前言
大家好,我是 Data Dev Team 的 TECH FRESH - Wayner Kao。這次非常高興有機會與交大資工系的同學們分享我在 LINE 的實習經驗。藉此機會,我也將相關的內容整理成摘要,希望能能幫助到有興趣的人!
實習動機
了解自己實習的動機和可能的好處在開始尋找或開始實習之前是相當重要的。以下是我對實習的一些看法:
1. 累積工作經驗:對我來說,實習最重要的是可以累積工作經驗。如果要申請研究所或是尋找其他實習、正職的工作機會,擁有相關的實習經驗,尤其是來自國際知名的軟體公司,將會非常有幫助。
2. 磨練技能:實習也是一個磨練自己技術和非技術技能的好機會。例如,商業�開發的情境與學校作業往往有很大的不同,實習可以讓你學習到平常用不到的工具和更具規模的開發流程。在不同的公司實習,你有機會遇到各種不同的機器學習問題,例如推薦系統、預測模型等。這些經驗可以幫助你在某些特定的問題和領域上建立深厚的背景知識和經驗。
3. 擴展人脈:在實習期間,你會遇到來自不同背景的人。這將讓你跳脫學校的限制並大大豐富你的視野。
4. 經濟獨立:雖然這可能不是最重要的考量因素,但實習可以為學生提供一定的經濟收入,使你有機會去彈性運用自己的財富。
5. 寶貴的經驗:作為實習生,在公司中與人相處和完成工作任務,雖然要兼顧課業和工作可能會很辛苦,但是這些都是很值得去體驗的獨特經驗。
整體而言,實習提供了許多寶貴的機會和經驗,可以幫助我們在學術和職業生涯中培養很好的基礎。
基於大型語言模型的問答系統
我參與的許多專案都與問答系統有關,這也是語言模型最常見的應用。然而,我們不僅僅是將文字輸入模型,而是使用"檢索增強生成"(Retrieval Augmented Generation,簡稱RAG)的架構。
當我們希望在特殊的場景下使用模型,例如回答與LINE使用或API開發相關的問題,我們的生成語言模型可能沒有看過相關的材料,也沒有用相關的材料進行訓練,因此無法準確地回答問題。考慮到收集訓練資料和訓練時間的成本,我們希望生成模型具有良好的閱讀和思考能力。這時,我們可以透過設計一個"檢索器"(retriever),使用向量搜索技術找到回答問題所需的文件(也就是知識),並將這些文件交給生成模型。這樣,生成模型就能參考這些文件來回答我們的問題。
在這種框架下,我們有許多模型可供選擇,如OpenAI的GPT系列,開源的羊駝系列,以及Hugging Face的Bloom等。我們可以使用簡單的prompt learning(也就是詠唱或下咒語的方式)來找出在某個使用情境下讓模型輸出最好的輸入。我們也可以使用監督式微調(Supervised Fine-tuning,簡稱SFT),或者強化學習等方法。
此外,我們還需要設計評估模型性能的方法,並設計安全機制以防止模型輸出有害內容。這些都是我們需要深思熟慮的問題。
內部讀書會
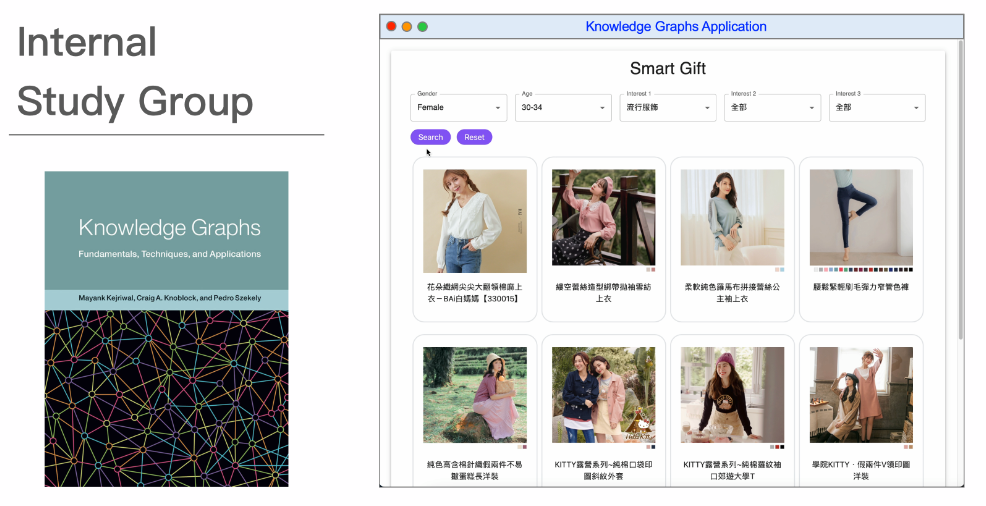
除了根據現有的需求進行開發外,我們也有內部的讀書會。我們會分組定期選擇一本書來閱讀,並每隔一段時間讓一組成員分享一個章節。最後,我們還會舉辦成果發表會。例如,上次讀書會的主題是知識圖譜,而我們的小組在成果發表會上就利用知識圖譜開發了一個禮物推薦系統。只需輸入送禮對象的性別、年齡、興趣等資訊,我們的系統就能推薦相應的商品。
在知識圖譜的情境下,我們需要將用戶和商品連結起來。然而,用戶和用戶之間、商品和商品之間其實也存在連接性。例如,我們可以考慮性別、年齡等人的特徵來將相關的用戶分成一群。商品之間可能也存在隱藏的關聯,而某些用戶與商品頁面、甚至廣告的互動則連結了人與商品。透過這些關係,我們可以不斷地擴展我們的圖譜,實際上也在圖譜中建立了一個無形的知識庫。我們再設計一些方法從圖譜中提取出推薦的機制,就完成了這樣的系統。
