はじめに
LINEアプリで提供するリアルタイムコミュニケーションサービスの1:1通話やグループ通話、LINEミーティングは、インターネットプロトコルを通じてリアルタイムに音声や映像データを送信します。これにより、ユーザーはどこでも便利に音声通話とビデオ通話を利用できます。
リアルタイムコミュニケーションサービスの中核課題は、リアルタイム性と高品質を同時に維持することです。サービス利用中にユーザーが感じる不便や問題点を把握して改善するには、客観的かつ公正な品質測定と評価が不可欠です。この記事では、まず、どのような側面から品質を測定しているかを紹介し、品質測定において代表的な3つの領域であるエコー除去(acoustic echo cancellation、以下AEC)と周波数特性(frequency response)、ロスに対するロバスト性(loss robustness)の測定方法について説明します。
品質測定の側面
私たちは、サービス品質の重要性を認識し、以下のようなさまざまな側面から徹底した品質測定を行っています。
アコースティック環境への対応
アコースティック環境とは、通話者の音響学的な環境を指します。通話者の空間的な特性は、通話品質に影響を与えます。たとえば、周囲が騒がしい場所や響きやすい場所にいると、通話品質が低下し、不便を感じることがあります。私たちは、このようなアコースティック環境での音声処理技術の性能を評価し、技術的な改善を導き出すため、無響室を備え、音声処理技術の性能に影響を与える音響変数を測定しています。
旧LINE Engineeringブログに掲載された「ビデオ会議の際に音声品質を向上する技術(韓国語)」という記事で、音声品質を高めるためのユーザーの通話環境の設定方法について説明していますので、ご参照ください。
アコースティック環境における音響変数には、バックグラウンドノイズと音量レベル、残響レベル、エコーなどがあります。これらの音響変数を性質ごとに定量化します。たとえば、バックグラウンドノイズの場合、周囲のノイズがどれだけ除去されるかを定量化し、エコーの場合、エコーがどれだけ除去されるかを定量化します。
これらの音響変数を測定するための無響室環境も備えています。無響室環境では、音響変数で多様なシミュレ�ーションを行い、実際の環境に近い環境を再現することができます。これにより、内部の音声処理技術が適切に動作しているかどうかを測定できます。たとえば、カフェでの通話環境をシミュレーションするために、カフェで録音したノイズを再生し、そのノイズが音声品質に与える影響を測定します。

ネットワーク環境の変化への対応
ネットワークでは、パケットロスとパケット遅延、帯域幅制限、ネットワーク混雑などの変化が継続的に発生し、このようなネットワーク環境の変化は、リアルタイム通話サービスの品質に非常に大きな影響を与えます。したがって、ユーザーが優れたサービス品質を常に経験できるようにするには、ネットワーク環境の変化がサービス品質に与える影響を測定し、高品質を維持するための技術と戦略を開発する必要があります。そのためには、まず、ネットワーク環境の変化をリアルタイムで正確に分析し、診断する技術が必要です。また、その診断結果に基づいて、ビットレート調整やデータ再送信など、サービス品質を維持するためのさまざまな戦略を行う必要があります。このような活動は、ユーザーが体感する品質に直接影響を与えるため、ネットワーク環境の変化に対応する技術や戦略を定量的に測定することは非常に重要です。
現実のネットワーク環境では、さまざまな形の変化が起こります。この変化を��状況ごとにモデル化してさまざまなシナリオを作成し、各シナリオを模擬実験に適用して現実のネットワーク環境における変化をシミュレーションします。また、そのときの品質(音質、画質、FPS(frames per second、1秒あたりのフレーム数)、データ使用量など)を定量的に測定し、ネットワーク環境の変化や対応策が有効に機能しているかを評価します。
下図は、実際の環境で発生するパケットロスをモデル化したシナリオを模擬実験で再現した例です。

上の例のように、ネットワークエミュレータを用いてパケットロスを発生させることで実際の環境を再現し、パケットロスによる音質低下を定量的に測定します。ネットワークエミュレータはパケットロス以外にもパケット遅延、帯域幅制限などのネットワーク環境の変化をシミュレーションでき、複数のネットワークエミュレータを接続することでさまざまなネットワーク環境の変化を同時にシミュレーションすることもできます。
このような模擬実験を通じてさまざまなネットワーク環境の変化をシミュレーションし、各環境での品質を定量的に測定しております。なお、このような測定を繰り返すことで、技術の信頼性を評価し、改善点を導き出しています。
グローバル環境への対応
LINEアプリは、グローバルサービスとして世界中で利用されています。そのため、グローバルユーザーに継��続的に優れた品質を提供することは、非常に重要です。しかし、各地域の通信ネットワークやインフラには、さまざまなISP(Internet service provider)やネットワークトポロジー、帯域幅割り当て、ネットワーク環境、管理方法が使用されています。また、Wi-Fiインフラや利用パターン、文化も異なり、平日か週末か、地域のイベントなどによってネットワーク環境が変わることもあります。
このような地域差や環境変化に対応するため、世界約15か国に独自開発した品質測定ツールを展開し、各国のネットワーク環境の特性を継続的にモニタリングしています。これにより、国ごと、地域ごとにネットワークの特性と変化を把握し、最適な設定を適用してユーザーに最高のサービス品質を提供しています。
独自開発した品質測定用のH/WとS/Wを搭載した測定ツールは、自動的に通話を行い、音声や映像の品質、遅延、通話接続時間などの各種品質指標を測定します。品質の測定には、POLQA(ITU-T P.863)やPSNR(ITU-T J.340)などの国際標準の指標だけでなく、標準以外でも業界で多く使用されている測定指標も活用しています。

このようなグローバル品質モニ��タリングを通じて、他のサービスと品質を比較分析し、強みと改善点を導き出します。グローバルモニタリングシステムでは、品質測定ツールで測定された指標を集計し、それを総合的なサービス品質評価スコアで表現します。サービス品質評価スコアは下図のように色分けされており、地域ごとに品質レベルが分かりやすくなっています。以下の地図で、緑は円滑なサービスで品質に問題がない地域、グレーは普通の品質の地域、赤は品質が良くないか測定できない地域を表しています。
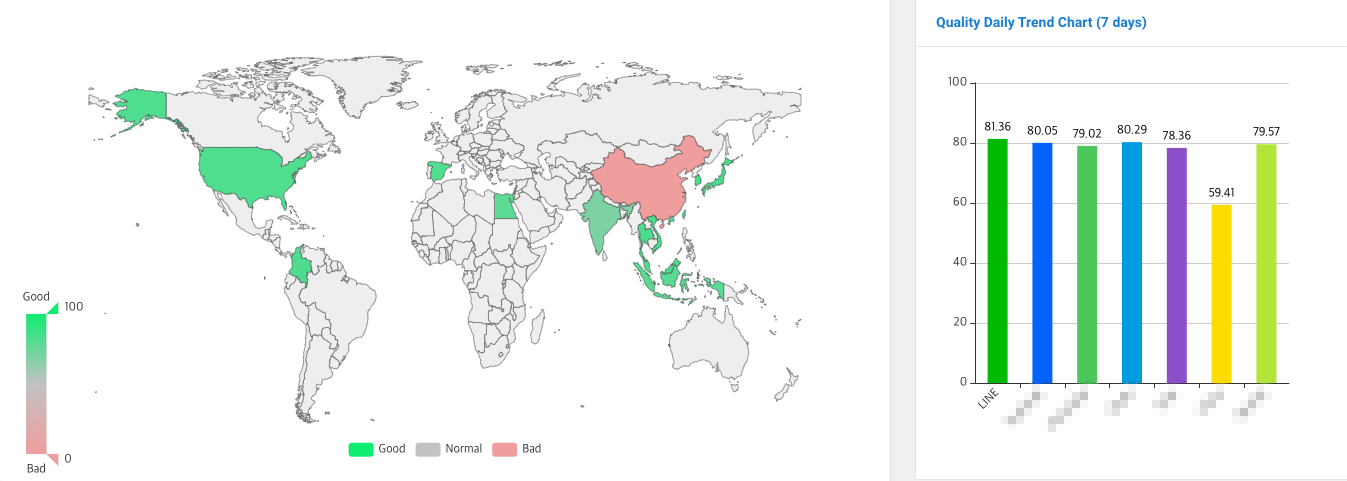
私たちは、このように各国と地域の独自のネットワークや環境を考慮し、品質を改善するための対応策を研究・実施しており、すべての地域で最高のサービス品質を提供するために努力を続けています。
外部テストの依頼
外部テストを依頼して独立した測定も実施しています。外部テストは、第三者の専門家が当社製品の性能を測定し、音声や映像の品質を定量的に分析する重要なプロセスです。
外部テストのプロセスでは、外部テスト業者と測定シナリオを目的に合わせて調整し、テスト環境下での品質変化を正確に把握します。さらに、他サービスとの性能比較を行い、市場での製品競争力を評価するプロセスも含まれます。これにより、中立的な立場で評価結果を受け止め、ユーザーの満足度を高めるための改善点を導き出します。
AECの性能測定
AEC(acoustic echo cancellation)とは、音声通話システムで発生する音響エコーを抑制する技術で、ユーザーの声が通話相手のマイクを通って再び聞こえてくる現象を低減する役割を果たします。以下は、音声通話システムでエコーが発生する例を示した図です。
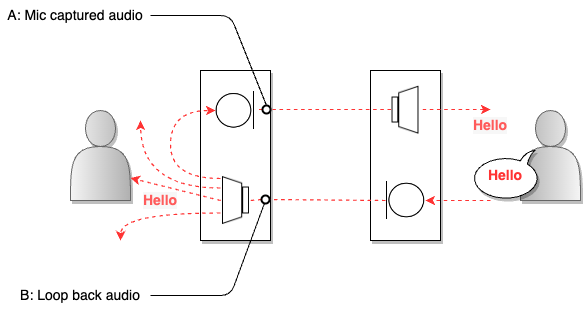
