Hello. We're Kang Hyun Yang and Byungchan Lee, backend developers at LINE Plus Contents Service Engineering. In our Contents Server Engineering team, we run a group called Tech Group. This group tackles common challenges faced by various teams, focusing on efficiently handling large volumes of traffic. During this process, we enhanced our caching process and developed an internal library called "req-shield" (initially named "Req-Saver" but renamed during the open-source process).
In this article, we want to share the background and detailed features of req-shield.
How applications typically use caching
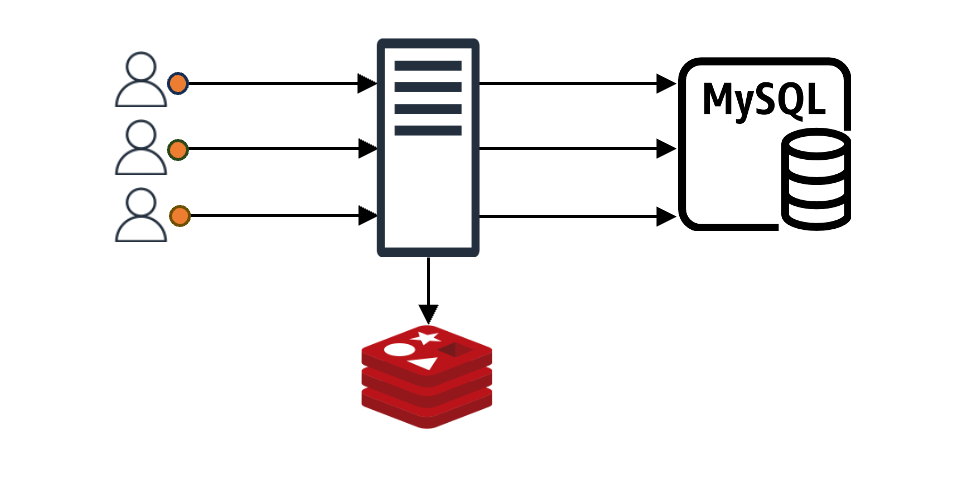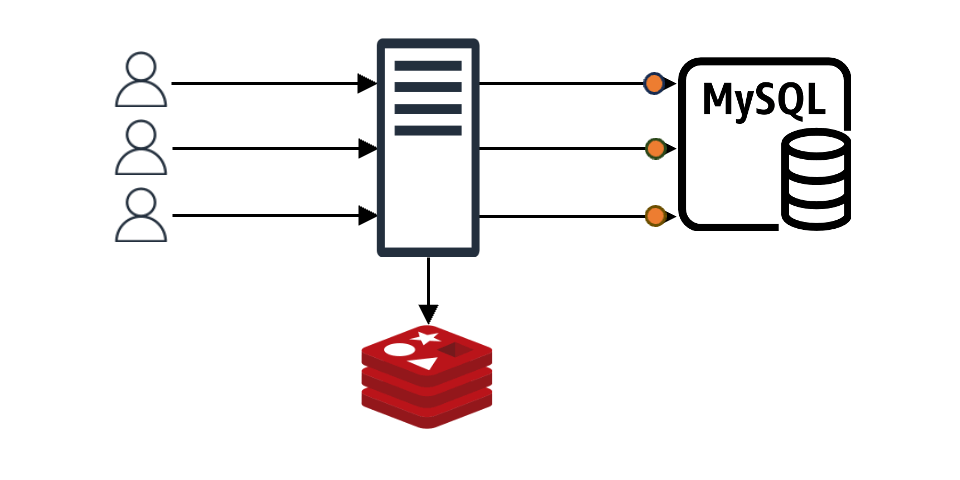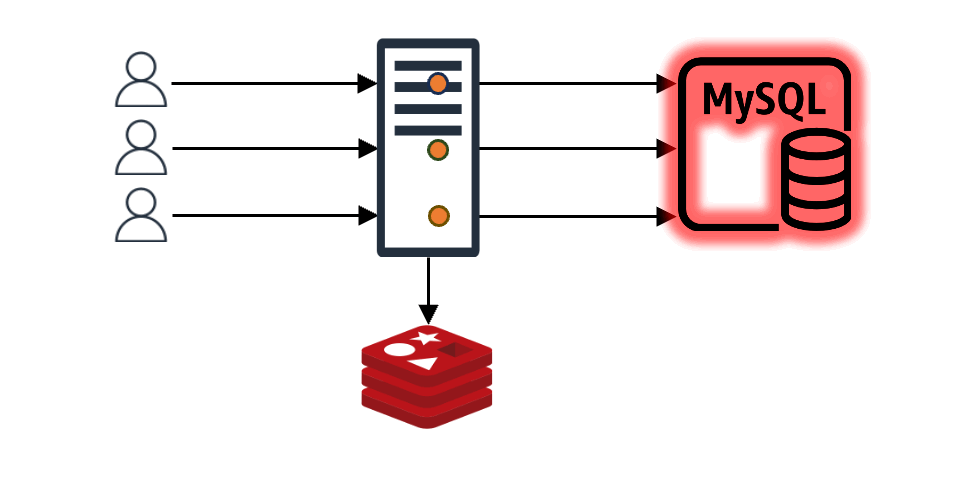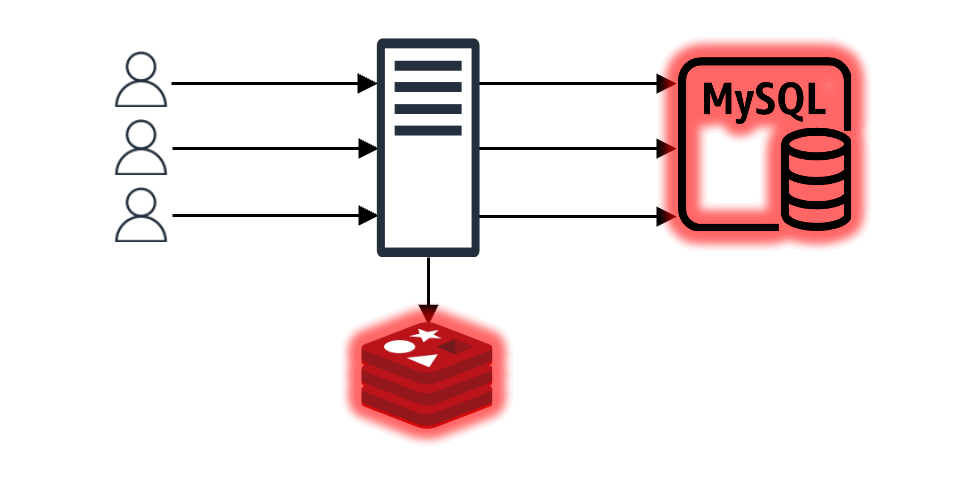
