LINE App 提供 LINE 一對一通話、LINE 群組通話、LINE 會議等即時通訊服務,透過網路即時傳輸音訊和視訊資料。這使得用戶可以在任何地方方便地體驗音訊和視訊通話。
即時通訊服務的核心挑戰是同時保持即時效能和良好的品質。為了識別和改善使用者在使用服務時可能遇到的任何不便或問題,客觀、公正的品質測量和評估至關重要。在本文中,我們將首先了解如何測量質量,然後探討質量測量的三個代表性領域:聲學迴聲消除 (AEC)、頻率響應和損耗穩健性。
品質測量的各個方面
我們認識到服務品質的重要性,並從以下各個方面全面衡量:
對聲學環境的回應
聲學環境是指撥打電話的人周圍的聲學環境。呼叫者的空間特徵會影響呼叫品質。例如,如果周圍環境吵雜或有迴聲,通話品質可能會下降,導致不適。我們的目標是評估語音處理技術在此類聲學環境中的表現並得出技術改進。為此,我們��建立了一個消音室,並測量影響語音處理技術表現的聲學變數。
首先,請參閱原LINE工程部落格上發表的文章《視訊會議期間提高語音品質的技術》(僅韓文),該文章解釋瞭如何設定呼叫者環境以提高語音品質。
聲學環境中的聲學變數包括背景噪音、音量水平、混響水平和迴聲。我們根據這些聲學變數的特徵對其進行劃分來量化它們。例如,對於背景噪聲,我們量化消除了多少環境噪聲,對於迴聲,我們量化消除了多少迴聲。
我們還有一個消音室環境來測量這些聲學變數。在消音室環境中,我們可以模擬各種聲學變量,以緊密地再現實際環境,並測量我們內部使用的語音處理技術是否正常運作。例如,為了模擬咖啡館的通話環境,我們播放在咖啡館錄製的背景噪音,並測量該噪音對語音品質的影響。

回應網路環境變化
網路中不斷發生丟包(packet loss)、封包延遲(packet delay)、頻寬節流(bandwidth throttling)、網路擁塞 (network congestion) 等變化,這些網路環境的變化對即時呼叫服務的品質產生重大影響。因此,為了確保使用者始終如一地體驗到卓越的服務質量,有必要衡量網路環境變化對服務品質的影響,並制定維持良好品質的技術和策略。為此,首先需要技術能夠即時準確地分析和診斷網路環境變化,並根據診斷結果實施碼率調整、資料重傳等各種策略來維持服務品質。定量衡量這些技術和策略非常重要��,因為它們對使用者感知的品質有直接影響。
現實中,網路環境的變化有多種形式。我們根據不同的情況對這些變化進行建模,創建各種場景,並將每個場景應用到模擬中,以模擬現實生活中的網路環境變化。然後,我們定量測量當時的品質(語音品質、視訊品質、每秒幀數(rames per second)、數據使用等),以評估網路環境變化和回應策略是否有效。
下圖是一個模擬範例,它重現了模擬真實環境中發生的資料包遺失的場景。

如上例,我們使用網路模擬器誘發丟包,重現實際環境,定量測量因丟包而導致的音質下降。除了丟包之外,網路模擬器還可以模擬封包延遲、頻寬節流等網路環境變化,並且透過連接多個網路模擬器,可以同時模擬各種網路環境變化。
透過這些模擬,我們透過模擬各種網路環境變化來定量測量每個環境中的質量,並透過重複這些測量來評估技術的可靠性並得出改進。
因應全球環境
LINE 應用程式是一項在世界各地使用的全球服務。因此,持續為全球用戶提供卓越的品質非常重要。然而,每個地區的通訊網路和基礎設施使用不同的網路服務供應商(ISP)、網路拓撲、頻寬分配、網路環境和管理方法。此外,Wi-Fi 基礎設施、使用模式和文化可能會有所不同,網路環境可能會根據諸如是在工作日、週末還是在區域活動期間撥打電話等因素而發生變化。
為了因應這些地區差異和環境變化,我們在全球約15個國家部署了自主研發的品質測量工具,持續監測各國的網路環境特徵。透過這一點,我們了解各國和地區的網路特點和變化,應用最優的設置,為用戶提供最佳的服務品質。
測量工具配備了我們自主開發的品質測量硬體和軟體,自動撥打電話並測量各種品質指標,例如語音和視訊品質、延遲和呼叫連接時間。在測量品質時,我們不僅使用POLQA(ITU-T P.863)和PSNR(ITU-T J.340)等國際標準測量指標,還使用非標準但業界廣泛使用的測量指標。

透過這種全球品質監控,我們將我們的品質與其他服務進行比較和分析,以確定我們的優勢和需要改進的領域。全局監控系統將品質測量工具測得的指標進行匯總,並表達為綜合服務品質評估分數。服務品質評估分數透過不同顏色區分,如下圖所示,方便了解各地區的服務品質水準。在下圖中,綠色表示品質平滑的區域,灰色表示品質一般的區域,紅色表示品質不佳或無法測量的區域。
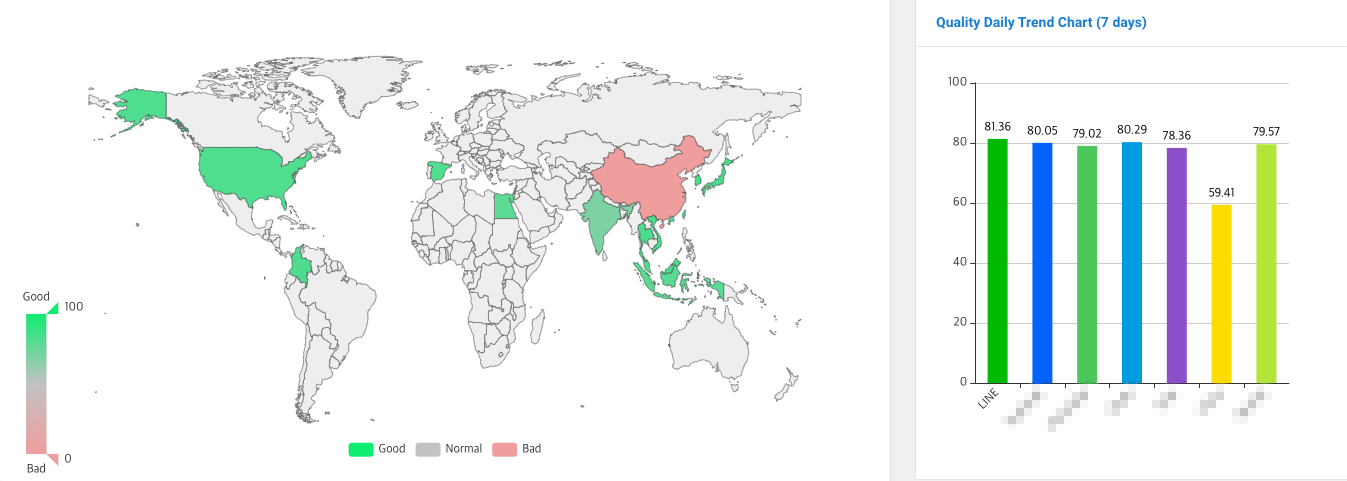
我們不斷研究和實施提高品質的措施,考慮到每個國家和地區獨特的網路和環境,不斷努力在所有地區提供最佳的服務品質。
外部測試
我們也透過外部測試進行獨立測量。外部測試是第三方專家衡量我們產品性能並定量分析語音和視訊品質的重要過��程。
在外部測試過程中,我們與外部測試公司協調測量場景,以精確掌握測試環境中的品質變化。此外,該過程還包括將性能與其他服務進行比較,以評估產品在市場上的競爭力。透過這種方式,我們從中立的角度接受品質評估,並進行改進以提高使用者滿意度。
測量 AEC 性能
AEC 是一種抑制語音通話系統中的迴聲的技術,可減少使用者的聲音通過對方麥克風後再次被聽到為迴聲的情況。下圖展示了語音呼叫系統中出現的迴聲範例。
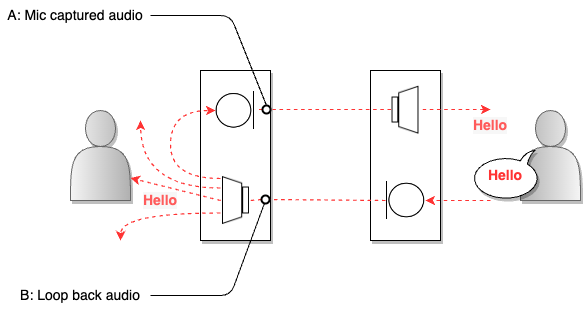