上の図で、右側のユーザーの音(B)が左側のユーザーのスピーカーから出ると、その音もマイクで集音(A)されます。音が何かに反響して返ってくることをエコーといいますが、集音した音を伝えるマイクは、反響の主な発生源といえます。このようにユーザーの声が相手のマイクで集音され、そのままユーザーに返ってくる場合、ユーザーは時間差で再び自分の声を聞くことになります。通話用AECは、このような音響エコーをリアルタイムで検出し、適切にフィルタリングして除去することで、音声通話の品質を向上させます。
私たちは、独自の技術でAECを開発しており、マシンラーニング技術を導入して高品質のエコー除去性能を提供しています。これにより、LINEアプリのユーザーがエコーによる不便を感じることなく、クリアで高音質な音声通話を楽しめるように品質を測定しています。測定方法について本格的に説明する前に、AECの性能測定と性能指標の説明に使う用語の意味を定義しておきます。
- Near-end:通話システムにおいて測定が行われる側にいるユーザーを指します。
- Far-end:Near-endと通話する相手側のユー�ザーを指します。
- Single talk(シングルトーク):Near-endまたはFar-endのどちらか片方だけが話している場合を指します。
- Double talk(ダブルトーク):Near-endとFar-endの両方が話している場合を指します。
AECの性能測定の方法
AECの性能は、音声を劣化させずにエコーを抑制する能力を定量化することで評価し、性能測定は以下の手順に従います。
測定環境の設定
まず、AECの性能を測定するための測定システムの環境を設定します。
品質測定ツールの選定
AECの性能評価や性能改善には、AECMOSを使用しています。AECMOSは、音声を劣化させずにエコーを抑制する能力を客観的な指標で測定するツールです。現在、業界や学界でAECの性能評価に使用されています。新しいアルゴリズムの性能を評価したり、既存の技術と比較したり、あるいは論文や研究報告書で実験結果を分析し、他の研究と比較して研究の有効性を証明する際に使用されています。
AECMOSには以下の3つの測定モードがあります。
- 48kHz、シナリオベースモデル(Run_1668423760_Stage_0.onnx)
- 16kHz、シナリオベースモデル(Run_1663915512_Stage_0.onnx)
- 16kHzモデル(Run_1663829550_Stage_0.onnx)
シナリオベースモデルは、ST FE(Far-end single talk)とST NE(Near-end single talk)、DT(Double talk)区間の情報を知っているため、より正確な��結果を導き出すことができます。こちらでは48kHz、シナリオベースモデルをAECの性能測定に使用しています。
AECMOSには、以下のように4つの詳細指標があります(詳しくは「性能指標の意味」のセクションを参照してください)。
|
指標 |
説明 |
| ST FE Echo DMOS |
Far-end single talkにおけるエコー除去の品質 |
| ST NE MOS |
Near-end single talkにおける音声保存の品質 |
| DT Echo DMOS |
Double talkにおけるエコー除去の品質 |
| DT Other MOS |
Double talkにおける音声保存品質 |
テストデータセットの選定
テストデータセットには、AEC challengeが提供するtest_set_icassp2022データセットを使用します。このデータセットは、DTケース300個、ST FEケース300個、ST NEケース200個の音源を提供しています。
測定対象モジュールの準備
性能��測定の対象となるAECモジュールを準備します。
AECの性能測定
測定環境の設定が完了したら、以下の手順でAECの性能を測定します。
- A(エコーが混じっている元の音声、AECMOSでは「Mic captured audio」と示す)とB(エコーの発生源となる音声、AECMOSでは「Loop back audio」と示す)をAECに入力します。
- シナリオファイルとAEC処理結果のC(エコーが除去された音声、AECMOSでは「Enhanced audio」と示す)とA、BをAECMOSの測定ツールに入力し、ST FE Echo DMOS、ST NE MOS、DT Echo DMOS、DT Other MOSを測定します。
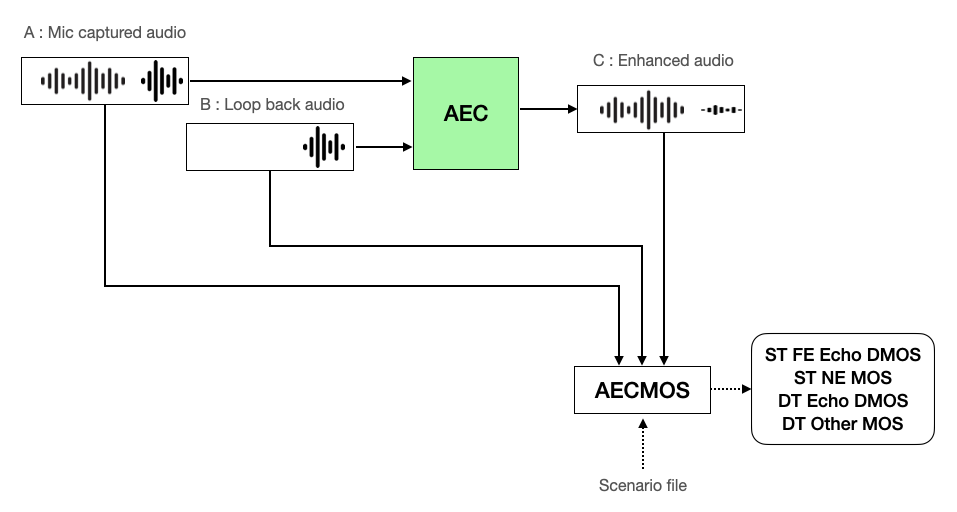
AECの性能評価
AECの性能測定の結果を分析して、どこで差が出たのか、何が改善され、何が足りていないのかを確認し、今後の開発と更新計画を策定します。
AECMOS指標の意味と指標による体感品質の比較
AECMOSで測定した指標の意味を確認し、指標別スコアに対する体感品質を比較してみます。以下では便宜上、Near-endを「私」として説明します。
性能指標の意味
前述のとおり、AECMOSには4つの指標があり、それぞれ以下のような意味を持ちます。
- ST FE Echo DMOS:エコーのみの環境(AにFar-endの音声だけが存在する環境)で、エコー除去後に残っているエコー量に対する尺度です。1~5のスコアで表され、数値が高いほどエコーがよく除去されたことを示します。
- ST NE MOS:Near-endの音声だけが存在し、エコーがない環境(AにNear-endの音声だけが存在する環境、Bの音声の存在有無は重要ではない)で保存された私の音声の品質に対する尺度です。1~5のスコアで表され、数値が高いほど音声品質が良いことを示します。
- DT Echo DMOS:ダブルトーク環境(AにNear-endの音声とFar-endの音声が一緒に存在する環境)で、エコー除去後に残っているエコーの品質に対する尺度です。1~5のスコアで表され、数値が高いほどエコーがよく除去されたことを示します。
- DT Other MOS:ダブルトーク環境(AにNear-endの音声とFar-endの音声が一緒に存在する環境)で、エコー除去後に保存された音声の品質に対する尺度です。1~5のスコアで表され、数値が高いほど音声品質が良いことを示します。
最高の通話品質を得るためには、すべてのスコアが均等に高くなる必要があります。しかし、現実的にはエコー信号だけを正確に判別することはほぼ不可能なため、エコー除去の過程で音声の劣化も発生します。特に、エコーと音声が同時に存在するダブルトーク区間では、2つの音声が混ざり合うため、エコを除去する過程で音声が劣化する可能性が高くなります。このため、エコー除去と音声保存はトレードオフの関係にあります。
ST FE Echo DMOSとDT Echo DMOSは、エコーをよく除去するほどスコアが上がり、ST NE MOSとDT Other MOSは音声をよく保存するほどスコアが上がります。したがって、ST FE Echo DMOSとDT Echo DMOSの高いスコアを狙っ��てすべての音声を除去すると、エコーと音声をすべて除去して高いスコアを得ることができますが、相手は私の声をきちんと聞くことができません。逆に、ST NE MOSとDT Other MOSの高いスコアを狙って信号を除去しないと、私の声がそのまま残って高いスコアを得ることができますが、エコーがひどくて会話が困難になります。
AECMOSの性能指標による体感品質の比較
以下の表では、AECMOSの4つの品質指標であるST FE Echo DMOSとST NE MOS、DT Echo DMOS、DT Other MOSのスコア帯別に音声品質の違いを体感することができます。
| ST FE Echo DMOS | オーディオ・キャプチャーの場所 | 音声ファイル | 説明 |
|---|---|---|---|
