들어가며
안녕하세요. AI Services Lab 팀의 ML 엔지니어 박희웅입니다. 저희 팀에서는 LINE 오픈챗과 관련해 다양한 AI/ML 모델을 개발해 서빙하고 있는데요. 지난 오프라인과 온라인 A/B 테스트를 통해 오픈챗 추천 모델 개선하기 포스트에서는 개인 취향에 맞는 오픈챗들을 추천하는 모델의 개선 과정에 대해 공유드렸고, 이후 오픈챗 해시태그 예측을 위한 다중 레이블 분류 모델 개발하기 포스트에서는 오픈챗을 생성할 때 해시태그 지정을 돕는 해시태그 예측 모델을 어떻게 개발했는지 공유드린 바 있습니다.
이번 글에서는 오픈챗들에서 오가는 메시지 콘텐츠로부터 유행하는 주제 키워드를 어떻게 추출할 수 있는지 소개드리고자 합니다.
배경
현재 오픈챗 서비스의 메인 화면은 채팅방 검색과 추천, 랭킹 기능 위주로 구성돼 있으며, 추천으로 노출되는 아이템은 대부분 채팅방 그 자체입니다. 오픈챗 주제를 키워드 나열 형태로 추천하고 있기는 하지만 키워드를 클릭하면 결국 이와 연관된 채팅방들이 노출되는 방식입니다.
이와 같은 메인 화면은 사용자에 따라서 지속적으로 재방문할만큼 매력적이지는 않을 수 있습니다. 각 채팅방은 일종의 작은 커뮤니티로 사용자가 하나의 채팅방을 파악하려면 커버뷰에 적힌 설명글과 메시지 요약글을 읽어보거나 실제로 채팅방에 입장해 이전에 오간 콘텐츠를 확인하는 등의 노력이 필요합니다. 따라서 이미 마음에 드는 채팅방을 발견하고 가입해서 활발히 참여하고 있는 사용자의 경우 새로운 채팅방을 탐색할 동기가 약해지면서 주로 채팅방 위주로 노출되는 메인 화면 방문이 뜸해질 수 있습니다.
여기서 고려해야 할 점은, 메인 화면 방문자 수가 오픈챗 서비스의 주요 KPI라는 것입니다. 서비스 활성도를 대표할 뿐 아니라 광고 매출과도 연결되기 때문입니다. 이러한 배경 하에 채팅방 대신 채팅방에서 주고받는 메시지 콘텐츠를 메인 화면에 노출해 보는 것을 구상하게 되었습니다.
오픈챗 서비스를 다른 마이크로 블로그 서비스와 비교해 보면 채팅방은 인플루언서의 계정에, 메시지는 계정에 게시된 포스트에 대응시킬 수 있는데요. 대부분의 마이크로 블로그 서비스는 주로 포스트를 메인 화면에 노출합니다. 일반적으로 마이크로 블로그 서비스는 신규 포스트를 보기 위해 서비스 메인 화면에 방문하는 사용자의 비율이 새로운 인물을 팔로잉하려는 비율보다 높을 것이기 때문입니다. 포스트를 탐색하는 와중에 취향에 맞는 계정을 발견하는 선순환이 발생할 수도 있고요.
| AS-IS | TO-BE |
|---|---|
 |  |
그런데 마이크로 블로그의 포스트와는 달리 대부분의 오픈챗 채팅방의 메시지 단건은 독립된 콘텐츠로 제공하기에는 적합하지 않습니다. 빠르게 주고받는 모바일 채팅의 특성상 오타나 비문이 많고 생략된 부분도 많기 때문에 채팅 중간의 메시지 하나만 떼어 놓으면 전체 맥락이 잘 파악되지 않기 때문입니다.
이에 따라 저희는 비슷한 주제의 메시지들을 묶어서 콘텐츠화하는 방향으로 가닥을 잡았으며, 이때 주제가 가시적으로 드러나도록 메시지에 등장한 주요 키워드 기반으로 묶는 방식을 채택했습니다. 이와 같은 접근 방식의 핵심은 메시지 텍스트 말뭉치에서 유행하는 주제 키워드를 추출하는 기법인데요. 이 기법을 어떻게 구현해 적용했는지 소개하겠습니다.
빈도 기반 트렌딩 키워드 선정
먼저 메시지 텍스트 말뭉치에서 지금 유행하는 '트렌딩 키워드'가 무엇인지를 어떤 기준과 방법으로 선정했는지 살펴보겠습니다.
트렌딩 키워드 탐지
유행하는 키워드를 탐지하는 방법으로 단순히 최근 등장 빈도가 높은 단어를 선택하는 방식을 떠올릴 수 있습니다. 하지만 오픈챗에 이 방식을 사용하면 검색 포털의 검색어라든가 뉴스 포털의 댓글 같이 해당 시점의 화제가 적절히 반영된 단어들이 뽑히지 않고, 인삿말이나 고마움, 웃음 표현과 같은 너무나 일상적인 단어들이 뽑힙니다. 오픈챗 커뮤니티는 사용자들이 일상적으로 담소를 나누는 공간이자 새 멤버들이 수시로 가입하는 공간이기에 인사나 소개, 환영의 말 등이 대화에서 높은 비중을 차지하기 때문입니다.
