LLM 애플리케이션 테스트의 어려움
GPT-4와 같은 대규모 언어 모델(large language model, 이하 LLM)이 대중화되고 이를 활용한 LLM 애플리케이션 역시 다양한 분야에서 본격적으로 사용되고 있습니다. 다양한 비즈니스 로직이 포함된 LLM 애플리케이션은 서비스의 품질을 보장하는 것 역시 작업 과정에서 굉장히 중요한 부분을 차지하는데요. LLM 애플리케이션은 그 복잡성만큼이나 테스트하는 것이 쉽지 않습니다. 입력값을 약간만 변경해도 완전히 다른 답변을 생성하기 때문입니다. LLM 애플리케이션은 프롬프트 체이닝(prompt chaining)과 에이전트 등을 통해 모델에 대해 여러 번의 추론(inference)을 수행하기 때문에 오차가 누적돼 변동성이 크고, 프롬프트를 약간만 수정해도 답변이 완전히 달라지는 등 굉장히 민감한 애플리케이션입니다.
이번 글에서는 LINE GAME PLATFORM 팀에서 다양한 LLM 애플리케이션을 개발하면서 이와 같이 민감한 LLM 애플리케이션 테스트 및 테스트 결과 평가 과정을 개선하고 자동화하기 위해 어떤 테스트 방법론을 사용했는지 공유하겠습니다.
테스트 및 테스트 평가 방법 개선
먼저 어떻게 테스트 및 테스트 결과 평과 과정을 개선했는지 살펴보겠습니다.
프롬프트별로 테스트 단위 세분화
저희는 먼저 LLM 애플리케이션의 변동성을 제어하기 위해 출력에 영향을 주는 항목을 하나씩 구분하는 작업을 진행했습니다. 프롬프트 체이닝이 수행되는 애플리케이션의 경우 단일 프롬프트를 테스트한 후 프롬프트 체이닝이 구현된 LLM 애플리케이션 전체를 테스트합니다. 각 항목을 평가할 수 있는 질문/답변 구성의 데이터 세트를 각 프롬프트별로 따로 만드는 것인데요. 프롬프트가 여러 개 연결돼 있는 프롬프트 체이닝의 경우 아래 그림과 같이 프롬프트별로 테스트 데이터 세트를 각각 마련합니다. 이런 작업은 매우 번거로운 일이긴 하지만, 이를 통해 개별 프롬프트의 성능을 독립적으로 평가할 수 있고, 이후 해당 프롬프트를 수정하더라도 전체 테스트는 지속적으로 진행할 수 있습니다.
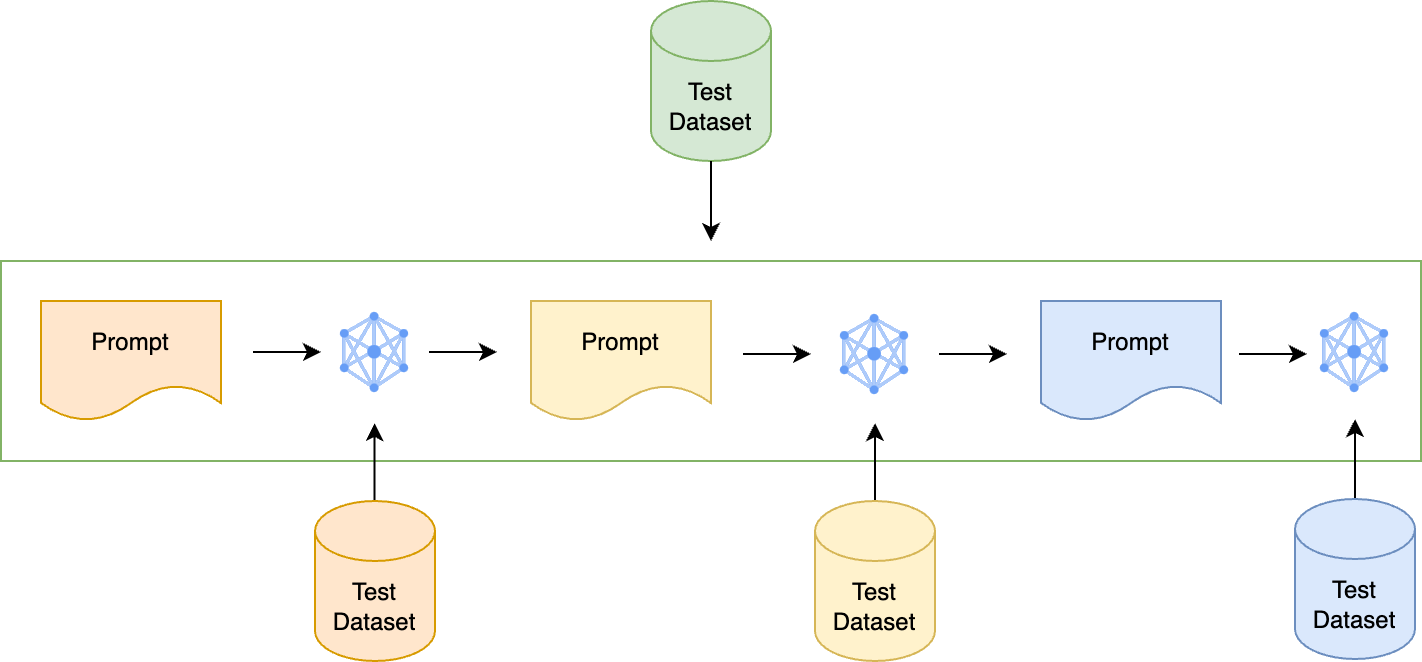
그렇다면 테스트 진행 후 테스트 결과는 어떤 방식으로 평가할까요?
정량 평가 도입 및 평가 지표 선정
도메인에 특화된 LLM 애플리케이션은 특정 분야의 복잡하고 세밀한 요구 사항을 충족해야 하므로 정확하게 평가하려면 도메인 전문가의 정성 평가가 필수입니다. 따라서 프롬프트나 모델을 수정하면서 성능을 비교하고 측정하기 위해서는 도메인 담당자의 추가 리소스가 투입돼야 하는데요. 이를 개선하기 위해 평가 과정을 자동화해 평가에 필요한 리소스를 줄일 수 있도록 새로운 평가 기준을 개발하기로 결정했고, 가장 쉽게 생각해 볼 수 있는 방법은 정량 평가였습니다.
정량 평가는 객관적인 지표로 모델의 성능을 평가하는 방식으로 일관적인 기준을 세워 빠르게 결과를 도출할 수 있다는 장점이 있습니다. 그러나 이 방식은 주로 단어 단위의 단순 매칭에 기반하기 때문에 아래 예시와 같이 다른 어휘를 사용하거나 문장 구조를 바꾸는 등 표현 방법이 달라지면 실제로는 정답임에도 평가 점수가 낮아질 수 있고 문맥을 고려하지 않는다는 한계가 있습니다.
- 정답 문장: The cat sleeps on the sofa.
- 비교 문장: The cat is sleeping on the sofa. → 정답 문장과 같은 의미에 유사한 어휘를 사용해 높은 유사도 점수 획득
- 비교 문장: A feline is resting on the couch. → 정답 문장과 같은 의미임에도 사용 어휘가 다르고 문장 구조가 달라 낮은 유사도 점수 획득
위와 같은 단점에도 불구하고, 사람의 개입 없이 빠른 평가 결과를 얻을 수 있다는 점이 자동화 프로세스에 적용하기에 적합했기에 저희는 단점을 보완해 사용하기로 결정했습니다. 단어 단위 단순 매칭의 한계를 극복하기 위해 문맥을 고려하고 의미의 유사성을 더욱 잘 반영할 수 있는 지표들을 응답 형태별로 추가했습니다. 일반적으로 우수한 모델들은 정량 평가에서도 좋은 성능을 보이는 경향이 있는데요. 이에 정량 지표를 이용해 모델 성능을 1차로 검증하는 파이프라인을 설계했습니다.
그럼 저희가 정량 평가에 활용한 주요 지표들을 유형별로 살펴보겠습니다.
로직 기반 평가 지표
정확한 매칭(exact match)
모델의 예측이 정답과 정확히 일치하는지 판단하는 지표입니다. 현실적으로 정답과 예측값이 온전히 일치하기는 어렵기에 활용성이 낮지만, 응답의 유형이 명확하게 정의된 경우에는 직관적으로 신속하게 활용할 수 있��기에 사용했습니다.
코사인 유사도(cosine similarity)
문장을 벡터화한 후 두 벡터 간의 코사인 각도를 이용해 유사성을 측정하는 방법입니다.
LLM은 창의적으로 응답을 생성하기 때문에 같은 의미의 문장도 매번 다르게 표현할 수 있습니다. 따라서 정확하게 평가하기 위해서는 문장 내 단어 간의 연관성을 이해하고 문맥을 파악하는 방법이 필요했는데요. 가장 빠르고 간단하게 사용할 수 있는 지표는 단순히 단어 매칭 여부를 기반으로 하는 N-그램 지표들이었으나 이런 지표들은 동의어나 단어의 가변성, 단어 간 연관성을 파악하지 못하는 한계가 있어 정확하게 평가할 수 없었습니다.
이런 한계를 극복하기 위해 문장을 벡터로 임베딩한 후 이를 기반으로 유사성을 측정하는 코사인 유사도 지표를 추가했습니다. 정성 평가만큼은 아니지만 정량 지표 중에서는 문맥을 고려할 수 있는 가장 효과적인 성능 지표로 알려져 있습니다.
METEOR
정답과 예측 문장 간의 정확한 일치, 동의어 일치, 형태소 일치를 기반으로 정렬을 수행한 후 정밀도(precision)와 재현율(recall)의 조화 평균(F-score)과 단어 연속성에 따른 페널티를 결합해 최종 점수를 계산하는 방법입니다. N-gram 기반 지표로 기존 N-gram 기반 지표의 한계를 보완해 동의어와 문장 구조의 유사성을 함께 고려하는 방법인데요. 코사인 유사도와 상호보완적으로 활용하고자 추가했습니다.