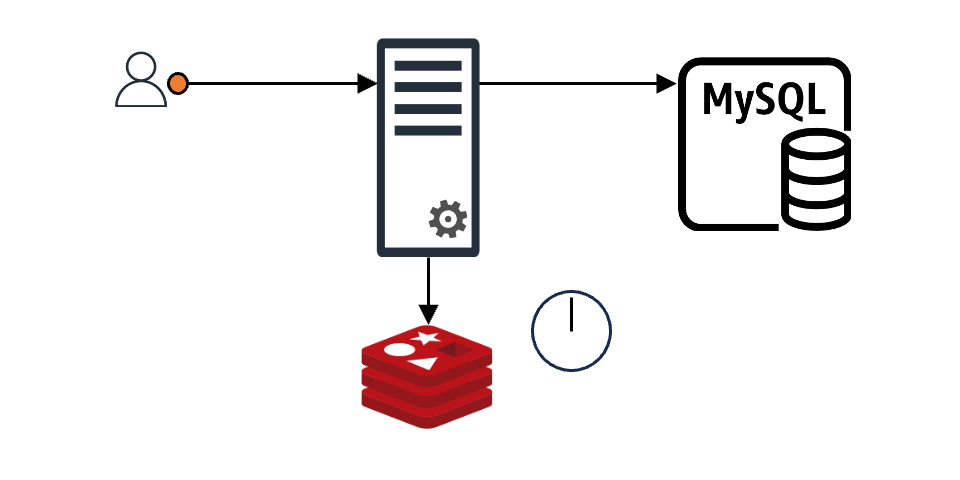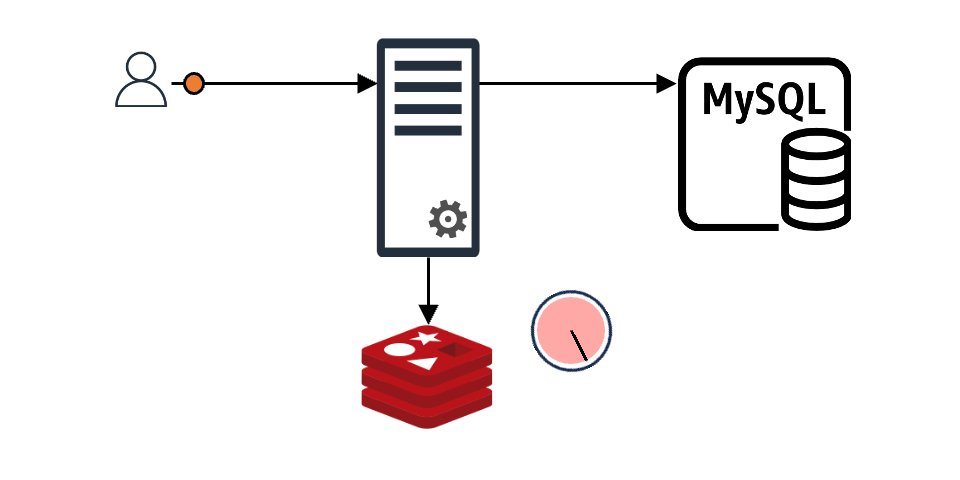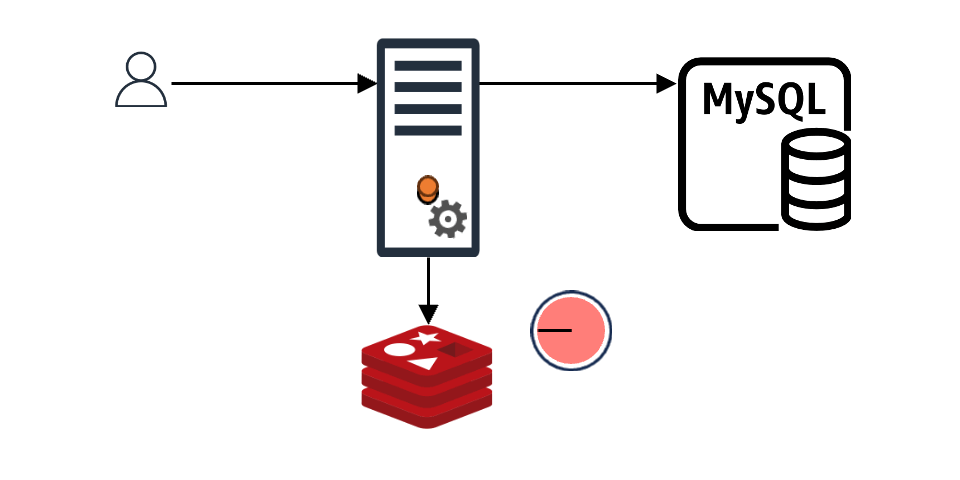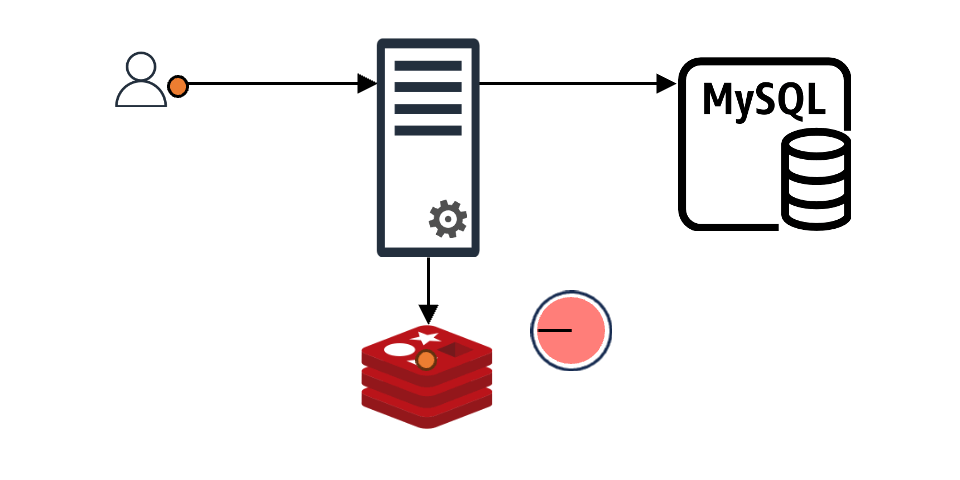
Typically, applications use caching like this:
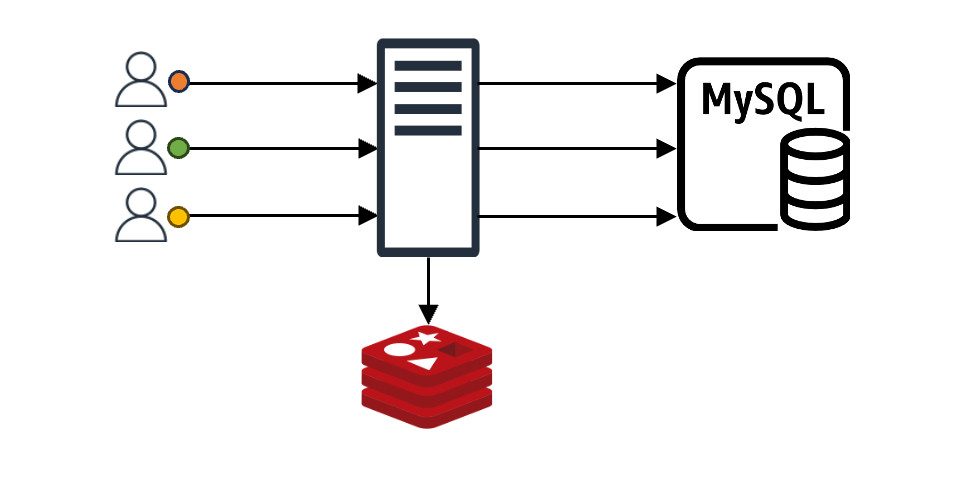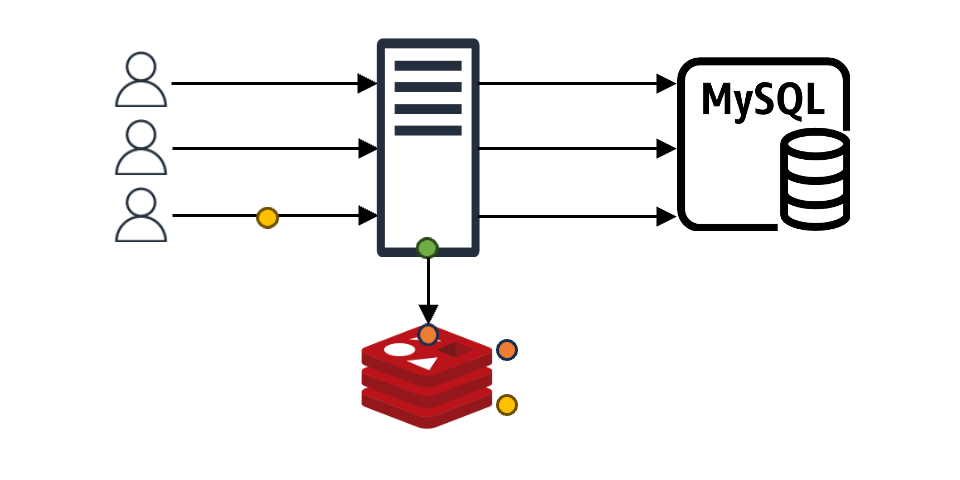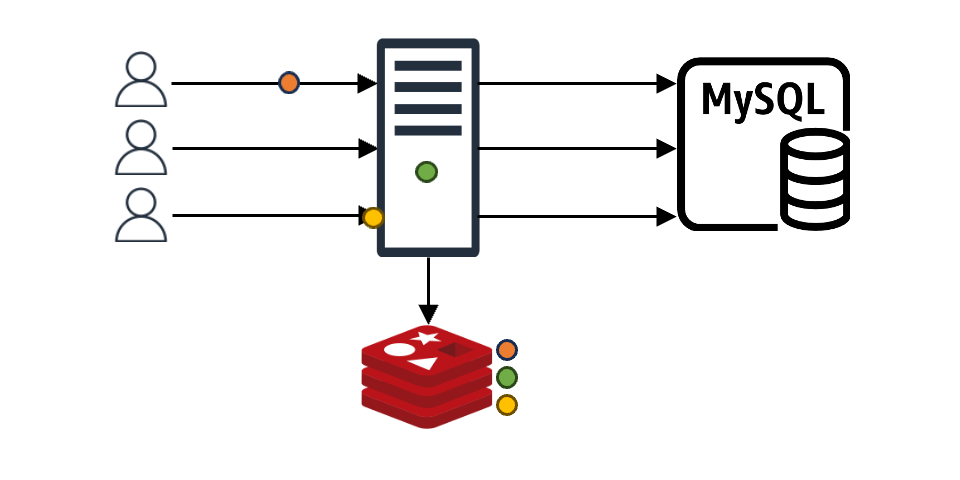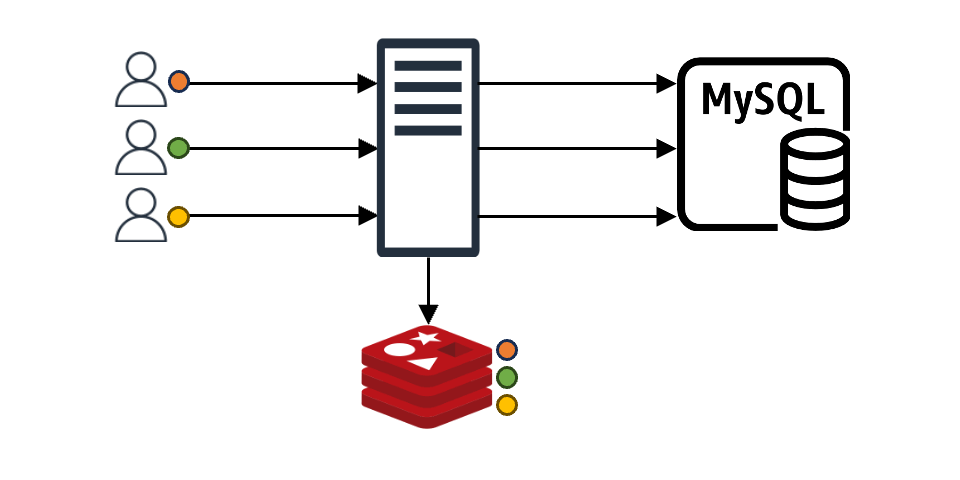
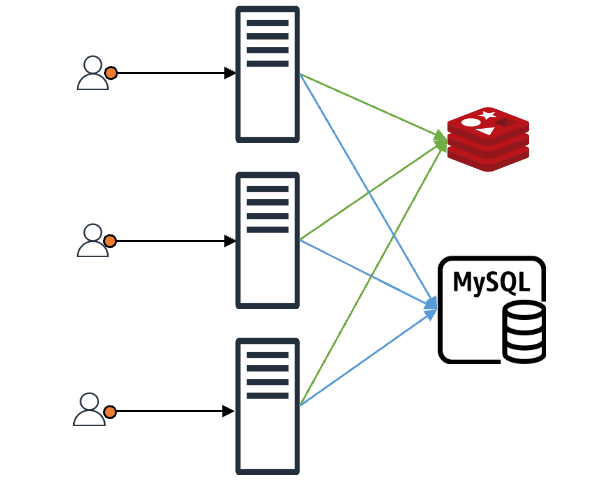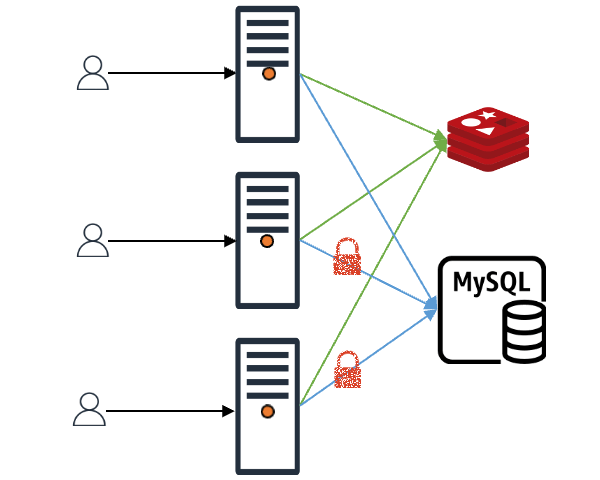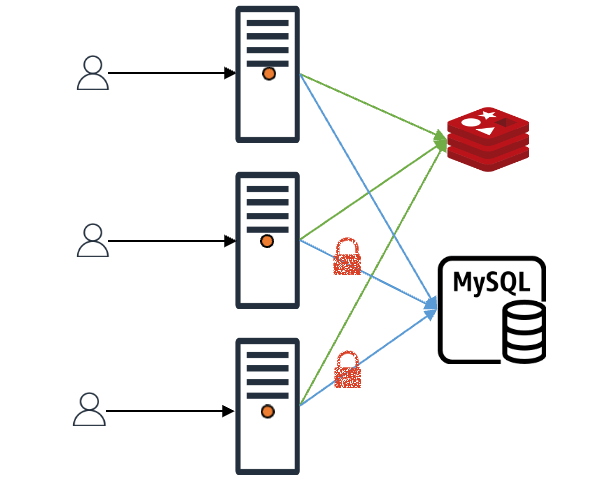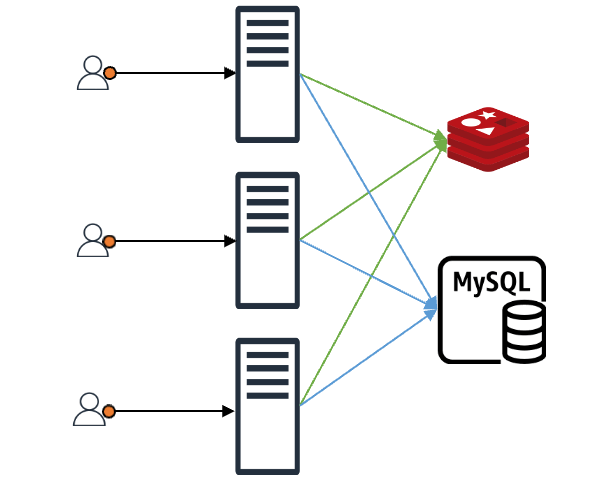
When a client makes a request, the client gets an immediate response if the requested content is in the cache. If it's not in the cache, the data is fetched from the backend data store (DB, server, file, and so on) and stored in the cache (represented as "MySQL" in the image for simplicity).
In this setup, imagine N client requests coming in. If the cache doesn't have the content for these N requests, all N requests will query the backend data store. Even if all N requests want the same value, they proceed N times. Without special measures, the data received from the backend is recorded in the cache N times, causing a load on both the backend store and the cache. This is known as the "thundering herd problem".
The development of req-shield began as we sought a solution to this "thundering herd problem".
The idea behind req-shield
The key to solving this problem was reducing client requests to the backend data store. We thought of applying two ideas based on whether the cache hit or not.
