Hello. I'm Dahee Eo, a site reliability engineer (SRE). Our team is responsible for Media Platform SRE work as well as global traffic management.
In our previous series, Adopting SLI/SLO for improving reliability, we covered the concepts and the motivation behind SLI/SLO and shared adoption examples across platforms and services.
- Adopting SLI/SLO for improving reliability - Part 1: Introduction and reasons for adoption
- Adopting SLI/SLO for improving reliability - Part 2: Platform implementation cases
- Adopting SLI/SLO for improving reliability - Part 3: A service adoption case study (to be published)
In this new series, Using SLI/SLO for improving reliability, we will discuss how to make service level indicators (SLIs) and service level objectives (SLOs) practical after adoption, including how to apply them in day-to-day operations and how to scale the approach.
In Part 1, I'd like to share how we built an SLI/SLO framework based on SLI/SLO, why we created an internal tool called LINE Status, and the key decisions and trade-offs we made along the way. Rather than simply summarizing the experience of building a tool, I'll focus on how we clarified the structure through repeated operational cycles, then automated and expanded it based on what we learned.
A common structure we found through repetition
Our SRE team applied SLI/SLO to major services and platforms, and we then began expanding it to other services and platforms so that SLI/SLO could become a common language for discussing service reliability internally.
After repeating this process several times, we realized there was a common pattern in how we define SLIs and align on SLOs, regardless of the specific characteristics of each service. The steps from initial adoption to establishing them as operational indicators were largely the same.
The SLI/SLO framework
To reuse that common flow, we organized the end-to-end process more explicitly and formed it into a framework. Our goal was to make it possible to define and operate SLI/SLO within a shared set of standards and a shared flow that doesn't depend on any single service.
At a high level, the SLI/SLO adoption process looks like this:
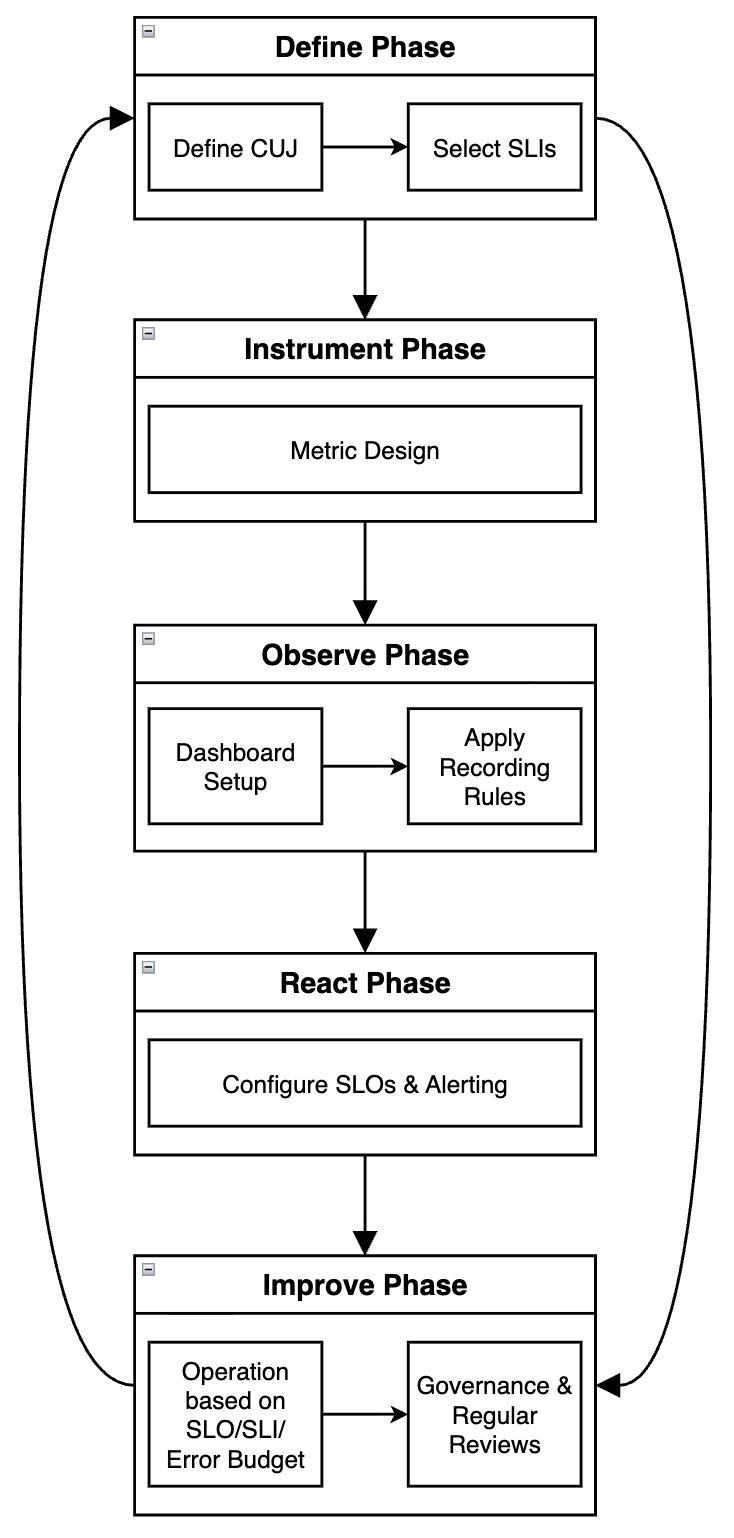
The table below describes the role of each of the five phases in the SLI/SLO framework in more detail.
| Category | Description |
|---|---|
| Define phase |
|
| Instrument phase |
|
| Observe phase |
|
| React phase |
|
| Improve phase |
|
We currently provide the SLI/SLO framework as a Confluence template. Each service team duplicates it and completes the sections phase by phase to define and operate their SLI/SLO. By consolidating what SREs previously had to explain and align on through one-off discussions into the template, supporting guides, and an FAQ, we've reduced the coordination overhead in the early stages. We're still in the initial stage and have applied it to only one service so far, but we plan to expand it to more services and iterate on it as we identify gaps.
How is our service doing right now?
