안녕하세요. HBase 팀 이욱입니다. 저는 16년간 데이터베이스 엔지니어로 일해 왔습니다. DBA(database administrator)의 업무에는 다양한 작업이 있으며, 그중에서 특히 데이터 마이그레이션은 일상다반사처럼 자주 수행하는 작업인데요. 그럼에도 DBA에게는 언제나 힘들고 때론 도전적인 작업입니다. 마이그레이션 작업 중에는 언제든 데이터 유실이나 데이터 정합성 관련 문제가 발생할 수 있기 때문입니다.
특히 RDBMS가 아닌 NoSQL인 HBase의 데이터 마이그레이션 작업에는 더욱 많은 공수와 도전이 수반됩니다. 저 역시 RDBMS에서 많은 데이터 마이그레이션 작업을 수행해 왔지만, NoSQL인 HBase 마이그레이션은 클러스터 수가 훨씬 많고 데이터 크기가 수백 테라바이트에서 수백 페타바이트에 달하기 때문에 더욱 어렵습니다.
이번 글에서는 최근에 진행한 Anzen 서비스(LINE Official Account 서비스)의 HBase 마이그레이션 작업 과정을 공유하고 작업하면서 얻은 지식을 나누려고 합니다. 이 글이 HBase에서 데이터 마이그레이션 작업을 계획하고 계신 분들께 도움이 되기를 바라며 시작하겠습니다.
HA 프로젝트를 시작한 배경
Anzen 서비스의 HA(high availablitiy) 프로젝트를 진행하게 된 배경은 크게 두 가지입니다.
서비스의 고가용성 확보
LINE 앱에서는 기업이나 단체, 공공기관 등에서 사용할 수 있는 공식 계정 서비스인 LINE Official Account 서비스를 제공하고 있습니다. 이 서비스에서 각 공식 계정은 Messaging API라는 API를 이용해 메시지를 주고받으며, 이 API에 대한 요청과 결과 로그는 HBase에 저장합니다.
이 로그는 LINE Official Account의 각 사용자에게 얼마의 비용을 청구할지 산정하는 데 사용하는 중요한 데이터인데요. 이전에는 장�애가 발생하면 이 데이터가 유실돼 정확한 데이터를 산출할 수 없는 문제가 발생했었습니다. 이에 IDC 장애나 자연재해 발생 시에도 서비스를 지속할 수 있도록 HA 환경을 구축하기로 결정했습니다.
소프트웨어 라이선스 비용 절약
기존에 사용하던 Cloudera 제품의 라이선스 비용이 날로 증가하며 점점 부담이 커지고 있었습니다. 이에 라이선스 비용을 줄이고 기술을 내재화하기 위해 오픈소스로 전환하는 것을 검토했고, 내부에서 Apache HBase를 이용해 준비하며 테스트한 결과 내재화에 성공해(참고: HBase 오픈소스 전환을 위한 HBH(HitBase Handler) 개발기) 마이그레이션 프로젝트가 시작됐습니다.
HBase의 특징
HBase는 대용량 데이터를 처리할 수 있는 분산형 NoSQL 데이터베이스로, 수평적 확장성이 뛰어납니다. 수십억 개의 행과 열을 효율적으로 처리할 수 있으며, 저비용으로 확장할 수 있습니다. RDBMS와 달리 스키마가 유연하고, 비정형 데이터를 쉽게 저장할 수 있어 빅데이터 처리에 적합합니다. 칼럼 기반 저장 방식을 사용하기 때문에 조회와 쓰기 속도가 빠릅니다. HBase는 특히 빅데이터를 처리하거나 실시간으로 데이터를 처리해야 하는 시스템에서 RDBMS보다 더 적합한 솔루션입니다.
다음은 HBase와 RDBMS의 특징을 비교한 표입니다.
| 특징 | HBase | RDBMS |
|---|---|---|
| 데이터 모델 | 비정형 데이터, 칼럼 기반 스토리지 | 정형 데이터, 행 기반 스토리지 |
| 확장성 | 수평적 확장 가능(노드를 추가해 확장) | 수직적 확장(고성능 하드웨어 필요) |
| 처리 가능한 데이터 크기 | 페타바이트 규모의 대용량 데이터 처리 가능 | 일반적으로 테라바이트 수준 |
| 속도 | 실시간 읽기/쓰기 가능 | 트랜잭션 처리에 최적화 |
| 스키마 유연성 | 스키마리스(동적으로 칼럼 추가 가능) | 고정된 스키마(사전 설계 필요) |
| 복제 및 고가용성 | 분산형, 자동 복제 및 장애 복구 지원 | 복제 및 백업이 필요할 때 추가 작업 필요 |
HBase의 복제 관련 구성 요소
앞서 HBase의 특징을 살펴봤는데요. 이제 HBase의 데이터 구성 요소 중 마이그레이션 작업 시 이용한 복제 관련 구성 요소 세 가지를 살펴보겠습니다.
HBase의 구성 요소 중 복제와 관련된 요소는 세 가지로 WAL(Write-Ahead Log)과 WALEdit, MemStore입니다. 이 세 구성 요소가 포함된 전체 HBase 쓰기 경로는 아래 그림과 같습니다.

각 구성 요소를 하나씩 살펴보겠습니다.
WAL
WAL은 HBase에서 데이터를 영구 저장하기 전에 로그 형태로 기록하는 저널 시스템입니다. RegionServer는 데이터를 MemStore에 쓰기 전에 먼저 WAL에 기록하며, 기록된 데이터는 이후 서버가 갑작스럽게 중단되거나 장애 발생 시 데이터를 복구하는 데 사용합니다. WAL에 기록된 데이터는 이후 HFile로 플러시되고, 데이터를 복구해야 할 때에는 WAL에 기록된 로그를 다시 읽어 복원합니다.