Rouge-L
정답과 예측 문장 간의 단어 배치 순서를 고려하면서 가장 긴 공통 부분 시퀀스를 기반으로 유사성을 측정하는 방법입니다.
현재 개발 중인 LLM 애플리케이션은 질문에 대한 서술형 응답뿐 아니라 경우에 따라 파일의 경로나 curl 명령어와 같은 코드 기반의 응답을 출력하기도 하는데요. 경로나 코드 같은 경우 모든 단어나 토큰이 정답 문장과 일치하더라도 그 순서가 다르면 의미가 완전히 달라지므로 순서가 일치하는 것이 매우 중요합니다. 앞서 문맥을 고려하기 위해 추가했던 코사인 유사도나 METEOR 지표들은 이 부분에서 한계를 드러내는데요. 아래 예시와 함께 살펴보겠습니다.
- 정답: curl -X GET http://example.com/data
- 틀린 응답: curl -X http://example.com/data
위 예시를 코사인 유사도나 METEOR로 평가하면 HTTP 메서드(GET)가 빠져 있음에도 유사도 점수가 높게 나옵니다. 반면 Rouge-L은 두 문장의 가장 긴 공통 부분 수열을 기반으로 평가하므로 토큰의 순서와 포함 여부가 고려되기 때문에 GET 메서드가 누락된 것이 구조적 차이로 간주돼 유사도 점수가 낮게 나옵니다.
이와 같이 순서가 중요하며 단어의 변형 없이 구조화된 텍스트에 대응하기 위해 Rouge-L 지표를 사용했습니다.
LLM 기반 평가 지표
LLM을 활용한 평가 지표로는 GPT 유사도(similarity)와 GPT 정확도(correctness)를 사용했습니다.
- GPT 유사도: GPT-4를 활용해 정답과 예측 문장 간의 유사도를 0~1 사이 점수로 산출하는 방법입니다.
- GPT 정확도: GPT-4를 활용해 정답과 예측 문장 간의 유사성 여부를 판단하는 방법으로 결과를 0(상이) 또는 1(유사)로 분류하는 방식입니다.
로직 기반 평가 지표들은 산출 방식에 따라서 평가 기준이 각기 다릅니다. 이런 지표들은 다양한 형태의 출력을 생성하는 LLM을 평가할 때 다방면에서 유연한 판단을 내리기 어렵기 때문에 사람이 평가하는 방식을 완전히 대체하기에는 부족함이 있다고 판단했습니다.
이런 한계를 보완하기 위해 LLM 자체를 활용한 평가 방법을 고려했습니다. LLM은 다양한 분야에서 뛰어난 능력을 보이며 제로 샷 문맥 내 학습(zero-shot in-context learning)을 통해 별도 예시 없이도 지시에 따라 우수한 성능을 발휘할 수 있습니다. National Taiwan University의 Cheng-Han Chiang, Hung-yi Lee는 Can Large Language Models Be an Alternative to Human Evaluation?라는 논문에서 ChatGPT를 이용해 테스트한 결과 대부분 인간 전문가와 일치하는 평가를 내렸다며 LLM이 인간의 평가를 대체하는 것이 가능함을 시사하기도 했습니다.
LLM을 활용한 평가 지표의 주요 장점은 다음과 같습니다.
- 높은 재현성: 인간이 평가할 때에는 같은 자격을 갖춘 사람에게 동일한 지침을 내려도 주관적 평가 기준이 다를 수 있는 반면, LLM 평가 결과는 사용한 모델과 랜덤 시드, 하이퍼 파라미터를 명시하면 같은 결과가 재현될 가능성이 높습니다.
- 샘플의 독립성 보장: 인간 평가에서는 현재의 평가가 이전 샘플들에 다소 영향을 받을 수 있는 반면, LLM 평가에서는 각 샘플의 평가가 서로 독립적입니다.
- 저렴한 비용과 빠른 속도: 사람이 직접 평가할 때보다 비용이 적게 들며, 보다 빠르게 결과를 확인할 수 있습니다.
이런 장점을 고려해 인간 평가와 유사한 역할을 담당할 수 있도록 위 두 지표를 추가해서 앞서 소개한 로직 기반의 다른 지표들과 함께 사용해 평가의 객관성을 높이면서 모델의 성능을 다각도에서 종합적으로 이해할 수 있기를 기대했습니다.
테스트를 자동화해야 하는 이유
LLM 애플리케이션을 테스트할 때 앞서 소개한 지표를 상황에 맞게 선별해서 사용합니다. 프롬프트별로 적합한 지표가 다르기 때문인데요. 만약 애플리케이션에서 사용하는 프롬프트가 많고 사용하는 지표가 많은데 프롬프트 변경에 따른 관련 작업을 전부 수동으로 진행한다면 테스트 과정이 매우 복잡하고 시간도 오래 걸릴 것입니다.
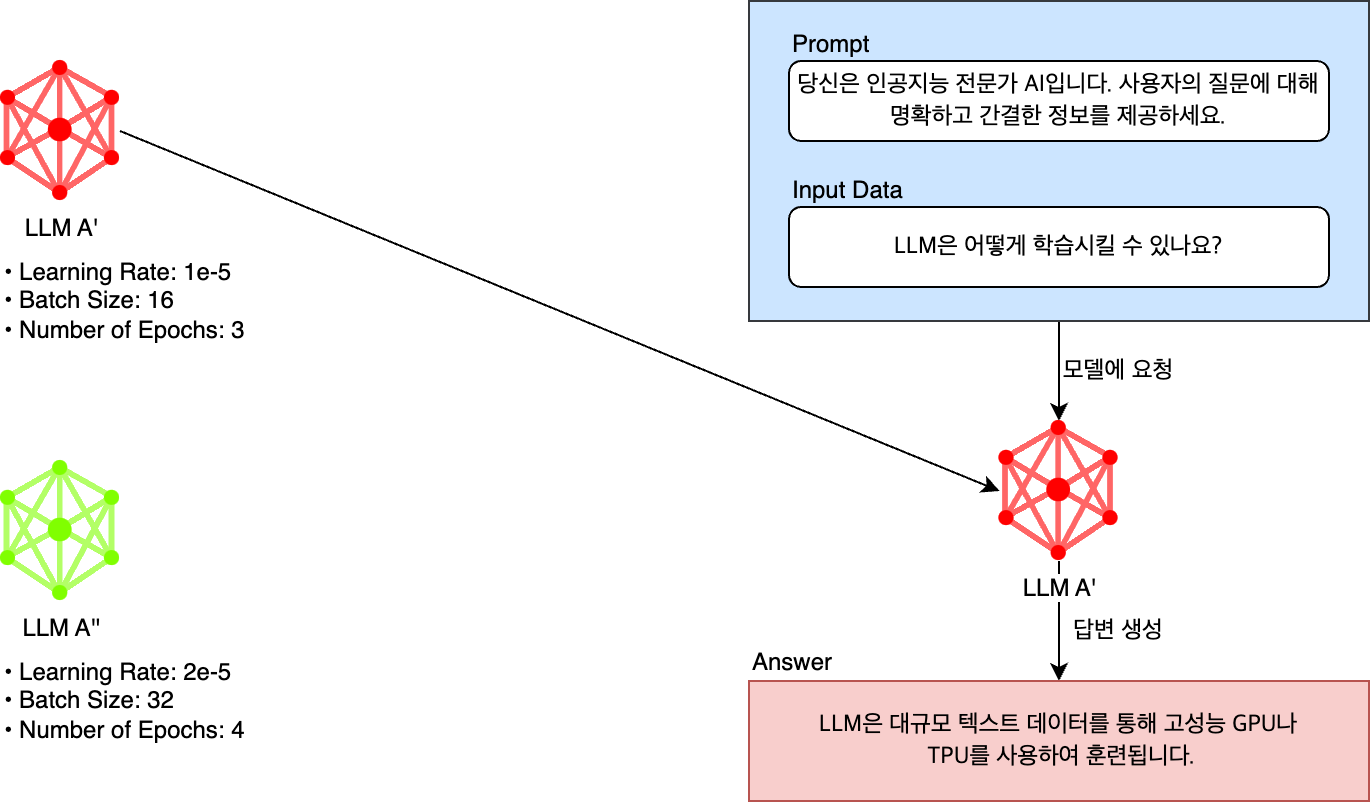
아래 예시를 살펴보겠습니다. 입력 데이터와 LLM은 동일한 상태에서 프롬프트만 변경해 질의한 것입니다. 'LLM이 무엇인가요?'라는 동일한 질문에 프롬프트에 따라 전혀 다른 품질의 응답이 나오는 것을 확인할 수 있습니다.