As we introduced and operated SLI/SLO across multiple services, we naturally became curious about the health of other services that our team doesn't manage directly.
We already had an API status page for LINE. However, it was designed primarily for external API users to check the status of LINE messaging, login, the LINE front-end framework (LIFF), and other external APIs. It also relied on manual updates when major issues occurred.
In contrast, we wanted to build a tool that internal users could use to understand the status of service components based on consistent criteria. We also wanted the status to be refreshed automatically based on SLI/SLO alerts and outage data.
Within the SRE team, we had detailed discussions about how to represent status. For example, should we reflect on-call alerts as-is, or express status based on error budgets? When defining SLI/SLO, our baseline wasn't simply whether a service is having an outage, but whether users are able to use the service well (user happiness) from a CUJ perspective. For that reason, we concluded it would be more consistent to express service status not as a binary "outage or not", but as an evaluation of whether SLOs are being met based on CUJ-defined SLI metrics. We also felt it was more appropriate to show not every CUJ equally, but primarily the items that best represent the service's core experience.
Based on real operational experience, we refined the criteria for status transitions and made the initial model more concrete. Because CUJ had already been established as a common concept through projects that introduced SLI/SLO to major services, we decided to build LINE Status, an internal service health check tool based on that concept.
A system design for automatic status management
LINE Status is not just a page that lists alerts. Our goal was a structure that shows each service's current status consistently based on collected events, and enables people to recognize as quickly as possible whether the current user experience is being impacted.
To achieve that, we first designed a backend server that collects SLI/SLO-based alerts from each service via webhooks. We store the collected events in a dedicated database and use them to manage both the current status and change history. This allows us to track not only the status at a specific point in time, but also the history of events that led to it.
We also decided that, to make it intuitive for all internal users, we should not expose terms like SLI or SLO directly. Instead, we display status names defined around user-facing capabilities. For example, for a messaging service we express status in terms of features users recognize, such as "Send messages" or "Read receipts". In other words, rather than surfacing technical metrics, the design focuses on whether the user experience is impacted.
With this design philosophy, we hoped LINE Status would become not just a monitoring tool, but also a channel for sharing service health across the organization.
Implementing LINE Status
Development took about a month, and we then iterated and improved it gradually based on feedback from colleagues.