복제에서 WAL은 핵심 역할을 담당합니다. 마스터 클러스터에서 WAL에 기록된 변경 사항이 슬레이브 클러스터로 복제되기 때문입니다. 마스터 클러스터의 RegionServer에서 WAL에 기록된 데이터를 슬레이브 클러스터의 RegionServer로 복사합니다.
WALEdit
WALEdit는 WAL에 기록되는 로그 항목 중 하나입니다. 특정 트랜잭션(예: 데이터 쓰기)의 세부 정보가 포함되며, 데이터 변경에 관한 모든 정보가 들어 있습니다. 어떤 데이터가 추가, 수정, 삭제됐는지 관련 정보가 포함되므로 복제 시스템에서 복제할 데이터 항목으로서 중요한 역할을 담당합니다.
WALEdit는 실제로 복제되는 데이터의 단위입니다. 마스터 클러스터에 기록된 WALEdit 항목을 필터링(특정 WALEdit가 복제 범위에 속하는지 확인)해서 배치 처리한 후, 복제 배치 크기(기본값 64MB, 변경 가능)로 묶어 슬레이브 클러스터로 전송합니다.
MemStore
MemStore는 HBase의 메모리 버퍼입니다. HBase는 데이터를 우선 MemStore에 저장한 후 일정 시점에 HFile 형식으로 디스크에 저장합니다. 이 과정을 플러시(flush)라고 합니다.
MemStore는 데이터를 빠르게 쓸 수 있는 메커니즘을 제공합니다. 플러시되기 전까지 데이터는 이곳에 임시 보관되며, MemStore가 가득 차면 플러시를 통해 데이터를 HFile 형식으로 디스크로 보내 영구 저장하고 MemStore를 비웁니다.
MemStore는 복제에 직접 연관되지는 않지만, 복제된 데이터를 수신한 슬레이브 클러스터는 WALEdit를 가져와 데이터 변경 정보를 읽어 그대로 적용한 후 해당 데이터를 이 MemStore에 저장합니다. 이 과정을 통해 마스터 클러스터에서 온 데이터가 슬레이브 클러스터에서도 동일한 상태로 유지됩니다. 이 과정이 완료된 후 MemStore가 가득 차면 마스터 클러스터와 같이 슬레이브 클러스터에서도 HFile 형태로 디스크로 플러시됩니다.
HBase 복제 토폴로지
그럼 이제 HBase 복제 토폴로지에 대해서 간략히 설명하겠습니다. HBase 복제 토폴로지에는 Master-Slave, Master-Master, Cyclic의 세 가지 방식이 있습니�다. 각 방식을 살펴보기 전에 우선 설명에 사용할 용어를 살펴보겠습니다.
- ReplicationSource
- 복제 진행 시 WAL 로그를 제공하는 원본 클러스터를 의미합니다.
status 'replication'명령어 실행 시Source로 표시됩니다. - 원본 클러스터의
PeerID,AgeOfLastShippedOp,SizeOfLogQueue,TimeStampsOfLastShippedOp,Replication Lag등의 다양한 정보를 알 수 있습니다. - 복제와 관련된 여러 가지 정보가 표시되므로 복제 작업이 어떻게 진행되고 있는지 현재 상태를 확인할 수 있습니다.
- 복제 진행 시 WAL 로그를 제공하는 원본 클러스터를 의미합니다.
- ReplicationSink
- 복제 진행 시 WAL 로그를 수신하는 타깃 클러스터를 의미합니다.
status 'replication'명령어 실행 시Sink로 표시됩니다.
- 복제 진행 시 WAL 로그를 수신하는 타깃 클러스터를 의미합니다.
이후 설명에서는 편의를 위해 원본 클러스터는 'ReplicationSource', 타깃 클러스터는 'ReplicationSink'로 표기하겠습니다. 양방향 복제의 경우 두 가지를 모두 표기합니다(실제 status 'replication' 명령어 실행 시 두 가지 모두 표기됩니다).
Master-Slave
기본 복제 모드로 복제가 단일 방향으로 진행됩니다. 한 클러스터의 트랜잭션이 다른 클러스터로 전송되며 작동합니다.

Master-Master
Master-Master 복제는 서로 다른 테이블 또는 같은 테이블에 대해 양방향으로 트랜잭션이 전송됩니다. 여기서 포인트는 두 클러스터 모두 마스터와 슬레이브 역할을 동시�에 담당한다는 것입니다.
그런데 그렇다면 만약 동일한 테이블을 복제하는 경우 무한 복제가 일어날까요?
예를 들어 보겠습니다. Brown과 Cony라는 두 클러스터가 있습니다. 각각 clusterid가 100과 200이며, 각 클러스터에는 복제하려는 슬레이브 클러스터에 해당하는 ReplicationSource/Sink가 있고, 두 클러스터의 #ID를 알고 있습니다.

이때 복제는 다음과 같이 진행됩니다.
- Cluster#Brown에서 데이터 변경이 발생하면, 이 변경 사항은 클러스터 ID가 Cluster#Brown의 ID(100)로 설정된 상태에서 Cluster#Cony로 전송됩니다.
- Cluster#Cony는 변경 사항을 WAL에 저장하고, ReplicationSource/Sink는 클러스터 ID를 확인하고 ID가 100이므로 Cluster#Brown 클러스터에서 발생한 변경이라는 것을 인식한 뒤 복제를 건너뜁니다.
위와 같이, 복제 진행 시 클러스터 ID를 확인해 클러스터 ID가 같으면 복제를 건너뛰는 방식으로 양쪽 클러스터 간에 동일한 데이터가 반복해서 복제되는 것을 방지할 수 있습니다.
Cyclic
이 방식은 순환 복제 방식으로, 아래와 같이 세 개의 클러스터가 순환하면서 복제를 설정합니다.
- Cluster#Brown은 Cluster#Cony로 복제
- Cluster#Cony는 Cluster#Sally로 복제
- Cluster#Sally는 다시 Cluster#Brown으로 복제
아래는 순환 복제 구조를 표현한 그림입니다.
