Introduction
Hello, I'm Healin Yoon from the UIT team. At LY Corp., we operate an in-house headless CMS called LandPress Content for our employees. In this article, I want to share our experience designing and developing change data capture (CDC) in LandPress Content.
How LandPress Content CDC works
This very blog that you're currently reading is also operated using LandPress Content. To share our technology and culture, data is added, modified, and deleted dozens of times a day. For example, the body of an article might be edited, or new author data might be added.
When such data changes occur, CDC in LandPress Content operates as follows:

- Detect data changes.
- Identify and capture expected changes when data changes occur.
- Data subject to change
- Data affected by the change
- Compare the captured data before and after the change to extract only the actual changed data.
- Send the final selected data to the pipeline.
Let's take a closer look at each step in this process.
Identifying and capturing expected changes
First, when a data change is detected, you need to identify and capture the expected changes. There are two types of changes: one for the data subject to change and another for the data affected by relationships.
LandPress Content supports setting relationships between data to help users structure their data more easily. When relationship data changes, it affects other data. Therefore, when detecting data changes, you need to design CDC to identify all changes, considering these relationships.
Identifying changes in the data subject to change
Here is the authors collection used to store author data. Let's change the English nickname of authors=1 in this collection.
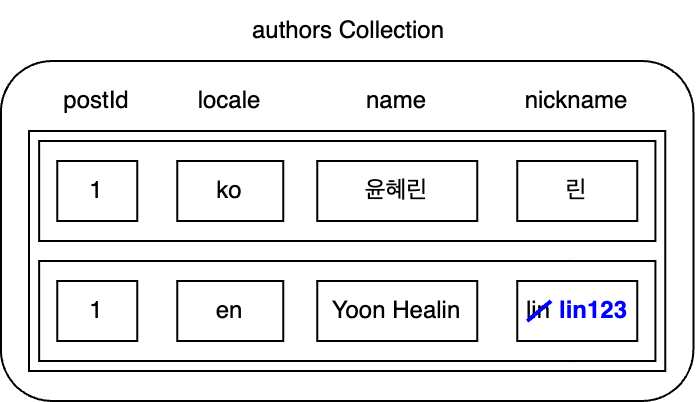
