들어가며
안녕�하세요. HBase 팀 김영주, 김동의입니다. HBase 팀에서는 LY의 많은 서비스를 지원하기 위해 수천 대 규모의 HBase를 운영하고 있습니다. HBase는 Hadoop 기반 칼럼형 분산 데이터베이스로 확장이 용이해 대용량 데이터를 다룰 때 많이 사용하는데요. 회사가 성장하면서 많은 서비스에서 HBase를 사용하고자 하는 니즈가 생겼고, 이를 지원하기 위해 저희 팀에서 전문적으로 HBase를 운영하고 있습니다.
개발 동기
HBase 도입 초기에는 Cloudera사의 Cloudera's Distribution for Hadoop(이하 CDH)을 솔루션으로 사용했습니다. CDH가 Hadoop 관련 운영 도구 중 주류였고 커뮤니티를 중심으로 많은 자료를 이용할 수 있었기 때문입니다.
하지만 현재 이 솔루션을 탈피하기 위한 작업을 진행하고 있습니다. 몇 가지 이유가 있는데요. 첫 번째 이유는 라이선스 비용입니다. 초기에는 라이선스 비용이 크지 않았지만 서비스가 늘어나고 노드 수가 많아지면서 라이선스 비용이 점점 증가해 무시할 수 없는 수준이 되었습니다. 두 번째 이유는, 상용 배포판의 매니저와 에이전트가 프로세스를 관리하기 때문에 사내 프라이빗 클라우드 플랫폼인 Verda에서 제공하기가 어려울 것이라고 판단했기 때문입니다. 세 번째 이유는 상용 배포판을 계속 사용하면 Cloudera사의 기술 지원에 의존할 수밖에 없어서 팀의 기술력 향상 측면에서 부정적이라고 판단했기 때문입니다.
이와 같은 이유로 HBase 팀에서는 CDH로 운영하고 있는 HBase 클러스터를 모두 오픈소스 HBase(이하 Apache HBase)로 이관하기로 결정하고, 내부적으로 HitBase라고 이름을 지었습니다. 또한 이관하기 위해서, Cloudera사의 클러스터 관리 도구인 Cloudera Manager(이하 CM)을 대체할 수 있는 HitBase Handler(이하 HBH)라는 관리용 도구를 만들기로 결정한 뒤 개발에 돌입해 2023년에 HBH v1 버전을 릴리스했습니다.
개발 완료 후 실제 운영 중인 서비스를 순차적으로 HitBase로 이관했고, 현재 약 50%의 HBase가 HitBase로 운영되고 있습니다. 이번 글에서는 저희가 2023년 한 해 동안 HBH를 어떻게 개발했는지 공유하려고 합니다.
요구 사항 분석
팀 내에서 개발에 투자할 수 있는 시간과 인력을 고려했을 때 처음부터 CM에 포함된 모든 기능을 HBH에서 지원하도록 만드는 것은 어려울 것이라고 판단했습니다. 요구 사항을 분석하며 논의한 결과, 우선 필요한 기능부터 넣은 뒤 CM에서 제공하는 기본 기능을 구현했고, 그 외 그동안 운영하면서 필요하다고 판단했던 리전 복구 및 백업과 실시간 인스펙터 기능을 추가했습니다. 아래는 HBH와 CM의 기능을 비교한 표입니다.
| 기능 | CM | HBH |
|---|---|---|
| 웹 UI | O | O |
| 호스트 관리 | O | O |
| 인스턴스 관리 | O | O |
| 설정 변경 관리 | O | △ |
| 설치 관리 | O | O |
| 컴포넌트 상태 체크 | O | △ |
| 클러스터 업그레이드 | O | X |
| Kerberos 보안 활성화 | O | X |
| 지표 수집 및 대시보드 | O | X |
| 리전 백업 및 복구(region backup & restore) | X | O |
| 실시간 인스펙터(HBase realtime inspector) | X | O |
O: 지원, X: 지원하지 않음, △: 부분적으로 지원
개발 과정
HBH 개발 과정은 다음과 같습니다. 각 과정을 하나씩 살펴보겠습니다.
- HBase 패키지(바이너리) 준비
- HBH 아키텍처 설계
- HitBase Installer 개발
- Supervisord 도입
- Job Generator/Executor 개발
- 설정 파일 관리 방법 확립
- 유틸리티 모듈 개발
HBase 패키지(바이너리) 준비
Apache HBase로 전환하기 위해서는 무엇보다도 문제없이 작동하는 HBase 바이너리 파일이 필요합니다. 이때 Hadoop 호환성 이슈를 피하려면 안정적이고 검증된 버전을 사용할 필요가 있는데요. 처음에는 직접 안정적인 버전의 Apache HBase를 빌드해서 사용해 보려고 했지만, 직접 바이너리를 만들 경우 버그나 이슈 발생 시 빠르게 패치를 만들어 대응해야 하는데 당장 도입해야 하는 입장에서 이와 같은 방법으로 안정적인 서비스를 제공하기에는 시간이 부족했습니다. 다행히도 사내 메시징 서비스와 관련해서 별도로 HBase 운영을 전문적으로 지원하는 팀에서 운영하던 바이너리를 제공받을 수 있었습니다. 수년간 메시징 서비스에서 사용된 만큼 안정성이 검증돼 있었기에 이 바이너리를 사용하기로 결정했습니다.
아래는 HBase와 HBase를 운영하는 데 필요한 바이너리들의 버전 정보입니다. HBase 메이저 버전에 따라 HitBase의 버전을 두 가지로 구분하고 있습니다. 접미사로 line*이 붙은 버전은 저희 회사에서 자체 관리하고 있는 버전이며, 붙지 않은 것은 오픈소스 버전입니다.
| 컴포넌트 | HitBase 1 | HitBase 2 |
|---|---|---|
| HBase | 1.4.13-line-px | 2.4.16-line-px |
| Zookeeper | 3.4.14 | 3.5.7 |
| Hadoop | 2.8.5-line-px | 3.3.3 |
| YARN | 2.8.5-line-px | 3.3.3 |
2. HBH 아키텍처 설계
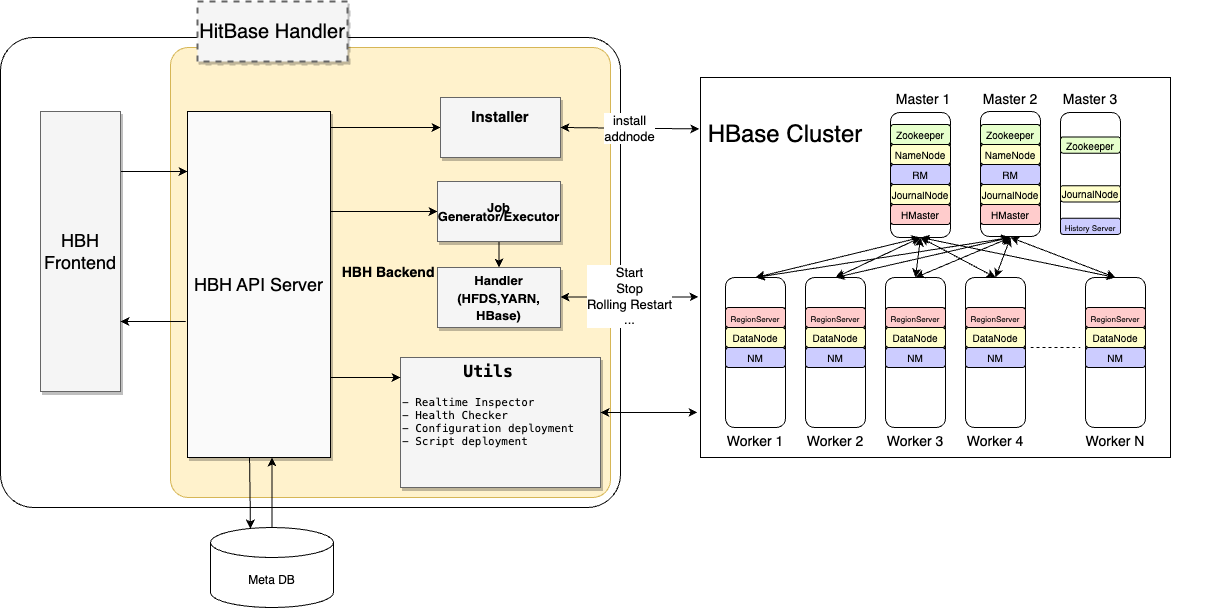
HBH는 크게 프런트엔드와 백엔드로 나뉩니다. 프런트엔드는 React 기반의 라이브러리로 사용자에게 웹 인터페이스를 제공하고, 백엔드에서 제공하는 REST API를 호출하는 역할을 담당합니다. 백엔드에는 Django와 Django REST 프레임워크를 기반으로 HBH의 핵심 기능을 구현해 놓았습니다. Django는 SQL 쿼리를 직접 작성하는 대신 Python 객체와 메서드를 사용해 손쉽게 데이터베이스와 통신할 수 있는 뛰어난 ORM 기능을 제공하고, 강력한 관리자 페이지 기능도 제공하고 있기 때문에 백엔드 프레임워크로 적합하다고 판단했습니다. HBH의 핵심 기능은 크게 HitBase Installer와 JobGenerator/Executor, 각종 핸들러, 유틸리티 모듈로 구분할 수 있습니다(각 기능의 세부 사항은 아래에서 하나씩 자세히 살펴보겠습니다).
