들어가며
안녕하세요. LINE Plus에서 Global E-Commerce Platform 개발을 맡고 있는 장효택입니다.
LINE Brand Catalog와 통합 커머스 검색 서비스(이하 통합 커머스 검색으로 통칭)에는 다양한 위치에 수많은 이미지가 사용되고 있습니다. 가장 흔하게 접할 수 있는 상품, 카탈로그 이미지부터 브랜드와 카테고리 영역 등에서도 이미지가 사용됩니다.

통합 커머스 검색에서는 외부 상점의 상품 이미지를 OBS라는 사내 미디어 플랫폼에 저장해서 사용자에게 보여줍니다. 이 과정에서 불필요한 이미지 중복 저장 방지와 성인 이미지 검출, 이미지 사용처 확인 등 다양한 기능을 최적화해 사용하기 위해 이미지의 고유 ID와 크기, 색상 정보, 성인 이미지 점수 등 여러 정보를 MySQL에 저장해 관리하고 있습니다.
현재 통합 커머스 검색에 존재하는 상품 수는 10억 개를 상회하고 각 상품은 여러 장의 이미지를 사용할 수 있기 때문에 결과적으로 26억 개가 넘는 이미지가 저장 및 관리되고 있는데요. 통합 커머스 검색 서비스의 규모가 계속 커지면서 DB 마이그레이션을 진행할 수밖에 없었습니다.
저희 팀은 DB 마이그레이션을 진행하면서 독특하게 Kafka 생태계와 ETL 데이터를 적극 활용하는 방법을 사용해서 MySQL에서 MongoDB로의 마이그레이션을 성공적으로 완료할 수 있었습니다. 이번 글에서는 마이그레이션을 결정한 순간부터 마이그레이션 성공 후 MongoDB로 운영하는 현재에 이르기까지의 경험을 공유하겠습니다.
마이그레이션이 필요하다는 신호
통합 커머스 검색에 새로운 상점이 입점하고 등록되는 상품이 계속 증가하면서 자연스레 저장하고 관리하는 이미지가 더욱 많아졌습니다. 새로 추가되는 이미지의 개수를 살펴보면 한 달에 적게는 4,000만 건에서 많게는 2억 건이 넘는 이미지가 새로 추가되고 있습니다.
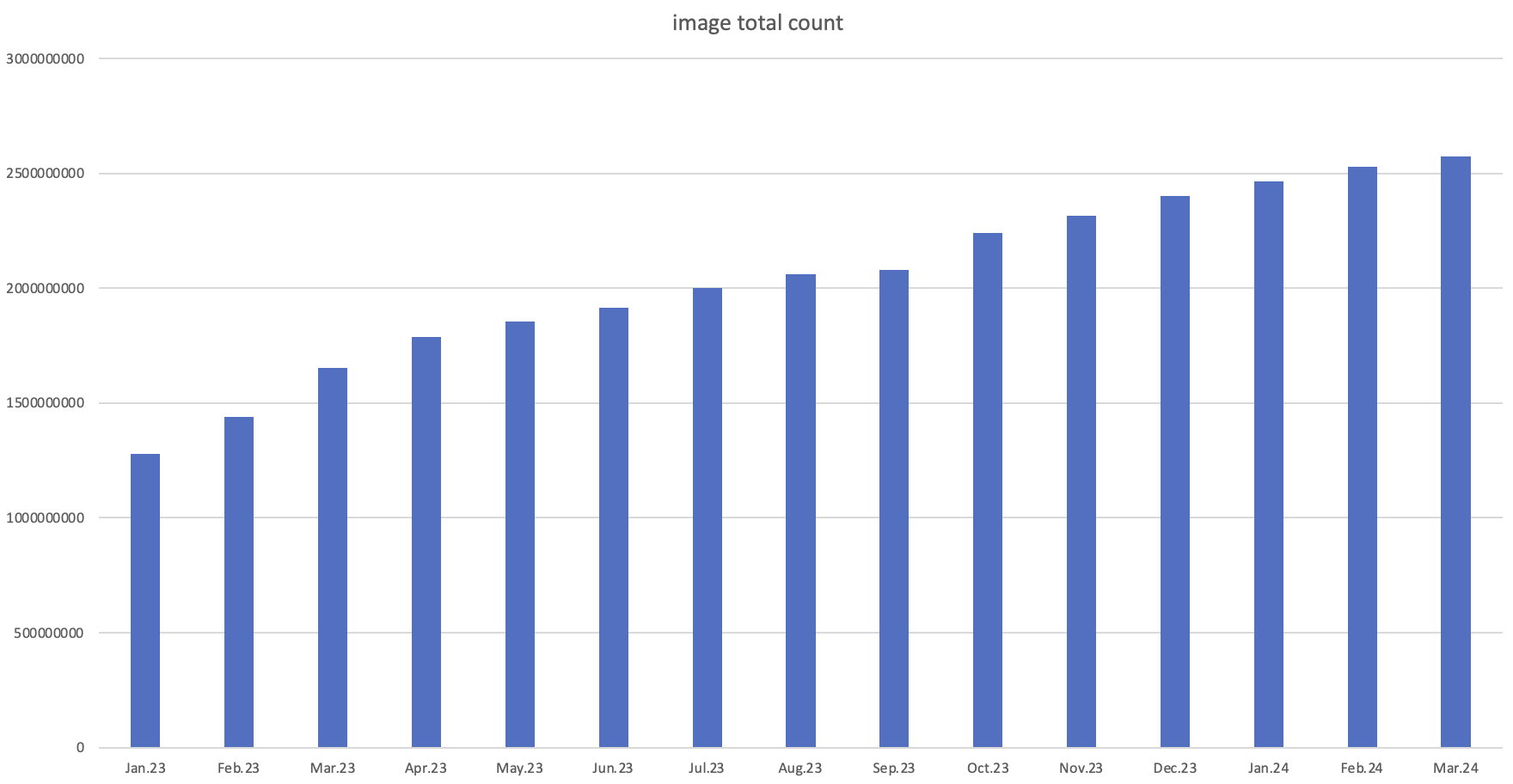
신규 이미지가 증가하면서 이미지의 정보를 저장하는 테이블(이하 이미지 테이블)과 이미지 사용처의 정보를 저장하는 테이블(이하 참조 테이블)이 빠르게 커졌습니다.
이와 같이 두 테이블의 크기가 빠르게 증가하면서 다음 두 가지 문제에 대한 우려가 커졌습니다.
MySQL 디스크가 가득찰 것으로 예상
MySQL에서는 이미지 관련 테이블뿐 아니라 통합 커머스 검색 서비스 운영에 필요한 다른 여러 테이블도 함께 존재하는데요. 이미지 관련 테이블이 빠르게 커지면서 MySQL의 디스크 사용량이 90%를 초과했고, 그중 이미지 관련 테이블의 비율이 70%을 초과했습니다. 한 달에 약 1%씩 크기가 증가하고 있었고, 이 추세라면 일 년 내에 이미지 테이블은 물론 다른 테이블에도 영향을 미칠 수 있는 상황이었습니다. 타 테이블들은 서로 연관성이 깊고, 안정성을 확보하기 위한 트랜잭션 작업과 스키마 정의가 필수라서 마이그레이션하기가 어려웠습니다.

