以前、LINEアプリで音声品質を測定するという記事で、LINEアプリにおけるアコースティック環境やネットワーク環境の変化、グローバル環境に対応する方法を紹介したことがあります。特に、アコースティック環境への対応方法と関連し、AEC(acoustic echo cancellation、エコー除去)の性能を測定する方法について詳しく説明しました。今回の記事では、アコースティック環境対応の重要な要素の一つであるノイズ抑制(noise suppression、以下NS)技術の性能を測定する方法を紹介します。
NS技術の紹介 - NSとは?
音は空気中で振動する波の形で伝わり、マイクはその音波を電気的な信号に変換する装置です。しかし、マイクは周囲のあらゆる音を拾うため、ユーザーの声だけでなく、バックグラウンドノイズも拾ってしまいます。そのため、マイクに拾われた信号にはユーザーの声と周囲のノイズが混在しており、そ��のノイズは通話品質を低下させる可能性があります。
NSは、周囲からのノイズを抑制し、ユーザーに対してよりクリアで高品質な音声通話を提供する技術です。実際、ノイズのない完璧に静かな環境を作ることは不可能であるため、ノイズの問題はNS技術によって解決されなければなりません。NS技術は、ユーザーがさまざまな環境下でクリアな音声通話ができるようにサポートしており、これはLINEアプリのユーザー体験の重要な要素です。
LINEアプリは独自の技術でNSを開発しており、ML(Machine Learning)技術を導入することで、高品質なノイズ抑制性能を提供しています。これにより、ユーザーは周囲のノイズによる不快感を最小限に抑えた、クリーンで高品質な音声通話を楽しめます。
NS性能の測定方法
定量的評価は、NS技術の性能を客観的に測定・評価できる重要な方法です。定量的評価により、NS技術のノイズ抑制能力を確実に把握し、ユーザーの通話体験を継続的に改善できます。
NS技術の性能を評価する上で最も重要な2つの要素は、オーディオ品質の維持とノイズ抑制能力の測定です。これは、その技術がユーザーの声など必要な音はそのまま維持しながら、バックグラウンドノイズをどれだけ低減できるかを評価することを意味します。
LINEアプリの開発では、定量的評価によってNS機能を効果的に管理し、ユーザーに最高の通話体験を提供するための努力を続けています。その一環として、NS技術の性能測定は以下の手順で行われます。
- 性能測定アプローチの確立
- データセットの選定
- テストデータセットの準備
- NS性能評価�指標の選定
- 測定システムの環境設定
- NS性能の測定
各手順を順番に説明します。
性能測定アプローチの確立
NS性能を測定するために確立したアプローチは、以下のとおりです。
-
再現性と一貫性の確保
標準化された評価ツールを使用し、再現可能な環境で性能を測定します。また、同じデータセットでネットワークの影響を最小限に抑えるために、ローカル環境でテストを行います。これにより、同じ条件下で一貫した結果を得ることができ、NS技術の性能変化や改善点を正確に把握できます。 -
信頼性の高い評価指標
国際的に認められた評価基準を用いて、業界や学界で広く認められている信頼性の高い性能指標を算出します。このように音声の明瞭度やノイズ抑制効果を示す指標を算出することで、NS技術性能の信頼性を確保できます。また、製品の性能を定量的に比較し、開発の方向性を設定できます。 -
さまざまなノイズ環境での性能確認
NS技術の性能をさまざまな環境で定量的に確認するため、以下のように測定を行います。
a. 大規模な音声データセット:性別、年齢などを考慮した多数の音声サンプルを含む音声データセットを使用します。
b. 多様なノイズタイプ:カフェ、道路、オフィスなどさまざまな環境からのノイズを含むノイズデータセットを使用します。
c. 合成比率の調整:NS技術の安定性を高めるため、元の音声とノイズをさまざまな比率で組み合わせテストを行います。
LINEアプリの開発では、上記のようなアプローチにより、NS技術がさまざまな環境でどれだけ効果的に機能するかを検証し、ユーザーに最高の音声通話体験を提供するために努力しています。
データセットの選定
私たちの目標は、人間が聞き取れるすべての可聴周波数帯域においてNS技術の性能を評価することです。そのために、48kHzの高解像度の音源をデータセットとして選定しました。48kHzのサンプリングレートを持つ音源は、人間の可聴周波数の範囲である約20Hzから20kHzまでの音を包括的に含み、NS技術がさまざまな周波数でどのように機能するかを高い精度で評価できます。
また、ノイズデータセットとして、18の異なるシーンで構成されたデータを選択しました。各シーンは異なる場所で録音されたもので、ユーザーの位置や環境によってNS技術がどのように異なる動作をするかを評価する上で重要な要素です。ユーザーの実際の環境は非常に多様であるため、そのような多様な環境でも効果的にノイズを抑制できるかどうかを検証するために、さまざまなシーンや場所で録音されたデータを使用します。