To be honest, I'm an engineer who doesn't typically work on front-end development. Even so, I actively used the vibe coding approach that has become popular recently to build the UI. One thing I learned in the process was that the clarity of the plan matters far more than the tool itself. For each feature, I wrote the requirements in Markdown and shared them with the AI. The more specific the documentation and the richer the context, the better the output quality. Rather than asking for something vaguely, I needed to clearly communicate the intent, including what status should be shown and how it should be presented, to get the result I wanted.
Next, I'd like to introduce the main screens of LINE Status. (Because it is an internal tool, we used example data rather than real service names and production data.)
First, the main page is designed so you can see the current status of all services at a glance.
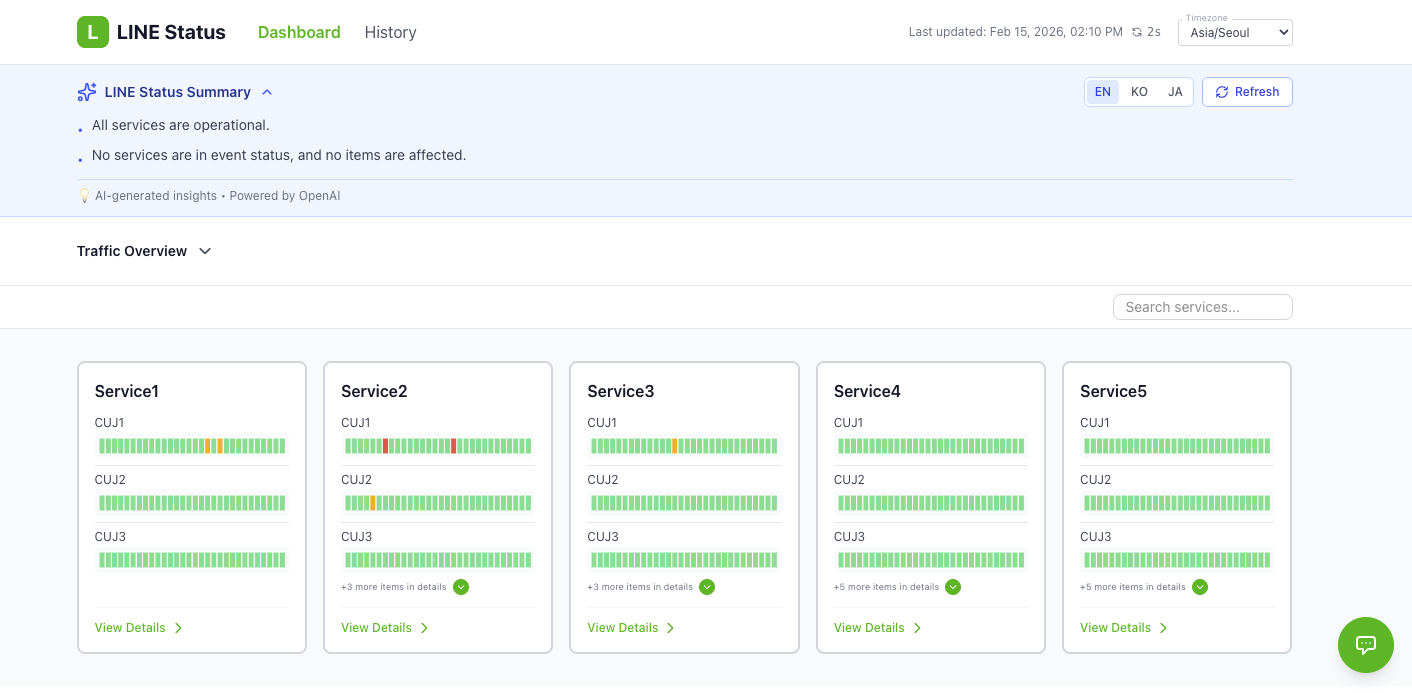
Key characteristics of the main page include:
- A one-line, AI-generated summary analysis
- A list of CUJ items on each service card to quickly confirm key capabilities
- Intuitive color coding (green: normal, yellow: event detected, red: outage)
Next is the service details page, where you can check critical user journey (CUJ) item-level status for a specific service.
