Orchestration Guildメンバーの福山です。普段はLINEレストランプラスというサービスで、フロン��トエンド開発を担当しています。
この記事は、Orchestration Development Workshop #10で開催した「コーディングAIが導くリスクベースド探索的テスト」の内容を紹介します。
近年、コーディング支援AIの普及により、「書く」工程の体験は大きく変わってきたと感じます。それに対して、「確かめる」工程・テスト設計・実行は、私の観測する範囲では、依然として個々のエンジニアの経験と勘という「暗黙知」に強く依存しているように感じます。「ここはベテランが見ないと不安」「前回バグった箇所だから今回も念入りに」、そうした判断は、特定の人の頭の中だけに閉じ込められたままになっていないでしょうか。
本記事では、Orchestration Guildで社内ワークショップとして共有したリスクベースド × AIエージェントによる探索的テストの取り組みを紹介します。ベテランの頭の中にあった判断基準が組織の仕組みへと変換されていく、そんな「暗黙知を形式知に変える」プロセスを読者のみなさんに持ち帰っていただくのが、本記事のゴールです。
※本記事中のスキル実行例・リスク分析表のサンプル・テストケースの題材(カート、クーポン、注文など)は、社内ワークショップ用に作成したサンプルアプリケーションをベースにしています。実プロダクトのデータではありません。
役割分担:何を人が担うか、何を人に残すか
最初に全体像をつかんでいただくために、何をAIに任せ、何を人が判断するのかを整理します。
| 工程 | 従来の人ベースのテスト計画 | AIエージェント+仕組み化のテスト計画 |
|---|---|---|
| 観点設計 | ベテランの記憶と経験で導出。属人化しやすい | 過去バグ履歴を構造化し、AIがリスク表として可視化できる |
| 繰り返し検証 | 集中力の維持が難しく、ムラが出やすい | AIが淡々と実行し、ムラなく網羅しやすい |
| 影響範囲調査 | コードベース全体を頭で追う必要がある | PR差分とリスク表を突合し、AIが追加観点を抽出できる |
| 環境整備 | 人が整備する | 同じく人が整備する必要がある(効きにくい領域) |
| 最終判断 | 人が文脈を踏まえて判断 | 同じく人が判断する(最終承認は人に残す) |
ポイントは、全工程をAIに置き換えるのではなく、効く領域と効きにくい領域を見極めて配分することです。本記事ではその境界線を、3つのステップと検証結果を通じて具体的に示していきます。
テストの現場で起きている「暗黙知」問題
このアプローチに取り組むきっかけになったのは、Orchestration Guildの取り組みの一環として実施した、社内のコマース領域を担当しているチームへのヒアリングでした。テスト工程に関する課題を聞き取ってい�く中で、以下のような声を聞くことができました。
- ショッピング・ユーザー・ストアといった軸の組み合わせが無限大に近く、特定の条件でしか発現しないバグを「経験と勘」で見つけている
- QAプロセスは整備中で、テストのノウハウがまだエンジニア内に十分蓄積されていない。属人化させず、誰でも同じ深さでテストできるようにしたい
- AIが台頭してきた時代において、これまであきらめていた部分を克服したい。AI Readyな状態にしたい
私自身、エンジニアとしてテスト判断に向き合ってきた身として、これらの声には強くうなずけるものがありました。「テスト、これで本当に十分だろうか」、この不安は、私の経験では、多くの現場に共通するものだと感じます。自分が見落とすと、それはそのまま本番事故につながる、そうしたプレッシャーは、多くの現場に形を変えて存在しているように思います。
▼ テスト判断が「暗黙知」に閉じ込められている現場の構造
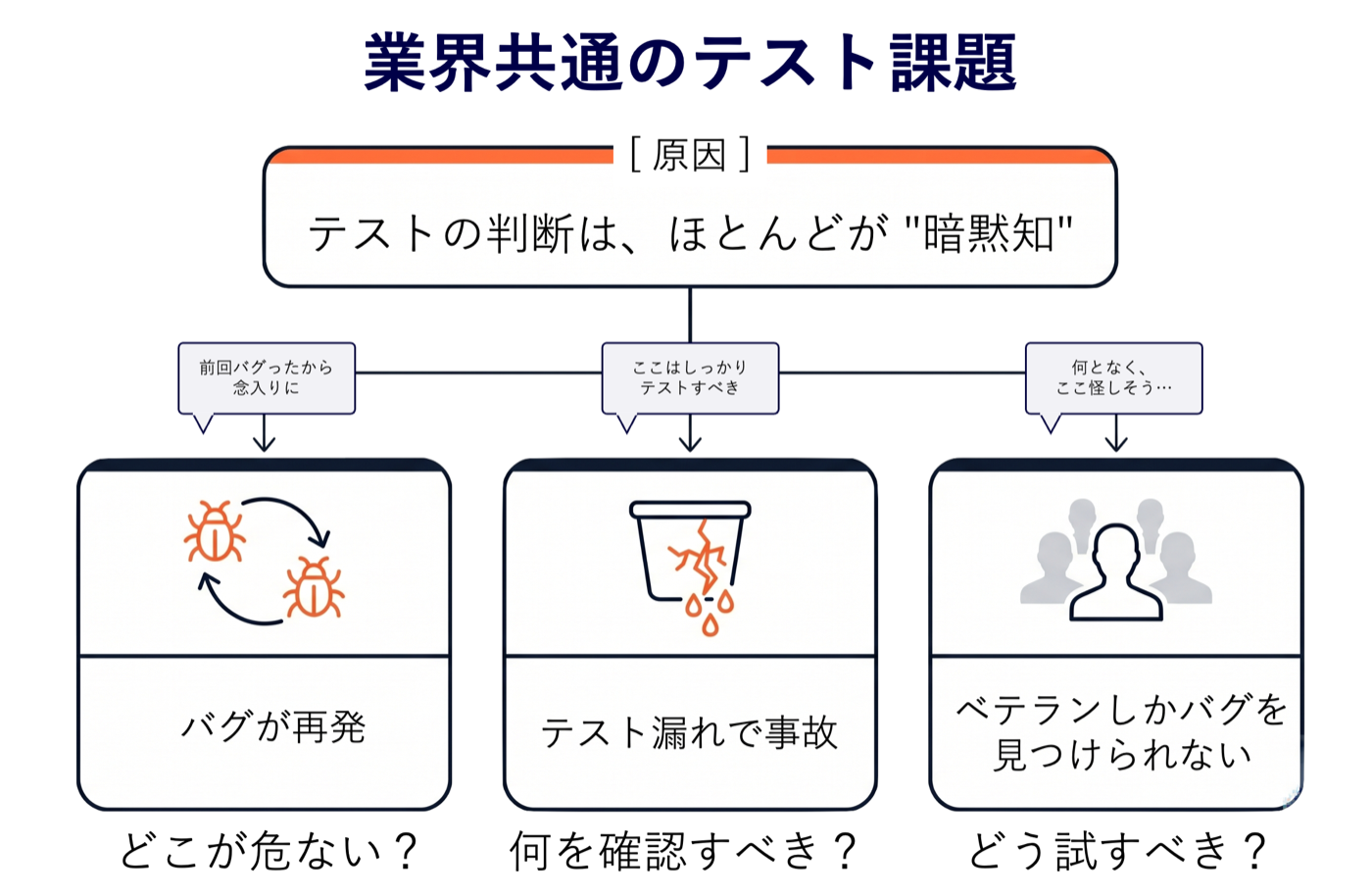
ヒアリングを通じて見えてきたのは、これは個人の気合いの話ではなく、構造的な課題だということでした。その根底にあるのは、「どこを重点的に確認すべきか」「どの条件の組み合わせが危ないのか」といったテスト判断の多くが、「暗黙知」で行われているという共通の構造です。
整理すると、こうなります。
| 暗黙知の現れ方 | 帰結 |
|---|---|
| 「前回バグったから念入りに」がベテランの記憶頼み | バグの再発 |
| 「ここはしっかりテストすべき」が共有されない | テスト漏れによる事故 |
| 「何となく怪しい」が言語化されない | ベテラン以外がバグを見つけられない |
ここで立てた問いはシンプルでした。
AIエージェントで「暗黙知」を「形式知」にできないか?