最後に、信頼性の高い評価結果を得るためには、十分な量の音源データが必要です。さまざまな音源を含めることで統計的に有意な結果を得ることができますが、それによってNS技術の一貫した性能を検証し、例外的なケースや特定の条件下での性能低下を把握できます。
これらの要素を考慮し、高解像度の48kHz音源とさまざまな環境で録音された18のシーンを含むノイズデータセットを選定しました。
グループA:音声データセット
音声データセットとして、韓国知能情報社会振興院が運営するAI統合プラットフォーム「AIハブ」で公開されている多言語通訳・翻訳朗読データのうち英語のデータを使用します。
- データの出典:https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=71524
- データ名:「Validation - 원천 데이터(ソースデータ) - VS_en_1」を使用(合計17,981個)
- 形式
- サンプリングレート:48kHz
グループB:ノイズデータセット
ノイズデータセットとしては、Demandデータセットを使用します。
- データの出典:https://zenodo.org/records/1227121
- ノイズの種類
- 全18のシーンで構成
- 各シーンごとに16チャンネル(複数の位置で同時に録音)
- 形式
- サンプリングレート:48kHz
- 長さ:5分
下の表は、Demandデータセットに含まれるノイズのシーンを示しています。6つの大分類に分けられ、各大分類は3つのシーンで構成されています。
| 分類 | シーン | 説明 |
|---|---|---|
| 家庭内 | Washing | 洗濯機が稼働している洗濯室 |
| Kitchen | 料理を準備しているキッチン | |
| Living | 音楽が流れるリビング | |
| 自然 | Field | スポーツ競技場 |
| River | 水が流れる小川 | |
| Park | 観光客の多い公園 | |
| オフィス | Office | 3人がパソコンを使用しているオフィス |
| Hallway | ��人が行き交うオフィスビルの廊下 | |
| Meeting | ミーティング中の会議室 | |
| 公共 | Station | 地下鉄の乗り換えエリア |
| Cafeteria | 混雑しているオフィスのカフェテリア | |
| Restaurant | ランチタイムの大学の食堂 | |
| 街 | Traffic | 交通量の多い交差点 |
| P Square | 観光客の多い公共広場 | |
| Cafe | 広場のカフェテリア | |
| 交通 | Metro | 地下鉄 |
| Bus | バス | |
| Car | 自家用車 |
テストデータセットの準備
テストデータセットは、音声対雑音比(Signal-to-Noise Ratio、以下SNR)と混合された信号のレベルがあらかじめ定義したレベルになるよう、音声データとノイズデータを混合して作成されます。
このデータセットを使用することで、NS技術の性能をさまざまなノイズ環境下で正確に評価でき、実際の利用環境でどのような性能を発揮するかを客観的に評価できます。
テストデータセットA:クリーンな音声のファイル
グループAから3,780個の音声データを重複なくランダムに選択します。
テストデータセットB:ノイズファイル
グループBのノイズデータ(16チャンネル*18シーン)から3,780個をランダムに選択します。
テストデータセットC:テストデータセットAとBを混合したファイル
テストデ�ータセットCの作成プロセスでは、テストデータセットAとBを混合し、実際の利用環境を模擬したテストデータセットを作ることに焦点を当てます。実際の利用環境で重要な変数としては、話者とマイクの距離、話者の声の大きさ、ノイズ発生源の位置などがあります。これらの変数は、以下のようにレベルやSNRの設定に直接影響を与えます。
- 話者とマイクの距離:話者とマイクの距離が離れるほど、話者の声は小さく録音され、レベルが低くなります。
- 話者の声の大きさ:話者の声が大きいほど、録音された音声データのレベルは高くなり、声が小さいほど、レベルは低くなります。
- ノイズ発生源の位置と性質:ノイズ発生源の位置と性質(例:小さくて一定のノイズ、大きくて断続的なノイズなど)は、SNRに大きな影響を与えます。ノイズの発生源がマイクに近いほど、またはノイズの強度が大きいほど、SNRは低くなります。これは、ノイズに対する音声信号の強度が低いことを意味します。
レベルとSNRは上記のような変数によって決定され、混合オーディオデータの音質やノイズ抑制技術の性能を評価する上で重要な要素となります。レベルはオーディオデータ全体の音量を決定し、SNRは音声信号に対するノイズの比率を表します。このレベルとSNRは、ノイズ抑制技術がどれだけ効果的にノイズを抑制できるかを評価するために使用されます。
