こちらの記事に加筆修正したものをDemaecan Tech Blogに掲載しています。(2025/08/07 追記)
出前館開発本部でサーバーサイド開発を担当している本多です。LINEヤフーのグループ会社である出前館とは資本業務提携を結んでおり、LINEヤフーが開発をサポートしています。本ブログでは以下についてお話しします。
- モノリス → マイクロサービスへのアーキテクチャ移行
- 多くのマイクロサービスがデータベースを共有するというアーキテクチャの中でのデータ不整合や不正なデータが生じている負債(-1 の状態)の原因。
- 0 → 1 ではなく、-1 → 1 での新規マイクロサービス開発における実践した手法。
出前館で取り組まれるマイクロサービスアーキテクチャとマイクロサービス化における"-1"の課題
近年、大規模なシステムを取り扱う企業・サービスでは、運用面や人的・インフラ的コスト面とトレードオフに、スケーラビリティや疎結合なシステムを構築するため、マイクロサービスアーキテクチャを推進しています。出前館においても、モノリシックアーキテクチャからマイクロサービスアーキテクチャへの移行が行われています。適切なドメイン領域(Order, Delivery, Shop, Cart, ..., )ごとにシステムが切り出され、ドメイン固有のロジックをマイクロサービスに隠蔽し、REST/gRPC を用いた API での連携や Kafka を利用したイベント連携を行い、システムの疎結合化を図る取り組みを行っています。現在では 90 を超えるマイクロサービスが稼働しています。
現状の出前館は、マイクロサービス化がされていないドメイン領域があったり、�マイクロサービス化された多くのシステムが一つの巨大なデータベースを共有し、複数のシステムが同じテーブルに対してデータの CRUD を行っているユースケースが多数存在しています。
本来、マイクロサービスでは、サービスごとにデータストアを持ち、そのドメイン領域におけるロジックを隠蔽化し、疎結合・高凝集のシステムを構築することが理想ですが、集約されるべきロジックが複数のマイクロサービスに分散されていて、データの不整合や不正なデータが生まれている状況が発生しています。
一般に、新規開発は 0 → 1 と表現されますが、未着手のドメイン領域におけるマイクロサービスの新規開発は、データの不整合や不正なデータが生まれている状況の "-1"の状態 からのスタートになり、この -1 の負債解消を考慮しながらの新規開発になります。本記事では、大規模システムのマイクロサービス化における -1 → 1 の新規開発において実践したアプローチをお話しします。
新規開発における実践した取り組み
オーナーシップを持つドメイン領域(データ/ロジック)について調査・把握をする
マイクロサービスに分割する粒度としてドメイン/境界付けられたコンテキスト、システムのボラティリティ(変更や更新が同じタイミング・原因で発生しやすい機能ごと)での抽出、データの性質(プライバシー面/セキュリティ面)、技術要素、組織粒度など多くの選択肢がある[1]と思いますが、出前館では、基本的に個々のドメインごとの切り出しでのマイクロサービス化が行われています。今回、新規開発したドメイン領域は、加盟店が出品している商品(食べ物や飲み物などのメニューデータ)を扱うドメインのマイクロサービスで、扱う情報としては、商品のマスタデータ、それに付随する付加データ群です。