When the requested data is not in the cache
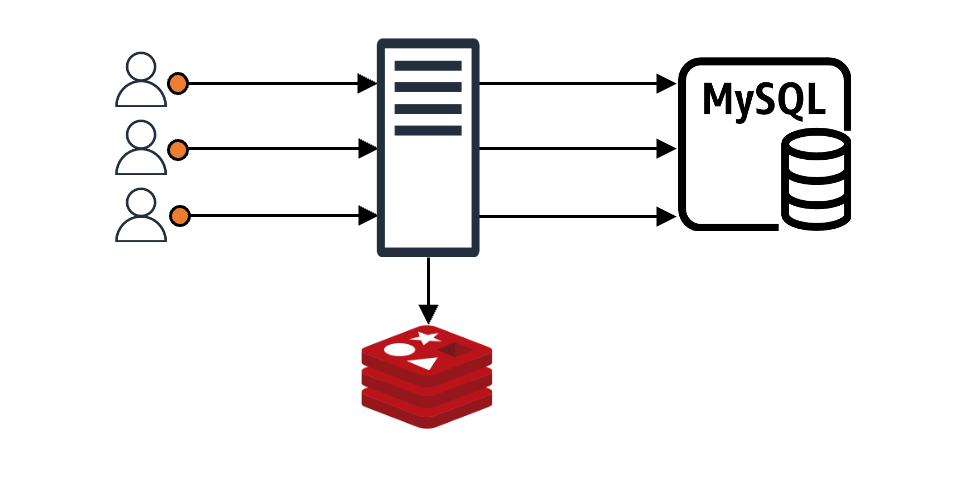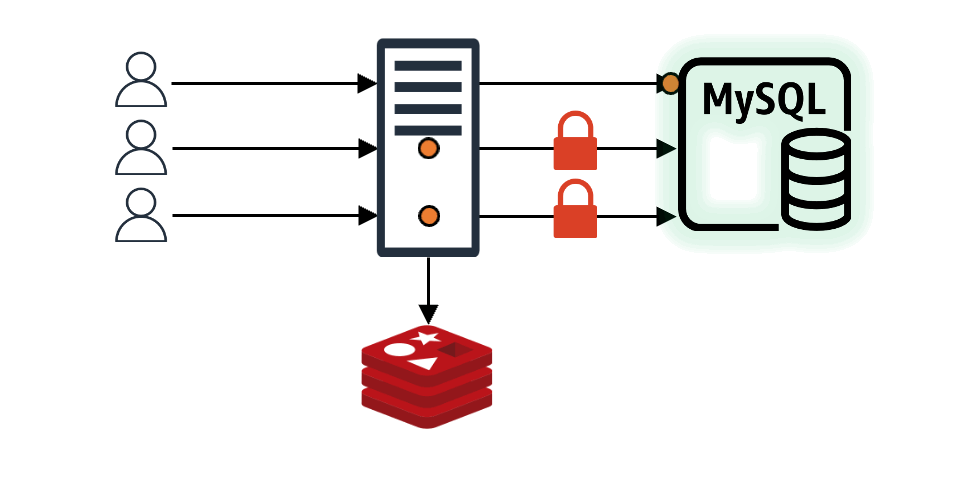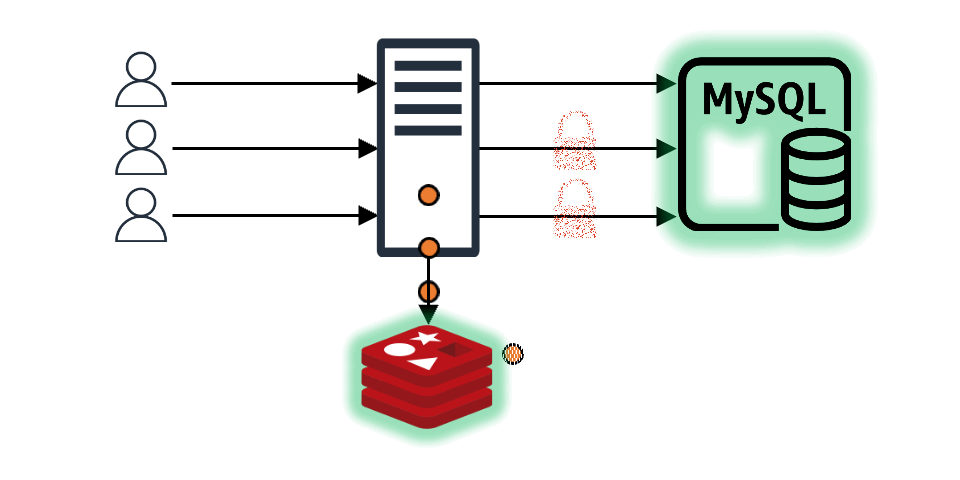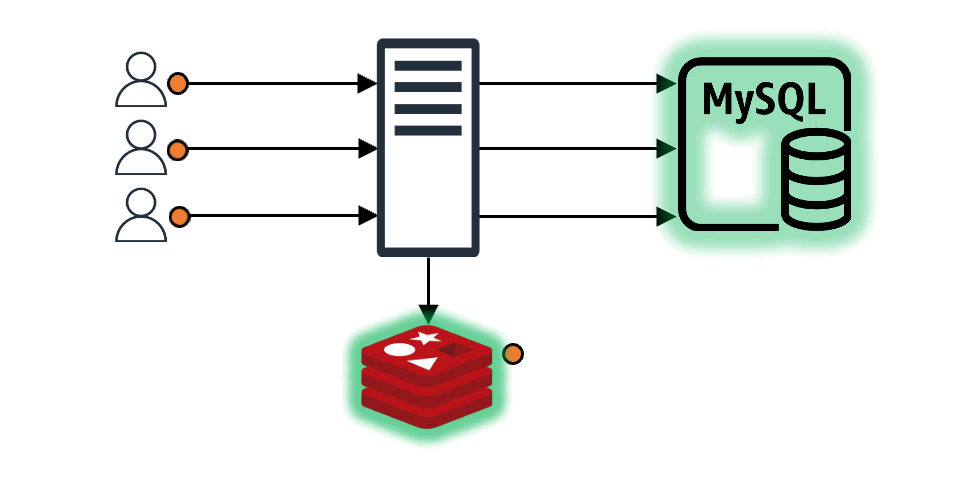
If the requested data isn't in the cache and needs to be fetched from the backend store and stored in the cache, the application can use local or global locks to send only specific requests to the backend store. The other requests wait until the locked request creates the data in the cache, solving the problem.
When the requested data is in the cache
Even when the requested data is in the cache and the client receives an immediate response, preventive measures for the future can be taken. For example, if the cache's TTL (time to live) is 10 seconds and the client queries the cache with 2-3 seconds left, the cache TTL can be updated immediately instead of waiting for expiration. This way, assuming constant traffic, the cache appears to exist continuously without expiration gaps.
Comparing the above in a time graph looks like this:
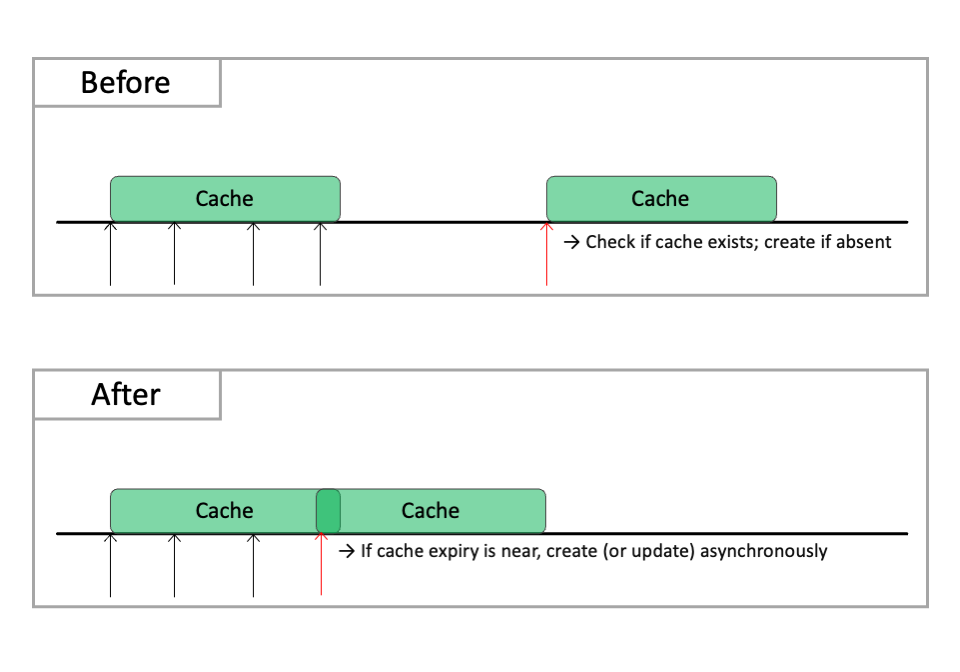
Implementation of the idea
Let's look at how each idea was implemented.
When the requested data is not in the cache
In this case, we actively used the lock mechanism.
There are mainly local locks and global locks. For global locks, since the library doesn't know which distributed lock the developer will use, we implemented it by simply injecting a function. When the developer creates an instance of req-shield, the global lock function is executed at the application level, recognizing that the lock is acquired. The request that acquires the lock represents the data acquisition and cache storage process. Requests that don't acquire the lock wait for the data to be stored in the cache for a set time.
Local locks actively use semaphores, and except for the fact that lock acquisition is done per server instance, the operation is the same as in the image above.
When the requested data is in the cache
In this case, we also actively use the lock mechanism, but there's a slight difference from the previous case.
Since the data is in the cache, requests that don't acquire the lock don't need to wait for the data to be stored in the cache. They can respond to the client immediately. The request that acquires the lock also responds to the client immediately and asynchronously updates the cache.