| Original | Mic captured audio (A) | 相手(Far-end)が一人で話し(B)、その音声が私のスピーカーから出力され、私のマイクで集音(A)されます。Aでエコーが聞こえます。 | |
| Loop back audio (B) | |||
| 1.x | Enhanced audio (C) | エコーがきちんと除去されていません。 | |
| 2.x | Enhanced audio (C) | エコーが減りましたが、残留エコーが聞こえる区間が多くあります。 | |
| 3.x | Enhanced audio (C) | 全体的にエコーが多く除去されていますが、残留エコーがときどき聞こえます。 | |
| 4.x | Enhanced audio (C) | エコーが完全に除去されて聞こえません。 |
| ST NE MOS | オーディオ・キャプチャーの場所 | 音声ファイル | 説明 |
|---|---|---|---|
| Original | Mic captured audio (A) |
エコーがない環境で私(Near-end)が話している間、Far-end側で大きな音が発生する状況です。BにはFar-endの音がありますが、Aには私の音声しかありません。 | |
| Loop back audio (B) | |||
| 1.x | Enhanced audio (C) | エコーがない環境にもかかわらず、Near-endの音声に大きな劣化が発生します。劣化した区間は聞き�取れません。 | |
| 2.x | Enhanced audio (C) | エコーがない環境にもかかわらず、Near-endの音声に劣化が発生します。劣化した区間は注意深く聞かないと聞き取れません。 | |
| 3.x | Enhanced audio (C) | エコーがない環境にもかかわらず、Near-endの音声にわずかな劣化が発生します。劣化はありますが、聞き取ることはできます。 | |
| 4.x | Enhanced audio (C) | Near-endの音声が劣化した区間はほとんどありません。 |
| DT Echo DMOS | オーディオ・キャプチャーの場所 | 音声ファイル | 説明 |
|---|---|---|---|
| Original | Mic captured audio (A) | Near-endが先に話し始め、Far-endも同時に話し出し(B)、両方の音声が私のマイクで一緒に集音(A)されます。 | |
| Loop back audio (B) | |||
| 1.x | Enhanced audio (C) | エコーがきちんと除去されていません。 | |
| 2.x | Enhanced audio (C) | エコーが減りましたが、残留エコーが聞こえる区間が多くあります。 | |
| 3.x | Enhanced audio (C) | 全体的にエコーが多く除去されましたが、残留エコーがときどき聞こえます。 | |
| 4.x | Enhanced audio (C) | エコーが完全に除去されて聞こえません。Near-endの音声が劣化しましたが、DT ECHO DMOSのスコアは残留エコー量のみを評価するため、高いスコアが測定されました。 |
| DT Other MOS | オーディオ・キャプチャーの場所 | 音声ファイル | 説明 |
|---|---|---|---|
| Original | Mic captured audio (A) | Near-endが先に話し始め、Far-endも同時に話し出し(B)、両方の音声が私のマイクで一緒に集音(A)されます。 | |
| Loop back audio (B) | |||
| 1.x | Enhanced audio (C) | ダブルトーク区間でNear-endの音声に大きな劣化が発生します。劣化した区間は聞き取れません。 | |
| 2.x | Enhanced audio (C) | ダブルトーク区間でNear-endの音声に劣化が発生します。劣化した区間は、話しているという状況のみ認識が可能です。 | |
| 3.x | Enhanced audio (C) | ダブルトーク区間でNear-endの音声にわずかな劣化が発生します。劣化した区間は注意深く聞かないと聞き取れません。 | |
| 4.x | Enhanced audio (C) | ダブルトーク区間でNear-endの音声に劣化はありますが、聞き取ることはできます。Far-endのエコー量は、DT Other MOSスコアには反映されませんが、DT Echo DMOS値に影響を与えます。 |
AEC性能測定の要約
私たちは、当社のAEC技術に信頼性を持たせるために評価を行い、改善に向けて、以下のような性能測定を行っています。
- 再現性と一貫性の確保:AECMOSを使用して、再現可能な環境で性能を測定します。同じデータベースを使用し、ネットワークへの影響を減らすためにローカルでテストを行います。このように、同じ環境で一貫した結果が得られる測定方法を使用することで、AEC技術の性能変化や改善点を正確に把握できます。
- 信頼できる指標の使用:AECMOS指標は、業界や学界でAECの性能評価や比較分析に広く活用されている重要な指標です。この指標を使用することで、測定した性能の信頼性を確保できます。また、製品の数値と性能を定量的に評価し、改善の方向性を設定できます。
- さまざまなエコー状況での性能確認:さまざまなエコー環境において、AEC技術がどのように機能するかを定量的に確認するために、以下の方法を使用します。
- 大規模なデータベース:シングルトーク、ダブルトークがシナリオに応じて混在する2400以上のデータベースを使用します。
- さまざまな録音環境:さまざまなオーディオデバイス(マイク、スピーカー)と環境で録音され、音声とエコーのサイズや特徴が異なるデータを使用します。
このように多様な条件下で信頼できる性能評価を行い、どのようなエコーの状況でも当社のAEC技術が有効に機能して、最高の音声品質を提供できるよう努力しています。
また、エコー除去と音声保存はトレードオフの関係にあることから生じる性能の問題を克服するため、マシンラーニングを用いたエコー除去技術も開発しました。その結果、全体的な性能指標は従来の技術に対して一様に向上しています。マシンラーニングの特性上、計算量が多いほど性能が向上しますが、リアルタイム通話サービスでは、まだ多くの計算量を使用できません。そのため、計算量を適切に調整し、チューニングを進めています(このような高性能なAECはLINEデスクトップアプリに限定して搭載しています)。
これまで多くの部分を改善してきました。今後は、ダブルトークの状況下でもさらに性能を向上させ、モバイルアプリにも高性能なAECを搭載することを目指しています。
周波数特性の測定
次に、周波数特性の測定方法について説明します。まず、周波数特性の測定に関連するいくつかの概念につ��いて簡単に解説し、周波数特性の測定方法と手順を紹介します。
周波数とサンプリングレートとは
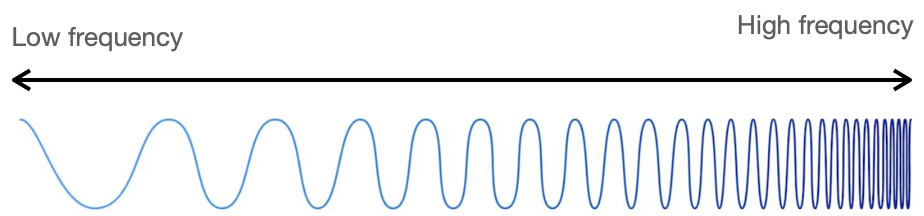
振動の周期的な繰り返し回数を周波数といいます。周波数は、通常1秒あたりの振動回数で表示され、単位はヘルツ(Hz)を使います。高い周波数は短い周期で素早く繰り返される振動を表し、低い周波数は長い周期でゆっくりと繰り返される振動を表します。
音は空気や他の媒質での振動で作られるため、音も周波数で表すことができます。周波数の高低は音の音高を決定します。高い周波数を持つ成分は高い音高を、低い周波数を持つ成分は低い音高を持ちます。たとえば、ピアノのド(C)音の周波数は約261.63Hzで、ミ(E)音の周波数は約329.63Hzです。