在上圖中,當右側使用者的聲音 (B) 透過左側使用者的揚聲器輸出時,該聲音也會被麥克風 (A) 收集。迴聲是指聲音從介質反射回來。傳遞收集到的聲音的麥克風可以被認為是主要的反射源。如果從對方的麥克風收集用戶的聲音並直接傳回給用戶,用戶會在短暫的延遲後再次聽到他們的聲音。通話 AEC 即時偵測這種聲學迴聲,並適當過濾和消除它,以提高語音通話品質。
我們正在利用自己的技術開發AEC,並引入機器學習技術,以提供高品質的迴聲消除性能。透過這一點,我們測量質量,以便 LINE 應用程式用戶可以享受乾淨、高音質的語音通話,而不會因迴聲而造成不適。在詳細介紹如何測量之前,我們先定義一下 AEC 效能測量和效能指標描述中使用的術語。
- 近端(Near-end):是指呼叫系統中位於進行測量一側的使用者。
- 遠端(Far-end):指與近端通話的使用者。
- 單方通話(Single Talk):指只有近端或遠端在講話。
- 雙方通話(Double Talk):指近��端和遠端同時講話。
AEC 性能測量方法
AEC 性能是透過量化抑制迴聲而不降低音訊品質的能力來評估的,並且在測量性能時遵循以下過程。
設定測量環境
首先,我們建立了測量 AEC 性能的測量系統環境。
選擇質量測量工具
我們使用AECMOS來評估和提高 AEC 性能。AECMOS 是一種透過客觀指標來衡量抑制迴聲而不降低音訊品質的能力的工具。目前業界和學術界使用它來評估 AEC 性能。它用於評估新演算法的性能,與現有技術進行比較,或分析研究論文或報告中的實驗結果並與其他研究進行比較,以證明研究的有效性。
AECMOS有以下三種測量模式:
- 48,000 Hz,基於場景的模型 (Run_1668423760_Stage_0.onnx)
- 16 kHz,以場景為基礎的模型 (Run_1663915512_Stage_0.onnx)
- 16 kHz 模型 (Run_1663829550_Stage_0.onnx)
基於場景的模型可以產生更準確的結果,因為它知道 ST FE (far-end single talk) 、ST NE (near-end single talk) 和 DT (double talk) 部分資訊。我們使用 48,000 Hz、基於場景的模型進行 AEC 效能測量。
AECMOS 有以下四個子指標(更多詳細信息,請參閱績效指標的意義部分)。
| Metric | 解釋 |
|---|---|
| ST FE Echo DMOS | 遠端單通話中的迴聲消除質量 |
| ST NE MOS | 近端單通話語音保留品質 |
| DT Echo DMOS | 雙方通話中的迴聲消除質量 |
| DT Other MOS | 雙方通話中的語音保留品質 |
選擇測試資料集
對於測試資料集,我們使用AEC挑戰賽提供的test_set_icassp2022資料集。此資料集提供了300個DT案例、300個ST FE案例和200個ST NE案例的聲源。
準備測量目標模組
準備將作為性能測量目標的 AEC 模組。
測量 AEC 性能
設定測量環境後,將依照以下步驟測量 AEC 性能:
- 將A(與迴聲混合的原始語音,在AECMOS中稱為「麥克風捕捉的音訊」)和B(作為迴聲來源的語音,在AECMOS中稱為「環回音訊」)輸入到AEC。
- 將場景檔案、AEC處理結果C(去除迴聲的聲音,AECMOS中稱為「增強音訊」)、A、B輸入到AECMOS測量工具中,測量 ST FE Echo DMOS、ST NE MOS、DT Echo DMOS、DT Other MOS。
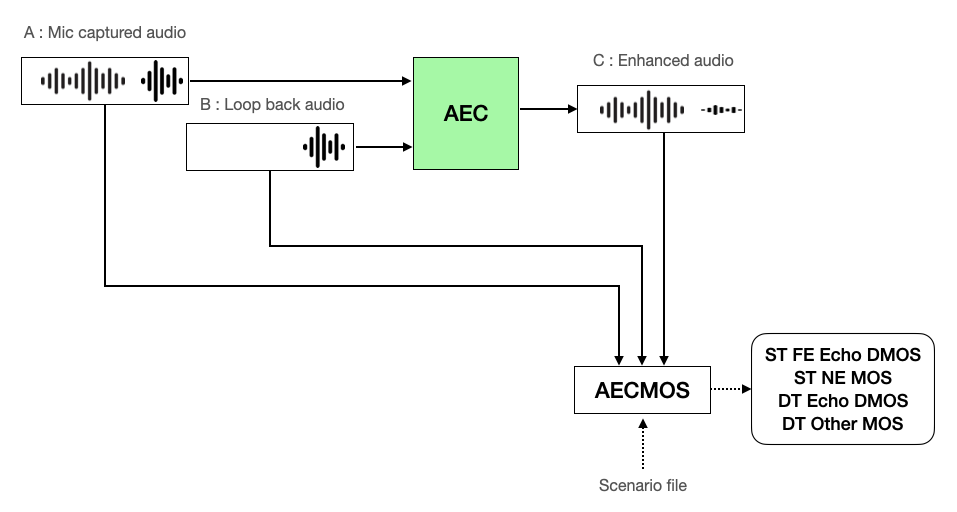
評估 AEC 性能
我們分析AEC績效測量的結果,看看哪裡出現了差異、改進了什麼、缺少什麼,然後據此制定未來的發展和更新計劃。
AECMOS 指標的意義以及各指標的感知品質比較
讓我們看看 AECMOS 測量的指標的含義,並比較每個指標分數的感知品質。為了方便起見,我們在解釋中假設近端是「我」。
績效指標的意義
前面提到,AECMOS 有四個指標,每個指標的意義如下:
- ST FE Echo DMOS:在只有迴聲的環境(A 中只有遠端語音的環境)中消除迴聲後剩餘的迴聲量的度量。它以 1 到 5 之間的分數表示,數字越高表示迴聲消除效果越好。
- ST NE MOS:衡量我在只有近端語音且無迴聲的環境中保存語音的品質(A中只有近端語音的環境,不存在B語音的環境)不重要)。它以 1 到 5 之間的分數表示,數字越高表示語音品質越好。
- DT Echo DMOS:雙端通話環境(近端和遠端語音皆在A的環境)中迴聲消除後剩餘迴聲品質的量測。它以 1 到 5 之間的分數表示,數字越高表示迴聲消除效果越好。
- DT Other MOS:雙端通話環境(近端和遠端語音均處於A的環境)中迴聲消除後保留語音品質的量測。它以 1 到 5 之間的分數表示,數字越高表示語音品質越好。
為了獲得最佳的通話質量,所有分數都應該很高。但實際上,僅準確地區分迴聲訊號幾乎是不可能的,因此在迴聲消除過程中也會出現語音劣化的情況。尤其是在迴聲和語音同時存在的雙講部分,兩種語音混合在一起,因此消除迴聲時語音劣化的可能性更大。正因為如此,迴聲消除和語音保留是一種權衡關係。
