이전에 LINE 앱에서 음성 품질을 측정하는 방법이라는 글에서 LINE 앱에서 어쿠스틱 환경과 네트워크 환경 변화, 글로벌 환경에 대응하는 방법을 소개한 바 있습니다. 특히, 어쿠스틱 환경에 대응하는 방법과 관련해서 AEC(acoustic echo cancellation, 에코 제거) 성능 측정 방법을 자세히 다뤘는데요. 이번 글에서는 어쿠스틱 환경 대응의 핵심 요소 중 하나인 잡음 제거(noise suppression, 이하 NS) 기술의 성능을 측정하는 방법을 소개하고자 합니다.
NS 기술 소개 - NS란 무엇인가요?
소리는 공기 중에서 진동하는 파동의 형태로 전달되며, 마이크는 이러한 소리 파동을 전기적 신호로 변환하는 장치입니다. 그런데 마이크는 주변 환경의 모든 소리를 포착하기 때문에 사용자의 목소리뿐 아니라 배경 잡음도 함께 포착됩니다. 따라서 마이크에 포착된 신호에는 사용자의 목소리와 주변 환경의 잡음이 섞여 있으며, 이런 잡음은 통화 품질을 저하시킬 수 있습니다.
NS는 주변 환경에서 발생하는 잡음을 제거해 사용자들에게 더 깨끗하고 좋은 품질의 음성 통화를 제공하는 기술입니다. 실제로 잡음이 없는 완벽하게 조용한 환경을 만드는 것은 불가능하기 때문에 잡음 문제는 NS 기술을 통해 해결해야 합니다. NS 기술은 사용자가 다양한 환경에서 명확한 음성 통화를 할 수 있도록 도와주며, 이는 LINE 앱 사용자 경험의 핵심 요소 중 하나입니다.
LINE은 자체 기술로 NS를 직접 개발하고 있으며 ML(Machine Learning) 기술을 도입해 고품질의 잡음 제거 성능을 제공하고 있습니다. 이를 통해 사용자는 주변 잡음으로 인한 불편함을 최소화한 깨끗하고 높은 품질의 음성 통화를 즐길 수 있습니다.
NS 성능 측정 방법
정량적 평가는 NS 기술의 성능을 객관적으로 측정하고 평가할 수 있는 중요한 방법입니다. 정량적 평가를 통해 기술의 잡음 제거 능력을 신뢰성 있게 파악해 사용자의 통화 경험을 지속적으로 개선할 수 있습니다.
NS 기술의 성능을 평가할 때 가장 중요한 요소 두 가지는 오디오 품질 유지와 잡음 제거 능력 측정입니다. 이는 해당 기술이 사용자의 음성과 같은 원하는 소리는 온전히 보존하면서 동시에 배경 잡음을 얼마나 줄이는지 평가한다는 의미입니다.
LINE은 정량적 평가를 통해 NS 기능을 효과적으로 관리하며 고객들에게 최상의 통화 경험을 제공하기 위한 노력을 지속하고 있는데요. NS 기술의 성능 측정은 다음과 같은 절차로 진행합니다.
- 성능 측정 접근 방식 수립
- 데이터 셋 선정
- 테스트 데이터 셋 준비
- NS 성능 평가 지표 선정
- 측정 시스템 환경 구성
- NS 성능 측정
각 절차를 순서대로 하나씩 살펴보겠습니다.
성능 측정 접근 방식 수립
NS 성능을 측정하기 위해 수립한 접근 방식은 다음과 같습니다.
재현성과 일관성 보장
표준화된 평가 도구를 사용해 반복 가능한 환경에서 성능을 측정합니다. 또한 동일한 데이터 셋으로, 네트워크의 영향을 최소화하기 위해 로컬 환경에서 테스트를 진행합니다. 이를 통해 동일한 조건에서 일관된 결과를 얻을 수 있으며, NS 기술의 성능 변화나 개선 사항을 정확하게 파악할 수 있습니다.
