LLMアプリケーションテストの難しさ
GPT-4のような大規模言語モデル(large language model、以下LLM)が普及し、それを活用したLLMアプリケーションもさまざまな分野で本格的に使用されています。さまざまなビジネスロジックが含まれているLLMアプリケーションは、サービスの品質を保証することも開発作業において非常に重要になっています。LLMアプリケーションはその複雑さゆえに、テストすることが容易ではありません。入力値を少し変更するだけで、全く異なる回答が生成されるためです。LLMアプリケーションは、プロンプトチェーン(prompt chaining)とエージェントなどを通じてモデルに対して何度も推論(inference)を行うため、誤差が累積して変動性が大きく、プロンプトを少し修正するだけで回答が全く異なるなど、非常にデリケートなアプリケーションです。
この記事では、LINE PlusのLINE GAME PLATFORMチームでさまざまなLLMアプリケーションを開発する中で、このようにデリケートなLLMアプリケーションのテストおよびテスト結果の評価プロセスを改善し、自動化するためにどのようなテスト方法論を使用したかを紹介します。
テストとテスト評価方法の改善
まず、テストとテスト結果の評価プロセスをどのように改善したかを見てみましょう。
テストセットをプロンプトごとに分離
まず、LLMアプリケーションの変動性を制御するために、出力に影響する項目を一つずつ区別する作業を行いました。プロンプトチェーンが実行されるアプリケーションの場合、単一のプロンプトをテストした後、プロンプトチェーンが実装されたLLMアプリケーション全体のテストを行います。各項目を評価できる質問と回答のデータセットをプロンプトごとに作るのですが、複数のプロンプトが連結されているプロンプトチェーンの場合、下図のようにプロンプトごとにテストデータセットをそれぞれ用意します。これは非常に面倒な作業ですが、これにより、各プロンプトの性能を独立して評価でき、後でそのプロンプトを修正しても全体のテストは継続的に行えます。
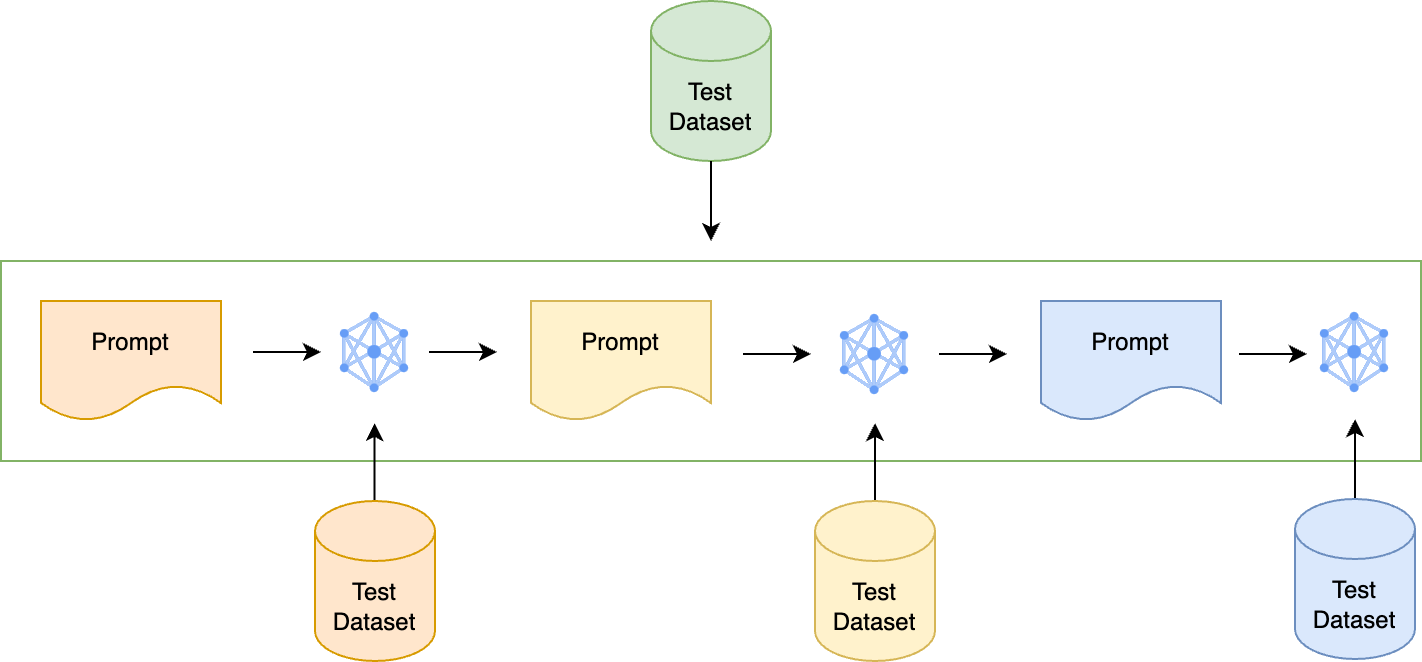
では、テスト実施後、テスト結果はどのような方法で評価するのでしょうか?
定量評価の導入と評価指標の選定
ドメインに特化したLLMアプリケーションは、特定の分野の複雑で細かな要件を満たす必要があるため、正確に評価するには、ドメイン専門家による定性評価が必須です。そのため、プロンプトやモデルを修正しながら性能の比較や測定を行うには、ドメイン担当者のリソースをさらに投入する必要があります。それを改善するために、評価プロセスを自動化し、評価に必要なリソースを削減できる新しい評価基準を開発することにし�ましたが、最も簡単に考えられる方法は定量評価でした。
定量評価は、客観的な指標を用いてモデルの性能を評価する方法であり、一貫した基準を設定し、迅速に結果を導き出すというメリットがあります。しかし、この方法は主に単語単位の単純なマッチングに基づいているため、以下の例のように異なる語彙を使用したり、文の構造を変えたりするなど表現方法が変わると、実際には正解であっても評価スコアが低くなる可能性や文脈を考慮しないという限界があります。
- 正解文:The cat sleeps on the sofa.
- 比較文:The cat is sleeping on the sofa. → 正解文と同じ意味で類似語彙を使い、高い類似度スコアを獲得
- 比較文:A feline is resting on the couch. → 正解文と同じ意味であるにもかかわらず、使用語彙や文の構造が異なるため、低い類似度スコアを獲得
上記のようなデメリットにもかかわらず、人間の介入なしで迅速な評価結果が得られるという点が自動化プロセスに適していたため、私たちはデメリットを補完していくことにしました。単語単位の単純マッチングの限界を破るために、文脈を考慮し、意味の類似性をよりよく反映できる指標を回答の形式ごとに追加しました。一般的に優れたモデルは定量評価でも良い性能を示す傾向があります。そのため、定量的指標を利用してモデルの性能の1次検証を行うパイプラインを設計しました。
では、私たちが定量評価に活用した主な指標をタイプごとに見てみましょう。
ロジックに基づく評価指標
完全一致(exact match)
モデルの予測が正解と完��全に一致するかを判断する指標です。現実的に正解と予測値が完全に一致することは難しいので活用性は低いですが、回答のタイプが明確に定義されている場合は、直感的に素早く活用できるため使用しました。
コサイン類似度(cosine similarity)
文をベクトル化した後、2つのベクトルがなす角のコサイン値を使用して類似性を測定する方法です。
LLMは創造的な回答を生成するため、同じ意味の文でも毎回異なる表現をすることがあります。そのため、正確に評価するには、文内の単語間の関係性を理解し、文脈を把握する方法が必要でした。最も迅速かつ簡単に使用できる指標としては、単純に単語のマッチングの有無をベースにしたN-gramを用いた指標がありましたが、それらの指標は同義語や単語の変動性、単語間の関係性を把握できないという限界があり、正確に評価できませんでした。
このような限界を打破するために、文のベクトル埋め込みを使用して類似度を測定するコサイン類似度を指標として追加しました。コサイン類似度 は、定性評価ほどではありませんが、定量的指標の中では文脈を考慮できる最も効果的な性能指標として知られています。
METEOR