따라서 저희는 일별로 단어의 등장 빈도를 집계하면서 빈도가 급격하게 증가하는 단어를 트렌딩 키워드로 정의했습니다. 집계 기간 단위를 하루로 설정한 이유는 두 가지입니다. 하나는 통계적으로 유의미한 샘플을 충분히 확보하기 위해, 또 하나는 대부분의 사용자들이 하루에 한번만 오픈챗 메인 화면에 방문한다는 데이터 분석 결과가 있었기 때문입니다.
빈도 증가량을 측정할 때는 일주일 전의 해당 단어의 빈도를 기준으로 삼았습니다. 이 방식에는 두 가지 이점이 있는데요. 첫 번째는 특정 주제가 화제로 떠오를 때 그 열기가 하루에 그치지 않는 경우가 종종 나타난다는 점에 기인합니다. 바로 전날과의 빈도 차이만 고려할 경우 화제성이 정점에 달해 피크가 지속되고 있음에도 증가량이 미미해 트렌딩 키워드로 탐지되지 않을 수 있습니다(이에 대한 사례는 아래에서 자세히 살펴보겠습니다). 두 번째는 이 방식을 사용하면 일주일마다 반복적으로 언급되는 요일 관련 단어들을 자연스럽게 억제할 수 있습니다. 참고로 같은 이유로 한 달 전 빈도와도 비교하도록 구현했는데요. 이 글에서는 논의를 간결히 하기 위해 해당 내용은 생략하겠습니다.
두 빈도값 간의 차이를 계량하는 지표로는 이표본 모비율 차 검정을 위한 Z-테스트 통계량을 사용했습니다. 각 단어별로 Z-테스트 통계량을 계산하고 이를 점수로 사용해 점수가 높은 키워드를 트렌딩 키워드로 선정합니다. 이 �방식은 메시지 하나하나가 독립적으로 작성된 메시지라고 간주하기는 어렵기 때문에 유의 확률에 기반해 엄밀하게 가설을 검정할 수는 없지만, 트렌딩 키워드로 가히 분류할 수 있는 최소 점수 임곗값을 정규 분포 곡선을 참고해 결정할 수 있습니다. 또한 빈도수가 작을 때 영향력이 커지는 노이즈 효과를 확률 분포 이론에 근거해 감안할 수 있다는 것도 좋은 점입니다.
통계랑 Z를 수식으로 살펴보기 위해 수식에 사용할 기호를 다음과 같이 정의하겠습니다.
- : 타깃 단어의 출현 빈도(term frequency, TF). 해당 단어를 포함하는 메시지의 수이며, 현재 TF에는 , 이전 기준선 TF에는 사용
- : 해당 날짜의 전체 메시지 수
위와 같이 기호를 정의했을 때 통계량 Z값은 다음과 같습니다.
여기서 주의해야 할 점은 빈도가 커질수록 비율 차이가 크지 않음에도 통계량 Z값이 크게 측정되는 경향이 있다는 것인데요. 이를 고려해 빈도가 최소 30% 이상 증가한 단어들만 대상으로 선정했습니다.
다음은 일본에서 장마가 시작된 어느 일주일간 일본 오픈챗에서 '梅雨入り'(장마 시작) 키워드의 빈도수를 집계한 뒤, 이를 바탕으로 비교 기준이 되는 날을 달리 설정했을 때 각각 계산된 Z값들이 변화하는 양상을 보여주는 그래프입니다. 비교 기준일로는 하루 전(파란선), 이틀 전(노란선), 사흘 전(초록선), 일주일 전(빨간선)을 선정했습니다(참고로 모든 데이터 분석에는 공개된 오픈챗 메시지만 이용됩니다).
