들어가며
안녕하세요. UIT 팀 윤혜린입니다. LY Corporation Group에서는 헤드리스 CMS인 LandPress Content를 사내 임직원 대상으로 운영하고 있습니다. 이 글에서는 LandPress Content에서 CDC(change data capture, 변경 데이터 캡처)를 설계하고 개발한 경험을 공유하고자 합니다.
LandPress Content CDC의 작동 흐름
LY Corporation의 기술과 개발 문화가 소개되는 이 기술 블로그도 LandPress Content로 운영되고 있습니다. 저희의 기술과 문화를 공유하기 위해 하루에도 수십 번씩 데이터 추가와 수정 및 삭제가 발생하고 있는데요. 예를 들어 글의 본문이 수정되기도 하고, 새로운 저자 데이터가 추가되기도 합니다.
위와 같은 데이터 변경이 발생했을 때, LandPress Content에서는 다음과 같은 흐름으로 CDC가 작동합니다.

- 데이터 변경을 감지합니다.
- 데이터 변경이 발생했을 때 예상되는 변경점을 식별하고 캡처합니다.
- 변경 대상 데이터
- 변경 대상 데이터에 영향을 받는 데이터
- 캡처된 데이터의 변경 전후��를 비교해 실제로 변경된 데이터만 추출합니다.
- 최종 선별된 데이터를 파이프라인으로 전달합니다.
위 흐름을 하나씩 조금 더 자세히 살펴보겠습니다.
예상되는 변경점 식별 후 캡처하기
먼저 데이터 변경이 감지됐을 때 예상되는 변경점을 식별하고 캡처해야 합니다. 이때 변경점에는 두 종류가 있습니다. 하나는 변경 대상이 되는 데이터의 변경점, 다른 하나는 연관 관계 데이터로 인한 변경점입니다.
LandPress Content는 사용자가 데이터를 더욱 구조적으로 편리하게 구성할 수 있도록 데이터 간 연관 관계 설정을 지원하는데요. 연관 관계로 맺어진 데이터는 변경 시 다른 데이터에도 영향을 미칩니다. 따라서 데이터의 변경을 감지했을 때 이런 연관 관계 설정까지 고려해 모든 변경점을 식별할 수 있도록 CDC를 설계해야 합니다.
변경 대상 데이터의 변경점 식별하기
다음은 저자 데이터를 저장하기 위해 사용하는 authors 컬렉션입니다. 이 컬렉션에서 authors=1의 영어 닉네임을 변경해 보겠습니다.
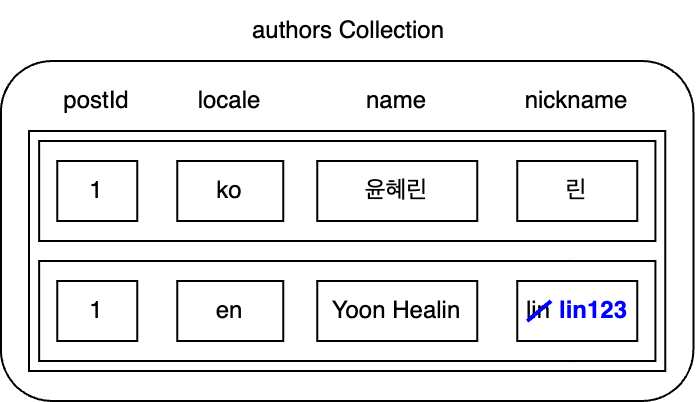
위와 같은 사례에서의 데이터 변경점은 매우 단순합니다.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | en | ||
| nickname | lin123 |
연관 관계 데이터의 변경점 식별하기
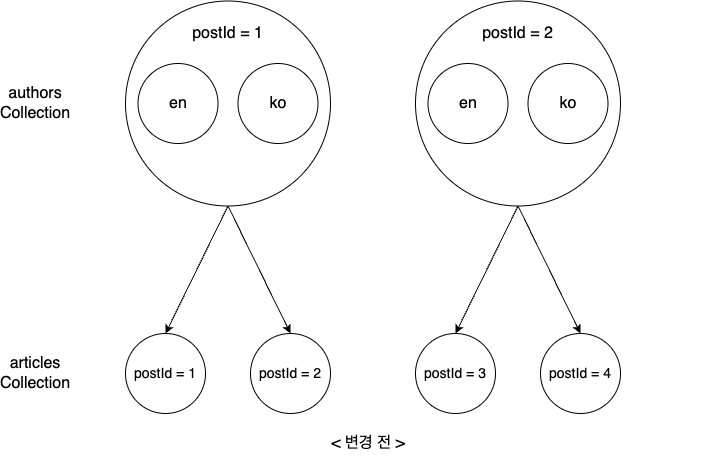
위 사례를 글 데이터를 저장하는 articles 컬렉션과 함께 살펴보겠습니다. 한 명의 저자는 여러 개의 글을 작성할 수 있으므로 authors 컬렉션과 articles 컬렉션은 1:N 관계인데요. 이때 authors=1과 authors=2가 각각 다음과 같이 articles와 연관 관계가 설정돼 있다고 가정해 보겠습니다.