The changes in this example are very simple.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | en | ||
| nickname | lin123 |
Identifying changes in relationship data
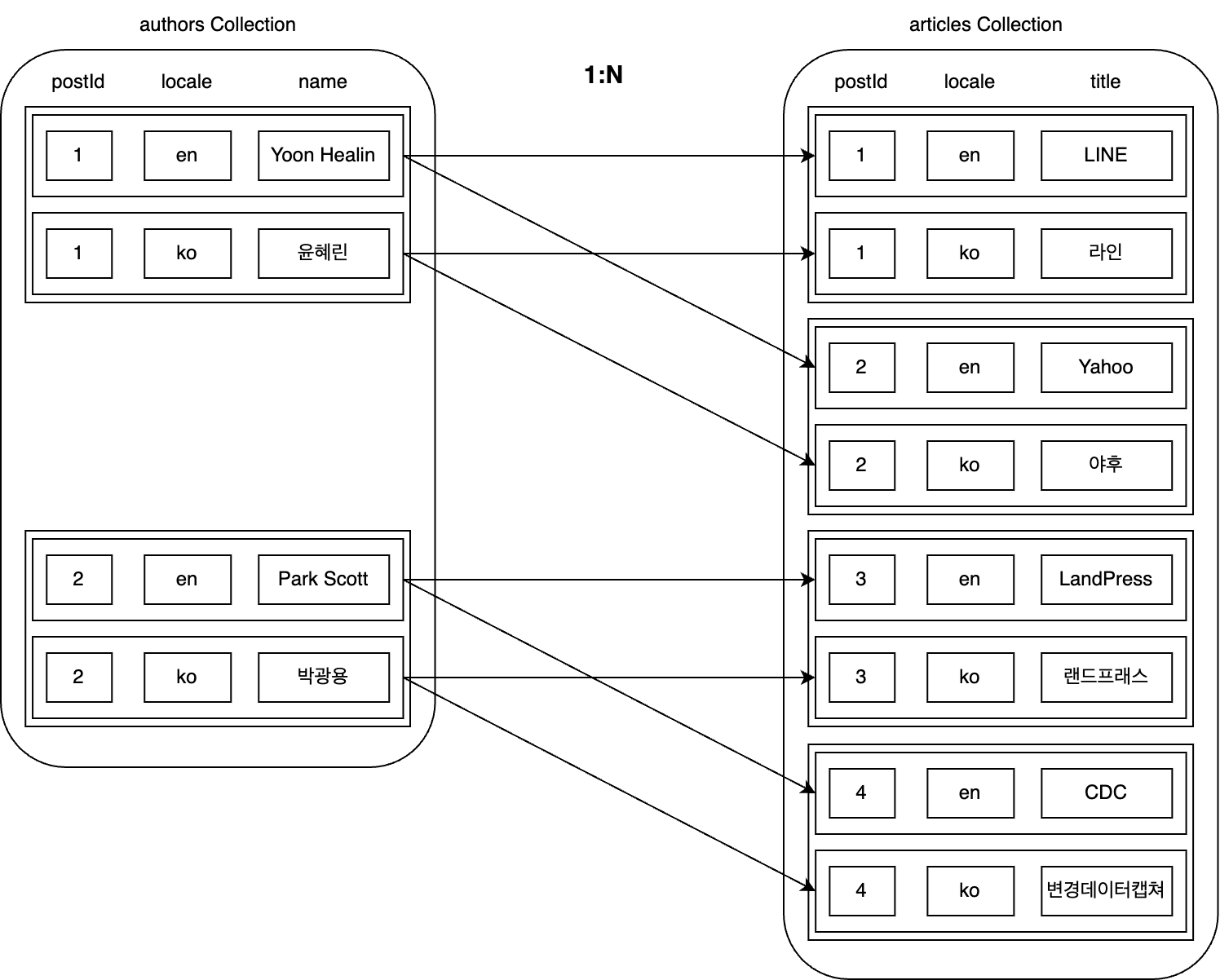
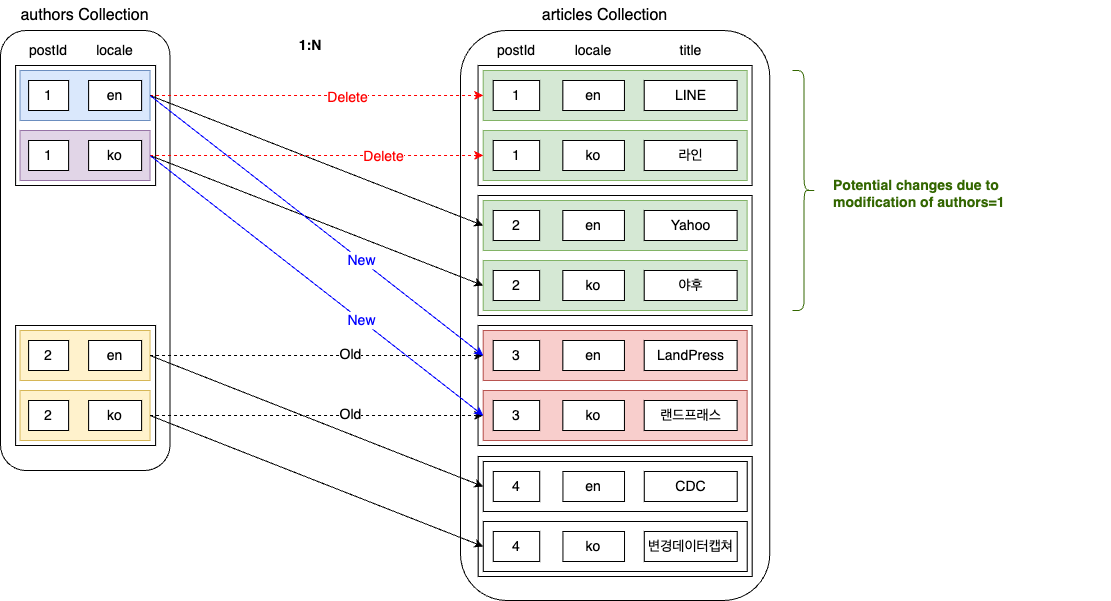
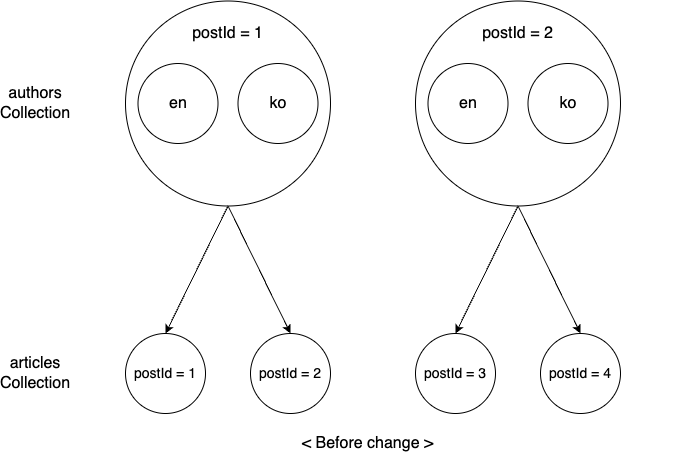
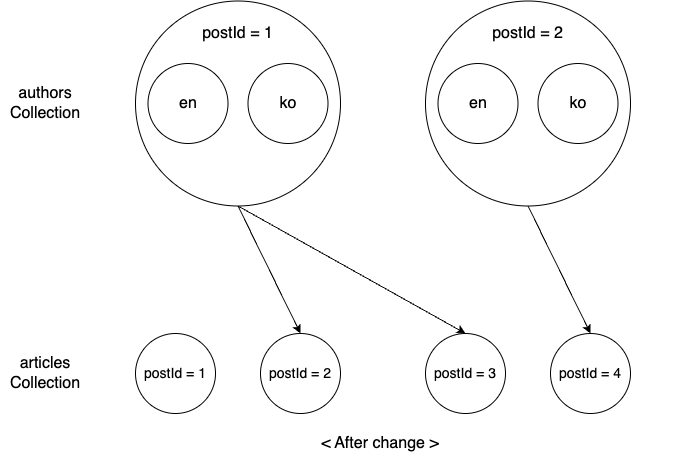
Let's look at the above example along with the articles collection that stores article data. Since one author can write multiple articles, the authors collection and the articles collection have a 1:N relationship. Let's assume that authors=1 and authors=2 are related to articles as follows.
Now, let's assume we found a mistake in matching authors and articles and corrected it as follows.
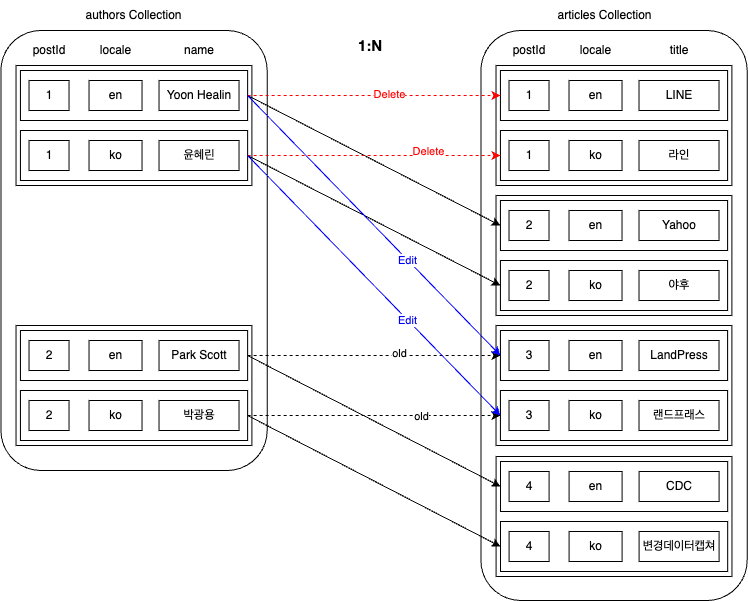
When relationship data changes like this, the changes become more complex. Changes can occur in five areas, which we will examine one by one.
