들어가며
안녕하세요. LINE+ Contents Service Engineering 조직에서 백엔드 개발을 맡고 있는 양강현, 이병찬입니다. 저희가 속해 있는 Contents Server Engineering에서는 Tech Group이라는 조직을 운영하고 있습니다. Tech Group은 여러 조직이 공통으로 직면한 문제를 해결하기 위해 활동하면서, 특히 대량의 트래픽을 효율적으로 처리하는 방안을 모색했습니다. 이 과정에서 캐싱 프로세스를 고도화하는 작업을 진행했고, 그 결과 'req-shield'라는 사내용 라이브러리를 개발했습니다(참고로 최초 글 발행 시에는 'Req-Saver'라는 이름이었으나 글 발행 후 오픈소스화하는 과정에서 'req-shield'로 이름을 변경해 글을 수정했습니다).
이 글에서는 req-shield를 개발한 배경과 세부 기능을 상세히 소개하고자 합니다.
일반적으로 애플리케이션이 캐시를 활용하는 방법
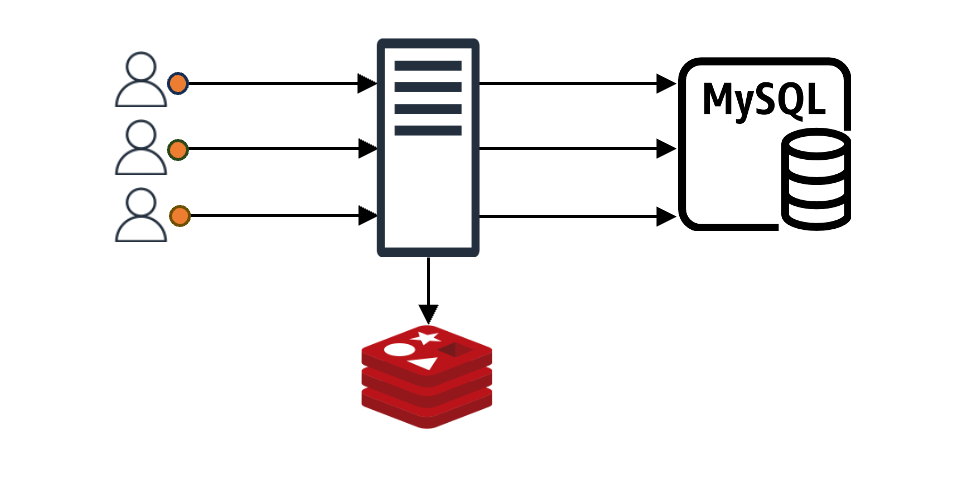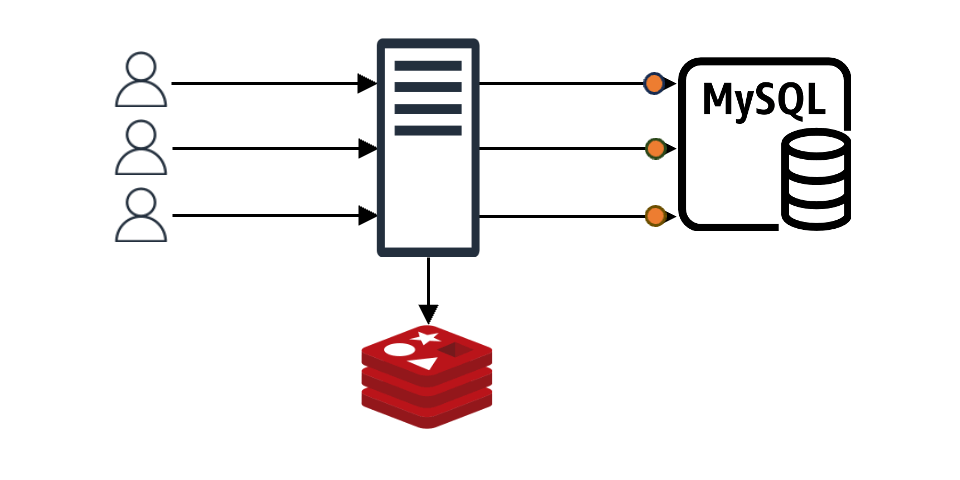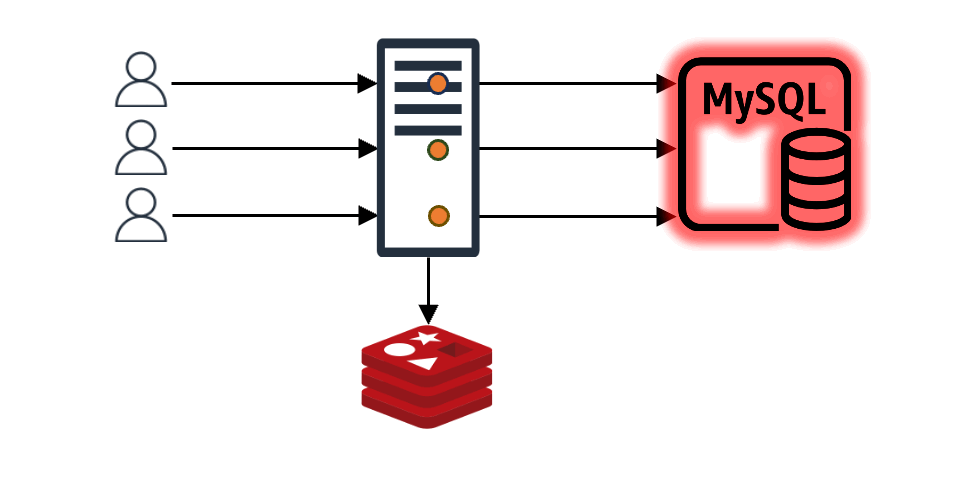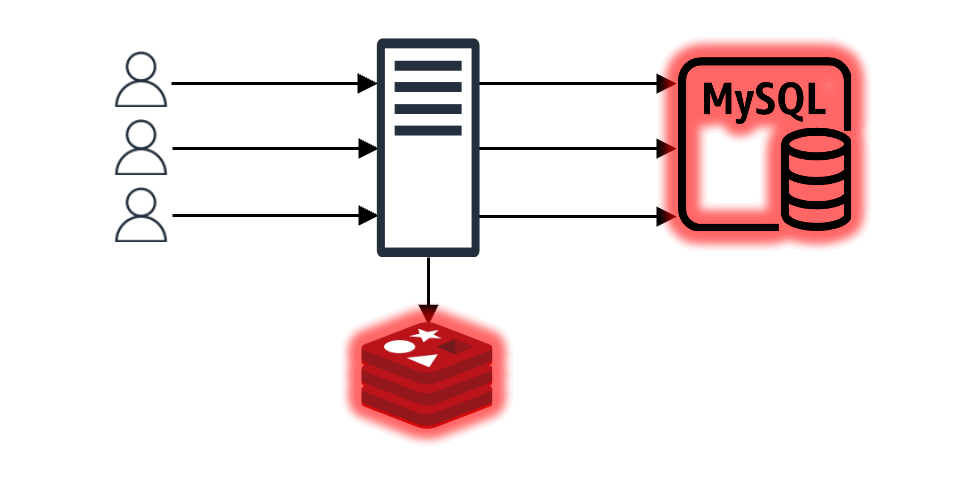
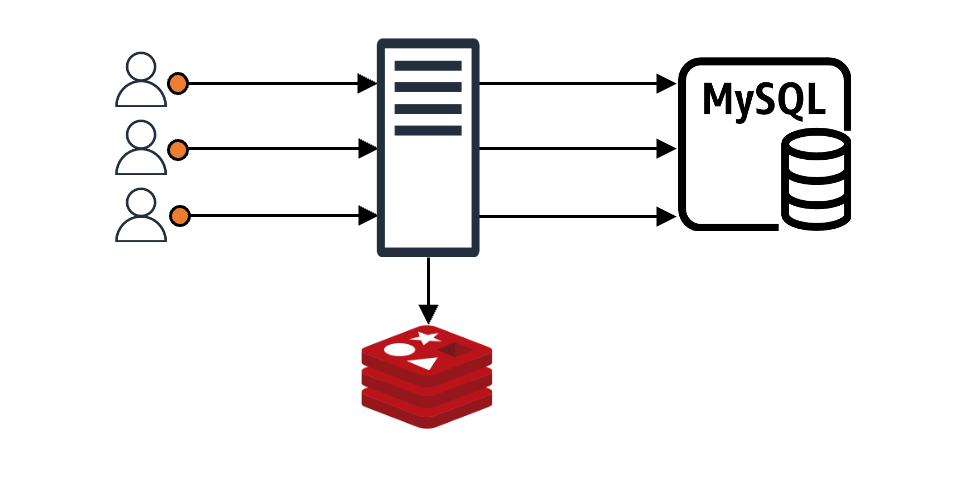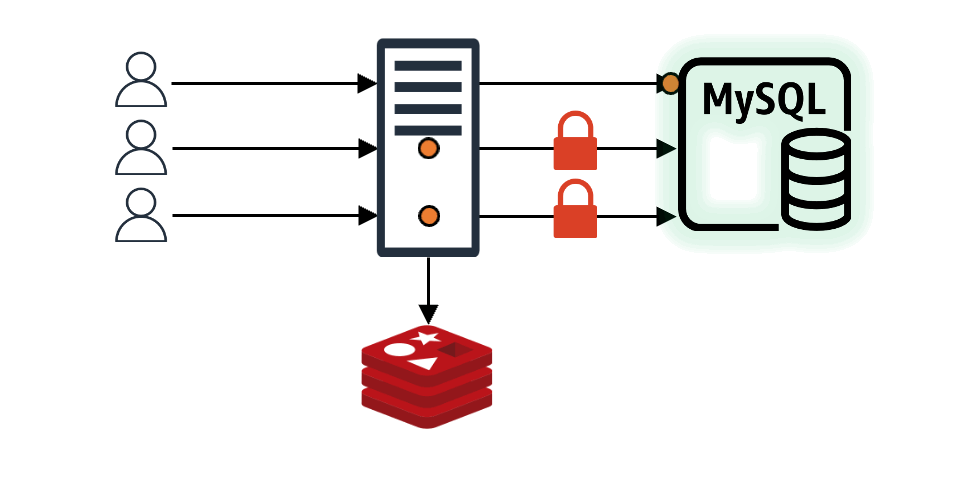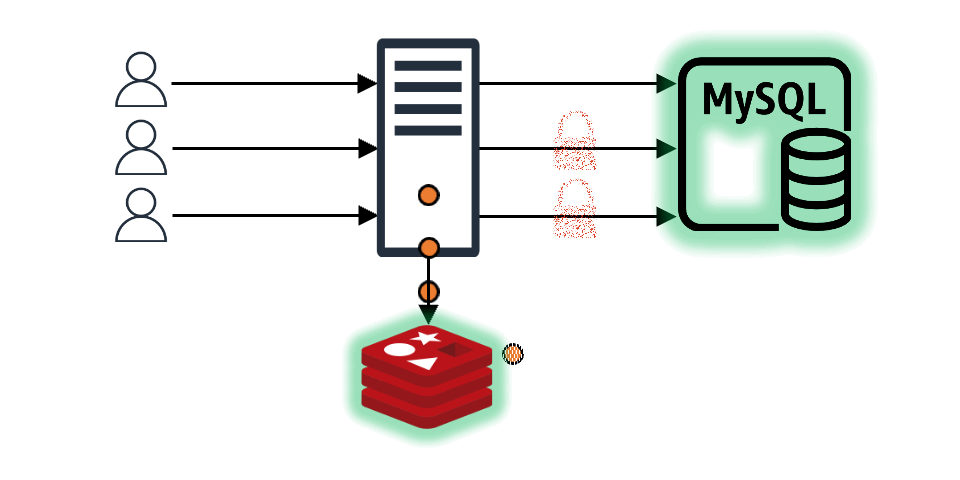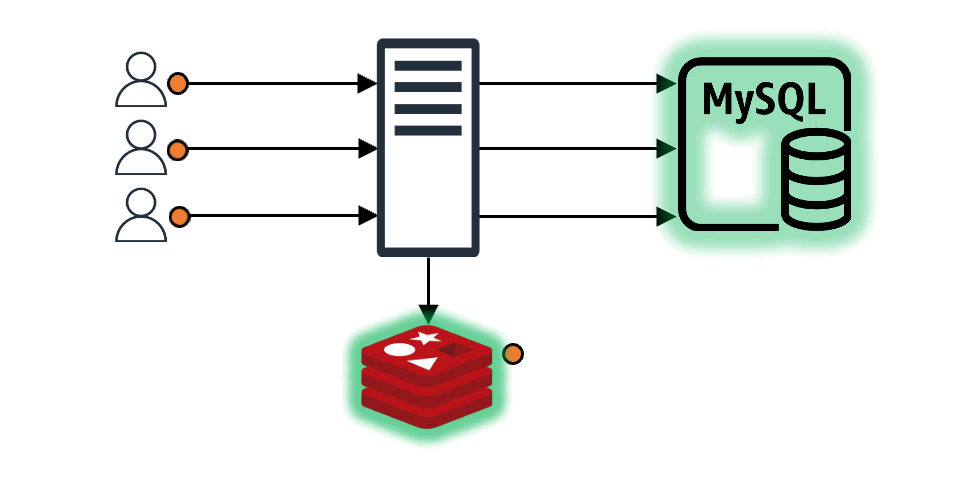
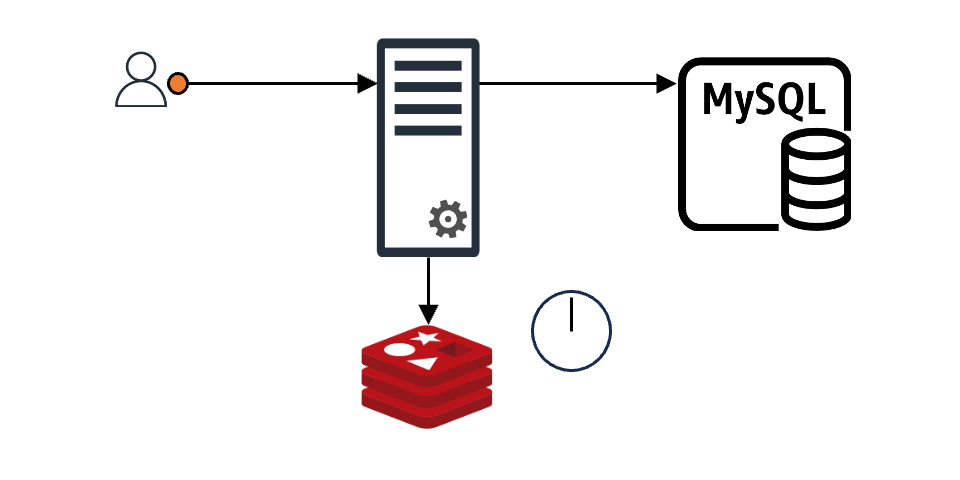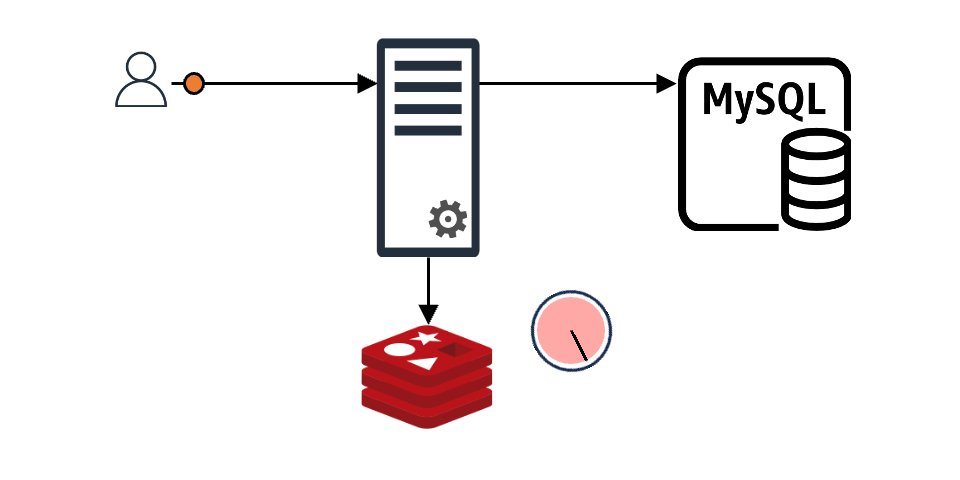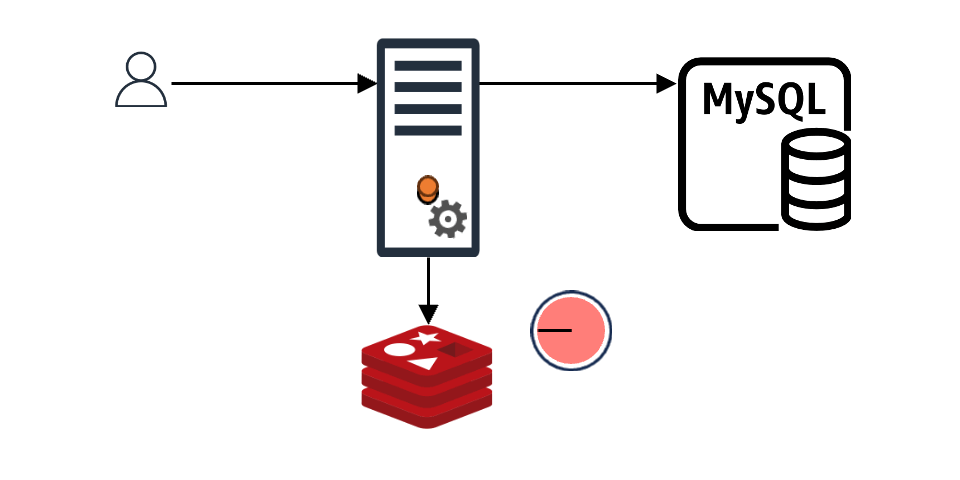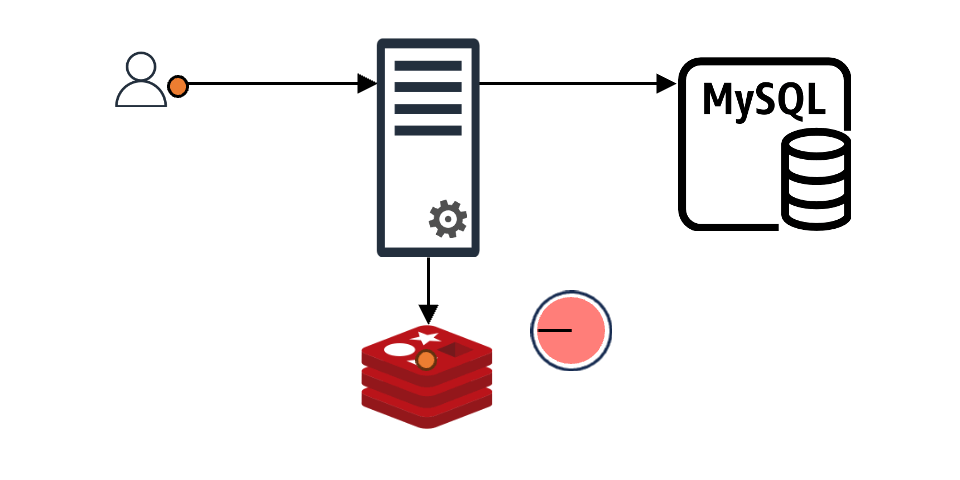
보통 애플리케이션이 캐시를 이용하는 모습은 아래와 같습니다.