ST FE Echo DMOS 和 DT Echo DMOS 分數隨著迴聲被更好地消除而增加,並且 ST NE MOS 和 DT Other MOS 分數隨著語音被更好地保留而增加。所以,如果ST FE Echo DMOS和DT Echo DMOS分數高的時候把所有聲音都去掉,分數高的時候迴聲和語音都可以去掉,但對方卻聽不到我的聲音。相反,如果在高 ST NE MOS 和 DT Other MOS 分數時不去除訊號,則在高分數時我的聲音保持完整,但由於迴聲嚴重而導致對話困難。
透過 AECMOS 性能指標比較感知質量
在下表中,您可以根據AECMOS的四個品質指標的得分範圍來感知語音品質的差異:ST FE Echo DMOS、ST NE MOS、DT Echo DMOS和DT Other MOS。
| ST FE Echo DMOS | 音訊擷取位置 | 音訊檔案 | 描述 |
|---|---|---|---|
| Original | 麥克風捕捉的音訊 (A) | 遠端(Far-End)的人單獨講話 (B),該聲音透過揚聲器輸出時由我的麥克風收集 (A)。您可以在 A 處聽到迴聲。 | |
| 環迴音訊 (Loop back audio) (B) | |||
| 1.x | 增強音訊(Enhanced audio) (C) | 迴聲沒有被很好地消除。 | |
| 2.x | 增強音訊 (C) | 迴聲減弱,但許多路段仍能聽到殘餘迴聲。 | |
| 3.x | 增強音訊 (C) | 總體而言,許多迴聲已被消除,但您偶爾可以聽到一些殘留的迴聲。 | |
| 4.x | 增強音訊 (C) | 迴聲已完全消除,聽不見。 |
| ST NE MOS | Audio Capture Location | Audio File | Description |
|---|---|---|---|
| Original | 麥克風捕捉的音訊 (A) |
這種情況是,當我(Near-End)在無迴聲的環境中講話時,遠端會發出很大的噪音。B 處有遠端噪音,但 A 處只有我的聲音。 | |
| 環迴音訊(Loop back audio) (B) | |||
| 1.x | 增強音訊(Enhanced audio) (C) | 儘管處於無迴聲環境中,近端語音仍顯著下降。退化的部分難以理解。 | |
| 2.x | 增強音訊 (C) | 儘管處於無迴聲環境中,近端語音仍會出現降級。您需要仔細聆聽才能理解降級的部分。 | |
| 3.x | 增強音訊 (C) | 儘管處於無迴聲環境中,近端語音仍略有下降。雖然有退化,但這是可以理解的。 | |
| 4.x | 增強音訊 (C) | 幾乎沒有任何部分近端語音品質下降。 |
| DT Echo DMOS | 音訊擷取位置 | 音訊檔案 | 描述 |
|---|---|---|---|
| Original | 麥克風捕捉的音訊 (A) | 近端先開始講話,遠端也跟著講話 (B)。兩個聲音都被我的麥克風 (A) 收集在一起。 | |
| 環迴音訊(Loop back audio) (B) | |||
| 1.x | 增強音訊(Enhanced audio) (C) | 迴聲沒有被很好地消除。 | |
| 2.x | 增強音訊 (C) | 迴聲減弱,但許多路段仍能聽到殘餘迴聲。 | |
| 3.x | 增強音訊 (C) | 總體而言,許多迴聲已被消除,但您偶爾可以聽到一些殘留的迴聲。 | |
| 4.x | 增強音訊 (C) | 迴聲已完全消除,聽不見。近端語音存在劣化,但由於 DT ECHO DMOS 分數僅評估殘留迴聲量,因此測得較高分數。 |
| DT Other MOS | 音訊擷取位置 | 音訊檔案 | 描述 |
|---|---|---|---|
| Original | 麥克風捕捉的音訊 (A) | 近端先開始講話,遠端也跟著講話 (B)。兩個聲音都被我的麥克風 (A) 收集在一起。 | |
| 環迴音訊(Loop back audio) (B) | |||
| 1.x | 增強音訊 (Enhanced audio)(C) | 在雙方通話部分,近端語音顯著下降。退化的部分難以理解。 | |
| 2.x | 增強音訊 (C) | 在雙方通話部分,近端語音會出現降級。你只能意識到有人在退化的部分說話。 | |
| 3.x | 增強音訊 (C) | 在雙方通話部分,近端語音略有下降。您需要仔細聆聽才能理解降級的部分。 | |
| 4.x | 增強音訊 (C) | 在雙方通話部分,近端語音會下降,但這是可以理解的。來自遠端的迴聲量不會反映在 DT Other MOS 分數中,但它確實會影響 DT Echo DMOS 值。 |
AEC 效能測量總結
我們按如下方式衡量性能,以可靠地評估和改進我們的 AEC 技術:
- 確保可重複性和一致性:我們使用 AECMOS 測量可重複環境中的效能。我們使用相同的資料庫在本地進行測試,以減少網路影響。使用在相同環境中提供一致結果的測量方法使我們能夠準確地了解 AEC 技術的性能變化和改進。
- 使用可靠的指標:AECMOS 指標是業界和學術界廣泛用於 AEC 效能評估和比較分析的關鍵指標。使用這個指標可以確保測量性能的可靠性,並使我們能夠定量評估產品的數量和性能並設定改進的方向。
- 驗證各種迴聲情況下的性能:我們使用以下方法來定量檢查 AEC 技術在各種迴聲環境中的工作情況。
- 大資料庫:我們使用超過2400個資料庫,根據場景單講和雙講混合。
- 多樣化的錄音環境:我們使用在各種音訊設備(麥克風、揚聲器)和環境下錄製的具有各種語音和迴聲音量和特徵的資料。
我們努力透過可靠地評估各種條件下的性能來提供最佳的語音質量,以便我們的 AEC 技術能夠在任何迴聲情況下有效運作。