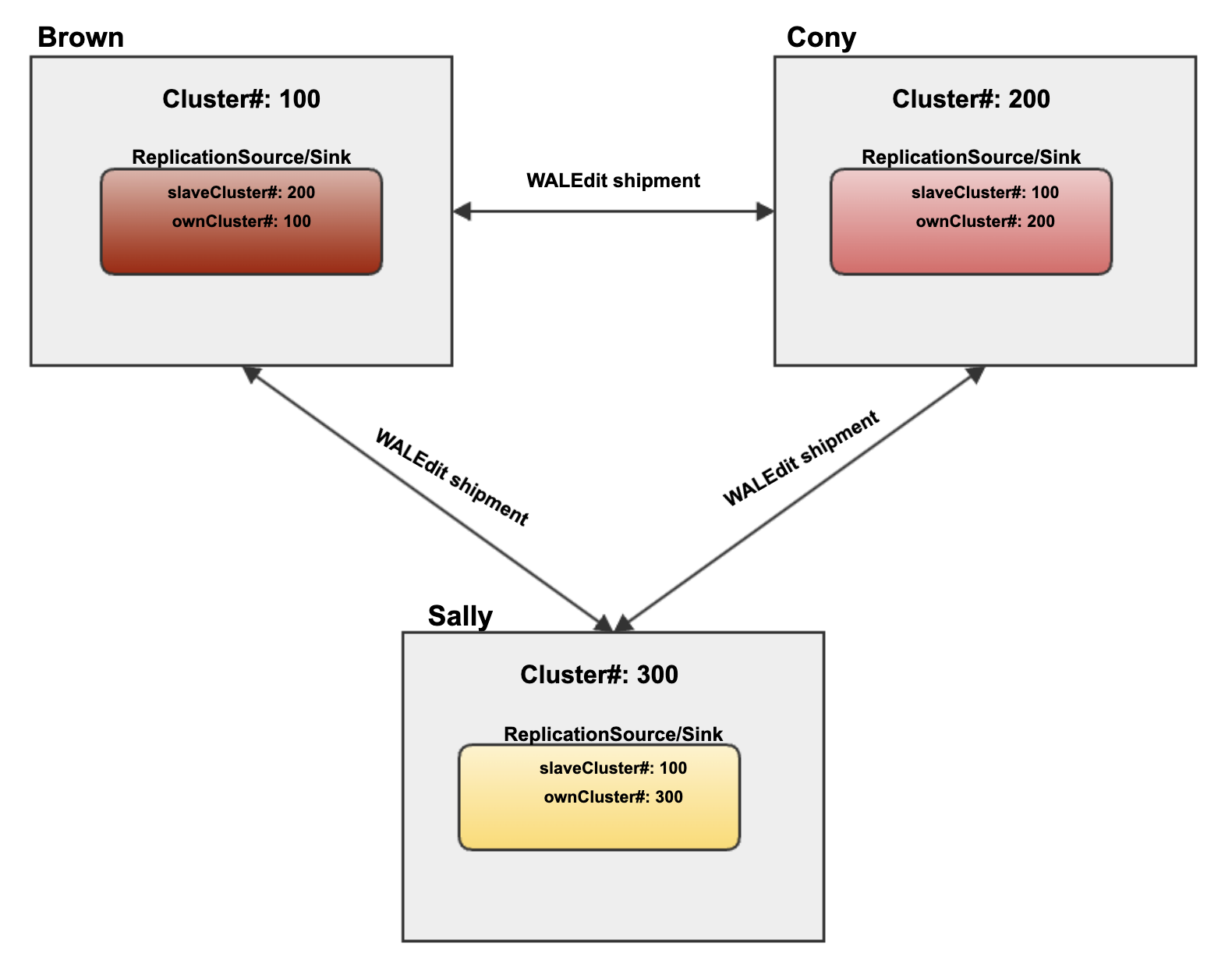
이 상태에서 Brown에서 새로운 변경이 발생하면 아래와 같은 순서로 복제가 진행됩니다.
- Cluster#Brown에서 새로운 데이터 변경 WALEdit M이 발생합니다.
- Cluster#Brown에서 변경 사항 WALEdit M이 Cluster#Cony로 복제됩니다.
- 이때 Master-Master 복제와 유사하게 클러스터 ID가 Cluster#Brown의 ID로 설정된 상태에서 Cluster#Cony로 전송됩니다.
- Cluster#Cony는 변경 사항 WALEdit M을 받은 후 다시 Cluster#Sally로 복제합니다.
- 이때 M의 클러스터 ID는 여전히 Cluster#Brown의 ID로 유지됩니다.
- Cluster#Sally는 WALEdit M을 수신하고 이를 WAL에 기록합니다.
- Cluster#Sally의 복제 인스턴스는 이 변경 사항의 클러스터 ID가 Cluster#Brown과 동일함을 확인합니다.
- Cluster#Sally의 복제 인스턴스는 클러스터 ID가 동일한 변경 사항이라는 것을 인지하고 Cluster#Brown으로의 복제를 건너뜁니다.
순환 복제 구조에서는 위와 같은 방식으로 데이터 중복 복제를 방지합니다.
선택한 구성 방식과 그 이유
저희는 전체 세 대의 클러스터(소스 클러스터, 타깃 클러스터 1, 타깃 클러스터 2)를 Master-Master와 Cyclic 모델을 혼합해 구성했습니다. 이와 같이 구성한 이유는 두 가지입니다.
첫째, 애플리케이션 엔드포인트를 신규 클러스터로 옮긴 후 예기치 못한 변수 때문에 롤백을 진행해야 하는 상황이 발생할 수 있기 때문입니다. 이런 경우 신규 클러스터로 들어온 쓰기 요청이 유실되면 안 되는데요. 이를 방지하기 위해서는 Master-Master 복제 설정이 필요합니다. Master-Master 복제 설정을 해 놓으면 롤백을 진행하더라도 해당 시점에 들어온 쓰기 요청이 �기존 클러스터에 그대로 복제돼 데이터 유실을 막을 수 있습니다.