HBase 클러스터를 안정적으로 운영하기 위해서는 Zookeeper와 Hadoop, YARN과 같은 다른 컴포넌트도 필요하며, 이에 따라 관리해야 할 프로세스의 수도 많아져 관리 도구가 필수입니다. 아래 그림 오른쪽을 살펴보면 Master 1 서버에서는 Zookeeper, NameNode, ResourceManager(RM), JournalNode, HMaster의 다섯 개 프로세스가, Worker 1 서버에서는 리전 서버(RegionServer), DataNode, NodeManager(NM)의 세 개의 프로세스가 한 대의 서버에서 실행되는 것을 볼 수 있습니다.
3. HitBase Installer 개발
HitBase를 설치하기 위해서는 정해진 순서대로 명령어를 수행하고 필수 프로그램을 설치하는 등의 다양한 작업이 필요한데요. 운영하는 서버의 수가 많기 때문에 설치 과정에서 발생할 수 있는 작업자의 실수를 방지하고 작업 시간을 줄이기 위해 시스템 자동화 엔진인 Ansible을 이용해 설치를 자동화했습니다.
Ansible을 백엔드에서 구동하기 위해서는 Python 라이브러리인 Ansible Runner를 사용합니다. Ansible Runner를 사용하면 인벤토리를 동적으로 생성해 Ansible Runner의 실행 인자로 넣거나 결과를 반환받을 수 있어 Ansible 플레이북을 함수처럼 사용할 수 있습니다. 인벤토리에는 서버의 역할을 지정하거나 설치에 필요한 변수를 넣을 수 있고, 지정한 동작을 수행한 뒤 반환 메시지를 통해 정상 작동 여부를 확인할 수 있습니다. 아래는 실제로 저희가 설치할 때 사용하는 HitBase Installer의 화면입니다. 필드 값을 채워 넣고 폼을 제출하면 클러스터 설치가 진행됩니다.
Ansible vault를 이용하면 패스워드나 토큰 등의 시크릿을 쉽고 편하게 관리할 수 있습니다.
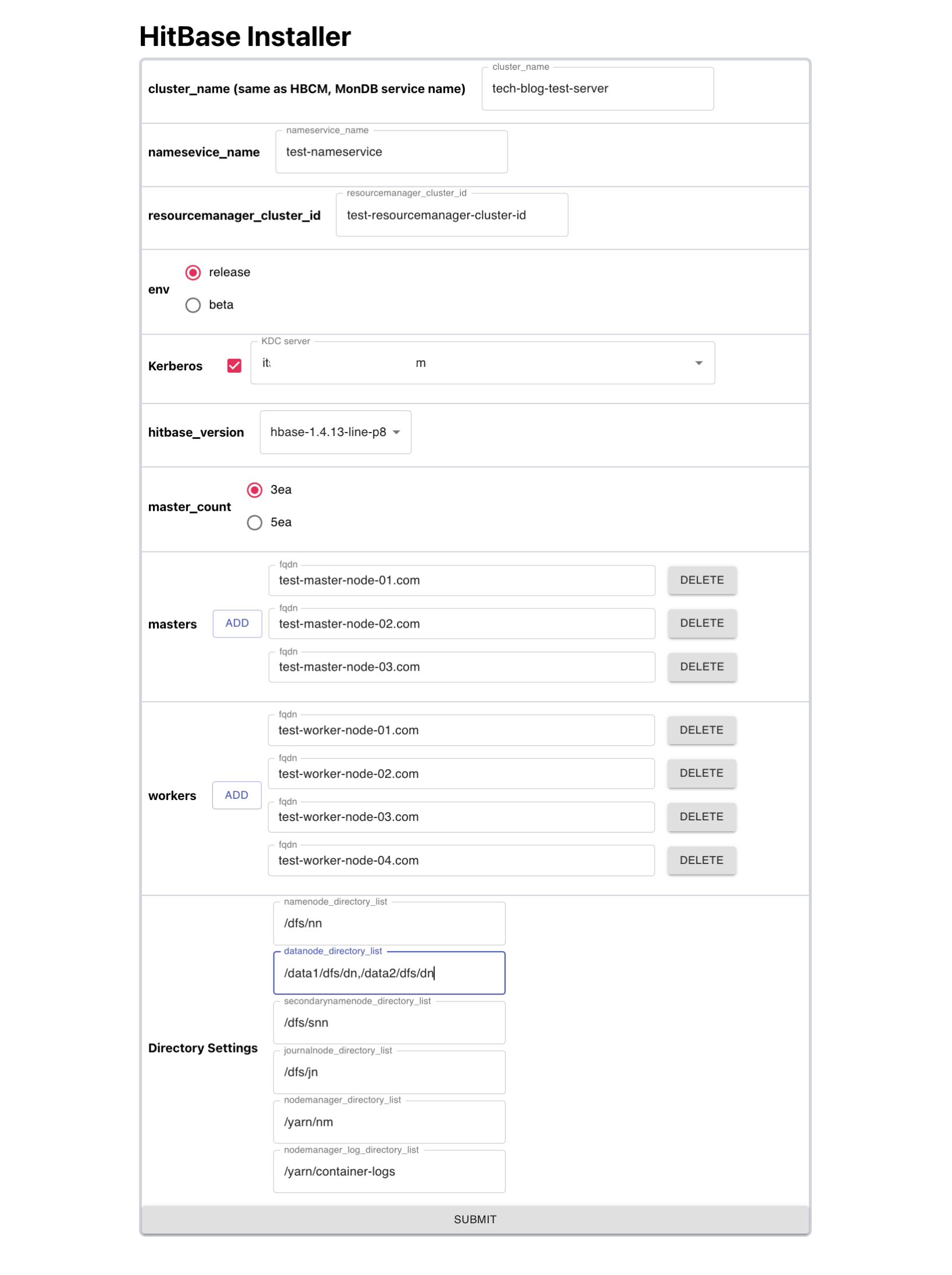
위에서부터 중요한 필드 값을 살펴보겠습니다. cluster_name은 말 그대로 클러스터의 �이름으로 관리하기 위해 임의로 붙이는 이름입니다. nameservice_name은 NameNode의 H/A 구성 시 Active와 Standby NameNode를 논리적으로 합쳐서 부르는 이름입니다. Kerberos 체크 박스로는 Kerberos 보안을 적용할지 말지 선택할 수 있습니다. 데이터 접근 제어를 위해서 Kerberos 보안을 적용하기로 결정했다면 Kerberos 티켓 정보를 관리하는 KDC(Kerberos Key Distribution Center) 서버를 선택합니다. hitbase_version(바이너리 버전)에서는 HitBase의 버전(1 혹은 2)을 선택하고, master_count에서는 마스터 노드의 수를 결정합니다. 마스터 노드의 수는 Zookeeper Quorum 숫자에 맞춰 3대 또는 5대로 설정합니다. masters와 workers에서는 마스터와 워커 서버의 호스트명을 추가로 기입합니다. 마지막으로 Directory Settings에서 프로세스가 사용하는 디렉터리 이름을 기입하면 설치가 진행됩니다.
nameservice의 이름에 언더바('_')가 포함되면 정상적인 H/A가 설정되지 않기 때문에 포함되지 않도록 주의해야 합니다.
아래는 설치 시 동적으로 생성되는 인벤토리의 예시입니다.
{
cluster_name: {
"children": {
"masters": {},
"workers": {},
"active_namenode": {},
"standby_namenode": {},
},
"vars": config_dict,
},
"masters": {"hosts": masters_dic},
"workers": {"hosts": workers_dic},
"active_namenode": {"hosts": active_namenode_dic},
"standby_namenode": {"hosts": standby_namenode_dic},
}마스터 노드 수를 3대 또는 5대로 설정하는 것은 Zookeeper의 숫자와 관련이 있습니다. 시스템의 일관성을 유지하기 위해서 Zookeeper를 사용하는데, Zookeeper에는 Zookeeper 노드 중 가장 최신의 상태를 가진 리더라는 특별한 멤버가 존재합니다. 이 리더를 선출할 때 과반수의 승인을 얻어야 하기 때문에 투표에 참여하는 Zookeeper Quorum은 홀수(3개 또는 5개)로 설정합니다. 가용성을 위해 5개를 권장하지만, 서비스 팀의 요구 사항에 따라 적은 수의 서버가 필요한 경우도 있어서 3개로 지원하기도 합니다.
