들어가며
안녕하세요. LINE Billing Platform 개발 팀의 김영재, 이정재입니다. LINE Billing Platform 개발 팀에서는 LINE 앱 내 여러 서비스에서 사용하는 결제 및 포인트 플랫폼을 이용한 결제 기능을 제공하고 있습니다.
저희 팀에서는 최근 가장 핵심 시스템이자 오랫동안 운영해 온 결제 시스템의 DB를 Nbase-T에서 Vitess로 마이그레이션했습니다. 마이그레이션하게 된 가장 큰 이유는 기존에는 비용이 들지 않았지만 최근 계약 관계에 변화가 발생해 라이선스 비용이 추가되는 상황이 되었기 때문입니다.
저희는 마이그레이션할 솔루션 선정 과정과 마이그레이션 후 실제 개발 및 운영 단계에서 Vitess를 어떻게 활용하고 있는지 두 편으로 나눠 소개하려고 합니다. 먼저 이번 글에서는 마이그레이션할 솔루션으로 Vitess를 선정한 과정과 이유를 말씀드리겠습니다.
PoC 후보 선정
마이그레이션 대상이 결제 코어 시스템이었기 때문에 솔루션을 선정할 때 성능 대비 운용 비용이 낮은 기준으로 어떤 솔루션이 있는지 조사했습니다. 그중 PoC까지 진행해 비교 분석했던 샤딩(sharding) 솔루션인 Apache ShardingSphere와 TiDB, Vitess의 특징을 소개하고, 진행 과정에서 발생한 이슈 및 이슈 해결 방법을 공유하겠습니다.
Apache ShardingSphere
Apache ShardingSphere의 경우 프락시와 JDBC 방식을 모두 지원하며, 각 방식의 특징은 다음과 같습니다.
| 카테고리 | 프락시 레이어 | JDBC 레이어 |
|---|---|---|
| 아키텍처 | 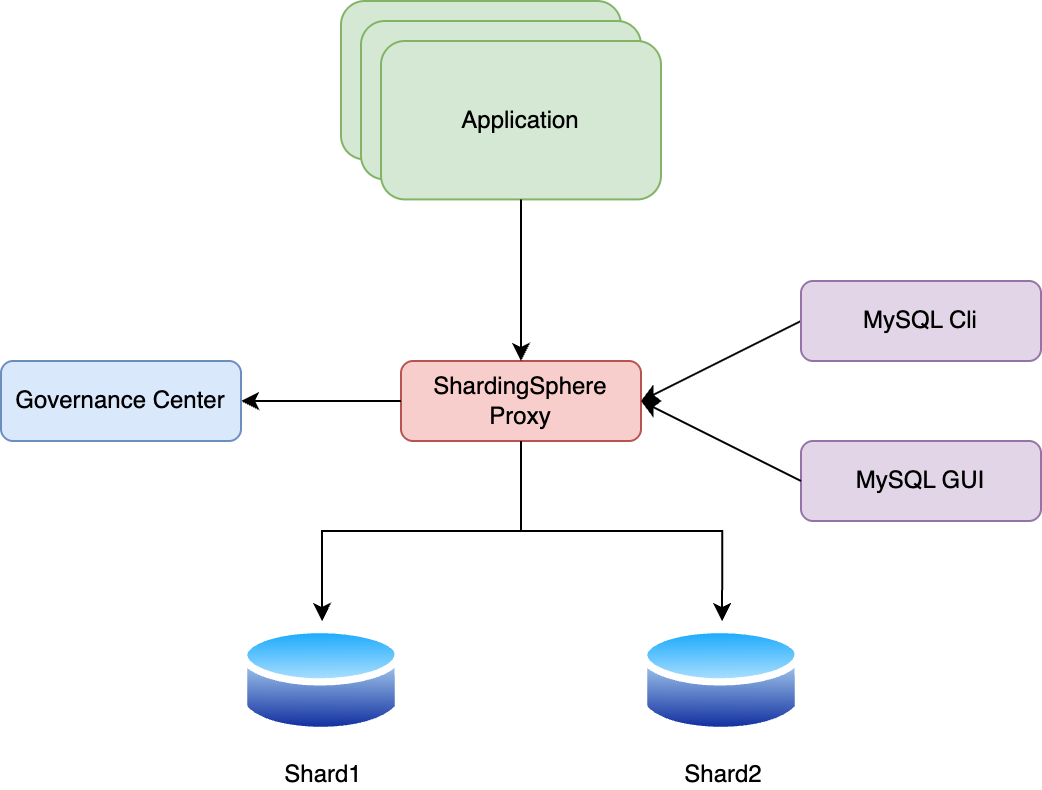 | 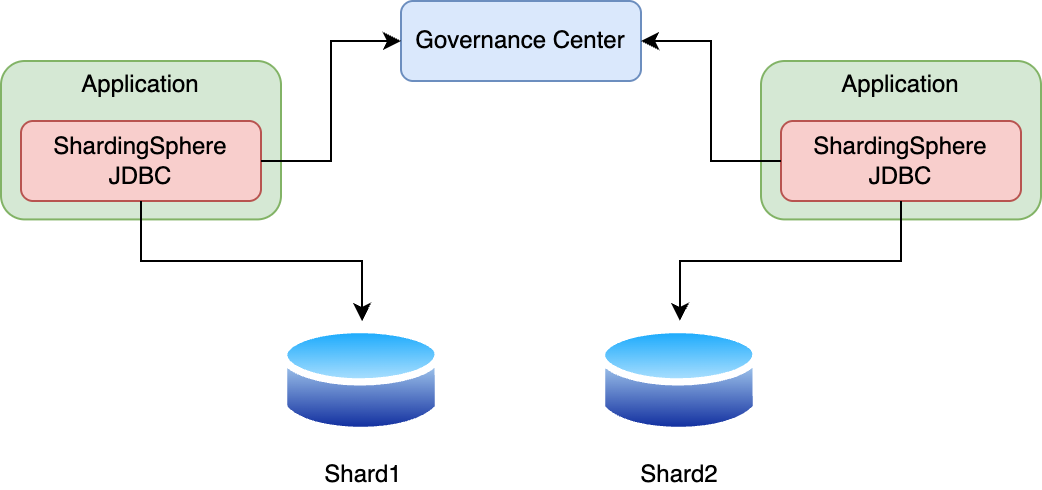 |
| 고가용성(high availability) |
|
|
| 오퍼레이션 |
|
|
| 리밸런싱 |
|
|
Apache ShardingSphere은 프락시와 JDBC 방식을 모두 지원하기 때문에 서비스 상황에 맞게 유연하게 애플리케이션을 구성할 수 있는 샤딩 솔루션입니다. 다양한 샤딩 전략을 제공하며, 분산 트랜잭션도 지원하는 등 여러 기본적인 기능에 충실합니다.
다만 프락시 레이어 방식은 SQL 통합 처리 정도의 매우 단순한 기능만 처리할 수 있다는 한계가 있습니다. JDBC 레이어 방식 또한 여러 컴포넌트에서 사용할 경우 개별 구현 포인트가 많아지고 관리 비용도 무시할 수 없다는 단점이 있습니다. 특히, 두 방식 모두 데이터가 각 샤드에 고르게 분배될 경우 데이터 리샤딩(리밸런싱)을 직접 구현해야 한다는 단점이 있습니다. 이러한 추가적인 개발 비용을 제외한다면 괜찮은 샤딩 솔루션이지만, 저희가 구현해야 할 추가적인 개발 포인트가 많아 PoC 대상에서는 제외되었습니다.
TiDB
TiDB의 경우 사내 MySQL DB 팀의 추천으로 알게 됐으며, 사내 VOOM 팀의 ESPA 조직에서 사용한 선례가 있어 PoC 진행시 MySQL DB 팀과 VOOM 팀의 많은 도움을 받았습니다.
TiDB는 MySQL 호환 분산형 SQL 데이터베이스입니다. 대규모 데이터 처리와 고가용성, 확장성을 목표로 OLTP(Online Transactional Processing) 및 OLAP(Online Analytical Processing) 워크로드 모두에 적합하도록 설계돼 있습니다. 기존 샤딩 솔루션과는 메커니즘이 완전히 다른데요. TiDB는 아래 그림과 같이 크게 세 개(TiDB, PD, 스토리지)로 나뉜 클러스터 영역으로 구성됩니다.