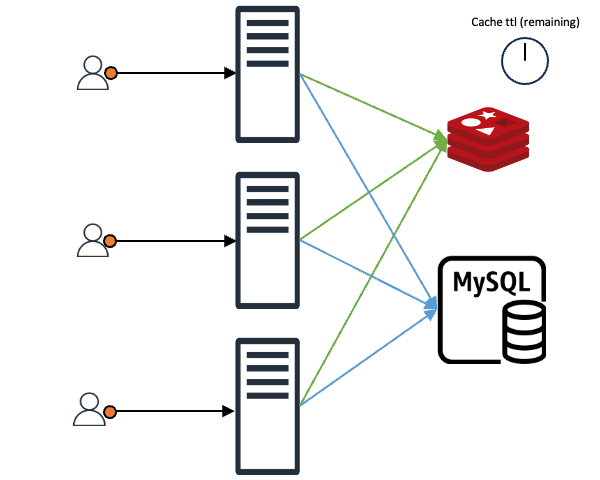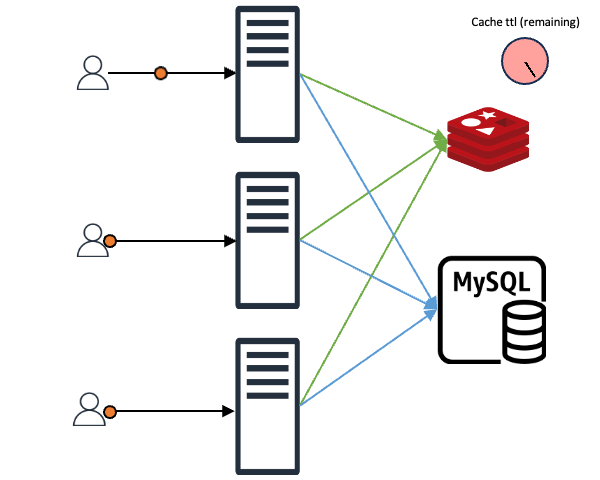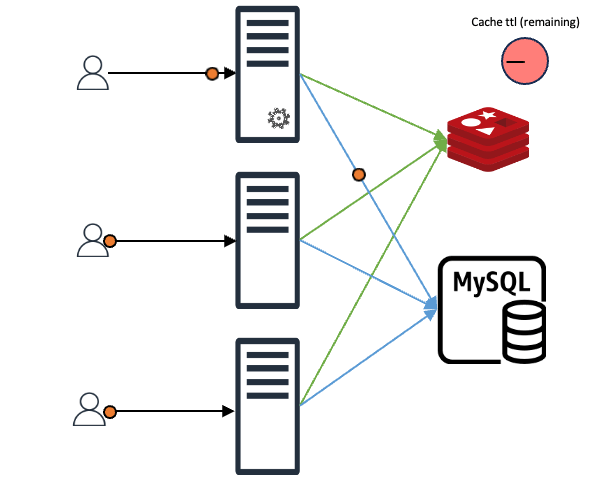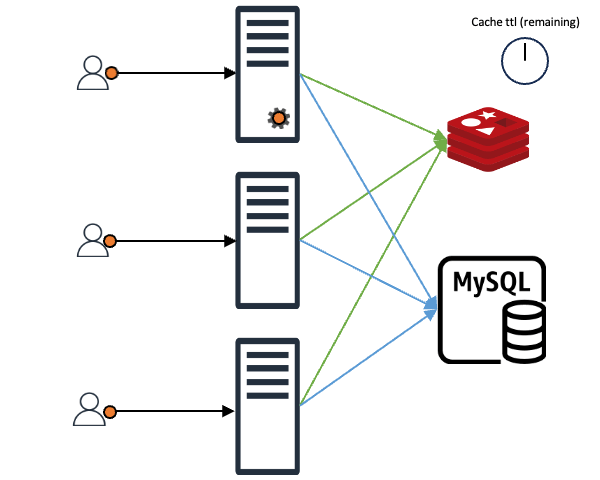
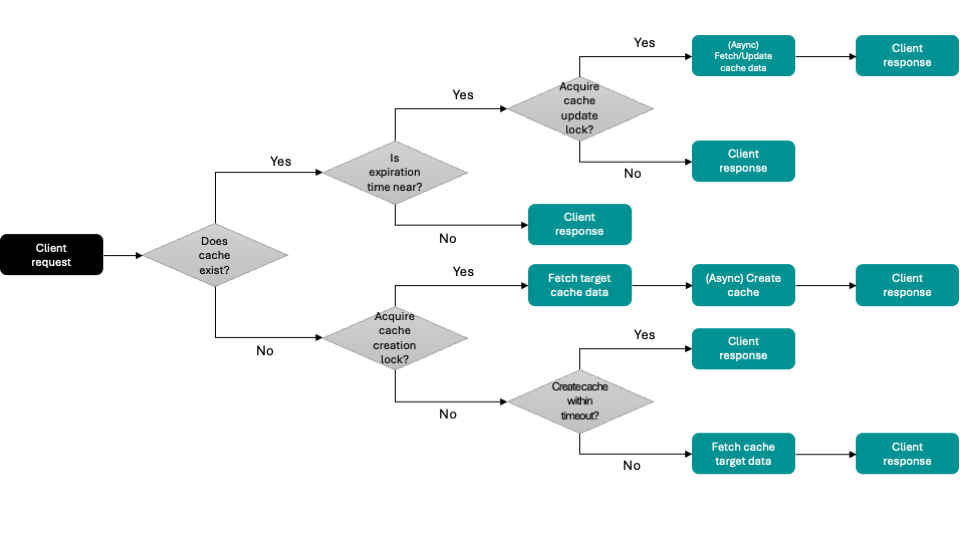
Summary of operation principles
The operation principles of req-shield are summarized in the flowchart below.
Module structure of req-shield
The modules of req-shield can be broadly divided into core modules, Spring modules, and support modules. Let's take a look at each module.
Core module
The core module is composed of three parts to be used according to each platform. Each module includes the main method and configuration files.
- core: Contains core logic for a general sequential-blocking method environment.
- core-reactor: Contains core logic based on Reactor.
- core-kotlin-coroutine: Contains core logic based on Kotlin Coroutine.
Developers can import the core module suitable for their environment, configure it, and execute the main method upon instance creation to use req-shield's features.
Below is a sample code that uses the req-shield instance for actual cache data retrieval and storage.
//Example method to query a domain called product using productId.
fun getProduct(productId: String): Product {
//Create a Req-Shield instance.
val reqShield = ReqShield(
ReqShieldConfiguration(
setCacheFunction = { key, data ->
cacheSpec.put(key, data, 3000)
true
}, //Function to use when entering data into the cache platform. Used by Req-Shield.
getCacheFunction = { key ->
cacheSpec.get(key)
}, //Function to use when querying data from the cache platform. Used by Req-Shield.
isLocalLock = true, //Whether to use a local lock as the lock mechanism. If false, a global lock is used.
decisionForUpdate = 70 //Setting to determine when to update the cache after a certain percentage of TTL has passed.
)
)
//getAndSetReqShieldData is the main method of Req-Shield, returning the ReqShieldData specified below.
return reqShield.getAndSetReqShieldData(
key = productId, //The cache key is also passed.
callable = { productRepository.findById(id) }, //Callable function that Req-Shield requests data from when the cache doesn't exist.
timeToLiveMillis = 3000).value as Product
}
//Class returned when calling getAndSetReqShieldData of Req-Shield. The actual cache value is in value.
data class ReqShieldData(
var value: Any?,
var status: Status,
val createdAt: Long,
val timeToLiveMillis: Long,
)In the Spring framework, it can also be created as a Bean and used as shown below.
@Bean
fun reqShield() = ReqShield(reqShieldConfiguration())
private fun reqShieldConfiguration() =
ReqShieldConfiguration(
setCacheFunction = { key, data ->
cacheSpec.put(key, data)
},
getCacheFunction = { key ->
cacheSpec.get(key)
},
isLocalLock = true,
decisionForUpdate = 70
)Spring module
Beyond the core module, we also configured a Spring-based module to use req-shield conveniently like annotations such as @Cacheable and @Transactional commonly used in the Spring framework.
The Spring-based module provides req-shield with annotations like @ReqShieldCacheable and @ReqShieldCacheEvict, based on the core module mentioned earlier. It is composed of three modules: MVC, WebFlux, and WebFlux Kotlin Coroutine, to match the technology stack mainly used by our development team.
- core-spring-mvc
- core-spring-webflux
- core-spring-webflux-kotlin-coroutine
The detailed implementation was done using Spring AOP, and you can use req-shield's features by adding some element values to the annotation as shown below.
//Example method to query a domain called product using productId.
//Values to be entered in the above settings can be set with annotations.
