こんにちは。LINEヤフーで画像処理エンジニアをしている植田です。先日2024年8月6日から9日まで熊本にて国内最大級の画像分野の学��会、第27回 画像の認識・理解シンポジウム MIRU2024が開催されました。
LINEヤフーもスポンサーとして協賛し、企業ブースの運営や研究発表・聴講のために参加しました。昨年はLINE・ヤフー個別で参加 (MIRU2023参加ブログ)していましたが、合併を経てLINEヤフーとして初めてMIRUへ参加させていただきました。
本記事では会場の様子やLINEヤフーの研究発表内容を紹介します。
MIRUとは?
国内の画像分野では言わずと知れた学会でもあるMIRUは画像処理や、人工知能(AI)の視覚機能を研究する分野「コンピュータビジョン」など、情報学における画像分野の一大学会です。開催地は年によって異なり日本全国各地で開催されています。今年は熊本県熊本市の熊本城ホールで開催されました。
会場内では招待・特別講演、企業展示、ポスター発表が行われており、オンサイトでの開催ということで会場は連日、多くの企業や研究者、学生で賑わっていました。
招待・特別講演では国際学会などで発表された最先端の研究発表から画像センシング技術の応用や評価方法、ロボット研究への応用に関する研究などさまざまな知見が得られる発表が行われていました。企業展示ではスポンサー企業の製品や研究開発の様子を知ることができました。ポスター発表では国内の画像領域の研究が一堂に集まっており、気軽に発表者に質問ができる環境で、参加者同士のディスカッションも盛んに行われる良いセッションでした。

LINEヤフーの研究発表
LINEヤフーからは招待講演・ポスター発表を含む10件の研究発表を行いました。このうち超解像の研究である「Real-SRGD: 分類器無しガイダンスによる実世界超解像向け拡散モデルの画像品質改善」でMIRUインタラクティブ発表賞を受賞しました。
画像生成系の研究
画像生成系の研究としてレイアウト生成、実世界超解像、教師なしドメイン適応による意味領域分割の3本の論文の発表を行いました。レイアウト生成の論文は国際学会 ECCV2024に採択されたものです。
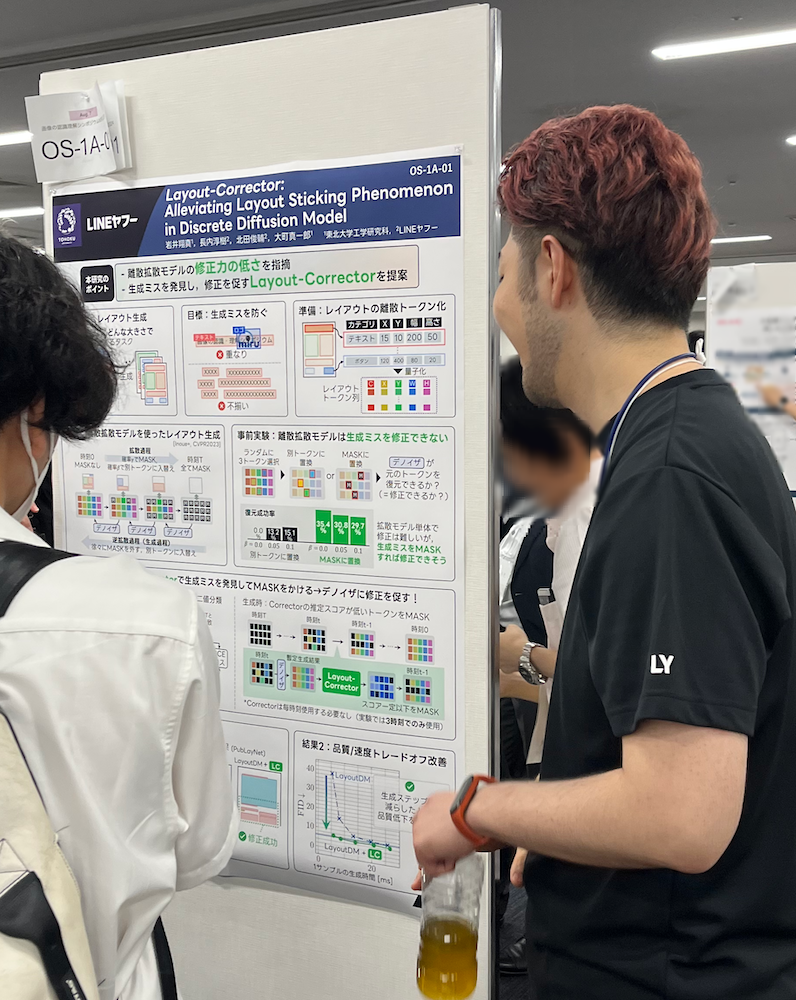
1. Layout-Corrector: Alleviating Layout Sticking Phenomenon in Discrete Diffusion Model
レイアウト生成はボタンやテキスト、ロゴなどのコンテンツを「どこに」「どんな大きさ」で配置するかを決定するタスクで、広告画像などのグラフィックデザイン生成への応用が期待されています。論文では生成したレイアウトのミスを発見するLayout-Correctorを導入して生成ミス部分(推定スコアが低いトークン部分)にMASKをかけ、デノイザに修正を促すことで生成ミスの修正に成功しました。
2. Real-SRGD: 分類器無しガイダンスによる実世界超解像向け拡散モデルの画像品質改善
この研究は、実世界のブラーやノイズ、圧縮アーティファクトなどの複雑な劣化を含む低解像度画像を、高解像度に復元する技術 RISR(実世界超解像)に焦点を当てています。条件付き画像生成で有力な分類器無しガイダンス(CFG)付き拡散モデルをRISRタスクに導入するために、劣化をBIR(ブラインド画像復元)、従来のSR(超解像)、RISRの3つのタスクに分割して擬似的なクラス情報とみなすことで性能を向上させました。この研究ではMIRUインタラクティブ発表賞を受賞しました。