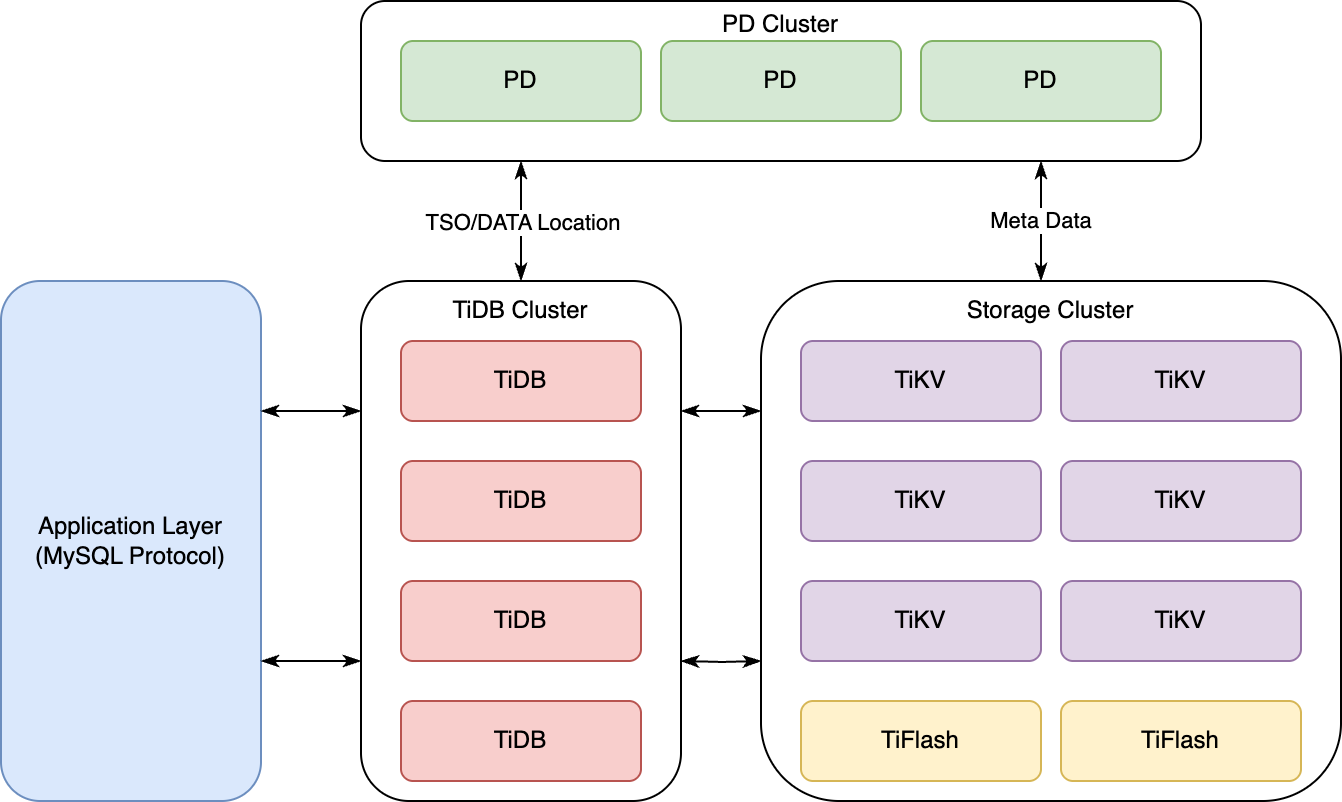
각 영역에서 수행하는 역할은 다음과 같습니다.
- 스토리지 클러스터: 스토리지 클러스터는 OLTP 워크로드를 위한 행 기반(row-based) 스토리지인 TiKV와, OLAP 워크로드를 위한 열 기반(column-based) 스토리지인 TFlash로 구성됩니다.
- 여기서 TiKV는 분산 키-값 저장소로, TiDB의 데이터 저장 계층을 구성 데이터를 분산해 저장하고, ACID 트랜잭션을 지원합니다. 이 영역에서 실제 데이터가 분산 저장됩니다.
- TiDB 클러스터: TiDB는 SQL 계층으로 MySQL 프로토콜을 지원하며, 사용자의 SQL 요청을 받아 이를 실행 계획으로 변환해 TiKV에 데이터를 읽고 쓰는 작업을 수행합니다.
- PD 클러스터: PD는 클러스터의 메타 데이터 관리 및 조정 작업을 담당합니다. TiKV 클러스터의 데이터 분할 및 배치를 관리하며, 클러스터의 전체적인 균형을 유지합니다.
TiDB는 실제로 MySQL 영역인 TiDB 클러스터에 데이터를 저장하는 것이 아니라 스토리지 클러스터 내의 TiKV에 데이터를 저장합니다. 따라서 별도의 샤딩 전략이 필요하지 않고, 데이터 관리할 때 샤딩키값도 필요 없습니다. 메커니즘 자체가 전체 TiKV에 자동으로 리밸런싱되는 형태이기 때문에 부하와 데이터를 균등하게 분산할 수 있는데요. 이런 점을 고려했을 때 현재 저희 상황에서 개발과 DBA의 운용 비용을 상당히 줄일 수 있는 이점이 있다고 판단해 PoC를 진행했습니다.
Vitess
Vitess는 대규모 MySQL 데이터베이스 클러스터를 관리하기 위한 오픈 소스 데이터베이스 클러스터링 시스템입니다. YouTube에서 MySQL 데이터베이스의 확장 문제를 해결하기 위해 개발했으며, 현재는 CNCF(Cloud Native Computing Foundation)의 프로젝트로 관리되고 있습니다(참고).
Vitess의 특징은 다음과 같습니다.
- 확장성: 대량의 트래픽을 처리하기 위해 데이터베이스를 수평으로 확장할 수 있습니다. 이를 위해 샤딩 기술을 사용합니다.
- 고가용성: 자동 장애 조치 및 복제를 통해 고가용성(high availability, 이하 HA)을 보장합니다.
- 데이터베이스 추상화: 애플리케이션이 데이터베이스의 물리적 레이아웃을 알 필요 없도록 Vitess가 이를 추상화해 처리합니다.
- 쿼리 라우팅 및 최적화: 쿼리를 적절한 샤드로 라우팅하고 최적화해 성능을 향상시킵니다.
- 클라우드 네이티브: 컨테이너 환경에서 쉽게 배포하고 관리할 수 있도록 설계됐습니다.
Vitess는 서비스의 성격이나 상황에 따라 유연하게 선택할 수 있도록 클라우드와 베어 메탈(bare metal), 하이브리드 환경을 모두 제공합니다. 저희 서비스는 결제 시스템이라는 특성상 잠시라도 페일오버(failover)가 발생하면 회사에 손실이 발생하기 때문에 베어 메탈 방식, 즉 물리적인 서버에 직접 설치하는 방식을 선택했습니다. Vitess 베어 메탈 환경은 GitHub이나 Slack 등의 서비스에서도 사용하고 있는데요. 이와 같은 유수의 기업들이 사용하고 있다는 것도 큰 장점으로 작용했습니다.
Vitess 구성도
Vitess는 필요에 따라 매우 다양한 방식으로 구성할 수 있고, 컴포넌트별로 설정할 수 있는 옵션값도 상당히 다양합니다. 실제로 저희 팀에서도 다양한 옵션값을 테스트하는 데 많은 리소스를 사용했는데요. 다양한 기능을 제공해 주는 만큼 각 옵션의 기능과 내부 구조를 이해하는 게 중요한 솔루션입니다.
다음은 Vitess를 구성하는 컴포넌트와 각 컴포넌트의 관계를 간략히 표현한 그림입니다.