4. Supervisord 도입
HBH가 전체적인 클러스터를 관리한다면, 각 서버 내에서는 Supervisord로 프로세스를 관리합니다. 위 HBase 아키텍처 그림에서 확인할 수 있듯이 서버 한 대에서 여러 개의 프로세스가 실행되는데요. Supervisord에서는 프로세스 관리 기능에 더해 프로세스를 외부에서 제어할 수 있는 API도 제공하기 때문에 여러 프로세스를 원격에서 관리하기 용이합니다. API로 제공하는 오퍼레이션으로는 startProcess(), stopProcess(), getState()(호스트나 프로세스의 상태 확인)가 있습니다.
이 기능만으로도 HitBase를 관리하기 위해 필요한 요구 사항의 대부분을 구현할 수 있었지만, Supervisord가 제공하는 상태 체크 기능에는 하드웨어 정보가 포함돼 있지 않았습니다. 이에 기존 getState() 함수를 변경해 CPU와 RAM, 네트워크, 디스크, 스와프(swap) 메모리 상태를 추가로 반환하도록 만들었습니다. 하드웨어의 상태를 수집하는 데에는 OS에 관계없이 정보를 수집할 수 있다는 장점이 있는 psutil 라이브러리를 사용했습니다. 변경된 코드는 아래와 같습니다.
def getState(self):
"""Return current state of supervisord as a struct
@return struct A struct with keys int statecode, string statename
"""
self._update("getState")
state = self.supervisord.options.mood
statename = getSupervisorStateDescription(state)
# get H/W information from psutil
cpu_percent = psutil.cpu_percent()
cpu_count = psutil.cpu_count()
mem = psutil.virtual_memory()
swap_mem = psutil.swap_memory()
disk_partitaions = psutil.disk_partitions()
net_io_counters = psutil.net_io_counters()
data = {
"statecode": state,
"statename": statename,
# CPU
"cpu_percent": str(cpu_percent),
"cpu_count": str(cpu_count),
# mem
"mem_total": str(mem.total),
"mem_available": str(mem.available),
"mem_percent": str(mem.percent),
"mem_used": str(mem.used),
"mem_free": str(mem.free),
"mem_active": str(mem.active),
"mem_inactive": str(mem.inactive),
"mem_buffers": str(mem.buffers),
"mem_cached": str(mem.cached),
"mem_shared": str(mem.shared),
# swap_mem
"swap_mem_total": str(swap_mem.total),
"swap_mem_used": str(swap_mem.used),
"swap_mem_free": str(swap_mem.free),
"swap_mem_percent": str(swap_mem.percent),
# disk
"disk_partitaions": str(disk_partitaions),
# network
"net_io_counters_bytes_sent": str(net_io_counters.bytes_sent),
"net_io_counters_bytes_recv": str(net_io_counters.bytes_recv),
"net_io_counters_packets_sent": str(net_io_counters.packets_sent),
"net_io_counters_packets_recv": str(net_io_counters.packets_recv),
"net_io_counters_errin": str(net_io_counters.errin),
"net_io_counters_errout": str(net_io_counters.errout),
"net_io_counters_dropin": str(net_io_counters.dropin),
"net_io_counters_dropout": str(net_io_counters.dropout),
}
return data Supervisord는 Unix 계열 시스템에서 프로세스 관리를 도와주는 오픈소스 관리 도구로, Systemd와 유사하지만 Python으로 구현돼 확장하기 용이하다는 차이점이 있습니다. CM에서는 각 서버 내 프로세스 관리를 담당하는 cloudera-scm-agent와 Supervisord 두 가지를 사용합니다.
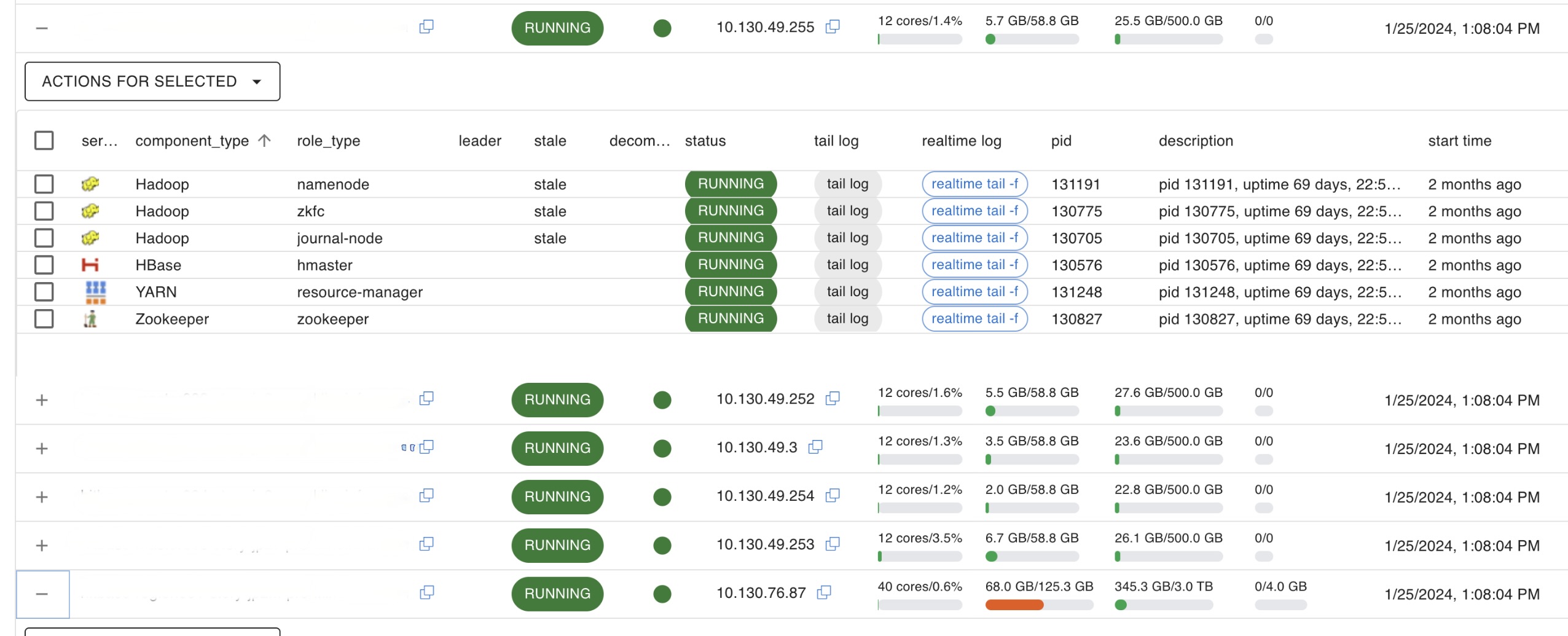
이렇게 수집한 데이터를 이용해 HBH의 호스트 탭에서 각 서버별 하드웨어 사용량을 실시간으로 확인할 수 있습니다. 만약 프로세스에 대한 정보를 추가로 수집하고 싶을 경우 getProcessInfo() 함수를 수정하면 API를 통해 추가 데이터를 가져올 수 있습니다.
HitBase에서 구동되는 Java 프로세스에 대한 지표는 JMX를 통해 수집하고 있어서 Supevisord에서 수집하는 데이터에는 포함시키지 않았습니다.
