こんにちは。LINEヤフーでVision&Language基盤モデル及び、AIモデルAPIの開発を担当している向山です。先日2025年7月29日から8月1日まで京都にて国内最大級の画像分野の学会、第28回 画像の認識・理解シンポジウム MIRU2025が開催されました。
LINEヤフーは、昨年に引き続きスポンサーとして協賛し、企業ブースの運営、研究発表などを行いました。
本記事では会場の様子やLINEヤフーの研究発表内容を紹介します。
MIRUとは?
MIRUは、国内における画像処理分野で広く知られる学会のひとつであり、コンピュータビジョンや人工知能(AI)の視覚機能など、情報学における画像関連技術の研究を対象としています。開催地は毎年異なり、日本各地の都市で開催されるのが特徴です。今年は京都府にある国立京都国際会館にて開催されました。
初日のチュートリアルセッションでは、ロボット基盤モデル、AIによる手話認識、さらには1人称視点映像の解析といった、先進的かつ多様なトピックが取り上げられました。続く招待講演や特別講演では、大規模言語モデル(LLM)や3Dモデルといった、幅広い領域の最新研究に触れることができ、参加者にとって大変有意義な機会となりました。
企業展示ブースでは、LINEヤフーも出展を行い、多くの学生や企業関係者で賑わいました。各スポンサー企業は、自社の研究活動や製品の紹介を積極的に行っており、産学連携の場としても非常に活発な様子が見られました。また、同フロアで開催されたポスターセッションでは、発表者との距離が近く、参加者が自由に質問できる雰囲気の中で、実りあるディスカッションが行われていました。研究に対する理解を深め、知見を広げる貴重な交流��の場となっていました。

会場当日の様子
MIRU当日、メインホールの1階席は聴講者で埋まり、熱気に包まれていました。各登壇者の発表後には、会場からの口頭質問に加え、Slack経由のオンライン質問にも対応しながら、活発なディスカッションが展開されました。オーラルセッションでは発表数の都合で質疑応答が十分に取れない場面もありましたが、その後のポスターセッションで議論をさらに深めることができました。
ポスターセッションは広々とした大広間に発表者が一堂に会し、参加者は自由なタイミングで各ポスターを巡って発表を聴講できました。発表後には論文内容の疑問点を直接尋ねたり、新たな提案を気軽に共有したりと、双方向のコミュニケーションが弾みました。ポスター会場は移動が困難になるほどの盛況ぶりで、コンピュータビジョン分野の近年の勢いを肌で感じられる貴重な機会となりました。
LINEヤフーの企業ブース
ポスターセッションに加えて、LINEヤフーの紹介を行う企業ブースを設置しました。企業ブースでは、LINEヤフーならではの取り組みを、マルチモーダルな動画検索や、しました。当日は大盛況で社内のヘルプスタッフが足りなくなる程の盛り上がりを見せ、社外の多くの方にLINEヤフーの独自の製品を知っていただく有意義な時間を提供できました。
マルチモーダル動画検索
テキストと�画像を組み合わせて検索できるこのマルチモーダル動画検索システムでは、ベクトル計算とインデックス検索を組み合わせたハイブリッド方式を採用しています。任意の画像を入力して、類似の動画が検索されるデモを展示しました。
アニメーションスタンプ作成システム
静止画のスタンプとプロンプトを用意することで、短い動くアニメーションスタンプが生成されるシステムのデモを実施しました。LINEヤフーならではの取り組みを発表でき、注目を浴びていました。
商品画像生成
