はじめに
こんにちは。UITチームのHealin Yoonです。LINEヤフーグループではヘッドレスCMSであるLandPress Contentを社内向けに運用しています。この記事では、LandPress ContentでCDC(change data capture、変更データキャプチャ)を設計・開発した経験を紹介したいと思います。
LandPress Content CDCの動作フロー
LINEヤフー株式会社の技術と開発文化を発信しているこのLINEヤフー Tech Blogも、LandPress Contentで運用されています。私たちの技術と文化を紹介するために、一日に何十回もデータの追加や修正、削除が発生しています。例えば、記事の本文が修正されたり、新しい著者データが追加されたりします。
上記のようなデータ変更が発生したとき、LandPress Contentでは以下のような流れでCDCが動作します。

- データ変更を検知します。
- データ変更が発生したとき、予想される変更点を識別してキャプチャします。
- 変更対象データ
- 変更対象データに影響を受けるデータ
- キャプチャされたデータの変更前後を比較し、実際に変更されたデータのみを抽出します。
- 最終的に選別されたデータをパイプラインに送ります。
上記の各ステップをより詳しく説明します。
予想される変更点を識別してキャプチャする
まず、データ変更が検知されたら、予想される変更点を識別してキャプチャする必要があります。この変更点には2つの種類があります。1つは変更対象となるデータの変更点、もう1つはリレーションシップデータによる変更点です。