ベテランの頭の中にしかない判断基準を、AIと仕組みの力で取り出して、誰が見ても同じ手順で再現できる形に落とし込めないか。これが、本記事で紹介する取り組みの出発点です。
アプローチ:リスクベースド × AIエージェント
暗黙知を形式知化する切り口として、私たちが選んだのはリスクベースドテストの考え方です。
リスクベースドテストとは、テスト対象の各領域に対して、「発生可能性(Likelihood)」と「影響度(Impact)」の2軸を評価し、その積として算出されるリスクレベルの高い領域から優先的に深くテストするアプローチです。考え方そのものは、ソフトウェアテスト業界では古くから語られてきたものです(例:ISTQB Foundation Level Syllabus)。
| 影響度:大 | 影響度:中 | 影響度:小 | |
|---|---|---|---|
| 発生可能性:高 | Critical | High | Medium |
| 発生可能性:中 | High | Medium | Low |
| 発生可能性:低 | Medium | Low | Low |
ただ、実際にやろうとすると、判断のほとんどが「ベテランの頭の中」に閉じてしまう。これが、これまで普及しきらなかった理由の1つとも考えられます。だからこそ、ここにAIエージェントの介在余地があります。
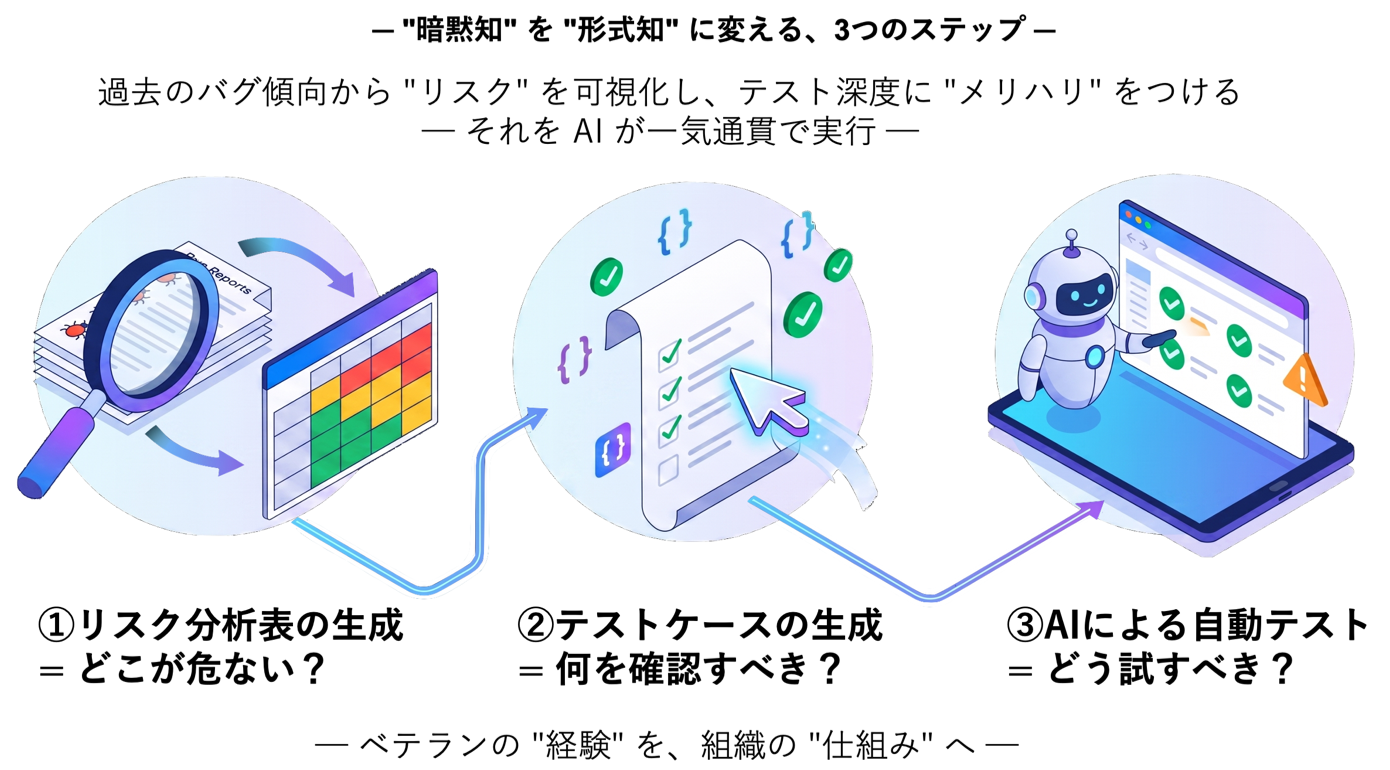
そこで、リスクベースドの考え方をAIエージェントに一気通貫で実行させることを思いつきました。整理するとこうなります。
| ステップ | 問い | AIエージェントの使い方 |
|---|---|---|
| (1)リスク分析 | どこが危ない? | 過去の不具合情報をAIにリスク分析させる |
| (2)テスト設計 | 何を確認すべき? | リスク分析結果をAIにインプットしてテストケースを生成させる |
| (3)テスト実行 | どう試すべき? | テストの実行をAIで自動化し、リスクの高いところは念入りに確認させる |
AIエージェントを使って、ベテランの頭の中にあった「どこが危ないか」「何を確認すべきか」「どう試すべきか」という判断基準を、リスク分析表やテストケースの形で形式知化する。さらに、テスト実行も自動化し、リスクが高いところは念入りに確認する。リスクベースド × AIエージェントによって、テストの暗黙知を形式知に変えるアプローチです。
▼ リスクベースド × AIエ��ージェントの3ステップ全体像
ステップ(1):リスク分析表の生成
最初のステップは、「どこが危ない?」を可視化するリスク分析表の生成です。
| 項目 | 内容 |
|---|---|
| 入力 | バグ起票チケット(GitHub Issue/JIRA) |
| 出力 | リスク分析表(MarkdownやHTML形式によるレポート) |
| AIエージェントの役割 | バグチケットの収集から分析、リスク分析表の生成までを担当 |
人がやる場合とAIに委ねた場合
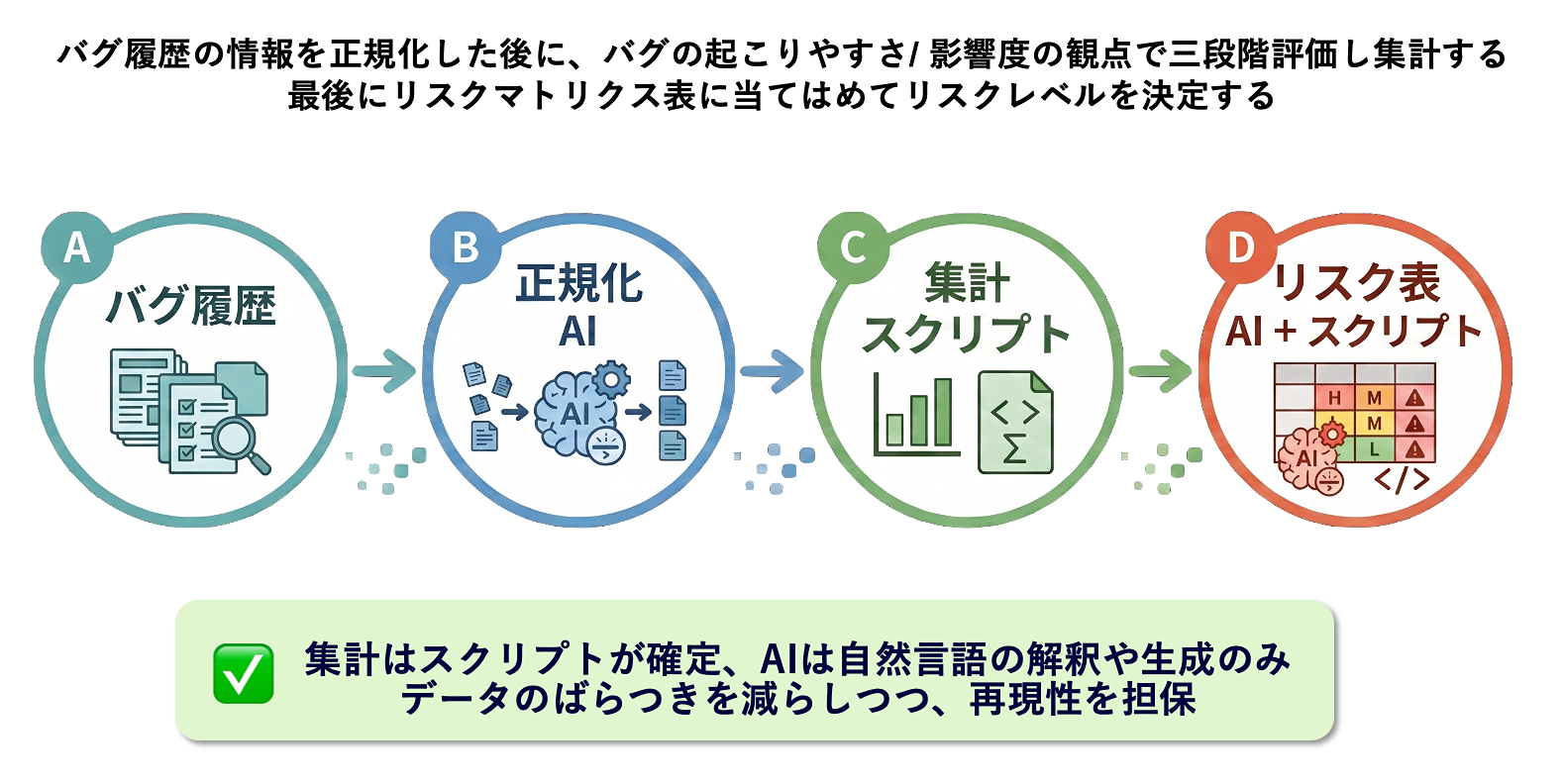
この作業を人がやる場合、過去のバグチケットを1件ずつ読み返し、機能領域を分類し、起こりやすさと影響度を頭の中で見積もり、Excelなりに転記していくことになります。件数によっては数時間〜1日程度かかることもあります。判断基準が人によって揺れるため、別の人がやれば違う表が出てきます、まさに「暗黙知」の温床です。
AIに委ねるとどうなるか。過去のバグチケットを読み込んで、リスク分析表を生成させる作業をAIに一気通貫で実行させることができます。AIは必要な情報の収集やリスクレベルの集計をツールやプログラムを駆使して自律的に作業を進めます。バグチケットの数が多くても淡々と処理でき、同じ基準で判断するため、人手でやるよりもムラなく再現性の高いリスク�分析表を生成できます。
設計判断:集計はプログラム、判断はAI
リスク分析表の生成をAIに実行させる上で、私がいちばん時間をかけて悩んだのが「どこまでをAIに任せるか」でした。
最初はすべてAIに任せようとしました。バグ履歴を読み込ませて、起こりやすさと影響度を採点させて、リスクマトリクスに整理させる。やってみると、AIは確かに一見もっともらしい表を出してくれます。ただ、同じ入力でも実行のたびに結果がぶれる。これは品質保証の文脈では大きな問題でした。
そこで以下のような設計判断をしました。
設計判断:データの集計と最終的なリスクレベルの算出はプログラムで確定的に行い、AIには「自然言語の解釈や生成」に集中してもらう。
判断のばらつきが出てはいけない集計部分はプログラムに固定し、自然言語のゆらぎを吸収する解釈や、リスク分析表のレポート文の生成などの「自然言語処理部分」はAIに任せる。この境界線を引いたことで、再現性と柔軟性の両立ができました。
▼ リスク分析表の生成のワークフロー