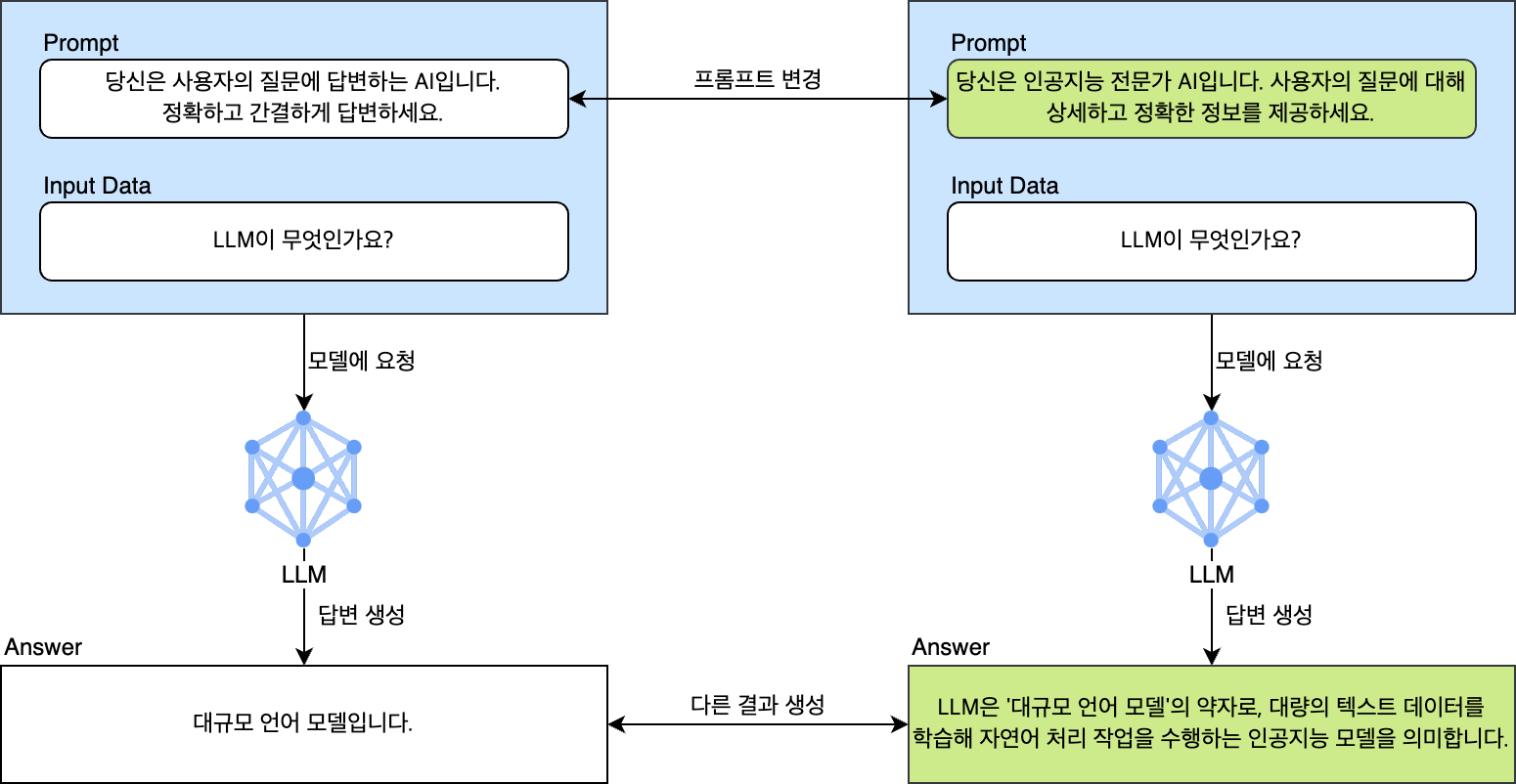
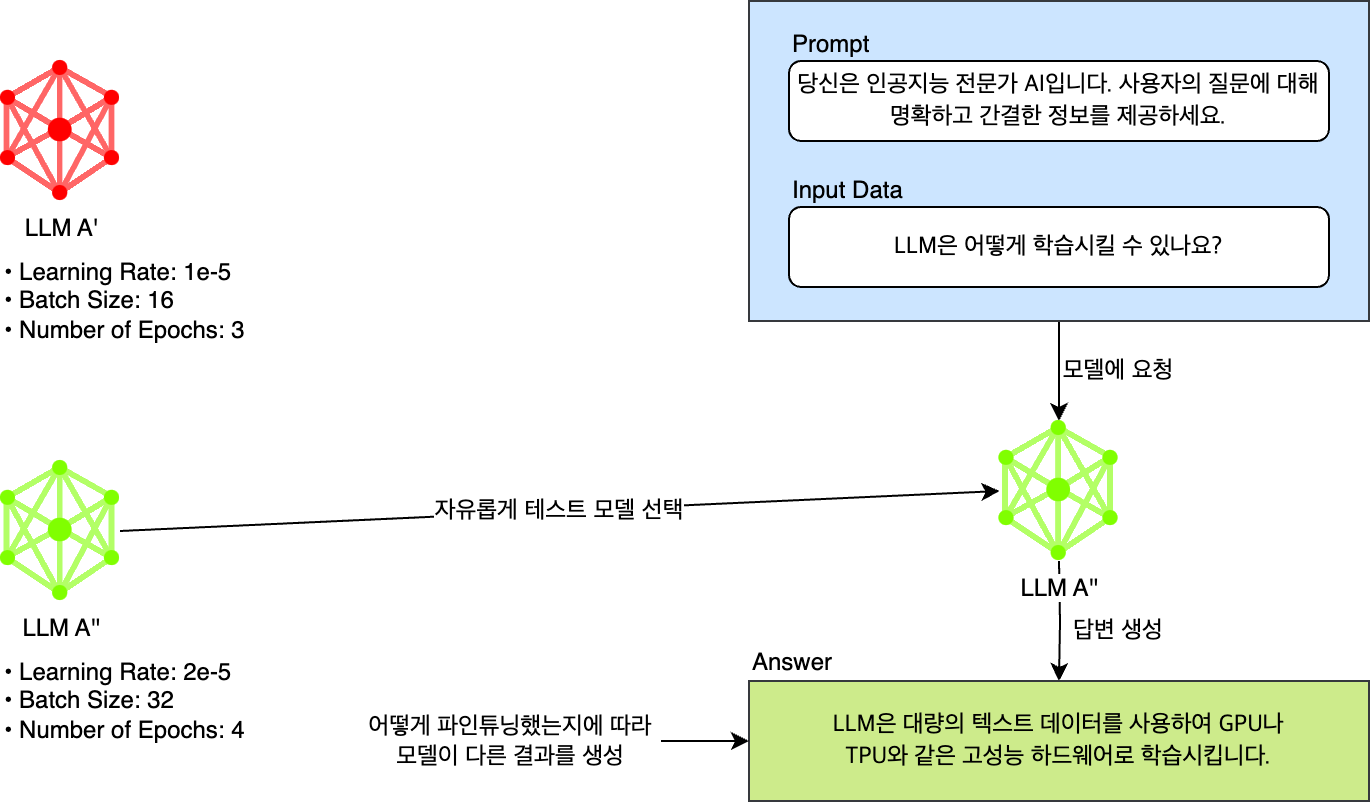
이처럼 LLM은 프롬프트의 미세한 변화에 민감하게 반응합니다. 따라서 더 높은 품질의 답변을 얻으려면 여러 가지 프롬프트를 개발하고 테스트하며 응답에 대한 지표를 확인해야 하는데요. 아래와 같이 여러 가지 프롬프트 중 원하는 것을 자유롭게 선택해서 테스트해 볼 수 없다면 최적화된 프롬프트를 결정하는데 얼마나 많은 시간이 걸릴지 알 수 없습니다.
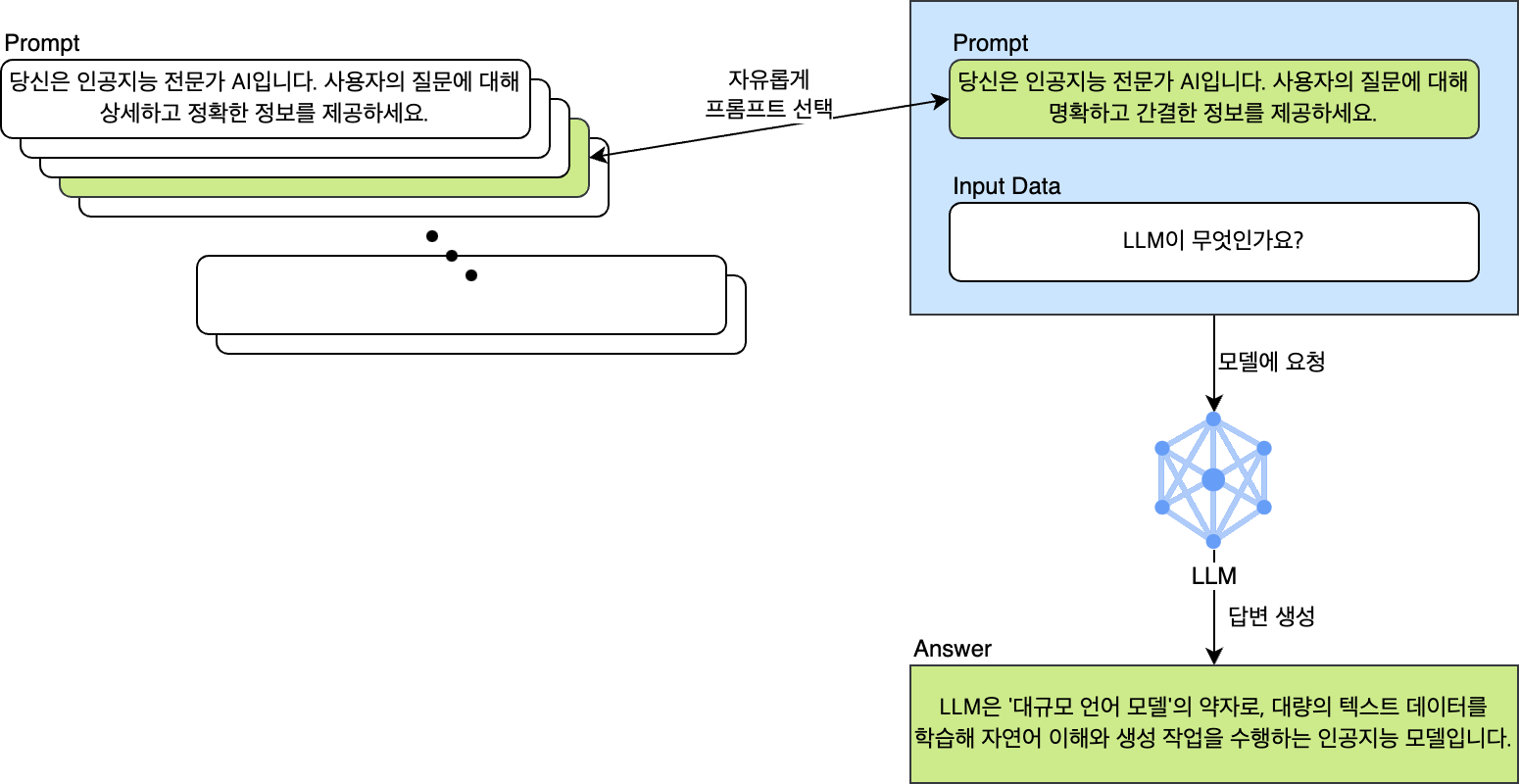
또한 목적에 따라 데이터를 모아 데이터 세트를 구성할 때 수천, 수만 개 이상의 데이터로 구성된 각 데이터 세트를 동적으로 프롬프트와 결합하거나 선택해 테스트해야 하는 작업을 자동화하지 않는다면 이 또한 매우 귀찮은 작업이 될 것입니다.