둘째, 타깃 클러스터 1과 타깃 클러스터 2의 데이터 보관 주기가 다르기 때문입니다. HBase에는 TTL(time to live)를 이용해 데이터 유효 기간을 설정할 수 있습니다. Anzen 서비스에서는 비즈니스 로직에 따라서 '액티브(hot) - 스탠바이(cold)' 형태로 운영하고 있는데요. 아래 표는 액티브와 스탠바이 각 테이블의 TTL을 정리한 표입니다.
| 액티브 | 스탠바이 | |
|---|---|---|
| 테이블 A | TTL => '2592000 SECONDS (30 DAYS)' | TTL => '10368000 SECONDS (120 DAYS)' |
| 테이블 B | TTL => 'FOREVER' | TTL => 'FOREVER' |
| 테이블 C | TTL => 'FOREVER' | TTL => 'FOREVER' |
| 테이블 D | TTL => '2592000 SECONDS (30 DAYS)' | TTL => '10368000 SECONDS (120 DAYS)' |
위 표와 같이 액티브 클러스터의 테이블 A와 테이블 D는 30일로 설정했고, 스탠바이 클러스터의 테이블 A와 테이블 D는 120일로 설정했습니다. 이를 통해 사용한 지 120일 이상 지난 오래된 콜드 데이터는 스탠바이에서 조회되고, 그보다 최근에 사용된 데이터인 핫 데이터는 액티브에서 조회됩니다. 또한 서버 HDFS 용량도 다르게 구성해 조금 더 유연하게 서버 비용을 줄이며 운영할 수 있었습니다.
HBase 복제 소개
HBase는 네임스페이스(namespace, RDBMS의 데이터베이스에 해당하는 개념) 또는 테이블 레벨에서 복제를 설정할 수 있습니다. 그런데 HBase는 마스터 클러스터가 다운됐을 때 자동으로 슬레이브 클러스터로 전환해 주는 자동 장애 조치는 지원하지 않습니다. 따라서 서비스를 지속하기 위해서는 사용자가 수동으로 엔드포인트를 변경해야 합니다.
앞서 말씀드렸듯 HBase에서 복제는 마스터 클러스터의 WAL에서 WALEdit를 다시 읽어 수행하는 방식으로 진행됩니다. 복제 범위에 포함되는 WALEdit 항목의 모든 마스터 클러스터의 트랜잭션을 슬레이브 클러스터에서 다시 수행하는 것입니다. WALEdit 항목은 슬레이브 클러스터의 RegionServer로 전송되며, WAL Reader는 WAL의 끝에 도달할 때까지 WALEdit를 읽으면서 읽은 항목을 전송합니다.
복제는 비동기로 진행되는데요. 슬레이브 클러스터는 마스터 클러스터보다 몇 분 정도 늦을 수 있으며, 특히 쓰기 중심 애플리케이션에서 지연이 발생할 수 있습니다. 지연 상황은 초 단위로 표시되는 Replication Lag 항목을 모니터링해 확인할 수 있습니다. 아래는 status 'replication' 명령어로 현재 복제 진행 상태와 지연을 확인해 본 것입니다.
hbase> status 'replication'
{HOSTNAME}
SOURCE: PeerID=6, AgeOfLastShippedOp=77, SizeOfLogQueue=2, TimeStampsOfLastShippedOp=Mon Sep 09 18:10:18 JST 2024, Replication Lag=279
SINK : AgeOfLastAppliedOp=0, TimeStampsOfLastAppliedOp=Thu Aug 29 10:24:56 JST 2024HBase 복제를 진행하기 위한 사전 준비
HBase 복제를 진행하기 위한 사전 준비는 아래와 같습니다.
- 테이블 크기 체크
- 타깃 서버 준비 및 클러스터 설치
- 역방향 DNS(reverse domain name service)
- krb5.conf 설정
- 소스와 타깃 간 Kerberos 인증 테스트
- 복제 시작
그럼 각 단계를 하나씩 살펴보겠습니다.
테이블 크기 체크
우선 마이그레이션 대상인, 즉 복제하고자 하는 테이블을 리스트 업해서 HDFS에서 각 테이블의 크기를 확인하고 전체 크기도 확인합니다. HBase는 RDMBS처럼 백업 & 복구 방식으로 데이터를 복구하지 않고 일반적으로 스냅숏(snapshot)을 이용해 데이터를 복구하는데요. 따라서 타깃 HBase 클러스터에서 추출한 스냅숏 데이터를 위한 공간도 추가로 필요하므로 크기 계산이 중요합니다. HBase의 네임스페이스별로 크기를 확인해야 합니다.
아래는 실제로 테이블 크기를 확인해 본 결과입니다.
40.5 T 121.6 T /hbase/data/namespace/tableA
3.5 T 10.5 T /hbase/data/namespace/tableB위 결과의 첫 줄을 살펴보겠습니다. 앞에 표시된 용량(40.5T)은 실제 데이터의 크기입니다. tableA의 경우 40.5 TB라는 것을 알 수 있습니다. 뒤에 표시된 용량은 복제를 포함한 데이터의 총량입니다. 저희는 복제 팩터(replication factor)를 3으로 설정했으므로 데이터의 총 크기는 40.5 TB * 3 = 121.6 TB인 것을 알 수 있습니다. 이를 고려해 타깃 클러스터의 용량을 산정합니다.
타깃 서버 준비 및 클러스터 설치
기본적으로 같은 스펙의 서버를 준비하며, 필요한 전체 크기를 개별 데이터 노드의 용량으로 나눠서 필요한 서버 수를 계산합니다.