신뢰할 수 있는 평가 지표
국제적으로 인정받는 평가 표준을 활용해 업계 및 학계에서 널리 인정받는 신뢰할 수 있는 성능 지표를 산출합니다. 이와 같은 방식으로 음성의 명료도와 잡음 제거 효과를 나타내는 지표를 산출함으로써 NS 기술 성능의 신뢰를 확보할 수 있으며, 제품의 성능을 정량적으로 비교하며 발전 방향을 설정할 수 있습니다.
다양한 잡음 환경에서 성능 확인
NS 기술의 성능을 다양한 환경에서 정량적으로 확인하기 위해 다음과 같이 성능을 측정합니다.
- 대용량 음성 데이터 셋: 성별, 나이 등을 고려한 다수의 음성 샘플이 포함된 음성 데이터 셋을 사용합니다.
- 다양한 잡음 유형: 카페, 도로, 사무실 등 다양한 환경의 잡음이 포함된 잡음 데이터 셋을 사용합니다.
- 합성 비율 조정: NS 기술의 안정성을 높이기 위해 원본 음성과 잡음을 다양한 비��율로 조합해 테스트합니다.
LINE은 이와 같은 접근 방식으로 NS 기술이 다양한 환경에서 얼마나 효과적으로 작동하는지 검증하며 사용자에게 최상의 음성 통화 경험을 제공하기 위해 노력하고 있습니다.
데이터 셋 선정
저희의 목표는 NS 기술의 성능을 사람이 들을 수 있는 모든 가청 대역에서 평가하는 것입니다. 이를 위해 48kHz의 고해상도 음원을 데이터 셋으로 선정했습니다. 48kHz의 샘플링 레이트를 가진 음원은 인간의 가청 주파수 범위인 대략 20Hz에서 20kHz까지의 소리를 포괄적으로 담을 수 있으며, 이를 통해 NS 기술이 다양한 주파수에서 어떻게 작동하는지 정밀하게 평가할 수 있습니다.
또한, 잡음 데이터 셋으로는 18개의 다양한 장면으로 구성된 데이터를 선택했습니다. 각 장면은 서로 다른 위치에서 녹음됐으며, 이는 NS 기술이 사용자의 위치와 환경에 따라 어떻게 다르게 작동하는지 평가하는 데 중요한 요소입니다. 사용자의 실제 환경은 매우 다양하기 때문에 이러한 다양한 환경에서도 효과적으로 잡음을 제거할 수 있는지 검증하기 위해 다양한 장면과 위치에서 녹음된 데이터를 사용합니다.
마지막으로 신뢰할 수 있는 평가 결과를 도출하기 위해서는 충분한 양의 음원 데이터가 필요합니다. 다양한 음원을 포함해야 통계적으로 유의미한 결과를 얻을 수 있으며, 이를 통해 NS 기술의 일관된 성능을 검증하고 예외적인 경우나 특정 조건에서의 성능 저하를 파악할 수 있습니다.
이런 사항들을 고려해 저희는 고해상도의 48kHz 음원과 다양한 환경에서 녹음된 18 개의 장면을 포함하는 잡음 데이터 셋을 선정했습니다.
Group A: 음성 데이터 ��셋
음성 데이터 셋으로는 한국지능정보사회진흥원의 AI 통합 플랫폼 다국어 통·번역 낭독체 데이터에서 영어 데이터를 사용합니다.
- 원본 출처: https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=71524
- 음원 경로: 'Validation - 원천 데이터 - VS_en_1' 사용(총 17,981개)
- 형식
- 샘플링 레이트: 48kHz
Group B: 잡음 데이터 셋
잡음 데이터 셋으로는 Demand 데이터 셋을 사용합니다.