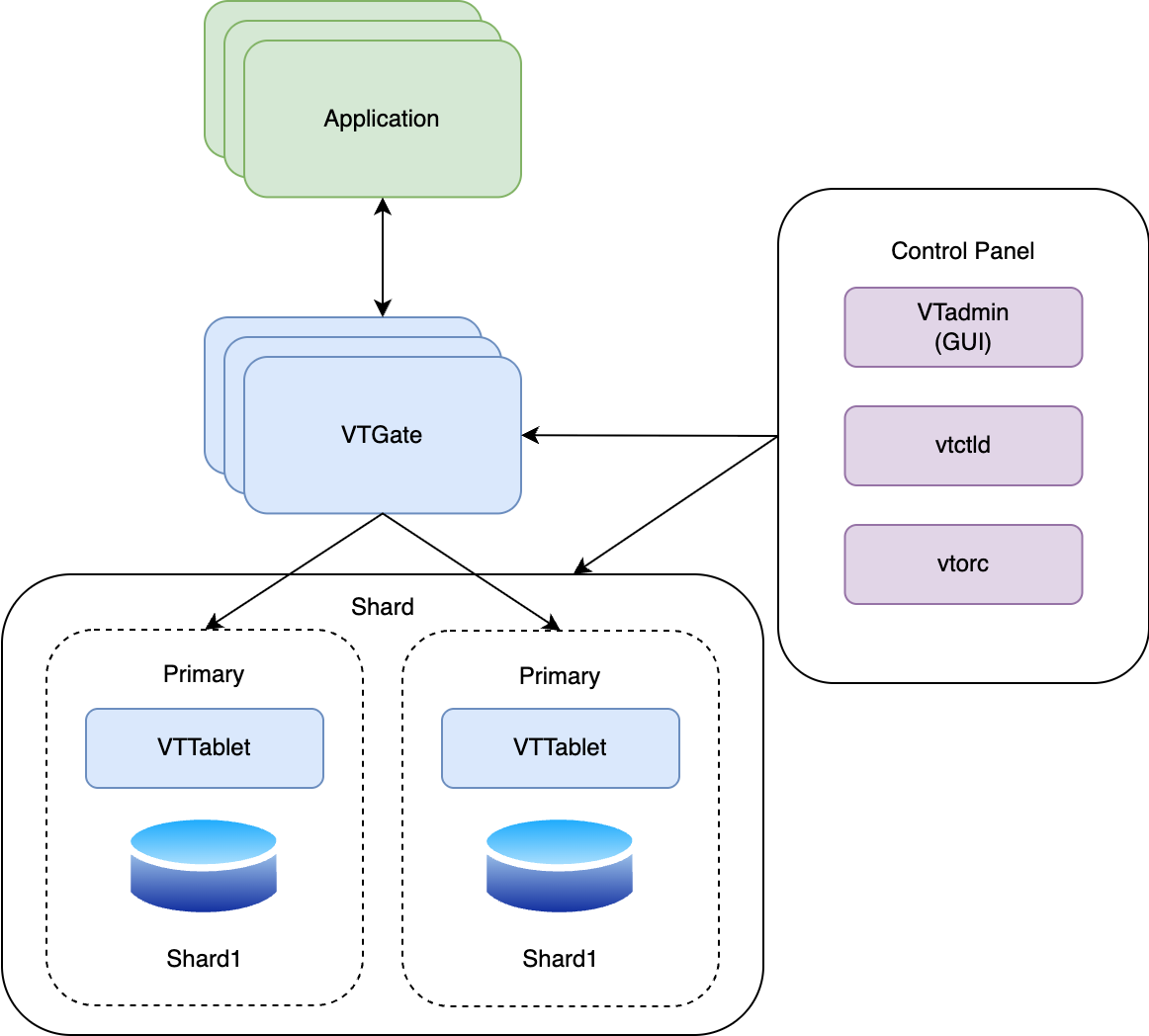
각 컴포넌트의 역할과 특징은 다음과 같습니다.
| 컴포넌트 | 설명 |
|---|---|
| VTGate |
|
| VTTablet |
|
| VTAdmin |
|
| VTctld |
|
| VTorc |
|
| 토폴로지 서버 |
|
PoC 진행
저희는 최종 선정된 두 후보인 TiDB와 Vitess를 기존 솔루션인 Nbase-T와 성능, 비용, 가이드, 기능, 운영 측면에서 비교 분석했습니다. 비교 방법과 결과를 공유하겠습니다. 참고로 Vitess의 경우 v20.0 버전을 기반으로 테스트했습니다.
PoC 환경 설정
실제 환경과 최대한 동일한 조건에서 PoC를 수행하기 위해 장비와 테이블 양식 및 기능을 통일했습니다. 아래 표는 각 솔루션별 스펙 정보를 정리한 것입니다.
| 솔루션 | 역할 | 사양 | 서버 개수 |
|---|---|---|---|
| Nbase-T | Shard DB | 8vCPU_16GB_100GB_SSD | 4대(프라이머리 2, 레플리카 2) |
| Vitess | Shard DB | 8vCPU_16GB_100GB_SSD | 4대(프라이머리 2, 레플리카 2) |
| Non Shard DB | 2vCPU_4GB_100GB_SSD | 1대 | |
| VTGate | 4vCPU_18GB_100GB_SSD | 4대 | |
| TiDB | TiDB | 8vCPU_16GB_100GB_SSD | 2대(프라이머리 2) |
| PD | 4vCPU_18GB_100GB_SSD | 3대 | |
| TiKV | 8vCPU_16GB_100GB_SSD | 4대 | |
| 모니터링 | 2vCPU_4GB_100GB_SSD | 1대 |
- 샤드 DB 4대는 프라이머리/레플리카 구조로 두 세트씩 구성했습니다.
- TiDB의 경우 TiDB MySQL DB는 실제 데이터 저장소의 역할이 아니므로 2대로, TiKV는 실제 저장소이므로 4대로 구성했습니다.
- Vitess의 경우 샤드 DB 대 VTGate의 비율을 1:1로 권장하기 때문에 최초에는 각 4대씩 1:1 비율로 구성했습니다.
성능 측면 ��비교 분석
저희는 실제 결제 API를 기반으로 한 시나리오(결제와 조회를 일정 비율로 요청) 성능 테스트를 진행했습니다. 스레드 개수를 단계적으로 증가시키며 스레드 대비 요청 처리량과 리소스 처리 상태를 확인했습니다.
성능 테스트 결과 순수 성능 관점에서는 가장 적은 장비로도 높은 TPS(transactions per second)와 함께 서버 자원을 효율적으로 사용하는 모습을 보여준 Nbase-T가 가장 좋은 솔루션이었습니다.
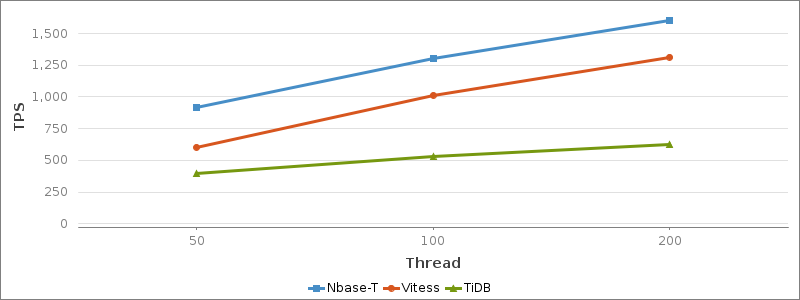
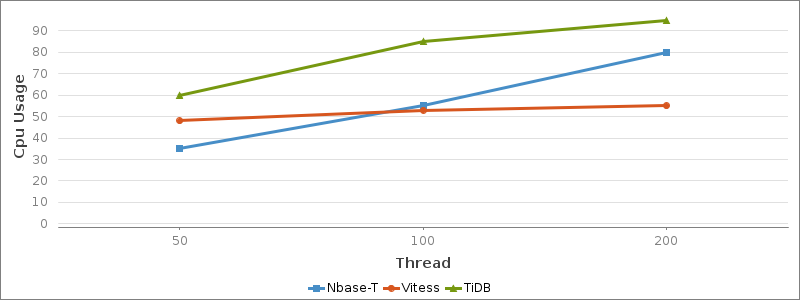
Nbase-T와 TiDB는 CPU 사용률이 스레드 개수에 비례해 선형적으로 증가하는 일반적인 형태를 보여줬습니다. 반면 Vitess는 스레드 개수가 증가해도 CPU 사용률이 더 오르지 못하고 50% 정도에서 계속 머물렀는데요. 이에 저희는 Vitess의 어떤 특정 부분에서 CPU 사용률을 제한하고 있다고 판단하고 조금 더 살펴봤습니다.
Vitess 병목 문제 해결
먼저 Vitess의 각 구간별 스레드 옵션을 설정해 봤지만 별다른 변화가 없었습니다. 이에 Vitess 구간별 모니터링을 진행했는데요. 이를 통해 CPU 사용률을 제한하는 근복적인 병목 구간이 VTGate임을 인지했고 먼저 아래와 같이 GO GC(garbage collector) 설정을 변경해 봤습니다.
GOMEMLIMIT설정 변경: Go 런타임이 메모리 사용량 기준으로 GC 트리거를 제어하면서 불필요한 GC 실행 빈도 감소 확인GOGC=off설정:GOGC를off로 설정하면 자동 GC가 비활성화되며, 이를 통해 GC 실행 빈도가 대폭 줄어들면서 쿼리 지연(latency)과 분산(variance) 감소 확인
위 조치로 어느 정도 효과를 보기는 했으나 그럼에도 DB 장비의 성능을 최대치까지 사용하지는 못했습니다. 이에 DB 장비 수준에 부합되도록 VTGate를 증설해 보기로 결정했는데요. 이때 DB 장비 대 VTgate의 적정 비율을 찾기 위해 테스트를 진행했습니다.