LandPress Contentは、ユーザーがより簡単にデータを構造化できるように、データ間のリレーションシップの設定をサポートしています。リレーションシップのデータが変更されると、他のデータにも影響を与えます。したがって、データの変更が検知されたとき、このようなリレーションシップの設定まで考慮してすべての変更点を識別するようにCDCを設計する必要があります。
変更対象データの変更点を識別する
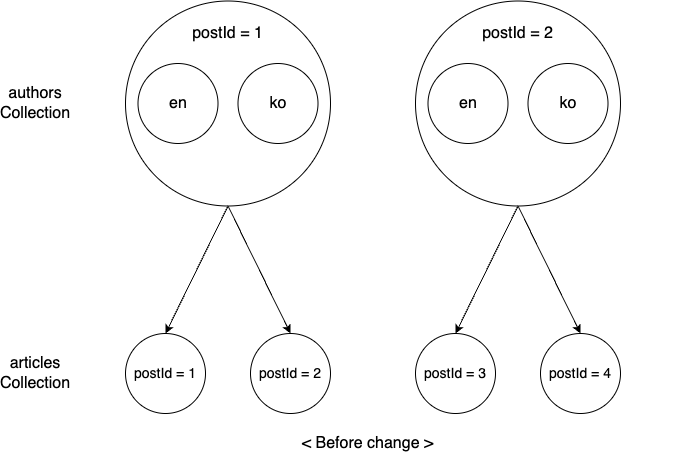
以下は、著者データを保存するために使用されるauthorsコレクションです。このコレクションでauthors=1の英語のニックネームを変更してみます。
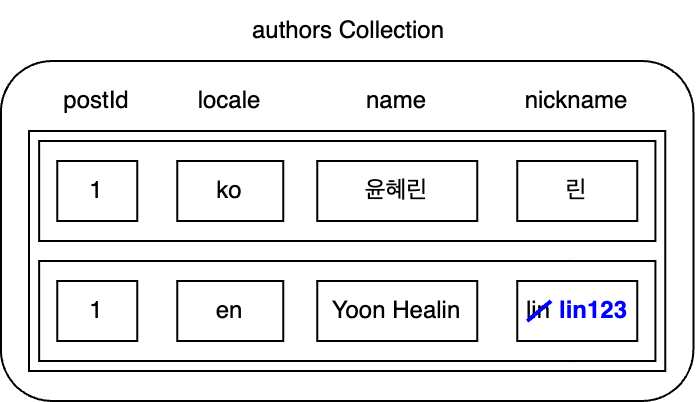
上記のような事例でのデータ変更点は非常にシンプルです。
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | en | ||
| nickname | lin123 |
リレーションシップデータの変更点を識別する
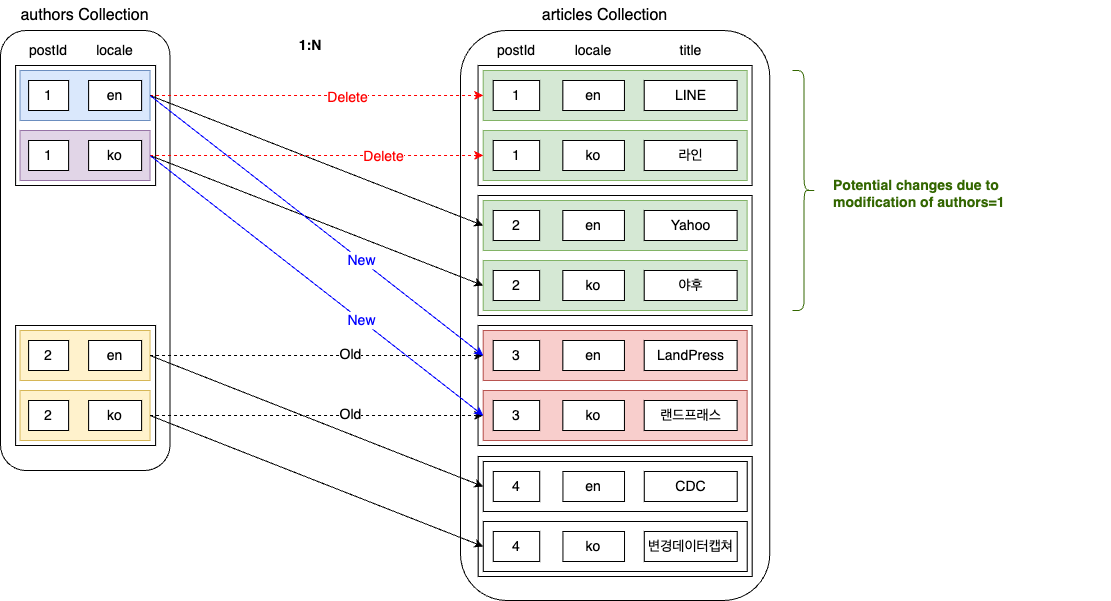
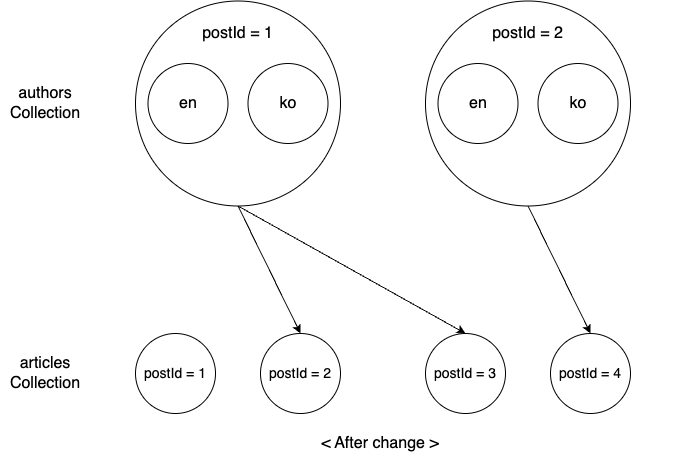
上記の事例を、記事データを保存するarticlesコレクションと一緒に見てみます。1人の著者は複数の記事を作成できるため、authorsコレクションとarticlesコレクションは1:Nの関係になります。ここでは、authors=1とauthors=2が、それぞれ以下のようにarticlesとリレーションシップが設定されているとします。
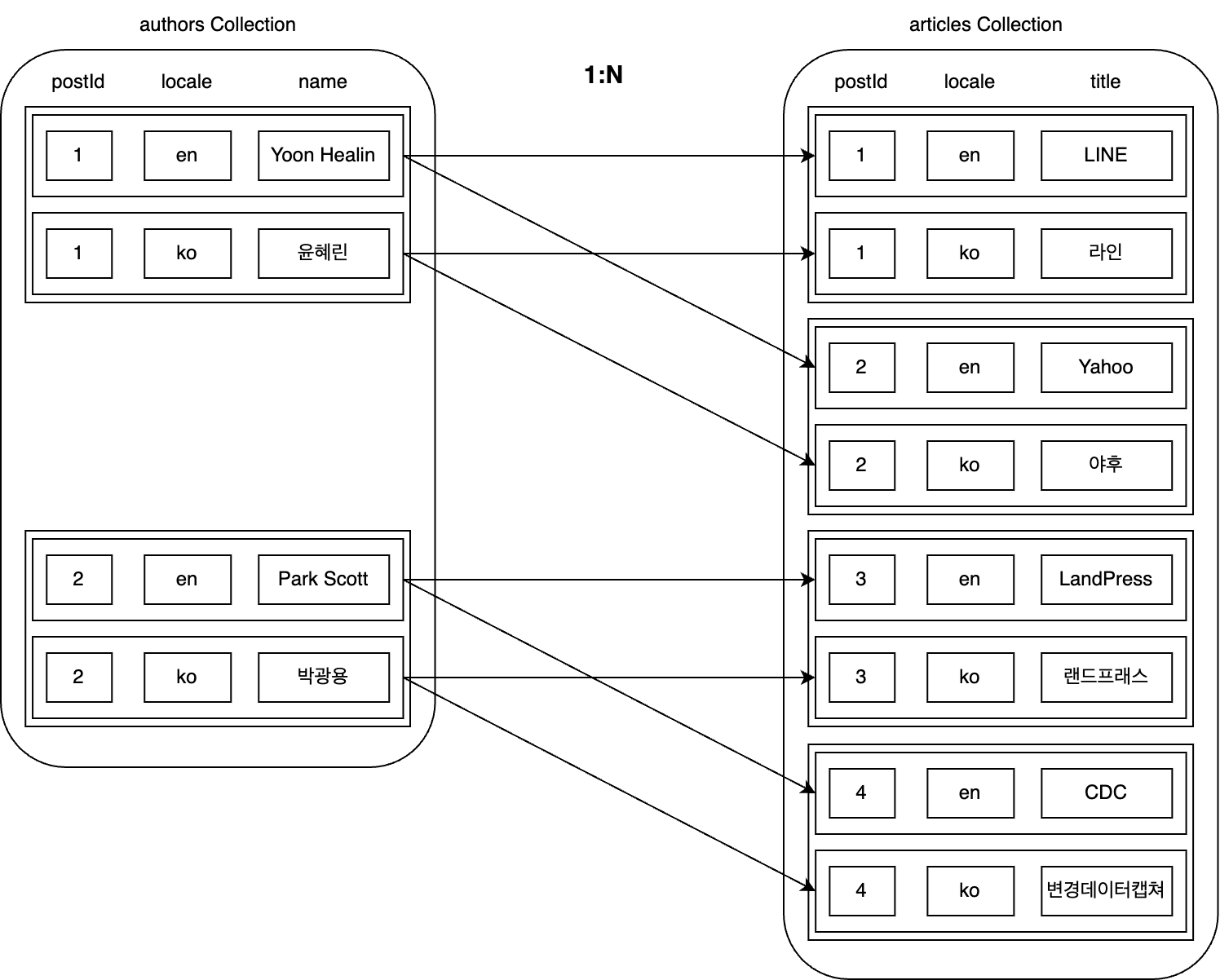
このような状況でauthorsとarticlesを誤ってマッチングしたことを発見し、以下のように修正したとします。
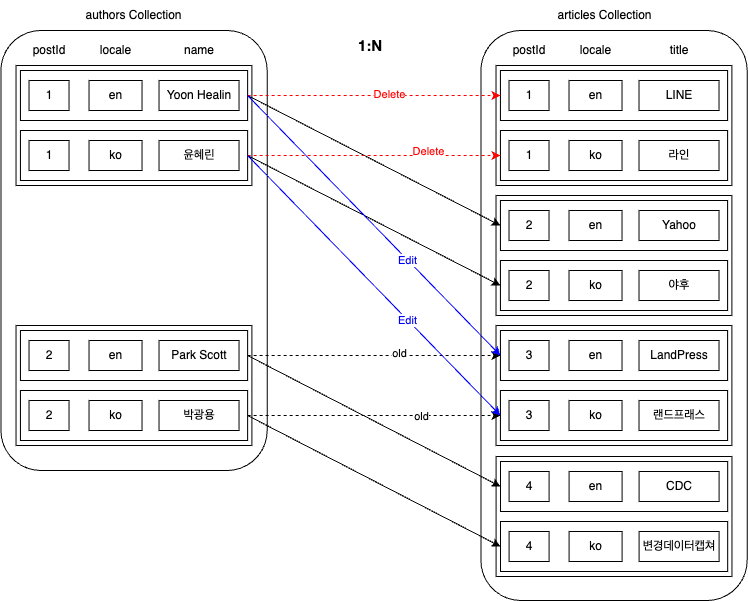