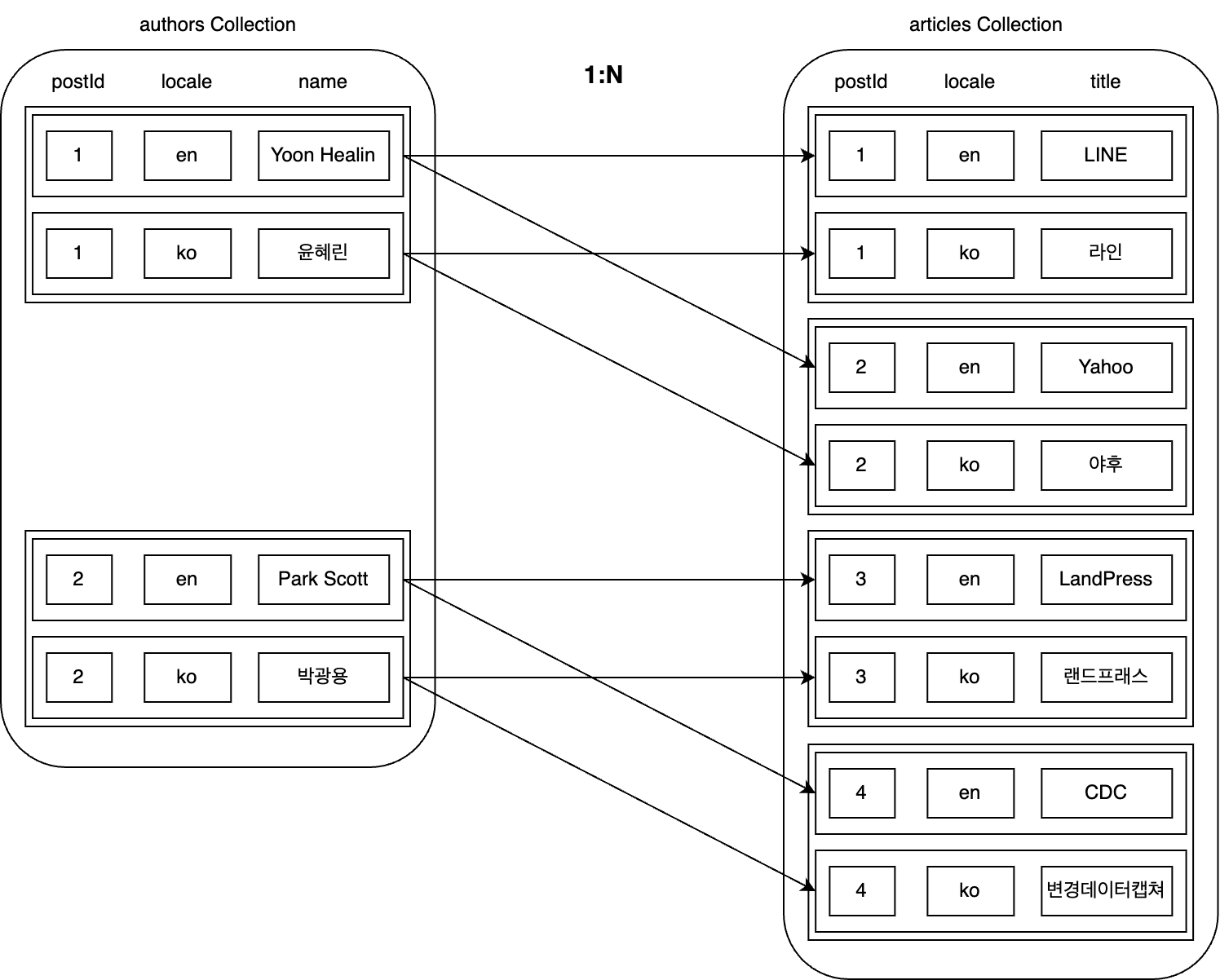
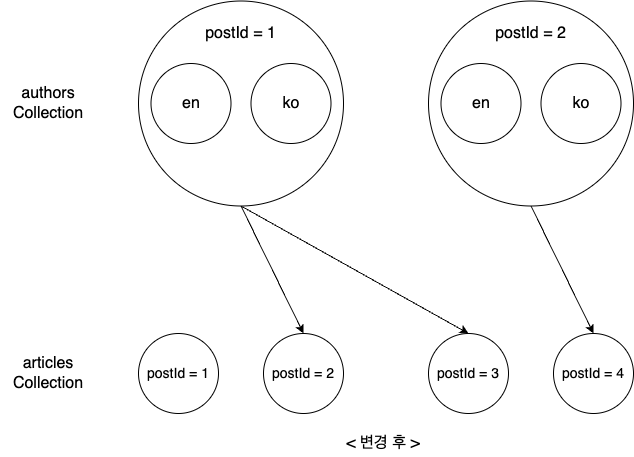
이 상황에서 authors와 articles를 잘못 매칭했다는 것을 발견하고 다음과 같이 수정했다고 가정해 보겠습니다.