まず、我々は、オーナーシップを持つドメイン領域に関して提供する機能やデータ構造など俯瞰した調査をし、整理しました。ドメイン駆動設計 (DDD: Domain Driven Design) / オブジェクト指向プログラミング (OOP: Oriented Object Programming) におけるソフトウェア開発の文脈では、まず第一に業務理解・ドメインや扱うデータやロジックに対する理解がなければ、ユーザーの要求を満たせられるソフトウェアは作れず、時間が経つに連れてコードベースが育ってきた時に保守性や拡張性のないソフトウェアになってしまいます。出前館には、各マイクロサービスが共有している 1 つの巨大なデータベースに 800 を超えるテーブルが存在し、その責務分離のため、各テーブルに対してオーナーシップを持つべきマイクロサービスが整理されています。テーブルの中には、他ドメインとの境界にまたがるものもあり、各マイクロサービス担当のチームとコミュニケーションをとり、どちらがオーナーシップを持つかの合意を形成しています。
今回、調査や仕様把握に困難であったのは、出前館はサービス・システムの歴史が長いため、技術スタックもレガシーな部分があったり、大規模なシステムであるものの、商品ドメインは今までオーナーシップを持っていた組織がなく、包括的にメンテナンスされていたわけではないため、仕様や設計は文書化されていることの方が少なく、開発者の中にもドメインを詳細に把握している人が数少ないという点でした。また、後述しますが、多くの問題もありました。
マイクロサービスへどう分解していくか
マイクロサービスを具体的にどう分解するかのプロセスとしては、BigBang / Strangler Fig / Parallel Run / Feature toggle ...など様々なアプローチがありますが、プロダクトとしての成長を止めずに、ビジネス価値を創出し、並行して出前館全体としてのシステムの疎結合化を行う必要があったため、段階的な移行が可能でマイクロサービスの分解としては、有名な Martin Fowler が提唱している Strangler Fig パターン[2] の手法を Fig1 の通り、おおまかなマイクロサービス化のアーキテクチャのロードマップを決め、進めていきます。
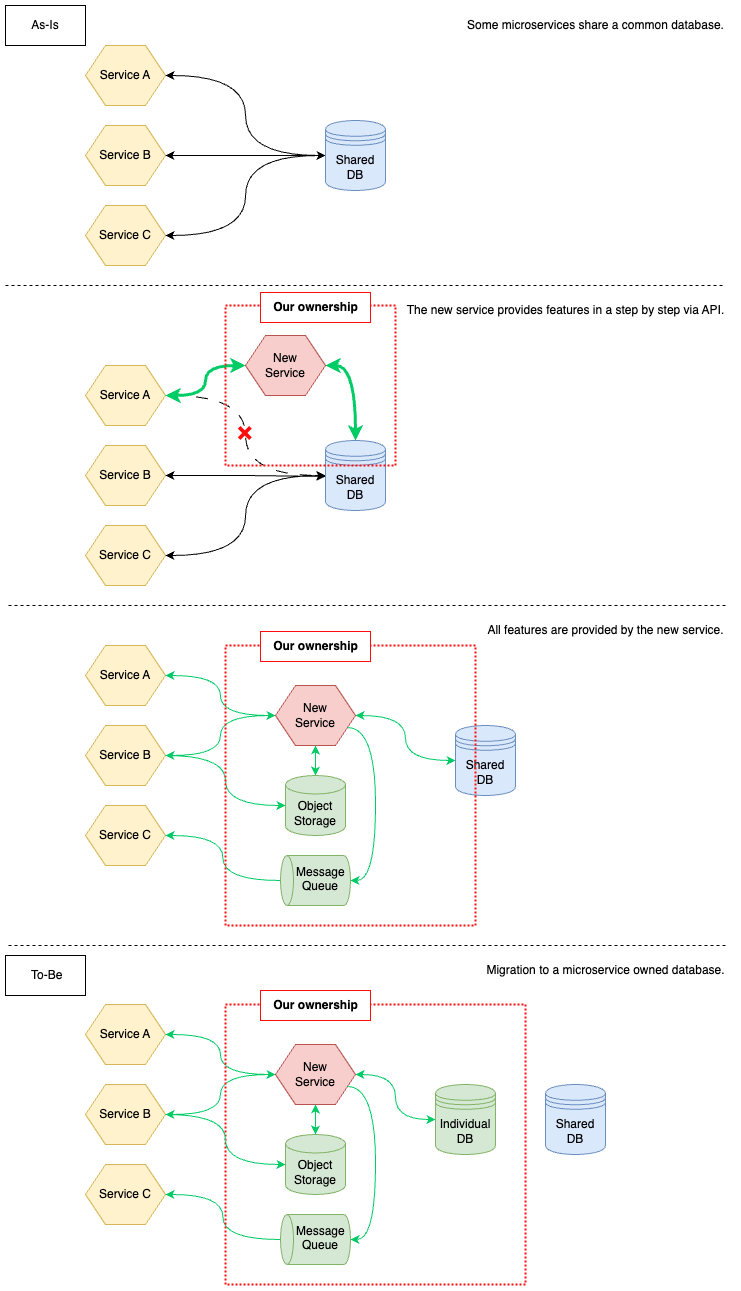
As-Is はデータベースを複数のマイクロサービスが共有している状態で、多くのマイクロサービスが、我々の持つオーナーシップのテーブルにアクセスしている状態です。ロードマップとしては、新しいマイクロサービスを立ち上げて、実装された機能を徐々に他サービスへ API やファイル連携、イベント連携などを提供し、データベースへの直接の CRUD を無くしていく方針です。要件に応じて、API による同期アーキテクチャ、ファイル連携のオブジェクトストレージ、Kafka などのメッセージキューなどの非同期アーキテクチャを導入し、我々が提供すべき全ての機能を他サービスに対して提供し、共有データベースから独自データベースへの切り替えを行うことをTo-Beとしました。