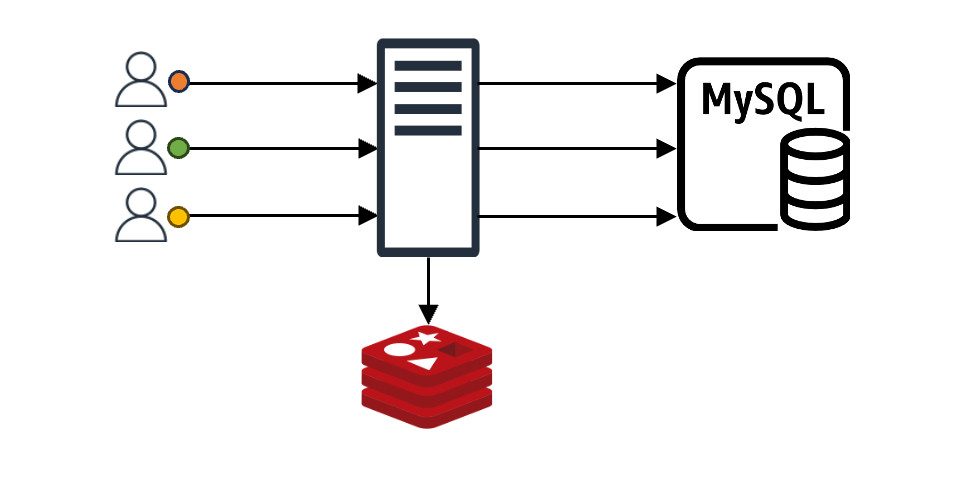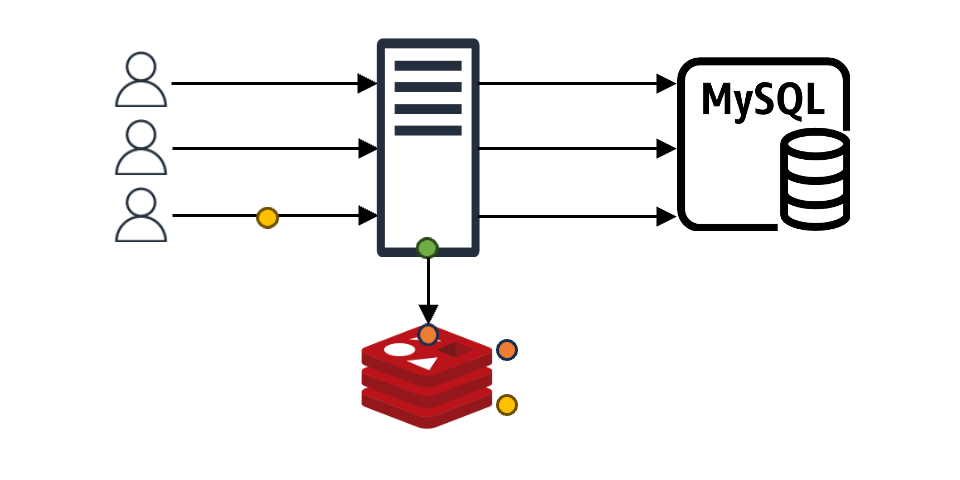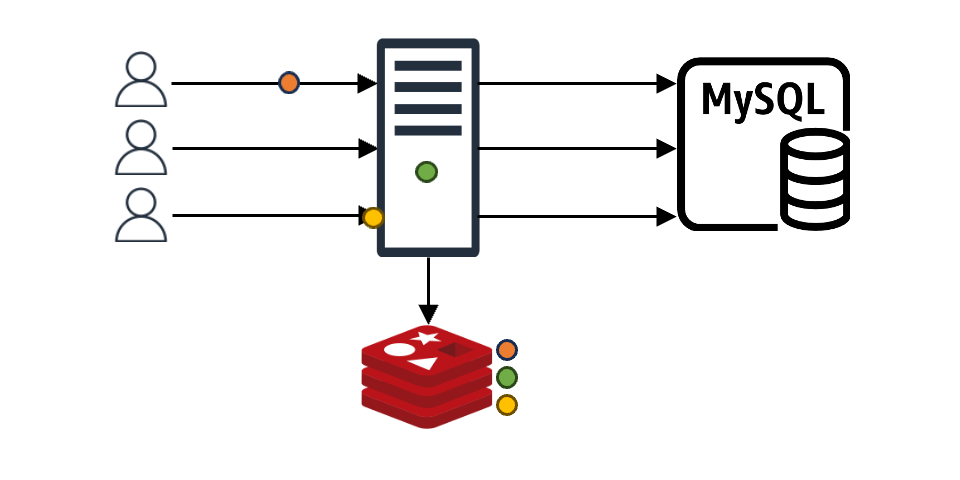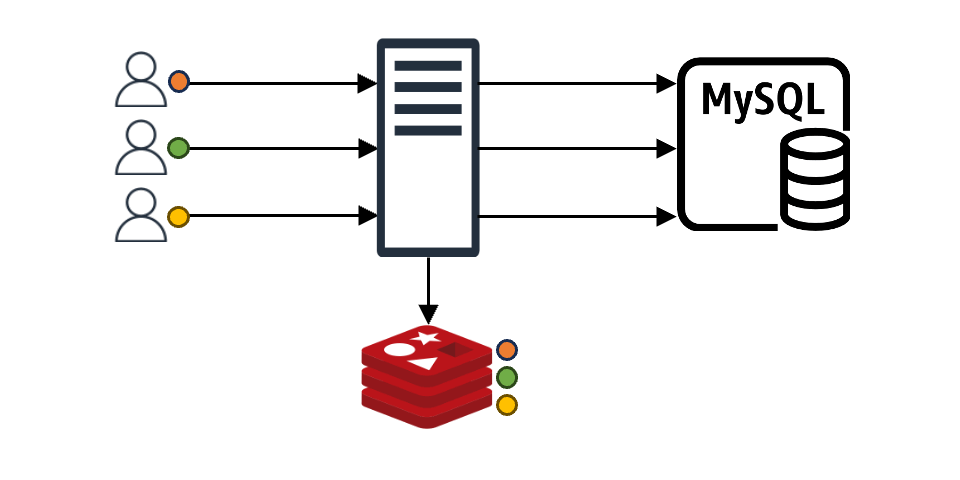
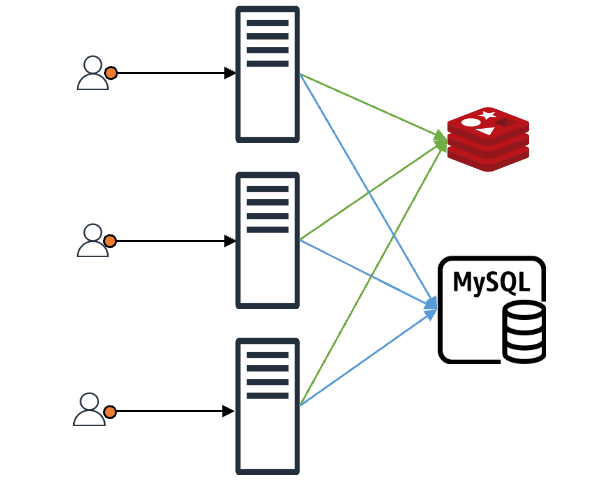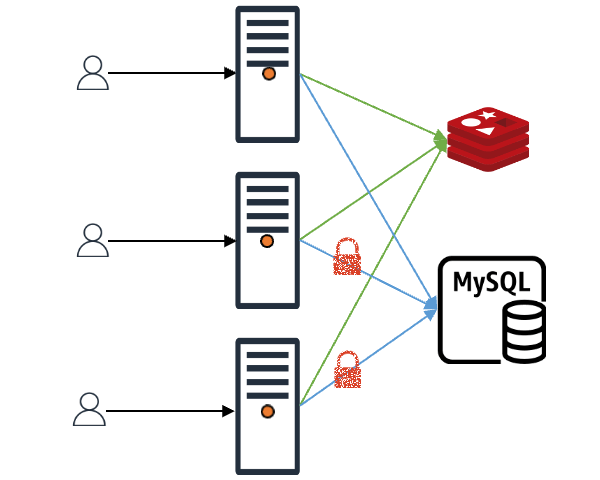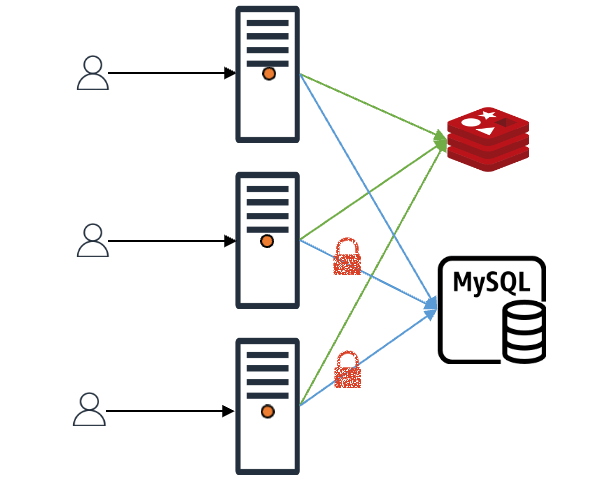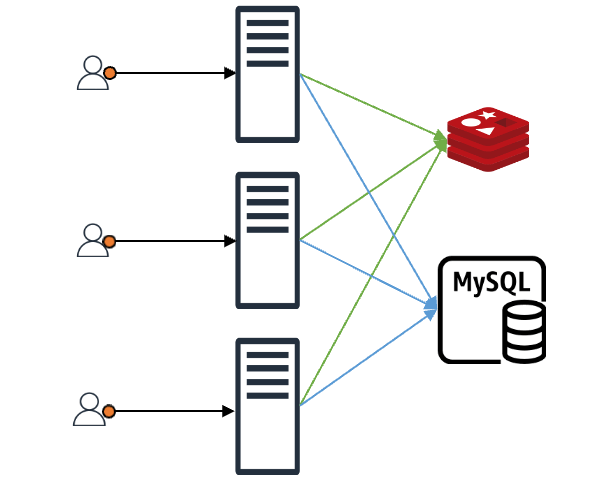
클라이언트가 어떤 요청을 했을 때 그 요청에 맞는 내용이 캐시에 있으면 클라이언트는 바로 응답을 받습니다. 만약 캐시에 없다면 캐시 뒤에 위치한 백엔드 데이터 스토어(DB, 서버, 파일 등)에서 데이터를 가져온 후 캐시에 저장합니다(위 그림에서는 편의상 'MySQL'로 표현).