正解と予測文間の完全な一致、同義語の一致、形態素の一致に基づいてソートを行った後、適合率(precision)と再現率(recall)の調和平均(F-score)と、単語の非連続性に対するペナルティを組み合わせて最終スコアを計算する方法です。N-gramベースの指標で、従来のN-gramベースの指標の限界を補完し、同義語と文構造の類似性を一緒に考慮する方法です。コサイン類似度と相互補完的に活用するために追加しました。
Rouge-L
正解と予測文間の単語の順序を考慮しながら、最長共通部分シーケンスをベースに類似性を測定する方法です。
現在開発中のLLMアプリケーションは、質問に対する自由記述回答だけでなく、場合によってはファイルのパスやcurlコマンドなどのコードベースの回答を出力することもあります。パスやコードのような場合、すべての単語やトークンが正解文と一致していても、その順序が違うと意味が全く異なるため、順序が一致することが非常に重要です。前述で文脈を考慮するために追加したコサイン類似度やMETEORは、その点で限界があります。以下の例で見てみましょう。
- 正解:curl -X GET http://example.com/data
- 不正解:curl -X http://example.com/data
上の例をコサイン類似度やMETEORで評価すると、HTTPメソッド(GET)が抜けているにもかかわらず、類似度スコアが高くなります。一方、Rouge-Lは2つの文の最長共通部分列に基づいて評価するため、トークンの順番やトークンを含めるかどうかが考慮されるため、 GET メソッドが抜けていることが構造的な違いとみなされ、類似度スコアが低くなります。
このように順序が重要で、単語の変形なしに構造化されたテキストに対応するためにRouge-L指標を使用しました。
LLMベースの評価指標
LLMを活用した評価指標としては、GPT類似度(similarity)とGPT正確度(correctness)を使用しました。
- GPT類似度:GPT-4を活用し、正解と予測文間の類似度を0~1のスコアで算出する方法です。
- GPT正確度:GPT-4を活用し、�正解と予測文間の類似性を判断する方法で、結果を0(非類似)または1(類似)に分類する方法です。
ロジックベースの評価指標は、算出方法によって評価基準がそれぞれ異なります。これらの指標は、さまざまな形の出力を生成するLLMを評価する際、多方面から柔軟に判断を下すことが難しいため、人間による評価方法を完全に代替するには不十分であると判断しました。
その限界を補完するために、LLM自体を活用した評価方法を検討しました。LLMは、さまざまな分野で優れた能力を発揮し、ゼロショット文脈内学習(zero-shot in-context learning)により、別途の例がなくても指示に従って優れた性能を発揮できます。National Taiwan UniversityのCheng-Han ChiangとHung-yi LeeはCan Large Language Models Be an Alternative to Human Evaluation?という論文で、ChatGPTを利用してテストした結果、ほとんどの場合、人間の専門家と一致する評価を下したとし、LLMが人間の評価を代替することが可能であることを示唆しました。
LLMを活用した評価指標の主なメリットは以下のとおりです。
- 高い再現性:人間が評価する場合、同じ資格を持った人に同じ指示を与えても主観的な評価基準が異なる可能性があるのに対し、LLMの評価結果は、使用したモデルとランダムシード、ハイパーパラメータを指定すれば、同じ結果が再現される可能性が高くなります。
- サンプルの独立性を保証:人間の評価では現在の評価が以前のサンプルに多少影響を受ける可能性があるのに対し、LLM評価では各サンプルの評価が互いに独立しています。
- 低コストと高速性:人間によって評価する場合よりもコストが低く、より迅速に結果を確認できます。
このようなメリットを考慮して、人間による評価に近い役割を担えるように上記の2つの指標を追加し、前述で紹介したロジックベースの他の指標と一緒に使用することで、評価の客観性を高めながらモデルの性能を多角的かつ総合的に理解できることを期待しました。
テストを自動化すべき理由
LLMアプリケーションのテストを行う際、前述で紹介した指標を状況に応じて選別し、使用します。プロンプトごとに適した指標が異なるためです。もし、アプリケーションで使用するプロンプトが多く、使用する指標も多いのに、プロンプトの変更に伴う関連作業をすべて手動で行う場合、テストプロセスが非常に複雑になってしまい、時間もかかることになります。
以下の例を見てみましょう。入力データとLLMは同じ状態で、プロンプトのみ変更して質問したものです。「LLMとは何ですか?」という同じ質問に対し、プロンプトによって回答の品質が全く異なることが確認できます。
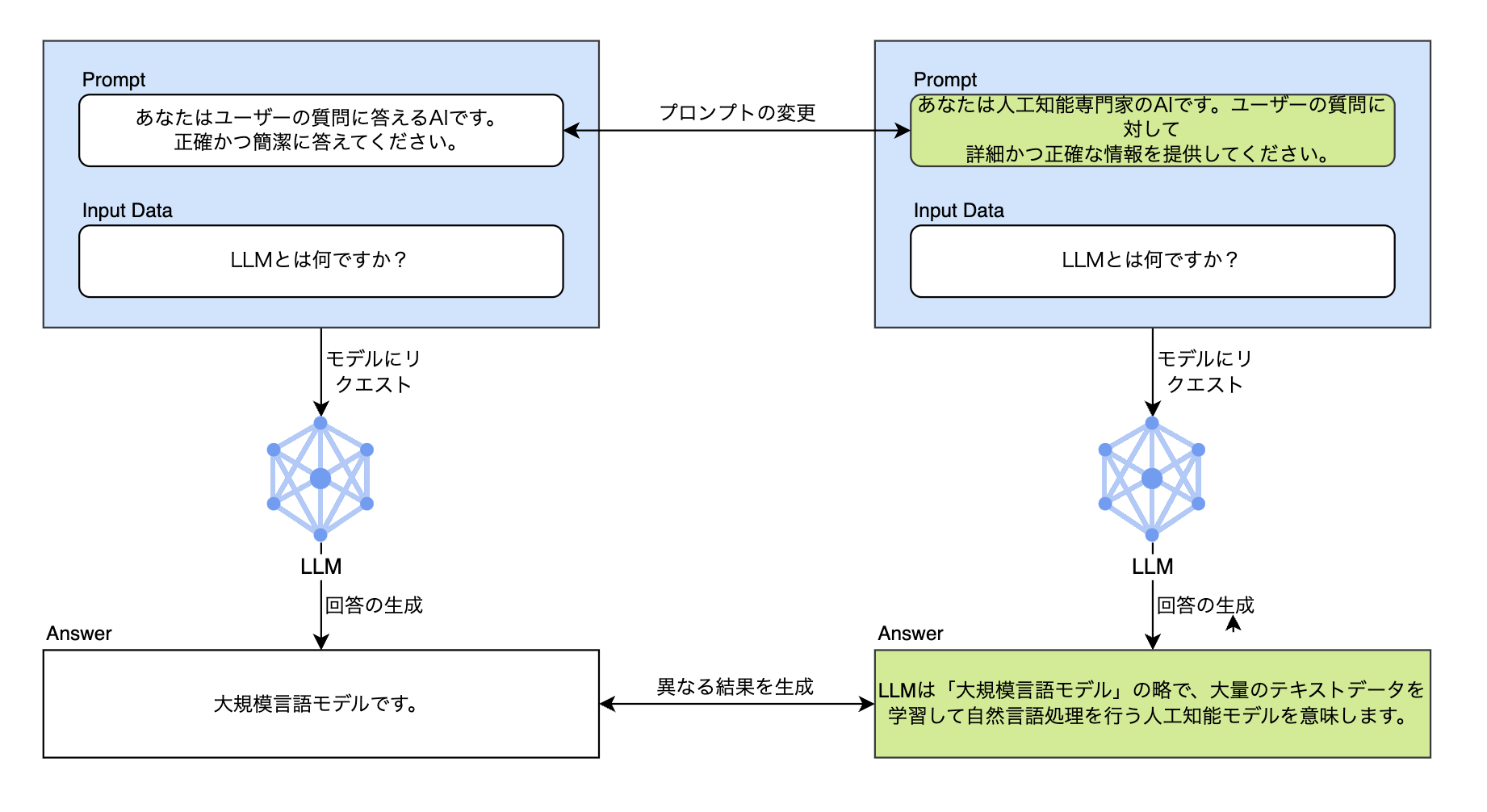
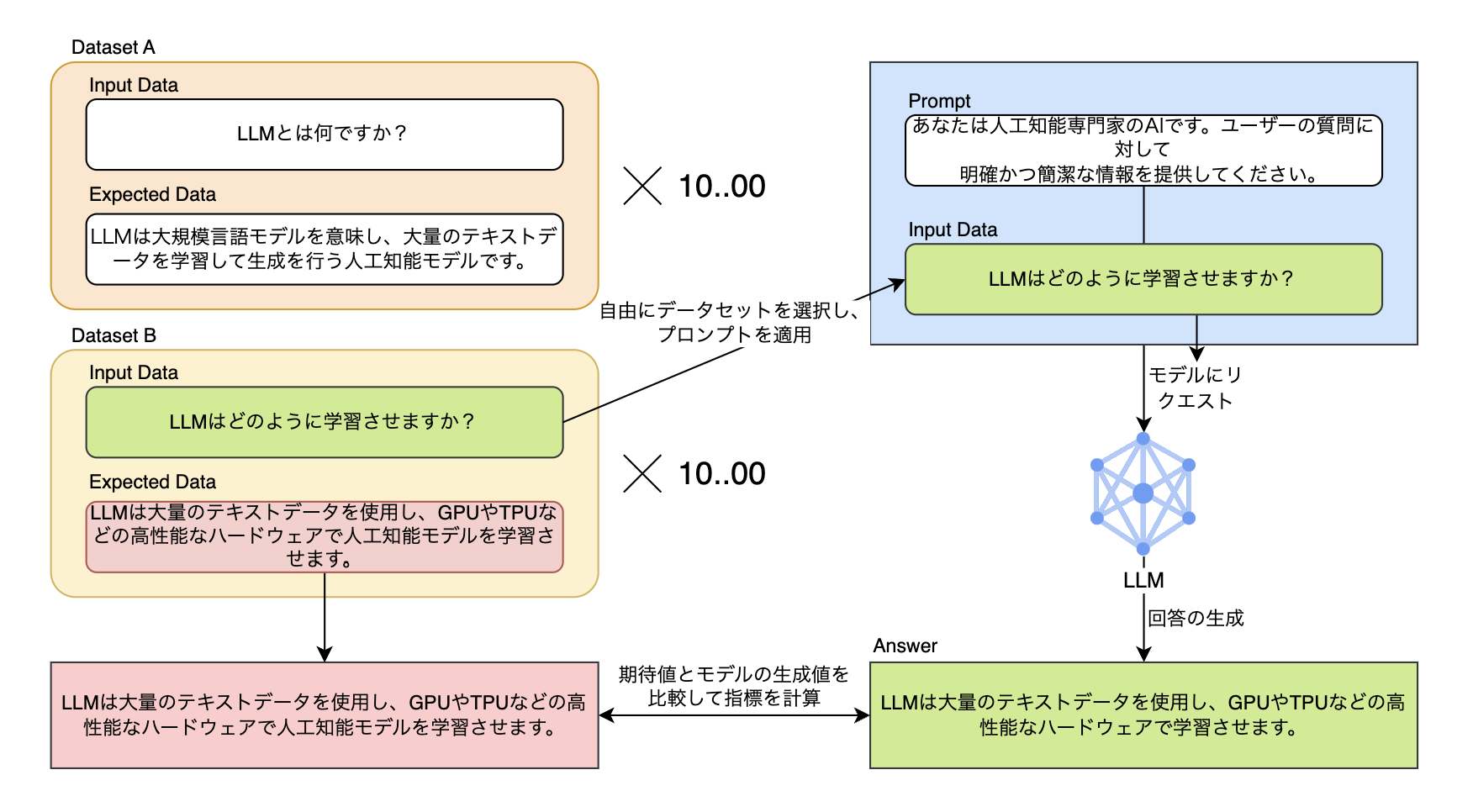
このように、LLMはプロンプトのわずかな変化に敏感に反応します。そのため、より高い品質の回答を得るには、さまざまなプロンプトを開発してテストを行い、回答に対する指標を確認する必要があ�ります。以下のように、さまざまなプロンプトの中から好きなものを自由に選択してテストすることができなければ、最適化されたプロンプトを決定するのにどれだけの時間がかかるか分かりません。
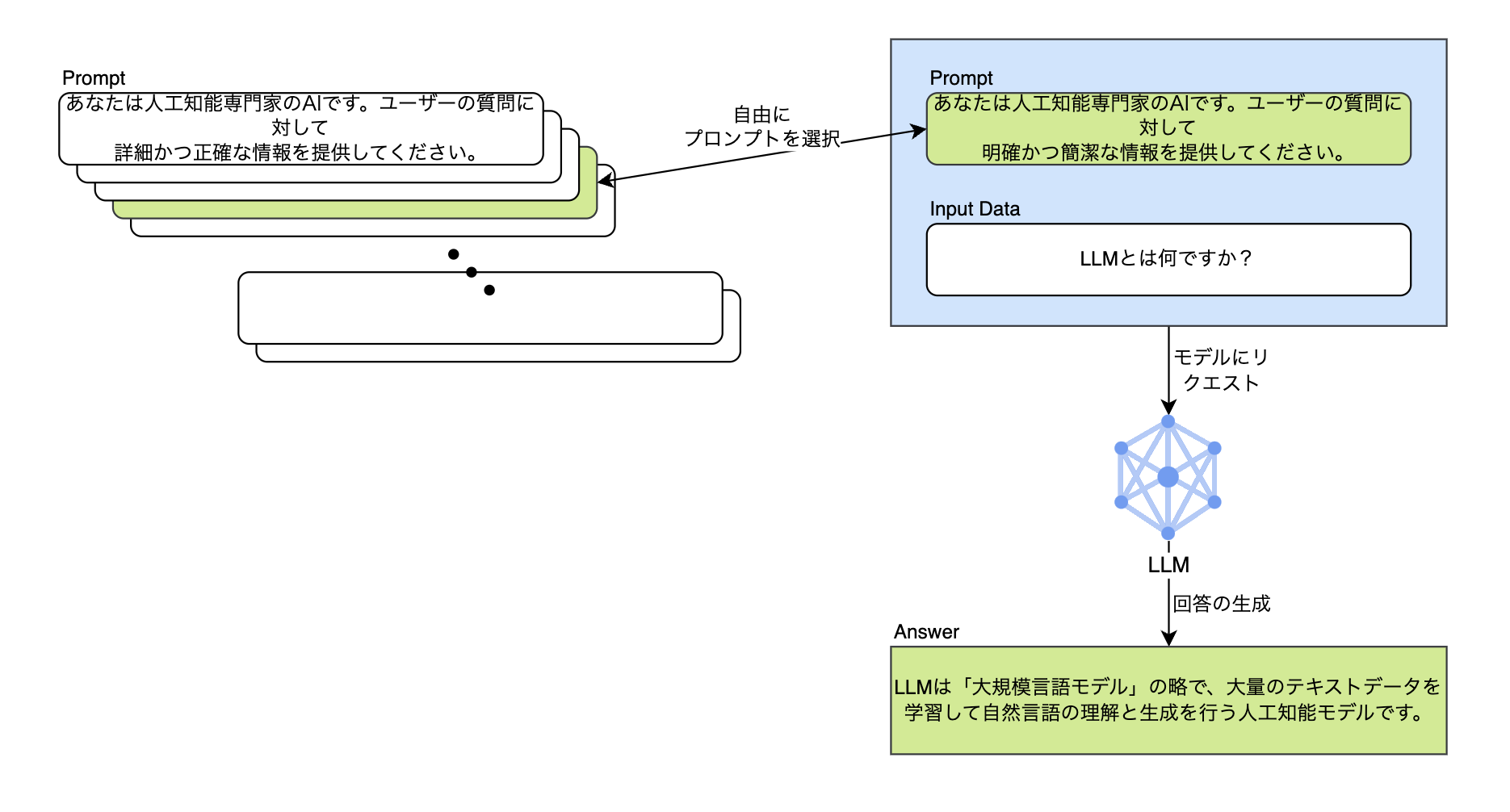
また、目的に応じてデータを集めてデータセットを構成する際に、数千、数万以上のデータで構成された各データセットを動的にプロンプトと組み合わせたり、選択したりしてテストする作業を自動化しなければ、非常に面倒な作業になります。