また、データベース移行を最後のステップに持ってきている理由としては、現状のテーブル構造は複雑であり、独自データベース化する際に、スキーマの変更を見据えている点やまず対象ドメインのテーブルの囲い込みを最優先とし、技術的に難易度の高い複数の永続化層に対して整合性を維持するダブルライトの仕組みを初期から導入するのはコストが高いため、避ける判断をしました。Ownership の赤線が徐々に広がるように、機能を提供するにあたって、オーナーシップを広げていき、あるべき責務分離を優先としました。
マイクロサービスとデータベース
一般的に多くのシステムでは、サービスの立ち上げ時には1つのアプリケーションと1つのデータベースのモノリシックなアーキテクチャとして構築し、その後、ビジネスのスケールや開発体制の増強によりマイクロサービスへのアーキテクチャ移行への意思決定が行われていると思います。アプリケーションを分割することとデータベースを分割することでは、難易度やそれにかかる人的リソース、インフラ的リソースが後者の方が大きくなります(JOIN前提で組まれていたSQLなどが使えなくなるための対応、データベースのインスタンス自体のコスト・それのメンテナンスする人的コストなど)。そのため、多くのサービスではアプリケーションとしては分かれていて、マイクロサービスではあるもののデータベースは共有したままというアーキテクチャがしばしば見られると思います。しかし、そのアーキテクチャではデータベースが単一障害点になってしまいます。複数のマイクロサービスがデータベースを共有しているということは、データベース起因で障害が発生した時に、影響範囲が大きくなり、最悪の場合、サービス停止にまで発展してしまいます。実際に出前館では、データベース起因の障害によってサービス停止まで発展したことが何度かあります。マイクロサービスのロードマップで最後にマイクロサービス個別のデータベースまで分解することをゴールとしていることは、上記のようなデータベースが単一障害点になることの改善を目指しています。また、単一障害点を排除する目的のみならず、出前館というサービスは、トラフィックも多くサービスに対して求められる非機能要件や将来的なビジネス規模を見据えるとスケーラビリティが必要不可欠です。マイクロサービスに個々のデータベースを持つことは、マイクロサービス単位でのスケーリング(またはスケーリングさせるための技術選定)が可能になります。
マイクロサービス化における新規開発での問題点
ロジックの分散
マイクロサービスでのロジック分散が起きている一因として、本来ロジックを持つべきマイクロサービスがなく、各システムが一つの巨大なデータベースを共有(データベースレベルでの結合)しているという点があります。マイクロサービス化していく過程として、さまざまなコンポーネントが参照するような依存性の高いデータを扱うマイクロサービスを先に切り出し、他のマイクロサービスは先に切り出したコンポーネントが提供する API に依存するように切り出すという流れが理想だと思います。