此外,我們還使用機器學習開發了迴聲消除技術,以克服由於迴聲消除和語音保留處於權衡關係而產生的效能問題。因此,與現有技術相比,整體效能指標得到了一致提高。雖然機器學習的特性透過更多的運算來提高效能,但我們仍然在透過適當調整運算量來進行調優,因為我們還不能在即時通話服務中使用大量的運算(這樣的高效能AEC僅安裝在LINE桌面中) )。
到目前為止,我們已經做出了許多改進。未來,我們的目標是進一步提高雙方通話情況下的效能,並在行動應用程式中安裝高性能 AEC。
測量頻率響應
接下來我們來看看頻率響應的測量方法。首先,我們簡單了解一下與頻率響應測量相關的幾個概念,以了解頻率響應測量方法和流程。
什麼是頻率和取樣率?
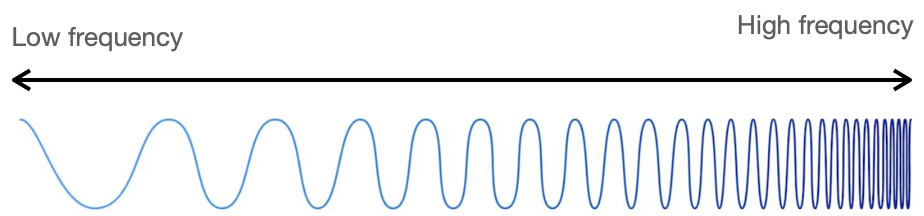
頻率是振動的週期性重複。頻率通常以每秒振動的次數來表示,使用的單位是赫茲(Hz)。高頻代表短週期快速重複的振動,而低頻代表長週期緩慢重複的振動。
由於聲音是由空氣或其他介質的振動產生的,因此聲音也可以用頻率來表示。頻率的高低決定了聲音的音高。頻率高的元件具有高音調,頻率低的元件具有低音調。例如,鋼琴上的C音符的頻率約為261.63Hz,E音符的頻率約為329.63Hz。
將類比訊號轉換為數位訊號時,會使用稱為取樣的過程。取樣是將原始訊號轉換為由每隔一定時間間隔的測量值(樣本)組成的訊號的過程,每秒取樣的頻率稱為取樣率。數位訊號處理中的重要概念之一,奈奎斯特-香農取樣定理( Nyquist-Shannon sampling theorem),用於確定以數位方式表示訊號所需的取樣率。根據這個定理,如果將取樣率設定為要數位化的訊號最大頻率的兩倍以上,就可以完美地以數位方式再現原始訊號。簡單來說,要將頻率為 20,000 Hz 的類比訊號數位化,需要使用超過 40,000 Hz 的取樣率。這樣,數位化訊號將包含與原始訊號幾乎相同的資訊。
什麼是頻率響應 (frequency response)?
頻率響應是衡量音訊系統輸出訊號在不同頻段傳輸的準確程度的指標,用於評估音訊系統再現從低頻段到高頻段的寬頻率範圍的效果。它按頻段比較輸入和輸出音量,並使用分貝(dB)作為測量單位。分貝以對數刻度表示,類似人耳感知的聲音音量。負值越大,代表越安靜,分貝值的差異越大,人類能感受到的聽覺差異就越大。
測量頻率響應是評估音頻系統性能的重要方法。能夠在更寬的頻率範圍內更準確地再現的音頻系統被認為是性能更高的音頻系統。這有助於更自然地再現音樂或聲音,並有助於為用戶提供高品質的音訊體驗。
在語音通話中,說話者的語音訊號包括從低音到高音的各種頻率。如果音訊系統能夠準確地再現這些不同的頻率,那麼語音通話的品質將會提高。因此,我們非常重視頻率響應,以便為用戶提供最佳的語音通話體驗,並根據頻率響應測量結果不斷改進 LINE 應用語音通話服務的頻率響應。
聲音頻率和頻率響應
可聽頻率是指人耳可以聽到的頻率範圍。通常,人耳可以聽到大約 20 Hz 到 20,000 Hz 之間的頻率。因此,頻率響應主要是在這個可聽頻率範圍內測量的。
頻率響應通常透過以圖形方式表示輸出訊號相對於每個頻帶的原始訊號的增益(強度變化)來評估。此圖直觀地表示了每個頻率的增益差異,使您可以看到每個頻段的系統輸出訊號的特徵。讓我們來看看下面測量的頻率響應結果的範例。
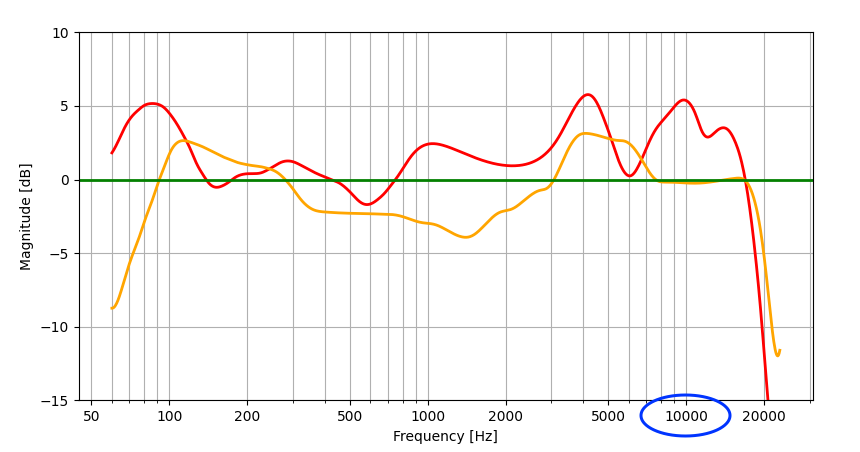
上圖顯示了兩個音頻系統的頻率響應,分別以紅色和橙色表示。在這裡,您可以輕鬆看到理想頻率響應(綠色)與紅色和橙色頻率響應之間的差異。例如,如果查看 10,000 Hz 左右的頻率響應(以藍色圓圈標記),則橙色頻率響應與理想頻率響應相似,但紅色頻率響應比理想頻率響應高約 5 dB。因此,我們可以說,在10,000 Hz時,橙色比紅色具有更理想的頻率響應特性。
按頻帶劃分的聲音特徵
聲音依頻段的特徵如下:
- 低於 100 Hz:歸類為低頻。該頻段的訊號對語音通話沒有幫助。事實上,如果這個部分的聲壓很高,聽者聽起來會感到不舒服。
- 100 Hz-250 Hz:歸類為中低頻。它主要負責語音通話中的低音和振動,並起到表達聲音穩定性的作用。
- 250 Hz-2,000 Hz:歸類為中頻。此頻段是聲音的主要部分之一,起到表達聲音清晰度和銳利度的作用。
- 2,000 Hz-8,000 Hz:歸類為高頻。高頻段處理聲音的高音部分和摩擦音([f]、[v])�等細節。
- 8,000 Hz-20,000 Hz:歸類為超高頻。此頻帶在表達齒擦音([s],[z])的特徵方面發揮作用。
- 20,000Hz以上:這個頻段幾乎沒有語音訊號,人的聽覺很難感知。
如何測量頻率響應
頻率響應受到音頻訊號流經的所有路徑的影響。在呼叫系統中,麥克風和揚聲器設備以及呼叫模組的特性都會產生影響。
我們使用虛擬音訊設備來精確測量通話模組的頻率響應。這是為了最大限度地減少頻率測量期間音頻設備的影響。虛擬音訊設備可以無失真地輸入和輸出音訊訊號,從而可以單獨精確測量LINE呼叫模組的特性。
下圖中的紅線代表測量頻率響應的目標路徑。透過使用虛擬音訊設備,我們可以從頻響測量結果中排除音訊設備的影響,以準確測量通話模組單獨的特性。這使得我們能夠有效地獲取準確分析呼叫模組的頻率響應並提高其品質所需的資訊。
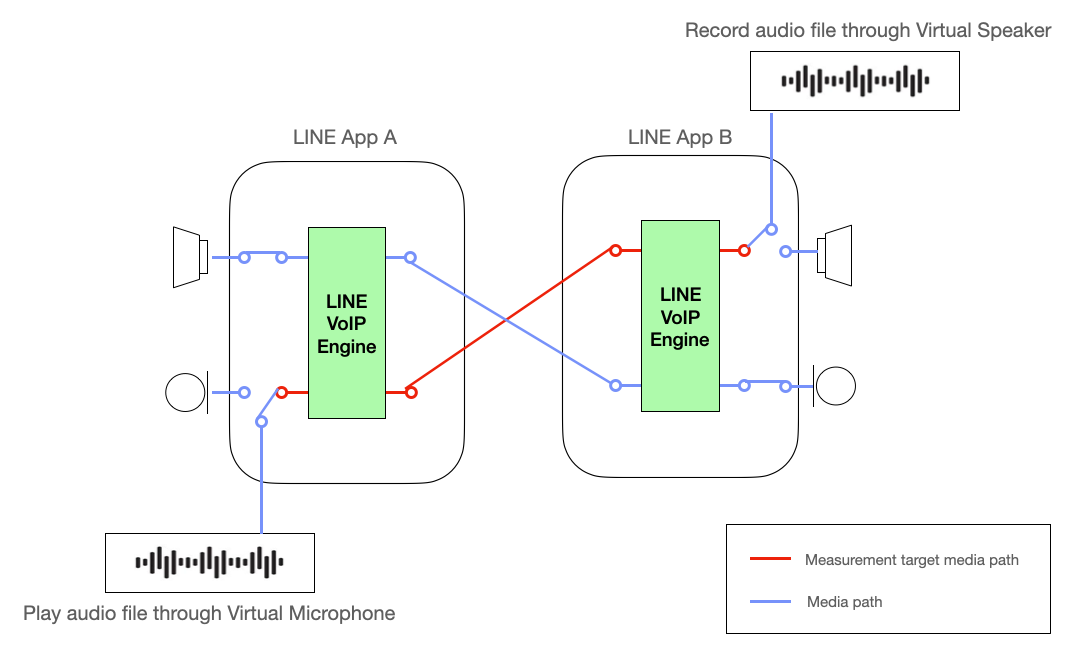
頻率響應測量程序
LINE 應用程式呼叫模組的頻率響應測量遵循以下步驟。
測試訊號的選擇
