はじめに
こんにちは。Service ReliabilityチームでSRE(Site Reliability Engineer)として働いているKi Cheol Cheonです。SREチームは、ユーザーに安定していて信頼性の高いサービスを提供するために、絶えず努力しています。具体的には、SLI(service level indicator)/SLO(service level objective)を用いてLINEメッセージングコアサービスの品質と信頼性を評価しており、需要予測や性能テスト、自動化、可観測性(Observability)の強化など、さまざまな分野のエンジニアリングに取り組んでいます。また、各チームが円滑にコミュニケーションを取り、コラボレーションできるよう支援する役割も担っています。
今回の記事は、信頼性向上のためのSLI/SLO導入vol.1 - 紹介と必要性と信頼性向上のためのSLI/SLO導入vol.2 - プラットフォームへの導入事例に続いて、LINEアプリのメッセージ、チャネル、認証サービスにおいてSLI/SLOを定義・導入した経験を紹介したいと思います。
SLI/SLOの実装のためのマインドセット
SLI/SLOは、単に指標を定めるレベルを超え、「サービスをどのような観点で捉えるか」を再定義するプロセスに近いものです。SLI/SLOを導入し、このプロセスを成功させるために備えておくべきマインドセットについて見ていきましょう。
サービスの理解と探究
SLI/SLOを実装するために最初に行うべきことは、ユーザーにどのようなサービスと機能を提供しているかを特定することです。このプロセスで、ユーザーがサービスを利用する際に経験する「ユーザージャーニー(user journey)」をリストアップし、「ユーザーがどのサービスを多く利用しているか」あるいは「必須となる機能は何か」など、ユーザーに提供するコアサービスや機能を定義することで、「クリティカルユーザージャーニー(critical user journey、以下CUJ)」を特定できます。また、このプロセスを通じて、サービスが組織のビジネス目標とどのように関連しているかを理解することで、SLOを組織の目標と一致させることができます。
コミュニケーションとコラボレーション