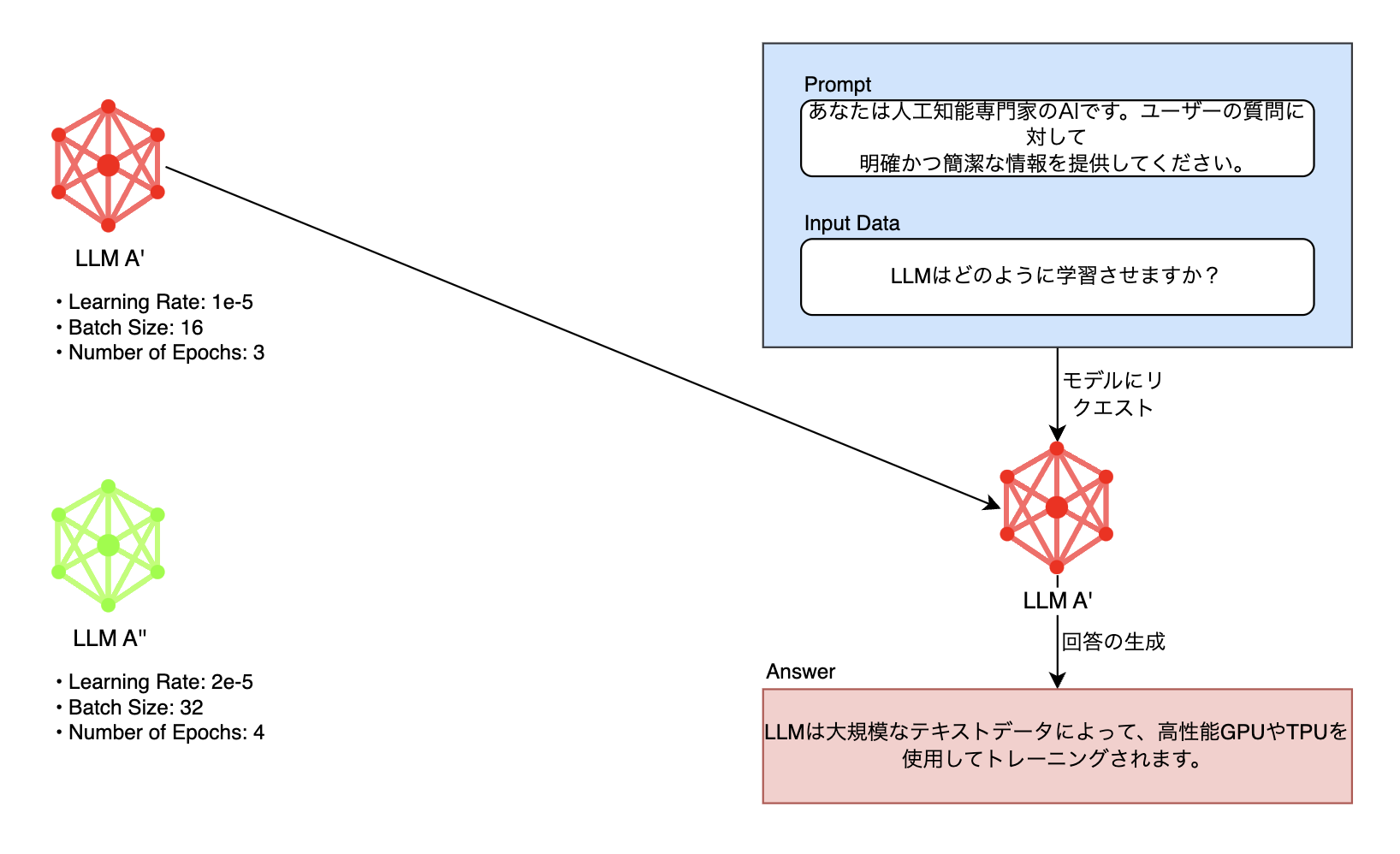
最後に、モデルはさまざまなハイパーパラメータとデータでファインチューニング(fine tuning)できます。または、複数のモデルで構成されたRAG(rag-augmented generation)ベースのLLMアプリケーションが評価対象になることもあります。最適なサービスを作るには、このようにさまざまなモデルをテストした後、それを評価して得られた指標を比較し、最適なモデルを選別する作業が必須になります。その作業も自動化が必要な機能でした。
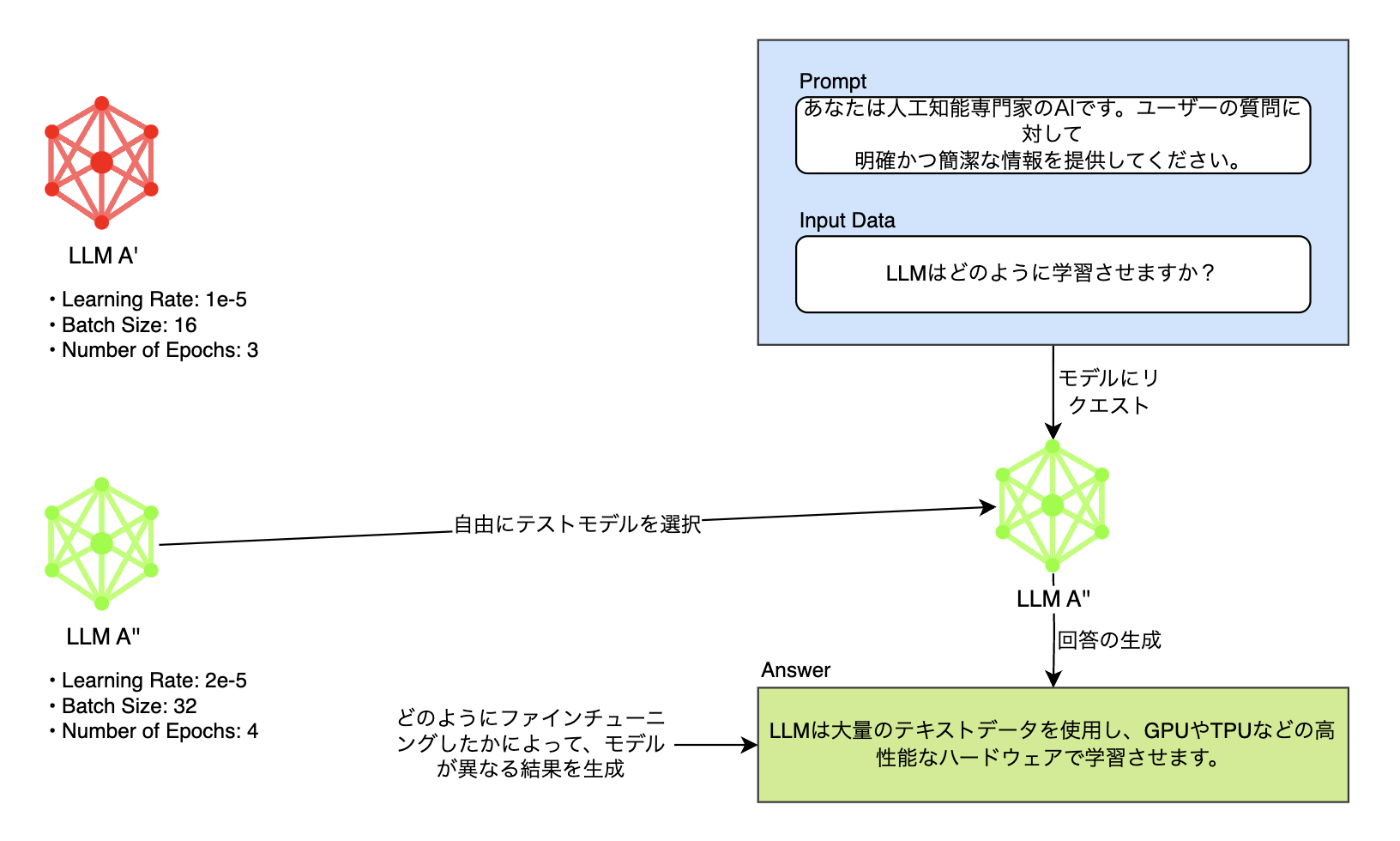
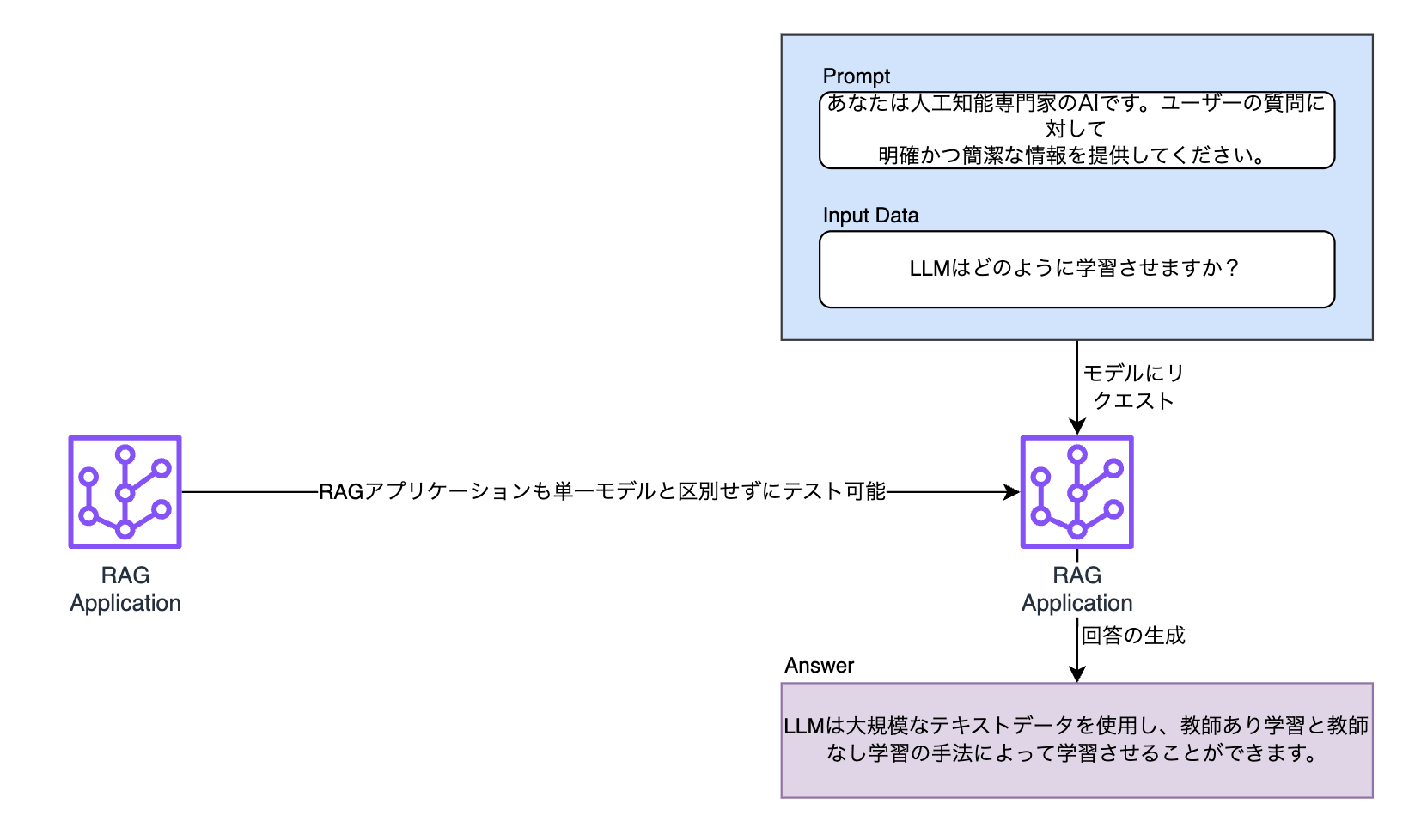
まとめますと、プロンプトとデータセット、モデルをいちいち開発者が変更しながら一つひとつテストする方法は非常に非効率的です。アプリケーションを効果的に最適化するには、それを自動化する必要があります。
私たちは自動化できる方法を模索し、大規模なテストと指標のカスタマイズに焦点を当ててテスト環境を構築することにしました。ここでテスト自動化作業に中核の役割を果たしたフレームワークが、Language Model Evaluation Harness(以下、Harness)です。私たちはテストを自動化するためのパイプラインを構築したとき、モデルとLLMアプリケーションを評価するコアコンポーネントをHarnessベースで開発しました。そのHarnessはどのようなフレームワークなのか、どのように使われるのか一つずつ見ていきましょう。
Harnessを利用したテストの自動化
Harnessは、言語モデルを評価するために非営利AI研究所EleutherAIによって開発されたオープンソースフレームワークです。基本的にGLUE、MMLU、HellaSwagなど60以上のベンチマークで構成されたタスク(task)をサポー��トし、新しいタスクをカスタマイズしてモデルを評価することもできます。
Harnessのメリットは以下のとおりです。
- オープンソースプロジェクトで、多くの研究者や開発者が協力し、継続的にアップデートしながらモデル評価に対して標準的な実装を提供しています。そのため、HugginfaceのOpen LLM Leaderboardでもモデル評価にHarnessを使用しています。
- 評価に使用するデータセットや指標、プロンプトなどを自由に設定できるため、要件に合ったテストを素早く実行できます。
- 評価を自由に拡張できる仕組みなので、社内のAIシステムに合った方法で評価をカスタマイズできます。
次は、基本的なHarnessの使い方と、私たちがどのようにカスタマイズして使っているのか、一つずつ紹介します。
Harnessの使い方
Harnessの基本的な使い方を説明します。
インストールと実行
Harnessをインストールして実行する方法はとても簡単です。まず、以下のようにHarnessリポジトリでプロジェクトをダウンロードし、依存パッケージをインストールします。
git clone https://github.com/EleutherAI/lm-evaluation-harness // プロジェクトのダウンロード
cd lm-evaluation-harness // プロジェクトディレクトリへ移動
pip install -e . // Harnessで使う依存パッケージのインストールインストール完了後、 lm_eval コマンドでHarnessを実行できます。
lm_eval --model hf \
--model_args pretrained=EleutherAI/gpt-j-6B \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8上の例の順番でコマンドの引数を見てみましょう。
--model:テストを行うモデルを選択します。上の例ではhf(Hugging Face)を選択しました。--model-args:モデルを実行するために必要な引数を設定します。上の例ではpretrained=EleutherAI/gpt-j-6Bを設定し、Hugging Faceを通じてモデルEleutherAI/gpt-j-6Bをテストしようとすることが分かります。--tasks:モデルにどのタスクをテストするかを決定します。,で区切って複数のタスクを選択でき、タスクグループを記入してそのグループに属するすべてのタスクをテストすることもできます。--device:モデルが使用するデバイスを設定します(例:cuda、cuda:0、cpu、mps)。--batch_size:評価に使用するバッチサイズを設定します。正の整数に設定するか、autoに設定することで、メモリに収まる最大のバッチサイズを自動的に選択し、評価速度を向上させることができます。
その他、モデル評価に関連する多くのオプションは、インターフェイスガイドで確認できます。
上記の lm_evalコマンドを実行して helloSwag 作業をテストした hf の EleutherAI/gpt-j-6B モデル評価の結果は、以下のように出力されます。
hf (pretrained=EleutherAI/gpt-j-6B), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: 8
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|-----:|--------|-----:|---|-----:|
|hellaswag| 1|none | 0|acc |0.5737|± |0.0049|
