はじめに
こんにちは。LINEヤフーでモーション生成やアニメーション生成の研究開発に取り組んでいる郁です。
このたび、我々のチームから次の 2 本の論文が CVPR 2026 に採択されました。
- Causal Motion Diffusion Models for Autoregressive Motion Generation
- ProjFlow: Projection Sampling with Flow Matching for Zero-Shot Exact Spatial Motion Control
いずれも、人の動きを自動生成するモーション生成をテーマにした研究です。モーション生成は、キャラクターアニメーション、アバター、動画生成、クリエイティブツールなど、さまざまな応用の基盤になります。
ただ、実用化を考えると、単に「自然に動く」だけでは足りません。複数の動きを滑らかにつなぎながら長いモーションを低遅延で生成できること、さらにユーザーが意図した軌道や姿勢を正確に反映できることが重要です。
本記事では、この 2 本を「長いモーションをどう滑らかに生成するか」と「意図した動きをどう正確に制御するか」という 2 つの観点から紹介します。まずモーション生成という分野の位置づけを整理したうえで、両者の違いと、それぞれがアニメーション生成にもたらす価値を見ていきます。
モーション生成の概要
モーション生成は、テキストや一部の条件を手がかりに、人の全身の動きを時系列データとして生成する技術です。
入力と出力をシンプルに言うと、次のようになります。
- 入力:テキスト、数フレームのキーポーズ、手や足の軌道、2D の観測結果など、動きに関する条件やヒント
- 出力:条件を満たす全身モーションの時系列データ。各フレームの関節位置や回転として表され、最終的にはキャラクターや人物のアニメーションとして利用できます
例えば、次のよう�なタスクがあります。
- 「走る」「踊る」といったテキストから全身の動きを作る
- 手や足の軌道だけを指定して、残りの全身動作は自然に補う
- 数フレームのキーポーズから、その間を滑らかにつなぐ
要するに、人がどう動くかを、自然さを保ったまま自動で描く技術です。今回の 2 本は、その中でも実用上とくに重要な「低遅延」と「制御性」を前に進める研究だといえます。
2 本の論文の位置づけ
| 論文 | 取り組む課題 | コアアイデア | 期待される価値 |
|---|---|---|---|
| CMDM | 複数の動きを滑らかにつなぎながら、長いモーションを因果的に低遅延で生成したい | 未来フレームを見ない生成と、過去の動きを引き継ぎながら次の動きを自然につなぐ frame-wise sampling を組み合わせる | ストリーミング生成、長尺生成、リアルタイム性 |