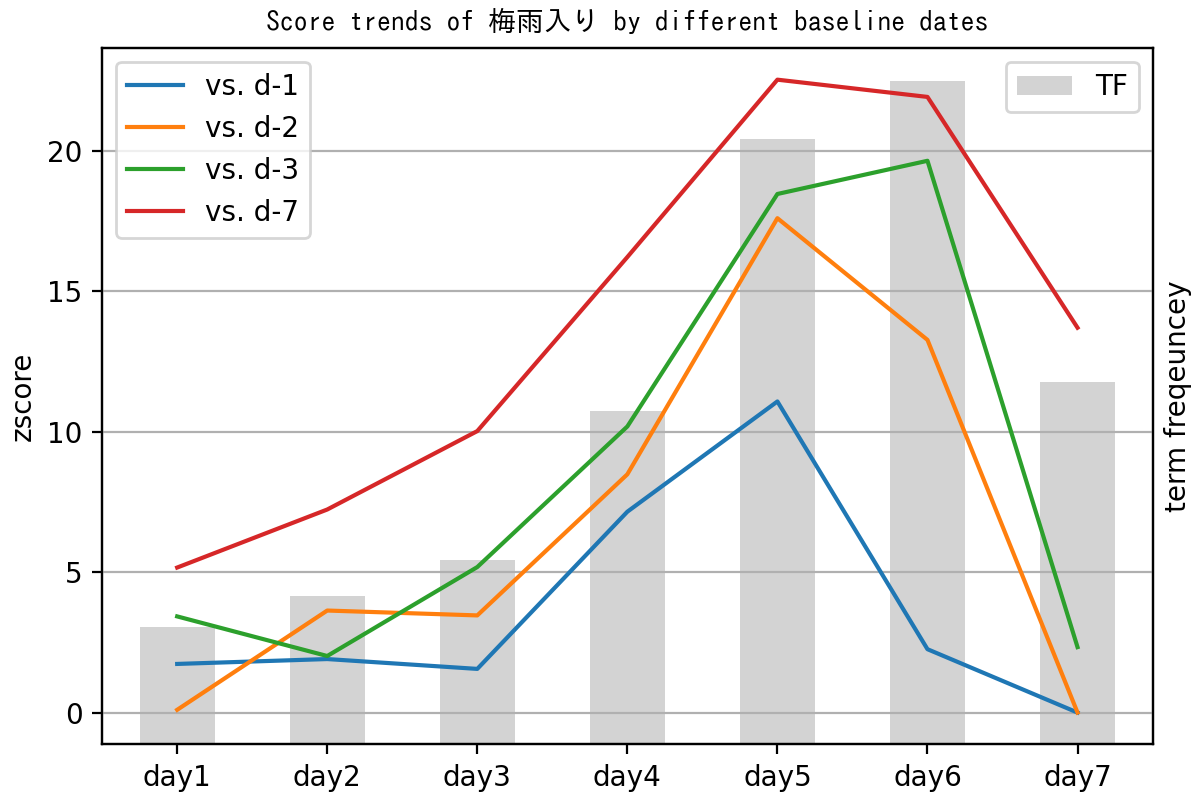
위 그래프에서 기준일이 하루 전(파란선)일 때를 보면, 6일째(day6)에서 빈도수가 계속 증가하고 있음에도 Z값이 급격하게 하락하는 것을 볼 수 있습니다. 또한 7일째에는 아직 빈도수가 4일째보다 높은 수준이지만, 기준일을 일주일 전(빨간선)으로 설정하지 않은 모든 그래프가 Z값이 3 미만으로 크게 낮아지는 것을 확인할 수 있습니다.
다음 표에서는 기준일에 따라 6일째에 상위 키워드 랭킹이 어떻게 선택되는지 보여줍니다. 사흘 전 또는 일주일 전을 비교 기준으로 삼을 때는 '梅雨入り' 키워드가 가장 트렌디한 것으로 선정됐지만, 기준일을 하루 전으로 두면 10위권 밖으로 밀려납니다. 또한 일주일 전을 기�준일로 설정한 결과에서는 '今週末' (이번 주말)이나 '今週' (금주) 같은 단어가 탐지되지 않는 것도 확인할 수 있습니다.
| 순위 | vs. d-1 | vs. d-2 | vs. d-3 | vs. d-7 |
|---|---|---|---|---|
| 1 | 大雨 | 大雨 | 梅雨入り | 梅雨入り |
| 2 | 宝箱 | 梅雨入り | 大雨 | 梅雨 |
| 3 | 雨降り | 梅雨 | 梅雨 | 金魚 |
| 4 | インドネシア | 線状降水帯 | 線状降水帯 | 大雨 |
| 5 | 梅雨 | 雨降り | 雨降り | 線状降水帯 |
| 6 | 足元 | 土砂降り | 今週末 | 満月 |
| 7 | 台風 | 利確 | 今週 | 九州 |
| 8 | 満月 | 今週末 | 土砂降り | インドネシア |
| 9 | 阪神 | 満月 | 満月 | cpi |
| 10 | 湿気 | メール | 小雨 | 梅雨明け |
MinHash 기반 메시지 중복 제거
메시지 묶음을 추천했는데 막상 묶음 속 메시지들이 거의 동일한 텍스트라면 사용자 입장에서는 유용하지 않은 중복 정보라고 느낄 것입니다. 만약 각 메시지가 독립적으로 작성됐다면 텍스트가 겹칠 가능성은 희박한데요. 현실에서는 복사 붙여넣기 등을 통해 메시지 내용이 동일한 경우가 다수 발생합니다. 따라서 중복에 가까운 텍스트를 빈도수 집계 이전에 제거해야 본래 의도에 부합하는 트렌딩 키워드를 추출할 수 있습니다.
저희는 완전히 문자열이 동일한 경우뿐 아니라 대부분의 텍스트가 겹치는 경우까지 커버하면서 대량의 데이터에 효율적으로 적용할 수 있는 MinHash 기반의 클러스터링 방식을 도입했습니다. MinHash 기법은 쉽게 말하면 일종의 차원 축소 방법입니다. 문서를 단어들의 집합으로 표현하고 이를 정수값으로 변환하는데, 이때 해시 함숫값들의 최소를 취하기에 'MinHash'라고 명명됐습니다.