上記のようにリレーションシップデータが変更される場合、データの変更点はより複雑になります。以下のように計5つの領域で変更が発生する可能性があります。一つずつ見ていきます。
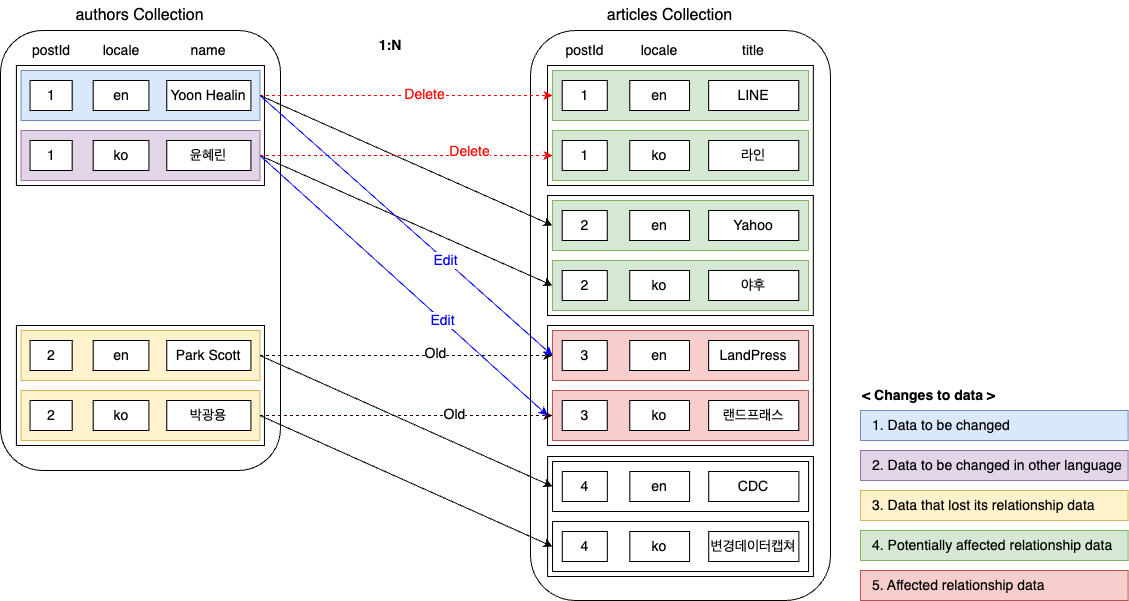
変更対象データ
ユーザーリクエストによって変更対象となるデータです。
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | en | ||
| articles | 2 |
変更対象データの他言語データ
各データは複数の言語で管理できます。言語が違うだけで同じデータなので、postIdを共有します。そうすることで、同じ著者が韓国語のページでは韓国語名で、英語のページでは英語名で紹介されます。そのとき、リレーションシップはpostIdに基づいて紐づけられます。したがって、特定の言語でリレーションシップデータを修正すると、他の言語のリレーションシップデータも修正されるため、識別データに含める必要があります。
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 1 |
| locale | ko | ||
| articles | 2 |
リレーションシップデータを奪われたデータ
articles=3は、もともとauthors=2と紐づけられていました。しかし、今回の変更でauthors=2はauthors=1にリレーションシップデータを奪われてしまいました。したがって、authors=2のデータにも変更が発生するため、識別データに含める必要があります。
| num | collection | key | value |
|---|---|---|---|