5. Job Generator/Executor 개발
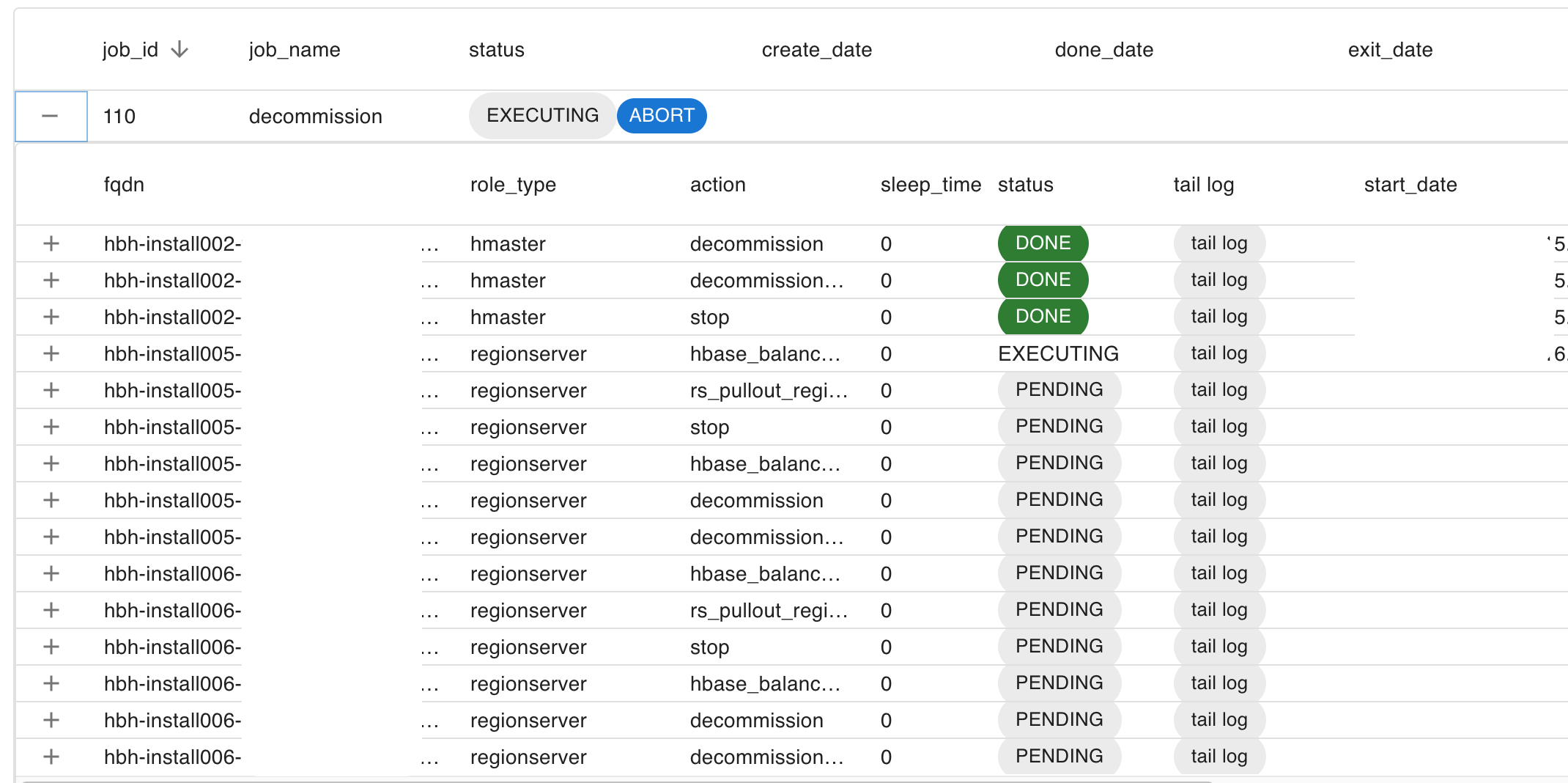
HBase 클러스터를 운영하면서 여러 가지 이유로 서버를 클러스터에서 잠시 제외하거나(decommission) 투입(recommission) 또는 재시작해야 하는 경우가 있습니다. 이런 상황에서 서비스 영향도를 최소화하려면 올바른 순서로 작업해야 합니다. 서버 수가 10대 이내의 작은 클러스터라면 각 서버에 접근해서 한 대씩 진행하는 것이 가능하지만 수십, 수백 대의 서버가 있는 클러스터에서 이렇게 작업한다면 작업자가 실수할 가능성이 높아지고 작업 시간 또한 길어집니다. 따라서 자동화된 도구를 이용하는 것이 바람직합니다.
자주 하는 작업 중 하나인 클러스터의 리전 서버 A에 대해 롤링 재시작(rolling restart) 작�업을 수행하는 것을 예로 들어보겠습니다. 리전 서버 A에 대해 일반적인 재시작을 하는 경우 리전 서버 A에 할당돼 있던 리전에 대한 복구 작업이 발생하고 데이터를 읽거나 쓸 수 없는 시간이 발생해 애플리케이션에 영향을 줄 수 있습니다. 이를 방지하기 위해 리전 서버 A에 할당돼 있던 리전을 모두 다른 리전 서버로 이동시킨 후 리전 서버 A를 재시작하고 해당 리전들을 재할당하는 작업이 롤링 재시작입니다. 아래는 이 과정을 나타낸 의사(pseudo) 코드입니다. 아래와 같은 순서로 작업을 진행하면, 리전이 다른 리전 서버로 모두 이동하고 중지되기 때문에 HBase를 사용하는 애플리케이션에 주는 영향을 최소화할 수 있습니다.
hbase_balancer_off()
create_region_backup()
// Region Server Restart
for 리전서버 in 리전서버s:
pullout_all_regions(리전서버)
restart(리전서버)
restore_all_regions(리전서버)
// HMaster Restart
for HMaster in HMasters:
restart(Hmaster)
hbase_balancer_on()위 과정에서 만약 운영자가 실수로 hbase_balancer_off()를 수행하지 않았다면 어떤 상황이 벌어질까요? 리전 밸런서가 임의로 리전 서버 A에 리전을 할당하고 재시작할 때 리전 복구 작업이 진행되며 복구가 진행되는 동안 리전을 정상적으로 사용할 수 없습니다. 이때 해당하는 리전을 사용하는 클라이언트는 데이터를 읽거나 쓸 수 없을 것입니다. 물론 이후 재요청이 전송돼 리전이 정상적으로 제공되는 상태가 되긴 하겠지만 응답 시간이 증가했으니 낮은 응답 시간을 제공해야 하는 저희 입장에서는 좋지 않은 상황입니다.
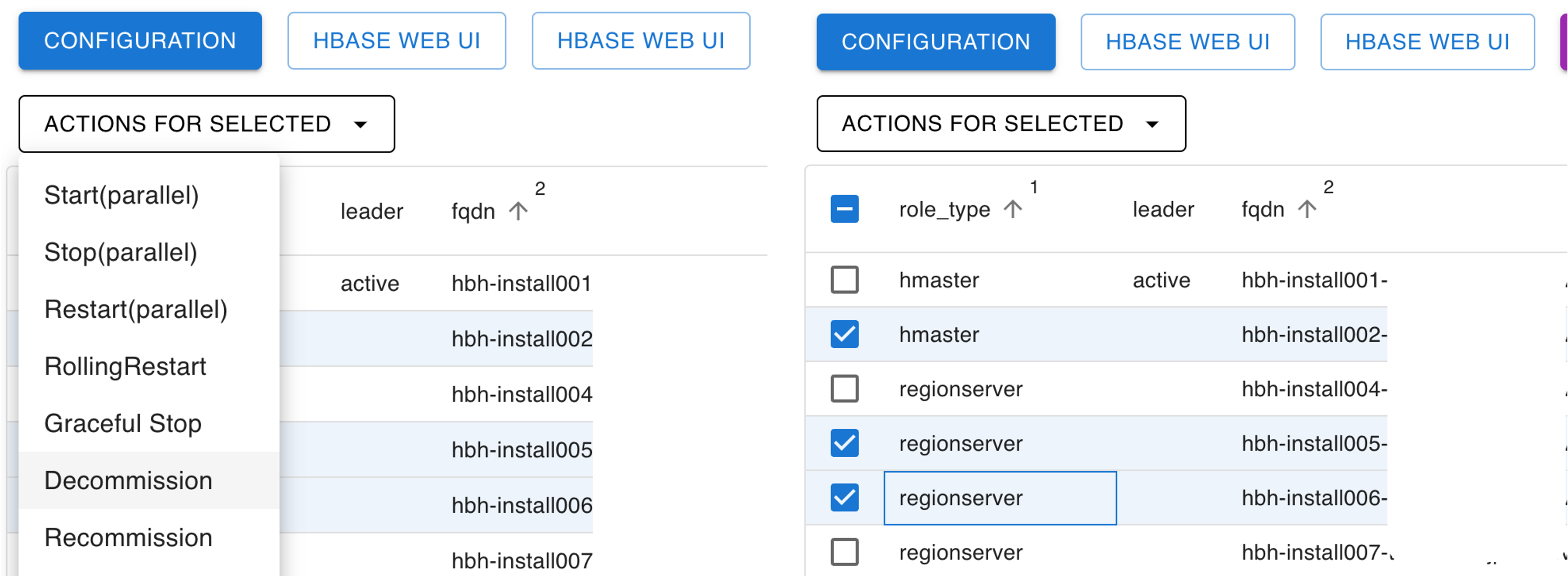
위와 같이 실행 순서가 중요한 작업들을 처리하기 위해서 Job Generator/Executor라는 것을 만들었습니다. Job Generator는 필요한 태스크(작업 단�위)를 생성하고, Job Executor는 이렇게 생성된 태스크를 순차적으로 실행합니다. 아래는 Job Generator/Executor가 롤링 재시작 잡을 수행하는 것을 확인할 수 있는 웹 UI입니다.