これらの変数を考慮してさまざまなレベルとSNRの条件を設定することで、実際の利用環境で起こりうるさまざまなシナリオを網羅できるテストデータセットCを作成します。これにより、ノイズ抑制技術の性能をより正確かつ包括的��に評価できます。
レベルは以下の段階に細分化されます。
- レベル(Level):-15、-20、-25、-30、-35、-40、-45dB(全7段階)
レベル値が-15dBの場合は大きな音を意味し、大きな声で会話しているか、話者とマイクの距離が近い環境を示します。一方、レベル値が-45dBの場合は非常に小さな音を意味し、静かな環境でのささやき声や、マイクとの距離が遠い状況に該当します。
SNRは以下の段階に細分化されます。
- SNR:-5、0、5、10、15、20dB(全6段階)
SNR値が-5dBの場合は、ノイズが音声信号よりも大きいことを示します。これは、非常に騒がしい環境での会話、例えば、工事現場付近や騒がしいカフェ内での通話などの状況を模擬しています。一方、SNR値が20dBの場合は、音声信号がノイズよりもはるかに大きいことを示します。これは、比較的静かなオフィス環境で明確な音声通話を行う場合などに当てはまります。
レベルとSNRの組み合わせにより、合計42(7レベル段階*6SNR段階)の条件が作成されます。各条件にテストデータが均等に分布するようにして、1つの条件ごとに5つのテストデータを作成します。その過程で、ノイズデータは音声データと同じ長さに調整され、特定のSNRに合わせて混合されたオーディオデータの音量はターゲットレベルに合わせて調整されます。
上記のプロセスにより、各シーンに対して合計210個(42条件*5データ)のデータセットを作成します。SNRとレベルごとのデータセット数は以下のとおりです。
| LEVEL/SNR | -5 | 0 | 5 | 10 | 15 | 20 |
|---|---|---|---|---|---|---|
| -15 | 5 | 5 | 5 | 5 | 5 | 5 |
| -20 | 5 | 5 | 5 | 5 | 5 | 5 |
| -25 | 5 | 5 | 5 | 5 | 5 | 5 |
| -30 | 5 | 5 | 5 | 5 | 5 | 5 |
| -35 | 5 | 5 | 5 | 5 | 5 | 5 |
| -40 | 5 | 5 | 5 | 5 | 5 | 5 |
| -45 | 5 | 5 | 5 | 5 | 5 | 5 |
テストデータセットの総数は以下のとおりです。
- シーン数(18)*シーンごとのテストデータセット数(210) = 合計3,780個
このテストデータセットは、ユーザーが日常生活で遭遇するさまざまな状況を幅広く反映するように設計されています。家庭内、オフィス、カフェ、道端、公共の場など、さまざまな場所でレベルとSNRを変化させながら、日常生活におけるさまざまなノイズ環境での通話状況を再現します。このように膨大な量のテストデータセットをNS技術の入力として提供することで、NS技術の性能を総合的に検証し、実際の利用環境で効率的に動作するかどうかを正確に評価できます。
NS性能評価指標の選定
LINEアプリの開発では、NS技術の性能評価を一貫して行い、結果の信頼性を高めることを目指しています。
一般に、NS技術の性能評価に多く参照されるITU-T P.835勧告は、バックグラウンドノイズが発生する環境での音声通話品質を主観的に評価するための具体的な手順を示しています。しかし、主観的な評価にはコストと時間がかかるだけでなく、評価者の主観によって結果に誤差が発生する可能性があるという限��界があります。このような問題を解決するために、HEAD acoustics社はITU-T P.835勧告に基づき、バックグラウンドノイズ環境下での音声通話の品質をより客観的に評価するために設計された、通話音声品質評価方法の3QUESTを開発しました。ETSI EG 202 369-3という標準規格として指定されたこの方法は、主観的な評価の限界を克服するために開発されたもので、さまざまなノイズ状況における製品性能の定量的評価をサポートします。人が音を聞いて評価に参加するITU-T P.835とは異なり、ソフトウェアを使って音を評価するため、入力が同じ場合は同じ評価結果が出ます。
私たちはこのHEAD acoustics社の3QUESTをNS評価ツールとして選定しました。3QUESTはS-MOS、N-MOS、G-MOSという3つの客観的な指標を提供します。
- S-MOS:ノイズ抑制後に保存された音声の品質を測定する指標です。1から5までの数字で表され、数字が高いほど音声品質が優れていることを示します。
- N-MOS:ノイズ抑制後に残存するノイズの量を測定する指標です。1から5までの数字で表され、数字が高いほどノイズ抑制の品質が良いことを示します。
- G-MOS:S-MOSとN-MOSを組み合わせた総合的な品質を示します。
以下の表は、ITU-T P.835のガイドによるS-MOS、N-MOS、G-MOSの主観的な評価方法をまとめたものです。下表を参照して3QUESTの結果指標を見てみると、音声の歪みや残留ノイズに対する評価者の主観的な認識度を確認できます。