| | |none | 0|acc_norm|0.7721|± |0.0042|上の例で最も重要なのは、どのモデルをテストするかを指定する--modelと、モデルに対して何をテストしてどのような結果を得るかタスクを指定する--tasksです。このとき、チームでファインチューニングした単一モデルやRAG LLMアプリケーションはHarnessに別途登録されていないため、LMという抽象クラスを開発して新しいモデルとして追加する必要があります。タスクもそれぞれのニーズに応じて作成したデータセットとプロンプト、指標をテストするためにYAMLファイルを利用してカスタマイズできます。
つまり、HarnessでLMクラスとYAMLファイルによるモデルとデータセット、プロンプトに対するカスタムインターフェイスが提供されており、開発者はそれを利用して自由にLLMを評価できます。以下は、評価プロセスにおいてカスタムインターフェイスの使用ポイントを簡単に図で示したものです。
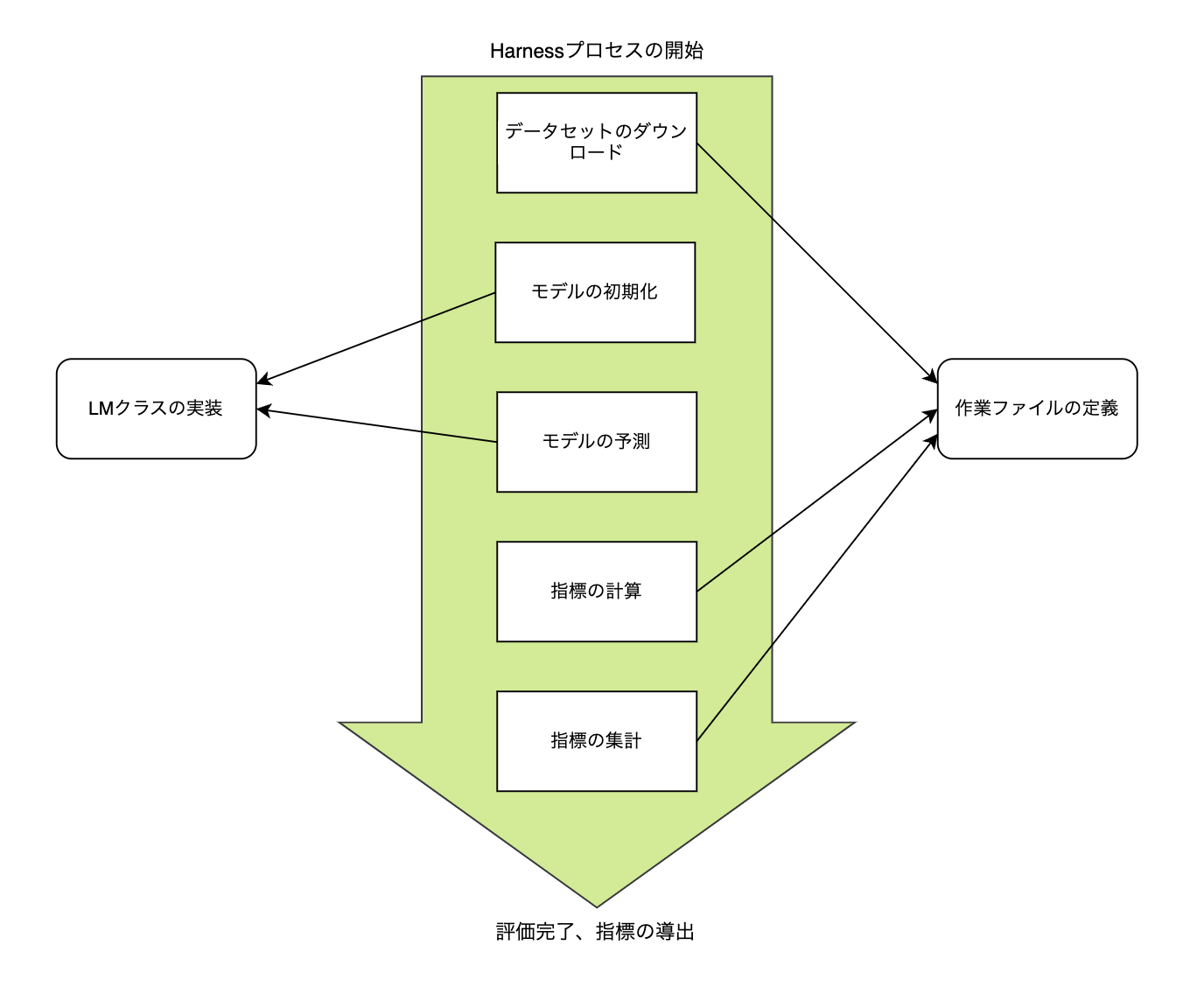
では、LM抽象クラスを直接実装してチームで開発したモデルを登録する方法を説明します。
モデルクラスの実装
前述で簡単に説明したとおり、新しいモデルを追加するときは、まず、Harnessパッケージ内の抽象クラスであるLMを継承するモデルクラスを作成します。lm_evalコマンドの--model_argsで入力される引数はコンストラクタのパラメータに渡され、モデルクラスはそれを利用して必要なモデルを特定したり、ハイパーパラメータを設定したりするなどの初期化作業を行います。
例えば、前述のlm_evalコマンドの例のようにHugginfaceに依存関係がある場合、以下のようにモデルクラスのコンストラクタを実装できます。
@register_model("my_custom_lm")
class MyCustomLM(LM):
def __init__(self,
model_name: str,
**kwargs):
self._model = AutoModelForCausalLM.from_pretrained(model_name)
self._tokenizer = AutoTokenizer.from_pretrained(model_name)
...上記のようにモデルクラスを実装するときは、最初にコンストラクタを通じて、モデルクラスが質問に対して即座に答えられる状態にするための初期化ロジックを実装します。初期化ロジックで初期化されたモデルクラスは、次に紹介する3つの抽象メソッドを実装することで質問に答えられます。モデルクラスの最終的な目的はデータセットに対してモデルに質問した結果を返すことですが、そのために求める指標に応じて以下の3つのメソッドのうち1つ以上を実装します。
@register_model("my_custom_lm")
class MyCustomLM(LM):
def __init__(self, ...,**kwargs):
#...
def loglikelihood(self, requests: list[Instance]) -> list[tuple[float, bool]]:
#...
def loglikelihood_rolling(self, requests: list[Instance]) -> list[tuple[float, bool]]:
#...
def generate_until(self, requests: list[Instance]) -> list[str]:
#...
#...モデルの質疑応答のために1つではなく3つのメソッドをサポートする理由は、各メソッドの回答の形が人間が認識で��きる文字列形式か、それともトークナイザーでデコードする前のトークン形式かによって求められる指標が違うためです。下の表は3つのメソッドの特徴をまとめたものです。
| 抽象メソッド名 | 戻り値 | 得られる指標 | 説明 |
|---|---|---|---|
generate_until | list[str] | 完全一致(exact_match)や類似度 | テストデータセットの各リクエストに対し、LMがuntilに設定された文字列に達するか、max_gen_toksのサイズに達するまで、モデルが生成した回答を人間が認識できる文字列形式でlistを生成して返すメソッドです。 |
loglikelihood | list[tuple[float, bool]] | パープレキシティ(perplexity)、正確度(Accuracy)など | リクエストに対するターゲット文字列を受け取り、LMがリクエストを入力として予測を生成して、ターゲット文字列が生成される対数尤度(loglikelihood)を返します。結果としては、対数尤度(ll)とターゲット文字列が、欲張りサンプリングによって生成されたかどうか(is_greedy)を表す値が返されます。 |
loglikelihood_rolling | list[tuple[float, bool]] | 単語(word)パープレキシティ、バイトパーフレキシティなど | loglikelihoodの特殊なケースで、モデルは入力文字列全体に対して対数尤度を計算します。単語パープレキシティ、バイトパープレキシティなどを求めるときに使います。 |
上記の3つのメソッドをすべて実装する必要はありません。要件によって得られる指標を確認し、必要なメソッドを実装すれば良いでしょう。
以下は3つのメソッドのうちgenerate_untilを実装した例です。コンストラクタで初期化したモデルとトークナイザーを使ってモデルに質問した後、回答された結果をリスト形式で返します。