| ProjFlow | 指定した軌道や姿勢を正確に守りながら自然に動かしたい | モーション制御を線形逆問題として定式化し、各ステップで厳密に制約へ投影する | 正確な制御、ゼロショット、編集しやすさ |
共通しているのは、どちらもモーション生成を「動きが出せる」段階から「実際に使えるアニメーション生成」へ近づけようとしている点です。一方で、焦点は明確に異なります。CMDM は時間方向の生成方法を改善し、ProjFlow はユーザーの意図をどれだけ正確に反映できるかに取り組んでいます。
論文 1:CMDM で複数の動きを滑らかにつなぎな��がら長いモーションを生成する
1 本目の論文 Causal Motion Diffusion Models for Autoregressive Motion Generation では、複数の動きを滑らかにつなぎながら、長いモーションを低遅延で生成するための枠組みを提案しました。
既存の高品質な motion diffusion model の多くは、時系列全体を見渡して生成するため、未来のフレームまで参照してしまいます。品質面では有利ですが、過去の情報だけをもとに次の動きを出したいストリーミング生成には向きません。一方、完全な自己回帰モデルは順次生成できますが、系列が長くなるほど誤差が蓄積しやすいという課題があります。
CMDM は、この両者の長所を取り込もうとする手法です。ポイントは、過去の動きを引き継ぎながら次の動きを自然につなぎ、継ぎ目の違和感を抑えたまま長いモーションを生成し続けられることにあります。
論文では、この設計を Motion-Language-Aligned Causal VAE (MAC-VAE)、Causal Diffusion Transformer (Causal-DiT)、Frame-Wise Sampling Schedule (FSS) の 3 つの要素で構成しています。
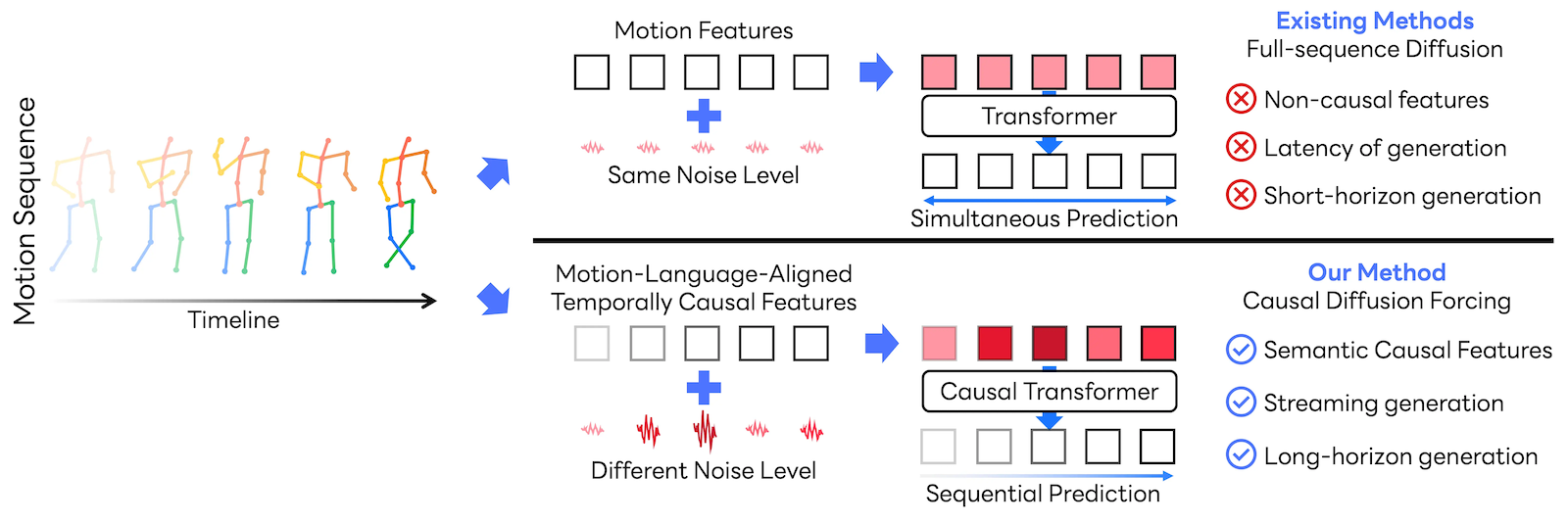 従来法が系列全体をまとめて生成するのに対し、CMDM は過去の情報だけを使って順次生成します。ストリーミング生成の考え方を示した図です。
従来法が系列全体をまとめて生成するのに対し、CMDM は過去の情報だけを使って順次生成します。ストリーミング生成の考え方を示した図です。
全体像に続いて、次のパイプライン図を見ると CMDM の内部構成も分かりやすくなります。MAC-VAE がモーションを因果的な latent 表現に圧縮し、Causal-DiT がテキスト条件のもとで各フレームを順に denoise します。さらに FSS が過去フレームと未来フレー�ムでノイズ量を調整しながら、長いモーションを滑らかにつないでいきます。
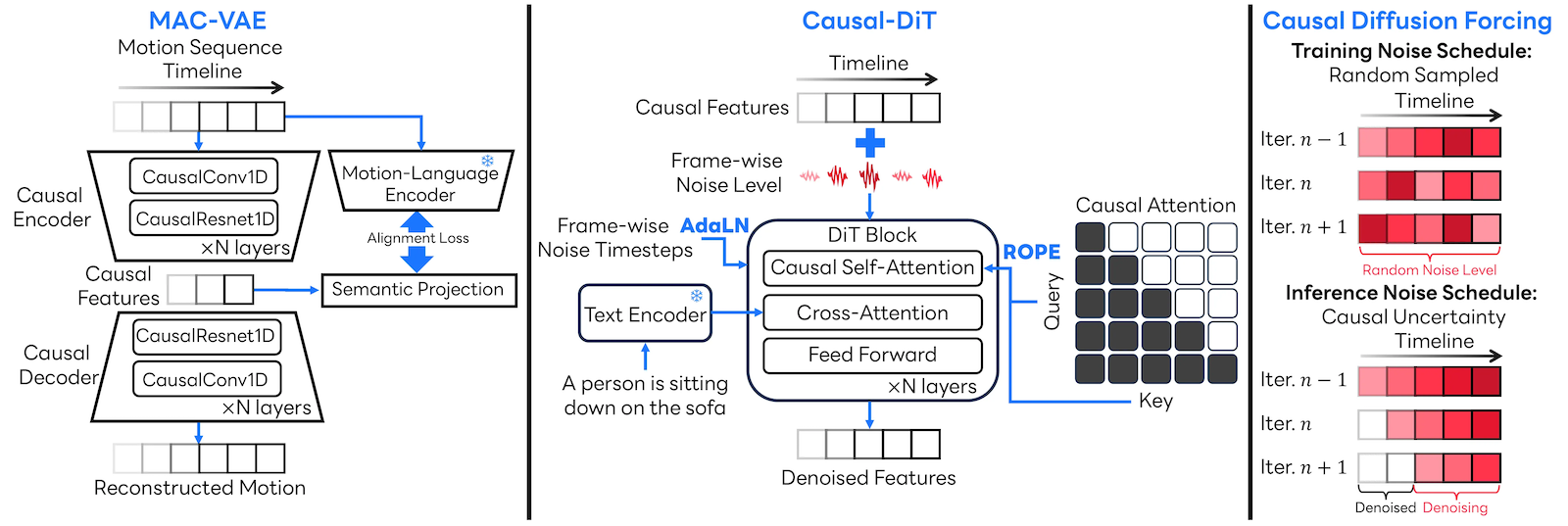 CMDM のパイプライン。MAC-VAE、Causal-DiT、FSS の 3 要素が連携し、過去の動きを引き継ぎながら次の動きを順に生成していく流れを示した図です。赤みが強いほどノイズレベルが高く、未来側ほど不確実性が大きいことを表しています。