ワークフローの実装方法と動作例
ワークフローはAgent Skillsとして実装し、コマンドで呼び出せるようにしました。
実行すると、AIは過去のバグチケットを1�件ずつ読み込み、機能領域と原因を整理してくれます。
例えば、「BUG-03」というチケットに機能領域の記載がなかった場合、AIは原因コードである cartRepository.ts の内容から、feature-area-list.md のリストを参照して「カート・注文確定」という機能領域に分類します。報告者が「優先度:Low」と書いていても、priority-criteria.md の基準と照らして基準より低ければ、AIが引き上げの補正提案を出します(補正は引き上げのみで、引き下げは禁止)。
最初にこの補正ログが流れたとき、印象的だったのは、ベテランが頭の中でやっている「いや、これ Low じゃないでしょ」という指摘を、AIが基準書に照らして代わりにやってくれているという発見でした。
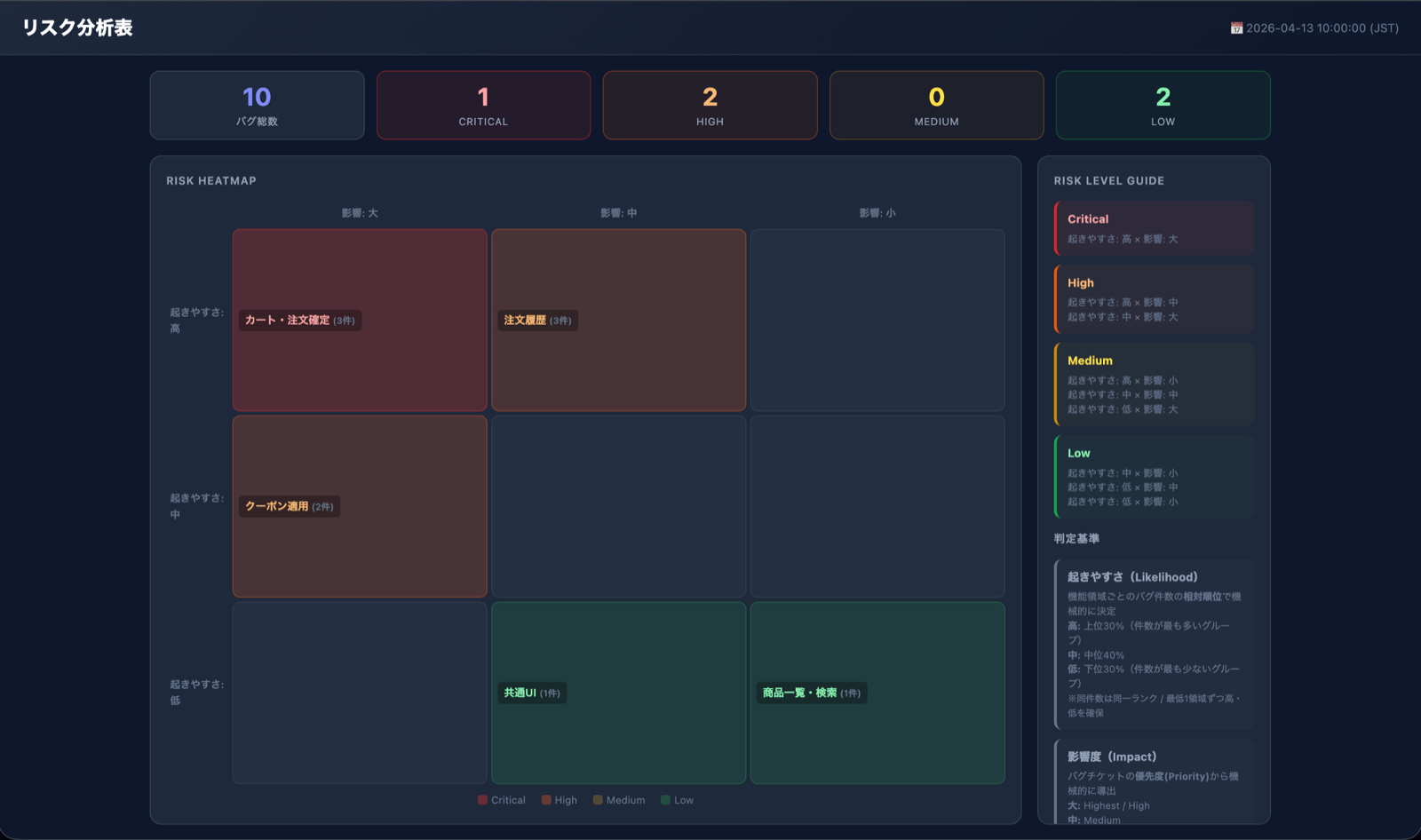
▼ 生成されたリスク分析表のサンプル
ディレクトリ構成
スキルは Agent Skills の標準的なファイル配置に倣って、次の構造で配置しています。
risk-table-generation/
├── SKILL.md # スキル本体
├── scripts/
│ ├── aggregate-risk.sh # 集計シェルスクリプト(決定的)
│ └── convert.sh # HTML変換シェルスクリプト(pandoc使用)
├── references/
│ ├── feature-area-list.md # 機能領域リスト
│ └── priority-criteria.md # 優先度判定基準
└── assets/
��├── template.html # HTMLレポートのテンプレート
└── style.css # HTMLレポートのスタイルAgent Skillsの内容
実際にワークショップで紹介したスキルの内容は以下の通りです。
※本記事では社外公開用に一部内容を調整しています。
---
name: risk-table-generation
description: "過去のバグ案件(JIRA / GitHub Issue・PR)を分析し、機能領域ごとのリスク傾向を可視化したリスク表を生成する。「リスク表生成」「risk table」「リスク分析」で発動。"
compatibility: "gh CLI(GitHub Issue/PR取得時)、pandoc(HTMLレポート生成時)"
---
過去のバグ案件を取得・分析し、機能領域ごとのリスク傾向をまとめたリスク表を生成してください。
## リスク分析のフレームワーク
**起きやすさ(Likelihood)× 影響の大きさ(Impact)** でリスクスコアを算出します。
### 発生可能性 (Likelihood) の決定ルール
機能領域ごとのバグ件数のみで機械的に決定する。**LLMが変更規模・バグ種別・コード複雑さで補正してはならない。**
1. 機能領域ごとのバグ件数を集計する
2. バグ件数の多い順にソートする
3. 相対順位で `高/中/低` を割り当てる(上位30% = 高 / 中位40% = 中 / 下位30% = 低)
4. 同件数は同一ランクにする
### 影響度 (Impact) の決定ルール
バグチケットの優先度(Priority)から機械的に導出する。**LLMが独自に判断してはならない。**
| チケットの優先度 | → 影響度 |
| ---------------- | -------- |
| Highest / High | 大 |
| Medium | 中 |
| Low / Lowest | 小 |
機能領域の影響度は、その領域に属するバグの中で**最も高い影響度**を採用する(保守的評価)。
### リスクマトリクス
| | Impact: 大 | Impact: 中 | Impact: 小 |
| ------------------ | ---------- | ---------- | ---------- |
| **Likelihood: 高** | Critical | High | Medium |
| **Likelihood: 中** | High | Medium | Low |
| **Likelihood: 低** | Medium | Low | Low |
## 機能領域リスト
バグの分類に使用する機能領域は `references/feature-area-list.md` で定義する。
**リストにある名前をそのまま使用し、LLMが自由に命名してはならない。**
## 実行手順
### Step 1: チケット取得
入力ソース(JIRA / GitHub Issue・PR)に応じてバグチケットを取得する。