두 집합의 MinHash 값이 같을 확률이 두 집합의 Jaccard 유사도와 일치한다는 훌륭한 성질에 기반해서, 독립된 k개의 MinHash 값들을 얻고 이를 시그니처 삼아(이른바 k-MinHash 시그니처) 두 문서의 시그니처들이 일치하는 비율을 근사된 유사도로 활용할 수 있습니다.
저희는 이것을 다음과 같이 적용했습니다.
- 먼저 텍스트를 토큰화하고 관심 있는 토큰들만 기계적인 방식으로 걸러냅니다. 저희는 명사 위주로만 남겼습니다.
- 각 메시지는 남겨진 토큰들의 세트로 표현합니다. 이 과정을 '슁글링(shingling)'이라고 부르며, 세트의 원소를 '슁글(shingle)'이라고 일컫습니다. 정확도를 높이기 위해 슁글 단위를 n-그램 토큰으로 구성할 수도 있습니다.
- 이로부터 메시지마다 k 크기의 MinHash 시그니처를 구합니다.
- 동일한 시그니처를 갖는 메시지를 하나의 클러스터로 엮습니다. 앞서 소개했듯 시그니처 일치율을 유사도 삼아 거리 기반 클러스터링을 적용해 볼 수도 있지만, 저희 문제에서는 중복 메시지 몇 건이 제거되지 않거나 잘못 제거돼도 심대한 영향이 있지는 않기에 보다 간단한 방식을 택했습니다.
- 클러스터당 하나의 메시지만 남기고 나머지는 중복으로 간주해 제거합니다.

위 과정에서 시그니처 길이인 k값을 크게 정하면 완전히 동일한 텍스트만 동일한 클러스터로 할당되며, k값을 낮출수록 중첩이 적은 텍스트도 같은 클러스터로 묶입니다. 중복 제거 목적에 부합하는 적당한 k값을 결정하기 위해서는 클러스터 내 메시지 간 유사성 지표가 필요한데요. 기존의 일반적인 클러스터링 평가 지표는 인스턴스 쌍마다 유사도를 계산하고 이를 취합하는 방식이어서 연산량이 많습니다. 이에 저희는 그 대신 다음과 같이 클러스터 내 집합들 에 대해 선형 시간(linear time) 복잡도로 계산 가능한 다양성 지표를 정의했습니다.
이 지표는 이면서 일 때, 즉 어떤 두 집합도 교집합이 없을 때 1이 되며, 반대로 일 때, 곧 모든 집합이 같을 때 0이 됩니다. 경우에는 집합의 개수가 많아질수록 교집합 크기 항의 영향이 작아져 와 같은 식으로 근사되는데요. 이때에는 평균적으로 비중만큼이 다른 집합에서 나타나지 않고 딱 한 번만 등장하는 고유한 원소들로 구성됐다고 가늠할 수 있습니다.
이로부터 자연스럽게 집합의 중첩도를 으로 정의했습니다. 최종적으로 각 클러스터마다 중첩도를 구한 후 전체 클러스터의 평균을 계산해 클러스터링의 품질을 측정합니다.
이렇게 정의한 중첩도는 정밀도 개념의 지표라고 할 수 있습니다. 여기에 더해 커버리지를 살펴보기 위해서 탐지되는 중복 메시지의 양에 해당하는, 즉 크기 2 이상의 클러스터로 묶이는 메시지 수도 파라미터를 선택할 때 함께 비교합니다.
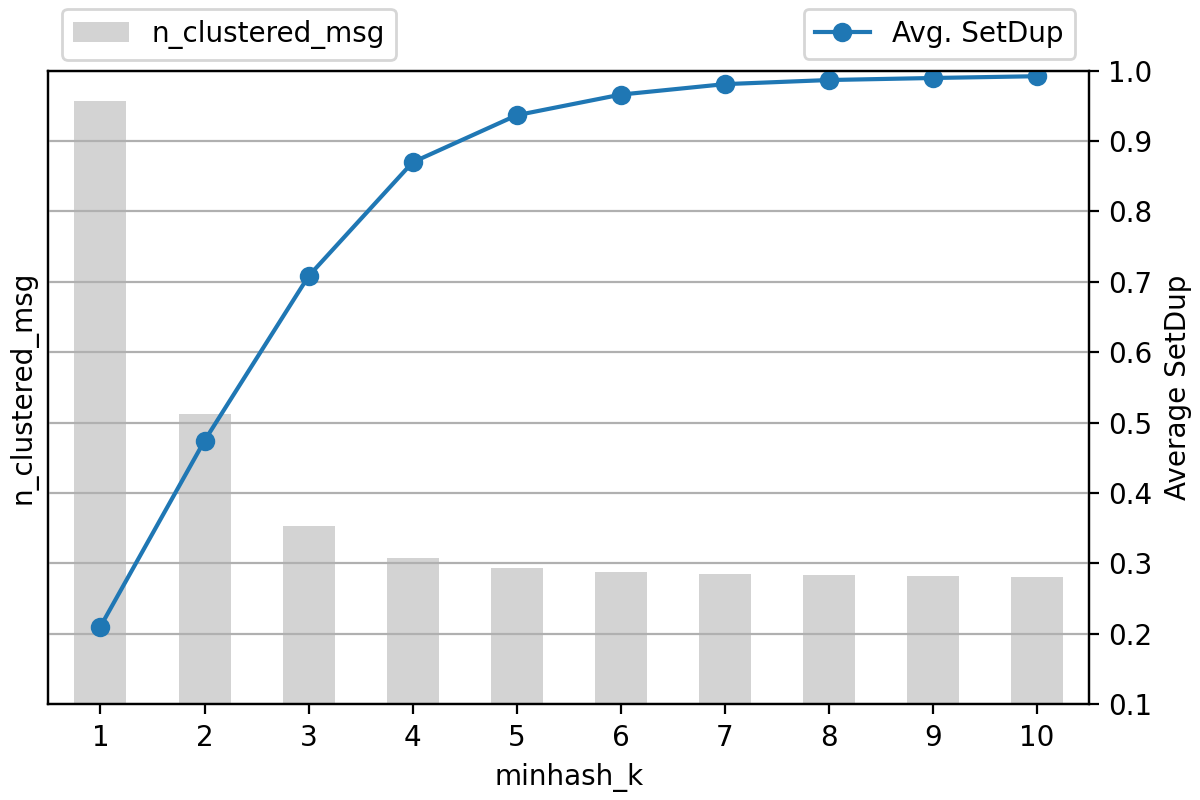
아래 그래프는 k값을 달리했을 때 MinHash 클러스터링의 품질을 비교한 것입니다. k값이 커질수록 중첩도는 증가하는 반면 탐지되는 중복 메시지의 양(n_clustered_msg)은 줄어드는 것을 확인할 수 있습니다. 대략 90% 이상 중첩된 텍스트는 중복으로 간주해도 무방하다는 판단 하에 k값을 5로 결정했습니다.