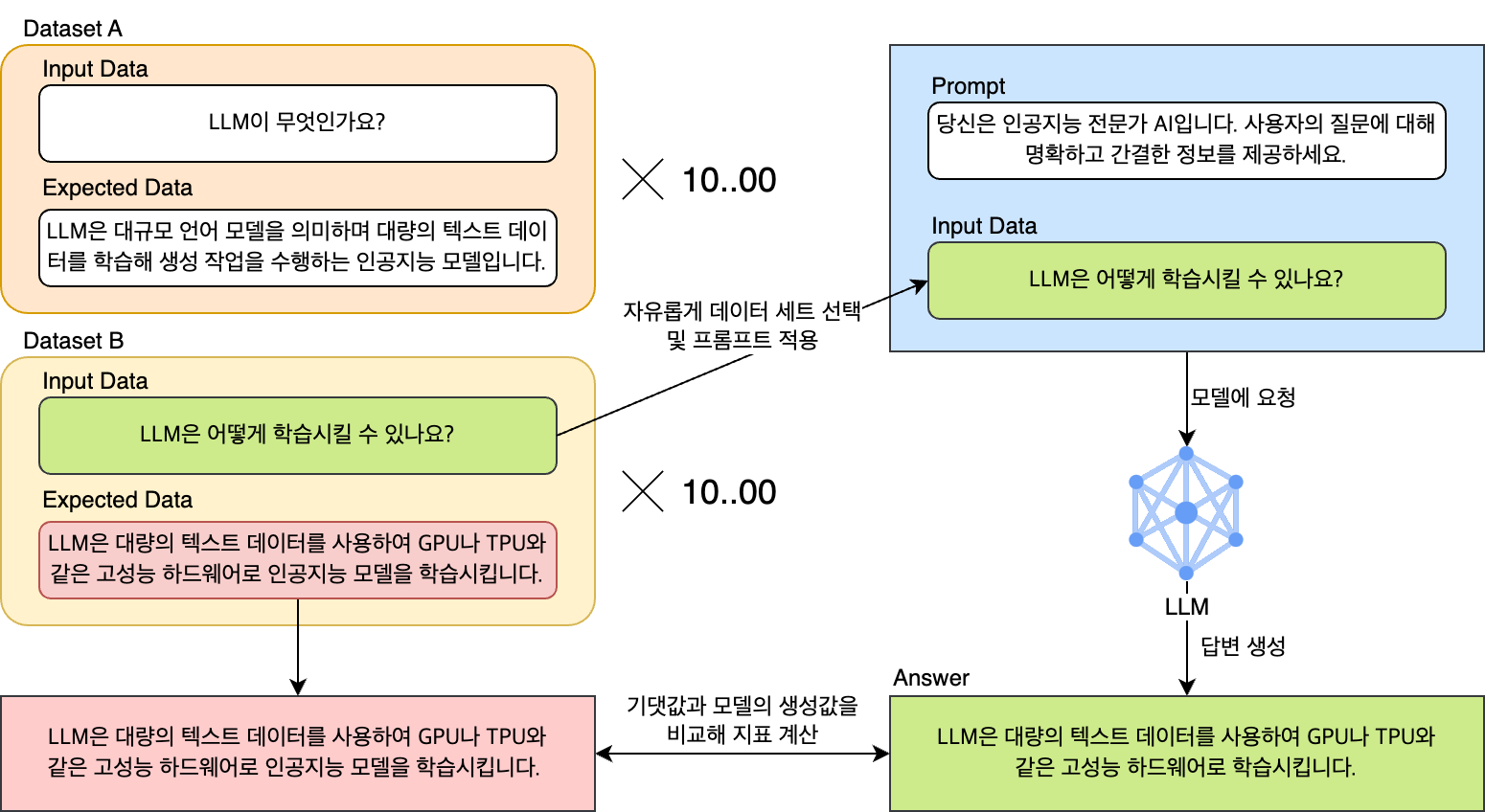
마지막으로 모델은 여러 가지 하이퍼 파라미터와 데이터로 파인 튜닝(fine tuning)할 수 있습니다. 또는 여러 개의 모델로 구성된 RAG(rag-augmented generation) 기반 LLM 애플리케이션이 평가 대상이 될 수 있습니다. 최적의 서비스를 만들기 위해서는 이처럼 여러 가지 모델을 테스트한 뒤 이를 평가해서 얻은 지표를 비교해 최적의 모델을 선별하는 과정이 꼭 필요한데요. 이 작업 또한 자동화가 꼭 필요한 기능이었습니다.
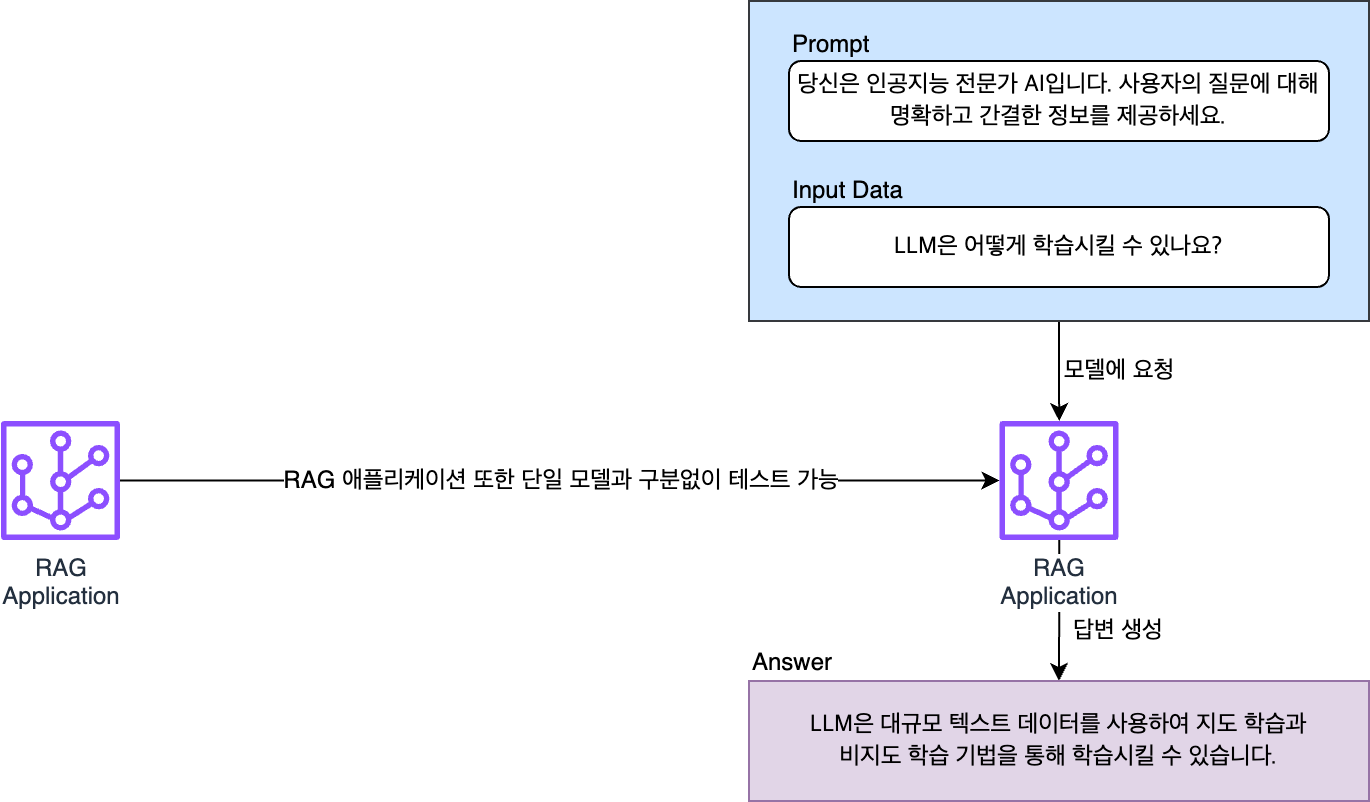
정리하면, 프롬프트와 데이터 세트, 모델을 일일이 개발자가 변경해 가며 하나하나 테스트하는 방식은 매우 비효율적입니다. 애플리케이션을 효과적으로 최적화하기 위해서는 이를 자동화할 필요가 있습니다.
저희는 자동화할 수 있는 방법을 모색했고, 대규모 테스트와 지표 커스터마이징에 초점을 맞춰 테스트 환경을 구축하기로 결정했습니다. 여기서 테스트 자동화 작업에 핵심 역할을 한 프레임워크가 바로 Language Model Evaluation Harness(이하 Harness)입니다. 저희는 테스트를 자동화하기 위한 파이프라인을 구축할 때 모델과 LLM 애플리케이션을 평가하는 핵심 컴포넌트를 Harness 기반으로 개발했는데요. Harness가 어떤 프레임워크인지, 어떻게 사용하는지 하나씩 살펴보겠습니다.
Harness를 이용한 테스트 자동화
Harness는 언어 모델을 평가하기 위해 비영리 AI 연구소 EleutherAI에서 개발한 오픈소스 프레임워크입니다. 기본적으로 GLUE, MMLU, HellaSwag 등 60개 이상의 벤치마크로 구성된 작업(task)을 지원하며, 새로운 작업을 커스터마이징해서 모델을 평가할 수도 있습니다.
Harness의 장점은 다음과 같습니다.
- 오픈소스 프로젝트로, 많은 연구자와 개발자가 협력해 지속적으로 업데이트하면서 모델 평가에 대해 표준과 같은 구현을 제공합니다. 이런 이유로 Hugginface의 Open LLM Leaderboard에서도 모델 평가에 Harness를 사용하고 있습니다.
- 평가에 사용할 데이터 세트와 지표, 프롬프트 등을 자유롭게 설정할 수 있기 때문에 요구 사항에 맞는 테스트를 빠르게 실행해 볼 수 있습니다.