アナログ信号をデジタル信号に変換するときは、サンプリングというプロセスを経ます。サンプリングとは、元の信号を一定周期の測定値(サンプル)で構成された信号に変換するプロセスを指し、1秒間にサンプリングする回数をサンプリングレートといいます。デジタル信号処理で重要な概念の1つであるナイキスト・シャノンサンプリング定理は、デジタルで信号を表現するために必要なサンプリングレートを決めるために用いられます。この整理によると、デジタル化する信号�の最大周波数の2倍以上にサンプリングレートを設定すれば、元の信号を完全にデジタルで再現することができます。簡単に言えば、周波数が20,000Hzのアナログ信号をデジタル化するには、40,000Hz以上のサンプリングレートを使う必要があるということです。これにより、デジタル化された信号には、元の信号とほぼ同じ情報が含まれることになります。
周波数特性とは
周波数特性は、オーディオシステムの出力信号が多様な周波数帯域でどれだけ正確に伝達されるかを示す指標で、オーディオシステムが低周波数帯域から高周波数帯域までどれだけ広い周波数範囲をうまく再生するかを評価するときに使われます。周波数帯域ごとに入出力の音量を比較し、測定単位としてデシベル(decibel、dB)を使います。デシベルは、人間の耳で感じる音の大きさに近いように、ログスケールで表現します。負数になるほど小さい音を意味し、デシベル値の差が大きいほど、人間は聴覚的に大きな違いを感じます。
周波数特性の測定は、オーディオシステムの性能を評価する重要な方法です。より広い周波数範囲でより正確に再生するほど、より優れたオーディオシステムとみなされます。これは、音楽や音声をより自然に再生するのに役立ち、ユーザーに高品質のオーディオ体験を提供することに貢献します。
音声通話では、話者の音声信号は、低音域から高音域まで広い周波数範囲に存在します。オーディオシステムがこのようにさまざまな周波数を正確に再生できれば、音声通話の品質は向上します。そのため、私たち�はユーザーに最高の音声通話体験を提供するために周波数特性を重視し、周波数特性の測定結果に基づいてLINEアプリの音声通話サービスの周波数特性を継続的に改善しています。
可聴周波数と周波数特性
可聴周波数とは、人間の耳に聞こえる周波数の範囲を指します。一般的に、人間の耳は約20Hz~20kHzの周波数を聞くことができます。そのため、周波数特性は主にこの可聴周波数の範囲内で測定されます。
周波数特性は、通常、周波数帯域ごとに元の信号に対する出力信号のゲイン(gain、強度の変化)をグラフ化して評価します。このグラフは、周波数ごとにゲインの差を視覚化したもので、周波数帯域ごとにシステムの出力信号の特徴を確認できます。以下の周波数特性を測定した結果の例を見てみましょう。
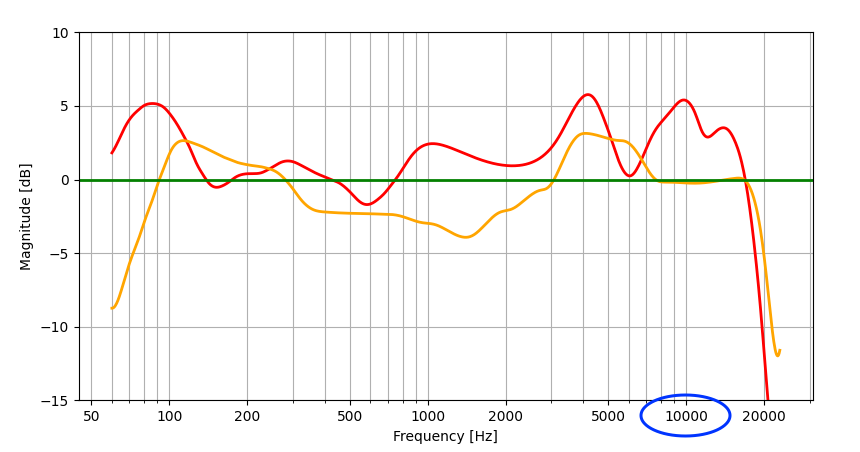
上のグラフは、2つのオーディオシステムの周波数特性をそれぞれ赤とオレンジ色で示しています。ここでは、理想的な周波数特性(緑)と赤、オレンジの周波数特性との違いが一目で分かります。たとえば、10kHz(青丸印)付近の周波数特性を見ると、オレンジの周波数特性の場合は理想的な周波数特性に近いですが、赤の周波数特性の場合は理想的な周波数特性より約5dBほど大きく出力しています。した�がって、10kHzでは、オレンジの方が赤より理想的な周波数特性を持っているといえます。
周波数帯域別音声の特徴
周波数帯域別音声の特徴は以下のとおりです。
- 100Hz以下:低周波数に分類されます。音声通話でこの帯域の信号は、音声に何の役にも立ちません。むしろ、この部分の音圧が高いと、聞き取りにくい音声に聞こえることがあります。
- 100Hz~250Hz:中低周波数に分類されます。音声通話で主に音声の低音と振動を担当し、音声の安定性を表現する役割を果たします。
- 250Hz~2kHz:中周波数に分類されます。この帯域は音声の主要な部分の一つで、音声の明瞭さと鮮明さを表現する役割を果たします。
- 2kHz~8kHz:高周波数に分類されます。高周波帯域は、音声の高音部分や摩擦音([f]、[v])などの細部を担当します。
- 8kHz~20kHz:超高周波数に分類されます。この周波数帯域は、音声の歯擦音([s]、[z])の特性を表現する役割を果たします。
- 20kHz以上:音声信号がほとんど存在しない帯域で、人間の聴覚で知覚しにくい領域です。
周波数特性の測定方法
周波数特性は、音声信号が流れるすべての経路に影響されます。通話システムでは、マイクとスピーカー、通話モジュールの特性が影響を与えます。
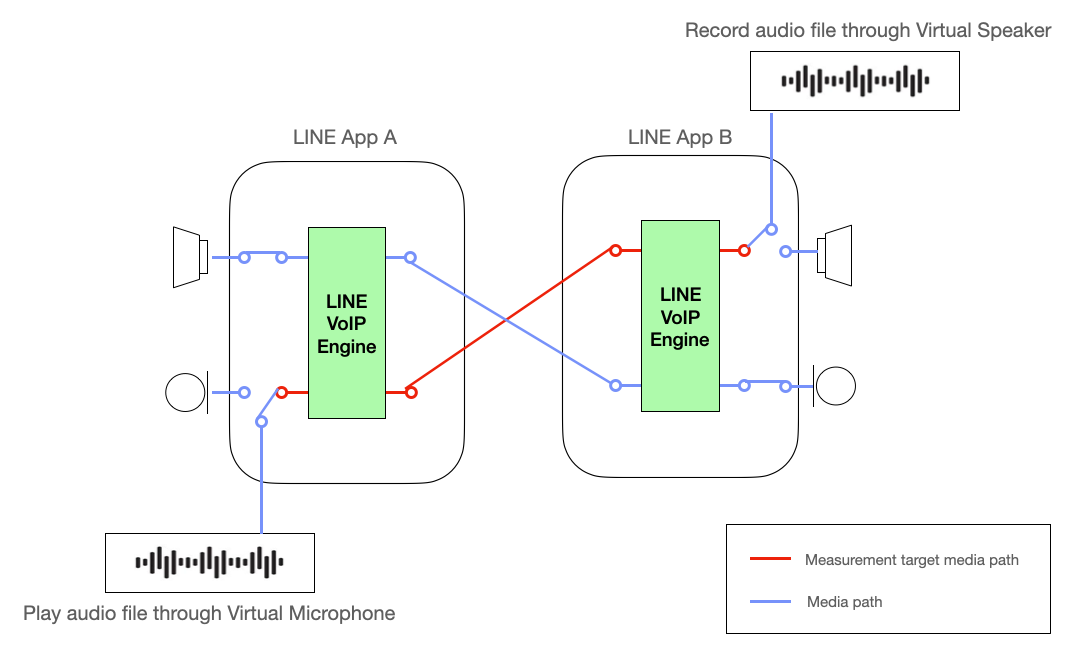
私たちは、通話モジュールの周波数特性を正確に測定するために、仮想オーディオデバイスを使用します。これは、周波数測定時にオーディオデバイスの影響を最小限に抑えるためです。仮想オーディオデバイスは、音声信号を歪みなく入出力できるため、LINE通話モジュール単体の特性を正確に測定できます。
下図の赤線は、周波数特性測定の対象経路を示しています。仮想オーディオデバイスを使用することで、周波数特性の測定結果からオーディオデバイスの影響を排除し、通話モジュール単体の特性を正確に測定できます。これにより、通話モジュールの周波数特性を正確に分析し、品質の向上に必要な情報を効果的に得ることができます。
周波数特性測定の手順
LINEアプリの通話モジュールの周波数特性測定は、以下の手順で行います。
テスト信号の選択
測定したいオーディオシステムに適したテスト信号を選択します。このテスト信号の周波数帯域は、通常、20Hz~20kHzの可聴周波数範囲の音声信号で構成されます。テスト信号を音声信号で構成する理由は、通話モジュールが音声以外の信号を主にノイズとみなし、除去できるためです。
テスト信号としては、IEEEが提供する通信装置の電気音響性能評価規格(IEEE 269-2010)の信号を使用します。以下のリンクは、このような測定に使用するテスト信号です。
- Media file(https://standards.ieee.org/wp-content/uploads/import/download/269-2010_downloads.zip)
- IEEE_269-2010_Male_mono_48_kHz.wav:初期安定化用の音源
- IEEE_269-2010_Male_mono_48_kHz.wav、IEEE_Female_mono_48_kHz.wav:周波数特性測定用の音源
測定システムの環境設定1 - 測定環境の設定
周波数特性を測定するためのシステム環境を設定します。
- Adobe Audition(https://www.adobe.com/kr/products/audition.html):テスト信号を再生し、測定対象のオーディオシステムの出力信号を録音するS/Wです。
- VB-AUDIO(https://vb-audio.com/Cable/):仮想オーディオデバイスを使用して、音声信号を歪みなく、マイク入力とスピーカー出力ができるS/Wです。インストール後、VB-Cableという仮想マイク/スピーカーデバイスを使用できます。
- 周波数特性測定ツール:測定用信号と出力信号、2つのwavファイルを入力すると、周波数特性を描画するコードです。
import sys
import warnings
import numpy as np
import matplotlib.pyplot as plt
import scipy.io.wavfile as wf
from scipy.io.wavfile import WavFileWarning
from numpy import ComplexWarning
from scipy.interpolate import make_interp_spline
# Calculate the center frequencies of 1/12 octave bands.
def calculate_octave_bands (start_freq, end_freq):