CMDM のパイプライン。MAC-VAE、Causal-DiT、FSS の 3 要素が連携し、過去の動きを引き継ぎながら次の動きを順に生成していく流れを示した図です。赤みが強いほどノイズレベルが高く、未来側ほど不確実性が大きいことを表しています。
この流れの中で特に重要なのがノイズの扱いです。従来の full-sequence diffusion では、系列全体に同じ diffusion step のノイズを載せてまとめて denoise することが多いのに対し、CMDM では各フレームに独立したノイズ段階を割り当てます。つまり、全フレームを同じノイズ条件で一括処理するのではなく、各フレームがそれぞれ異なるノイズ条件で学習され、推論時もその因果構造を保ったまま順に生成されます。
CMDM のポイント
- モーションの意味を保った中間表現 (latent space) へ圧縮しつつ、未来を見ない因果的な表現を学習します
- diffusion transformer 側でも未来を参照しない causal attention を使い、各フレームが過去だけに依存するように設計しています
- 従来の diffusion のように系列全体へ同じノイズレベルを一様にかけるのではなく、各フレームに別々のノイズ段階を与えて学習・推論することで、過去はより確定し、未来はより不確実という因果構造をそのまま扱えます
- Frame-Wise Sampling Schedule により、過去フレームのノイズを途中まで除いた状態を次フレーム生成に使い、動き同士を滑らかにつなぎながら低遅延化と安定化を両立しています
つまり、CMDMは、「すべてのフレームをまとめて同一のノイズ条件で生成する」のではなく、すでに確定した過去の動きを活用しながら、フレームごとに異なる不確実性を持たせ、複数の動きを継ぎ目なく順につないで長いモーションを生成する設計です。
この設計により、長いモーションでも時間的一貫性を保ちやすく、複数の動きを滑らかにつないで生成できます。また、ストリーミング生成に対応可能な応答速度を備えており、論文ではモーション生成のベンチマークにおいて高い意味整合性と滑らかさが示されています。さらに、frame-wise sampling schedule によって高速な生成も実現しています。
リアルタイムに近い応答が求められるアニメーション生成においては、「長いモーションを継ぎ目なく低遅延で出力し続けられる」ことが非常に重要です。
CMDM の生成サンプル
以下は CMDM の生成サンプルです。複数の動きを順につなぎながら、時間的なつながりを保って長いモーションを生成している様子を確認できます。
論文 2:ProjFlow で意図した動きを正確に制御する