이 테스트를 진행할 때에는 프라이머리 샤드를 세 대로 늘려서 테스트했으며, 이에 맞춰 VTGate 역시 세 대부터 시작해 그 배수로 개수를 늘려보면서 변화를 확인했습니다. 아래는 테스트하면서 TPS와 CPU 사용률 수치 변화를 기록한 것입니다.
| VTGate | TPS | VTGate 상태 |
|---|---|---|
| 3 | 3835 |
|
| 6 | 6420 |
|
| 9 | 8637 |
|
| 12 | 10354 |
|
| 15 | 11671 |
|
| 18 | 12295 |
|
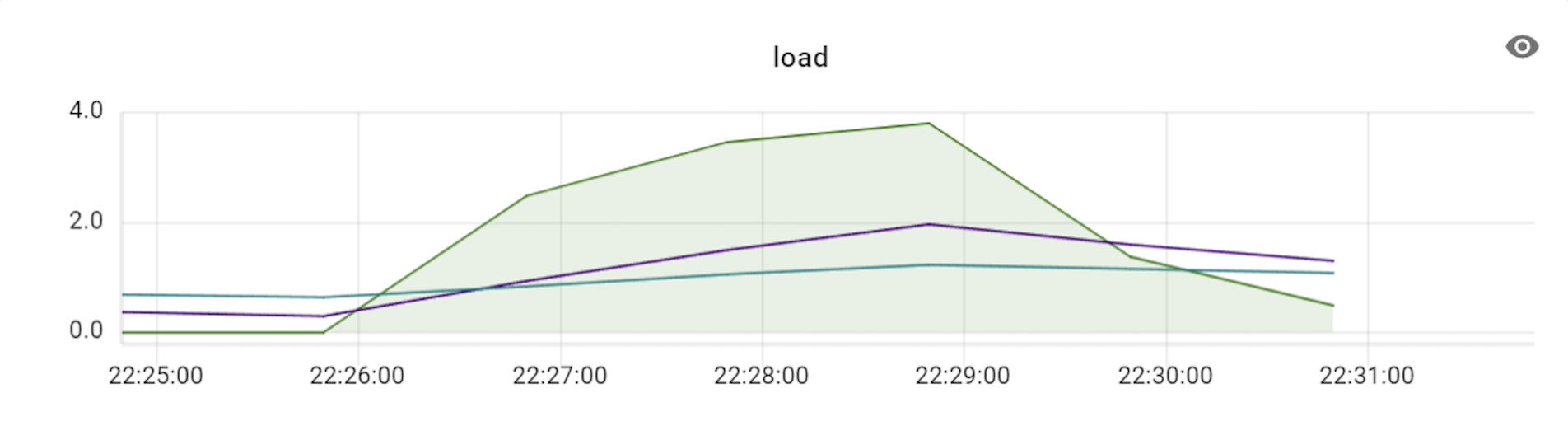
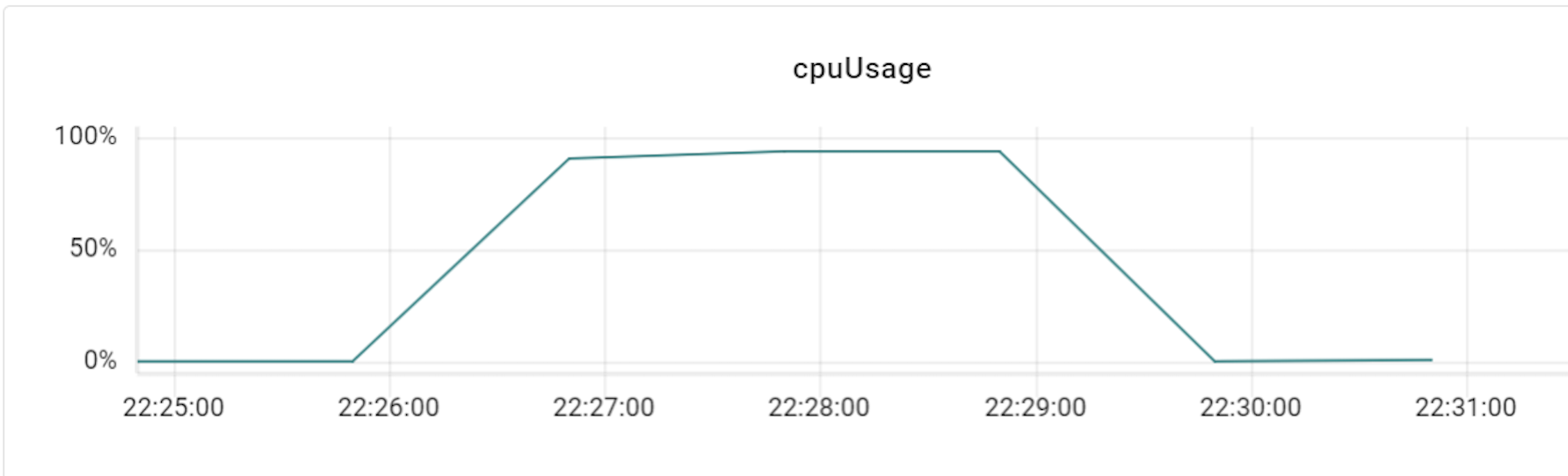