bands = []
while start_freq <= end_freq:
bands.append (start_freq)
start_freq *= 2** (1/12) # Increase by 1/12 octave.
return bands
# Ignore the WavFileWarning
warnings.filterwarnings ("ignore", category=WavFileWarning)
warnings.filterwarnings ("ignore", category=ComplexWarning)
if len (sys.argv) != 3:
print ("Usage: python script.py <ref_audio_file.wav> <deg_audio_file.wav>")
sys.exit (1)
ref_fs, ref_audio_data = wf.read (sys.argv[1]) # Load the reference audio file
deg_fs, deg_audio_data = wf.read (sys.argv[2]) # Load the degraded audio file
# Check if sample rates are different
if ref_fs != deg_fs:
print ("Error: Sample rates are different. Cannot process audio files with different sample rates.")
exit ()
# Check if sample types are different
if ref_audio_data.dtype != deg_audio_data.dtype:
print ("Error: Sample rates are different. Cannot process audio files with different sample types.")
exit ()
# Check the audio sample type
if ref_audio_data.dtype == np.float32:
kMaxSample = 1.0
else:
kMaxSample = 32768 # For int16, 0 dBFS is 32678 with an int16 signal
kNfft = 32768
win = np.hamming (kNfft)
num_segments = min (len (ref_audio_data), len (deg_audio_data)) // kNfft
ref_audio = np.zeros ( (kNfft, num_segments))
deg_audio = np.zeros ( (kNfft, num_segments))
# Take a slice and multiply by a window
for i in range (num_segments):
ref_audio[:, i] = ref_audio_data[i * kNfft : (i + 1) * kNfft] * win
deg_audio[:, i] = deg_audio_data[i * kNfft : (i + 1) * kNfft] * win
# Initialize arrays to store spectral data for each frame
num_frames = ref_audio.shape[1]
ref_audio_sp = np.zeros ( (kNfft // 2 + 1, num_frames))
ref_audio_s_mag = np.zeros ( (kNfft // 2 + 1, num_frames))
deg_audio_sp = np.zeros ( (kNfft // 2 + 1, num_frames))
deg_audio_s_mag = np.zeros ( (kNfft // 2 + 1, num_frames))
# Process each frame
for i in range (num_frames):
ref_audio_sp[:, i] = np.fft.rfft (ref_audio[:, i]) # Calculate real FFT for each frame
ref_audio_s_mag[:, i] = np.abs (ref_audio_sp[:, i]) * 2 / np.sum (win) # Scale the magnitude of FFT for each frame
deg_audio_sp[:, i] = np.fft.rfft (deg_audio[:, i]) # Calculate real FFT for each frame
deg_audio_s_mag[:, i] = np.abs (deg_audio_sp[:, i]) * 2 / np.sum (win) # Scale the magnitude of FFT for each frame
avg_ref_audio_s_mag = np.mean (ref_audio_s_mag, axis=1)
avg_deg_audio_s_mag = np.mean (deg_audio_s_mag, axis=1)
f_axis = np.linspace (0, ref_fs/2, len (avg_ref_audio_s_mag))
center_frequencies = calculate_octave_bands (60, ref_fs / 2)
# Aggregate the spectral data in the frequency domain into 1/12 octave bands.
ref_band_spectra = []
deg_band_spectra = []
for center_freq in center_frequencies:
lower = center_freq / (2** (1/24)) # Lower frequency limit of the band.
upper = center_freq * (2** (1/24)) # Upper frequency limit of the band.
indices = np.where ( (f_axis >= lower) & (f_axis <= upper))
ref_band_spectrum = np.mean (avg_ref_audio_s_mag[indices])
ref_band_spectra.append (ref_band_spectrum)
deg_band_spectrum = np.mean (avg_deg_audio_s_mag[indices])
deg_band_spectra.append (deg_band_spectrum)
ref_band_spectra=np.array (ref_band_spectra)
ref_band_spectra=20 * np.log10 (ref_band_spectra / kMaxSample) # Convert to dBFS
deg_band_spectra=np.array (deg_band_spectra)
deg_band_spectra=20 * np.log10 (deg_band_spectra / kMaxSample) # Convert to dBFS
diff_spectrum=deg_band_spectra-ref_band_spectra
#smoothing