選擇適合您要測量的音訊系統的測試訊號。此測試訊號的頻帶通常由語音訊號組成,可聽頻率範圍內的訊號為20 Hz 至20,000 Hz。之所以將測試訊號與語音訊號合成,是因為呼叫模組主要可以將語音以外的訊號視為雜訊並去除它們。
測試訊號採用IEEE提供的通訊設備電聲性能評估標準(IEEE 269-2010)的訊號。下面的連結是用於此類測量的測試訊號。
- 下載媒體文件
- IEEE_269-2010_Male_mono_48_kHz.wav:初始穩定聲源
- IEEE_269-2010_Male_mono_48_kHz.wav、IEEE_Female_mono_48_kHz.wav:頻率響應測量聲源
設定測量系統環境 1 - 配置測量環境
設定測量頻率響應的系統環境。
- Adobe Audition:這是一款播放測試訊號並記錄被測音訊系統輸出訊號的軟體。
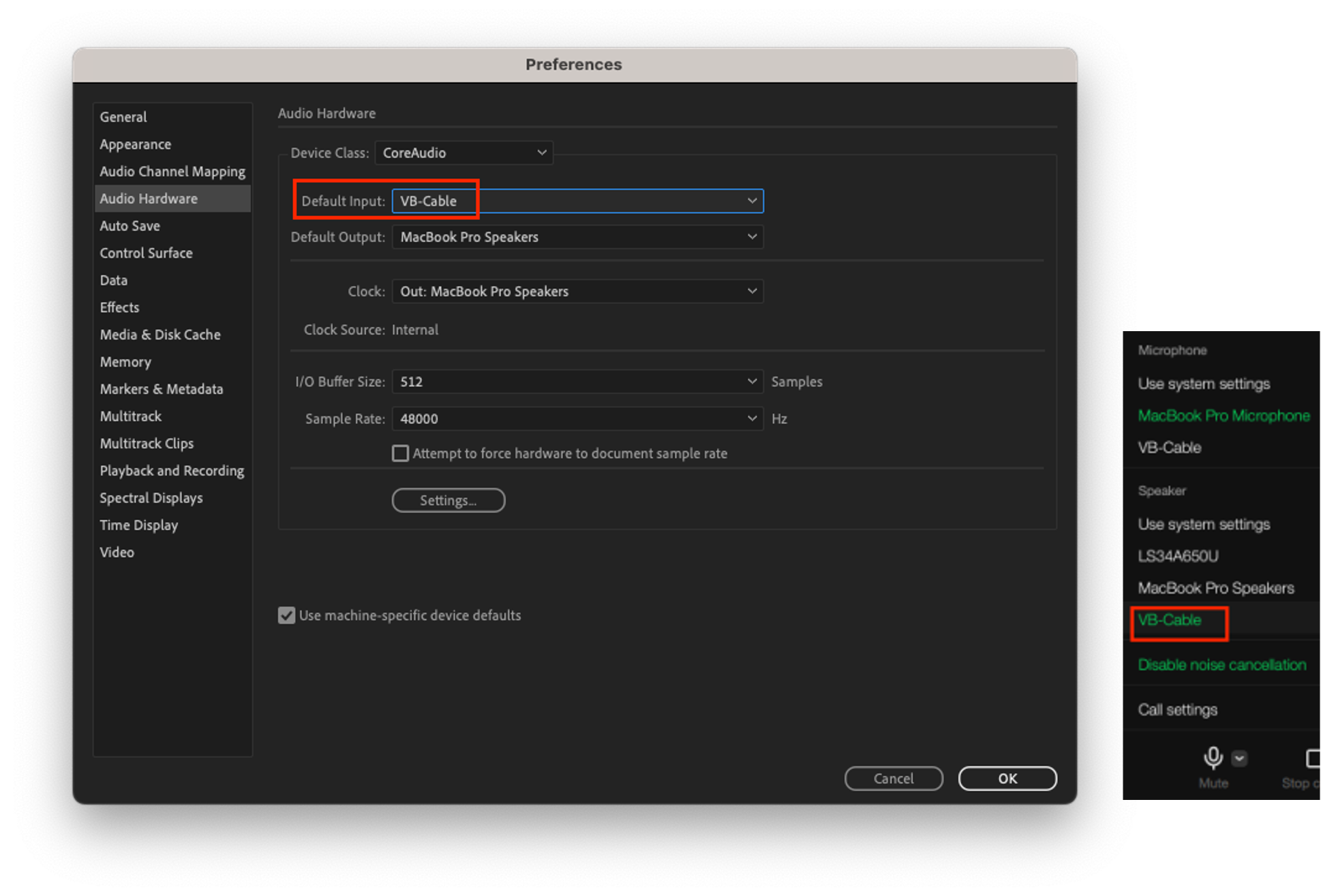
- VB-AUDIO :這是一款可讓您使用虛擬音訊裝置使用麥克風輸入和揚聲器輸出而不會使音訊訊號失真的軟體。安裝後,您可以使用VB-Cable,它是一個虛擬麥克風/揚聲器設備。
- 頻率響應測量工具:這是一個程式碼,它採用兩個 wav 檔案、測量訊號和輸出訊號,並繪製頻率響應。
設定測量系統環境2 - 連接測量音頻系統
我們使用兩台設備 A 和 B 來測量 LINE 語音通話的頻率響應。
- 設備A和B的通用設定:將VB-Cable的輸入/輸出取樣率設定為48,000 Hz。這允許表示高達 24,000 Hz 的訊號,覆蓋人類聽覺的整個範圍。
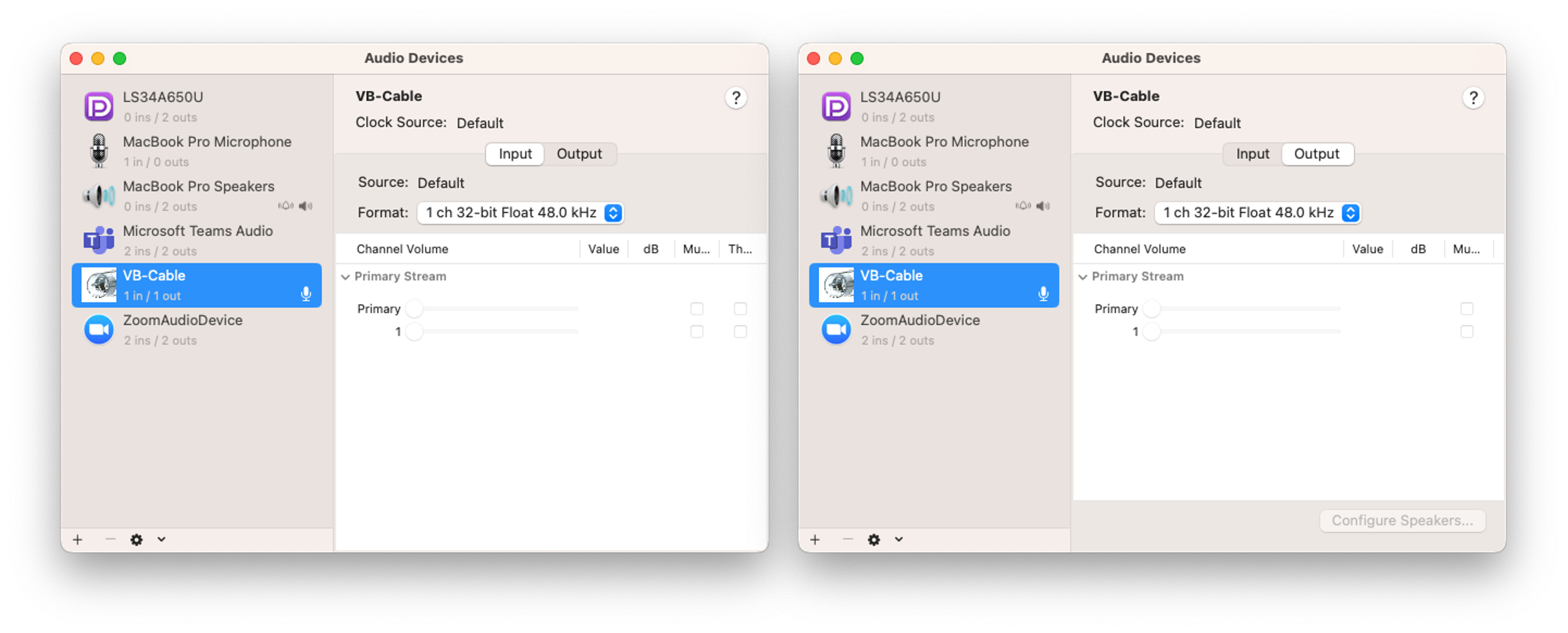
- 在裝置 A 上,將 Adobe Audition 的揚聲器輸出設為 VB-Cable,並將 LINE 應用程式的麥克風設定為 VB-Cable。Adobe Audition 中播放的音訊透過 VB-Cable 傳送到 LINE 應用程式的麥克風輸入。
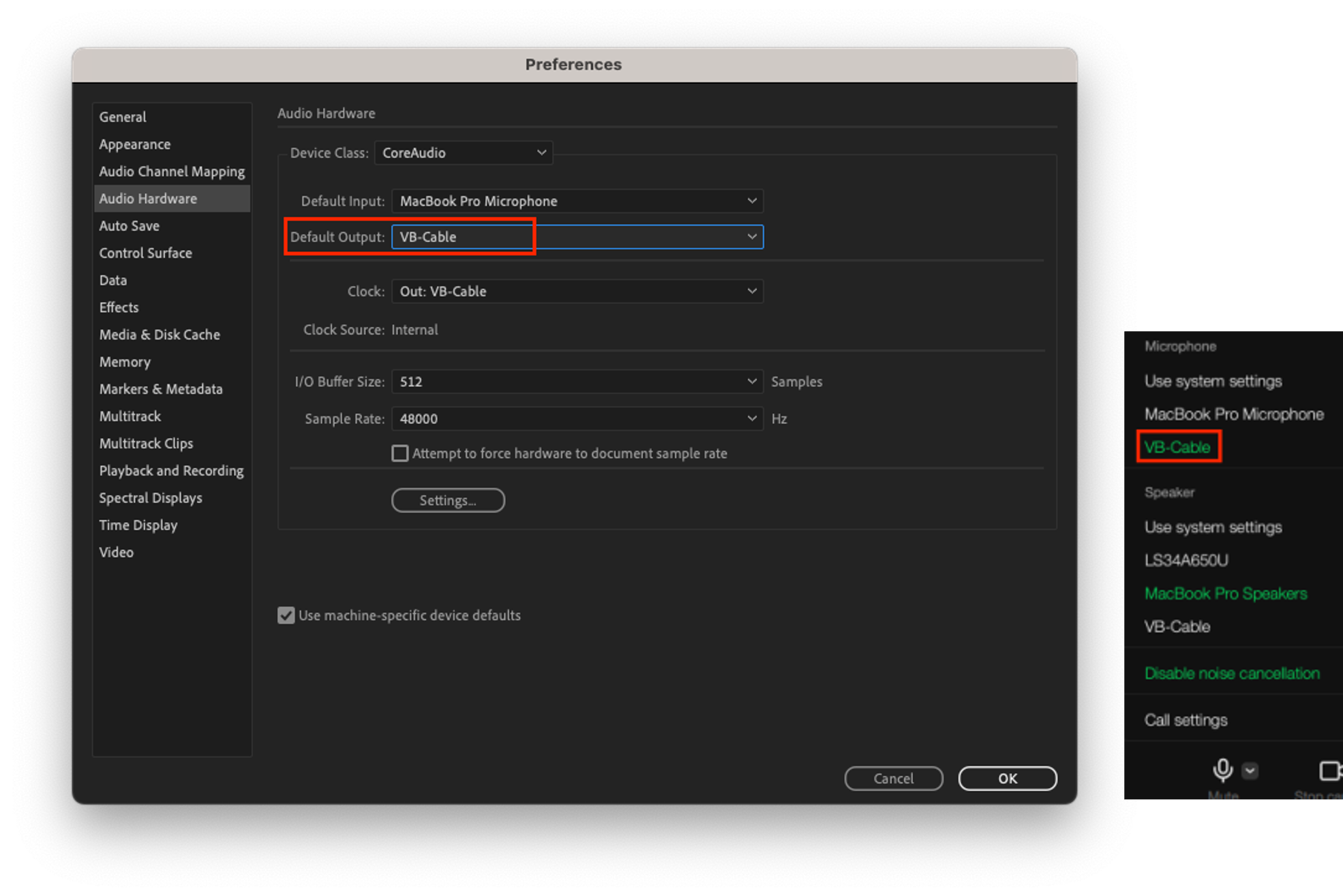
- 在裝置 B 上,將 LINE 應用程式的揚聲器裝置設定為 VB-Cable,並將 Adobe Audition 的麥克風輸入設定為 VB-Cable。LINE 應用程式的揚聲器輸出透過 VB-Cable 傳送到 Adobe Audition 的音訊輸入。
訊號驗證和頻率響應測量
- 播放穩定訊號
連接 LINE 應用語音通話,並在裝置 A 上的 Adobe Audition 中播放穩定訊號 IEEE_269-2010_Male_mono_48_kHz.wav 15 秒以上。此步驟是為了確保語音通話模組有時間適應。正在播放穩定訊號。 - 錄製系統輸出訊號
在裝置 B 上的 Adobe Audition 中開始錄製,以錄製通話系統的輸出。正在錄製的檔案的取樣率為 48,000 Hz。 - 播放測量訊號
在裝置 A 上的 Adobe Audition 中播放測量訊號。測量訊號為 IEEE_269-2010_Male_mono_48_kHz.wav 和 IEEE_Female_mono_48_kHz.wav 聲源。每個音源共包含四句,依女、男順序交替播放,一次一句。 - 驗證系統輸出訊號
所有句子播放完成後,停止裝置 B 上的錄音。測量訊號經過設備A的發送端和設備B的接收端後記錄在設備B上。現在記錄的音頻檔案反映了LINE應用音頻系統的頻率響應特性。 - 音量調節(必要時執行此步驟)
LINE 應用程式會進行音量調節,例如降低大聲的音量、增大小聲的音量,為使用者提供統一的音量。這可能會導致原始聲音和輸出音量之間存在差異。這種音量差異可能會在頻率響應分析過程中導致意外的解釋錯誤,因此在測量頻率響應之前,您可以選擇調整裝置 A 上的音訊播放音量,以使輸出音量相似。如果變更裝置A上的音訊播放音量,請重新從步驟1開始。如果在頻率響應測量過程中執行了音量調整步驟,則必須在測量結果中指定播放音量調整量。 - 測量頻率響應
將測量訊號(步驟 3)和系統輸出訊號(步驟 4)輸入頻率響應分析工具以建立頻率響應圖。如果您在步驟 5 中執行了音量調整過程,請將步驟 5 中調整的音量反映在測量訊號(步驟 3)中,並將其輸入到頻率響應分析工具中。頻段是在手機和耳機中使用的 1/12 倍頻程中測量的。
測量損耗穩健性
在即時通訊服務中,實現對丟包具有穩健性的機制對於提供良好的語音品質和穩定的服務至關重要。我們先來看看為什麼會發生丟包以及如何處理,然後探討如何在 LINE 應用中衡量丟包穩健性。
丟包和語音質量
如前所述,即時通訊服務透過網際網路協定即時傳輸語音資料。這些服務對於即時性非常重要,因此它們使用用戶資料報協定(UDP)而不是傳輸控制協定(TCP)來減少延遲。
TCP 檢查並重新傳送所有資料包以實現可靠的資料傳輸,因此當發生丟包時,延遲會增加。因此,它會降低即時通訊服務的用戶體驗。另一方面,UDP 適合即時通信,因為它沒有像 TCP 那樣的檢查和重發過程。然而,UDP 無法保證封包的傳輸,並且缺乏像 TCP 那樣的流量控製或錯誤復原功能。因此,當透過網路傳輸的資料包遺失時��,可能會發生語音遺失。
丟包的原因和影響
資料包可能因各種原因遺失。這些封包可能會因為網路擁塞而遺失,也可能因為網路頻寬達到極限或同時傳輸的資料量過多而導致部分封包遺失,導致路由器或交換器無法處理封包。在無線網路中,由於訊號幹擾、訊號突然減弱或建築物中的障礙物等因素,資料包可能會遺失。
那麼,丟包對語音品質有什麼影響呢?