- 원본 출처: https://zenodo.org/records/1227121
- 잡음 종류
- 총 18개 장면으로 구성
- 각 장면마다 16채널(서로 다른 위치에서 동시에 녹음)
- 형식
- 샘플링 레이트: 48kHz
- 길이: 5분
아래 테이블은 Demand 데이터 셋에 포함된 잡음 장면입니다. 6개의 대분류가 있고 각 대분류는 3개의 장면으로 구성됩니다.
| 분류 | 장면 | 설명 |
|---|---|---|
| 주거 | Washing | 세탁기가 작동 중인 세탁실 |
| Kitchen | 음식 준비 중인 주방 | |
| Living | 노래가 재생되고 있는 거실 | |
| 자연 | Field | 스포츠 경기장 |
| River | 물이 흐르는 시냇가 | |
| Park | 많은 관광객이 있는 공원 | |
| 사무 | Office | 세 명이 컴퓨터를 사용 중인 사무실 |
| Hallway | 지나가는 사람이 있는 사무실 건물 내 복도 | |
| Meeting | 논의 중인 회의실 | |
| 공공 | Station | 지하철 환승 지역 |
| Cafeteria | 번잡한 사무실 카페테리아 | |
| Restaurant | 점심시간 대학 식당 | |
| 거리 | Traffic | 번잡한 교통 교차로 |
| P Square | 많은 관광객이 있는 공공 광장 | |
| Cafe | 공공 광장의 카페테리아 | |
| 교통 | Metro | 지하철 |
| Bus | 버스 | |
| Car | 개인 승용차 |
테스트 데이터 셋 준비
테스트 데이터 셋은 음성 대 잡음 비율(Signal-to-Noise Ratio, 이하 SNR)과 혼합된 신호의 레벨이 사전에 정의해 놓은 레벨이 되도록 만들기 위해서 음성 데이터와 잡음 데이터를 혼합해서 만듭니다.
이렇게 준비한 데이터 셋을 사용하면 NS 기술의 성능을 다양한 소음 환경 하에서 정밀하게 평가할 수 있고, 실제 사용 환경에서 어떤 성능을 발휘하는지 객관적으로 평가할 수 있습니다.
테스트 데이터 셋 A: 깨끗한 목소리가 있는 파일
Group A에서 음성 데이터 3,780개를 무작위로 중복 없이 선정합니다.
테스트 데이터 셋 B: 잡음 파일
Group B의 잡음 데이터(16채널 * 18장면) 중에서 3,780개를 무작위로 선정합니다.
테스트 데이터 셋 C: 테스트 데이터 셋 A와 B를 혼합한 파일
테스트 데이터 셋 C의 생성 과정은 테스트 데이터 셋 A와 테스트 데이터 셋 B를 혼합해 실제 사용 환경을 모사하는 테스트 데이터 셋을 만드는 데 초점을 둡니다. 실제 사용 환경에서 중요하게 작용하는 변수로는 화자와 마이크 간 거리와 화자의 목소리 크기, 잡음 소스의 위치 등이 있으며 이러한 변수들은 다음과 같이 레벨과 SNR 설정에 직접적인 영향을 미칩니다.
- 화자와 마이크 간 거리: 화자와 마이크 사이의 거리가 멀어질수록 화자의 목소리는 더 작게 녹음되며 레벨이 낮아집니다.
- 화자의 목소리 크기: 화자의 목소리가 클수록 녹음된 음성 데이터의 레벨은 높아지고, 목소리가 작을 경우 레벨은 낮아집니다.
- 잡음 소스의 위치와 성질: 잡음 소스의 위치와 성질(예: 작고 일정한 소음, 크고 간헐적인 소음 등)은 SNR에 큰 영향을 미칩니다. 잡음 소스가 마이크와 가까울수록 또는 잡음의 세기가 클수록 SNR은 낮아집니다. 이는 잡음 대비 음성 신호의 강도가 낮다는 것을 의미합니다.
레벨과 SNR은 위와 같은 변수들에 의해 결정되며, 이들은 혼합된 오디오 데이터의 음질과 잡음 제거 기술의 성능 평가에 중요한 요소가 됩니다. 레벨은 오디오 데이터의 전반적인 음량을 결정하고 SNR은 음성 신호 대비 잡음의 비율을 나타내며, 잡음 제거 기술이 얼마나 효과적으로 잡음을 제거할 수 있는지 평가하는 데 사용됩니다.