- 평가를 자유롭게 확장할 수 있는 구조이기 때문에 사내 AI 시스템에 맞는 방식으로 평가를 커스터마이징할 수 있습니다.
이제 기본적인 Harness 사용법과 저희가 어떻게 커스터마이징해서 사용하고 있는지 하나씩 설명하겠습니다.
Harness 사용 방법
이제 기본적인 Harness 사용법을 설명하겠습니다.
설치 및 실행
Harness를 설치하고 실행하는 방법은 매우 간단합니다. 먼저 아래와 같이 Harness 리포지터리에서 프로젝트를 다운로드하고 의존성 패키지를 설치합니다.
git clone https://github.com/EleutherAI/lm-evaluation-harness // 프로젝트 다운로드
cd lm-evaluation-harness // 프로젝트 디렉터리로 이동
pip install -e . // Harness에서 사용하는 의존성 패키지 설치설치 완료 후 lm_eval 명령어로 Harness를 실행해 볼 수 있습니다.
lm_eval --model hf \
--model_args pretrained=EleutherAI/gpt-j-6B \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8위 예시의 순서대로 명령어의 인자를 살펴보겠습니다.
--model: 테스트를 진행할 모델을 선택합니다. 위 예시에서는 Hugging Face(hf)를 선택했습니다.--model-args: 모델을 실행하기 위해 필요한 인자를 설정합니다. 위 예시에서는pretrained=EleutherAI/gpt-j-6B를 설정해 Hugging Face를 통해 모델 EleutherAI/gpt-j-6B를 테스트하려고 한다는 것을 알 수 있습니다.--tasks: 모델에 어떤 작업을 테스트할지 결정합니다. ,로 구분해 여러 개의 작업을 선택할 수 있고, 작업 그룹을 기입해 그룹에 속한 모든 작업을 테스트할 수도 있습니다.--device: 모델이 사용할 기기를 설정합니다(예:cuda,cuda:0,cpu,mps).--batch_size: 평가에 사용할 배치 크기를 설정합니다. 양수 정수로 설정하거나,auto로 설정해 메모리에 맞는 가장 큰 배치 크기를 자동으로 선택해 평가 속도를 높일 수 있습니다.
그 외 모델 평가와 관련된 수많은 옵션은 인터페이스 가이드 문서에서 확인할 수 있습니다.
위 lm_eval을 명령어를 실행해 helloSwag 작업을 테스트한 hf의 EleutherAI/gpt-j-6B 모델 평가 결과는 아래와 같이 출력됩니다.
hf (pretrained=EleutherAI/gpt-j-6B), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: 8
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|-----:|--------|-----:|---|-----:|
|hellaswag| 1|none | 0|acc |0.5737|± |0.0049|
| | |none | 0|acc_norm|0.7721|± |0.0042|위 예시에서 가장 중요한 부분은 어떤 모델을 테스트할 것인지 지정하는 --model과, 모델에 대해서 무엇을 테스트하고 어떤 결과를 얻을 것인지 작업을 지정하는 --tasks입니다. 이때 팀에서 파인 튜닝한 단일 모델이나 RAG LLM 애플리케이션은 Harness에 따로 등록돼 있지 않기 때문에 LM이라는 추상 클래스를 개발해 새로운 모델로 추가해야 합니다. 작업 또한 각자의 니즈에 따라 작성한 데이터 세트와 프롬프트, 지표를 테스트하기 위해 YAML 파일을 이용해 커스터마이징할 수 있습니다.
즉 Harness에서는 LM 클래스와 YAML 파일을 이용해 모델과 데이터 세트, 프롬프트에 대한 커스텀 인터페이스를 제공하며, 개발자는 이를 이용해 자유롭게 LLM을 평가할 수 있습니다. 다음은 평가 과정에서 커스텀 인터페이스의 사용 지점을 간단하게 그림으로 나타낸 것입니다.
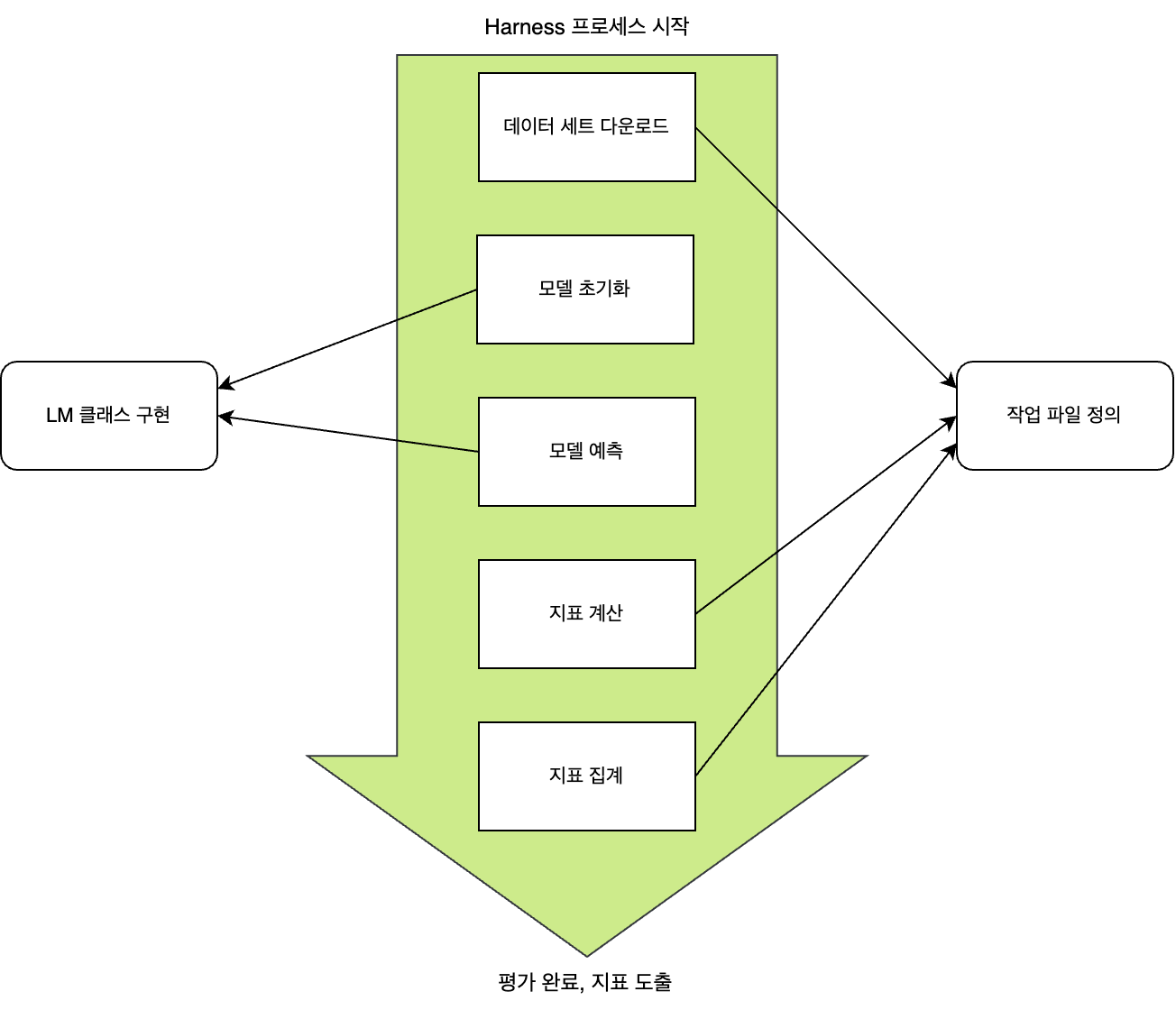
그럼 먼저 어떻게 LM 추상 클래스를 직접 구현해 팀에서 개발한 모델을 등록할 수 있는지 알아보겠습니다.
모델 클래스 구현
앞서 간단히 살펴본 것처럼 새로운 모델을 추가할 때에는 먼저 Harness 패키지 내부의 추상 클래스인 LM을 상속받는 모델 클래스를 생성합니다. lm_eval 명령어의 --model_args로 입력되는 인자는 생성자의 파라미터로 넘어오며, 모델 클래스는 이를 이용해 필요한 모델을 특정하거나 하이퍼 파라미터를 설정하는 등의 초기화 작업을 진행합니다.
예를 들어 앞서 살펴본 lm_eval 명령어 예시와 같이 Hugginface에 의존성이 있다면 아래와 같이 모델 클래스 생성자를 구현할 수 있습니다.
@register_model("my_custom_lm")
class MyCustomLM(LM):
def __init__(self,
model_name: str,
**kwargs):
self._model = AutoModelForCausalLM.from_pretrained(model_name)
self._tokenizer = AutoTokenizer.from_pretrained(model_name)
...위와 같이 모델 클래스를 구현할 때에는 가장 먼저 생성자를 통해 모델 클래스가 질의에 즉시 답변할 수 있는 상태로 만들기 위한 초기화 로직을 구현합니다. 초기화 로직을 통해 초기화된 모델 클래스는 이어서 소개할 세 가지 추상 메서드를 구현함으로써 질의에 답변할 수 있습니다. 모델 클래스의 궁극적인 목적은 데이터 세트에 대해 모델에 질의한 결과를 반환하는 것인데요. 이를 위해 구하고자 하는 지표에 따라 아래 세 메서드 중 하나 이상을 구현합니다.
@register_model("my_custom_lm")
class MyCustomLM(LM):
def __init__(self, ...,**kwargs):
#...
def loglikelihood(self, requests: list[Instance]) -> list[tuple[float, bool]]:
#...
def loglikelihood_rolling(self, requests: list[Instance]) -> list[tuple[float, bool]]:
#...
def generate_until(self, requests: list[Instance]) -> list[str]:
#...