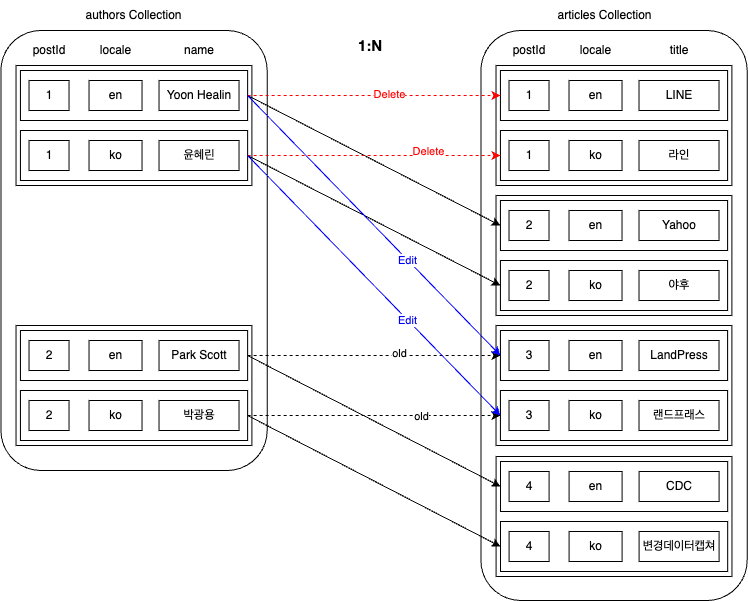
위와 같이 연관 관계 데이터가 변경될 경우 데이터 변경점은 조금 더 복잡해집니다. 다음과 같이 총 5개 영역에서 변경이 발생할 수 있는데요. 하나씩 살펴보겠습니다.