def generate_until(self, requests: List[Instance]) -> List[str]:
responses = []
for request in requests:
input_text = request.args[0]
inputs = self._tokenizer(input_text, return_tensors="pt")
outputs = self._model.generate(**inputs, max_length=50)
generated_text = self._tokenizer.decode(outputs[0], skip_special_tokens=True)
responses.append(generated_text)
return responsesこのように自由にモデルクラスを実装でき、前述のlm_evalコマンドの実行例(--model hf)のように、すでに実装されてい��るモデルを使うこともできます。ちなみに、hfも抽象クラスLMを実装する方法でプロジェクト内に定義されたもので、使用可能なモデルは以下のリンクから確認できます。
タスクの定義
Harnessにおいてタスク(task)は、データセットとプロンプト、指標を定義して管理する役割を担当します。つまり、「どのようなデータセットをどのようなプロンプトと組み合わせて使用し、モデルに質問して得られた答えでどのような指標を計算するのか」をYAMLファイルに定義して管理することがタスクと言えます。YAMLファイルは基本的にlm_eval/tasks/パスに保存され、lm_evalコマンドを使ってHarnessを実行すると、Harnessはそのパスでタスクの名前で指定されたYAMLファイルを見つけ、ファイルに定義されたとおりにテストを実行します。
では、 lambada_openai タスクを定義する例とともにYAMLファイルにタスクを定義する方法を説明します。
まず、タスクの名前を設定します。設定した名前で、 lm_eval コマンドで --tasks オプションを指定してテストできます。
task: lambada_openai次に、データセットを設定します。データセットは基本的にHuggin Faceのデータセットハブからダウンロードしますが、dataset_path設定でデータセットハブから取得するデータセットを選択し、dataset_name設定��でそのデータセット内の特定のサブデータセットを選択できます。詳しくは、Hugging FaceのLoad a dataset from the Hubを参照してください。
dataset_path: EleutherAI/lambada_openai
dataset_name: default次に、output_typeを設定します。output_typeは、タスクに使用するモデルの出力タイプを意味します。出力タイプとしては、前述のgenerate_untilとloglikelihood、loglikelihood_rollingの3つのタイプにmultiple_choiceを追加して、合計4つのタイプが存在します。multiple_choiceは、固定されている有限なセットのラベル単語のうち1つを選択し、すべてのラベル単語のloglikelihoodを比較して評価するタイプです。
output_type: loglikelihood次に、データセットのデータをどのように処理するかを設定します。以下のようにJinja2テンプレートを使うか、!function文を使ってYAMLファイルと同じパスにPythonファイルを定義して使うことができます。
### jinja2
doc_to_text: "{{text.split(' ')[:-1]|join(' ')}}"
doc_to_target: "{{' '+text.split(' ')[-1]}}"
### python code
doc_to_text: !function utils.doc_to_text
doc_to_target: !function utils.doc_to_target- utils.py
def doc_to_text(text):
words = text.split(' ')
return ' '.join(words[:-1])
def doc_to_target(text):
words = text.split(' ')
return ' ' + words[-1]doc_to_textはデータセットの単一データごとに入力値の前処理�を行い、doc_to_targetはモデルに期待する出力値の後処理を行います。チームでは、doc_to_textオプションを利用して動的にプロンプトを適用するための機能を実装しましたが、それについてはまた別途詳しく説明します。
最後に- metric: perplexityのように設定して求める指標を決定します。aggregationは、評価結果をどのように集計するかを設定するオプションです。aggregationは省略できます。
metric_list:
- metric: perplexity
aggregation: perplexity
higher_is_better: false
- metric: acc
aggregation: mean
higher_is_better: true先に設定した指標がどのように計算されるかについての情報は、lm_eval/api/metrics.pyにメソッドとして定義されています。以下はperplexityの実装です。
- lm_eval/api/metrics.py
...