3. 拡散モデルを用いた意味領域分割のための擬似マスク生成における教師なしドメイン適応
拡散モデルを活用した意味領域分割のための擬似マスク生成手法を基に、ファインチューニングおよびアダプターモジュールの追加を通じて、教師なしドメイン適応を行う新たな手法を提案しました。
動画・音声系の研究
動画・音声系の研究として4本の論文の発表を行いました。
1. 動画生成における文字崩れの評価のためのデータセットと評価指標の提案
現状の動画生成モデルの課題である文字崩れ(色、フォント、文字の可読性の欠如など)の評価のためのデータセットTEgoと評価尺度EMCLRの提案を行いました。EMCLRは可読性だけでなく、従来の評価指標で見過ごされていた色やフォントなどの文字の性質に関する評価も可能となっています。
2. 動画クラスタリングのためのDINOの動画への拡張の検討
静止画のための自己教師あり学習モデルのDINOを時間方向に拡張し、行動認識のベンチマークを用いて動画クラスタリングにおける性能評価ならびに画像や動画を複数の部分に分割して、それらを使用してデータを増強するMulti-cropや動画のデータ拡張が及ぼす影響についての分析を行いました。
3. Lighthouse: 再現可能で使いやすい動画区間検索のライブラリ
動画とテキストクエリを入力としてクエリの指す動画中の時間区間を予測する課題である動画区間検索に焦点を当てた研究で、動画区間検索の研究の再現実験を利用者が容易に行えるライブラリLighthouseの提案を行いました。yamlファイルを切り替えることで対応するさまざまな手法、データセットの再現実験を容易に行えるようになっています。
4. 音を発生させる物体を考慮した視聴覚表現学習
視聴覚表現学習モデルであるContrastive Audio-Visual Masked Auto-Encoder(CAV-MAE)に発音物を予測する損失を追加することで、映像と音声の対応が適切に取れた視聴覚表現を獲得しました。

動作生成系の研究
動作生成系の研究として国際会議 ICCV2023、CVPR2024に採択された2本の論文の発表を行いました。
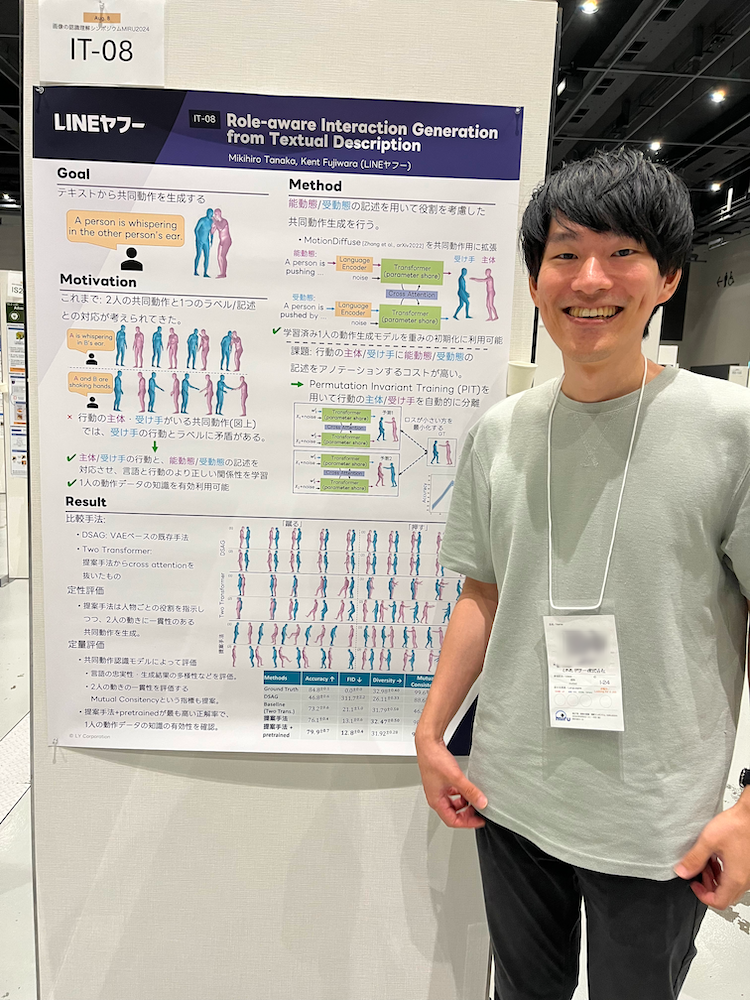
1. Role-aware Interaction Generation from Textual Description [paper]
この研究はテキスト記述から共同動作を生成することを目標としています。行動に主体と受け手がいるような共同動作の場合、受け手側の行動とラベルに矛盾が生じる課題に対して、「主体、受け手の行動」と「能動態、受動態の記述」を対応させることでテキストと行動のより正しい関係性を学習できるようになりました。
2. Exploring Vision Transformers for 3D Human Motion-Language Models with Motion Patches [paper]