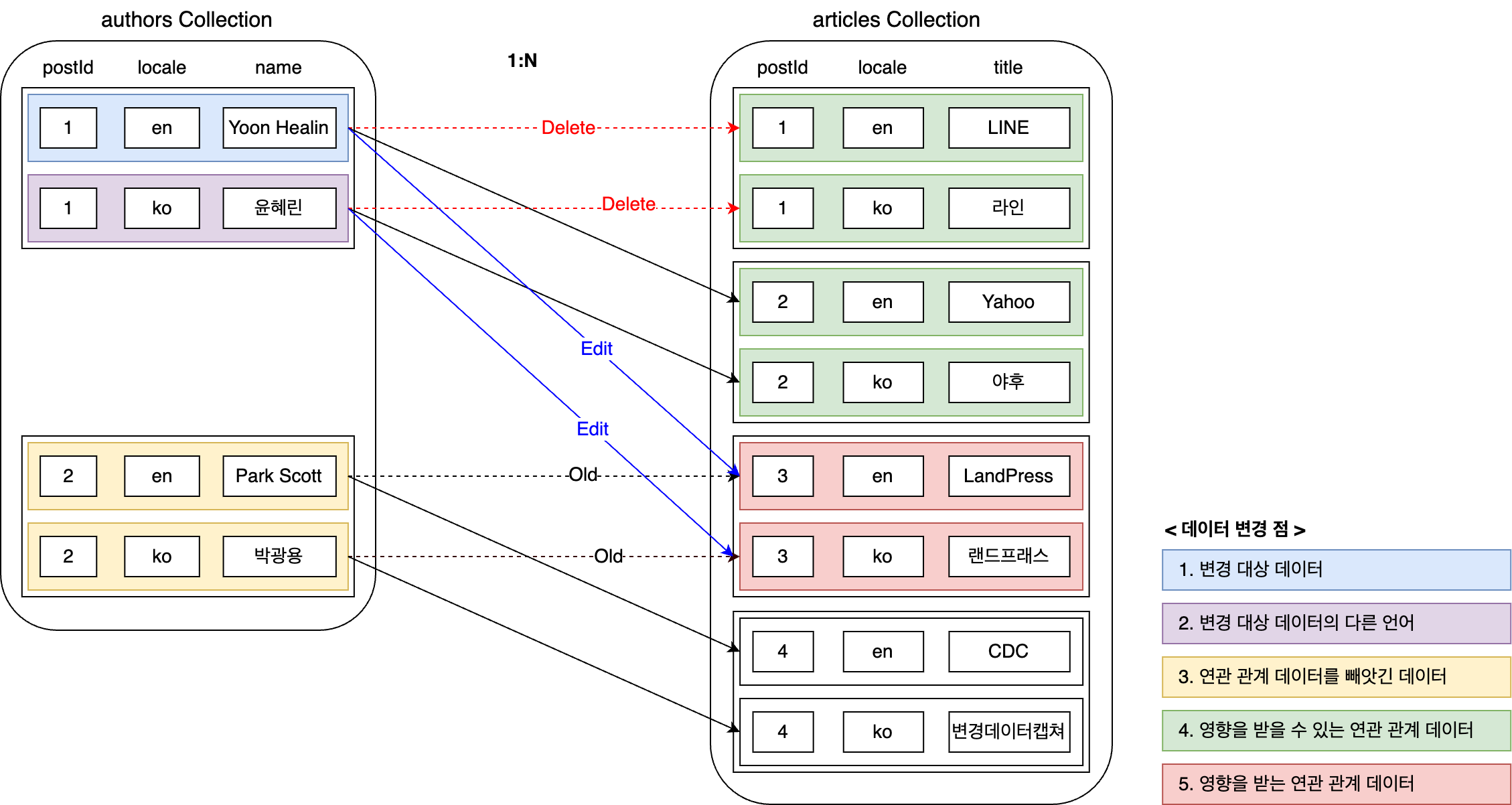
변경 대상 데이터
사용자 요청을 통해 변경 대상이 되는 데이터입니다.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | en | ||
| articles | 2 |
변경 대상 데이터의 다른 언어 데이터
각 데이터는 여러 언어로 관리될 수 있습니다. 동일한 데이터로 언어만 다르기 때문에 postId를 공유합니다. 동일한 저자가 한국어 페이지에서는 한국 이름으로, 영어 페이지에서는 영어 이름으로 소개될 수 있도록 말이죠. 이때 연관 관계는 postId를 기준으로 맺어집니다. 따라서 특정 언어에서 연관 관계 데이터를 수정하면 다른 언어의 연관 관계 데이터 또한 수정되므로 식별 데이터에 포함돼야 합니다.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | ko | ||
| articles | 2 |
연관 관계 데이터를 빼앗긴 데이터
articles=3는 원래 authors=2와 연관 관계를 맺고 있었습니다. 그런데 이번 변경으로 authors=2는 authors=1에게 연관 관계 데이터를 빼앗기고 말았습니다. 따라서 authors=2의 데이터에도 변경이 발생하므로 식별 데이터에 포함돼야 합니다.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 2 |
| locale | en | ||
| articles | 3 | ||
| 2 | postId | 2 | |
| locale | ko | ||
| articles | 3 |
영향을 받을 수 있는 연관 관계 데이터
다음으로는 영향을 받을 가능성이 있는 연관 관계 데이터입니다. 사용자가 authors=1에 연결된 articles를 수정하면, articles 관점에서는 연결된 authors 값이 변경될 가능성이 생깁니다. 따라서 식별 데이터에 포함하고 이후에 실제로 값이 변경됐는지 확인해야 합니다.