#...모델의 질의 답변을 위해 하나가 아니라 세 가지나 되는 메서드를 지원하는 이유는 각 메서드의 답변 형태가 사람이 알아볼 수 있는 문자열 형태인지 아니면 토크나이저로 디코드하기 전의 토큰 형태인지에 따라 구할 수 있는 지표가 다르기 때문입니다. 아래 표는 세 가지 메서드의 특징을 정리한 것입니다.
| 추상 메서드 이름 | 반환값 | 얻을 수 있는 지표 | 설명 |
|---|---|---|---|
generate_until | list[str] | 정확한 매칭(exact_match)이나 유사도 종류 | 테스트 데이터 세트의 각 요청에 대해 LM이 until로 설정된 문자열에 도달하거나 max_gen_toks 크기에 도달할 때까지, 모델이 생성한 답변을 사람이 알아볼 수 있는 문자열 형식으로 list를 생성해 반환하는 메서드입니다. |
loglikelihood | list[tuple[float, bool]] | 퍼플렉시티(perplexity), 정확도(accuracy) 등 | 요청에 대한 타깃 문자열을 받아서, LM이 요청을 입력으로 예측을 생성해서 타깃 문자열이 생성될 로그 확률(loglikelihood)을 반환합니다. 결과로는 로그 확률(ll)과 타깃 문자열이 탐욕적 샘플링에 의해 생성됐는지(is_greedy)를 나타내는 값이 반환됩니다. |
loglikelihood_rolling | list[tuple[float, bool]] | 단어(word) 퍼플렉시티, 바이트 퍼플렉시티 등 | loglikelihood에 대한 특이 케이스로 모델은 입력 문자열 전체에 대해 로그 확률을 계산합니다. 단어 퍼플렉시티, 바이트 퍼플렉시티 등을 구할 때 사용합니다. |
위 세 가지 메서드를 꼭 모두 구현할 필요는 없습니다. 요구 사항에 따라 얻을 수 있는 지표를 확인해 필요한 메서드만 구현해도 됩니다. 아래는 세 메서드 중 generate_until을 구현한 예시입니다. 생성자를 통해 초기화한 모델과 토크나이저를 이용해 모델에 질의한 뒤 응답받은 결과를 리스트 형태로 반환합니다.
def generate_until(self, requests: List[Instance]) -> List[str]:
responses = []
for request in requests:
input_text = request.args[0]
inputs = self._tokenizer(input_text, return_tensors="pt")
outputs = self._model.generate(**inputs, max_length=50)
generated_text = self._tokenizer.decode(outputs[0], skip_special_tokens=True)
responses.append(generated_text)
return responses이와 같이 자유롭게 모델 클래스를 구현할 수 있으며, 앞서 살펴본 lm_eval 명령어 실행 예시(--model hf)와 같이 이미 구현돼 있는 모델을 사용할 수도 있습니다. 참고로 hf 또한 추상 클래스 LM을 구현하는 방식으로 프로젝트 내부에 정의돼 있는 것이며, 사용 가능한 모델은 아래 링크에서 확인할 수 있습니다.
작업 정의
Harness에서 작업(task)은 데이터 세트와 프롬프트, 지표를 정의하고 관리하는 역할을 담당합니다. 즉 '어떤 데이터 세트를 어떤 프롬프트와 결합해 사용하고, 모델에 질의해 얻은 답변으로 어떤 지표를 계산할 것인가'를 YAML 파일에 정의해 관리하는 것이 작업이라고 볼 수 있습니다. YAML 파일은 기본적으로 lm_eval/tasks/ 경로에 저장되며, lm_eval 명령어를 이용해 Harness를 실행하면 Harness는 해당 경로에서 작업 이름으로 지정된 YAML 파일을 찾아 파일에 정의된 대로 테스트를 실행합니다.
그럼 lambada_openai 작업을 정의하는 예시와 함께 어떻게 YAML 파일에 작업을 정의하는지 설명하겠습니다.
가장 먼저 작업 이름을 설정합니다. 설정한 이름으로 lm_eval 명령어에서 --tasks 옵션을 지정해 테스트할 수 있습니다.
task: lambada_openai다음으로 데이터 세트를 설정합니다. 데이터 세트는 기본적으로 Huggin Face의 데이터 세트 허브에서 다운로드하는데요. dataset_path 설정으로 데이터 세트 허브에서 가져올 데이터 세트를 선택하고, dataset_name 설정으로 해당 데이터 세트 내 특정 서브 데이터 세트를 선택할 수 있습니다. 자세한 설명은 Hugging Face의 Load a dataset from the Hub 문서를 참고해 주세요.
dataset_path: EleutherAI/lambada_openai
dataset_name: default다음으로 output_type을 설정합니다. output_type은 작업에 사용할 모델의 아웃풋 유형을 의미합니다. 아웃풋 유형으로는 앞서 설명한 generate_until과 loglikelihood, loglikelihood_rolling의 세 가지 유형에 multiple_choice를 더해 총 네 가지 유형이 존재합니다. multiple_choice는 고정돼 있는 유한한 집합의 레이블 단어 중 하나를 선택하고, 모든 레이블 단어의 loglikelihood을 비교해 평가하는 유형입니다.
output_type: loglikelihood다음으로 데이터 세트의 데이터를 어떻게 처리할지 설정합니다. 아래처럼 Jinja2 템플릿을 사용하거나 !function 문법을 사용해 YAML 파일과 같은 경로에 Python 파일을 정의해 사용할 수 있습니다.
### jinja2
doc_to_text: "{{text.split(' ')[:-1]|join(' ')}}"
doc_to_target: "{{' '+text.split(' ')[-1]}}"
### python code
doc_to_text: !function utils.doc_to_text
doc_to_target: !function utils.doc_to_targetdef doc_to_text(text):
words = text.split(' ')
return ' '.join(words[:-1])
def doc_to_target(text):
words = text.split(' ')
return ' ' + words[-1]doc_to_text는 데이터 세트의 단일 데이터별 입력값을 전처리하고, doc_to_target은 모델에게 기대하는 출력값을 후처리합니다. 팀에서는 doc_to_text 옵션을 이용해 동적으로 프롬프트를 적용하기 위한 기능을 구현했는데요. 이에 관해서는 아래에서 별도로 자세히 살펴보겠습니다.
마지막으로 - metric: perplexity와 같이 설정해 구하고자 하는 지표를 결정합니다. aggregation은 평가 결과를 어떻게 집계할 것인지를 설정하는 옵션입니다. aggregation은 생략할 수 있습니다.
metric_list:
- metric: perplexity
aggregation: perplexity
higher_is_better: false
- metric: acc
aggregation: mean
higher_is_better: true앞서 설정한 지표가 어떻게 계산되는지에 대한 정보는 lm_eval/api/metrics.py에 메서드로 정의돼 있습니다. 아래는 perplexity에 대한 구현입니다.
- lm_eval/api/metrics.py
...
# Certain metrics must be calculated across all documents in a benchmark.
# We use them as aggregation metrics, paired with no-op passthrough metric fns.
@register_aggregation("perplexity")
def perplexity(items):
return math.exp(-mean(items))
...
@register_metric(
metric="perplexity",
higher_is_better=False,
output_type="loglikelihood",
aggregation="perplexity",
)
def perplexity_fn(items): # This is a passthrough function
return items데코레이터 @register_aggregation(...)을 통해 aggregation 메서드를, @register_metric(...)을 통해 단일 데이터에 대한 지표 메서드를 등록할 수 있습니다. 보통 지표 메서드에서 각 모델 생성 결과에 대한 지표를 계산하는데요. perplexity의 경우 데이터 세트의 모든 데이터를 참고해 계산해야 하기 때문에 위 코드에서는 지표 메서드는 어떤 작동도 하지 않도록 구현해 놓았습니다.
지금까지 살펴본 내용을 정리하면, 현재 Harness에서 테스트할 수 있는 작업 중 하나인 lambada_openai를 아래와 같이 구성할 수 있습니다.
tag:
- lambada
task: lambada_openai
dataset_path: EleutherAI/lambada_openai
dataset_name: default
output_type: loglikelihood
test_split: test
doc_to_text: "{{text.split(' ')[:-1]|join(' ')}}"
doc_to_target: "{{' '+text.split(' ')[-1]}}"
should_decontaminate: true
doc_to_decontamination_query: "{{text}}"
metric_list:
- metric: perplexity
aggregation: perplexity
higher_is_better: false
- metric: acc
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
dataset_kwargs:
trust_remote_code: trueHarness를 이용해 LLM 테스트 및 결과 평가 자동화
Harness에서는 기본적으로 YAML 설정 파일을 이용해 정적으로 작업을 관리합니다. 이 방식은 다양한 옵션의 테스트를 직관적으로 관리할 수 있다는 장점이 있지만, LLM 평가 자동화를 위해서는 데이터 세트와 프롬프트 등을 동적으로 선택해서 테스트할 수 있어야 했기에 추가 개발이 필요했습니다.
저희는 이를 개발하기 위해, Harness가 테스트를 시작할 때 작업을 구성하기 위해 필요한 정보(데이터 세트, 프롬프트, 지표)�를 외부에서 입력받아 이를 기반으로 먼저 YAML 설정 파일을 동적으로 생성하고, 이를 Harness가 참조해 테스트를 진행하는 방식을 선택했습니다.
아래는 YAML 설정 파일을 생성하는 코드의 일부입니다.
...
yaml_content = {
"group": task_group_name,
"task": task_name,
"dataset_path": "harness/datasets/builder.py",
"dataset_name": "test",
"test_split": "test",
"dataset_kwargs": {"trust_remote_code": "True"},
"output_type": output_type,
"metric_list": [{"metric": metric} for metric in selected_metrics],
"filter_list": [
{
"name": output_name,
"filter": [
{
"function": "utils.OutputAbstractionFilter",
"output_name": output_name,
}
],
}
for output_name in output_names
],
}
...이 코드에서 중요한 부분만 간단히 살펴보겠습니다.
데이터 세트별 평가 지표 설정
가장 먼저 지표입니다. 데이터 세트별로 평가가 필요한 지표가 다르기 때문에 평가 지표에 대한 정보는 데이터 세트의 루트 경로에서 'metric_output_info.json'이라는 이름으로 관리하고 있습니다. 아래는 예시 데이터 세트 'Example Bot'에서 관리하고 있는 지표 정보의 예시입니다.