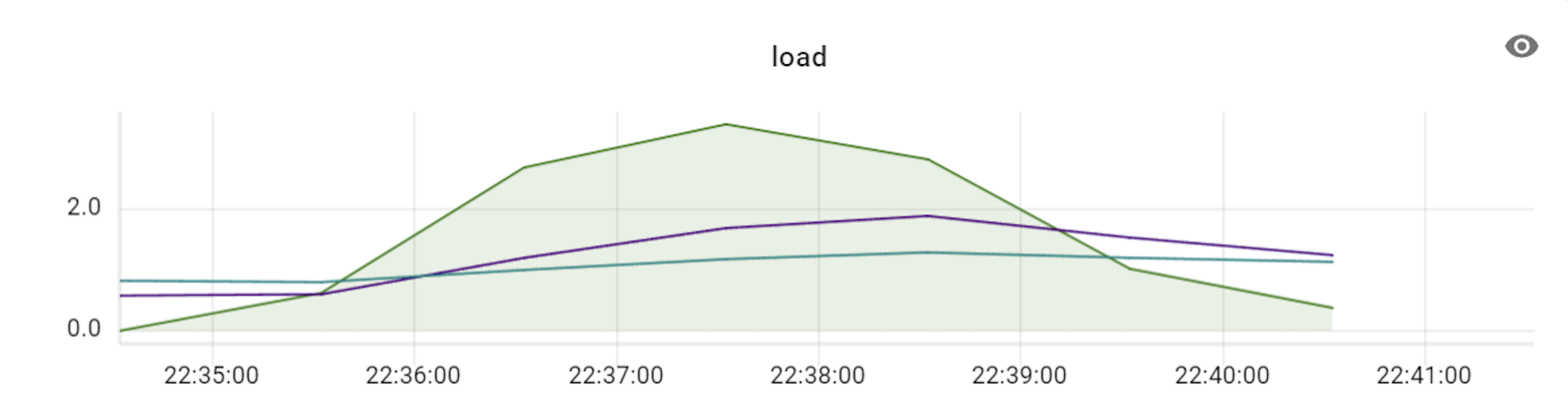
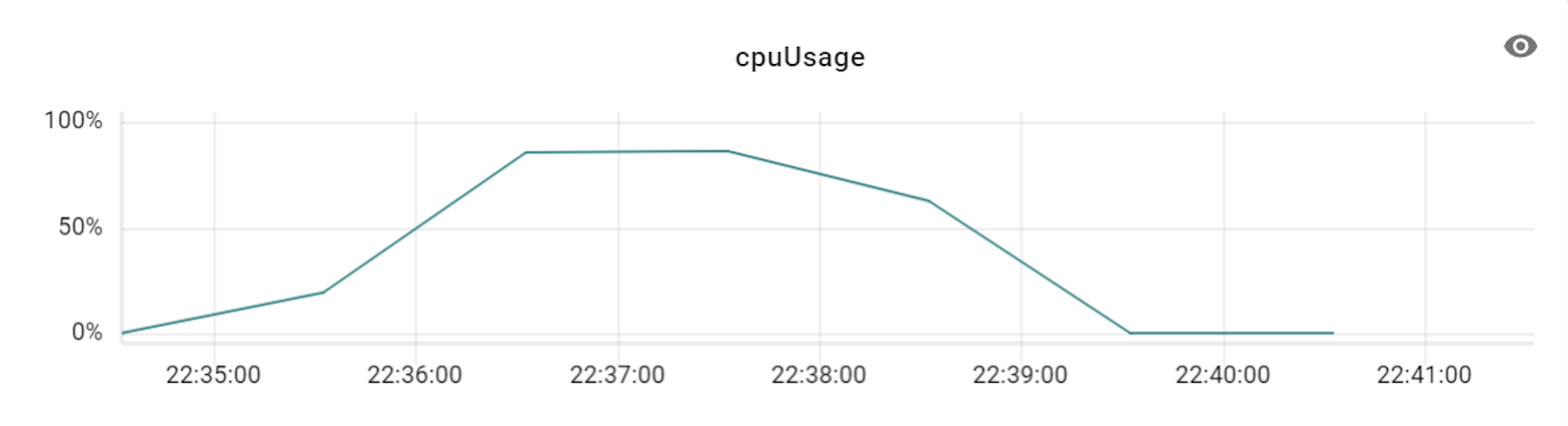
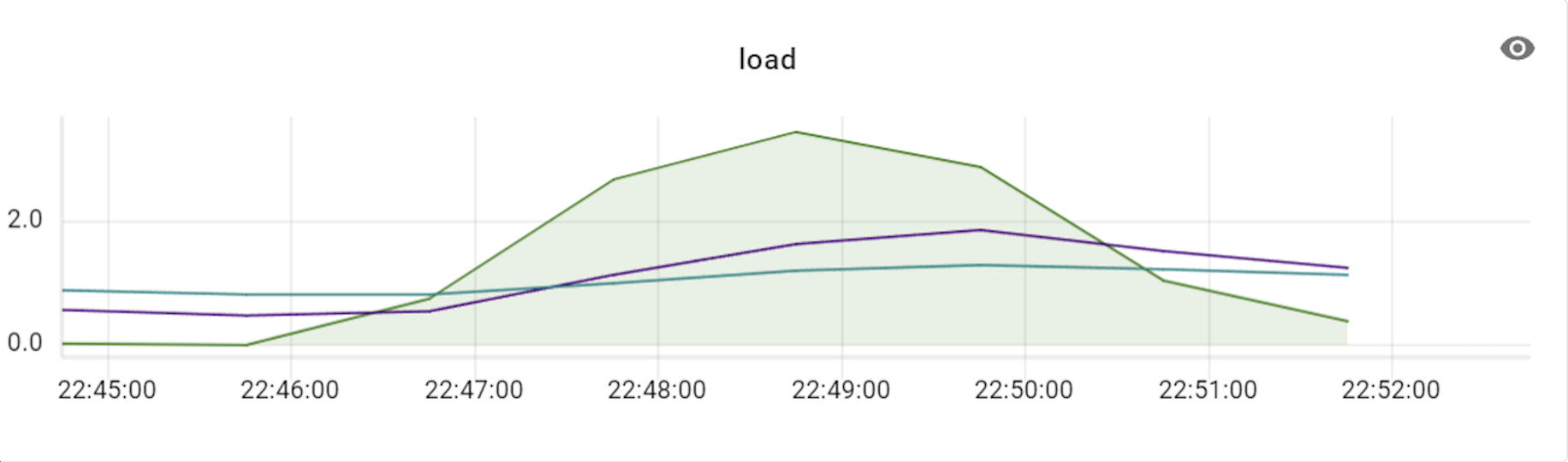
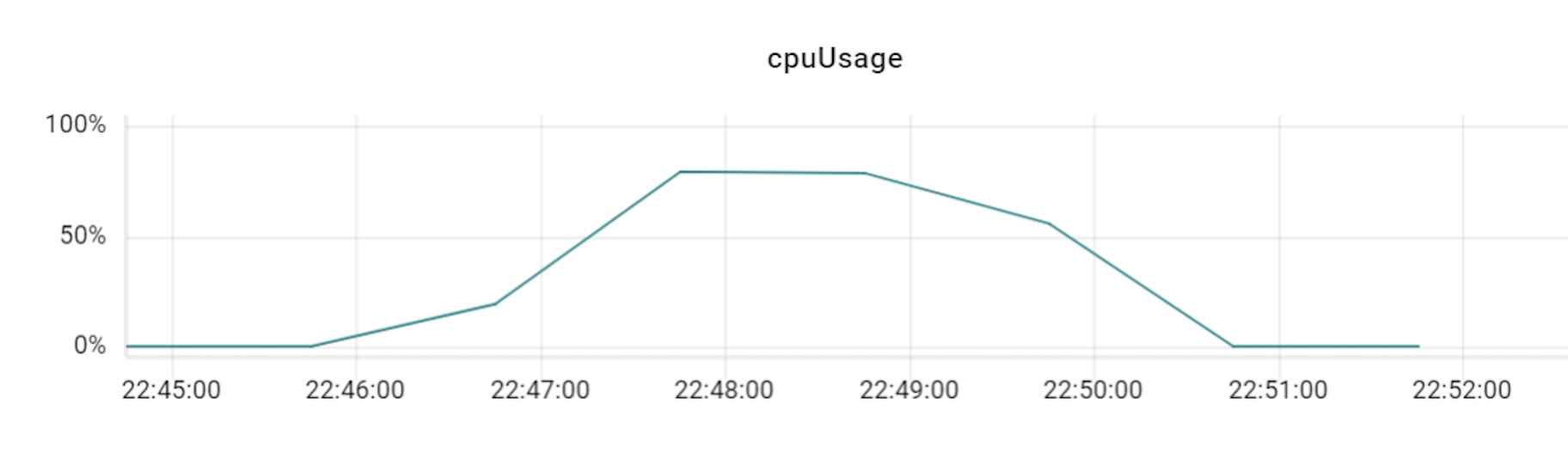
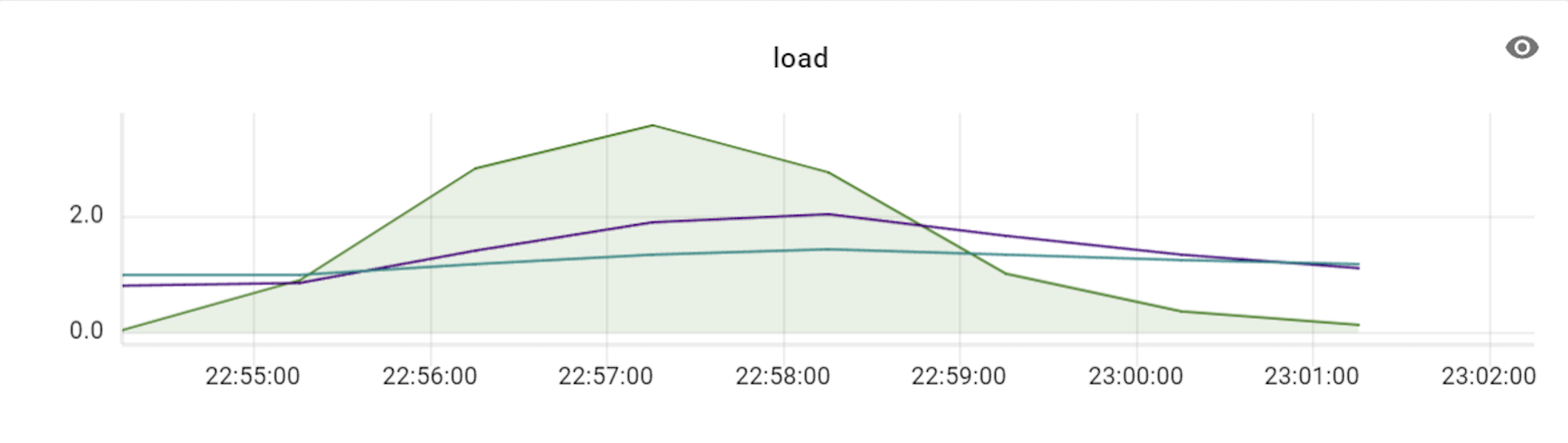
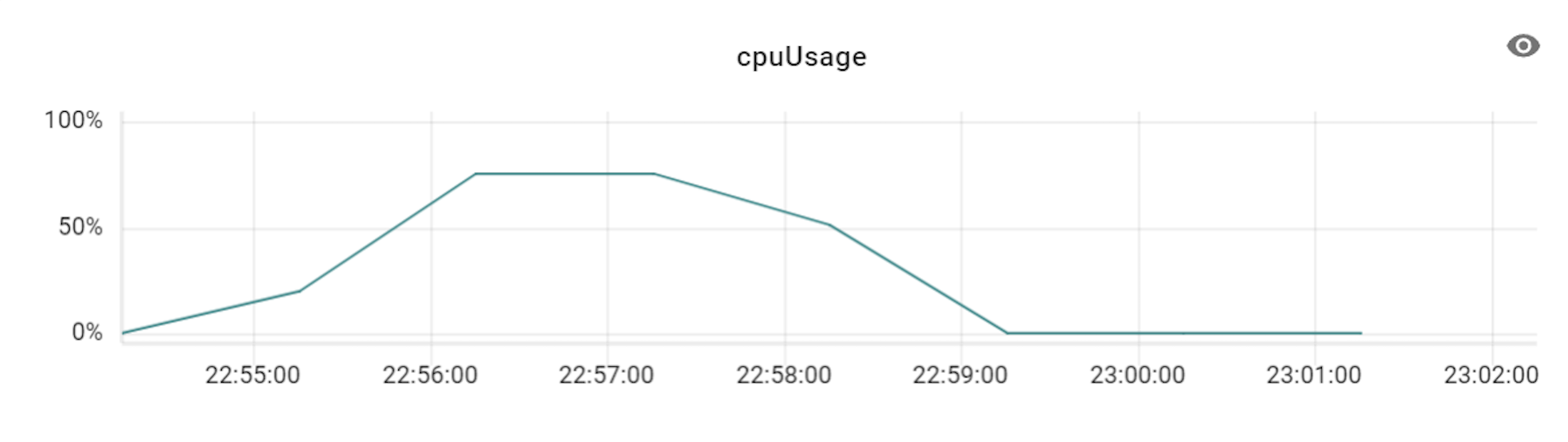
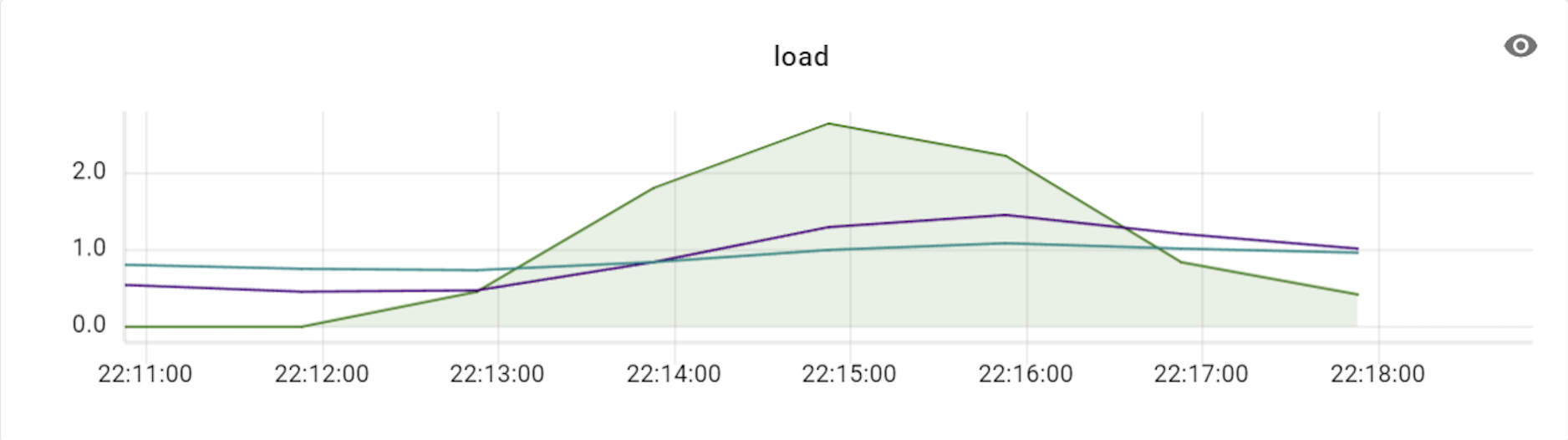
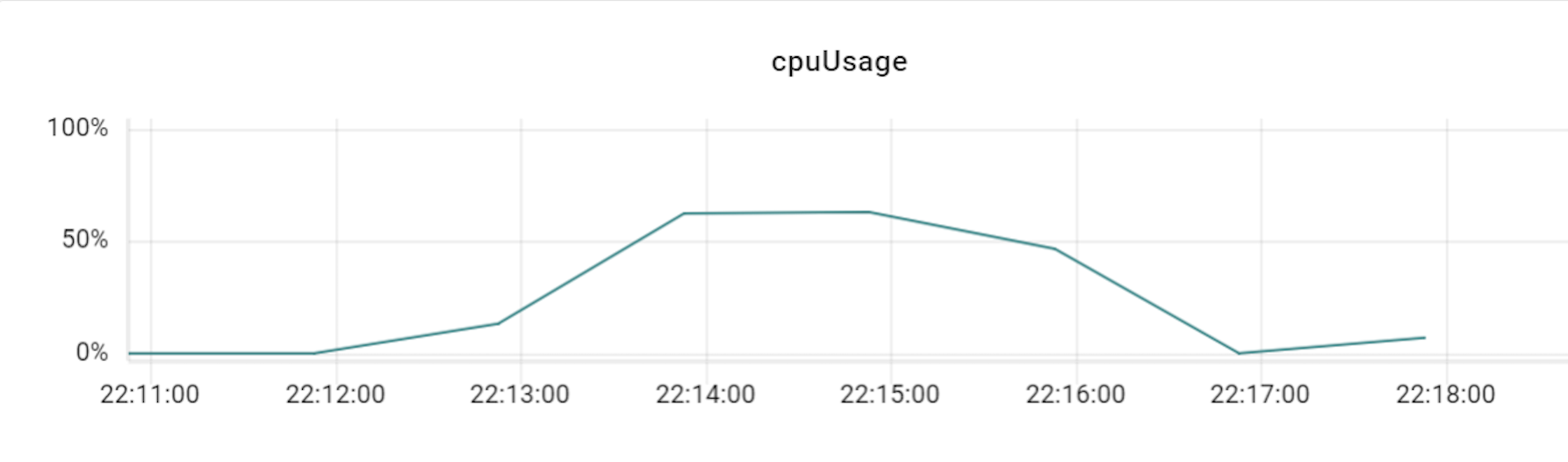