商品画像生成の展示では、商品の画像とプロンプトから物体を変更することなく背景部分だけを置き換えるデモを実施しました。他にも雰囲気変換のデモでは、商品画像とスタイル画像から、背景を含めた画像全体の雰囲気を生成AIで変換する様子を展示しました。
LINEヤフーの研究発表
スポンサーブースの他に、招待講演なども含め 13件の研究発表をしました。発表では、質問者と熱いディスカッションを交わし、新たな気付きの発見や知見の共有ができました。
具体的な研究のタイトルと概要は以下に紹介します。
歩ける地図:局所座標による高次元データの動的可視化
従来の2次元埋め込みでは失われがちな局所構造に着目し、各データ点の近傍のみを PCAにより2次元投影する「歩ける地図」を提案しました。点ごとに独立した座標系を用いることで詳細な近接関係を保持し、インタラクティブな操作によって全体像を把握でき�る点が特徴です。
動画キャプション生成におけるハルシネーション区間検出
動画キャプションに混入する誤情報(ハルシネーション)を単語・フレーズレベルで特定する新タスク「ハルシネーション区間検出」を定義し、1,167件の注釈付きデータセットHLVCを構築しました。VideoLLMを用いたベースライン評価により、区間単位での誤り分析が可能となりました。

拡散モデルのノイズ最適化による未学習ジェスチャーの挿入
テキスト駆動型拡散モデルに対し、ノイズ最適化を施すことで学習データに存在しないジェスチャーを後付け生成する手法を開発しました。キーフレーム指定が不要となり、多様なモーション表現の拡張が期待されます。
多角的な名寄せに基づく大規模Eコマースデータセットの構築
テキスト・画像特徴量、JANコード、CLIP Score などを段階的に組み合わせた 8段階パイプラインを設計し、店舗やプラットフォームごとに異なる商品タイトルや画像などの不均一な情報を、一意の製品として高精度に統合したデータセットを構築しました。このデータセットを学習に用いることで、eコマース類似画像検索モデルにおいて最大 11.8% の性能向上を確認しました。

プライバシー保護のためのVision Transformer モデルの暗号化法
既存手法LIEの脆弱性を克服するため、直行行列を鍵としViTの入出力および構造を暗号化するLVEを提案しました。平文重みが公開されている状況でも鍵推定を困難にしつつ、高速推論と高精度を維持します。
視聴覚認識のためのトリモーダル学習と自動データ生成の提案
音声・映像・テキストの三つ組を自動生成し、Language-Guided CAV-MAEで統合的に学習する手法を開発しました。手動アノテーションを不要としつつ、検索および分類タスクで従来法を大幅に上回る性能を示しました。
二次元拡散モデルを用いた二次元人体姿勢の三次元化
2D拡散モデルで複数の擬似視点を生成し、三次元アノテーションに依存しない3D姿勢推定を実現しました。多様な動作に対して高い推定精度と計算効率を兼ね備えることを確認しております。
拡散モデルのノイズ最適化を用いた多人数インタラクション動作生成
ペア用拡散モデルを再帰的に適用し、中心キャラクターを軸に多人数インタラクションを生成する手法を提案しました。位置・向きに対する物理ペナルティで衝突等を抑制し、追加学習なしで自然かつ一貫した動作を得ました。
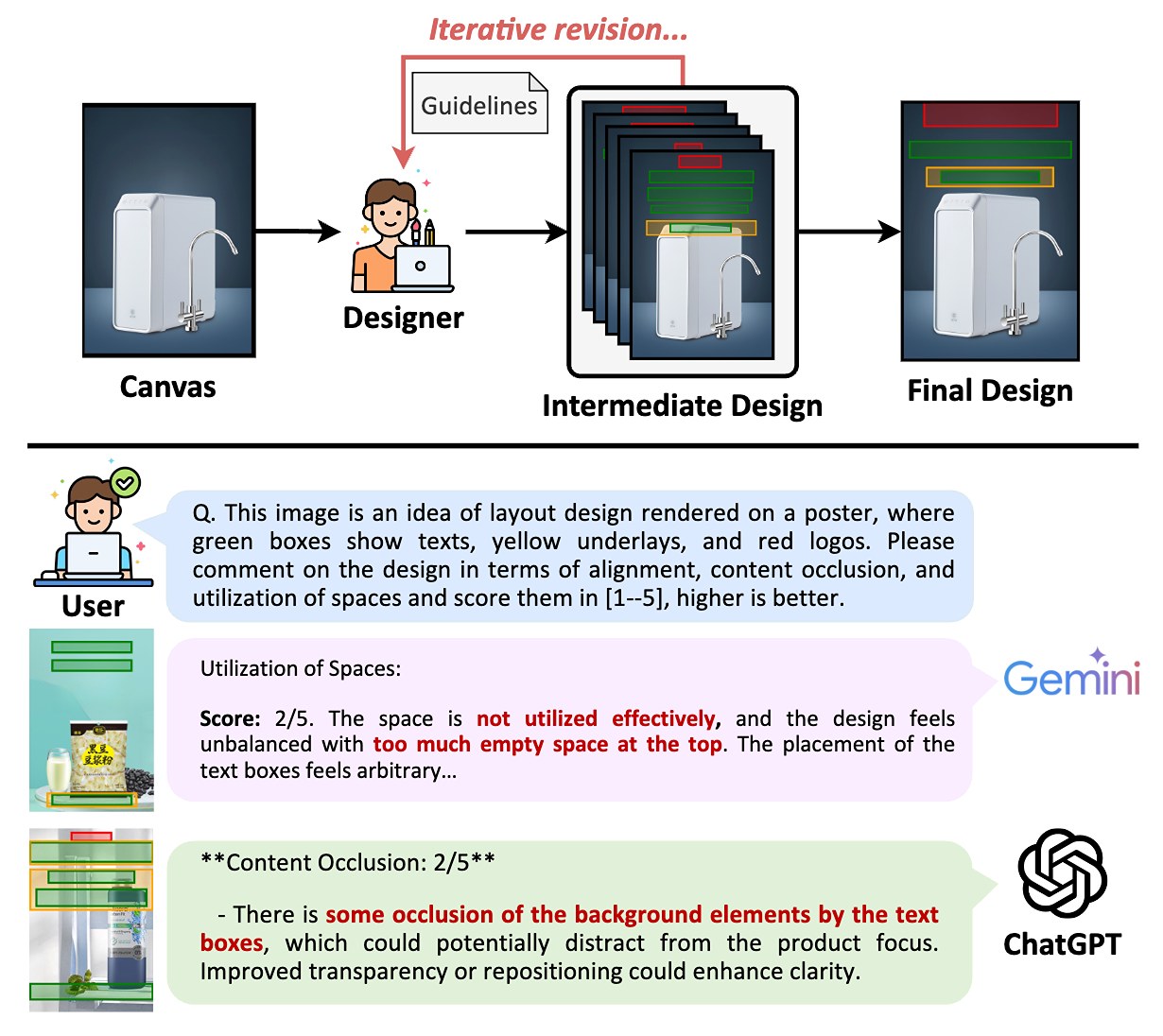
VASCAR:Content-Aware Layout Generation via Visual-Aware Self-Correction