この研究は動作データ不足に対処するため、新たな動作シーケンスの表現方法として「モーションパッチ」を導入し、Vision Transformers(ViT)を動作エンコーダーとして利用した手法を提案しています。モーションパッチは、動作シーケンスをボディパーツごとに分割・ソートして作成され、ViTのカラー画像パッチとしてみなすことができます。異なるスケルトン構造に対しても対応でき、テキストから動作への検索、クロススケルトン認識、ゼロショット動作分類、人間インタラクション認識などさまざまなタスクに適応が可能です。
クラウドソーシングの�評価
1. CLIPスコアによるワーカー評価
弊社サービスであるYahoo!クラウドソーシングのようにインターネット上で簡易に仕事を依頼できるサービスは便利ですが、ワーカー(依頼された仕事をする人)の質によって仕事の品質が変わるため、ワーカーの評価は重要です。この論文ではワーカーに画像説明文生成タスクを行ってもらい、人手による説明文と画像とのCLIPスコアで評価を行うことで、比較的コストを掛けずに優良ワーカーのフィルタリングを行えるようになりました。

LINEヤフーの企業ブース
研究発表に加えて、LINEヤフーの紹介を行う企業ブースを設置しました。企業ブースでは、LINEヤフーの画像技術を用いたサービスや取り組みの紹介を行いました。研究の取り組みはもちろんYahoo!クラウドソーシングなどの弊社サービスを知っていただく良い機会になりました。
デモブースでは商品クリエイティブ生成、日本語CLIPを用いたゼロショット画像分類、動画にマッチした音楽の推薦、モーション生成のデモを披露しました。
1. 商品クリエイティブ生成
来訪者が撮影した商材写真をアップロードすると、商材領域を自動抽出し、適切な背景画像、レイアウト、キャッチコピーを生成します。また、フォントカラーの推薦なども行い、最終的に商材に沿った広告画像��を生成するデモを披露しました。
2. 日本語CLIPを用いたゼロショット画像分類
LINEヤフーでは高性能な日本語版大規模視覚言語基盤モデルの開発を行っています。独自に日本ドメインデータを社内外から収集し、既存の日本語CLIPモデルの中で最高性能を達成しました。このモデルを利用したゼロショット画像分類のデモを披露しました。
3. 動画にマッチした音楽の推薦
動画の特徴から音響的、歌詞的にマッチした楽曲を検索し、推薦理由と合わせて出力するデモを披露しました。
4. モーション生成
画像や絵(四肢があるもの)に対してモーションプロンプトで動作の指示文を入力すると、指示文に沿って画像や絵が動き出すデモを披露しました。

LINEヤフーとしてのMIRUでの学会ブース設置は今回が初めてでしたが、近い業界の企業の方、大学の先生方、学生などたくさんの方が来てくださり、終始大盛況でした。普段はなかなか関わる機会がない方々と交流できて楽しかったです。来年のMIRUは京都での開催となります。また皆様に面白いと思っていただけるような研究・デモ紹介ができるよう頑張っていきたいと思います。
終わりに
会場や懇親会にて議論・フィードバックをくださった皆様、誠にありがとうございました。LINEヤフーではエンジニア・研究者が技術��開発を通して業界の発展に寄与しつつ、より便利なサービスを作るために役立てていく活動をしていきたいと思います。画像分野以外でも多くの研究開発を行っています。最新の成果はLINEヤフーの研究開発をご覧ください。