center_frequencies_smooth = np.logspace (np.log10 (min (center_frequencies)), np.log10 (max (center_frequencies)), 1000)
spline_ref = make_interp_spline (center_frequencies, ref_band_spectra, k=3)
spline_deg = make_interp_spline (center_frequencies, deg_band_spectra, k=3)
spline_diff = make_interp_spline (center_frequencies, diff_spectrum, k=3)
ref_band_spectra_smooth = spline_ref (center_frequencies_smooth)
deg_band_spectra_smooth = spline_deg (center_frequencies_smooth)
diff_spectrum_smooth = spline_diff (center_frequencies_smooth)
plt.semilogx (center_frequencies_smooth, ref_band_spectra_smooth, label='Input', color='cornflowerblue')
plt.semilogx (center_frequencies_smooth, deg_band_spectra_smooth, label='Output', color='orange')
plt.semilogx (center_frequencies_smooth, diff_spectrum_smooth, label='Output-Input', color='limegreen')
# Add a green target line at 0dB
plt.axhline (y=0, color='green', linestyle='-', label='Target')
plt.xlabel ('Frequency [ Hz]')
plt.ylabel ('Magnitude [dB]')
plt.legend ()
plt.grid (which='both', axis='both')
frequency_labels = [50, 100, 200, 500, 1000, 2000, 5000, 10000, 20000]
plt.xticks (frequency_labels, [str (label) for label in frequency_labels])
plt.ylim (-130, 20)
plt.show ()測定システムの環境設定2 - 測定オーディオシステムの接続
LINE音声通話の周波数特性を測定するために、AとBの2台の装置を使用します。
-
A、B装置の共通設定:VB-Cableの入出力サンプリングレートを48kHzに設定します。これは最大24kHzまでの信号を表現できるため、人間の聴覚周波数をすべてカバーできます。
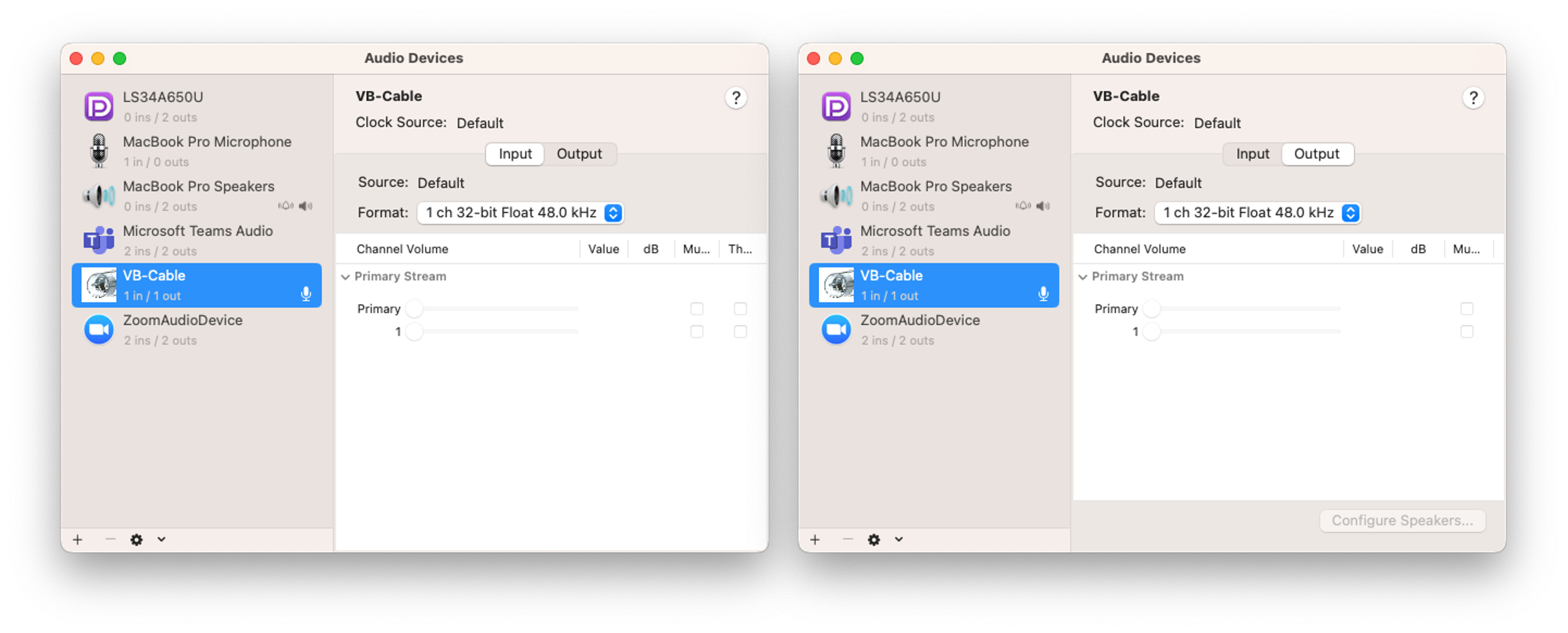
- A装置では、Adobe Auditionのスピーカー出力をVB-Cableに設定し、LINEアプリのマイクをVB-Cableに設定します。Adobe Auditionで再生された音声は、VB-Cableを通じてLINEアプリのマイク入力に送られます。
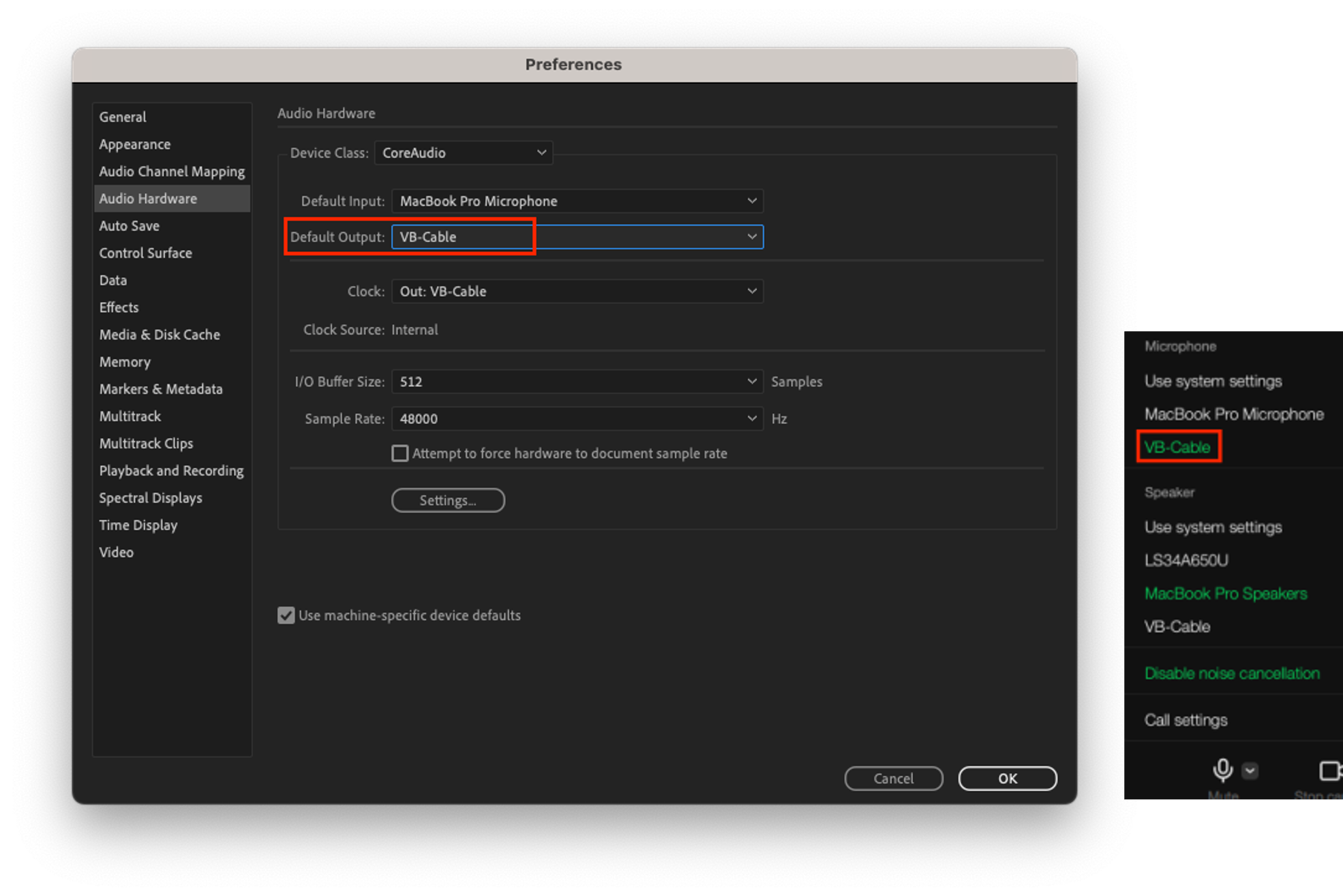
- B装置では、LINEアプリのスピーカーをVB-Cableに設定し、Adobe Auditionのマイク入力をVB-Cableに設定します。LINEアプリのスピーカー出力は、VB-Cableを通じてAdobe Auditionの音声入力に送られます。
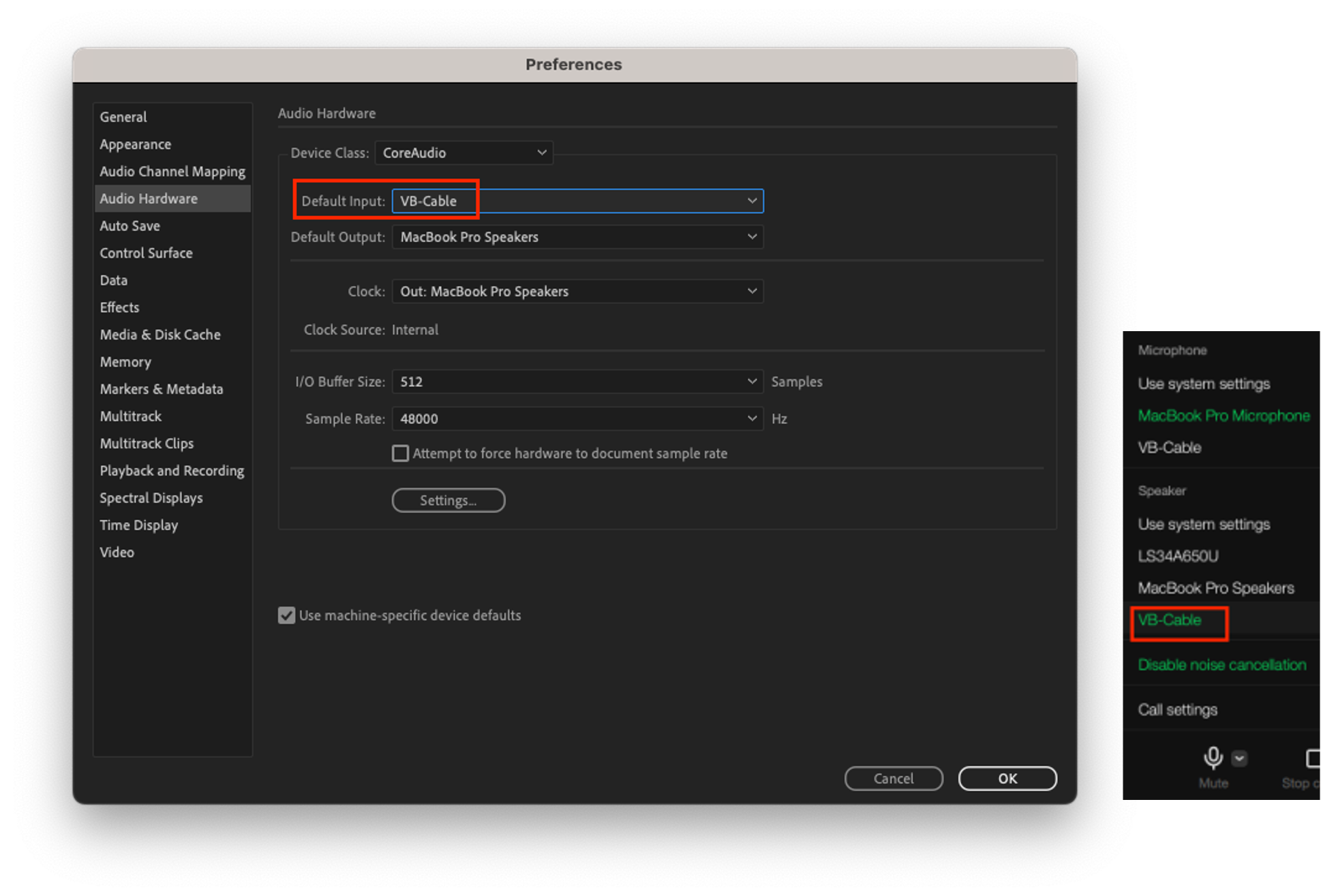
信号検証と周波数特性測定
- 安定化信号の再生
LINEアプリの音声通話を接続し、AのAdobe Auditionでは安定化信号のIEEE_269-2010_Male_mono_48_kHz.wavを15秒以上再生します。このステップは、安定化信号の再生中に音声通話モジュールが適応する時間を確保するためです。 - システム出力信号の録音
通話システムの出力を記録するため、BのAdobe Auditionで録音を開始します。このとき、録音されるファイルのサンプリングレートは48kHzを使用します。 - 測定用信号の再生
AのAdobe Auditionで測定用信号を再生します。測定用信号としては、IEEE_269-2010_Male_mono_48_kHz.wavとIEEE_Female_mono_48_kHz.wavの2つの音源を使用します。各音源には合計4つの文が含まれており、女性、男性の順に1文ずつ交互に再生します。 - システム出力信号の検証
すべての文の再生が完了したら、Bの録音を停止します。測定用信号がAの送信端とBの受信端を経て、Bで録音されました。これで、録音されたオーディオファイルには、LINEアプリのオーディオシステムの周波数特性が反映されています。 - 音量調整(このステップは必要に応じて実施)
LINEアプリは、ユーザーに均一な音量を提供するために、大きな声は小さく、小さな声は大きくするなど、音量調整を行います。これにより、元の音と出力音量に差が生じることがあります。この音量の差は、周波数特性解析時に意図しない解析エラーを引き起こす可能性があります。周波数特性を測定する前に、Aのオーディオ再生音量を調整して出力音量を元の音量に近く調整するステップを選択的に実施できます。Aのオーディオ再生音量を変更した場合は、ステップ1からやり直します。もし、周波数特性測定の過程で音量調整ステップを行った場合、測定結果には必ず再生音量の調整量を明記する必要があります。 - 周波数特性測定
周波数特性解析ツールに、測定用信号(ステップ3)とシステム出力信号(ステップ4)を入力して周波数特性グラフを作成します。ステップ5で音量調整を行った場合は、ステップ5で調整した音量を測定用信号(ステップ3)に反映し、周波数特性解析ツールに入力します。周波数帯域は、ハンドセットとヘッドセットで使用される1/12オクターブ帯域で測定されます。
ロスに対するロバスト性(loss robustness)の測定
リアルタイムコミュニケーションサービスでは、パケットロス(loss)に強い(robust)メカニズムを実装しなければ、良好な音声品質と安定したサービスを提供することができません。まず、パケットロスが発生する理由とその対応について確認し、LINEアプリでロスに対するロバスト性を測定する方法を説明します。
パケットロスと音声品質
前述のように、リアルタイムコミュニケーションサービスでは、インターネットプロトコルを介し、リアルタイムで音声データを送信します。このようなサービスは、リアルタイム性が重要であるため、遅延時間を短縮するためにTCP(Transmission Control Protocol)の代わりにUDP(User Datagram Protocol�)を使用します。
TCPは信頼性の高いデータ送信のために、すべてのデータパケットを確認して再送するため、パケットロスが発生すると遅延時間が長くなります。そのため、リアルタイムコミュニケーションサービスではユーザー体験が低下する可能性があります。一方、UDPはTCPのような確認と再送処理がないため、リアルタイム通信に適しています。しかし、UDPではデータパケットの送信が保証されず、TCPのようなフロー制御やエラー回復機能がありません。そのため、ネットワークを介して送信したデータパケットが失われ、音声が失われる問題が発生する可能性があります。
パケットロスの原因と影響