SLI/SLOは、さまざまな部署やチームが協力して実装・管理すべき指標であり、目標です。個人や特定のチームが定義・実装するものではなく、すべてのステークホルダーが共に目標を設定し、合意して初めて価値が生まれます。サービスを最もよく理解している担当組織がCUJを定義し、インフラ組織は、大規模な指標を測定・管理できるインフラ環境を構築する必要があります。SREは、SLI/SLOを測定するための手法やツールを実装し、SLOを通じてサービスの安定性と信頼性をモニタリング・管理する役割を担います。
各組織が担う役割をまとめると、以下のとおりです。
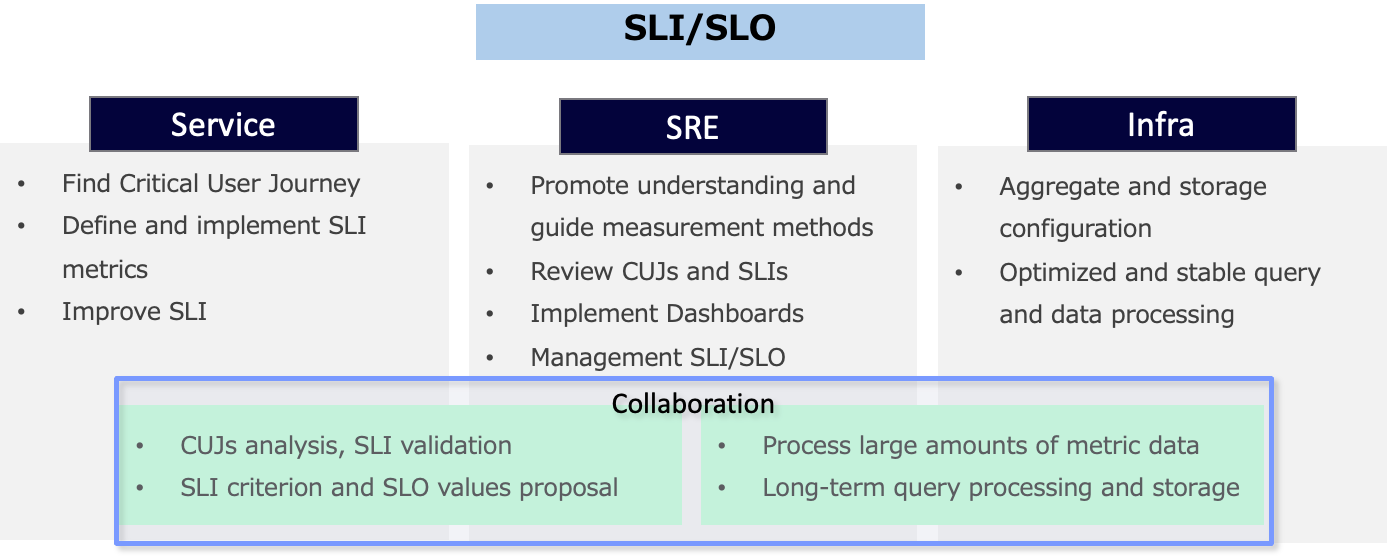
すべてのサービス関係者がSLI/SLOの重要性を理解し、その達成に向けた責任を分担する文化を醸成することが重要です。そうして初めて、サービス運用時、または新規サービスや機能のリリース時に、ユーザーが安定してサービスを利用できているかを確認する指標としてSLOを活用できるようになります。
SLI/SLOの実装方法
それでは、実際にSLI/SLOを実装するための具体的な手順を説明します。
CUJの分析
最初のステップは、ユーザー体験とビジネス目標を考慮したコアサービスや機能であるCUJを定義することです。

ユーザーに提供しているサービスや機能をリストアップした後、自らに以下のような問いを投げかけることで、CUJを具体化できます。
- ユーザーがサービスで最も頻繁に利用している機能は何か?
- ユーザーに必ず提供すべき機能は何か?
例えば、以下ようにLINEアプリサービスの起点となるLINE会員登録機能や、最も基本となるメッセージの送受信機能などのコア機能を定義します。その他にも、ユーザー認証や暗号化といったセキュリティの観点から主要な機能や、LINEログインまたはプロフィール情報など、LINEサービス�を活用して他のサービスを利用可能にするサービスや機能も対象となり得るでしょう。
Critical user journey (CUJ)
Focus on selecting key features and services. Consider user experience and business objectives

もちろん、すべてのサービスや機能が重要であり、そのすべてを安定して提供すべきなのは言うまでもありません。しかし、このステップの核心は、その中でも最も重要な対象のみを選別することであり、その際に重要なのはユーザーの視点から定義することです。
SLIの実装
CUJを定義した後は、SLIを定義します。