| num | collection | key | value |
|---|---|---|---|
| 1 | articles | postId | 1 |
| locale | en | ||
| authors | 1 | ||
| 2 | postId | 1 | |
| locale | ko | ||
| authors | 1 | ||
| 3 | postId | 2 | |
| locale | en | ||
| authors | 1 | ||
| 4 | postId | 2 | |
| locale | ko | ||
| authors | 1 |
영향을 받는 연관 관계 데이터
마지막으로 articles=3은 authors의 변화에 영향을 받는 것이 확정된 연관 관계 데이터입니다. 따라서 식별 데이터에 포함돼야 합니다.
| num | collection | key | value |
|---|---|---|---|
| 1 | articles | postId | 3 |
| locale | en | ||
| authors | 1 | ||
| 2 | postId | 3 | |
| locale | ko | ||
| authors | 1 |
변경점 캡처하기
변경점을 모두 �식별했다면 이제 변경 전과 후의 데이터를 캡처할 차례입니다. 이 과정에 필요한 데이터베이스 조회는 사용자 요청의 트랜잭션 내에서 진행돼야 하므로, 응답 속도 저하를 방지하기 위해 중복 조회가 발생하지 않도록 설계했습니다. 연관 관계 데이터를 조회할 때는 불필요한 데이터 수집을 피하기 위해 최소 식별 정보(postId와 언어 정보)만을 가져와 활용했습니다.
캡처할 때는 변경 전 데이터와 변경 후 데이터 중 어느 시점을 기준으로 캡처할지 선택해야 하는데요. 생성은 변경 이전의 값이 없고, 삭제는 변경 이후의 값이 없기 때문에 어느 시점을 기준으로 캡처하는지에 따라 다음과 같은 차이가 발생합니다.

LandPress Content는 데이터 생성 및 삭제에 대한 CDC를 모두 수행하기 위해서 생성과 수정은 변경 이후의 값을 기준으로, 삭제는 변경 이전의 값을 기준으로 데이터를 저장하고 있습니다.

캡처한 변경점에서 실제로 변경된 지점만 선별하기
위와 같은 과정으로 예상되는 변경점을 식별한 뒤 캡처까지 마쳤습니다. 하지만 이 데이터를 모두 저장할 수는 없습니다. '실제로 변경이 발생한 지점'만 선별하는 과정이 필요합니다. 실제로 변경이 발생했는지 확인하기 위해 캡처한 데이터의 변경 전과 후의 값을 ��비교합니다.
위 예시의 변경 전후를 비교해 실제로 발생한 부분을 표시하면 다음과 같습니다.