이와 같은 구조에서 만약 N개의 클라이언트 요청이 들어왔다고 가정해 보겠습니다. 이때 캐시에 N개의 요청에 맞는 내용이 없으면 N개 요청 모두가 백엔드 데이터 스토어에 데이터를 요청하며, N개의 요청이 원하는 값이 같다고 해도 N번의 요청이 그대로 진행됩니다. 더불어 특별한 조치를 취하지 않는다면 백엔드 데이터 스토어에서 받은 데이터를 캐시에 N번 기록하는 작업도 진행됩니다. 이는 백엔드 스토어와 캐시 모두에 부하를 일으키는 원인이 되며, 이를 'Thundering Herd 문제'라고도 합니다.
req-shield 개발은 바로 이 'Thundering Herd 문제'를 해결할 수 있는 방법을 모색하는 과정에서 시작됐습니다.
req-shield의 아이디어
이 문제는 백엔드 데이터 스토어를 향하는 클라이언트의 요청을 어떻게 하면 줄일 수 있을지가 관건이었고, 캐시 히트 여부에 따라 두 가지 아이디어를 적용할 수 있다고 생각했습니다.
요청받은 데이터가 캐시에 존재하지 않을 때
요청받은 데이터가 캐시에 존재하지 않아 백엔드 스토어에서 가져와 캐시에 적재해야 할 때, 애플리케이션 단에서 로컬 혹은 글로벌 락(lock)을 이용해 특정 요청만 백엔드 스토어로 보내고 나머지 요청은 락을 잡은 요청이 캐시에 데이터를 생성할 때까지 대기한다면 문제를 해결할 수 있습니다.
요청받은 데이터가 캐시에 존재할 때
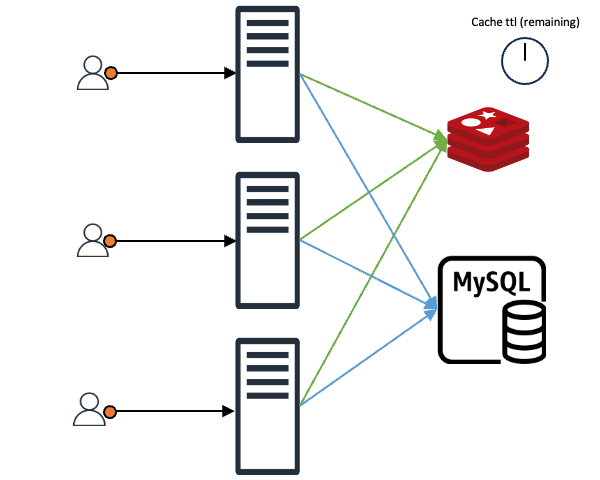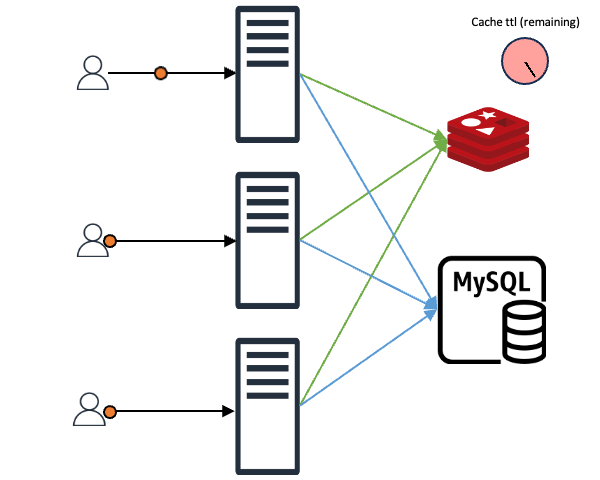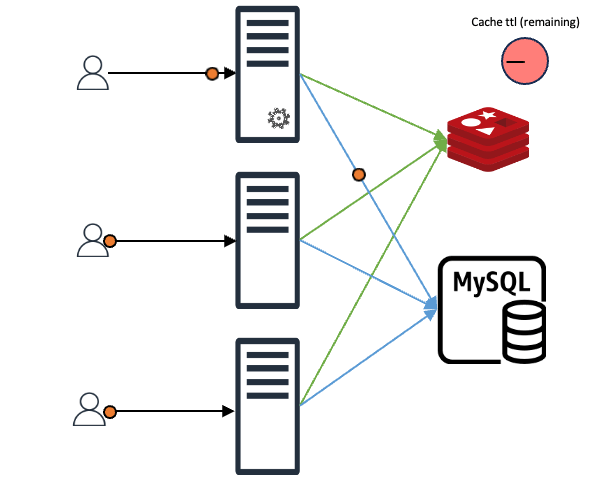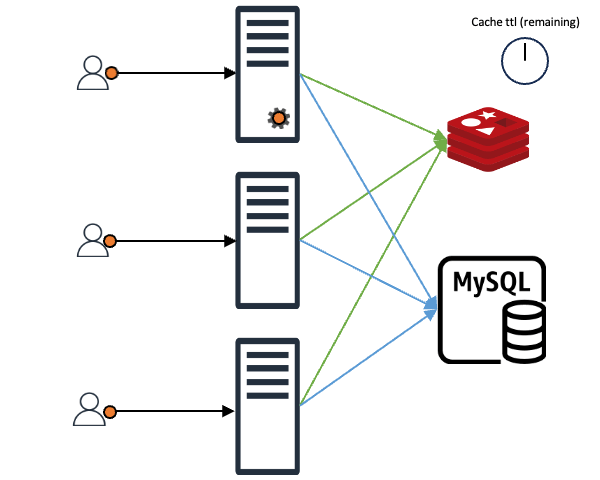
요청받은 데이터가 캐시에 존재해 바로 클라이언트에게 응답하는 경우에도 미래를 위한 예방 조치를 할 수 있습니다. 예를 들어 조회하고자 하는 캐시의 TTL(time to live)이 10초이고 클라이언트가 해당 캐시를 조회할 때 TTL이 2~3초 정도 남은 시점이라면 캐시 만료를 기다리지 말고 바로 캐시 TTL을 갱신하는 것입니다. 이를 통해 일정한 트래픽이 들어온다는 전제하에 캐시가 만료되는 공백 시간 없이 마치 캐시가 연속적으로 존재하는 것과 같은 효과를 기대할 수 있습니다.
위 내용을 시간 그래프 형태로 비교하면 아래와 같습니다.
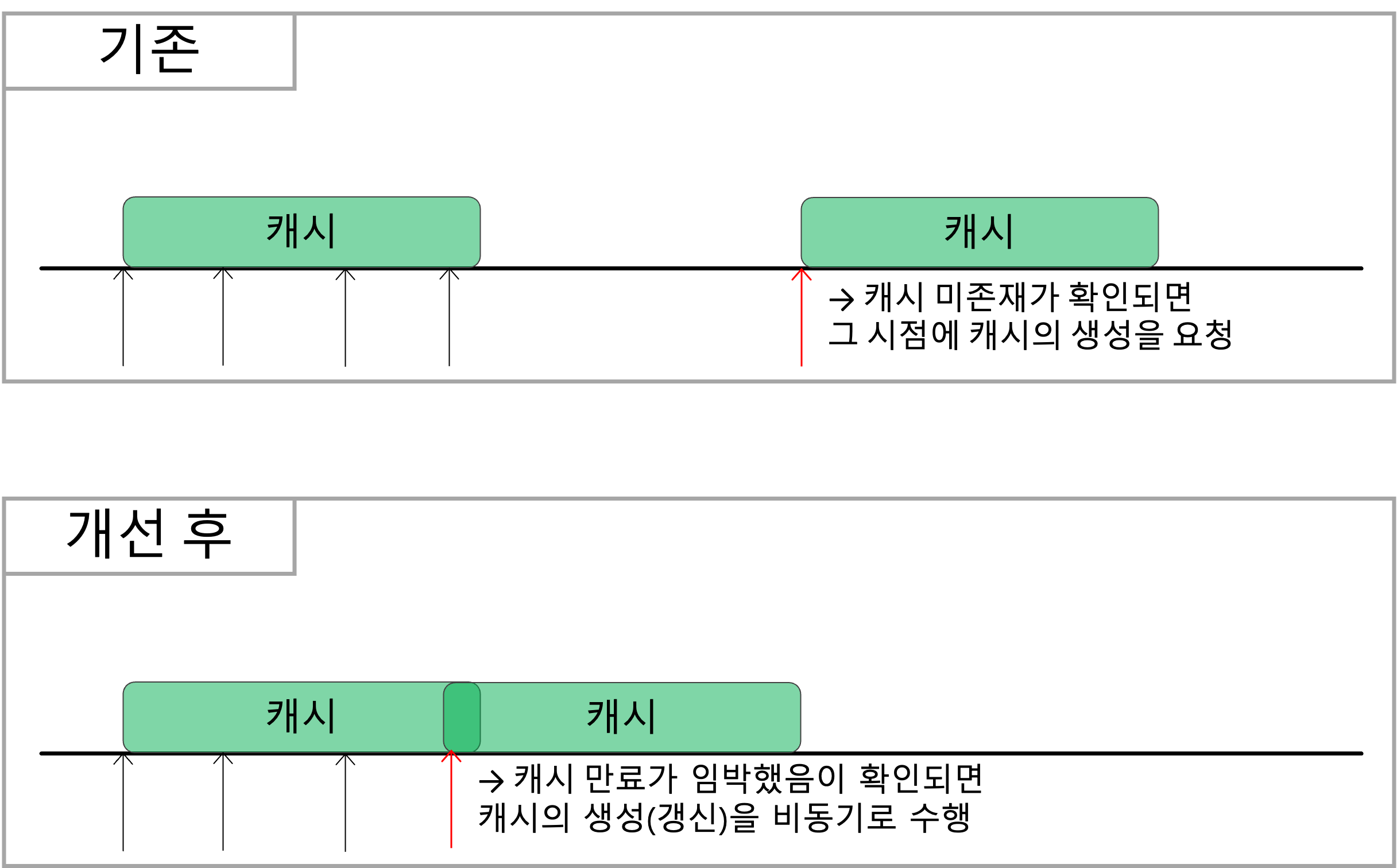
아이디어 구현 방법
각 아이디어를 어떻게 구현했는지 하나씩 살펴보겠습니다.