SLIとは、CUJごとにどのような指標を設定し、測定するかを定義するものです。
- どのポイントで測定するのか?
- ゲートウェイやフロントエンド、バックエンドなど、CUJごとにより正確に測定できる場所を選定します。
- どのAPIを使って測定するのか?
- 指標の計算を複雑にしないよう、CUJごとに代表的なAPIを選定します。
次に、成功と失敗を判定する基準(SLI criterion)を定義します。一般的には応答時間と応答成功率の大きく2つの軸で測定し、それぞれの基準値は以下のように定義します。
- 応答時間:全リクエストに対する応答時間の何パーセンタイルを基準とするか、またその基準となる応答時間をどの程度以内であれば成功とみなすかを定義します。
- 応答成功率:測定期間中、どの程度の応答成功率を維持すべきかを定義します。
例えば、「メッセージ送信機能については、99.9パーセンタイルのリクエストに対する応答時間を500ms未満とし、全リクエストの99.999%が成功応答を受け取るサービスを提供する」といった形で定義します。

このステップの核心は、測定ポイントと対象、そして成功と失敗を判定する明確な基準を定義することです。特に、成功と失敗を判定する基準を明確に定義してこそ、SLOの達成状況を測定可能になります。もし、変数が多くて測定が不可能な場合や、成功と失敗の基準を明確に定義できない場合は、そのCUJを測定対象から除外することも可能です。測定が複雑な場合は、SLI専用の指標を作成することを推奨します。
SLOターゲット設定
SLIを定義した後は、SLOを定義します。

このス��テップでは、「測定期間中、SLI基準に適合した信頼性と安定性が保証されたサービスを提供する」という目標を定義します。例えば、以下のように「28日間で99.9%、すなわち合計40,320分のうち40,280分間、SLIで定義された応答時間と応答成功率を達成する」と定義します。
Service level objective (SLO)
The objectives or specific ranges the service needs to achieve, based on the measured SLIs

このステップの核心は、実際に達成可能な現実的な目標を設定することです。SLOを高く設定しすぎると、それを達成するために相応のコストを追加しなければならず、逆に低く設定しすぎるとサービスの質が低下し、ユーザー体験を損なう恐れがあります。そのため、安定性とコストのバランスを適切に考慮して設定する必要があります。