在即時通訊業務中,來自麥克風的語音訊號被編解碼器壓縮,壓縮後的資料以數十毫秒的間隔透過網路傳輸。語音資料包的遺失意味著該部分語音的遺失。在視訊會議或日常通話中,對方的聲音可能會被切斷或變得難以理解,這會幹擾溝通。

語音遺失恢復技術
那麼,丟包導致的語音遺失該如何恢復呢?目前業界採用多種技術和機制來恢復丟包,主要包括:
- 丟包隱藏 (PLC)
PLC 是一種在丟包部分插入遺失語音資料的技術。這可以減輕因丟包而導致的語音品質下降,並改善使用者體驗。它對於輕微丟失非常有效,無需額外的資料來進行丟失恢復,但其有效性會隨著丟包的增加而降低。 - 前向糾錯(FEC)
FEC 是一種透過新增錯誤校正碼來恢復封包遺失的方法。發送方隨原始來源資料包一起傳輸一些恢復訊息,接收方使用此恢復訊息來恢復遺失的來源資料包。雖然它的延遲比重傳更短,但它的缺點是增加了資料使用量,因為它需要提前發送恢復訊息。 - 資料包重傳
這是一��種透過請求發送方重新發送遺失的資料包來恢復資料包遺失的方法。從遺失請求到重新投遞所需的時間可能會導致嚴重的延遲。
LINE 應用中使用的語音遺失復原技術
由於每種丟包恢復技術都有其優點和缺點,因此LINE應用程式根據網路情況適當地使用這些技術來恢復丟包。
發送頁面
在LINE應用程式中,我們本質上使用了2-D FEC保護技術,這是 RFC 8627 的應用。
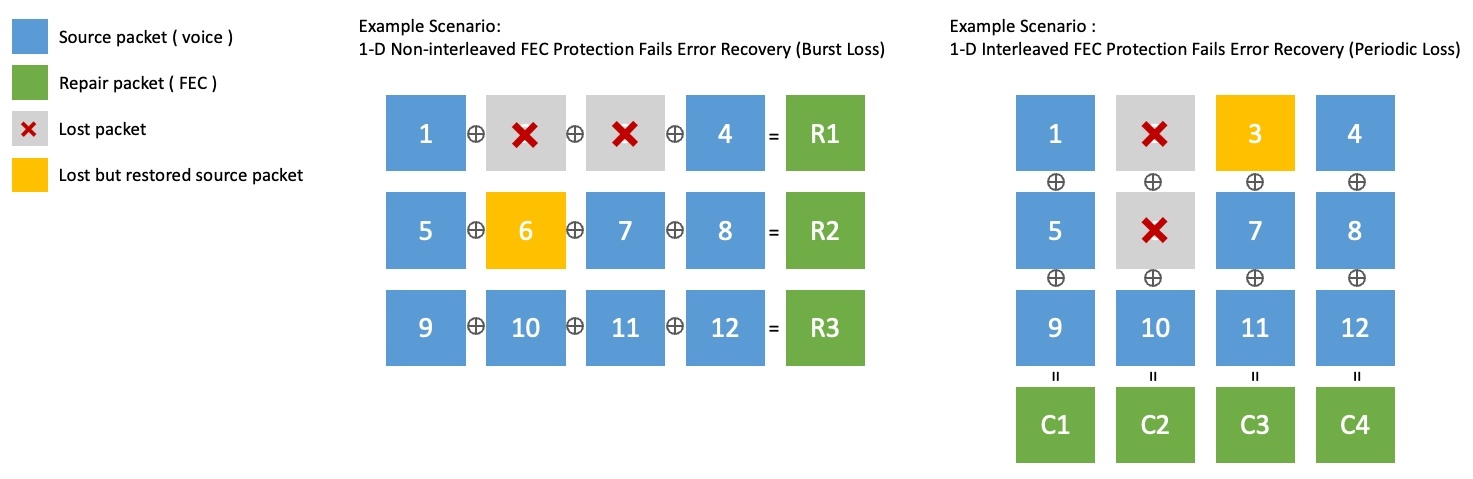
單維FEC透過一組以行為單位(一維非交錯)或以列為單位(一維交錯)的來源資料包進行異或運算來產生復原資料包。但是,它有一個限制,即無法恢復連續兩次以上的資料包遺失。下圖顯示了此限制的範例。
- 在下圖左側的 1-D Non-interleaved 中,封包 6 被恢復,但連續的封包遺失 2 和 3 無法恢復。
- 在下圖右側的1-D Interleaved中,資料包3被恢復,但連續丟包2和6無法恢復。
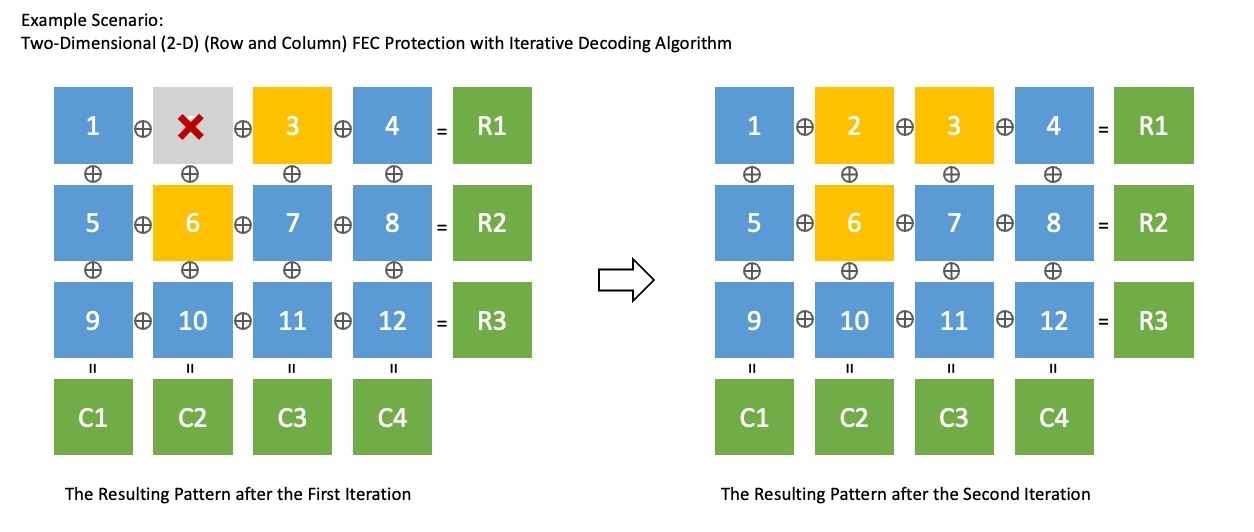
 2-D FEC 保護是一種結合了單一維度 Interleaved FEC 和非 interleaved FEC 的技術。它可以回應各種遺失模式,並且透過迭代解碼演算法,可以比一般FEC更有效地恢復遺失。下圖顯示了在與上述相同的情況下使用 2-D FEC 保護在兩次重複中恢復所有資料包的範例。
2-D FEC 保護是一種結合了單一維度 Interleaved FEC 和非 interleaved FEC 的技術。它可以回應各種遺失模式,並且透過迭代解碼演算法,可以比一般FEC更有效地恢復遺失。下圖顯示了在與上述相同的情況下使用 2-D FEC 保護在兩次重複中恢復所有資料包的範例。
然而,如果丟包率變得非常高,2-D FEC 保護可能就不夠了。在這種情況下,我們使用一種技術來定期重新發送相同的原始資料包兩次或更多次。發送者透過即時監控丟包率來決定是否使用二維FEC保護或定期重送。
接收端
在接收方,使用發送方發送的恢復訊息來恢復遺失的資料包。如果仍然存在遺失,則請求重新傳送遺失的資料包。重傳會造成延遲,所以限制不要在網路延遲高的環境下操作。最後,對於未發生即時丟包恢復的語音部分,透過PLC減輕音質的下降。
如何客觀評價語音品質
首先,讓我們看看如何評估我們是否適當地回應丟包並確保良好的語音品質。為此,我們首先需要能夠定量、客觀地評估語音質量,我們需要測量單向延遲,我們需要檢查數據使用是否合適。讓我們逐一看一下。