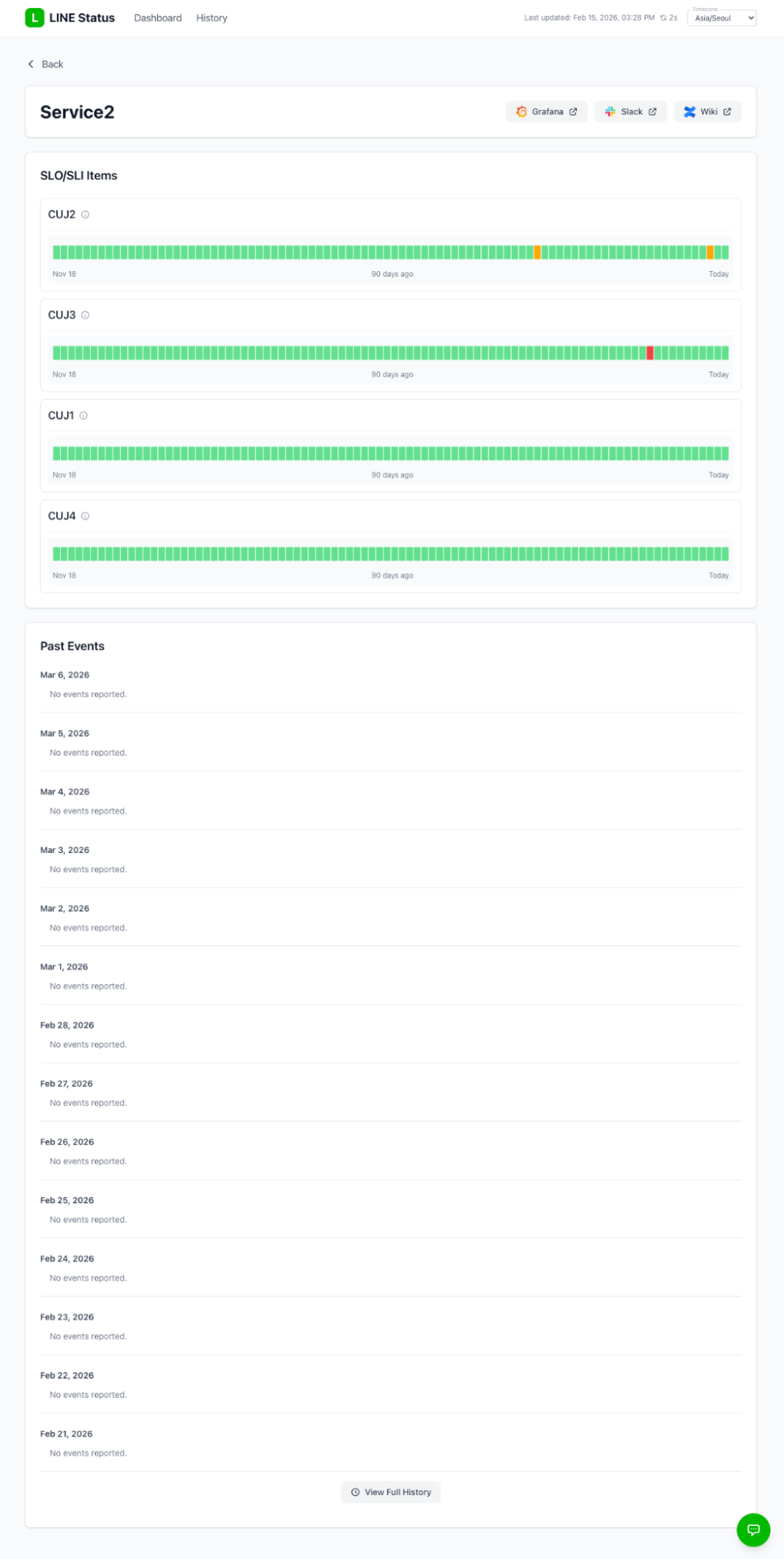
Key characteristics of the service details page include:
- Shows the most recent events at the top instead of a simple descending sort
- Displays recent events in a timeline format
- Allows you to review this month's event history in the Past Events section
The next screen is the history page, where you can review the history across all services.