右邊是我們當時的DEMO畫面。我們的系統根據使用者的輸入推薦了30-34歲的女性可能感興趣或是目前最受歡迎的流行服飾。
Learning-on-demand
如果你有意投入機器學習相關的研究和實習,需要了解的事情實在繁多。從基本的線性回歸和梯度下降,到模仿學習、強化學習等複雜的算法;在模型方面,每隔一段時間就會有最新的先進模型發表,而且這個時間間隔正在逐步縮短。此外,還需要持續關注新推出的工具以便實作。
最具挑戰性�的是,機器學習涵蓋了許多子領域,如自然語言處理(NLP)、電腦視覺(CV)、遊戲、機器人等,每一個領域都相當深奧。專精其中一個子領域的某個問題都相當困難,更不用說成為跨領域的專家。事實上,即使是學校教授,大多數也專精於某一個領域。雖然這些領域都廣義上屬於機器學習的範疇,但找到自己有興趣的方向並深入鑽研是必要的。
那麼,如何在這片廣大的知識海洋中開始累積自己的知識呢?我建議你可以參考"按需學習"(Learning-on-Demand)的原則。簡單來說,就是先學習你目前需要的知識。例如,如果你對自然語言處理有興趣,你可能會在網路上、老師或同學那裡聽到"Attention is All You Need"這篇論文。你可以從閱讀這篇論文開始,並在不熟悉的地方進行查詢。例如,你可能在"Related Works"部分看到該論文引用了RNN,如果你不了解RNN,可以查詢RNN的原理。在方法部分,你可能發現這篇論文採用了"Residual Dropout"的機制,如果你不了解它,可以查詢相關的介紹。最後,在"Evaluation Metrics"部分,你可能看到這篇論文使用了BLEU score來評估模型,你可以進一步查詢這個分數的含義。
根據"按需學習"的原則,我們不一定要按照技術發展的順序,從很久以前的論文開始閱讀。相反,我們可以選擇一篇最新的、自己感興趣的論文來閱讀,並在閱讀過程中查詢不熟悉的部分。這樣,我們可以在無形中累積許多基礎知識。隨著時間的推移,你會發現在閱讀新的論文時,需要進一步查詢的部分逐漸減少。
如何準備
以下是我認為求職過程中重要的事情,也是我當初有做過的準備:
1. 選擇有競爭力的職位:首先,你需要確保自己選擇的職位與你的經驗和技能對應。例如,如果你的履歷上都是機器學習的專案,那麼投遞前端的實習可能不是最佳選擇。以我自己為例,雖然我也會寫一點前後端,但與許多厲害的人相比,我的經驗相對不足。然而,我選修了許多AI的課程,並有相關的專題和實習經驗,因此對我來說,Data Dev Team的職缺是我最有機會、最具競爭力的選擇。
2. 做好功課:就像前面提到的,你可以參考官方網站、部落格,或者尋找曾經在該公司工作或應徵過的人的分享,了解這份工作的具體內容。除了確認自己是否具備資格,瞭解如何準備、自己的不足之處外,更重要的是確定這份工作是否是你想要爭取和體驗的。
3. 審視自己的條件:回頭審視自己的履歷,自己提出可能的面試問題,並擬定答案。我當初是將這個過程記錄在Notion裡,方便整理和閱讀。
4. STAR原則:在面試時,你可以參考STAR(Situation、Task、Action、Result)原則來描述自己的過去經驗。這種方法可以幫助你清晰、有組織地回答面試問題,展現你的技能和成就。
LINE實��習生活
在LINE的實習生活是多彩多姿、相當愉快的。不僅能在舒適的辦公環境中工作,還有許多各類型的活動可以參與。這些活動提供了很好的機會,不僅可以累積技術知識和發表的經驗,還可以與同事和其他實習生進行深入的交流,創造了許多難忘的回憶。
結語

最後,台灣的資料開發與機器學習的實習機會並不多見。因此,作為一間國際級且規模龐大的軟體公司,LINE提供了一個極佳的實習機會給對此類工作有興趣的學生。除了工作經驗之外,實習生還可以享受公司提供的優質福利,並有機會認識對技術發展同樣充滿熱情的朋友,一起學習與討論。我強烈推薦在這個領域有經驗、想要進一步發展的同學們,來LINE體驗這個實習機會!