しかし、商品(メニュー)ドメインにおいては、マイクロサービス化における包括的な戦略がとられていなく、商品(メニュー)をオーナーシップにもつマイクロサービスが作られず、他のマイクロサービスから作られている歴史的な経緯もあり、同じ機能の処理を実装していました。一見、モノリスからマイクロサービスとして疎結合という観点は前進していますが、高凝集という観点ではむしろ後退しています。Fig2 の通り、ある機能では多くのシステムに同じ機能が実装されていて、複数のアクターが同じテーブルに対して CRUD しているケースも存在していました。
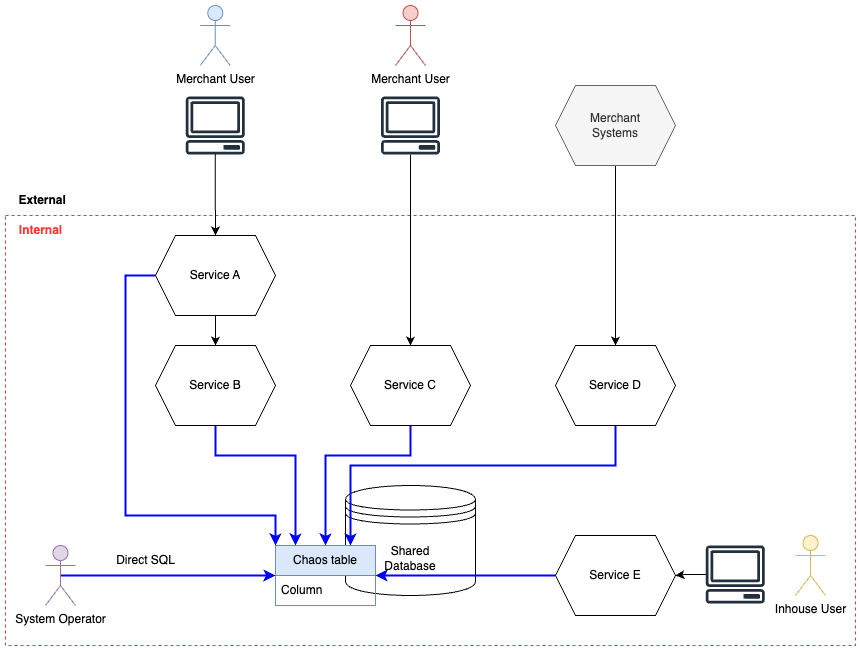
不正なデータや整合性の取れていないデータの存在
商品ドメインのテーブルには多くの不正なデータや整合性の取れてないデータが多く存在していました。この理由として、Fig2 の状態を含め改めて整理すると、
- 複数のマイクロサービスが、個々に同じ機能を実装している
- 歴史のあるレガシーなコードの処理や仕様が改善されないまま残り続けている
- マイクロサービスがその処理を独自の仕様に変更し、実装している
- システム経由ではなく、手運用で SQL を実行してデータを入稿するオペレーションが存在している
などの要因がありました。さらにこれに加えて、古くからある仕様が複雑であると同時に、データ構造の複雑さ、処理の複雑さなどが顕在し、結果、多くの不正なデータや整合性の取れていないデータを生み出すことを助長していました。
対応策
分散したロジックをどう凝集していくか
ロードマップ部分でも記載しましたが、機能ごとの要件に応じて、適切なアーキテクチャによるデータ連携(API による同期連携、オブジェクトストレージやメッセージキューによる非同期連携)の仕組みを提供し、システム間の連携方法を切り替えることで、データベースレイヤーの結合をなくし、マスタデータに対するデータ操作を単一のコンポーネントのみが実装することができ、多くのマイクロサービスに分散してしまったロジックを無くし、全体アーキテクチャとしての凝集度を�高めます。
しかし、出前館は歴史が長い点に加え、ビジネスモデルも一般的なECサイトなどと比較し、toC領域(消費者)、toB領域(加盟店、配達員)などステークホルダーが多く、扱うシステムもその分増えるため、企画を含めた開発体制も大きくなり、同じ機能でも部署ごとに認識や仕様が違っていたり、マイクロサービスに実装されたロジックがそれぞれで少しずつ違うことが生じていました。この際、複数のマイクロサービスで同じ機能とみなせるものは、部署横断で企画/開発を巻き込んで、積極的に統合していくような合意を得るため、コミュニケーションによる調整を行いました。
不正なデータをどう扱うか
アプリケーション設計
まず前提として、アプリケーションの設計について軽く説明します。我々のチームでは、技術選定として Spring Boot + Kotlin で開発しています。ソフトウェアアーキテクチャとして Gradle におけるマルチプロジェクトで以下のような構成のソフトウェアアーキテクチャを設計しました。
% tree -dL 1
.
