
大家好,我是賴仲哲,目前在 LINE 擔任 Data Engineer,這篇文章主要分享 Data Engineer 日常點滴,希望對 LINE Data Engineer 有興趣的學生或者是業界人士能有些幫助與了解。
這篇文章會分享
- 前言
- 實際的工作內容
- 台灣實作的機會
- 產業趨勢與職涯發展
#前言
關於什麼是資料工程師(Data Engineer)?我相信大家都已經Google過或是問過ChatGPT,這邊就不多說,直接看以下這張…
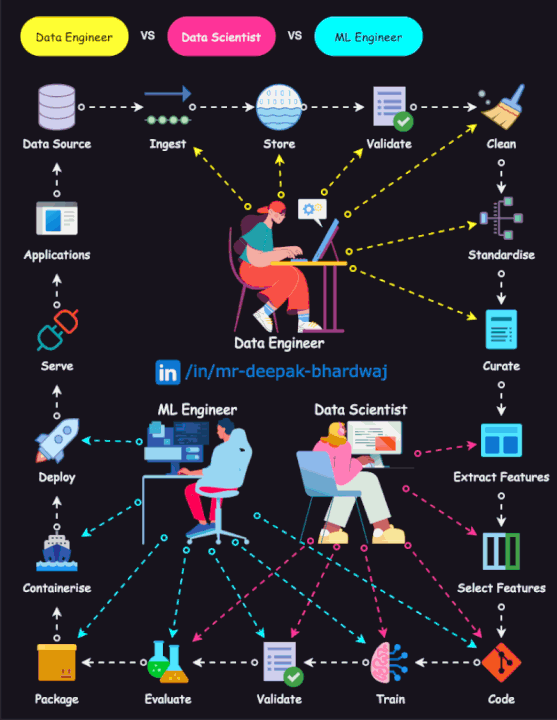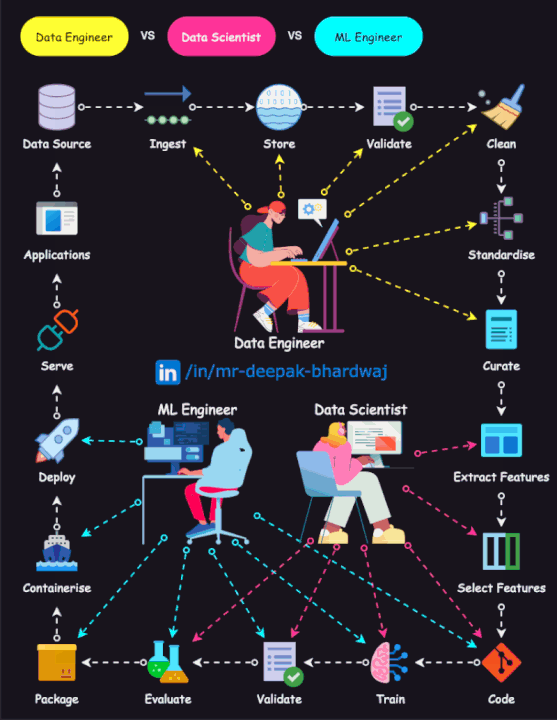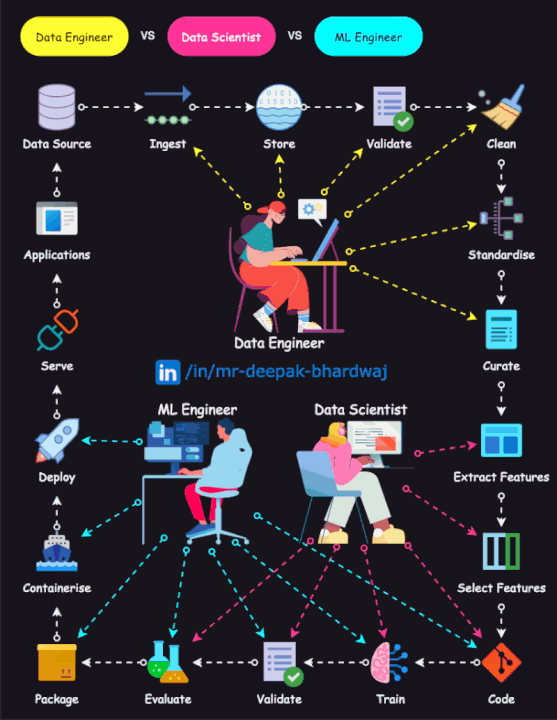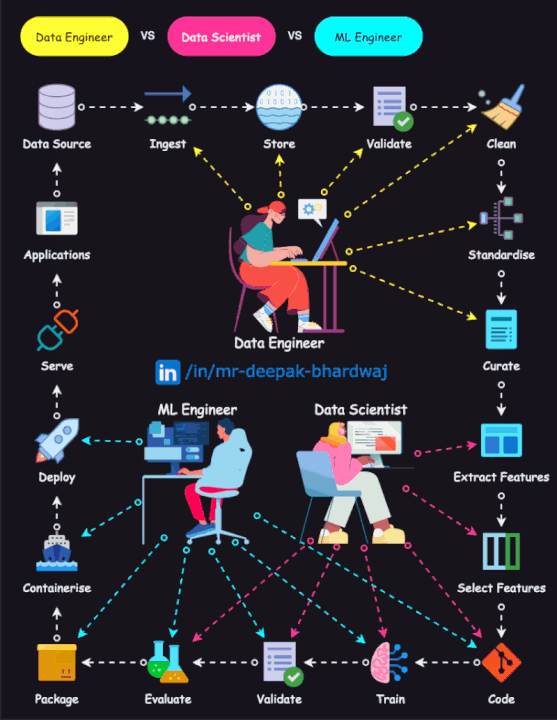 </picture>
</picture>(ref:https://www.linkedin.com/pulse/data-engineer-vs-scientist-ml-heba-al-haddad/)
簡單說,如果把水當作資料(Data)的話,資料工程師就像是『水管工人』,建立一些水管(Pipeline),將源頭的水經過一些手法處理(ex.過濾/萃取/加工/補充/驗證),然後引導到自家可能有一個水塔(Database)裡面,讓需要這些水的使用者可以方便去飲用,不用自己額外去處理這樣。
當然,每間公司對於這個職缺工作內容的守備範圍,各不相同,我聽過有管到很源頭的(機房???),也有完全沒有這個職缺,叫MLE/DS自己去拿資料,可能資料就躺在公司某台Server folder底下,要用就請自己去拿。(笑)
那麼,作為水管工人可能會遇到什麼情況呢?