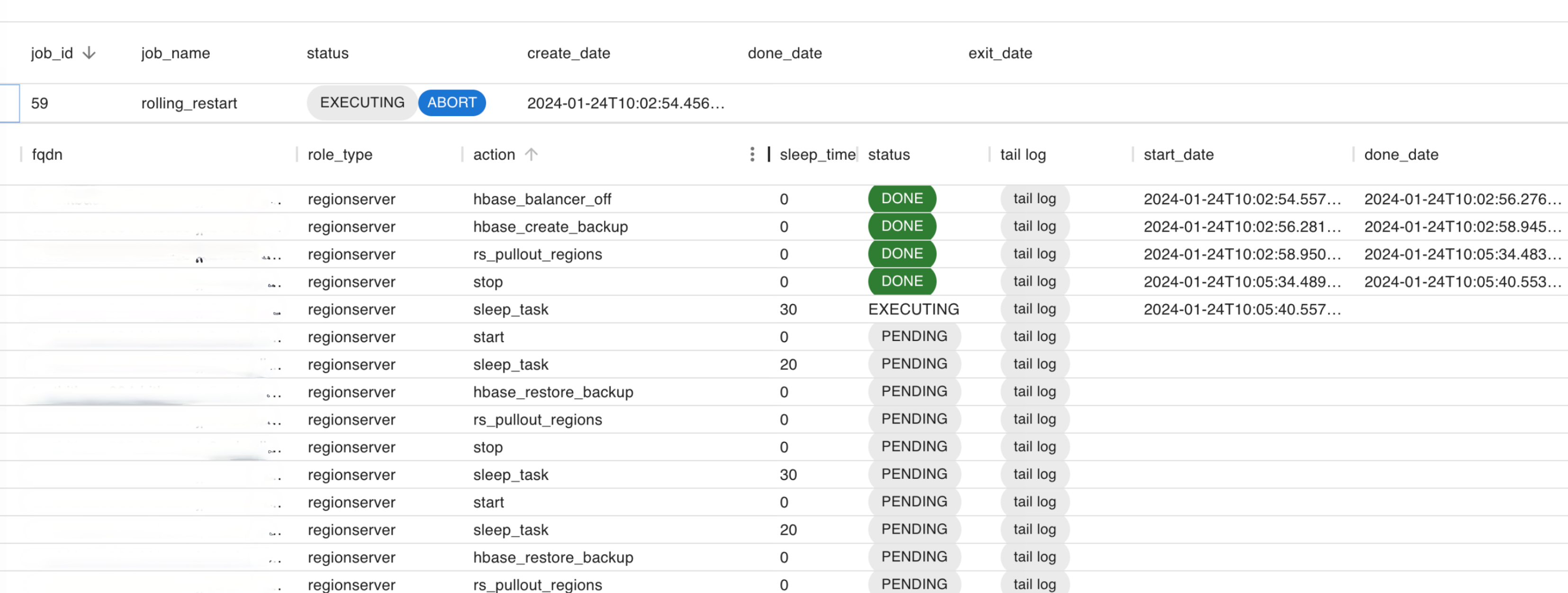
HBase 롤링 재시작 기능은 CM의 상용 버전에서만 지원됩니다.
Job Generator
Job Generator에 대해 조금 더 자세히 알아보겠습니다. Job Generator는 사용자가 요청한 잡을 수행하기 위한 태스크를 생성하는 역할을 담당합니다. 앞서 설명했던 HBase 롤링 재시작처럼 HBH를 사용하는 운영자는 추상화된 작업을 실행하는데요. 프로세스에 따라서 실제로 작업에서 수행하는 태스크는 달라질 수 있습니다. 예를 들어 제외(decommission) 작업을 선택하면 일반적인 HBase의 리전 서버 프로세스는 가지고 있는 모든 리전을 다른 리전 서버들에 배포한 후 프로세스를 중지하도록 합니다. DataNode 제외 작업 시 NameNode에 서버를 등록하고 갱신한 다음, 실제로 해당 DataNode가 가진 데이터 블록이 모두 다른 DataNode로 이전될 때까지 대기한 후 프로세스를 중지하도록 잡을 생성합니다. 이외에도 다양한 케이스에서 작업을 생성하기 위해 Job Generator를 사용합니다.
Job Executor
잡을 생성하기만 하고 실행하지 못한다면 반쪽짜리 기능이겠죠? Job Generator가 생성한 잡은 Job Executor로 전달돼 수행됩니다. Job Executor는 HDFS, HBase, YARN 핸들러와, Supervisord API, CLI(Command line interface) 명령어 등을 조합해 태스크를 수행합니다.
Supervisord API는 XML-RPC 프로토콜을 제공하는데 Python에는 xmlrpc라는 라이브러리가 있기 때문에 Django 코드 내에서 쉽게 호출할 수 있습니다. CLI 명령어를 입력해야 하는 경우에도 Ansible Runner를 사용해 실행합니다. 반면 HDFS나 HBase, YARN에 접근할 때에는 Java로 작성된 클라이언트 라이브러리를 사용해야 하는데요. 이 라이브러리들은 순수 Python 환경에서는 사용할 수 없었습니다. 물론 HBase에서 제공하는 REST API나 Thrift API를 제공하는 별도의 프로세스를 구동시켜 Java 이외의 언어에서 접근하는 방법도 있었지만, 해당 프로세스가 중지되면 HBH가 정상 작동하지 않기 때문에 별도로 관리해야 하는 불편함이 있었습니다. 다행히 Python에서 JVM을 구동할 수 있는 Jpype라는 라이브러리를 통해 백엔드에서 클라이언트 라이브러리를 실행할 수 있었습니다.
아래 Python 코드는 Jpype로 HBase Admin 객체에 접근하는 예시입니다. Jpype의 놀라운 점은 Python에서 단순히 Java 코드를 실행할 수 있을 뿐 아니라, Java 코드를 Python 코드 내부에 작성할 수 있다는 점입니다. Java 객체를 변수에 담을 때 Python처럼 타입을 명시하지 않거나 Java의 예외 처리를 Python의 try/except 문으로 처리할 수 있습니다.
import jpype, os
import jpype.imports
# ../api/view/actions/jars/v1 경로에는 HBase 접속에 필요한 Jar 파일이 모두 존재해야 합니다.
jars_path = os.path.join(settings.BASE_DIR, "../api/view/actions/jars/v1")
if jpype.isJVMStarted() is False:
jpype.startJVM(classpath=[jars_path + "/*"])
from org.apache.hadoop.hbase import HBaseConfiguration
from org.apache.hadoop.hbase.exceptions import TimeoutIOException
from org.apache.hadoop.hbase import HBaseIOException, UnknownRegionException
conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("hbase.zookeeper.quorum", ",".join(master_nodes))
connection = ConnectionFactory.createConnection(self.conf)
admin = connection.getAdmin()
print("admin", admin)6. 설정 파일 관리 방법 확립
HBase나 HDFS, YARN, Zookeeper와 같이 다양한 컴포넌트를 사용하고 있기 때문에 관리해야 할 설정 파일의 숫자도 상당히 많습니다. 개발 초기에는 GitHub과 연동돼 데이터 버전 관리가 가능한 Central Dogma를 사용해 설정 파일을 관리하고 사내 툴을 통해 배포했습니다. 이 방식으로 몇 개월 정도 테스트 클러스터를 운영해 봤는데요. 설정 파일 이력 관리와 운영자의 실수를 줄인다는 관점에서는 굉장히 좋은 방법이었지만, GitHub에서 설정 파일을 변경한 뒤 리뷰를 받고 병합하고 배포한 뒤 프로세스를 재시작하는 과정이 번거로웠습니다.
이를 보완하기 위해 설정 파일을 HBH에서 관리하는 방향으로 구조를 변경했습니다. 설정 페이지 왼쪽에서 변경하고자 하는 파일을 선택할 수 있고, 오른쪽에서 설정값을 변경한 뒤 저장하면 모든 서버에 변경된 설정 파일을 배포합니다.