데이터가 너무 많아 스키마 변경 어려움
서비스를 운영하다 보면 필드를 변경하거나 새로 추가해야 하는 일이 발생하는데요. 이미지 테이블의 경우 데이터가 워낙 많다 보니 스키마를 변경하면 시스템이 느려지거나 멈추는 현상(hang up)이 발생해 쉽게 변경할 수 없었습니다.
MongoDB를 선택한 이유
앞으로 수억 건의 대규모 이미지 유입이 예정돼 있었기에 그전에 안정적인 DB를 구축하는 것이 중요한 상황이었습니다. 다양한 선택지가 있었는데요. 그중에서 MongoDB는 아래와 같은 장점이 있었습니다.
- 샤딩(sharding)을 이용한 확장이 자유로워 신규 이미지가 대규모로 유입돼도 쉽게 대응할 수 있다.
- 서비스를 최적화하기 위해 이미지 정보를 추가하는 일이 발생하는데 스키마리스(schemaless) 특성이 있어서 스키마 변경에 부담이 없다.
이미 최대 성능을 사용하고 있어서 더 이상 스케일 업을 할 수 없는 MySQL을 대체하기에는 MongoDB가 가장 적합하다고 판단했고, MongoDB로 마이그레이션하기로 결정했습니다.
마이그레이션 개요
마이그레이션의 긴 여정을 떠나기 전에 아래 그림과 함께 전체 흐름을 살펴보겠습니다. 초록색 박스는 MySQL의 데이터를 MongoDB로 옮기고, 실시간으로 동기화된 상태 만드는 작업들을 의미합니다. 주황색 박스는 MySQL을 사용하는 Image service의 DB를 MongoDB로 전환하는 작업들을 의미합니다.

마이그레이션 과정을 한 번에 이해하지 못하셔도 괜찮습니다. 마이그레이션에서 사용했던 모듈을 순서대로 살펴볼 예정이며, 길을 잃지 않도록 중간중간 어느 모듈을 설명하는지 함께 표기할 테니 마이그레이션 여정의 끝까지 함께 하시길 기원해 봅니다. 그러면 본격적으로 마이그레이션 여정을 떠나보겠습니다.
MySQL과 MongoDB 동기화
먼저, MySQL과 MongoDB 간 동기화를 어떻게 했는지 살펴보겠습니다. 아래 내용은 특히 Kafka와 MongoDB로 대규모 데이터를 다룰 때 알아두면 도움이 될 것 같습니다.
데이터 클렌징으로 마이그레이션 준비
빠르고 안전하게 마이그레이션하려면 우선 마이그레이션할 데이터의 양을 줄이는 것이 중요합니다. 서두에서 말했듯 저희는 약 26억 건의 이미지를 저장하고 있었고, 각 이미지의 사용처를 관리하는 데이터도 약 26억 건 존재했습니다. 최대한 데이터를 줄여야 마이그레이션 시간을 절약하고 DB 리소스도 절감할 수 있기에 마이그레이션 6개월 전부터 참조 데이터 클렌징을 시작했습니다. 그 결과 사용하지 않는 이미지 사용처를 관리하는 참조 데이터 약 16억 건을 제거하는 데 성공해 마이그레이션해야 하는 데이터를 약 36억 건으로 줄일 수 있었습니다.
| 이미지 데이터 레코드 수 | 참조 데이터 레코드 수 | 합계 |
|---|---|---|
| 2,598,092,887 | 1,020,047,542 | 3,618,140,429 |
마이그레이션 방법 수립: ETL(Extract, Transform, Load) 데이터와 CDC(Change Data Capture) 활용
통합 커머스 검색에서는 누락된 이미지 재처리와 성인 이미지 점수 계산 등을 수행하는 다양한 배치 잡을 수행하고 데이터를 분석하기 위해 매일 Hadoop 기반의 사내 빅데이터 분석 플랫폼인 IU를 기반으로 ETL 작업을 진행하고 있습니다. 이미지 서비스의 경우 Sqoop을 활용해 일자별로 이미지와 참조 전체 데이터를 IU에 파티션별로 저장하고 있습니다. MySQL에서 MongoDB로 데이터를 옮기는 방법에는 여러 가지가 있을 텐데요. 저희는 ETL 데이터를 적극 활용하기로 결정했습니다.
ETL 데이터를 어떻게 활용하는지 아래 그림과 함께 예시를 들어보겠습니다.

먼저 오늘이 4월 22일이라고 가정하겠습니다. 4월 22일의 ETL 데이터를 그대로 MongoDB에 삽입하면 MongoDB는 ETL에서 데이터를 추출한 시점(4/22 08:30:00)의 MySQL과 유사한 상태라고 볼 수 있습니다. 유사한 상태라고 말하는 이유는 정확한 ETL 시점을 판단하기 어려울뿐더러, 여러 익스큐터(executor)에서 모두 같은 시간에 데이터를 추출한다고 볼 수 없기 때문입니다.
만약 여기서 멈춘다면 ETL에서 데이터를 추출한 시점부터 현재 시각까지의 변경 사항은 반영되지 않는데요. 이를 보완하기 위해 ETL에서 데이터를 추출한 시점부터는 MySQL의 변경 사항을 CDC(Change Data Capture) 데이터를 통해 MongoDB에 반영합니다. 이를 통해 MySQL과 MongoDB가 동기화된 상태를 유지할 수 있습니다.
ETL 데이터를 MongoDB로 이관
큰 그림을 확인했으니 이제 구체적으로 하나씩 살펴보겠습니다. 먼저 Synchronizer from ETL 실행과 제거 모듈인데요. 여기서 제거 모듈은 모든 작업이 완료된 후 더 이상 필요 없어진 실행 모듈을 제거하는 간단한 모듈이기 때문에 따로 설명하지 않고, 실행 모듈만 구체적으로 살펴보겠습니다.