@ReqShieldCacheable(key = "product_cacheKey", decisionForUpdate = 70, timeToLiveMillis = 6000)
fun getProduct(productId: String): Product {
log.info("get product (Simulate db request) / productId : $productId")
//TODO : develop..
return Product(productId, "product_$productId")
}Support module
There is also a support module that includes common data classes, utilities, and test packages. The support module contains testContainer-related code used when running test codes, providing an environment where each module can easily test using platforms like Redis.
Load testing method and results
To verify the performance of req-shield, we conducted load testing in the following test environment.
- Application
- Spring Boot 2.7.17
- Redis (Docker in local environment): 6.2.7-alpine
- Redis cache TTL: 20 seconds
- Backend query simulation: sleep 3 seconds (set to a relatively high delay to clearly see the difference when simulating query execution time)
- req-shield settings
- decisionForUpdate: 70% (update when 70% of the cache's TTL remains)
- TTL: 20 seconds
- NGrinder settings
- vUser: 100 (4 processes * 25 threads)
- No ramp-up
- Test duration: 5 minutes
- Redis keys: Randomly extract and use 10 keys
The test results showed that req-shield's cache update logic significantly impacted performance. Let's look at each environment.
Load testing method and results in Spring MVC environment
In the Spring MVC environment, we conducted load testing in three scenarios. First, we tested with the sync attribute of Spring Cacheable set to false and true, and then tested using req-shield to compare the results (we'll explain more about the sync attribute of Spring Cacheable in the "Issues and solutions during development" section below). Let's look at the load test results.
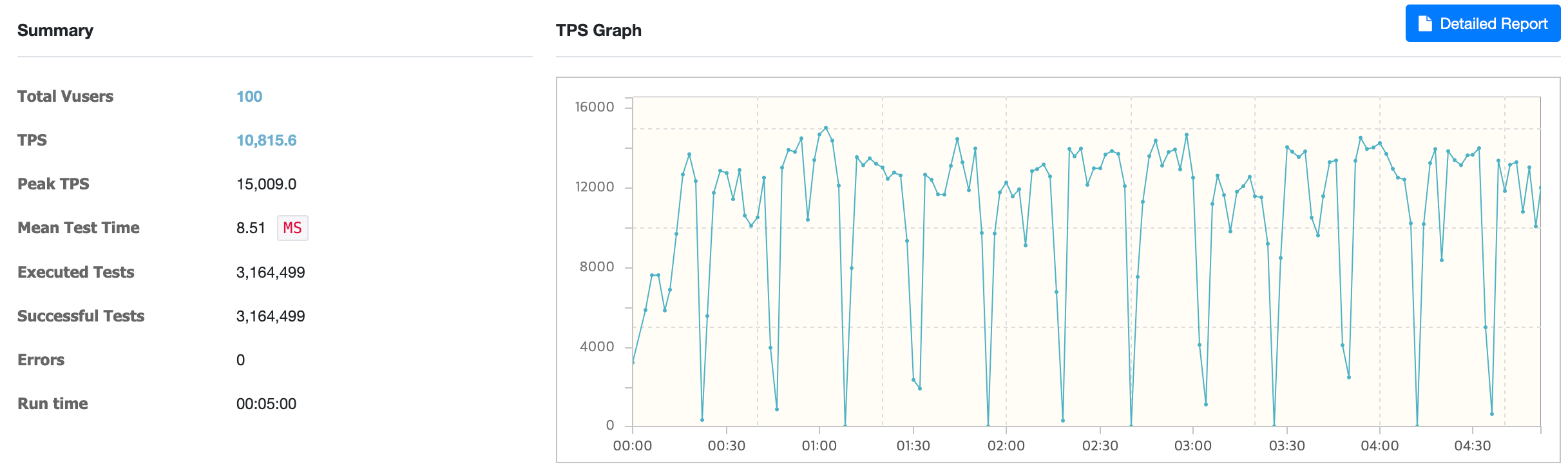
@Cacheable & sync = false
With @Cacheable & sync = false, the average TPS was about 10,815.
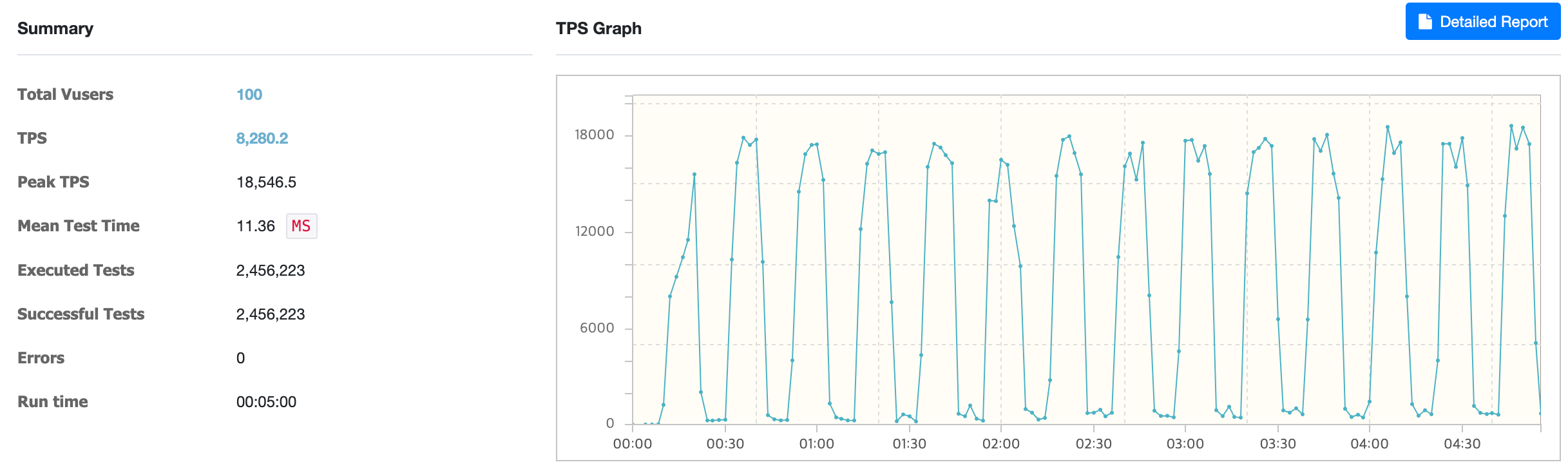
@Cacheable & sync = true
With @Cacheable & sync = true, the average TPS was about 8,280.
Using req-shield
Using req-shield, the average TPS was about 16,799.
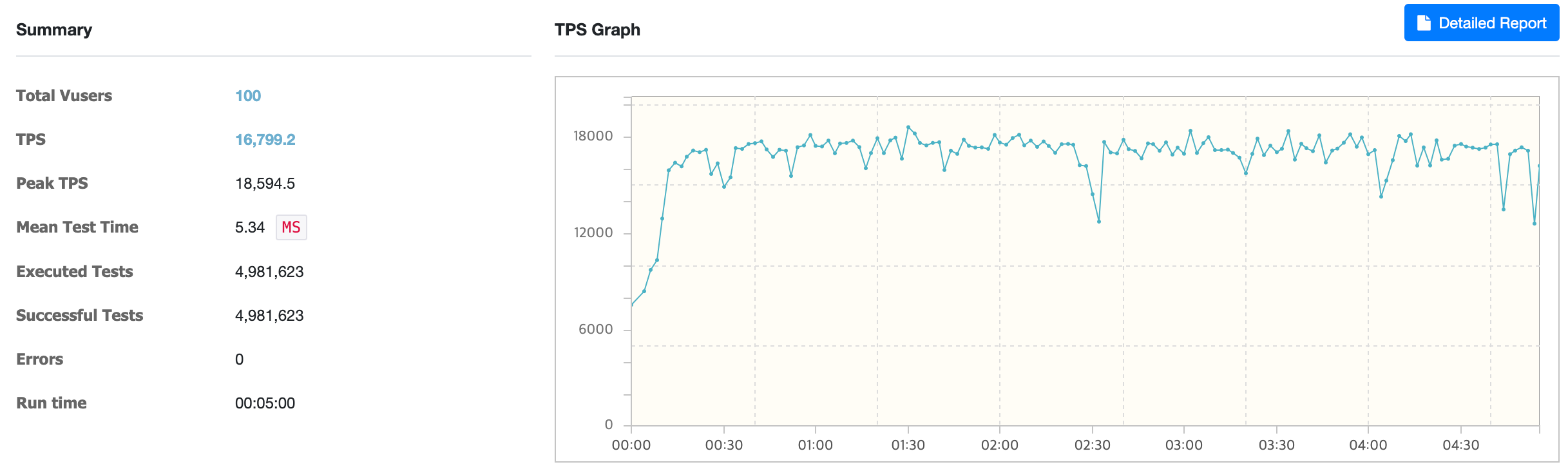
Comparison of load test results
Comparing the load test results, using req-shield improved performance by 55.31% compared to @Cacheable & sync = false and by 102.88% compared to @Cacheable & sync = true.