다음은 클러스터링 결과 중 메시지 수가 많은 클러스터의 샘플입니다. 상위 클러스터는 중첩도가 거의 1에 근접하며 사실상 같은 텍스트들로 구성돼 있었습니다. 클러스터 내에서 공통으로 등장하는 키워드들을 살펴보면 'paypay', 'temu', 'shein', 'tiktok', '無料'(무료), '招待'(초대), 'ギフト'(기프트) 등 외부 서비스의 마케팅 이벤트와 관련된 내용임을 짐작할 수 있는데요. 이처럼 오픈챗 메인 화면에 추천하기에는 부적합한 키워드들이 추출되지 않도록 MinHash 기반 메시지 중복 제거 방식을 통해 제어할 수 있습니다.
| 클러스터 크기 | SetDup | 공통 단어 |
|---|---|---|
| 3836 | 99.95% | [ため, 招待, 分, 最大, タップ, ポイント, paypay, temu] |
| 1474 | 99.89% | [追加, 招待, 無料, get, 公式, 協力, ギフト, アカウント, temu] |
| 1112 | 99.39% | [ステップ, 招待, 活動, 一流, フリーギフト, ギフト, temu] |
| 1087 | 99.95% | [shein, 招待, 無料, よう, アプリ, 獲得, 手, 入手, ギフト] |
| 576 | 99.05% | [報酬, 今, 参加, lite, tiktok, get] |
| 519 | 99.97% | [報酬, スター, 一緒, lite, tiktok, get] |
| 486 | 100.00% | [報酬, pr, tiktok, get, ログイン, 一緒, お友達, lite] |
| 301 | 99.64% | [天魔, 孤城, 園, 空中庭園, モンスト, 人達同士, マルチ, マルチプレイ, 一緒, タップ, url] |
| 296 | 99.72% | [おやつ, 猫ちゃん, ため, 無料, 下, 手, 猫, 獲得, リンク, ギフト, タップ] |
| 296 | 99.93% | [shein, あと, プレゼント, 招待, 無料, クリック, 今, 手, 前] |
동시 발생 빈도 기반 키워드 품질 향상
앞서 소개한 트렌딩 키워드 점수화 공식에서는 해당 키워드의 빈도를 독립적으로 고려했습니다. 하지만 단어가 언급된 전후 맥락 또한 중요한 정보입니다. 다른 단어와의 동시 발생 빈도를 맥락 정보로 활용해 트렌딩 키워드 품질을 향상시키는 방법들을 이야기해 보겠습니다.
NPMI 기반 부적절한 키워드 필터
오픈챗 메인 페이지는 남녀노소 제한 없이 접근할 수 있는 공간입니다. 이를 고려할 때 몇몇 키워드는 분명 오픈챗 커뮤니티의 트렌드를 일부 반영하기는 하지만 미성년자들에게 노출하기에는 바람직하지 않은 것들이 있습니다. 대표적으로 경마나 경륜, 경정 등 경주 종목의 베팅과 관련된 키워드들입니다.
처음에는 관련 키워드를 모두 블랙리스트로 구성해서 이와 일치하거나 부분 문자열로 포함하는 단어는 트렌딩 키워드로 추출되지 않도록 만들어 봤습니다. 그랬더니 ��미처 예상치 못했던 단어들이, 예를 들어 오랜만에 경기가 열리는 지방 도시 이름이라던가 말이나 기수 또는 참가 팀 이름 등 미리 지정하는 게 사실상 불가능한 단어들이 걸러지지 못하고 추천 키워드로 추출됐습니다.