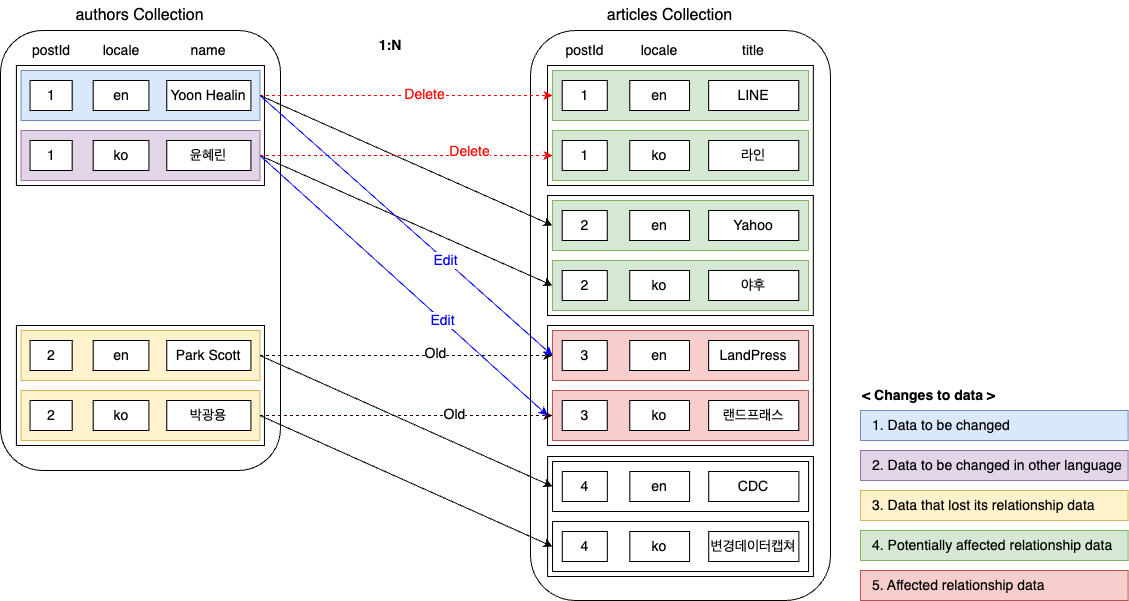
Data subject to change
This is the data subject to change through user requests.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | en | ||
| articles | 2 |
Other language data of the data subject to change
Each data can be managed in multiple languages. Since it is the same data with different languages, it shares the postId. For example, the same author can be introduced with a Korean name on the Korean page and an English name on the English page. The relationship is based on the postId. Therefore, if you modify the relationship data in one language, you must include the relationship data in other languages in the identified data.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | ko | ||
| articles | 2 |
Data that lost its relationship
articles=3 was originally related to authors=2. However, due to this change, authors=2 lost its relationship data to authors=1. Therefore, changes occur in the data of authors=2, so it must be included in the identified data.
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 2 |
| locale | en | ||
| articles | 3 | ||
| 2 | postId | 2 | |
| locale | ko | ||
| articles | 3 |
Potentially affected relationship data
Next is the potentially affected relationship data. If the user modifies the articles connected to authors=1, there is a possibility that the connected authors value will change from the articles' perspective. Therefore, you need to include it in the identified data and later check if the value actually changed.
| num | collection | key | value |
|---|---|---|---|
| 1 | articles | postId | 1 |
| locale | en | ||
| authors | 1 | ||
| 2 | postId | 1 | |
| locale | ko | ||
| authors | 1 | ||
| 3 | postId | 2 | |
| locale | en | ||
| authors | 1 | ||
| 4 | postId | 2 | |
| locale | ko | ||
| authors | 1 |
Relationship data affected by the change
Finally, articles=3 is the data confirmed to be affected by the change in authors. Therefore, it must be included in the identified data.
| num | collection | key | value |
|---|---|---|---|
| 1 | articles | postId | 3 |
| locale | en | ||
| authors | 1 | ||
| 2 | postId | 3 | |
| locale | ko | ||
| authors | 1 |
Capturing changes
Once you have identified all the changes, it's time to capture the data before and after the change. Since the database queries required for this process must be performed within the user's transaction, we designed it to avoid duplicate queries to prevent response time delays. When querying relationship data, we only retrieved the minimum identification information (postId and language information) to avoid unnecessary data collection.