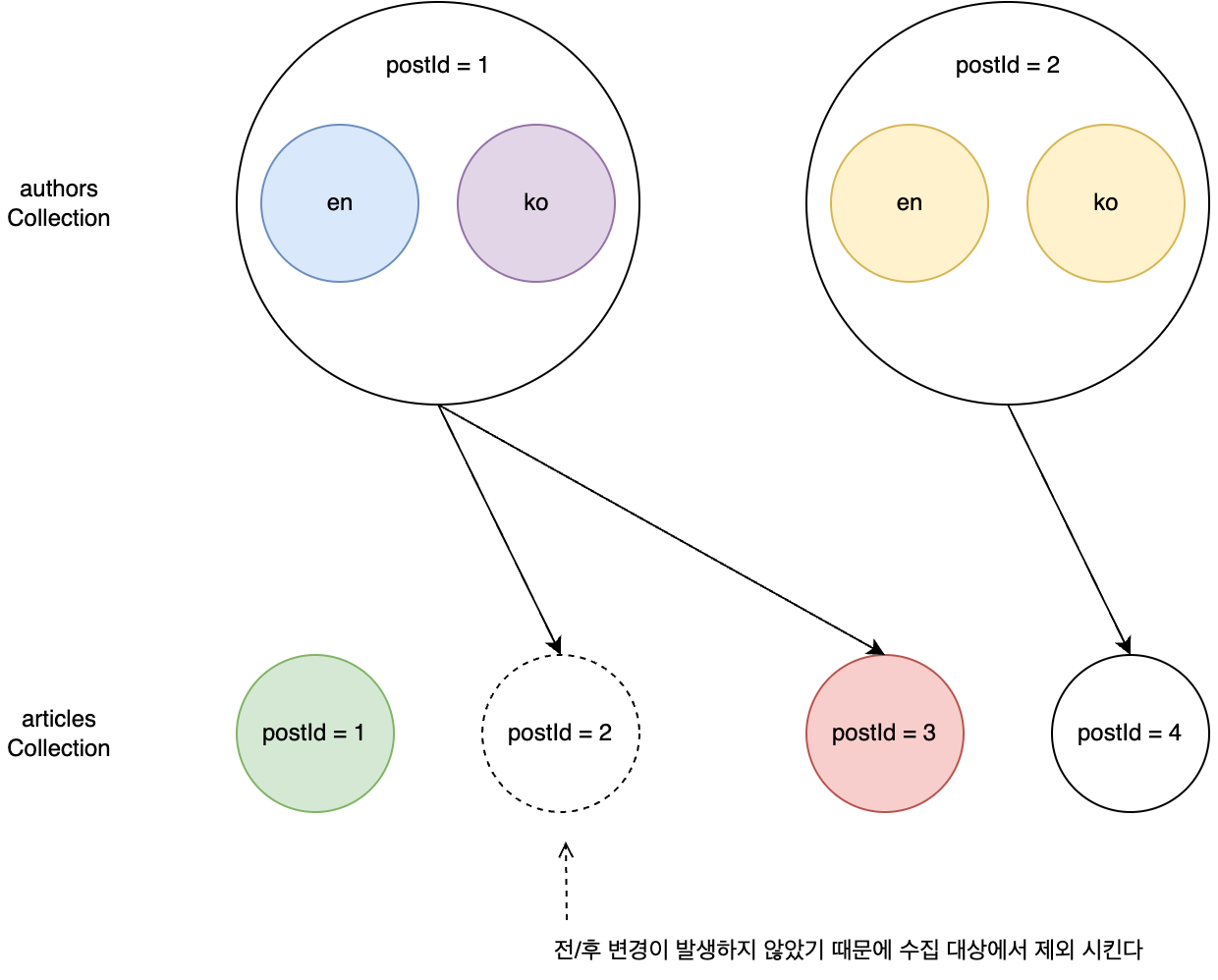
참고로 이 과정은 사용자 요청 트랜잭션의 밖에서 수행하도록 설계해 사용자 응답 대기 시간을 줄였습니다.
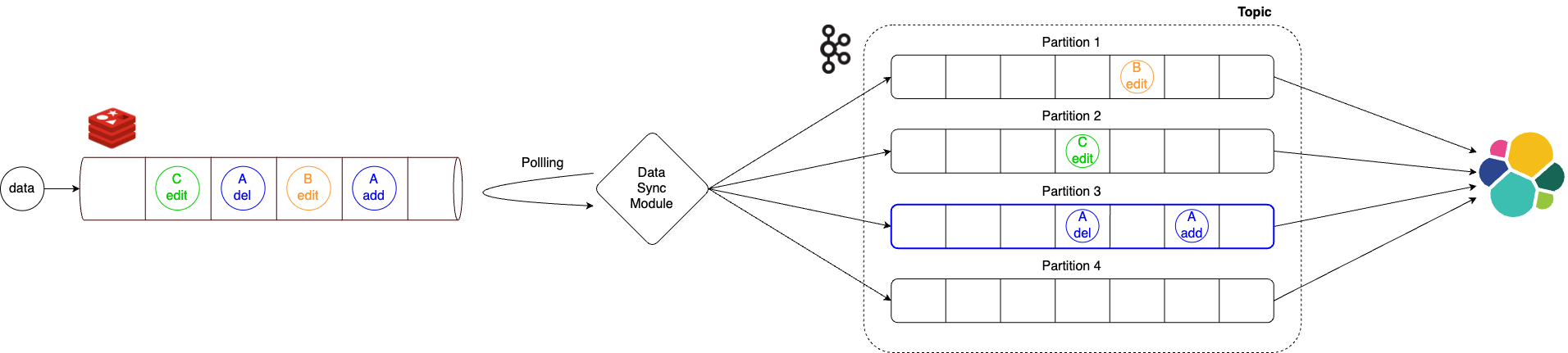
선별한 데이터를 데이터 파이프라인으로 전달하기
이제 선별한 데이터를 가공 및 저장하기 위해 데이터 파이프라인으로 전달합니다.