Synchronizer from ETL 실행 단계는 IU에 있는 데이터를 MongoDB로 옮기는 단계입니다. 어떤 식으로 내부 구현을 할 지 고민하던 중 팀에서 사용하고 있는 hive-to-kafka라는 모듈이 눈에 들어왔습니다. hive-to-kafka는 아래와 같이 Spark SQL로 Hive 테이블을 조회한 결과를 JSON 형태의 Kafka 메시지로 만들어 특정 토픽에 전송해 주는 배치 모듈입니다.
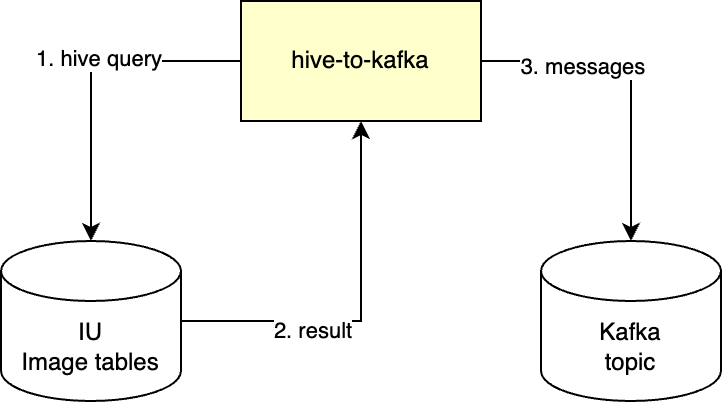
이 모듈을 이용해 특정 날짜의 이미지 ETL 테이블 전체를 조회하는 쿼리를 만들어 Kafka 메시지로 발행하고, 그 메시지를 Kafka 컨슈머를 통해 MongoDB에 저장하면 될 것 같았습니다.
분명 생각만으로는 너무 아름답게 잘 흘러갈 것 같은데요. 여기서 대상이 수십억 건이라는 것을 간과하면 안 됩니다. 메시지를 소비해서 MongoDB에 �저장하는 것은 뒷이야기고, 먼저 어떻게 36억 건의 메시지를 성공적으로 발행할지 살펴봐야 합니다.
테스트 삼아 hive-to-kafka를 사용해서 이미지 테이블의 메시지 3,000만 건을 발행해 봤더니 메시지 용량이 24GB였습니다. 이미지 테이블 전체를 추출한다면 2,080GB에 달할 것으로 예상됐고, 복사본 수(replication factor)를 1로 해도 브로커별로 115GB의 공간이 필요했습니다.
| 이미지 메시지 용량(3,000만 건) | 예상 전체 용량 | Kafka 브로커별 저장될 용량 |
| 24GB | 2,080GB | 115GB |
당시 브로커의 리소스에 여유가 있지 않았기에 전체 데이터를 추출해서 브로커에 할당하는 것은 선택할 수 없었고, 이를 해결하기 위해 Kafka의 메시지 압축 기능을 사용했습니다.
Kafka의 메시지 압축 기능
Kafka에는 압축 기능이 존재합니다. 압축해서 용량을 획기적으로 줄인다면 전체 메시지를 발행해도 Kafka 브로커의 디스크가 가득 차는 것을 피할 수 있을지도 모릅니다.
아래 표는 IBM Developer 사이트에 올라온 'Message compression in Apache Kafka' 포스팅에서 가져온 Kafka 압축 기능에서 지원하는 각 압축 유형의 특성을 비교 정리한 표입니다.
| 압축 유형 | 압축 비율 | CPU 사용량 | 압축 속도 | 네트워크 대역폭 사용량 |
|---|---|---|---|---|
| Gzip | Highest | Highest | Slowest | Lowest |
| Snappy | Medium | Moderate | Moderate | Medium |
| Lz4 | Low | Lowest | Fastest | Highest |
| Zstd | Medium | Moderate | Moderate | Medium |
각 ��압축 유형은 리소스 사용률과 압축률 등에서 차이를 보입니다. 따라서 어떤 압축 유형이 가장 적합할지 비교해 봐야 하는데요. 이때 고려해야 할 또 한 가지 사항이 높은 압축률을 달성하려면 적은 양의 메시지를 압축하는 것보다 다량의 메시지를 압축하는 것이 좋다는 것입니다.
이를 위해 두 가지를 설정할 수 있습니다. batch.size와 linger.ms입니다. batch.size는 한 번에 전송할 수 있는 배치 크기의 상한선을 정합니다. 만약 누적된 레코드의 바이트 크기가 batch.size보다 작으면 더 많은 레코드가 모일 때까지 linger.ms 시간만큼 대기할 수 있습니다. batch.size의 기본값은 16384이고, linger.ms의 기본값은 0인데요. linger.ms값이 0이면 batch.size만큼 모이지 않아도 레코드를 전송할 수 있는 상황이면 즉시 레코드를 전송합니다. 앞서 말씀드렸듯 다량의 메시지를 보내는 것이 압축률 측면에서 효과적이기에 linger.ms를 설정해 batch.size가 모일 때까지 잠시 기다리는 것이 좋은데요. hive-to-kafka는 쿼리의 결과를 바로 프로듀싱하기에 linger.ms를 설정해도 큰 지연이 없을 것으로 생각했습니다.
아래 표는 이미지 데이터에는 어떤 압축 타입이 효과가 좋은지 확인하기 위해 각 압축 타입과 linger.ms, batch.size를 조절해 테스트를 진행한 결과입니다.
| 압축 유형 | linger.ms(단위: 밀리초) | batch.size(단위: 바이트) | 압축 전 용량 | 압축 후 용량 | 미압축 대비 압축률 |
|---|---|---|---|---|---|
| 압축하지 않음 | x | 16384 | 24GB | 24GB | - |
| 압축하지 않음 | x | 32768 | 24GB | 25GB | 104% |
| lz4 | 3000 | 16384 | 24GB | 9GB | 62.53% |
| lz4 | 6000 | 16384 | 24GB | 9GB | 62.53% |
| lz4 | 3000 | 32768 | 24GB | 9GB | 62.53% |
| lz4 | x | 16384 | 24GB | 13GB | 45.82% |
| gzip | 3000 | 16384 | 24GB | 7GB | 70.82% |
| gzip | 3000 | 32768 | 24GB | 7GB | 70.82% |
| gzip | x | 16384 | 24GB | 10GB | 58.79% |
| snappy | 3000 | 16384 | 24GB | 10GB | 58.79% |
| snappy | x | 16384 | 24GB | 12GB | 50% |
| zstd | x | 16384 | 24GB | 13GB | 45.82% |
압축률은 60%만 넘으면 브로커의 리소스에는 충분한 여유가 생기기에 그 외에 CPU 사용량과 압축 속도도 고려했습니다. 또한 압축되는 크기가 크면 추후 컨슈머에서 소비 속도가 느려질 수 있기에 비슷한 압축률이라면 압축 해제하는 데 리소스가 적게 드는 작은 batch.size를 선택하고자 했습니다. linger.ms의 경우에도 메시지가 빠르게 생성되기에 긴 시간을 설정해도 큰 효과가 있지 않아서 동일한 압축률이라면 짧은 시간으로 선택했습니다.
위 사항을 종합적으로 판단했을 때 lz4 압축 타입에 linger.ms는 3000, batch.size는 16384를 설정하는 것이 가장 효과적이라고 판단했습니다.
자, 이제 메시지 압축에도 성공해 전체 메시지를 발행할 수 있게 됐습니다. 그런데 고려해야 할 점이 하나 더 있습니다. 저희는 샤딩(sharding)한 MongoDB에 데이터를 넣어야 합니다. 수십 억 건의 데이터를 단시간에 삽입되기에 유실 없이 잘 저장되도록 MongoDB의 부하와 상태 관리에도 신경을 써야 합니다.
메시지 키와 MongoDB 샤드 부하 간의 상관 관계
성공적으로 발행된 ETL 메시지를 MongoDB에 저장할 때 긴 시간이 걸린다면 뒤에 이어지는 CDC 기반 마이그레이션 작업에서 처리할 메시지양이 많아집니다. 그렇게 되면 메시지 보관 기간이 길어지면서 Kafka 리소스를 더 많이 차지합니다. 또한 CDC 기반 마이그레이션 작업은 멱등성을 보장할 수 있도록 구성하긴 했지만 예상치 못한 상황이 발생할 수도 있기에 마이그레이션 시간이 늘어나는 것은 피하고자 했습니다.

따라서 최대한 빠르고 안전하게 메시지를 소비해 ETL 기반 마이그레이션을 완료해야 한다는 목표가 생겼습니다. 쿠버네티스의 리소스는 충분해서 처리량을 높이기 위해 토픽의 파티션을 늘리고 그에 맞게 파드를 실행할 수 있었는데요. 고민했던 점은 '어떻게 MongoDB가 이 높은 처리량을 감당할 수 있도록 만들까?'였습니다.
문제 해결을 시작하기 전에 MongoDB를 이해할 필요가 있습니다. MongoDB의 샤드는 청크(chunk)라는 논리적 단위의 집합으로 구성돼 있습니다. 청크는 샤드 키(아래 그림에선 x)로 청크의 범위를 표현합니다. 아래와 같은 상황에서 만약 x: -100이라는 키를 가지고 있는 문서(document)가 삽입된다면, 해당 문서는 Chunk 1에 포함됩니다.