### Step 2: チケットの正規化・分類
各チケットに対し、以下の2段階で判定する。
- **形式チェック**:機能領域は `references/feature-area-list.md` のリスト名と一致するか、優先度はJIRA形式か
- **妥当性チェック**:優先度を `references/priority-criteria.md` の基準と照合し、基準より低ければ**引き上げ**る(補正は引き上げのみ。引き下げ禁止)
正規化結果を `risk-tables/tickets-YYYYMMDD-HHMMSS.tsv` に保存し、後続の集計スクリプトの入力とする。
### Step 3: スクリプト集計
正規化TSVから集計スクリプトでリスクサマリーを生成する。**この出力値がリスク表の確定値となり、AIが上書きしてはならない。**
scripts/aggregate-risk.sh \
--input risk-tables/tickets-YYYYMMDD-HHMMSS.tsv --format md
### Step 4: リスク表の生成
Step 3の集計結果を**そのまま転記**し、AIは定性分析(バグの傾向・根拠の記述)のみ担当する。
リスクサマリーの数値(起きやすさ・影響・リスクレベル・バグ件数)はスクリプト出力を使用し、AIが変更してはならない。
出力先: `risk-tables/risk-table-YYYYMMDD-HHMMSS.md`
### Step 5: HTML変換
scripts/convert.sh risk-tables/risk-table-YYYYMMDD-HHMMSS.md
pandocが未インストールの場合はスキップし、ユーザーにインストールを案内する。
## 注意事項
- リスク分析はあくまでAIによる推定であることを明記する
- 判定材料が不足している場合は、保守的に(リスクを高めに)評価するステップ(2):テストケースの生成
「どこが危ないか」が見えたら、次は「何を確認すべきか」をテストケースに落とし込みます。テストケースの生成も、AIエージェントで生成できるような仕組みを作りました。
| 項目 | 内容 |
|---|---|
| 入力 | リスク分析表 + プルリクエスト差分 |
| 出力 | テストケースドキュメント(Markdown形式) |
| AIエージェントの役割 | リスク分析表とPR差分を突合して、リスクレベルに応じた粒度のテストケースを生成する |
人がやる場合とAIに委ねた場合
この作業を人がやる場合、PRの差分を読み、変更箇所が触る機能領域を特定し、過去その領域でどんなバグが起きたかを記憶から引き出し、テスト観点を書き出していきます。レビュー・テスト計画の中でも特に時間のかかる工程で、しかも「過去のバグ傾向」をすべて覚えているベテランでないと観点が不足しがちです。
AIに委ねるとどうなるか。リスク分析表(過去のバグ傾向)とPR差分の2入力をAIが突合し、リスクが高い領域ほどテストケースを厚く生成する、というロジックを自動化できるので、ベテランの頭の中にある「ここは過去にバグが多かったから、今回も念入りに確認すべき」という判断基準を、AIがテストケースの生成ルールとして実行してくれます。
設計判断:差分とリスクの2入力を必ず突合する
PR差分だけから��テストケースを生成すると、「変更されたコードに対して直接的に確認すべき項目」しか出てきません。一方、過去バグ傾向だけから生成すると、現在のPRと無関係な汎用的なケースが大量に出てしまいます。両者を突合することで、「今回のPRで変更された範囲のうち、過去にバグの発生回数が比較的多い箇所」に重みを置いたテストケースが生成されます。リスクが高いと判定された機能領域に該当する変更ほど、テストケースが追加で生成される、という挙動になります。ワークショップで実演した時は、これら2つだけを入力にしてましたが、例えば、機能の仕様書や設計ドキュメントもAIに読み込ませて、さらに仕様観点も加味して生成する、という拡張もできると思います。どの入力を与えるか、どの入力を優先するか、は設計判断のポイントになります。
設計判断:基本となるテストケースをあらかじめ用意しておく
もう一つの工夫は、各機能の基本となるテストケースをあらかじめ用意しておいて、生成時に参照させることです。
最初はテストケースを用意せず、ゼロから生成させていたのですが、機能ドメインの基本観点(例:カートなら「カートに入れる/数量変更/上限超過」)をAIが思いつかずに抜け落とすことがありました。これは、テスト工程としては大きなリスクになり得る欠落です。
そこで、各機能ドメインごとに「最低限ここは押さえてほしい」という基本観点をMarkdownで用意するようにしました。テストケース生成時は、AIはまず基本となるテストケースを理解した上で、さらにリスク分析表とPR差分を踏まえて追加観点を生成する、という二段構えです。これによって、生成されるテストケースの最低品質ラインが安定しました。基本となるテストケースは「AIへの教科書」であると同時に、「組織の形式知の置き場」でもあります。