# Certain metrics must be calculated across all documents in a benchmark.
# We use them as aggregation metrics, paired with no-op passthrough metric fns.
@register_aggregation("perplexity")
def perplexity(items):
return math.exp(-mean(items))
...
@register_metric(
metric="perplexity",
higher_is_better=False,
output_type="loglikelihood",
aggregation="perplexity",
)
def perplexity_fn(items): # This is a passthrough function
return itemsデコレータ@register_aggregation(...)を使ってaggregationメソッドを、@register_metric(...)を使って単一データに対する指標メソッドを登録できます。通常は、指標メソッドで各モデル生成結果に対する指標を計算しますが、perplexityの場合、データセットのすべてのデータを参考にして計算する必要があるため、上記のコードでは指標メソッドは何も動作しないように実装しました。
今までの内容を整理すると、現在Harnessでテストできる作業の一つであるlambada_openaiを以下のように構成できます。
tag:
- lambada
task: lambada_openai
dataset_path: EleutherAI/lambada_openai
dataset_name: default
output_type: loglikelihood
test_split: test
doc_to_text: "{{text.split(' ')[:-1]|join(' ')}}"
doc_to_target: "{{' '+text.split(' ')[-1]}}"
should_decontaminate: true
doc_to_decontamination_query: "{{text}}"
metric_list:
- metric: perplexity
aggregation: perplexity
higher_is_better: false
- metric: acc
aggregation: mean
higher_is_better: true
metadata:
version: 1.0
dataset_kwargs:
trust_remote_code: trueHarnessを利用したLLMテストおよび結果評価の自動化
Harnessでは基本的にYAML設定ファイルを使って静的にタスクを管理します。この方式はさまざまなオプションのテストを直感的に管理できるというメリットがありますが、LLM評価の自動化のためには、データセットとプロンプトなどを動的に選択してテストする必要があり、追加開発が必要でした。
その開発のために私たちは、Harnessがテストを開始する際にタスクの構成に必要な情報(データセット、プロンプト、指標)を外部から入力を受け、それをもとにまずYAML設定ファイルを動的に生成し、これをHarnessが参照してテストを行う方法を選択しました。
以下はYAML設定ファイルを生成するコードの一部です。
...
yaml_content = {
"group": task_group_name,
"task": task_name,
"dataset_path": "harness/datasets/builder.py",
"dataset_name": "test",
"test_split": "test",
"dataset_kwargs": {"trust_remote_code": "True"},
"output_type": output_type,
"metric_list": [{"metric": metric} for metric in selected_metrics],
"filter_list": [
{
"name": output_name,
"filter": [
{
"function": "utils.OutputAbstractionFilter",
"output_name": output_name,
}
],
}
for output_name in output_names
],
}
...このコードで重要な部分を簡単に説明します。
データセットごとに評価指標を設定する
最初は指標です。データセットごとに評価が必要な指標が異なるため、評価指標についての情報はデータセットのルートパスで「metric_output_info.json」という名前で管理しています。以下は例のデータセット「Example Bot」で管理している指標情報の例です。
- Technical-Support-Bot/metric_output_info.json
{
"default": ["rougeL", "cosine_similarity", "gpt_similarity", "gpt_correctness"]
}このように指定した指標のうち、以下のように各出力タイプ(generate_until、loglikelihoodなど)に合った指標をフィルタリングして追加します。
"output_type": output_type,
"metric_list": [{"metric": metric} for metric in selected_metrics],フィルターを利用してモデルの単一回答で出力ごとに複数指標を計算する
チームで開発したLLMアプリケーションをテストする際に、モデルの単一回答に対しても複数の評価指標が必要という要件がありました。その要件を反映するため、HarnessのFilterというオプションを使用しています。Filterを利用すれば、モデルの回答をさまざまな方法で後処理し、後処理した回答ごとに異なる評価ができます。
例で見てみましょう。以下を「API Test Bot」という仮想のLLMアプリケーションが生成した回答と仮定します。
{
"method": "GET",
"path": "/users/{{number}}"
"expected_status_code": 200,
"purpose": "Get user's information",
...
}上の例を見ると、JSON形式の応答でキーごとに特性が異なることが分かります。それぞれのキーを出力として定義し、その特性によって異なる指標を求めることで、モデルをより細かく評価しようとしました。
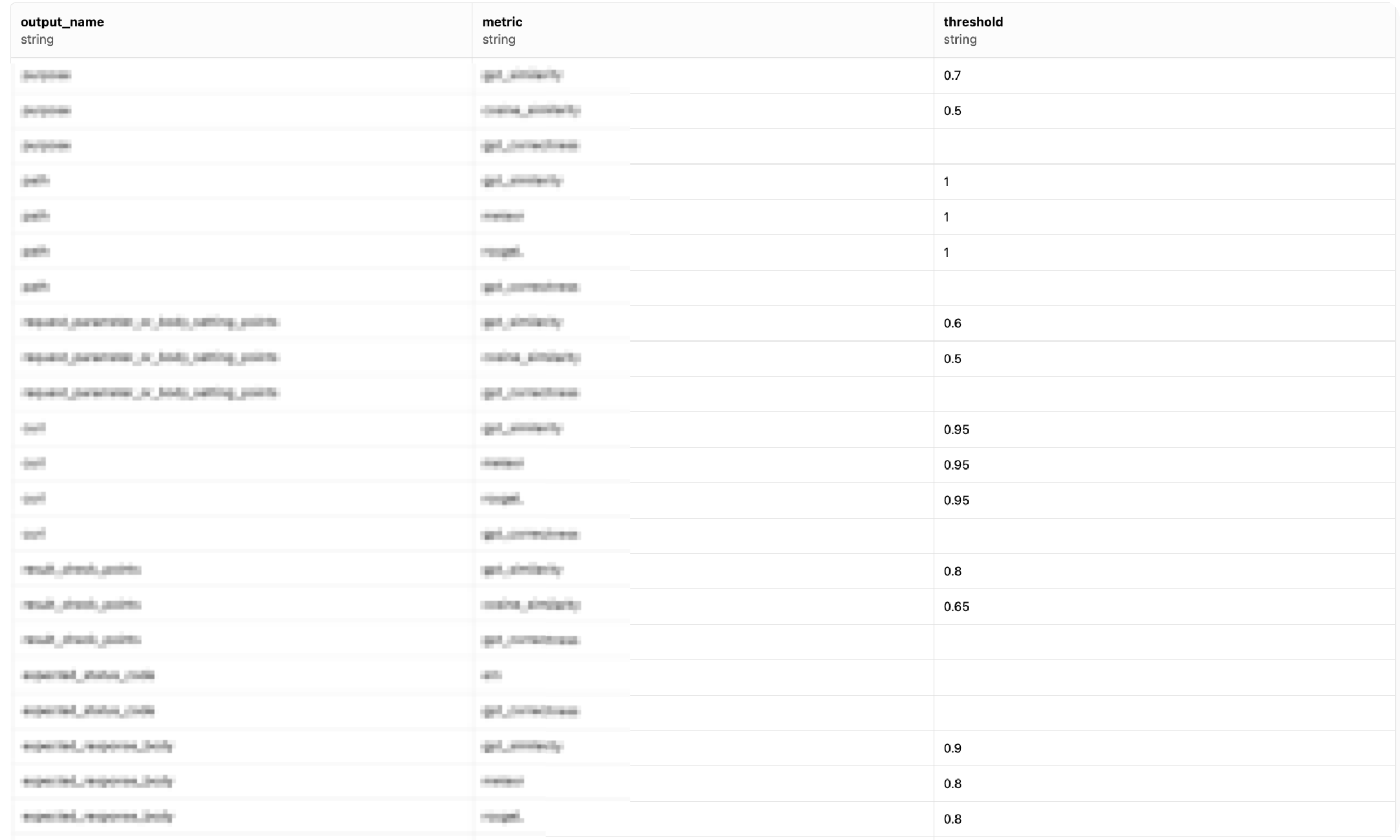
そのために、以下のように指標を定義するmetric_output_info.jsonで出力ごとに求めるべき指標情報を定義しました(thresholdは、その指標の定量評価においての必要最低限の得点を意味します)。
- metric_output_info.json
{
"method": [
"em"
],
"path": [
{"name": "gpt_similarity", "threshold": 1},
{"name": "meteor", "threshold": 1},
{"name": "rougeL", "threshold": 1}
],
"expected_status_code": [
"em"
],
"purpose": [
{"name": "gpt_similarity", "threshold": 0.7},
{"name": "cosine_similarity", "threshold": 0.5}
],
...