만약 샤드 키가 연속된 형태로 들어오면 어떻게 될까요? 아래 그림처럼 범위 기반 샤딩을 사용한다면 특정 청크에 데이터와 부하가 쏠릴 수 있습니다. 또한 값이 증가하는 형태의 키가 들어온다면 항상 최대 키의 상한을 포함하는 청크로 라우팅됩니다. 따라서 범위 기반 샤딩에서 부하를 여러 청크에 균등하게 나누려면 다양한 키 값이 섞인 상태로 삽입되는 것이 이상적입니다.

만약 해시 샤딩을 쓴다면 단조롭게 증가하는 키가 들어와도 해시 함수를 거치면서 �다른 청크로 라우팅될 수 있습니다. 따라서 여러 청크로 나눠서 라우팅하기 위해서는 해시 샤딩이 가장 편리한 방법이었는데요. 저희는 해시 샤딩과 범위 기반 샤딩을 모두 고려하고 있었습니다. MongoDB ETL 작업 시 MongoDB Connector for Spark를 사용하는데 MongoDB Connector for Spark에는 범위 기반 샤딩에서만 작동하는 파티셔너가 있었기 때문입니다. 따라서 최대한 여러 선택지를 마련하고자 두 샤딩을 모두 고려해야 했습니다.
범위 기반 샤딩을 사용한다면 삽입되는 문서의 키를 단조롭지 않게 만들어야 했습니다. 쿼리의 결과가 곧 발행되는 메시지의 순서이고, MongoDB에 삽입되는 순서이기 때문에 쿼리 결과의 순서가 랜덤하게 나오면 비로소 저희가 바라는 그림이 완성되는 것인데요. 다행히도 Spark SQL에는 rand()라는 난수를 반환하는 함수가 있기에 SORT BY rand()로 결과의 순서를 랜덤하게 만들 수 있었습니다.
SELECT * FROM db.image_table WHERE dt='20240422' SORT BY rand()
# dt는 날짜로 구분되는 hive의 partition field입니다.만약 SORT BY를 사용하기 어려운 상황이라면 성능이 조금 떨어지긴 하지만 ORDER BY rand()로 대체할 수 있습니다.
청크 부하 최적화
위 작업을 통해 저장할 문서의 키가 무작위로 들어오는 데까지 성공했다고 해도 아직 방심하긴 이릅니다. 샤드 개수가 세 개라고 가정했을 때, 비어 있는 컬렉션에 샤딩을 적용하면 아래 그림처럼 청크가 구성됩니다.

적합한 샤드 키를 설정하고 삽입되는 문서 키의 순서가 랜덤한 상황에서 빠른 속도로 많은 양의 데이터를 넣는다고 가정했을 때 다음과 같은 문제가 발생할 수 있습니다.
- 범위 기반 샤딩: 청크 1번에만 있기에 청크가 분할되기 전까지는 부하가 분산되지 않습니다. 삽입되는 양이 많다면 청크 분할이 많이 발생할 것이고, 이때 분할 속도가 데이터 삽입 속도를 따라가지 못한다면 청크에 큰 부하가 걸릴 수 있습니다.
- 해시 샤딩: 샤드마다 청크가 있기에 부하는 분산되겠지만 범위 기반 샤딩과 동일하게 분할과 청크 부하 문제가 발생할 수 있습니다.
따라서 삽입할 데이터의 크기를 안다면 미리 청크를 만들어서 샤드의 부하와 분할로 인한 부하를 줄일 수 있습니다. 초기 청크를 설정하는 방법은 각 샤딩 방식에 따라 다릅니다.
| 샤딩 방식 | 방법 | 설명 |
|---|---|---|
| 범위 기반 샤딩 | db.adminCommand( { split: <database>.<collection>, middle: <document> } ) | 범위 기반 샤딩에서는 numInitalChunks를 설정할 수 없기에 대체 방법으로 MongoDB의 Split이라는 명령어를 사용해 임의로 청크를 쪼갭니다. |
| 해시 샤딩 | sh.shardCollection("dbName.tableName", {shardKey : 'hashed'}, { numInitialChunks: 100 }) |
컬렉션에 샤딩을 설정할 때 샤드가 5개라고 가정하고 예시처럼 |
저희는 위 방법을 이용해 사전에 아래와 같이 비어있는 청크를 여러 개 생성했습니다.
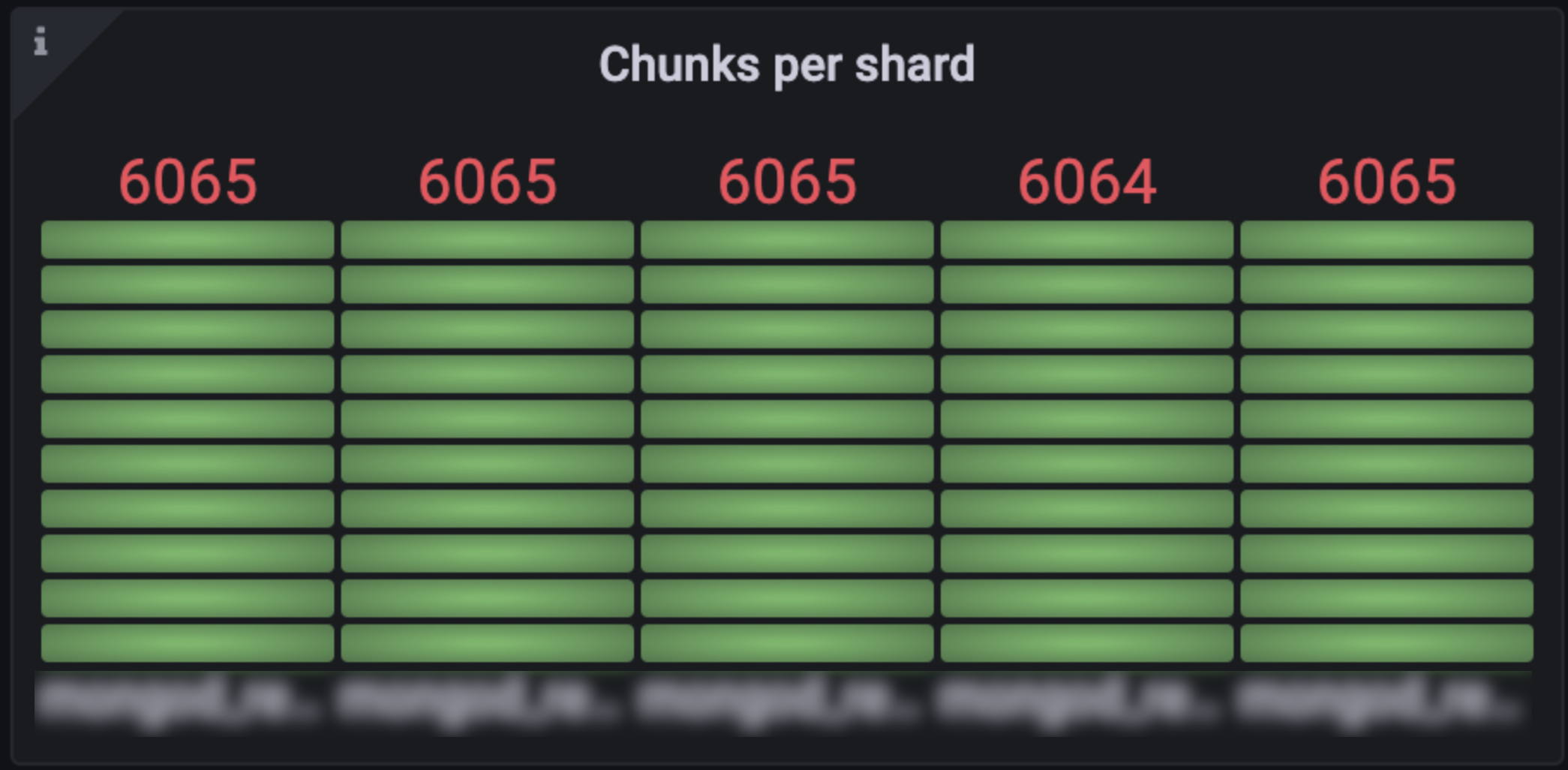
MongoDB 모니터링 항목
메시지를 MongoDB에 저장할 때에는 처리량을 늘리기 위해 Kafka의 batchMode를 이용해 벌크로 메시지를 받아오고, MongoDB에 대량 삽입(bulk insert)으로 저장했습니다. 높은 처리량 때문에 대규모 DML이 발생하기에 MongoDB 모니터링은 필수인데요. 주의 깊게 모니터링하면서 수집한 지표를 공유하겠습니다.
샤드별 DML 수치
샤드별로 부하가 제대로 분산되는지 확인할 수 있습니다. 아래 그래프는 부하 분산이 제대로 되지 않을 때의 모습입니다. 처음 마이그레이션을 시도할 때 미리 청크를 만들어 놓지 않아서 특정 청크와 샤드에 부하가 집중됐습니다. 해당 지표를 통해 부하 분산이 원활하지 않다는 것을 파악하고 앞서 말씀드린 방법으로 초기 청크를 생성했습니다.