이런 변수들을 고려해 다양한 레벨과 SNR 조건을 설정함으로써 실제 사용 환경에서 발생할 수 있는 다양한 시나리오를 포괄할 수 있는 테스트 데이터 셋 C를 생성합니다. 이를 통해 잡음 제거 기술의 성능을 보다 정확하고 포괄적으로 평가할 수 있습니다.
레벨은 다음과 같은 단계로 세분화됩니다.
- 레벨(Level): -15, -20, -25, -30, -35, -40, -45 dB (총 7단계)
레벨 값이 -15dB인 경우는 큰 소리를 의미하며, 이는 큰 목소리로 대화하거나 화자와 마이크 간 거리가 짧은 환경을 의미합니다. 반면, 레벨 값이 -45dB인 경우는 매우 작은 소리를 나타냅니다. 이는 조용한 환경에서의 속삭임이나 마이크와의 거리가 먼 상황에 해당할 수 있습니다.
SNR은 다음과 같은 단계로 세분화됩니다.
- SNR: -5, 0, 5, 10, 15, 20 dB (총 6단계)
SNR 값이 -5dB인 경우는 잡음이 음성 신호보다 더 크다는 것을 나타냅니다. 이는 매우 시끄러운 환경에서의 대화, 예를 들어 공사 현장 근처나 시끄러운 카페 내에서의 통화와 같은 상황을 모사합니다. 반면, SNR 값이 20dB인 경우는 음성 신호가 잡음보다 훨씬 더 크다는 것을 의미합니다. 이는 상대적으로 조용한 사무실 환경에서 명확한 음성 통화를 할 때와 같은 상황에 해당할 수 있습니다.
레벨과 SNR 조합에 따라 총 42(7레벨 단계 * 6 SNR 단계)가지 조건이 생성됩니다. 각 조건별로 테스트 데이터를 균등하게 분포하도록 만들어 한 조건당 5개의 테스트 데이터를 생성합니다. 이 과정에서 잡음 데이터는 음성 데이터와 동일한 길이로 조정되며, 특정 SNR에 맞추고 혼합된 오디오 데이터의 음량을 타깃 레벨에 맞게 조절합니다.
위 과정을 통해 각 장면에 대해 총 210개(42조건 * 5개 데이터)의 데이터 셋을 생성합니다. SNR 및 레벨별 데이터 수는 다음과 같습니다.
| 레벨/SNR | -5 | 0 | 5 | 10 | 15 | 20 |
|---|---|---|---|---|---|---|
| -15 | 5 | 5 | 5 | 5 | 5 | 5 |
| -20 | 5 | 5 | 5 | 5 | 5 | 5 |
| -25 | 5 | 5 | 5 | 5 | 5 | 5 |
| -30 | 5 | 5 | 5 | 5 | 5 | 5 |
| -35 | 5 | 5 | 5 | 5 | 5 | 5 |
| -40 | 5 | 5 | 5 | 5 | 5 | 5 |
| -45 | 5 | 5 | 5 | 5 | 5 | 5 |
총 테스트 데이터 셋의 수는 다음과 같습니다.
- 장면 수(18) * 장면당 테스트 데이터 셋 수(210) = 총 3,780개
이 테스트 데이터 셋은 사용자가 일상에서 접할 수 있는 다양한 상황을 광범위하게 반영하도록 설계됐습니다. 가정, 사무실, 카페, 도로변, 공공장소 등 다양한 장소에서 레벨과 SNR을 바꿔가며 일상생활에서 발생할 수 있는 다양한 잡음 환경 속에서 통화하는 상황을 재현합니다. 이처럼 방대한 양의 테스트 데이터 셋을 NS 기술에 입력으로 제공해서 NS 기술의 성능을 광범위하게 검증하며 실제 사용 환경에서 효율적으로 작동하는지 정밀하게 평가할 수 있습니다.
NS 성능 평가 지표 선정
LINE에서는 NS 기술의 성능을 일관되게 평가하고 결과의 신뢰도를 높이는 것을 목표로 하고 있습니다.