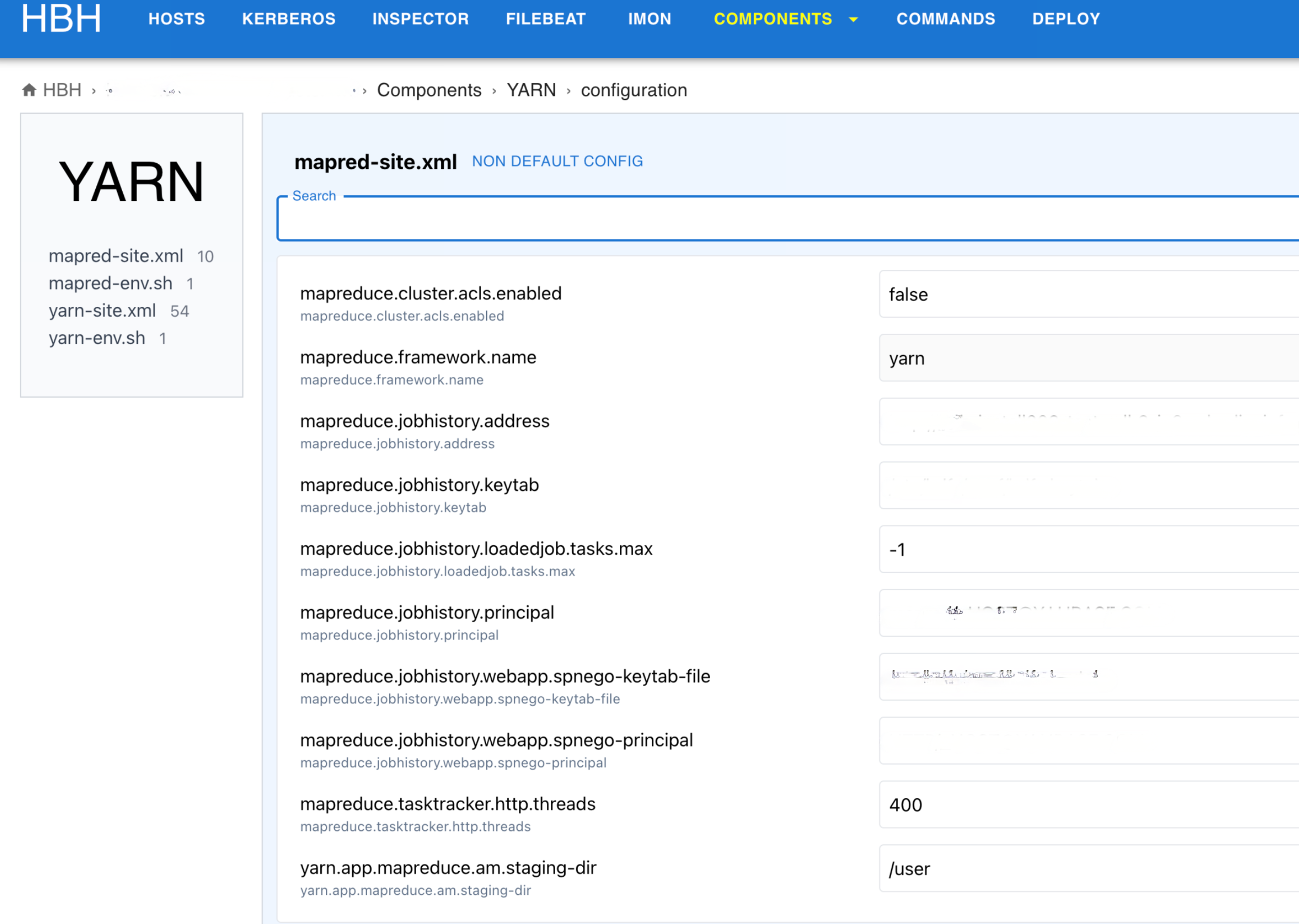
Hadoop의 설정 파일은 대부분 XML 파일인데요. Jinja2 라이브러리를 활용하면 설정값들을 Hadoop 설정 XML 형식에 맞게 동적으로 변환할 수 있습니다. 설정값을 데이터베이스에 저장해 놓은 뒤 아래와 같은 방법으로 <name>과 <value>에 설정값이 할당된 XML 파일을 생성할 수 있습니다.
hbase-site.xml.j2
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
{% for config in configs %}
<property>
<name>{{config.name}}</name>
<value>{{config.value}}</value>
</property>
{% endfor %}
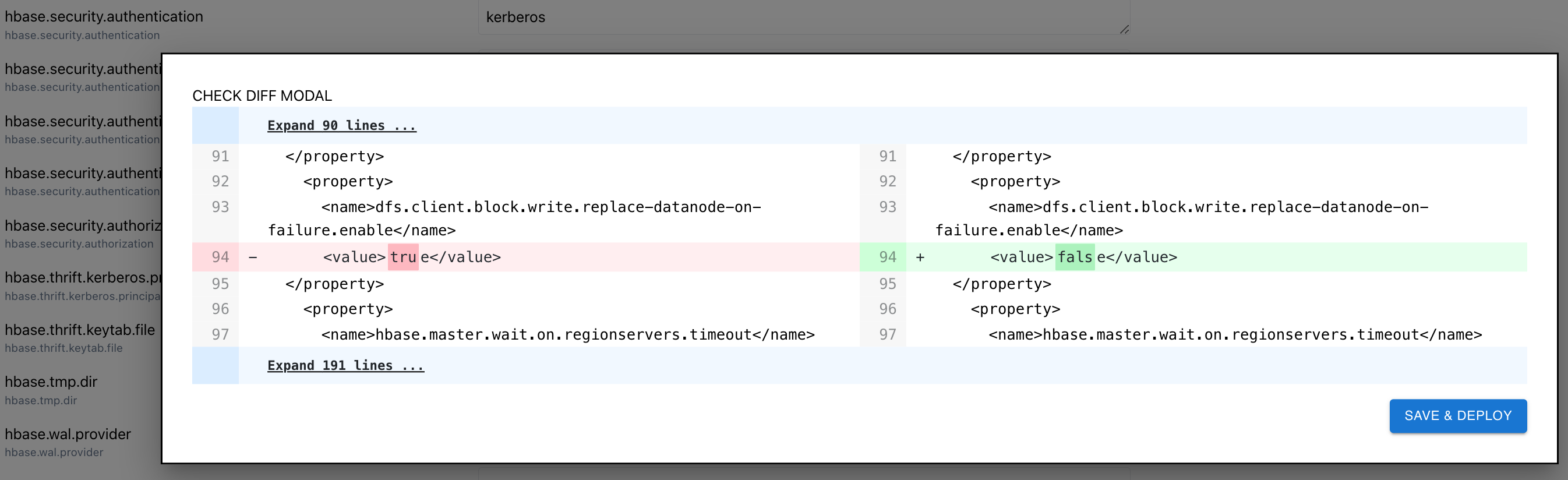
</configuration>설정 파일 변경 후에는 웹 UI에서 어떤 부분이 수정됐는지 직관적으로 확인할 수 있습니다.
7. 유틸리티 모듈 개발
실시간 인스펙터 개발
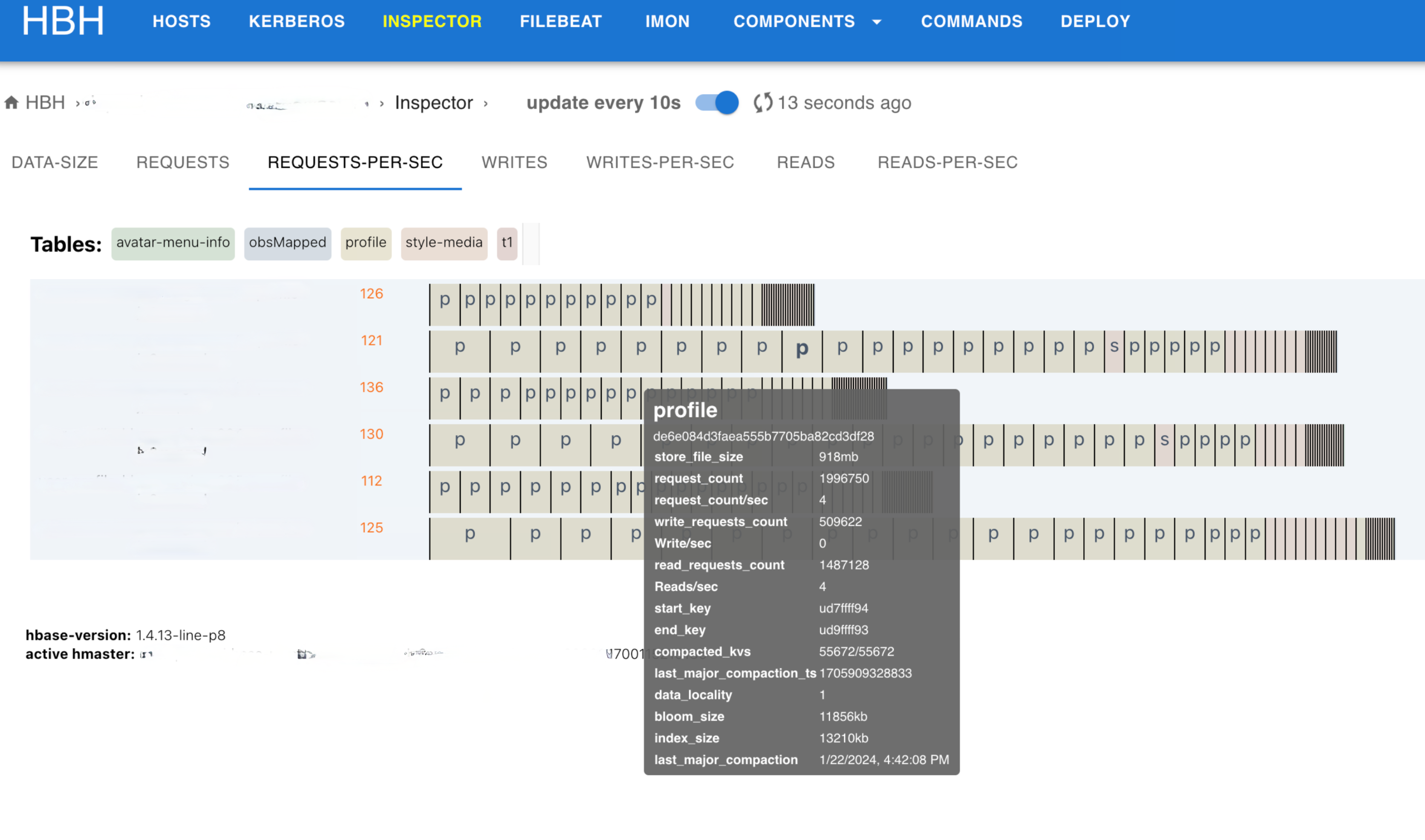
HBase에서는 테이블을 리전 단위로 나눠 사용하며, 적절하게 리전을 나누고 분배하면 부하 분산이 가능하기 때문에 최적의 성능을 낼 수 있습니다. 따라서 각 리전을 모니터링하는 것은 HBase 운영에 필수적입니다. 리전이 적절히 나뉘지 않으면 요청이 한 곳으로 몰리는 핫스팟이 발생해 HBase의 성능이 저하됩니다. HBase 팀은 그동안 CDH를 운영하면서 리전의 핫스팟을 모니터링하는 시각화 도구로 오픈소스를 이용해 왔는데요. HitBase로 전환 후 호환성 문제가 발생해 실시간 인스펙터라는 이름으로 직접 모니터링 시각화 도구를 개발했습니다.