Load testing method and results in Spring WebFlux environment
In Spring WebFlux, we conducted load testing using ReactiveRedisOperator.
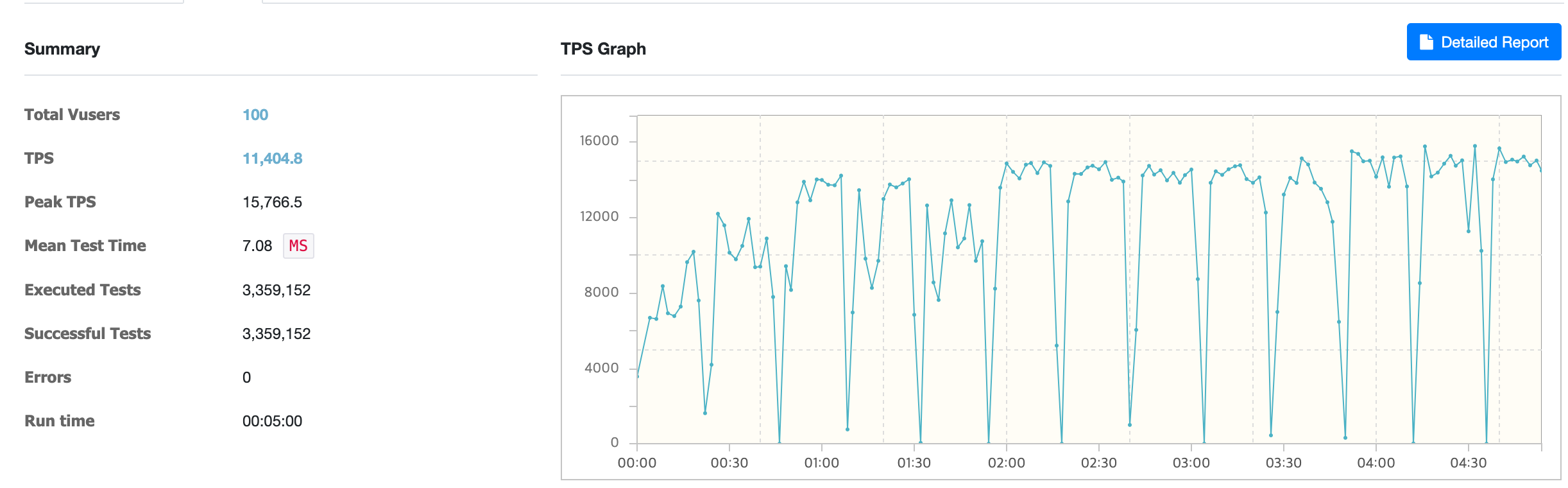
Using ReactiveRedisOperator
Using ReactiveRedisOperator, the average TPS was about 11,404.
Using req-shield
Using req-shield, the average TPS was about 17,257.
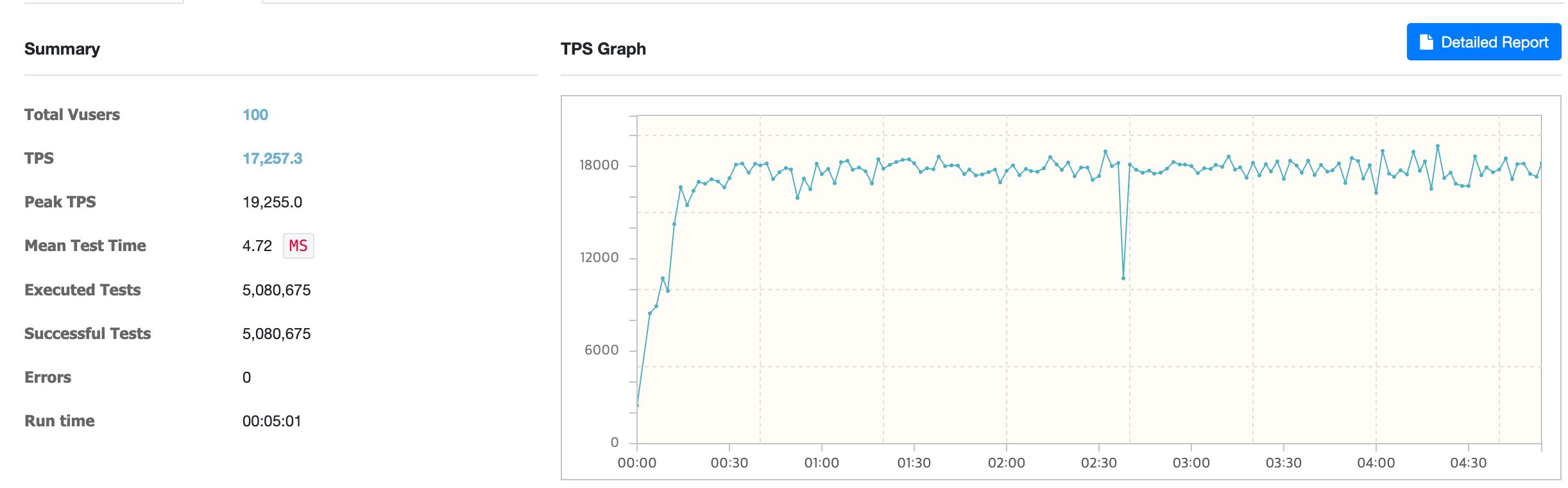
Comparison of load test results
Comparing the load test results, using req-shield improved performance by about 51.34% on average TPS.
Load testing method and results in Spring WebFlux and Kotlin Coroutine environment
In the environment using Spring WebFlux and Kotlin Coroutine, we conducted load testing using ReactiveRedisOperator.
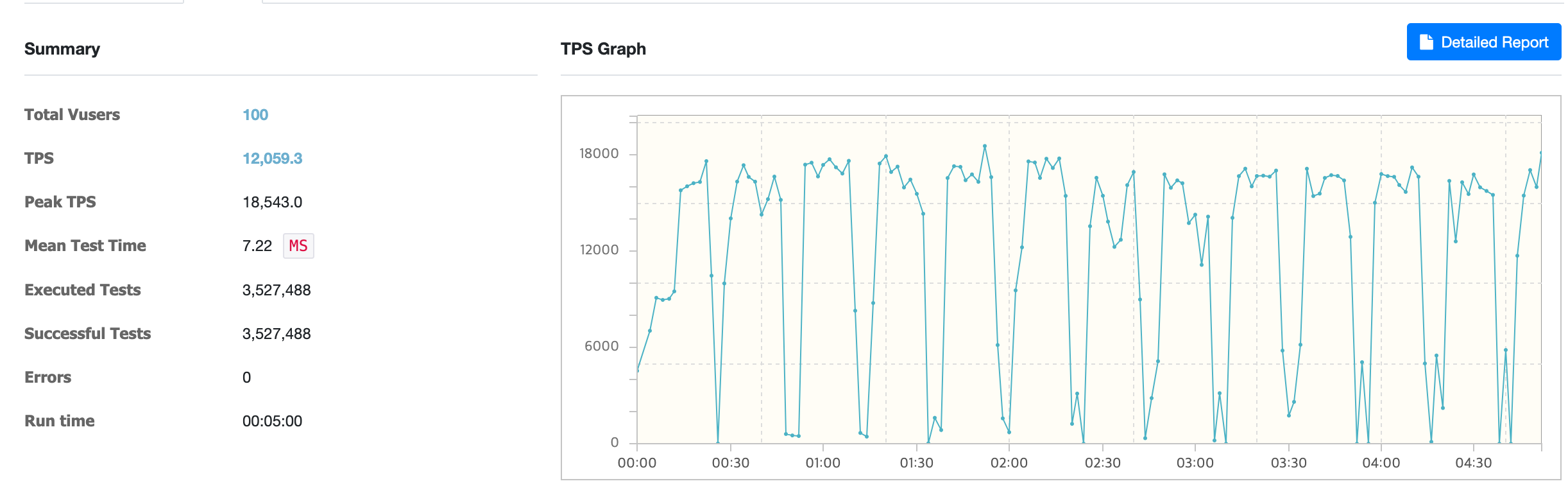
Using ReactiveRedisOperator
Using ReactiveRedisOperator, the average TPS was about 12,059.
Using req-shield
Using req-shield, the average TPS was about 16,335.