일반적으로 NS 기술의 성능을 평가하기 위해 많이 �참고하는 ITU-T P.835 권고안은 배경 잡음이 발생하는 환경에서 음성 통화 품질을 주관적으로 평가할 수 있는 구체적인 절차를 제공합니다. 그러나 주관적 평가는 비용과 시간이 많이 소요될 뿐 아니라 평가자의 주관에 따라 결과에 오차가 발생할 수 있다는 한계가 있습니다. 이러한 문제를 해결하기 위해 HEAD acoustics사는 ITU-T P.835 권고안을 기반으로 하되, 배경 잡음이 있는 환경에서 음성 통화 품질을 보다 객관적으로 평가하기 위해 설계된 청취 품질 평가 방법인 3QUEST를 만들었습니다. ETSI EG 202 369-3라는 표준으로 지정된 이 방법은 주관적 평가의 한계를 극복하고자 개발됐으며, 다양한 잡음 상황에서 제품의 성능을 정량적으로 평가할 수 있도록 지원합니다. 사람이 직접 소리를 들으며 평가에 참여해 측정하는 ITU-T P.835와는 달리 소프트웨어가 소리를 평가하기 때문에 입력이 같은 경우 동일한 평가 결과가 나옵니다.
저희는 이 HEAD acoustics사의 3QUEST를 NS 평가 도구로 선정했습니다. 3QUEST는 S-MOS, N-MOS, G-MOS라는 세 가지 객관적 지표를 제공합니다.
- S-MOS: 잡음 제거 후 보존된 음성의 품질을 측정하는 지표로 1부터 5까지의 숫자로 표현하며, 숫자가 높을수록 음성 품질이 우수하다고 판단합니다.
- N-MOS: 잡음 제거 후 남아있는 잡음의 양을 측정하는 지표로 1부터 5까지의 숫자로 표현하며, 숫자가 높을수록 잡음 제거 품질이 좋다고 판단합니다.
- G-MOS: S-MOS와 N-MOS를 조합한 종합적인 품질을 나타냅니다.
다음 테이블은 ITU-T P.835에서 가이드하는 S-MOS, N-MOS, G-MOS의 주관적 평가 방법을 요약한 것입니다. 3QUEST의 결과 지표를 아래 테이블을 참고해 살펴보면 음성 왜곡과 잔여 잡음에 대한 평가자의 주관적 인식 정도를 확인할 수 있습니다.
| Determination of subjective speech MOS (S-MOS) | Determination of subjective noise MOS (N-MOS) | Determination of subjective global MOS (G-MOS) |
|---|---|---|
|
Attending ONLY to the SPEECH SIGNAL, select the category which best describes the sample you just heard. 5 - NOT DISTORTED |
Attending ONLY to the BACKGROUND, select the category which best describes the sample you just heard. 5 - NOT NOTICEABLE |
Select the category which best describes the sample you just heard for purposes of everyday speech communication. 5 - EXCELLENT |
출처 : https://global.head-acoustics.com/downloads/eng/application_notes/telecom/Appl_note_3QUEST_e0.pdf
LINE에서는 3QUEST의 세 가지 지표 중 S-MOS와 N-MOS의 두 가지 객관적 지표를 선정해 평가를 진행합니다. G-MOS는 NS 모듈의 전반적인 통화 품질을 평가하는 지표이기 때문�에 특정 지표의 성능 개선이 필요할 때 그 영향을 직접 파악하기 어려울 수 있어 제외했습니다. 대신 S-MOS와 N-MOS 지표만을 별도로 평가하면 음성 품질과 잡음 제거 품질, 각각의 개선 사항을 보다 정밀하게 도출하고 적용할 수 있습니다.