}
このように定義したファイルを使って以下のようにoutput_nameによってFilterオプションを動的に設定します。output_namesはmethod、path、purposeなどの出力名のリストを意味します。
"filter_list": [
{
"name": output_name,
"filter":
{
"function": "utils.OutputAbstractionFilter",
"output_name": output_name,
}
],
}
for output_name in output_names
],上の例でutils.OutputAbstractionFilterはHarnessのFilterクラスを実装したクラスで、モデルの回答データからouput_nameに該当するデータだけ抽出して返します。その結果、出力ごとにテストを行うことが可能になります。
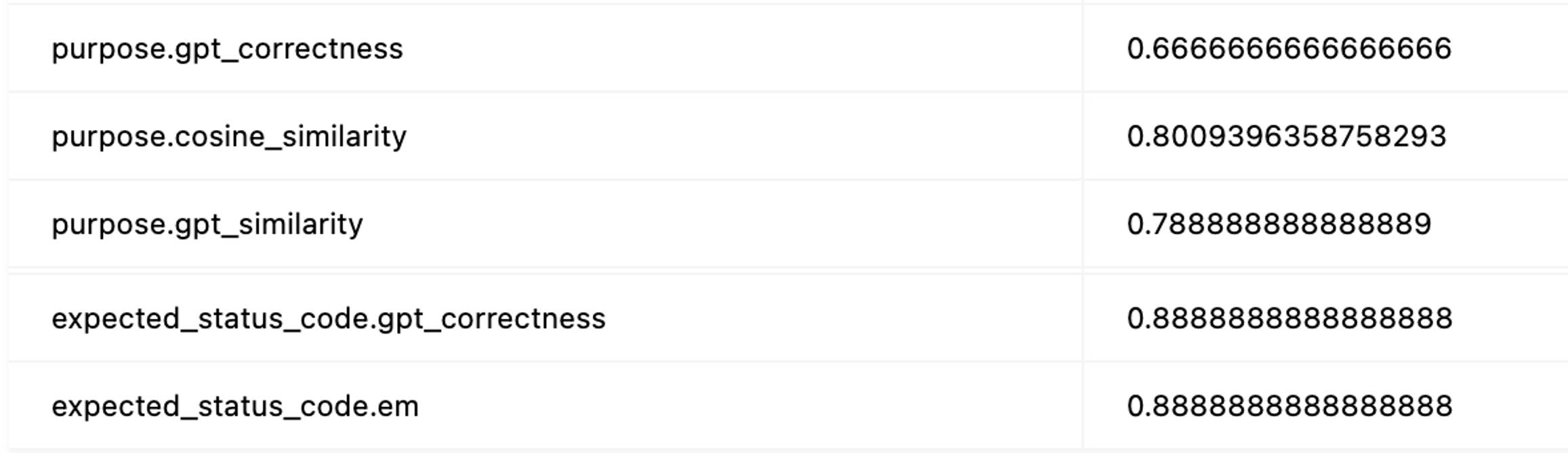
以下はFilterを使った場合の評価指標の集計結果の一部です。モデルの回答でpurpose、expected_responseのような出力ごとに異なる指標を計算し、集計していることが確認できます。
動的プロンプト適用機能を実装する
プロンプトのわずかな違いにもモデルの回答は大きく変わることがあるため、自由にプロンプトを変更しながらテストできるように動的にプロンプトを適用する機能は必須でした。その機能の実装に、前述のタスクのdoc_to_textオプションを使用しました。
Harnessでは、YAMLファイルで定義されたタスクをapi/task.pyのConfigurableTaskクラスで管理します。doc_to_textオプションもConfigurableTaskで管理しますが、その一部を確認すると以下のようになります。
def doc_to_text(self, doc):
...
doc_to_text = self.config.doc_to_text
...�つまり、YAMLファイルにdoc_to_textが設定されている場合はそれを使い、そうでない場合は他のオプションでプロンプトを適用します。私たちはこれを動的に適用するため、ConfigurableTaskをオーバーライドしたCustomConfigurableTaskを作り、CustomConfigurableTaskでdoc_to_textが内部ライブラリによって指定されたプロンプトを取得してデータセットと組み合わせるように実装しました。
def doc_to_text(self, doc):
return self._prompt_manager.apply_template(doc)動的プロンプトは、self._prompt_managerがテストを実行するときに渡されたprompt_idに合ったプロンプトを事前にダウンロードした後、上のメソッドでパラメータdocで渡されるデータセットのデータにプロンプトを適用する方法で動作します。
ここまでHarnessの基本的な使い方と、私たちのチームでLLM評価の自動化パイプラインを構成するためにHarnessをどのように使っているのか見てきました。次は、現在使っている指標を紹介します。