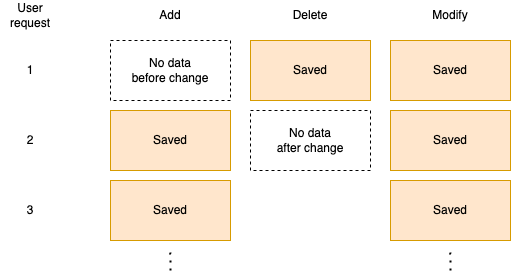
When capturing, you need to choose whether to capture based on the data before or after the change. Since creation has no value before the change and deletion has no value after the change, the following differences occur depending on when the data is captured.
To perform CDC for both data creation and deletion, LandPress Content stores data based on the value after the change for creation and modification, and based on the value before the change for deletion.
Selecting only the actual changes from the captured changes
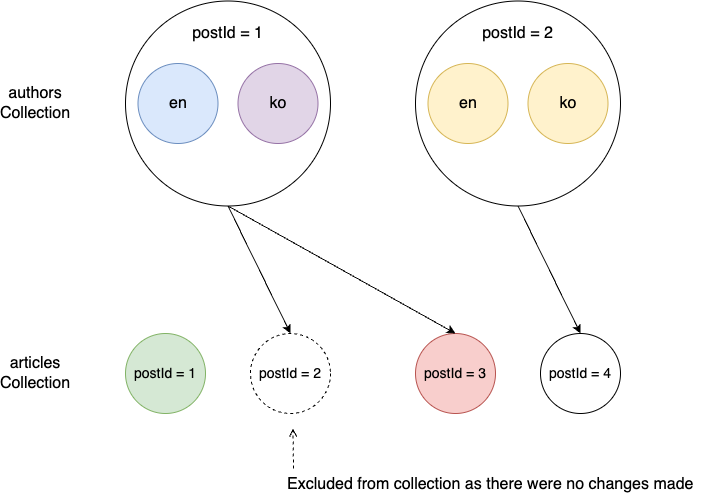
After identifying and capturing the expected changes, you can't store all this data. You need to select only the "actual changes". To verify if an actual change occurred, compare the values of the captured data before and after the change.