パケットはさまざまな原因で失われます。ネットワークの混雑で失われることもあれば、ネットワークの帯域幅が限界に達した場合や、過度に大量のデータが同時に送信される場合、ルーターやスイッチでパケットを処理できず、一部のパケットが失われることもあります。また、無線ネットワークでは、信号の干渉や突然の信号の弱まり、建物内の障害物などによってパケットが失われることがあります。
では、パケットロスは音声品質にどのような影響を与えるのでしょうか。
リアルタイムコミュニケーションサービスでは、マイクからの音声信号をコーデックで圧縮します。圧縮されたデータはパケットに乗せられ、インターネットを介して数十ミリ秒間隔で送信されます。音声データのパケットが失われるということは、その区間の音声が失われることを意味します。ビデオ会議や日常の通話で、相手の音声�が途切れたり、聞き取りにくくなったりするため、コミュニケーションに支障をきたすことがあります。

音声損失の回復技術
では、パケットロスによって損失した音声はどのように回復できるのでしょうか。現在、業界ではパケットロスを回復するためにさまざまな技術とメカニズムを使用しており、その代表として以下の技術があります。
- パケットロス隠蔽(packet loss concealment、以下PLC)
- PLCは、パケットロスの区間で欠落した音声データを補間する技術です。これにより、パケットロスによる音質劣化は緩和し、ユーザー体験は向上します。回復のための追加のデータが必要なく、ロスが少ない場合には有効ですが、パケットロスが大きくなるほど効果は低下します。
- 順方向エラー訂正(forward error correction、以下FEC)
- FECは、エラー訂正コードを追加してデータのパケットロスを回復する方法です。送信側で元のソースパケットと一緒に一部の回復情報も送信し、受信側はこの回復情報を使用して失われたソースパケットを回復します。再送より遅延時間は短いですが、事前に回復情報を送る必要があるため、データ使用量が増えるというデメリットがあります。
- パケット再送(packet retransmission)
- 受信側から送信側に、失われたパケットの再送を要求することで、パケットロスを回復する方法です。要求から再送されるまでに時間がかかるため、かなりの遅延が発生する可能性があります。
LINEアプリで使用する音声損失の回復技術
上記のように、パケットロスを回復する技術にはそれぞれメリットとデメリットあるため、LINEアプリではネットワーク状況に応じて上記の技術を適切に使い分けてパケットロスを回復しています。
送信側
LINEアプリでは、基本的にRFC 8627を応用した2-D FEC Protection技術を利用しています。
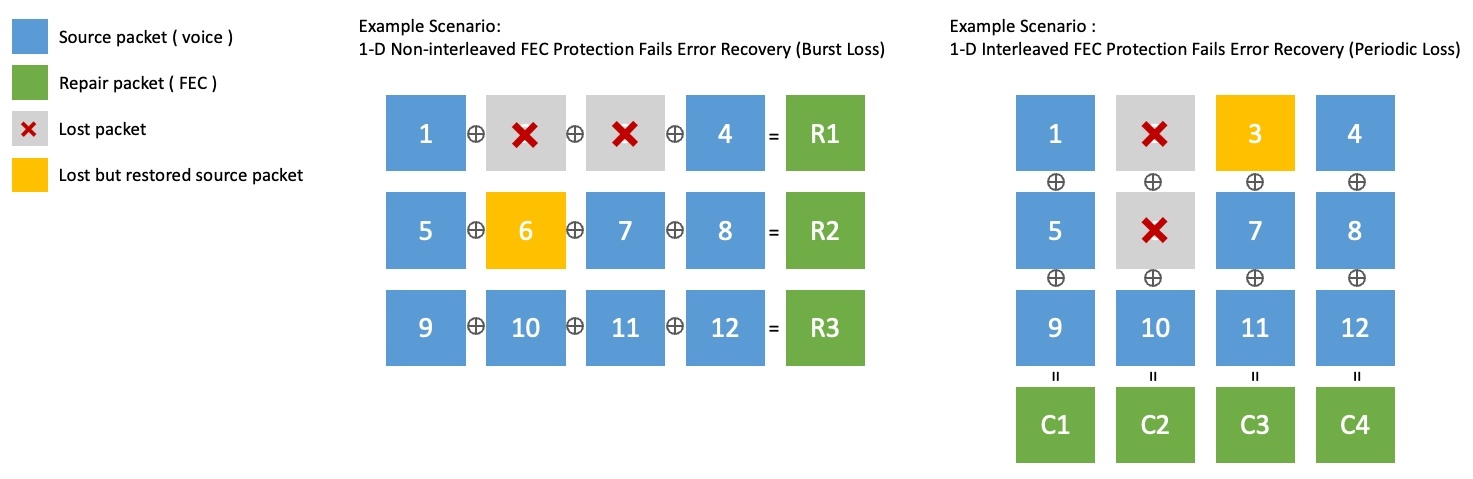
1次元のFECは、ソースパケットのグループを行単位(1-D Non-interleaved)、または列単位(1-D Interleaved)でXOR演算し、回復パケットを生成します。しかし、2回以上の連続したパケットロスは回復できないという限界があります。下図はこのような限界を示す例です。
- 下図の左側の1-D Non-interleavedでは、パケット6は回復しましたが、2と3の連続したパケットロスは回復できません。
- 下図の右側の1-D Interleavedでは、パケット3は回復しましたが、2と6の連続したパケットロスは回復できません。
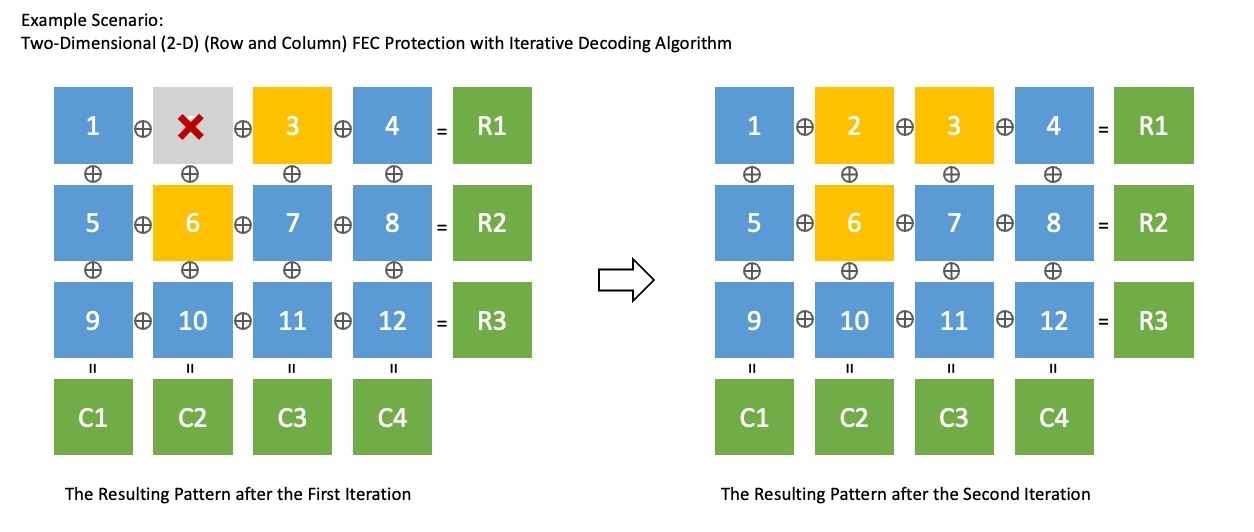
 2-D FEC Protectionは、1次元のInterleaved FECとnon-interleaved FECを組み合わせた技術です。さまざまなパターンのロスに対応でき、反復復号アルゴリズム(iterative decoding algorithm)で通常のFECより効果的にロスを回復できます。下図は、上記と同じ状況下で2-D FEC Protectionを使用し、2回の繰り返しでパケットをすべて回復した例です。
2-D FEC Protectionは、1次元のInterleaved FECとnon-interleaved FECを組み合わせた技術です。さまざまなパターンのロスに対応でき、反復復号アルゴリズム(iterative decoding algorithm)で通常のFECより効果的にロスを回復できます。下図は、上記と同じ状況下で2-D FEC Protectionを使用し、2回の繰り返しでパケットをすべて回復した例です。
しかし、パケットロス率が非常に高くなると、2-D FEC Protectionでも十分でない場合があります。このような状況では、同じ元のパケットを周期的に2回以上再送する手法を用います。送信側は、パケットロス率をリアルタイムでモニタリングし、2-D FEC Protectionを使うか、周期的な再送手法を使うかを決めます。
受信側
受信側では、送信側から送信された回復情報を利用して失われたパケットを回復しますが、それでもロスがある場合は、失われたパケットの再送を要求します。再送は遅延が発生するため、ネットワークレイテンシー(network latency)が高い環境では動作しないように制限しています。最後に、リアルタイムのパケットロス回復が行われていない音声区間については、PLCで音質劣化を緩和します。
音声品質を客観的に評価する方法
まず、パケットロスに適切に対応し、良好な音声品質を保証しているかを評価する方法について説明します。そのためには、まず音声品質を定量的かつ客観的に評価でき、片道遅延を測定し、データ使用量が適切かどうかを確認する必要があります。一つずつ見ていきます。
音声品質評価
MOSと主観的な音声品質評価
MOS(mean opinion score)は、音声通話や音声ベースのサービスの音声品質を評価するために使用する最も一般的な尺度です。1から5までの尺度で表し、数値が大きいほど音声品質が良いことを示します。この方法は、実際の音声信号を聞いて感じる音質を主観的に評価する主観的音質測定法に由来します。
音声品質に対する主観的評価は、ITU-T P.800勧告を主に使用します。この勧告では、主観評価時の環境についても厳格に規定しています。たとえば、評価文を録音して聴くための環境の場合、空間は30~120m3、残響時間は500ms以下(最適200~300ms)、室内の騒音はスペクトルにピークがない30dBA以下である必要があります。また、評価参加者は直近6か月間、いかなる主観評価に参加していないこと、特に主観的評価の聴取には直近1年間参加していないことが条件となります。他にも評価条件や環境から生じる偏差を取り除くために、さまざまな条件が提示されています。そのため、主観的な音声品質評価に�は、多くの費用と時間がかかってしまう問題があります。
客観的な音声品質評価とPOLQA
主観的な音声品質評価の問題を解決するために、音声品質を客観的に評価できる方法が必要になります。そのために、原音声信号と比較して主観的な音質測定結果に近い評価ができるいくつかの音声品質評価アルゴリズムが開発されました。
複数のアルゴリズムのうち、現在広く使われているグローバル標準アルゴリズムは、POLQA(Perceptual Objective Listening Quality Analysis)です。ITU-T(International Telecommunication Union - Telecommunication Standardization Sector)で標準化したこのアルゴリズムは、音声サービスとコーデックの品質評価に広く利用されています。POLQAは、音声品質評価を行う際に、人間の聴覚システムを模倣して音質を評価し、ネットワーク伝送や音声コーデックの圧縮、パケットロス、遅延などのネットワーク環境の変化による音質劣化を評価できます。