Write Ticket 사용량
MongoDB의 기본 엔진인 Wired Tiger는 동시성 제어를 위해 읽기와 쓰기 티켓을 생성하고 관리합니다. 만약 특정 샤드에서만 티켓이 고갈된다면 부하가 제대로 분산되지 않는다는 것을 알 수 있고, 전체적으로 티켓이 부족하다면 부하가 심하다고 판단할 수 있습니다.
아래 그래프는 쓰기 티켓 가용량을 나타내는 그래프입니다. 수치가 낮을수록 사용량이 높은 것인데요. 빨간 그래프만 사용 가능한 티켓이 0에 수렴하는 것을 알 수 있습니다. 쓰기 부하가 제대로 분산되지 않고 있거나 MongoDB가 처리할 수 있는 쓰기 용량을 초과했다는 것을 의미합니다. 후자의 경우 MongoDB의 스펙을 올리거나 쓰기 부하를 낮춰야 합니다.

복제 지연(replication lag)
짧은 시간에 너무 많은 데이터가 삽입되면 복제가 설정된 DB에서는 복제 지연이 발생할 수 있고, 지연이 너무 길어지면 서비스 불가 상태가 될 수 있습니다. 따라서 복제 지연이 너무 커진다면 삽입 속도 조절을 고려해야 합니다.
아래 상단 그림의 그래프에서는 지연이 수십 초로 올라갔다가 떨어지지만, 하단 그림의 주황색 그래프는 지연이 계속 쌓이다 끊어지는 모습이 보입니다. 복제 지연이 쌓이다 서비스 불가 상태가 된 것으로 복제 지연이 줄어들지 않는다면 oplog의 크��기를 적정 수준으로 증가시키거나 쓰기 부하를 줄이는 것을 고려해야 합니다.


CPU와 메모리 사용량
MongoDB의 CPU와 메모리 사용량도 모니터링했습니다. 느린 쿼리(slow query) 발생 시 CPU를 많이 사용하는데 이때 가용할 수 있는 CPU 자원이 존재해야 MongoDB가 다운되는 것을 피할 수 있습니다.


ETL 데이터 MongoDB로 마이그레이션 완료
이로써 ETL 시점의 MySQL 이미지 테이블들을 MongoDB에 성공적으로 마이그레이션했습니다. 하지만 아직은 MySQL과 MongoDB가 서로 완전히 동기화된 상태가 아닙니다. ETL 시점부터 메시지를 전부 소비한 지금까지의 이미지 테이블 변경 사항이 아직 MongoDB에 반영되지 않았기 때문입니다.
이제 ETL 시점부터 현재와 미래까지 동기화해 주는 MySQL Cdc Connector와 메시지를 소비하는 Kafka 컨슈머에 관해 이야기해 보겠습니다.
MySQL CDC 기반 데이터 동기화
다음으로 살펴볼 모듈은 MySQL CDC 기반 데이터를 동기화하기 위한 Synchronizer from MySQL CDC 실행과 제거 모듈입니다. 앞서와 마찬가지로 ��제거 모듈은 모든 작업이 완료된 후 더 이상 필요 없어진 실행 모듈을 제거하는 간단한 모듈이기 때문에 따로 설명하지 않고, 실행 모듈만 구체적으로 살펴보겠습니다.

ETL 이후부터 현재까지의 변경 사항을 MongoDB에 적용하려면 CDC 토픽에 들어온 MySQL CDC 메시지를 MongoDB에 반영하면 되는데 이때 언제부터의 메시지를 소비할 것인지를 정해야 합니다. 사실 ETL 데이터가 정확히 어느 시점의 데이터인지는 알 수 없으며, 시점을 정했을 때 오차가 발생할 확률도 높습니다. 따라서 우선 누락된 메시지를 없애기 위해 ETL을 내리는 시점 직전으로 MySQL CDC 오프셋을 조절했습니다.

이렇게 조치하면 누락된 메시지는 없을 테지만 이미 ETL 테이블에 반영된 메시지가 존재할 수 있는데요. 각 CDC 메시지는 멱등성이 보장된 데이터가 아니기에 중복 처리를 하면 문제가 발생합니다. 즉, 중복된 메시지는 다시 처리되지 않게 로직을 구현해야 합니다.
CDC에 대한 멱등성 보장
이미지 테이블에 updatedDate라는 필드가 존재했기에 해당 필드를 사용해서 최신 메시지만 적용하도록 메시지를 판별하는 함수를 구현했습니다. 이로써 중복 메시지가 들어와도 최신 변경 사항만 적용할 수 있습니다.
fun isNewerMessage(message: Value): Boolean {
val existingImage = imageRepository.findById(message.id)
return existingImage.isEmpty || mapper.convertValue(message.updateDate.get(), OffsetDateTime::class.java).isAfter(existingImage.get().updatedDate)
}CDC 키 칼럼 변경
참조 테이블의 경우 PK 자체에는 큰 의미가 없고, 타 테이블과의 연관 관계도 없습니다. 또한 MySQL 참조 테이블의 PK는 AUTO_INCREMENT를 설정한 Long 타입이었지만, MongoDB에서 동일하게 AUTO_INCREMENT를 설정한 Long 타입을 사용하려면 별도의 Sequences 컬렉션이 필요했기에 ObjectId를 사용하도록 설계했습니다.