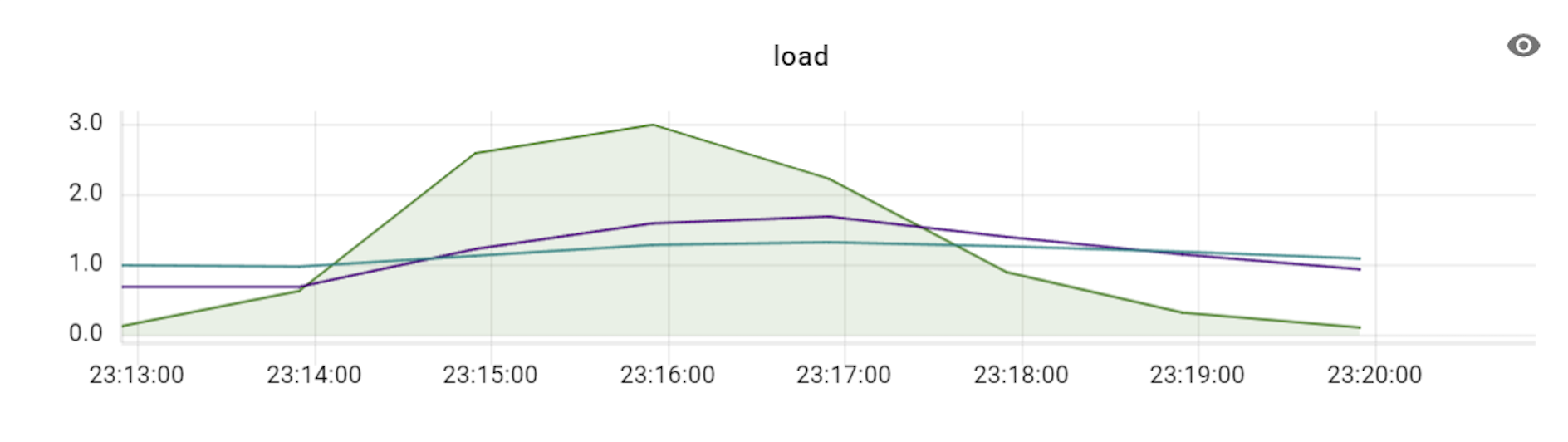
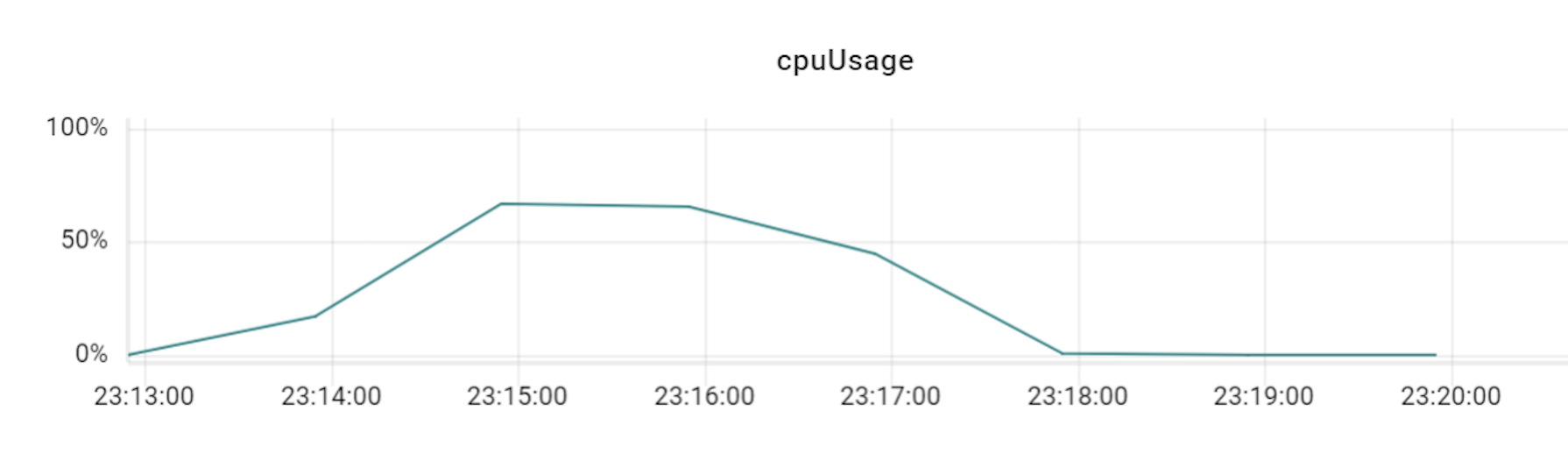
위 표와 같이 TPS가 3배의 비율(DB 장비 3대에 VTGate 9대)까지는 큰 폭으로 상승하다가 4배 비율부터는 상승량이 조금씩 감소하기 시작했습니다. 즉, Vitess의 경우 프라이머리 샤드 개수와 VTGate 개수의 비율을 최소 1:3 정도로는 유지해야 Vitess DB의 최대 성능을 발휘할 수 있는 것입니다. 더불어 알게 된 사실은, VTGate 자체는 로직이 복잡하지 않기 때문에 고성능의 서버가 필요하지 않았습니다. 따라서 VTGate 서버의 사양을 낮추고 대신 개수를 늘리는 것이 훨씬 효과적이었습니다.