아래 표의 음원을 재생하면 S-MOS와 N-MOS 점수대별 음성 품질의 차이를 체감할 수 있습니다.
| S-MOS | 오디오 파일 | 노트 |
|---|---|---|
| 1.x | ||
| 2.x | ||
| 3.x | ||
| 4.x | 깨끗한 음성 |
Contains information from VCTK Dataset which is made available under the ODC Attribution License.
| N-MOS | 오디오 파일 | 노트 |
|---|---|---|
| 2.x | ||
| 3.x | ||
| 4.x | 깨끗한 음성 |
Contains information from VCTK Dataset which is made available under the ODC Attribution License.
측정 시스템 환경 구성
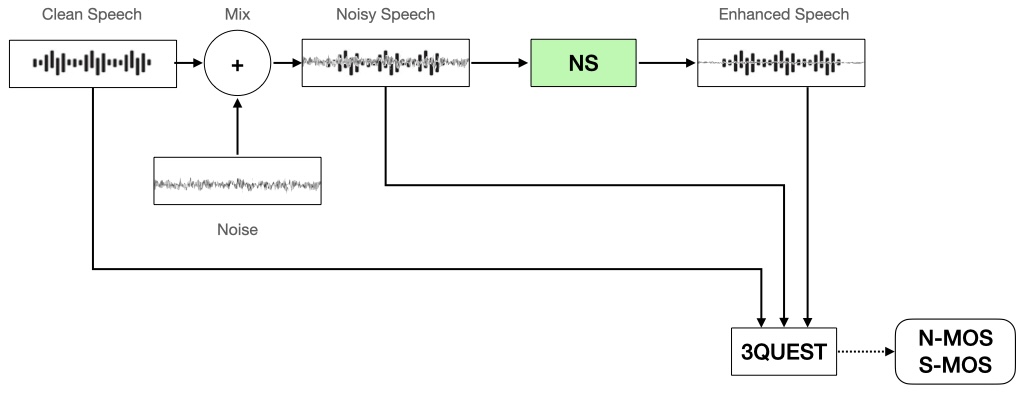
테스트 데이터 셋 구성과 평가 지표 선정 준비가 완료되면 NS 모듈의 성능을 측정하기 위한 측정 시스템 환경을 구성합니다. 구성 요소는 다음과 같습니다.
- 테스트 데이터 셋 : 테스트 데��이터 셋 A(음성 데이터), 테스트 데이터 셋 B(잡음 데이터), 테스트 데이터 셋 C(믹스 데이터)
- 3QUEST: 테스트 데이터 셋 A(레퍼런스, Clean Speech), 테스트 데이터 셋 C(Clean Speech + Noise = Noisy Speech), NS 모듈의 출력(Enhanced Speech)의 세 가지 파일을 분석해 음성 손상 정도와 잡음 제거 능력을 측정하는 툴
- NS 모듈: 성능 측정 대상이 되는 NS 모듈
NS 성능 측정
NS 성능 측정은 아래와 같은 절차로 진행합니다.
- 테스트 데이터 셋 A(Clean speech)와 테스트 데이터 셋 B(Noise)를 혼합한 테스트 데이터 셋 C(Noisy speech)를 NS 모듈에 입력한다.
- NS 모듈의 처리 결과(Enhanced Speech)와 테스트 데이터 셋 A, 테스트 데이터 셋 C를 3QUEST 측정 툴에 입력해 N-MOS와 S-MOS를 측정한다.
- 장면/SNR/레벨별 N-MOS와 S-MOS 점수 분포를 확인하고 NS 모듈의 성능을 평가한다.
맺음말
LINE에서는 이와 같이 체계적인 접근 방식으로 자사의 NS 기술 성능을 정밀하게 평가하고 지속적으로 개선해 나가고 있습니다. 다양한 환경에서의 광범위한 테스트와 신뢰할 수 있는 평가 지표를 활용해 사용자에게 최상의 음성 통화 경험을 제공하기 위한 기술적 기반을 마련하고 있습니다. 앞으로도 사용자의 커뮤니케이션 품질을 향상하기 위한 연구와 개발에 지속적으로 투자할 것이며, 이를 통해 사용자들이 어떠한 환경에서도 명확하고 깨끗한 음성 통화를 즐길 수 있도록 노력할 것입니다.