이처럼 MySQL의 키와 MongoDB의 키가 서로 다르기 때문에 양 DB에서 공유하는 키는 없다고 볼 수 있습니다. 따라서 양 DB 간 데이터의 정합성을 파악하기 위한 별도의 키가 필요해 image_id와 reference_type, reference_id(MongoDB에서는 imageId, referenceType, referenceId)를 조합한 고유키를 사용하기로 결정했습니다. 이와 같은 고유키를 만들어 메시지 키로 사용하지 않으면 다음과 같은 문제가 발생할 수 있습니다.
저희가 사용하고 있는 Debezium MySQL Connector는 기본적으로 PK를 메시지의 키로 사용합니다. 따라서 파티션을 분배할 때 ID가 다르면 다른 파티션으로 분배될 수 있습니다. 예를 들어 동일한 필드값의 행이 삭제된 뒤 바로 생성됐다고 가정해 보겠습니다. 삭제되고 생성되면 ID값이 달라지기에 할당되는 파티션도 달라질 수 있습니다. 아래와 같이 두 개의 메시지가 들�어왔을 때 결과가 두 개로 나뉠 수 있습니다.

첫 번째 케이스(Case 1)는 우연히 생성 메시지가 먼저 소비된 상황입니다. 만약 MongoDB에 고유키가 설정돼 있다면 '유일성(무결성) 제약 조건 위반(unique constraint violation)'이 발생할 것이고, 고유키가 설정돼 있지 않더라도 imageId, referenceId, referenceType의 조합키로 삭제하기에 존재하는 결과가 없을 것입니다.
두 번째 케이스(Case 2)는 실제로 MySQL에서 실행된 것과 같은 순서로 삭제 메시지가 먼저 소비됐습니다. 결과 또한 이상 없이 MySQL과 동일하게 나올 것입니다.
이처럼 메시지 처리 순서에 따라 결과가 달라지는 것을 막기 위해서는 CDC 메시지의 키를 변경해야 합니다. 동일한 의미를 갖는 데이터는 같은 파티션에 할당돼야 멱등성을 보장할 수 있습니다. 저희가 사용하고 있는 Debezium MySQL Connector에서는 message.key.columns라는 속성으로 키를 정의하는 방식을 변경할 수 있는데요. 이를 이용해 아래와 같이 동일한 의미의 메시지는 같은 파티션에 할당되도록 설정해서 CDC 메시지 처리의 멱등성을 보장했습니다.
"message.key.columns": "db_name.table_name:image_id,reference_id,reference_type"이것으로 ETL과 Kafka Connect를 통해 MySQL과 MongoDB 간 동기화까지 완료했습니다. 이제 본격적으로 이미지를 사용하는 곳에서 MySQL이 아닌 MongoDB를 사용하도록 바꿔보겠습니다.
이미지 API의 DB 전환하기

내부 논의 결과 가장 시급한 것은 안전하게 DB를 옮겨 기존 MySQL을 사용하는 다른 서비스에 문제가 없게 만드는 것이었습니다. 따라서 테이블의 스키마 구조 변경이나 이미지 테이블을 사용하는 소스 코드의 변경을 최대한 줄이고자 했습니다.
MongoDB 사용 시 고려할 점
MySQL에서 MongoDB로 마이그레이션했다고 해서 그 운영 방식이 기존 MongoDB를 운영하는 것과 큰 차이가 있지는 않습니다. 다만 MySQL에서 MongoDB로 전환할 때 확인했던 포인트는 있는데요. 어떤 포인트였는지 공유하겠습니다.
샤드 키 설정
@Sharded(shardKey = {"imageId"})
@Document(collection = "imageReferences")
public class ImageReference@Sharded는 샤딩에 대한 메타 정보를 제공합니다. shardKey는 기본값으로 엔티티의 ID값이 할당되는데요. 이미지 서비스에서는 imageId, referenceId, referenceType 조합으로 고유 인덱스(unique index)를 설정하기 위해 인덱스의 접두사인 imageId를 샤드 키로 선정했습니다.
쓰기 고려(write concern) 설정
쓰기 고려는 레플리카셋을 사용할 때 어느 수준에서 쓰기 작업을 완료했다고 승인할지 결정하는 옵션입니다. MongoDB는 먼저 프라이머리에 데이터를 저장한 뒤 세컨더리에 데이터를 동기화하는데요. 이때 어느 수준까지 동기화해야 작업을 완료했다고 판단할지를 쓰기 고려를 이용해 설정할 수 있습니다.
사용 가능한 설정값과 각 값에 따른 판단 기준은 아래와 같습니다.
| 설정값 | 작업 완료 판단 기준 |
|---|---|
| w: 0 | 쓰기 작업 완료 여부를 확인하지 않습니다. 다만 소켓 오류와 네트워크 오류 발생 시 해당 오류는 반환합니다. |
| w: 1 | 프라이머리에 쓰기 작업을 완료하면, 작업을 완료했다고 판단합니다. |
| w: 2 | 레플리카셋의 멤버 중 두 대에 쓰기 작업을 완료하면, 작업을 완료했다고 판단합니다. |
| w: majority | 전체 레플리카셋의 과반 이상에 쓰기 작업을 완료하면, 작업을 완료했다고 판단합니다. |
쓰기 고려에는 위 w 옵션 외에도 디스크 저널 영역에 기록이 저장됐는지 확인하는 journal(j), 동기화의 시간 제한을 설정하는 writeTimeout(wtimeout) 등의 옵션을 제공합니다. 필요한 경우 추가로 적용할 수 있습니다.
저희가 사용 중인 MongoDB 4.4에서는 w가 기본적으로 1로 설정돼 있습니다. WriteConcernResolver를 통해 원하는 수준으로 쓰기 고려를 설정할 수 있는데요. 저희는 안정성을 추구하기 위해 프라이머리 한 대와 세컨더리 한 대에 쓰기를 완료하고 작업 승인을 하고자 W2(w: 2)로 설정했습니다.
@Bean
public WriteConcernResolver writeConcernResolver() {
return action -> WriteConcern.W2;
}물론 쓰기 고려의 수준이 높을수록 항상 좋은 것은 아닙니다. 안정성이 증가하는 만큼 성능에서 손실이 발생합니다(참고: Benchmarking MongoDB – Driving NoSQL Performance). 이미지 API의 경우 API 관점에선 DB에서 소요되는 시간이 워낙 작아서 DML에 소비되는 시간이 늘어나도 큰 무리가 없다고 판단했습니다. 실제로 API 성능 테스트에서도 체감되는 성능 저하가 없었기에 성능보다 안정성에 중점을 두고 쓰기 고려 수준을 높였습니다.
TransactionManager 설정
MySQL에서는 이미지와 참조 테이블을 함께 다루는 경우가 있어서 트랜잭션을 사용하고 있었는데요. MySQL에서 사용하던 로직을 그대로 MongoDB에 적용하고자 했습니다.
MongoDB에서 트랜잭션은 선택 사항이기에 기본적으로 TransactionManager가 등록돼 있지 않습니다. 별도로 TransactionManager를 추가해야 합니다.
@Bean
MongoTransactionManager transactionManager(MongoDatabaseFactory dbFactory) {
return new MongoTransactionManager(dbFactory);
}아무래도 MySQL과 MongoDB의 트랜잭션이 동일하지 않다 보니 주의할 부분이 존재했습니다. 예를 들어 아래 오류가 발생해 멀티 문서 트랜잭션에서 충돌이 발생해 DML이 중단되는 경우가 있었습니다.
WriteConflict error: this operation conflicted with another operation. Please retry your operation or multi-document transaction
MongoDB 라우터 캐시의 버전이 달라서 DML이 실패하며 아래와 같은 오류가 발생하기도 했습니다.
version mismatch detected for database.collection
즉 서비스 중에 여러 이유로 DML을 재시도해야 하는 경우가 발생했고, 이에 따라 리포지터리에서는 DML 누락을 막기 위해 �재시도 로직이 꼭 필요했습니다. 이에 DB 작업을 전담하는 서비스 계층를 하나 더 생성해 트랜잭션에서 발생할 수 있는 오류를 핸들링해 재시도하도록 만들었습니다.