아래는 실시간 인스펙터 화면에서 리전 정보를 시각화한 예시입니다. 특별히 요청이 많이 들어온 리전은 다른 리전에 비해 폭이 넓게 표시되기 때문에 핫스팟 리전일 확률이 높습니다.
Health Checker 개발
예전에는 광부들이 지하 갱도로 내려갈 때 이산화탄소나 메탄가스 농도에 민감한 카나리아라는 새를 �두어 마리 함께 데리고 다녔다고 합니다. 가스 중독의 위험을 피하기 위해 이 새를 일종의 경고 지표로 사용한 것이죠. 클러스터의 상태를 확인하기 위해 Health Checker가 주기적으로 컴포넌트의 상태를 확인합니다. 대표적으로 Zookeeper 컴포넌트의 테스트인 Canary 테스트가 있습니다. Health Checker에는 Zookeeper가 정상적으로 동작하는지 확인하기 위해 주기적으로 Quorum의 리더가 존재하는지 확인하거나 Active NameNode가 작동하고 있는지 확인하는 테스트가 있습니다. Health Checker에서 테스트가 실패하면 이메일이나 Slack으로 알림을 보내 운영자가 클러스터의 상태 이상을 인지하도록 합니다.
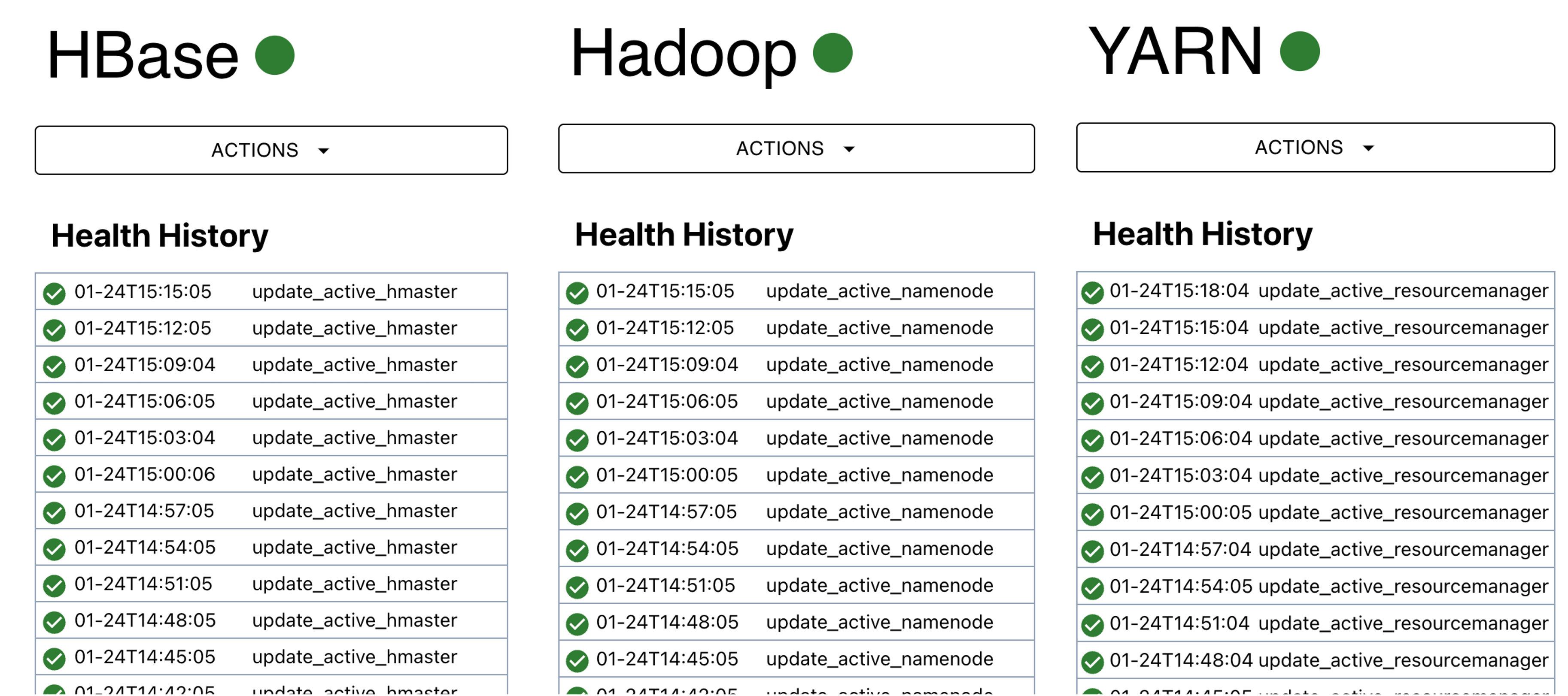
CM에서는 Service Monitor라는 별도의 프로세스가 주기적으로 컴포넌트의 상태를 확인합니다.
리전 백업 및 복구(region backup & restore) 기능 개발
리전 백업 및 복구가 어떤 역할을 수행하는지 말씀드리기 위해서 먼저 리전 서버와 DataNode의 위치가 성능에 어떤 영향을 주는지 살펴보겠습니다.
HBase에서는 데이터를 저장하기 위해 HDFS를 사용합니다. 실제 HBase의 데이터는 HDFS의 DataNode에 블록 형태로 관리되는데요. 리전 서버와 HDFS의 DataNode가 물리적으로 다른 서버에 위치할 경우 네트워크를 통해 데이터를 조회해야 해서 비효율적입니다. 반면 DataNode와 리전 서버가 동일한 서버에 존재하면 short-circuit read라는 것을 활용해 로컬 파일 �시스템에 직접 접근해서 데이터를 읽을 수 있기 때문에 훨씬 더 높은 성능을 제공할 수 있습니다. 즉, DataNode와 리전 서버가 동일한 서버에 존재해 short circuit read를 사용할 수 있도록 관리하는 것이 성능 관점에서 중요한 일입니다. 만약 그렇게 관리하지 못하다면 각 요청의 응답 시간이 느려질 수 있고, 그 상태에서 네트워크 대역폭마저 낮다면 많은 데이터를 다루는 배치 잡 등의 수행 시간이 늘어날 수 있습니다.
이때 리전 서버에서 관리하는 데이터가 동일한 서버의 DataNode에 있는 비율을 지역성(locality)이라고 합니다. 지역성이 100%라면 모든 데이터를 short circuit read를 통해 읽을 수 있는 것이죠. 리전 서버는 데이터를 정리하는 압축(compaction) 작업을 진행하면서 동일한 서버에 위치한 DataNode에 데이터를 쓰는데요. 이를 주기적으로 실행하면 자연스럽게 지역성이 높아집니다. 그런데 서버가 갑자기 다운되거나 서비스 아웃이 필요해서 리전 서버를 잠시 정지하고 재기동해야 하는 상황이 발생하면 리전 밸런서가 작동하면서 기존 리전과 DataNode의 배치가 달라질 수 있습니다. 지역성이 떨어질 수 있는 것이죠. 따라서 이와 같은 상황이 발생했을 때 리전의 위치를 원래대로 복구하기 위해 작업 전 또는 주기적으로 리전의 위치 정보를 백업해 둬야 합니다. 이를 위해 HBH에서는 리전 위치에 대한 정보를 데이터베이스에 백업하고, 이 정보를 이용해서 리전의 지역성을 높은 상태로 유지할 수 있도록 돕습니다. 아래는 HBH에서 제공하는 리전 백업 및 복구 기능의 UI입니다.