이를 해결하려면 데이터 기반의 통계적 기법이 필요했으며, 저희는 동시 발생 빈도(co-occurrence frequency) 기반의 키워드 세트 확장 방식을 도입했습니다. 이 방식이 어떤 절차로 작동하는지 말씀드리겠습니다.
먼저 작은 시드 키워드 집합을 설정합니다. 실험해 보니 경주와 관련된 다섯 개 단어들("競馬", "競艇", "競輪", "レース", "馬券")만으로도 원하는 결과를 얻을 수 있었습니다. 관리 측면이나 과도한 탐지를 피하기 위해 시드 집합은 이처럼 최소한으로 설정하는 게 바람직합니다. 다음으로 후보로 선정된 트렌딩 키워드에 대해 각 시드 단어와의 동시 발생 빈도 기반의 연관성 지표를 계산합니다. 시드 단어들 중 하나라도 연관성 점수가 미리 정해둔 임계치를 넘는 것이 있으면 해당 후보 단어를 트렌딩 키워드에서 제외합니다.
이때 연관성 지표로는 Normalized pointwise mutual information(이하 NPMI)를 채택했습니다. PMI와 NPMI 값을 산출하는 수식을 살펴보기 위해 먼저 다음과 같이 기호를 정의하겠습니다.
- : 단어 x와 y 각각의 출현 빈도
- : 단어 x와 y의 동시 출현 빈도
- : 전체 메시지 수
- :
위와 같이 정의했을 때 PMI 및 NPMI 값은 다음과 같습니다.
NPMI 지표는 범위가 -1 ~ 1 사이로 한정되고 각 등장 확률이 독립적이면 값이 0, 함께 등장하는 경우가 많으면 양수, 반대이면 음수 값이 돼 수치의 의미를 직관적으로 파악할 수 있습니다.
다음은 앞서 설정한 시드 단어들과 NPMI 값이 높게 나타난 단어들입니다.
| 단어 | 시드 | NPMI | 단어 | 시드 | NPMI | 단어 | 시드 | NPMI |
|---|---|---|---|---|---|---|---|---|
| あーちゃん | 競艇 | 0.841 | ワイド | レース | 0.476 | コース | レース | 0.315 |
| note | 競艇 | 0.684 | 耐久 | レース | 0.465 | 決勝 | レース | 0.315 |
| 狙い馬 | レース | 0.647 | 11r | レース | 0.452 | イン | レース | 0.308 |
| 好勝負 | レース | 0.636 | 直線 | レース | 0.445 | 最終 | レース | 0.304 |
| 注目馬 | レース | 0.636 | 京都 | レース | 0.424 | パワー | レース | 0.303 |
| 連単 | 馬券 | 0.627 | f1 | レース | 0.423 | スタート | レース | 0.296 |
| 単穴 | レース | 0.619 | 丸亀 | レース | 0.407 | 期待 | レース | 0.286 |
| 穴馬 | レース | 0.609 | ノート | 競艇 | 0.402 | スピード | レース | 0.285 |
| 近走 | レース | 0.592 | 富士 | レース | 0.402 | 上位 | レース | 0.284 |
| 未勝利 | レース | 0.590 | 予想 | 競馬 | 0.393 | 東京 | レース | 0.280 |
| 騎手 | レース | 0.567 | 出来 | レース | 0.391 | ペース | レース | 0.280 |
| 前走 | レース | 0.566 | 予選 | レース | 0.377 | タイム | レース | 0.270 |
| 発走 | レース | 0.561 | ご用意 | レース | 0.368 | スーパー | レース | 0.252 |
| 回収率 | レース | 0.547 | 先週 | 競馬 | 0.368 | 参戦 | レース | 0.245 |
| 馬場 | レース | 0.546 | 天候 | レース | 0.367 | プラス | レース | 0.239 |
| ダービー | 馬券 | 0.543 | 有利 | レース | 0.355 | 更新 | レース | 0.239 |
| 24h | レース | 0.529 | 本線 | レース | 0.352 | 大会 | レース | 0.228 |
| 馬連 | レース | 0.508 | 展開 | レース | 0.348 | 結果 | レース | 0.227 |
| 勝負 | レース | 0.491 | 狙い | レース | 0.325 | アップ | レース | 0.225 |
| 的中 | レース | 0.483 | ベスト | レース | 0.325 | 日本 | 競馬 | 0.224 |
샘플을 보면 NPMI > 0.5 구간에서는 馬(말 마)가 들어간 단어가 많이 보이는 등 대부분 경주와 관련된 상황에서 화제가 될만한 키워드들이었습니다. �반면 NPMI < 0.3 구간에서는 東京(동경), 日本(일본) 등 자주 언급되는 지명이나 '期待(기대)', '大会(대회)', '結果(결과)' 등의 일반적인 단어들도 포함됐습니다. 0.3 < NPMI < 0.5 구간은 경쟁과 관련은 높지만 경주 베팅 이외의 상황에서도 종종 언급될 법한 단어들, 예를 들어 '勝負(승부)', '予選(예선)', '有利(유리)' 등이 나타났습니다.