- Technical-Support-Bot/metric_output_info.json
{
"default": ["rougeL", "cosine_similarity", "gpt_similarity", "gpt_correctness"]
} 이렇게 지정한 지표 중에서 아래와 같이 각 아웃풋 유형(generate_until, loglikelihood 등)에 맞는 지표를 필터링해 추가합니다.
"output_type": output_type,
"metric_list": [{"metric": metric} for metric in selected_metrics],필터를 이용해 모델의 단일 응답에서 아웃풋별 다중 지표 계산
팀에서 개발한 LLM 애플리케이션을 테스트할 때 모델의 단일 응답에 대해서도 여러 가지 평가 지표가 필요하다는 요구 사항이 있었습니다. 이 요구 사항을 반영하기 위해 Harness의 Filter라는 옵션을 사용하고 있습니다. Filter를 이용하면 모델의 응답을 여러 가지 방법으로 후처리한 뒤 후처리한 응답별로 다르게 평가할 수 있습니다.
예시와 함께 살펴보겠습니다. 아래 응답을 'API Test Bot'이라는 가상의 LLM 애플리케이션이 생성한 응답이라고 가정하겠습니다.
{
"method": "GET",
"path": "/users/{{number}}"
"expected_status_code": 200,
"purpose": "Get user's information",
...
}위 예시를 보면 JSON 형식의 응답에서 각 키마다 특성이 다르다는 것을 알 수 있는데요. 각각의 키를 아웃풋으로 정의하고 그 특성에 따라 다른 지표를 구함으로써 더 세밀하게 모델을 평가하고자 했습니다.
이를 위해 아래와 같이 지표를 정의하는 metric_output_info.json에 아웃풋별로 구해야 하는 지표 정보를 정의했습니다(threshold는 해당 지표가 정량 평가에서 넘어야 할 최소 점수를 의미합니다).
- metric_output_info.json
{
"method": [
"em"
],
"path": [
{"name": "gpt_similarity", "threshold": 1},
{"name": "meteor", "threshold": 1},
{"name": "rougeL", "threshold": 1}
],
"expected_status_code": [
"em"
],
"purpose": [
{"name": "gpt_similarity", "threshold": 0.7},
{"name": "cosine_similarity", "threshold": 0.5}
],
...
}
이렇게 정의한 파일을 이용해 아래와 같이 output_name에 따라 Filter 옵션을 동적으로 설정합니다. output_names은 method, path, purpose와 같은 아웃풋 이름 목록을 의미합니다.
"filter_list": [
{
"name": output_name,
"filter":
{
"function": "utils.OutputAbstractionFilter",
"output_name": output_name,
}
],
}
for output_name in output_names
],위 예제에서 utils.OutputAbstractionFilter는 Harness의 Filter 클래스를 구현한 클래스로, 모델의 응답 데이터에서 ouput_name에 해당하는 데이터만 뽑아내 반환합니다. 그 결과 각 아웃풋별로 테스트하는 게 가능해집니다.
아래는 Filter를 사용했을 때 얻어낸 평가 지표 집계 결과의 일부입니다. 모델의 응답에서 purpose, expected_response와 같은 아웃풋별로 다른 지표를 계산하고 집계하는 것을 확인할 수 있습니다.
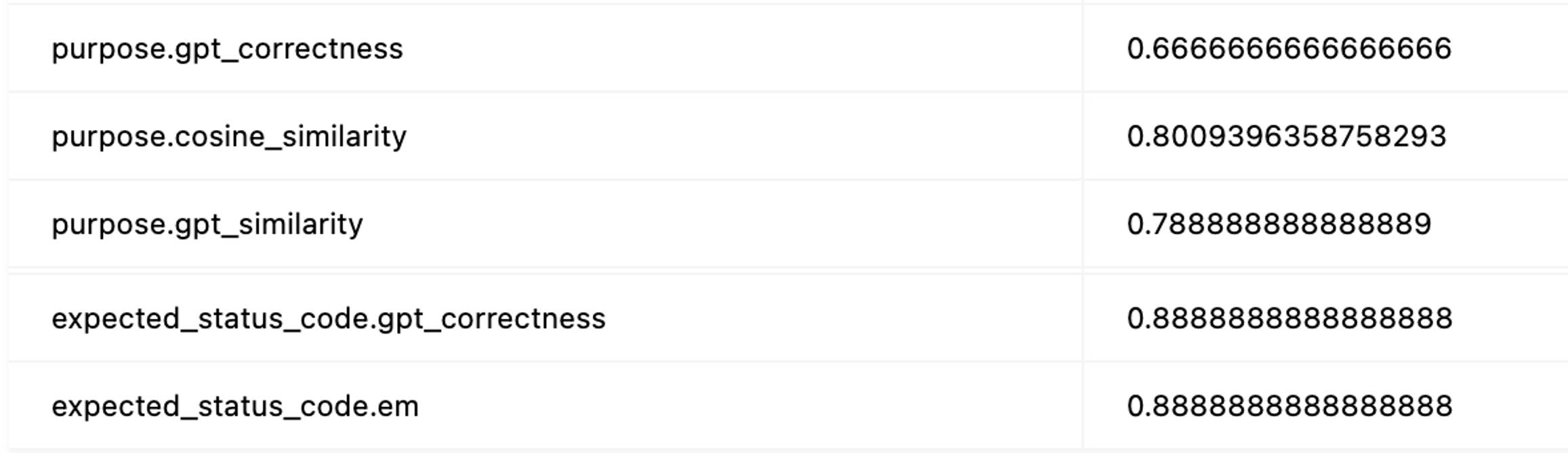
동적 프롬프트 적용 기능 구현
프롬프트의 미세한 차이에도 모델 응답은 크게 달라질 수 있기 때문에 자유롭게 프롬프트를 변경해 가며 테스트할 수 있도록 동적으로 프롬프트를 적용하는 기능은 필수였습니다. 이 기능을 구현하기 위해 앞서 살펴본 작업의 doc_to_text 옵션을 사용했습니다.
Harness에서는 YAML 파일로 정의된 작업을 api/task.py의 ConfigurableTask 클래스로 관리합니다. doc_to_text 옵션 또한 ConfigurableTask에서 관리하는데요. 그중 일부를 확인하면 아래와 같습니다.
def doc_to_text(self, doc):
...
doc_to_text = self.config.doc_to_text
...즉 YAML 파일에 doc_to_text가 설정돼 있다��면 이를 사용하고, 아니면 다른 옵션을 통해 프롬프트를 적용합니다. 저희는 이를 동적으로 적용하기 위해 ConfigurableTask를 오버라이드한 CustomConfigurableTask를 만들고, CustomConfigurableTask에서 doc_to_text가 내부 라이브러리를 통해 지정된 프롬프트를 가져와서 데이터 세트와 결합하도록 구현했습니다.
def doc_to_text(self, doc):
return self._prompt_manager.apply_template(doc)동적 프롬프트는 self._prompt_manager가 테스트를 실행할 때 전달받은 prompt_id에 맞는 프롬프트를 미리 다운로드한 뒤, 위 메서드에서 파라미터 doc으로 전달되는 데이터 세트 데이터에 프롬프트를 적용하는 방식으로 작동합니다.
지금까지 Harness의 기본적인 사용법과 저희 팀에서 LLM 평가 자동화 파이프라인을 구성하기 위해 어떻게 Harness를 사용하고 있는지 알아봤습니다. 이제 현재 사용하고 있는 지표를 소개하겠습니다.
사용한 지표 및 지표 집계 방법
모델 성능을 테스트하기 위해 사용하는 지표는 아래와 같은 기준으로 응답 형태에 따라 선택할 수 있게 돼 있습니다.
| 응답 형태 | 설명 | 특성 | 테스트 평가 지표 |
|---|---|---|---|
| 문장 | 서술 방��식의 응답 |
|
의미적 유사도(코사인 유사도, METEOR, GPT 유사도, GPT 정확도) |
| 명령어, 경로 등 | 코드나 경로 등 정해진 형식 내에서 변경이 발생하는 응답 |
| ROUGE-L, METEOR |
| 숫자, 카테고리 등 | 유형이 정해진 응답 |
| 정확한 매칭 |
각 지표별로 값의 범위가 다르기 때문에 쉽게 해석할 수 있도록 각 점수를 이진화해 정답과 오답으로 변환할 수 있도록 설계했습니다. 또한 같은 지표라도 도메인마다 정답을 판단하는 임계치가 다를 수 있기 때문에 성능 평가 시 도메인별 지표 평균 정답값의 분포를 기반으로 지표별 임곗값(threshold)을 입력하면 자동으로 계산되도록 시스템을 구축했습니다.
임곗값 지정 및 지표 점수 이진화
아래와 같이 각 지표별로 임곗값을 지정해 점수를 이진화할 수 있습니다. threshold에 지정된 값보다 높을 경우 1(정답), 그렇지 않을 경우 0(오답)으로 처리합니다.