서버를 구매할 때에는 서버 배송 기간 등의 외부 요인과 내부 설치 및 준비 기간 등의 내부 요인을 모두 고려해서 보통 3개월 전에 스펙을 산정해 준비합니다. 개별 데이터 노드의 용량이 작으면 서버 수가 너무 많아지는데요. 무작정 많은 데이터 노드로 구성할 경우 하드웨어와 네트워크 유지 관리 비용이 증가하니 적절한 데이터 노드 용량을 계산해 서버를 준비합니다.
저희는 클러스터는 기존 Cloudera 5.16.2 버전을 사용하고 있었고, HBase 버전은 1.x 버전대를 사용하고 있었는데요. 이와 호환되는 Apache HBase 1.4.13 버전을 테스트해 내부 패키징을 통해 설치했습니다.
역방향 DNS
일반적으로 우리는 도메인 이름으로 웹브라우저에서 특정 인터넷 사이트에 접근하는데 이때 도메인 이름이 해당 사이트의 IP 주소로 변환돼 해당 사이트에 접속하게 됩니다. 역방향 DNS는 말대로 이 흐름이 역으로 흘러가는 것으로, IP 주소를 이용해 호스트 이름을 조회하는 것입니다.
HBase 복제를 이용한 마이그레이션에서는 마스터 클러스터에서 발생한 데이터 변경 사항이 슬레이브 클러스터로 복제됩니다. 이 과정에서 HBase와 HDFS는 서버 간 통��신을 위해 IP 주소와 호스트 이름을 변환하고, 이를 기반으로 통신과 인증을 수행하는데요. 이때 역방향 DNS 조회가 가능해야 마스터 클러스터의 노드들이 슬레이브 클러스터의 노드들과 원활히 통신할 수 있으며, 복제된 데이터를 정확히 전달할 수 있습니다. 따라서 이를 위해 사전에 역방향 DNS 설정을 해야 합니다.
krb5.conf 및 auth_to_local 설정
복제 진행 시 Kerberos 인증을 사용하는 클러스터라면 krb5.conf 설정이 필수입니다. 이와 관련해 우선 먼저 몇 가지 개념을 설명하겠습니다.
- Realm
- Realm은 Kerberos에서 영역의 이름을 나타내는 도메인입니다.
- 사용자 또는 서비스가 인증되는 관리 도메인을 의미하며, 보통 대문자로 표기합니다(예: LYCORP.COM).
- 서로 다른 Realm 간 인증은 Cross-Realm 설정을 통해 가능합니다(이와 관련해서는 아래에서 별도로 자세히 살펴보겠습니다).
- FQDN(fully qualified domain name)
- FQDN은 호스트 전체 도메인 이름을 의미하며, 호스트 이름과 도메인 이름을 포함해 DNS 내에서 해당 호스트의 정확한 위치를 나타냅니다.
- HBase 서버의 Kerberos 주체(principal)에 FQDN을 포함해 인증이 진행되도록 합니다.
- 예를 들어 FQDN이 'test-master.lycorp.com'인 Kerberos 주체는 'hbase/test-master.lycorp.com@LYCORP.COM'입니다.
- krb5.conf
- krb5.conf는 Kerberos 클라이언트 및 서비스가 KDC(key distribution center)와 어떻게 상호작용할지 정의하는 Kerberos 설정 파일입니다.
- Realm과 KDC 서버 정보, 네트워크 설정 등 Kerberos 인증에 필요한 중요한 설정 정보가 들어있으며, 이 정보를 통해 서버와 클라이언트가 어디서 인증받을지, 어떤 Realm과 서버를 ��신뢰할지 알 수 있습니다.
- 기본 위치는 '/etc/krb5.conf'입니다.
동일 Realm 안에서 복제할 때에는 krb5.conf 설정에 호스트 FQDN과 Realm만 매핑하면 문제없는데요. 서로 다른 Realm 간 복제하는 경우에는 각 도메인 영역에 서로 다른 클러스터의 설정을 추가해야 합니다.
LINE.EXAMPLE.COM 클러스터에서 EXAMPLE.COM으로 복제하는 경우를 예로 들어 어떤 설정이 추가로 필요한지 살펴보겠습니다.
krb5.conf 설정 파일에 Realms 설정
먼저 각 클러스터 간 Realm이 다르므로 Realm 정보를 각 클러스터에 넣어야 합니다. 클러스터 A Realm이 LINE.EXAMPLE.COM, 클러스터 B Realm이 EXAMPLE.COM이라고 할 때, krb5.conf 설정 파일의 realms 영역과 domain_realm 영역에 아래와 같이 설정을 추가합니다.
[libdefaults]
default_realm = LINE.EXAMPLE.COM
[realms]
LINE.EXAMPLE.COM = {
kdc = kdc01.LINE.EXAMPLE.COM :88
admin_server = kdc01.LINE.EXAMPLE.COM :749
default_domain = LINE.EXAMPLE.COM
}
EXAMPLE.COM = {
kdc = kdc01.example.com:88
admin_server = kdc01.example.com:749
default_domain = example.com
}
[domain_realm]
.LINE.EXAMPLE.COM = LINE.EXAMPLE.COM
LINE.EXAMPLE.COM = LINE.EXAMPLE.COM
.example.com = EXAMPLE.COM
example.com = EXAMPLE.COMauth_to_local 설정
auth_to_local을 설정하는 이유는 서로 Kerberos Realm이 다른 클러스터 간의 인증 문제를 해결하기 위해서입니다. Kerberos 기반의 HBase 복제 시 각 클러스터는 다른 Realm을 사용할 수 있습니다. 예를 들어 클러스터 A의 사용자가 user@REALM_A이고 클러스터 B의 사용자가 user@REALM_B일 때, 각 클러스터가 상대방의 Kerberos 주체를 주 로��컬 사용자로 올바르게 해석하지 못하면 인증이 실패할 수 있습니다.