요청받은 데이터가 캐시에 존재하지 않을 때
이 경우에는 락(lock) 메커니즘을 적극 활용했습니다.
락은 크게 로컬 락과 글로벌 락이 있는데요. 먼저 글로벌 락은 라이브러리 입장에서 개발자가 어떤 분산(distributed) 락을 사용할지 모르기 때문에 단순히 함수를 주입받는 방법으로 구현했습니다. 개발자가 req-shield의 인스턴스를 생성할 때 주입한 글로벌 락 함수를 애플리케이션 단에서 실행함으로써 글로벌 락을 취득했다고 인식한 후, 락을 취득한 요청이 대표로 데이터 취득 및 캐시 적재 작업을 진행합니다. 락을 취득하지 못한 요청들은 설정된 시간 동안 데이터가 캐시에 적재되기를 기다립니다.
로컬 락은 세마포어(semaphore)를 적극 사용 중이며, 락 취득이 서버 인스턴스마다 진행된다는 점만 빼고 나머지 작동 방식은 위 그림과 같습니다.
요청받은 데이터가 캐시에 존재할 때
이 경우 역시 락 메커니즘을 적극적으로 활용하지만 전자와 살짝 다른 부분이 있습니다.
우선 캐시에 데이터가 존재하기 때문에 락을 취득하지 못한 요청들이 캐시에 데이터가 적재되기를 기다릴 필요가 없습니다. 바로 클라이언트에게 응답하면 됩니다. 락을 취득한 요청 역시 바로 클라이언트에게 응답하며, 비동기로 캐시 갱신을 진행합니다.
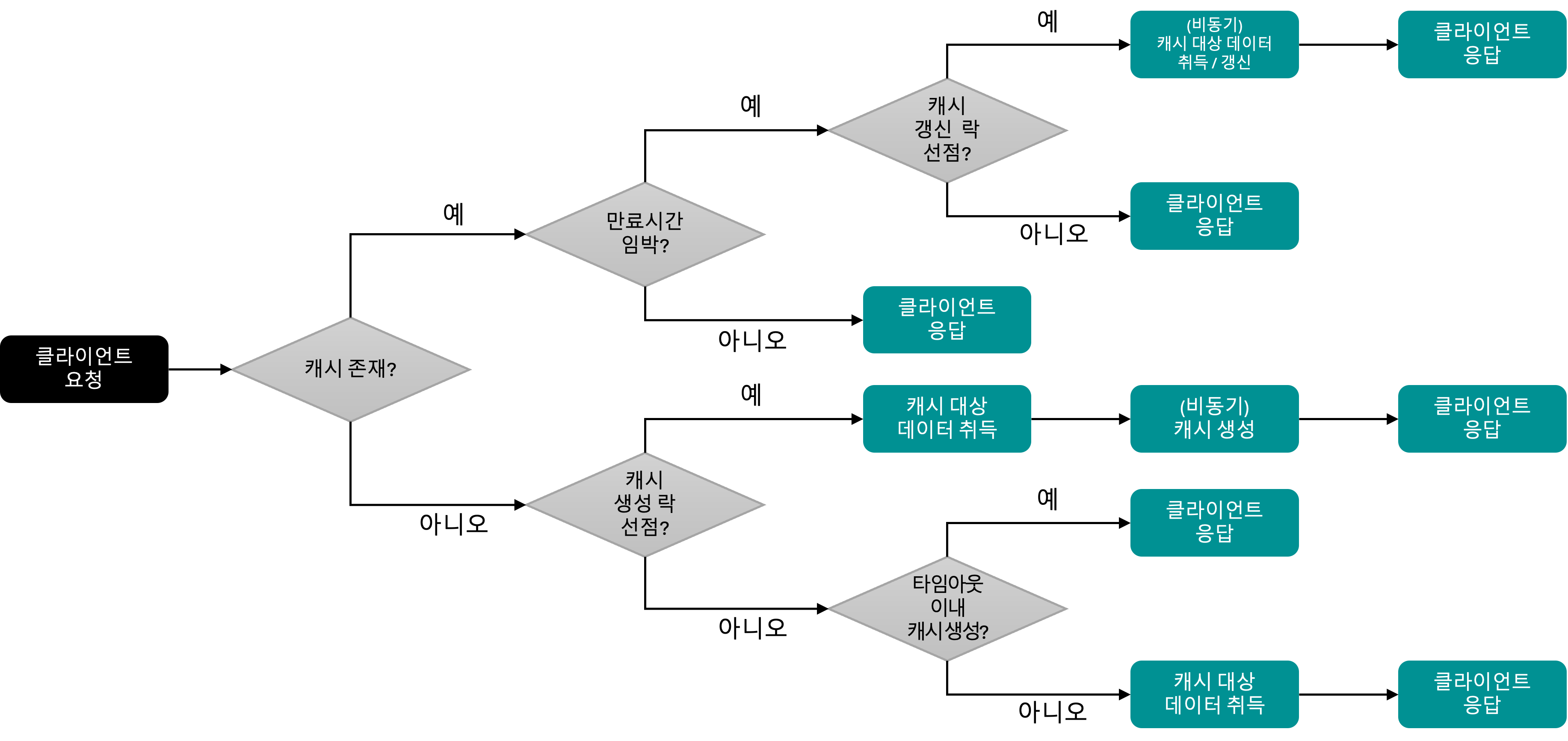
작동 원리 정리
req-shield의 작동 원리를 순서도로 정리하면 아래와 같습니다.
req-shield의 모듈 구조
req-shield의 모듈은 크게 코어 모듈과 Spring 모듈, 지원 모듈로 나눌 수 있습니다. 각 모듈을 살펴보겠습니다.
코어 모듈
코어 모듈은 각 플랫폼에 맞게 사용할 수 있도록 아래 세 가지로 구성했습니다. 각 모듈에는 메인 메서드와 설정 파일이 포함돼 있습니다.
- core: 일반적인 순차적 블로킹(sequencial-blocking) 메서드 환경 하에서의 코어 로직이 포함되어 있습니다.
- core-reactor: Reactor 기반의 코어 로직이 포함되어 있습니다.
- core-kotlin-coroutine: Kotlin Coroutine 기반의 코어 로직이 포함되어 있습니다.
개발자는 각자의 환경에 맞는 코어 모듈을 import로 가져와서 설정 작업을 진행한 후 인스턴스 생성과 동시에 메인 메서드를 실행해 req-shield의 기능을 사용할 수 있습니다.
아래는 req-shield 인스턴스를 생성한 후 실제 캐시 데이터 취득 및 저장에 활용하는 샘플 코드입니다.
//productId을 이용하여 product라는 도메인을 조회하는 예시 메서드입니다.
fun getProduct(productId: String): Product {
//Req-Shield instance를 생성합니다.
val reqShield = ReqShield(
ReqShieldConfiguration(
setCacheFunction = { key, data ->
cacheSpec.put(key, data, 3000)
true
}, //cache platform에 data를 입력할 때 사용할 function입니다. Req-Shield가 사용합니다.
getCacheFunction = { key ->
cacheSpec.get(key)
}, //cache platform으로 부터 data를 조회할 때 사용할 function입니다. Req-Shield가 사용합니다.
isLocalLock = true, //락 메커니즘으로 로컬 락을 사용할지 여부입니다. false면 글로벌 락을 사용합니다.
decisionForUpdate = 70 //TTL의 몇 %가 지났을 때 캐시를 갱신할지 판단하는 설정입니다.
)
)
//getAndSetReqShieldData는 Req-Shield의 메인 메서드로, 하단에 명시된 ReqShieldData를 리턴받습니다.
return reqShield.getAndSetReqShieldData(
key = productId, //캐시의 키도 같이 전달합니다.
callable = { productRepository.findById(id) }, //캐시가 존재하지 않을 때 Req-Shield가 데이터를 요청할 callable 함수입니다.
timeToLiveMillis = 3000).value as Product
}
//Req-Shield의 getAndSetReqShieldData를 호출하면 리턴 받는 클래스입니다. value에 실제 캐시 값이 들어갑니다.
data class ReqShieldData(
var value: Any?,
var status: Status,
val createdAt: Long,
val timeToLiveMillis: Long,
)Spring 프레임워크에서 아래와 같이 Bean으로 생성한 후 사용할 수도 있습니다.
@Bean
fun reqShield() = ReqShield(reqShieldConfiguration())
private fun reqShieldConfiguration() =
ReqShieldConfiguration(
setCacheFunction = { key, data ->
cacheSpec.put(key, data)
},
getCacheFunction = { key ->
cacheSpec.get(key)
},
isLocalLock = true,
decisionForUpdate = 70
)Spring 모듈
코어 모듈에서 더 나아가, req-shield를 Spring 프레임워크에서 흔히 사용하는 @Cacheable, @Transactional 같은 애너테이션(annotation)처럼 편리하게 사용할 수 있도록 Spring 기반의 모듈도 구성했습니다.