▼ テストケース生成のワークフロー
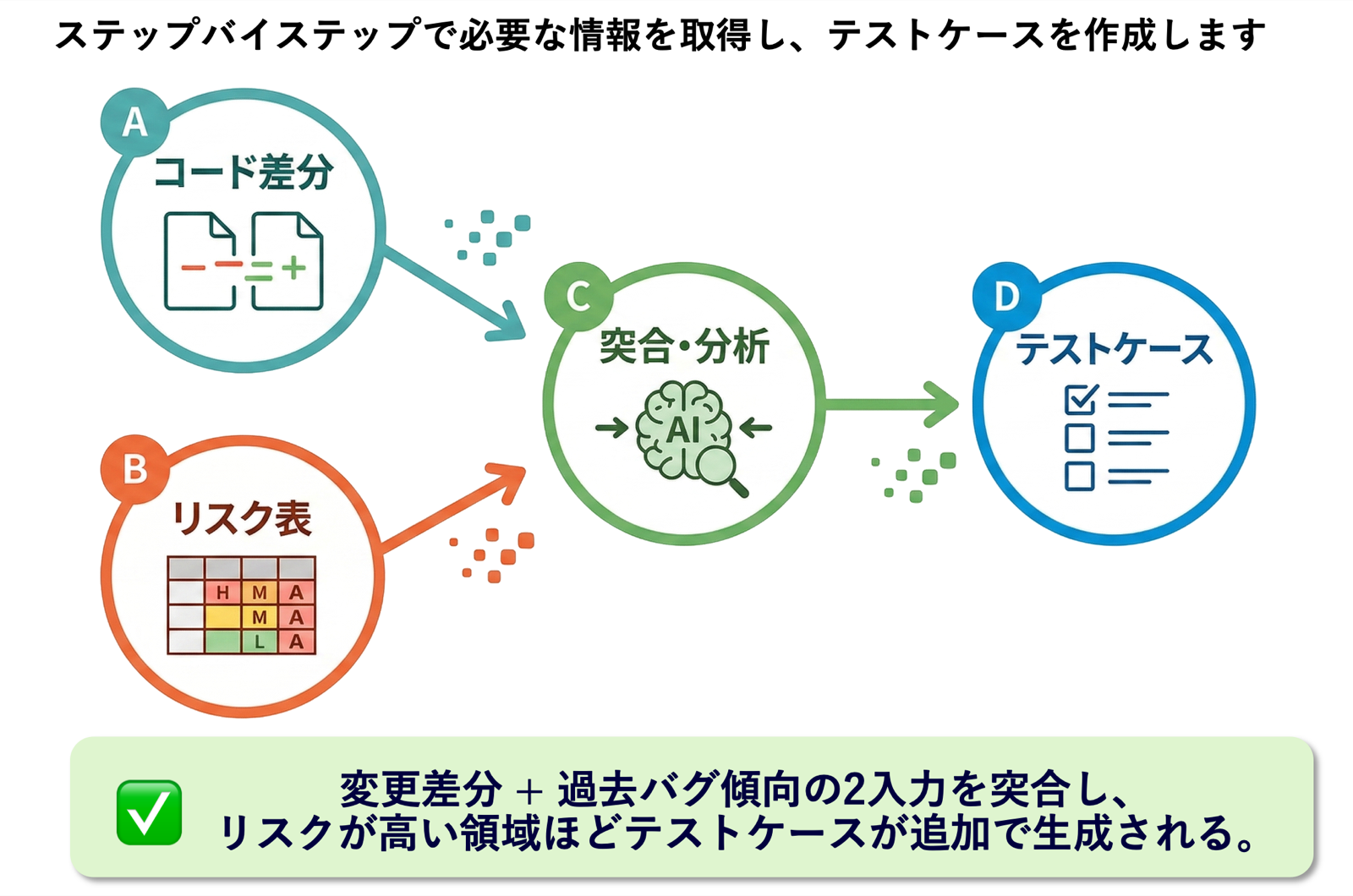
ワークフローの実装方法と動作例
このワークフローもAgent Skillsとして実装し、コマンドで呼び出せるようにしました。実行すると、AIはリスク分析表とPR差分を突合して、リスクレベルに応じた粒度のテストケースを生成してくれます。
▼ 生成されたテストケースのサンプル
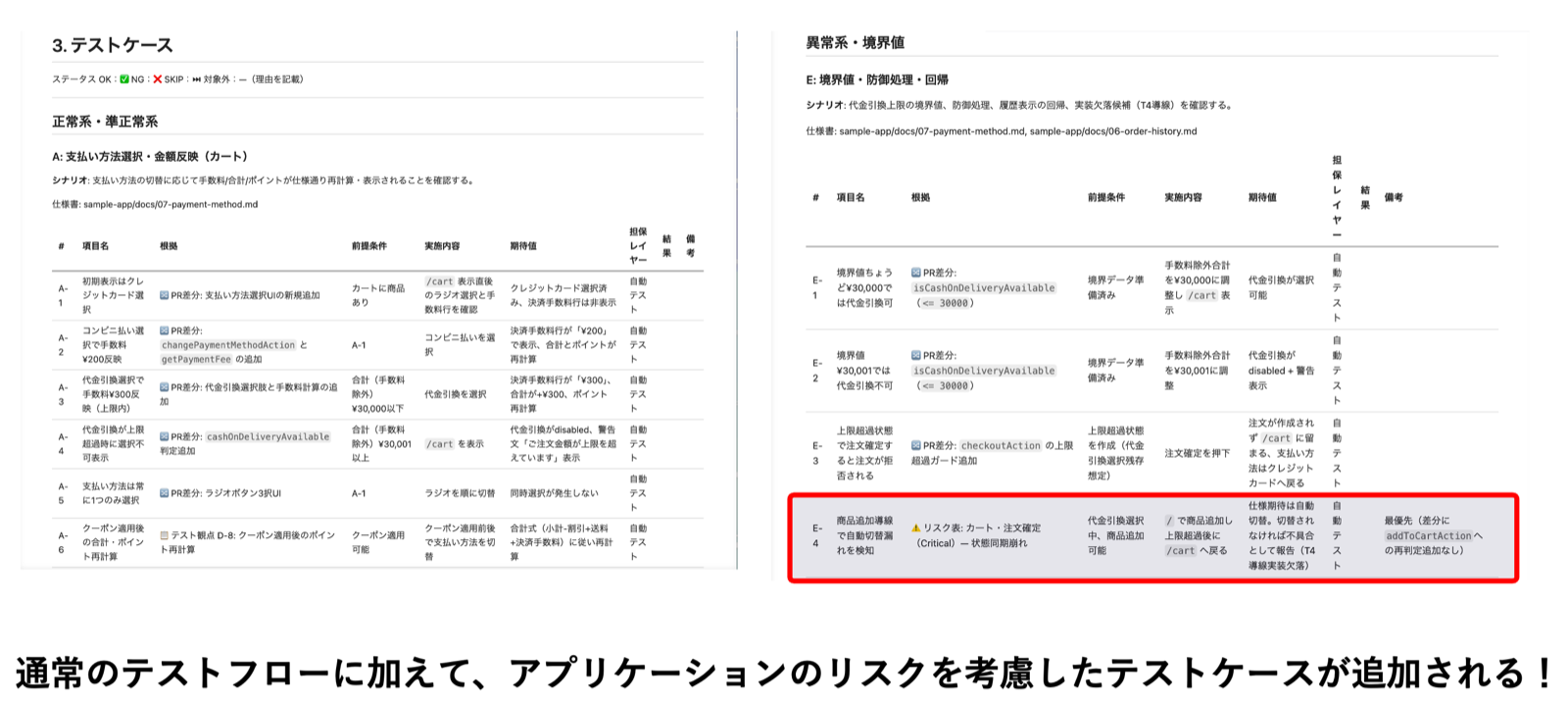
ディレクトリ構成
test-case-generation/
├── SKILL.md
└── references/ # 機能別のテスト観点リスト
├── cart.md # カート関連の観点
├── common.md # 共通UIの観点
├── coupon.md # クーポン関連の観点
├── order.md # 注文関連の観点
├── product-detail.md # 商品詳細の観点
└── product-list.md # 商品一覧の観点Agent Skillsの内容
※本記事では社外公開用に一部内容を調整しています。
---
name: test-case-generation
description: "PR情報とリスク表からテストケースを生成します。「テストケース生成」「test case」で発動。"
---
変更差分とリスク表を元に、リスクに応じた粒度のテストケースを生成してください。
## 入力
| 引数 | 説明 |
| ----------------- | --------------------------------------------------------------------- |
| `--pr {番号}` | 指定したPRの差分を使用 |
| `--branch` | 現在のブランチとmainの差分を使用(デフォルト) |
| `--staged` | ステージ済みの変更を使用 |
| `--commit {hash}` | 特定コミットの変更を使用 |
| リスク表パス | `risk-tables/` 内のリスク表ファイル。省略時は最新のリスク表を自動検出 |
## 実行手順
1. **変更差分の取得**:指定されたオプションに応じて `gh pr diff` / `git diff` などで取得
2. **リスク表の読み取り**:機能領域ごとのリスクレベル(Critical/High/Medium/Low)と過去バグ傾向を取得
3. **テスト観点リストの読み取り**:`references/` 配下の機能別テスト観点ファイルを読み、既存観点ID一覧を把握
4. **変更内容とリスク表の突合**:影響する機能領域を特定し、リスクレベルと過去バグ傾向を確認
5. **操作導線の洗い出し**:変更対象の振る舞いを引き起こす全ての操作導線をコード差分から特定
6. **仕様書の確認**:関連する仕様書があれば、期待動作をテストケースに反映
7. **テストケースの生成**:リスクレベルに応じた粒度で生成(次節)
8. **テストケースファイルの保存**:`test-cases/test-cases-YYYYMMDD-HHMMSS.md`
## テスト深度の基準
| リスクレベル | テスト深度 | テストケースの粒度 |
| --------------- | ---------- | -------------------------------------------------------------------- |
| Critical / High | 網羅的 | 正常系全パターン + 境界値 + 異常系 + 組み合わせ + 過去バグの再発確認 |
| Medium | 標準 | 基本正常系 + 代表的な境界値 + 代表的な異常系 |
| Low | 基本確認 | 基本正常系のみ |
## テストケース生成の観点
正常系 / 境界値 / 異常系 / 組み合わせ / 回帰 / 副作用 / 操作導線
## 自動化可否の判定基準
各テストケースには「自動化可否」を必ず付与する。判定根拠を1行コメントで添えること。
| 自動化可否 | 判定基準 | 後続処理 |
| ---------- | ------------------------------------------------------ | ---------------------------------- |
| 自動 | UTやE2Eなどの自動テストで検証可能なもの | UT/E2Eなどの自動テストで実装・実行 |