개발 당시에는 로직과 스키마 수정을 최소화하기 위해 아래와 같은 보호 코드도 추가해 놓았는데요. 추후 이미지 컬렉션이 참조 컬렉션을 포함하는 구조로 리팩토링해 트랜잭션이 없는 구조로 만들려고 합니다.
@Service
@RequiredArgsConstructor
@Retryable(value = { MongoTransactionException.class, UncategorizedMongoDbException.class }, maxAttempts = 3)
public class ImageServiceDB 변경 이후 테스트 방법
소스 코드에서 MongoDB를 사용하도록 변경했다면 이전과 동일하게 작동하는지 테스트해야 합니다. 저희는 안정성을 확보하기 위해 총 세 단계의 테스트를 구축했습니다.
리포지터리 테스트
서비스 로직에는 변경을 가하지 않았기에 기존에 사용하던 MySQL 리포지터리의 동작과 MongoDB 리포지터리의 동작이 일치하는지 확인하면 됩니다. 우선 기존 리포지터리 코드 전환을 마무리했다는 가정 하에 테스트할 때 참고했던 내용을 공유드리겠습니다.
DB 레벨에서 MongoDB의 로직을 테스트할 때는 @DataMongoTest를 사용했습니다. 이때 임베디드 인메모리 MongoDB를 사용할 수 있다면 우선적으로 사용합니다. 기존 DB 상황에 영향을 받지 않고 테스트하는 게 훨씬 안전하기에 저희는 Flapdoodle의 임베디드 MongoDB를 함께 사용했습니다. 아래와 같이 Gradle에서 testImplementation을 사용하면 테스트 환경에서만 임베디드 MongoDB를 사용할 수 있습니다.
testImplementation "de.flapdoodle.embed:de.flapdoodle.embed.mongo"@DataMongoTest는 전체 자동 설정(auto-configuration) 대신 MongoDB 테스트에 필요한 빈(bean)만 등록하기에 팀 내에서 사용하는 커스텀 빈이 있다면 추가해야 합니다(참고로 JUnit 4를 사용한다면 @ExtendWith(SpringExtension.class)도 추가해야 합니다).
저희 팀에서는 Auditor를 사용해서 생성일, 변경일, 생성자, 변경자 등을 자동으로 설정했습니다. 테스트 환경에서는 토큰이나 식별자를 받을 수 없기에 고정된 사용자를 받아오도록 아래와 같이 설정을 추가했습니다.
@DataMongoTest
@Import({ MongoAuditConfiguration.class, LspMongoCommonConfiguration.class, TestAuditorConfiguration.class })
class ImageRepositoryTest
---
public class TestAuditorConfiguration {
private final String TEST_ID = "TEST_ID";
@Bean
public AuditorAware<String> auditorAware() {
return () -> Optional.of(TEST_ID);
}
}전체 시나리오 테스트
다음으로 시나리오 통합 테스트를 진행했습니다. 이미지가 생성되고 삭제되는 동안 다양한 API가 사용되는데요. 이를 서비스별로 일련의 시나리오로 작성할 수 있습니다. 다음은 예시로 상품에서 사용하는 이미지의 라이프 사이클을 시나리오로 작성한 것입니다.

리포지터리 테스트에서 확인하지 못한 부분이 존재할 수 있기에 각 서비스별로 위와 같은 시나리오를 준비했습니다. 그 후 알파에는 MongoDB, 베타에는 MySQL 서버를 설치해서 두 서버에 동일한 시나리오의 요청을 보낸 뒤 API 반환 값이나 중간중간 이미지의 상태 값을 비교해서 일치하는지 확인했습니다(이 과정에서 서로 다른 결과를 반환하는 케이스를 발견해 수정한 케이스도 있었습니다). 시나리오 테스트에서 문제 없는 것을 확인한 뒤에는 베타 환경에 배포해 이미지 API에서 오류가 발생하지 않는지 긴 시간 모니터링을 진행했습니다.
성능 측정
향후 확장성과 자유로운 스키마 변경을 염두에 두고 DB를 변경하고 있지만 만약 성능에 큰 이슈가 있다면 다른 방법을 찾아야 할 것입니다. 저희는 성능을 비교하기 위해 동일한 성능의 배포 환경을 구성하고 사용하는 이미지만 변경해 성능 테스트를 진행했습니다. 테스트는 가장 호출 수가 많은 API를 대상으로 TPS를 측정하는 방식으로 진행했습니다.
테스트에 사용한 파드 스펙은 다음과 같습니다.
| replicas | 1 |
| javaOpts | -Xmx1g -XX:+UseG1GC |
| resources.limit.cpu | 2 |
| resources.limit.memory | 1500Mi |
| resources.request.cpu | 200m |
| resources.request.memory | 1500Mi |
테스트에 사용한 도구와 테스트 방법은 다음과 같습니다.
| 테스트 도구 | 테스트 지속 시간 | 사용자 수 |
|---|---|---|
| ngrinder | 3분 | 30 |
성능 측정 결과 아래와 같이 MySQL이 미세하게 성능이 우수했지만, 사용에 지장이 있는 정도의 성능 저하는 아니었기에 계획대로 마이그레이션을 진행했습니다.
| MySQL | MongoDB | |||||||
|---|---|---|---|---|---|---|---|---|
| API | TPS | 실행 수 | 에러 수 | 평균 응답 시간 | TPS | 실행 수 | 에러 수 | 평균 응답 시간 |
| 이미지 생성 및 삭제 API | 2,199 | 387,233 | 0 | 13.49ms | 2,071 | 364,699 | 0 | 14.30ms |
| 이미지 다운로드 API | 443 | 78,047 | 0 | 67.40ms | 442 | 77,850 | 0 | 67.57ms |
현재 성능 차이가 발생한 이유가 쓰기 고려 때문인 것으로 판단하고 있습니다. 추후 성능 향상이 필요하다면 쓰기 고려 수준을 조정하�고 샤드 스펙을 올릴 수 있습니다. 또한 현재 기준으로는 MySQL이 미묘하게 빠를 수 있지만 향후 서비스가 지속 성장한다면 확장이 용이한 MongoDB의 효용성이 더 높아질 것으로 예상합니다. 실제로 운영 환경에 마이그레이션을 완료하고 API 소요 시간 모니터링을 진행했는데 비슷한 성능이 나왔습니다.
DB 스위칭 프로세스
각 모듈을 고민하고 개발한 뒤 테스트까지 모두 완료했습니다. 이제 하나의 파이프라인으로 만들면 마이그레이션이 끝납니다.
MySQL에서 MongoDB로 데이터를 동기화하는 작업은 실제 서비스에 영향을 주지 않기에 비교적 가벼운 마음으로 작업할 수 있습니다. 하지만, 이미지 API의 이미지를 바꾸는 과정에는 MySQL과 MongoDB 간 동기화가 됐는지 확인하는 작업이 존재하기에 잠시 DML을 실행하지 못하는 다운 타임이 발생합니다.
만약 실시간으로 많은 상품의 이미지가 들어오는 상황에서 DML이 누락된다면 큰 장애로 이어질 텐데요. 다행히 통합 커머스 검색의 이미지 처리는 Kafka를 기반으로 구성돼 있기에 DML을 실행할 수 없어 이미지 처리가 어려운 상황에서는 이미지 처리 메시지를 토픽 큐에 쌓아놓았다가 DML이 가능해진 시점에 메시지를 소비하면 됩니다.
그럼 DB 스위칭 과정을 조금 더 자세히 살펴보겠습니다.