이를 해결하기 위해 auth_to_local 규칙을 설정해 Kerberos 주체를 로컬 사용자로 변환합니다. 이 설정을 통해 복제 시 각 클러스터는 상대 클러스터의 사용자 계정을 자신의 로컬 사용자로 인식해 인증을 처리합니다. 아래와 같이 소스 클러스터와 타깃 클러스터에 각각 상대 Realm 정보 설정을 추가합니다.
- core-site.xml
# Source Cluster
<property>
<name>hadoop.security.auth_to_local</name>
<value>
RULE:[1:$1@$0](.*@\QLINE.EXAMPLE.COM\E$)s/@\QLINE.EXAMPLE.COM\E$//
RULE:[2:$1@$0](.*@\QLINE.EXAMPLE.COM\E$)s/@\QLINE.EXAMPLE.COM\E$//
DEFAULT
</value>
</property>- core-site.xml
# Target Cluster
<property>
<name>hadoop.security.auth_to_local</name>
<value>
RULE:[1:$1@$0](.*@\QEXAMPLE.COM\E$)s/@\QEXAMPLE.COM\E$//
RULE:[2:$1@$0](.*@\QEXAMPLE.COM\E$)s/@\QEXAMPLE.COM\E$//
DEFAULT
</value>
</property>Cross-Realm Kerberos 인증 테스트
이제 사전 준비 작업의 마지막 순서인 Kerberos 인증 테스트입니다. 이 테스트를 진행하지 않고 복제를 진행할 경우 인증 오류가 발생할 수 있습니다. 이를 미연에 방지하려면 꼭 테스트를 진행해야 합니다.
Cross-Realm 트러스트가 정상적으로 작동하려면 두 KDC에 동일한 krbtgt 주체와 암호가 있어야 하고, 두 KDC가 동일한 암호화 유형을 사용하도록 구성해야 합니다.
우선 Cross-Realm 환경에서는 아래와 같이 각 Kerberos 서버에 krbtgt 주체를 생성합니다.
kadmin: addprinc -e "<enc_type_list>" krbtgt/EXAMPLE.COM@LINE.EXAMPLE.COM
kadmin: addprinc -e "<enc_type_list>" krbtgt/LINE.EXAMPLE.COM@EXAMPLE.COM그런 다음 생성된 krbt를 이용해 Cross-Ream Kerberos 인증 테스트를 진행합니다. HDFS Keytab(key table의 약자로 Kerberos 인증에서 사용하는 키 저장 파일)으로 Kerberos 티켓을 발급받은 후 타깃 클러스터의 HDFS 파일 시스템에 접속해서 조회되는지 확인합니다.
# klist
Ticket cache: FILE:/tmp/krb5cc_p116773
Default principal: hdfs/hostname@LINE.EXAMPLE.COM
Valid starting Expires Service principal
03/13/24 19:07:37 03/14/24 19:07:37 krbtgt/LINE.EXAMPLE.COM @LINE.EXAMPLE.COM
renew until 03/20/24 19:07:37
# hdfs dfs -ls hdfs://line-hbase-active.line.example.com:8020/
Found 4 items
drwx------ - hbase hbase 0 2024-01-30 17:50 hdfs://line-hbase-active.line.example.com:8020/hbase
drwxr-xr-x - hdfs supergroup 0 2023-11-27 13:56 hdfs://line-hbase-active.line.example.com:8020/in
drwxr-xr-x - hdfs supergroup 0 2023-11-27 13:56 hdfs://line-hbase-active.line.example.com:8020/tmp
drwxr-xr-x - hdfs supergroup 0 2023-11-27 13:57 hdfs://line-hbase-active.line.example.com:8020/user위와 같이 정상적으로 조회된다면 Cross-Realm 설정이 제대로 진행된 것입니다.
이것으로 HBase 복제를 위한 작업이 모두 끝났습니다. 이제 복제 진행 시 발생할 수 있는 문제점과 해결 방법을 설명하겠습니다.
작업 중 마주친 주요 도전 과제와 해결 방법
HBase 클러스터의 고가용성을 확보하기 위해 HBase의 복제를 이용한 마이그레이션 작업을 진행하면서 겪었던 어려움은 Export Snapshot과 VerifyReplication이라는 기능과 관련이 있습니다. 우선 이 두 기능이 무엇인지 설명하겠습니다.
- Export Snapshot
- 생성된 스냅숏을 다른 클러스터로 내보내는 기능입니다.
- 주로 데이터를 백업하거나 복제 환경에서 데이터를 이동하기 위해 사용합니다.
- VerifyReplication
- HBase에서 제공하는 도구로, 복제된 데이터의 마스터와 슬레이브 간 일관성을 검증할 때 사용하는 도구입니다.
- Export Snapshot을 이용해 스냅숏을 내보낸 뒤 Restore Snapshot이라는 기능을 이용해 스냅숏을 복원할 때 데이터가 정상적으로 복제됐는지 검증할 때 사용합니다.
- 마스터와 슬레이브의 데이터를 비교해 정상 여부를 판단하며, 데이터 크기가 클수록 오래 걸립니다.
Export Snapshot
HBase 복제 시 스냅숏을 만든 후 Export Snapshot 기능을 실행하는데요. 이때 몇 가지 주의할 점이 있습니다.
디스크 용량 확인
우선 첫 번째로 디스크 용량 이슈에 주의해야 합니다.
스냅숏은 해당 시점의 데이터 복사본을 저장하는 것은 아니지만, 참조 링크를 통해 데이터가 변경되거나 삭제되더라도 WAL 파일이 삭제되지 않고 보존되기 때문에 디스크 사용량이 증가하는데요. 이를 잘 처리하지 않으면 HDFS 디스크가 가득 차면서 서비스 장애로 이어질 수 있습니다.
또한 WAL뿐 아니라 HDFS 파일 크기도 커집니다. HBase의 스냅숏은 HFile을 참조하는데요. 스냅숏이 생성되면 그 시점 이전에 존재하던 HFile은 삭제되지 않고 보존됩니다. 즉, 해당 스냅숏이 삭제되기 전까지 기존 데이터가 유지되기 때문에 디스크 공간을 추가로 차지합니다.