| 手動 | モック不可な依存があるもの、UX上の主観判断が必要なもの | このフローの対象外(人が別途実施) |
## 出力ドキュメントの構成
1. 概要 ← 変更情報を表形式で記載(PR / リスク表 / 変更ファイル数 / 影響領域)
2. テスト観点 ← テスト対象・範囲・環境・因子・保証/やらないこと・前提条件
3. テストケース ← 正常系・準正常系 / 異常系・境界値 で分離、各ケースに根拠列を必須
4. テスト対象外 ← 理由付きで明記
## テストケースのグルーピングルール
- **正常系・準正常系** と **異常系・境界値** でセクションを分離する
- 各グループ(A, B, C, ...)には**シナリオ説明**(何を検証するか1文)と**仕様書リンク**を付ける
- グループは機能領域ごとに分ける(1グループ10件前後を目安)
## 根拠列の記載ルール
各テストケースの「根拠」列に、そのケースが存在する理由を以下の3種別で記載する:
| 種別 | フォーマット | 使用場面 |
| ---------- | ---------------------------------------------------------- | ------------------------------ |
| テスト観点 | `テスト観点 {ID}: {観点名}` | references の既存観点に該当 |
| リスク表 | `リスク表: {機能領域}({リスクレベル})— {バグ傾向の要約}` | リスク表の過去バグ傾向から導出 |
| PR差分 | `PR差分: {変更内容の要約}` | 今回のPRで変更された機能の確認 |
## 注意事項
- テストケースはAIによる提案であり、人によるレビュー・追加・削除を推奨します
- セキュリティに関わる変更(認証・認可・入力検証など)は、リスクレベルに関わらず網羅的にテストケースを生成してくださいこのスキルを初めて回したとき、出力されたテストケースの中に、私が事前に思いつかなかった観点が混じっていました。「カートに上限ぎりぎりまで入れた状態でクーポンを適用したら、上限判定が壊れる可能性がある」、そんなケースです。リスク分析表の中に「カート上限関連バグ」が複数件あったことから派生してきた観点でした。自分1人では拾いきれなかったテストの抜け漏れが、過去のバグ傾向から自然に浮かび上がる、暗黙知の形式知化が、こういう形で実現できるのだと実感した瞬間でした。
ステップ(3):AIによる自動テスト
3つ目のステップでは、「どう試すべきか」をAIに実行させる仕組みを作りました。生成されたテストケースをもとに、AIがブラウザを操作してテストを実行し、怪しい挙動があれば探索的に追加の操作も試してくれる、という内容です。
| 項目 | 内容 |
|---|---|
| 入力 | テストケース |
| 出力 | テストの実行結果と検出した不具合のレポート |
| AIエージェントの役割 | テストケースの操作手順を忠実に再現し、リスクが高いところは探索的に確認する |
人がやる場合とAIに委ねた場合
この作業を人がやる場合、生成されたテストケースを1件ずつブラウザで再現し、結果を記録していきます。画面の操作やキャプチャの保存など単純ではあるものの、繰り返しの作業であるため、怪しい挙動があったとしても疲れていると見逃してしまう可能性があります。
AIに委ねるとどうなるか。AIがブラウザを操作してテストケースを忠実に再現し、さらにリスクが高いところは探索的に操作して確認する、ということができます。淡々と作業をこなしてくれるので、怪しい挙動があっても見逃すリスクが減りますし、リスクが高いところはさらに念入りに確認することもできます。
設計判断:アプリケーションの操作はツールに委譲する
AIエージェントが本来集中すべきは「テストケースを忠実に再現すること」と「結果を構造化して残すこと」であり、ブラウザ操作のプリミティブを自前実装する価値は薄いと判断し、テスト自動化ツールを採用しました。これにより、本体は「テストケース文を読み、対応する操作をツールに投げ、結果を集約する」というシンプルな責務に集中できます。ワークショップでは、Microsoft が公開している microsoft/playwright-mcp を使用して、Playwright のブラウザ操作を MCP 経由で実行する構成を紹介しました。この部分は、他のテスト自動化ツール(例:Selenium、Puppeteerなど)に置き換えることも可能ですし、MCPに拘らずPlaywright CLIを直接呼び出す構成も考えられます。また、API / アプリの領域でも自動化ツールは多数あるので、UIテスト以外の領域でも導入することができます。テスト自動化の実装方法は複数考えられますが、いずれにせよテストケースの再現と結果の集約に集中できる設計にすることが重要です。
設計判断:全てのテストケースが成功した場合は、探索的テストに移行する