Vitess 옵션 성능 테스트: queryserver-config-transaction-cap
저희는 Vitess를 튜닝하면서 다양한 옵션을 테스트해 봤는데요. 그중에서 유의미한 결과가 도출된 queryserver-config-transaction-cap 옵션 설정 사례를 공유하겠습니다. 참고로 Vitess는 버전별로 옵션이 상이하기 때문에 각 버전에 따른 옵션의 형태를 꼭 확인하셔야 합니다.
queryserver-config-transaction-cap은 VTTablet 옵션 중 하나입니다. VTTablet은 앞서 MySQL 인스턴스 앞에 위치해 MySQL과의 직접적인 인터페이스를 담당하며 데이터베이스 요청을 처리하는 컴포넌트라고 말씀드렸는데요. queryserver-config-transaction-cap은 DB가 트랜잭션 처리를 받을 수 있는 허용치를 조절하는 옵션으로, 기본값은 20으로 설정돼 있습니다. 저희 시스템의 경우 결제 트랜잭션이 많이 발생하기에 트랜잭션 허용치를 적절히 조절할 필요가 있는데요. 아래는 스레드가 700개인 상태에서 설정값을 50 혹은 100 정도로 수치를 늘렸을 때 성능이 얼마나 개선되는지 테스트한 결과입니다.
| queryserver-config-transaction-cap 설정값 | TPS | VTGate 상태 |
|---|---|---|
| 50 | 11268 |
|
| 100 | 15639 |
|
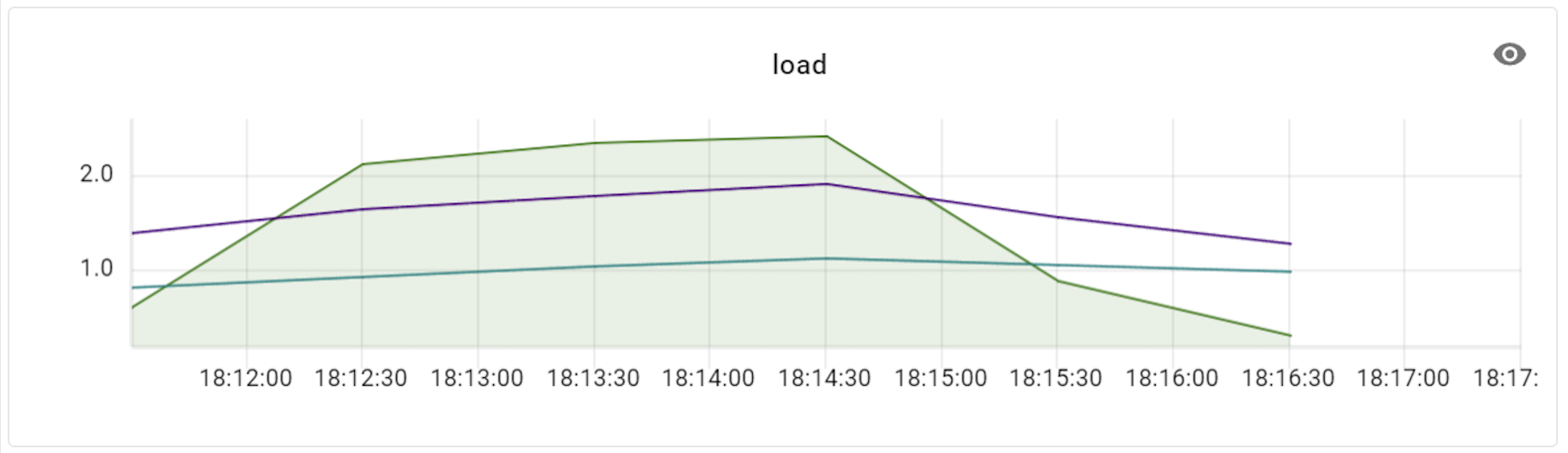
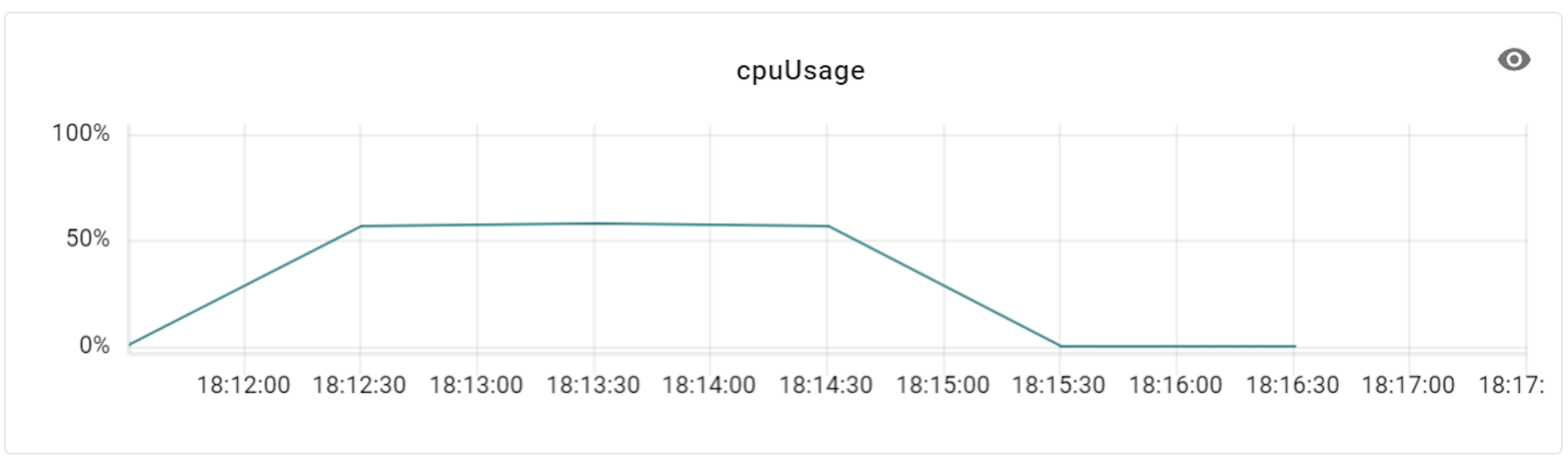
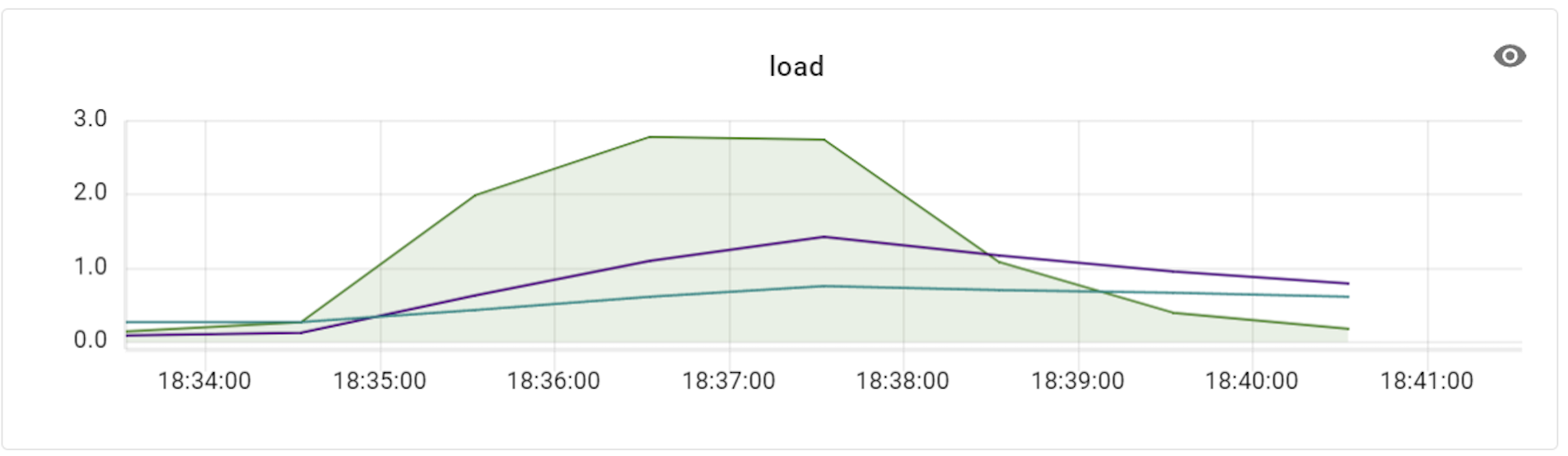
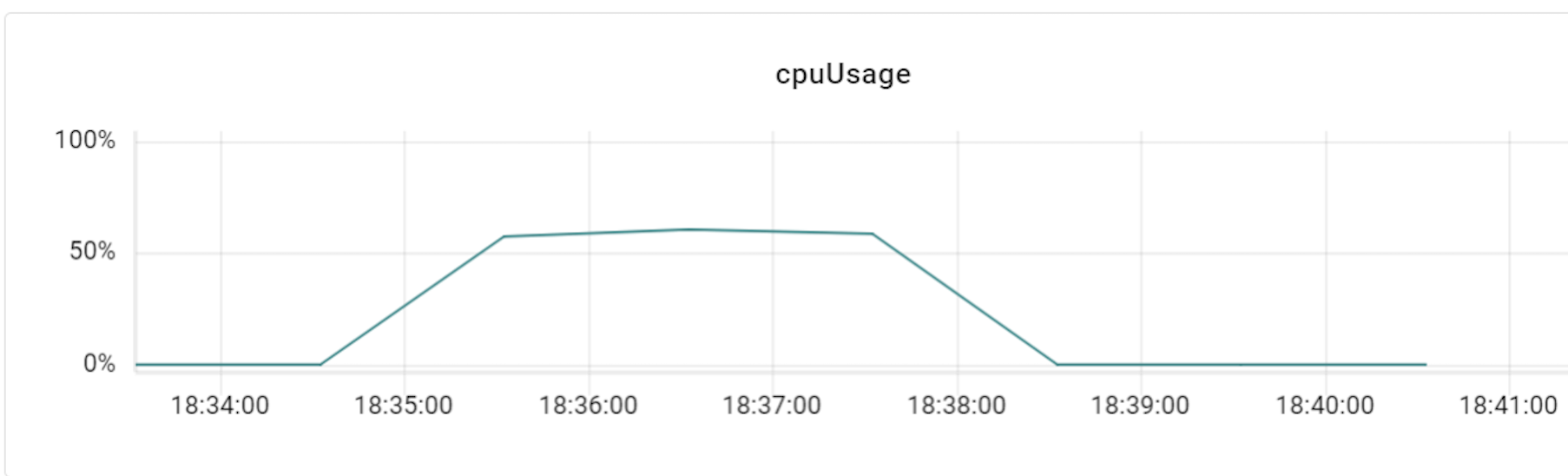
성능 테스트 결과
결론적으로 Vitess는 Nbase-T에 비해 단위 성능은 낮지만 상대적으로 안정적이고 일관적인 성능을 보여줬습니다. 특히 서버 자원을 효율적으로 사용했고, 트래픽 대비 응답 시간의 편차가 크지 않아 안정적이었습니다. TiDB의 경우 TiDB와 TiKV를 1:3 비율로 맞춰 장비를 추가할수록 성능이 향상됐지만 클러스터마다 장비 대수가 최소 3배 정도 더 필요했고, 기본적으로 서버 자원을 많이 사용했습니다. 즉 성능 테스트 결과, 새로운 솔루션들은 기존과 같은 성능을 내기 위해서 기존 솔루션보다 각각 일정 비율로 추가 장비가 필요하다는 것을 알 수 있었습니다.
비용 측면 비교 분석
저희는 최초에 비용 문제 때문에 마이그레이션을 시작했습니다. 따라서 성능 테스트 결과에 따라 기존과 같은 성능을 발휘하는 수준에서의 각 솔루션의 비용도 분석할 필요가 있었습니다.
아래는 각 솔루션별로 기존 시스템과 동일한 성능을 발휘할 수 있는 수준으로 운영했을 때 매월 발생할 인프라 비용을 예시로 정리해 본 것입니다. 예시를 위해 같은 사양의 경우 서버 단가는 모두 임의의 같은 비용으로 가정했습니다(아래 비용은 실제 비용이 아닌 이해를 돕기 위한 예시입니다).
| 솔루션 | 상세 분류 | 사양 | 인프라 | 월별 비용 | 월별 비용 총합 |
|---|---|---|---|---|---|
| Nbase-T | Nbase DB |
|
| 1,000,000 | 1,000,000 |
| Vitess | Vitess DB |
|
| 1,000,000 | 1,050,000 |