語音品質評估
MOS和主觀語音品質評估
平均意見分數 (MOS) 是用於評估語音通話或基於語音的服務的語音品質的最常用衡量標準。它以 1 到 5 的範圍表示,數字越大表示語音品質越好。這種方法起源於主觀品質測量方法,即人們聆聽實際的語音訊號並主觀評估感知的聲音品質。
語音品質的主觀評價主要採用ITU-T P.800建議。該建議也嚴格規範了主觀評價的環境。例如,錄製和聆聽評價語句的環境需求空間為30-120立方米,殘響時間小於500毫秒(最佳200-300毫秒),室內噪音小於30分貝,無峰值。光譜。此外,評估人員在過去六個月內不應參與任何主觀評估,特別是在過去一年內不應參與聽取主觀評估。也提出了各種條件來消除評估條件或環境可能產生的偏差。因此,主觀語音品質評估不可避免地存在需�要大量成本和時間的問題。
客觀語音品質評估與POLQA
為了解決主觀語音品質評價問題,需要一種客觀評價語音品質的方法。為此,已經開發了各種語音品質評估演算法,透過與原始語音訊號進行比較來提供類似於主觀品質測量結果的評估。
在各種演算法中,廣泛使用的全球標準演算法是感知客觀聽力品質分析(POLQA)。該演算法由國際電信聯盟 - 電信標準化部門 (ITU-T) 標準化,廣泛用於評估語音服務和編解碼器的品質。POLQA在進行語音品質評估時,透過模仿人類聽覺系統來評估音質,提供因網路傳輸、語音編解碼壓縮、丟包、延遲等網路環境變化而導致的音質損失的評估。
與主觀評價一樣,POLQA 也使用 MOS 作為語音品質評價的衡量標準。這樣可以客觀地測量和比較語音通話和語音服務的品質。以下是 POLQA 針對實際聲源評估的 MOS 分數範例。您可以感知每個 POLQA MOS 分數的實際語音品質。
| POLQA MOS | 範例音訊 |
|---|---|
| Original | |
| 4.5 | |
| 3.5 | |
| 2.5 | |
| 1.5 |
評估單向延遲
即使語音品質再好,如果語音傳送的單向延遲較大,雙向通訊只會很不方便。單向延遲是 VoIP 或電話等通訊服務的重要參數之一,它是指語音從一點出發並到達目的地所需的時間。
單向傳輸時間的標準建議ITU-T G.114 (05/2003)單向傳輸時間建議一般網路中單向延遲不應超過400 ms。但是,在某些例外情況下,可以超出此限制。例如,在丟包率較高的網路環境中,如果有一些丟包恢復的等待時間,即使單向時延稍長一些,也能在一定程度上恢復丟包,這樣對用戶體驗會更好。 。因此,您需要測量單向延遲,看看這種遺失恢復機制是否得到了適當的控制。
評估數據使用情況
近年來,隨著行動網路的進步,語音資料的使用通常不再是一個大問題。然而,由於 LINE 應用程式在全球範圍內使用,因此有必要考慮網路效能較差的情況。
要恢復丟包,您需要使用額外的資料。這可能會增加位元率,可能導致網路擁塞。特別是對於視訊等高位元率媒體,您需要更加小心。因此,您需要測量資料使用情況,以檢查遺失復原的資料使用情況是否適當。
如何測量丟包環境下的語音質量
現在我們已經有了客觀評估語音品質的方法,接下來我們來看看如何在丟包的環境下測量語音品質。
語音品質和延遲分析
我們使用專業的語音品質分析設備(語音品質分析儀)進行可靠、客觀的語音品質測量。數位語音電平分析儀(DSLA)是一種可以測量通訊設備和網路中通話品質的設備。DSLA將原始語音訊號作為輸入註入發送方終端,並捕捉接收方終端播放的語音訊號,與原始語音訊號進行比較和分析。分析完成後,提供各種分析結果。如前所述,使用 POLQA 演算法可以獲得客觀結果。換句話說,您可以測量 POLQA MOS 和語音單向延遲。