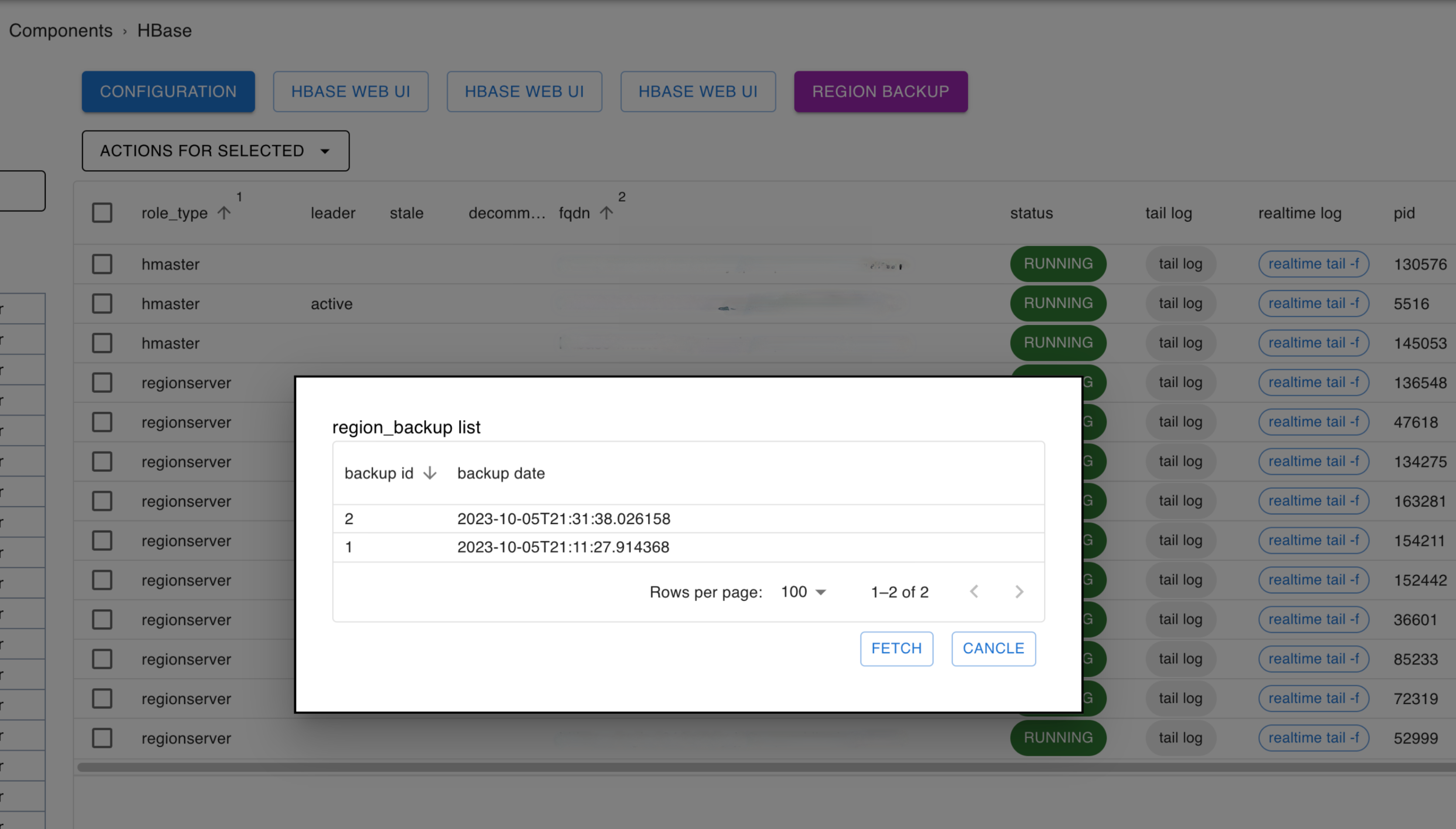
HBase의 기본적으로 탑재된 리전 밸런서는 주기적으로 작동하면서 알고리즘에 따라 리전들을 임의의 리전 서버로 분배합니다.
모니터링 설정
앞서 설명한 실시간 인스펙터는 내부 리전 모니터링만을 위한 시스템이고, HitBase를 운영하기 위해서는 로그나 JMX 기반의 지표를 추가로 수집해 관리해야 합니다.
먼저 로그는 각 서버의 Filebeat에서 Kafka로 전송되고, 이를 Logstash에서 가공해 Elasticsearch에 저장합니다. 이 작업에는 사내에서 프라이빗 클라우드로 제공되는 VKS(k8s)와 VES(Elasticsearch)를 적극 활용했습니다. 그동안 운영하면서 지표만으로는 파악하기 어려운 이슈 상황이 발생하기도 했는데요. 이제는 수집한 로그를 활용해 보다 다각도로 이슈 상황을 파악하며 알림을 받고 있습니다.
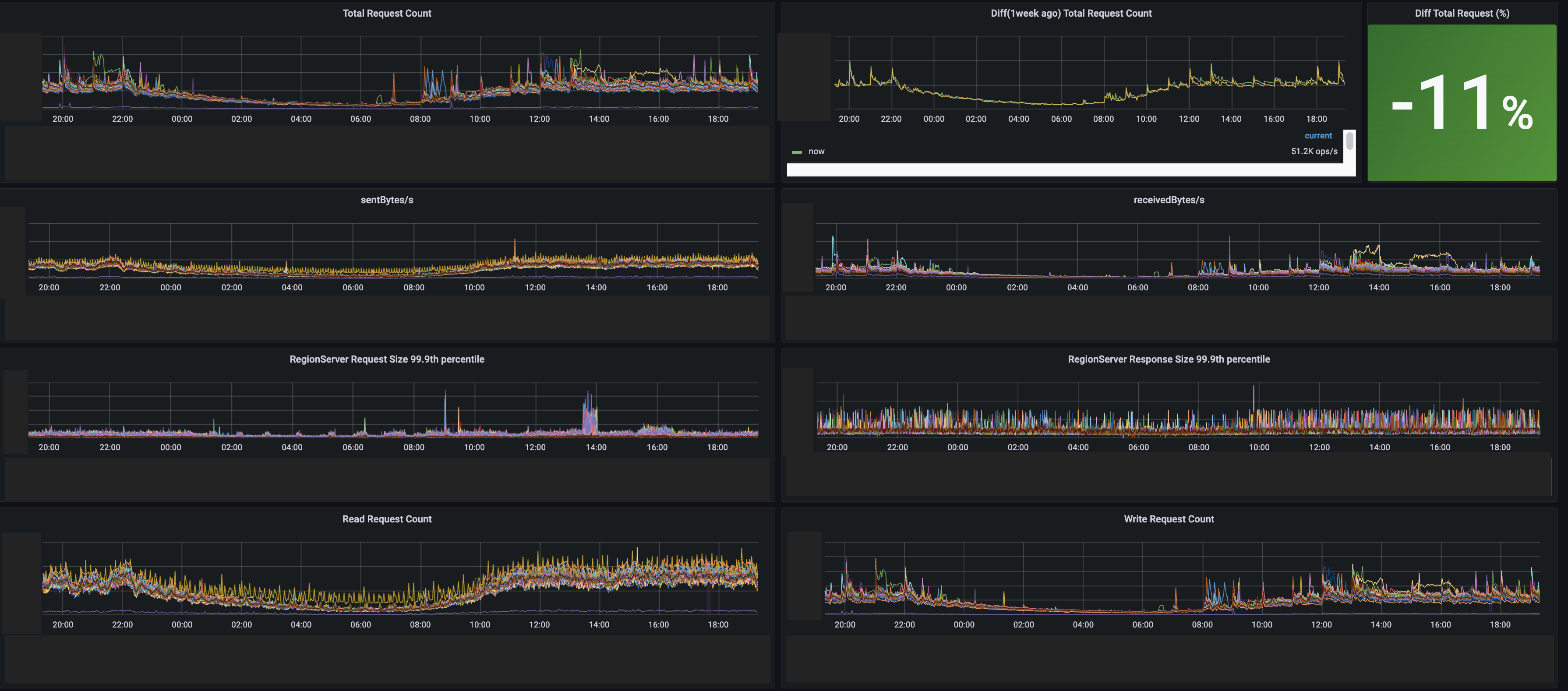
지표는 OS와 Zookeeper, HDFS, HBase에 대해서 수집하고 있습니다. Java 프로세스의 JMX 데이터를 이용해 필요한 데이터를 최종적으로 IMON(공통 모니터링 시스템)과 DBONE(DB 전용 모니터링 시스템)로 저장하고 Grafana 대시보드를 이용해서 아래와 같이 시각화하고 있습니다.
마치며
HBH(Hitbase Handler)는 '어떻게 하면 상용 배포판에 의존하지 않고 HBase를 잘 운영할 수 있을까?'라는 고민을 해결하는 과정에서 만들었습니다. 현재는 테스트 커버리지를 높이는 작업이나 Hadoop 에코 시스템의 다른 컴포넌트들로 확장이 가능한 구조로 변경하는 등 상용 배포판에 준하는 기능을 제공할 수 있도록 준비하고 있습니다. 당장은 아니지만 HBH를 오픈소스로 공개할 계획도 가지고 있는데요. 이를 위해서 사내 시스템과의 의존성을 제거하고 소스 코드의 품질을 높이는 작업도 진행하고 있습니다. 저희의 HBH 개발기가 상용 배포판으로 HBase 클러스터를 운영하시는 분들이나 오픈소스 HBase로 전환하는 것을 고려하시는 분들께 도움이 되면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.