2 本目の論文 ProjFlow: Projection Sampling with Flow Matching for Zero-Shot Exact Spatial Motion Control では、生成されたモーションを「自然さを保ったまま、狙いどおりに動かす」ための制御手法を提案しました。
モーション生成を実際の制作で使おうとすると、「この手はこの軌道を通ってほしい」「このフレームではこの位置に来てほしい」といった制約を入れたくなります。しかし既存手法の多くは、制約を緩やかに満たす設計のため、少しずれが残ったり、追加学習や推論時の最適化が必要になったりします。
ProjFlow は、多くのモーション制御タスクを線形逆問題として統一的に扱える点に着目し、各ステップで生成結果を制約集合へ投影するサンプラーを提案しました。
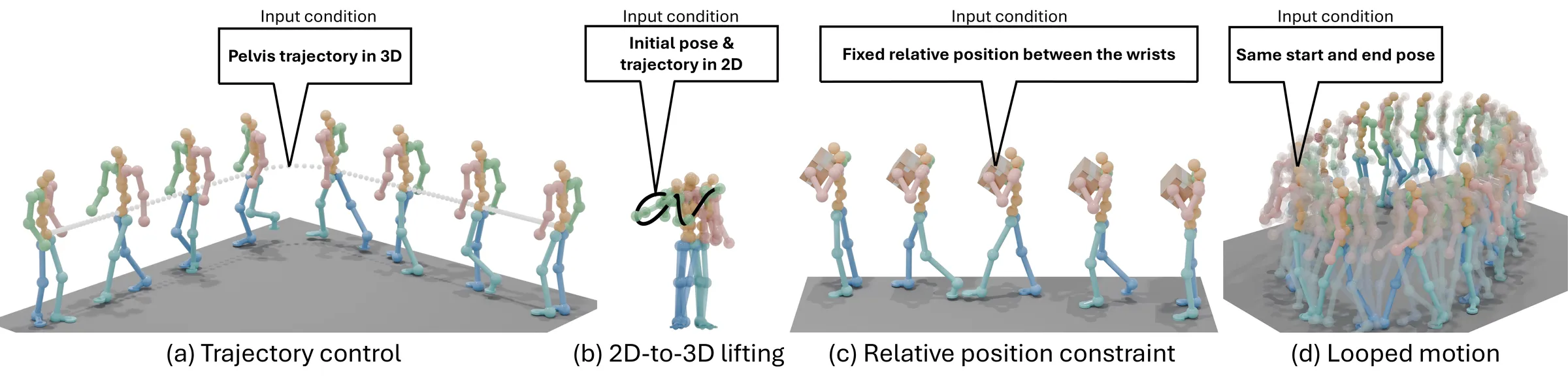 ProjFlow は、軌道追従、2D-to-3D、相対位置の固定、ループ生成など、さまざまな制御を一つの見方で扱います。ユーザーが指定した条件を守りながら、自然な全身モーションを保つことを目指した図です。
ProjFlow は、軌道追従、2D-to-3D、相対位置の固定、ループ生成など、さまざまな制御を一つの見方で扱います。ユーザーが指定した条件を守りながら、自然な全身モーションを保つことを目指した図です。
次の手法図を見ると、ProjFlow が各サンプリングステップで何をしているかも分かります。まず現在の状態から clean endpoint を予測し、そのあと線形制約を満たすように projection をかけ、最後に補正後の endpoint から次の状態を再構成します。このとき補正量を kinematics-aware metric で測ることで、特定の関節だけを無理に合わせるのではなく、骨格全体として自然な修正になるように設計されています。
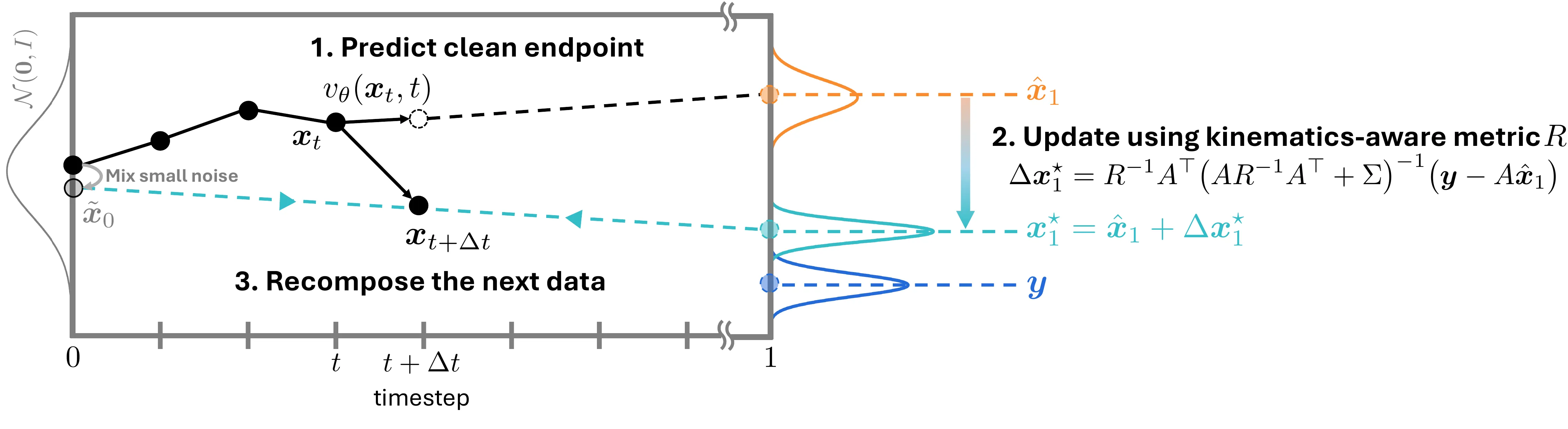 ProjFlow �の projection sampling step。各タイムステップで clean endpoint を予測し、線形観測制約へ投影したうえで、補正後の endpoint から次の状態を再構成します。観測ノイズの共分散は制約への引き寄せの強さを制御し、kinematics-aware metric は修正が骨格構造に沿って広がるように働きます。
ProjFlow �の projection sampling step。各タイムステップで clean endpoint を予測し、線形観測制約へ投影したうえで、補正後の endpoint から次の状態を再構成します。観測ノイズの共分散は制約への引き寄せの強さを制御し、kinematics-aware metric は修正が骨格構造に沿って広がるように働きます。