| Vitess GW |
|
| 50,000 | ||
| TiDB | TiDB |
|
| 1,000,000 | 3,006,000 |
| TiKV |
|
| 1,400,000 | ||
| PD |
|
| 100,000 | ||
| TiFlash |
|
| 500,000 | ||
| 모니터링 |
|
| 6,000 |
위와 같이 가정했을 때, TiDB의 경우 개발자와 DBA의 운용 비용을 줄여주는 기능과 형태였지만 기본 장비 비용이 기존보다 최소 3배 이상 필요했습니다. 결과적으��로 불필요한 비용을 줄이면서 최대한 성능을 보여주는 솔루션은 Vitess였습니다.
그 외 측면 비교 분석
솔루션을 도입하기 위한 PoC를 진행하면서 성능과 비용 측면 외에도 솔루션을 사용하면서 참고할 수 있는 가이드나 제공 기능, 운영 측면에서도 비교 분석을 진행했습니다. 각 분야별로 비교 분석 결과를 정리한 표를 공유드립니다.
가이드 측면 비교 분석
| Nbase-T | Apache ShardingShpere | Vitess | TiDB | |
|---|---|---|---|---|
| 커뮤니티 지원 |
✅
|
✅ |
✅ |
✅ |
| 사용 사례 |
|
|
|
|
| 예제 코드 | ❌ |
✅ |
✅ |
✅ |
기능 측면 비교 분석
| Nbase-T | Apache ShardingShpere | Vitess | TiDB | |
|---|---|---|---|---|
| 샤딩 전략 |
|
| ||
| 분산 트랜잭셕 | ❌ |
✅ |
✅
|
✅
|
| 프락시 서버 지원 | ✅ |
⚠️(제한적 지원)
|
✅
| ❌ |
| 멀티 노드 쿼리(one connection to all node) | ✅ | ❌ |
✅
| ✅ |
운영 측면 비교 분석
| Nbase-T | Apache ShardingShpere | Vitess | TiDB | |
|---|---|---|---|---|
| 리밸런싱 | ✅ | ❌ |
✅
|
✅
|
| 고가용성 | ⚠️(제한적 지�원) |
⚠️(제한적 지원)
|
✅
| ✅ |
| 자동 스케일 아웃 | ❌ |
❌
|
❌
| ✅ |
| 관리 및 운영 도구 |
✅
|
✅ |
✅
|
✅
|
마치며
다양한 플랫폼을 조사한 결과 기존에 사용하던 Nbase-T와 비교해 저희에게 가장 합리적인 플랫폼은 Vitess였습니다. 각 솔루션의 장단점을 간략히 요약하면 다음과 같습니다.
ShardingSphere: 개발자가 모든 것을 제어할 수 있다는 이점이 있지만 리밸런싱 기능을 비롯해 현재 저희 팀에서 사용하고 기능들을 사용하려면 추가 개발이 필요해 추가 비용이 발생한다는 단점이 있습니다.
TiDB: 개발자가 사용하기 편리하며 내부 DBA 팀의 지원까지 받을 수 있지만, 다른 플랫폼 대비 서버 비용이 약 3배 이상 든다는 단점이 있습니다.
Vitess: 성능과 비용 측면에서 가장 합리적이었고, 필요한 기능 이상을 제공하며, 많은 트래픽을 처리하고 있는 여러 회사에서 사용하고 있는 검증된 플랫폼이라는 장점이 있습니다. 다만 DBA와 개발자가 높은 학습 비용을 감내해야 한다는 단점이 있습니다.
저희 팀은 추가 학습 비용을 어느 정도 감내하기로 하고 최종적으로 Vitess를 선택했습니다. 이 글이 여러분의 상황과 서비스의 방향성에 맞춰서 샤딩 솔루션을 선정하고 도입하는 데 도움이 되기를 바라며 이만 마치겠습니다.