丟包模型與仿真
在網路中,由於網路擁塞、路由器緩衝區溢位、訊號幹擾等原因,丟包的情況多種多樣。其中,隨機丟包是最常見的丟包模式,即資料包在網路中隨機遺失。另外,突發丟包是指連續遺失多個資料包的情況。在這種情況下,突發分組丟失具有各種建模方法,並且存在諸如狀態和根據該狀態的概率之類的各種變量,因此根據模型和變量,丟失發生的程度存在差異。因此,當我們測試效能時,我們使用隨機丟包模式。
此外,我們也使用名為 PacketStorm的專業網路模擬器進行可靠且精確的網路模擬。使用此設備,您不僅可以測試資料包遺失的效能,還可以測試各種網路傳輸損傷的效能,例如延遲、抖動、重新排序和限制。如果您僅模擬隨機丟包模式,您也可以使用其他工具,例如 macOS 提供的 Network Link Conditioner。
測量場景
我們來看看在丟包環境下測量兩個終端語音品質的場景。
設定測量環境
首先將終端A、B分別連接到 DSLA(語音品質分析設備)端口,然後進行網路。網路傳輸損傷可以應用於發送方的上行鏈路或接收方的下行鏈路。
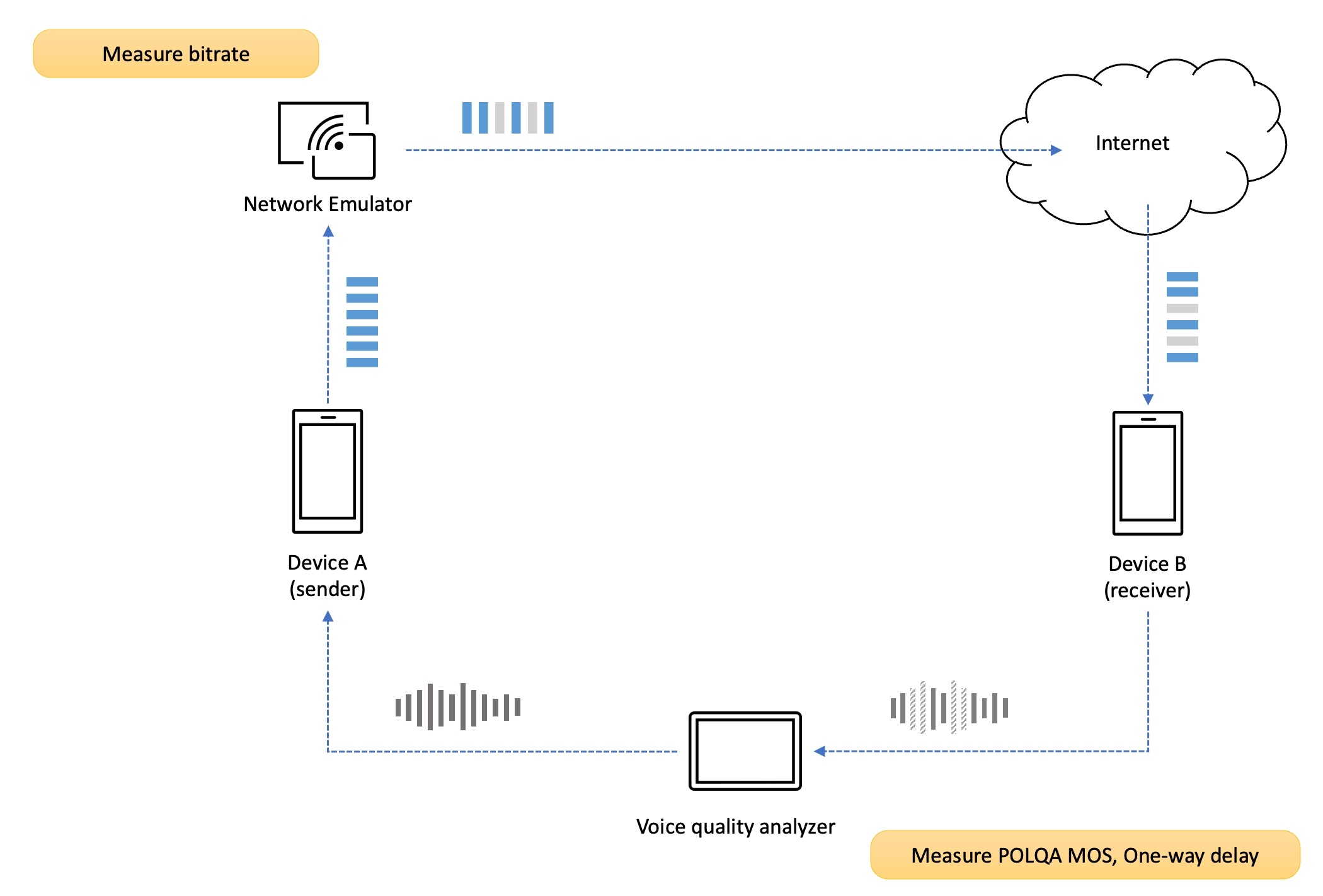
我們對這兩個場景進行了測量,上圖顯示了將丟包的傳輸損傷應用於發送方上行鏈路的範例。
轉接電話
接下來,您需要連線呼叫。LINE一對一通話時,兩個終端連接通話;LINE群組通話時,兩個終端機加入同一個群組。
測量與分析
現在開始使用語音品質分析設備測量語音品質和語音延遲。由於隨機丟包並不總是相同的模式,因此語音品質和語音延遲的測量結果每次都會有所不同。即使在相同的情況下,MOS 值的差異也會因語音資料包遺失的部分而有很大差異。由於恢復遺失資料包時發生的延遲,語音延遲也可能存在差異。因此,最好重複DSLA測試以增加評估數據的可靠性。我們在一個方向上測量和分析至少 50 次。
分析測量結果
測試結束後,收集語音品質(POLQA MOS)、語音單向延遲、資料使用等結果。收集到的結果可以以多種形式進行分析。例如,您可以根據遺失率來比較 MOS 的分佈或延遲測量結果,如下所示。
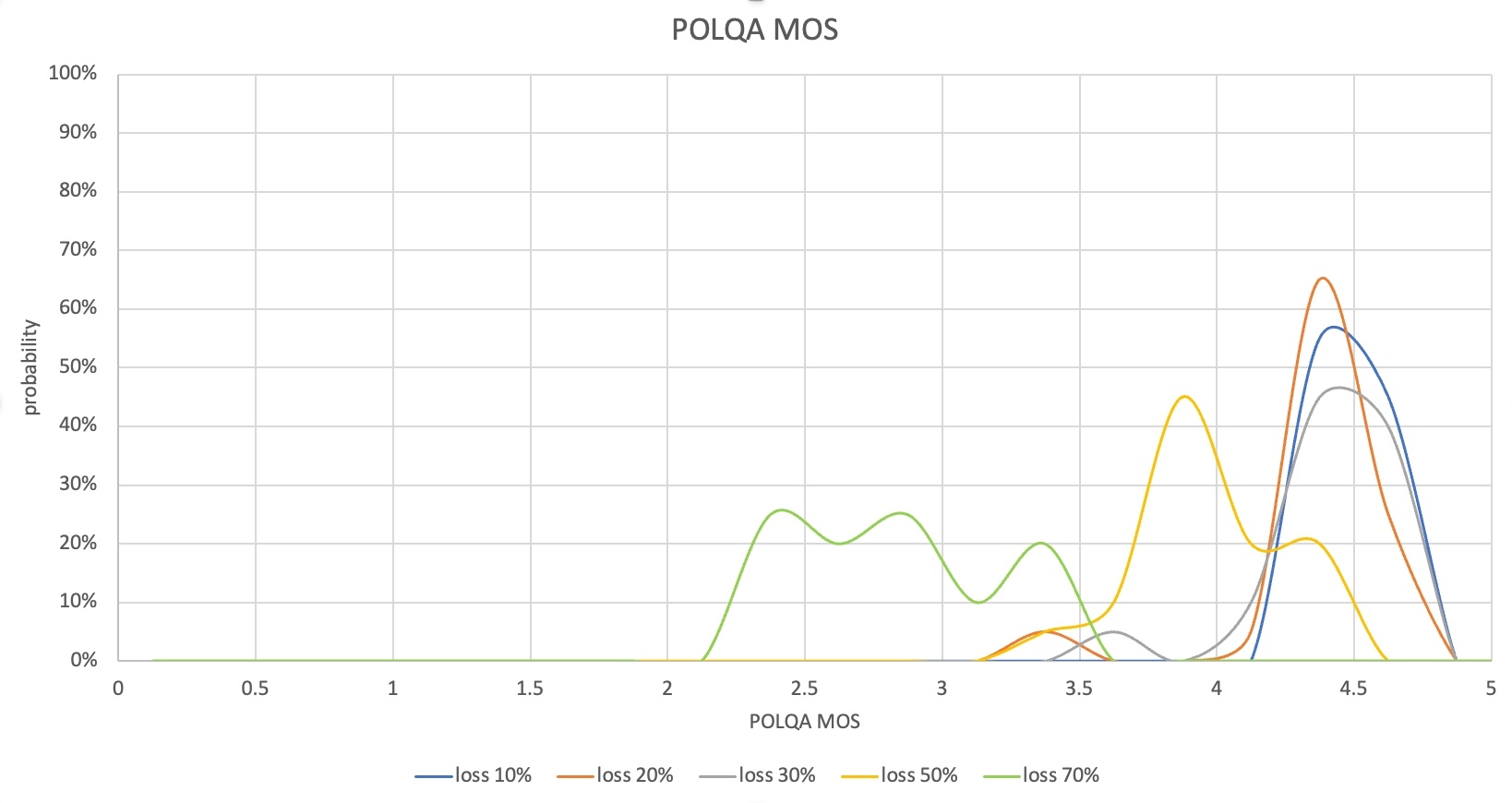
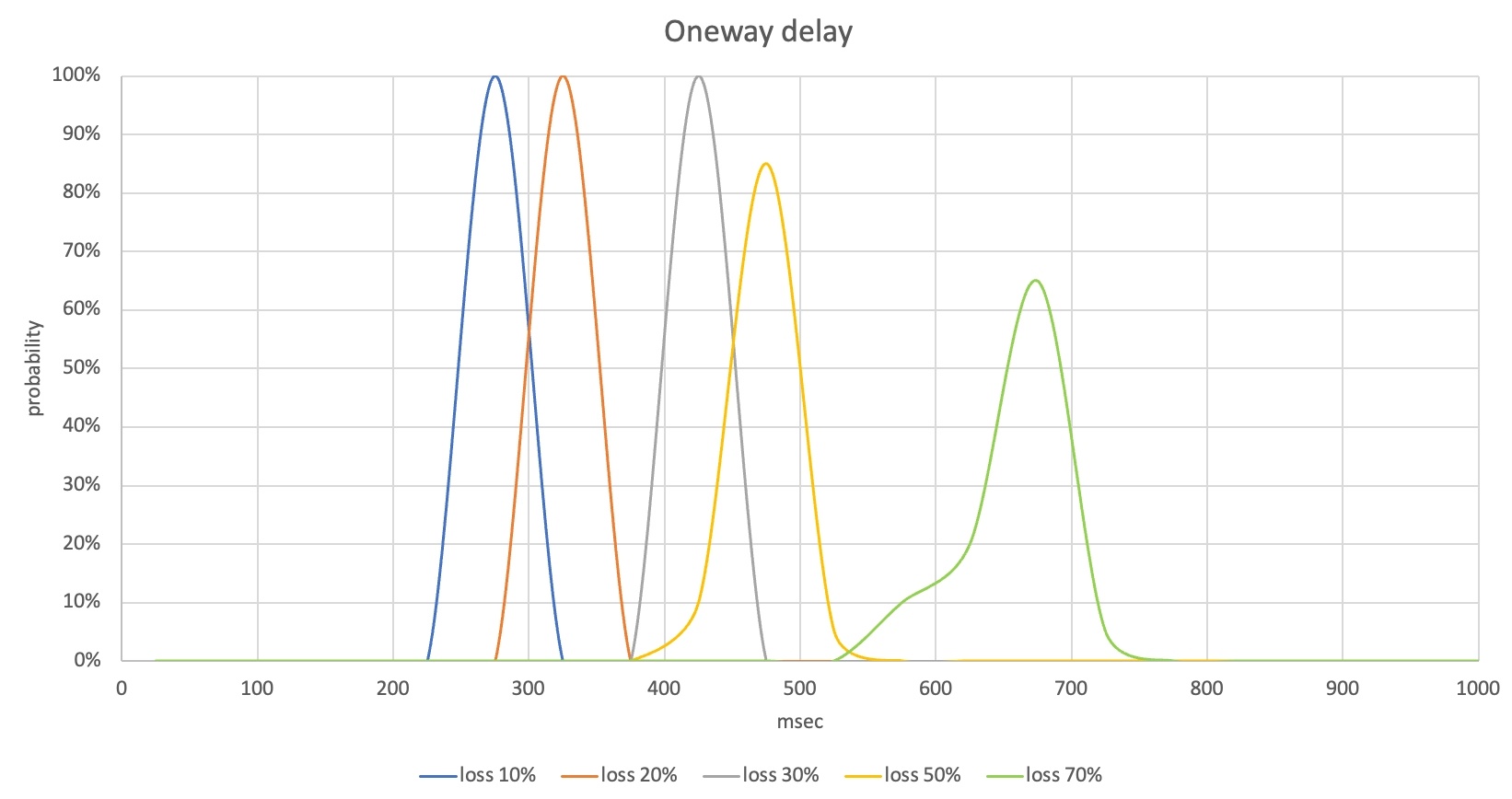
在這種情況下,丟包率高達30%,POLQA MOS分佈為4-4.6,這表示大部分丟包已經恢復。由於語音單向時延也控制在400ms出頭,處於不影響業務的水平。然而,從50%的丟失率來看,有些語音部分丟失,POLQA MOS較低,而在70%的丟失率下,很多情況下MOS在2點範圍內,所以你會感覺不舒服實際溝通。
從此場景的測量結果可以確認,需要提高丟包恢復效能,從丟包率50%以上降低單向語音延遲。此時,由於遺失復原時資料使用量會增加,因此需要一起分析資料使用量測量結果。
結論
在本文中,我們了解了我們測量 LINE 應用程式的通話品質的哪些方面,並詳細解釋瞭如何在各種品質測量方法中測量 AEC、頻率響應和損耗穩健性。如果有機會,我們還計劃分享這次未能介紹的其他技術和測量方法,包括噪音抑制。
我們致力於利用全球標準的評測演算法、專業的設備以及我們自己的技術,從各個方面衡量和提高語音和視訊質量,讓LINE應用程式用戶在任何情況下都能享受到出色的語音和視訊通話體驗。我們將不斷努力和改進,讓用戶隨時隨地體驗最佳的通話品質。感謝您閱讀這篇長文章。