image-noramlizer는 앞서 설명드린 것처럼 Kafka를 통해 이미지 처리가 필요한 상품 정보를 전송받고 이미지 API를 활용해 이미지 처리를 담당하는 모듈입니다. MySQL에서 MongoDB로 스위칭할 때 DB 간 �정합성 검사 때문에 DML 실행이 실패하니, image-normalizer를 중단해 MySQL 이미지 API의 DML을 최대한 줄입니다. 이후 DB 스위칭이 마무리되면 새로운 DB에서 DML이 작동하도록 image-normalizer를 다시 실행합니다.
다음으로 MySQL CDC 토픽 지연(topic lag)이 0건인지 확인합니다. 이는 DML이 더 이상 발생하지 않는 상황에서 CDC 토픽의 메시지를 전부 소비하면 비로소 MySQL과 MongoDB가 일치하는 상황이라고 볼 수 있기 때문입니다.
이후 MySQL과 MongoDB의 정합성을 확인합니다. 이때 MySQL과 MongoDB 간 데이터를 하나하나 비교하려고 하면 너무 긴 시간이 소요됩니다. 정합성 검사가 길어질수록 이미지 처리가 지연되는 것이기에 적당한 타협이 필요합니다. 저희는 이미지의 데이터는 비교하지 않고, 각각의 레코드 수 동일 여부를 확인했습니다. 만약 레코드 수가 같다면 현재 두 DB 간 상태가 일치한다고 판단하고 마이그레이션을 진행합니다. 만약 레코드 수가 다르다면 Synchronizer from MySQL CDC 단계에서 누락된 변경 사항이 있다고 판단하고 롤백을 진행합니다.
이렇게 간략하게 정합성 검사를 할 수 있던 이유는 CDC 기반으로 마이그레이션을 진행하고 있을 때 MySQL 기반 ETL과 MongoDB 기반 ETL 작업을 동시에 수행하고 있었기 때문입니다. 각각의 스냅샷 데이터를 기반으로 정합성을 검사하고 있었기에 실제 DB를 스위칭할 때에는 최대한 DB 다운 시간을 줄여서 작업을 완료하기 위해 레코드 수만 비교했습니다.
앞서 언급한 DML 관련 문제 상황을 제외하고도 개발할 때는 항상 변수가 존재합니다. 코드 오류나 개발자의 작업 오류 등 문제가 발생할 수 있는 상황은 즐비합니다. 따라서 MongoDB로 전환한 후에도 자유롭게 롤백할 수 있어야 합니다. 롤백을 준비한다는 것은 MongoDB로 전환한 뒤 언제든 MySQL로 전환할 수 있고, MySQL로 다시 전환했을 때 MongoDB와 MySQL의 상태가 일치하게 만들어야 한다는 것입니다.
여기서 Synchronizer from MongoDB CDC가 MongoDB와 MySQL의 상태를 일치시키는 역할을 합니다. Synchronizer from MongoDB CDC는 Synchronizer from MySQL CDC의 MongoDB 버전이라고 할 수 있는데요. 앞서 MySQL을 기준으로 설명했기에 자세한 설명은 생략하고 간단히 말씀드리겠습니다. 이미지 API의 이미지를 바꿀 때 DB는 읽기 전용 상태가 됩니다. 그때 MongoDB의 변경을 메시지로 만들어주는 커넥터와 그 메시지를 MySQL에 반영하는 컨슈머를 작동하면 앞으로 MongoDB를 사용하는 이미지 API가 작동할 때 MySQL에도 변경이 반영됩니다.
이와 같이 MongoDB와 MySQL 간 동기화가 유지되기에 만약 MongoDB를 사용하는 서비스에서 장애가 발생해서 롤백해야 한다면, 위 파이프라인에서 MySQL과 MongoDB를 반대로 진행하면 됩니다.
마치며
파이프라인까지 구성하고, 실제로 베타와 운영에 순차적으로 적용하며 성공적으로 마이그레이션을 완료했습니다. 마이그레이션의 중요한 목표 중 하나였던 MySQL의 디스크가 꽉 차는 문제를 해소하는 관점에서 살펴보면 마이그레이션를 통해 가용 디스크 크기를 총 2.17TB 확보했습니다.
| 마이그레이션 이전 크기 | 마이그레이션 이후 크기 | |
|---|---|---|
| MySQL 백�업 | 6.93TB (91%) | 287GB (4%) |
| MySQL 데이터 | 2.4TB (86%) | 430GB (15%) |
앞으로 이미지는 MongoDB에서 얼마든지 확장할 수 있는 구조로 다룰 수 있게 됐고, MySQL을 사용하는 다른 서비스도 확보한 용량을 기반으로 다양한 작업을 안전하게 진행할 수 있습니다. 더불어 스키마 변경 시 작업이 멈출 걱정이 없기에 더 좋은 서비스를 위해 신규 필드를 추가할 수 있게 됐고, 이러한 장점을 기반으로 다양한 이미지 개선 작업을 진행하고 있습니다.
아마 모든 팀이 저희 팀과 같은 상황이 아니기에 MySQL에서 MongoDB로 마이그레이션할 때 이번 글에서 소개한 프로세스를 동일하게 적용하는 것은 어려울 수도 있다고 생각하는데요. 만약 마이그레이션할 데이터의 크기가 작다면, Kafka Connect만으로도 이 글에서 소개한 프로세스와 비슷하게 프로세스를 구축할 수 있을 것 같습니다. ETL을 통해 기존 데이터를 마이그레이션하는 것을 Debezium connector for MySQL의 snapshot.mode로 대체해서 기존 데이터를 메시지로 만들고, 이후 프로세스는 동일하게 진행하는 것입니다. 저희 팀의 경우 데이터가 워낙 많고 최적화하는 과정도 필요했기에 이렇게 진행하지 못했지만, 저희가 떠올렸던 좋은 아이디어 하나를 소개하는 측면에서 말씀드립니다.
처음 마이그레이션을 설계할 때에는 너무나 큰 데이터 규모에 어떻게 접근해야 할지 막막했습니다. 또한 테스트나 베타 환경�에서는 문제가 없었지만, 실제 환경에서는 워낙 많은 데이터를 다루며 작업하다 보니 생각도 못 했던 문제들이 많이 발생하기도 했습니다. 하지만 이 작업은 앞으로 통합 커머스 검색이 안정적으로 서비스를 운영하며 확장해 나가기 위해서 꼭 필요한 작업이었는데요. 성공적으로 마이그레이션할 수 있도록 마지막까지 도와주신 팀원 분들과 DBA 분들께 이 자리를 빌려 깊은 감사의 말씀드립니다.
대규모 데이터를 다룰 때는 모듈의 설계, 효율적인 코드 작성도 중요하지만 그만큼 실제로 데이터가 존재하는 DB를 이해하는 것이 중요했고, 이번 작업을 통해 그와 관련해 값진 지식과 경험을 쌓을 수 있었습니다. 확장이 자유로운 MongoDB로 성공적으로 마이그레이션한만큼, 이른 시일 내 통합 커머스 검색에 상품과 이미지가 많아져 많은 샤드를 추가하게 되길 기원합니다.