VASCARは、大規模vision & language modelを用いて、画像内容に合わせたレイアウト(例:HTML)を自動生成する手法です。デザイナーが何度も修正を重ねるプロセスに着想を得て、LVLMが生成したレイアウトをレンダリング画像と比較し、自ら改善を繰り返す「自己修正」型アプローチを採用。追加の学習なしでGPT-4oやGeminiなどに適用でき、実験とユーザ調査で既存手法を上回る品質を達成しました。
SCAdapter:A Content-Style Disentanglement Approach for Diffusion-Based Style Transfer
SCAdapterは、拡散モデルによるスタイル転送で「コンテンツ」と「スタイル」を明確に分離・再結合する新手法です。CLIP画像空間でソース画像から純粋なコンテンツ特徴、参照画像からスタイル特徴を抽出し交差汚染を防止。自己注意やテキスト反転を使わずに拡散過程を制御でき、推論速度を2倍以上高速化します。特に写真から写真へのスタイル転送で高い写実性と転送品質を実証し、従来法を上回る性能を示しました。
Video Consistency Distance for Temporally Consistent Image-to-Video Generation
Video Consistency Distance (VCD) は、画像 → 動画生成(I2V)における “時間的一貫性” を強化するために導入された新しい評価指標です��。従来の報酬最適化は見た目や全体整合性を重視するあまり、条件画像とのフレームごとの整合性が損なわれる課題がありました。VCDは動画フレーム特徴を周波数空間で解析し、条件画像との時間的整合性を定量化。それを報酬として拡散モデルをファインチューニングすることで、追加の動画データなしで時間的一貫性を大幅に向上させつつ、他の品質指標は維持されることを複数のI2Vデータセットで実証しました。
Chronologically Accurate Retrieval for Temporal Grounding of Motion-Language Models (ECCV2024)
本研究では、言語と3Dヒューマンモーションの潜在空間におけるイベント時系列の認識不足に着目し、イベント順序を入れ替えた否定例を活用するChronologically Accurate Retrieval(CAR)手法を提案しました。CARにより既存モデルの時間理解の弱点を評価するとともに、同手法で学習したモデルがテキスト-モーション検索とテキストからのモーション生成で精度を向上させることを確認しました。
ReMoGPT:Part-Level Retrieval-Augmented Motion-Language Models (AAAI2025)
本研究では、身体部位レベルの特徴を用いたモーション-テキスト統合モデル ReMoGPT を提案しました。部位ごとの参照動作をマルチモーダル検索で取得してプロンプトに組み込み、Q&A 形式でインストラクションチューニングすることで、多様かつ稀な動作を含む検索・生成・キャプション各タスクで追加学習なしに高精度を達成しました。
おわりに
MIRU運営並びに、ブースやポスターでのインタラクショ�ンをしてくださった皆様、誠にありがとうございます。引き続き、LINEヤフーとしてはエンジニアリングおよび研究の分野で、多くの貢献ができるよう邁進していきます。本ブログは画像処理の研究にフォーカスしたものでありますが、コンピュータービジョン・マルチモーダル分野以外でも多くの研究開発を行っています。最新の成果はLINEヤフーの研究開発をご覧ください。