| 1 | authors | postId | 2 |
| locale | en | ||
| articles | 3 | ||
| 2 | postId | 2 | |
| locale | ko | ||
| articles | 3 |
影響を受ける可能性のあるリレーションシップデータ
次は、影響を受ける可能性のあるリレーションシップデータです。ユーザーがauthors=1に紐づけられたarticlesを修正した場合、articlesから見て、紐づけられたauthorsの値が変更される可能性があります。したがって、それを識別データに含め、後で実際に値が変更されたかどうかを確認する必要があります。
| num | collection | key | value |
|---|---|---|---|
| 1 | articles | postId | 1 |
| locale | en | ||
| authors | 1 | ||
| 2 | postId | 1 | |
| locale | ko | ||
| authors | 1 | ||
| 3 | postId | 2 | |
| locale | en | ||
| authors | 1 | ||
| 4 | postId | 2 | |
| locale | ko | ||
| authors | 1 |
影響を受けるリレーションシップデータ
最後に、articles=3はauthorsの変更に影響を受けることが確定されたリレーションシップデータです。したがって、識別データに含める必要があります。
| num | collection | key | value |
|---|---|---|---|
| 1 | articles | postId | 3 |
| locale | en | ||
| authors | 1 | ||
| 2 | postId | 3 | |
| locale | ko | ||
| authors | 1 |
変更点をキャプチャする
変更点をすべて識別したら、次は変更前と変更後のデータをキャプチャします。そのときに必要なデータベース照会は、ユーザーリクエストのトランザクション内で実行される必要があるため、応答速度の低下を防ぐために重複照会が発生しないように設計しました。リレーションシップデータを照会する際には、不必要なデータ収集を避けるために、最小限の識別情報(postIdと言語情報)のみを取得して利用しました。
キャプチャするときは、変更前のデータと変更後のデータのうち、どの時点を基準にキャプチャするかを選択する必要があります。作成は変更前の値がなく、削除は変更後の値がないため、どの時点を基準にキャプチャするかによって以下のような違いが生じます。
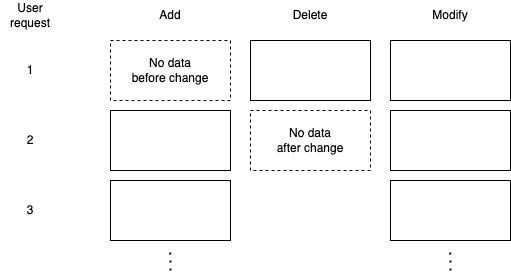
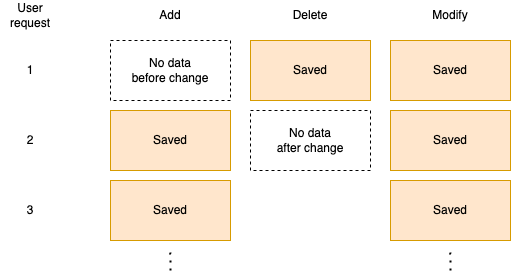
LandPress Contentは、データの作成と削除の両方に対するCDCを実行するために、作成と修正の場合は変更後の値を基準に、削除の場合は変更前の値を基準にデータを保存しています。
キャプチャした変更点から実際に変更された点のみを選別する
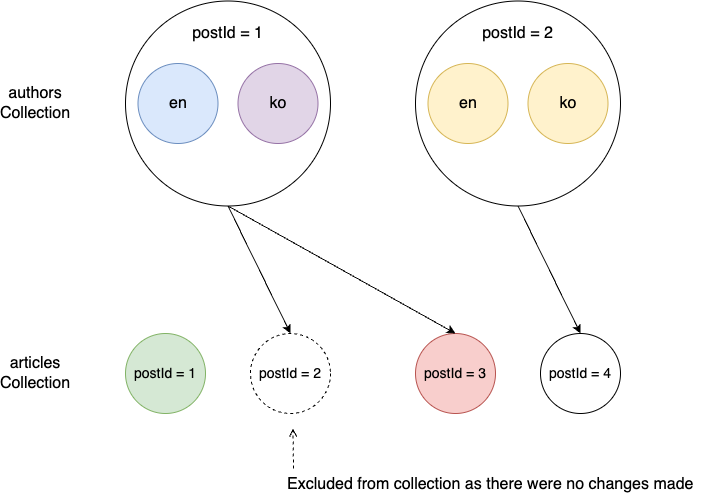
上記のようなプロセスで予想される変更点を識別し、キャプチャまで完了しました。しかし、そのデータをすべて保存することはできません。「実際に変更があった点」のみを選別する必要があります。実際に変更があったかどうかを確認するために、キャプチャしたデータの変更前後の値を比較します。