검토 결과 이 구간의 단어들은 트렌딩 키워드로써 크게 매력적이지 않은데다가 리스크를 줄인다는 측면에서도 제외하는 게 나을 것 같아 0.3으로 임곗값을 결정했습니다.
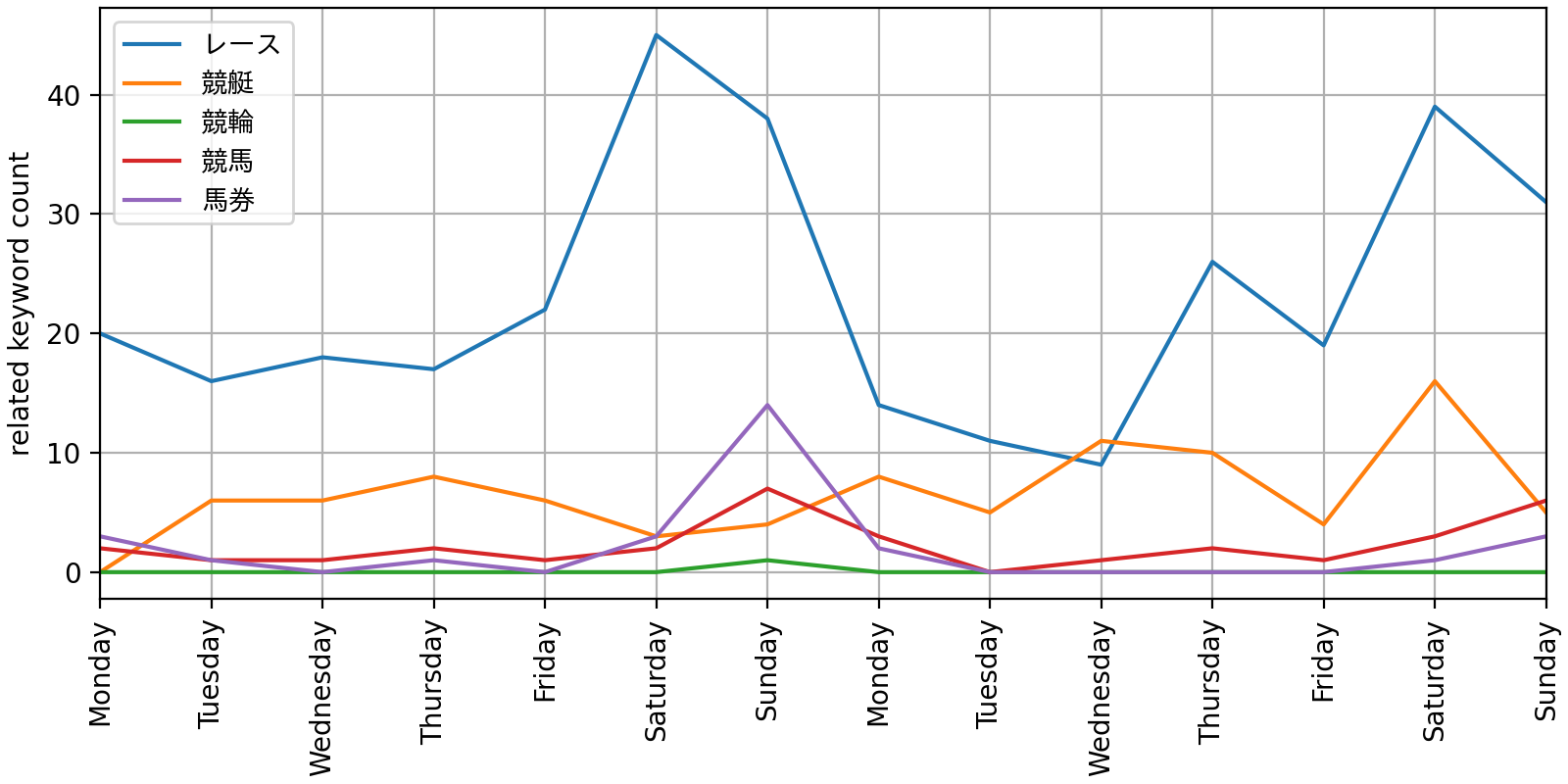
아래 그래프는 2주간 각 시드 단어별로 탐지된 연관 키워드 수의 추이를 보여줍니다. 어떤 키워드가 여러 시드 단어에 연관될 경우 NPMI 값이 가장 높은 쪽으로 분류했는데요. 경기가 많이 열리는 주말에 더 많이 검출된 것을 확인할 수 있습니다.
MMR 방식을 이용한 상위 키워드 다양화
앞서 말씀드린 중복된 메시지를 추천하는 것을 지양하는 것처럼, 너무 유사한 단어들을 트렌딩 키워드로 나란히 노출하는 것 또한 바람직하지 않습니다. 트렌딩 키워드를 추출하는 목적은 관련된 메시지 묶음을 보여주는 것인데 서로 다른 키워드에 같은 내용의 메시지가 나온다면 사용자가 금방 흥미를 잃을 수 있습니다. 따라서 공통 발생 빈도가 높은 키워드들은 동시에 선택되지 않도록 조정이 필요합니�다.