| Determination of subjective speech MOS (S-MOS) | Determination of subjective noise MOS (N-MOS) | Determination of subjective global MOS (G-MOS) |
|---|---|---|
|
Attending ONLY to the SPEECH SIGNAL, select the category which best describes the sample you just heard. 5 - NOT DISTORTED |
Attending ONLY to the BACKGROUND, select the category which best describes the sample you just heard. 5 - NOT NOTICEABLE |
Select the category which best describes the sample you just heard for purposes of everyday speech communication. 5 - EXCELLENT |
出典:https://global.head-acoustics.com/downloads/eng/application_notes/telecom/Appl_note_3QUEST_e0.pdf
LINEアプリの開発では、3QUESTの3つの指標のうち、S-MOSとN-MOSの2つの客観的な指標を選択して評価を行っています。G-MOSは、NSモジュールの総合的な通話品質を評価する指標です。そのため、特定の指標の性能改善が必要な場合、その影響を直接把握することが難しいので除外しました。代わりに、S-MOSとN-MOSの指標だけを別々に評価することで、音声品質とノイズ抑制品質、それぞれの改善点をより正確に導き出し、適用できます。
下表の音源を再生すると、S-MOSとN-MOSのスコア帯ごとに音声品質の違いを体感できます。
| S-MOS | オーディオファイル | ノート |
|---|---|---|
| 1.x | ||
| 2.x | ||
| 3.x | ||
| 4.x | クリーンな音声 |
Contains information from VCTK Dataset which is made available under the ODC Attribution License.
| N-MOS | オーディオファイル | ノート |
|---|---|---|
| 2.x | ||
| 3.x | ||
| 4.x | クリーンな音声 |
Contains information from VCTK Dataset which is made available under the ODC Attribution License.
測定システムの環境設定
テストデータセットの構成と評価指標の選定が完了したら、NSモジュールの性能を測定するための測定システム環境を設定します。構成要素は以下のとおりです。
- テストデータセット:テストデータセットA(音声データ)、テストデータセットB(ノイズデータ)、テストデータセットC(ミックスデータ)
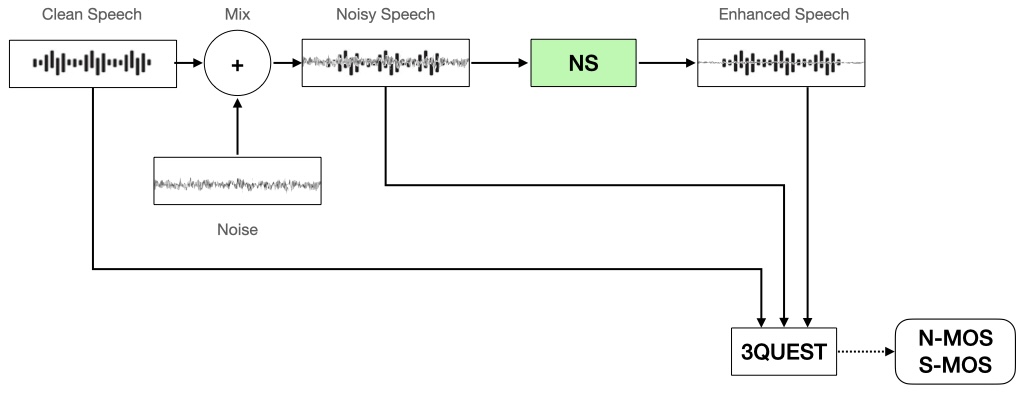
- 3QUEST:テストデータセットA(リファレンス、Clean Speech)、テストデータセットC(Clean Speech + Noise = Noisy Speech)、NSモジュールの出力(Enhanced Speech)の3つのファイルを分析し、音声の劣化度合いとノイズ抑制能力を測定するツール
- NSモジュール:性能測定の対象となるNSモジュール
NS性能の測定
NS性能の測定は以下の手順で行います。
- テストデータセットA(Clean speech)とテストデータセットB(Noise)を混合したテストデータセットC(Noisy speech)をNSモジュールに入力します。
- NSモジュールの処理結果(Enhanced Speech)とテストデータセットA、テストデータセットCを3QUEST測定ツールに入力し、N-MOSとS-MOSを測定します。
- シーン/SNR/レベルごとのN-MOSとS-MOSのスコア分布を確認し、NSモジュールの性能を評価します。
おわりに
LINEヤフー株式会社では、このような体系的なアプローチにより、当社のNS技術の性能を精密に評価し、継続的に改善を行っています。さまざまな環境での広範なテストを行い、信頼できる評価指標を活用することで、ユーザーに最高の音声通話体験を提供するための 技術基盤を構築しています。今後もユーザーのコミュニケーション品質を向上させるための研究開発に投資を続け、それによってユーザーがどのような環境でもクリアでクリーンな音声通話を楽しめるように努力していきます。