The following example shows the actual changes after comparing the data before and after the change.
Note that this process is designed to be performed outside the user's transaction to reduce user response waiting time.
Sending the selected data to the data pipeline
Now, send the selected data to the data pipeline for processing and storage.
Initially, we used Kafka partitioning to design the pipeline in a parallel structure to quickly process large amounts of data. However, this structure had a problem where the order of change events for the same item wasn't guaranteed. For example, if an item was added and then deleted, the data could arrive in the order of deletion and then addition, causing edge cases where the item remained in the search engine even after deletion.
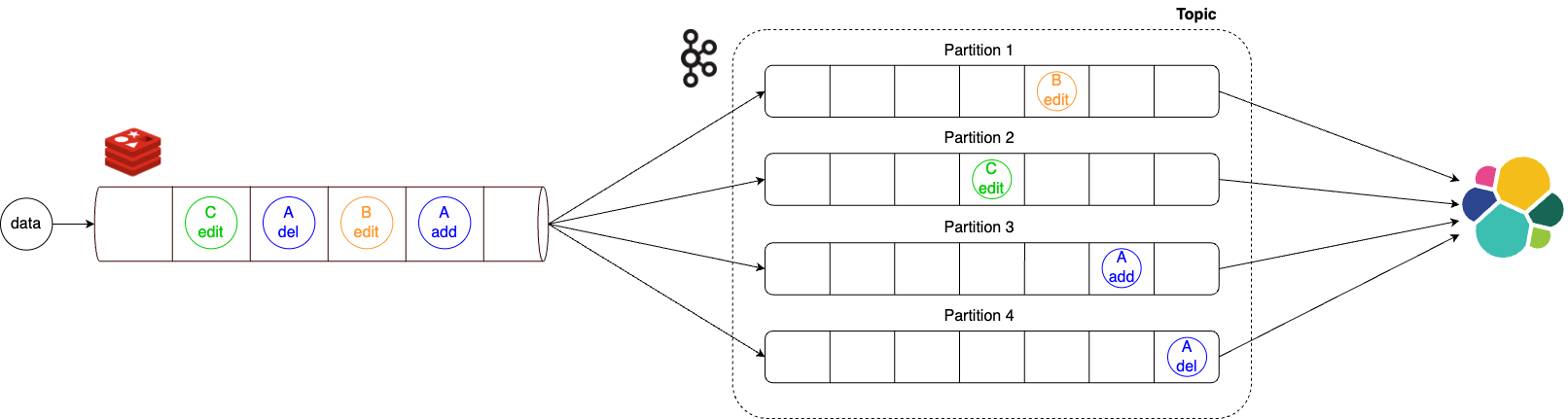
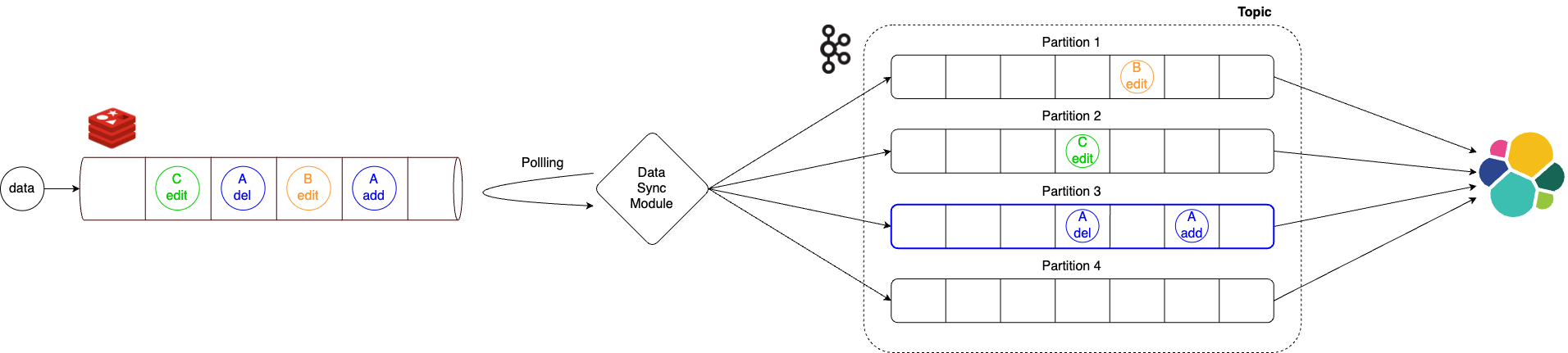
To solve this problem, we developed an intermediate module that guarantees the order of event occurrence and designed it so that events for the same item are only sent to the same partition, ensuring the order of event occurrence.
Conclusion
The developed CDC is used in LandPress Content's item history and search functions as you can see in the screenshots below.
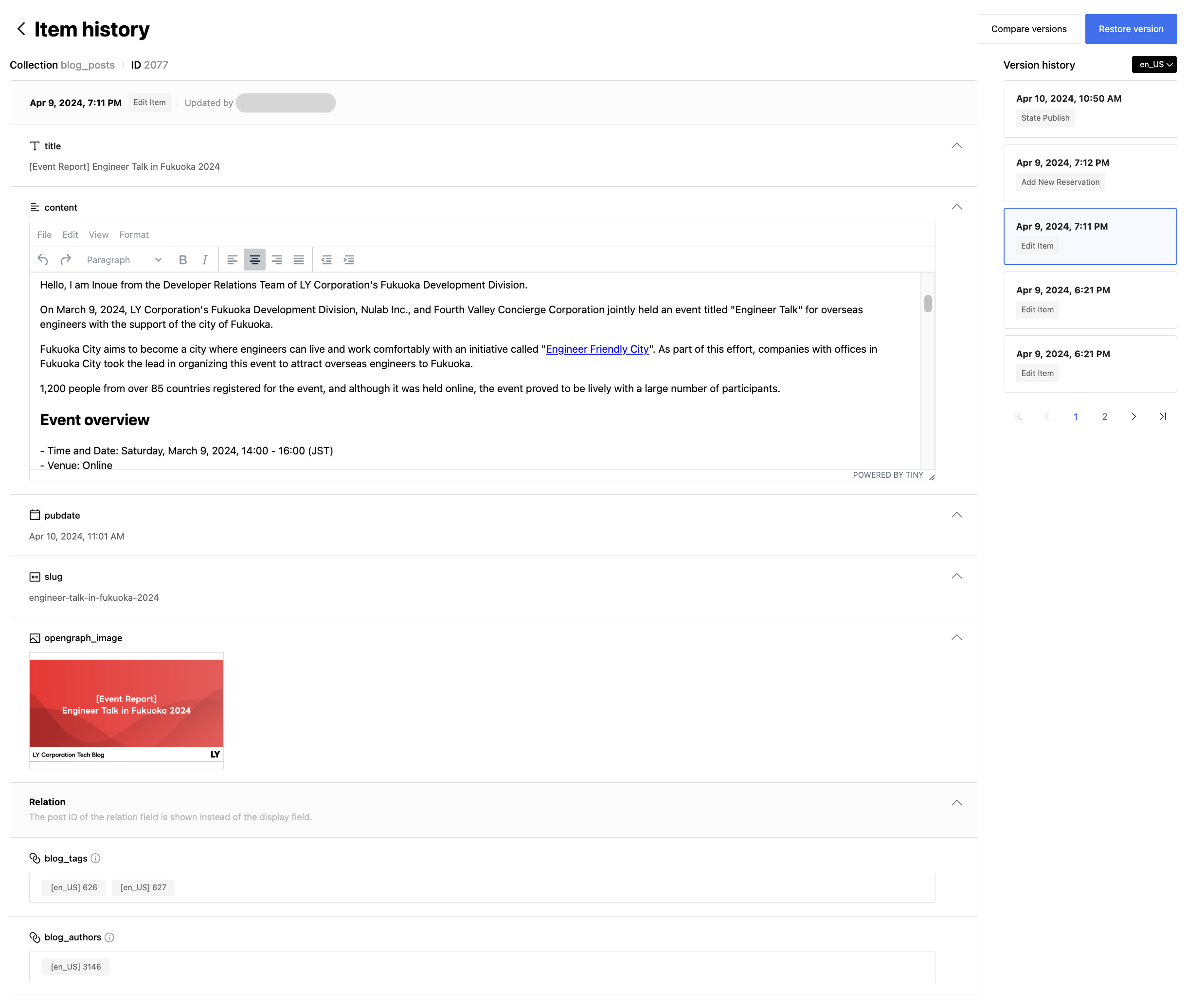
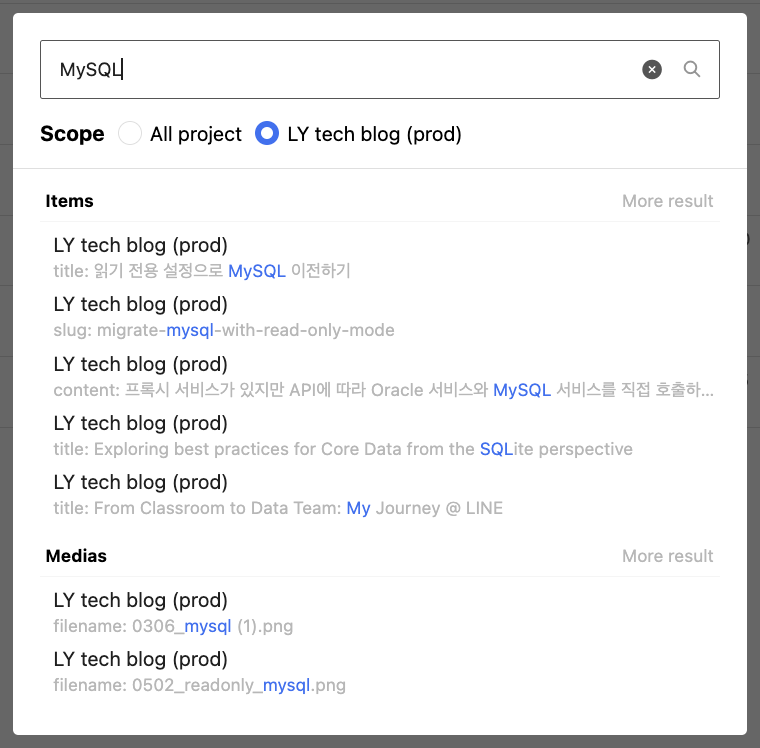
In this article, I shared the development process of CDC for the LandPress Content service. We put a lot of thought into the design process to efficiently and reliably handle large data changes. I hope this article helps those who are facing similar challenges. Thank you for reading this long article.