テストケースを忠実に再現するだけでなく、怪しい挙動がないか探索的に操作して確認することも重要なポイントです。全てのテストケースが成功した場合は、そこで終わりにせず、さらに「リスクの高い領域を中心に、怪しい挙動がないか探索的に操作して確認する」フェーズに移行する設計にしました。テストケースの生成時点では想定していなかった検証観点が、実際の操作中に見つかることもあるため、テストケースの再現と探索的テストの両方をAIに実行させることで、より不具合を見つけやすい設計にしています。
▼ テスト実行のワークフロー
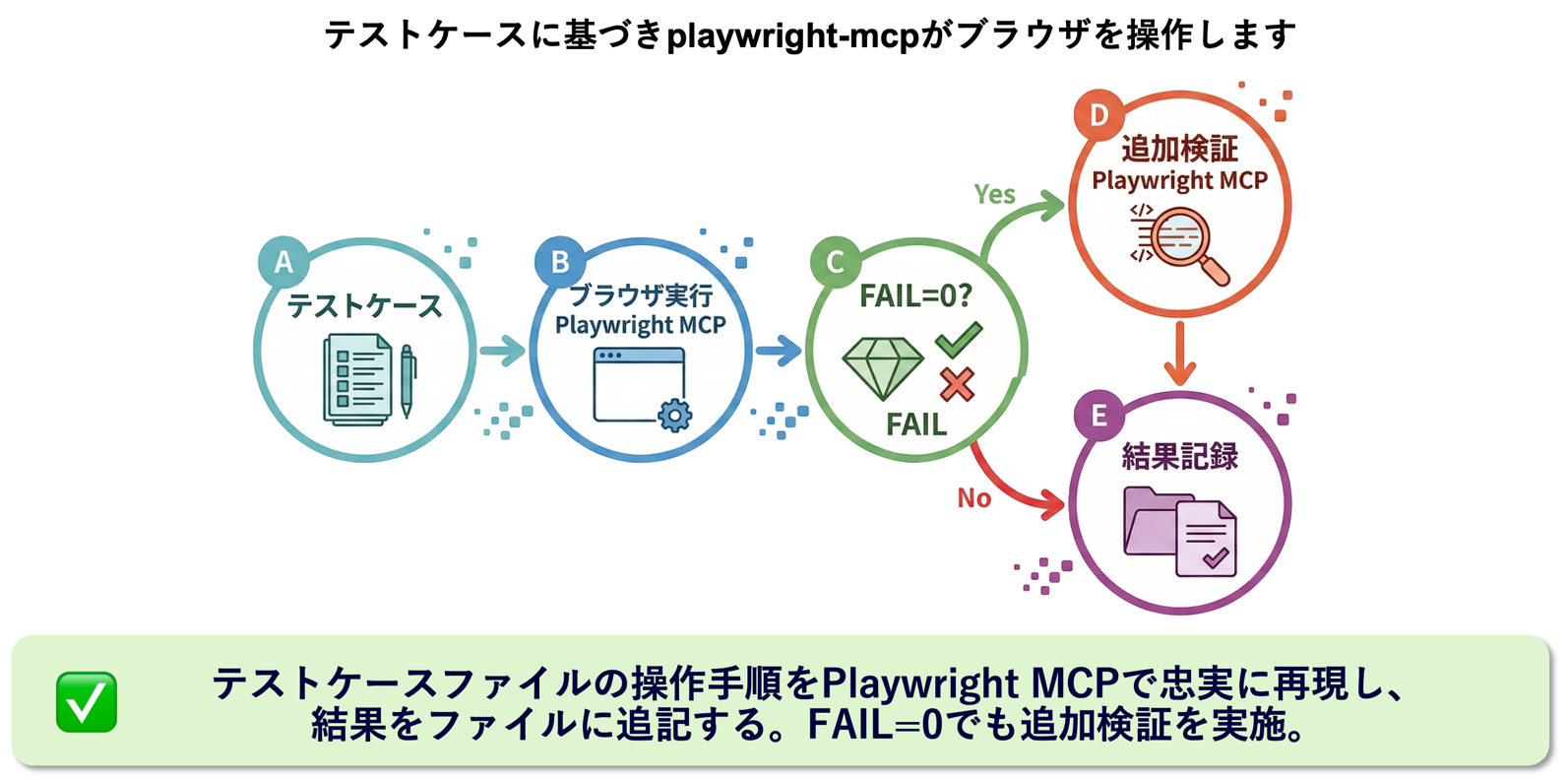
ワークフローの実装方法と動作例
このワークフローもAgent Skillsとして実装し、コマンドで呼び出せるようにしました。実際に実行した場合、AIは以下のように回答し、テストケースのファイルに結果を追記していきます。
対象URL: http://localhost:3000
実行件数: 18
結果: PASS 17 / FAIL 1 / SKIP 0
[FAIL] C-4: 商品追加導線で上限超過時に代金引換が自動解除されない
期待: 上限超過時に「代金引換」決済オプションがUIから自動解除される
実際: 上限超過後も「代金引換」がチェック可能なまま残っている
詳細: artifacts/runs/20260415-1832/C-4-failure.png▼ AIがブラウザを操作してテストを実行している様子とその結果
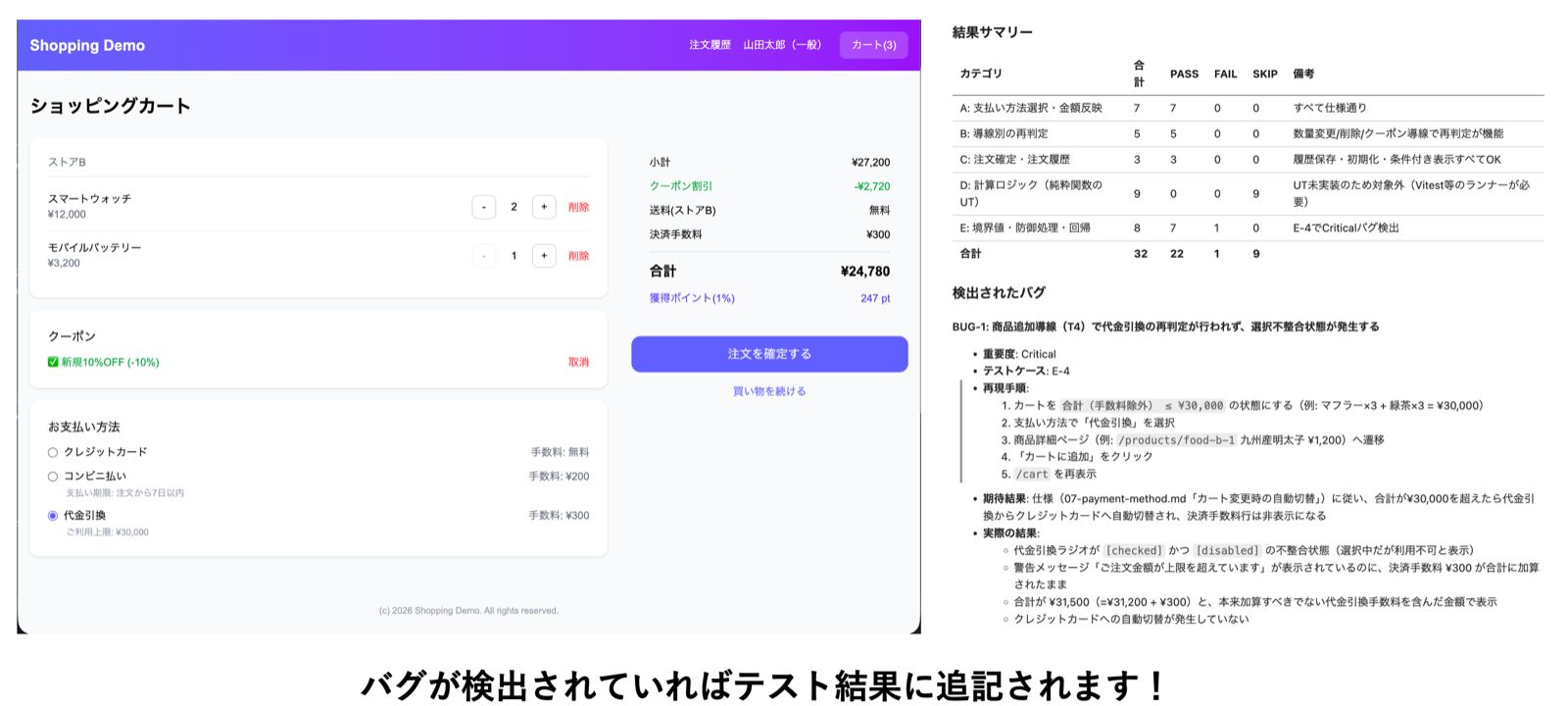
ディレクトリ構成
test-case-execution/
└── SKILL.md # スキル本体(references / templates は持たず、SKILL.md単体で完結)Agent Skillsの内容
※本記事では社外公開用に一部内容を調整しています。
---
name: test-case-execution
description: "テストケースファイルに基づきPlaywright MCPでブラウザテストを実行します。「テスト実行」「test run」で発動。"
allowed-tools: mcp__playwright__*
---
テストケースファイルに基づいて、Playwright MCPでブラウザテストを実行してください。
## 実行手順
1. **テストケースファイルの読み取り**:`test-cases/` 配下の最新ファイルから、テストケース一覧・各機能領域のリスクレベル・操作導線の対応表を把握
2. **対象ケースの絞り込み**:**「自動化可否: 自動」のケースのみを対象**にする。「手動」と判定されたケースはこのスキルの対象外(人が別途実施)
3. **テスト対象の起動確認**:対象URL(デフォルト `http://localhost:3000`)にアクセスし、アプリが起動していることを確認
4. **テストの実行**:操作手順に従って Playwright MCP でブラウザ操作を実行
- 操作導線を忠実に再現する(テストケースの操作手順を改変しない)
- 前提条件を正確にセットアップしてから実行
- FAILしたケースは必ずスクリーンショットを取得
5. **FAIL=0時の追加検証**(必須):以下を実施
- 操作導線の網羅性レビュー(特に画面遷移をまたぐ操作)
- SKIPケースの再検討
- Critical/Highリスク領域でテスト観点が不足していないか自己レビュー
- 必要があれば追加テストを実施し「追加検証結果」セクションに記録
6. **結果の記録**:テストケースファイル末尾に実行結果を追記
## 判定基準
| 判定 | 条件 |
| ---- | ------------------------------------------------------ |
| PASS | 期待結果と実際の結果が一致 |
| FAIL | 期待結果と実際の結果が不一致 |
| SKIP | 前提条件の構築が困難、またはテスト環境の制約で実行不可 |
## 結果記録のフォーマット
テストケースファイルの末尾に以下を追記する:
## テスト実行結果
- 実行日時: {datetime}
- 実行方法: Playwright MCP によるブラウザ操作
- 対象URL: {url}
### 結果サマリー
| カテゴリ | 合計 | PASS | FAIL | SKIP | 備考 |
| -------- | ---- | ---- | ---- | ---- | ---- |
| ... | N | N | N | N | ... |
### 検出されたバグ
#### BUG-{N}: {バグタイトル}
- 重要度: Critical / High / Medium / Low
- テストケース: {No}
- 再現手順: ...