Spring 기반 모듈은 앞서 말씀드린 코어 모듈을 기반으로 @ReqShieldCacheable, @ReqShieldCacheEvict라는 애너테이션으로 req-shield를 사용할 수 있도록 제공하며, 저희 개발 팀에서 주로 사용하는 기술 스택에 맞게 MVC와 WebFlux, WebFlux Kotlin Coroutine의 세 가지 모듈로 구성했습니다.
- core-spring-mvc
- core-spring-webflux
- core-spring-webflux-kotlin-coroutine
세부 구현은 Spring AOP를 이용해서 구현했으며, 아래와 같이 애너테이션에 몇몇 엘리먼트 값을 추가해 req-shield의 기능을 이용할 수 있습니다.
//productId을 이용해 product라는 도메인을 조회하는 예시 메서드입니다.
//상기 설정에 입력할 값들을 애너테이션과 함께 설정할 수 있습니다.
@ReqShieldCacheable(key = "product_cacheKey", decisionForUpdate = 70, timeToLiveMillis = 6000)
fun getProduct(productId: String): Product {
log.info("get product (Simulate db request) / productId : $productId")
//TODO : develop..
return Product(productId, "product_$productId")
}지원 모듈
공통으로 사용되는 데이터 클래스와 유틸, 테스트 패키지가 포함된 지원(support) 모듈도 존재합니다. 지원 모듈에는 테스트 코드를 실행할 때 이용하는 테스트 컨테이너(testContainer) 관련 코드들이 들어있어 각 모듈에서 쉽게 Redis 등의 플랫폼을 이용해 테스트할 수 있는 환경을 제공합니다.
부하 테스트 진행 방법 및 결과 소개
req-shield의 성능을 확인하기 위해 아래와 같은 테스트 환경에서 부하 테스트를 진행했습니다.
- 애플리케이션
- Spring Boot 2.7.17
- Redis(로컬 환경의 Docker): 6.2.7-alpine
- Redis 캐시 TTL: 20초
- 백엔드 쿼리 시뮬레이션: sleep 3초(쿼리 실행 시 걸리는 시간을 시뮬레이션하는 것으로 명확한 차이를 확인하기 위해 다소 높은 딜레이로 설정)
- req-shield 설정
- decisionForUpdate: 70%(캐시의 TTL이 70% 남았을 때 갱신)
- TTL: 20초
- NGrinder 설정
- vUser: 100(프로세스 개수 4 * 스레드 개수 25)
- 램프 업(ramp-up): 하지 않음
- 테스트 시간: 5 분
- Redis 키: 10개를 랜덤으로 추출해 사용
테스트 결과 req-shield의 캐시 갱신 로직이 성능에 큰 영향을 주고 있다는 것을 알 수 있었는데요. 환경별로 하나씩 살펴보겠습니다.
Spring MVC 환경에서의 부하 테스트 방법 및 결과
Spring MVC 환경에서는 총 세 가지 경우로 나눠 부하 테스트를 진행했습니다. 먼저 Spring Cacheable의 sync 속성을 각각 false와 true로 설정한 상태에서 부하 테스트를 실시했고, 이어서 req-shield를 사용한 경우를 테스트해 그 결과를 비교했습니다(Spring Cacheable의 sync 속성에 관해서는 아래 '개발 과정 중 발생한 이슈와 해결한 방법' 섹션에서 보다 자세히 설명하겠습니다). 그럼 부하 테스트 결과를 살펴보겠습니다.
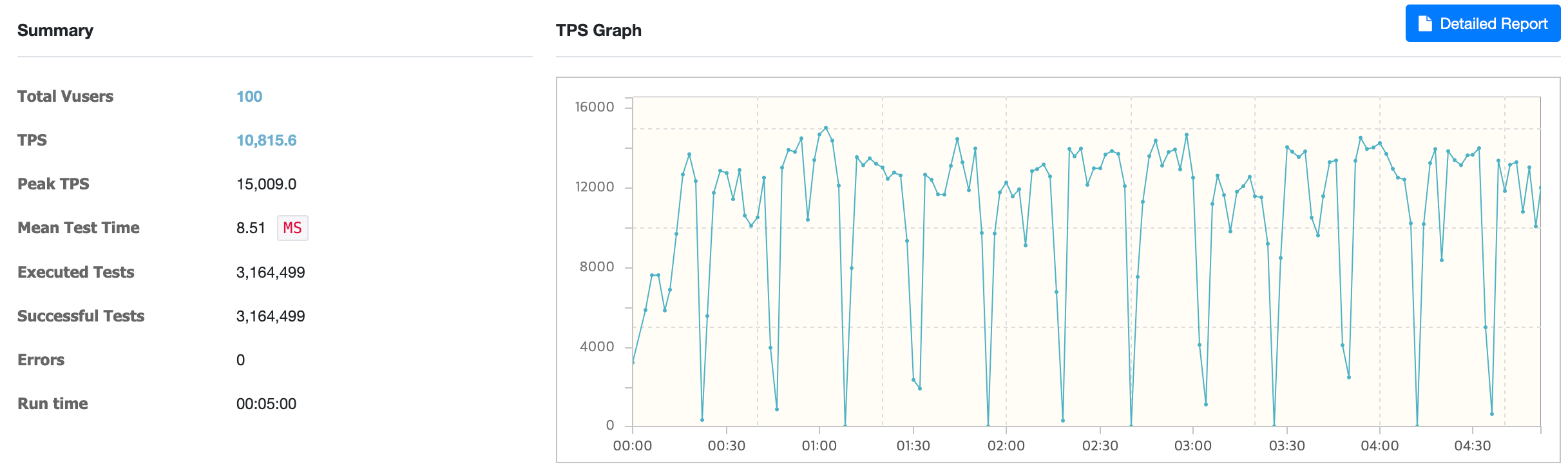
@Cacheable & sync = false 설정 시
@Cacheable & sync = false 설정 시 평균 TPS는 약 10,815였습니다.
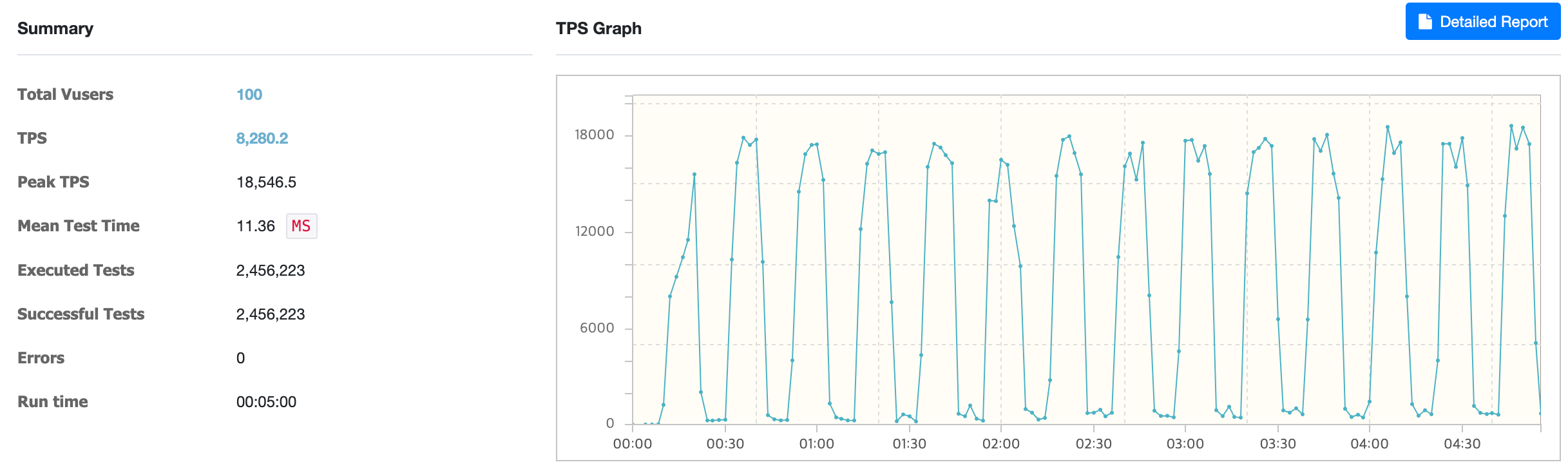
@Cacheable & sync = true 설정 시
@Cacheable & sync = true 설정 시 평균 TPS는 약 8,280이었습니다.
req-shield 사용 시
req-shield 사용 시 평균 TPS는 약 16,799였습니다.
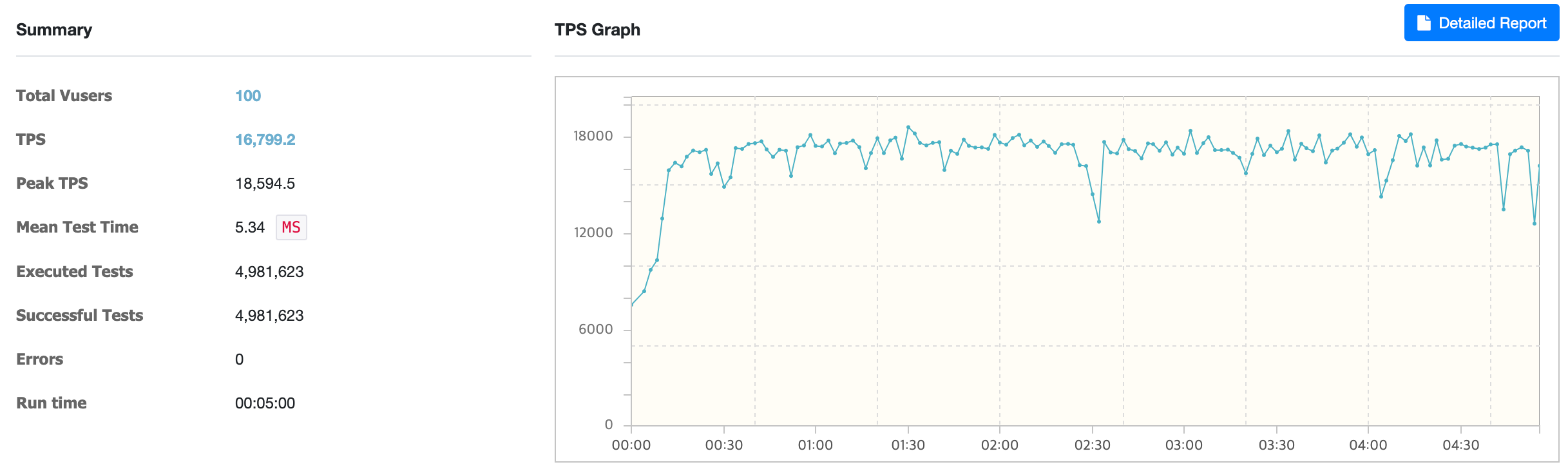
부하 테스트 결과 비교
부하 테스트 결과 req-shield 사용 시 평균 TPS 기준으로 @Cacheable & sync = false 설정에 비해서는 55.31%, @Cacheable & sync = true 설정에 비해서는 102.88% 성능이 향상됐습니다.