使用した指標と指標の集計方法
モデルの性能をテストするために使用する指標は、以下のような基準で回答の形式に応じて選択できるようになっています。
| 回答の形式 | 説明 | 特性 | テスト評価指標 |
|---|---|---|---|
| 文 | 記述形式の回答 |
|
意味的類似度(コサイン類似度、METEOR、GPT類似度、GPT正確度) |
| コマンド、パスなど | コードやパスなど決められた形式内で変更が発生する回答 |
| ROUGE-L、METEOR |
| 数字、カテゴリーなど | タイプが決まっている回答 |
| 完全一致 |
指標ごとに値の範囲が異なるため、簡単に解釈できるように各スコアをバイナリ化し、正解と不正解に変換できるように設計しました。また、同じ指標でもドメインごとに正解を判断するしきい値が異なる場合があるため、性能評価時にドメイン別指標の平均正解値の分布に基づいて指標ごとのしきい値(threshold)を入力すると自動的に計算されるようにシステムを構築しました。
しきい値の指定と指標スコアのバイナリ化
以下のように、指標ごとにしきい値を指定してスコアをバイナリ化できます。thresholdに指定された値より高い場合は1(正解)、そうでない場合は(不正解)として処理します。
集計された指標の確認
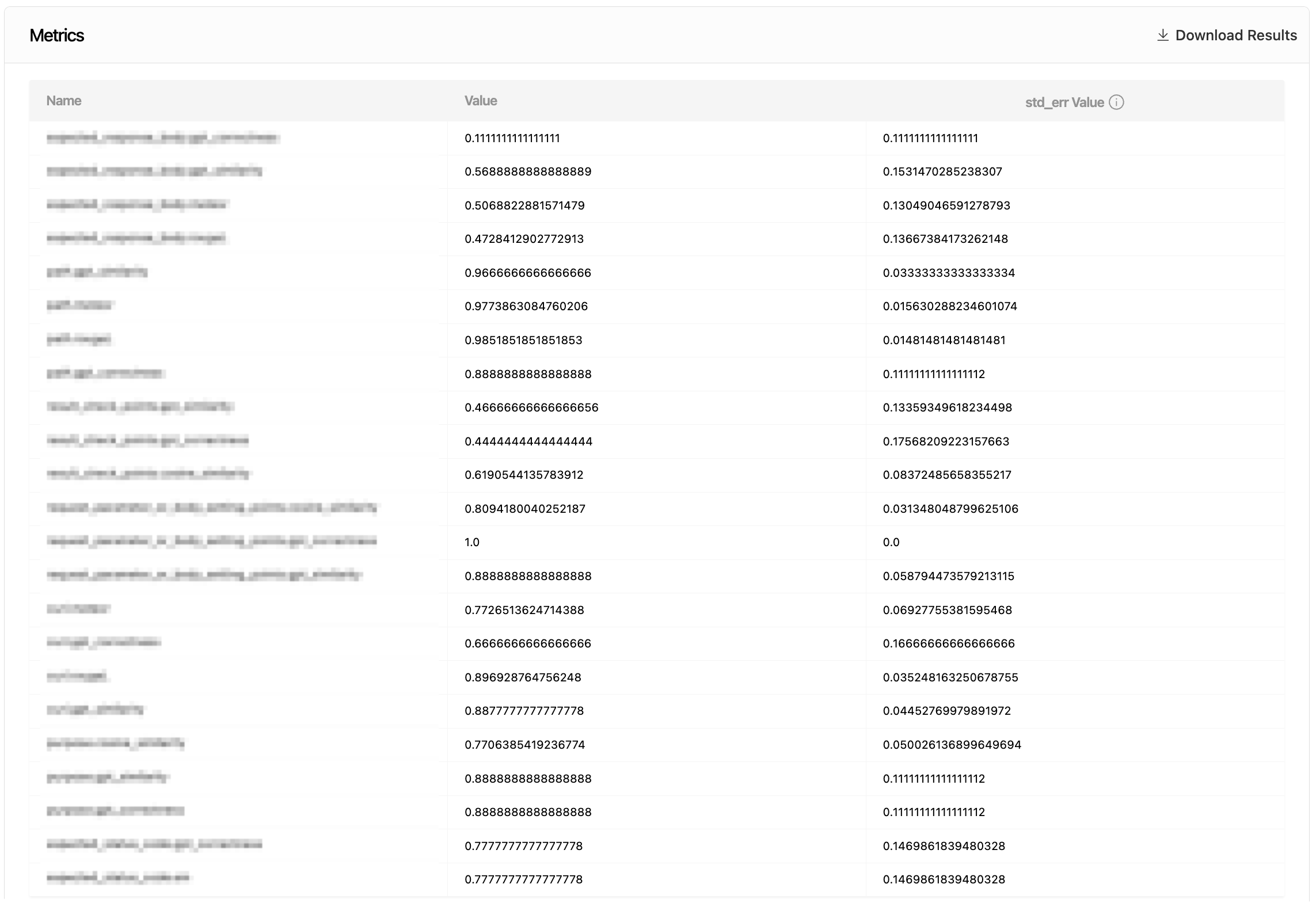
テストセットを構成して大規模なバッチテストを行うと、以下のように集計された指標を確認できます。テストセットごとに使用したい指標と集計基準が異なる場合があるため、それを調整できるように開発しました。結果は、Excel(.xlsx)ファイルまたはJSONファイルでダウンロードでき、テストケースごとに指標を確認することも可能です。
テスト全体の流れ
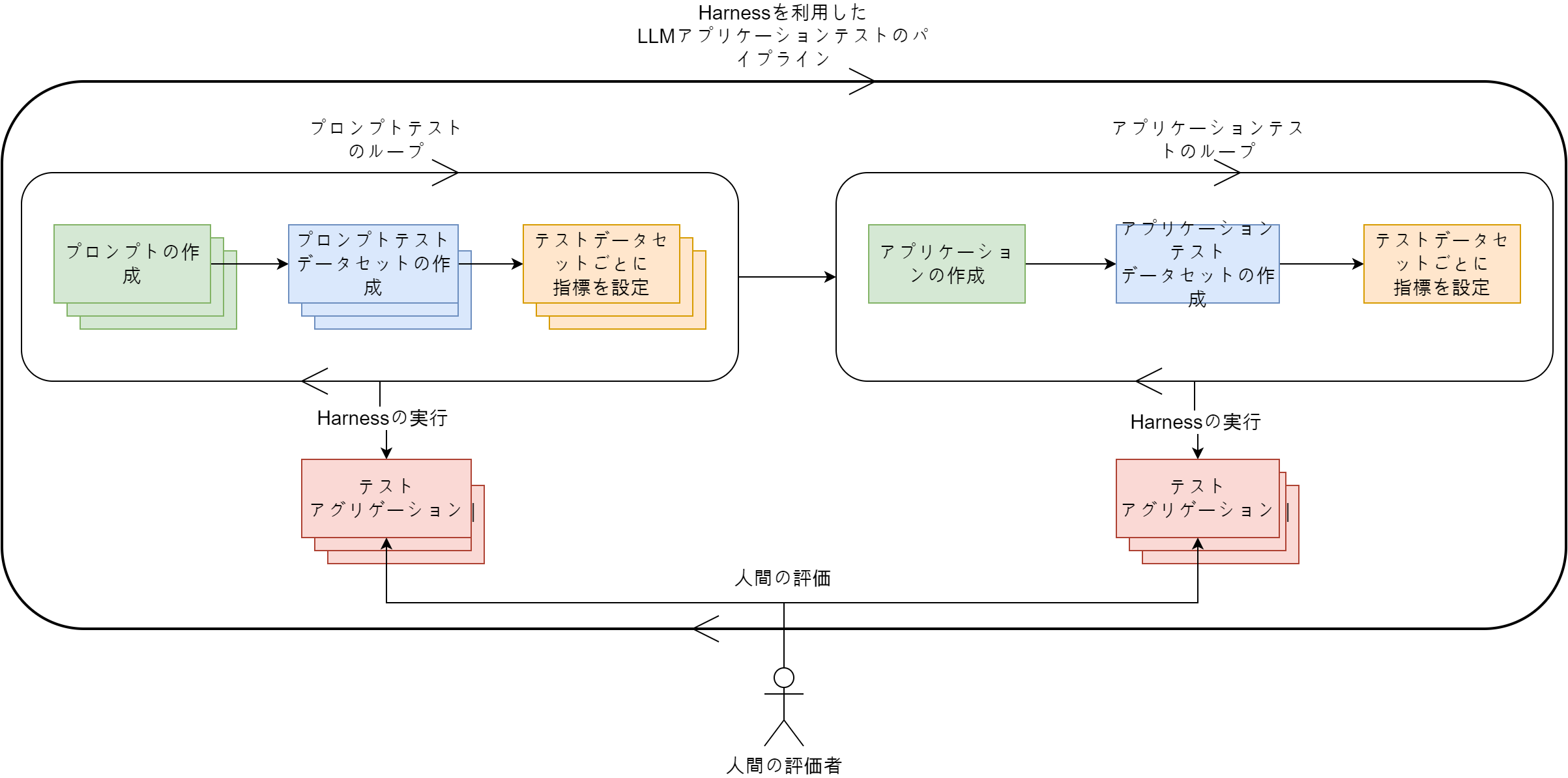
これまで紹介したテストプロセスをまとめて図式化すると、以下のとおりです。
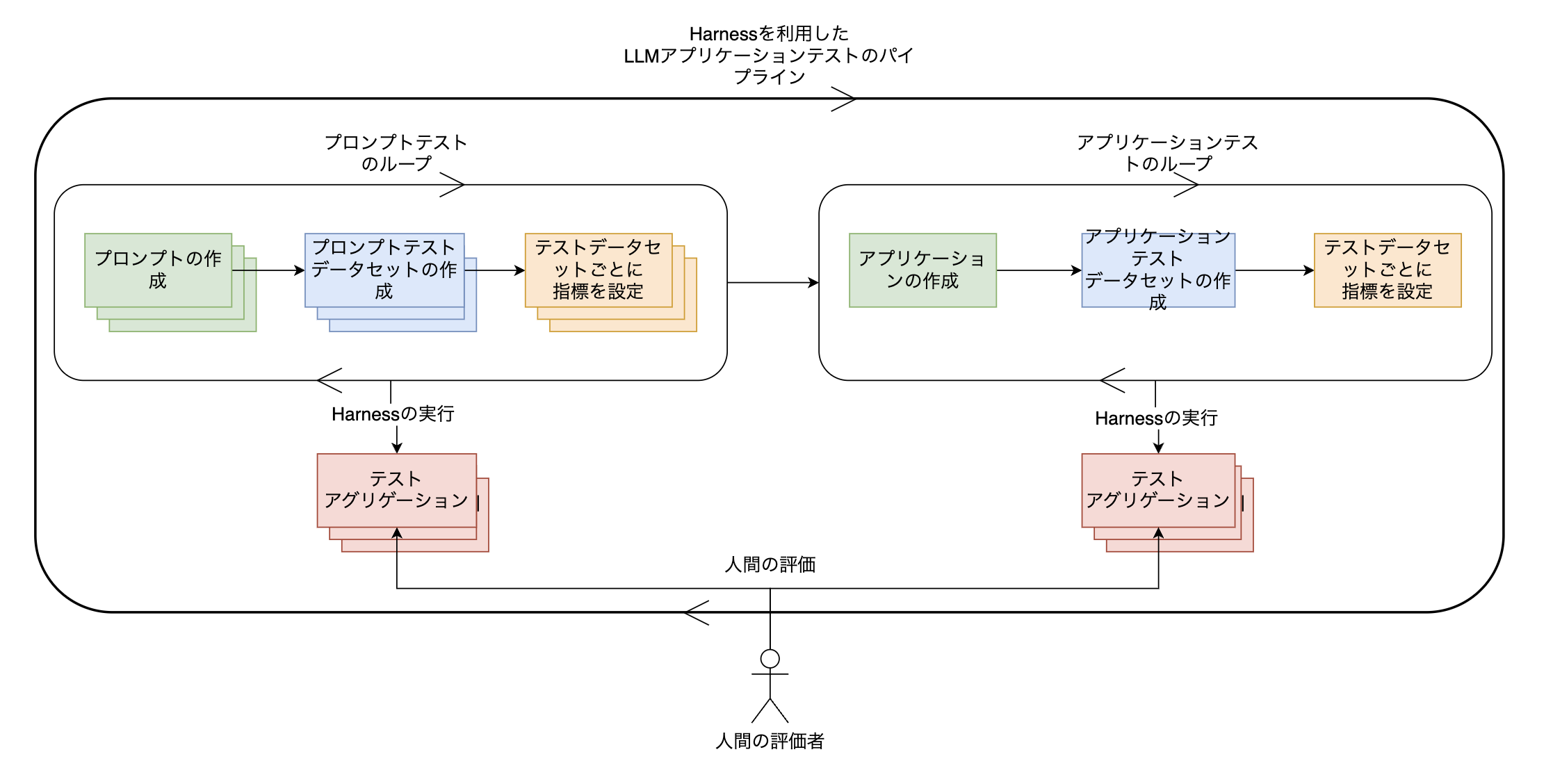
プロンプトごとにテストデータセットを作成し、指標を設定してプロンプトごとにテストを繰り返します。同様に、アプリケーションもテストデータセットを作成し、指標を設定してテストを繰り返します。このように、最小の構成単位のテストと、各構成単位が集まった全体のテストを繰り返し行いながら、希望する指標が出るまでアプリケーションを修正していきます。LINE PlusのLINE GAME PLATFORMチームは、このようなパイプラインをもとに、LLMアプリケーションの性能を高度化しています。
おわりに
ここまで、LINE PlusのLINE GAME PLATFORMチームで複雑なLLMアプリケーションの品質を保証するために行ったテスト自動化のプロセスについて説明しました。まだ定石と言えるテスト方法はないドメインですが、私たちが行った方法からインサイトを得ていただければ幸いです。長文でしたが、読んでいただきありがとうございました。