최초에는 대량의 데이터를 빠르게 처리하기 위해 Kafka 파티셔닝을 사용해 파이프라인을 병렬 구조로 설계했는데요. 이 구조에서는 동일 아이템에 대한 변경 이벤트의 발생 순서가 보장되지 않는 문제가 있었습니다. 예를 들어 아이템 추가 → 아이템 삭제 순으로 변경이 발생했는데 아이템 삭제 → 아이템 추가 순으로 데이터가 도착할 수 있었으며, 이 때문에 아이템이 삭제된 후에도 검색 엔진에는 데이터가 남아 있는 등의 엣지 케이스가 발생할 수 있었습니다.
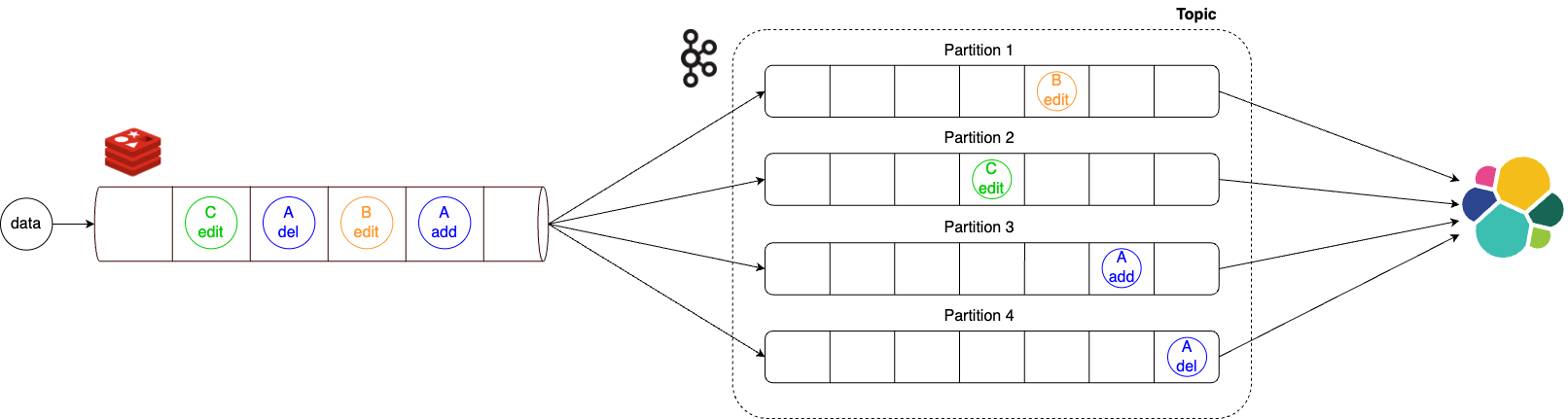
이 문제를 해결하기 위해 이벤트 발생 순서를 보장하는 중간 모듈을 개발했고, 동일한 아이템의 경우 같은 파티션에만 전달되도록 설계해 이벤트 발생 순서가 보장될 수 있도록 변경했습니다.