이는 제가 앞선 포스팅에서 소개했던 해시태그 추천 결과의 다양화 문제와 흡사한 상황으로 당시 도입했던 Maximal Marginal Relevance(MMR) 방식을 동일하게 적용해 볼 수 있습니다. 리마인드 차원에서 다시 말씀드리면, MMR 기법은 점수순으로 아이템을 하나씩 선택하되 목록 형태 결과의 다양화를 위해 앞서 뽑힌 아이템과의 유사도를 페널티 항으로 고려하는 접근 방식입니다.
이를 수식으로 살펴보기 위해 다음과 같이 기호를 정의하겠습니다.
- : 키워드 i의 원래 트렌드 점수, 점수로는 Z 통계량의 로그값 사용
- : 페널티 가중치 파라미터
- : 두 키워드 i와 j의 유사도
- : 재랭킹 대상이 되는 전체 트렌드 키워드 집합
- : k번째 단계까지 선택된 트렌드 키워드 집합
위와 같이 기호를 정의했을 때, k+1 순위 키워드는 다음과 같이 조정된 스코어 값이 가장 큰 키워드 i를 선택합니다.
키워드 간 유사도로는 앞서 소개했던 NPMI 지표를 채택했습니다. 페널티 항을 이용한 소프트 제약(soft constraint)과 더불어 NPMI 값이 일정 수준 이상인 키워드가 상위에 선택됐다면 아예 더 이상 뽑히지 않게 만드는 로직도 추가했습니다.
다음은 값을 달리해 다양화 기법을 적용한 결과 샘플입니다.
| 순위 | 기존 목록 | ||||
|---|---|---|---|---|---|
| 1 | イラン | イラン | イラン | イラン | イラン |
| 2 | イスラエル | 大雨 | 大雨 | 大雨 | 大雨 |
| 3 | 大雨 | 土砂降り | 土砂降り | 土砂降り | 土砂降り |
| 4 | 予報 | 雨予報 | 雨予報 | 雨予報 | 雨予報 |
| 5 | 土砂降り | 雨降り | 雨降り | 雨降り | 雨降り |
| 6 | 雨予報 | 予報 | one | one | one |
| 7 | 雨降り | one | 湿度 | 湿度 | 湿度 |
| 8 | 中止 | 函館 | 予報 | 函館 | 函館 |
| 9 | 小雨 | 中止 | 函館 | イオン | イオン |
| 10 | one | 小雨 | イオン | 釣り | 釣り |
원래 순위에서는 'イラン'(이란)과 'イスラエル'(이스라엘)이 나란히 1, 2위를 차지했지만 다양화를 적용하자 두 단어의 NPMI 값이 임계치를 넘었기에 상위로 뽑힌 'イラン' 만 남았습니다. '予報'(예보)와 '中止'(중지)는 '大雨' (큰비)와 어느 정도 관련도가 있어 값이 커질수록 하위로 내려가는 것을 볼 수 있습니다. 날짜를 달리해 여러 차례 적용해 보니 페널티 가중치가 2 이상이면 가중치를 더 늘리더라도 대체로 순위가 유지되는 것을 관찰했습니다. 검토 결과 다양성이 충분히 확보되는 편이 바람직하다고 의견이 모여 페널티 가중치가 2 이상인 구간에서 값을 결정했습니다.
참고로 위 예제에서 '土砂降り'(토사 내림, 장대비), '雨予報'(비 예보), '雨降り'(강우) 등 비와 연관된 키워드가 다양화 후에도 여럿 남아있는데요. 서로 간의 NPMI 값은 0.3 미만으로 실제 이들이 함께 등장하는 메시지 수는 비교적 많지 않음을 확인했습니다.
마치며
지금까지 통계적 기법들을 활용해 오픈챗 메시지 데이터에서 유행하는 트렌딩 키워드를 추출하는 방식을 소개드렸습니다. 검정 통계량 기반으로 빈도가 급증한 단어를 트렌딩 키워드로 탐지하는 한편, 텍스트 클러스터링으로 중복 메시지를 제거하고, 공통 발생 빈도에 근거해 부적절한 키워드 제거 및 상위 키워드를 다양화해 추출되는 키워드의 품질을 향상시켰습니다. 향후 LLM을 이용해 추출된 키워드를 기반으로 트렌딩 리포트를 생성한다거나, 여타 패밀리 서비스의 트렌딩 토픽과 연계해 시너지를 추구하는 것도 유망한 장래 과제가 될 것입니다.
모든 것의 기본이자 중심은 사용자라는 기준에 따라 사용자들이 오픈챗 서비스에서 흥미롭고 유용한 콘텐츠를 많이 발견하고 이를 매개로 활발하게 활동할 수 있도록 노력하겠습니다. 끝까지 읽어주셔서 감사합니다.