실제로 프로젝트를 진행하면서 아래와 같이 디스크 사용량이 증가하며 장애로 이어질 뻔했습니다.
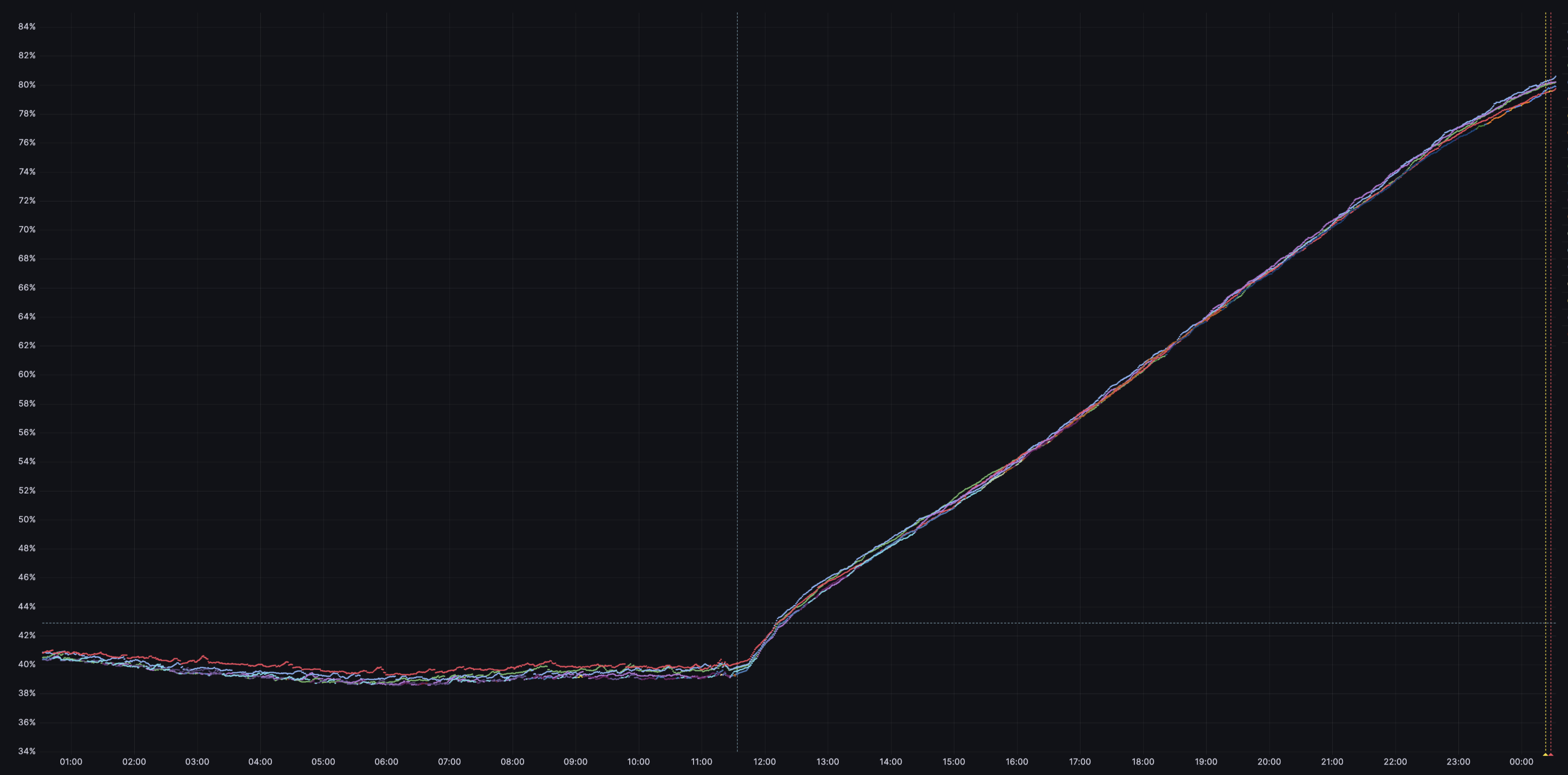
위 상황은 수백 TB의 테이블에서 오전에 스냅숏을 생성한 뒤 VerifyReplication 작업을 진행 중이던 클러스터에서 발생했습니다. 자정 즈음에 모니터링 알람을 받고 조치를 취해 다행히 장애는 막을 수 있었지만, 단 몇 시간 만에 디스크 사용량이 50% 이상으로 증가했던 정말 아찔한 순간이었습니다. 이와 같이 스냅숏을 생성한 뒤에는 트래픽이 많은 서비스라면 디스크 사용량을 필히 모니터링해야 합니다.
이런 문제를 사전에 예방하려면 대용량 클러스터의 경우 스냅숏을 생성할 때 여러 개 테이블을 동시에 생성하지 않는 게 좋습니다. 또한 VerifyReplication 작업이 끝난 스냅숏은 반드시 삭제한 후 다음 스냅숏 작업을 진행하는 것을 권장하며, 스냅숏 작업 진행 전 디스크 사용량도 확인하는 게 좋습니다. 이런 사항을 명심한다면 작업으로 인한 장애 발생을 막을 수 있습니다.
Export Snapshot 작업 실패 방지
두 번째로 Export Snapshot 작업이 실패할 수 있습니다. 보통 대용량 테이블을 내보내기할 때 실패합니다. 적게는 수 시간에서 많게는 수일 동안 애써서 진행한 Export Snapshot 작업이 실패한다면 어떨까요? 시간이 낭비되고 복제 설정이 지연되면서 전체 작업 일정이 지연될 수 있습니다. 따라서 사전에 해당 문제를 예방하는 것이 중요합니다.