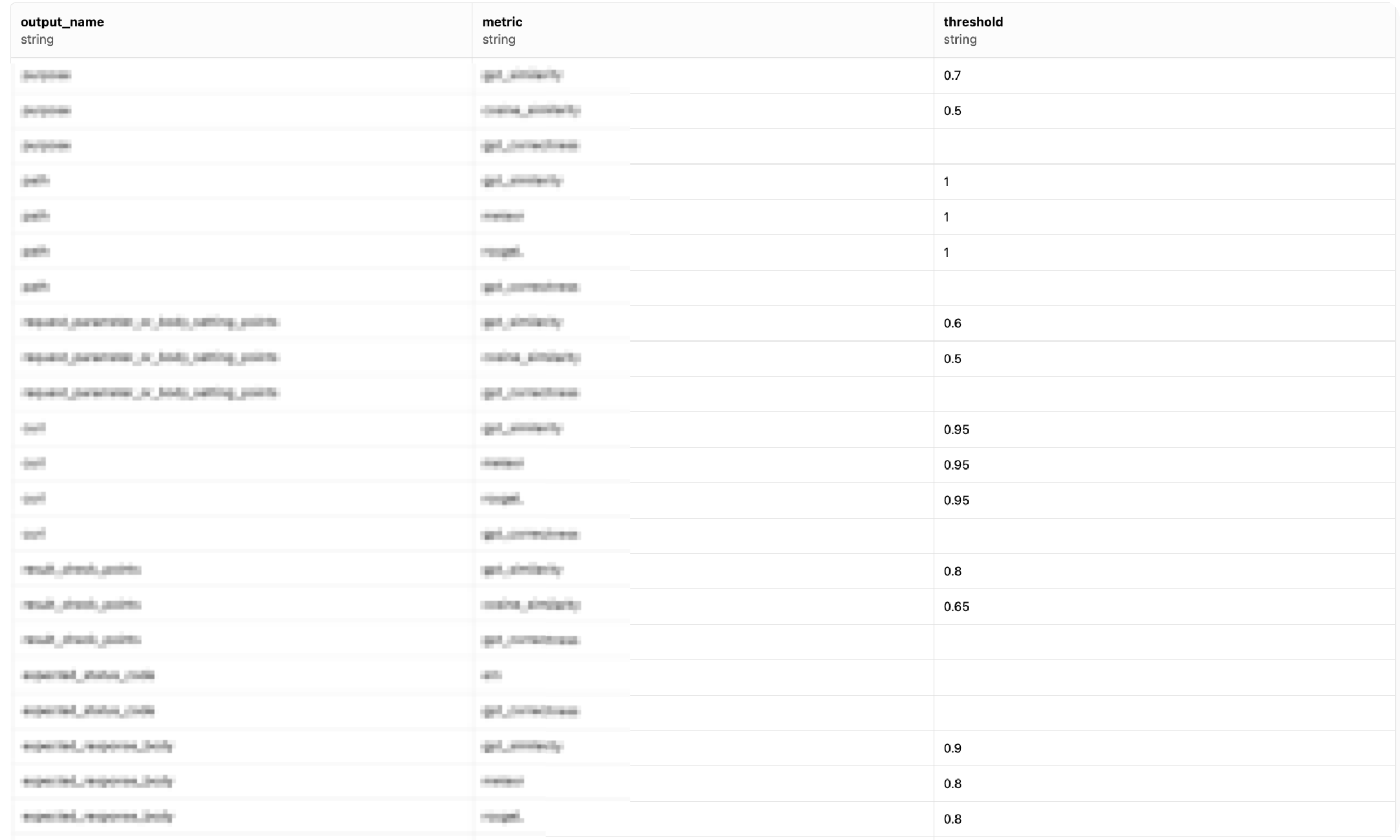
집계된 지표 확인
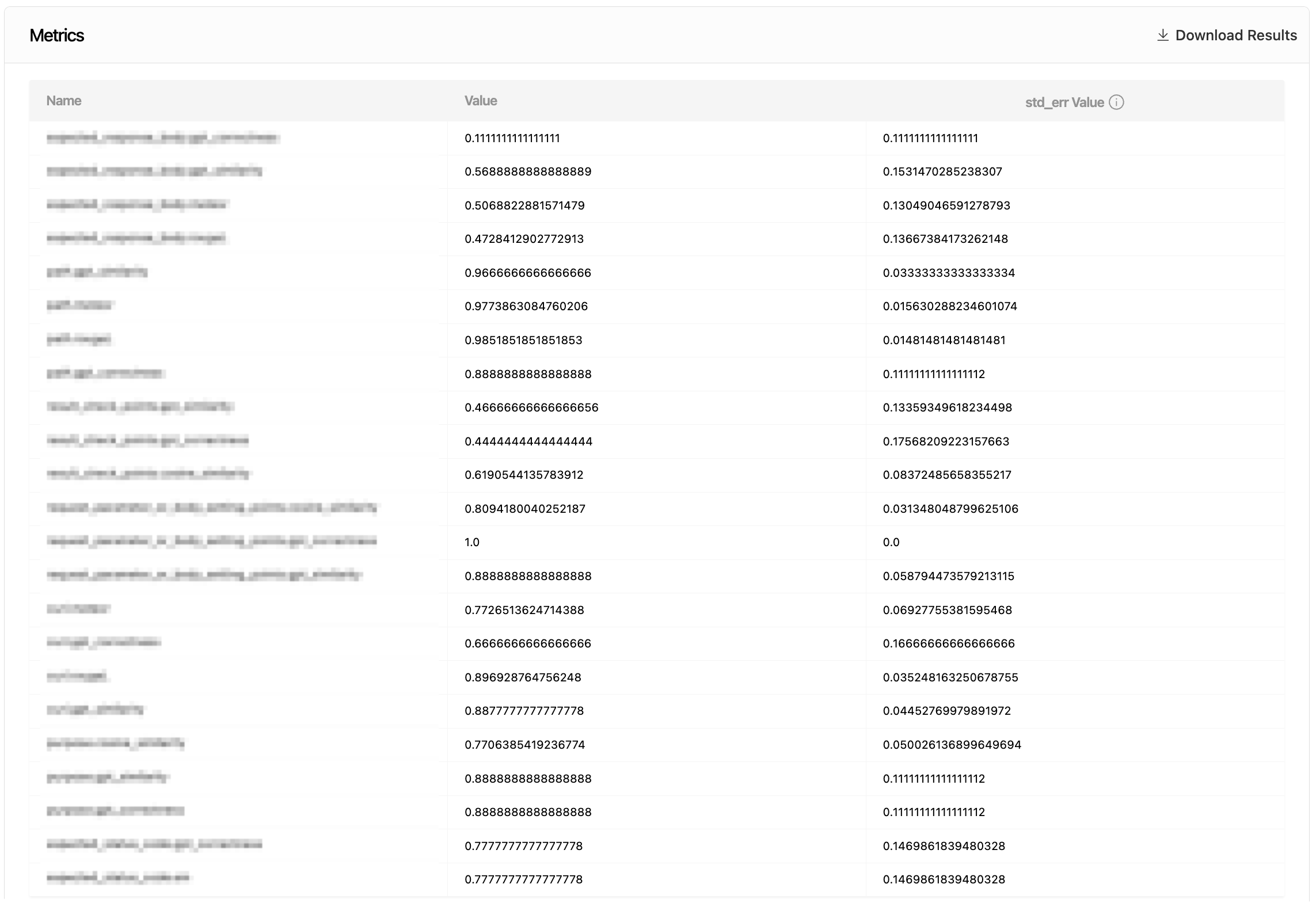
테스트 세트를 구성해 대규모 배치 테스트를 수행하면 아래와 같이 집계된 지표를 확인할 수 있습니다. 테스트 세트마다 사용하고자 하는 지표와 집계 기준이 다를 수 있기 때문에 이를 조정할 수 있도록 개발했습니다. 결과는 Excel(.xlsx) 파일 또는 JSON 파일로 다운로드할 수 있으며, 각 테스트 케이스별로 지표를 확인하는 것도 가능합니다.
전체 테스트 흐름
지금까지 소개한 테스트 과정을 종합해 도식으로 표현하면 아래와 같습니다.
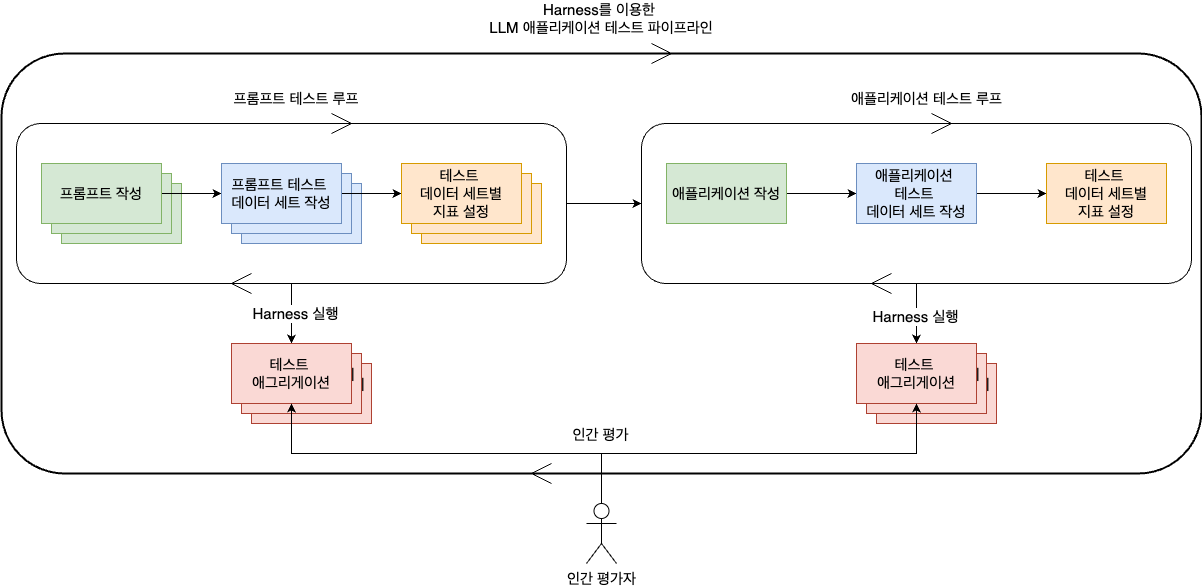
프롬프트별로 테스트 데이터 세트를 작성하고 지표를 설정해 프롬프트별로 테스트를 반복합니다. 마찬가지로 애플리케이션도 테스트 데이터 세트를 작성하고 지표를 설정해 테스트를 반복합니다. 이처럼 가장 작은 구성단위의 테스트와 각 구성단위가 모인 전체 집합의 테스트를 반복적으로 진행하면서 원하는 지표가 나올 때까지 애플리케이션을 수정합니다. LINE GAME PLATFORM 팀은 이와 같은 파이프라인을 기반으로 LLM 애플리케이션의 성능을 고도화해 나가고 있습니다.
마치며
지금까지 LINE GAME PLATFORM 팀에서 복잡한 LLM 애플리케이션의 품질을 보장하기 위해 진행했던 테스트 자동화 과정을 설명드렸습니다. 아직 정석적인 테스트 방식이 없는 도메인인데요. 저희가 진행한 방식을 참고하시면서 인사이트를 얻어 가시면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.