├── api
├── batch
├── config
├── domain
├── gradle
├── infrastructure
├── newrelic
├── self-hosted-runner
└── testUtil各ランタイム(API / Batch)での application レイヤーと domain レイヤー, 外部への疎通を担う infrastructure レイヤーに大きくわかれ、domain レイヤーには infrastructure の interface を実装し、依存性逆転をさせています。パッケージは gradle の依存関係で、依存の方向を単一方向に強制させる仕組みにしています。ここでは、細かくソフトウェ��アアーキテクチャについての話は展開しませんが、大きく仕組みとしてシステムが持つ Domain ロジックと Usecase ロジックの概念を捉えられるようにしています。Domain ロジックは、汎用的で機能に関係なくドメイン全てにわたって適用されるルール、Usecase ロジックは特定の機能に適用されるルールという整理にしています。
データに対して自浄作用のある実装
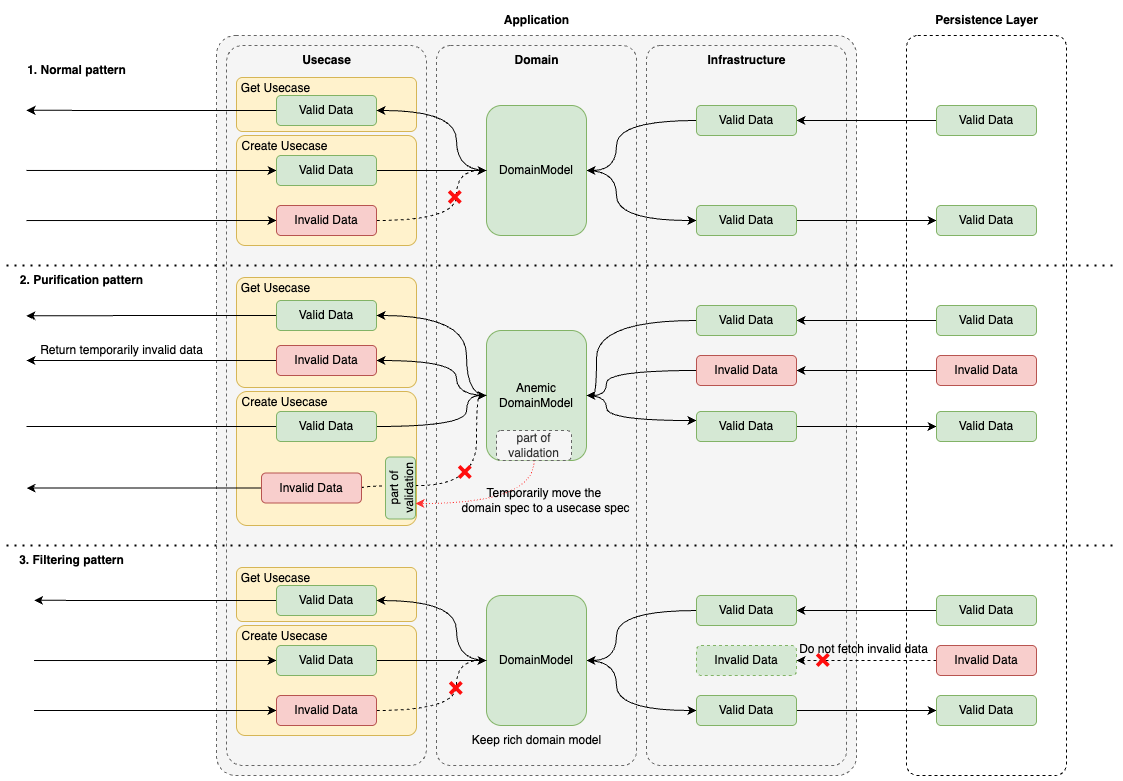
上記のアプリケーション設計を踏まえ、Fig3 に実装パターンとデータフローを示しました。Fig3.1 で示した実装パターンは、基本的なアプリケーションの実装パターンで、特定のユースケースに適用されるロジックを Usecase に、扱うドメインに汎用的に適用されるロジックを Domain に実装します。しかし、共有データベースに、他マイクロサービスから永続化されている不正データが存在し、かつデータを返却しなければならない時、Domain の実装を固くしてしまうと、Domain model に変換するときに、不正データを扱うことができなく返却が不可能になり、デグレードが発生してしまいます。このとき、我々は Fig3.2 で示したようにデータに対して自浄作用のある実装を行いました。意図的に、Domain Model の validation を緩めることでデータを許容し、Create の Usecase に本来 Domain で実装される validation を実装します。こうすることで、このアプリケーションを通って作成される新規のデータは valid な状態で作成されつつ、invalid なデータも一時的に返却可能にでき、自浄作用のあるアプリケーションの実装をしました。
本来の新規開発であればこのような実装は、ドメインモデルに実装されるべきロジックが流出しているため、よく言うドメインモデル貧血症[3][4]という状態になり、DDD では広く知られたアンチパターンとされています。しかし、このようなレガシーシステムに対して、あえてロジックの実装する箇所を変更し、アプリケーションとしての過渡期を設けることで、不正なデータに対して要件を満たせるように柔軟に対応しました。
そもそも、この場合、CQRS を導入し、Command モデルと Query モデルを分けて Read/Write のユースケースでそれぞれのモデルを使う選択肢もありましたが、ローンチ時にはコードベースの複雑さや肥大化を避けたく、Read/Write での interface が統一されている単一のモデルを常に扱うシンプルさを維持したい目的があり、CQRS の導入を見送っています。
以下に、実装したコードのサンプルを示します。
data class DomainModel(
val valueObjectA: ValueObjectA,
val valueObjectB: ValueObjectB
) {
init {
// This domain logic is temporarily moved to usecase
// require(valueObjectA > valueObjectB) { "Value object A must be greater than value object B" }
}
:
}
@Component
class CreateUsecase(
private val xxxRepository: XxxRepository
) {
fun execute(request: Request): Response {
val valueObjectA = ValueObjectA(request.a)
val valueObjectB = ValueObjectB(request.b)
// This validation logic is temporarily moved to usecase
require(valueObjectA > valueObjectB) { "Value object A must be greater than value object B" }