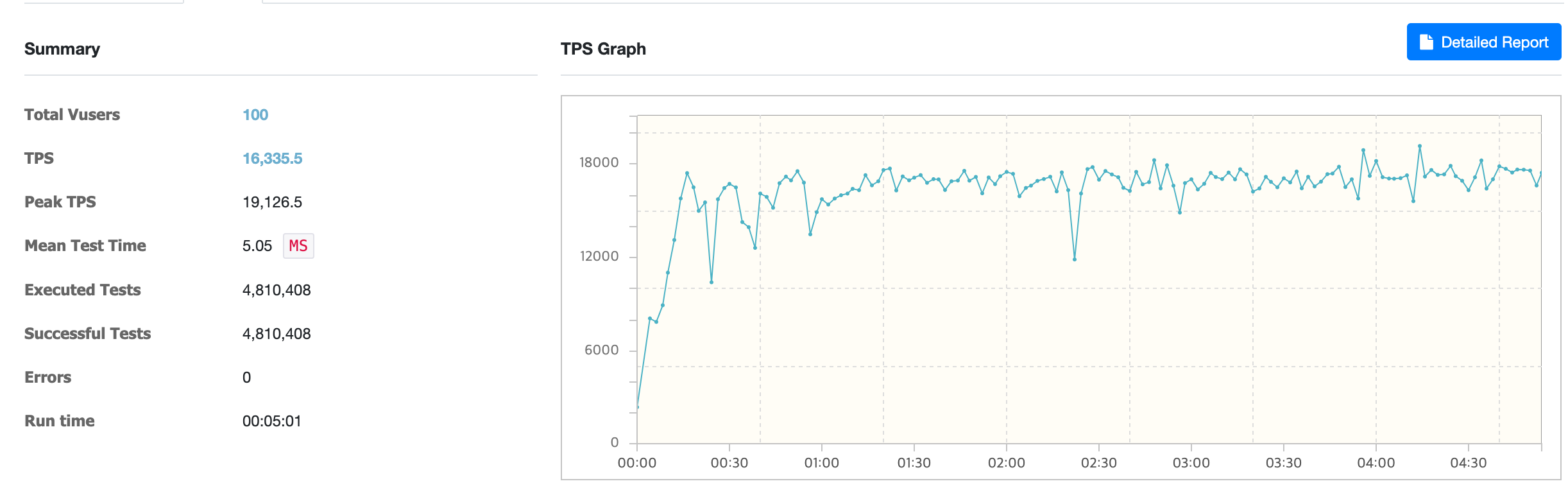
Comparison of load test results
Comparing the load test results, using req-shield improved performance by about 35.45% on average TPS.
Issues encountered during development
Support for the sync attribute of Spring Cacheable and performance degradation issue when using the attribute
The @Cacheable in the Spring framework has an attribute called sync. The default value is false, but when set to true, it changes requests to the backend data store to be sequential, like synchronized, when simultaneous requests with the same argument come in. This attribute has two drawbacks.
First, depending on the cache provider, the sync option may or may not be supported. The CacheManager and Redis cache, which are supported by default in the Spring framework, support the sync attribute. However, before using the sync option, you should check if the cache provider you intend to use supports the sync option.
Next, based on the commonly used RedisCacheManager, using the sync setting inevitably results in some performance degradation. As of spring-data-redis 2.7.17, which we used as a reference during development, synchronized is used to send only one request to the backend data store (from spring-data-redis 3.0 and above, the implementation was changed to ReentrantLock, but the phenomenon is the same). When the cache is hit, the performance difference due to the sync attribute is not significant, but when the cache is missed, all incoming requests before the cache is updated perform logic with synchronized as shown in the code below, inevitably causing performance degradation.
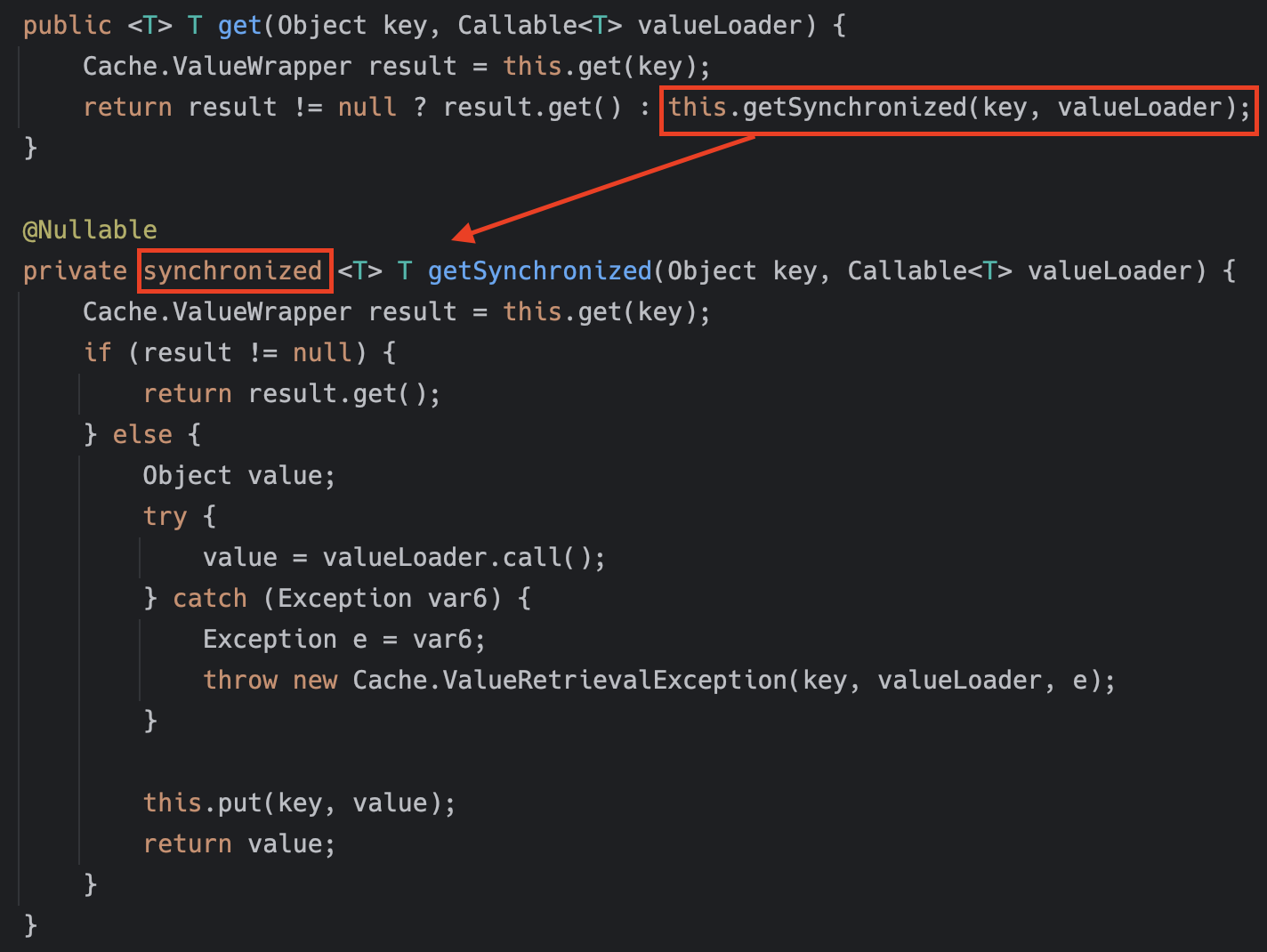
As shown in the load test data above, setting sync=true resulted in about 20% performance degradation compared to sync=false.
Conclusion
Like all libraries, req-shield is not a cure-all. There are situations where req-shield is needed, but there are also cases where it's not necessary. From a developer's perspective, the cases where req-shield shines are as follows:
- Systems with high traffic
- Systems where clients retrieve common (non-personalized) data
- Systems with short or medium cache TTL cycles
- Systems where the backend data store is heavily loaded or responds slowly
Developing the req-shield library and seeking solutions to the "thundering herd problem" provided us with valuable opportunities to grow through technical challenges. We gained experience in applying lock mechanisms carefully, implementing cache TTL update logic, and integrating with the Spring framework, all of which played crucial roles in problem-solving. Additionally, through load testing, we confirmed that req-shield outperforms existing methods, proving that our chosen approach was effective.
We're genuinely pleased that the effort we put into the development process bore fruit, and the valuable lessons and experiences gained from this project will be a precious asset for tackling new challenges in the future. We sincerely hope this article can inspire other developers, even just a little, and with that, we'll conclude here.