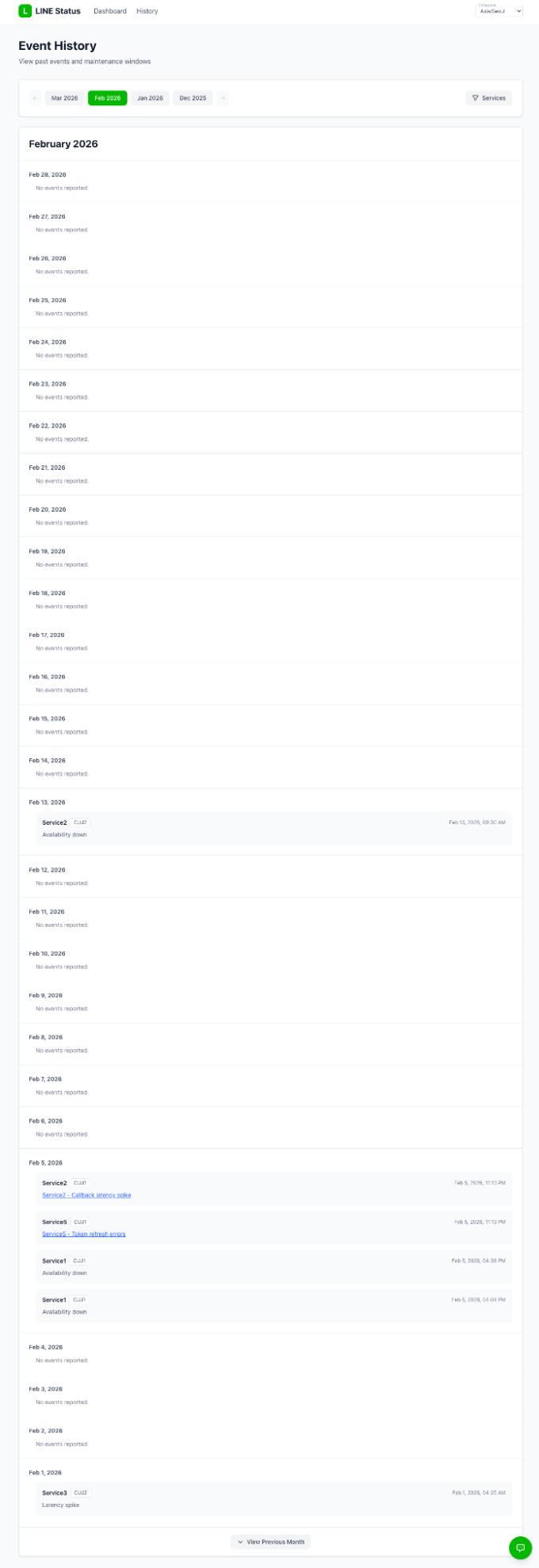
Key characteristics of the history page include:
- Helps you understand the impact scope per service during an event
- Lets you browse past history grouped by month
Connecting the SLI/SLO framework and LINE Status
As we implemented LINE Status, the connection between it and the SLI/SLO framework became clear. Once a service adopts SLI/SLO using the framework, registering that service in LINE Status allows the entire organization to check its status against the same criteria. In other words, the phase where we define SLI/SLO and the phase where the organization views those results together are connected.
Importantly, LINE Status is not only about visualizing status. Its core role is to provide a shared interface so that developers and operators can recognize service health using the same standards. Instead of each team looking at separate monitoring dashboards through their own lens, we need to be able to assess together whether the user experience is impacted, based on CUJ-defined SLIs and whether SLOs are being met. This is especially important during events, when we need to recognize status quickly from a user-experience perspective.
We designed LINE Status with those points in mind. As we accumulate operational experience, we plan to refine CUJs and the SLI/SLO criteria further. This will allow users to quickly understand which service experiences are currently impacted, across components, based on LINE Status rather than interpreting individual alerts. We believe this can improve not only monitoring convenience, but also decision-making speed and how teams communicate.
We are still in the early stages, but in the long term we aim to expand SLI/SLO through the SLI/SLO framework and LINE Status as a shared common language for describing service health across the organization. Our goal is to establish a foundation that enables gradual expansion of SLI/SLO-based operations without relying excessively on any specific team or role.
Conclusion
Building the SLI/SLO framework and developing LINE Status would not have been possible alone. I would like to sincerely thank everyone who discussed, experimented, and shared diverse perspectives with us.
In 2026, our work to use and expand SLI/SLO to improve the reliability of LINE services will continue. In this series, Using SLI/SLO for improving reliability, we will share the considerations, trial and error, and outcomes from that journey step by step. Thank you for reading this long post.