제 경험에 비춰볼 때 보통 테이블 크기가 1 TB 이상인 테이블을 대상으로 Export Snapshot 작업을 진행할 때 실패했습니다. 이때 아래와 같은 에러 메시지가 표시됩니다.
24/04/29 15:49:40 ERROR snapshot.SnapshotReferenceUtil: Can't find hfile: a0236612402f4e78a7483f2b9069f4a1 in the real (hdfs://클러스터 주소) directory for the primary table이와 같은 오류가 발생하는 이유는 HBase에서 Export Snapshot 작업을 수행하고 있을 때 HFileCleaner가 파일을 삭제하기 때문입니다. 이를 방지하기 위해서 아래 두 가지 설정값을 수정해야 합니다.
hbase.master.hfilecleaner.plugins.snapshot.period
hbase.master.hfilecleaner.ttl두 설정값을 증가시켜 스냅숏과 HFileCleaner가 동시에 실행되지 않도록 조정하면 스냅숏 생성 과정에 파일이 손실되는 것을 방지할 수 있습니다.
참고로, 마이그레이션 작업을 완료한 뒤에는 반드시 위 설정을 원복해야 합니다. 그렇지 않으면 HFileCleaner가 제때 작동하지 않아 디스크가 가득 차는 문제가 발생할 수 있습니다.
VerifyReplication
VerifyReplication은 HBase�에서 복제 설정 후 정상적으로 복제가 수행됐는지, 소스 클러스터에서 발생한 변경 내역이 타깃 클러스터에 잘 복제됐는지 검증해 데이터 무결성을 보장하기 위해 사용하는 중요한 도구로 MapReduce 기반으로 작동합니다. 소스와 타깃 클러스터 간 복제된 데이터가 동일한지, 오류가 발생하지는 않았는지 비교하는 데 사용합니다. 복제 진행 과정(스냅숏 생성, 스냅숏 내보내기, 스냅숏 가져오기, 복제 등)에서 누락된 데이터가 있는지 확인하기 위해 VerifyReplication를 사용하며, 확인 후 누락된 데이터가 발견되면 복구합니다.
이와 같은 VerifyReplication을 사용할 때에는 주의해야 할 점이 몇 가지 있습니다.
우선 VerifyReplication을 사용할 때 성능 저하가 발생할 수 있습니다. VerifyReplication 작업은 데이터가 많을수록 당연히 시스템 자원도 많이 소모하고 작업 시간도 오래 걸리기 때문에 수십, 수백 테라바이트에서 페타바이트에 달하는 데이터를 대상으로 실행할 때에는 주의 깊게 모니터링할 필요가 있습니다.
두 번째는 대규모 데이터를 처리하면서 병목이 발생할 가능성이 있습니다. 이 작업은 클러스터의 네트워크 I/O에 영향을 주는데요. 소스 클러스터와 타깃 클러스터 모두의 네트워크 대역폭과 클러스터의 운영 트래픽에 영향을 끼쳐 병목 현상이 발생할 수 있습니다.
저희는 실제로 오래된 서버의 네트워크 카드 속도가 느려 병목 현상이 발생한 적이 있습니다. 신규 서버는 대부분 문제가 없겠지만 오래된 레거시 서버가 많은 환경이라면 네트워크 카드의 속도도 반드시 한 번 확인해 봐야 합니다.
이와 같은 문제들을 해결할 수 있는 방법으로는 아래와 같이 몇 가지가 있습니다.
첫 번째 방법은, 특정 시간을 범위로 지정하거나 특정 열을 선택해 VerifiyReplication을 진행하는 방법입니다. 수백 TB에서 수백 PB 급의 클러스터라면 전체 데이터를 비교하기보다는 검증해야 할 데이터의 범위를 제한해 최적화할 수 있습니다.
아래는 시작 시간과 종료 시간을 지정한 것입니다. 이렇게 지정하면 해당 시간에 발생한 트랜잭션만 비교 검증합니다.
hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication --starttime=<timestamp> --endtime=<timestamp> 혹은 아래와 같이 특정 열만 선택해 비교할 수도 있습니다. families=family1,family2처럼 여러 칼럼 패밀리(column family)를 콤마로 구분해 지정할 수 있습니다.
hbase org.apache.hadoop.hbase.mapreduce.replication.VerifyReplication --starttime=<timestamp> --endtime=<timestamp> --families=A두 번째 방법은 샘플링하는 것입니다. 데이터를 샘플링해서 일부분만 검증하는 방식으로 최적화할 수 있습니다. 저희는 대용량 클러스터의 데이터 검증 작업을 진행할 때 개발 팀과 논의 후 시간 제한 방법과 샘플링 방법을 혼합해 사용하기도 했습니다.
맺음말
HBase는 RDBMS와는 다른 매력이 있는 NoSQL 데이터베이스입니다. 수백 TB에서 PB에 이르는 대용량 데이터를 다루는 경험을 해 볼 수 있습니다. 저는 이번에 HBase 클러스터 HA 구축 프로젝트를 진행하면서 기존에 자세히 알지 못했던 복제 메커니즘을 보다 깊이 이해할 수 있었고, 대용량 클러스터 복제와 관련된 많은 노하우를 습득할 수 있었습니다. 또한 서비스 면에서는 더 이상 데이터 유실에 대한 걱정 없이 서비스를 운영할 수 있게 되었고, 유지 보수 측면에서도 이전보다 유연하게 대처할 수 있게 되었습니다. 개인적으로 너무나 만족했던 시간이었습니다.
이 글을 읽으며 느끼신 것처럼 HBase 복제 설정은 여러모로 손이 많이 가고 시간이 오래 걸리는 작업인데요. 앞으로 기회가 된다면 해당 작업을 고도화 및 자동화해 작업에 드는 시간과 비용을 줄여보고 싶습니다. 추후 관련 내용으로 다시 지면을 통해 뵙기를 바라며 이만 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