Spring WebFlux 환경에서의 부하 테스트 방법 및 결과
Spring WebFlux에서는 ReactiveRedisOperator를 이용해 부하 테스트를 진행했습니다.
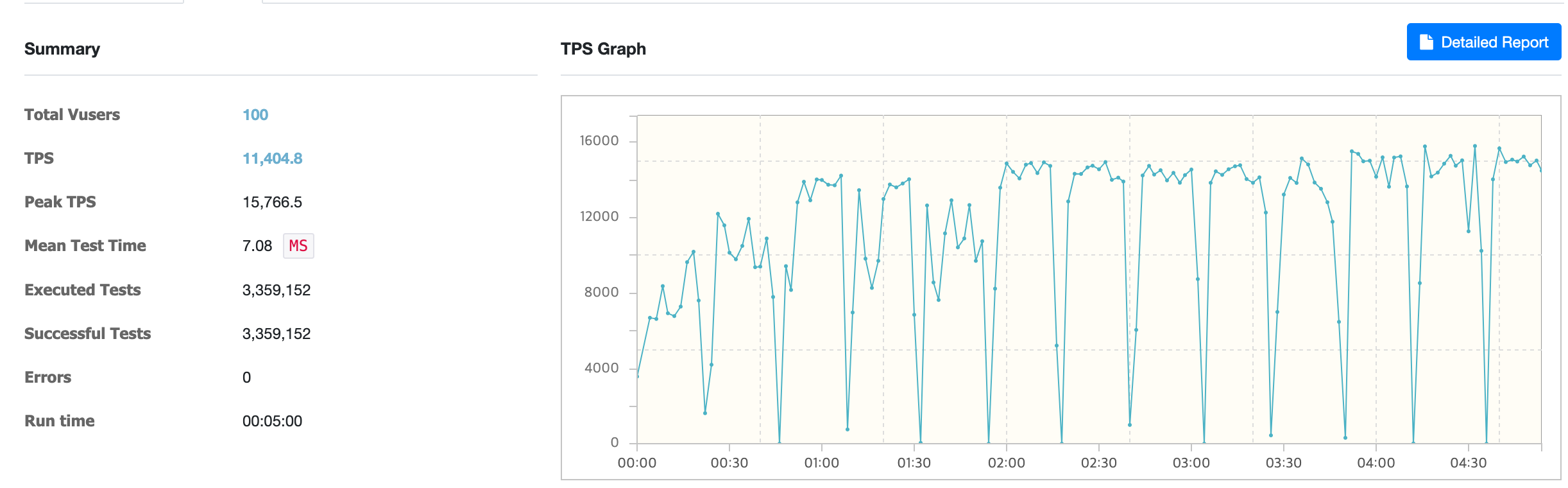
ReactiveRedisOperator 사용 시
ReactiveRedisOperator 사용 시 평균 TPS는 약 11,404였습니다.
req-shield 사용 시
req-shield 사용 시 평균 TPS는 약 17,257이었습니다.
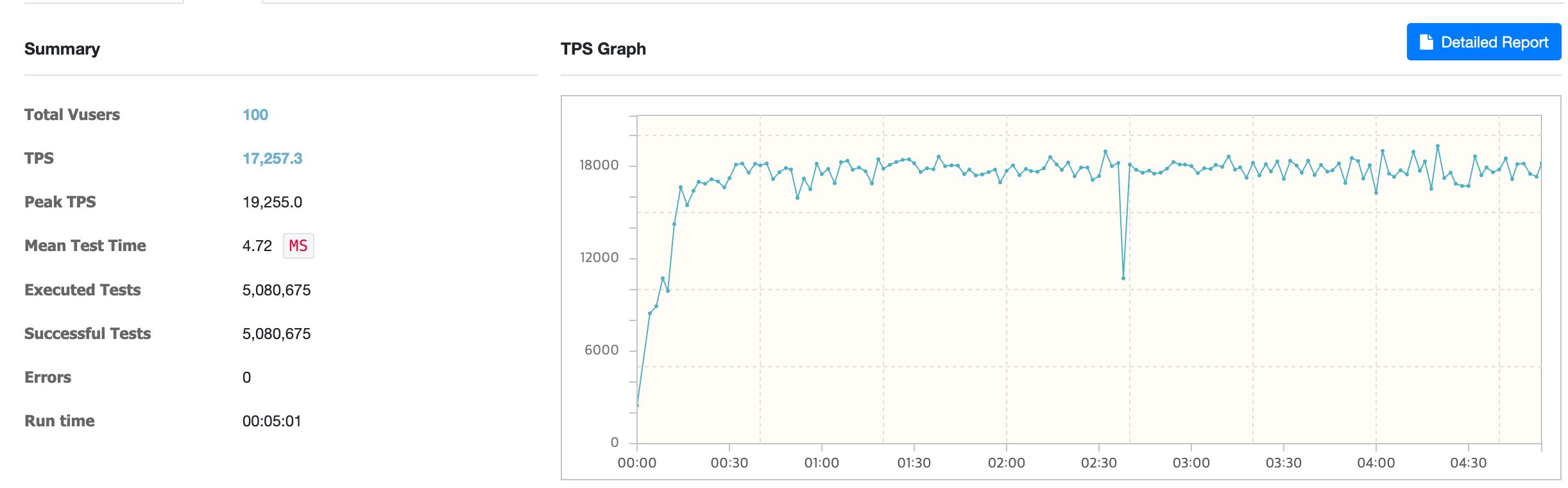
부하 테스트 결과 비교
부하 테스트 결과를 비교하니 req-shield를 사용했을 때 평균 TPS 기준으로 성능이 약 51.34% 향상됐습니다.
Spring WebFlux와 Kotlin Coroutine 환경에서의 부하 테스트 방법 및 결과
Spring WebFlux와 Kotlin Coroutine를 사용한 환경에서는 ReactiveRedisOperator를 이용해 부하 테스트를 진행했습니다.
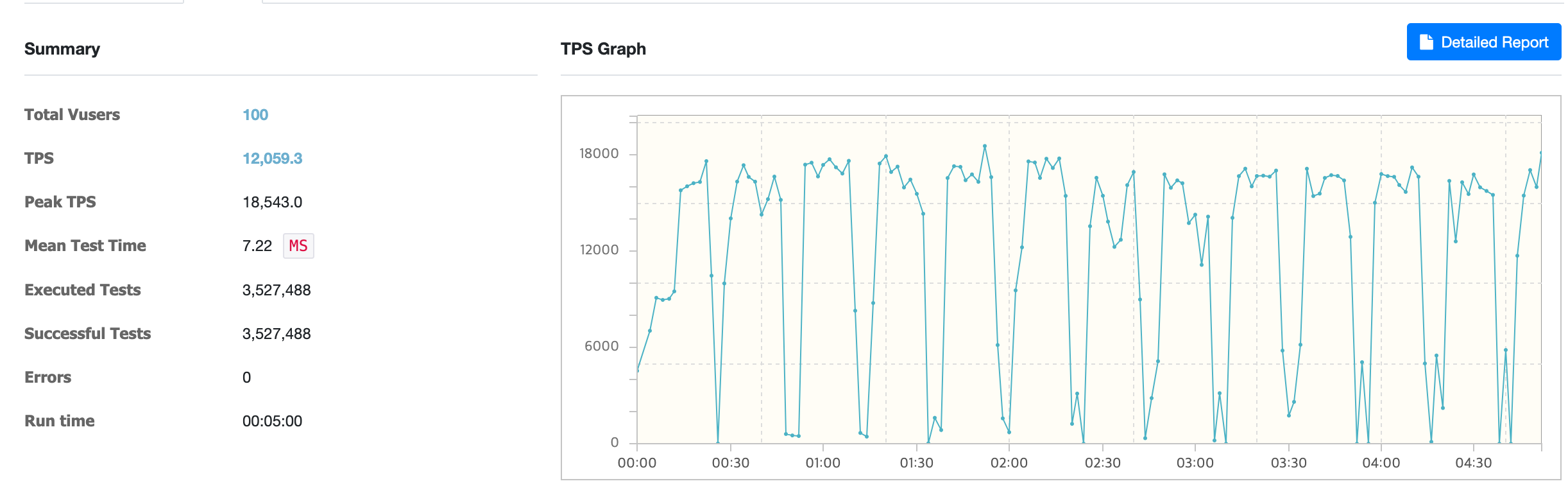
ReactiveRedisOperator 사용 시
ReactiveRedisOperator 사용 시 평균 TPS는 약 12,059였습니다.
req-shield 사용 시
req-shield 사용 시 평균 TPS는 약 16,335였습니다.