POLQAでも主観的評価と同様に、音声品質評価の尺度としてMOSを使用します。これにより、音声通話と音声サービスの品質を客観的に測定し、比較できます。以下は、実際の音源をPOLQAで評価したMOSスコアのサンプルです。POLQA MOSスコア別に実際の音声品質を体感できます。
| POLQA MOS | Sample audio |
|---|---|
| Original | |
| 4.5 | |
| 3.5 | |
| 2.5 | |
| 1.5 |
片道遅延の評価
音声の品質が良くても、音声が届くまでの片道遅延が大きければ、双方向のコミュニケーションは不便になります。片道遅延は、VoIPや電話などの通信サービスにおいて重要なパラメータの1つであり、音声がある地点から出発して目的地に到着するまでの時間を意味します。
片道送信時間に対する標準勧告であるITU-T G.114 (05/2003) One-way transmission timeでは、通常のネットワークで片道遅延が400msを超えないことを推奨しています。ただし、例外的にこの制限を超える場合も一部あります。たとえば、パケットロス率が大きいネットワーク環境では、片道遅延が多少長くなるとしても、パケットロスを回復するための待ち時間を置いて、ロスがある程度回復された方がユーザー体験として良いでしょう。したがって、このような損失回復メカニズムが適切に制御されているかどうか、片道遅延を測定する必要があります。
データ使用量の評価
最近はモバイルネットワークの発達により、音声データの使用量があまり問題にならないことも多いです。しかし、LINEアプリは世界中で使用されているため、ネットワークのパフォーマンスが悪い場合も考慮する必要があります。
パケットロスを回復するためには、追加のデータが必要になりますが、これはビットレートを増加させ、ネットワークの混雑を引き起こす可能性があります。特に、ビデオのようにビットレートが高いメディアの場合はさらに注意が必要です。したがって、データ使用量を測定し、ロスの回復に使用するデータ使用量が適切かどうかを確認する必要があります。
パケットロスの環境における音声品質の測定方法
音声品質を客観的に評価する方法を確保したので、ここからはパケットロスが発生する環境で音声品質を測定する方法について説明します。
音声品質と遅延の分析
私たちは、信頼性の高い客観的な音声品質測定のために、専門的な音声品質分析装置(voice quality analyzer)を使用しています。DSLA(Digital Speech Level Analyzer)という装置ですが、通信機器やネットワークでの通話品質を測定できます。DSLAは、送信側の端末に元の音声信号を入力し、受信側の端末で再生される音声信号をキャプチャして元の音声信号と比較分析します。分析完了後、さまざまな分析結果を提供しますが、前述のPOLQAアルゴリズムを利用して客観的な結果を得ることができます。つまり、POLQA MOSや音声の片道遅延を測定できます。
パケットロスモデルとエミュレーション
ネットワークでは、ネットワークの混雑やルーターのバッファオーバーフロー、信号の干渉などの理由により、さまざまなパターンのパケットロスが発生します。その中でもランダムパケットロス(random packet loss)は、最も一般的なパケットロスのパターンで、パケットがネットワークでランダムに失われることです。また、バーストパケットロス(burst packet loss)とは、複数のパケットが連続して失われる場合を指します。この場合、バーストパケットロスはモデル化方法も多様で、状態やその状態による確率など多くの変数が存在し、モデルや変数によってロスの発生度合いに差が出ます。そのため、性能テストではランダムなパケットロスパターンを使用して�います。
また、信頼性と精度の高いネットワークエミュレーションを行うために、PacketStormという専門的なネットワークエミュレータを使用しています。この装置を使えば、パケットロスだけでなく、遅延(delay)やジッター(jitter)、順序変更(reordering)、帯域幅制限(throttling)などさまざまなネットワーク伝送障害(network impairment)についても性能をテストできます。もし、ランダムなパケットロスパターンのみをエミュレーションする場合は、macOSが提供するNetwork Link Conditionerのような他のツールを使用することもできます。
測定シナリオ
パケットロス環境で、2台の端末の音声品質を測定するシナリオを見てみます。
測定環境の設定
まず、端末AとBを音声品質分析装置(DSLA)のポートにそれぞれ接続し、ネットワークを設定します。ネットワーク伝送障害は、送信側のアップリンク(up-link)または受信側のダウンリンク(down-link)に適用します。
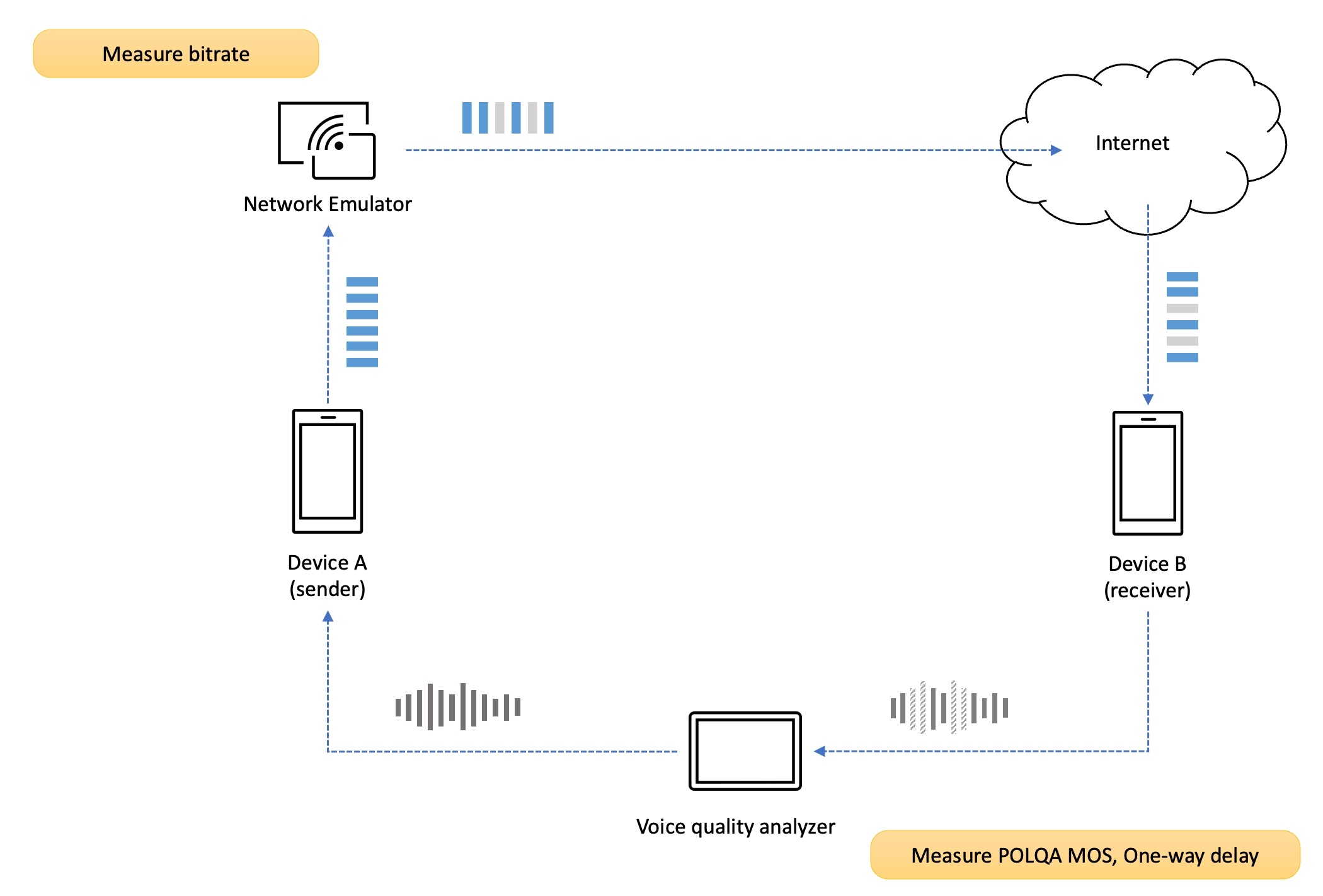
私たちは両方のシナリオを測定しますが、上の図は送信側のアップリンクにパケットロスという伝送障害を適用した例です。
通話の接続
次に、通話を接続する必要があります。LINE 1:1通話の場合は両端末でお互い通話�を接続し、LINEグループ通話の場合は両参加者が同じグループに参加します。
測定と分析
次に、音声品質分析装置を利用して、音声品質と音声遅延の測定を開始します。ランダムパケットロスは常に同じパターンではないため、音声品質と音声遅延の測定結果は毎回異なります。同じ状況であっても、音声パケットのどの区間が失われたかによってMOS値の差は大きく変わります。失われたパケットを回復する際に発生する遅延により、音声遅延に差が出ることもあります。したがって、DSLAテストを繰り返して評価データの信頼性を高めることが良いです。私たちは、片道で最低50回以上の測定と分析を行っています。
測定結果の分析
テストが終了したら、音声品質(POLQA MOS)と音声の片道遅延(One-way delay)、データ使用量の結果を収集します。収集した結果はさまざまな形で分析できます。一例として、以下のようにロス率によってMOSや遅延の測定結果の分布を比較できます。
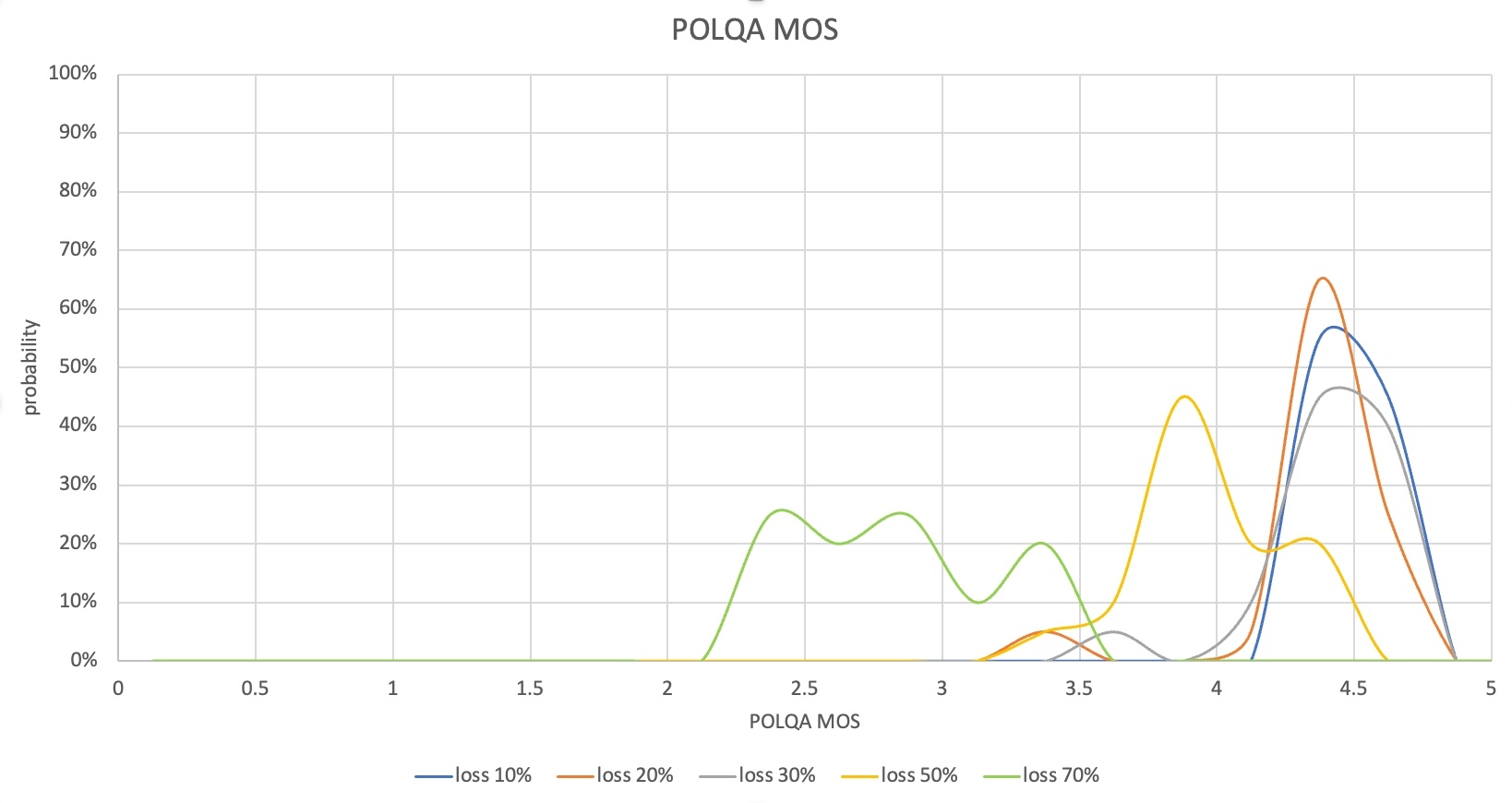
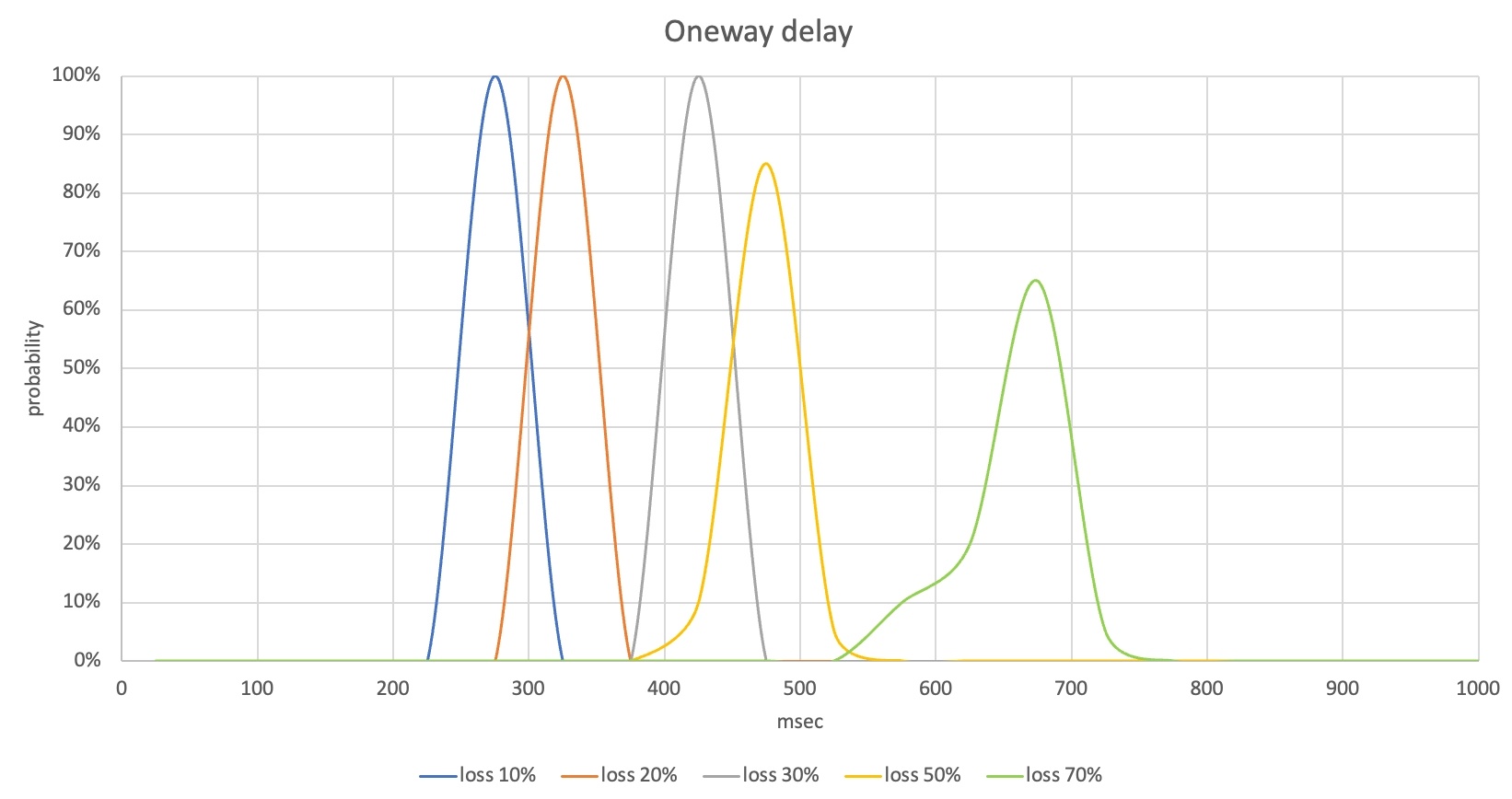
この場合、ロス率30%まではPOLQA MOS分布が4~4.6となり、ほとんどのパケットロスを回復していることが分かります。音声の片道遅延も400ms前半に抑えられ、サービスに不便を感じないレベルです。しかし、ロス率50%からは一部の音声区間が失われてPOLQA MOSが低くなり、ロス率70%ではMOSが2ポイント台となったケースが多く、実際のコミュニケーションでも不便を感じることになります。
このシナリオの測定結果から、ロス率50%以上において、ロスの回復性能の改善と音声の片道遅延の低減が必要であることが確認できます。このとき、ロスを回復するためにデータ使用量が増加する可能性があるため、データ使用量の測定結果も合わせて分析する必要があります。
おわりに
この記事では、LINEアプリの通話品質をどのような側面から測定しているかを紹介し、さまざまな品質測定方法のうち、AECと周波数特性、ロスに対するロバスト性を測定する方法について詳しく解説しました。機会があれば、ノイズ除去(noise suppression)をはじめ、今回紹介できなかった他の技術や測定方法についても紹介したいと思います。
私たちは、LINEアプリのユーザーがどのような状況でも優れた音声通話やビデオ通話を体験できるよう、グローバル標準の評価アルゴリズムと専門的な機器、独自の技術を利用して、さまざまな側面から音声や映像の品質の測定と改善に取り組んでいます。いつでもどこでも、最高の通話品質を体験していただけるよう、努力と改善を続けてまいります。長文でしたが、最後まで読んでいただきありがとうございました。