- 雜質過多(Dirty Data)- 原始水源可能含有雜質,如泥沙、微生物(缺失值、錯誤值),需要透過 過濾(Filtering) 去除不必要的部分,例如刪除缺失值、標準化數據格式。
- ��有害物質(Corrupted Data)- 可能含有有害的化學物質(錯誤數據或異常數據),需要透過 驗證(Validation) 確保數據的完整性,例如異常值偵測、邏輯校驗。
- 水的礦物質比例不均(不一致的資料格式)- 例如不同來源的水(數據)可能有不同的pH值、礦物質含量(單位不一致、時間戳格式不同)。需要 標準化(Standardization) 處理,例如統一時間格式、統一數值單位。
- 水量不足(數據缺失)- 有時候源頭水量不足(部分數據缺失),可能影響使用者飲用,當上游水量補充回來時,下游的我們也需要進行 回補(Backfill)的動作。
- 水的礦物質含量不符合標準(資料不完整或不精確)- 例如水裡該有鈣和鎂,但卻只有鈉。可能需要 增強(Enrichment),如從其他水源(資料源)補充必要資訊。
- 水流速太慢(數據管線效能問題)- 若水管過細,水流速就會變慢,影響最終使用者的體驗(數據處理效能低),需要 優化管線(Pipeline Optimization),如使用分散式運算處理、增加快取機制等技術。
當然還有一些不同的情況,這邊就簡單列舉常見的。最後補充一點,有良好的資料管線平台(Data Pipeline Platform),可以協助資料工程師方便去管理/監控/彈性擴充/了解資料的血緣脈絡(因為中間可能經過很多手的轉換)。
實際的工作內容
這邊我想分成兩個面向來看:
- Data/Domain/Target User
- Routine/Data Pipeline Platform/Data Processing
關於第一點,不同產業所使用的資料差異很大,像我知道有些製造業/半導體產業,關注在產線上,製成物的品質檢測,可能透過拍照影像的方式,然後進行影像模型識別為良品或不良品。
而在LINE台灣,我目前是在電商產品的資料團隊,處理的是電商的資料,電商的資料大多都屬於結構化的資料(ex.使用者/商品/廠商等資訊),電商平台的目的也很明確,希望來逛電商平台的使用者都能願意在此平台進行下單購買商品,所以我們會去”收集使用者不同行為的資料,轉換成相對應的Event/Feature”,接著訓練出不同種(by 個人/整體/xxx)的推薦模型,其中收集源頭的數據並轉換成MLE/DS所需的資料就是資料工程師(DE)在做的事情。
(如果對我們推薦模型有興趣的,推薦看我同事們(MLE/DS)去年在iThome所分享的內容:https://www.ithome.com.tw/article/165216)
再來第二點,講一點更日常的,其實不論做什麼產業的資料工程師,上班的第一件事情,大多都是看看警報有沒有響起,所有的水管是否順利跑完,沒有任何異常,這件事情非常重要!也因為如此,在LINE台灣這邊,目前大多數是使用Airflow(Data Pipeline Platform),去進行資料管線上的管理,或是當今天有異常時,能快速找尋問題點,排除問題。最後就是Data Processing的技術,主要就兩種:(1)PySpark:為了快速處理大量的資料,採取分散式處理的方式,以及(2)SQL:資料上的快速POC。
台灣實作的機會
- 就資料領域(Domain)來說,我認為去業界實習,能接觸到『真實的資料』以及『實際的應用情境』。就我目前所知,LINE台灣Data Team每一年都會有Intern的職缺,如果對這一塊有興趣,非常鼓勵學生們報名(分享一些學生們在LINE實習的感想)。(LY Corporation Tech Blog/LINE TECH FRESH 2025 Summer Class)
- 就Data Pipeline Platform相關技術來說,我認為參與業界實習之外,也可以多參與技術研討會或是開源專案項目,也能獲得滿滿的技術力提升。
產業趨勢與職涯發展
其實第一張圖就說明DE/MLE/DS這三個角色需要互相合作,而AI模型這一塊,又是現在目前整個科技產業的重要發展方向。我相信,各家公司在AI這一塊勢必會再投入更多資源與人才,資料工程師(Data Engineer),這個角色具備極大的未來發展潛力。
最後,如果可以,建議學弟妹在學校中,可以修一些基礎知識的課程,例如:資料庫、資料處理、分散式處理、大數據、容器化和雲端技術,這些都是成為資料工程師的重要技能。