마치며
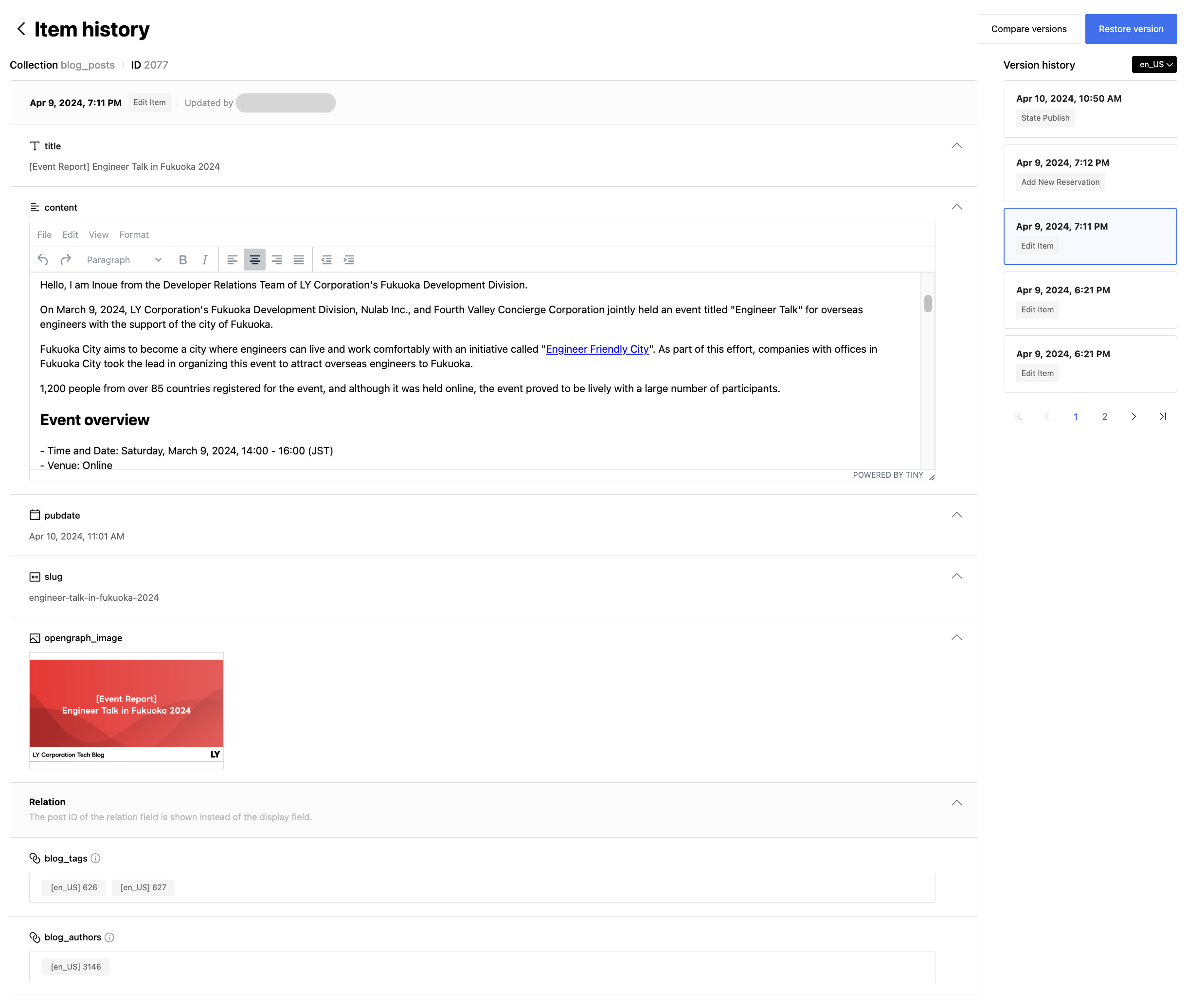
이렇게 개발된 CDC는 LandPress Content의 아이템 히스토리 기능과 검색 기능 등에 활용하고 있습니다.
이번 글에서는 LandPress Content 서비스의 CDC 개발 과정을 공유드렸습니다. 대량의 데이터 변화를 효율적이고 안정적으로 처리하기 위해 설계 과정에서부터 많이 고민하며 개발했는데요 비슷한 고민을 하시는 분들께 조금이나마 도움이 되기를 바라며 마치겠습니다. 긴 글 읽어주셔서 감사합니다.