ProjFlow のポイント
- ユーザーが与える軌道や姿勢条件を、線形制約として統一的に表現します
- 各ステップで予測した「完成形に近い motion」を制約集合へ投影し、条件を厳密に満たす方向へ補正します
- 補正量は kinematics-aware metric で測ることで、関節ごとの局所的な破綻ではなく、骨格全体として自然な修正になるようにしています
- 追加学習なしの zero-shot で使え、推論時に内側の最適化ループを回さなくてもよい設計です
つまり ProjFlow は、「手先だけを無理やり合わせる」のではなく、骨格全体のつながりを考えながら、指定した動きにぴったり合うよう全身を自然に調整する手法です。
論文では、trajectory control や motion inpainting、2D-to-3D reconstruction といったタスクで、制約を厳密に満たしながら自然なモーションを生成できることを示しました。アニメーションの編集や制作支援では、生成結果が少しでも制約からずれると手修正が増えてしまうため、これは非常に重要な性質です。
ProjFlow の制御サンプル
以下は ProjFlow の制御サンプルです。指定した空間条件を守りながら、自然な全身モーションを維持している様子を確認できます。
おわりに
CVPR 2026 に採択された 2 本の論文を、モーション生成という共通テーマのもとで紹介しました。
LINEヤフーでは、画像生成に加え、キャラクターや人物の動きを扱うアニメーション生成技術にも取り組んでいます。その観点から見ると、今回の 2 本は異なるアプローチで基盤技術を前進させる研究です。
1 本目の CMDM は、複数の動きを滑らかにつなぎながら長時間のモーションを低遅延で生成するという、ストリーミング生成の課題に取り組んだ研究です。2 本目の ProjFlow は、自然さを保ちながら意図した条件を厳密に満たすという、モーション制御の課題に取り組んだ研究です。
2 本をあわせて見ると、実用的なモーション生成には「自然に動く」ことに加え、長時間の動きを低遅延で継続的に生成できること、そして意図どおりに正確に制御できることの両方が重要であると分かります。どれほど自然なモーションでも応答が遅ければ対話的な生成には不向きですし、逆に制御しやすくても全身の動きが不自然であればアニメーションとして成立しません。生成品質・低遅延・制御性の 3 つを同時に高めることが、実運用に近いモーション生成において重要です。
今回の成果は、LINEヤフーのアニメーション生成技術を、よりインタラクティブで編集しやすく、実運用に耐えうるものへと発展させるための重要な一歩だと考えています。今後もLINEヤフーでは、生成品質だけでなく、速度や制御性も含めて��、アニメーション生成技術の研究開発を進めていきます。