可視化
最後に、サービスに関わるすべてのステークホルダーが現在のSLOの状態を簡単に確認できるよう、前述で定義したSLI/SLOを可視化したダッシュボードを実装します。

以下の例のように、SLOとエラーバジェット(error budget)をまとめて確認できるダッシュボードを実装することで、現在のSLOの全体像を一目で把�握できます。さらに、CUJごとの詳細ダッシュボードも実装しておけば、SLI指標をより詳細に確認できます。
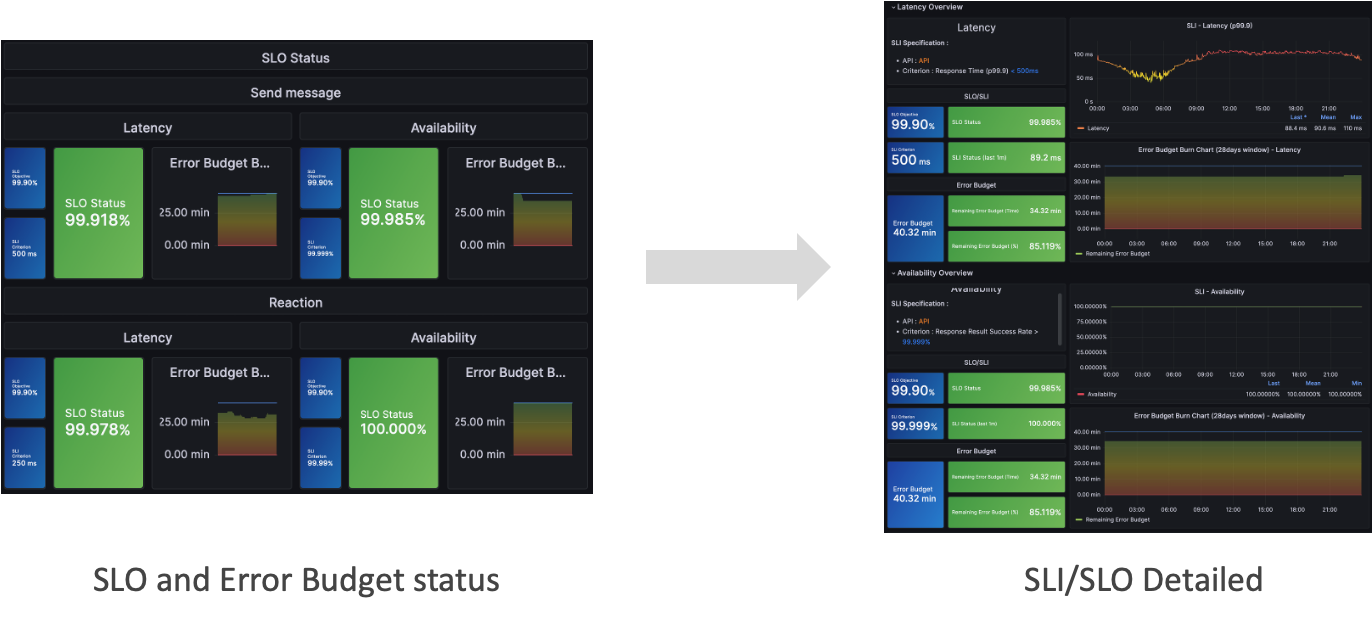
このステップの核心は、ダッシュボードに情報を詰め込みすぎるのではなく、数値や色を用いてシンプルに構成し、全体像を一目で素早く把握できるようにすることです。例えば、目標を安定して達成している指標は緑、注意が必要な項目はオレンジ、目標未達の項目は赤で表示すれば、現状を簡単かつ迅速に把握できます。
SLI/SLOの活用
ここからは、SLI/SLOをどのように活用するかについて説明します。
信頼性と安定性を定量的に把握するための指標
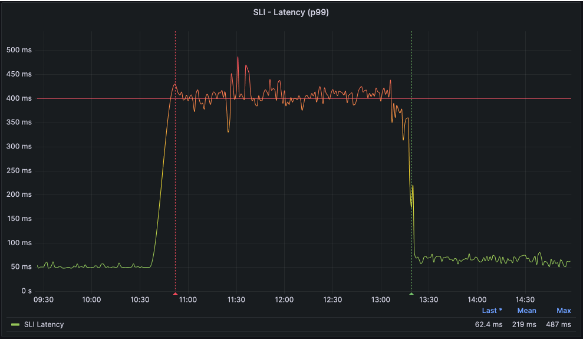
サービスの状態を伝える際、「遅くなった」や「不安定だ」といった表現の代わりに、定量的な指標として定義されたSLIを利用すれば、より正確に状況を表現できます。例えば、以下のような状況では、「サービスの応答時間がSLI基準である400msを超えているため、ユーザー体験を損なっている」と表現できます。
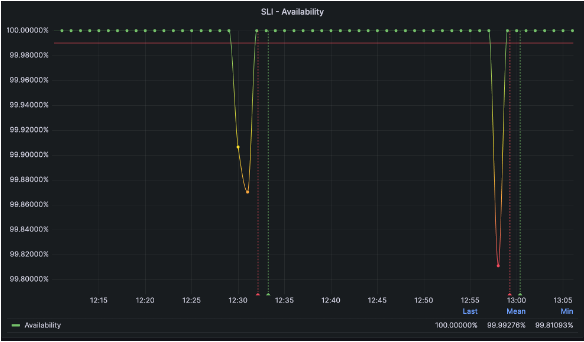
また、以下のような状況では、「サービスの応答成功率が99.99%を下回っており、その結果、ユーザーがサービスの利用に支障をきたしている」と表現できます。さらに、ダッシュボードを確認することで、応答成功率が目標に達しなかった時間帯にどのような問題が発生していたかも把握可能です。
このように、定量的な数値とそれを可視化したダッシュボードを活用することで、サービスの状態をより明確にモニタリング・分析できるようになります。
リソース配分の基準としての活用
SLOを通じて現在の目標達成状況を確認でき、エラーバジェットによって許容可能な障害時間を把握できます。また、これはSLOを達成するために必要な予防策や対応活動に投入すべきリソースを算出するための基準として活用できます。
