 대부분의 패킷 손실을 복구한 것으로 볼 수 있습니다. 음성의 단방향 지연도 400ms 초반으로 제어됐기 때문에 서비스에 불편함이 없는 수준입니다. 그런데 손실률 50%부터는 일부 음성 구간이 손실돼 POLQA MOS가 낮아지는 경우가 발생했고, 손실률 70%에서는 MOS가 2점대를 기록한 경우가 많았기 때문에 실제 커뮤니케이션에도 불편을 느끼게 될 것입니다.
이 시나리오의 측정 결과에서는 손실률 50% 이상에서의 손실 복구 성능 개선 및 음성 단방향 지연을 줄일 필요가 있다는 것을 확인할 수 있습니다. 이때 손실 복구를 위해 데이터 사용량이 증가할 수 있으므로 데이터 사용량 측정 결과를 함께 분석해야 합니다.
마치며
이 글에서는 LINE 앱 통화 품질을 어떤 측면에서 측정하고 있는지 살펴보고, 여러 품질 측정 방법 중 AEC와 주파수 응답, 손실 강건성을 측정하는 방법을 자세하게 설명드렸습니다. 기회가 된다면 잡음 제거(noise suppression)를 비롯해 이번에 소개하지 못한 다른 기술과 측정 방법도 공유하려고 합니다.
저희는 LINE 앱 사용자들이 어떤 상황에서도 뛰어난 음성 및 영상 통화 경험을 누릴 수 있도록 글로벌 표준 평가 알고리즘과 전문 장비 및 자체 기술로 다양한 측면에서 음성 및 영상 품질을 측정하고 개선하는 데 노력을 아끼지 않고 있습니다. 사용자가 언제 어디서나 최상의 통화 품질을 경험할 수 있도록 지속적으로 노력하고 개선해 나가겠습니다. 긴 글 읽어주셔서 감사합니다.