- 期待結果 / 実際の結果 / 原因箇所 / スクリーンショット
### 追加検証結果
(FAIL=0時の追加検証を実施した場合のみ記載)
## 注意事項
- FAIL=0の場合でも、追加検証を省略しない。特に高リスク領域では必ず追加検証を実施する
- リトライによってFAILをPASSに見せかけない
- 「自動化可否: 手動」のケースは別途人が実施し、結果サマリーには含めない社内での検証結果
ここまで紹介した3つの方法を、社内で運用されているアプリケーションで検証してみたので、その結果を共有します。
検証の前提条件
| 項目 | 内容 |
|---|---|
| 対象タスク | パフォーマンス改善のPR(数百行規模) |
| 検証範囲 | 一部機能に対してローカル環境のみで検証 |
| 使用モデル | Claude Opus 4.7 |
| 実行ツール | Claude Code/Playwright MCP |
| 実行者 | 著者本人(Agent Skillsの設計者・運用習熟者) |
| 検証ケース数 | 1ケース(N=1) |
数値サマリー
実際に試したところ、以下の結果が得られました。
| 指標 | 値 | 算出根拠 |
|---|---|---|
| 自動生成されたテストケース数 | 41件 | スキルの出力ファイル |
| 完了したテストケース数 | 41件中 29件(約70%) | UTと自動テストの合計(29 / 41 ≈ 0.707) |
| リスクを考慮した追加ケース数 | 41件中 14件(約34%) | 「(リスク追加)」ラベル付きケース(14 / 41 ≈ 0.341) |
| PRレビューの所要時間 | 約30分(体感としては 手作業より大きく短縮された) | この検証ケースに限った体感比較 |
※本結果は本記事のメソドロジーを実証するために実施した1回限りの検証であり、特定の検証環境・条件下での一例です。すべてのプロジェクトで同様の効果を保証するものではありません。
リスク�表の生成からテストケース生成、自動テスト実行までAIが一気通貫で走り切ってくれるため、人は「AIの出力を確認して最終判断する」フェーズにすぐ入れるのが大きな違いでした。
良かった点/改善が必要な点
数値だけだと伝わりにくいので、定性的な所感も書き残しておきます。
良かった点
- 異常系の繰り返し検証を、AIがムラなく網羅してくれた。人だと集中力が切れて確認が粗くなりがちな箇所を、AIは淡々とこなしてくれます。
- リスク分析の過程で、実装漏れのユニットテストが浮上した。AIがその場でコード修正案まで提案してくれて、過去バグの再発予防につながる体制づくりに役立った事例がありました。これは想定していなかった有益な副次効果でした。
改善が必要な点
- 「自動テスト可能」と判定したケースが、モックやデータの都合で実際には動かないケースが出ました。リスク表とテストケースの段階では整理されているように見えても、テスト環境が用意できていないと実行段階で詰まります。テスト環境整備の課題は、テスト自動化ツールの導入と同じ課題が残っているという気づきがありました。
ここで得た学びは、「任せるべき領域と、人が向き合うべき領域の境界が、このフローで明確になった」という1点です。観点生成と繰り返し検証はAIに任せていい。一方で、テスト環境を整えるところは依然として人の仕事であり、ここを軽く見ると後工程で詰まりやすいと感じます��。
これから取り組むチームへのおすすめステップ
3つの手法を一気に導入する必要はありません。スモールスタートで効果を体感し、自分のチームに合わせてカスタマイズしていくのがおすすめです。
おすすめの3ステップ
| ステップ | 想定所要時間 | 最低限揃えるもの |
|---|---|---|
| (1)リスク分析表の生成を試す | 5分〜30分 | 過去3カ月分のバグレポート |
| (2)1つのPR・1機能領域でテストケース生成 | 30分〜1時間 | 上記リスク表 + 対象PR |
| (3)1ケースだけAIに自動テスト実行させる | 30分 | テスト環境(ローカルでOK) + テスト自動化ツール(Playwrightなど) |
(1)リスク分析表の生成:過去3カ月分のバグ報告書(JIRAやIssueなど)を入力するだけで、データ整備状況にもよりますが、数分〜30分程度で試作できます。出力されたリスク表を眺めるだけでも、自分のチームのバグ傾向の偏りが浮かび上がってきて、それ自体が学びになります。
(2)テストケース生成:1つのPR・1つの機能領域から始めるのがおすすめです。AIが生成したケースと、既存のテストケースとの差分を眺めると、テストの抜け漏れが見えてきやすくなります。暗黙知の形式知化を実感できる第1歩になります。
(3)AIによる自動テスト実行:最初は欲張らず、1ケースだけAIに自動実行させて感覚をつかんでください。シンプルな回帰テストや、何度も繰り返す必要がある操作が題材として向いています。「ここを毎回手で確認するのは手間だった」という日々の小さな課題感から始めるのがコツです。
あなたのチームに当てはまるか:チェックリスト
最後に、本アプローチがあなたのチームで効きやすいかどうかを判断するチェックリストを置いておきます。
効きやすい条件
- 過去3カ月分以上のバグ履歴がチケット化されている(JIRA/GitHub Issue/その他)
- レビュー・テスト工程が特定のメンバーに集中している
- 異常系・回帰テストの繰り返しに時間を要している
- テスト自動化の環境が(最低限)整っている
- AIエージェントを使える人が1人以上チームにいる
慎重になるべき条件
- バグ履歴がほとんどチケット化されていない(インプットがない)
- モックや外部依存が複雑で、テスト自動化の環境がほぼ整っていない
- AIの出力を最終承認できる人がいない(人による最終判断レイヤーが薄い)
- リスク評価より「全件テスト」の文化が強く、優先順位付けが受け入れられにくい
このチェックリストで「効きやすい条件」が多く当てはまるチームから、まず(1)のリスク分析表生成だけでも試していただくのが良さそうです。
おわりに:個人の暗黙知を組織の形式知に変える
3つのアプローチを設計しながら、私の中で1つの考えが形になりました。
AIエージェントは、個人の暗黙知を組織の形式知に変えることができる
ベテランの頭の中にあった「ここは危ない」「これくらいは押さえないと」という直感は、これまで本人にしかアクセスできない資産でした。それを、リスク表やテストケースという誰もが読める形に変換してくれるのが、AIエージェントを使うことの大きな価値だと感じています。
テスト以外にも、設計レビュー、障害対応、リリース判断など、個人の暗黙知のまま放置されている領域はまだあります。アプローチの組み合わせ次第で、こうした領域も少しずつ形式知化して、組織全体で共有していけるように今後も取り組んでいきたいと思います。