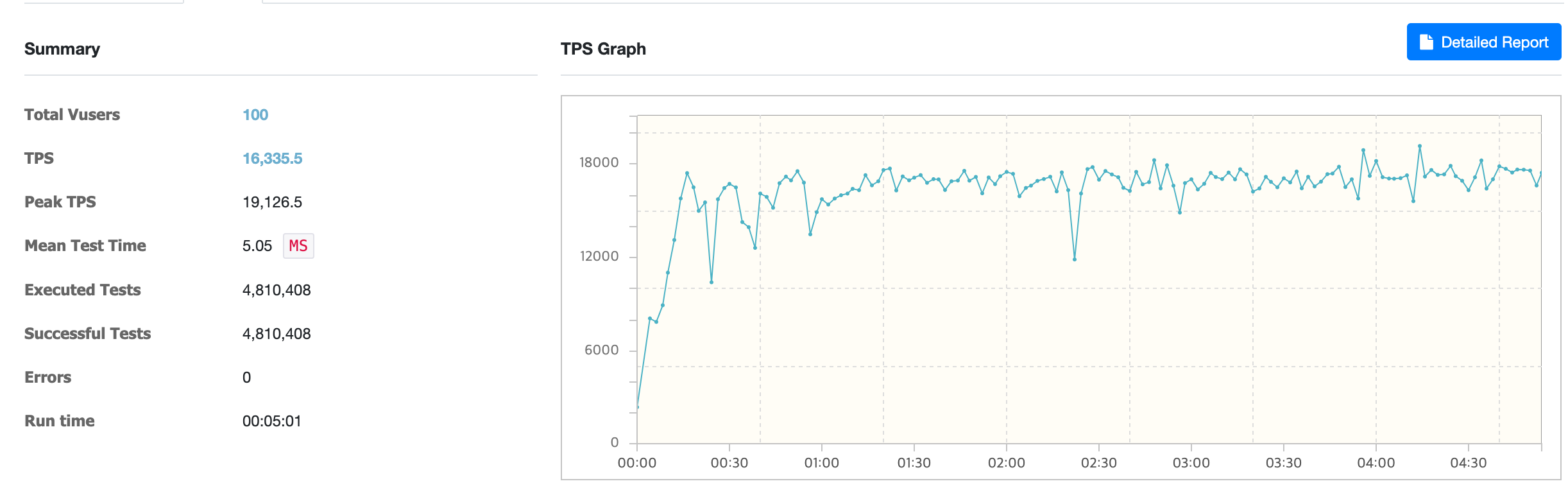
부하 테스트 결과
부하 테스트 결과를 비교하니 평균 TPS 기준으로 req-shield를 사용했을 때 성능이 35.45%가량 향상됐습니다.
개발 과정 중 발생한 이슈
Spring Cacheable의 sync 속성 지원 여부와 속성 사용에 따른 성능 감소 이슈
Spring 프레임워크의 @Cacheable에는 sync라는 속성이 있습니다. 기본값은 false인데 true로 설정하면 같은 인수(argument)로 동시에 요청이 들어왔을 때 백엔드 데이터 스토어로의 요청을 synchronized 같이 순차적으로 변경하는 역할을 하는데요. 이 속성에는 아래와 같은 두 가지 단점이 있습니다.
먼저 캐시 제공자(provider)에 따라 sync 옵션을 지원하기도, 지원하지 않기도 합니다. Spring 프레임워크에서 기본적으로 지원하는 CacheManager와 Redis 캐시에서는 sync 속성을 지원합니다만, sync 옵션을 사용하기 전에는 사용하려는 캐시 제공자가 sync 옵션을 지원하는지 확인 후 사용해야 합니다.
다음으로 주로 사용되는 RedisCacheManager를 기준으로, sync 설정을 사용하면 약간의 성능 감소가 불가피합니다. 저희가 개발 시 기준으로 삼은 spring-data-redis 2.7.17을 기준으로, 백엔드 데이터 스토어로 하나의 요청만을 보내기 위해서 synchronized를 사용하기 때문입니다(spring-data-redis 3.0 이상부터 ReentrantLock으로 구현이 변경됐지만 현상은 동일). 캐시 히트된 경우에는 sync 속성 여부에 따른 성능 차이가 크지 않지만, 캐시 미스인 경우 캐시가 업데이트되기 전까지 들어온 모든 요청이 다음 코드와 같이 synchronized로 로직을 수행하기 때문에 필연적으로 성능 하락이 발생합니다.
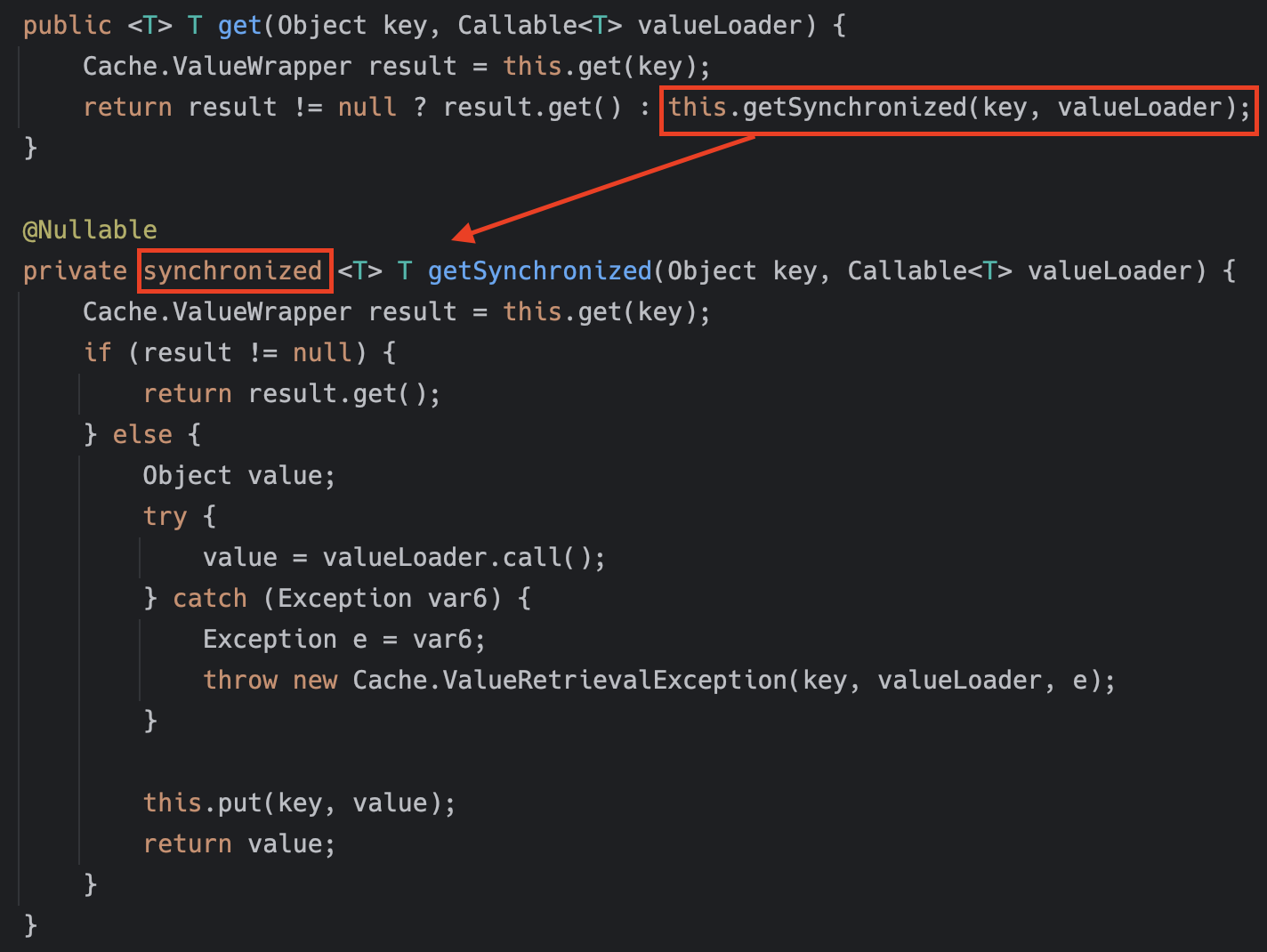
앞서 부하 테스트 자료에도 나와 있는데요. 실제로 sync=true로 설정한 경우 sync=false인 경우에 비해 20% 정도의 성능 저하가 발생했습니다.
마치며
모든 라이브러리가 그렇듯 req-shield는 만병통치약이 아닙니다. req-shield가 필요한 상황도 있지만 사용할 필요가 없는 경우도 존재합니다. 개발자 입장에서 req-shield가 빛을 발하는 케이스를 정리하면 아래와 같습니다.
- 대량의 트래픽이 발생하는 시스템
- 클라이언트가 공통된(개인화되지 않은) 데이터를 취득하는 시스템
- 캐시 TTL의 주기가 단기 혹은 중기인 시스템
- 백엔드 데이터 스토어의 부하가 크거나 응답이 다소 느린 시스템
req-shield 라이브러리를 개발하며 'Thundering Herd 문제'의 해결책을 모색해 나간 저희의 여정은 기술적인 도전을 통해 성장할 수 있는 소중한 기회를 제공했습니다. 락 메커니즘의 세심한 적용과 캐시 TTL의 갱신 로직 구현, Spring 프레임워크와의 통합 등 문제 해결에 중요한 역할을 한 각 기술 요소를 접하고 사용한 경험을 얻을 수 있었으며, 더불어 부하 테스트를 통해 req-shield가 기존 방식들보다 성능이 우수하다는 것을 확인하고 저희가 선택한 접근법이 효과적이었다는 것을 입증할 수 있었습니다.
개발 과정에서 기울인 정성이 결실을 맺을 수 있어서 진심으로 기쁘며, 이번 프로젝트를 통해 얻은 소중한 교훈과 경험은 앞으로 직면할 새로운 도전을 헤쳐 나갈 수 있는 귀중한 자산이 될 것이라고 생각합니다. 이 글이 다른 개발자분들께도 조금이나마 영감을 드릴 수 있기를 진심으로 희망하며 이만 마치겠습니다.