val domainModel = DomainModel(valueObjectA, valueObjectB)
xxxRepository.save(domainModel)
return Response.ok()
}
}
@Component
class GetUsecase(
private val xxxRepository: XxxRepository
) {
fun execute(request: Request): Response {
// Invalid data can be restored to the Domain Model
val domainModel = xxxRepository.findById(request.id) // The repository returns data where "valueObjectA < valueObjectB"
return Response.fromDomainModel(domainModel)
}
}DomainModel で validation すべきロジックを Create のユースケースに一時的に実装を移植し、データの新規作成では全てのロジックが適用され、あるべきデータのみが作られ、Get の Usecase では、データとしては不正ではあるものの現状返却しなければならないデータを、to-be のコードの形を保ったまま実現することができます。共有データベース側の CRUD を他マイクロサービスから剥がし、データのクレンジング・パッチが終わったタイミングで、Domain Model 側に validation ロジックを戻すことで最終的に全てのロジックが Domain Model に実装され、Always valid domain model の DomainModel を常に扱え、固いアプリケーションとして実装することができます。
データフィルタリング
共有データベースでは思いもしないような不正データが混入している場合があります(データが持っている期間の開始時刻と終了時刻が逆転しているなど。※実例)。返す必要のないと判断できるほどの不正なデータは、Fig3.3 のようにデータフェッチ自体をせず、過度にドメインモデルからロジックが流出してしまうことを防ぎました。
データパッチ・データクレンジング
他マイクロサービスから我々がオーナーシップを持つテーブルへの直アクセスを無くした後、対象のテーブルに含まれているデータに対してデータクレンジングやデータパッチを行います。
データがあるべき状態になったことで、上記の自浄作用のある実装として行っていた validation の位置を故意に Usecase へ移植していた部分をあるべき DomainModel の位置に戻すことができ、マ��クロの部分(システム間のアーキテクチャ、オーナーシップ)とミクロの部分(アプリケーションの構造)含めて、マイクロサービス化の小さな一歩が達成できます。
上記のフローを、我々が扱うドメインとして持つ機能の一つずつ、丁寧に実施していくことでマイクロサービス化を推し進めています。
おわりに
今回紹介した手法、開発におけるフローやアプリケーションアーキテクチャ・データの扱いなどは、言うまでもなく銀の弾丸ではなく、各事業の内容やフェーズ・プロダクト・ドメイン・扱うユースケース・組織など様々な要因によってケースバイケースでとりうるべきアプローチは異なると思います。
AI の目新しさが話題の昨今ですが、多くのエンジニアは日々レガシーと立ち向かっていると思うので、このブログが、レガシーに立ち向かっている・これから立ち向かうエンジニアの一助となれば幸いです。
さいごに、日々成長している出前館という環境で、優秀なエンジニアが多く在籍し、複雑かつ変化の激しい多様な要素が混在するシステム・組織に一緒に立ち向かっていける人材をLINEヤフー株式会社では募集しています。
引用
[1] Sam Newman, Building Microservices, 2nd Edition (2021)
[2] Martin Fowler, https://martinfowler.com/bliki/OriginalStranglerFigApplication.html, https://martinfowler.com/bliki/StranglerFigApplication.html (2004, 2024)
[3] Martin Fowler, https://martinfowler.com/bliki/AnemicDomainModel.html (2003)
[4] https://learn.microsoft.com/ja-jp/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/microservice-domain-model#rich-domain-model-versus-anemic-domain-model