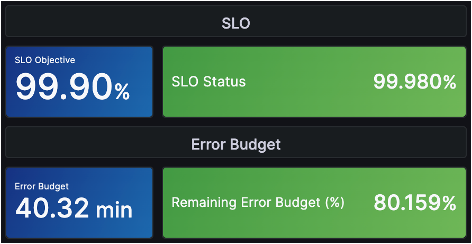
もしサービスがSLOを満たしており、エラーバジェットも十分に確保されているのであれば、サービスは安定して運用されていると判断し、新機能のリリースなどにリソースをより積極的に投入できます。例えば、以下のような状況であれば、「SLOの目標値99.9%を上回る99.98%を達成しており、エラーバジェットも80%以上と余裕があるため安定している」と判断できます。これを踏まえて、新機能のリリースやリリースサイクルの前倒しにリソースを振り向けることができます。
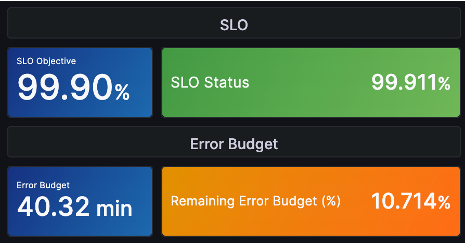
一方、以下のようにエラーバジェットが10%しか残っていない場合は、SLOを確実に達成し、サービスの安定性を高める方向にリソースを投入するといった意思決定が可能になります。
オンコール対応時の活用
現在、各サービスのオンコール(on-call)体制では、エラーバジェットの状態変化に応じたアラート機能を導入し、サービスの状態把握や問題発生時の対応に活用しています。また、定期ミーティングでのSLOの状態確認や、目標を達成するための予防活動を行う際にも役立てられています。
以下は、エラーバジェットの状態に関するアラートメッセージの例です。


おわりに
サービスにおいて、信頼性と安定性は中核的な価値です。また、ユーザーの利便性を高め、新しい機能を提供することも、ビジネスにおいて極めて重要な価値です。SLOは、定量的な指標を通じて、サービスの信頼性とビジネスの目標とのバランスを取るのに役立つと確信しています。
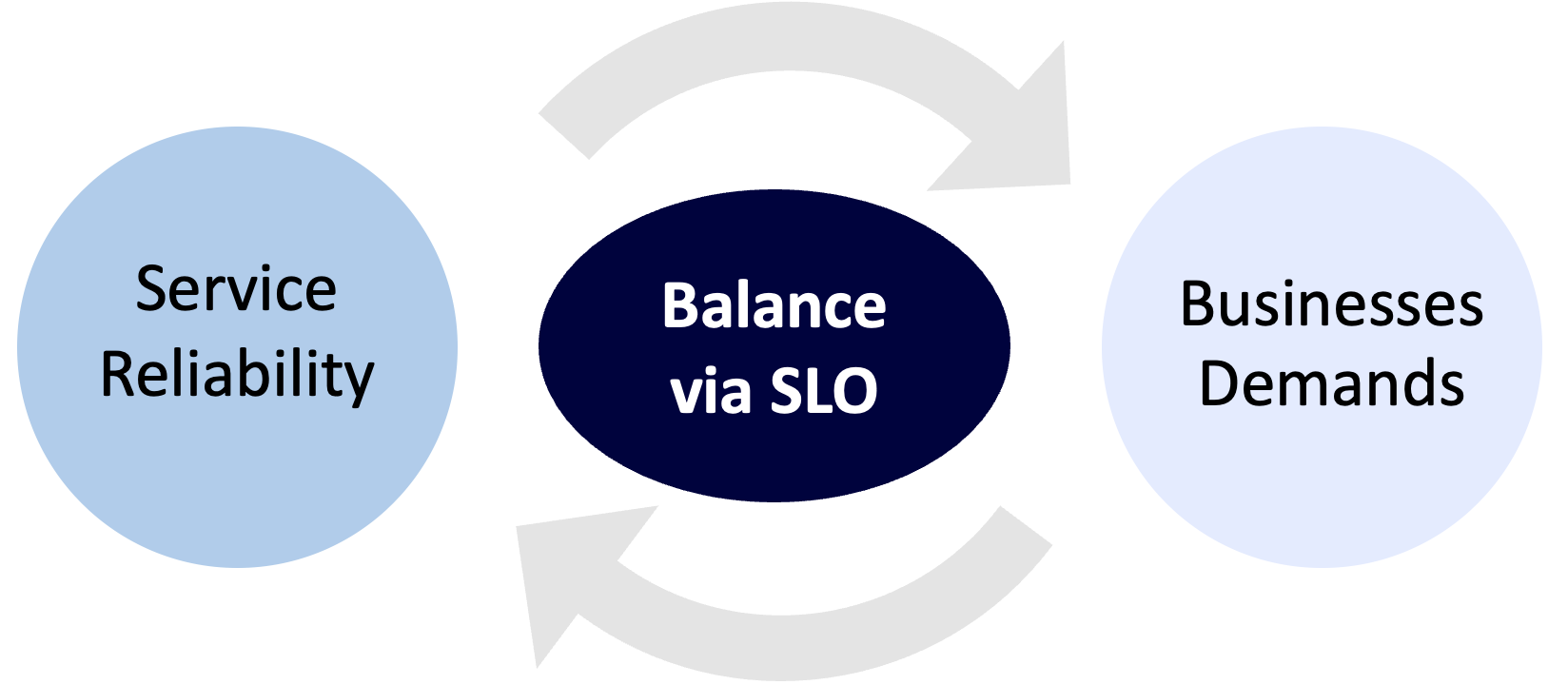
この記事が、SLI/SLOに関心をお持ちの方や、サービスへの導入を検討されている方のお役に立てば幸いです。最後に、SREという役割に関する私の見解をまとめた言葉を紹介して本記事を締めくくります。長文でしたが、お読みいただきありがとうございました。
Core tenets of SRE
Focus on providing stability and reliability to our customers
And strive for continuous improvement and innovation.