上の例の変更前後を比較し、実際に変更があったことを表示すると、以下のようになります。
参考までに、このプロセスはユーザーリクエストのトランザクションの外で実行されるように設計し、ユーザーの応答待ち時間を短縮しました。
選別したデータをデータパイプラインに送信する
次に、選別したデータを加工・保存するために、データパイプラインに送信します。
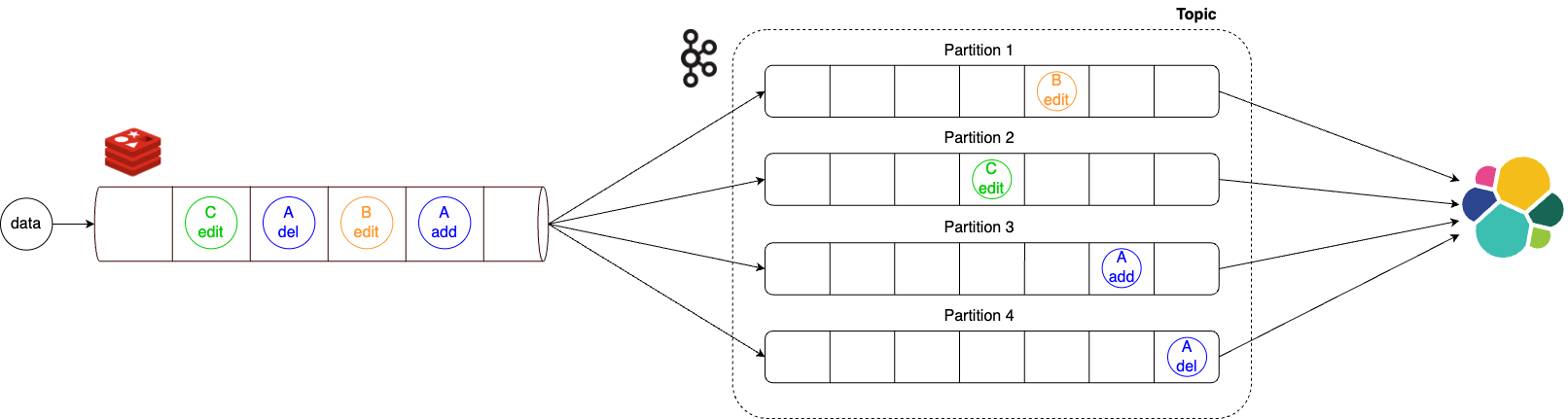
当初は、大量のデータを迅速に処理するために、Kafkaパーティショニングを使用してパイプラインを並列構造で設計しました。しかし、この構造では同じアイテムに対する変更イベントの発生順序が保証されないという問題がありました。例えば、アイテム追加→アイテム削除の順に変更があったのに、アイテム削除→アイテム追加の順にデータが到着することがあり、そのため、アイテムが削除された後も検索エンジンにはデータが残ってしまうなどのエッジケースが発生する可能性がありました。
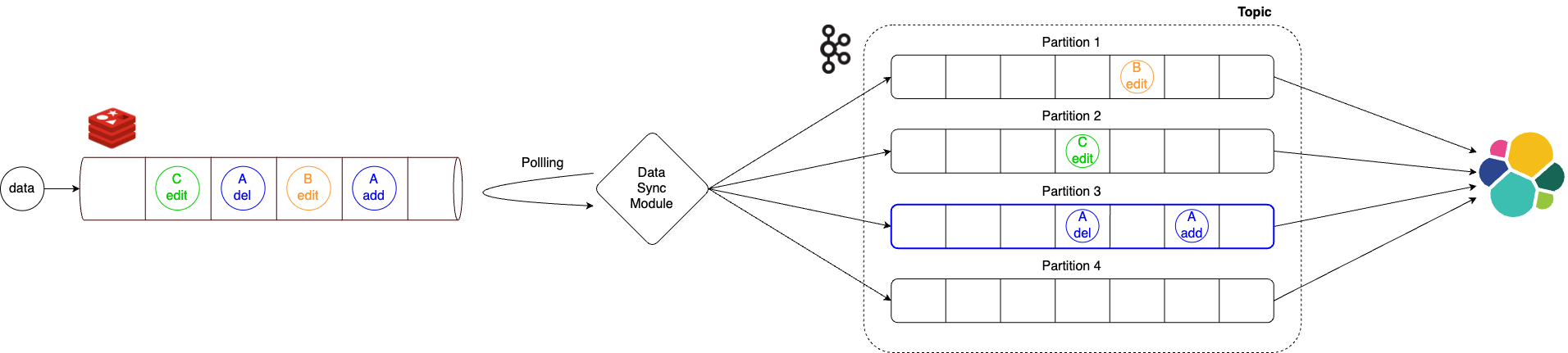
この問題を解決するために、イベント発生順序を保証する中間モジュールを開発し、同じアイテムの場合は同じパーティションにのみ送信されるように設計することで、イベント発生順序が保証されるように変更しました。
おわりに
こうして開発されたCDCは、LandPress Contentのアイテム履歴機能や検索機能などに利用されています。
今回の記事では、LandPress ContentサービスのCDC開発プロセスを紹介しました。大量のデータの変化を効率的かつ安定的に処理するために、設計プロセスからいろいろ工夫して開発しました。この記事が、同じような課題で悩んでいる方に少しでも役に立つことを願っております。長文でしたが、読んでいただきありがとうございました。


